
Vous publiez la dernière mise à jour logicielle et les rapports commencent à affluer.
Soudain, un seul indicateur régit tout, du CSAT/NPS au retard dans la feuille de route : le temps de résolution des bugs.
Les dirigeants y voient un indicateur de respect des engagements : pouvons-nous livrer, apprendre et protéger nos revenus dans les délais prévus ? Les praticiens en subissent les conséquences : tickets en double, propriété floue, escalades bruyantes et contexte dispersé entre Slack, les feuilles de calcul et divers outils.
Cette fragmentation allonge les cycles, masque les causes profondes et transforme la hiérarchisation des priorités en une simple conjecture.
Le résultat ? Un apprentissage plus lent, des validations non effectuées et un retard qui pèse discrètement sur chaque sprint.
Ce guide est votre manuel complet pour mesurer, comparer et réduire le temps de résolution des bugs. Il montre concrètement comment l'IA modifie le flux de travail par rapport aux processus manuels traditionnels.
Qu'est-ce que le temps de résolution des bugs ?
Le temps de résolution des bogues correspond au temps nécessaire pour corriger un bogue, mesuré à partir du moment où le bogue est signalé jusqu'à sa résolution complète.
En pratique, le chronomètre démarre lorsqu'un problème est signalé ou détecté (par les utilisateurs, l'assurance qualité ou la surveillance) et s'arrête lorsque la correction est mise en œuvre et fusionnée, prête à être vérifiée ou publiée, selon la définition de « terminé » de votre équipe.
Exemple : un crash P1 signalé à 10 h le Monday, avec une correction fusionnée à 15 h le mardi, a un temps de résolution d'environ 29 heures.
Ce n'est pas la même chose que le temps de détection des bogues. Le temps de détection mesure la rapidité avec laquelle vous identifiez un défaut après sa survenue (déclenchement d'alarmes, détection par des outils de test d'assurance qualité, rapports des clients).
Le temps de résolution mesure la rapidité avec laquelle vous passez de la prise de conscience à la correction : triage, reproduction, diagnostic, mise en œuvre, révision, test et préparation à la publication. Considérez la détection comme « nous savons que cela ne fonctionne pas » et la résolution comme « c'est corrigé et prêt ».
Les équipes utilisent des limites légèrement différentes ; choisissez-en une et soyez cohérent afin que vos tendances soient réelles :
- Signalé → Résolu : Se termine lorsque la correction du code est fusionnée et prête pour le contrôle qualité. Bon pour le débit d'ingénierie.
- Signalé → Fermé : Comprend la validation QA et la mise en production. Idéal pour les SLA ayant un impact sur les clients.
- Détecté → Résolu : commence lorsque la surveillance/l'assurance qualité détecte le problème, avant même qu'un ticket n'existe. Utile pour les équipes à forte production.
🧠 Anecdote amusante : un bug original et hilarant dans Final Fantasy XIV a été salué pour son caractère si spécifique que les lecteurs l'ont surnommé « le bug le plus spécifique corrigé dans un MMO en 2025 ». Il se manifestait lorsque les joueurs fixaient le prix d'éléments entre exactement 44 442 gil et 49 087 gil dans une zone d'évènement particulière, provoquant des déconnexions dues à ce qui pourrait être un bug de dépassement de capacité d'entier.
Pourquoi est-ce important ?
Le temps de résolution est un levier de cadence de publication. Des délais longs ou imprévisibles obligent à réduire la portée, à appliquer des correctifs et à geler les publications ; ils créent un retard dans la planification, car les cas extrêmes (valeurs aberrantes) perturbent les sprints plus que ne le suggère la moyenne.
Cela est également directement lié à la satisfaction des clients. Les clients tolèrent les problèmes lorsqu'ils sont rapidement pris en compte et résolus de manière prévisible. Les corrections lentes, ou pire, les corrections variables, entraînent des escalades, nuisent au CSAT/NPS et mettent en péril les renouvellements.
En bref, si vous mesurez clairement le temps nécessaire à la résolution des bugs et que vous le réduisez de manière systématique, vos feuilles de route et vos relations s'amélioreront.
📖 En savoir plus : Comment hiérarchiser les bugs pour une résolution efficace des problèmes
Comment mesurer le temps nécessaire à la résolution des bugs ?
Commencez par déterminer où commence et où s'arrête votre chronomètre.
La plupart des équipes choisissent soit « Signalé → Résolu » (le correctif est fusionné et prêt à être soumis à la vérification), soit « Signalé → Fermé » (le contrôle qualité a validé et la modification est publiée ou autrement fermée).
Choisissez une définition et utilisez-la de manière cohérente afin que vos tendances soient significatives.
Vous avez maintenant besoin d’indicateurs observables. Décrivons-les :
Principaux indicateurs à surveiller pour le suivi des bugs :
| 📊 Indicateur | 📌 Ce que cela signifie | 💡 Comment cela peut vous aider | 🧮 Formule (le cas échéant) |
|---|---|---|---|
| Nombre de bugs 🐞 | Nombre total de bugs signalés | Offre une vue d'ensemble de l'état du système. Le nombre est élevé ? Il est temps d'enquêter. | Nombre total de bogues = tous les bogues enregistrés dans le système {ouverts + fermés} |
| Bugs ouverts 🚧 | Bugs qui n'ont pas encore été corrigés | Affiche la charge de travail actuelle. Aide à établir les priorités. | Bugs ouverts = Nombre total de bugs - Bugs fermés |
| Bugs fermés ✅ | Bugs résolus et vérifiés | Suivi des progrès et du travail accompli. | Bugs fermés = nombre de bugs ayant le statut « Fermé » ou « Résolu ». |
| Gravité des bugs 🔥 | Criticité du bug (par exemple, critique, majeur, mineur) | Facilite le triage en fonction de l'impact. | Suivi comme champ catégoriel, sans formule. Utilisez des filtres/regroupements. |
| Priorité des bugs 📅 | Urgence de la correction d'un bug | Facilite la planification des sprints et des versions. | Il s'agit également d'un champ catégoriel, généralement classé (par exemple, P0, P1, P2). |
| Temps de résolution ⏱️ | Délai entre le signalement d'un bug et sa résolution | Mesure la réactivité. | Temps de résolution = date fermée - date de rapports |
| Taux de réouverture 🔄 | Pourcentage de bugs réouverts après avoir été fermés | Reflète la qualité des corrections ou les problèmes de régression. | Taux de réouverture (%) = {Bugs réouverts ÷ Total des bugs fermés} × 100 |
| Fuite de bugs 🕳️ | Bugs qui se sont glissés dans la production | Indique l'efficacité de l'assurance qualité/des tests logiciels. | Taux de fuite (%) = {Bugs de production ÷ Nombre total de bugs} × 100 |
| Densité des défauts 🧮 | Bugs par unité de taille de code | Met en évidence les zones de code à risque. | Densité des défauts = nombre de bugs ÷ KLOC {kilolignes de code} |
| Bugs assignés vs non assignés 👥 | Distribution des bugs par propriété | Assurez-vous que rien ne passe entre les mailles du filet. | Utilisez un filtre : Non attribué = Bugs pour lesquels le champ « Attribué à » est vide. |
| Âge des bugs ouverts 🧓 | Combien de temps un bug reste-t-il non résolu ? | Identifie les risques de stagnation et d'accumulation des retards. | Âge du bug = date actuelle - date de signalement |
| Bugs en double 🧬 | Nombre de rapports en double | Met en évidence les erreurs dans les processus d'admission. | Taux de duplication = Duplications ÷ Nombre total de bugs × 100 |
| MTTD (temps moyen de détection) 🔎 | Temps moyen nécessaire pour détecter les bugs ou les incidents | Mesure l'efficacité de la surveillance et de la sensibilisation. | MTTD = Σ(temps de détection - temps d'introduction) ÷ nombre de bugs |
| MTTR (temps moyen de résolution) 🔧 | Temps moyen nécessaire pour corriger complètement un bug après sa détection | Suivez la réactivité des ingénieurs et le temps de correction. | MTTR = Σ(temps de résolution - temps de détection) ÷ nombre de bugs résolus |
| MTTA (temps moyen de reconnaissance) 📬 | Temps écoulé entre la détection du bug et le moment où quelqu'un commence à travailler dessus | Affiche la réactivité de l'équipe et la réactivité des alertes. | MTTA = Σ(temps confirmé - temps détecté) ÷ nombre de bugs |
| MTBF (temps moyen entre pannes) 🔁 | Temps entre la résolution d'une défaillance et l'apparition de la suivante | Indique la stabilité au fil du temps. | MTBF = temps de fonctionnement total ÷ nombre de pannes |
⚡️ Archive de modèles : 15 modèles et formulaires gratuits pour le suivi des bogues
Facteurs qui influent sur le temps nécessaire à la résolution des bugs
Le temps de résolution est souvent assimilé à « la rapidité avec laquelle les ingénieurs codent ».
Mais ce n'est qu'une partie du processus.
Le temps de résolution des bogues est la somme de la qualité à la réception, de l'efficacité du flux dans votre système et du risque de dépendance. Lorsque l'un de ces éléments faiblit, la durée du cycle s'allonge, la prévisibilité diminue et les escalades se multiplient.
