
Layanan pertama beberapa di antaranya mudah. Satu putaran, satu saluran, dan kemudian cadangan.
Namun, ketika perusahaan Anda memiliki puluhan microservices, beberapa wilayah, dan kepemilikan berlapis, eskalasi manual tidak lagi menjadi alur kerja yang efisien dan justru menjadi beban.
Panduan ini menjelaskan cara mengotomatisasi jalur eskalasi insiden yang dapat disesuaikan dengan pertumbuhan organisasi teknik Anda tanpa menimbulkan celah dalam sistem piket Anda.
Dan kita juga akan melihat bagaimana ClickUp dapat diintegrasikan ke dalam sistem eskalasi yang dapat diandalkan oleh tim teknik Anda. 🎯
⭐ Template Terpilih
Tanggapi dengan cepat dan efektif selama keadaan darurat, mulai dari bencana alam hingga pelanggaran data, menggunakan Template Rencana Tindakan Insiden (IAP) ClickUp.

Template ini menyediakan bagian-bagian yang telah ditentukan sebelumnya untuk:
- Tentukan tujuan insiden dan prioritas respons.
- Tetapkan struktur komando yang jelas
- Koordinasikan tindakan antar tim secara real-time.
- Catat keputusan, jadwal, dan pembaruan penting saat terjadi.
- Tetap terhubung dengan proses eskalasi dan tindak lanjut.
Dan karena terintegrasi dengan ClickUp, fitur ini berfungsi sebagai dokumen komando insiden real-time, bukan daftar periksa statis.
Mengapa Mengotomatisasi Jalur Eskalasi Insiden
Ketika tim Anda mengelola sistem kompleks dengan SLA yang ketat, eskalasi manual hanya akan memperlambat proses. Eskalasi otomatis membuat proses respons menjadi lebih terprediksi dan minim stres, bahkan saat menghadapi insiden yang menekan.
Inilah alasan mengapa Anda harus mengotomatisasi jalur eskalasi organisasi Anda. 👇
Risiko eskalasi manual
Ketika Anda harus menangani puluhan layanan, rotasi piket yang beragam, dan kepemilikan yang terus berubah, langkah-langkah yang dilakukan secara manual dengan cepat menjadi masalah.
Kesalahan umum meliputi:
- Notifikasi yang terlewat atau tertunda ketika seseorang melewatkan email, SMS, atau notifikasi chat.
- Kebingungan selama serah terima tugas, terutama ketika jalur eskalasi tidak didokumentasikan dengan jelas.
- Eskalasi ke tim yang salah karena peta kepemilikan tidak diperbarui
- Hambatan yang disebabkan oleh ketergantungan pada satu orang untuk 'mengirimkan peringatan ke tahap berikutnya'
📖 Baca Juga: Cara Menulis Laporan Insiden
Manfaat otomatisasi
Otomatisasi ITSM memberikan struktur dan momentum pada jalur eskalasi Anda. Alih-alih berharap seseorang melihat peringatan, sistem Anda akan menjalankan urutan yang telah ditentukan secara instan dan konsisten.
Inilah manfaat yang diperoleh tim saat menggunakan AI untuk mengotomatisasi tugas:
- Waktu respons yang lebih cepat karena peringatan mencapai orang atau tim yang tepat dalam hitungan detik.
- Pelaksanaan yang konsisten dari langkah-langkah eskalasi, bahkan pada pukul 3 pagi, ketika pengambilan keputusan menjadi lebih lambat.
- Redundansi bawaan yang memastikan tim cadangan menerima pemberitahuan jika tim piket utama melewatkan peringatan.
- Visibilitas yang jelas di seluruh tim karena semua orang memahami bagaimana proses eskalasi berlangsung.
- Kurangi penanganan darurat dan tingkatkan pengalaman piket yang lebih terprediksi.
📖 Baca Juga: Contoh Rencana Kelangsungan Bisnis
Mengurangi kelelahan akibat peringatan dan pengawasan manusia
Kelelahan akibat notifikasi merusak efektivitas tim jaga. Ketika tim Anda terlalu sering menerima notifikasi, atau untuk alasan yang salah, mereka berhenti merespons dengan segera. Otomatisasi membantu menyaring dan menaikkan prioritas hanya hal-hal yang benar-benar memerlukan perhatian manusia.
Dengan logika eskalasi otomatis:
- Peringatan dengan sinyal rendah atau duplikat akan ditekan sebelum mencapai tim piket.
- Aturan berdasarkan tingkat keparahan memastikan masalah minor tidak mengganggu seseorang secara tidak perlu.
