
Você já estava no meio de um jantar quando seu telefone vibrou com um “alerta crítico” que acabou não sendo nada mais do que registros de rotina? É frustrante, mas pelo menos você sabia que o Opsgenie estava lá para te ajudar.
Agora vem o verdadeiro desafio: a Atlassian parou de vender o Opsgenie e, em breve, o suporte completo será encerrado. Para equipes que dependem dele para agendamento de plantões, escalações e alertas, esse é um alerta que ninguém queria receber.
O bom é que você não precisa esperar até o último minuto. Reservar um tempo para explorar outras opções agora significa que sua equipe poderá se adaptar a uma nova rotina sem o estresse de decisões precipitadas.
Neste artigo, apresentaremos as melhores alternativas ao Opsgenie, compararemos seus pontos fortes e mostraremos por que o ClickUp oferece à sua equipe uma maneira mais tranquila e conectada de trabalhar.
⭐ Modelo em destaque
Permita que suas equipes de TI registrem incidentes com precisão e identifiquem tendências que informam melhorias de longo prazo. O modelo de relatório de incidentes de TI do ClickUp ajuda você a registrar detalhes de incidentes em um formato consistente e confiável.

Alternativas ao Opsgenie em resumo
Aqui está uma comparação rápida das melhores opções alternativas ao Opsgenie para ajudá-lo a escolher a opção certa com base nos principais recursos, preços e avaliações dos usuários.
| Ferramenta | Ideal para | Principais recursos | Preços | Avaliações |
| ClickUp | Gerenciamento de trabalho completo com fluxos de trabalho de incidentes, planejamento de recursos e automação para equipes de todos os tamanhos. | Notificações personalizáveis, automação para escalonamentos, tarefas e listas de incidentes, status personalizados, chat em tempo real, painéis para análises pós-incidente, mais de 1.000 integrações. | Plano gratuito disponível; personalizações para empresas. | G2: 4,7/5 (mais de 10.500) Capterra: 4,6/5 (mais de 4.500) |
| PagerDuty | Alertas de incidentes em tempo real e automação em escala para grandes empresas | Alertas multicanais, políticas de escalonamento, agendamento de plantões, AIOps para redução de ruído, integrações com mais de 600 ferramentas. | Plano gratuito; planos pagos a partir de US$ 25/mês por usuário | G2: 4,5/5 (900+) Capterra: 4,6/5 (200+) |
| xMatters | Gerenciamento de incidentes e automação de fluxo de trabalho econômicos para equipes em crescimento | Fluxos de trabalho automatizados, gerenciamento adaptável de incidentes, agendamento de plantões, inteligência de sinais, mais de 200 integrações | Plano gratuito; planos pagos a partir de US$ 9/mês por usuário | G2: 4,5/5 (670+) Capterra: 4,6/5 (140+) |
| AlertOps | Redução de ruído com tecnologia de IA e resposta rápida para equipes de pequeno a médio porte | Redução de ruído com IA OpsIQ, escalonamentos flexíveis, cobertura de plantão, automação de fluxo de trabalho sem código, mais de 200 integrações | Plano gratuito; planos pagos a partir de US$ 10/mês por usuário | G2: 4,7/5 (150+) Capterra: 4,7/5 (20+) |
| Splunk On-Call | Simplificando o agendamento de plantões e reduzindo o esgotamento de equipes grandes | Escalonamentos automatizados, aplicativos móveis, equilíbrio de carga de trabalho, recomendações de ML, trilhas de auditoria | Preços personalizados | G2: 4,6/5 (50+) Capterra: 4,5/5 (30+) |
| Datadog | Observabilidade completa com monitoramento de segurança para empresas | Monitoramento de infraestrutura + log + aplicativos, segurança na nuvem, detecção de anomalias com IA, mais de 900 integrações | Plano gratuito; planos pagos a partir de US$ 15/mês por usuário | G2: 4,4/5 (660+) Capterra: 4,6/5 (320+) |
| Squadcast | Plantão unificado e resposta a incidentes com preços acessíveis para equipes de médio porte. | Agendamentos automatizados, deduplicação, manuais de operações, páginas de status, análises pós-incidente | Plano gratuito; planos pagos a partir de US$ 12/mês por usuário | G2: 4,4/5 (300+) Capterra: Avaliações insuficientes |
| FireHydrant | Runbooks automatizados e propriedade de serviços para empresas | Runbooks, agendamento de plantões Signals, catálogo de serviços, colaboração Slack/Teams, retrospectivas enriquecidas por IA | Plano gratuito; planos pagos a partir de US$ 9.600/ano por usuário | G2: 4,5/5 (130+) Capterra: Avaliações insuficientes |
| TaskCall | Gerenciamento de incidentes acessível com automação para equipes de médio a grande porte | Agendamento dinâmico de plantões, roteamento com inteligência artificial, alertas multicanais, cobertura DevOps + BizOps | Plano gratuito; planos pagos a partir de US$ 9/mês por usuário | G2: Avaliações insuficientes Capterra: Avaliações insuficientes |
| ilert | Gerenciamento de incidentes com foco em IA e privacidade para equipes em expansão | Alertas multicanais, assistente de resposta com IA, agendamento de plantões, páginas de status automatizadas, integrações com ITSM + ferramentas de monitoramento | Plano gratuito; planos pagos a partir de US$ 24/mês por usuário | G2: Avaliações insuficientes Capterra: 4,7/5 (60+) |
| Zenduty | Resposta a incidentes em grande escala impulsionada por IA para equipes de pequeno a grande porte | Gerenciamento de incidentes ZenAI, agendamento avançado de plantões, manuais automatizados, mais de 150 integrações | Plano gratuito; planos pagos a partir de US$ 6/mês por usuário | G2: 4,6/5 (135+) Capterra: Avaliações insuficientes |
| Incident.io | Resposta a incidentes nativa do Slack para empresas de médio a grande porte | Incidentes de ponta a ponta no Slack, AI SRE, agendamento de plantões, páginas de status automatizadas, painéis de insights | Plano gratuito; planos pagos a partir de US$ 19/mês por usuário | G2: 4,8/5 (180+) Capterra: Avaliações insuficientes |
Critérios-chave para avaliar alternativas ao Opsgenie
Sei que ainda temos quase dois anos antes que ela seja totalmente descontinuada, mas não vejo motivo para esperar 😛
Sei que ainda temos quase dois anos antes que ela seja totalmente descontinuada, mas não vejo motivo para esperar 😛
Esse comentário de um usuário do Reddit captura a realidade que muitas equipes de PMO de TI estão enfrentando. Sim, o Opsgenie foi um bom companheiro por anos, mas confiar nele apenas porque é familiar não ajudará quando o suporte terminar.
O mais sensato a fazer agora é analisar o que tornou o Opsgenie útil em primeiro lugar e usar essas mesmas qualidades como guia ao escolher sua próxima plataforma de gerenciamento de incidentes.
Aqui estão algumas das características que merecem atenção:
- Envie alertas oportunos por meio de vários canais, como telefone, e-mail, SMS ou notificações push.
- Mantenha as notificações direcionadas para que a pessoa certa seja informada sem sobrecarregar o resto da equipe.
- Incorpore políticas de escalonamento que garantam que incidentes críticos nunca sejam ignorados.
- Centralize as atualizações de incidentes para que as equipes possam ter uma visão geral enquanto gerenciam os incidentes.
- Forneça análises pós-incidente para aprender com incidentes semelhantes e melhorar ao longo do tempo.
- Ofereça recursos de integração com ferramentas nas quais suas equipes de TI já confiam.
A Opsgenie construiu sua reputação ajudando equipes de DevOps a reduzir a fadiga de alertas, manter a clareza nos agendamentos de plantão e resolver incidentes sem confusão. Ao explorar cada alternativa ao Opsgenie, mantenha esses mesmos valores em mente.
As 12 melhores alternativas ao Opsgenie
O Opsgenie pode estar chegando ao fim, mas isso não significa que sua equipe precisa perder o ritmo. Aqui estão algumas alternativas adequadas que darão confiança às suas equipes de operações durante momentos críticos.
Como avaliamos softwares no ClickUp
Nossa equipe editorial segue um processo transparente, baseado em pesquisas e neutro em relação aos fornecedores, para que você possa confiar que nossas recomendações são baseadas no valor real do produto.
Aqui está um resumo detalhado de como analisamos softwares na ClickUp.
1. ClickUp (ideal para lidar com fluxos de trabalho de incidentes juntamente com um gerenciamento de projetos mais amplo)
Ao deixar o Opsgenie, as equipes se preocupam menos com a perda de alertas e mais com a adaptação a um novo fluxo de trabalho de gerenciamento de incidentes.
O problema principal é a dispersão do trabalho, em que atualizações, agendas e políticas estão espalhadas por diferentes aplicativos, e-mails e documentos. Essa fragmentação consome energia e obriga as equipes a recomeçarem do zero a cada incidente.
Pesquisas mostram que os funcionários passam 117 minutos vasculhando e-mails e 153 minutos em mensagens do Microsoft Teams por dia útil, com interrupções a cada dois minutos.
O ClickUp surge como uma alternativa ao Opsgenie, reunindo todo esse trabalho desconectado em um único espaço de trabalho convergente. Veja como seus recursos atendem a esses desafios em profundidade.
