
マッキンゼーの社会経済レポートによると、ナレッジワーカーは、仕事をするために必要な情報を検索・収集するだけで、毎週10時間近く、つまり週の労働時間の約4分の1を費やしています。これは、チャットのスレッドや共有ドライブをくまなく調べたり、たまたまオンラインになっている人の記憶を頼りにしたりすることに費やされる、無駄な時間です。
通常、問題はチームに知識が不足していることではありません。問題は、知識が散在しており、個々の頭の中に閉じ込められていることです。
社内ナレッジベースは、全員が検索可能な一箇所で答えを見つけられるようにすることで、この問題を解決します。このガイドでは、ゼロからの構築方法、適切なソフトウェアの選び方、そして公開後も長期にわたり有用性を維持する方法について解説します。
要約
- 社内ナレッジベースとは、社内情報のためのプライベートで検索可能なホームであり、従業員および社内の関係者のみがアクセスできます。
- 7つのステップで構築しましょう:範囲の定義、所有者の割り当て、ソフトウェアの選定、構造の整理、主要記事の作成、許可の設定、そして公開と改善の繰り返し
- 初日から完全なアーカイブを構築するのではなく、チームから最も頻繁に寄せられる20の質問から始めましょう
- 所有者を1名指名しましょう。所有者がいないナレッジベースは、情報が古くなり、やがて機能しなくなります。
- ソフトウェアを選ぶ際は、価格ではなく、検索の精度、編集のしやすさ、許可設定、連携機能、および組み込みのAI機能を基準にしましょう
- 四半期ごとの監査、記事ごとの所有者、およびレビュー期限を設定して、常に最新の状態を維持しましょう
社内ナレッジベースとは?
社内ナレッジベースとは、従業員や社内の関係者だけがアクセスできる、企業情報の集約された検索可能なリポジトリです。同僚に質問する前にチームが確認する「唯一の信頼できる情報源」と考えてください。最新の社内ナレッジベースではAI検索の活用が進んでおり、ユーザーはフォルダ内をくまなく探す代わりに、自然な言葉で質問を入力できるようになっています。
サポート、エンジニアリング、人事、オペレーションなど、迅速な回答を必要とするあらゆるチーム向けに設計されています。普段なら同僚の肩を叩いて質問するような場面でも、代わりにこのナレッジベースを活用します。
これがなければ、知識は人の頭の中に留まったり、チャットのスレッドに埋もれたり、誰も見つけられないファイルの中に眠ったままになってしまいます。そのコストは、単に検索に費やす時間だけではありません。作業の重複、顧客への回答の不統一、そして新入社員一人ひとりのオンボーディング体験の悪化といった問題も生じます。
社内ナレッジベースは、顧客向けヘルプセンターとは異なります。ヘルプセンターは一般向けに公開され、ユーザーに製品について解説します。一方、社内ナレッジベースはログインが必要な場所にあり、自社の従業員向けに作成されています。
| Aspect | 社内ナレッジベース | 外部ヘルプセンター |
|---|---|---|
| 対象読者 | 従業員および社内チーム | 顧客および一般の方 |
| アクセス | ログインまたはファイアウォールの内側 | オープン型またはセルフサービス型のサインイン |
| コンテンツ | SOP、ポリシー、ランブック、意思決定 | 製品の使い方、よくある質問(FAQ)、ガイド |
| トーン | 簡潔に。社内用語の略語でも構いません | 洗練された、ブランドを前面に押し出した |
なぜチームに社内ナレッジベースが必要なのでしょうか?
チームに社内ナレッジベースが必要な理由は、情報が散在していると、オンボーディングの遅延、質問の繰り返し、メンバーの離職に伴う専門知識の喪失、顧客への回答の不統一といった、現実的かつ繰り返し発生するコストが生じるからです。以下に、それぞれの具体的な事例をご紹介します。
- オンボーディングが数ヶ月も長引く: 新入社員は、たまたま手が空いている人の暗黙知に頼らざるを得ません。彼らがどれほど早く業務に慣れるかは、再現可能なシステムではなく、隣に座っている人次第になってしまいます。
- 同じ質問に何度も答える羽目になる: シニアエンジニア、サポートリーダー、人事担当者は、本来やることになっている仕事をせずに、まるで「人間検索エンジン」のようになってしまいます
- 知識が失われてしまう: ベテラン社員が退職すると、文書化されていないプロセスや苦労して得た背景知識も、その人とともに失われてしまいます。永久に
- 分散型チームにはセルフサービスは通用しない: リモートや非同期で働くチームでは、同僚の肩を叩いて質問することができないため、未解決の質問ひとつひとつが仕事を数時間停滞させる障害となってしまいます
- 顧客への回答に一貫性がない: 共通の信頼できる情報源がないと、サポート部門と営業部門が同じ質問に対して異なる回答をしてしまい、顧客はその違いに気づいてしまいます
社内ナレッジベースには何を盛り込むべきか?
