

Een klantenservicebot die van elke interactie leert. Een verkoopassistent die zijn strategie aanpast op basis van realtime inzichten. Dit zijn niet alleen concepten, ze zijn echt, dankzij AI learning agents.
Maar wat maakt deze agents uniek en hoe doet een lerende agent zijn functie om dit aanpassingsvermogen te bereiken?
In tegenstelling tot traditionele AI-systemen die werken met een vaste programmering, evolueren leeragenten.
Ze passen zich aan, verbeteren en verfijnen hun acties in de loop van de tijd, waardoor ze onmisbaar zijn voor industrieën zoals autonome voertuigen en de gezondheidszorg, waar flexibiliteit en precisie onontbeerlijk zijn.
Zie ze als AI die slimmer wordt door ervaring, net als mensen.
In deze blog verkennen we de sleutelcomponenten, processen, soorten en toepassingen van leeragenten in AI. 🤖
⏰ 60-seconden samenvatting
Hier volgt een korte inleiding over leeragenten in AI:
Wat ze doen: Zich aanpassen door middel van interacties, bijvoorbeeld klantenservicebots die antwoorden verfijnen.
Belangrijkste toepassingen: Robotica, gepersonaliseerde diensten en slimme systemen zoals thuisapparaten.
Kernonderdelen:
- Learning Element:* Verzamelt kennis om prestaties te verbeteren
- Prestatie-element: Voert taken uit op basis van geleerde kennis
- Kritisch: Evalueert acties en geeft feedback
- Probleemgenerator: Identificeert mogelijkheden voor verder leren
Leermethoden:
- Supervised Learning: Herkent patronen met behulp van gelabelde gegevens
- Unsupervised Learning: Identificeert structuren in ongelabelde data
- Versterkend leren:Leert door proefversies en fouten
Real-World Impact: Verbetert aanpassingsvermogen, efficiëntie en besluitvorming in verschillende industrieën.
⚙️ Bonus: Voel je je overweldigd door AI-jargon? Bekijk onze uitgebreide woordenlijst van AI-termen om basisconcepten en geavanceerde terminologie gemakkelijk te begrijpen.
**Wat zijn lerende agenten in AI?
Lerende agenten in AI zijn systemen die zich in de loop van de tijd verbeteren door te leren van hun omgeving. Ze passen zich aan, nemen slimmere beslissingen en optimaliseren acties op basis van feedback en gegevens.
In tegenstelling tot traditionele AI-systemen, die gefixeerd blijven, evolueren leeragenten voortdurend. Dit maakt ze essentieel voor robotica en gepersonaliseerde aanbevelingen, waar voorwaarden onvoorspelbaar en voortdurend veranderend zijn.
**Lerende agenten werken in een feedbacklus: ze nemen de omgeving waar, leren van feedback en verfijnen hun acties. Dit is geïnspireerd op de manier waarop mensen leren van ervaring.
Sleutelcomponenten van lerende agenten**
Leeragenten zijn meestal samengesteld uit verschillende onderling verbonden componenten die samenwerken om aanpassingsvermogen en verbetering in de loop van de tijd te garanderen.
Hier zijn enkele kritieke componenten van dit leerproces. 📋
Lerend element
De kernverantwoordelijkheid van de agent is het verwerven van kennis en het verbeteren van prestaties door het analyseren van gegevens, interacties en feedback.
Met behulp van AI-technieken zoals leren onder toezicht, leren door versterking en leren zonder toezicht, past de agent zijn gedrag aan en past het aan om zijn functie te verbeteren.
📌 Voorbeeld: Een virtuele assistent zoals Siri leert na verloop van tijd de voorkeuren van gebruikers, zoals vaak gebruikte commando's of specifieke accenten, om nauwkeurigere en persoonlijkere antwoorden te geven.
Prestatie-element**
Dit onderdeel voert Taken uit door interactie met de omgeving en het nemen van beslissingen op basis van beschikbare informatie. Het is in wezen de 'actie-arm' van de agent.
Voorbeeld: In autonome voertuigen verwerkt het prestatie-element verkeersgegevens en omgevingsvoorwaarden om realtime beslissingen te nemen, zoals stoppen voor rood licht of obstakels ontwijken.
Kritiek
De criticus evalueert de acties van het prestatie-element en geeft feedback. Deze feedback helpt het leerelement te bepalen wat goed werkte en wat verbetering behoeft.
Voorbeeld: In een aanbevelingssysteem analyseert de criticus interacties van gebruikers (zoals klikken of overslaan) om te bepalen welke suggesties succesvol waren en helpt het leerelement toekomstige aanbevelingen te verfijnen.
Probleemgenerator
Deze component moedigt exploratie aan door nieuwe scenario's of acties voor te stellen die de agent kan testen.