Fluxos de trabalho de resposta automatizados
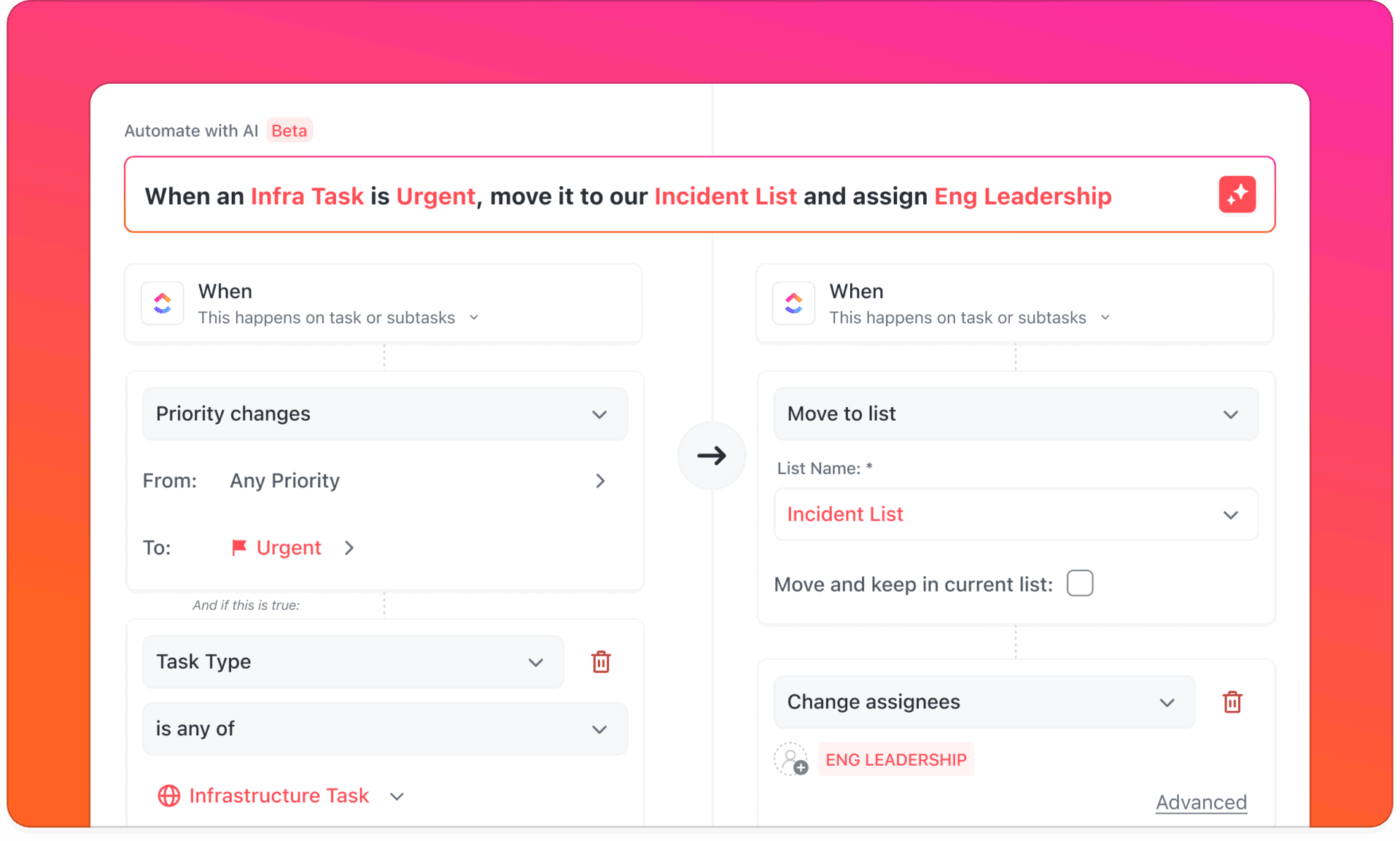
Com alertas provenientes de ferramentas de monitoramento, ferramentas de chat e e-mail, é difícil saber o que é importante e quem deve responder.
Com o ClickUp Automations e os AI Agents, os alertas se transformam em ações significativas. Os alertas recebidos podem criar e atribuir tarefas automaticamente ao engenheiro de plantão, notificando a pessoa certa sem distrair o resto da equipe.
Se não houver resposta dentro de um prazo definido, o sistema automaticamente encaminha a questão de acordo com seus procedimentos padrão.
📌 Exemplo: É relatada uma interrupção de servidor de alta prioridade. O ClickUp Automations cria uma nova tarefa na sua lista de Incidentes, marca-a como urgente, atribui-a ao engenheiro de plantão e envia um alerta push para o celular. Ao mesmo tempo, o seu Agente de IA personalizado publica uma mensagem curta no canal de incidentes no ClickUp Chat para que a equipe seja informada, mas não sobrecarregada.
Clareza e responsabilidade em torno das tarefas
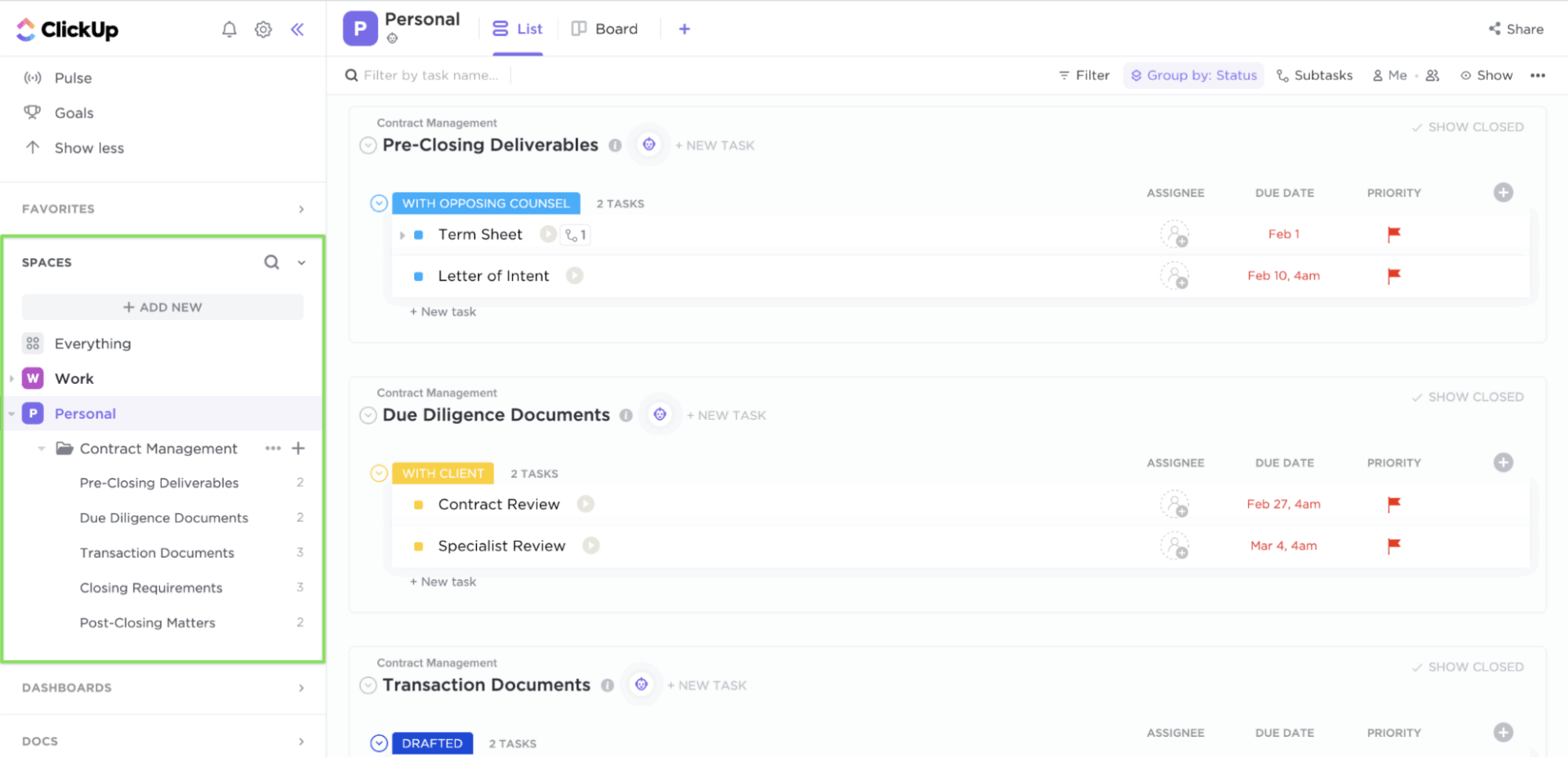
Quando um incidente ocorre, as equipes muitas vezes perdem tempo tentando descobrir o que fazer e quais são os próximos passos. O ClickUp Tasks traz clareza aos seus processos de gerenciamento de incidentes.
Cada tarefa pode ter um responsável, prioridade e prazo claros. Dentro de cada tarefa, você pode adicionar listas de verificação, links de manuais e capturas de tela. Os campos personalizados capturam a gravidade, os serviços afetados ou o estágio de escalonamento, enquanto os status e listas de tarefas personalizadas do ClickUp eliminam a incerteza, mapeando o processo de resposta em uma sequência clara.
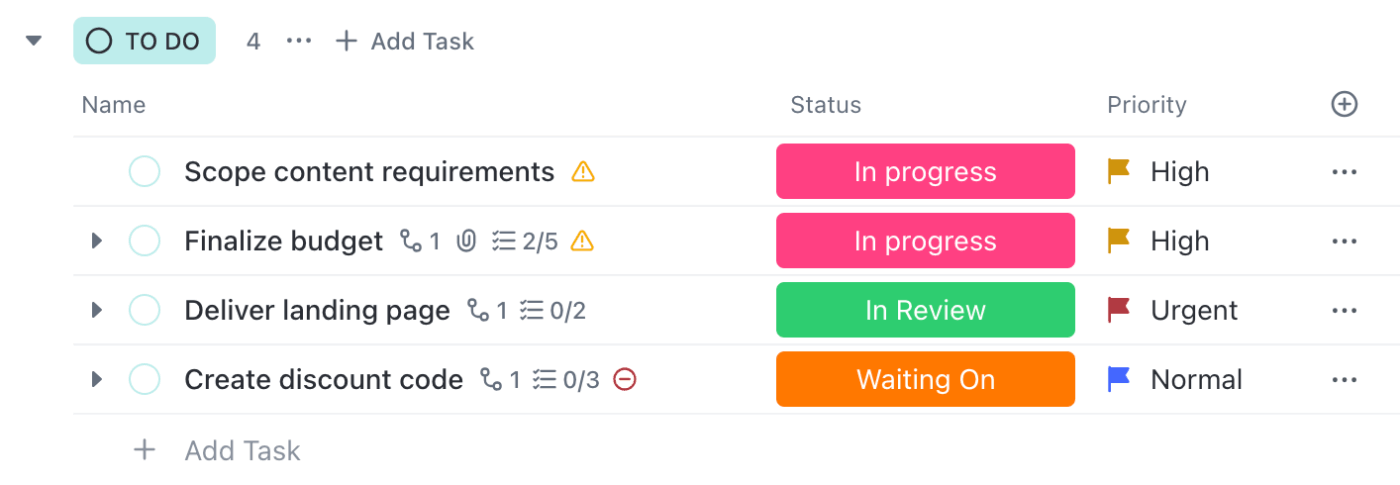
📌 Exemplo: Um incidente “relatado” passa para “em investigação” assim que o engenheiro abre a tarefa. As etapas de mitigação são rastreadas em uma lista de verificação, com notas e registros adicionados na descrição. Cada mudança de status notifica apenas as pessoas relevantes, para que os engenheiros possam trabalhar enquanto os líderes se mantêm informados.