社内ナレッジベースには、社内規定、標準業務手順書(SOP)、役割別のオンボーディングガイド、技術ドキュメント、製品の背景情報、意思決定記録、よくある質問(FAQ)、再利用可能なテンプレートなどを掲載すべきです。まずはチームが最も頻繁に検索する内容から始め、徐々に範囲を広げていきましょう。各カテゴリの内容は以下の通りです。
- 社内規定やハンドブック: 有給休暇のルール、経費精算のガイドライン、行動規範など。新入社員が入社初週に検索するようなあらゆる情報
- 標準業務手順書(SOP): コードのデプロイ、返金の処理、給与計算など、繰り返し行われる仕事のためのステップごとの手順書
- 役割別のオンボーディングガイド: 画一的な歓迎ドキュメントではなく、エンジニアリング、デザイン、営業、サポートの各部門に合わせた独自のオンボーディングパス
- 技術ドキュメント: APIリファレンス、アーキテクチャの決定事項、環境セットアップ、トラブルシューティングの手順書
- 製品および機能に関するドキュメント: サポートや営業担当が顧客の質問に正確に回答するために必要な、社内仕様書、リリースノート、および背景情報
- ミーティングのメモや決定事項の記録: なぜその決定がなされたのかを検索可能な形で記録しておくことで、チームが次の四半期に同じ議論を蒸し返すことを防ぎます
- FAQおよびトラブルシューティング記事: 毎週チャットで寄せられる質問を、いつでも検索可能な恒久的な場所にまとめました
- テンプレートとチェックリスト: プロジェクトのキックオフ、事後検証、ベンダー評価などに再利用可能な出発点
優れたナレッジベースは、立ち上げ当初から網羅的なものではありません。まずは、チームが最も頻繁に検索したり質問したりするコンテンツから始め、そこから徐々に拡充していきましょう。
社内ナレッジベースの構築ステップ
ナレッジベースの構築は、単発のプロジェクトではなく、一連のプロセスです。失敗の原因は、ソフトウェアの質が悪いからではありません。多くの場合、責任者がおらず、セットアップやメンテナンスが行われていないことが原因です。以下の7つのステップでは、技術的なセットアップだけでなく、ナレッジベースを継続的に運用するための人的な側面についても解説します。
ステップ1:目標と範囲を明確にする
ツールを導入する前に、次の3つの質問に答えてください。「どのような問題を解決しようとしているのか?」「主な対象者は誰か?」「成功とはどのような状態か?」
- 課題から始める: オンボーディングの時間を短縮したいですか?チャットでの繰り返しの質問を減らしたいですか?メンバーが退職した際の知識の喪失を防ぎたいですか?それぞれの目標によって、最初に何を文書化すべきかが形になります。
- 範囲を限定する: すべてを一度に文書化しようとしないでください。まず、1つの部門や1つのユースケース(例:エンジニアリング部門の新入社員オンボーディング)から始め、そこから徐々に拡大していきましょう。
- 事前に成功の定義を明確に: 構築を始める前に、「機能している」とはどういう状態かを決めておきましょう。例えば、新入社員が同僚に尋ねることなくセットアップを完了できる、あるいはサポート担当者がエスカレーションすることなく特定のチケットタイプを解決できる、といった具合です。
ステップ2:ナレッジベースの所有者を任命する
放置されて機能しなくなるナレッジベースは、すべて「見捨てられた」ものです。委員会ではなく、1人の所有者を指名し、構造、品質、情報の最新性を管理させましょう。
- これは新たな人員配置ではなく、役割の一つです: 多くの場合、テクニカルライターや運用責任者、あるいはすでにほとんどの質問に対応しているベテランのチームメンバーが担当します。
- 担当業務: 構造の定義、投稿内容の確認、古くなったコンテンツのアーカイブ化、そして実際に利用されているかどうかの追跡
- 貢献者と所有者: 誰でも貢献や編集の提案を行うことができます。所有者は、それらの貢献が一定の品質基準を満たし、構成に合致していることを確認します。
ステップ3:適切なナレッジベースソフトウェアを選ぶ
ここでは、特定の製品ではなく、評価基準に焦点を当てましょう。チームが実際に必要としているものを基準に、候補リストを作成してください。
- 検索の精度: 部分的な検索語句や自然言語のクエリから、適切な記事を抽出できるでしょうか?検索機能が不十分であることが、ナレッジベースが活用されない最大の理由です。
- 編集体験: 現代的なドキュメントエディターのような使い心地か、それともマークアップのスキルが必要か? 操作のハードルが低ければ低いほど、より多くの人が貢献できるようになります
- 許可設定: 人事や財務データなどの機密性の高いコンテンツを特定のチームに限定してアクセスできるようにしつつ、それ以外のコンテンツは誰でも閲覧できるようにすることは可能でしょうか?
