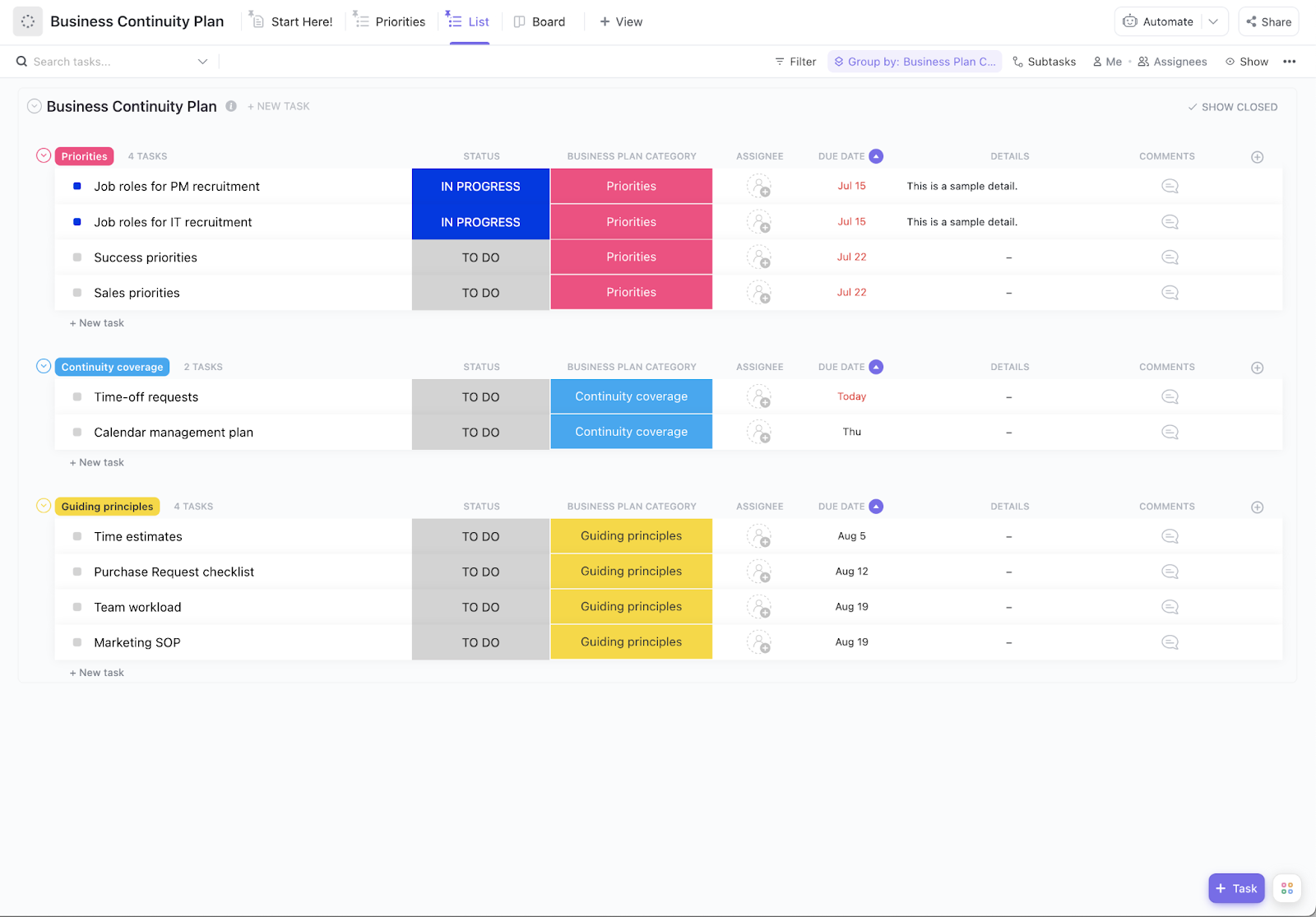

IT-rampen kunnen zonder waarschuwing toeslaan.
Van servercrashes tot cyberaanvallen: zonder een solide herstelplan kan uw bedrijf te maken krijgen met urenlange downtime, gegevensverlies en ernstige financiële schade. 54% van de ernstige storingen kost meer dan 100.000 dollar.
Deze blog leidt u door het opstellen van een uitgebreid IT-noodherstelplan dat uw systemen beschermt, duidelijke hersteldoelstellingen definieert en ervoor zorgt dat uw team precies weet wat het moet doen als er iets misgaat.
Wat is een IT-rampherstelplan?
Als uw servers nu zouden crashen, zou uw team dan precies weten wat te doen? 🛠️
Een IT-rampenherstelplan (DR) is uw gedocumenteerde strategie voor het herstellen van IT-systemen en gegevens na een storing, van natuurrampen tot cyberaanvallen. Het is in feite uw draaiboek om technologie weer online te krijgen wanneer er iets misgaat.
💡 DR versus bedrijfscontinuïteit
Disaster recovery (DR) richt zich specifiek op het herstellen van uw IT-infrastructuur en gegevens. Business continuity (BC) is breder en heeft tot doel uw hele bedrijf operationeel te houden tijdens en na een crisis, zelfs als de IT niet werkt. Beschouw DR als een belangrijk onderdeel van uw algehele BC-strategie.
💡 DR versus bedrijfscontinuïteit
Disaster recovery (DR) richt zich specifiek op het herstellen van uw IT-infrastructuur en gegevens. Business continuity (BC) is breder en heeft tot doel uw hele bedrijf operationeel te houden tijdens en na een crisis, zelfs als de IT niet werkt. Beschouw DR als een belangrijk onderdeel van uw algehele BC-strategie.
Uw noodherstelplan is belangrijk omdat downtime meer kost dan alleen geld. Elke minuut dat uw systemen offline zijn, kan het vertrouwen van klanten ondermijnen, de bedrijfsvoering verstoren en zelfs leiden tot boetes wegens niet-naleving. Een uitgebreid noodherstelplan is uw routekaart naar veerkracht.
Een goed plan omvat:
- Procedures voor back-ups van gegevens: hoe en waar u kopieën van kritieke informatie opslaat, zodat u deze kunt herstellen
- Stappen voor systeemherstel: de exacte volgorde om diensten in de juiste volgorde weer online te brengen
- Verantwoordelijkheden van het team: wie doet wat tijdens een incident om verwarring te voorkomen?
- Communicatieprotocollen: hoe u belanghebbenden, van uw team tot uw klanten, op de hoogte houdt
- Hersteldoelstellingen: uw specifieke doelstellingen voor hoe snel systemen weer operationeel moeten zijn en hoeveel gegevensverlies acceptabel is.
Veelvoorkomende IT-rampscenario's en gevolgen
Rampen zijn niet alleen Hollywood-scenario's; ze gebeuren elke dag bij bedrijven. Als u begrijpt waartegen u zich beschermt, kunt u een veel sterkere verdediging opbouwen.