Atualizações que não interrompem o fluxo de trabalho
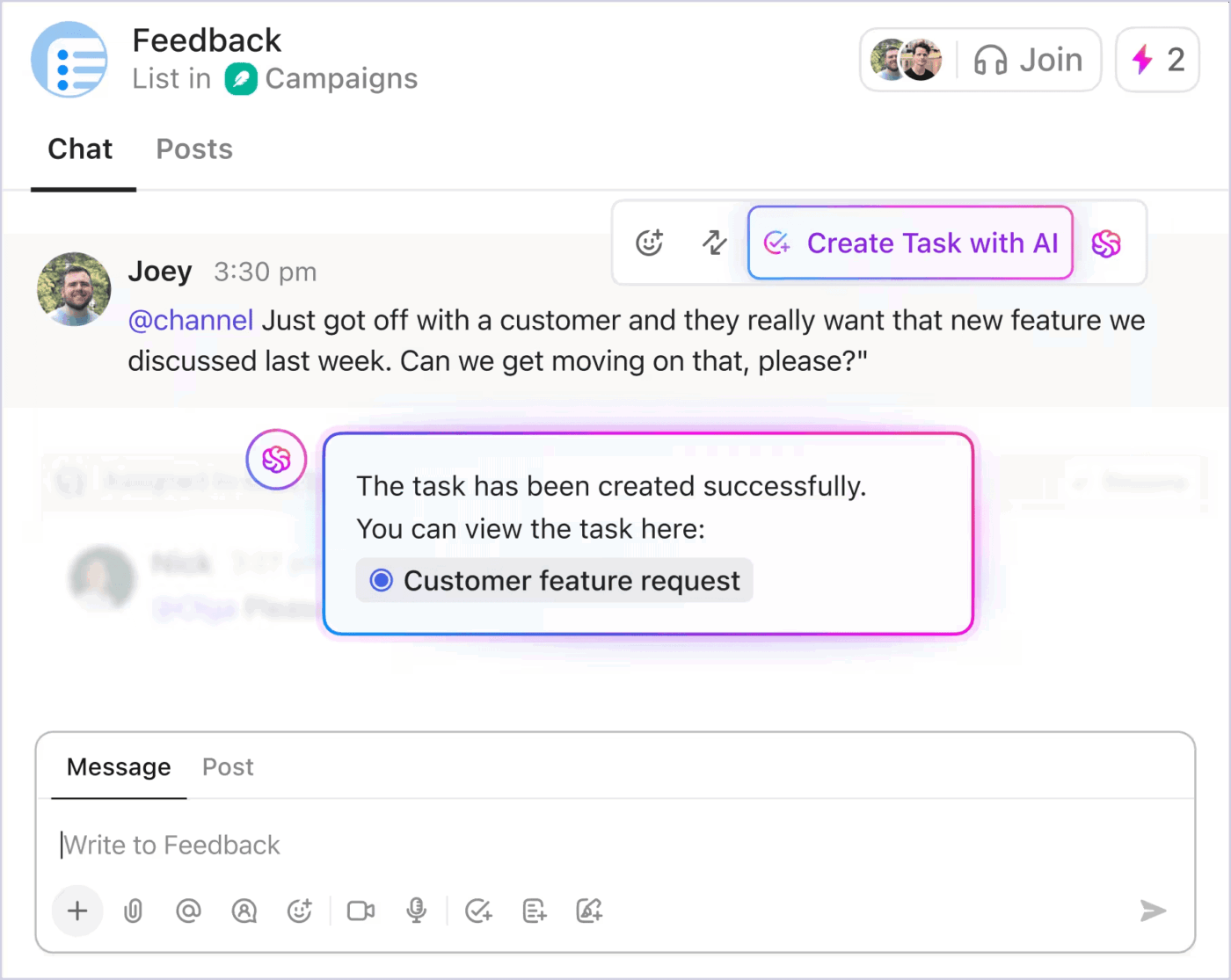
Durante incidentes críticos, as atualizações das partes interessadas não devem interromper os esforços de resposta. O ClickUp Chat resolve isso anexando a conversa diretamente à tarefa do incidente. Os membros da equipe e os líderes podem acompanhar o tópico, ver as decisões tomadas e adicionar comentários em tempo real.
O ClickUp também se integra ao Slack e ao Microsoft Teams, permitindo que as atualizações apareçam nos canais que as pessoas já seguem.
Procurando as melhores dicas quando se trata de colaboração em tempo real? Aqui está um guia:
Análises pós-incidente que levam a mudanças duradouras
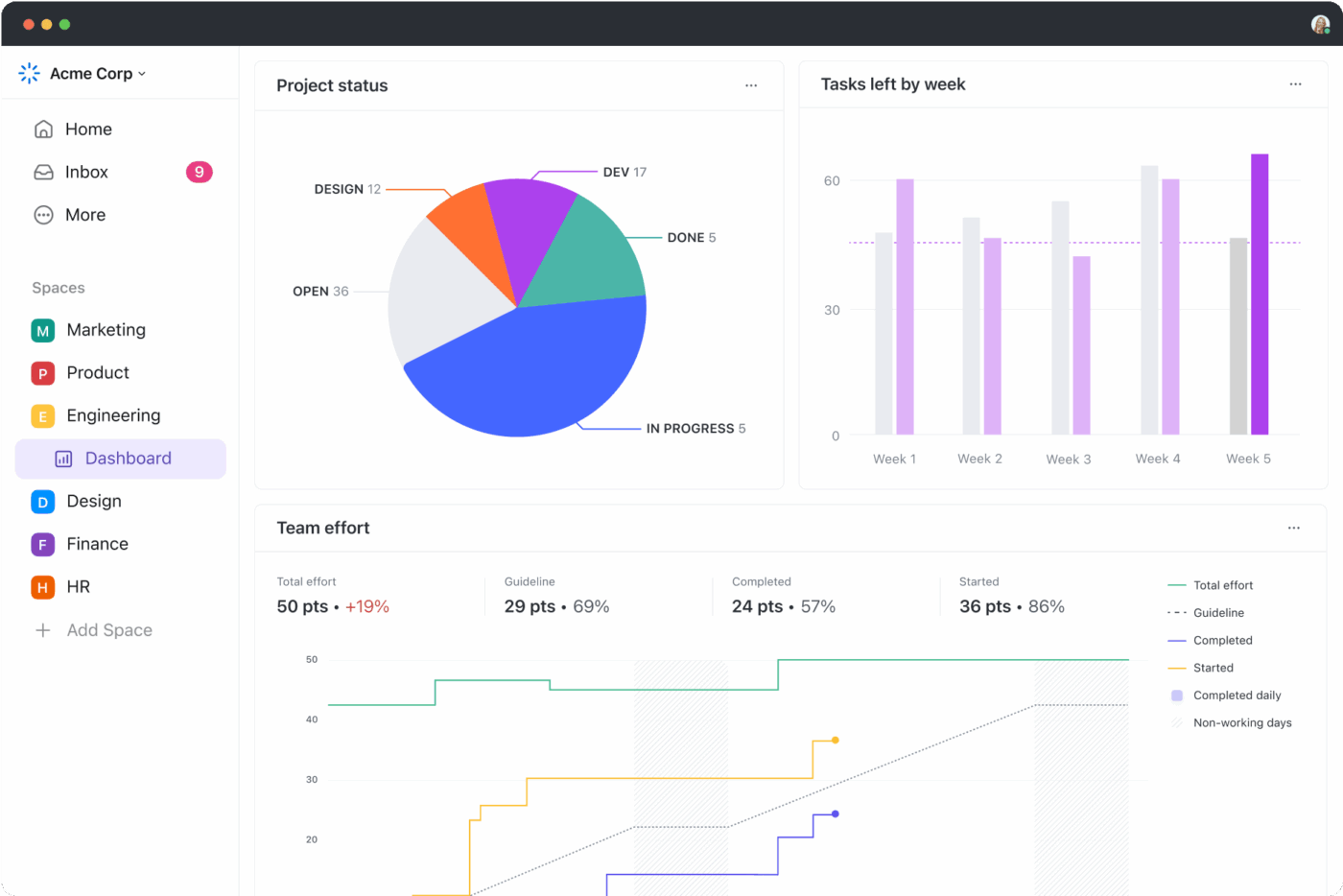
Muitas vezes, as análises pós-incidente são escritas, mas esquecidas. O ClickUp Docs mantém-nas vivas, armazenando análises pós-incidente padronizadas diretamente ao lado das tarefas do incidente.
Enquanto isso, os painéis do ClickUp exibem métricas como tempo médio de resolução, frequência de incidentes e padrões recorrentes. Essa visibilidade ajuda as equipes de TI e DevOps a passar de um modo reativo de combate a incêndios para uma melhoria proativa.
💡 Dica profissional: as análises pós-incidente podem levar horas de redação, edição e pesquisa de contexto. O ClickUp Brain muda isso ao reunir notas, cronogramas e itens de ação automaticamente. Ele pode resumir uma tarefa de incidente, redigir um relatório pós-incidente no ClickUp Docs e até mesmo sugerir as próximas etapas com base em incidentes semelhantes.
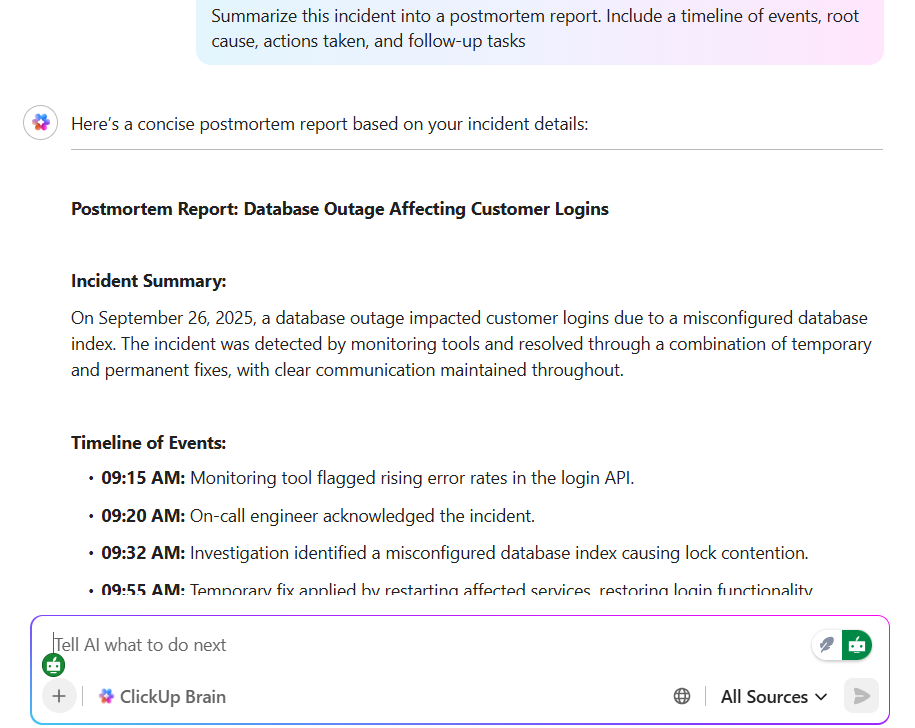
Com o ClickUp Brain Max, você obtém a velocidade adicional do Talk to Text do ClickUp — dite seus pensamentos em tempo real e veja-os se transformarem em notas refinadas, prontas para serem compartilhadas. Juntos, eles ajudam as equipes a economizar quase um dia inteiro por semana, eliminando o trabalho pesado de escrever e pesquisar, para que você possa se concentrar em prevenir o próximo incidente, em vez de recontar o último.
Organize-se e economize tempo com modelos

Em uma emergência, você realmente aprende a valorizar um processo claro e passo a passo.
O modelo de plano de ação para incidentes do ClickUp é exatamente isso. Ele define exatamente o que precisa ser feito, quem precisa fazer e em que ordem. Ele mantém todos alinhados, reduz riscos e garante que nenhuma etapa seja esquecida.