- 連携機能: チャットツールやプロジェクト管理ツールなど、チームがすでに利用しているツールと接続できますか?
- AI機能: コンテンツを要約する、関連記事を提案する、あるいは質問に直接回答するが可能か? 組み込みのAI検索機能は、今や最低限求められる要件となっています。
- 構造: コンテンツが増加しても検索し続けられるよう、ネストされたカテゴリ、タグ、相互リンクをサポートしていますか?
どのツールカテゴリーも、万人に最適なものというわけではありません。適切なナレッジマネジメントソフトウェアの選択は、チームのサイズ、技術的な習熟度、そしてどの程度の構造化が必要かによって異なります。
ステップ4:コンテンツ構造を整理する
その構造次第で、ユーザーは必要な情報を見つけられるか、それとも諦めてチャットで質問することになるかが決まります。
- トップレベルの分類軸を1つ選択してください: チーム別(エンジニアリング、人事、サポート)またはコンテンツの種類別(SOP、ポリシー、ガイド)のいずれかで整理し、両方を併用しないでください。もう一方については、タグや相互リンクを活用してください。
- 記事のタイトルは質問形式にする: ユーザーが実際に検索しそうな表現でタイトルを付けましょう。「経費報告書の提出方法」の方が、「財務、経費規定 v3.2」よりも効果的です。
- 階層は浅く保つ: 2階層が最適です。3階層になるとコンテンツが見つけにくくなり、1階層ではフラットなリストになってしまい、検索が困難になります。
- 標準テンプレートを使用する: すべての記事に同じセクション(目的、ステップ、関連記事、最終更新日)を設けることで、貢献者が一貫性のあるコンテンツを作成できるようになります
ステップ5:主要な記事を作成し、情報を充実させる
多くのチームがここで行き詰まってしまいます。6ヶ月もかかるような骨の折れる作業にならずに、コンテンツを作成する方法をご紹介します。
- まずは「トップ20」から始めましょう: チャットの履歴を検索したり、サポートチケットを確認したり、マネージャーに尋ねたりして、チーム内で最も頻繁に寄せられる20の質問を見つけましょう。まずはそれらを書き出してください。
- 「完璧より『十分』が勝る』: 粗削りでも正確な記事は、まだ存在していない洗練された記事よりもはるかに有用です。
- スキャンしやすい文章を心がけましょう: 段落は短く、箇条書きを活用し、必要に応じてスクリーンショットを挿入しましょう。60秒以内に答えが必要な読者を想定して執筆してください。
- 既存のコンテンツを再活用する:オンボーディングドキュメント、チャットのスレッド、録画されたビデオ、古いwikiなどから情報を集めましょう。知識がすでに手元にあるのに、一から作り直す必要はありません。
ステップ6:許可とアクセス制御の設定
すべての情報を全員に可視化すべきというわけではありませんが、その大部分は可視化すべきです。
- デフォルトで公開設定にする: ほとんどのコンテンツは、全従業員がアクセスできるようにすべきです。アクセス制限を厳しすぎると、セルフサービスの意義が失われてしまいます。