Natuurrampen en fysieke schade
Gebeurtenissen zoals overstromingen, branden, aardbevingen en grote stroomuitval kunnen hele datacenters binnen enkele minuten vernietigen. Toen een groot datacenter in Nashville bijvoorbeeld door een overstroming werd getroffen, verloren sommige bedrijven weken aan gegevens en waren ze maanden bezig met herstelwerkzaamheden. De beste bescherming hiertegen is geografische redundantie, wat betekent dat u uw infrastructuur over meerdere fysieke locaties verspreidt, zodat één gebeurtenis niet alles kan platleggen.
Cyberaanvallen en gegevenslekken
Ransomware, Distributed Denial-of-Service (DDoS)-aanvallen en datalekken verschillen van fysieke rampen. Ze zijn vaak moeilijker te detecteren, kunnen zich ongemerkt verspreiden via verbindingen en richten zich vaak ook op uw back-up-systemen, waardoor herstel bijzonder uitdagend is. De frequentie en complexiteit van deze cyberaanvallen blijven toenemen in alle sectoren. Ransomware komt nu voor in 44% van alle bevestigde inbreuken, waardoor het een van de grootste bedreigingen is.
Hardware storingen en gegevensverlies
Soms gaan zelfs de meest geteste en betrouwbare back-upsystemen kapot. Servercrashes, storingen in de opslagruimte en storingen in netwerkapparatuur kunnen zonder waarschuwing optreden. Zelfs als u over redundante (back-up)systemen beschikt, kunnen deze toch tegelijkertijd uitvallen als ze gemeenschappelijke componenten of stroombronnen delen, waardoor er één enkel storingspunt ontstaat.
👀 Wist u dat: In oktober 2025 kreeg AWS te maken met een grote storing toen een bug in het interne DNS-beheersysteem voor Amazon DynamoDB ervoor zorgde dat domeinnaamresolutie mislukte in de datacenterregio US-EAST-1. Dit 'kleine' technische defect triggerde een cascade van storingen in tientallen AWS-services en legde honderden populaire apps en platforms wereldwijd plat, van berichten- en sociale apps tot banken, gaming-sites en meer. Voor veel mensen zorgde de storing ervoor dat een groot deel van het internet tijdelijk 'verdween', wat aantoont hoe kwetsbaar onze digitale infrastructuur is wanneer zoveel afhankelijk is van een handvol cloudproviders.
Softwarefouten en serviceonderbrekingen
Een beschadigde database, een mislukte software-update of een simpele configuratiefout kan hele platforms platleggen. U zult wellicht merken dat één verkeerd geconfigureerde regel code een cascade-effect kan hebben op systemen met verbinding, waardoor een grootschalige storing met een groot bereik ontstaat. Goed veranderingsmanagement en speciale testomgevingen zijn uw beste vrienden bij het minimaliseren van deze risico's.
Menselijke fouten en verkeerde configuraties
Onbedoelde verwijderingen, onjuiste configuraties en ongeoorloofde wijzigingen blijven een van de meest voorkomende oorzaken van IT-storingen. Eén verkeerd commando of een verwijderd bestand kan urenlange downtime en verslechtering van de dienstverlening triggeren. Training en toegangscontroles helpen wel, maar kunnen menselijke fouten niet volledig uitsluiten.
📮ClickUp Insight: 92% van de werknemers gebruikt inconsistente methoden om actiepunten bij te houden, wat resulteert in gemiste beslissingen en vertraagde uitvoering.
Of u nu follow-upaantekeningen verstuurt of spreadsheets gebruikt, het proces is vaak versnipperd en inefficiënt. Met de ClickUp-taakbeheermogelijkheden hoeft u zich hier nooit meer zorgen over te maken. Maak met één klik taken aan vanuit chats, ClickUp-taakopmerkingen, documenten en e-mails!
Belangrijkste onderdelen van een IT-rampherstelplan
Een solide DR-plan is uw complete draaiboek om weer online te komen. Elk van deze componenten bouwt voort op de andere om een uitgebreide bescherming voor uw bedrijf te creëren.
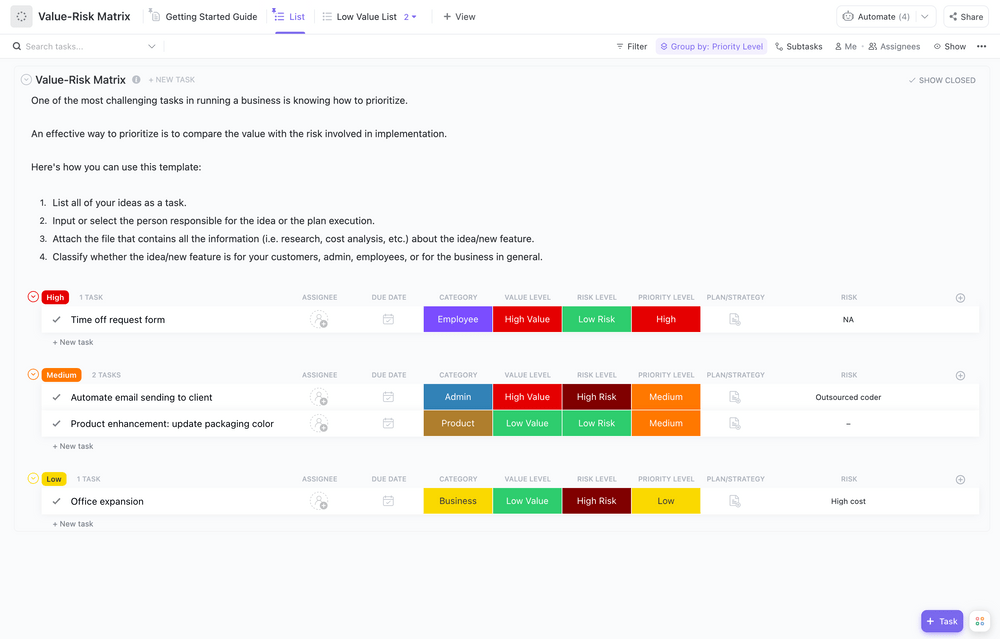
Risicobeoordeling en prioritering
Eerst moet u weten waar u mee te maken hebt. Een risicobeoordeling is het proces waarbij u uw kwetsbaarheden in kaart brengt en de waarschijnlijkheid en impact van elke potentiële bedreiging evalueert. U kunt dit organiseren in een risicomatrix om te zien welke bedreigingen het ernstigst zijn.
Uw beoordeling moet het volgende omvatten:
- Kritieke systemen: wat absoluut moet blijven draaien om uw Business te laten functioneren
- Gevoeligheid van gegevens: Welke informatie heeft het hoogste beschermingsniveau nodig (zoals klantgegevens)?