La qualité de la prise en charge donne le ton
Les rapports qui arrivent sans étapes de reproduction claires, sans détails sur l'environnement, sans journaux ou sans informations sur la version/la compilation entraînent des allers-retours supplémentaires. Les rapports en double provenant de plusieurs canaux (assistance, assurance qualité, surveillance, Slack) ajoutent du bruit et fragmentent la propriété.
Plus vous identifiez rapidement le contexte approprié (et supprimez les doublons), moins vous aurez besoin de transferts et de clarifications par la suite.
La hiérarchisation et le routage déterminent qui traite le bug et à quel moment.
Les libellés de gravité qui ne correspondent pas à l'impact sur les clients/l'entreprise (ou qui évoluent au fil du temps) provoquent un déséquilibre dans la file d'attente : les tickets les plus urgents passent en tête de file tandis que les défauts à fort impact restent en attente.
Des règles de routage claires par composant/propriétaire et une file d'attente unique permettent d'éviter que le travail P0/P1 ne soit noyé sous le travail « récent et bruyant ».
La propriété et les transferts sont des tueurs silencieux
Si l'on ne sait pas clairement si un bug relève de la compétence de l'équipe mobile, de l'équipe d'authentification backend ou de l'équipe plateforme, il est renvoyé. Chaque renvoi réinitialise le contexte.
Les fuseaux horaires aggravent encore la situation : un bug signalé en fin de journée sans propriétaire désigné peut perdre 12 à 24 heures avant que quiconque ne commence à le reproduire. Des définitions strictes de « qui est propriétaire de quoi », avec un DRI (responsable désigné) d'astreinte ou hebdomadaire, éliminent cette dérive.
La reproductibilité dépend de l'observabilité
Des journaux clairsemés, des identifiants de corrélation manquants ou l'absence de traces d'erreurs transforment le diagnostic en conjecture. Les bugs qui n'apparaissent qu'avec des indicateurs, des locataires ou des formes de données spécifiques sont difficiles à reproduire en développement.
Si les ingénieurs ne peuvent pas accéder en toute sécurité à des données nettoyées similaires à celles utilisées en production, ils finissent par instrumenter, redéployer et attendre, pendant des jours plutôt que des heures.
La parité de l'environnement et des données vous garantit une transparence totale.
« Ça marche sur ma machine » signifie généralement « les données de production sont différentes ». Plus votre développement/staging diverge de la production (configuration, services, versions tierces), plus vous passerez de temps à courir après des fantômes. Les instantanés de données sécurisés, les scripts de seed et les contrôles de parité réduisent cet écart.
Le travail en cours (WIP) et la concentration stimulent le débit réel.
Les équipes surchargées traitent trop de bogues à la fois, dispersent leur attention et passent sans cesse d'une tâche à l'autre et d'une réunion à l'autre. Les changements de contexte ajoutent des heures invisibles.
Une limite de travail en cours visible et une tendance à terminer ce qui a été commencé avant de se lancer dans un nouveau travail feront baisser votre médiane plus rapidement que n'importe quel effort individuel.
La révision du code, l'intégration continue et la vitesse de l'assurance qualité sont des goulots d'étranglement classiques.
Les temps de compilation lents, les tests instables et les SLA de révision peu clairs ralentissent des corrections qui pourraient être rapides. Un correctif de 10 minutes peut prendre deux jours à attendre un réviseur ou à s'intégrer dans un pipeline de plusieurs heures.
De même, les files d'attente d'assurance qualité qui regroupent les tests ou qui reposent sur des tests manuels peuvent ajouter plusieurs jours au processus « Signalé → Fermé », même lorsque le processus « Signalé → Résolu » est rapide.
Les dépendances allongent les files d'attente
Les changements inter-équipes (schéma, migrations de plateformes, mises à jour SDK), les bugs des fournisseurs ou les évaluations des boutiques d'applications (mobile) entraînent des temps d'attente. Sans suivi explicite « Bloqué/En attente », ces temps d'attente gonflent de manière invisible vos moyennes et masquent l'emplacement réel du goulot d'étranglement.
Le modèle de publication et la stratégie de restauration sont importants
Si vous effectuez des livraisons par lots avec des portes manuelles, même les bugs résolus restent en attente jusqu'au prochain lot. Les Feature Flags, les versions canary et les voies de correctifs rapides raccourcissent la queue, en particulier pour les incidents P0/P1, en vous permettant de dissocier le déploiement des correctifs des cycles de livraison complets.
L'architecture et la dette technique fixent votre plafond