- Peringatan hanya akan ditingkatkan jika sistem mendeteksi tidak ada respons dalam jangka waktu yang telah ditentukan.
- Tim menghabiskan lebih sedikit waktu untuk menyaring gangguan dan lebih banyak waktu untuk menyelesaikan masalah yang sebenarnya.
Mendukung kepatuhan terhadap SLA dan kebijakan piket
Eskalasi otomatis memudahkan untuk tetap mematuhi peraturan tanpa pengawasan manual yang terus-menerus. Bagi pemimpin operasi IT yang mengelola SLA yang ketat atau komitmen keandalan internal, AI berfungsi sebagai panduan yang memastikan perilaku yang diharapkan. Hal ini membantu Anda:
- Pastikan pemberitahuan insiden mengikuti aturan yang telah ditentukan untuk pengalihan.
- Jaga batas waktu respons SLA secara otomatis dengan eskalasi terjadwal.
- Terapkan jadwal piket tanpa bergantung pada spreadsheet yang sudah usang.
- Buat jejak audit untuk setiap peringatan, eskalasi, dan konfirmasi.
🎥 Ingin menjalankan seluruh alur kerja eskalasi secara otomatis? Super Agents siap membantu. 👇🏼
🔍 Tahukah Anda? Pusat Kendali Misi NASA pada dasarnya beroperasi berdasarkan logika eskalasi otomatis. Jika data telemetri keluar dari rentang normal, sistem secara instan meneruskan peringatan otomatis ke spesialis sesuai bidangnya.
Apa Itu Kebijakan Eskalasi dalam Manajemen Insiden?
Kebijakan eskalasi adalah kumpulan aturan yang telah ditentukan sebelumnya yang menentukan siapa yang akan diberitahu, kapan pemberitahuan dilakukan, dan bagaimana tanggung jawab dialihkan ke atas atau antar tim.
Bayangkan ini sebagai peta jalan terstruktur yang mencegah insiden terhenti, memastikan ahli yang tepat terlibat pada waktu yang tepat, dan membantu tim memenuhi SLA.
Sebuah kebijakan manajemen eskalasi yang terstruktur dengan baik biasanya mencakup:
- Routing berbasis aturan yang menentukan siapa yang selanjutnya bertanggung jawab ketika seseorang tidak merespons atau tidak dapat menyelesaikan insiden.
- Pemicu waktu yang secara otomatis mengeskalasi setelah 5, 15, atau 30 menit berdasarkan tingkat keparahan.
- Metode pemberitahuan seperti panggilan telepon, SMS, obrolan, atau email
- Tingkat rencana eskalasi dari Level 1 (piket utama) > Level 2 (insinyur senior/pakar bidang) > Level 3 (pimpinan).
- Harapan dokumentasi agar responden baru dapat mengambil alih tanpa kehilangan konteks kritis.
Jenis-jenis kebijakan eskalasi
Berikut adalah jenis kebijakan utama yang harus dipahami oleh tim Anda:
1. Eskalasi hierarkis (Vertikal)
Peringatan naik ke rantai komando, dari insinyur junior ke spesialis senior hingga pimpinan. Gunakan ini ketika situasi memerlukan keahlian yang lebih mendalam, wewenang pengambilan keputusan, atau visibilitas eksekutif.
2. Eskalasi fungsional (Horizontal)
Alih-alih naik ke atas, peringatan tersebut bergerak melintasi tim ke fungsi yang bertanggung jawab atas sistem yang terkena dampak. Hal ini ideal untuk insiden yang terkait dengan domain spesifik, seperti basis data, jaringan, pembayaran, atau API.
3. Eskalasi berdasarkan waktu
Ini merupakan inti dari sebagian besar sistem otomatis. Dalam jenis ini, peringatan akan diteruskan ke tingkat berikutnya setelah jangka waktu tertentu, seringkali terkait langsung dengan SLAs. Hal ini sangat penting terutama saat Anda membutuhkan respons yang terjamin di luar jam kerja.
4. Eskalasi berdasarkan dampak
Eskalasi berdasarkan dampak bergantung pada tingkat keparahan atau dampak bisnis, bukan hierarki atau waktu. Hal ini berguna untuk gangguan layanan, kegagalan pembayaran, masalah yang berdampak pada pelanggan, atau pelanggaran keamanan.
5. Eskalasi paralel
Di sini, beberapa orang atau tim diberitahu secara bersamaan. Eskalasi paralel digunakan untuk masalah dengan tingkat keparahan tinggi yang memerlukan keahlian khusus atau untuk situasi di mana penundaan apa pun tidak dapat diterima.