- Afhankelijkheden: Welke andere systemen of processen vallen uit wanneer elk systeem uitvalt?
📖 Lees meer: Hoe IT-infrastructuurbeheer te implementeren
Bedrijfsimpactanalyse en kriticiteit
Bereken vervolgens de werkelijke kosten van downtime. Met een business impact analysis (BIA) kunt u de financiële en operationele impact van een storing voor elk systeem bepalen. Zo kunt u uw systemen indelen in kriticiteitsniveaus om prioriteiten te stellen voor uw herstelinspanningen.
| Kritiek | Minder dan een uur | Betalingsverwerking, klantendatabases |
| Hoog | Eén tot vier uur | E-mail, interne communicatiemiddelen |
| Medium | Vier tot 24 uur | Ontwikkelomgevingen, tools voor rapportage |
| Laag | 24+ uur | Archiefsystemen, niet-productieve test servers |
RTO- en RPO-doelstellingen
Deze twee acroniemen vormen de kern van uw herstelstrategie.
- Hersteltijddoelstelling (RTO): Dit is de maximale tijd dat u zich kunt veroorloven dat een systeem niet beschikbaar is. Het geeft antwoord op de vraag: "Hoe snel moet dit weer online zijn?"
- Recovery Point Objective (RPO): Dit is de maximale hoeveelheid gegevens die u zich kunt veroorloven te verliezen, gemeten in tijd. Het geeft antwoord op de vraag: "Hoeveel gegevens kunnen we verliezen zonder grote schade?"
Uw interne e-mailsysteem heeft bijvoorbeeld een RTO van vier uur, maar uw klantgerichte e-commercedatabase heeft mogelijk een RPO van slechts 15 minuten, wat betekent dat u niet meer dan 15 minuten aan gegevens over transacties mag verliezen.
Plan voor gegevensback-up en -herstel
Uw back-upplan is uw ultieme vangnet. Een veelgebruikte best practice is de 3-2-1-regel: bewaar ten minste drie kopieën van uw belangrijke gegevens, sla ze op twee verschillende soorten media op en bewaar een van die kopieën buiten het bedrijf.
U kunt ook kiezen uit verschillende soorten back-ups:
- Volledige back-ups: een complete kopie van alle gegevens, meestal wekelijks of maandelijks uitgevoerd.
- Incrementele back-ups: alleen back-ups van wijzigingen die zijn aangebracht sinds de laatste back-up van welk type dan ook.
- Differentiële back-ups: maakt een back-up van alle wijzigingen die zijn aangebracht sinds de laatste volledige back-up.
Het belangrijkste is dat u uw back-upherstelproces regelmatig test. Een niet-geteste back-up is slechts een hoop, geen plan.
💟 Bonus: Leg cruciale details vast tijdens stressvolle incidenten met behulp van ClickUp Brain MAX's spraak-naar-tekstfunctie, zodat u nooit belangrijke informatie mist, zelfs als typen niet praktisch is. Spreek gewoon uw observaties uit en laat de AI de documentatie verzorgen.
Communicatieplan en updates voor belanghebbenden
Wanneer zich een ramp voordoet, is een duidelijk communicatieplan van cruciaal belang. Uw plan moet notificatieketens definiëren, hoe vaak u updates verstrekt en welke kanalen u voor elk type incident gebruikt.
Verschillende groepen hebben verschillende informatie nodig:
- Interne teams: hebben technische details en specifieke actiepunten nodig
- Klanten: U wilt weten wat de status van de service is en wanneer u verwacht dat het probleem is opgelost.
- Leveranciers: Mogelijk moet u een beroep doen op hen om u te ondersteunen of om escalaties te behandelen.
- Regelgevende instanties: Afhankelijk van uw branche kunnen formele notificaties vereist zijn.
Tools zoals deze kant-en-klare sjabloon voor een communicatieplan van ClickUp kunnen u helpen om tijdens een crisis sneller te handelen met een vast protocol.

Test- en trainingsprogramma
Een plan dat u nooit test, is een plan dat zal mislukken. Regelmatig testen brengt hiaten en zwakke punten aan het licht voordat zich een echte ramp voordoet.
Plan verschillende soorten tests gedurende het jaar:
- Tafeloefeningen: uw team doorloopt een rampscenario op papier om de logica van het plan te controleren.
- Gedeeltelijke failovers: u test het herstel van specifieke, niet-kritieke componenten of services.
- Volledige DR-tests: u voert een volledige failover uit naar uw back-up-systemen (de ultieme test).
Werk na elke test uw documentatie bij en train nieuwe leden van het team onmiddellijk in de procedures.
📖 Lees meer: Hoe u effectief IT-beleid en -procedures ontwikkelt
Stappen voor het opstellen van een IT-noodherstelplan
Het opstellen van uw DR-plan hoeft geen overweldigende taak te zijn.
Hier leest u hoe u dit stap voor stap kunt aanpakken. 🙌
Stap 1: Maak een inventaris van uw bedrijfsmiddelen
U kunt niet beschermen wat u niet weet dat u hebt. Begin met het opstellen van een lijst van bedrijfsmiddelen waarin alle hardware, software, opslagplaatsen en afhankelijkheden in uw omgeving worden vermeld. Zorg ervoor dat u contactgegevens van leveranciers, licentiesleutels en configuratiegegevens opneemt, zodat u deze tijdens een herstel snel kunt raadplegen.

De ClickUp ITAM-sjabloon combineert incidentbeheer, probleembeheer, veranderingsbeheer, eenvoudige oplossingen voor activabeheer en kennisbeheer. Onze ITSM-sjabloon voor bekende fouten vereenvoudigt het bijhouden van bekende fouten in uw systemen. Bekijk al onze IT-sjablonen zodra uw doel verandert.
Pas uw werkstroom aan in elke gewenste stijl voor elke ITAM-fase, van implementatie en configuratie tot onderhoud en buitengebruikstelling.
Stap 2: Classificeer kritieke diensten
Bepaal nu welke van die bedrijfsmiddelen essentieel zijn en welke slechts een extraatje zijn. Breng de serviceafhankelijkheid van uw systemen in kaart door kaarten te maken die laten zien hoe uw systemen met elkaar verbonden zijn en van elkaar afhankelijk zijn. Besteed speciale aandacht aan klantgerichte services die een directe invloed hebben op de omzet of de gebruikerservaring.
🎥 Bekijk deze praktische walkthrough waarin wordt gedemonstreerd hoe u met de krachtige functies van ClickUp een gestructureerd plan op hoog niveau kunt opstellen, van het stellen van doelen tot het toewijzen van taken en het bijhouden van de voortgang.
