
Você lança a atualização de software mais recente e os relatórios começam a chegar.
De repente, uma métrica passa a governar tudo, desde CSAT/NPS até atrasos no roadmap: o tempo de resolução de bugs.
Os executivos veem isso como uma métrica de cumprimento de promessas: podemos entregar, aprender e proteger a receita dentro do prazo? Os profissionais sentem o peso disso na prática: tickets duplicados, responsabilidades pouco claras, escalações confusas e contexto espalhado pelo Slack, planilhas e ferramentas separadas.
Essa fragmentação prolonga os ciclos, oculta as causas principais e transforma a priorização em adivinhação.
O resultado? Aprendizado mais lento, compromissos não cumpridos e um acúmulo de tarefas que sobrecarrega silenciosamente cada sprint.
Este guia é o seu manual completo para medir, comparar e reduzir o tempo de resolução de bugs, mostrando, de forma concreta, como a IA muda o fluxo de trabalho em comparação com os processos manuais tradicionais.
O que é o tempo de resolução de bugs?
O tempo de resolução de bugs é o tempo necessário para corrigir um bug, medido desde o momento em que o bug é relatado até que seja totalmente resolvido.
Na prática, o relógio começa a contar quando um problema é relatado ou detectado (por usuários, controle de qualidade ou monitoramento) e para quando a correção é implementada e mesclada, pronta para verificação ou lançamento, dependendo de como sua equipe define “concluído”.
Exemplo: uma falha P1 relatada às 10h da manhã de segunda-feira, com uma correção incorporada às 15h da terça-feira, tem um tempo de resolução de aproximadamente 29 horas.
Não é o mesmo que o tempo de detecção de bugs. O tempo de detecção mede a rapidez com que você reconhece um defeito após ele ocorrer (disparo de alarmes, ferramentas de teste de controle de qualidade que o encontram, clientes que o relatam).
O tempo de resolução mede a rapidez com que você passa da identificação à correção — triagem, reprodução, diagnóstico, implementação, revisão, teste e preparação para lançamento. Pense na detecção como “sabemos que está com defeito” e na resolução como “está consertado e pronto”.
As equipes utilizam limites ligeiramente diferentes; escolha um e seja consistente para que suas tendências sejam reais:
- Relatado → Resolvido: Termina quando a correção do código é mesclada e está pronta para o controle de qualidade. Bom para o rendimento da engenharia.
- Relatado → Fechado: Inclui validação de controle de qualidade e lançamento. Ideal para SLAs que afetam o cliente.
- Detectado → Resolvido: Começa quando o monitoramento/QA detecta o problema, mesmo antes da existência de um ticket. Útil para equipes com grande volume de produção.
🧠 Curiosidade: Um bug peculiar, mas hilário, no Final Fantasy XIV ganhou elogios por ser tão específico que os leitores o apelidaram de “A correção de bug mais específica em um MMO 2025”. Ele se manifestava quando os jogadores precificavam itens entre exatamente 44.442 gil e 49.087 gil em uma zona de evento específica, causando desconexões devido ao que poderia ser uma falha de estouro de inteiro.
Por que isso é importante
O tempo de resolução é uma alavanca da cadência de lançamento. Tempos longos ou imprevisíveis forçam cortes de escopo, hotfixes e congelamentos de lançamento; eles criam dívidas de planejamento porque a cauda longa (outliers) atrapalha os sprints mais do que a média sugere.
Isso também está diretamente ligado à satisfação do cliente. Os clientes toleram problemas quando eles são reconhecidos rapidamente e resolvidos de maneira previsível. Correções lentas — ou pior, correções variáveis — geram escalações, prejudicam o CSAT/NPS e colocam as renovações em risco.
Em resumo, se você medir o tempo de resolução de bugs de forma clara e sistemática e reduzi-lo, seus planos e relacionamentos melhorarão.
Como medir o tempo de resolução de bugs?
Primeiro, decida onde seu relógio começa e para.
A maioria das equipes escolhe entre Relatado → Resolvido (a correção foi mesclada e está pronta para verificação) ou Relatado → Fechado (o controle de qualidade validou e a alteração foi lançada ou fechada).
Escolha uma definição e use-a de forma consistente para que suas tendências sejam significativas.
Agora você precisa de algumas métricas observáveis. Vamos descrevê-las:
Principais métricas de rastreamento de bugs a serem observadas:
| 📊 Métrica | 📌 O que isso significa | 💡 Como isso ajuda | 🧮 Fórmula (se aplicável) |
|---|---|---|---|
| Contagem de bugs 🐞 | Número total de bugs relatados | Oferece uma visão geral da integridade do sistema. Número alto? É hora de investigar. | Total de bugs = Todos os bugs registrados no sistema {Abertos + Fechados} |
| Bugs abertos 🚧 | Erros que ainda não foram corrigidos | Mostra a carga de trabalho atual. Ajuda na priorização. | Erros abertos = Total de erros - Erros fechados |
| Erros fechados ✅ | Erros resolvidos e verificados | Acompanha o progresso e o trabalho realizado. | Erros fechados = Contagem de erros com status “Fechado” ou “Resolvido” |
| Gravidade do bug 🔥 | Criticidade do bug (por exemplo, crítico, grave, menor) | Ajuda na triagem com base no impacto. | Rastreado como campo categórico, sem fórmula. Use filtros/agrupamento. |
| Prioridade do bug 📅 | Qual é a urgência da correção de um bug? | Ajuda no planejamento de sprints e lançamentos. | Também é um campo categórico, normalmente classificado (por exemplo, P0, P1, P2). |
| Tempo para resolver ⏱️ | Tempo entre o relatório do bug e a correção | Mede a capacidade de resposta. | Tempo para resolver = data de encerramento - data de relatório |
| Taxa de reabertura 🔄 | % de bugs reabertos após serem fechados | Reflete a qualidade da correção ou problemas de regressão. | Taxa de reabertura (%) = {Erros reabertos ÷ Total de erros fechados} × 100 |
| Vazamento de bugs 🕳️ | Erros que passaram despercebidos na produção | Indica a eficácia do controle de qualidade/teste de software. | Taxa de vazamento (%) = {Erros de produção ÷ Total de erros} × 100 |
| Densidade de defeitos 🧮 | Erros por unidade de tamanho do código | Destaca áreas de código propensas a riscos. | Densidade de defeitos = Número de bugs ÷ KLOC {Kilo Lines of Code} |
| Erros atribuídos vs. não atribuídos 👥 | Distribuição de bugs por propriedade | Garanta que nada seja esquecido. | Use um filtro: Não atribuído = Bugs em que “Atribuído a” está nulo |
| Idade dos bugs abertos 🧓 | Por quanto tempo um bug permanece sem solução | Identifica riscos de estagnação e atrasos. | Idade do bug = data atual - data em que foi relatado |
| Erros duplicados 🧬 | Número de relatórios duplicados | Destaca erros nos processos de admissão. | Taxa de duplicidade = Duplicatas ÷ Total de bugs × 100 |
| MTTD (Tempo médio para detecção) 🔎 | Tempo médio necessário para detectar bugs ou incidentes | Mede a eficiência do monitoramento e da conscientização. | MTTD = Σ(Tempo detectado - Tempo introduzido) ÷ Número de bugs |
| MTTR (Tempo médio de resolução) 🔧 | Tempo médio para corrigir totalmente um bug após a detecção | Acompanha a capacidade de resposta da engenharia e o tempo de correção. | MTTR = Σ(Tempo resolvido - Tempo detectado) ÷ Número de bugs resolvidos |
| MTTA (Tempo médio para reconhecimento) 📬 | Tempo desde a detecção até alguém começar a trabalhar no bug | Mostra a reatividade da equipe e a capacidade de resposta a alertas. | MTTA = Σ(Tempo reconhecido - Tempo detectado) ÷ Número de bugs |
| MTBF (Tempo médio entre falhas) 🔁 | Tempo entre uma falha resolvida e a próxima ocorrência | Indica estabilidade ao longo do tempo. | MTBF = Tempo total de atividade ÷ Número de falhas |
⚡️ Arquivo de modelos: 15 modelos e formulários gratuitos de relatório de bugs para rastreamento de bugs
Fatores que afetam o tempo de resolução de bugs
O tempo de resolução é frequentemente equiparado à “velocidade com que os engenheiros programam”.
Mas isso é apenas uma parte do processo.
O tempo de resolução de bugs é a soma da qualidade na entrada, da eficiência do fluxo pelo sistema e do risco de dependência. Quando qualquer um desses fatores falha, o tempo de ciclo se prolonga, a previsibilidade diminui e as escaladas se tornam mais intensas.