🔍 Tahukah Anda? Sebuah studi terbaru tentang sinyal peringatan menemukan bahwa peringatan yang sangat mencolok atau 'keras/terang' dapat memperlambat waktu respons, terutama jika peringatan tersebut tidak terduga. Namun, begitu jenis peringatan menjadi terduga (misalnya, bagian dari sistem eskalasi/notifikasi yang dirancang sebelumnya), waktu respons membaik. Hal ini menyarankan bahwa saat Anda mengotomatisasi jalur eskalasi, Anda tidak boleh membanjiri orang dengan peringatan prioritas tinggi.
Kapan Memicu Eskalasi Otomatis
Sekarang setelah Anda memahami struktur jalur eskalasi, langkah selanjutnya adalah menentukan kapan aturan-aturan ini harus dijalankan secara otomatis.
Berikut adalah situasi inti yang memicu eskalasi otomatis, membentuk lapisan logika di balik kebijakan Anda. 💁
Eskalasi berdasarkan tingkat keparahan
Eskalasi otomatis akan aktif ketika tingkat keparahan atau dampak insiden melebihi ambang batas tertentu. Insiden dengan tingkat keparahan tinggi memerlukan perhatian segera dari pihak berwenang, dan eskalasi otomatis akan melewati hambatan dan melibatkan ahli dalam hitungan detik.
📌 Contoh: Gangguan layanan penuh, kegagalan gerbang pembayaran, atau penurunan kinerja signifikan yang memengaruhi banyak pengguna atau sistem inti memerlukan eskalasi otomatis.
Eskalasi berdasarkan waktu
Jika tidak ada yang menanggapi atau menyelesaikan insiden dalam jendela waktu yang ditentukan, peringatan akan secara otomatis ditingkatkan ke tingkat berikutnya. Hal ini mencegah tiket terhenti, terutama di luar jam kerja normal, atau ketika penanggap pertama tidak tersedia atau kelebihan beban.
📌 Contoh: Setelah 10-15 menit tanpa tanggapan, insiden dinaikkan dari petugas pertama ke insinyur senior; setelah 30-60 menit lagi tanpa penyelesaian, insiden dinaikkan ke tingkat yang lebih tinggi.
Eskalasi kontekstual
Logika eskalasi ini mempertimbangkan atribut kontekstual insiden, seperti layanan atau sistem yang terkena dampak, pemilik layanan, segmen pelanggan yang terkena dampak (internal vs. eksternal, VIP vs. reguler), atau domain fungsional (database, jaringan, integrasi). Berdasarkan konteks tersebut, peringatan diarahkan ke penanggap atau tim yang paling relevan.
Di sini, Anda menghindari membebani tim dengan insiden yang tidak relevan, mengurangi waktu respons, dan memastikan spesialis menangani masalah di bidang keahlian mereka.
📌 Contoh: Peningkatan latensi pada layanan pembayaran harus langsung memberitahu tim pembayaran, atau kesalahan backend pada microservice penagihan harus memberitahu tim penagihan.
Eskalasi berbasis metadata
Alat peringatan dan insiden modern menangkap metadata seperti sumber asal (alat pemantauan atau aturan peringatan mana yang memicu insiden), identitas pengguna/pelanggan, lokasi, frekuensi historis insiden serupa, atau label. Hal ini memungkinkan Anda menerapkan logika yang lebih rinci dan cerdas daripada mengandalkan aturan keparahan atau waktu yang kasar.
📌 Contoh: Peringatan berulang dari subsistem yang sama mungkin menandakan masalah yang lebih mendalam dan sistemik, sehingga memerlukan eskalasi yang lebih cepat. Atau, peringatan untuk pelanggan VIP mungkin memicu pemberitahuan tambahan.
Menggabungkan pemicu untuk membangun kebijakan eskalasi yang lebih cerdas dan adaptif
Dalam praktiknya, banyak tim tidak hanya mengandalkan satu jenis pemicu. Sebaliknya, mereka membangun kebijakan eskalasi hibrida yang menggabungkan tingkat keparahan, waktu, konteks, dan aturan metadata.
Pendekatan berlapis ini memungkinkan tim untuk membuat kebijakan eskalasi yang responsif (cepat saat diperlukan) dan cerdas (selektif untuk meminimalkan gangguan), yang menghasilkan hasil insiden yang lebih baik dan alokasi sumber daya yang lebih efisien.
🔍 Tahukah Anda? Pada abad ke-18, awak kapal laut menggunakan rantai eskalasi yang ketat selama keadaan darurat. Jika seorang pelaut berpangkat rendah melihat bahaya, mereka membunyikan lonceng dan meneruskan pesan ke atas hierarki hingga kapten membuat keputusan akhir.
