
Większość zespołów traktuje generowanie kodu SQL jak sztuczkę magiczną. Wpisujesz pytanie i otrzymujesz zapytanie.
Ale rzeczywistość jest taka: Snowflake Cortex Analyst działa tylko tak dobrze, jak model semantyczny, który najpierw zbudujesz, a jego ustawienia nie są proste. Po opanowaniu korzystania z Snowflake Cortex do generowania zapytań SQL zespoły ds. danych mogą teraz w ciągu kilku sekund przekształcać język naturalny w złożone, wykonalne zapytania.
W tym przewodniku omówiono rzeczywisty proces wdrażania, od zdefiniowania modelu semantycznego YAML po wysyłanie zapytań do hurtowni danych przy użyciu języka naturalnego, dzięki czemu przed rozpoczęciem pracy zrozumiesz zarówno możliwości tego rozwiązania, jak i wymagania wstępne.
Przyjrzymy się również, gdzie Snowflake Cortex ma swoje ograniczenia i w jaki sposób ClickUp może zapewnić wsparcie dla szerszych cykli pracy związanych z generowaniem zapytań SQL.
Czym jest Snowflake Cortex Analyst?
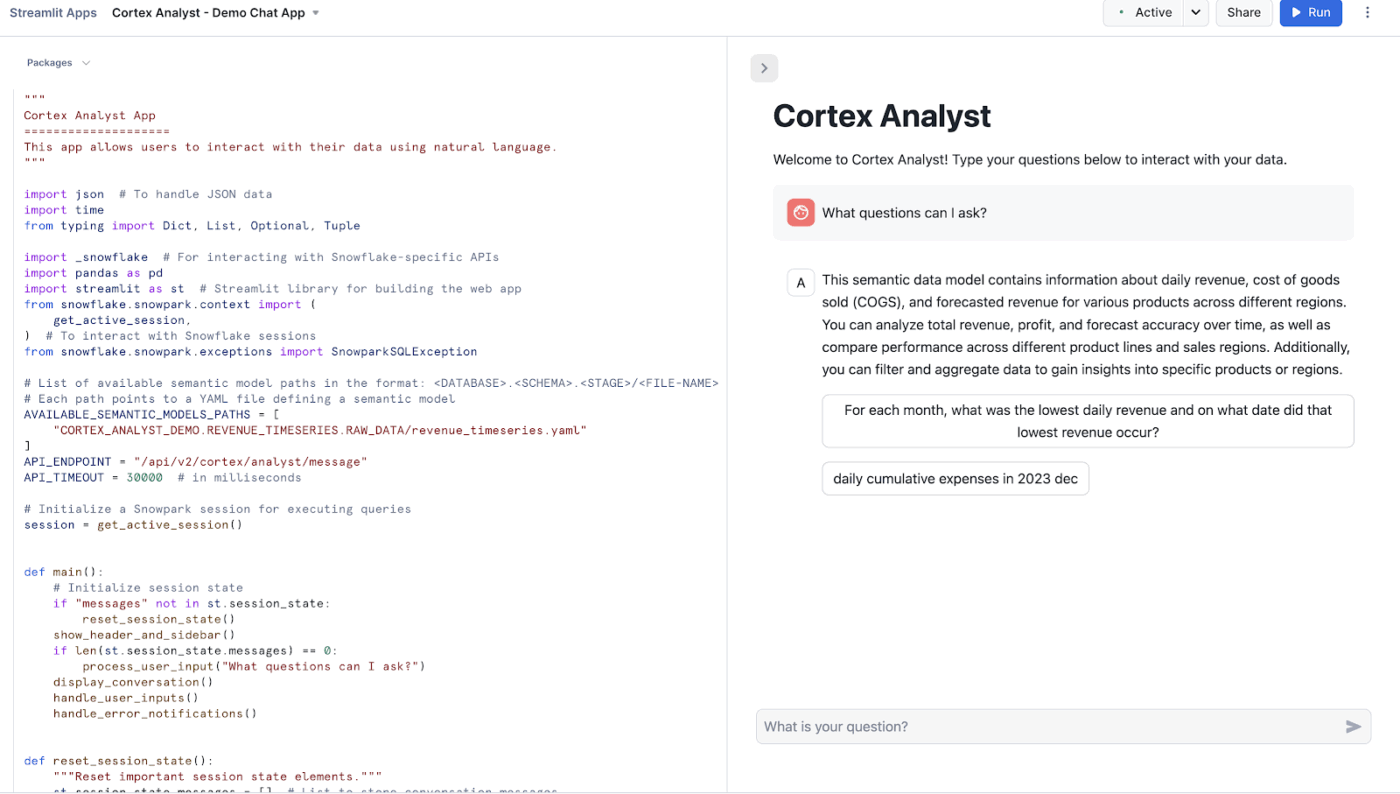
Snowflake Cortex Analyst to w pełni zarządzana usługa, która umożliwia tworzenie aplikacji konwersacyjnych opartych na danych analitycznych.