A qualidade da admissão define o tom
Relatórios que chegam sem etapas claras de reprodução, detalhes do ambiente, registros ou informações de versão/compilação exigem mais idas e vindas. Relatórios duplicados de vários canais (suporte, controle de qualidade, monitoramento, Slack) adicionam ruído e fragmentam a responsabilidade.
Quanto mais cedo você capturar o contexto certo — e eliminar duplicatas —, menos transferências e esclarecimentos serão necessários posteriormente.
A priorização e o encaminhamento determinam quem trata do bug e quando.
Rótulos de gravidade que não correspondem ao impacto no cliente/negócio (ou que mudam com o tempo) causam agitação na fila: os tickets mais urgentes passam à frente, enquanto os defeitos de alto impacto ficam parados.
Regras de roteamento claras por componente/proprietário e uma única fila de verdade impedem que o trabalho P0/P1 seja enterrado sob “recente e barulhento”.
A responsabilidade e as transferências são assassinos silenciosos
Se não estiver claro se um bug pertence à equipe móvel, de autenticação de back-end ou de plataforma, ele é rejeitado. Cada rejeição redefine o contexto.
Os fusos horários agravam essa situação: um bug relatado no final do dia sem um responsável designado pode perder de 12 a 24 horas antes que alguém comece a reproduzi-lo. Definições rígidas de “quem é responsável por quê”, com um DRI de plantão ou semanal, eliminam esse atraso.
A reprodutibilidade depende da observabilidade
Logs esparsos, IDs de correlação ausentes ou falta de rastreamentos de falhas transformam o diagnóstico em suposições. Bugs que só aparecem com sinalizadores, locatários ou formatos de dados específicos são difíceis de reproduzir no desenvolvimento.
Se os engenheiros não conseguem acessar com segurança dados sanitizados semelhantes aos de produção, eles acabam instrumentando, reimplantando e esperando — dias em vez de horas.
A paridade do ambiente e dos dados mantém você honesto
“Funciona na minha máquina” geralmente significa “os dados de produção são diferentes”. Quanto mais seu desenvolvimento/staging divergir da produção (configuração, serviços, versões de terceiros), mais tempo você gastará perseguindo fantasmas. Instantâneos de dados seguros, scripts de semente e verificações de paridade reduzem essa lacuna.
O trabalho em andamento (WIP) e o foco impulsionam o rendimento real
Equipes sobrecarregadas lidam com muitos bugs ao mesmo tempo, fragmentam sua atenção e se dividem entre tarefas e reuniões. A mudança de contexto adiciona horas invisíveis.
Um limite visível de trabalho em andamento e uma tendência para concluir o que foi iniciado antes de iniciar um novo trabalho reduzirão sua mediana mais rapidamente do que qualquer esforço individual.
A revisão de código, a integração contínua (CI) e a velocidade da garantia de qualidade (QA) são gargalos clássicos.
Tempos de compilação lentos, testes instáveis e SLAs de revisão pouco claros atrasam correções que, de outra forma, seriam rápidas. Um patch de 10 minutos pode levar dois dias à espera de um revisor ou ficar preso em um pipeline que leva horas.
Da mesma forma, filas de controle de qualidade que agrupam testes ou dependem de testes manuais podem adicionar dias inteiros ao processo de “Relatado → Fechado”, mesmo quando o processo de “Relatado → Resolvido” é rápido.
As dependências aumentam as filas
Alterações entre equipes (esquema, migrações de plataforma, atualizações de SDK), bugs de fornecedores ou revisões da loja de aplicativos (dispositivos móveis) geram estados de espera. Sem um rastreamento explícito de “Bloqueado/Pausado”, essas esperas inflacionam invisivelmente suas médias e ocultam onde está o verdadeiro gargalo.
O modelo de lançamento e a estratégia de reversão são importantes
Se você faz lançamentos em grandes lotes com portas manuais, mesmo os bugs resolvidos ficam parados até o próximo lançamento. Sinalizadores de recursos, lançamentos canários e faixas de hotfixes reduzem o tempo de espera, especialmente para incidentes P0/P1, permitindo que você separe a implantação da correção dos ciclos completos de lançamento.
A arquitetura e a dívida tecnológica definem seu limite máximo
O acoplamento rígido, a falta de costuras de teste e os módulos legados opacos tornam as correções simples arriscadas. As equipes compensam com testes extras e revisões mais longas, o que prolonga os ciclos. Por outro lado, o código modular com bons testes de contrato permite que você avance rapidamente sem danificar os sistemas adjacentes.
A comunicação e a higiene do status influenciam a previsibilidade
Atualizações vagas (“estamos analisando”) geram retrabalho quando as partes interessadas solicitam estimativas de tempo de conclusão, o suporte reabre tickets ou o produto é escalado. Transições de status claras, notas sobre reprodução e causa raiz e uma estimativa de tempo de conclusão publicada reduzem a rotatividade e protegem o foco da sua equipe de engenharia.
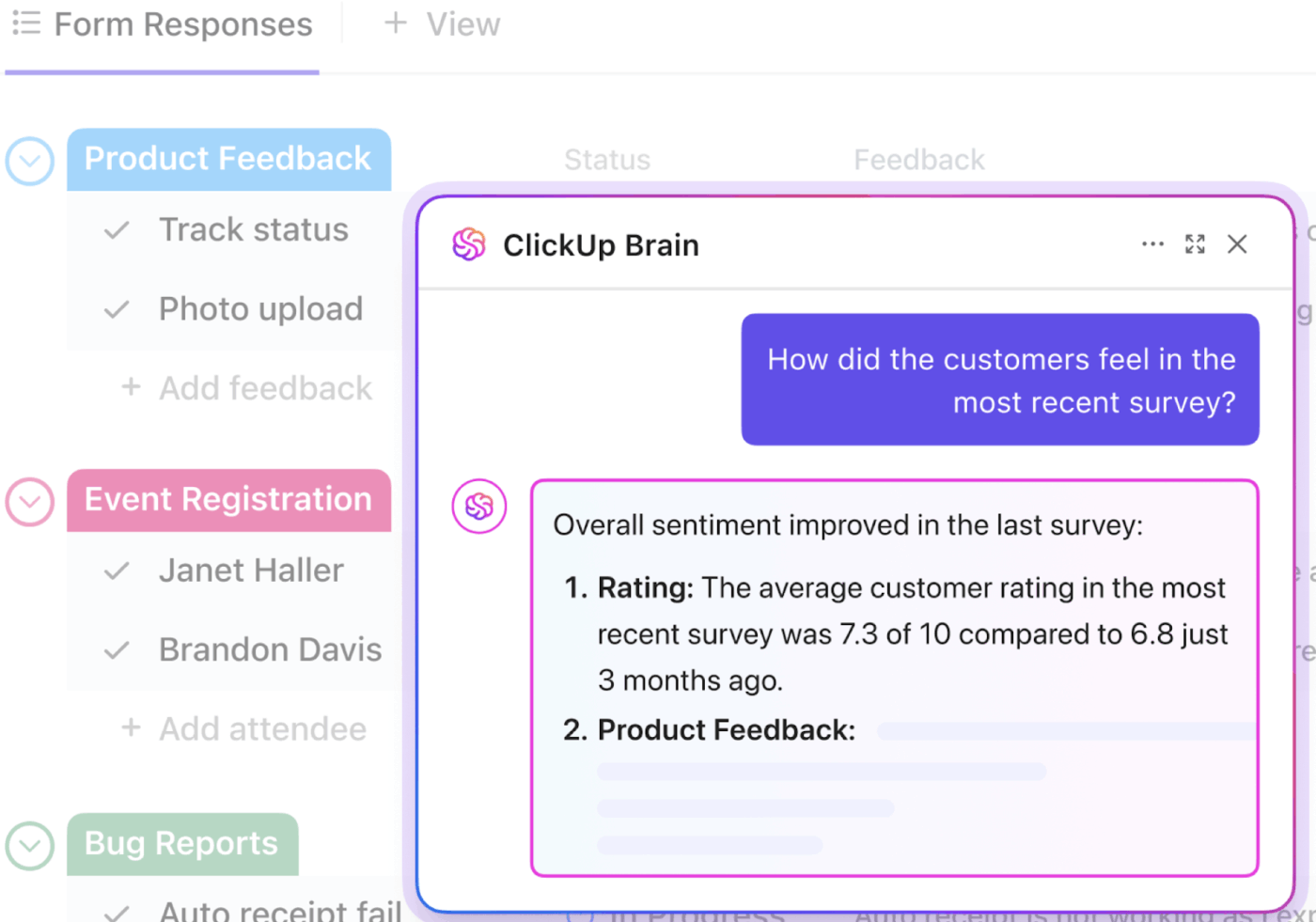
📮ClickUp Insight: O profissional médio passa mais de 30 minutos por dia procurando informações relacionadas ao trabalho — isso significa mais de 120 horas por ano perdidas vasculhando e-mails, threads do Slack e arquivos espalhados.
