

Er zijn twee soorten AI-assistenten: een die alles weet tot vorige week, en een die weet wat er een minuut geleden is gebeurd.
Als u de eerste AI-assistent zou vragen: "Is mijn vlucht nog steeds vertraagd?", zou deze kunnen antwoorden op basis van het schema van gisteren en zou het antwoord onjuist kunnen zijn. De tweede assistent, die wordt aangedreven door actuele gegevens, controleert live updates en geeft u het juiste antwoord.
De tweede assistent is wat we live kennis noemen, in actie gezien.
En het vormt de basis van agentische AI-systemen – systemen die niet alleen vragen beantwoorden, maar ook handelen, beslissen, coördineren en zich aanpassen. Hier ligt de focus op autonomie, aanpassingsvermogen en doel-gerichte redeneren .
In deze blog gaan we dieper in op wat live kennis betekent in de context van AI, waarom het belangrijk is, hoe het werkt en hoe u het kunt gebruiken in echte werkstroom.
Of u nu werkzaam bent in operations, productontwikkeling, ondersteunen of management, dit artikel geeft u de basis om de juiste vragen te stellen, systemen te evalueren en te begrijpen hoe live kennis uw technologie en bedrijfsresultaten kan veranderen. Laten we erin duiken.
Wat is live kennis in agentische AI?
Live kennis verwijst naar informatie die realtime, up-to-date en beschikbaar is voor een AI-systeem op het moment dat het moet handelen.
Het is een term die meestal wordt gebruikt in de context van agentische en omgevings-AI: AI-agenten die uw mensen, kennis, werk en processen zo goed kennen dat ze naadloos en proactief op de achtergrond kunnen werken.
Live kennis betekent dat de AI niet alleen vertrouwt op de dataset waarop hij is getraind of de momentopname van kennis bij implementatie. In plaats daarvan blijft hij leren, maakt hij verbinding met actuele werkstroom en past hij zijn acties aan op basis van wat er op dit moment daadwerkelijk gebeurt.
Wanneer we dit bespreken in de context van AI-agenten (d.w.z. systemen die handelen of beslissingen nemen), stelt live kennis hen in staat om veranderingen in hun omgeving waar te nemen, nieuwe informatie te integreren en op basis daarvan de volgende stappen te kiezen.
Hoe dit verschilt van statische trainingsgegevens en traditionele kennisbanken
De meeste traditionele AI-systemen worden getraind op basis van een vaste dataset, zoals tekst, afbeeldingen of logbestanden, en vervolgens geïmplementeerd. Hun kennis verandert niet, tenzij u ze opnieuw traint of bijwerkt.
Het is alsof je een boek over computers uit de jaren 90 leest en vervolgens een MacBook uit 2025 probeert te gebruiken.
Traditionele kennisbanken (voorbeeld: de FAQ-opslagplaats van uw bedrijf of een statische database met productspecificaties) worden weliswaar periodiek bijgewerkt, maar zijn niet ontworpen om continu nieuwe informatie te streamen en zich aan te passen.
Live kennis onderscheidt zich doordat het continu en dynamisch is: uw agent werkt op basis van een live feed in plaats van op een cachekopie.
Kortom:
- Statische training = "wat het model wist toen het werd gebouwd"
- Live kennis = "wat het model weet terwijl de wereld verandert, in realtime"
De relatie tussen live kennis en agentautonomie
Agentische AI-systemen zijn gebouwd om meer te doen dan alleen vragen beantwoorden.
Ze kunnen:
- Coördineer acties
- Abonnement meerstapswerkstroom
- Werk met minimale menselijke input
Om dit effectief te doen, hebben ze een diepgaand inzicht nodig in de huidige situatie, inclusief de status van systemen, de nieuwste bedrijfsstatistieken, de context van klanten en externe gebeurtenissen. Dat is precies wat live kennis biedt.
Hiermee kan de agent voelen wanneer voorwaarden veranderen, zijn beslissingspad aanpassen en handelen op een manier die aansluit bij de huidige realiteit van het bedrijf of de omgeving.
Hoe live kennis werkversnippering en onderbroken werkstroom oplost
Live kennis – realtime, met verbinding toegang tot informatie in al uw tools – lost direct alledaagse problemen op die worden veroorzaakt door wildgroei op het werk. Maar wat is dat eigenlijk?
Stel je voor dat je aan een project werkt en de laatste feedback van de client nodig hebt, maar die staat verstopt in een e-mailthread, terwijl het projectplan in een aparte tool staat en de ontwerpbestanden in weer een andere app. Zonder live kennis verspil je tijd met schakelen tussen platforms, teamgenoten om updates vragen of zelfs belangrijke details missen.
Live kennis biedt het beste scenario waarin u direct die feedback kunt zoeken en vinden, de laatste projectstatus kunt bekijken en toegang hebt tot de nieuwste ontwerpen – allemaal op één plek, ongeacht waar de gegevens zich bevinden.
Een marketingmanager kan bijvoorbeeld tegelijkertijd toegang krijgen tot campagnaresultaat uit analysetools, creatieve assets bekijken op een ontwerpplatform en teamdiscussies controleren via chat-apps. Een supportmedewerker kan de volledige geschiedenis van een klant bekijken – e-mails, tickets en chatlogs – zonder tussen systemen te hoeven schakelen.
Dit betekent minder tijd verspillen aan het zoeken naar informatie, minder gemiste updates en snellere, zelfverzekerder beslissingen. Kortom, live kennis zorgt voor een verbinding tussen uw versnipperde digitale wereld, waardoor het dagelijks werk soepeler en met meer productiviteit verloopt.
Als 's werelds eerste geconvergeerde AI-werkruimte biedt ClickUp's Live Intelligence AI Agent dit alles en nog veel meer. Bekijk het hier in actie. 👇🏼
📖 Lees meer: AI in kennisbeheer: voordelen, use cases en tools
Belangrijkste componenten die live kennissystemen mogelijk maken
Achter elk live kennissysteem schuilt een onzichtbaar netwerk van bewegende delen: continu gegevens verzamelen, bronnen verbinden en leren van resultaten. Deze componenten werken samen om ervoor te zorgen dat informatie niet alleen in opslagruimte blijft zitten, maar ook in werkstroom stroomt, wordt bijgewerkt en zich aanpast terwijl het werk plaatsvindt.
In praktische termen is live kennis gebaseerd op een combinatie van gegevensverplaatsing, integratie-intelligentie, contextueel geheugen en feedbackgestuurd leren. Elk onderdeel heeft een specifieke rol in het informeren en proactief houden van uw werkruimte, in plaats van reactief.
Een van de grootste uitdagingen in dynamische organisaties is werkversnippering. Naarmate teams nieuwe tools en processen gaan gebruiken, kan kennis snel versnipperd raken over verschillende platforms, kanalen en formaten. Zonder een systeem om deze verspreide informatie te bundelen en zichtbaar te maken, gaan waardevolle inzichten verloren en verspillen teams tijd met zoeken of dubbel werk. Live kennis pakt werkversnippering direct aan door informatie uit alle bronnen continu te integreren en te verbinden, zodat kennis toegankelijk, actueel en bruikbaar blijft, ongeacht de herkomst ervan. Deze uniforme aanpak voorkomt versnippering en stelt teams in staat om slimmer te werken, niet harder.