Wykorzystuje on specjalistyczny agent tekst-do-SQL, aby przekształcić pytania sformułowane w języku naturalnym w dokładne, wykonalne zapytania. Usługa ta wypełnia lukę między złożonymi strukturami danych a użytkownikami biznesowymi, którzy potrzebują odpowiedzi bez konieczności pisania kodu.
Najważniejsze funkcje obejmują:
- Zapewnienie precyzyjnego interfejsu do pracy z danymi ustrukturyzowanymi
- Wykorzystanie modeli semantycznych do zrozumienia specyficznej logiki biznesowej i terminologii
- Oferujemy interfejs API REST, który ułatwia integrację z aplikacjami niestandardowymi lub narzędziami BI
- Zapewnienie prywatności danych poprzez przetwarzanie żądań w ramach zabezpieczeń Snowflake
📮 ClickUp Insight: 88% respondentów naszej ankiety korzysta z AI do zadań osobistych, ale ponad 50% unika jej używania w pracy. Jakie są trzy główne przeszkody? Brak płynnej integracji, luki w wiedzy lub obawy dotyczące bezpieczeństwa.
A co, jeśli sztuczna inteligencja jest wbudowana w Twój obszar roboczy i jest już bezpieczna? ClickUp Brain, wbudowany asystent AI ClickUp, sprawia, że staje się to rzeczywistością. Rozumie podpowiedzi w języku potocznym, rozwiązując wszystkie trzy obawy związane z wdrożeniem AI, jednocześnie zapewniając połączenie między czatem, zadaniami, dokumentami i wiedzą w całym obszarze roboczym.
Znajdź odpowiedzi i spostrzeżenia za pomocą jednego kliknięcia!
Wymagania wstępne dotyczące generowania kodu SQL w Snowflake Cortex
Rozpoczęcie pracy ze Snowflake Cortex bez odpowiednich ustawień prowadzi do frustracji. Możesz uzyskać niedokładne wyniki, tracić czas na rozwiązywanie problemów i błędnie uznać, że narzędzie nie działa, podczas gdy prawdziwym problemem jest słaba podstawa.
Aby tego uniknąć, musisz najpierw zadbać o trzy podstawowe elementy.
1. Skonfiguruj bazę danych i tabele
Twoja AI jest tak inteligentna, jak dane, do których ma dostęp. Jeśli schemat Twojej bazy danych to labirynt tajemniczych nazw kolumn, takich jak cust_dat_v2_final, zarówno analitycy, jak i AI będą mieli trudności z jego zrozumieniem.
To zamieszanie powoduje, że AI generuje nieprawidłowe połączenia lub pobiera dane z niewłaściwych kolumn, a Twój zespół traci godziny na próby rozszyfrowania schematu, zanim będzie mógł w ogóle napisać zapytanie.
Na początek upewnij się, że Twoje oprogramowanie do hurtowni danych zawiera tabele, które ma wykorzystywać Cortex Analyst do tworzenia zapytań. W miarę możliwości używaj jasnych, opisowych nazw kolumn. Na przykład kolumna o nazwie customer_lifetime_value jest znacznie bardziej intuicyjna zarówno dla ludzi, jak i dla AI niż clv_01.
Aby kontynuować ustawienia, Twoja rola w Snowflake będzie wymagała następujących uprawnień:
- ZASTOSOWANIE: W bazie danych i schemacie zawierającym Twoje tabele
- SELECT: W tabelach, które mają być przedmiotem zapytań przeprowadzanych przez Cortex Analyst
- SCENA TWORZENIA: W schemacie, który jest wymagany do przesłania pliku modelu semantycznego
📖 Przeczytaj również: Jak korzystać z Snowflake Cortex do analizy biznesowej
2. Utwórz plik modelu semantycznego
Największą przeszkodą w przypadku każdego narzędzia do konwersji tekstu na SQL jest to, że sztuczna inteligencja nie posługuje się specyficznym językiem Twojej firmy. Nie wie z natury, że „ARR” oznacza „Annual Recurring Revenue” (roczny przychód cykliczny) ani że tabela klientów łączy się z tabelą zamówień na polu customer_id.