Cara Mendesain Jalur Eskalasi yang Efektif
Merancang jalur eskalasi melibatkan pembuatan sistem yang secara andal mengarahkan peringatan yang tepat ke orang yang tepat dengan gesekan minimal.
Berikut ini adalah kerangka kerja praktis, langkah demi langkah yang dapat Anda gunakan dalam lingkungan yang kompleks dan terdistribusi.
P.S. Kami juga akan membahas bagaimana fitur-fitur tertentu di ClickUp dapat membantu Anda di sini! 🤩
Langkah #1: Tentukan kriteria, tingkat, dan tanggung jawab eskalasi yang jelas
Mulailah dengan mendefinisikan apa yang dimaksud dengan insiden yang memerlukan eskalasi. Dokumenkan kriteria objektif sehingga setiap insinyur piket, baik yang baru menjadi penanggap L1 maupun SRE berpengalaman, menafsirkan tingkat keparahan insiden dengan cara yang sama.
Ini menyediakan alur kerja eskalasi yang jelas, menghilangkan ambiguitas, dan memastikan otomatisasi hanya aktif ketika benar-benar diperlukan.
Termasuk kriteria seperti:
- Ambang batas keparahan: Layanan tidak tersedia, kegagalan pembayaran, masalah autentikasi, kerusakan data, dan peringatan keamanan.
- Dampak: Gangguan layanan yang berdampak pada pelanggan, penurunan kualitas layanan internal, kegagalan API mitra, masalah kepatuhan, atau risiko keamanan.
- Kontekstual bisnis yang kritis: Dampak pada pelanggan bernilai tinggi, alur yang memengaruhi pendapatan, sistem berisiko tinggi (misalnya, pembayaran, penagihan).
Setelah kriteria dan pemicu ditentukan, tentukan siapa yang akan menerima pemberitahuan dan apa tanggung jawab mereka di setiap titik eskalasi.
Tentukan tingkat dengan jelas:
- Level satu (manajer insiden piket utama): Bertindak sebagai penanggap pertama dan bertanggung jawab atas konfirmasi, triase awal, dan upaya mitigasi.
- Level dua (cadangan/spesialis/pakar): Menyediakan keahlian teknis mendalam dan menyelesaikan masalah sistem yang kompleks.
- Level tiga (manajer teknik/pimpinan): Mengawasi insiden besar, menyetujui tindakan besar, mengoordinasikan komunikasi antar tim, dan memicu eskalasi vendor jika diperlukan.
🚀 Keunggulan ClickUp: Gunakan ClickUp Docs untuk menjaga sumber informasi tunggal yang akurat mengenai kriteria, tingkat, dan tanggung jawab eskalasi, serta mendokumentasikan peran dan tanggung jawab, termasuk siapa:
- Mengakui dan mengurangi
- Berkomunikasi dengan pemangku kepentingan
- Mengelola eskalasi dari vendor atau mitra eksternal
- Memimpin komando insiden
Anda juga dapat menghubungkan peran-peran spesifik ini dengan tugas-tugas ClickUp yang relevan untuk menjaga konteks tetap terhubung.
Bangun basis pengetahuan Anda sendiri:
Setelah kriteria eskalasi dan tanggung jawab ditetapkan, tim memerlukan cara yang konsisten untuk mencatat, melacak, dan menganalisis insiden teknis. Template Laporan Insiden ClickUp menyediakan sistem terstruktur dan mudah diakses untuk mendokumentasikan insiden IT dan operasional di satu tempat.
Dibangun di dalam ClickUp Docs, fitur ini membantu tim respons insiden mencatat detail kritis seperti tingkat keparahan insiden, layanan yang terdampak, garis waktu, ringkasan penyebab utama, langkah mitigasi, dan tindakan tindak lanjut.
Langkah #2: Standarisasi pembuatan insiden
Sebelum jalur eskalasi bahkan diaktifkan, tim Anda memerlukan cara yang andal untuk menangkap, menormalisasi, dan memperkaya data insiden. Jika catatan insiden awal tidak lengkap atau tidak konsisten, bahkan logika eskalasi yang paling canggih pun akan gagal.
Standarisasi harus:
- Saring peringatan masuk: Ubah peringatan menjadi bidang kustom yang konsisten seperti tingkat keparahan, kategori, layanan yang terdampak, jenis insiden, dan status konfirmasi.
- Otomatiskan pengayaan insiden: Impor metadata, termasuk kluster, ID deployment, pemilik layanan, atau ketergantungan.