Outro desafio na área de TI é documentar incidentes de maneira eficaz para que padrões possam ser identificados e evitados no futuro. O modelo de relatório de incidentes de TI do ClickUp simplifica a geração de relatórios, transformando cada problema em um ponto de dados valioso.
Melhores recursos do ClickUp
- Reduza a fadiga de alertas com as notificações personalizáveis do ClickUp, que garantem que apenas as pessoas certas sejam alertadas.
- Automatize a criação, atribuição e relatório de tarefas de incidentes com o ClickUp Automations e os AI Agents.
- Crie fluxos de trabalho claros para incidentes com as tarefas, listas e status do ClickUp, além de modelos de relatórios de incidentes para orientar cada etapa da resposta.
- Permita a colaboração em equipe com o ClickUp Chat e o ClickUp Docs, para que conversas, atualizações e conclusões acompanhem o incidente.
- Acompanhe o status das tarefas e os relatórios de incidentes por meio dos painéis do ClickUp.
- Gere insights a partir de incidentes e tarefas concluídas e crie ou atualize SOPs para melhorias futuras com o ClickUp Brain.
Limitações do ClickUp
- A flexibilidade da plataforma pode parecer excessiva para equipes menores que desejam apenas alertas básicos e gerenciamento de plantões.
Preços do ClickUp
Avaliações e comentários sobre o ClickUp
- G2: 4,7/5 (mais de 10.500 avaliações)
- Capterra: 4,6/5 (mais de 4.500 avaliações)
O que os usuários estão dizendo sobre o ClickUp
Este usuário do G2 relatou:
Trabalhar em conjunto em um projeto ficou muito mais fácil desde a implementação do ClickUp, pois as tarefas podem ser facilmente atribuídas aos membros e você pode acompanhar o progresso por meio do chat. Ele ainda envia notificações por e-mail e alertas de atraso no caso de uma tarefa não concluída.
Trabalhar em conjunto em um projeto ficou muito mais fácil desde a implementação do ClickUp, pois as tarefas podem ser facilmente atribuídas aos membros e você pode acompanhar o progresso por meio do chat. Ele ainda envia notificações por e-mail e alertas de atraso no caso de uma tarefa não concluída.
📖 Leia também: Como redigir um relatório de incidente no trabalho
2. PagerDuty (ideal para alertas de incidentes em tempo real e automação em escala)
Se você está deixando o Opsgenie, sua primeira preocupação é simples. A pessoa certa receberá o alerta, no momento certo, no canal certo?
O PagerDuty foi criado para eliminar esse estresse. Você define serviços, horários e políticas claras de escalonamento para que a responsabilidade nunca seja questionada. Sinais do CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom e outros chegam em um único lugar e são agrupados em um único incidente, em vez de 15 pings separados.
A Inteligência de Eventos reduz duplicatas e correlaciona problemas relacionados, o que diminui a fadiga de alertas sem silenciar os problemas reais. Os respondentes podem confirmar ou escalar a partir do aplicativo móvel ou diretamente do Slack ou Teams, com salas de incidentes e pontes criadas automaticamente.
Após a resolução, as análises revelam o tempo para reconhecer, o tempo para resolver e os pontos críticos recorrentes, para que você possa corrigir as causas principais em vez de perseguir os sintomas.
Melhores recursos do PagerDuty
- Permita que os usuários personalizem alertas por SMS, telefone, e-mail, push e Slack para reduzir o ruído sem perder incidentes críticos.
- Simplifique a configuração com alertas de teste, integrações de serviços e um design simples de políticas de escalonamento.
- Suporte para escalas de plantão e escalações que notificam a pessoa certa e continuam até serem confirmadas.
- Habilite ações de incidentes baseadas no Slack, como reconhecer, resolver e escalar diretamente no chat.
- Reduza a fadiga de alertas com o AIOps, que agrupa duplicatas e destaca incidentes urgentes.
Limitações do PagerDuty
- Os líderes de equipe não podem personalizar totalmente os métodos de entrega de alertas no nível da equipe, limitando a flexibilidade quando os gerentes desejam regras de escalonamento consistentes.
- Os alertas por e-mail não têm a capacidade de resposta por ação, obrigando os responsáveis pela resposta a clicar na plataforma em vez de gerenciar diretamente da caixa de entrada.
- Recursos avançados, como AIOps e licenças de comunicação com as partes interessadas, têm custos adicionais elevados.
Preços do PagerDuty
- Gratuito
- Profissional: US$ 25/mês por usuário
- Negócios: US$ 49/mês por usuário
- Empresa: Preços personalizados
Avaliações e comentários sobre o PagerDuty
- G2: 4,5/5 (mais de 900 avaliações)
- Capterra: 4,6/5 (mais de 200 avaliações)
O que os usuários estão dizendo sobre o PagerDuty
Este usuário do G2 mencionou:
Adoro que o pager duty tenha vários alertas sonoros diferentes, alguns deles são hilários. Desde que comecei a usar o pager duty, tenho conseguido responder a incidentes e envolver as equipes com mais eficiência.
Adoro que o pager duty tenha vários alertas sonoros diferentes, alguns deles são hilários. Desde que comecei a usar o pager duty, tenho conseguido responder a incidentes e envolver as equipes com mais eficiência.
📖 Leia também: O que é um plano de contingência e como desenvolvê-lo?
3. xMatters (ideal para gerenciamento e automação de incidentes com boa relação custo-benefício)
Um usuário do Reddit resumiu isso da melhor maneira:
Você recebe o que paga, mas paga menos. Tem tudo o que você deseja, embora definitivamente não seja tão sofisticado quanto o PagerDuty.
Você recebe o que paga, mas paga menos. Tem tudo o que você deseja, embora definitivamente não seja tão sofisticado quanto o PagerDuty.
Essa frase resume o posicionamento da xMatters: acessível, confiável e forte nas áreas mais importantes.
Se você está deixando o Opsgenie, sua dor geralmente é dupla. Muito barulho que acorda as pessoas erradas e incerteza sobre quem é responsável pela próxima ação. O xMatters resolve ambos os problemas, permitindo que você mapeie serviços e escalas de plantão e, em seguida, encaminhe alertas com contexto preciso para que a pessoa certa seja contatada no canal certo.
Os usuários apreciam as notificações direcionadas com detalhes úteis, além de uma trilha de auditoria completa que mostra quem foi chamado, quem confirmou e quando. Esse registro facilita as revisões pós-incidente e as verificações de conformidade.
O criador de fluxos de trabalho de baixo código transforma um sinal do Datadog, Prometheus ou ServiceNow em uma sequência clara de ações.
Com automação de fluxo de trabalho e gerenciamento adaptativo de projetos DevOps em seu núcleo, o xMatters ajuda as equipes a se moverem mais rapidamente e a eliminar o ruído dos alertas.
Melhores recursos do xMatters
- Automatize fluxos de trabalho de incidentes com integrações sem código e com pouco código que aceleram a resolução e reduzem as tarefas manuais.
- Gerencie escalas de plantão e escalações de forma integrada para que a pessoa certa seja sempre alertada no momento certo.
- Aplique o gerenciamento adaptativo de incidentes para minimizar o impacto no cliente e capturar aprendizados de cada evento.
- Filtre o ruído com inteligência de sinal, correlação de alertas e notificações aprimoradas para um contexto mais claro.
- Acesse análises acionáveis para identificar ineficiências e melhorar a colaboração entre equipes.
Limitações do xMatters
- A interface e a experiência do usuário parecem menos refinadas em comparação com os concorrentes.
- Relatórios e análises avançadas são limitados nos planos de nível inferior.
- A cobertura do suporte global varia de acordo com o plano selecionado.
Preços do xMatters
- Gratuito
- Starter (Essentials): US$ 9/mês por usuário
- Base (Padrão): US$ 39/mês por usuário
- Avançado: Preços personalizados
Avaliações e comentários sobre o xMatters
- G2: 4,5/5 (mais de 670 avaliações)
- Capterra: 4,6/5 (mais de 140 avaliações)
O que os usuários dizem sobre o xMatters
Esta análise da Capterra apresentou:
Quando temos um incidente de segurança de dados na empresa, o Xmatters ativa os protocolos de resposta imediatamente: ele organiza os protocolos de ação da equipe de acordo com suas funções. As notificações são enviadas por vários meios.
Quando temos um incidente de segurança de dados na empresa, o Xmatters ativa os protocolos de resposta imediatamente: ele organiza os protocolos de ação da equipe de acordo com suas funções. As notificações são enviadas por vários meios.
📮 ClickUp Insight: 28% dos funcionários dizem que o trabalho os acompanha após o expediente, e outros 8% frequentemente têm dificuldade para desligar. Isso significa que mais de um terço leva o estresse para casa.
Use os lembretes do ClickUp para proteger sua rotina noturna. Defina um lembrete diário de encerramento, notificações silenciosas fora do horário de trabalho e reserve tempo pessoal em sua agenda. Desligar-se deve ser uma escolha sua.
💫 Resultados reais: a Lulu Press economiza cerca de uma hora por pessoa por dia com as automações do ClickUp, levando a um aumento de 12% na eficiência.
4. AlertOps (ideal para redução de ruído com tecnologia de IA e resposta rápida a incidentes)
O volume de alertas continua a aumentar, com 88% das equipes relatando um aumento no último ano e quase metade afirmando que esses picos foram superiores a 25%. Esse tipo de ruído constante leva à fadiga de alertas, que 76% dos SOCs (Centros de Operações de Segurança) agora citam como seu principal desafio.
Essa é a realidade que você traz para qualquer substituto do Opsgenie. A próxima ferramenta que você escolher deve ser capaz de avaliar quais alertas merecem ação. O AlertOps se baseia nisso com o OpsIQ, um núcleo de IA que filtra duplicatas, correlaciona sinais relacionados, resume o contexto e sugere as próximas etapas para que os respondentes vejam um incidente claro em vez de um feed rolante.
Você pode começar com a programação de plantão padrão ou criar a sua própria e, em seguida, encaminhar por telefone, SMS, aplicativo móvel, chat ou e-mail com regras de escalonamento que continuam funcionando até que alguém assuma a responsabilidade pelo problema. O encaminhamento de chamadas ao vivo direciona os clientes para a equipe de plantão atual com base em programações em tempo real, e as políticas baseadas em SLA são escalonadas antes de uma violação, e não depois.
Além disso, a plataforma se integra a mais de 200 ferramentas, desde monitoramento e emissão de tickets até O365 e Slack, para que a triagem não seja prejudicada pela falta de contexto.
Melhores recursos do AlertOps
- Filtre e suprime alertas duplicados com a redução de ruído impulsionada por IA da OpsIQ™, que resume os alertas e sugere resoluções automaticamente.
- Gerencie escalas de plantão com regras de escalonamento flexíveis, cobertura 24 horas por dia e encaminhamento de chamadas ao vivo para questões críticas dos clientes.
- Automatize a triagem e os fluxos de trabalho usando modelos de TI sem código para acelerar a resposta e garantir que os incidentes sejam tratados de forma consistente.