Bez tego kontekstu AI może wygenerować kod SQL, który jest poprawny pod względem technicznym, ale błędny pod względem logicznym, dostarczając odpowiedzi, które wydają się poprawne, ale są niebezpiecznie mylące.
Rozwiązaniem jest model semantyczny. Jest to plik YAML, który pełni rolę niestandardowej „warstwy tłumaczeniowej”, ucząc Cortex Analyst specyficznego słownictwa i logiki Twojej firmy. Tworzenie i utrzymywanie tego pliku wymaga wspólnego wysiłku między inżynierami danych, którzy korzystają z narzędzi ETL w celu poznania schematu, a analitykami biznesowymi znającymi terminologię.
Plik modelu semantycznego powinien zawierać następujące kluczowe elementy:
| Komponent | Cel |
| Tabela | Zawiera listę wszystkich tabel wraz z opisem ich przeznaczenia w języku potocznym |
| Kolumny | Określa typ semantyczny każdej kolumny (np. kategorię lub metrykę) i może zawierać próbki wartości |
| relacje | Określa, w jaki sposób tabele łączą się za pomocą połączeń, eliminując wszelkie domysły ze strony AI |
| Zweryfikowane zapytania | Zawiera przykładowe pary pytań i kodu SQL, które stanowią przydatne wskazówki dla modelu LLM |
3. Skonfiguruj usługę Cortex Search (opcjonalnie)
Czasami potrzebne odpowiedzi są ukryte w nieustrukturyzowanym tekście, takim jak opisy produktów, zgłoszenia do wsparcia technicznego czy transkrypcje rozmów. Standardowe zapytania SQL nie mają dostępu do tych danych, co oznacza, że często nie znasz odpowiedzi na pytanie „dlaczego” stojące za „czym”.
Opcjonalnie możesz tutaj dodać usługę Snowflake Cortex Search Service. Jest to warstwa typu „search-as-a-service”, która pozwala na jednoczesne składanie zapytań zarówno w tabelach ustrukturyzowanych, jak i w nieustrukturyzowanych danych tekstowych przy użyciu agentów AI do analizy danych.
Należy skonfigurować Cortex Search, jeśli analitycy muszą zadawać pytania wymagające wyodrębnienia kontekstu z tekstu przed wygenerowaniem kodu SQL. Na przykład można najpierw wyszukać wszystkie recenzje produktów zawierające frazę „problem z baterią”, a następnie wygenerować zapytanie SQL w celu agregacji danych dotyczących sprzedaży wyłącznie tych produktów.
W przypadku generowania czystego kodu SQL dla tabelek strukturalnych ta usługa nie jest konieczna.
🧠 Ciekawostka: Na początku lat 70. badacze z IBM, Donald Chamberlin i Raymond Boyce, stworzyli „Structured English Query Language”. Musieli zmienić nazwę na SQL, ponieważ „SEQUEL” był już zastrzeżonym znakiem towarowym brytyjskiej firmy lotniczej.
Przewodnik krok po kroku dotyczący generowania kodu SQL za pomocą Cortex Analyst
Wykonałeś już prace przygotowawcze, ale teraz stoisz przed pustym ekranem, niepewny co do rzeczywistego cyklu pracy. Jak przekształcić pytanie, które masz w głowie, w działające zapytanie SQL? Gdy sposób pracy nie jest jasny, nowe narzędzia często pozostają niewykorzystane, a inwestycja w ich ustawienia idzie na marne.
Ten praktyczny proces jest zaskakująco prosty. Przyjrzyjmy się temu bliżej!
Krok 1: Przygotuj dane w Snowflake
Przede wszystkim Twoje dane strukturalne muszą znajdować się w Snowflake. Każda aplikacja Cortex Analyst jest skierowana albo na pojedynczą tabelę, albo na widok złożony z jednej lub więcej tabel. Upewnij się, że Twoje tabele zostały utworzone i zapełnione.
Jeśli ładujesz dane z plików płaskich:
- Prześlij swoje pliki danych (np. CSV) do Snowflake Stage
- Użyj komendy COPY INTO, aby załadować dane ze stage'u do tabel
- Przed przejściem dalej sprawdź, czy załadowanie danych przebiegło z powodzeniem
📖 Przeczytaj również: Jak korzystać z Snowflake Cortex do analizy danych w Enterprise
Krok 2: Stwórz model semantyczny (lub widok semantyczny)
To najważniejszy krok ustawień. Siła Cortex Analyst wynika z połączenia dużych modeli językowych (LLM) z modelami semantycznymi — plikiem YAML, który znajduje się obok schematu bazy danych i koduje kontekst biznesowy.