- Pastikan setiap insiden mencatat konteks: Catat siapa yang melaporkannya, bagaimana insiden tersebut terdeteksi, lingkungan (produksi/staging), dan log atau tangkapan layar yang relevan.
Buat formulir ClickUp langsung dari daftar tempat insiden dilacak dan desainnya agar mencerminkan realitas operasional Anda serta data relevan yang menjadi dasar logika eskalasi Anda. Dengan cara ini, alih-alih pesan yang terfragmentasi di chat, email, atau dashboard, setiap insiden masuk ke sistem Anda dalam format yang konsisten sehingga otomatisasi dapat bertindak dengan andal.

Grupkan bidang secara sengaja agar setiap insiden sepenuhnya dikontekstualisasikan:
- Identifikasi (judul, ringkasan)
- Klasifikasi (tingkat keparahan, jenis, layanan yang terdampak)
- Sumber (pemantauan, pengguna, API)
- Bukti (log, tangkapan layar)
- Kontekstual bisnis (tingkat SLA, dampak pelanggan)
Setiap pengiriman formulir secara otomatis membuat tugas baru di ClickUp, dengan semua respons dipetakan ke Bidang Kustom ClickUp. Hal ini memastikan bahwa insiden dinormalisasi pada saat pembuatan, menghilangkan ambiguitas, dan menghilangkan kebutuhan akan respons insiden manual.
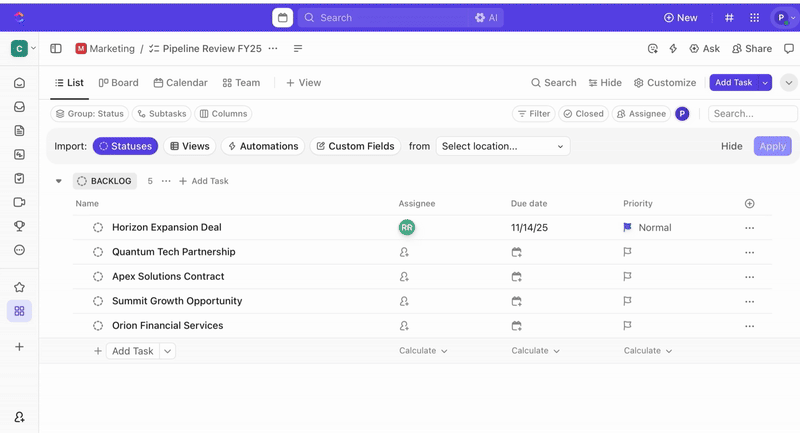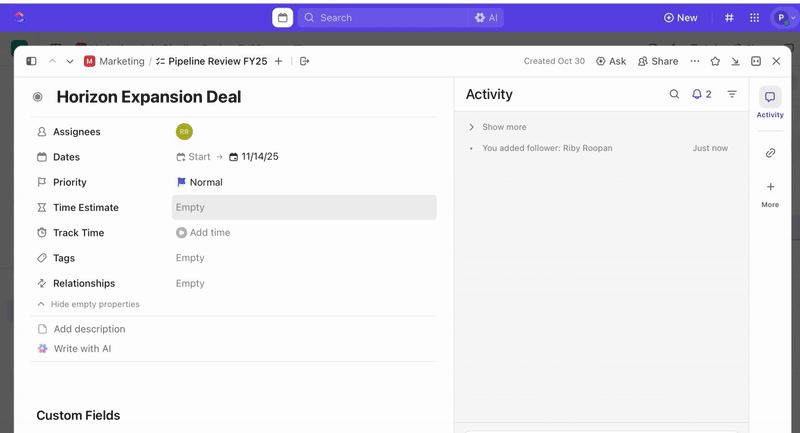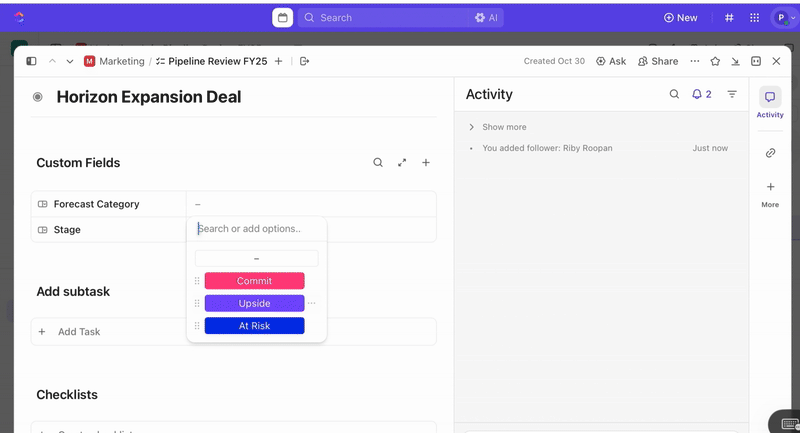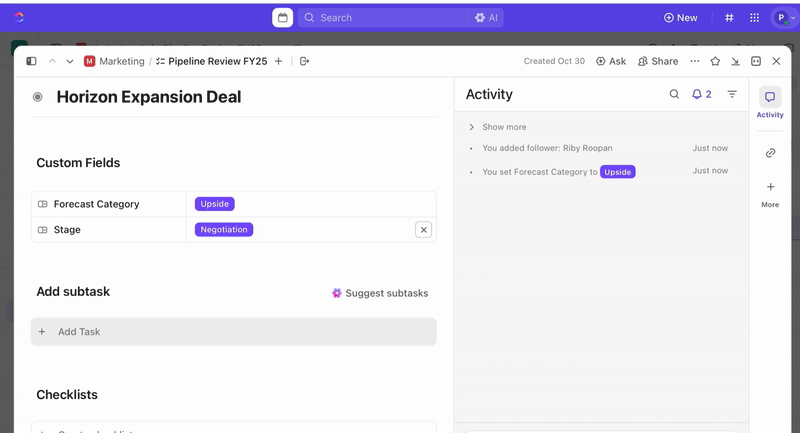
Setelah tugas dibuat, Anda dapat menggunakan Bidang Kustom untuk mengelola triase dan prioritas (misalnya, tingkat keparahan, dampak, grup penanggap), serta mendefinisikan Status Kustom ClickUp yang mencerminkan tahap insiden Anda (Baru > Triase > Penyelidikan > Mitigasi > Selesai).
Langkah #3: Bangun jalur eskalasi (yaitu, urutan + waktu + saluran)
Ini adalah inti dari jalur tersebut. Susun jalur tersebut secara bertahap, di mana setiap tahap menentukan siapa yang akan diberitahu, melalui saluran apa, dan setelah berapa lama tanpa ada konfirmasi atau penyelesaian.