- 機密性に応じたアクセスリミット: 報酬データ、法的ドキュメント、セキュリティ運用マニュアル、財務情報などについては、チーム単位または役割単位でのアクセスリミットが必要になる場合があります。
- 編集とビューの分離: 一般的なモデルでは、誰でも編集を提案できますが、変更を公開できるのは指定された所有者だけです。
- ゲストや外部委託業者への対応: 外部パートナーと連携する場合は、彼らにどの情報を閲覧させるか(あるいは一切閲覧させないか)を決定してください
ステップ7:公開、チームへのトレーニング、そして改善を繰り返す
誰も利用しないナレッジベースは、単なるドキュメントの墓場です。
- まずは限定公開から: まず1つのパイロットチームに導入し、構成、検索機能、不足点に関するフィードバックを収集した上で、改善を行ってから全社展開しましょう。
- 「知識ベースをデフォルトの回答源にする」: すでに文書化されている質問が寄せられた場合は、改めて回答するのではなく、該当する記事がリンクされていることを共有しましょう。そうすることで、まず知識ベースを確認する習慣が身につきます。
- 利用状況の追跡: どの記事がビューされているか、どの検索で結果が出ないかを確認しましょう。検索結果が出ないケースは、何が不足しているかを正確に示してくれます。
- レビューのスケジュールを設定する: コンテンツを更新する頻度を月次または四半期ごとに設定し、各記事の所有者が担当セクションの更新責任を負うようにします
- フィードバックを反映させる: 各記事に「この情報は役に立ちましたか?」というボタンを追加し、その反応をもとに書き直しの優先順位を決定しましょう
AIナレッジベースの構築をお考えですか?このビデオでその方法をご紹介します。
社内ナレッジベースの管理におけるベストプラクティスとは?
ナレッジベースの構築自体は簡単です。それを常に最新の状態に保ち、有用なものにし続けることこそが、本当の仕事なのです。
- 記事ごとの所有者を割り当てる: すべての記事には、内容の正確性を保証する所有者が明確に定められています。役割が変更される際は、黙って所有権を引き継ぐのではなく、公に引き継ぎが行われます。
- 有効期限を設定する: 期限のある記事には「最終確認日」のタグを付けましょう。その日が過ぎると、所有者に更新またはアーカイブするよう通知が届きます。
- 「検索」を重視し、「ファイル整理」は後回しに: ユーザーが実際に検索する言葉を使いましょう。タイトルには社内用語や略語ではなく、自然な言葉を使いましょう。
- 唯一の正規バージョンを維持する: 同じ情報が3か所に存在する場合は、信頼できる情報源を1つ選び、残りのコンテンツはその情報源へリダイレクトしましょう。コンテンツが重複していると、情報がない場合よりも悪影響があります。どのバージョンを信頼すべきか、誰も判断できなくなってしまうからです。
- 情報提供を簡単に:「役立つコンテンツを知った」から「公開された」までのステップが少なければ少ないほど、より多くのコンテンツが寄せられます。機密性のないコンテンツについては、承認プロセスのボトルネックを解消しましょう。