Um assistente de IA inteligente integrado ao seu espaço de trabalho pode mudar isso. Conheça o ClickUp Brain. Ele fornece insights e respostas instantâneas, exibindo os documentos, conversas e detalhes de tarefas certos em segundos — para que você possa parar de pesquisar e começar a trabalhar.
💫 Resultados reais: Equipes como a QubicaAMF recuperaram mais de 5 horas por semana usando o ClickUp — o que representa mais de 250 horas por ano por pessoa — ao eliminar processos desatualizados de gerenciamento de conhecimento. Imagine o que sua equipe poderia criar com uma semana extra de produtividade a cada trimestre!
Indicadores principais de que seu tempo de resolução será prolongado
❗️Aumento do “tempo de reconhecimento” e muitos tickets sem proprietário por mais de 12 horas
❗️Aumento das fatias “Tempo em revisão/CI” e instabilidade frequente dos testes
❗️Alta taxa de duplicidade na admissão e rótulos de gravidade inconsistentes entre as equipes
❗️Vários bugs permanecem em “Bloqueado” sem uma dependência externa nomeada
❗️Taxa de reabertura aumentando (correções não são reproduzíveis ou as definições de conclusão são vagas)
Diferentes organizações percebem esses fatores de maneiras diferentes. Os executivos os veem como ciclos de aprendizado perdidos e perdas de receita; os operadores os veem como ruído de triagem e responsabilidades pouco claras.
Ajustar a entrada, o fluxo e as dependências é como você reduz toda a curva — mediana e P90.
Quer saber mais sobre como escrever relatórios de bugs melhores? Comece aqui. 👇🏼
Referências do setor para o tempo de resolução de bugs
Os benchmarks de resolução de bugs mudam de acordo com a tolerância ao risco, o modelo de lançamento e a rapidez com que você pode enviar as alterações.
É aqui que você pode usar medianas (P50) para entender seu fluxo típico e P90 para definir promessas e SLAs — por gravidade e origem (cliente, controle de qualidade, monitoramento).
Vamos detalhar o que isso significa:
| 🔑 Termo | 📝 Descrição | 💡 Por que isso é importante |
|---|---|---|
| P50 (mediana) | O valor médio — 50% das correções de bugs são mais rápidas do que isso e 50% são mais lentas. | 👉 Reflete seu tempo de resolução típico ou mais comum. É útil para entender o desempenho normal. |
| P90 (90º percentil) | 90% dos bugs são corrigidos dentro desse prazo. Apenas 10% levam mais tempo. | 👉 Representa um limite no pior caso (mas ainda assim realista). Útil para definir promessas externas. |
| SLAs (Acordos de Nível de Serviço) | Compromissos que você assume — internamente ou com os clientes — sobre a rapidez com que as questões serão resolvidas | 👉 Exemplo: “Resolvemos bugs P1 em 48 horas, 90% das vezes.” Ajuda a construir confiança e responsabilidade |
| Por gravidade e origem | Segmente suas métricas por duas dimensões principais: • Gravidade (por exemplo, P0, P1, P2)• Fonte (por exemplo, cliente, controle de qualidade, monitoramento) | 👉 Permite um acompanhamento e uma priorização mais precisos, para que os bugs críticos recebam atenção mais rapidamente. |
Abaixo estão os intervalos direcionais com base nos setores que equipes maduras costumam ter como alvo; trate-os como faixas iniciais e, em seguida, ajuste-os ao seu contexto.
SaaS
Sempre ativo e compatível com CI/CD, portanto, hotfixes são comuns. Problemas críticos (P0/P1) geralmente têm como meta uma mediana inferior a um dia útil, com P90 dentro de 24 a 48 horas. Problemas não críticos (P2+) geralmente têm uma mediana de 3 a 7 dias, com P90 dentro de 10 a 14 dias. Equipes com sinalizadores de recursos robustos e testes automatizados tendem a ser mais rápidas.
Plataformas de comércio eletrônico
Como a conversão e os fluxos do carrinho são essenciais para a receita, o padrão é mais alto. Problemas P0/P1 são normalmente mitigados em poucas horas (reversão, sinalização ou configuração) e totalmente resolvidos no mesmo dia; P90 até o final do dia ou <12 horas é comum em épocas de pico. Problemas P2+ geralmente são resolvidos em 2 a 5 dias, com P90 em 10 dias.
Software empresarial
Validações mais pesadas e janelas de mudança do cliente diminuem o ritmo. Para P0/P1, as equipes têm como meta uma solução alternativa dentro de 4 a 24 horas e uma correção em 1 a 3 dias úteis; P90 dentro de 5 dias úteis. Itens P2+ são frequentemente agrupados em trens de lançamento, com medianas de 2 a 4 semanas, dependendo dos cronogramas de implementação do cliente.
Jogos e aplicativos móveis
Os back-ends de serviço ao vivo se comportam como SaaS (sinalizações e reversões em minutos ou horas; P90 no mesmo dia). As atualizações do cliente são limitadas pelas revisões da loja: P0/P1 geralmente usam alavancas do lado do servidor imediatamente e enviam um patch do cliente em 1 a 3 dias; P90 em uma semana com revisão acelerada. As correções P2+ são normalmente programadas para o próximo sprint ou lançamento de conteúdo.
Banca/Fintech
Os controles de risco e conformidade impulsionam um padrão de “mitigar rapidamente, mudar com cuidado”. P0/P1 são mitigados rapidamente (sinalizações, reversões, mudanças de tráfego em minutos ou horas) e totalmente corrigidos em 1 a 3 dias; P90 em uma semana, levando em conta o controle de mudanças. P2+ geralmente leva de 2 a 6 semanas para passar pelas revisões de segurança, auditoria e CAB.
Se seus números estiverem fora desses intervalos, analise a qualidade da admissão, o encaminhamento/propriedade, a revisão de código e o rendimento de controle de qualidade, bem como as aprovações de dependência, antes de assumir que a “velocidade de engenharia” é o problema principal.
🌼 Você sabia? De acordo com uma pesquisa da Stack Overflow de 2024, os desenvolvedores usaram cada vez mais a IA como sua fiel companheira na jornada de codificação. Impressionantes 82% usaram IA para realmente escrever código — isso é que é um colaborador criativo! Quando ficavam presos ou procuravam soluções, 67,5% confiavam na IA para buscar respostas, e mais da metade (56,7%) contava com ela para depurar e obter ajuda.
Para alguns, as ferramentas de IA também se mostraram úteis para documentar projetos (40,1%) e até mesmo para criar dados ou conteúdo sintéticos (34,8%). Curioso sobre uma nova base de código? Quase um terço (30,9%) usa IA para se atualizar. Testar código ainda é uma tarefa manual para muitos, mas 27,2% também adotaram a IA nessa área. Outras áreas, como revisão de código, planejamento de projetos e análise preditiva, apresentam menor adoção de IA, mas está claro que a IA está se integrando cada vez mais a todas as etapas do desenvolvimento de software.
📖 Leia mais: Como usar a IA para garantir a qualidade
Como reduzir o tempo de resolução de bugs
A rapidez na resolução de bugs se resume a eliminar o atrito em cada etapa, desde o recebimento até a liberação.
Os maiores ganhos vêm de tornar os primeiros 30 minutos mais inteligentes (entrada limpa, responsável certo, prioridade certa) e, em seguida, comprimir os loops que se seguem (reproduzir, revisar, verificar).
Aqui estão nove estratégias que funcionam juntas como um sistema. A IA acelera cada etapa, e o fluxo de trabalho fica organizado em um único lugar, para que os executivos tenham previsibilidade e os profissionais tenham fluidez.
1. Centralize o recebimento e capture o contexto na fonte
O tempo de resolução de bugs aumenta quando você precisa reconstruir o contexto a partir de threads do Slack, tickets de suporte e planilhas. Canalize todos os relatórios — suporte, controle de qualidade, monitoramento — para uma única fila com um modelo estruturado que coleta componentes, gravidade, ambiente, versão/compilação do aplicativo, etapas para reproduzir, esperado x real e anexos (logs/HAR/telas).
A IA pode resumir automaticamente relatórios longos, extrair etapas de reprodução e detalhes do ambiente de anexos e sinalizar possíveis duplicatas para que a triagem comece com um registro coerente e enriquecido.
Métricas a serem observadas: MTTA (confirmação em minutos, não em horas), taxa de duplicatas, tempo de “Informações necessárias”.

2. Triagem e encaminhamento assistidos por IA para reduzir o MTTA
As correções mais rápidas são aquelas que chegam imediatamente à mesa certa.