Het duwt de agent buiten zijn comfortzone en zorgt voor voortdurende verbetering. Het voorkomt ook suboptimale resultaten door het bereik van de ervaring van de agent uit te breiden.
Voorbeeld: In e-commerce AI kan de probleemgenerator gepersonaliseerde marketingstrategieën voorstellen of gedragspatronen van klanten simuleren. Dit helpt de AI om zijn aanpak te verfijnen en aanbevelingen te doen die zijn afgestemd op verschillende voorkeuren van gebruikers.
Het leerproces in lerende agenten
Leeragenten vertrouwen voornamelijk op drie sleutelcategorieën om zich aan te passen en te verbeteren. Deze worden hieronder beschreven. 👇
1. Toezichthoudend leren
De agent leert van gelabelde datasets, waarbij elke invoer overeenkomt met een specifieke uitvoer.
Deze methode vereist een grote hoeveelheid nauwkeurig gelabelde gegevens voor training en wordt veel gebruikt in toepassingen zoals beeldherkenning, taalvertaling en fraudedetectie.
Voorbeeld: Een e-mailfiltersysteem leert e-mails te classificeren als spam of niet op basis van historische gegevens. Het leerelement identificeert patronen tussen de input (content van e-mails) en de output (labels voor classificatie) om nauwkeurige voorspellingen te doen.
2. Leren zonder toezicht
Verborgen patronen of relaties in gegevens komen tevoorschijn als de agent informatie analyseert zonder expliciete labels. Deze aanpak werkt goed voor het detecteren van anomalieën, het creëren van aanbevelingssystemen en het optimaliseren van gegevenscompressie.
Het helpt ook om inzichten te identificeren die misschien niet meteen zichtbaar zijn met gelabelde gegevens.
Voorbeeld: Klantsegmentatie in marketing kan gebruikers groeperen op basis van hun gedrag om gerichte campagnes te ontwerpen. De focus ligt op het begrijpen van structuur en het vormen van clusters of associaties.
3. Versterkend leren
In tegenstelling tot het bovenstaande, houdt versterkingsleren (RL) in dat agenten acties ondernemen in een omgeving om cumulatieve beloningen in de loop van de tijd te maximaliseren.
De agent leert door proefvluchten en fouten en krijgt feedback in de vorm van beloningen of straffen.
de keuze van de leermethode hangt af van het probleem, de beschikbaarheid van gegevens en de complexiteit van de omgeving. Versterkingsleren is van vitaal belang voor Taken zonder directe supervisie, omdat het feedbacklussen gebruikt om acties aan te passen.
Technieken voor versterkingsleren
- Policy iteration: Optimaliseert de beloningsverwachtingen door direct een beleid te leren dat toestanden in kaart brengt met acties
- Waarde iteratie: Bepaalt optimale acties door de waarde van elk toestands-actiepaar te berekenen
- Monte Carlo methoden: Simuleert meerdere toekomstige scenario's om actiebeloningen te voorspellen, vooral nuttig in dynamische en probabilistische omgevingen
Voorbeelden van echte RL-toepassingen
- Autonoom rijden: RL-algoritmen trainen voertuigen om veilig te navigeren, routes te optimaliseren en zich aan te passen aan verkeersvoorwaarden door continu te leren van gesimuleerde omgevingen
- **Versterkingsleren heeft Google's AlphaGo in staat gesteld menselijke kampioenen te verslaan door optimale strategieën te leren voor complexe spellen zoals Go
- **Dynamische prijsstelling: e-commerce platforms gebruiken RL om prijsstrategieën aan te passen op basis van vraagpatronen en acties van concurrenten om inkomsten te maximaliseren
🧠 Leuk weetje: Lerende agenten hebben menselijke kampioenen verslagen in spellen als Chess en Starcraft, wat hun aanpassingsvermogen en intelligentie aantoont.
Q-learning en neurale netwerkbenaderingen
Q-learning is een veelgebruikt RL-algoritme waarbij agenten de waarde van elk status-actiepaar leren door exploratie en feedback. De agent bouwt een Q-tabel, een matrix die verwachte beloningen toekent aan toestands-actieparen.
De agent kiest de actie met de hoogste Q-waarde en verfijnt de tabel iteratief om de nauwkeurigheid te verbeteren.
Voorbeeld: Een AI-drone die leert om efficiënt pakjes te bezorgen, gebruikt Q-learning om routes te evalueren. Nog te doen door beloningen toe te kennen voor tijdige leveringen en straffen voor vertragingen of botsingen. Na verloop van tijd wordt de Q-tabel verfijnd om de meest efficiënte en veilige leveringsroutes te kiezen.