Hier volgt een overzicht van de belangrijkste bouwstenen die dit mogelijk maken en hoe ze in de praktijk tot leven komen:
| Component | Wat het doet | Hoe het werkt |
|---|---|---|
| Datapijplijnen | Voeg continu nieuwe gegevens toe aan het systeem | Datapijplijnen gebruiken API's, gebeurtenis streams en webhooks om nieuwe informatie uit meerdere tools en omgevingen op te halen of te pushen. |
| Integratielagen | Maak een verbinding tussen gegevens uit verschillende interne en externe systemen in één uniforme weergave. | Integratielagen synchroniseren informatie tussen apps zoals CRM's, databases en IoT-sensoren, waardoor silo's en duplicaties worden verwijderd. |
| Context- en geheugensystemen | Help AI herinneren wat relevant is en vergeten wat niet relevant is. | Deze systemen creëren een 'werkgeheugen' voor agents, waardoor ze de context van recente gesprekken, acties of werkstroom kunnen behouden en verouderde gegevens kunnen verwijderen. |
| Ophaal- en updatemechanismen | Geef systemen toegang tot de meest recente informatie op het moment dat ze die nodig hebben. | Opzoektools query gegevens op vlak voordat een reactie of beslissing wordt genomen, zodat de meest recente updates worden gebruikt. Interne opslagplaatsen worden automatisch bijgewerkt met nieuwe inzichten. |
| Feedbackloops | Maak continu leren en verbeteren op basis van resultaten mogelijk. | Feedbackmechanismen herzien eerdere acties met nieuwe gegevens, vergelijken verwachte met werkelijke resultaten en passen interne modellen dienovereenkomstig aan. |
Samen zorgen deze componenten ervoor dat AI verschuift van 'kennis op een bepaald moment' naar 'continu realtime inzicht'.
Waarom live kennis belangrijk is voor AI-agents
AI-systemen zijn slechts zo goed als de kennis waarop ze zijn gebaseerd.
In moderne werkstroom verandert de kennis met de minuut. Of het nu gaat om veranderend aangepast sentiment, evoluerende productgegevens of realtime operationele prestaties, statische informatie verliest snel zijn relevantie.
Dat is waar live kennis essentieel wordt.
Live kennis stelt AI-agenten in staat om de overstap te maken van passieve responders naar adaptieve probleemoplossers. Deze agenten synchroniseren continu met de voorwaarden in de echte wereld, detecteren veranderingen zodra deze zich voordoen en passen hun redeneringen in realtime aan. Deze mogelijkheid maakt AI veiliger, betrouwbaarder en beter afgestemd op menselijke doelen in complexe, dynamische systemen.
Limiet van statische kennis in dynamische omgevingen
Wanneer AI-systemen alleen statische gegevens gebruiken (d.w.z. wat ze wisten op het moment van training of laatste update), lopen ze het risico beslissingen te nemen die niet meer in overeenstemming zijn met de werkelijkheid. Bijvoorbeeld omdat marktprijzen zijn veranderd, serverprestaties zijn verslechterd of de beschikbaarheid van producten is veranderd.
Als een agent deze veranderingen niet opmerkt en er geen account voor houdt, kan dit leiden tot onnauwkeurige reacties, ongepaste acties of, erger nog, risico's.
Onderzoek wijst uit dat naarmate systemen steeds autonomer worden, het vertrouwen op verouderde gegevens een aanzienlijke kwetsbaarheid wordt. AI-kennisbanken kunnen helpen deze kloof te overbruggen. Bekijk deze video voor meer informatie hierover. 👇🏼
🌏 Wanneer chatbots niet over de juiste live kennis beschikken:
De AI-aangedreven virtuele assistent van Air Canada gaf een klant onjuiste informatie over het reisbeleid van de luchtvaartmaatschappij in geval van overlijden. De klant, Jake Moffatt, rouwde om het overlijden van zijn grootmoeder en gebruikte de chatbot om te informeren naar kortingstarieven.
De chatbot informeerde hem ten onrechte dat hij een ticket tegen de volledige prijs kon kopen en binnen 90 dagen een terugbetaling van de korting voor rouw kon aanvragen. Op basis van dit advies boekte Moffatt dure vluchten. Het daadwerkelijke beleid van Air Canada vereiste echter dat een kortingstarief voor rouw vóór de reis moest worden aangevraagd en niet met terugwerkende kracht kon worden toegepast.
Praktijkscenario's waarin live kennis van cruciaal belang is
Air Canada is slechts één voorbeeld. Hier zijn nog meer scenario's waarin live kennis het verschil kan maken:
- Klantenservicemedewerkers: een AI-assistent die de laatste verzendstatus of voorraad niet kan controleren, zal slechte antwoorden geven of kansen missen om op te volgen.
- Financiële agenten: aandelenkoersen, valuta-koersen of economische indicatoren veranderen met de seconde. Een model zonder live gegevens loopt achter op de realiteit van de markt.
- Agenten in de gezondheidszorg: gegevens over patiënten (hartslag, bloeddruk, laboratoriumresultaten) kunnen snel veranderen. Agenten die geen toegang hebben tot actuele gegevens kunnen waarschuwingssignalen missen.
- DevOps- of operationele agents : systeemstatistieken, incidenten, gebruiker gedrag – veranderingen hier kunnen snel escaleren. Agents hebben live bewustzijn nodig om op het juiste moment te kunnen waarschuwen, herstellen of escaleren.
Zillow heeft zijn woningverkoopactiviteiten (Zillow Offers) stopgezet nadat zijn AI-model voor het bepalen van woningprijzen er niet in slaagde om de snel veranderende huizenmarkt tijdens de pandemie nauwkeurig te voorspellen, wat leidde tot enorme financiële verliezen door te veel te betalen voor onroerend goed. Dit benadrukt het risico van modelafwijkingen wanneer economische indicatoren snel veranderen.
Impact op de besluitvorming en nauwkeurigheid van agents
Wanneer live kennis wordt geïntegreerd, worden agents betrouwbaarder, nauwkeuriger en sneller. Ze kunnen 'verouderde' beslissingen vermijden, de vertraging bij het detecteren van veranderingen verminderen en adequaat reageren.
Ze bouwen ook vertrouwen op: gebruikers weten dat de agent 'weet wat er aan de hand is'.
Vanuit het oogpunt van besluitvorming zorgt live kennis ervoor dat de 'input' voor de planning en actiestappen van de agent op dat moment geldig is. Dit leidt tot betere resultaten, minder fouten en flexibelere processen.
Waarde en concurrentievoordelen
Voor organisaties biedt de overstap van statische naar live kennis in AI-agents verschillende voordelen:
- Snellere reactie op veranderingen: wanneer uw AI weet wat er op dit moment gebeurt, kunt u sneller handelen.
- Gepersonaliseerde en actuele interactie: de aangepaste klantervaring verbetert wanneer reacties de meest recente context weerspiegelen.
- Operationele veerkracht: systemen die afwijkingen of veranderingen snel detecteren, kunnen risico's beperken.
- Concurrentievoordeel: als uw agents zich in realtime kunnen aanpassen en anderen niet, krijgt u een voorsprong op het gebied van snelheid en inzicht.
Kortom, live kennis is een strategische capaciteit voor organisaties die voorop willen blijven lopen bij veranderingen.
Hoe live kennis werkt: kerncomponenten
Live kennis staat voor live werkstroom, bewustzijn en aanpassingsvermogen.
Wanneer kennis in realtime stroomt, helpt dit teams om snellere, slimmere beslissingen te nemen.
Zo werken live kennissystemen achter de schermen, aangedreven door drie sleutellagen: realtime databronnen, integratiemethoden en agentarchitectuur.
Component 1: Real-time databronnen
Elk live kennissysteem begint met zijn inputs: de gegevens die voortdurend binnenstromen vanuit uw tools, apps en dagelijkse werkstroom. Deze inputs kunnen afkomstig zijn van vrijwel elke plek waar u uw werk doet: een klant die een supportticket indient in Zendesk, een verkoper die dealaantekeningen bijwerkt in Salesforce of een ontwikkelaar die nieuwe code naar GitHub pusht.
Zelfs systemen met automatisering leveren signalen: IoT-sensoren leveren rapportage over de prestaties van apparatuur, marketing-dashboards leveren live campagnecijfers en financiële platforms werken realtime omzetcijfers bij.