- Integre com mais de 200 ferramentas prontas para uso, incluindo Slack, O365, Jira, Dynatrace e ConnectWise, além de integrações personalizadas para aplicativos internos.
Limitações do AlertOps
- A configuração da programação pode parecer pouco intuitiva no início e pode exigir tentativa e erro.
- A interface do usuário tem algumas falhas ocasionais, com alguns recursos avançados exigindo etapas extras para configuração.
- Foram relatados atrasos na sincronização do calendário com sistemas externos, como o Outlook.
Preços do AlertOps
- Starter: Gratuito
- Padrão: US$ 10/mês por usuário
- Premium: US$ 22/mês por usuário
- Empresa: US$ 34/mês por usuário
Avaliações e comentários do AlertOps
- G2: 4,7/5 (mais de 150 avaliações)
- Capterra: 4,7/5 (mais de 20 avaliações)
O que os usuários dizem sobre o AlertOps
Esta avaliação da G2 deixa isso claro:
Passamos a maior parte do terceiro trimestre do ano passado testando ferramentas de programação/alertas para uma de nossas equipes de TI. Depois de encontrar o AlertOps, parei de procurar. Ele é acessível, a equipe é incrivelmente prestativa e paciente no processo de configuração e implementação e, desde que tudo foi totalmente configurado e colocado em funcionamento, não tivemos nenhum problema!
Passamos a maior parte do terceiro trimestre do ano passado testando ferramentas de programação/alertas para uma de nossas equipes de TI. Depois de encontrar o AlertOps, parei de procurar. Ele é acessível, a equipe é incrivelmente prestativa e paciente no processo de configuração e implementação e, desde que tudo foi totalmente configurado e colocado em funcionamento, não tivemos nenhum problema!
5. Splunk On-Call (ideal para simplificar o agendamento de plantões e reduzir o esgotamento)
Se você já assistiu ao clássico sketch Abbott e Costello “Quem está em primeiro lugar?”, sabe como é confuso tentar descobrir quem é realmente responsável por quê. As rotações de plantão podem parecer da mesma forma quando não há um sistema claro em vigor.
É aí que o Splunk On-Call entra em cena. ✨
Você mapeia equipes e programações uma vez, e os alertas chegam com contexto em qualquer dispositivo. Os respondentes podem confirmar, redirecionar ou adiar a partir do aplicativo iOS ou Android, e a plataforma pode abrir uma sala para colaboração e iniciar a revisão pós-incidente sem etapas extras.
Um mecanismo de regras anexa manuais de operações e painéis aos incidentes para que a primeira pessoa chamada nunca comece do zero. O aprendizado de máquina sugere os respondedores certos com base em incidentes semelhantes, o que ajuda a reduzir o tempo para reconhecer e resolver.
Melhores recursos do Splunk On-Call
- Automatize escalonamentos e fluxos de trabalho de resposta a incidentes para obter reconhecimento e resolução mais rápidos.
- Use aplicativos iOS e Android para receber, adiar, redirecionar ou resolver alertas diretamente de um dispositivo móvel.
- Simplifique o agendamento com rotações, substituições e políticas de escalonamento projetadas para equilibrar as cargas de trabalho de maneira justa.
- Obtenha o contexto do incidente e trilhas de auditoria históricas para apoiar uma triagem mais rápida e análise pós-incidente.
- Aplique recomendações de aprendizado de máquina para identificar os respondedores certos com base em dados de resoluções anteriores.
Limitações do Splunk On-Call
- A interface pode parecer complexa no início, e a navegação requer algum ajuste.
- Atrasos ocasionais durante períodos de alto tráfego afetam a capacidade de resposta em tempo real.
- As opções de licenciamento e gerenciamento de usuários são mais limitadas em comparação com alguns concorrentes.
Preços do Splunk On-Call
- Preços personalizados
Avaliações e comentários sobre o Splunk On-Call
- G2: 4,6/5 (mais de 50 avaliações)
- Capterra: 4,5/5 (mais de 30 avaliações)
O que os usuários dizem sobre o Splunk On-Call
Esta avaliação da G2 observa:
A possibilidade de criar equipes e configurar turnos entre elas é um dos recursos mais úteis disponíveis nesta plataforma. O Splunk On-Call oferece integrações fáceis com várias ferramentas, tornando sua configuração muito simples de configurar.
A possibilidade de criar equipes e configurar turnos entre elas é um dos recursos mais úteis disponíveis nesta plataforma. O Splunk On-Call oferece integrações fáceis com várias ferramentas, tornando sua configuração muito simples de configurar.
📝Leia também: Eliminando a proliferação da IA: como a IA contextual transforma a produtividade no local de trabalho
6. Datadog (ideal para observabilidade completa com monitoramento de segurança integrado)
Para os usuários do Opsgenie, o problema é o contexto. Um alerta é disparado, mas você ainda precisa procurar logs, rastreamentos, métricas e sinais de segurança para saber o que realmente está errado.
O Datadog reúne essas visualizações em uma única linha do tempo. Infraestrutura, contêineres, serverless, bancos de dados e aplicativos ficam ao lado de logs, rastreamentos e RUM para que os respondedores não precisem adivinhar.
O Watchdog e os novos recursos de IA destacam anomalias, agrupam sinais relacionados e resumem o impacto provável, o que reduz as idas e vindas durante a triagem. Se você já possui uma ferramenta de paging, pode alimentá-la com alertas do Datadog.
Se você deseja permanecer no Datadog, o Gerenciamento de Incidentes oferece proprietários, cronogramas, atualizações das partes interessadas e acompanhamentos sem sair da plataforma.
Os benefícios práticos aparecem rapidamente. Menos alertas ruidosos, pois as duplicatas são agrupadas. Análise mais rápida da causa raiz, pois cada alerta traz as métricas e os registros que o explicam. Postura de segurança mais forte, pois as configurações incorretas e as vulnerabilidades aparecem junto com os dados de desempenho.
Com mais de 900 integrações, SLOs (Objetivos de Nível de Serviço) claros e painéis, sua equipe pode passar do sinal à correção em um único lugar, em vez de ficar alternando entre abas. Essa é uma boa escolha para migrações do Opsgenie que também desejam eliminar lacunas de observabilidade.
Melhores recursos do Datadog
- Monitore infraestrutura, logs, aplicativos, bancos de dados e cargas de trabalho sem servidor a partir de uma única plataforma.
- Ambientes de nuvem seguros com gerenciamento de vulnerabilidades integrado, mapeamento de conformidade e gerenciamento de direitos.
- Use monitoramento sintético e monitoramento de usuários reais para detectar problemas antes que os clientes percebam.
- Automatize fluxos de trabalho com mais de 900 integrações e painéis pré-construídos.
- Aplique recursos de IA e aprendizado de máquina, como Watchdog e LLM Observability, para detecção de anomalias e insights inteligentes.
Limitações do Datadog
- Os preços podem aumentar rapidamente com um grande número de hosts e complementos.
- A interface e os painéis podem parecer complicados para novos usuários.
- Alguns recursos avançados de segurança estão disponíveis apenas em planos de nível superior.
Preços do Datadog
- Gratuito
- Pro: US$ 15/mês por host
- Empresa: US$ 23/mês por host
- DevSecOps Pro: US$ 22/mês por host
- DevSecOps Enterprise: US$ 34/mês por host
Avaliações e comentários do Datadog
- G2: 4,4/5 (mais de 660 avaliações)
- Capterra: 4,6/5 (mais de 320 avaliações)
O que os usuários dizem sobre o Datadog
Esta avaliação da Capterra citou:
No geral, após alguns altos e baixos, eles têm sido um bom parceiro. Sua ferramenta é extremamente poderosa e permite muitas práticas excelentes em torno da observabilidade, mas você precisa pagar por ela.
No geral, após alguns altos e baixos, eles têm sido um bom parceiro. Sua ferramenta é extremamente poderosa e permite muitas práticas excelentes em torno da observabilidade, mas você precisa pagar por ela.
7. Squadcast (ideal para atendimento de plantão e resposta a incidentes unificados com excelente custo-benefício)
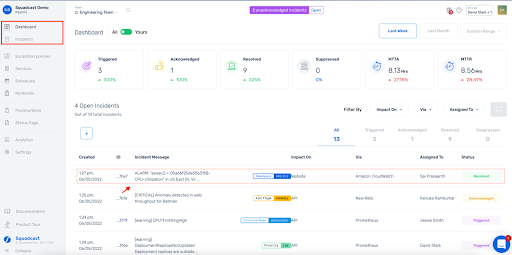
Quando você lida com várias escalas e regras específicas do cliente fora do horário comercial, precisa de alertas para respeitar essas regras sem precisar de ajuda.
Esse é o nicho em que o Squadcast conquista a confiança. 🌟
Os usuários observaram que as escalas e substituições são fáceis de modelar e que o aplicativo móvel continuará escalando se o primeiro respondente não atender, para que questões críticas não sejam ignoradas.
Para MSPs e equipes com muitos clientes, as pessoas gostam que você possa definir cobertura 24 horas por dia, 7 dias por semana, para determinados clientes, enquanto permite que outros acionem alertas fora do horário comercial apenas para incidentes críticos. A interface do usuário facilita a visualização de incidentes ativos e quem está de plantão.
Há mais do que apenas paging. A automação confiável move os incidentes por meio de fluxos de trabalho consistentes com runbooks e atualizações de status, rastreamento de SLO e cronogramas que revelam padrões nos quais você pode realmente agir, e os preços são transparentes o suficiente para que equipes menores não se sintam excluídas.
Melhores recursos do Squadcast
- Automatize o agendamento de plantões com escalonamentos e substituições flexíveis.
- Reduza a fadiga de alertas consolidando e deduplicando notificações.
- Resolva incidentes mais rapidamente com manuais de operações e fluxos de trabalho
- Mantenha as partes interessadas informadas por meio de páginas de status personalizáveis.
- Capture análises pós-incidente e insights para construir uma cultura de aprendizagem.
Limitações do Squadcast
- As visualizações de programação podem ficar confusas quando muitas escalas estão ativas, o que torna mais difícil verificar quem está de plantão rapidamente.
- Foram relatados atrasos ocasionais na sincronização de alertas de determinadas integrações.
- O plano gratuito é limitado para equipes que desejam páginas de status e análises mais detalhadas.
Preços do Squadcast
- Pro: US$ 12/mês por usuário
- Premium: US$ 19/mês por usuário
- Empresa: Preços personalizados
Avaliações e comentários do Squadcast
- G2: 4,4/5 (mais de 300 avaliações)
- Capterra: Avaliações insuficientes
O que os usuários estão dizendo sobre o Squadcast
Esta avaliação da G2 mencionou:
O Squadcast pode receber informações de várias ferramentas de monitoramento que temos e é fácil configurar escalas e substituições para quem deve ser alertado para diferentes tipos de problemas.
O Squadcast pode receber informações de várias ferramentas de monitoramento que temos e é fácil configurar escalas e substituições para quem deve ser alertado para diferentes tipos de problemas.