Q-tabellen worden echter onpraktisch in complexe omgevingen met hoog-dimensionale ruimten.
Neurale netwerken stappen hier in en benaderen de Q-waarden in plaats van ze expliciet op te slaan. Deze verschuiving stelt reinforcement learning in staat om meer ingewikkelde problemen aan te pakken.
Diepe Q-netwerken (DQN's) gaan nog een stap verder en maken gebruik van diep leren om ruwe, ongestructureerde gegevens zoals afbeeldingen of sensorgegevens te verwerken. Deze netwerken kunnen zintuiglijke informatie direct in kaart brengen in acties, waardoor uitgebreide functie-engineering overbodig wordt.
Voorbeeld: In zelfrijdende auto's verwerken DQN's real-time sensorgegevens om rijstrategieën te leren, zoals het veranderen van rijstrook of het vermijden van obstakels, zonder voorgeprogrammeerde regels.
Met deze geavanceerde methoden kunnen agenten hun leercapaciteiten opschalen naar taken die veel rekenkracht en aanpassingsvermogen vereisen.
⚙️ Bonus: Leer hoe je een AI-kennisbank die het informatiebeheer stroomlijnt, de besluitvorming verbetert en de productiviteit van teams verhoogt.
Het leerproces voor agenten hecht waarde aan het ontwikkelen van strategieën voor intelligente besluitvorming in realtime. Dit zijn de sleutelaspecten die de besluitvorming ondersteunen:
- Exploratie vs. uitbuiting: Agenten balanceren tussen het verkennen van nieuwe acties om betere strategieën te vinden en het uitbuiten van bekende acties om beloningen te maximaliseren
- Multi-agent besluitvorming: In samenwerkende of competitieve instellingen, interacteren agenten en passen strategieën aan op basis van gedeelde doelen of tegengestelde tactieken
- Strategische afwegingen: Agenten leren ook om doelen te prioriteren op basis van de context, zoals het afwegen van snelheid en nauwkeurigheid in een bezorgsysteem
🎤 Podcast Alert: Blader door onze lijst met populaire AI-podcasts om je inzicht in de werking van lerende agenten te verdiepen.
Soorten AI-agenten
Leeragenten in kunstmatige intelligentie zijn er in verschillende formulieren, elk aangepast aan specifieke Taken en uitdagingen.
Laten we eens kijken naar hun werkingsmechanismen, unieke kenmerken en voorbeelden uit de praktijk. 👀
Eenvoudige reflex-agenten**
Dergelijke agenten reageren direct op stimuli op basis van vooraf gedefinieerde regels. Ze gebruiken een voorwaarde-actie (als-dan) mechanisme om acties te kiezen op basis van de huidige omgeving zonder rekening te houden met de geschiedenis of toekomst.
Karakteristieken
- Werkt op basis van een logisch voorwaarden-actiesysteem
- Past zich niet aan veranderingen aan en leert niet van acties in het verleden
- Presteert het best in transparante en voorspelbare omgevingen
Voorbeeld
Een thermostaat functioneert als een eenvoudige reflexagent door de verwarming in te schakelen wanneer de temperatuur onder een ingestelde drempel zakt en uit te schakelen wanneer de temperatuur stijgt. Hij neemt beslissingen puur op basis van de huidige temperatuurmetingen.
🧠 Leuk weetje: Sommige experimenten wijzen leeragenten gesimuleerde behoeften toe, zoals honger of dorst, om ze aan te moedigen doelgericht gedrag te ontwikkelen en te leren hoe ze effectief aan deze "behoeften" kunnen voldoen.
Modelgebaseerde reflexagenten**
Deze agenten houden een intern model van de wereld bij waarmee ze rekening kunnen houden met de effecten van hun acties. Ze leiden ook de toestand van de omgeving af die verder gaat dan wat ze direct kunnen waarnemen.
Kenmerken
- Gebruikt een opgeslagen model van de omgeving voor het nemen van beslissingen
- Maakt een schatting van de huidige toestand om om te gaan met gedeeltelijk waarneembare omgevingen
- Biedt meer flexibiliteit en aanpassingsvermogen in vergelijking met eenvoudige reflexagenten
Voorbeeld
Een Tesla zelfrijdende auto gebruikt een modelgebaseerde agent om door wegen te navigeren. Het detecteert zichtbare obstakels en voorspelt de beweging van voertuigen in de buurt, inclusief die in de dode hoek, met behulp van geavanceerde sensoren en realtime gegevens. Hierdoor kan de auto nauwkeurige en weloverwogen beslissingen nemen, wat de veiligheid en efficiëntie ten goede komt.
🔍 Wist je dat? Het concept van lerende agenten bootst vaak gedrag na dat bij dieren wordt waargenomen, zoals proefvluchten en fouten leren of leren op basis van beloning.