Use regras simples e IA para classificar a gravidade, identificar os prováveis responsáveis por componente/área de código e atribuir automaticamente com um relógio SLA. Defina faixas claras para P0/P1 em comparação com todo o resto e torne inequívoco “quem é o responsável por isso”.
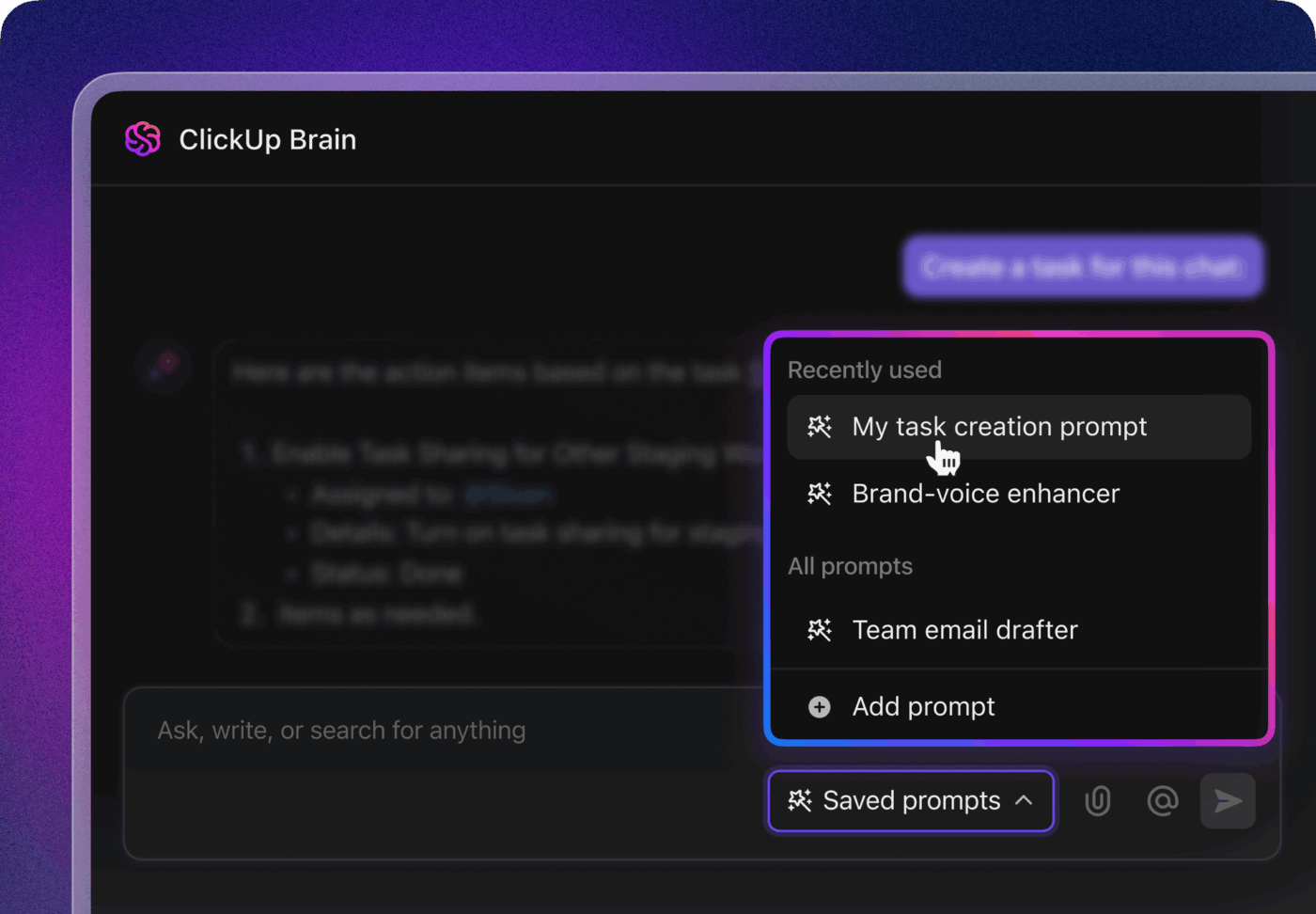
As automações podem definir prioridades a partir de campos, encaminhar por componente para uma equipe, iniciar um temporizador de SLA e notificar um engenheiro de plantão; a IA pode propor a gravidade e o responsável com base em padrões anteriores. Quando a triagem passa a levar de 2 a 5 minutos, em vez de 30 minutos de debate, seu MTTA diminui e seu MTTR acompanha essa redução.
Métricas a serem observadas: MTTA, qualidade da primeira resposta (o primeiro comentário solicita as informações corretas?), contagem de transferências por bug.
Veja como isso funciona na prática:
3. Priorize por impacto nos negócios com níveis explícitos de SLA
“A voz mais alta vence” torna as filas imprevisíveis e corrói a confiança dos executivos que acompanham o CSAT/NPS e as renovações.
Substitua isso por uma pontuação que combine gravidade, frequência, ARR afetado, criticidade do recurso e proximidade com renovações/lançamentos — e respalde-a com níveis de SLA (por exemplo, P0: mitigar em 1 a 2 horas, resolver em um dia; P1: no mesmo dia; P2: dentro de um sprint).
Mantenha uma faixa P0/P1 visível com limites de WIP para que nada fique para trás.
Métricas a serem observadas: resolução P50/P90 por nível, taxa de violação de SLA, correlação com CSAT/NPS.
💡Dica profissional: os campos Prioridades de tarefas, Campos personalizados e Dependências do ClickUp permitem calcular uma pontuação de impacto e vincular bugs a contas, feedback ou itens do roteiro; além disso, as Metas no ClickUp ajudam a vincular a adesão ao SLA aos objetivos da empresa, o que responde diretamente às preocupações dos executivos sobre o alinhamento.
4. Transforme a reprodução e o diagnóstico em uma atividade única
Cada loop extra com “você pode enviar os registros?” aumenta o tempo de resolução.
Padronize o que é considerado “bom”: campos obrigatórios para compilação/confirmação, ambiente, etapas de reprodução, esperado x real, além de anexos para logs, despejos de memória e arquivos HAR. Utilize telemetria cliente/servidor para que os IDs de falhas e solicitações possam ser vinculados a rastreamentos.
Utilize o Sentry (ou similar) para rastreamentos de pilha e vincule essa questão diretamente ao bug. A IA pode ler logs e rastreamentos para propor um domínio de falha provável e gerar uma reprodução mínima, transformando uma hora de análise visual em alguns minutos de trabalho focado.
Armazene manuais de procedimentos para classes comuns de bugs para que os engenheiros não precisem começar do zero.
Métricas a serem observadas: tempo gasto “aguardando informações”, porcentagem reproduzida na primeira tentativa, taxa de reabertura vinculada à falta de reprodução.
5. Reduza o ciclo de revisão e teste de código
Grandes PRs atrasam. Busque patches cirúrgicos, desenvolvimento baseado em trunk e sinalizadores de recursos para que as correções possam ser enviadas com segurança. Pré-designe revisores por propriedade do código para evitar tempo ocioso e use listas de verificação (testes atualizados, telemetria adicionada, sinalizador atrás de um kill switch) para garantir a qualidade.
A automação deve mover o bug para “Em revisão” na abertura do PR e para “Resolvido” na fusão; a IA pode sugerir testes de unidade ou destacar diferenças arriscadas para focar a revisão.
Métricas a serem observadas: Tempo em “Em revisão”, taxa de falha de alteração para PRs de correção de bugs e latência de revisão P90.
Você pode usar integrações GitHub/GitLab no ClickUp para manter seu status de resolução sincronizado; as automações podem aplicar a “definição de concluído”.
📖 Leia mais: Como usar a IA para automatizar tarefas
6. Paralelize a verificação e torne a paridade do ambiente de controle de qualidade uma realidade
A verificação não deve começar dias depois ou em um ambiente que nenhum dos seus clientes usa.
Mantenha o “pronto para QA” rigoroso: hotfixes orientados por sinalizadores validados em ambientes semelhantes aos de produção com dados de semente que correspondem aos casos relatados.
Sempre que possível, configure ambientes efêmeros a partir do ramo de bugs para que o controle de qualidade possa validar imediatamente; a IA pode então gerar casos de teste a partir da descrição do bug e regressões anteriores.
Métricas a serem observadas: Tempo em “QA/Verificação”, taxa de rejeição da QA de volta para o desenvolvimento, tempo médio para encerramento após a fusão.

📖 Leia mais: Como escrever casos de teste eficazes
7. Comunique o status de forma clara para reduzir o custo de coordenação
Uma boa atualização evita três ping de status e uma escalação.
Trate as atualizações como um produto: curtas, específicas e voltadas para o público (suporte, executivos, clientes). Estabeleça uma cadência para P0/P1 (por exemplo, a cada hora até que seja mitigado, depois a cada quatro horas) e mantenha uma única fonte de verdade.