- 四半期ごとの監査: 分析機能を活用して、ビュー数がゼロの記事(削除またはマージ)、情報が古くなった記事(更新またはアーカイブ)、アクセス数は多いものの評価が低い記事(書き直し)を特定しましょう。
- 日常の仕事との連携: ユーザーがすでに使用しているツール内でコンテンツを表示することで、情報を探すために仕事を切り替える必要がなくなります
適切に管理されたナレッジベースは、単なる静的なアーカイブではなく、まるで「生きている製品」のようなものです。ソフトウェアと同様に、ロードマップやバックログがあり、定期的にリリースが行われます。
ナレッジベースにAIを導入する予定ですか?まずはこちらをお読みください。
Google Researchの調査によると、AIシステムが古い情報を参照した場合、その「幻覚」発生率は10.2%から66.1%へと急増することが明らかになりました。知識ベースのメンテナンスを怠ると、AIは中立性を保てなくなります。むしろ、自信を持って誤った回答を出す確率が6倍にも高まります。情報源を常に最新の状態に保てばAIの性能は向上しますが、放置して古びさせてしまうと、AIは「何もない状態」よりも劣ったものになってしまいます。
なぜ多くの社内ナレッジベースは失敗するのか
研究者たちは数十年にわたり、ナレッジマネジメントの取り組みの多くが失敗に終わると警告してきました。『Journal of Knowledge Management』誌に掲載された画期的な研究によると、こうしたプログラムが失敗する原因は、技術の不備ではなく、ビジネスの実際の業務プロセスに組み込まれるのではなく、単なるITプロジェクトとして付け足されてしまったことにあることが明らかになりました。
多くのチームがナレッジベースを構築していますが、その大半は1年以内に利用を中止してしまいます。その原因はツール自体にあることはほとんどありません。失敗の原因となるのは以下の4つのパターンであり、それぞれに対処法があります。
- 「誰も信用しないから、誰も使わない」: ナレッジベースを台無しにする最も早い方法は、たった一つの間違った回答です。誰かが古い記事に従って失敗してしまうと、その人は確認するのをやめ、再びチャットで質問するようになってしまいます。更新日や記事ごとの所有者を明記することで、古いコンテンツが誰かを誤解させる前にフラグが立てられるようにし、この問題を解決しましょう。
- 検索で有用な結果が得られない場合: 「経費報告書」と検索した際に、「財務ポリシー v3.2」というタイトルのドキュメントが表示されると、ユーザーは2回目の検索で諦めてしまいます。記事のタイトルは、ユーザーが実際に検索する質問そのものにし、キーワードの完全一致ではなく、自然言語検索に対応したツールを活用しましょう。
- 所有者がいない: 「全員」が所有するナレッジベースは、実質的に誰も所有者ではないのと同じです。構造や情報の最新性を管理する所有者が一人もいないと、投稿は整理されずに積み上がり、不要な情報は削除されません。運用が滞り始める前ではなく、立ち上げ前に所有者を一人指名しましょう。