De functies van softwareagenten en virtuele assistenten
Deze agenten werken in digitale omgevingen en voeren autonoom specifieke Taken uit.
Virtuele assistenten zoals Siri of Alexa verwerken input van gebruikers met behulp van natuurlijke taalverwerking (NLP) en voeren acties uit zoals het beantwoorden van query's of het bedienen van slimme apparaten.
Kenmerken
- Vereenvoudigt dagelijkse taken zoals het maken van een planning, het instellen van herinneringen of het bedienen van apparaten
- Voortdurend verbeteren met behulp van leeralgoritmen en interactiegegevens van gebruikers
- Werkt asynchroon, reageert in real-time of wanneer getriggerd
Voorbeeld
Alexa kan muziek afspelen, herinneringen instellen en smart home-apparaten bedienen door spraakcommando's te interpreteren, verbinding te maken met cloud-gebaseerde systemen en de juiste acties uit te voeren.
🔍 Wist je dat? Utility-agents, die zich richten op het maximaliseren van uitkomsten door verschillende acties te evalueren, werken vaak samen met learning-agents in AI. Lerende agenten verfijnen hun strategieën na verloop van tijd op basis van ervaring en ze kunnen utility-based besluitvorming gebruiken om slimmere keuzes te maken.
Multi-agent systemen en speltheoretische toepassingen
Deze systemen bestaan uit meerdere op elkaar inwerkende agenten die samenwerken, concurreren of onafhankelijk van elkaar werken om individuele of collectieve doelen te bereiken.
Bovendien wordt hun gedrag in concurrerende scenario's vaak gestuurd door speltheoretische principes.
Kenmerken
- Vereist coördinatie of onderhandeling tussen agenten
- Werkt goed in dynamische en verdeelde omgevingen
- Simuleert of beheert complexe systemen zoals bevoorradingsketens of stadsverkeer
Voorbeeld
In het magazijnautomatiseringssysteem van Amazon werken robots (agents) samen om items te verzamelen, sorteren en transporteren. Deze robots communiceren met elkaar om botsingen te voorkomen en een soepele werking te garanderen. Speltheoretische principes helpen bij het beheren van concurrerende prioriteiten zoals het balanceren van snelheid en bronnen om ervoor te zorgen dat het systeem efficiënt werkt.
Toepassingen van lerende agenten
Leeragenten hebben veel industrieën getransformeerd door efficiëntie en besluitvorming te verbeteren.
Hier zijn enkele sleutel toepassingen. 📚
Robotica en automatisering**
Leeragenten vormen de kern van moderne robotica, waardoor robots autonoom en adaptief kunnen werken in dynamische omgevingen.
In tegenstelling tot traditionele systemen die voor elke Taak een gedetailleerde programmering vereisen, stellen leeragenten robots in staat zichzelf te verbeteren door interactie en feedback.
Hoe het werkt
Robots die zijn uitgerust met learning agents gebruiken technieken zoals reinforcement learning om te interageren met hun omgeving en de resultaten van hun acties te evalueren. Na verloop van tijd verfijnen ze hun gedrag, waarbij ze zich richten op het maximaliseren van beloningen en het vermijden van straffen.
Neurale netwerken gaan nog een stap verder en stellen robots in staat om complexe gegevens te verwerken, zoals visuele input of ruimtelijke lay-outs, waardoor geavanceerde besluitvorming mogelijk wordt.
Voorbeelden
- Autonome voertuigen: In de landbouw gebruiken leermiddelen autonome tractoren om door velden te navigeren, zich aan te passen aan variërende bodemvoorwaarden en het plant- of oogstproces te optimaliseren. Ze gebruiken real-time gegevens om de efficiëntie te verbeteren en verspilling tegen te gaan
- Industriële robots: In de productie stemmen robotarmen die zijn uitgerust met leeragenten hun bewegingen af om de precisie, efficiëntie en veiligheid te verbeteren, zoals in assemblagelijnen voor auto's
📖 Lees ook: AI-hacks die je sneller, slimmer en beter maken
Simulatie en agentgebaseerde modellen
Leeragenten sturen simulaties aan die een kosteneffectieve, risicoloze manier bieden om complexe systemen te bestuderen.
Deze systemen bootsen dynamieken uit de echte wereld na, voorspellen uitkomsten en optimaliseren strategieën door agenten te modelleren met verschillende gedragingen en aanpassingsmogelijkheden.
Hoe het werkt
Lerende agenten in simulaties observeren hun omgeving, testen acties en passen hun strategieën aan om de effectiviteit te maximaliseren. Ze leren voortdurend en verbeteren zich in de loop van de tijd, waardoor ze de resultaten kunnen optimaliseren.