A IA pode elaborar atualizações seguras para o cliente e resumos internos a partir do histórico de tarefas, incluindo status em tempo real por gravidade e equipe. Para executivos como seu diretor de produto, transfira os bugs para iniciativas para que eles possam ver se o trabalho crítico de qualidade ameaça as promessas de entrega.
Métricas a serem observadas: Tempo entre atualizações de status em P0/P1, CSAT das partes interessadas nas comunicações.
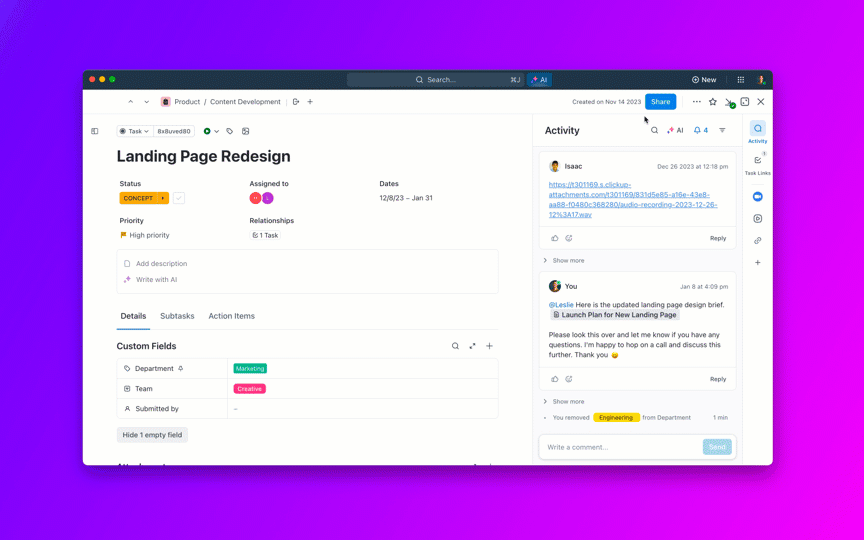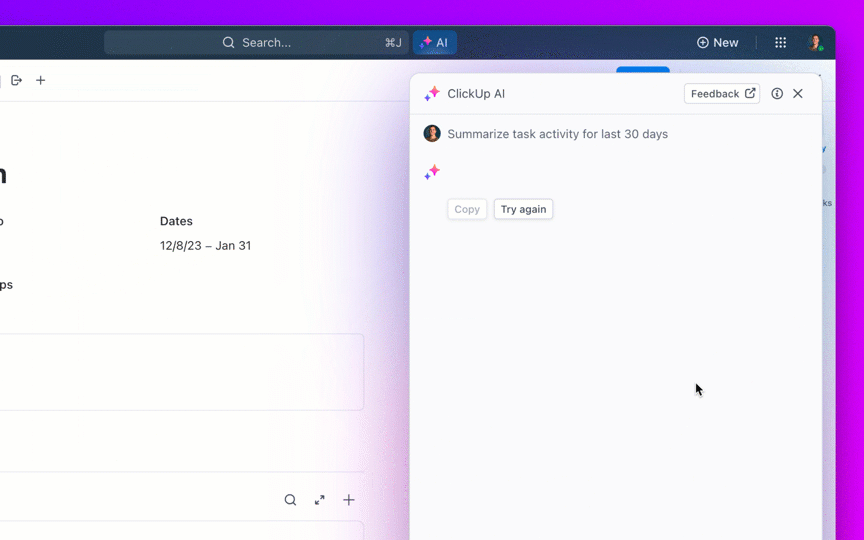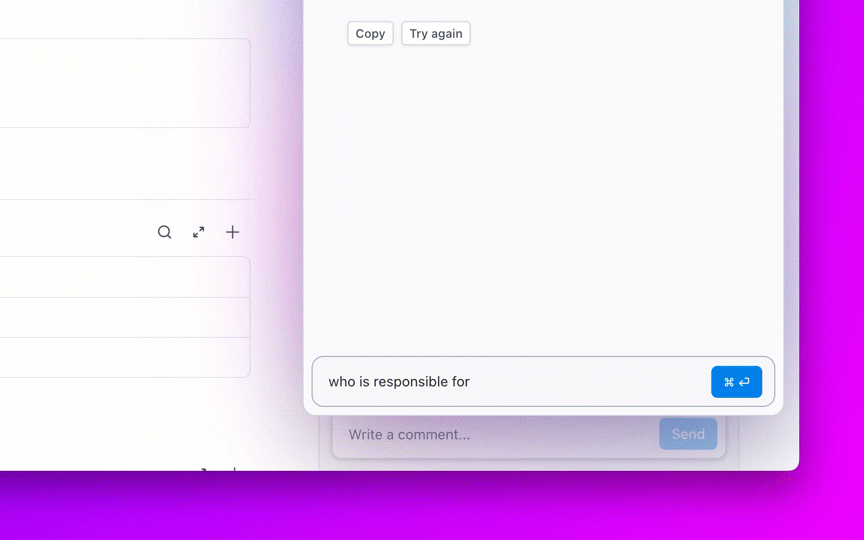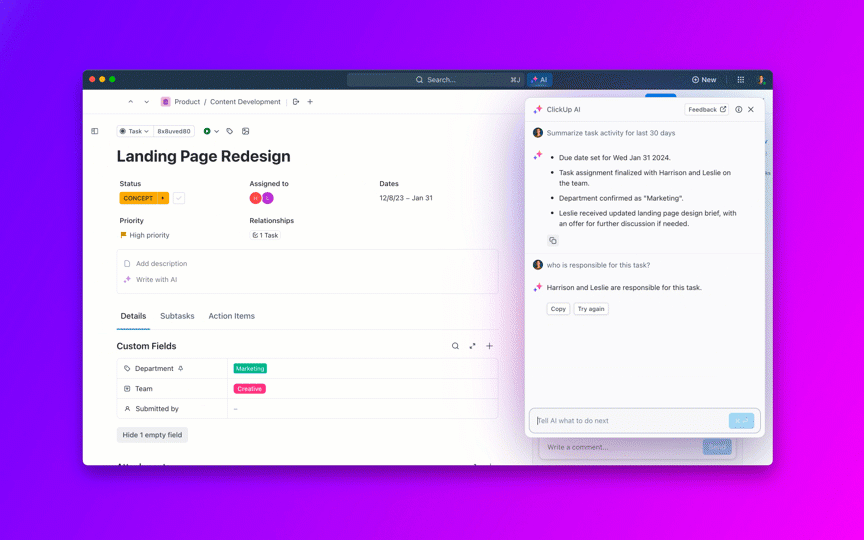
8. Controle o tempo de espera dos backlogs e evite que eles fiquem “abertos para sempre”
Um backlog crescente e obsoleto sobrecarrega silenciosamente cada sprint.
Defina políticas de envelhecimento (por exemplo, P2 > 30 dias aciona revisão, P3 > 90 dias requer justificativa) e programe uma “triagem de envelhecimento” semanal para mesclar duplicatas, fechar relatórios obsoletos e converter bugs de baixo valor em itens de backlog do produto.
Use a IA para agrupar o backlog por tema (por exemplo, “expiração do token de autenticação”, “instabilidade no upload de imagens”) para que você possa programar semanas de correção temática e eliminar uma classe de defeitos de uma só vez.
Métricas a serem observadas: contagem de backlog por faixa etária, % de problemas encerrados como duplicatas/obsoletos, velocidade temática de burn-down.
9. Feche o ciclo com a causa raiz e a prevenção
Se a mesma classe de defeito continuar ocorrendo, suas melhorias no MTTR estão mascarando um problema maior.
Faça análises rápidas e imparciais das causas raiz em P0/P1 e P2s de alta frequência; identifique as causas raiz (lacunas nas especificações, lacunas nos testes, lacunas nas ferramentas, instabilidade na integração), vincule-as aos componentes e incidentes afetados e acompanhe as tarefas de acompanhamento (proteções, testes, regras de lint) até a conclusão.
A IA pode redigir resumos de RCA e propor testes preventivos ou regras de lint com base no histórico de alterações. E é assim que você passa de apagar incêndios para ter menos incêndios.
Métricas a serem observadas: taxa de reabertura, taxa de regressão, tempo entre recorrências e porcentagem de RCAs com ações de prevenção concluídas.

Juntas, essas mudanças comprimem o caminho de ponta a ponta: reconhecimento mais rápido, triagem mais clara, priorização mais inteligente, menos atrasos na revisão e no controle de qualidade e comunicação mais clara. Os executivos obtêm previsibilidade vinculada ao CSAT/NPS e à receita; os profissionais obtêm uma fila mais tranquila, com menos mudanças de contexto.