Le couplage étroit, l'absence de joints de test et les modules hérités opaques rendent les corrections simples risquées. Les équipes compensent cela par des tests supplémentaires et des révisions plus longues, ce qui allonge les cycles. À l'inverse, un code modulaire avec de bons tests de contrat vous permet d'avancer rapidement sans perturber les systèmes adjacents.
La communication et la gestion du statut influencent la prévisibilité
Les mises à jour vagues (« en cours d'examen ») entraînent des retouches lorsque les parties prenantes demandent des délais d'exécution, que le support rouvre des tickets ou que le produit est escaladé. Des transitions de statut claires, des notes sur la reproduction et la cause profonde, ainsi qu'un délai d'exécution affiché réduisent le taux de désabonnement et permettent à votre équipe d'ingénieurs de rester concentrée.
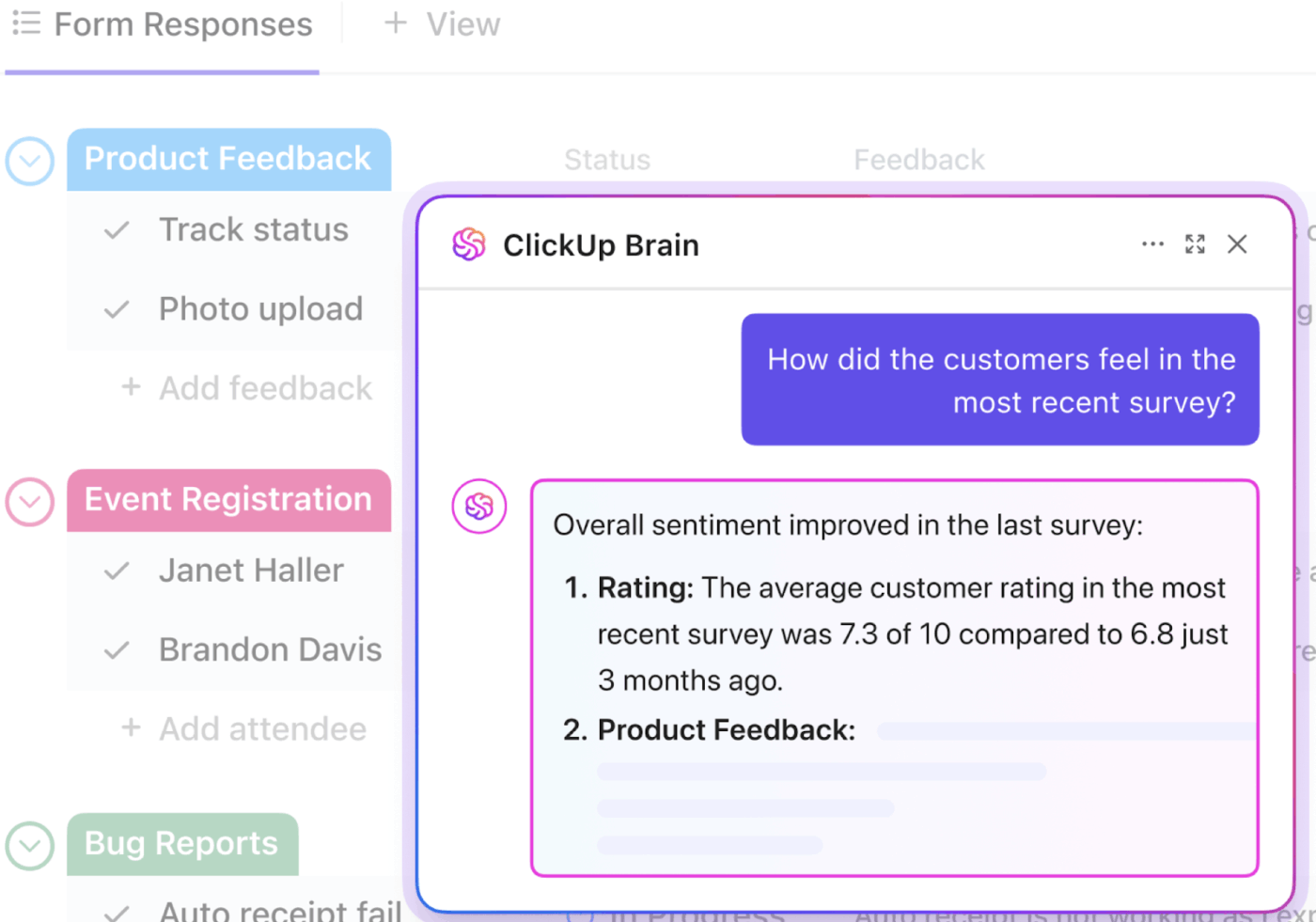
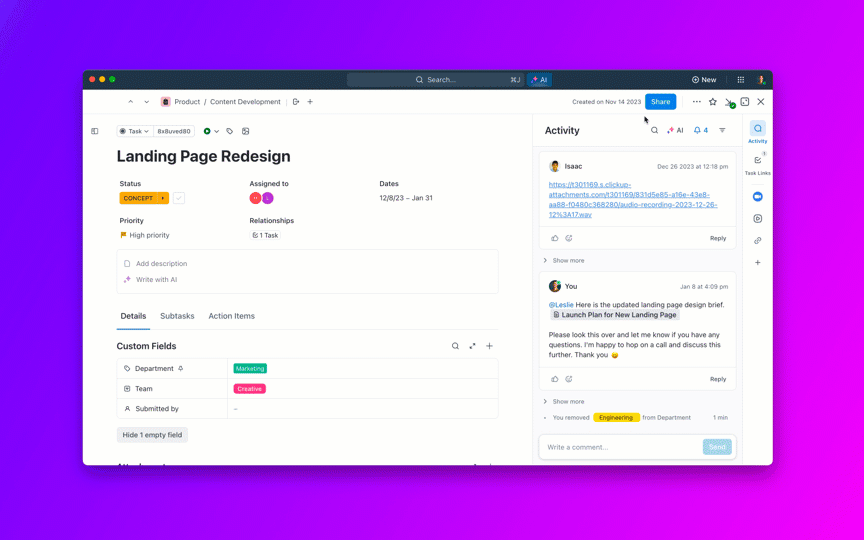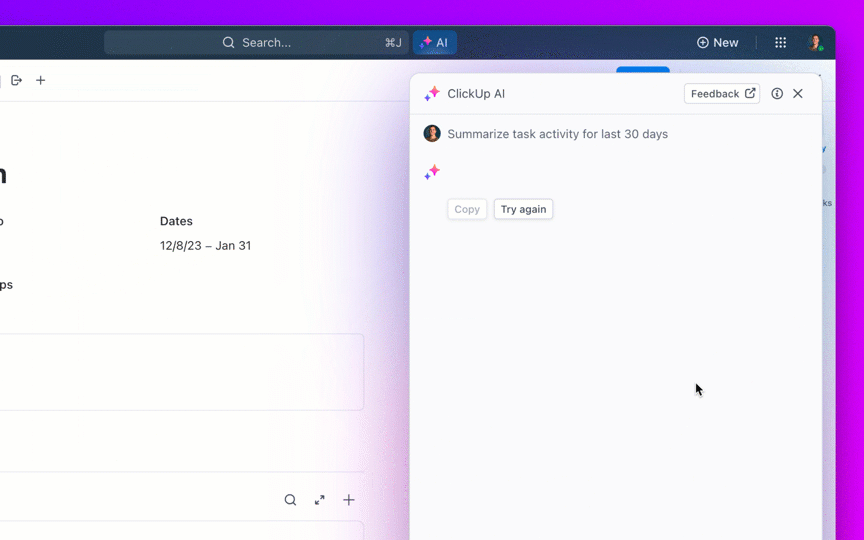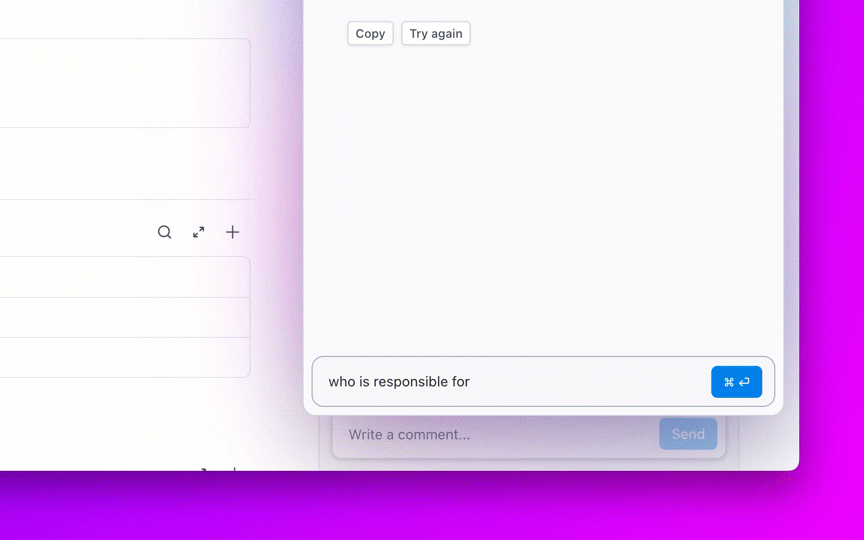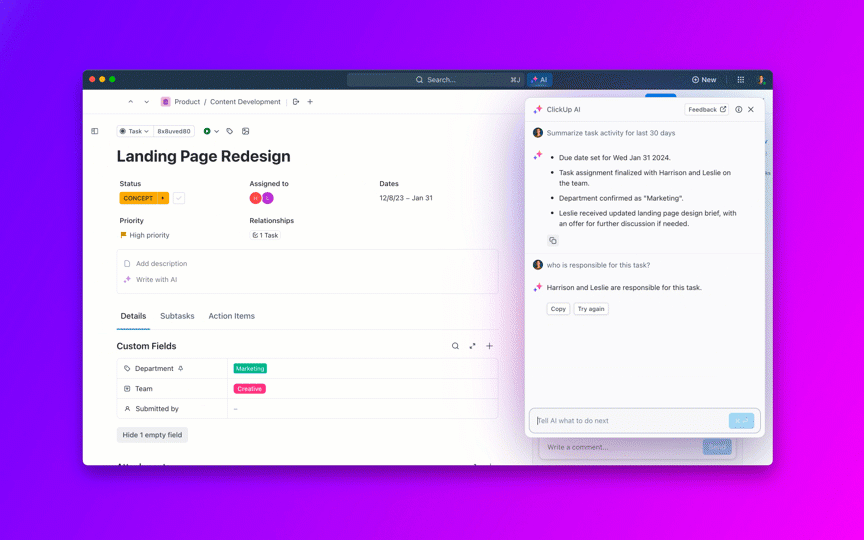
📮ClickUp Insight : En moyenne, un professionnel passe plus de 30 minutes par jour à rechercher des informations liées à son travail, soit plus de 120 heures par an perdues à fouiller dans ses e-mails, ses fils de discussion Slack et ses fichiers éparpillés.
Un assistant IA intelligent intégré à votre environnement de travail peut changer cela. Découvrez ClickUp Brain. Il fournit des informations et des réponses instantanées en faisant apparaître les bons documents, discussions et détails de tâches en quelques secondes, afin que vous puissiez arrêter de chercher et commencer à travailler.
💫 Résultats concrets : des équipes telles que QubicaAMF ont gagné plus de 5 heures par semaine grâce à ClickUp, soit plus de 250 heures par an et par personne, en éliminant les processus de gestion des connaissances obsolètes. Imaginez ce que votre équipe pourrait accomplir avec une semaine supplémentaire de productivité chaque trimestre !
Indicateurs avancés indiquant que votre délai de production va augmenter
❗️Augmentation du « temps de reconnaissance » et nombreux tickets sans propriétaire pendant plus de 12 heures
❗️Augmentation des tranches « Temps en révision/CI » et instabilité fréquente des tests
❗️Taux élevé de doublons dans les admissions et libellés de gravité incohérents entre les équipes
❗️Plusieurs bogues sont bloqués sans dépendance externe nommée.
❗️Taux de réouverture en hausse (les corrections ne sont pas reproductibles ou les définitions de « terminé » sont floues)
Ces facteurs sont perçus différemment selon les organisations. Les dirigeants les considèrent comme des cycles d'apprentissage manqués et des pertes de revenus, tandis que les opérateurs les perçoivent comme un bruit de triage et un manque de clarté quant à la propriété.
En ajustant l'admission, le flux et les dépendances, vous pouvez faire baisser l'ensemble de la courbe, tant la médiane que le P90.
Vous souhaitez en savoir plus sur la rédaction de meilleurs rapports de bogues? Commencez ici. 👇🏼
📖 En savoir plus : Le cycle de vie des tests logiciels (STLC) : aperçu et phases
Références du secteur en matière de temps de résolution des bugs
Les critères de référence en matière de résolution des bugs varient en fonction de la tolérance au risque, du modèle de publication et de la rapidité avec laquelle vous pouvez déployer les modifications.
C'est ici que vous pouvez utiliser les médianes (P50) pour comprendre votre flux type et P90 pour définir des engagements et des SLA, par gravité et par source (client, assurance qualité, surveillance).
Voyons ce que cela signifie concrètement :
| 🔑 Terme | 📝 Description | 💡 Pourquoi est-ce important ? |
|---|---|---|
| P50 (médiane) | La valeur moyenne : 50 % des corrections de bugs sont plus rapides que cela, et 50 % sont plus lentes. | 👉 Reflète votre temps de résolution habituel ou le plus courant. Utile pour comprendre les performances normales. |
| P90 (90e centile) | 90 % des bugs sont corrigés dans ce délai. Seuls 10 % prennent plus de temps. | 👉 Représente une limite dans le pire des cas (mais toujours réaliste). Utile pour définir des promesses externes. |
| SLA (accords de niveau de service) | Les engagements que vous prenez, en interne ou auprès des clients, concernant la rapidité avec laquelle les problèmes seront résolus. | 👉 Exemple : « Nous résolvons les bugs P1 dans les 48 heures, dans 90 % des cas. » Contribue à renforcer la confiance et la responsabilité |
| Par gravité et source | Segmentez vos indicateurs selon deux dimensions clés : • Gravité (par exemple, P0, P1, P2)• Source (par exemple, client, assurance qualité, surveillance) | 👉 Permet un suivi et une hiérarchisation plus précis, afin que les bugs critiques soient traités plus rapidement. |
Vous trouverez ci-dessous des intervalles indicatifs basés sur les secteurs d'activité que les équipes expérimentées ciblent souvent ; considérez-les comme des intervalles de départ, puis adaptez-les à votre contexte.