📖 Leia também: Gestão de riscos de segurança cibernética
8. FireHydrant (ideal para runbooks automatizados e propriedade de serviços)
Este software de gerenciamento de incidentes oferece um processo bem estruturado que mantém os serviços funcionando perfeitamente.
O FireHydrant concentra as respostas em runbooks, um catálogo de serviços e um espaço de trabalho compartilhado. Declare um incidente e a plataforma cria um canal no Slack ou Teams, anexa o runbook correto, obtém a propriedade do catálogo de serviços e inicia uma linha do tempo auditável.
Enquanto isso, sua IA mantém os custos baixos com resumos instantâneos de incidentes, sugestões de atualizações para as partes interessadas e transcrições de reuniões ao vivo, para que a equipe possa se concentrar na mitigação, em vez de tomar notas.
As equipes também destacam o suporte responsivo e uma abordagem API first com o Terraform, que permite que os líderes de operações conectem o FireHydrant aos fluxos de trabalho existentes sem atritos.
Melhores recursos do FireHydrant
- Automatize a resposta a incidentes com manuais que codificam as melhores práticas.
- Gerencie escalas de plantão e alertas com o Signals, completo com políticas de escalonamento.
- Centralize a responsabilidade por meio do Catálogo de Serviços para que os engenheiros certos respondam imediatamente.
- Colabore diretamente no Slack ou no Teams com canais e atualizações gerados automaticamente.
- Use retrospectivas e análises enriquecidas por IA para capturar insights e aprimorar a confiabilidade ao longo do tempo.
Limitações do FireHydrant
- Recursos avançados de automação exigem planos de nível superior
- Curva de aprendizado para configurar fluxos de trabalho personalizados e integrações
- Respondentes e manuais de procedimentos limitados no plano básico
Preços do FireHydrant
- Gratuito: avaliação por duas semanas
- Platform Pro: US$ 9.600/ano por usuário
- Empresa: Preços personalizados
Avaliações e comentários do FireHydrant
- G2: 4,5/5 (mais de 130 avaliações)
- Capterra: Avaliações insuficientes
O que os usuários dizem sobre o FireHydrant
Este usuário do G2 comentou:
Funcionando totalmente no Slack ou em alguma outra ferramenta de chat/colaboração, o FireHydrant se integra e permite que você abra/atualize/resolva incidentes sem precisar sair do local onde a ação de resposta a incidentes está ocorrendo.
Funcionando totalmente no Slack ou em alguma outra ferramenta de chat/colaboração, o FireHydrant se integra e permite que você abra/atualize/resolva incidentes sem precisar sair do local onde a ação de resposta a incidentes está ocorrendo.
9. TaskCall (ideal para gerenciamento de incidentes acessível com automação)
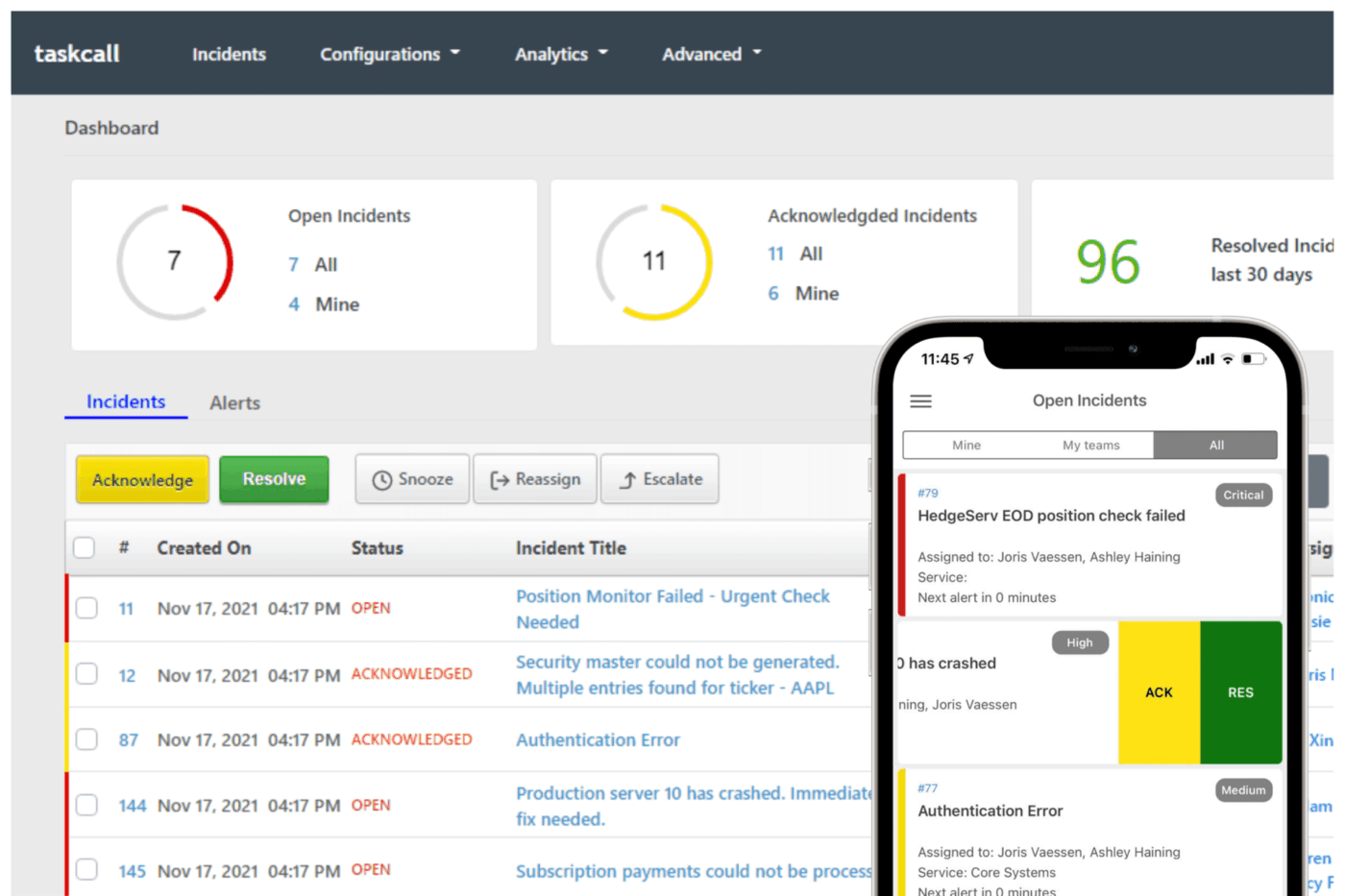
Em um estudo recente sobre riscos cibernéticos, a resposta a incidentes foi identificada como um dos principais controles que as organizações devem fortalecer para reduzir a exposição.
Isso ressalta como os fluxos de trabalho rápidos e confiáveis para incidentes se tornaram essenciais.
As equipes geralmente tropeçam não no alerta em si, mas na confusão que se segue. Quem está realmente no comando agora? O alerta pertence ao aplicativo, à infraestrutura ou às operações do cliente? Como manter os líderes informados sem atrapalhar a solução?
O TaskCall lida diretamente com esses momentos. O plantão é determinado a partir do conteúdo do incidente, para que o encaminhamento chegue ao respondente certo, e o escalonamento automático cubra as lacunas. As notificações chegam por telefone, SMS, push, e-mail ou chat.
Para reduzir o ruído, a inteligência de eventos correlaciona duplicatas e suprime pings de baixo valor. O contexto é reunido através da extração de sinais de ferramentas como AWS, Datadog, Slack, Jira e Zendesk, o que significa que os engenheiros veem o impacto e a responsabilidade, em vez de um fluxo de alertas brutos.
Melhores recursos do TaskCall
- Automatize o agendamento de plantões com rotações dinâmicas e escalonamentos em vários níveis.
- Reduza o ruído com inteligência de eventos alimentada por IA e roteamento condicional.
- Lide com incidentes em DevOps, IT-Ops e BizOps em uma plataforma unificada.
- Integre com ferramentas de monitoramento, registro e suporte, como AWS, Jira, Zendesk e Slack.
- Ofereça cobertura total com aplicativos móveis, notificações push, SMS e alertas de voz.
Limitações do TaskCall
- Plano gratuito limitado a cinco usuários, o que pode não ser suficiente para equipes em crescimento.
- A maioria das análises e painéis está limitada aos planos mais caros.
Preços do TaskCall
- Gratuito
- Starter: US$ 9/mês por usuário
- Negócios: US$ 19/mês por usuário
- Operações digitais: US$ 29/mês por usuário
Avaliações e comentários do TaskCall
- G2: Avaliações insuficientes
- Capterra: Avaliações insuficientes
10. ilert (ideal para gerenciamento de incidentes com foco em IA e privacidade)
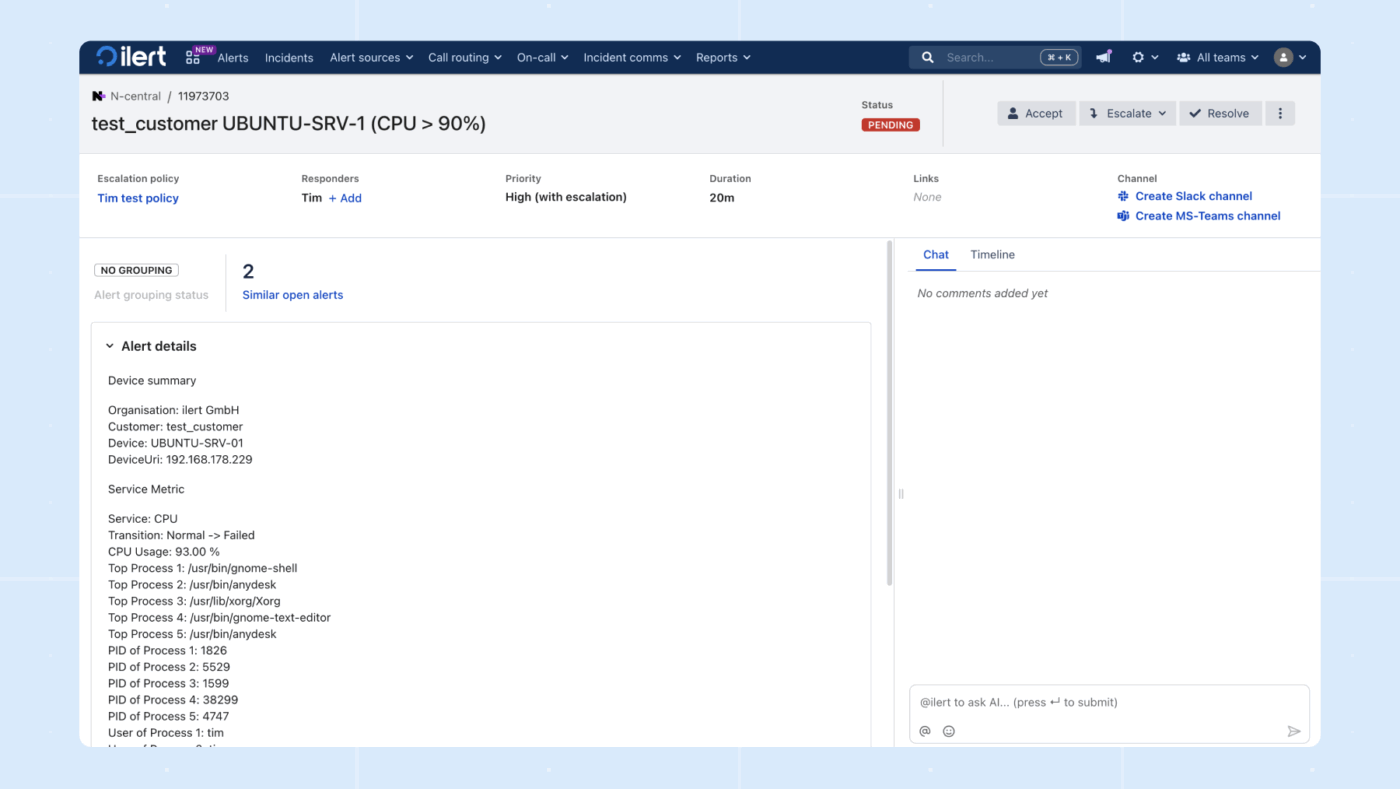
O ilert é uma plataforma de gerenciamento de plantões e alertas de incidentes com forte foco em confiabilidade e privacidade de dados. Ele ajuda as equipes a garantir que alertas críticos dos sistemas de monitoramento cheguem prontamente aos engenheiros de plantão certos.