- 「投稿するのが面倒すぎる」: 記事の追加にチケットの作成や承認待ちが必要だと、誰も手を付けようとしなくなり、知識は個々の頭の中に閉じ込められたままになってしまいます。機密性のない情報については、「知っていること」から「公開される」までのステップを簡略化しましょう。
これら4つの共通する原則は、ナレッジベースは「プロジェクト」ではなく「習慣」であるということです。人々が「まずナレッジベースを確認する」という信頼を失った瞬間、それは失敗に終わります。これは決して新しい話ではありません。2000年にはすでに、スタンフォード大学のロバート・サットンが、仕事が理解されている者が管理責任を負わない場合、情報倉庫は忘れ去られたファイルの「ゴミ捨て場」になってしまうと警告していました。
どの社内ナレッジベースソフトウェアを検討すべきか?
「これ」という唯一の最適なツールは存在せず、チームの働き方に最も適したツールがあるだけです。主なカテゴリーごとの比較はこちらです。
| ツール | 最適な用途 | 強み | 制限事項 |
|---|---|---|---|
| Guru | 正確で文脈に沿った回答を求めるチーム | 堅牢な検証ワークフロー、ブラウザやチャット用の拡張機能、作業画面上にカードを表示する機能 | 長文のドキュメントや一般的なプロジェクト文書にはあまり適していません |
| Slite | すっきりとしたシンプルなナレッジベースを求める小規模チーム | 高速で、無料のシンプルなエディターと堅牢な検索機能 | 規模が拡大しても、構造やガバナンスに関する制約は少なくて済みます |
| Notion | 柔軟で多目的に活用できるワークスペースを求めるチーム | ページベースの柔軟性により、ナレッジベースに加え、一般的なドキュメントの管理にも最適です | 柔軟性には一長一短があり、強力なガバナンスがなければすぐに混乱を招いてしまいます |
| Confluence | すでにAtlassianスタックを導入している、エンジニアリング中心の組織 | 詳細な構造、充実した許可設定、Jiraとの緊密な連携 | 技術的な知識のない貢献者にとっては、セットアップがやや複雑で、編集操作の操作感が時代遅れに感じられる |
| ClickUp | 仕事のすぐそばでナレッジを活用したいチーム | KBは、タスク、ドキュメント、チャットと並んで1つのワークスペース内に配置され、これらすべてを対象としたAI検索機能が組み込まれています。 | 初期セットアップに手間がかかります。ナレッジベースのみを利用し、プラットフォームの他の機能は使用しないチームには向かない可能性があります。 |
| Zendesk | 主な利用シーンがエージェントの知識管理であるサポートチーム | サポートワークフローやチケットとリンクされている記事の作成に最適 | 全社的な社内ドキュメントとしてはあまり適していない |
ClickUpで社内ナレッジベースを構築した方法
ここでは、当社チーム向けにこれをどのように設定したかをご紹介します。
私たちはClickUp Docsを基盤として活用しています。Docsはネストされたページ、リッチフォーマット、リアルタイムの共同編集に対応しており、タスクやプロジェクトと同じワークスペース内に存在します。これにより、ドキュメントはそれが説明する仕事と密接に結びついた状態が保たれます。wiki形式のドキュメントハブにより、すべての情報を一箇所で閲覧・整理できるようになります。