- Tentukan ‘batas waktu konfirmasi’ dan ‘batas waktu penyelesaian’.
Berikut adalah contoh alur kerja:
- Tahap satu: Petugas jaga pertama yang dihubungi melalui SMS/saluran obrolan harus memberikan konfirmasi dalam waktu 5-10 menit.
- Tahap dua: Jika tidak ada konfirmasi atau tindakan dalam 15-20 menit ke depan, eskalasikan ke tim cadangan/SRE + insinyur senior melalui SMS/saluran obrolan/email.
- Tahap tiga: Jika masih belum terselesaikan setelah 30-60 menit tambahan, eskalasikan ke manajer teknik/pimpinan dan secara opsional aktifkan saluran 'insiden besar'.
- Tentukan apakah jalur eskalasi harus 'diulang' (memberikan pemberitahuan ulang ke tingkat yang sama) atau 'dilanjutkan ke tingkat berikutnya'.
- Untuk insiden kritis, atur pemberitahuan berulang hingga ada yang merespons. Untuk insiden prioritas rendah, Anda mungkin ingin menggunakan alur eskalasi tunggal.
- Pastikan jalur tersebut didokumentasikan menggunakan templat respons layanan pelanggan dan dapat diakses oleh semua personel yang relevan.
❗️ Catatan: ‘Waktu tunggu konfirmasi’ adalah lama waktu yang dimiliki oleh penanggap pertama untuk mengonfirmasi bahwa mereka telah melihat peringatan, sementara ‘waktu tunggu penyelesaian’ adalah lama waktu yang dimiliki oleh tim untuk memperbaiki atau mengatasi masalah sebelum eskalasi berikutnya dimulai.
Langkah #4: Terapkan otomatisasi dan dukungan alat
Setelah kriteria, proses triase, dan standar pengayaan Anda ditetapkan, langkah berikutnya adalah mengaktifkan eskalasi tanpa bergantung pada manusia untuk mengingat kapan atau kepada siapa eskalasi harus dilakukan. Di sinilah ClickUp Automations menjadi bagian inti dari alur kerja Anda.

Anda dapat mengatur peluang otomatisasi yang merespons sinyal yang sama yang digunakan tim Anda selama insiden. Berikut beberapa contoh:
- Jika tingkat keparahan ditingkatkan menjadi SEV-1 ➡️ Segera tugaskan SRE senior + beritahukan saluran obrolan piket.