Stap 3: Beoordeel risico's en bedreigingen
Beoordeel risico's en bedreigingen door de waarschijnlijkheid en impact van elk type bedreiging voor uw specifieke situatie te evalueren. Houd rekening met uw geografische risico's (bevindt u zich in een aardbevingsgebied of overstromingsgebied?) en eventuele branchespecifieke bedreigingen (zoals wijzigingen in de regelgeving of gerichte cyberaanvallen). Documenteer alles in een risicoregister, zodat u het in de loop van de tijd kunt bijhouden.

De ClickUp-sjabloon voor risicobeoordeling op het Whiteboard creëert een visuele dimensie voor uw risicobeoordelingsproces. Het helpt bij het beoordelen en categoriseren van risico's en inspireert uw team om inzichten te delen en samen te werken in een boeiend en visueel format.
Met deze sjabloon kunt u:
- Evalueer risicocategorieën en mogelijke gevolgen
- Analyseer gegevens om mogelijke aandachtspunten te identificeren
- Bepaal preventieve maatregelen om risico's te verminderen
Met functies waarmee u kunt tekenen, schrijven en plaknotities toevoegen, is deze Whiteboard-sjabloon voor risicobeheer perfect voor het evalueren van de risico's van uw project.
Stap 4: Stel RTO- en RPO-doelen vast
Werk rechtstreeks samen met uw zakelijke belanghebbenden om te bepalen wat zij als aanvaardbare downtime en gegevensverlies beschouwen voor elk serviceniveau dat u eerder hebt geïdentificeerd. U moet een evenwicht vinden tussen de kosten van sneller herstel en de impact op het bedrijf – niet alles hoeft onmiddellijk te worden hersteld zonder gegevensverlies. Zorg dat u goedkeuring van het management krijgt voor deze targets.
Stap 5: Definieer back-up- en failover-paden
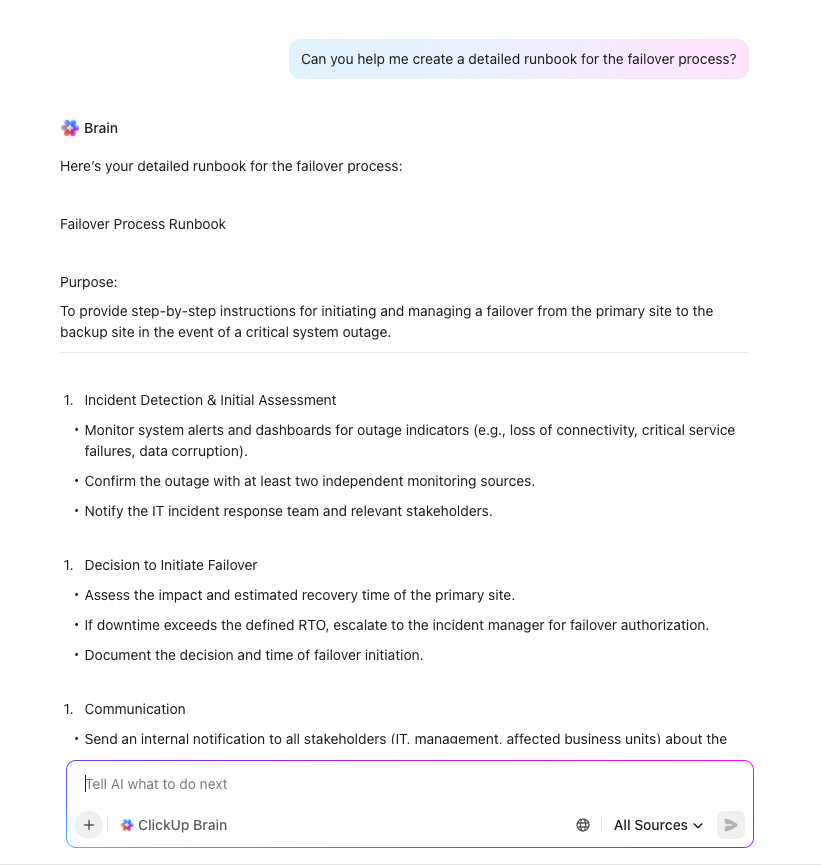
Nu uw doelen zijn ingesteld, kunt u uw technische oplossingen ontwerpen. Creëer back-upstrategieën die zijn afgestemd op de RPO van elk systeem en plan gedetailleerde failoverprocedures, inclusief alternatieve verwerkingslocaties en noodtoegangsmethoden. Voeg netwerkdiagrammen en stapsgewijze runbooks toe om de uitvoering foolproof te maken.
Stap 6: Toewijzen van rollen en escalatie
Definieer de structuur van uw DR-team met duidelijke verantwoordelijkheden en beslissingsbevoegdheid. Maak uitgebreide contactlijsten met primaire en back-uppersoneel voor elke rol. Een RACI-matrix (Responsible, Accountable, Consulted, Informed) is een uitstekend hulpmiddel om verwarring tijdens een stressvolle situatie te voorkomen.
Stap 7: Documenteer en communiceer het plan
Documenteer en communiceer het plan met duidelijke, stapsgewijze procedures die iedereen in uw team kan volgen, zelfs onder druk. Het is cruciaal om deze documentatie op te slaan op een goed toegankelijke locatie die gescheiden is van uw primaire infrastructuur. Zorg ervoor dat elk teamlid precies weet waar het plan te vinden is tijdens een crisis.