Samen vormen deze diverse datastromen de basis van live kennis: een continue, onderling verbonden informatiestroom die weergeeft wat er op dit moment in uw bedrijfsecosysteem gebeurt. Wanneer een AI-systeem direct toegang heeft tot deze input en deze kan interpreteren, gaat het verder dan passieve gegevensverzameling en wordt het een realtime medewerker die teams helpt sneller te handelen, zich aan te passen en beslissingen te nemen.
API's en webhooks
API's en webhooks vormen het bindweefsel van de moderne werkplek. API's maken gestructureerde, on-demand deel van gegevens mogelijk.
ClickUp-integraties helpen u bijvoorbeeld om binnen enkele seconden updates van Slack of Salesforce op te halen. Webhooks gaan nog een stap verder door automatisch updates door te geven wanneer er iets verandert, zodat uw gegevens up-to-date blijven zonder dat u ze handmatig hoeft te synchroniseren. Samen elimineren ze 'informatievertraging' en zorgen ze ervoor dat uw systeem altijd een actuele weergave is van wat er op dit moment gebeurt.
Database-verbindingen
Dankzij realtime databaseverbindingen kunnen modellen operationele gegevens monitoren en daarop reageren terwijl deze zich ontwikkelen. Of het nu gaat om klantinzichten uit een CRM of voortgang uit uw projectmanagementtool, deze directe pijplijn zorgt ervoor dat uw AI-beslissingen gebaseerd zijn op live, accurate informatie.
Streamverwerkingssystemen
Streamverwerkingstechnologieën zoals Kafka en Flink zetten ruwe gebeurtenisgegevens om in directe inzichten. Dit kan betekenen dat er realtime waarschuwingen worden gegeven wanneer een project vastloopt, dat de werklast automatisch wordt verdeeld of dat knelpunten in de werkstroom worden geïdentificeerd voordat ze obstakels worden. Deze systemen geven teams inzicht in hun activiteiten terwijl deze zich ontvouwen.
Externe kennisbanken
Geen enkel systeem kan in isolatie floreren. Door verbinding te maken met externe kennisbronnen – productdocumentatie, onderzoeksbibliotheken of openbare datasets – krijgen live systemen een mondiale context.
Dit betekent dat uw AI-assistent niet alleen begrijpt wat er gebeurt in uw werkruimte, maar ook waarom het belangrijk is binnen het grotere geheel.
📖 Lees meer: Hoe kennisgebaseerde agents in AI te gebruiken
Component 2: Methoden voor kennisintegratie
Zodra de gegevens stromen, is de volgende stap om ze te integreren in een levende, ademende kennislaag die voortdurend evolueert.
Dynamische contextinjectie
Context is het geheime ingrediënt dat ruwe gegevens omzet in zinvolle inzichten. Dankzij dynamische contextinjectie kunnen AI-systemen de meest relevante, actuele informatie – zoals recente projectupdates of teamprioriteiten – precies op het moment dat beslissingen worden genomen, integreren. Het is alsof u een assistent heeft die precies op het juiste moment weet wat u nodig hebt.
Bekijk hoe Brain Agent dat doet binnen ClickUp:
Real-time opvraagmechanismen
Traditionele AI-zoekopdrachten zijn gebaseerd op opgeslagen informatie. Real-time opvragen gaat verder door continu verbonden bronnen te scannen en te vernieuwen, waardoor alleen de meest actuele en relevante content wordt weergegeven.
Wanneer u ClickUp Brain bijvoorbeeld om een project-samenvatting vraagt, gaat het niet op zoek in oude bestanden, maar haalt het nieuwe inzichten uit de meest recente live gegevens.
Updates van de kennisgrafiek
Kennisgrafieken brengen relaties tussen mensen, taken, doelen en ideeën in kaart. Door deze grafieken in realtime bij te werken, zorgt u ervoor dat afhankelijkheden mee evolueren met uw werkstroom. Wanneer prioriteiten verschuiven of nieuwe taken worden toegevoegd, wordt de grafiek automatisch opnieuw in evenwicht gebracht, waardoor teams een duidelijk en altijd accuraat weergave krijgen van hoe het werk met elkaar in verbinding staat.
Benaderingen voor continu leren
Door continu te leren kunnen AI-modellen zich aanpassen op basis van feedback van gebruikers en veranderende patronen. Elke opmerking, correctie en beslissing wordt trainingsdata, waardoor het systeem slimmer wordt in hoe uw team daadwerkelijk werkt.
Component 3: Agentarchitectuur voor live kennis
De laatste laag, en vaak ook de meest complexe, is hoe AI-agenten kennis beheren, onthouden en prioriteren om de samenhang en het reactievermogen te behouden.
Geheugenbeheersystemen
Net als mensen moet AI weten wat het moet onthouden en wat het moet loslaten. Geheugensystemen zorgen voor een evenwicht tussen kortetermijngeheugen en langetermijnopslag, waarbij essentiële context (zoals lopende doelen of clientvoorkeuren) wordt bewaard en irrelevante informatie wordt weggefilterd. Zo blijft het systeem scherp en wordt het niet overbelast.
Contextvensteroptimalisatie
Contextvensters bepalen hoeveel informatie een AI tegelijk kan 'zien'. Wanneer deze vensters zijn geoptimaliseerd, kunnen agents lange, complexe interacties beheren zonder belangrijke details uit het oog te verliezen. In de praktijk betekent dit dat uw AI de volledige projectgeschiedenis en gesprekken kan oproepen – niet alleen de laatste paar berichten – waardoor nauwkeurigere en relevantere reacties mogelijk zijn.
Maar naarmate organisaties meer AI-tools en -agenten gaan gebruiken, ontstaat er een nieuwe uitdaging: AI-wildgroei. Kennis, acties en context kunnen versnipperd raken over verschillende bots en platforms, wat leidt tot inconsistente antwoorden, dubbel werk en gemiste inzichten. Live kennis lost dit op door informatie te verenigen en contextvensters in alle AI-systemen te optimaliseren, zodat elke agent put uit één enkele, actuele bron van waarheid. Deze aanpak voorkomt versnippering en stelt uw AI in staat om consistente, uitgebreide te ondersteunen.
Prioritering van informatie
Niet alle kennis verdient evenveel aandacht. Intelligente prioritering zorgt ervoor dat de AI zich richt op wat echt belangrijk is: urgente taken, verschuivende afhankelijkheden of grote prestatieveranderingen. Door te filteren op impact voorkomt het systeem dat er een overdaad aan gegevens ontstaat en vergroot het de duidelijkheid.
Cachingstrategieën
Snelheid stimuleert acceptatie. Door veelgebruikte informatie, zoals recente opmerkingen, taakupdates of prestatiestatistieken, in de cache op te slaan, kan deze direct worden opgehaald en wordt de systeembelasting verminderd. Dit betekent dat uw team soepel en in realtime kan samenwerken, zonder vertraging tussen actie en inzicht.
Live kennis transformeert werk van reactief naar proactief. Wanneer realtime gegevens, continu leren en intelligente agentarchitectuur samenkomen, raken uw systemen niet meer achterop.
Het vormt de basis voor snellere beslissingen, minder blinde vlekken en een meer verbonden AI-ecosysteem.
📮ClickUp Insight: 18% van de respondenten van onze enquête wil AI gebruiken om hun leven te organiseren met behulp van kalenders, taken en herinneringen. Nog eens 15% wil dat AI routinetaken en administratief werk afhandelt.
Om dit te doen, moet een AI in staat zijn om: de prioriteiten voor elke taak in een werkstroom te begrijpen, de nodige stappen uit te voeren om taken aan te maken of aan te passen, en geautomatiseerde werkstroom-instellingen in te stellen.
De meeste tools hebben één of twee van deze stappen op werk uitgewerkt. ClickUp heeft gebruikers echter geholpen om meer dan 5 apps te consolideren met behulp van ons platform met ClickUp Brain MAX!
