
Jesteś pewien, że dokument istnieje. Widziałeś go w zeszłym tygodniu.
Jednak po wypróbowaniu wszystkich możliwych kombinacji słów kluczowych — „wyniki marketingowe za III kwartał”, „wyniki za III kwartał”, „raport marketingowy za październik” — pasek wyszukiwania Twojej firmy pozostaje pusty. To frustrujące poszukiwanie informacji jest klasycznym objawem przestarzałego wyszukiwania słów kluczowych.
Systemy te wyszukują tylko dokładne dopasowania słów i pomijają to, co naprawdę masz na myśli. Cohere skutecznie rozwiązuje ten problem, zapewniając inteligentną warstwę wyszukiwania, która tworzy połączenia między Twoimi systemami.
Jeśli więc zastanawiasz się, „jak korzystać z Cohere do wyszukiwania w Enterprise”, mamy dla Ciebie rozwiązanie. Ten przewodnik wyjaśnia wszystko.
Czym jest Cohere AI i dlaczego ma znaczenie dla wyszukiwania korporacyjnego?
Cohere to platforma AI, która tworzy duże modele językowe (LLM) specjalnie do użytku w Enterprise. W przypadku wyszukiwania wewnętrznego oznacza to przejście od wyszukiwania opartego na słowach kluczowych do semantycznego, inteligentnego wyszukiwania, które rozumie intencje, kontekst i znaczenie.
Większość narzędzi do wyszukiwania korporacyjnego nadal opiera się na dosłownym dopasowywaniu słów kluczowych. Jeśli dokładne słowa nie pojawiają się w tytule lub treści dokumentu, wynik często jest pomijany. Cohere zmienia to, umożliwiając systemom wyszukiwania zrozumienie, czego faktycznie szuka użytkownik, a nie tylko tego, co wpisał.
Zespoły próbujące samodzielnie stworzyć wyszukiwarkę opartą na AI zazwyczaj spędzają miesiące na tworzeniu baz danych wektorowych, osadzaniu potoków i zmianie rankingu modeli. Nawet po wykonaniu całej tej pracy wyszukiwarka często nie działa tak, jak powinna, ponieważ znajduje się w oddzielnym systemie, niezwiązanym z rzeczywistym miejscem pracy, odłączonym od zadań, dokumentów i cykli pracy.
Potężne narzędzie do wyszukiwania w przedsiębiorstwie, takie jak Cohere, wykorzystuje generowanie wspomagane wyszukiwaniem (RAG) w celu połączenia inteligentnego wyszukiwania ze sztuczną inteligencją. Takie podejście sprawia, że Twoja wewnętrzna wiedza staje się zasobem dostępnym natychmiast.
W przypadku Cohere narzędzie to konwertuje dokumenty na osadzenia, czyli numeryczne reprezentacje znaczenia. Gdy ktoś wyszukuje hasło „kwartalny raport przychodów”, system wyszukuje dokumenty związane z tą koncepcją, takie jak „Wyniki finansowe za IV kwartał” lub „Podsumowanie zysków”, nawet jeśli nie zawierają one dokładnie tych słów kluczowych.
Właśnie dlatego Cohere ma znaczenie dla wyszukiwania korporacyjnego. Zmniejsza złożoność wdrożenia, poprawia dokładność wyników i umożliwia wyszukiwanie, które działa tak, jak faktycznie myślą i zadają pytania pracownicy w nowoczesnych systemach pracy.
📮ClickUp Insight: Ponad połowa wszystkich pracowników (57%) traci czas na przeszukiwanie wewnętrznych dokumentów lub bazy wiedzy firmy w celu znalezienia informacji związanych z pracą.
A kiedy nie mogą? 1 na 6 osób ucieka się do osobistych rozwiązań — przeszukuje stare e-maile, notatki lub zrzuty ekranu, aby poskładać wszystko w całość.
ClickUp Brain eliminuje konieczność wyszukiwania, zapewniając natychmiastowe odpowiedzi oparte na AI, pobierane z całego obszaru roboczego ClickUp i zintegrowanych aplikacji innych firm, dzięki czemu bez trudu uzyskasz potrzebne informacje.
Najważniejsze funkcje Cohere dla wyszukiwania Enterprise
Podczas oceny rozwiązań wyszukiwania opartych na AI marketingowy szum może utrudniać określenie, które funkcje faktycznie rozwiązują Twoje problemy. Ogólne obietnice „inteligentniejszego wyszukiwania” nie pomagają zespołom inżynierów i produktowym w podejmowaniu świadomych decyzji.
W rzeczywistości niezawodny system wyszukiwania opiera się na szeregu odrębnych modeli AI, które współpracują ze sobą.
Cohere oferuje kilka modeli, które można wykorzystać niezależnie lub połączyć w celu stworzenia zaawansowanej architektury wyszukiwania. Zrozumienie tych podstawowych funkcji jest pierwszym krokiem do zaprojektowania systemu, który spełni konkretne potrzeby Twojego zespołu.