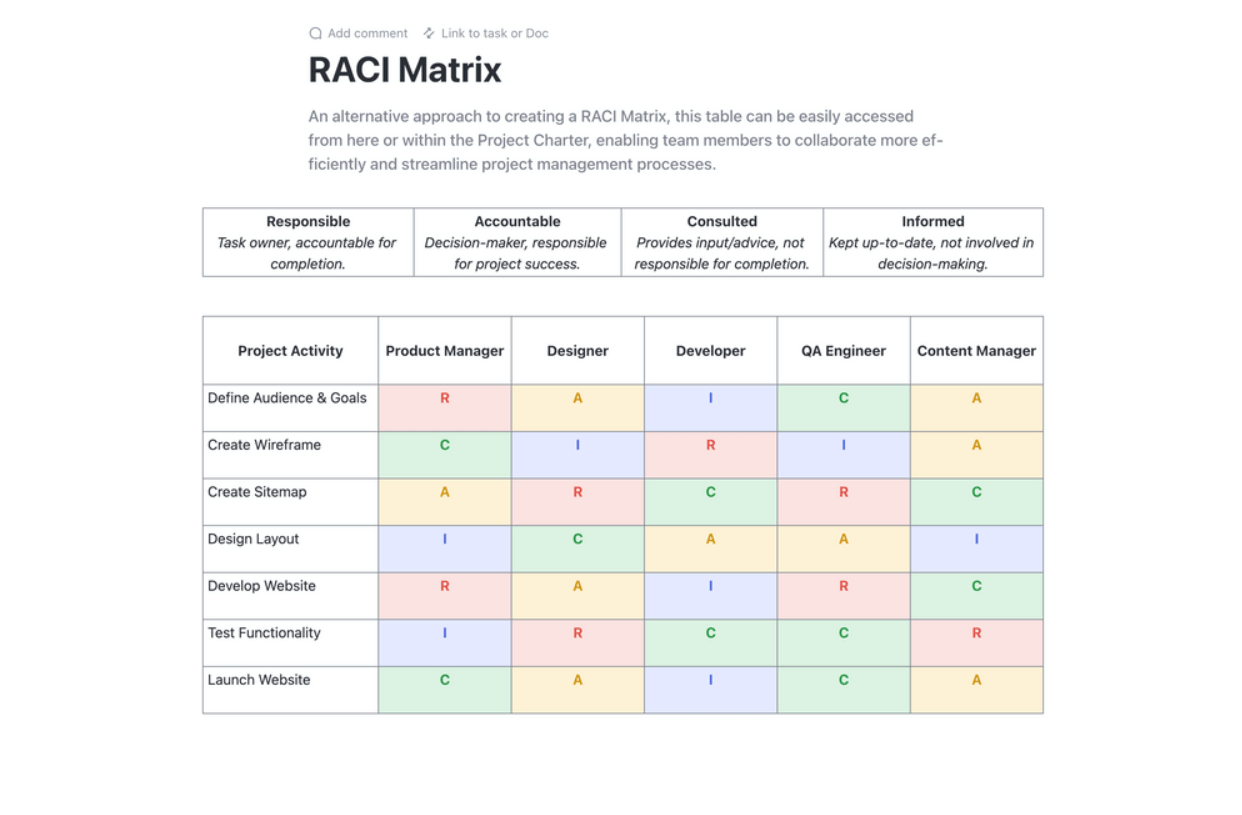
Stroomlijn uw projectplanning met de RACI-planningssjabloon van ClickUp. Deze Doc-sjabloon is een gamechanger en biedt een duidelijk overzicht om de rollen en verantwoordelijkheden van het team met betrekking tot projecttaken te definiëren. Omarm het RACI-raamwerk (Responsible, Accountable, Consulted en Informed) om iedereen op één lijn te krijgen en te zorgen voor verantwoordelijkheid en afstemming met de organisatiedoelen.
Stap 8: Testen, evalueren en verbeteren
Plan tien slotte driemaandelijkse tests om uw procedures te valideren en eventuele hiaten te identificeren. Documenteer alle lessen die u uit elke test en eventuele echte incidenten hebt geleerd, en gebruik deze om uw plan bij te werken. Creëer een systematisch systeem voor het bijhouden van verbeteringen om ervoor te zorgen dat alle gevonden problemen worden opgelost.
🌼 Wist u dat: In 2017 kreeg GitLab te maken met een grote database-uitval. Tijdens het herstel ontdekten ze dat verschillende van hun back-upmethoden al dagenlang stilzwijgend faalden. Dit incident leerde de hele tech-industrie een cruciale les: back-upvalidatie is niet onderhandelbaar. Een niet-geteste back-up is eigenlijk helemaal geen back-up.
🌼 Wist u dat: In 2017 kreeg GitLab te maken met een grote database-uitval. Tijdens het herstel ontdekten ze dat verschillende van hun back-upmethoden al dagenlang stilzwijgend faalden. Dit incident leerde de hele tech-industrie een cruciale les: back-upvalidatie is niet onderhandelbaar. Een niet-geteste back-up is eigenlijk helemaal geen back-up.
Strategieën en oplossingen voor noodherstel
Niet elke organisatie heeft dezelfde DR-aanpak nodig. Laten we uw opties bekijken op basis van uw budget, herstelbehoeften en beschikbare middelen.
Aanpak voor back-ups en herstel
Dit is de eenvoudigste en meest kosteneffectieve methode. Hierbij worden regelmatig back-ups gemaakt naar een externe locatie (zoals de cloud of een secundair datacenter) en worden deze vervolgens handmatig hersteld wanneer dat nodig is. Deze aanpak is het meest geschikt voor niet-kritieke systemen die een langere RTO kunnen verdragen, aangezien het herstel uren of zelfs dagen kan duren.
Hoge beschikbaarheid en redundantie
Deze strategie is erop gericht om single points of failure te elimineren door gebruik te maken van meerdere actieve systemen. Technieken zoals load balancing, serverclustering en RAID-opslagruimte zorgen ervoor dat als één component uitvalt, een andere component onmiddellijk het werk overneemt. Hoewel deze aanpak duurder is om op te zetten en te onderhouden, kan hij de downtime tot slechts enkele seconden of minuten beperken, waardoor hij ideaal is voor kritieke diensten.
Replicatie- en failoveropties
Replicatie houdt in dat gegevens vrijwel in realtime naar een secundaire locatie worden gekopieerd, waardoor het gegevensverlies tijdens een ramp tot een minimum wordt beperkt.
- Synchrone replicatie: schrijft gegevens tegelijkertijd naar zowel de primaire als de secundaire locatie, waardoor geen gegevens verloren gaan. Hiervoor is echter een hoge bandbreedte nodig en het kan uw primaire systeem vertragen.
- Asynchrone replicatie: schrijft gegevens eerst naar de primaire site en kopieert deze vervolgens met een kleine vertraging naar de secundaire site. Dit is goedkoper en heeft minder invloed op de prestaties, maar u accepteert een klein risico op gegevensverlies.
Cloudgebaseerde noodherstel en DRaaS
Disaster Recovery as a Service (DRaaS) is voor veel bedrijven een populaire keuze geworden. Het biedt pay-as-you-go-prijzen, onmiddellijke geografische verdeling en automatisering van het herstel zonder dat u uw eigen fysieke DR-locaties hoeft te bouwen en te onderhouden. Cloud DR elimineert de enorme kapitaalkosten van een back-updatacenter en biedt tegelijkertijd snellere schaalbaarheid en meer flexibiliteit dan traditionele hot-, warm- of cold-site-benaderingen.
Hoe ClickUp de planning van IT-noodherstel stroomlijnt
Het beheren van een DR-plan via verspreide spreadsheets, documenten en e-mailketens creëert een eigen rampenrisico.
Dit soort werkverspreiding, de fragmentatie van werk over meerdere, niet-gekoppelde tools die niet met elkaar communiceren, en contextverspreiding, waarbij teams uren verspillen met het zoeken naar informatie die verspreid is over apps en platforms, leidt tot verwarring, verouderde informatie en trage responstijden wanneer elke seconde telt.
Met ClickUp Converged AI-werkruimte – één veilig platform waar al uw werk-apps, gegevens en werkstroomen samen met contextuele AI als intelligentielaag worden ondergebracht – dat projectmanagement, documentatie en teamcommunicatie combineert. U hoeft niet langer met meerdere platforms te jongleren en kunt uw DR-planning, -testen en -incidentrespons in één uniform systeem onderbrengen.