Soorten live kennissystemen
In dit gedeelte gaan we dieper in op de verschillende architecturale patronen voor het leveren van live kennis aan AI-agents: hoe de gegevens stromen, wanneer de agent updates krijgt en welke afwegingen daarbij komen kijken.
Pull-gebaseerde systemen
In een pull-gebaseerd model vraagt de agent om gegevens wanneer hij die nodig heeft. Zie het als een student die halverwege een les zijn hand opsteekt: "Wat is het huidige weer?" of "Wat is de laatste voorraadstand?" De agent trigger een query naar een live bron (API, database) en gebruikt het resultaat in zijn volgende redeneringsstap.
👉🏽 Waarom pull-based gebruiken? Het is efficiënt wanneer de agent niet altijd live gegevens nodig heeft. U voorkomt dat alle gegevens continu worden gestreamd, wat kostbaar of onnodig kan zijn. Het geeft ook meer controle: u bepaalt zelf wat u precies wilt ophalen en wanneer.
👉🏽 Nadelen: Er kan vertraging optreden: als het opvragen van gegevens tijd kost, kan de agent wachten en langzamer reageren. Ook loopt u het risico updates tussen peilingen te missen (als u alleen periodiek controleert). Een medewerker van de klantenservice kan bijvoorbeeld alleen de API voor de verzendstatus opvragen wanneer een klant vraagt: "Waar is mijn bestelling?", in plaats van een constante live feed van verzendgebeurtenissen bij te houden.
Push-gebaseerde systemen
Hier wacht het systeem niet tot de agent erom vraagt, maar stuurt het updates naar de agent zodra er iets verandert. Het is net als een nieuwsbericht abonneren: als er iets gebeurt, wordt u onmiddellijk op de hoogte gebracht. Voor een AI-agent die gebruikmaakt van live kennis betekent dit dat hij altijd over actuele context beschikt terwijl gebeurtenissen zich ontvouwen.
👉🏽 Waarom push-based gebruiken? Het biedt minimale latentie en een hoge responsiviteit omdat de agent op de hoogte is van veranderingen zodra deze zich voordoen. Dit is waardevol in contexten met hoge snelheid of hoge risico's (bijv. financiële handel, monitoring van de systeemgezondheid).
👉🏽 Nadelen: Het kan duurder en complexer zijn om te onderhouden. De agent kan veel updates ontvangen die niet relevant zijn, waardoor filtering en prioritering nodig is. U hebt ook een robuuste infrastructuur nodig om continue streams te verwerken. Een DevOps AI-agent ontvangt bijvoorbeeld webhook-waarschuwingen wanneer het CPU-gebruik van de server een drempel overschrijdt en start een schaalactie.
Hybride benaderingen
In de praktijk combineren de meest robuuste live kennissystemen zowel pull- als push-benaderingen. De agent abonneert zich op kritieke gebeurtenissen (push) en haalt af en toe bredere contextuele gegevens op wanneer dat nodig is (pull).
Dit hybride model helpt een evenwicht te vinden tussen reactievermogen en kosten/complexiteit. In een scenario met een verkoopagent kan de AI bijvoorbeeld pushnotificaties ontvangen wanneer een lead een voorstel opent, terwijl hij ook CRM-gegevens over de geschiedenis van die klant ophaalt bij het opstellen van zijn volgende outreach.
Gebeurtenisgestuurde architecturen
Aan de basis van zowel push- als hybride systemen ligt het concept van een gebeurtenis-gestuurde architectuur.
Hier is het systeem gestructureerd rond gebeurtenissen (zakelijke transacties, sensormetingen, gebruikersinteracties) die logische stromen, beslissingen of statusupdates triggeren.
Volgens brancheanalyses worden streamingplatforms en 'streaming lakehouses' steeds meer uitvoeringslagen voor agentische AI, waardoor de grens tussen historische en live data verdwijnt.
In dergelijke systemen verspreiden gebeurtenissen zich via pijplijnen, worden ze verrijkt met context en worden ze doorgegeven aan agents die redeneren, handelen en vervolgens mogelijk nieuwe gebeurtenissen genereren.
De live-kennisagent wordt zo een knooppunt in een realtime feedbackloop: waarnemen → redeneren → handelen → bijwerken.
👉🏽 Waarom dit belangrijk is: Bij gebeurtenisgestuurde systemen is live kennis niet alleen een add-on, maar wordt het een integraal onderdeel van hoe de agent de werkelijkheid waarneemt en beïnvloedt. Wanneer er een gebeurtenis plaatsvindt, werkt de agent zijn wereldmodel bij en reageert hij dienovereenkomstig.
👉🏽 Afwegingen: Het vereist ontwerp voor gelijktijdigheid, latentie, volgorde van gebeurtenissen, afhandeling van storingen (wat als een gebeurtenis verloren gaat of vertraging oploopt?) en 'wat als'-logica voor scenario's die niet waren voorzien.
Live kennis implementeren: technische benaderingen
Het opbouwen van live kennis vereist engineering intelligence die voortdurend in ontwikkeling is. Achter de schermen combineren organisaties API's, streamingarchitecturen, context-engines en adaptieve leermodellen om informatie actueel en bruikbaar te houden.
In dit gedeelte bekijken we hoe deze systemen tot leven komen: de technologieën die realtime bewustzijn mogelijk maken, de architecturale patronen die het schaalbaar maken en de praktische stappen die teams nemen om over te stappen van statische kennis naar continue, live intelligentie.
Retrieval-Augmented Generation (RAG) met live databronnen
Een veelgebruikte aanpak is het combineren van een groot taalmodel (LLM) met een live opzoeksysteem, vaak aangeduid als RAG.
In RAG-gebruiksscenario's voert de agent, wanneer hij moet reageren, eerst een opzoekstap uit: hij query't actuele externe bronnen (vector databases, API's, documenten). Vervolgens gebruikt de LLM die opgehaalde gegevens (in zijn prompt of context) om de output te genereren.
Voor live kennis zijn de bronnen geen statische archieven, maar continu bijgewerkte, live feeds. Dit zorgt ervoor dat de output van het model de huidige stand van zaken weerspiegelt.
Implementatiestappen:
- Identificeer live bronnen (API's, streams, databases)
- Index ze of maak ze doorzoekbaar (vector database, kennisgrafiek, relationele opslag)
- Bij elke activering van een agent: haal recente relevante records op en voeg ze toe aan de prompt/context.
- Reactie genereren
- Optioneel kunt u het geheugen of de kennisopslag bijwerken met nieuwe feiten die zijn ontdekt.
MCP-servers en realtime protocollen
Nieuwere standaarden, zoals het Model Context Protocol (MCP), hebben tot doel te definiëren hoe modellen interageren met live systemen: data-eindpunten, AI-tools, oproepen en contextueel geheugen.
Volgens een whitepaper zou MCP voor AI dezelfde rol kunnen spelen als HTTP ooit voor het web deed (modellen verbinden met tools en gegevens).
In de praktijk betekent dit dat uw agentarchitectuur mogelijk het volgende bevat:
- Een MCP-server die inkomende verzoeken van het model of de agentlaag verwerkt.
- Een servicelaag die verbinding maakt met interne/externe tools, API's en live datastromen
- Een contextbeheerslaag die de status, het geheugen en relevante recente gegevens bijhoudt.
Door de interface te standaardiseren, maakt u het systeem modulair: agents kunnen verschillende databronnen, tools en geheugengrafieken aansluiten.
Updates van de vector-database
Bij het omgaan met live kennis onderhouden veel systemen een vectordatabase (embeddings) waarvan de content continu wordt bijgewerkt.
Embeddings vertegenwoordigen nieuwe documenten, live gegevenspunten en entiteitsstatussen. Zo is het ophalen van gegevens altijd actueel. Wanneer er bijvoorbeeld nieuwe sensorgegevens binnenkomen, zet u deze om in een embedding en voegt u deze toe aan de vectoropslag, zodat deze bij volgende queries wordt meegenomen.