Widoki semantyczne są obecnie metodą zalecaną przez Snowflake dla Cortex Analyst. Przechowują one wskaźniki biznesowe, związki i definicje bezpośrednio w Snowflake. Starsza wersja plików modeli semantycznych YAML nadal działa, ale Snowflake kieruje nowe implementacje w stronę widoków semantycznych.
Twój model semantyczny lub widok powinien zawierać:
- Opisy tabel i kolumn: Proste wyjaśnienia znaczenia poszczególnych pól
- Wskaźniki biznesowe: definicje pól obliczeniowych, takich jak przychody, wskaźnik rezygnacji lub współczynnik konwersji
- Filtry i synonimy: alternatywne terminy, których mogą używać użytkownicy (np. „anulowane” przypisane do konkretnej wartości statusu)
- Zweryfikowane zapytania: Repozytorium zweryfikowanych zapytań Snowflake przechowuje zatwierdzone pary pytań i kodu SQL. Gdy pytanie użytkownika przypomina jeden z tych wpisów, Cortex Analyst może odwołać się do niego podczas generowania kodu SQL.
🤝 Przyjazne przypomnienie: Snowflake zaleca używanie nie więcej niż 10 tabel i nie więcej niż 50 wybranych kolumn, aby uzyskać optymalną wydajność w cyklu pracy Snowsight.
Krok 3: Prześlij model semantyczny do środowiska Snowflake Stage
Jeśli korzystasz z modelu semantycznego opartego na YAML, należy go przygotować, aby Cortex Analyst mógł odwołać się do niego w czasie wykonywania.
- Prześlij plik .yaml do wewnętrznej sceny Snowflake (np. RAW_DATA)
- Sprawdź, czy plik pojawił się w etapie za pomocą interfejsu użytkownika Snowsight lub komendy LIST @stage_name
- Zapamiętaj ścieżkę etapu; będziesz się do niej odwoływać w wywołaniach API lub konfiguracji aplikacji
Jeśli korzystasz z widoku semantycznego, ten krok jest obsługiwany natywnie w Snowflake i nie jest wymagane oddzielne przesyłanie danych.
🔍 Czy wiesz, że? W języku SQL wartość NULL nie oznacza zera ani pustego pola. Oznacza ona nieznane lub brakujące dane, co prowadzi do nieintuicyjnych zachowań, takich jak porównania, które nie zwracają ani wartości true, ani false.
Krok 4: Wyślij pytanie w języku naturalnym za pośrednictwem interfejsu API REST
Teraz rozpoczyna się faktyczne generowanie kodu SQL. Interfejs API REST generuje zapytanie SQL dla danego pytania, wykorzystując model semantyczny lub widok semantyczny podany w żądaniu.
Zbuduj żądanie API przy użyciu:
- wiadomości; szyk zawierający pytanie użytkownika z rolą: „user”
- Odwołanie do modelu semantycznego lub widoku semantycznego
- Twój preferowany model (lub pozostaw ustawienie „auto”, aby Cortex wybrał najlepszy)
Możesz prowadzić wieloetapowe rozmowy, w których możesz zadawać pytania uzupełniające oparte na poprzednich zapytaniach.
Krok 5: Przetwarzanie odpowiedzi API
Każda wiadomość w odpowiedzi może zawierać wiele bloków zawartości różnych typów. Trzy wartości obecnie świadczące wsparcie dla pola typu to: tekst, sugestie i SQL.
Oto znaczenie poszczególnych typów:
- SQL: Cortex osiągnął powodzenie w generowaniu zapytania; oto kod, który należy wykonać
- tekst: Wyjaśnienie lub odpowiedź w języku naturalnym towarzysząca zapytaniu SQL
- sugestie: Zawartość typu „sugestia” jest uwzględniana w odpowiedzi tylko wtedy, gdy pytanie użytkownika było niejednoznaczne, a Cortex Analyst nie mógł zwrócić instrukcji SQL dla tego zapytania. Użyj ich, aby wyjaśnić lub doprecyzować pytanie
🔍 Czy wiesz, że... Kolejność, w jakiej piszesz kod SQL, nie jest kolejnością jego wykonywania. Nawet jeśli najpierw wpiszesz SELECT, bazy danych faktycznie przetwarzają FROM i WHERE przed wybraniem kolumn. To dezorientuje zarówno początkujących, jak i doświadczonych użytkowników.