Gecentraliseerde DR-documentatie met ClickUp Docs en ingebouwde AI-assistentie
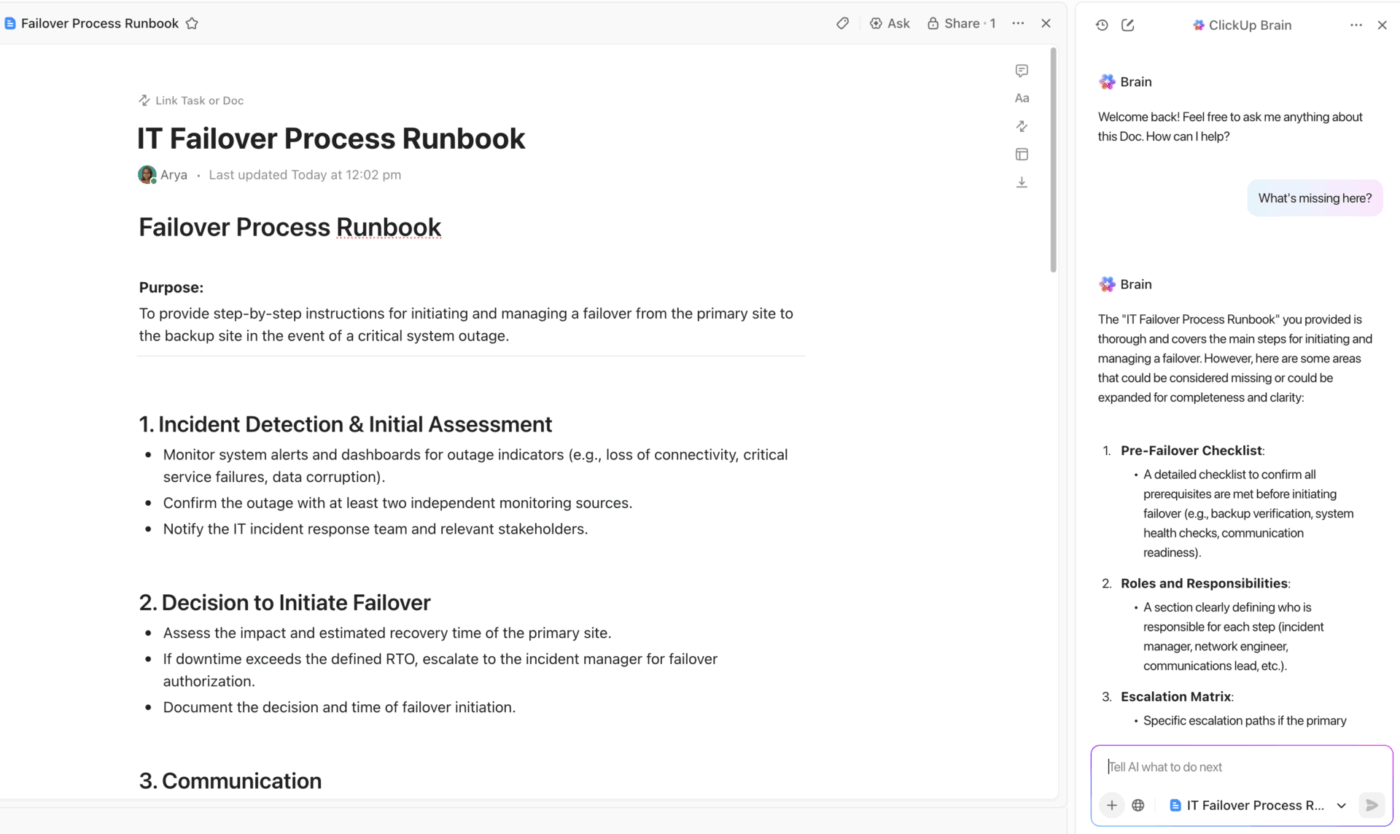
Zorg ervoor dat uw team altijd over één enkele bron van waarheid beschikt met ClickUp Docs.
Stel uw volledige noodherstelplan op in een samenwerkingsruimte waar iedereen tijdens een incident in realtime kan bijdragen. Koppel documenten rechtstreeks aan incidenttaken en -projecten voor naadloze navigatie en neem diagrammen of runbooks op om cruciale informatie precies daar te bewaren waar u die nodig hebt.
Het beste van alles is dat u uw documenten kunt beveiligen om onbedoelde bewerkingen te voorkomen en dat u met gedetailleerde ClickUp-toestemmingen kunt bepalen wie gevoelige herstelprocedures kan bekijken of wijzigen. Elke wijziging wordt bijgehouden in de geschiedenis van het document, zodat u over een volledig controlespoor beschikt.
AI-gestuurd planaanmaken met ClickUp Brain
Versnel de planning van disaster recovery en elimineer kritieke hiaten met ClickUp Brain, uw contextuele AI-assistent die uw hele werkruimte begrijpt. In tegenstelling tot generieke AI-tools maakt ClickUp Brain gebruik van de echte taken, documenten en werkstroom van uw organisatie om nauwkeurige, bruikbare ondersteuning te bieden voor DR-initiatieven.
Geef ClickUp Brain gewoon een opdracht zoals 'Maak een checklist voor noodherstel voor ons e-commerceplatform' en ontvang direct een uitgebreide, op maat gemaakte sjabloon die aansluit bij uw systemen, processen en nalevingsvereisten. Het kan u helpen met:
- Contextbewustzijn: ClickUp Brain heeft toegang tot de structuur, content en toestemming van uw werkruimte. Het kan verwijzen naar taken, documenten, opmerkingen en zelfs gekoppelde apps, en biedt antwoorden en acties die zijn afgestemd op uw daadwerkelijke werk – niet alleen algemene suggesties.
- Probleemoplossing en begeleiding: Los problemen direct op, krijg stapsgewijze instructies of vraag om best practices voor elke ClickUp-functie. Brain kan u door complexe processen leiden, repetitieve taken automatiseren en helpen bij het oplossen van blokkades.
- Automatisering en versnelling van werkstroomen: gebruik vooraf gebouwde of aangepaste AI-agents om werkstroomen met meerdere stappen te automatiseren, verzoeken te triëren of terugkerende werkzaamheden te beheren, waardoor u elke week uren tijd bespaart.
- Diepgaand zoeken: vind informatie die ergens in uw werkruimte verborgen zit, inclusief taken, documenten en geïntegreerde tools, zelfs als deze al jaren oud is of moeilijk te vinden is op basis van standaardzoekfuncties.
- Realtime samenvattingen en updates: genereer direct projectupdates, samenvattingen van vergaderingen of rapporten over de voortgang op basis van live werkruimtegegevens.