Osadzanie dla semantycznego wyszukiwania wektorowego
Największą frustracją związaną ze starymi systemami wyszukiwania jest ich niezdolność do znajdowania informacji powiązanych koncepcyjnie. Szukasz „przewodnika dla nowych pracowników”, a nie znajdujesz dokumentu o tytule „Lista kontrolna pierwszego dnia pracy nowego pracownika”. Dzieje się tak, ponieważ system dopasowuje słowa, a nie znaczenie.
Model osadzania, wraz z wyszukiwaniem neuronowym, rozwiązuje ten problem poprzez konwersję tekstu na wektory — długie listy liczb, które oddają znaczenie semantyczne. Proces ten, zwany osadzaniem, umożliwia systemowi identyfikację dokumentów, które są podobne pod względem koncepcyjnym, nawet jeśli nie zawierają żadnych wspólnych słów kluczowych. Zasadniczo narzędzie wyszukiwania automatycznie rozpoznaje synonimy i powiązane idee.
Oto kluczowe aspekty modelu osadzania Cohere:
- Wsparcie dla wielu formatów: najnowsza wersja, Embed 4, może przetwarzać zarówno tekst, jak i obrazy, umożliwiając jednoczesne przeszukiwanie różnych typów zawartości.
- Funkcje wielojęzyczne: możesz wyszukiwać informacje w dokumentach w różnych językach bez konieczności ich wcześniejszego tłumaczenia.
- Opcje wymiarowości: Możesz wybrać rozmiar wektorów. Wyższe wymiary pozwalają uchwycić więcej niuansów, ale wymagają większej pojemności pamięci i mocy obliczeniowej.
📖 Więcej informacji: Przykłady zastosowań wyszukiwania AI dla Enterprise
Zmieniaj kolejność wyników, aby poprawić ich trafność.
Czasami wyszukiwanie zwraca listę odpowiednich dokumentów, ale ten najważniejszy znajduje się na drugiej stronie. To zmusza użytkowników do przeglądania wyników, co powoduje stratę czasu i utratę zaufania do systemu wyszukiwania.
Jest to problem związany z rankingiem. System znalazł właściwe informacje, ale nie potrafił ich poprawnie uszeregować według ważności.
Model Rerank Cohere rozwiązuje ten problem dzięki dwuetapowemu procesowi. Najpierw należy użyć szybkiej metody wyszukiwania (np. wyszukiwania semantycznego), aby zebrać duży zestaw potencjalnie istotnych dokumentów. Następnie należy przekazać tę listę do modelu Rerank, który wykorzystuje bardziej wymagającą obliczeniowo architekturę cross-encoder do analizy każdego dokumentu pod kątem konkretnego zapytania i zmiany ich kolejności w celu uzyskania maksymalnej trafności.
Jest to szczególnie przydatne w sytuacjach o wysokiej stawce, gdzie precyzja ma kluczowe znaczenie, np. gdy pracownik pomocy technicznej szuka właściwej odpowiedzi dla klienta lub członek zespołu szuka konkretnego fragmentu w dokumencie. Chociaż wydłuża to nieco czas przetwarzania, poprawa jakości wyników często jest warta tego kompromisu.
📖 Więcej informacji: Przykłady automatyzacji cyklu pracy i przypadki użycia
Przykłady zastosowań Enterprise Search dla Teams
Funkcje AI są interesujące, ale stają się użyteczne dopiero wtedy, gdy zastosujesz je do rozwiązywania rzeczywistych problemów biznesowych. Powodzenie wdrożenia wyszukiwania Enterprise zaczyna się od zidentyfikowania tych konkretnych problemów. 👀
Oto kilka praktycznych scenariuszy, w których zespoły mogą zastosować wyszukiwanie oparte na Cohere:
- Wyszukiwanie w bazie wiedzy: Pomóż pracownikom znaleźć odpowiedzi w wewnętrznej dokumentacji, wiki, bazie wiedzy obsługi klienta i standardowych procedurach operacyjnych (SOP) .
- Obsługa klienta: umożliwia agentom szybką lokalizację odpowiednich artykułów pomocy i rozwiązań z przeszłości podczas rozmowy z klientem — analiza McKinsey pokazuje, że zastosowanie generatywnej AI w cyklach pracy obsługi klienta pozwala uzyskać wzrost wydajności o 30–45%.
- Kwestie prawne i zgodność z przepisami: przeszukuj miliony umów, polityk i dokumentów regulacyjnych z wykorzystaniem rozumienia semantycznego, aby znaleźć konkretne klauzule lub precedensy.
- Badania i rozwój: Umożliwiaj inżynierom wyszukiwanie odpowiednich wcześniejszych prac, patentów i dokumentacji technicznej, aby uniknąć powielania wysiłków.
- HR i wdrażanie nowych pracowników: wyświetlaj odpowiednie zasady, materiały szkoleniowe, przykłady cykli pracy i procedury dla nowych pracowników, aby mogli samodzielnie znaleźć odpowiedzi na swoje pytania.