SaaS
Toujours actif et compatible avec CI/CD, les correctifs sont donc courants. Les problèmes critiques (P0/P1) visent souvent une médiane inférieure à une journée de travail, avec un P90 dans les 24 à 48 heures. Les problèmes non critiques (P2+) sont généralement résolus en 3 à 7 jours en médiane, avec un P90 dans les 10 à 14 jours. Les équipes disposant de Feature Flags robustes et de tests automatisés ont tendance à être plus rapides.
Plateformes de commerce électronique
Les flux de conversion et de panier étant essentiels pour le chiffre d'affaires, la barre est placée plus haut. Les problèmes P0/P1 sont généralement atténués en quelques heures (restauration, signalement ou configuration) et entièrement résolus le jour même ; les problèmes P90 sont généralement résolus avant la fin de la journée ou en moins de 12 heures pendant les périodes de forte activité. Les problèmes P2+ sont souvent résolus en 2 à 5 jours, les problèmes P90 en moins de 10 jours.
Logiciels d'entreprise
Une validation plus rigoureuse et des fenêtres de modification plus longues ralentissent le rythme. Pour les P0/P1, les équipes visent une solution de contournement dans un délai de 4 à 24 heures et une correction dans un délai de 1 à 3 jours ouvrables ; pour les P90, dans un délai de 5 jours ouvrables. Les éléments P2+ sont souvent regroupés dans des trains de publication, avec des délais médians de 2 à 4 semaines selon les calendriers de déploiement des clients.
Jeux et applications mobiles
Les backends de service en direct se comportent comme des SaaS (drapeaux et rollbacks en quelques minutes à quelques heures ; P90 le jour même). Les mises à jour des clients sont limitées par les évaluations des magasins : P0/P1 utilisent souvent immédiatement des leviers côté serveur et livrent un patch client en 1 à 3 jours ; P90 dans un délai d'une semaine avec une évaluation accélérée. Les corrections P2+ sont généralement programmées dans le sprint suivant ou la prochaine mise à jour de contenu.
Banque/Fintech
Les barrières de risque et de conformité favorisent un modèle « atténuer rapidement, changer avec prudence ». Les P0/P1 sont atténués rapidement (drapeaux, retours en arrière, transferts de trafic en quelques minutes ou quelques heures) et entièrement corrigés en 1 à 3 jours ; les P90 en une semaine, en tenant compte du contrôle des changements. Les P2+ prennent souvent 2 à 6 semaines pour passer les contrôles de sécurité, les audits et les examens du CAB.
Si vos nombres se situent en dehors de ces intervalles, examinez la qualité des admissions, le routage/la propriété, la révision du code et le débit de l'assurance qualité, ainsi que les approbations de dépendance avant de supposer que la « vitesse d'ingénierie » est le problème principal.
🌼 Le saviez-vous ? Selon un sondage Stack Overflow réalisé en 2024, les développeurs ont de plus en plus recours à l'IA comme assistant de confiance tout au long du processus de codage. Pas moins de 82 % d'entre eux utilisaient l'IA pour écrire du code, ce qui en fait un collaborateur créatif ! Lorsqu'ils étaient bloqués ou à la recherche de solutions, 67,5 % s'appuyaient sur l'IA pour trouver des réponses, et plus de la moitié (56,7 %) s'en servaient pour déboguer et obtenir de l'aide.
Pour certains, les outils d'IA se sont également révélés utiles pour documenter des projets (40,1 %) et même pour créer des données ou du contenu synthétiques (34,8 %). Vous êtes curieux de découvrir une nouvelle base de code ? Près d'un tiers (30,9 %) utilisent l'IA pour se mettre à niveau. Le test de code reste une tâche manuelle fastidieuse pour beaucoup, mais 27,2 % ont également adopté l'IA dans ce domaine. D'autres domaines tels que la révision de code, la planification de projet et l'analyse prédictive connaissent une adoption moindre de l'IA, mais il est clair que celle-ci s'intègre progressivement à toutes les étapes du développement logiciel.
📖 En savoir plus : Comment utiliser l'IA pour l'assurance qualité
Comment réduire le temps nécessaire à la résolution des bugs
La rapidité de résolution des bugs repose sur l'élimination des frictions à chaque étape, de la réception à la publication.
Les gains les plus importants proviennent d'une utilisation plus intelligente des 30 premières minutes (prise en charge claire, propriétaire approprié, priorité appropriée), puis de la compression des boucles qui suivent (reproduction, révision, vérification).
Voici neuf stratégies qui fonctionnent ensemble comme un système. L'IA accélère chaque étape et le flux de travail est clairement organisé en un seul endroit, ce qui permet aux dirigeants d'avoir une meilleure prévisibilité et aux praticiens de bénéficier d'un flux plus fluide.
1. Centralisez la réception et capturez le contexte à la source
Le temps nécessaire à la résolution des bogues s'allonge lorsque vous devez reconstituer le contexte à partir de fils de discussion Slack, de tickets d'assistance et de feuilles de calcul. Regroupez tous les rapports (assistance, assurance qualité, surveillance) dans une seule file d'attente à l'aide d'un modèle structuré qui recueille les informations suivantes : composant, gravité, environnement, version/build de l'application, étapes de reproduction, résultats attendus vs résultats réels et pièces jointes (journaux/HAR/captures d'écran).
L'IA peut résumer automatiquement les longs rapports, extraire les étapes de reproduction et les détails de l'environnement à partir des pièces jointes, et signaler les doublons potentiels afin que le triage commence avec un dossier cohérent et enrichi.
Indicateurs à surveiller : MTTA (réponse en quelques minutes, pas en quelques heures), taux de duplication, temps « Information requise ».

📖 En savoir plus : La puissance des formulaires ClickUp : rationaliser le travail des équipes logicielles
2. Triage et acheminement assistés par l'IA pour réduire considérablement le MTTA
Les corrections les plus rapides sont celles qui aboutissent immédiatement sur le bon bureau.
Utilisez des règles simples et l'IA pour classer la gravité, identifier les propriétaires potentiels par composant/zone de code et attribuer automatiquement une horloge SLA. Définissez des couloirs clairs pour les P0/P1 par rapport à tout le reste et rendez la question de la propriété sans ambiguïté.
Les automatisations permettent de définir des priorités à partir de champs, d'acheminer les tickets vers une équipe en fonction des composants, de lancer un chronomètre SLA et d'avertir un ingénieur de garde. L'IA peut proposer un niveau de gravité et un propriétaire en fonction des modèles passés. Lorsque le triage ne prend plus 30 minutes de discussion, mais seulement 2 à 5 minutes, votre MTTA diminue, tout comme votre MTTR.
Indicateurs à surveiller : MTTA, qualité de la première réponse (le premier commentaire demande-t-il les bonnes informations ?), nombre de transferts par bug.
Voici comment cela se traduit dans la pratique :
3. Hiérarchisez les priorités en fonction de l'impact commercial grâce à des niveaux de SLA explicites.
Le principe « la voix la plus forte l'emporte » rend les files d'attente imprévisibles et sape la confiance des dirigeants qui surveillent les indices CSAT/NPS et les renouvellements.
Remplacez cela par un score qui combine la gravité, la fréquence, l'ARR affecté, la criticité des fonctionnalités et la proximité des renouvellements/lancements, et appuyez-le sur des niveaux de SLA (par exemple, P0 : atténuer en 1 à 2 heures, résoudre en une journée ; P1 : le jour même ; P2 : dans un sprint).
Conservez une voie P0/P1 avec des limites de travail en cours (WIP) afin que rien ne soit négligé.
Indicateurs à surveiller : résolution P50/P90 par niveau, taux de violation des SLA, corrélation avec CSAT/NPS.
💡Conseil de pro : les champs « Priorités des tâches », « Champs personnalisés » et « Dépendances » de ClickUp vous permettent de calculer un score d'impact et de lier les bogues aux comptes, aux commentaires ou aux éléments de la feuille de route. De plus, les « Objectifs » dans ClickUp vous aident à lier le respect des SLA aux objectifs de l'entreprise, ce qui répond directement aux préoccupations des dirigeants en matière d'alignement.
4. Faites de la reproduction et du diagnostic une activité en une seule étape
Chaque boucle supplémentaire avec « pouvez-vous envoyer les journaux ? » allonge le temps de résolution.
Normalisez ce qui constitue une « bonne » pratique : champs obligatoires pour la compilation/validation, environnement, étapes de reproduction, résultats attendus par rapport aux résultats réels, ainsi que les pièces jointes pour les journaux, les vidages sur incident et les fichiers HAR. Utilisez la télémétrie client/serveur afin que les identifiants d'incident et les identifiants de requête puissent être associés aux traces.
Utilisez Sentry (ou un outil similaire) pour les traces de pile et liez ce problème directement au bug. L'IA peut lire les journaux et les traces pour proposer un domaine de défaillance probable et générer une reproduction minimale, transformant ainsi une heure d'examen visuel en quelques minutes de travail ciblé.
Stockez des guides pratiques pour les types de bugs courants afin que les ingénieurs n'aient pas à repartir de zéro.