Simulaties zijn zeer effectief in supply chain management, stedelijke abonnementen en robotica-ontwikkeling.
Voorbeelden
- Verkeersmanagement: Gesimuleerde agenten modelleren de verkeersstroom in steden. Hierdoor kunnen onderzoekers interventies zoals nieuwe wegen of rekeningrijden testen voordat ze worden geïmplementeerd
- Epidemiologie: In pandemische simulaties bootsen lerende agenten menselijk gedrag na om de verspreiding van ziekten te beoordelen. Het helpt ook bij het evalueren van de effectiviteit van beheersingsmaatregelen zoals sociale distantiëring
💡 Pro Tip: Optimaliseer de voorbewerking van gegevens in AI machinaal leren om de nauwkeurigheid en efficiëntie van lerende agenten te verbeteren. Invoer van hoge kwaliteit zorgt voor betrouwbaardere besluitvorming.
Intelligente systemen**
Leeragenten sturen intelligente systemen aan door real-time gegevensverwerking en aanpassing aan gedrag en voorkeuren van gebruikers mogelijk te maken.
Van slimme apparaten tot autonome schoonmaakapparaten, deze systemen transformeren de manier waarop gebruikers omgaan met technologie, waardoor alledaagse taken efficiënter en persoonlijker worden.
Hoe het werkt
Apparaten zoals de Roomba gebruiken sensoren en leermiddelen aan boord om de lay-out van het huis in kaart te brengen, obstakels te vermijden en schoonmaakroutes te optimaliseren. Ze verzamelen en analyseren voortdurend gegevens, zoals gebieden die vaak schoongemaakt moeten worden of de plaatsing van meubels, waardoor ze bij elk gebruik beter presteren.
Voorbeelden
- Slimme thuisapparaten: Thermostaten zoals Nest leren schema's en temperatuurvoorkeuren van gebruikers. Ze passen de instellingen automatisch aan om energie te besparen en het comfort te behouden
- Robotstofzuigers: De Roomba verzamelt veel datapunten per seconde. Dit leert hem om rond meubels te bewegen en drukke plekken te identificeren om efficiënt schoon te maken
Deze intelligente systemen benadrukken de praktische toepassingen van lerende agenten in het dagelijks leven, zoals het stroomlijnen van workflows en het verbeteren van de werkstroom het automatiseren van repetitieve taken voor verbeterde efficiëntie.
🔍 Wist je dat? Roomba verzamelt meer dan 230.400 gegevenspunten per seconde om je huis in kaart te brengen.
Internetforums en virtuele assistenten
Leeragenten zijn essentieel voor het verbeteren van online interacties en digitale assistentie. Ze stellen forums en virtuele assistenten in staat om gepersonaliseerde ervaringen te leveren.
Hoe het werkt
Learning agents modereren discussies op forums en identificeren en verwijderen spam of schadelijke content. Interessant is dat ze gebruikers ook relevante onderwerpen aanbevelen op basis van hun browsegeschiedenis. AI virtuele assistenten zoals Alexa en Google Assistant gebruiken leeragenten om natuurlijke taalinput te verwerken, waardoor hun contextueel begrip na verloop van tijd verbetert.
Voorbeelden
- **De moderatiebots van Reddit maken gebruik van leeragenten om berichten te scannen op regelovertredingen of giftig taalgebruik. Dergelijke op AI gebaseerde hygiëne houdt online gemeenschappen veilig en aantrekkelijk
- Virtuele assistenten: Alexa leert voorkeuren van gebruikers, zoals favoriete afspeellijsten of veelgebruikte commando's voor slimme huizen, om gepersonaliseerde en proactieve assistentie te verlenen
⚙️ Bonus: Leer
hoe u AI op uw werkplek kunt gebruiken
om productiviteit te verhogen en taken te stroomlijnen met intelligente agents.
Uitdagingen bij het ontwikkelen van lerende agenten
Het ontwikkelen van leeragenten brengt technische, ethische en praktische uitdagingen met zich mee, waaronder het ontwerp van algoritmen, computationele eisen en implementatie in de echte wereld.
Laten we eens kijken naar enkele sleuteluitdagingen waarmee AI-ontwikkeling geconfronteerd wordt terwijl het zich ontwikkelt. 🚧
Balanceren tussen exploratie en exploitatie
Lerende agenten worden geconfronteerd met het dilemma van het balanceren tussen exploratie en exploitatie.
Hoewel algoritmen zoals epsilon-greedy kunnen helpen, is het bereiken van de juiste balans sterk contextafhankelijk. Bovendien kan overmatige exploratie leiden tot inefficiëntie, terwijl overmatig vertrouwen op exploitatie suboptimale oplossingen kan opleveren.