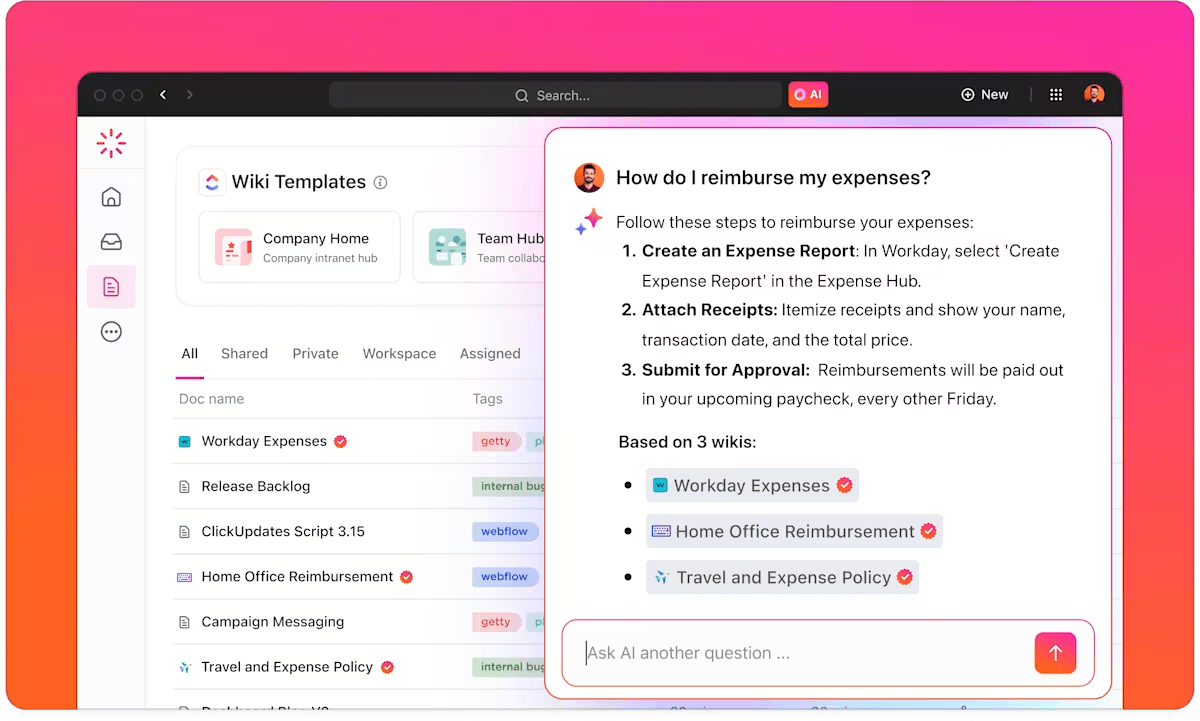
回答を探す際には、私たちはClickUp Brainを活用しています。カテゴリを閲覧したりキーワードを推測したりする代わりに、誰でも平易な言葉で質問を投げかけるだけで、既存のドキュメント、タスク、コメントから直接回答を引き出すことができます。これはネイティブAIであるため、ワークスペース全体の文脈を完全に把握しています。これにより、通常は導入の妨げとなる検索の煩わしさが解消されます。
ClickUpの許可設定は「ドキュメント」「フォルダ」「スペース」の各レベルで機能するため、ほとんどのコンテンツは公開したままにしておき、機密性の高い資料のみを適切なチームに限定してアクセスできるようにしています。ゲストアクセスは、閲覧範囲を制限する必要がある外部業者や他部門のパートナーを対象としています。
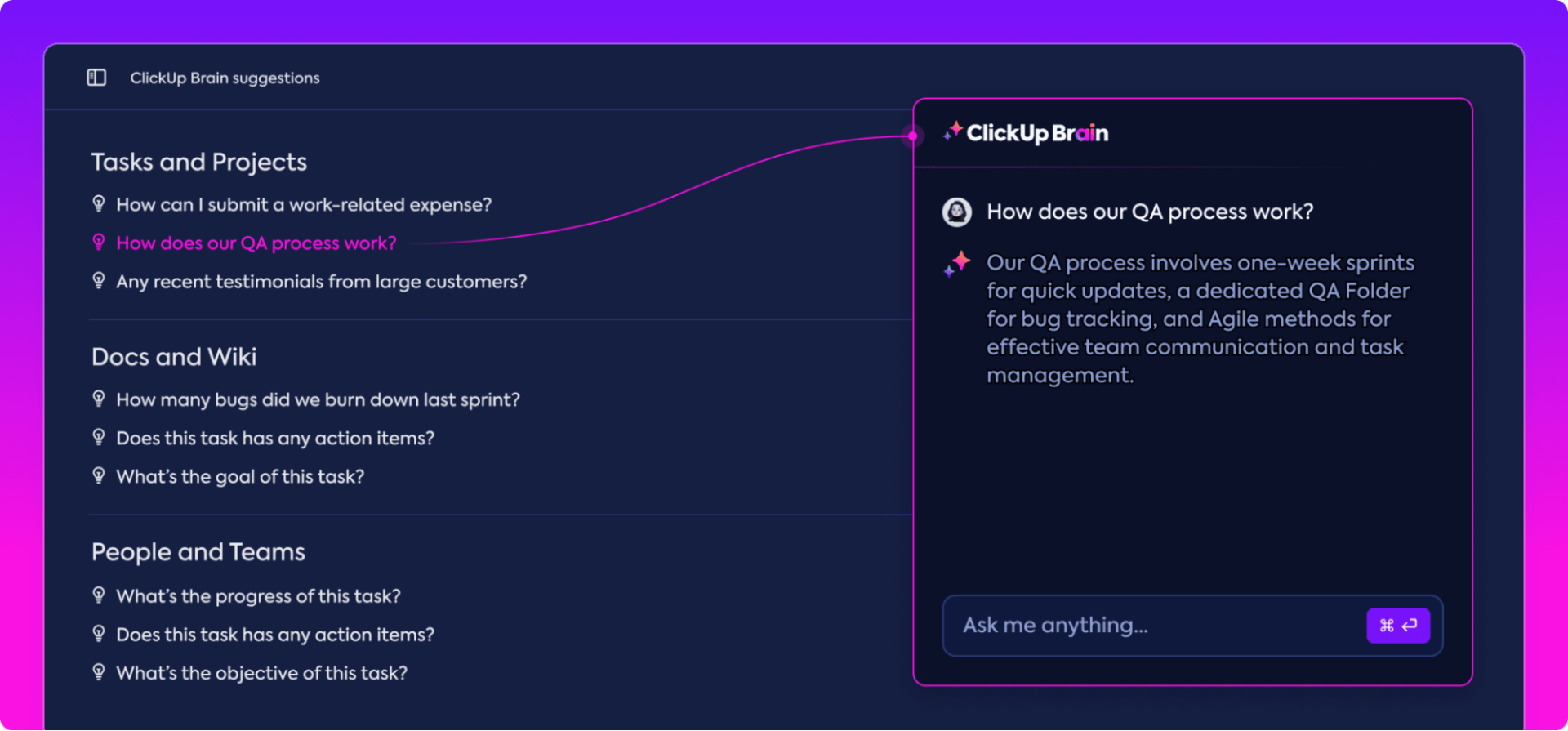
ClickUpの「企業検索」は、ドキュメント、タスク、コメント、連携アプリをインデックス化することで、これらを統合します。ナレッジベースは孤立した存在ではなく、すべての情報を横断する統一された検索機能の一部です。
また、ClickUpの社内ナレッジベース用テンプレートも活用しています。これにより、あらかじめ用意されたカテゴリ、記事のフォーマット、タグ付けのルールを利用できます。
実際に試してみましょう:ClickUpの「ナレッジベーステンプレート」には、ナレッジ記事、FAQ、リソース用のセクションがあらかじめ用意された、すぐに使えるドキュメントと、組み込みのヘルプセンターレイアウトが含まれています。カテゴリを一から作成するのではなく、すでに整った構造から始めましょう。
率直なトレードオフ:ClickUpの真価は、ナレッジベースが仕事が行われるツール内に統合されている点にあり、これによりコンテキストの切り替えが不要になります。もし、他の機能を持たないスタンドアロンの単一目的のナレッジベースのみを必要としているのであれば、より広範なプラットフォームは不要な機能が多すぎる可能性があります。
「アーカイブ」ではなく「習慣」を築こう
ナレッジベースは、決して「完了」することはありません。一度コンテンツを詰め込んで放置するだけのフォルダではなく、所有者やバックログがあり、定期的な更新が行われる「製品」として扱ってください。アーカイブが完全になるのを待ってから始める必要はありません。チーム内で繰り返し質問されている「気にかかる疑問」を1つ選び、今日すぐにドキュメント化しましょう。そして、実際に使われていく中で、次に何を構築すべきかが自然と見えてくるはずです。
タスク、チーム、ナレッジがすべてネイティブAIを通じて接続される単一のソリューションをお探しなら、ClickUpの統合型AIワークスペースが役立ちます。ClickUpを無料で始めましょう。
社内ナレッジベースに関するよくある質問