Indicateurs à surveiller : temps passé à « attendre des informations », pourcentage reproduit dès le premier passage, taux de réouverture lié à l'absence de reproduction.
📖 En savoir plus : Comment utiliser l'IA dans le développement de logiciels (cas d'utilisation et outils)
5. Raccourcissez la boucle de révision et de test du code
Les gros PR bloquent. Optez pour des correctifs chirurgicaux, un développement basé sur le tronc et des Feature Flags afin que les corrections puissent être livrées en toute sécurité. Prédéfinissez les réviseurs en fonction de la propriété du code afin d'éviter les temps morts, et utilisez des checklists (tests mis à jour, télémétrie ajoutée, indicateur derrière un kill switch) afin de garantir la qualité.
L'automatisation doit faire passer le bug à l'état « En cours de révision » lors de l'ouverture du PR et à l'état « Résolu » lors du fait de fusionner ; l'IA peut suggérer des tests unitaires ou mettre en évidence les différences risquées afin de concentrer la révision.
Indicateurs à surveiller : temps passé en « en cours de révision », taux d'échec des modifications pour les PR de correction de bogues et latence de révision P90.
Vous pouvez utiliser les intégrations GitHub/GitLab dans ClickUp pour synchroniser le statut de vos résolutions ; les automatisations peuvent appliquer la « définition du terminé ».
📖 En savoir plus : Comment utiliser l'IA pour automatiser les tâches
6. Parallélisez la vérification et rendez l'environnement d'assurance qualité réellement homogène
La vérification ne doit pas commencer plusieurs jours plus tard ou dans un environnement qu'aucun de vos clients n'utilise.
Maintenez un niveau élevé de « préparation pour l'assurance qualité » : correctifs basés sur des indicateurs validés dans des environnements similaires à ceux de production avec des données de base correspondant aux cas signalés.
Dans la mesure du possible, configurez des environnements éphémères à partir de la branche des bogues afin que l'équipe d'assurance qualité puisse les valider immédiatement. L'IA peut ensuite générer des cas de test à partir de la description du bogue et des régressions passées.
Indicateurs à surveiller : temps passé en « QA/vérification », taux de rebond de la QA vers le développement, temps médian pour clôturer après avoir fusionné.

📖 En savoir plus : Comment rédiger des cas de test efficaces
7. Communiquez clairement le statut pour réduire les coûts de coordination
Une bonne mise à jour évite trois vérifications de statut et une escalade.
Traitez les mises à jour comme un produit : courtes, spécifiques et adaptées au public (assistance, dirigeants, clients). Établissez une cadence pour les P0/P1 (par exemple, toutes les heures jusqu'à ce que le problème soit résolu, puis toutes les quatre heures) et conservez une source unique d'informations.
L'IA peut rédiger des mises à jour sécurisées pour les clients et des résumés internes à partir de l'historique des tâches, y compris le statut en temps réel par gravité et par équipe. Pour les cadres tels que votre directeur de produit, regroupez les bogues en initiatives afin qu'ils puissent voir si du travail critique lié à la qualité menace les promesses de livraison.
Indicateurs à surveiller : temps entre les mises à jour de statut sur P0/P1, satisfaction des parties prenantes (CSAT) en matière de communication.
8. Contrôlez l'ancienneté des retards et évitez les « cas ouverts indéfiniment ».
Un backlog croissant et obsolète pèse discrètement sur chaque sprint.
Définissez des politiques de vieillissement (par exemple, P2 > 30 jours déclenche une révision, P3 > 90 jours nécessite une justification) et planifiez un « triage de vieillissement » hebdomadaire pour fusionner les doublons, fermer les rapports obsolètes et convertir les bogues de faible valeur en éléments de backlog de produit.
Utilisez l'IA pour regrouper les retards par thème (par exemple, « expiration du jeton d'authentification », « instabilité du téléchargement d'images ») afin de pouvoir planifier des semaines de correction thématiques et éliminer une catégorie de défauts en une seule fois.
Indicateurs à surveiller : nombre de retards par tranche d'âge, pourcentage de problèmes fermés comme doublons/obsolètes, vitesse de burn-down thématique.
9. Fermez la boucle avec la cause première et la prévention
Si le même type de défaut revient sans cesse, vos améliorations MTTR masquent un problème plus important.
Effectuez rapidement une analyse des causes profondes sans reproche sur les P0/P1 et les P2 à haute fréquence ; identifiez les causes profondes (lacunes dans les spécifications, les tests ou les outils, instabilité de l'intégration), associez-les aux composants et incidents concernés, et suivez les tâches de suivi (protections, tests, règles de lint) jusqu'à leur achèvement.
/IA peut rédiger des résumés RCA et proposer des tests préventifs ou des règles de lint basées sur l'historique des modifications. C'est ainsi que vous passerez de la lutte contre les incendies à une réduction du nombre d'incendies.
Indicateurs à surveiller : taux de réouverture, taux de régression, délai entre les récidives et pourcentage de RCA avec mesures de prévention achevées.

Ensemble, ces changements raccourcissent le processus de bout en bout : reconnaissance plus rapide, triage plus clair, hiérarchisation plus intelligente, moins de blocages dans la révision et l'assurance qualité, et communication plus claire. Les dirigeants bénéficient d'une prévisibilité liée au CSAT/NPS et au chiffre d'affaires ; les praticiens bénéficient d'une file d'attente plus calme avec moins de changements de contexte.
📖 En savoir plus : Comment effectuer une analyse des causes profondes
Outils d'IA qui aident à réduire le temps de résolution des bugs
L'IA peut réduire le temps de résolution à chaque étape : réception, triage, acheminement, correction et vérification.
Cependant, les véritables gains apparaissent lorsque les outils comprennent le contexte et permettent de faire avancer le travail sans intervention humaine.
Recherchez des systèmes qui enrichissent automatiquement les rapports (étapes de reproduction, environnement, doublons), hiérarchisent les priorités en fonction de l'impact, acheminent les rapports vers le bon propriétaire, rédigent des mises à jour claires et s'intègrent étroitement à votre code, à votre CI et à votre observabilité.
Les meilleurs outils d'IA prennent également en charge des flux de travail de type agent : des bots qui surveillent les SLA, relancent les réviseurs, escaladent les éléments bloqués et résument les résultats pour les parties prenantes. Voici notre sélection d'outils d'IA pour une meilleure résolution des bogues :
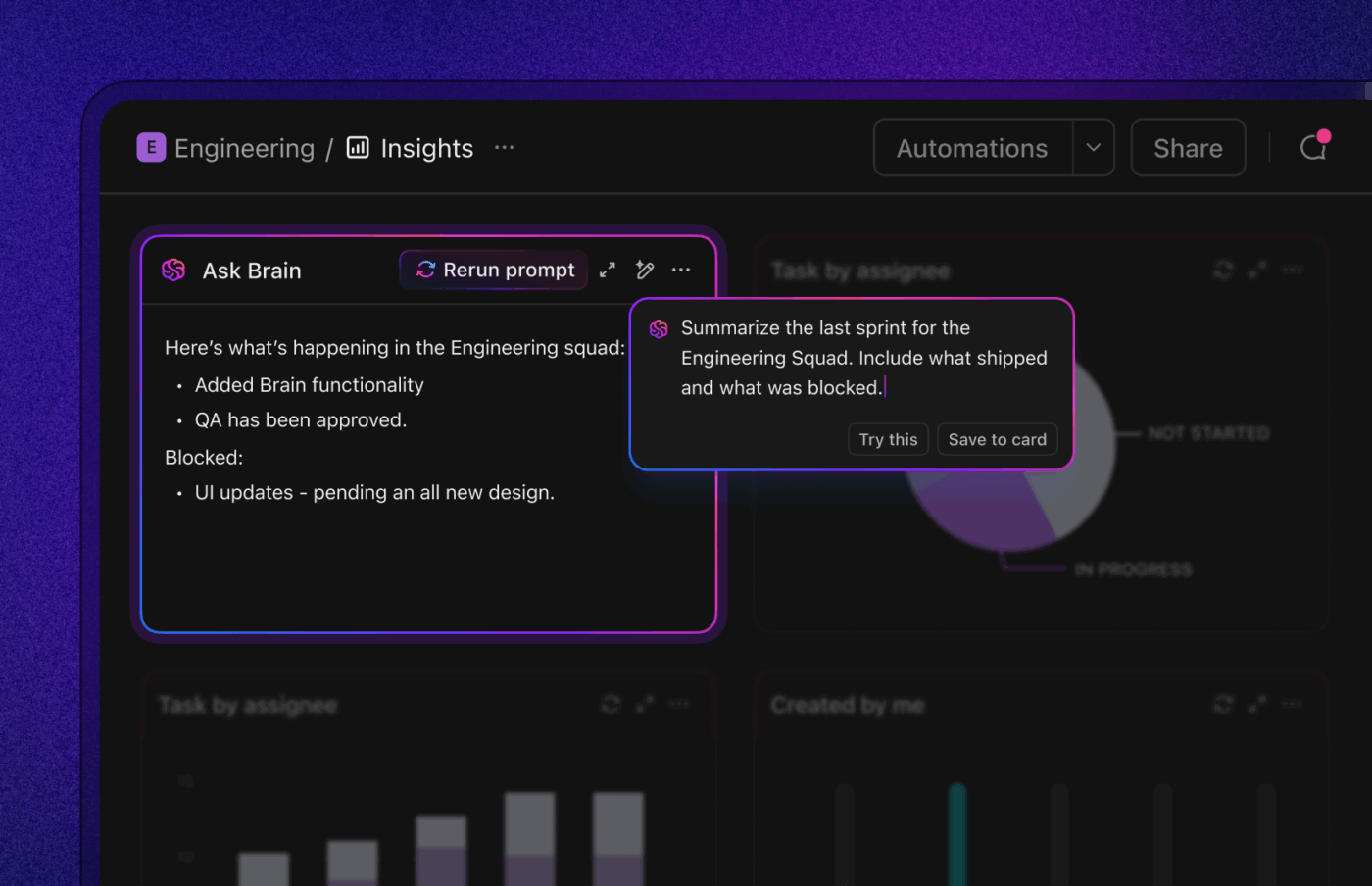
1. ClickUp (idéal pour l'IA contextuelle, les automatisations et les flux de travail agentiels)
Si vous souhaitez bénéficier d'un flux de travail rationalisé et intelligent pour la résolution des bugs, ClickUp, l'application tout-en-un pour le travail, regroupe en un seul endroit l'IA, les automatisations et l'assistance au flux de travail.