A plataforma oferece agendamento flexível de plantões, políticas de escalonamento em várias camadas e notificações por vários canais, incluindo push, SMS e chamadas de voz.
O encaminhamento que respeita a programação atual e o caminho de escalonamento significa que as chamadas dos clientes chegam à pessoa certa, em vez de ficarem pulando de um telefone para outro.
No Slack ou no Teams, os respondentes trabalham no incidente no chat, enquanto o Ilert captura o contexto, os cronogramas e os acompanhamentos.
O AI Voice Agent atende sua linha direta, coleta os detalhes certos e notifica imediatamente o engenheiro de plantão. O Responder analisa métricas, registros e alterações recentes em toda a sua pilha, revela as causas prováveis, sugere quem mais deve ser chamado e até propõe um caminho de reversão para uma mitigação mais rápida.
Você mantém o controle em todas as etapas.
Melhores recursos do ilert
- Forneça alertas multicanais confiáveis por voz, SMS, push e chat.
- Automatize o gerenciamento de plantões com rotas de escalonamento e programação.
- Forneça atualizações rápidas por meio de páginas de status com tecnologia de IA e comunicações com as partes interessadas.
- Use o ilert Responder AI para analisar incidentes, identificar as causas principais e sugerir ações.
- Integre-se a ferramentas de monitoramento e ITSM, como Prometheus, Datadog, Jira e Slack.
Limitações do ilert
- Os preços podem parecer altos para equipes menores.
- Algumas integrações exigem um esforço extra de configuração.
- O aplicativo móvel poderia se beneficiar de recursos mais avançados.
Preços do ilert
- Gratuito
- Pro: US$ 24/mês por usuário
- Escala: US$ 49/mês por usuário
- Empresa: Preços personalizados
Avaliações e comentários do ilert
- G2: Avaliações insuficientes
- Capterra: 4,7/5 (mais de 60 avaliações)
O que os usuários dizem sobre o ilert
Esta avaliação da Capterra relatou:
Acho essa ferramenta muito intuitiva e eficaz para gerenciar turnos de plantão em equipes de TI. Ela oferece flexibilidade, permitindo respostas diretamente pelo aplicativo, SMS ou telefonema, o que a torna especialmente prática em cenários reais.
Acho essa ferramenta muito intuitiva e eficaz para gerenciar turnos de plantão em equipes de TI. Ela oferece flexibilidade, permitindo respostas diretamente pelo aplicativo, SMS ou telefonema, o que a torna especialmente prática em cenários reais.
11. Zenduty (ideal para resposta a incidentes em grande escala com base em IA)
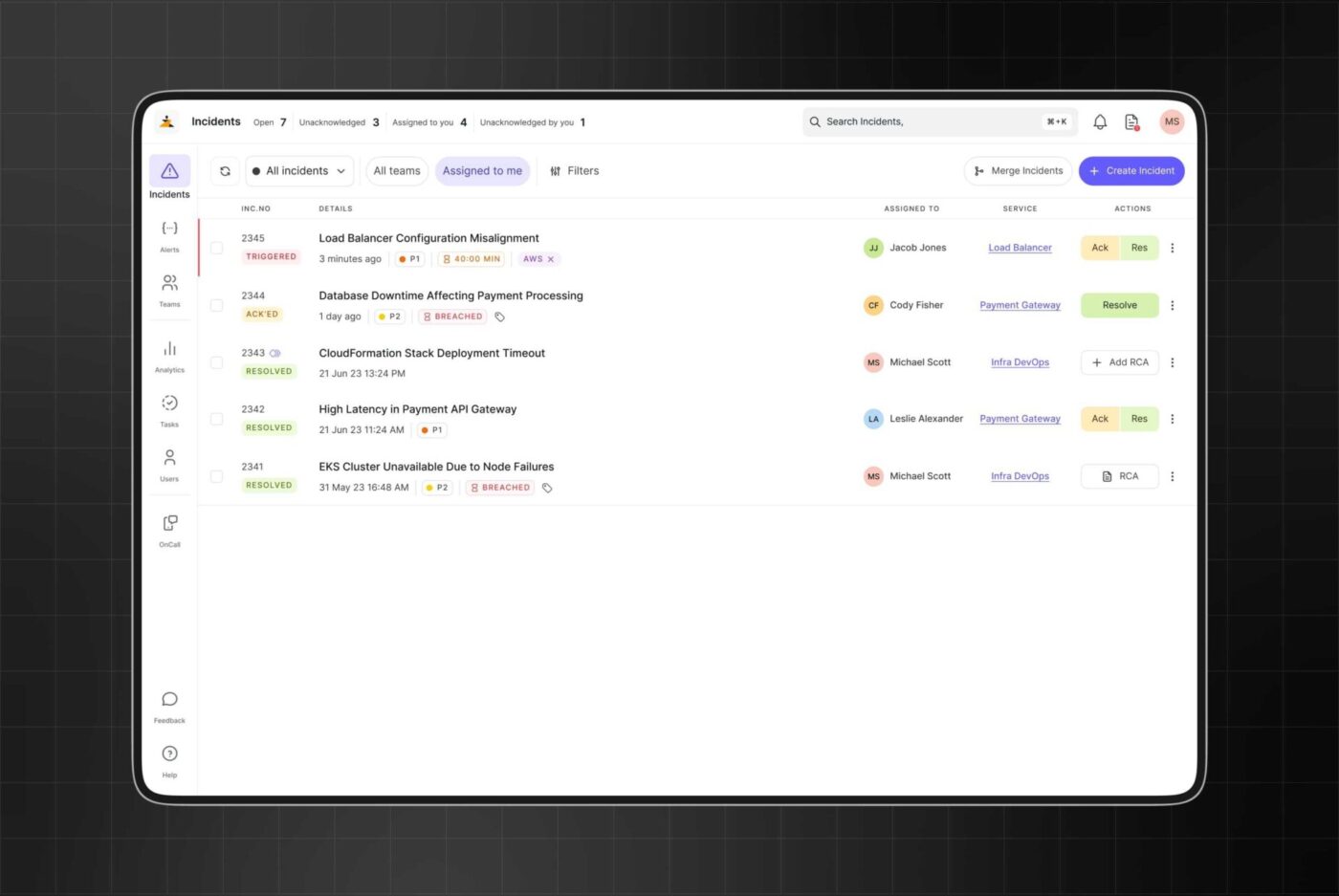
O Zenduty ajuda as equipes de engenharia e DevOps a se concentrarem nos sinais importantes, reduzindo o MTTR (tempo médio de resolução) e oferecendo às organizações uma plataforma única e confiável para gerenciar incidentes.
Os usuários elogiam consistentemente os alertas rápidos e confiáveis, com push, chamadas e SMS chegando sem atrasos, para que os engenheiros de plantão possam confirmar a notificação e voltar ao trabalho. As equipes também gostam de poder personalizar as notificações por gravidade, serviço ou tipo de incidente, para que a pessoa certa seja contatada no momento certo, em vez de todos ao mesmo tempo.
A plataforma oferece suporte à resposta colaborativa a incidentes, com funções de incidente, modelos de tarefas e canais de comunicação integrados. Uma característica importante é sua abordagem baseada no Sistema de Comando de Incidentes (ICS), que fornece uma estrutura organizada para gerenciar incidentes em grande escala.
Se você deseja migrar do Opsgenie, o Zenduty é uma boa opção, com seu suporte à migração recebendo avaliações positivas.
Melhores recursos do Zenduty
- Ofereça gerenciamento de incidentes baseado em IA com o ZenAI.
- Ofereça suporte a agendamentos avançados de plantão com rotações e escalonamentos personalizáveis.
- Automatize manuais de incidentes para que as tarefas e acompanhamentos sejam rastreados de forma consistente.
- Integre-se perfeitamente com mais de 150 ferramentas, como Slack, Teams, Jira, Datadog e Grafana.
- Envie alertas móveis em tempo real no iOS, Android e até mesmo em smartwatches.
Limitações do Zenduty
- A funcionalidade de pesquisa pode misturar vários incidentes, dificultando o rastreamento.
- Alguns recursos avançados são restritos a planos de nível superior.
- A sobreposição de notificações em configurações complexas pode levar à duplicação de alertas.
Preços do Zenduty
- Gratuito
- Starter: US$ 6/mês por usuário
- Crescimento: US$ 16/mês por usuário
- Empresa: US$ 25/mês por usuário
Avaliações e comentários sobre o Zenduty
- G2: 4,6/5 (mais de 135 avaliações)
- Capterra: Avaliações insuficientes
O que os usuários dizem sobre o Zenduty
Esta avaliação da G2 observou:
O que mais gosto no Zenduty são suas informações baseadas em análises. Ao analisar incidentes, podemos acompanhar tendências, como quais dias, serviços ou turnos tiveram mais problemas, identificar o que deu errado e determinar as áreas que precisam de melhorias.
O que mais gosto no Zenduty são suas informações baseadas em análises. Ao analisar incidentes, podemos acompanhar tendências, como quais dias, serviços ou turnos tiveram mais problemas, identificar o que deu errado e determinar as áreas que precisam de melhorias.
📖 Leia também: Melhor software de gerenciamento de operações de TI
12. Incident.io (melhor para resposta a incidentes nativa do Slack)
Vamos imaginar por um segundo que estamos no meio de um incidente. O pager toca. As pessoas acordam. No Opsgenie, você confirma, procura a sala certa e copia o contexto para outro lugar para que todos possam ver o que está acontecendo.
Esse salto é o momento que a maioria das equipes deseja corrigir. É aqui que o incident.io se diferencia.