Krok 6: Wykonaj wygenerowany kod SQL w Snowflake
Po uzyskaniu bloku SQL z odpowiedzi uruchom go w swojej wirtualnej hurtowni Snowflake. Wygenerowane zapytanie SQL jest wykonywane w wirtualnej hurtowni Snowflake w celu wygenerowania ostatecznego wyniku. Dane pozostają w granicach zarządzania Snowflake.
Najważniejsze informacje dotyczące momentu wykonania:
- Cortex Analyst jest w pełni zintegrowany z zasadami kontroli dostępu opartej na rolach (RBAC) w Snowflake, co gwarantuje, że generowane i wykonywane zapytania SQL są zgodne ze wszystkimi ustalonymi zasadami kontroli dostępu
- Jeśli użytkownik nie ma dostępu do tabeli, wykonanie zapytania zakończy się niepowodzeniem, tak samo jak w przypadku ręcznie napisanego kodu SQL.
- Na tym etapie obowiązują koszty obliczeniowe magazynu danych, niezależne od opłat za korzystanie z Cortex Analyst.
Krok 7: Udoskonalaj i powtarzaj
Nie zawsze można mieć pewność, że za pierwszym razem uda się stworzyć idealne zapytanie. Oto jak z czasem poprawiać wyniki:
- Dodaj sprawdzone zapytania do swojego modelu semantycznego w przypadku pytań, które pojawiają się wielokrotnie
- Wzbogać swój model semantyczny o lepsze opisy, synonimy i filtry, gdy Cortex błędnie zinterpretuje jakiś termin
- Wykorzystaj rozmowę wieloetapową do kontynuacji, na przykład: „Teraz filtruj to według regionu”. Rozmowy wieloetapowe umożliwiają zadawanie pytań uzupełniających, które opierają się na poprzednich zapytaniach.
- Monitoruj wykorzystanie za pomocą CORTEX_ANALYST_USAGE_HISTORY i historii zapytań Snowflake, aby wykrywać wzorce w nieudanych lub niedokładnych zapytaniach
🧠 Ciekawostka: Jeden brakujący warunek JOIN może spowodować ogromne problemy. Pominięcie warunku JOIN może doprowadzić do powstania iloczynu kartezjańskiego, co powoduje gwałtowny wzrost liczby wierszy, a czasem nawet awarię systemu.
Najlepsze praktyki dotyczące dokładności funkcji Snowflake Text-to-SQL
Jakość modelu semantycznego bezpośrednio wpływa na dokładność generowanych zapytań. Oto najlepsze praktyki, które pozwalają zwiększyć dokładność. 🛠️
- Dodaj zweryfikowane zapytania do swojego modelu semantycznego: To najważniejsza rzecz, jaką możesz zrobić. Dodaj wiele przykładowych par „pytanie-SQL”, które odzwierciedlają sposób, w jaki Twój zespół naprawdę zadaje pytania
- Używaj opisowych nazw kolumn i tabel: Model działa lepiej, gdy nazwy kolumn i tabel są zrozumiałe same w sobie. Jeśli nie możesz zmienić schematu, dodaj jasne opisy w pliku YAML dla wszelkich niejasnych nazw kolumn
- Dodaj próbki wartości: Dodanie próbkowych danych dla kolumn kategorycznych (takich jak status lub region) pomaga modelowi zrozumieć dostępne prawidłowe opcje filtrowania
- Testuj w skrajnych przypadkach: Podczas tworzenia aplikacji celowo zadawaj niejednoznaczne lub podchwytliwe pytania, aby zidentyfikować, gdzie Twój model semantyczny wymaga dodatkowego kontekstu lub wyjaśnienia.
- Udoskonalaj swój model semantyczny: Traktuj swój model semantyczny jak żywy dokument. Powinien on być stale aktualizowany w ramach iteracyjnego procesu opartego na tym, które zapytania kończą się sukcesem, a które nie
ClickUp: prostsza alternatywa dla Snowflake Cortex
Snowflake Cortex sprawdza się dobrze, gdy zespoły chcą generować kod SQL i uruchamiać zapytania w danych ustrukturyzowanych. Zespoły definiują schematy, mapują związki i piszą zapytania w celu uzyskania wniosków. Takie ustawienia mają sens w środowiskach z dużą ilością danych, zwłaszcza gdy za raportowanie odpowiadają analitycy.
Wiele zespołów nie potrzebuje jednak pełnej warstwy SQL, aby uzyskać odpowiedzi na codzienne pytania operacyjne. Menedżerowie produktu, kierownicy programów i zespoły operacyjne często potrzebują szybkich odpowiedzi związanych z bieżącą pracą.