ClickUp Brain fait apparaître instantanément le contexte approprié : il résume les longs fils de discussion sur les bogues, extrait les étapes de reproduction et les détails de l'environnement à partir des pièces jointes, signale les doublons potentiels et suggère les actions à entreprendre. Au lieu de se perdre dans Slack, les tickets et les journaux, les équipes obtiennent un dossier clair et complet sur lequel elles peuvent immédiatement agir.
Les automatisations et les agents Autopilot de ClickUp permettent de faire avancer le travail sans intervention constante. Les bugs sont automatiquement acheminés vers la bonne équipe, des propriétaires sont désignés, des accords de niveau de service (SLA) et des dates d'échéance sont fixés, les statuts sont mis à jour au fur et à mesure de l'avancement des travaux et les parties prenantes reçoivent des notifications en temps opportun.

Ces agents peuvent même trier et classer les problèmes, regrouper les rapports similaires, se référer à l'historique des corrections pour suggérer des solutions possibles et escalader les éléments urgents, ce qui permet de réduire le MTTA et le MTTR même en cas de pic de volume.
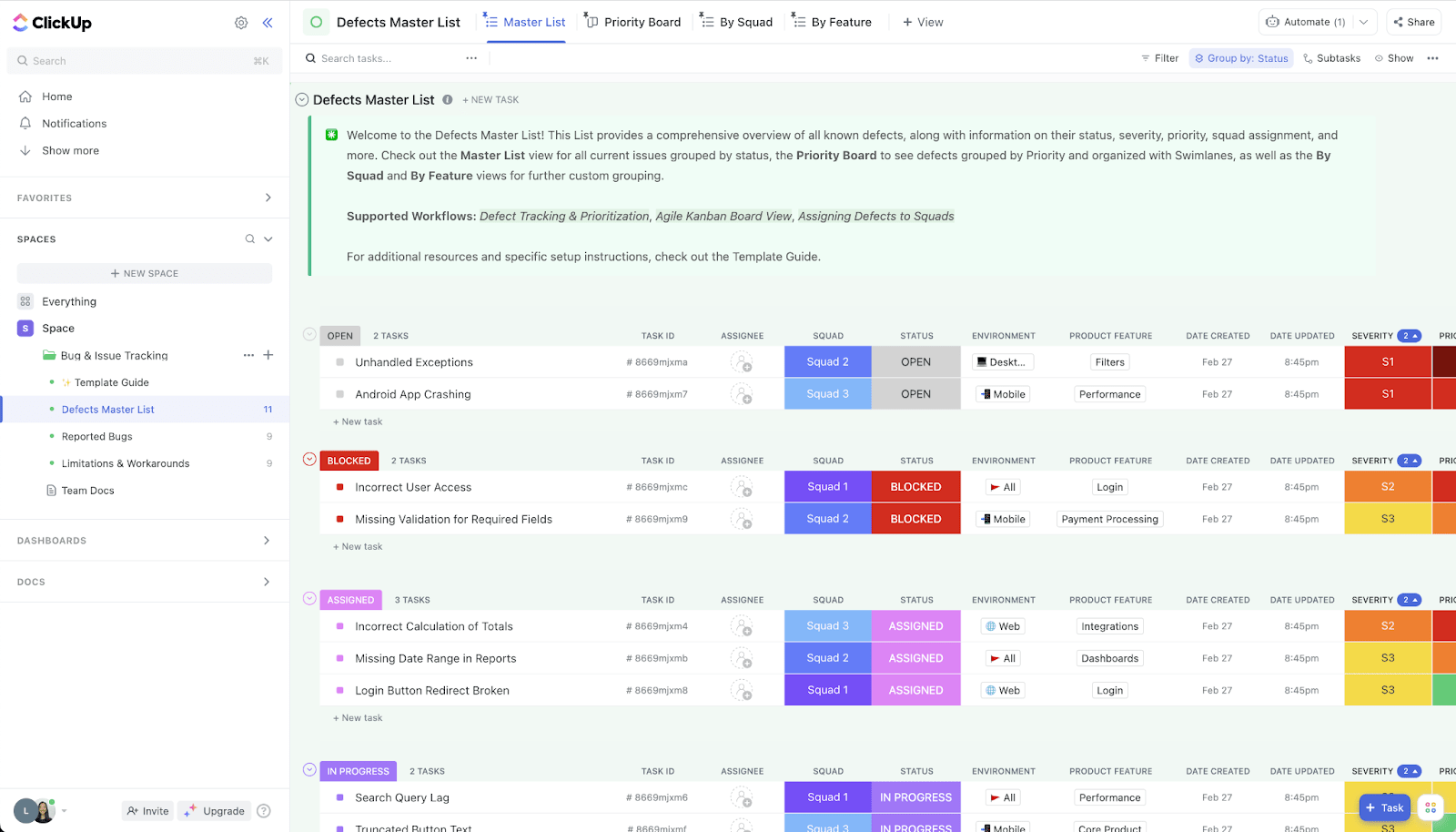
🛠️ Vous voulez un kit d'outils prêt à l'emploi ? Le modèle ClickUp Bug & Issue Tracking Template est une solution puissante de ClickUp for Software conçue pour aider les équipes d'assistance, d'ingénierie et de production à rester facilement au courant des bogues et des problèmes logiciels. Grâce à des vues personnalisables telles que Liste, Tableau, Charge de travail, Formulaire et Échéancier, les équipes peuvent visualiser et gérer leur processus de suivi des bogues de la manière qui leur convient le mieux.
Les 20 statuts personnalisés et les 7 champs personnalisés du modèle permettent de créer un flux de travail sur mesure, garantissant ainsi le suivi de chaque problème, de sa découverte à sa résolution. Les automatisations intégrées prennent en charge les tâches répétitives, libérant ainsi un temps précieux et réduisant les efforts manuels.
💟 Bonus : Brain MAX est votre assistant de bureau alimenté par l'IA, conçu pour accélérer la résolution des bugs grâce à des fonctionnalités intelligentes et pratiques.
Lorsque vous rencontrez un bug, il vous suffit d'utiliser la fonction de reconnaissance vocale de Brain MAX pour dicter le problème. Vos notes vocales sont instantanément transcrites et peuvent être jointes à un ticket de bug nouveau ou existant. Sa fonction Enterprise Search explore tous vos outils connectés, tels que ClickUp, GitHub, Google Drive et Slack, pour faire apparaître les rapports de bugs, les journaux d'erreurs, les extraits de code et la documentation associés, afin que vous disposiez de tout le contexte nécessaire sans avoir à changer d'application.
Vous avez besoin de coordonner une correction ? Brain MAX vous permet d'attribuer le bug au bon développeur, de définir des rappels automatiques pour les mises à jour de statut et de suivre la progression, le tout depuis votre bureau !
2. Sentry (idéal pour capturer les erreurs)
Sentry réduit le MTTD et le temps de reproduction en capturant les erreurs, les traces et les sessions utilisateur en un seul endroit. Le regroupement des problèmes basé sur l'IA réduit le bruit ; les règles « Suspect Commit » et de propriété identifient le propriétaire probable du code, ce qui permet un routage instantané. Session Replay fournit aux ingénieurs le chemin exact de l'utilisateur et les détails de la console/du réseau pour reproduire le problème sans aller-retour interminables.
Les fonctionnalités de Sentry IA permettent de résumer le contexte du problème et, dans certaines piles, de proposer des correctifs Autofix qui font référence au code incriminé. L'impact pratique : moins de tickets en double, une attribution plus rapide et un chemin plus court entre le signalement et le correctif fonctionnel.
3. GitHub Copilot (idéal pour réviser le code plus rapidement)
Copilot accélère le cycle de correction dans l'éditeur. Il explique les traces de pile, suggère des correctifs ciblés, écrit des tests unitaires pour verrouiller la correction et crée des scripts de reproduction.
Copilot Chat peut passer en revue le code défaillant, proposer des refactorisations plus sûres et générer des commentaires ou des descriptions PR qui accélèrent la révision du code. Associé aux révisions requises et à l'intégration continue, il réduit considérablement le temps nécessaire au « diagnostic → mise en œuvre → test », en particulier pour les bugs bien délimités et clairement reproductibles.