📖 Leia mais: Como realizar uma análise da causa raiz
Ferramentas de IA que ajudam a reduzir o tempo de resolução de bugs
A IA pode reduzir o tempo de resolução em todas as etapas: recebimento, triagem, encaminhamento, correção e verificação.
No entanto, os ganhos reais vêm quando as ferramentas entendem o contexto e mantêm o trabalho em andamento sem precisar de supervisão.
Procure sistemas que enriquecem relatórios automaticamente (etapas de reprodução, ambiente, duplicatas), priorizam por impacto, encaminham para o responsável certo, redigem atualizações claras e se integram perfeitamente ao seu código, CI e observabilidade.
Os melhores deles também oferecem suporte a fluxos de trabalho semelhantes aos de agentes: bots que monitoram SLAs, alertam revisores, escalam itens paralisados e resumem os resultados para as partes interessadas. Aqui está nossa seleção de ferramentas de IA para uma melhor resolução de bugs:
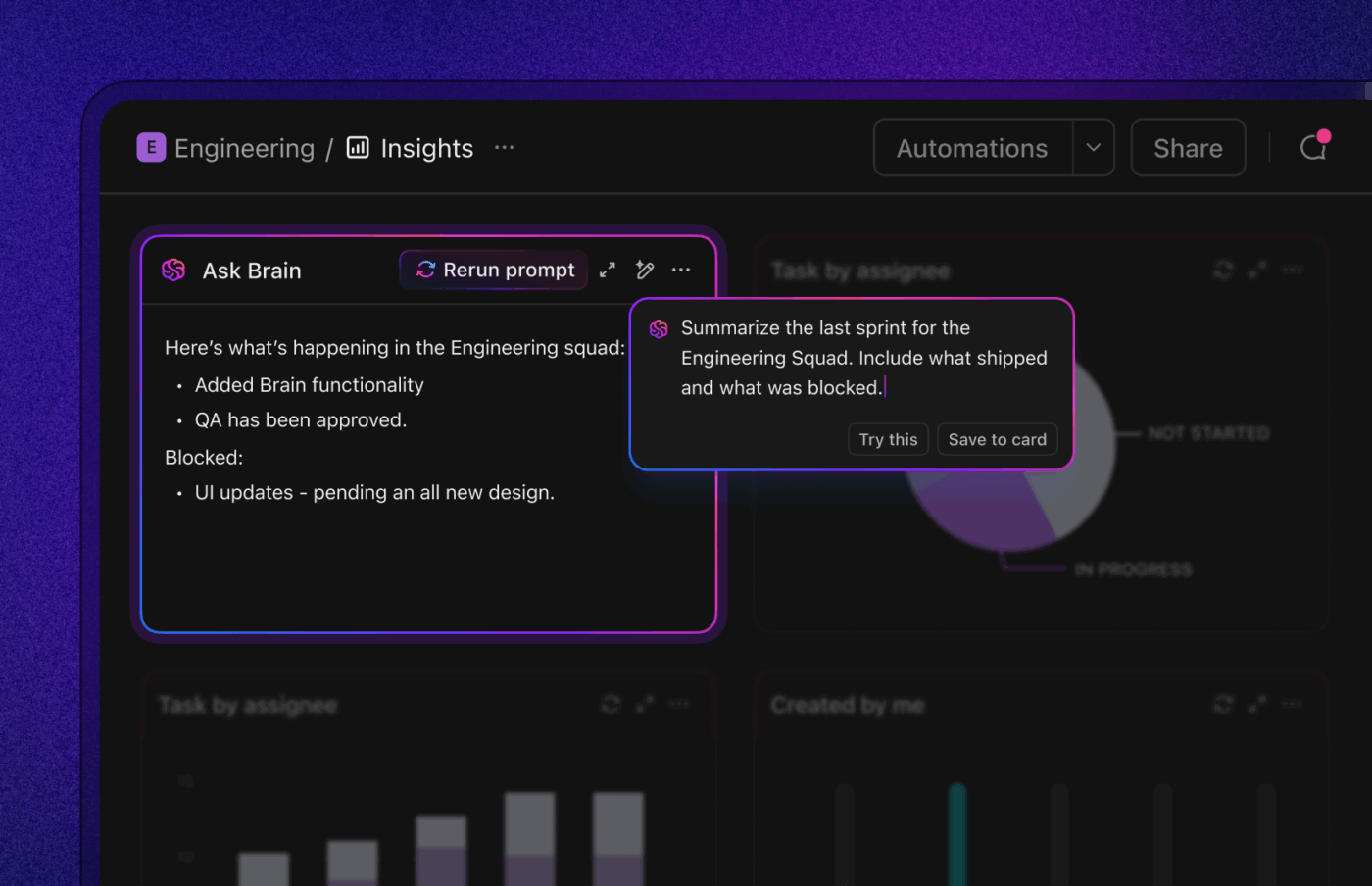
1. ClickUp (ideal para IA contextual, automações e fluxos de trabalho agentivos)
Se você deseja um fluxo de trabalho simplificado e inteligente para a resolução de bugs, o ClickUp, o aplicativo completo para o trabalho, reúne IA, automações e assistência ao fluxo de trabalho em um só lugar.
O ClickUp Brain exibe o contexto certo instantaneamente, resumindo longas discussões sobre bugs, extraindo etapas para reproduzir e detalhes do ambiente a partir de anexos, sinalizando possíveis duplicatas e sugerindo as próximas ações. Em vez de vasculhar o Slack, tickets e registros, as equipes obtêm um registro limpo e enriquecido com o qual podem agir imediatamente.
As automações e os agentes autopilot do ClickUp mantêm o trabalho em andamento sem a necessidade de acompanhamento constante. Os bugs são encaminhados automaticamente para a equipe certa, os responsáveis são designados, os SLAs e os prazos são definidos, os status são atualizados à medida que o trabalho avança e as partes interessadas recebem notificações oportunas.

Esses agentes podem até mesmo classificar e categorizar problemas, agrupar relatórios semelhantes, consultar correções históricas para sugerir possíveis caminhos a seguir e escalar itens urgentes — de modo que o MTTA e o MTTR diminuam mesmo quando o volume aumenta.
🛠️ Quer um kit de ferramentas pronto para usar? O modelo de rastreamento de bugs e problemas do ClickUp é uma solução poderosa da ClickUp for Software, projetada para ajudar as equipes de suporte, engenharia e produto a controlar bugs e problemas de software com facilidade. Com visualizações personalizáveis, como lista, quadro, carga de trabalho, formulário e linha do tempo, as equipes podem visualizar e gerenciar seu processo de rastreamento de bugs da maneira que melhor lhes convier.
Os 20 status personalizados e os 7 campos personalizados do modelo permitem um fluxo de trabalho personalizado, garantindo que cada problema seja rastreado desde a descoberta até a resolução. As automações integradas cuidam das tarefas repetitivas, liberando tempo valioso e reduzindo o esforço manual.
💟 Bônus: O Brain MAX é o seu companheiro de desktop com inteligência artificial, projetado para acelerar a resolução de bugs com recursos inteligentes e práticos.
Quando você encontrar um bug, basta usar o recurso de conversão de voz em texto do Brain MAX para ditar o problema — suas notas faladas são transcritas instantaneamente e podem ser anexadas a um ticket de bug novo ou existente. Sua Pesquisa Empresarial vasculha todas as suas ferramentas conectadas — como ClickUp, GitHub, Google Drive e Slack — para exibir relatórios de bugs, logs de erros, trechos de código e documentação relacionados, para que você tenha todo o contexto necessário sem precisar alternar entre aplicativos.
Precisa coordenar uma correção? O Brain MAX permite que você atribua o bug ao desenvolvedor certo, defina lembretes automáticos para atualizações de status e acompanhe o progresso — tudo a partir do seu desktop!
2. Sentry (ideal para capturar erros)
O Sentry reduz o MTTD e o tempo de reprodução, capturando erros, rastreamentos e sessões de usuários em um único lugar. O agrupamento de problemas orientado por IA reduz o ruído; as regras de “Suspect Commit” e propriedade identificam o provável proprietário do código, para que o encaminhamento seja instantâneo. O Session Replay fornece aos engenheiros o caminho exato do usuário e os detalhes do console/rede para reproduzir sem idas e vindas intermináveis.
Os recursos de IA do Sentry podem resumir o contexto do problema e, em algumas pilhas, propor patches de correção automática que fazem referência ao código problemático. O impacto prático: menos tickets duplicados, atribuição mais rápida e um caminho mais curto entre o relatório e o patch funcional.
3. GitHub Copilot (ideal para revisar códigos mais rapidamente)
O Copilot acelera o ciclo de correção dentro do editor. Ele explica rastreamentos de pilha, sugere patches direcionados, escreve testes de unidade para fixar a correção e estrutura scripts de reprodução.