- Wsparcie sprzedaży: pomóż przedstawicielom handlowym znaleźć odpowiednie studia przypadków, informacje o konkurencji i informacje o produktach, aby szybciej finalizować transakcje.
Wspólnym mianownikiem jest to, że skuteczne wyszukiwanie korporacyjne musi być zintegrowane z istniejącym zarządzaniem cyklem pracy. Samodzielny pasek wyszukiwania nie wystarczy. Twój zespół musi mieć możliwość znalezienia informacji i natychmiastowego podjęcia działań bez konieczności zmiany narzędzi.
🛠️ Zestaw narzędzi: Stwórz wewnętrzny hub, z którego Twój zespół będzie faktycznie korzystał. Szablon bazy wiedzy ClickUp pozwala uporządkować wszystkie informacje — od instrukcji po standardowe procedury operacyjne — i ułatwia ich wyszukiwanie, dzięki czemu nikt nie musi zgadywać, gdzie znajdują się potrzebne informacje.

Jak skonfigurować Cohere dla wyszukiwania Enterprise
Przejście od oceny wyszukiwania opartego na AI do jego faktycznego wdrożenia może wydawać się trudnym zadaniem. Zwłaszcza jeśli Twój zespół nie ma doświadczenia w pracy z dużymi modelami językowymi.
Chociaż złożoność ustawień będzie zależała od skali i istniejącego stosu technologicznego, podstawowe kroki tworzenia systemu wyszukiwania opartego na Cohere są spójne. Ta sekcja zawiera praktyczny przewodnik dla zespołu technicznego.
Wymagania wstępne i dostęp do API
Zanim zaczniesz pisać kod, musisz przygotować narzędzia i dostęp. Te wstępne ustawienia pomagają zapobiec problemom z bezpieczeństwem i przeszkodom w przyszłości.
Oto, czego potrzebujesz, aby rozpocząć:
- Konto API Cohere: Zarejestruj się na stronie Cohere, aby uzyskać klucze API.
- Środowisko programistyczne: większość zespołów korzysta z języka Python, ale dostępne są również zestawy SDK dla innych języków.
- Baza danych wektorowych: Będziesz potrzebować miejsca do przechowywania osadzeń dokumentów, takiego jak Pinecone, Weaviate, Qdrant lub usługa zarządzana, taka jak Amazon OpenSearch.
- Korpus dokumentów: Zbierz zawartość, którą chcesz udostępnić do wyszukiwania (np. pliki PDF, pliki tekstowe, rekordy baz danych).
Możesz również uzyskać dostęp do modeli Cohere za pośrednictwem Amazon Bedrock, co może uprościć rozliczenia i bezpieczeństwo, jeśli Twoja firma już działa w ekosystemie AWS.
Generuj osadzenia za pomocą Cohere Embed
Kolejnym krokiem jest przekształcenie dokumentów w wektory umożliwiające wyszukiwanie. Proces ten obejmuje przygotowanie zawartości, a następnie przetworzenie jej za pomocą modelu Cohere Embed.
Sposób przygotowania dokumentów, a zwłaszcza ich podział na mniejsze fragmenty, ma ogromny wpływ na jakość wyszukiwania. Nazywa się to strategią podziału na fragmenty.
Typowe strategie dzielenia na fragmenty obejmują:
- Fragmenty o stałej wielkości: najprostsza metoda, ale może powodować niezręczne dzielenie zdań lub myśli w połowie.
- Semantyczne dzielenie na fragmenty: bardziej zaawansowana metoda, która uwzględnia strukturę dokumentu, np. dzielenie na końcu akapitów lub sekcji.
- Nakładające się fragmenty: podejście to obejmuje niewielką ilość powtarzającego się tekstu między fragmentami, aby pomóc zachować kontekst między granicami.
Po podziale dokumentów na fragmenty należy wysłać je partiami do interfejsu API Embed w celu wygenerowania reprezentacji wektorowych. Zazwyczaj jest to proces jednorazowy dla istniejących dokumentów, a nowe lub zaktualizowane dokumenty są osadzane w miarę ich tworzenia.
📖 Więcej informacji: Czym jest wewnętrzna wyszukiwarka? Najlepsze narzędzia i jak działają
Przechowuj i wyszukuj wektory
Nowo utworzone wektory potrzebują miejsca. Baza danych wektorów to specjalistyczna baza danych przeznaczona do przechowywania i wykonywania zapytań dotyczących osadzeń na podstawie ich podobieństwa.
Proces zapytania działa w następujący sposób:
- Użytkownik wpisuje zapytanie wyszukiwania
- Twoja aplikacja wysyła to zapytanie do tego samego modelu Cohere Embed, aby przekształcić je wektorowo.
- Wektor zapytania jest wysyłany do bazy danych, która wyszukuje najbardziej podobne wektory dokumentów.
- Baza danych zwraca pasujące dokumenty, które można następnie wyświetlić użytkownikowi.