Het beheren van hoge rekenkosten
Het trainen van geavanceerde leeragenten vereist vaak uitgebreide computationele middelen. Dit is meer van toepassing in omgevingen met complexe dynamica of grote toestandsactieruimten.
Vergeet niet dat algoritmen zoals versterkingsleren met neurale netwerken, zoals Deep Q-Learning, veel rekenkracht en geheugen vereisen. Je zult hulp nodig hebben om real-time leren praktisch te maken voor toepassingen met beperkte middelen.
Overwin schaalbaarheid en transfer learning
Het schalen van leeragenten om effectief te werken in grote, multidimensionale omgevingen blijft een uitdaging. Transfer learning, waarbij agents kennis van het ene domein toepassen op het andere, staat nog in de kinderschoenen.
Dit heeft hun vermogen om te generaliseren over verschillende Taken of omgevingen gelimiteerd.
📌 Voorbeeld: Een AI-agent die is getraind voor schaken zou moeite hebben met Go vanwege de enorm verschillende regels en doelstellingen, wat de uitdaging van het overbrengen van kennis tussen domeinen benadrukt.
Kwaliteit en beschikbaarheid van gegevens**
De prestaties van leeragenten zijn sterk afhankelijk van de kwaliteit en diversiteit van de trainingsgegevens.
Onvoldoende of bevooroordeelde gegevens kunnen leiden tot onvolledig of foutief leren en resulteren in suboptimale of onethische beslissingen. Bovendien kan het verzamelen van echte gegevens voor training duur en tijdrovend zijn.
⚙️ Bonus: Verken
om je begrip van andere agenten te vergroten.
Tools en bronnen voor het leren van agents
Ontwikkelaars en onderzoekers vertrouwen op verschillende hulpmiddelen om lerende agenten te bouwen en te trainen. Frameworks zoals TensorFlow, PyTorch en OpenAI Gym bieden een basisinfrastructuur voor het implementeren van machine learning algoritmen.
Deze tools helpen ook bij het creëren van gesimuleerde omgevingen. Sommige AI apps vereenvoudigen en verbeteren dit proces ook.
Voor traditionele benaderingen van machinaal leren blijven tools zoals Scikit-learn betrouwbaar en effectief.
Voor het beheren van AI onderzoeks- en ontwikkelingsprojecten,
ClickUp
biedt meer dan taakbeheer -fungeert als een gecentraliseerde hub voor het organiseren van taken, het bijhouden van voortgang en maakt naadloze samenwerking tussen teams mogelijk.
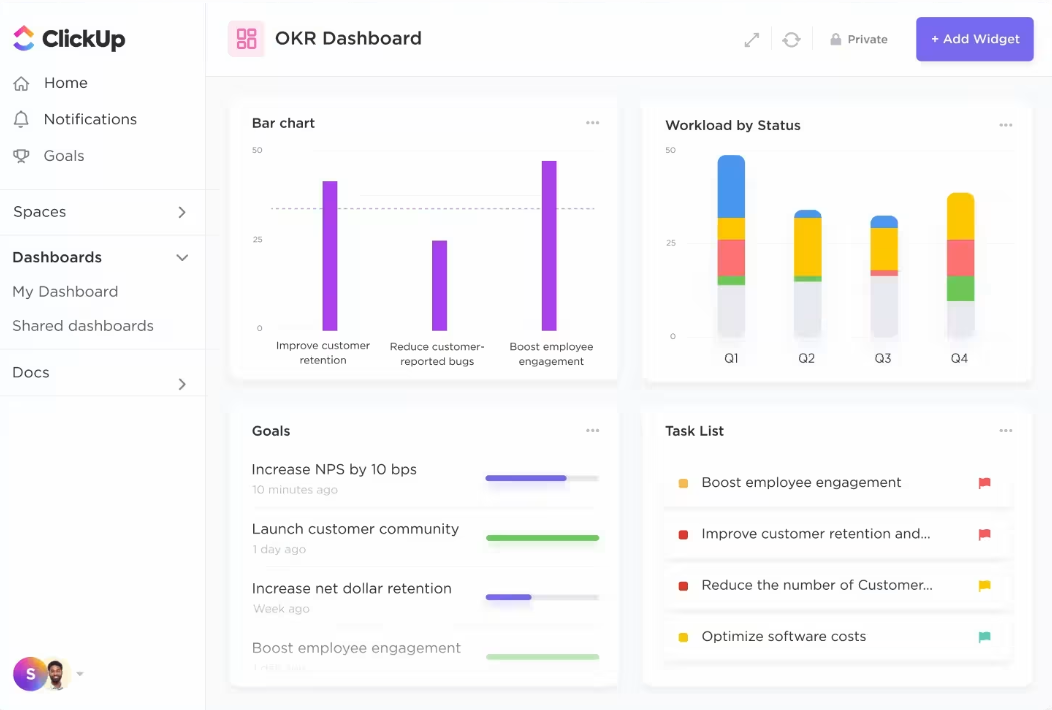
Gebruik ClickUp voor AI Projectmanagement om de output van uw team te verbeteren ClickUp voor AI projectmanagement vermindert handmatige inspanningen om de status van Taken te beoordelen en taken toe te wijzen.