ClickUp oferuje łatwiejszą ścieżkę. Teams zadają pytania prostym językiem, przeglądają pulpity nawigacyjne na żywo i podejmują działania w oparciu o wnioski bez konieczności pisania kodu SQL lub tworzenia modeli semantycznych.
Szybsze generowanie i udoskonalanie kodu SQL
Snowflake Cortex koncentruje się na generowaniu zapytań SQL na podstawie ustrukturyzowanych zbiorów danych w środowisku hurtowni danych. Rozwiązanie to sprawdza się dobrze, gdy dane są już przechowywane w Snowflake i masz opracowane schematy.

ClickUp Brain zapewnia wsparcie dla generowania kodu SQL w bardziej elastyczny sposób, skupiając się na wykonaniu. Zespoły generują, udoskonalają i przechowują zapytania SQL bezpośrednio w swoim obszarze roboczym, gdzie już odbywają się analizy, dyskusje i podejmowane są decyzje.
Załóżmy, że analityk produktu pracuje nad analizą retencji w ClickUp. Zamiast przełączać się między narzędziami w celu napisania zapytań, zwraca się do ClickUp Brain:
📌 Wypróbuj następującą podpowiedź: Napisz zapytanie SQL, aby obliczyć siedmiodniowy wskaźnik retencji dla użytkowników pogrupowanych według kohorty rejestracji.
ClickUp Brain generuje ustrukturyzowane zapytanie, które obejmuje grupowanie kohort, filtry dat oraz logikę retencji. Analityk wkleja zapytanie do Snowflake lub innej hurtowni danych i natychmiast je uruchamia.
Pomaga to:
- Twórz połączenia między wieloma tabelami, takimi jak użytkownicy, zamówienia i zdarzenia
- Przekształcaj proste pytania dotyczące produktów sformułowane w języku angielskim w logikę SQL gotową do wykonania
- Debuguj nieprawidłowe zapytania i wyjaśnij problemy, takie jak nieprawidłowe połączenia lub brakujące warunki
- Przepisuj zapytania, aby uzyskać lepszą wydajność lub czytelność
Na przykład podczas przeglądu eksperymentu wzrostowego specjalista ds. marketingu prosi: „Napisz zapytanie SQL, aby porównać współczynniki konwersji między dwiema stronami docelowymi w ciągu ostatnich 14 dni”.
ClickUp Brain generuje zapytanie przy użyciu agregacji warunkowej i filtrów daty. Zespół uruchamia je w Snowflake i weryfikuje wyniki eksperymentu.
📌 Wypróbuj następującą podpowiedź: Popraw to zapytanie SQL, w którym połączenie powoduje powielanie wierszy, i wyjaśnij, na czym polega problem.