Você declara diretamente no Slack e um espaço limpo aparece com funções, cronograma e as próximas duas ou três etapas já definidas. Você pode ligar, enviar mensagem de texto, e-mail ou simplesmente tocar para confirmar. O trabalho começa imediatamente e permanece visível.
Os usuários continuam descrevendo o mesmo ritmo depois de mudarem. Um canal é criado com apenas o sinal de que você precisa. O aplicativo solicita acompanhamentos e redige um resumo conciso enquanto você ainda está resolvendo o problema. As atualizações de status para os clientes estão prontas para serem enviadas sem sair da conversa. Isso por si só reduz as conversas que geralmente circulam em salas paralelas e mensagens diretas.
A adoção tem sido simples para equipes de tamanhos muito diferentes. Grupos menores falam sobre conectá-lo ao Linear e ao New Relic em algumas semanas e obter valor real desde o primeiro dia. Organizações maiores compartilham que o implementaram em várias equipes em aproximadamente um mês e não atrasaram o trabalho do roadmap para fazê-lo.
Melhores recursos do Incident.io
- Gerencie incidentes de ponta a ponta diretamente no Slack ou no Microsoft Teams.
- Use o AI SRE para sugerir correções, investigar problemas e redigir comunicações.
- Gerencie escalas de plantão com redução de ruído impulsionada por IA
- Automatize as atualizações da página de status para clientes e partes interessadas
- Obtenha insights sobre tendências, cronogramas e métricas MTTx com painéis de controle.
Limitações do Incident.io
- A interface pode parecer sobrecarregada com muitas notificações do Slack.
- A configuração avançada (como caminhos de escalonamento) pode exigir ajustes finos.
- Alguns recursos de IA estão limitados apenas ao inglês.
Preços do Incident.io
- Básico: Gratuito
- Equipe: US$ 19/mês por usuário
- Pro: US$ 25/mês por usuário
- Empresa: Preços personalizados
Avaliações e comentários do Incident.io
- G2: 4,8/5 (mais de 180 avaliações)
- Capterra: Avaliações insuficientes
O que os usuários dizem sobre o Incident.io
Esta avaliação do G2 compartilhou:
Para mim, o incident.io oferece o equilíbrio perfeito entre não atrapalhar e, ao mesmo tempo, fornecer estrutura, processo e coleta de dados para o gerenciamento de incidentes.
Para mim, o incident.io oferece o equilíbrio perfeito entre não atrapalhar e, ao mesmo tempo, fornecer estrutura, processo e coleta de dados para o gerenciamento de incidentes.
💡Dica profissional: use agentes pré-construídos para responder às perguntas da equipe ou compartilhar atualizações, ou configure um agente de IA personalizado do ClickUp para monitorar o status das tarefas e prazos e enviar lembretes, escalar problemas ou atualizar status conforme necessário, para fazer as coisas avançarem.
Este vídeo mostra como:
O que esperar durante e após a migração do Opsgenie
Mudar do Opsgenie pode parecer como empacotar uma casa onde você morou por anos. Cada programação, regra de escalonamento e integração tem seu lugar, e a ideia de levar tudo isso para uma nova casa pode parecer assustadora.
A Atlassian oferece uma ferramenta de migração no aplicativo para mudar para o Jira Service Management ou Compass. O processo é estruturado, previsível e projetado para minimizar interrupções.
Se você decidir usar qualquer uma dessas opções, basta revisar seu plano, definir a data de migração e deixar que a ferramenta faça o trabalho pesado. Vamos ver como isso funciona e avaliar se essa é uma boa escolha para sua organização.
Visão geral do fluxo de migração
Etapa 1 → Analise e escolha o seu caminho
Avalie seu plano Opsgenie e decida se o Jira Service Management (focado em ITSM) ou o Compass (focado em desenvolvedores) é a opção certa para você.
Etapa 2 → Programe a data da migração
Escolha um cronograma que funcione para o seu ciclo de faturamento e a disponibilidade da sua equipe.
Etapa 3 → Aprovar o faturamento
Seu administrador de faturamento da Atlassian confirma o plano para que o novo produto possa ser provisionado.
Etapa 4 → Migração de dados em segundo plano
Os dados do Opsgenie começam a ser sincronizados enquanto sua equipe continua trabalhando normalmente.
Etapa 5 → Transição e encerramento
Você tem 120 dias para finalizar a mudança antes que o Opsgenie seja desativado.
Em resumo, eis o que você pode esperar:
- Use a ferramenta de migração guiada para automatizar o trabalho pesado.
- Mantenha acesso total ao Opsgenie durante e após a migração, até o desligamento.
- Siga os guias de migração personalizados no Jira Service Management ou no Compass.
- Ajuste os fluxos de trabalho e reconfigure as configurações durante o período de transição de 120 dias.
- Garanta a continuidade de alertas, programações e integrações sem interrupções.
Prós e contras da migração do Opsgenie para o Jira Service Management
Prós:
- Ele pode criar um fluxo de trabalho unificado e contínuo.
- Para equipes que já investiram pesadamente no ecossistema Atlassian, essa pode ser uma decisão conveniente e econômica.
- A análise pós-incidente eficaz do Jira simplifica o processo de acompanhamento das ações de acompanhamento.
- A consolidação dos dados de incidentes no JSM permite relatórios mais poderosos e holísticos.
Contras:
- Algumas das funcionalidades avançadas do Opsgenie independente podem não estar imediatamente disponíveis no JSM.
- Mudar para um ambiente JSM mais amplo pode aumentar a complexidade e o ruído.
- As equipes precisarão ser retreinadas na nova interface e nos novos fluxos de trabalho do JSM.
Aqui estão algumas opiniões dos usuários do Reddit sobre o assunto
Este usuário do Reddit achou que a mudança funcionou para eles no geral:
Não foi tão ruim para nós. Preciso verificar novamente a configuração de funções e permissões, mas tudo pareceu funcionar muito bem, exceto se você tiver exatamente os mesmos nomes de equipe do Jira que o equivalente do OpsGenies. Eles não se integraram bem e alguns deles foram danificados. Recomendo que você os altere, se for o caso.
Não foi tão ruim para nós. Preciso verificar novamente a configuração de funções e permissões, mas tudo pareceu funcionar muito bem, exceto se você tiver exatamente os mesmos nomes de equipe do Jira que o equivalente do OpsGenies. Eles não se integraram bem e alguns deles foram danificados. Recomendo que você os altere, se for o caso.
Aqui está outra pessoa que claramente não teve a melhor experiência:
Caso alguém esteja considerando essa opção: mudamos para o Jira Service Management, que faz parte do nosso pacote já pago (a empresa está economizando agressivamente). É tão ruim que nem consigo explicar. Não considere isso como uma opção.
Caso alguém esteja considerando essa opção: mudamos para o Jira Service Management, que faz parte do nosso pacote já pago (a empresa está economizando agressivamente). É tão ruim que nem consigo explicar. Não considere isso como uma opção.
E outra pessoa que já está pensando em mudar novamente após seis meses com o JSM:
O JSM é horrível. Não é de forma alguma comparável ao PagerDuty, Rootly ou Incident.io. Também mudamos para ele há cerca de seis meses no trabalho e já estamos procurando alternativas. É muito inflexível, quase não tem integrações, não tem um bom suporte ao Slack e os alertas e páginas de plantão estão sendo perdidos pelos engenheiros com uma taxa de sucesso bastante alta (nunca tivemos esse problema no OpeGenie).
O JSM é horrível. Não é de forma alguma comparável ao PagerDuty, Rootly ou Incident.io. Também mudamos para ele há cerca de seis meses no trabalho e já estamos procurando alternativas. É muito inflexível, quase não tem integrações, não tem um bom suporte ao Slack e os alertas e páginas de plantão estão sendo perdidos pelos engenheiros com uma taxa de sucesso bastante alta (nunca tivemos esse problema no OpeGenie).
A outra alternativa oferecida pela Atlassian, o Compass, não é uma alternativa direta ao Opsgenie. Em vez disso, é uma plataforma de experiência do desenvolvedor projetada para mapear e gerenciar os componentes, serviços e dependências de uma arquitetura de software complexa.
Recomendamos que você avalie esses fatores antes de decidir qual alternativa ao Opsgenie é a melhor para sua equipe.
Opsgenie toca, ClickUp atende
Mudar do Opsgenie pode parecer um grande passo, mas encare isso como uma oportunidade de facilitar a vida da sua equipe.
Você viu como as outras ferramentas se comparam, cada uma com seus pontos fortes, mas também com suas limitações.
No entanto, o ClickUp conquista corações discretamente. 🤗
Veja por quê: Ele reúne suas tarefas, comunicações e fluxos de trabalho em um único lugar. Você não precisa alternar entre telas ou combinar ferramentas separadas. Em vez disso, sua equipe permanece conectada, com clareza sobre as prioridades e confiança sobre o que precisa ser feito a seguir.
Escolher a solução certa para gerenciamento de incidentes não se resume apenas a alertas — trata-se de criar uma estrutura robusta de gerenciamento de incidentes que ofereça suporte à eficiência operacional a longo prazo. Com o ClickUp, sua equipe pode gerenciar incidentes de forma proativa, reduzindo o ruído e criando consistência em todas as respostas. 😌
Se você está pronto para ter menos dores de cabeça e mais clareza, agora é a hora de se inscrever no ClickUp!
Perguntas frequentes (FAQ)
As migrações do Opsgenie devem ser programadas antes de abril de 2027. Após essa data, os dados do Opsgenie não estarão mais acessíveis.
Algumas das alternativas mais fortes incluem Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty e incident.io. Cada uma oferece um equilíbrio diferente entre gerenciamento de plantões, automação e integrações. No entanto, se você deseja uma plataforma completa com tecnologia de IA que mantenha seus fluxos de trabalho, comunicações e documentação em um só lugar, escolha o ClickUp.
O Jira Service Management inclui a maioria dos recursos principais do Opsgenie, como alertas, agendamento de plantões e fluxos de trabalho de incidentes, mas certas funções avançadas podem ser diferentes. O Compass é uma opção para equipes de desenvolvimento focadas em catálogos de serviços e rastreamento de componentes.
Sim. A Atlassian fornece uma ferramenta de migração integrada ao aplicativo que transfere alertas, escalas e políticas de escalonamento automaticamente. Você pode até testar a migração em uma conta de demonstração antes de confirmar.
Sim. Ferramentas como Cabot, OpenDuty e Alertmanager podem ser personalizadas como substitutos de código aberto, embora possam exigir mais configuração e manutenção.
Os custos dependem da plataforma que você escolher. O Jira Service Management, o Compass e outras alternativas oferecem preços diferenciados, geralmente por usuário por mês. Algumas ferramentas de código aberto são gratuitas, mas exigem custos de infraestrutura e suporte.
Sim. Sua equipe pode continuar usando o Opsgenie durante o período de migração, e as integrações permanecerão ativas até que o Opsgenie seja desativado permanentemente. Depois disso, elas precisarão ser reconfiguradas em sua nova plataforma.