In plaats van elke taak handmatig te controleren of uit te zoeken wie beschikbaar is, doet AI het zware werk. Het kan automatisch de voortgang bijwerken, knelpunten identificeren en de beste persoon voor elke taak voorstellen op basis van werklast en vaardigheden.
Op deze manier besteed je minder tijd aan vervelende beheerder en meer tijd aan wat belangrijk is: je projecten vooruit helpen.
Hier zijn enkele AI-functies die eruit springen. 🤩
ClickUp Brain
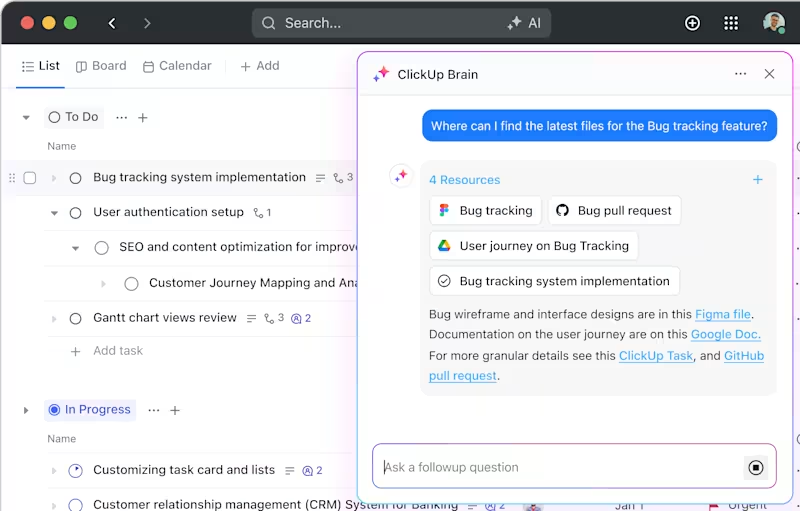
ClickUp Brein
, een AI-assistent die in het platform is ingebouwd, vereenvoudigt zelfs de meest complexe projecten. Het splitst uitgebreide studies op in beheersbare Taken en Subtaken, zodat u georganiseerd en op schema blijft.
Heb je snel toegang nodig tot experimentele resultaten of documentatie? Typ gewoon een query en ClickUp Brain haalt alles wat u nodig hebt binnen enkele seconden op. U kunt zelfs vervolgvragen stellen op basis van bestaande gegevens, waardoor het aanvoelt als uw persoonlijke assistent.
Bovendien koppelt het automatisch taken aan relevante bronnen, waardoor u tijd en moeite bespaart.
Stel dat je een onderzoek uitvoert naar hoe versterkingslerende agenten na verloop van tijd beter worden.
U hebt meerdere fasen - literatuuronderzoek, gegevensverzameling, experimenten en analyse. Met ClickUp Brain kunt u vragen: "Verdeel deze studie in taken", en er worden automatisch subtaakjes aangemaakt voor elke fase.
Je kunt het dan vragen om relevante papers over Q-learning op te halen of datasets over agentprestaties op te halen, wat het onmiddellijk doet. Terwijl u door de taken werkt, kan ClickUp Brain specifieke onderzoeksartikelen of resultaten van experimenten rechtstreeks aan de taken koppelen, zodat alles overzichtelijk blijft.
Of u nu onderzoekskaders of alledaagse projecten aanpakt, ClickUp Brain zorgt ervoor dat u slimmer werkt, niet harder.