4. Snyk by DeepCode IA (idéal pour repérer les modèles)
L'analyse statique alimentée par l'IA de DeepCode détecte les défauts et les modèles non sécurisés pendant que vous codez et dans les PR. Elle met en évidence les flux problématiques, explique pourquoi ils se produisent et propose des corrections sécurisées adaptées à votre base de code.
En détectant les régressions avant la fusion et en guidant les développeurs vers des modèles plus sûrs, vous réduisez le taux d'apparition de nouveaux bugs et accélérez la correction des erreurs logiques complexes difficiles à repérer lors de la révision. Les intégrations IDE et PR permettent de rester proche du lieu où le travail est effectué.
5. Watchdog et AIOps de Datadog (idéal pour l'analyse des journaux)
Watchdog de Datadog utilise le ML pour mettre en évidence les anomalies dans les journaux, les indicateurs, les traces et la surveillance des utilisateurs réels. Il corrèle les pics avec les marqueurs de déploiement, les changements d'infrastructure et la topologie afin de suggérer les causes profondes probables.
Pour les défauts ayant un impact sur les clients, cela signifie une détection en quelques minutes, un regroupement automatique pour réduire le bruit des alertes et des pistes concrètes sur les endroits à examiner. Le temps de triage diminue, car vous commencez par « ce déploiement a touché ces services et les taux d'erreur ont augmenté sur ce point de terminaison » au lieu de partir de zéro.
⚡️ Archive de modèles : Modèles gratuits de suivi des problèmes et de journaux dans Excel et ClickUp
6. New Relic IA (idéal pour identifier et résumer les tendances)
La boîte de réception des erreurs de New Relic regroupe les erreurs similaires entre les services et les versions, tandis que son assistant IA résume l'impact, met en évidence les causes probables et lie les traces/transactions concernées.
Les corrélations de déploiement et l'intelligence des changements d'entité permettent de déterminer clairement si une version récente est en cause. Pour les systèmes distribués, ce contexte réduit de plusieurs heures les échanges entre les équipes et permet de transmettre le bug au bon propriétaire avec une hypothèse solide déjà formulée.
7. Rollbar (idéal pour les flux de travail d’automatisation)
Rollbar est spécialisé dans la surveillance des erreurs en temps réel grâce à un système intelligent d'empreintes digitales qui regroupe les doublons et suit les tendances d'occurrence. Ses résumés basés sur l'IA et ses indications sur les causes profondes aident les équipes à comprendre l'étendue du problème (utilisateurs affectés, versions concernées), tandis que la télémétrie et les traces de pile fournissent des indices rapides pour reproduire le problème.
Les règles de flux de travail de Rollbar permettent de créer automatiquement des tâches, d'attribuer des niveaux de gravité et de les acheminer vers les propriétaires, transformant ainsi les flux d'erreurs bruyants en files d'attente prioritaires accompagnées de leur contexte.
8. PagerDuty AIOps et automatisation des runbooks (le meilleur des diagnostics à faible intervention)
PagerDuty utilise la corrélation des évènements et la réduction du bruit basée sur le ML pour regrouper les alertes en incidents exploitables.
Le routage dynamique achemine instantanément le problème vers la personne d'astreinte appropriée, tandis que l'automatisation des runbooks permet de lancer des diagnostics ou des mesures d'atténuation (redémarrer les services, revenir en arrière sur un déploiement, activer/désactiver un indicateur de fonctionnalité) avant qu'un humain n'intervienne. En termes de temps de résolution des bogues, cela se traduit par un MTTA plus court, des mesures d'atténuation plus rapides pour les P0 et moins d'heures perdues à cause de la fatigue liée aux alertes.
Le fil conducteur est l'automatisation et l'IA à chaque étape. Vous détectez plus tôt, acheminer plus intelligemment, arrivez plus rapidement au code et communiquez le statut sans ralentir les ingénieurs, ce qui se traduit par une réduction significative du temps de résolution des bugs.
📖 En savoir plus : Comment utiliser l'IA dans DevOps
Exemples concrets d'utilisation de l'IA pour la résolution des bugs
L'IA est donc officiellement sortie des laboratoires. Elle réduit le temps de résolution des bugs dans la pratique.
Voyons comment !
| Domaine / Organisation | Comment l'IA a été utilisée | Impact / Avantage |
|---|---|---|
| Ubisoft | Développement de Commit Assistant, un outil d'IA formé sur une décennie de code interne, qui prédit et prévient les bugs à l'étape de codage. | L'objectif est de réduire considérablement le temps et les coûts : jusqu'à 70 % des dépenses liées au développement de jeux vidéo sont traditionnellement consacrées à la correction des bugs. |
| Razer (plateforme Wyvrn) | Lancement de QA Copilot (intégré à Unreal et Unity), un outil basé sur l'IA qui automatise la détection des bugs et génère des rapports d'assurance qualité. | Améliorez la détection des bugs jusqu'à 25 % et réduisez de moitié le temps consacré à l'assurance qualité. |
| Google / DeepMind & Project Zero | Lancement de Big Sleep, un outil d'IA qui détecte de manière autonome les failles de sécurité dans les logiciels open source tels que FFmpeg et ImageMagick. | Identification de 20 bugs, tous vérifiés par des experts humains et devant faire l'objet d'un correctif. |
| Chercheurs de l'université de Berkeley | À l'aide d'un benchmark appelé CyberGym, des modèles d'IA ont analysé 188 projets open source, découvrant 17 vulnérabilités, dont 15 bogues « zero-day » inconnus, et générant des exploits de preuve de concept. | Démontre les capacités évolutives de l'IA en matière de détection des vulnérabilités et de révision automatisée des exploits. |
| Spur (start-up de Yale) | Développement d'un agent IA qui traduit les descriptions de cas de test en langage clair en routines de test automatisées de sites Web, ce qui revient en fait à un flux de travail d'assurance qualité auto-généré. | Permet des tests autonomes avec un minimum d'intervention humaine. |
| Reproduction automatique des rapports de bugs Android | Utilisation du NLP + apprentissage par renforcement pour interpréter le langage des rapports de bogues et générer des étapes permettant de reproduire les bogues Android. | Nous avons atteint une précision de 67 %, un taux de rappel de 77 % et reproduit 74 % des rapports de bogues, surpassant ainsi les méthodes traditionnelles. |
Erreurs courantes dans la mesure du temps de résolution des bugs
Si vos mesures sont erronées, votre plan d'amélioration le sera également.
La plupart des « mauvais nombres » dans les flux de travail de résolution des bugs proviennent de définitions vagues, de flux de travail incohérents et d'analyses superficielles.
Commencez donc par les bases : ce qui compte comme démarrage/arrêt, comment vous gérez les attentes et les réouvertures, puis lisez les données telles que vos clients les perçoivent. Cela inclut :
❌ Limites floues : mélanger les statuts « Signalé → Résolu » et « Signalé → Fermé » dans le même tableau de bord (ou passer d'un mois à l'autre) rend les tendances insignifiantes. Choisissez une limite, documentez-la et appliquez-la à toutes les équipes. Si vous avez besoin des deux, publiez-les sous forme d'indicateurs distincts avec des libellés clairs.
❌ Approche basée uniquement sur les moyennes : se fier à la moyenne masque la réalité des files d'attente comportant quelques cas particuliers de longue durée. Utilisez la médiane (P50) pour votre temps « typique », P90 pour la prévisibilité/les SLA, et conservez la moyenne pour la planification des capacités. Regardez toujours la distribution, pas seulement un nombre.
❌ Pas de segmentation : regrouper tous les bugs mélange les incidents P0 avec les incidents P3 cosmétiques. Segmentez par gravité, source (client vs. assurance qualité vs. surveillance), composant/équipe et « nouveau vs. régression ». Votre P0/P1 P90 correspond à ce que ressentent les parties prenantes ; votre médiane P2+ correspond à ce sur quoi s'appuient les plans d'ingénierie.
❌ Ignorer le temps « en pause » : Vous attendez les journaux des clients, un fournisseur externe ou une fenêtre de lancement ? Si vous ne suivez pas les statuts « Bloqué »/« En pause » comme des statuts de première classe, votre temps de résolution devient un argument. Signalez à la fois le temps calendaire et le temps actif afin que les goulots d'étranglement soient visibles et que les débats cessent.
❌ Écarts de normalisation du temps : le mélange des fuseaux horaires ou le passage entre les heures ouvrables et les heures calendaires en cours de route fausse les comparaisons. Normalisez les horodatages sur un seul fuseau horaire (ou UTC) et décidez une fois pour toutes si les SLA sont mesurés en heures ouvrables ou en heures calendaires ; appliquez cette décision de manière cohérente.
❌ Données d'entrée erronées et doublons : les informations manquantes sur l'environnement/la version et les tickets en double allongent les délais et brouillent la propriété. Standardisez les champs obligatoires lors de la saisie, enrichissez automatiquement les données (journaux, version, appareil) et supprimez les doublons sans réinitialiser le délai. Clôturez les doublons en tant que problèmes liés, et non comme de « nouveaux » problèmes.
❌ Modèles de statut incohérents : les statuts personnalisés (« QA Ready-ish », « Pending Review 2 ») masquent le temps passé dans chaque statut et rendent les transitions d'état peu fiables. Définissez un flux de travail canonique (Nouveau → Trié → En cours → En révision → Résolu → Fermé) et vérifiez les états hors chemin.