- Jika status tetap tidak berubah selama X menit ➡️ Memicu eskalasi ke tingkat berikutnya
- Jika batas waktu terlampaui (misalnya, batas waktu konfirmasi) ➡️ Eskalasi ke L2
Dan inilah di mana ClickUp Brain membawa hal ini ke level yang lebih tinggi. Ia menggunakan konteks dari ruang kerja Anda untuk memberikan jawaban instan, menghasilkan pembaruan secara otomatis, dan mendukung akses ke pengetahuan.
Gunakan alat seperti AI Prioritize untuk secara otomatis mengevaluasi insiden dan menetapkan Prioritas yang tepat menggunakan logika Anda sendiri. Contoh prompt:
- Jika insiden mempengaruhi produksi dan berdampak pada pelanggan, tetapkan Prioritas: Urgent
- Jika penanggung jawab adalah tim SRE dan log menyebutkan 'latency', tetapkan Prioritas: Tinggi
- Jika deskripsi mengandung kata kunci keamanan seperti 'pelanggaran', tetapkan Prioritas: Urgent
Dan, setelah prioritas ditetapkan, AI Assign mengambil alih dan secara otomatis mengalokasikan insiden berdasarkan kondisi yang Anda tentukan.
Anda dapat membuat prompt seperti:
- Jika Prioritas adalah Urgent dan layanan yang terdampak mengandung 'pembayaran', alokasikan ke Senior SRE.
- Jika jenis insiden adalah database dan wilayahnya adalah US-East, alokasikan ke DB On-Call.
- Jika nama tugas mengandung kata 'keamanan', berikan tugas tersebut kepada Pemimpin SecOps.
Uji prompt ini pada tiga tugas pertama sebelum diterapkan ke seluruh daftar.
🚀 Keunggulan ClickUp: Deploy bot otomatisasi cerdas yang beroperasi di dalam Workspace Anda dan merespons aktivitas real-time dengan ClickUp Super Agents.
Mereka sepenuhnya memahami tugas, dokumen, obrolan, dan proses Anda, sehingga setiap tindakan otomatis dilakukan secara kontekstual.
Misalnya, Anda dapat menempatkan Team StandUp Agent di folder 'Production Incidents' sehingga secara otomatis memposting ringkasan harian setiap pagi. Tim Anda akan menerima gambaran instan yang menunjukkan jumlah insiden yang dibuka, insiden mana yang belum terselesaikan, dan perubahan apa yang terjadi dalam 24 jam terakhir.
Sekarang padukan dengan Ambient Answers Agent di saluran ‘#incident-room’ Anda. Ketika tim respons bertanya, misalnya, ‘Di mana runbook SEV-1?’ atau ‘Apakah API ini pernah gagal sebelumnya?’, agen ini akan mengambil informasi dari pengetahuan workspace Anda untuk memberikan respons instan dan akurat.

Langkah #5: Standarkan saluran komunikasi
Saat insiden meningkat, cara dan tempat tim berkomunikasi sama pentingnya dengan siapa yang diberitahu. Tanpa saluran yang terstandarisasi, pembaruan informasi hilang, keputusan diulang, dan pemangku kepentingan menerima informasi yang bertentangan.
Tentukan saluran eskalasi yang jelas untuk setiap tahap siklus hidup insiden, dan gunakan secara konsisten di seluruh tim:
| Kriteria | Nama saluran | Tujuan |
| SEV-1 atau SEV-2 terdeteksi | #insiden-kritis | Ruangan pusat untuk peringatan tingkat tinggi dan triase segera. |
| Pemeriksaan masalah sedang berlangsung | #ruang-kendali-insiden | Platform kolaborasi real-time untuk insinyur, tim produk, QA, dan dukungan. |
| Diperlukan visibilitas kepemimpinan | #pemimpin-insiden | Pembaruan penting untuk manajer dan eksekutif |
| Komunikasi dengan pelanggan diperlukan | #incident-comms | Ruangan untuk menyusun, meninjau, dan menyelaraskan komunikasi dengan pelanggan eksternal. |
| Rapat evaluasi pasca-insiden telah dimulai | #incident-retro | Diskusi terstruktur untuk catatan retrospektif, pembelajaran, dan tindakan yang perlu dilakukan. |
Setiap saluran memiliki audiens dan tujuan yang telah ditentukan, membantu tim mengurangi kebisingan sambil tetap menjaga tim yang relevan tetap terinformasi.