ClickUp Automatiseringen**
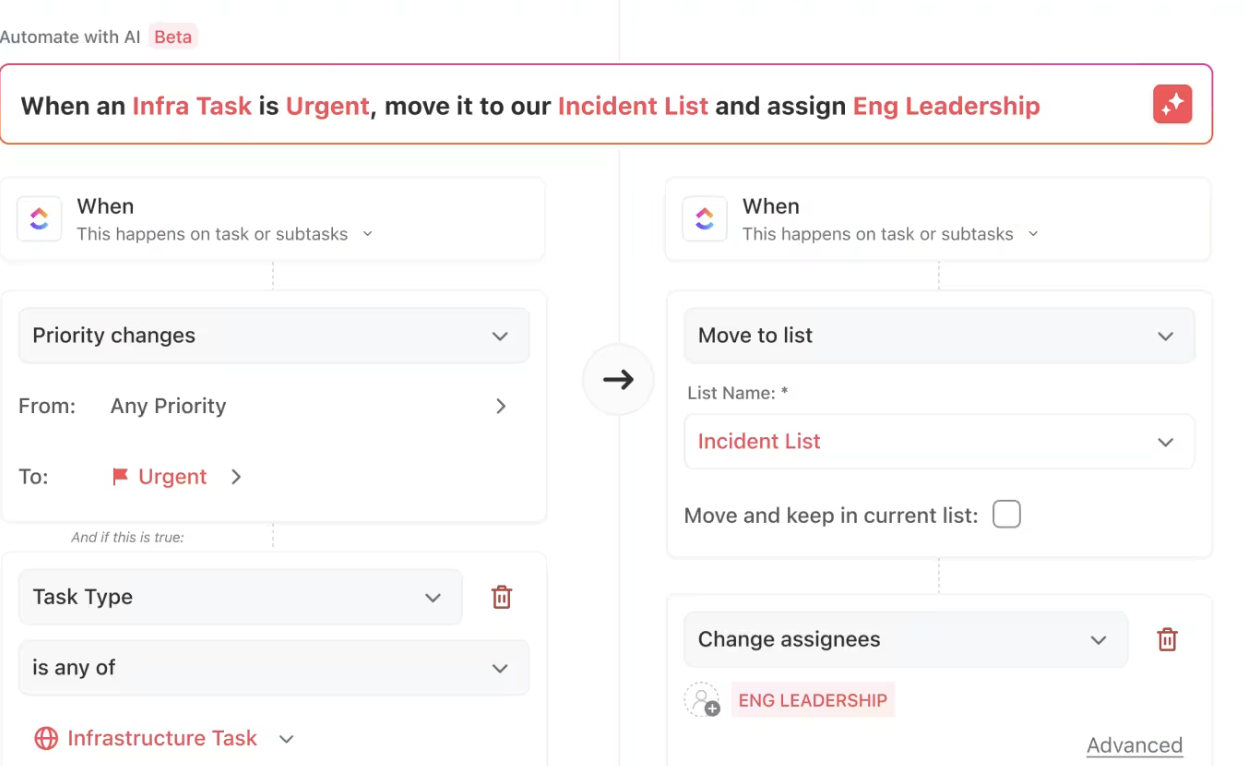
ClickUp-automatiseringen toepassen om de prioriteiten van taken, toegewezen personen en meer automatisch bij te werken ClickUp Automatiseringen is een eenvoudige maar krachtige manier om uw werkstroom te stroomlijnen.
Taken kunnen direct worden toegewezen zodra de eerste vereisten zijn voltooid, belanghebbenden worden geïnformeerd over mijlpalen in de voortgang en vertragingen worden gemarkeerd - en dat alles zonder handmatige tussenkomst.
Je kunt ook commando's in natuurlijke taal gebruiken, waardoor workflowbeheer nog eenvoudiger wordt. U hoeft zich niet te verdiepen in complexe instellingen of technisch jargon - vertel ClickUp gewoon wat u nodig hebt en het creëert de automatisering voor u.
Of het nu gaat om 'taken naar de volgende fase verplaatsen wanneer ze als Voltooid zijn gemarkeerd' of 'een taak aan Sarah toewijzen wanneer de prioriteit hoog is', ClickUp begrijpt uw verzoek en stelt het automatisch in.
📖 Lees ook: Hoe AI gebruiken voor productiviteit (Use Cases & Tools)
Ontwikkel leeragenten als een meester met ClickUp
Om AI-leeragenten te bouwen, hebt u een deskundige mix van gestructureerde werkstromen en adaptieve tools nodig. De extra vraag naar technische expertise maakt het des te uitdagender, vooral gezien de statistische en gegevensgebaseerde aard van dergelijke Taken.
Overweeg het gebruik van ClickUp om deze projecten te stroomlijnen. Deze tool ondersteunt niet alleen de organisatie, maar ook de innovatie van uw team door vermijdbare inefficiënties te verwijderen.
ClickUp Brain helpt complexe taken op te splitsen, relevante bronnen onmiddellijk op te halen en biedt inzichten op basis van ClickUp om uw projecten georganiseerd en op schema te houden. Ondertussen handelt ClickUp Automatiseringen repetitieve taken af, zoals het bijwerken van statussen of het toewijzen van nieuwe taken, zodat uw team zich kan concentreren op het grotere geheel.
Samen zorgen deze functies ervoor dat inefficiënties verdwijnen en uw team slimmer kan werken, waardoor innovatie en voortgang moeiteloos verlopen.
Aanmelden bij ClickUp
vandaag nog gratis. ✅