社内ナレッジベースと社内wikiの違いは何ですか?
社内Wikiは社内ナレッジベースの一種であり、具体的には、どの従業員でも自由にページを作成・編集できるものです。社内ナレッジベースはより広範なカテゴリーであり、従来のwikiでは実施されていない、より厳格な編集管理、承認ワークフロー、構造化された記事フォーマットなどが追加されることがよくあります。
社内ナレッジベースが実際に機能しているかどうかを、どのように測定すればよいでしょうか?
検索からクリックへの転換率、検索結果が0件だったケース、記事のフィードバックスコア、チャットやサポートチャネルでの繰り返し質問の減少率などを追跡しましょう。新入社員がオンボーディングのタスクをより早く完了し、ベテランのチームメンバーが同じ質問に繰り返し答える回数が減れば、ナレッジベースは本来の役割を果たしていると言えます。
部門横断的なチーム向けの社内ナレッジベースのコンテンツとして、どのような例が挙げられますか?
用語を統一するための共有用語集、設計からエンジニアリングへの仕様書引き継ぎ手順、サポートからエンジニアリングへの問題エスカレーション手順、そしてセキュリティプロトコルやブランドガイドラインといった全社的なポリシー。これらはすべてのチームに必要な参照資料ですが、特定のチームだけが管理しているわけではありません。
社内ナレッジベースの構築にはどれくらいの費用がかかりますか?
多くのチームは、すでに利用料を支払っているソフトウェアを使ってナレッジベースを構築するため、実際のコストはライセンス料ではなく時間です。専用のナレッジベースツールは通常、ユーザーあたり月額制ですが、オールインワンプラットフォームではナレッジベースが既存のプランに組み込まれています。より大きな投資となるのは、初期のコンテンツ作成と継続的なメンテナンスです。そのため、価格よりも、所有者を1人に絞ることが重要です。
社内ナレッジベースの設定にはどれくらい時間がかかりますか?
すべてを網羅しようとせず、チームからよく寄せられる質問トップ20から着手すれば、実用的な最初のバージョンは数ヶ月ではなく、数日で完成します。完全な網羅は継続的なプロセスであり、リリース時のマイルストーンではありません。「完了」を待っているチームは、決してリリースに至りません。
社内ナレッジベースの管理責任者は誰が担うべきでしょうか?
担当者を1名、通常はテクニカルライター、運用責任者、またはすでにチームの質問のほとんどに対応しているシニアICに任命します。委員会による所有権は、ナレッジベースが古くなってしまう最も一般的な原因です。なぜなら、情報の最新性について個人が責任を負わないためです。
AIは社内ナレッジベースの構築や維持管理を行うことができますか?
AIは、既存のチャットスレッドやドキュメントから記事の下書きを作成したり、古くなったコンテンツにフラグを立てたり、既存の資料から直接抽出した自然な言葉で質問に答えたりすることができます。ただし、正確性を確認する所有者が依然として必要です。なぜなら、古い情報に基づいてAIが生成した回答は、単に「より早く出される間違った答え」に過ぎないからです。