Wybierając bazę danych wektorową, należy również rozważyć, jaką miarę podobieństwa zastosować. Podobizna cosinusowa jest najczęściej stosowana w przypadku wyszukiwania tekstowego, ale istnieją również inne opcje dla różnych zastosowań.
| Miara podobieństwa | Najlepsze dla |
|---|---|
| Podobieństwo cosinusowe | Wyszukiwanie tekstu ogólnego przeznaczenia |
| Iloczyn skalarny | Kiedy ważna jest wielkość wektorów |
| Odległość euklidesowa | Dane przestrzenne lub geograficzne |
Wprowadź zmianę rankingu, aby uzyskać lepsze wyniki.
W przypadku wielu aplikacji wyniki z bazy danych wektorowej są wystarczająco dobre. Jednak gdy potrzebujesz absolutnie najlepszego wyniku na górze listy, warto dodać krok ponownego sortowania.
Jest to szczególnie ważne, gdy Twoja wyszukiwarka obsługuje system RAG, ponieważ jakość generowanej odpowiedzi zależy w dużej mierze od jakości pobranego kontekstu.
Proces ponownego sortowania jest prosty:
- Pobierz większy zestaw początkowych kandydatów z bazy danych wektorowej (np. 50 najlepszych wyników).
- Przekaż oryginalne zapytanie użytkownika i listę kandydatów do Cohere Rerank API.
- API zwraca tę samą listę dokumentów, ale uporządkowaną na podstawie bardziej precyzyjnego wyniku trafności.
- Wyświetlaj użytkownikowi najlepsze wyniki z listy ponownie uszeregowanych wyników.
Aby zmierzyć wpływ zmiany rankingu, możesz śledzić wskaźniki oceny offline, takie jak nDCG (Normalized Discounted Cumulative Gain) i MRR (Mean Reciprocal Rank).
💫 Aby uzyskać wizualny przegląd wdrażania funkcji wyszukiwania korporacyjnego, obejrzyj ten przewodnik, który przedstawia kluczowe koncepcje i praktyczne kwestie:
Najlepsze praktyki dotyczące wyszukiwania w Enterprise opartego na Cohere
Stworzenie systemu wyszukiwania to tylko pierwszy krok. Utrzymanie i poprawa jego jakości w miarę upływu czasu to czynnik, który odróżnia projekt osiągający powodzenie od projektu osiągającego porażkę. Jeśli użytkownicy będą mieli kilka złych doświadczeń, stracą zaufanie i przestaną korzystać z narzędzia. 🛠️
Oto kilka wniosków wyciągniętych z powodzenia wdrożeń wyszukiwania korporacyjnego:
- Zacznij od wyszukiwania hybrydowego: nie polegaj wyłącznie na wyszukiwaniu semantycznym. Połącz je z tradycyjnym algorytmem wyszukiwania słów kluczowych, takim jak BM25. Dzięki temu zyskasz to, co najlepsze z obu rozwiązań — wyszukiwanie semantyczne znajduje elementy powiązane koncepcyjnie, a wyszukiwanie słów kluczowych zapewnia możliwość znalezienia dokładnych dopasowań dla kodów produktów lub konkretnych nazw.
- Zainwestuj w higienę i jakość danych: Twoje wyniki wyszukiwania mogą być tylko tak dobre, jak Twoje dane. Czyste, dobrze zorganizowane dokumenty z jasnymi nagłówkami i akapitami zapewniają znacznie lepsze osadzenia.
- Rozważnie dziel na fragmenty: Sposób podziału dokumentów na fragmenty ma kluczowe znaczenie. Zamiast stosować arbitralne limity dotyczące liczby znaków, spróbuj dopasować fragmenty do logicznej struktury dokumentów, np. akapitów lub sekcji.
- Dodaj filtrowanie metadanych: Wyszukiwanie semantyczne jest potężnym narzędziem, ale czasami użytkownicy już wiedzą, czego szukają. Pozwól im filtrować wyniki według metadanych, takich jak data, dział lub typ dokumentu, zanim uruchomi się wyszukiwanie semantyczne.
- Monitoruj i powtarzaj: Zwracaj szczególną uwagę na to, czego szukają użytkownicy, które wyniki klikają i które zapytania nie zwracają żadnych wyników. Dane te są nieocenione przy identyfikowaniu luk w zawartości i ulepszaniu systemu.
- Eleganckie radzenie sobie z niepowodzeniami: Żaden system wyszukiwania nie jest idealny. Gdy wyszukiwanie zwraca słabe wyniki, zapewnij pomocne rozwiązania zastępcze, takie jak sugerowanie alternatywnych zapytań lub oferowanie powiadomienia eksperta.
📖 Więcej informacji: Spersonalizowane wyszukiwanie: zwiększ wydajność i popraw jakość pracy
Ograniczenia Cohere for Enterprise Search
Chociaż Cohere dostarcza potężne modele AI, nie jest to rozwiązanie typu „plug-and-play” (nie do końca).