Overwegingen bij de implementatie:
- Hoe vaak voegt u live gegevens opnieuw in?
- Hoe laat u verouderde embeddings verlopen?
- Hoe voorkomt u dat uw vectoropslag te groot wordt en hoe zorgt u voor een hoge query-snelheid?
API-orkestratiepatronen
Agenten roepen zelden één enkele API aan; ze roepen vaak meerdere eindpunten achtereenvolgens of parallel aan. Live kennisimplementaties vereisen coördinatie. Bijvoorbeeld:
- Stap 1: Controleer de live voorraad-API
- Stap 2: Als de voorraad laag is, controleer dan de ETA API van de leverancier.
- Stap 3: Genereer een aangepast bericht op basis van gecombineerde resultaten
Deze orchestration-laag kan caching, retry-logica, rate limiting, fallbacks en data-aggregatie omvatten. Het ontwerpen van deze laag is cruciaal voor stabiliteit en prestaties.
Gebruik van tools en functieaanroepen
In de meeste AI-frameworks gebruiken agents tools om actie te ondernemen.
Een tool is gewoon een vooraf gedefinieerde functie die de agent kan aanroepen, zoals get_stock_price(), check_server_status() of fetch_customer_order().
Moderne LLM-frameworks maken dit mogelijk door middel van functieaanroepen, waarbij het model beslist welke tool moet worden gebruikt, de juiste parameters doorgeeft en een gestructureerd antwoord ontvangt waarop het kan redeneren.
Live kennisagenten gaan nog een stap verder. In plaats van statische of gesimuleerde gegevens maken hun tools rechtstreeks verbinding met realtime bronnen: live databases, API's en gebeurtenis-stromen. De agent kan actuele resultaten ophalen, deze in hun context interpreteren en onmiddellijk handelen of reageren. Deze brug tussen redeneren en gegevens uit de echte wereld is wat een passief model transformeert in een adaptief, continu bewust systeem.
Implementatiestappen:
- Definieer toolfuncties die live databronnen (API's, databases) omvatten.
- Zorg ervoor dat de agent kan selecteren welke tool hij moet aanroepen en argumenten kan produceren.
- Leg tool-output vast en integreer deze in de redeneringscontext.
- Zorg voor logboekregistratie, foutafhandeling en fallback (wat als de tool niet werkt?).
📖 Lees meer: MCP vs. RAG vs. AI-agenten
Gebruiksscenario's en toepassingen
Live kennis evolueert snel van concept naar concurrentievoordeel.
Van realtime projectcoördinatie tot adaptieve klantenservice en voorspellend onderhoud: organisaties zien nu al tastbare voordelen op het gebied van snelheid, nauwkeurigheid en vooruitziendheid.
Hieronder vindt u enkele van de meest aansprekende manieren waarop live kennis vandaag de dag wordt toegepast en hoe dit de betekenis van 'intelligent werk' in de praktijk herdefinieert.
Klantenservicemedewerkers met live productvoorraad
In de detailhandel kan een chatbot die ondersteunt en is gekoppeld aan live voorraad- en verzendsystemen vragen beantwoorden als "Is dit op voorraad?", "Wanneer wordt het verzonden?" of "Kan ik een spoedlevering krijgen?".
In plaats van te vertrouwen op statische FAQ-gegevens (die bijvoorbeeld 'niet op voorraad' kunnen aangeven, zelfs als er net voorraad is binnengekomen), query't de agent realtime voorraad- en verzend-API's.
Financiële agents met marktgegevensfeeds
Financiële werkstroom vereist onmiddellijke informatieverzameling.
Een AI-agent met een verbinding met marktgegevens-API's (aandelenkoersen, valuta-koersen, economische indicatoren) kan live veranderingen monitoren en menselijke handelaren waarschuwen of autonoom handelen binnen gedefinieerde parameters.
De live kennislaag is wat een eenvoudig analytisch dashboard (statische rapporten) onderscheidt van een autonome agent die een plotselinge daling in waarde waarneemt en een hedge of transactie triggert.
De virtuele assistent van Bank of America, 'Erica', toont met succes de waarde aan van het gebruik van realtime gegevens voor AI-agenten in de financiële sector. Het verwerkt jaarlijks honderden miljoenen client-interacties door toegang te krijgen tot actuele account-informatie, gepersonaliseerde en onmiddellijke begeleiding te bieden op het gebied van financiën, te helpen bij transacties en budgetten te beheren.
Agents in de gezondheidszorg met patiëntmonitoring
In gezondheidsinstellingen betekent live kennis verbinding maken met patiëntsensoren, medische apparatuur, elektronische patiëntendossiers (EPD's) en het streamen van vitale functies.
Een AI-agent kan de hartslag, het zuurstofgehalte en de laboratoriumresultaten van een patiënt in realtime monitoren, deze vergelijken met drempelwaarden of patronen, en clinici waarschuwen of aanbevolen acties ondernemen (bijv. de voorwaarde escaleren). Vroegtijdige waarschuwingssystemen op basis van live data-analyse helpen al om sepsis of hartfalen aanzienlijk eerder te identificeren dan traditionele benaderingen.
Nvidia ontwikkelt bijvoorbeeld een AI-agentplatform voor bedrijven dat taakspecifieke agents aanstuurt, waaronder een agent die is ontworpen voor het Ottawa Hospital om patiënten 24 uur per dag te helpen. De agent begeleidt patiënten bij de voorbereiding op een operatie, het herstel na een operatie en de revalidatie-stappen.
Zoals Kimberly Powell, VP en GM van Nvidia Healthcare, uitlegt, is het doel om clinici meer tijd te geven en tegelijkertijd de ervaringen van patiënten te verbeteren.
DevOps-agenten met systeemstatistieken
In IT-operaties monitoren live kennisagenten logboeken, telemetrie, infrastructuurevenementen en API's voor servicestatus. Wanneer de latentie piekt, fouten zich verspreiden of bronnen uitgeput raken, kan de agent herstelmaatregelen triggeren: een service opnieuw opstarten, extra capaciteit vrijmaken of verkeer omleiden. Omdat de agent op de hoogte blijft van de live systeemstatus, kan hij effectiever handelen en downtime verminderen.
Verkoopagenten met CRM-integratie
In de verkoop betekent live kennis dat een agent wordt gekoppeld aan het CRM, communicatieplatforms en recente leadactiviteiten.
Stel je een verkoopassistent voor die bijhoudt wanneer een potentiële klant een offerte opent en vervolgens de vertegenwoordiger waarschuwt: "Je offerte is zojuist in weergave. Wil je nu een vervolgafspraak plannen?" De agent kan live engagementgegevens, leadcontext en historische winstpercentages dynamisch ophalen om tijdige, gepersonaliseerde suggesties te doen. Dit tilt de outreach van generieke naar contextbewuste actie.
JPMorgan Chase maakte tijdens een recente marktcrisis gebruik van AI-agenten om sneller advies te geven, meer clients te bedienen en de omzet te verhogen. Hun AI-gestuurde "Coach"-assistent hielp financiële adviseurs om tot 95 % sneller inzichten te verkrijgen, waardoor het bedrijf de bruto-omzet tussen 2023-24 met ~20 % kon verhogen en een toename van 50 % in het aantal clients in de komende 3-5 jaar kon targeten.
Ontgrendel live intelligentie voor uw organisatie met ClickUp
De teams van vandaag hebben meer nodig dan statische tools. Ze hebben een werkruimte nodig die het werk actief begrijpt, verbindt en versnelt. ClickUp is de eerste geconvergeerde AI-werkruimte, ontworpen om live intelligentie te leveren door kennis, automatisering en samenwerking te integreren in één enkel, uniform platform.