- Vereenvoudiging van technische documentatie: zet complexe technische documenten om in duidelijke, bruikbare procedures of checklists die uw team kan volgen, zelfs onder druk.
- Multi-model intelligence: Kies uit toonaangevende AI-modellen (OpenAI GPT-4. 1, GPT-5, Claude, Gemini en meer) voor de beste resultaten bij elke Taak – geen aparte abonnementen nodig.
- Veilig en toestemmingsbewust: Brain heeft alleen toegang tot informatie waarvoor u al toestemming hebt om deze te bekijken, waardoor strikte normen voor privacy en naleving worden gehandhaafd.
- Conversational interface: gebruik @brain in opmerkingen of tijdens het chatten om contextuele inzichten te krijgen, antwoorden op te stellen of automatiseringen te triggeren zonder uw werkstroom te verlaten.
- Aangepaste prompts en opgeslagen werkstroomen: sla prompts op voor terugkerende behoeften en gebruik ze opnieuw, zodat je consistentie garandeert en tijd bespaart voor je hele team.
💡Pro-tip: Mis nooit meer een les uit uw incidentbeoordelingsvergaderingen door elk detail vast te leggen met ClickUp AI Notetaker. Deze tool kan deelnemen aan uw virtuele vergaderingen, de hele discussie transcriberen en automatisch een lijst met actiepunten genereren op basis van de geleerde lessen. Zo ontstaat een doorzoekbare incidentgeschiedenis, zodat u snel eerdere gebeurtenissen en hun oplossingen kunt raadplegen.

Geautomatiseerde DR-werkstroomen met ClickUp-automatiseringen
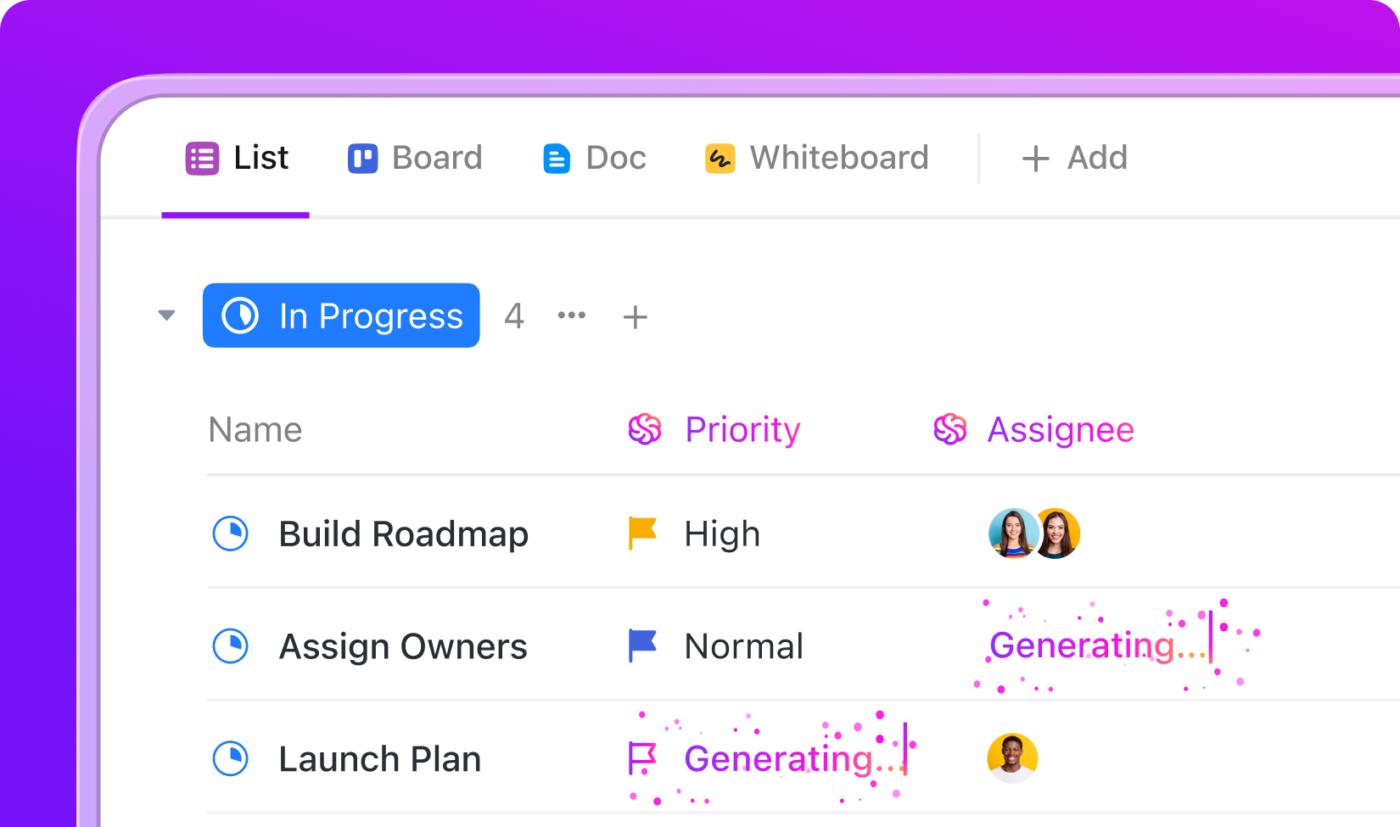
Stel je voor dat je team te maken krijgt met een plotselinge storing: elke seconde telt en je kunt je geen enkele stap veroorloven. Met ClickUp AI Agents en automatiseringen hoef je niet in paniek te raken of op je geheugen te vertrouwen. Zodra een incident wordt gemeld, komt de ClickUp AI in actie, begeleidt je team en neemt het drukke werk uit handen, zodat jij je kunt concentreren op het oplossen van het probleem.
Zo werkt het in een echt scenario:
- Wanneer iemand een taak markeert als 'Incident gemeld', maakt ClickUp Agent automatisch een checklist met responsstappen, wijst deze toe aan de juiste personen en start een timer om bij te houden hoe lang het herstel duurt.
- Als het incident als 'kritiek' wordt gemarkeerd, kan een agent onmiddellijk een e-mail naar uw managementteam sturen en een speciale chatroom opzetten – uw 'war room' – zodat iedereen op één plek kan communiceren.
- De AI kan eerdere incidentrapporten en relevante documentatie opvragen, zodat uw team alles wat het nodig heeft binnen handbereik heeft.
Bekijk hier de werkstroom:
Met ClickUp AI Agents krijgt u een betrouwbare digitale teamgenoot die uw team helpt kalm, georganiseerd en effectief te blijven, zelfs wanneer de druk hoog is.