Stworzenie gotowego do użycia rozwiązania do wyszukiwania w przedsiębiorstwie wiąże się z poważnymi wyzwaniami, które zespoły często nie doceniają. Zrozumienie tych limitów ma kluczowe znaczenie dla podjęcia świadomej decyzji i uniknięcia kosztownych niespodzianek w przyszłości.
Największym problemem jest to, że otrzymujesz zestaw narzędzi, a nie gotowy produkt. W związku z tym Twój zespół jest odpowiedzialny za budowę i utrzymanie całej infrastruktury związanej z wyszukiwaniem jako usługą.
Oto kilka kluczowych limitów, które należy wziąć pod uwagę:
| Wyzwanie | Dlaczego staje się to problemem |
|---|---|
| Wymaga specjalistycznej wiedzy | Do zbudowania, uruchomienia i utrzymania systemu potrzebni są doświadczeni inżynierowie AI i danych. Nie jest to coś, co większość zespołów może skonfigurować lub posiadać bez większego wysiłku. |
| Wymagane niestandardowe integracje | Modele nie tworzą automatycznie połączeń z istniejącymi narzędziami. Każde źródło danych musi być podłączone i utrzymywane ręcznie. |
| Wysokie koszty bieżącej konserwacji | Indeksy wyszukiwania muszą być stale odświeżane w miarę zmian zawartości lub aktualizacji modeli, co powoduje ciągłe obciążenie operacyjne. |
| Niepołączone z Twoim obszarem roboczym | AI rozumie język, ale nie funkcjonuje w miejscu, w którym faktycznie pracuje Twój zespół, co powoduje rozbieżność między wyszukiwaniem a realizacją. |
| Zmiana kontekstu jest nieunikniona | Użytkownicy znajdują informacje w jednym miejscu, a następnie przełączają się na inne narzędzia, aby je wykorzystać, co negatywnie wpływa na wydajność i popularność rozwiązania. |
📖 Więcej informacji: Free szablony baz wiedzy w programie Word i ClickUp
Jak korzystać z ClickUp jako alternatywy dla wyszukiwania korporacyjnego
W tej chwili kompromis powinien być oczywisty.
Wyszukiwanie korporacyjne jest potężnym narzędziem, ale samodzielne jego tworzenie oznacza konieczność posiadania potoków pozyskiwania danych, strategii fragmentacji, odświeżania osadzeń, logiki ponownego porządkowania wyników oraz ciągłej konserwacji. Jest to długoterminowe zobowiązanie infrastrukturalne, a nie wdrożenie funkcji.
Jako pierwsze na świecie zintegrowane środowisko pracy oparte na AI, ClickUp eliminuje tę warstwę, wprowadzając wyszukiwanie oparte na AI bezpośrednio do obszaru roboczego.
Ma to znaczenie, ponieważ większość problemów związanych z wyszukiwaniem nie jest tak naprawdę problemami związanymi z wyszukiwaniem. Są to problemy związane z rozproszeniem pracy . Gdy praca jest rozproszona między niepołączonymi narzędziami, zespoły są zmuszone do ciągłego poszukiwania kontekstu. Wynikiem jest strata czasu, powielanie wysiłków i podejmowanie decyzji bez pełnej widoczności.
ClickUp rozwiązuje ten problem u źródła, łącząc pracę, kontekst i inteligencję w jednym obszarze roboczym ClickUp. Przyjrzyjmy się, jak to działa w praktyce.
Uzyskaj odpowiedzi uwzględniające kontekst z całego obszaru roboczego dzięki ClickUp Brain.
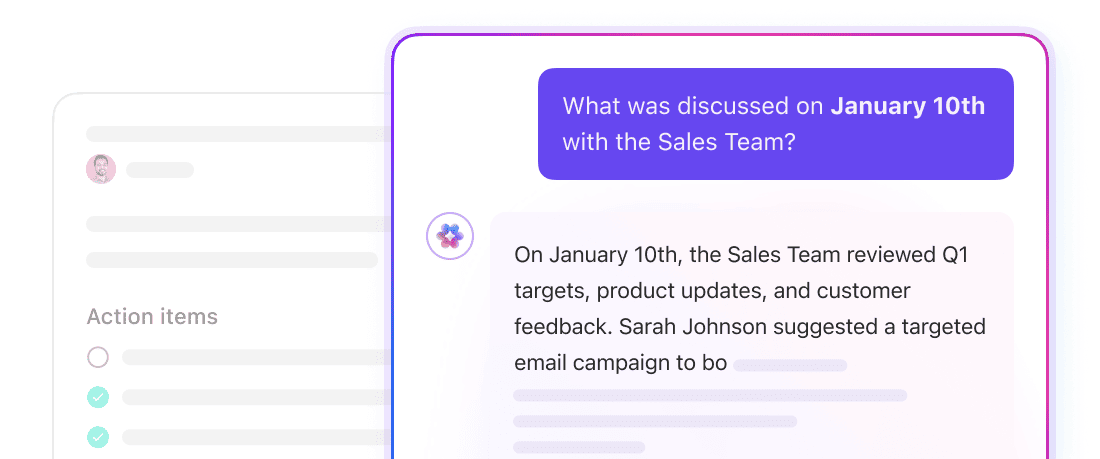
ClickUp Brain to kontekstowa warstwa AI, która działa w całym obszarze roboczym. Może odpowiadać na pytania, podsumowywać informacje i wyświetlać istotne zadania, ponieważ ma już dostęp do podstawowej struktury obszaru roboczego: zadań ClickUp, dokumentów ClickUp, komentarzy ClickUp i innych.