Uniforme zoekfunctie voor ondernemingen: realtime kennis binnen handbereik
Vind direct antwoorden, ongeacht waar de informatie zich bevindt. ClickUp's Enterprise Search maakt verbinding tussen taken, documenten, chat en geïntegreerde tools van derden in één enkele, door AI aangestuurde zoekbalk. Query's in natuurlijke taal leveren contextrijke resultaten op, waarbij gestructureerde en ongestructureerde gegevens worden samengebracht, zodat u sneller beslissingen kunt nemen.
- Zoek in taken, documenten, chatten en geïntegreerde tools van derden met behulp van één enkele AI-aangedreven zoekbalk.
- Gebruik natuurlijke taalquery's om gestructureerde en ongestructureerde gegevens op te halen uit alle aangesloten externe bronnen.
- Breng direct beleid, projectupdates, bestanden en vakkennis naar voren met contextrijke resultaten.
- Index en maak verbinding met informatie uit Google Drive, Slack en andere platforms voor een holistische weergave.
Automatiseer, coördineer en redeneer in werkstroom met AI-agenten
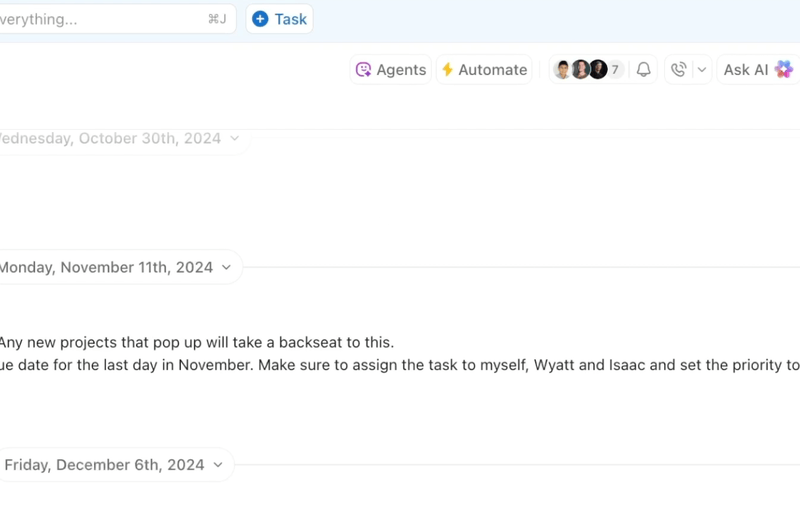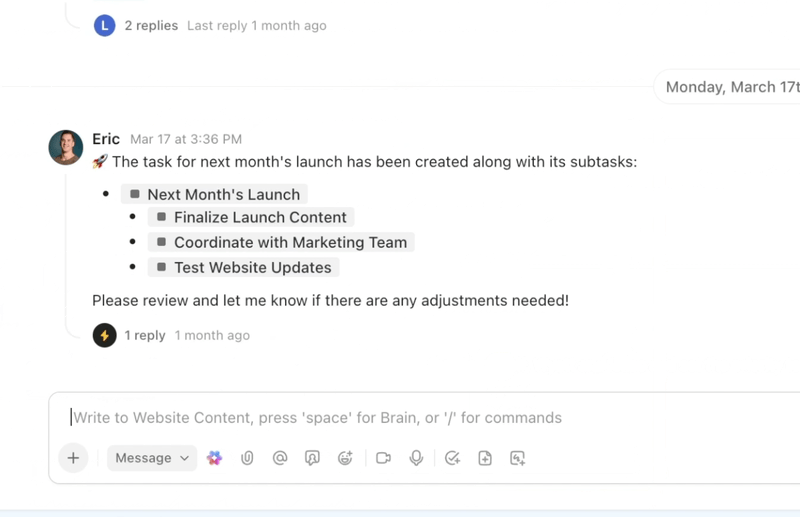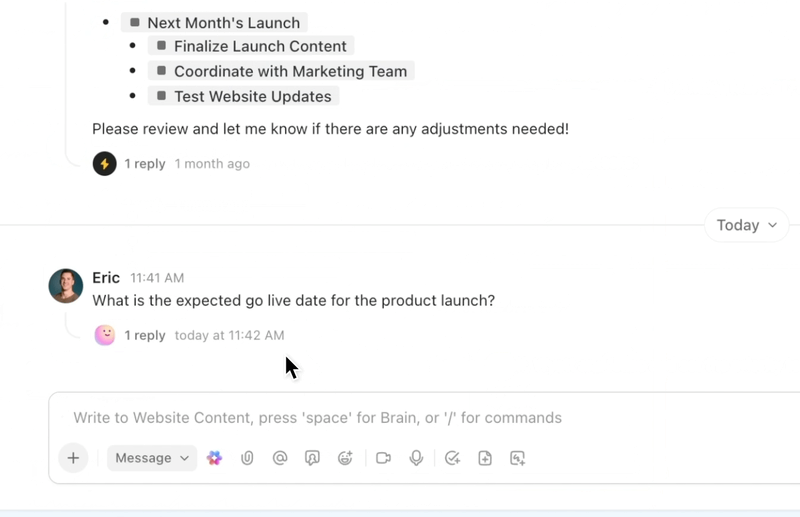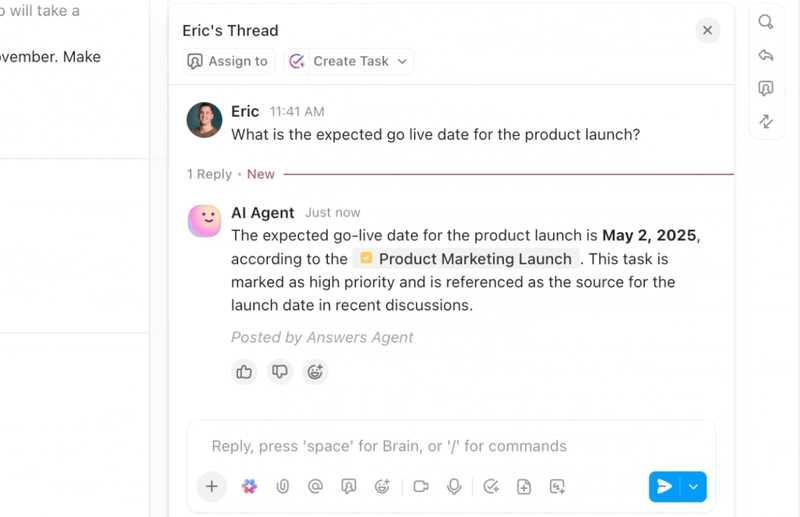
Automatiseer repetitieve taken en coördineer complexe processen met intelligente AI-agenten die fungeren als digitale teamgenoten. De AI-agenten van ClickUp maken gebruik van realtime werkruimtegegevens en context, waardoor ze kunnen redeneren, actie ondernemen en zich kunnen aanpassen aan veranderende zakelijke behoeften.
- Implementeer aanpasbare AI-agents die taken automatiseren, verzoeken triëren en meerstapwerkstroom uitvoeren.
- Vat vergaderingen samen, genereer content, werk taken bij en trigger automatiseringen op basis van realtime gegevens.
- Pas acties aan op basis van context, afhankelijkheden en bedrijfslogica met behulp van geavanceerde redeneermogelijkheden.