Real-time bijhouden met ClickUp dashboard
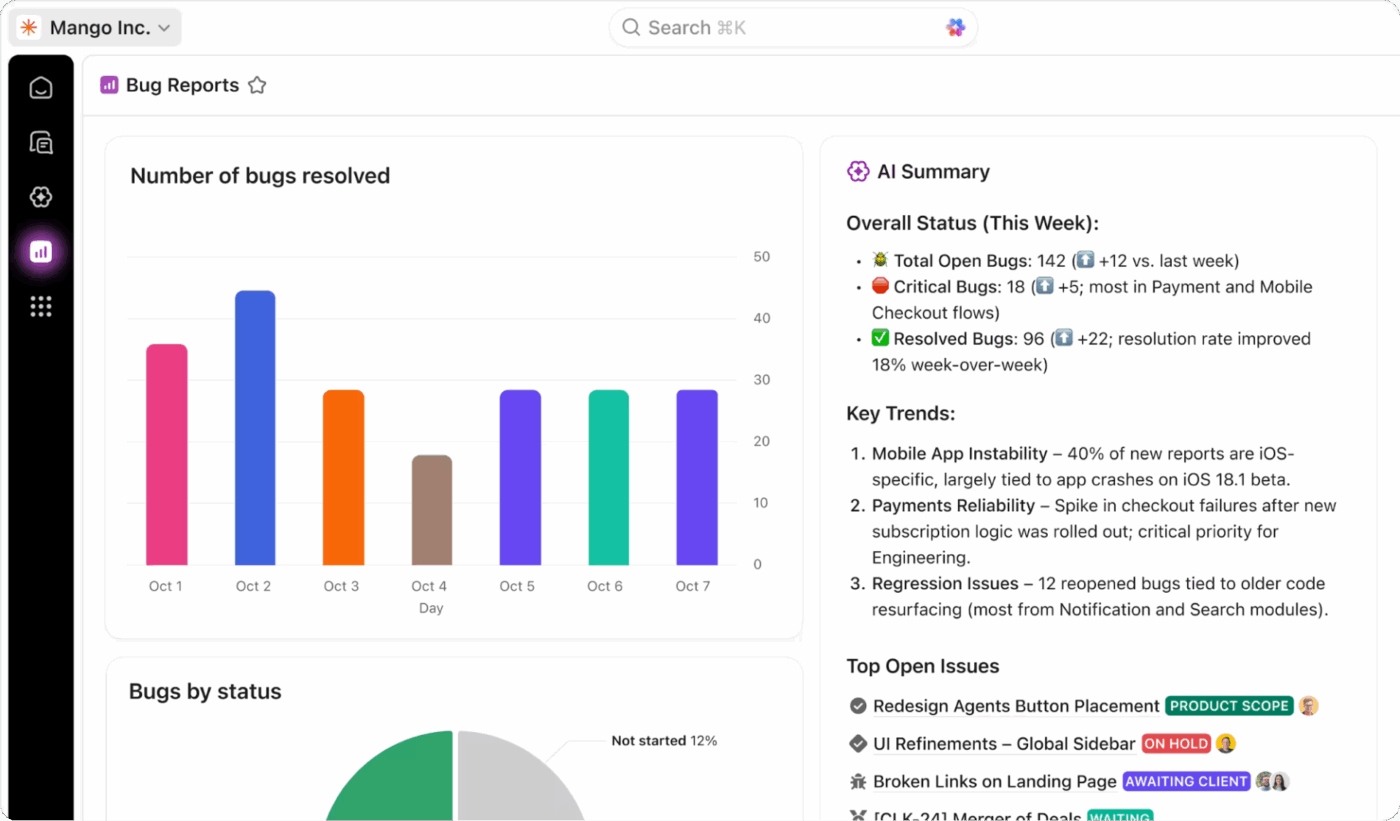
Krijg volledig inzicht in de status van uw DR-programma door alles in realtime bij te houden met ClickUp Dashboards. U kunt widgets maken om uw RTO- en RPO-prestaties tijdens tests te monitoren, de voltooiingspercentages van tests bij te houden en incidenttrends in de loop van de tijd te bekijken.
Voeg ClickUp aangepaste velden toe aan uw taken om de kriticiteit van het systeem, de herstelstatus en testresultaten bij te houden, en breng vervolgens al die gegevens samen in één weergave. Deze dashboards bieden u direct bruikbare rapporten die altijd up-to-date zijn met realtime gegevens van de test- en incidentresponsactiviteiten van uw team.
📖 Lees meer: Hoe maak je een checklist voor risicobeoordeling?
Stel vandaag nog uw DR-plan op
Elke dag dat u zonder DR-plan werkt, is een gok die u zich niet kunt veroorloven. Rampen zijn onvermijdelijk – of ze nu door de natuur, technologische storingen of menselijke fouten worden veroorzaakt – maar uw voorbereiding bepaalt of ze kleine ongemakken of grote rampen worden.
Een uitgebreid DR-plan vereist inzicht in uw risico's, het documenteren van duidelijke procedures en het regelmatig testen daarvan. De juiste tools maken dit proces beheersbaar door een einde te maken aan de chaos van verspreide documenten en handmatige processen.
Zelfs eenvoudige noodplannen zijn beter dan niets wanneer zich een ramp voordoet. Door regelmatig te testen en bij te werken, verandert uw DR-plan van een stoffig document in een levend systeem dat uw bedrijf echt beschermt.
Zet vandaag nog de eerste stap en begin met het opstellen van uw DR-plan met ClickUp. Ga gratis aan de slag met ClickUp en breng al uw noodherstelplanning, documentatie en incidentrespons samen op één uniform platform. ✨
Veelgestelde vragen
U moet uw DR-plan minstens vier keer per jaar herzien en het onmiddellijk bijwerken na belangrijke infrastructuurwijzigingen of echte incidenten. De meeste organisaties voeren jaarlijks een grondige herziening uit om alle geleerde lessen te integreren en zich aan te passen aan nieuwe technologieën.
IT-teams, teams voor veiligheid en planners voor bedrijfscontinuïteit leiden doorgaans de DR-planning en -tests. Ze hebben echter cruciale input nodig van operationele en businessunit-leiders om ervoor te zorgen dat het plan aansluit bij de werkelijke bedrijfsbehoeften en -prioriteiten.
Gebruik stopwatches en duidelijke tijdstempels om tijdens elke test de werkelijke hersteltijden te vergelijken met uw gedefinieerde target. Het is van cruciaal belang om eventuele verschillen tussen uw target en de werkelijke prestaties in uw testrapporten te documenteren, zodat u op basis daarvan toekomstige verbeteringen kunt doorvoeren.
Projectmanagementplatforms zoals ClickUp zijn ideaal voor het centraliseren van documentatie, de automatisering van werkstroomprocessen en het bijhouden van statistieken voor uw volledige DR-programma. U kunt ze vervolgens koppelen aan gespecialiseerde DR-tools die de technische aspecten van gegevensreplicatie en systeemfailover afhandelen.