ClickUp Brain identyfikuje problem z połączeniem, koryguje zapytanie i wyjaśnia, w jaki sposób doszło do powielenia wierszy z powodu nieprawidłowych warunków połączenia.
Zastąp raportowanie oparte na SQL
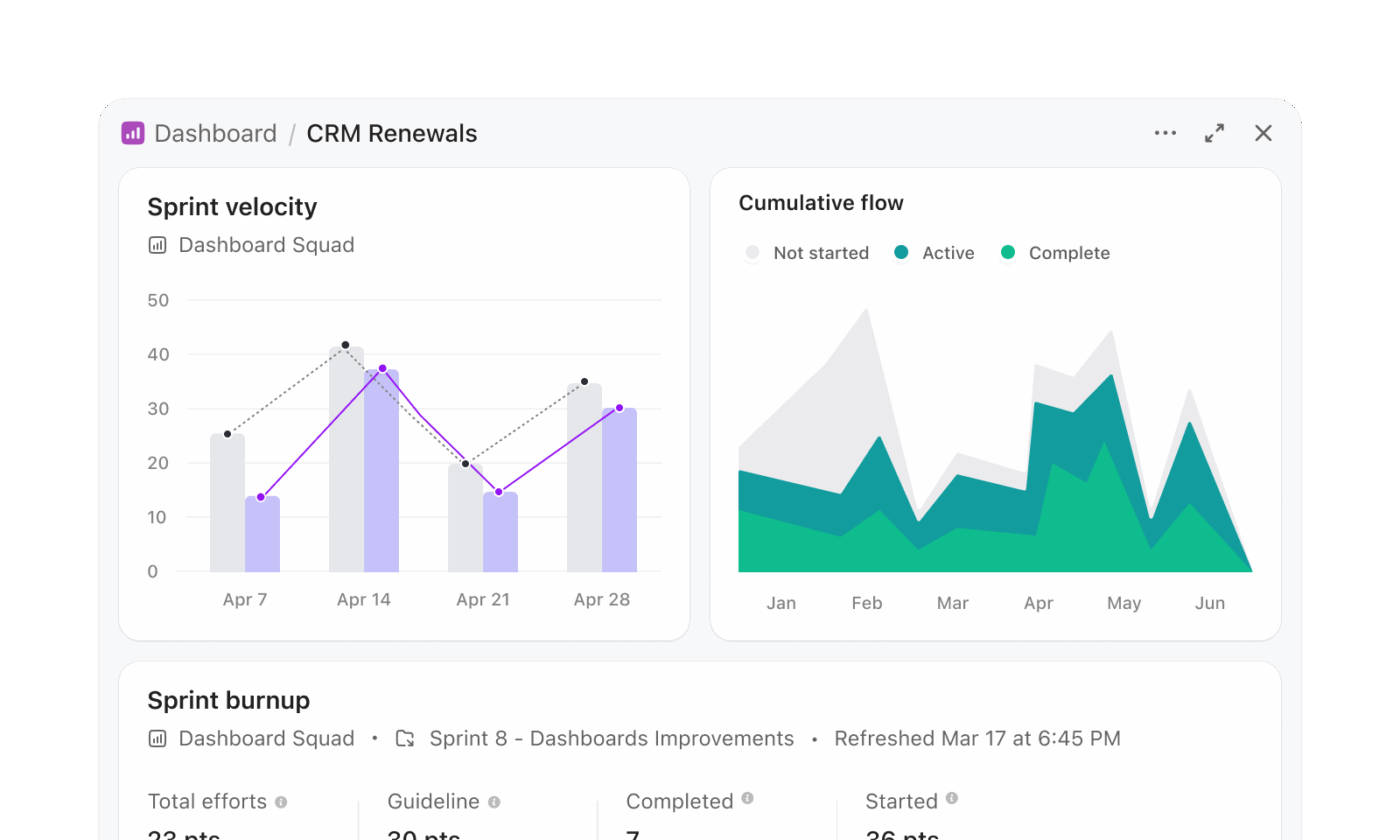
Cykl pracy w Snowflake Cortex często obejmuje generowanie kodu SQL, uruchamianie zapytań i wizualizację wyników w oddzielnej warstwie. Pulpity nawigacyjne ClickUp eliminują ten wieloetapowy proces i przedstawiają wnioski bezpośrednio na podstawie bieżącej pracy.
Zespół zarządzający programem, który prowadzi śledzenie gotowości do wydania, może stworzyć pulpit nawigacyjny bez konieczności pisania zapytań. Na przykład pulpit nawigacyjny dotyczący wydania może zawierać:
- Karta listy zadań przefiltrowana tak, aby wyświetlać zadania przeterminowane we wszystkich zespołach produktowych
- Karta obciążenia przedstawiająca dystrybucję zadań wśród inżynierów
- Wykres słupkowy porównujący zadania zakończone z zadaniami oczekującymi w poszczególnych sprintach
- Karta obliczeniowa do śledzenia średniego czasu realizacji
Załóżmy, że kierownik projektu przegląda ten pulpit przed spotkaniem przed wydaniem. Od razu zauważa, że usługi zaplecza wykazują wyższe wskaźniki opóźnień. Otwiera kartę listy zadań i sprawdza, które konkretnie zadania powodują ryzyko.
Prawdziwy użytkownik ClickUp udostępnia swoją opinię:
ClickUp pozwala nam SZYBKO przekazywać sobie projekty, ŁATWO sprawdzać ich status i daje naszej przełożonej wgląd w nasze obciążenie pracą w dowolnym momencie, bez konieczności przerywania nam pracy. Dzięki ClickUp z pewnością oszczędzamy co najmniej jeden dzień w tygodniu. Liczba e-maili ZNACZNIE się zmniejszyła.
ClickUp pozwala nam SZYBKO przekazywać sobie projekty, ŁATWO sprawdzać ich status i daje naszej przełożonej wgląd w nasze obciążenie pracą w dowolnym momencie, bez konieczności przerywania nam pracy. Dzięki ClickUp zyskaliśmy co najmniej jeden dzień w tygodniu, jeśli nie więcej. Liczba e-maili ZNACZNIE się zmniejszyła.
Wykorzystuj wnioski bez potoków danych
Snowflake Cortex koncentruje się na generowaniu wniosków na podstawie danych. Teams nadal muszą samodzielnie interpretować wyniki i być wyzwalaczem odpowiednich działań.