Nie ma potrzeby definiowania rozmiarów fragmentów ani zarządzania osadzeniami. Brain wykorzystuje natywny model danych ClickUp, aby zrozumieć, w jaki sposób informacje są ze sobą połączone. Zadaj pytanie typu „Co blokuje uruchomienie w czwartym kwartale?”, a Brain może pobrać kontekst z zadań, komentarzy i dokumentów powiązanych z tą inicjatywą.
ClickUp Brain oferuje również wsparcie dla wielu modeli AI, co pozwala na wykorzystanie różnych zapytań do najbardziej odpowiedniego modelu do wnioskowania, podsumowywania lub generowania. Dzięki temu nie musisz ograniczać swoich cykli pracy do mocnych stron lub ograniczeń jednego modelu.
Gdy potrzebujesz zewnętrznego kontekstu, Brain może przeprowadzać wyszukiwania w Internecie bezpośrednio z obszaru roboczego, zwracając podsumowane wyniki bez konieczności opuszczania ClickUp lub otwierania osobnej zakładki przeglądarki.
Wyszukuj, nawiguj i wykonuj zadania dzięki ClickUp Enterprise Search.
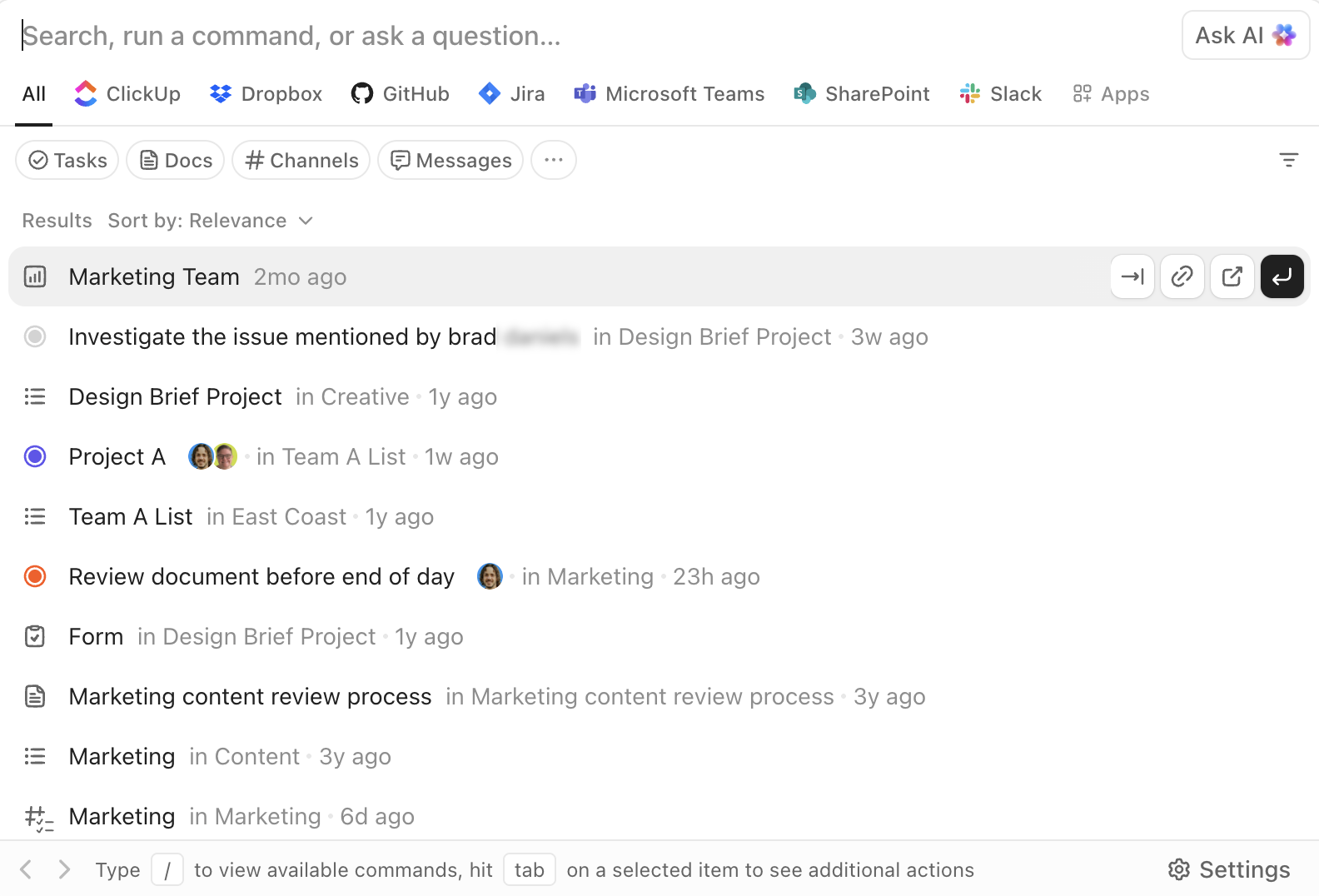
Wyszukiwarka ClickUp Enterprise Search jest dostępna z dowolnego miejsca w obszarze roboczym. Umożliwia wyszukiwanie zadań, dokumentów, komentarzy i załączników, a także połączonych aplikacji innych firm, takich jak Google Drive, Slack, GitHub i innych, w zależności od integracji.