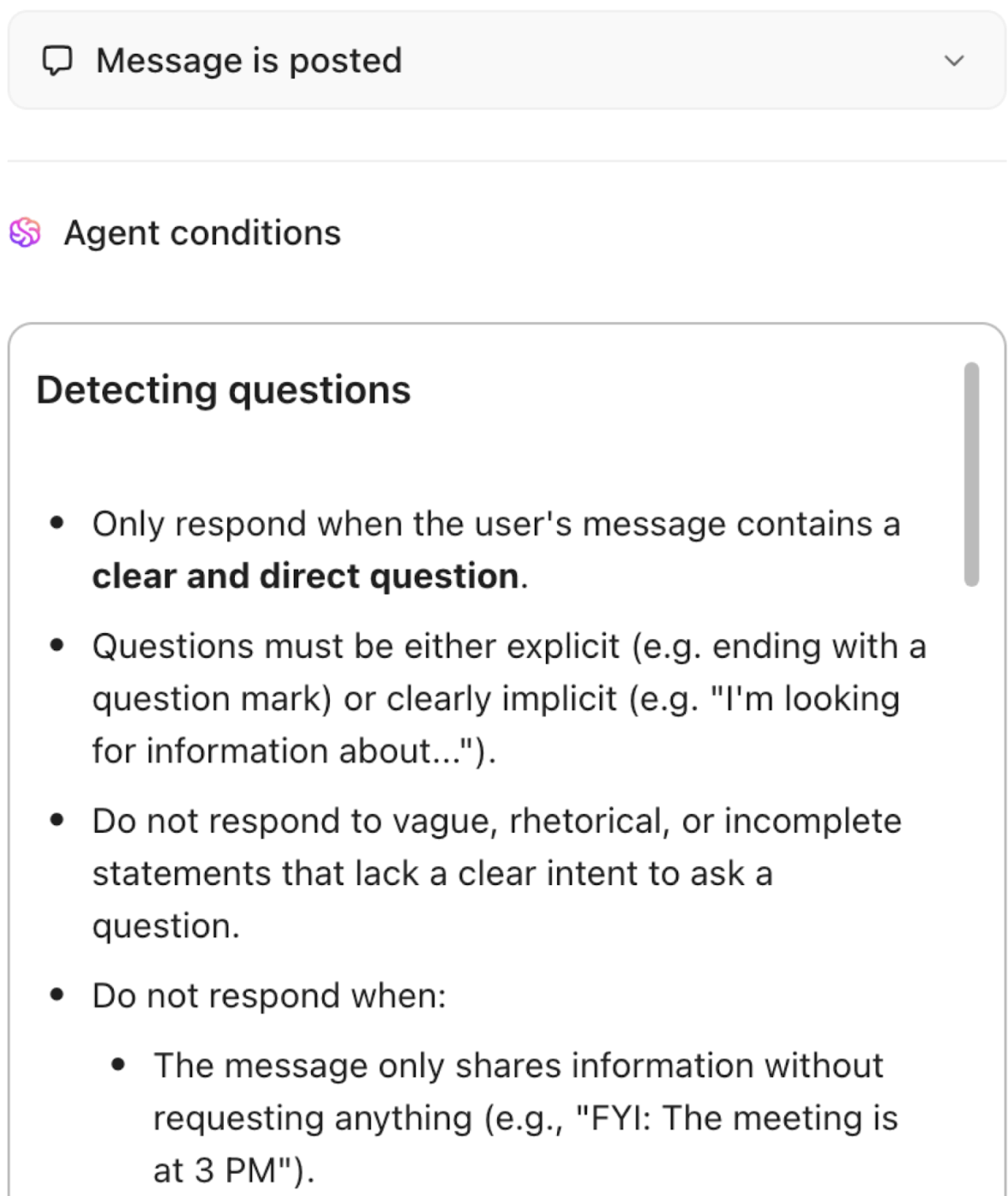
Live kennisbeheer: dynamisch, contextueel en altijd up-to-date
Transformeer statische documentatie in een levende kennisbank. ClickUp Knowledge Management indexeert en koppelt automatisch informatie uit taken, documenten en gesprekken, zodat kennis altijd actueel en toegankelijk is. AI-gestuurde suggesties tonen relevante content terwijl u werkt, terwijl slimme organisatie en toestemming gevoelige gegevens veilig houden.
- Indexeer en koppel automatisch informatie uit ClickUp-taak, ClickUp-documenten en gesprekken voor een levende kennisbank.
- Breng relevante content naar voren met AI-gestuurde suggesties terwijl u werkt.
- Organiseer kennis met gedetailleerde toestemming voor veilig en vindbaar deel.
- Houd documentatie, onboarding-gidsen en institutionele kennis altijd actueel en toegankelijk.
Convergent samenwerken: contextueel, verbonden en bruikbaar
Samenwerking in ClickUp is diep geïntegreerd in uw werk.
Realtime bewerken, AI-aangedreven samenvattingen en contextuele aanbevelingen zorgen ervoor dat elk gesprek bruikbaar is. ClickUp Chat, Whiteboards, Docs en Tasks zijn met elkaar verbonden, zodat brainstormen, plannen en uitvoeren in één werkstroom plaatsvinden.
Het helpt u:
- Werk in realtime samen met geïntegreerde documenten, whiteboards en taken, die allemaal aan elkaar zijn gekoppeld voor naadloze werkstroom.
- Zet gesprekken om in bruikbare volgende stappen met AI-aangedreven samenvattingen en aanbevelingen.
- Visualiseer afhankelijkheden, blokkades en projectstatus met live updates en slimme notificaties.
- Stel cross-functionele teams in staat om te brainstormen, plannen en uitvoeren in een uniforme omgeving.
ClickUp is niet zomaar een werkruimte. Het is een live intelligentieplatform dat de kennis van uw organisatie bundelt, werk automatiseert en teams voorziet van bruikbare inzichten, allemaal in realtime.
We hebben de beste zoeksoftware voor ondernemingen vergeleken en dit zijn de resultaten:
Uitdagingen en best practices
Hoewel live kennis krachtige voordelen biedt, brengt het ook risico's en complexiteit met zich mee.
Hieronder vindt u de sleutel AI-uitdagingen waarmee organisaties worden geconfronteerd, samen met praktijken om deze te verminderen.
| Uitdaging | Beschrijving | Best practices |
|---|---|---|
| Optimalisatie van latentie en prestaties | Verbinding maken met live gegevens zorgt voor vertraging door API-aanroepen, streamverwerking en opvragen. Als reacties vertraging oplopen, lijden de gebruikerservaring en het vertrouwen daaronder. | ✅ Sla minder kritieke gegevens op in de cache om overbodige ophalingen te voorkomen✅ Geef prioriteit aan kritieke, tijdgevoelige feeds; vernieuw andere feeds minder vaak✅ Optimaliseer het ophalen en invoegen van context om de wachttijd van het model te verkorten✅ Monitor continu de latentiecijfers en stel prestatiedrempels in |
| Actualiteit van gegevens versus rekenkosten | Het bijhouden van realtime gegevens voor alle bronnen kan kostbaar en inefficiënt zijn. Niet alle informatie hoeft elke seconde te worden bijgewerkt. | ✅ Classificeer gegevens op basis van kriticiteit (moet live zijn versus kan periodiek zijn)✅ Gebruik gelaagde updatefrequenties✅ Breng waarde en kosten in evenwicht — update alleen zo vaak als dit van invloed is op beslissingen |
| Veiligheid en toegangscontrole | Live systemen maken vaak verbinding met gevoelige interne of externe gegevens (CRM, EHR, financiële systemen), waardoor er risico's ontstaan op ongeoorloofde toegang of lekken. | ✅ Handhaaf minimale toegangsrechten voor API's en limiet de toestemming van agents✅ Controleer alle gegevensverzoeken die de agent doet✅ Pas versleuteling, beveiligde kanalen, verificatie en activiteitenlogging toe ✅ Gebruik anomaliedetectie om ongewoon toegangsgedrag te signaleren |
| Foutafhandeling en terugvalstrategieën | Live databronnen kunnen uitvallen als gevolg van API-downtime, latentiepieken of onjuist gevormde gegevens. Agents moeten deze verstoringen op een elegante manier afhandelen. | ✅ Implementeer herhalingspogingen, time-outs en terugvalmechanismen (bijv. cachegegevens, escalatie naar mensen)✅ Registreer en monitor foutstatistieken zoals ontbrekende gegevens of latentieafwijkingen✅ Zorg voor een soepele degradatie in plaats van een stille storing |
| Naleving en gegevensbeheer | Live kennis omvat vaak gereguleerde of persoonlijke informatie, wat strikt toezicht en traceerbaarheid vereist. | ✅ Classificeer gegevens op basis van gevoeligheid en pas bewaarbeleid toe✅ Behoud de herkomst van gegevens: houd de oorsprong, updates en het gebruik bij✅ Zorg voor governance voor agenttraining, geheugen en gegevensupdates✅ Betrek juridische en compliance-teams in een vroeg stadium, vooral in gereguleerde sectoren |
De toekomst van live kennis in AI
In de toekomst zal live kennis zich blijven ontwikkelen en de functie van AI-agenten blijven vormen: van reactie naar anticipatie, van geïsoleerde agenten naar netwerken van samenwerkende agenten, en van gecentraliseerde cloud naar edge-gedistribueerde architecturen.