Superagenci ClickUp AI wypełniają tę lukę i przekształcają spostrzeżenia w działania. Działają oni jako wirtualni współpracownicy oparci na sztucznej inteligencji, którzy nieustannie monitorują dane w obszarach roboczych i podejmują działania w zależności od warunków.
Załóżmy, że kierownik programu nadzoruje wiele inicjatyw produktowych. Super Agent może:
- Monitoruj zadania w różnych projektach i wykrywaj, kiedy zaległe zadania przekraczają określony próg
- Zidentyfikuj wzorce, takie jak powtarzające się opóźnienia na tym samym etapie cyklu pracy
- Utwórz zadanie podsumowujące projekty, na które ma to wpływ, i przypisz je kierownikowi programu
- Powiadamiaj właścicieli zespołów, gdy krytyczne zadania pozostają nierozwiązane po upływie terminów
Na przykład podczas cyklu wydawniczego Super Agent wykrywa, że w dwóch zespołach nie dotrzymano terminów wykonania ponad 10 zadań o wysokim priorytecie. Tworzy on zadanie ClickUp zatytułowane „Ryzyko związane z wydaniem: niedotrzymane terminy”, dołączając do niego wszystkie istotne zadania jako załączniki i przypisując je kierownikowi programu do natychmiastowego przeglądu.
Teams mogą również bezpośrednio komunikować się z Super Agentem: „Przeanalizuj wszystkie aktywne projekty i zaznacz ryzyko związane z realizacją w tym sprincie”.
Super Agent sprawdza terminy, zależności i status zadań, a następnie publikuje uporządkowane podsumowanie w obszarze roboczym.
Oto jak ustawić własnego Super Agenta w ClickUp:
Scentralizuj cykle pracy danych dzięki ClickUp
Narzędzia typu „tekst-to-SQL”, takie jak Snowflake Cortex, zwiększają dostępność danych. Jednocześnie uzyskanie wiarygodnych wyników nadal wymaga wysiłku.
Zespoły potrzebują przejrzystych schematów, solidnych modeli semantycznych i ciągłej iteracji, aby zapewnić dokładność wyników. Nawet po wygenerowaniu właściwego zapytania praca nie kończy się na tym. Ktoś nadal musi zinterpretować wyniki, udostępnić spostrzeżenia i przekształcić je w decyzje.
ClickUp oferuje inne podejście. Zamiast oddzielać analizę od wykonania, ClickUp tworzy połączenie między tymi elementami. Zespoły generują zapytania SQL, dokumentują wnioski, współpracują nad wynikami i podejmują działania w tym samym obszarze roboczym.
ClickUp Brain pomaga w pisaniu i udoskonalaniu zapytań, a pulpity nawigacyjne i agenci AI pomagają zespołom śledzić wyniki i realizować zadania bez konieczności przełączania się między narzędziami.
Snowflake Cortex pomaga uzyskać odpowiedzi. ClickUp pomaga je wykorzystać. Zarejestruj się w ClickUp już dziś!
Często zadawane pytania
Snowflake Cortex Analyst to wyspecjalizowana usługa w ramach szerszego pakietu Snowflake Cortex AI. Cortex Analyst koncentruje się konkretnie na generowaniu zapytań SQL na podstawie tekstu przy użyciu modeli semantycznych, podczas gdy Cortex AI obejmuje szerszy zakres funkcji LLM, wnioskowanie modeli uczenia maszynowego oraz możliwości wyszukiwania.
Tak, Cortex Analyst może wysyłać zapytania do tabel Apache Iceberg zarządzanych przez Snowflake. Jeśli tabele są dostępne w środowisku Snowflake i prawidłowo zdefiniowane w modelu semantycznym, można generować zapytania do tych tabel.
Dokładność złożonych zapytań zależy niemal wyłącznie od jakości modelu semantycznego. Model z dobrze zdefiniowanymi związkami między tabelami, licznymi zweryfikowanymi zapytaniami i opisowymi metadanymi zapewni znacznie dokładniejsze wyniki w przypadku połączeń wielotabelowych i złożonych agregacji.
Ceny Snowflake Cortex Analyst są zgodne z modelem opartym na zużyciu Snowflake, co oznacza, że rozliczenie opiera się na kredytach obliczeniowych wykorzystanych podczas procesu generowania zapytań. Aby zapoznać się z aktualnymi stawkami, należy zawsze odwoływać się do oficjalnej dokumentacji cenowej Snowflake.