Pasek poleceń AI zamienia wyszukiwanie w warstwę wykonawczą. Możesz przechodzić do elementów, tworzyć zadania, zmieniać statusy, przypisywać właścicieli lub otwierać określone widoki bezpośrednio z tego samego interfejsu. Nie jest to tylko „znajdź i przeczytaj”, ale „znajdź i działaj”.
Ponieważ wyszukiwanie jest wbudowane w interfejs użytkownika obszaru roboczego, wyniki są zawsze przydatne. Nie musisz pobierać informacji osobno, a następnie przełączać się między narzędziami, aby z nich skorzystać. Cykl pracy przebiega w jednym miejscu.
Ogranicz rozrost narzędzi dzięki ClickUp BrainGPT.
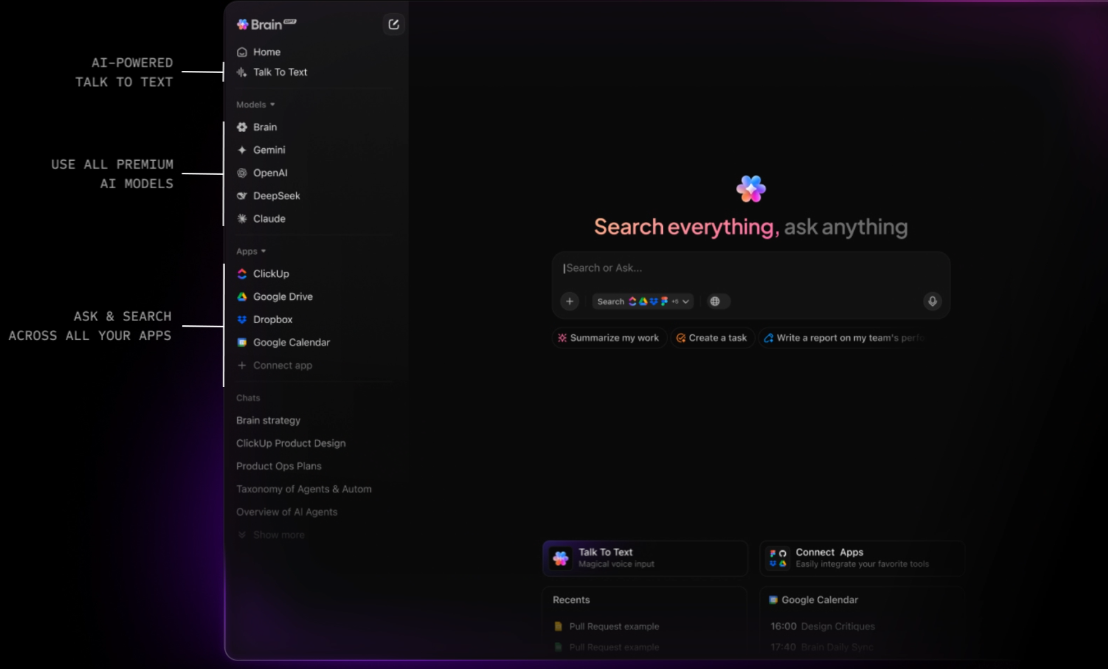
ClickUp BrainGPT rozszerza możliwości wyszukiwania poza przeglądarkę, oferując samodzielną aplikację komputerową i rozszerzenie do przeglądarki Chrome. Łączy się bezpośrednio z Twoim obszarem roboczym ClickUp i wyświetla te same informacje kontekstowe bez konieczności otwierania najpierw ClickUp lub którejkolwiek z połączonych aplikacji.
Z poziomu jednego interfejsu możesz wyszukiwać zadania, dokumenty, komentarze i połączone narzędzia, w tym Gmaila i inne integracje. Funkcja Talk-to-Text oparta na głosie pozwala na natychmiastowe wyszukiwanie lub rejestrowanie pytań, co jest szczególnie przydatne w przypadku szybkich wyszukiwań lub pracy w terenie.