Voorspellende kennisopslag
In plaats van te wachten op verzoeken, zullen agents proactief gegevens die ze waarschijnlijk nodig hebben vooraf ophalen en in de cache opslaan. Voorspellende cachingmodellen analyseren historische toegangspatronen, temporele context (bijv. openingstijden van de markt) en gebruikersintenties om documenten, nieuwsfeeds of telemetrie vooraf te laden in snelle lokale opslagplaatsen, waardoor de agent kan reageren met een latentie van minder dan een seconde.
Gebruiksscenario's: een beleggingsagent laadt vooraf winstverslagen en liquiditeitsoverzichten voordat de markt opengaat; een klantenservice-medewerker haalt vooraf recente tickets en productdocumenten op voordat een gepland ondersteuningsgesprek plaatsvindt. Onderzoek toont aan dat AI-gestuurde voorspellende prefetching en cacheplaatsing de hitpercentages aanzienlijk verbeteren en de latentie in edge- en contentleveringsscenario's verminderen.
Opkomende standaarden en protocollen
Interoperabiliteit zal de voortgang versnellen. Protocollen zoals het Model Context Protocol (MCP) en initiatieven van leveranciers (bijvoorbeeld Algolia's MCP Server) bouwen gestandaardiseerde manieren voor agents om live context van externe systemen op te vragen, in te voeren en bij te werken. Standaarden verminderen op maat gemaakte glue code, verbeteren veiligheidscontroles (duidelijke interfaces en verificatie) en maken het gemakkelijker om opslagplaatsen, geheugenlagen en redeneerengines van verschillende leveranciers te combineren. In de praktijk kunnen teams door het gebruik van MCP-achtige interfaces opslagplaatsen voor het ophalen van gegevens uitwisselen of nieuwe datafeeds toevoegen met minimale herbewerking door agents.
Integratie met edge- en gedistribueerde systemen
Live kennis aan de rand biedt twee belangrijke voordelen: verminderde latentie en verbeterde privacy/controle. Apparaten en lokale gateways zullen compacte agents hosten die lokaal waarnemen, redeneren en handelen, en selectief synchroniseren met cloudopslagplaatsen wanneer het netwerk of beleid dit toestaat.
Dit patroon is geschikt voor productie (waar fabrieksmachines lokale controlebeslissingen nemen), voertuigen (boordagenten die reageren op sensorfusie) en gereguleerde domeinen waar gegevens lokaal moeten blijven. Industrie-enquêtes en edge-AI-rapporten voorspellen snellere besluitvorming en minder afhankelijkheid van de cloud naarmate gedistribueerd leren en federatieve technieken volwassen worden.
Voor teams die live-kennisstacks bouwen, betekent dit het ontwerpen van gelaagde architecturen waar kritieke, latentiegevoelige inferentie lokaal wordt uitgevoerd, terwijl langetermijnleren en zware modelupdates centraal plaatsvinden.
Kennis delen tussen meerdere agents
Het model met één agent maakt plaats voor ecosystemen met samenwerkende agents.
Multi-agent frameworks stellen verschillende gespecialiseerde agents in staat om situationeel bewustzijn te delen, gedeelde kennisgrafieken bij te werken en acties te coördineren, waardoor ze bijzonder nuttig zijn bij wagenparkbeheer, toeleveringsketens en grootschalige operaties.
Nieuw onderzoek naar op LLM gebaseerde multi-agent systemen toont methoden voor gedistribueerde planning, rolspecialisatie en consensusvorming tussen agents. In de praktijk hebben teams behoefte aan gedeelde schema's (gemeenschappelijke ontologieën), efficiënte pub/sub-kanalen voor statusupdates en logica voor conflictoplossing (wie heeft voorrang op wat en wanneer).
Continu leren en zelfverbetering
Live kennis zal het ophalen, redeneren, onthouden, handelen en continu leren samenvoegen tot gesloten lussen. Agents zullen resultaten observeren, corrigerende signalen integreren en herinneringen of kennisgrafieken bijwerken om toekomstig gedrag te verbeteren.
De grootste technische uitdagingen zijn het voorkomen van catastrofaal vergeten, het behouden van herkomst en het waarborgen van de veiligheid van online updates. Recente onderzoeken naar online continu leren en agentaanpassing schetsen praktische benaderingen (episodische geheugenbuffers, replay-strategieën en beperkte fijnafstemming) die voortdurende modelverbetering mogelijk maken en tegelijkertijd drift limiet. Voor productteams betekent dit investeren in gelabelde feedbackpijplijnen, veilige updatingsbeleid en monitoring die modelgedrag koppelt aan real-world KPI's.
Live kennis naar uw werk brengen met ClickUp
De volgende grens van AI in het werk is niet alleen slimmere modellen.
Live kennis vormt de brug tussen statische intelligentie en adaptieve actie, waardoor AI-agenten kunnen werken met een realtime begrip van projecten, prioriteiten en voortgang. Organisaties die hun AI-systemen kunnen voeden met actuele, contextuele en betrouwbare gegevens, zullen de ware belofte van omgevingsintelligentie kunnen waarmaken: naadloze coördinatie, snellere uitvoering en betere beslissingen in elk team.
ClickUp is gebouwd voor deze verschuiving. Door taken, documenten, doelen, chat en inzichten te verenigen in één systeem met verbinding, geeft ClickUp AI-agenten een levende, ademende bron van waarheid – geen statische database. Dankzij de contextuele en omgevingsgebonden AI-mogelijkheden blijft informatie in elke werkstroom actueel, waardoor automatisering op basis van de werkelijkheid verloopt en niet op basis van verouderde momentopnames.
Naarmate het werk steeds dynamischer wordt, zullen tools die de context in beweging begrijpen, de volgende stap in productiviteit bepalen. De missie van ClickUp is om dat mogelijk te maken: waar elke actie, update en elk idee direct de volgende stap informeert en waar teams eindelijk ervaren wat AI kan doen als kennis live blijft.
Veelgestelde vragen
Live kennis verhoogt de prestaties door actuele context te provider: beslissingen worden gebaseerd op actuele feiten in plaats van verouderde gegevens. Dat leidt tot nauwkeurigere reacties, snellere reactietijden en meer vertrouwen bij de gebruiker.
Hoewel veel agents dit kunnen, is het niet voor alle agents noodzakelijk. Agents die in stabiele contexten met weinig veranderingen werken, hebben er misschien niet zoveel baat bij. Maar voor elke agent die te maken heeft met dynamische omgevingen (markten, aangepaste klanten, systemen) is live kennis een krachtige enabler.
Testen omvat het simuleren van veranderingen in de echte wereld: varieer de live-inputs, voeg gebeurtenissen toe, meet de latentie, controleer de output van agents en controleer op fouten of verouderde reacties. Monitor end-to-end werkstroom, gebruiker-resultaten en systeemrobuustheid onder live-voorwaarden.