O Copilot Chat pode analisar códigos com falhas, propor refatorações mais seguras e gerar comentários ou descrições de PR que agilizam a revisão do código. Combinado com as revisões necessárias e CI, ele reduz em horas o processo de “diagnóstico → implementação → teste”, especialmente para bugs bem delimitados com reprodução clara.
4. Snyk da DeepCode AI (ideal para identificar padrões)
A análise estática alimentada por IA da DeepCode encontra defeitos e padrões inseguros enquanto você codifica e em PRs. Ela destaca fluxos problemáticos, explica por que eles ocorrem e propõe correções seguras que se adaptam às expressões idiomáticas da sua base de código.
Ao detectar regressões antes da fusão e orientar os desenvolvedores para padrões mais seguros, você reduz a taxa de ocorrência de novos bugs e acelera a correção de erros lógicos complexos que são difíceis de identificar na revisão. As integrações IDE e PR mantêm isso próximo ao local onde o trabalho é realizado.
5. Watchdog e AIOps da Datadog (ideal para análise de logs)
O Watchdog da Datadog usa ML para detectar anomalias em logs, métricas, rastreamentos e monitoramento de usuários reais. Ele correlaciona picos com marcadores de implantação, alterações de infraestrutura e topologia para sugerir possíveis causas principais.
Para defeitos que afetam o cliente, isso significa minutos para detecção, agrupamento automático para reduzir o ruído de alertas e pistas concretas sobre onde procurar. O tempo de triagem diminui porque você começa com “esta implantação afetou esses serviços e as taxas de erro aumentaram neste endpoint”, em vez de começar do zero.
⚡️ Arquivo de modelos: Modelos gratuitos de rastreamento de problemas e registros no Excel e ClickUp
6. New Relic AI (ideal para identificar e resumir tendências)
A Caixa de Entrada de Erros da New Relic agrupa erros semelhantes em todos os serviços e versões, enquanto seu assistente de IA resume o impacto, destaca as causas prováveis e fornece links para os rastreamentos/transações envolvidos.
As correlações de implantação e a inteligência de mudança de entidade tornam óbvio quando uma versão recente é a culpada. Para sistemas distribuídos, esse contexto reduz horas de pings entre equipes e encaminha o bug para o responsável certo, com uma hipótese sólida já formada.
7. Rollbar (ideal para fluxos de trabalho automatizados)
A Rollbar é especializada em monitoramento de erros em tempo real com impressão digital inteligente para agrupar duplicatas e rastrear tendências de ocorrência. Seus resumos baseados em IA e dicas sobre a causa raiz ajudam as equipes a entender o escopo (usuários afetados, versões impactadas), enquanto a telemetria e os rastreamentos de pilha fornecem pistas rápidas para reprodução.
As regras de fluxo de trabalho do Rollbar podem criar tarefas automaticamente, classificar a gravidade e encaminhar para os responsáveis, transformando fluxos de erros ruidosos em filas priorizadas com contexto anexado.
8. PagerDuty AIOps e automação de runbook (o melhor em diagnósticos de baixo contato)
O PagerDuty usa correlação de eventos e redução de ruído baseada em ML para transformar alertas em incidentes acionáveis.
O roteamento dinâmico encaminha o problema para o plantão certo instantaneamente, enquanto a automação do runbook pode iniciar diagnósticos ou mitigação (reiniciar serviços, reverter uma implantação, alternar um sinalizador de recurso) antes que um humano se envolva. Para o tempo de resolução de bugs, isso significa um MTTA mais curto, mitigação mais rápida para P0s e menos horas perdidas com fadiga de alertas.
O fio condutor é a automação mais IA em todas as etapas. Você detecta mais cedo, encaminha de forma mais inteligente, chega ao código mais rapidamente e comunica o status sem atrasar os engenheiros — tudo isso se soma a uma redução significativa no tempo de resolução de bugs.
📖 Leia mais: Como usar IA em DevOps
Exemplos reais do uso de IA para resolução de bugs
Portanto, a IA saiu oficialmente do laboratório. Ela está reduzindo o tempo de resolução de bugs na prática.
Vamos ver como!
| Domínio/Organização | Como a IA foi usada | Impacto/benefício |
|---|---|---|
| Ubisoft | Desenvolvemos o Commit Assistant, uma ferramenta de IA treinada com uma década de código interno, que prevê e previne bugs na fase de codificação. | O objetivo é reduzir drasticamente o tempo e os custos — tradicionalmente, até 70% das despesas com desenvolvimento de jogos são gastas na correção de bugs. |
| Razer (Plataforma Wyvrn) | Lançamento do QA Copilot (integrado ao Unreal e ao Unity), alimentado por IA, para automatizar a detecção de bugs e gerar relatórios de controle de qualidade. | Aumente a detecção de bugs em até 25% e reduza pela metade o tempo de controle de qualidade. |
| Google / DeepMind e Project Zero | Apresentamos o Big Sleep, uma ferramenta de IA que detecta autonomamente vulnerabilidades de segurança em softwares de código aberto, como FFmpeg e ImageMagick. | Identificamos 20 bugs, todos verificados por especialistas humanos e programados para correção. |
| Pesquisadores da UC Berkeley | Usando uma referência chamada CyberGym, modelos de IA analisaram 188 projetos de código aberto, descobrindo 17 vulnerabilidades — incluindo 15 bugs “zero-day” desconhecidos — e gerando exploits de prova de conceito. | Demonstra a capacidade evolutiva da IA na detecção de vulnerabilidades e na proteção automatizada contra explorações. |
| Spur (startup da Yale) | Desenvolvemos um agente de IA que traduz descrições de casos de teste em linguagem simples em rotinas automatizadas de teste de sites — efetivamente, um fluxo de trabalho de controle de qualidade que se autoescreve. | Permite testes autônomos com o mínimo de intervenção humana. |
| Reprodução automática de relatórios de bugs do Android | Utilizou PNL + aprendizado por reforço para interpretar a linguagem dos relatórios de bugs e gerar etapas para reproduzir bugs do Android. | Alcançou 67% de precisão, 77% de recall e reproduziu 74% dos relatórios de bugs, superando os métodos tradicionais. |
Erros comuns na medição do tempo de resolução de bugs
Se sua medição estiver incorreta, seu plano de melhoria também estará.
A maioria dos “números ruins” nos fluxos de trabalho de resolução de bugs vem de definições vagas, fluxos de trabalho inconsistentes e análises superficiais.
Comece pelo básico: o que conta como início/fim, como você lida com esperas e reaberturas e, em seguida, analise os dados da maneira como seus clientes os experimentam. Isso inclui:
❌ Limites difusos: misturar Relatado→Resolvido e Relatado→Fechado no mesmo painel (ou alternar de mês para mês) torna as tendências sem sentido. Escolha um limite, documente-o e aplique-o em todas as equipes. Se precisar de ambos, publique-os como métricas separadas com rótulos claros.
❌ Abordagem baseada apenas em médias: confiar na média esconde a realidade das filas com alguns outliers de longa duração. Use a mediana (P50) para o seu tempo “típico”, P90 para previsibilidade/SLAs e mantenha a média para planejamento de capacidade. Sempre observe a distribuição, não apenas um único número.
❌ Sem segmentação: agrupar todos os bugs mistura incidentes P0 com P3s cosméticos. Segmente por gravidade, origem (cliente x controle de qualidade x monitoramento), componente/equipe e “novo x regressão”. Seu P0/P1 P90 é o que as partes interessadas sentem; sua mediana P2+ é o que a engenharia planeja.
❌ Ignorando o tempo “pausado”: Esperando por registros do cliente, um fornecedor externo ou uma janela de lançamento? Se você não rastrear Bloqueado/Pausado como um status de primeira classe, seu tempo de resolução se tornará um argumento. Relate tanto o tempo do calendário quanto o tempo ativo para que os gargalos fiquem visíveis e os debates parem.
❌ Lacunas na normalização do tempo: misturar fusos horários ou alternar entre horário comercial e horário civil no meio do processo corrompe as comparações. Normalize os carimbos de data/hora para um fuso horário (ou UTC) e decida uma vez se os SLAs são medidos em horas comerciais ou civis; aplique isso de forma consistente.
❌ Entrada incorreta e duplicatas: A falta de informações sobre o ambiente/compilação e os tickets duplicados aumentam o tempo e confundem a responsabilidade. Padronize os campos obrigatórios na entrada, enriqueça automaticamente (logs, versão, dispositivo) e elimine duplicatas sem redefinir o tempo — feche as duplicatas como questões vinculadas, não como questões “novas”.