Zamiast dodawać kolejne narzędzie do wyszukiwania oparte na AI, Brain GPT konsoliduje wyniki wyszukiwania w jednym miejscu, które już rozumie Twoją pracę.
To prawdziwa zmiana. ClickUp nie wymaga tworzenia wyszukiwania korporacyjnego. Ten zintegrowany obszar roboczy osadza je bezpośrednio w systemie, w którym odbywa się praca, eliminując koszty infrastruktury przy zachowaniu mocy, dokładności i szybkości.
📖 Więcej informacji: Najlepsze przykłady systemów zarządzania wiedzą
Bonus: Strategiczne porównanie między niestandardowym rozwiązaniem a natywną AI w obszarze roboczym
| Podstawowa wartość | Maksymalna elastyczność; własna kontrola | Gotowe do użycia; domyślnie uwzględniające kontekst |
| Wdrożenie | Miesiące: Wymaga od zespołów inżynierów zbudowania potoków danych. | Minuty: przełączanie jednym kliknięciem dla całego obszaru roboczego |
| Pobieranie danych | Instrukcja: Musisz zbudować i utrzymywać ETL i bazę danych wektorów. | Automatyczne: dostęp w czasie rzeczywistym do zadań, dokumentów i czatu |
| Logika uprawnień | Wymaga ręcznego kodowania (wysokie ryzyko wycieku danych) | Dziedziczone natywnie z hierarchii ClickUp |
| Głębia kontekstowa | Semantyczne (oparte na znaczeniu) | Operacyjne (wie, kto jest przypisany do jakich zadań) |
| Interfejs użytkownika | Musisz zaprojektować i zbudować pasek wyszukiwania/czat. | Wbudowane (pasek wyszukiwania, widoki dokumentów i zadań) |
| Działanie cyklu pracy | Brak: użytkownik znajduje informacje, a następnie przełącza się na inne narzędzia, aby kontynuować pracę. | Wysoki: Znajdź informacje i natychmiast przekształć je w zadanie |
| Najlepsze dla | Firmy technologiczne tworzące własne oprogramowanie | Teams, które chcą wyeliminować „rozproszenie narzędzi” i działać szybko |
Wyszukiwanie nie powinno Cię powstrzymywać!
Wyszukiwanie semantyczne nie jest już czynnikiem wyróżniającym. Jest to obecnie standard.
Rzeczywisty koszt wyszukiwania Enterprise pojawia się wszędzie indziej: czas inżynierów potrzebny do jego stworzenia i utrzymania, infrastruktura wymagana do zapewnienia jego dokładności oraz tarcia powstające, gdy wyszukiwanie odbywa się poza narzędziami, w których faktycznie odbywa się praca. Znalezienie odpowiedniego dokumentu nie ma większego znaczenia, jeśli podjęcie działania w oparciu o niego nadal wymaga przełączania się między systemami.
Dlatego problem nie polega tylko na „lepszym wyszukiwaniu”. Chodzi o wyeliminowanie luki między informacją a wykonaniem.
Gdy wyszukiwanie jest wbudowane bezpośrednio w obszar roboczy, kontekst jest domyślnie zachowywany. Odpowiedzi są nie tylko pobierane, ale także natychmiast gotowe do użycia. Zadania mogą być aktualizowane, decyzje dokumentowane, a praca może być kontynuowana bez konieczności tworzenia kolejnych przekazów.
Dla zespołów, które nie chcą poświęcać miesięcy na budowanie i utrzymywanie niestandardowej infrastruktury wyszukiwania, praca w zintegrowanym obszarze roboczym AI całkowicie zmienia sytuację. ClickUp zapewnia wyszukiwanie na poziomie przedsiębiorstwa, oparte na sztucznej inteligencji, jako część systemu, z którego Twój zespół już korzysta do planowania, współpracy i realizacji zadań.
✅ Zacznij korzystać z ClickUp za darmo.
Często zadawane pytania
Cohere koncentruje się w szczególności na zastosowaniach korporacyjnych, takich jak wyszukiwanie, oferując modele takie jak Embed i Rerank, które są specjalnie zaprojektowane do zadań związanych z wyszukiwaniem. OpenAI zapewnia szersze modele ogólnego przeznaczenia, które można dostosować do wyszukiwania, ale mogą one wymagać większej regulacji.
Tak, Cohere udostępnia interfejsy API, które umożliwiają integrację z innymi narzędziami, jednak wymaga to niestandardowego rozwoju i zasobów inżynieryjnych. Alternatywne rozwiązanie, takie jak ClickUp, oferuje natywne wyszukiwanie oparte na AI, które działa od razu po uruchomieniu, eliminując potrzebę jakichkolwiek prac integracyjnych.
Branże posiadające duże, nieustrukturyzowane repozytoria dokumentów — takie jak sektor prawny, opieki zdrowotnej, usług finansowych i technologii — odnoszą największe korzyści z wyszukiwania semantycznego. Każda organizacja borykająca się z problemami związanymi z zarządzaniem wiedzą może odnotować znaczną poprawę.