❌ Ignorer le temps passé dans chaque statut : un simple nombre correspondant au « temps total » ne vous permet pas de savoir où le travail est bloqué. Enregistrez et examinez le temps passé dans les statuts « Trié », « En cours d'examen », « Bloqué » et « Assurance qualité ». Si l'examen du code P90 éclipse la mise en œuvre, votre solution n'est pas de « coder plus vite », mais de débloquer la capacité d'examen.
🧠 Anecdote : Le dernier Cyber Challenge de la DARPA a mis en évidence une avancée révolutionnaire dans l'automatisation de la cybersécurité. Le concours mettait en scène des systèmes d'IA conçus pour détecter, exploiter et corriger de manière autonome les vulnérabilités des logiciels, sans intervention humaine. L'équipe gagnante, « Team Atlanta », a découvert de manière impressionnante 77 % des bugs injectés et a réussi à en corriger 61 %, démontrant ainsi la puissance de l'IA non seulement pour trouver les failles, mais aussi pour les corriger activement.
❌ Reopen blindness : traiter les réouvertures comme de nouveaux bugs réinitialise le compte à rebours et flatte le MTTR. Suivez le taux de réouverture et le « temps nécessaire à la clôture définitive » (depuis le premier rapport jusqu'à la clôture définitive, tous cycles confondus). Une augmentation des réouvertures indique généralement une reproduction faible, des lacunes dans les tests ou une définition vague de la notion de « terminé ».
❌ Pas de MTTA : les équipes se focalisent sur le MTTR et ignorent le MTTA (temps de reconnaissance/prise en charge). Un MTTA élevé est un avertissement concernant une résolution longue. Mesurez-le, définissez des SLA en fonction de la gravité et effectuez l'automatisation du routage/de l'escalade pour le maintenir à un niveau bas.
❌ IA/automatisation sans garde-fous : laisser l'IA définir la gravité ou fermer les doublons sans vérification peut entraîner une classification erronée des cas limites et fausser les indicateurs. Utilisez l'IA pour les suggestions, exigez une confirmation humaine pour les cas P0/P1 et vérifiez mensuellement les performances du modèle afin que vos données restent fiables.
Renforcez ces maillons et vos diagrammes de temps de résolution refléteront enfin la réalité. À partir de là, les améliorations s'accumulent : une meilleure prise en charge réduit le MTTA, des états plus clairs révèlent les véritables goulots d'étranglement et les P90 segmentés donnent aux dirigeants des promesses que vous pouvez tenir.
⚡️ Archive de modèles : 10 modèles de cas de test pour les tests logiciels
Bonnes pratiques pour une meilleure résolution des bugs
En résumé, voici les points essentiels à retenir !
| 🧩 Bonnes pratiques | 💡 Ce que cela signifie | 🚀 Pourquoi est-ce important ? |
| Utilisez un système de suivi des bugs robuste | Suivez tous les bugs signalés à l'aide d'un système centralisé de suivi des bugs. | Garantit qu'aucun bug n'est perdu et permet une visibilité du statut des bugs dans toutes les équipes. |
| Rédigez des rapports détaillés sur les bugs | Incluez le contexte visuel, les informations sur le système d'exploitation, les étapes de reproduction et la gravité. | Aidez les développeurs à corriger les bugs plus rapidement en leur fournissant toutes les informations essentielles dès le départ. |
| Catégorisez et hiérarchisez les bugs | Utilisez une matrice de priorités pour trier les bugs en fonction de leur urgence et de leur impact. | Permet à l'équipe de se concentrer en priorité sur les bugs critiques et les problèmes urgents. |
| Tirez parti des tests automatisés | Exécutez automatiquement des tests dans votre pipeline CI/CD. | Offre d'assistance pour une détection précoce et la prévention des régressions. |
| Définissez des directives claires en matière de rapports | Fournissez des modèles et des formations sur la manière de préparer les rapports sur les bugs. | Cela permet d'obtenir des informations précises et une communication plus fluide. |
| Suivez les indicateurs clés | Mesurez le temps de résolution, le temps écoulé et le temps de réponse. | Permet le suivi et l'amélioration des performances à l'aide de données historiques. |
| Adoptez une approche proactive | N'attendez pas que les utilisateurs se plaignent, testez de manière proactive. | Augmentez la satisfaction client et réduisez la charge d'assistance. |
| Tirez parti des outils intelligents et du ML | Utilisez l'apprentissage automatique pour prédire les bugs et suggérer des corrections. | Améliore l'efficacité dans l'identification des causes profondes et la correction des bugs. |
| Alignez-vous sur les SLA | Réalisez les réunions pour respecter les accords de niveau de service convenus pour la résolution. | Renforcez la confiance et répondez aux attentes des clients en temps opportun. |
| Réviser et améliorer en permanence | Analysez les bugs réouverts, recueillez des commentaires et modifiez les processus. | Favorise l'amélioration continue de votre processus de développement et de la gestion des bugs. |
Résolution simplifiée des bugs grâce à l'IA contextuelle
Les équipes les plus rapides en matière de résolution des bogues ne comptent pas sur des exploits héroïques. Elles conçoivent un système : des définitions claires du début et de la fin, une prise en charge propre, une hiérarchisation en fonction de l'impact sur l'activité, une propriété claire et des boucles de rétroaction étroites entre le support, l'assurance qualité, l'ingénierie et la mise en production.
ClickUp peut être le centre de commande alimenté par l'IA de votre système de résolution des bogues. Centralisez tous les rapports dans une seule file d'attente, standardisez le contexte à l'aide de champs structurés et laissez l'IA de ClickUp trier, résumer et hiérarchiser les tâches, tandis que les automatisations appliquent les accords de niveau de service, signalent les retards et maintiennent la coordination entre les parties prenantes. Associez les bogues aux clients, au code et aux versions afin que les dirigeants puissent voir l'impact et que les praticiens restent dans le flux.
Si vous êtes prêt à réduire le temps de résolution des bugs et à rendre votre feuille de route plus prévisible, inscrivez-vous à ClickUp et commencez à mesurer l'amélioration en quelques jours, et non en trimestres.
Foire aux questions
Quel est un bon temps de résolution des bugs ?
Il n'existe pas de nombre « idéal » : tout dépend de la gravité, du modèle de publication et de la tolérance au risque. Utilisez les médianes (P50) pour les performances « typiques » et P90 pour les promesses/SLA, puis segmentez par gravité et source.
Quelle est la différence entre la résolution d'un bug et sa clôture ?
La résolution intervient lorsque la correction est mise en œuvre (par exemple, code fusionné, configuration appliquée) et que l'équipe considère que le défaut est corrigé. La clôture intervient lorsque le problème est vérifié et officiellement résolu (par exemple, validation QA dans l'environnement cible, publication ou marquage « ne corrigeras pas/duplicata » avec justification). De nombreuses équipes mesurent les deux : Signalé→Résolu reflète la vitesse d'ingénierie ; Signalé→Fermé reflète le flux de qualité de bout en bout. Utilisez des définitions cohérentes afin que les tableaux de bord ne mélangent pas les étapes.
Quelle est la différence entre le temps de résolution des bugs et le temps de détection des bugs ?
Le temps de détection (MTTD) correspond au temps nécessaire pour découvrir un défaut après son apparition ou sa livraison, via la surveillance, l'assurance qualité ou les utilisateurs. Le temps de résolution correspond au temps nécessaire entre la détection/le signalement et la mise en œuvre de la correction (et, si vous préférez, sa validation/sa publication). Ensemble, ils définissent la fenêtre d'impact sur le client : détecter rapidement, reconnaître rapidement, résoudre rapidement et publier en toute sécurité. Vous pouvez également suivre le MTTA (temps de reconnaissance/d'attribution) pour repérer les retards de triage qui annoncent souvent une résolution plus longue.
Comment l'IA aide-t-elle à résoudre les bugs ?
/IA compresse les boucles qui ralentissent généralement le processus : réception, triage, diagnostic, correction et vérification.
- Réception et triage : résume automatiquement les longs rapports, extrait les étapes de reproduction/l'environnement, signale les doublons et suggère le niveau de gravité/la priorité afin que les ingénieurs puissent commencer avec un contexte clair (par exemple, ClickUp AI, Sentry IA).
- Routage et SLA : prédit le composant/propriétaire probable, définit des chronomètres et escalade lorsque le MTTA ou les délais d'examen dépassent les limites, réduisant ainsi le « temps d'attente » inactif (automatisations ClickUp et flux de travail de type agent).
- Diagnostic : regroupe les erreurs similaires, établit une corrélation entre les pics et les validations/versions récents, et indique les causes profondes probables à l'aide de traces de pile et du contexte du code (Sentry IA et similaires).
- Mise en œuvre : suggère des modifications de code et des tests basés sur les modèles de votre référentiel, accélérant ainsi la boucle « écriture/correction » (GitHub Copilot ; Snyk Code IA par DeepCode).
- Vérification et communication : rédige des cas de test à partir des étapes de reproduction, rédige des notes de mise à jour et des mises à jour pour les parties prenantes, et résume le statut pour les dirigeants et les clients (ClickUp AI). Utilisés ensemble — ClickUp comme centre de commande avec Sentry/Copilot/DeepCode dans la pile — les équipes réduisent les temps MTTA/P90 sans avoir recours à des mesures héroïques.