❌ Modelos de status inconsistentes: status personalizados (“QA Ready-ish”, “Pending Review 2”) ocultam o tempo no status e tornam as transições de estado pouco confiáveis. Defina um fluxo de trabalho canônico (Novo → Triagem → Em andamento → Em revisão → Resolvido → Fechado) e audite os estados fora do caminho.
❌ Ignorando o tempo em status: um único número de “tempo total” não pode indicar onde o trabalho está parado. Capture e analise o tempo gasto em Triagem, Em revisão, Bloqueado e QA. Se a revisão de código P90 supera a implementação, sua solução não é “codificar mais rápido”, mas sim desbloquear a capacidade de revisão.
🧠 Curiosidade: O último Desafio Cibernético de IA da DARPA apresentou um avanço revolucionário na automação da segurança cibernética. A competição contou com sistemas de IA projetados para detectar, explorar e corrigir vulnerabilidades em softwares de forma autônoma, sem intervenção humana. A equipe vencedora, “Team Atlanta”, descobriu de forma impressionante 77% dos bugs injetados e corrigiu com sucesso 61% deles, demonstrando o poder da IA não apenas para encontrar falhas, mas também para corrigi-las ativamente.
❌ Cegueira de reabertura: tratar reaberturas como novos bugs reinicia o relógio e aumenta o MTTR. Acompanhe a taxa de reabertura e o “tempo até o fechamento estável” (desde o primeiro relatório até o fechamento final em todos os ciclos). O aumento das reaberturas geralmente indica reprodução fraca, lacunas nos testes ou uma definição vaga de conclusão.
❌ Sem MTTA: As equipes se preocupam excessivamente com o MTTR e ignoram o MTTA (tempo de reconhecimento/propriedade). Um MTTA alto é um sinal de alerta para uma resolução demorada. Meça-o, defina SLAs por gravidade e automatize o encaminhamento/escalonamento para mantê-lo baixo.
❌ IA/automação sem proteções: Permitir que a IA defina a gravidade ou feche duplicatas sem revisão pode classificar erroneamente casos extremos e distorcer silenciosamente as métricas. Use a IA para sugestões, exija confirmação humana em P0/P1 e audite o desempenho do modelo mensalmente para que seus dados permaneçam confiáveis.
Aperte esses detalhes e seus gráficos de tempo de resolução finalmente refletirão a realidade. A partir daí, as melhorias se acumulam: uma melhor recepção reduz o MTTA, estados mais limpos revelam os verdadeiros gargalos e P90s segmentados dão aos líderes promessas que você pode cumprir.
⚡️ Arquivo de modelos: 10 modelos de casos de teste para testes de software
Práticas recomendadas para uma melhor resolução de bugs
Resumindo, aqui estão os pontos críticos a serem lembrados!
| 🧩 Melhores práticas | 💡 O que isso significa | 🚀 Por que isso é importante |
| Use um sistema robusto de rastreamento de bugs | Acompanhe todos os bugs relatados usando um sistema centralizado de rastreamento de bugs. | Garante que nenhum bug seja perdido e permite a visibilidade do status dos bugs entre as equipes. |
| Escreva relatórios detalhados de bugs | Inclua contexto visual, informações do sistema operacional, etapas para reproduzir e gravidade. | Ajuda os desenvolvedores a corrigir bugs mais rapidamente com todas as informações essenciais à disposição. |
| Categorize e priorize os bugs | Use uma matriz de prioridades para classificar os bugs por urgência e impacto. | Concentre a equipe primeiro nos bugs críticos e nas questões urgentes. |
| Aproveite os testes automatizados | Execute testes automaticamente em seu pipeline de CI/CD. | Apoia a detecção precoce e evita regressões. |
| Defina diretrizes claras para relatórios | Forneça modelos e treinamento sobre como relatar bugs. | Isso leva a informações precisas e uma comunicação mais fluida. |
| Acompanhe as principais métricas | Meça o tempo de resolução, o tempo decorrido e o tempo de resposta. | Permite o acompanhamento e a melhoria do desempenho usando dados históricos. |
| Use uma abordagem proativa | Não espere que os usuários reclamem — faça testes de forma proativa. | Aumente a satisfação do cliente e reduza a carga de suporte. |
| Aproveite as ferramentas inteligentes e o aprendizado de máquina | Use o aprendizado de máquina para prever bugs e sugerir correções. | Melhora a eficiência na identificação das causas principais e na correção de bugs. |
| Alinhe-se aos SLAs | Cumpra os acordos de nível de serviço acordados para a resolução. | Construa confiança e atenda às expectativas dos clientes em tempo hábil. |
| Revise e melhore continuamente | Analise bugs reabertos, colete feedback e ajuste processos. | Promove o aprimoramento contínuo do seu processo de desenvolvimento e gerenciamento de bugs. |
Resolução de bugs simplificada com IA contextual
As equipes mais rápidas na resolução de bugs não dependem de heroísmo. Elas projetam um sistema: definições claras de início/fim, entrada limpa, priorização do impacto nos negócios, responsabilidade bem definida e ciclos de feedback rigorosos entre suporte, controle de qualidade, engenharia e lançamento.
O ClickUp pode ser o centro de comando alimentado por IA para o seu sistema de resolução de bugs. Centralize todos os relatórios em uma única fila, padronize o contexto com campos estruturados e deixe a IA do ClickUp fazer a triagem, resumir e priorizar, enquanto as automações aplicam os SLAs, escalam quando os prazos são ultrapassados e mantêm as partes interessadas alinhadas. Vincule os bugs aos clientes, ao código e aos lançamentos para que os executivos vejam o impacto e os profissionais permaneçam no fluxo.
Se você está pronto para reduzir o tempo de resolução de bugs e tornar seu roteiro mais previsível, inscreva-se no ClickUp e comece a medir o aumento em dias, não em trimestres.
Perguntas frequentes
Qual é um bom tempo de resolução de bugs?
Não existe um único número “bom” — isso depende da gravidade, do modelo de lançamento e da tolerância ao risco. Use medianas (P50) para desempenho “típico” e P90 para promessas/SLAs, e segmente por gravidade e origem.
Qual é a diferença entre resolução de bugs e encerramento de bugs?
A resolução ocorre quando a correção é implementada (por exemplo, código mesclado, configuração aplicada) e a equipe considera o defeito resolvido. O encerramento ocorre quando o problema é verificado e formalmente concluído (por exemplo, QA validado no ambiente de destino, lançado ou marcado como não corrigido/duplicado com justificativa). Muitas equipes medem ambos: Relatado→Resolvido reflete a velocidade da engenharia; Relatado→Encerrado reflete o fluxo de qualidade de ponta a ponta. Use definições consistentes para que os painéis não misturem etapas.
Qual é a diferença entre o tempo de resolução de bugs e o tempo de detecção de bugs?
O tempo de detecção (MTTD) é o tempo que leva para descobrir um defeito após ele ocorrer ou ser enviado — por meio de monitoramento, controle de qualidade ou usuários. O tempo de resolução é o tempo que leva desde a detecção/relatório até a implementação da correção (e, se preferir, validação/lançamento). Juntos, eles definem a janela de impacto no cliente: detectar rapidamente, reconhecer rapidamente, resolver rapidamente e lançar com segurança. Você também pode acompanhar o MTTA (tempo para reconhecer/atribuir) para identificar atrasos na triagem que muitas vezes indicam uma resolução mais demorada.
Como a IA ajuda na resolução de bugs?
A IA comprime os ciclos que normalmente demoram: recebimento, triagem, diagnóstico, correção e verificação.
- Recebimento e triagem: resume automaticamente relatórios longos, extrai etapas/ambiente de reprodução, sinaliza duplicatas e sugere gravidade/prioridade para que os engenheiros comecem com um contexto claro (por exemplo, ClickUp AI, Sentry AI).
- Roteamento e SLAs: prevê o provável componente/proprietário, define temporizadores e escalona quando o MTTA ou as esperas de revisão atrasam, reduzindo o “tempo em status” ocioso (automações ClickUp e fluxos de trabalho semelhantes aos de agentes).
- Diagnóstico: agrupa erros semelhantes, correlaciona picos com commits/lançamentos recentes e aponta as prováveis causas principais com rastreamentos de pilha e contexto de código (Sentry AI e similares).
- Implementação: sugere alterações de código e testes com base em padrões do seu repositório, acelerando o ciclo de “escrever/corrigir” (GitHub Copilot; Snyk Code AI da DeepCode).
- Verificação e comunicações: escreve casos de teste a partir de etapas de reprodução, redige notas de lançamento e atualizações para as partes interessadas e resume o status para executivos e clientes (ClickUp AI). Usados em conjunto — ClickUp como centro de comando com Sentry/Copilot/DeepCode na pilha — as equipes reduzem os tempos MTTA/P90 sem depender de heroísmo.