🚀 Keunggulan ClickUp: Sesuaikan strategi saluran komunikasi Anda dengan lapisan komunikasi bawaan menggunakan ClickUp Chat. Setiap pemberitahuan, pembaruan, dan keputusan tetap terhubung langsung dengan Tugas, Daftar, atau Ruang Insiden tempat pekerjaan dilakukan.
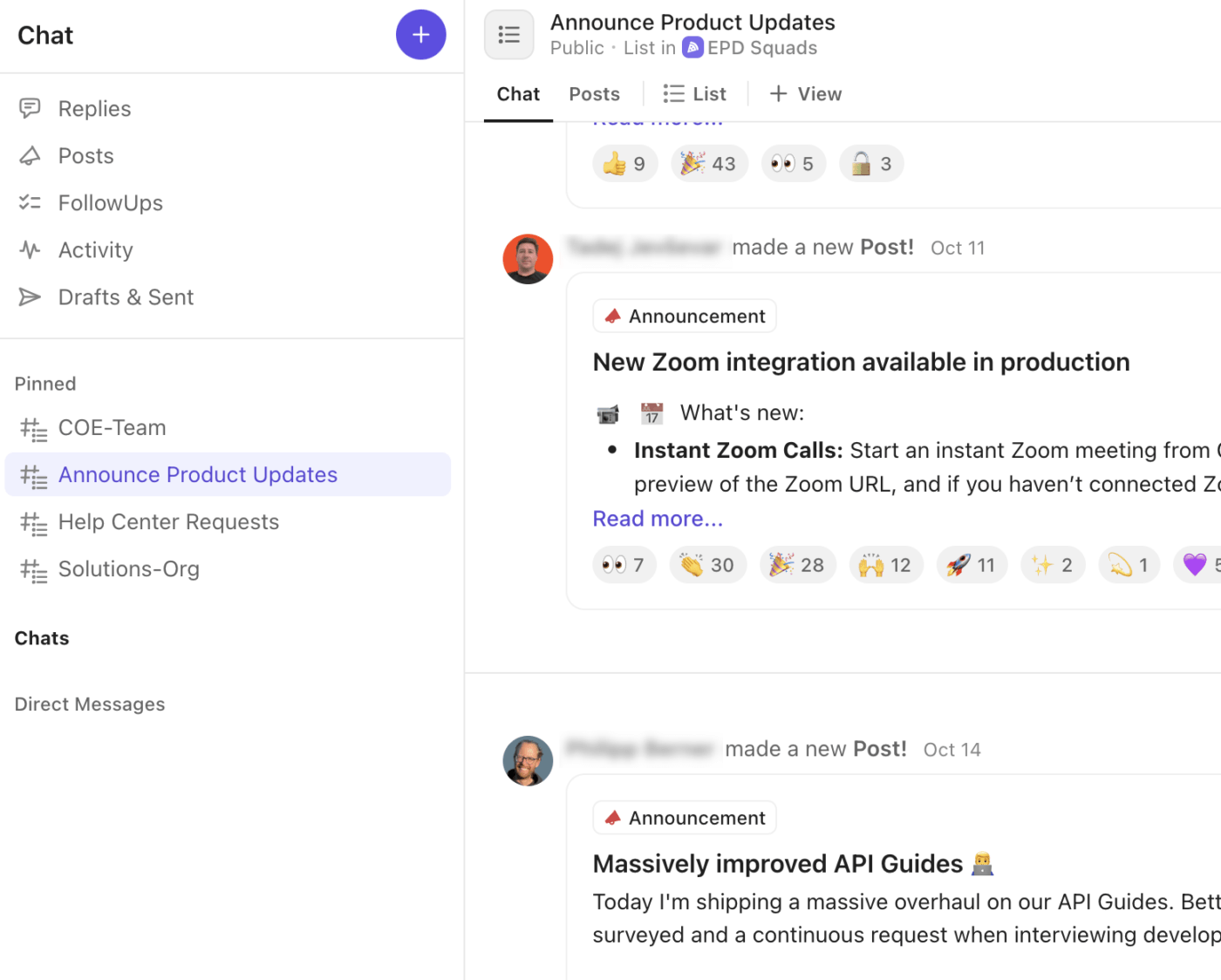
Begini cara ClickUp Chat meningkatkan alur kerja insiden Anda:
- Buat thread obrolan khusus untuk diskusi kritis, ruang komando, kepemimpinan, atau komunikasi dengan pelanggan.
- Ubah pesan obrolan menjadi Tugas ClickUp secara instan, memastikan keputusan dan tindak lanjut tidak hilang dalam percakapan.
- Ikuti panggilan audio atau video cepat dengan ClickUp SyncUps untuk koordinasi insiden secara langsung atau briefing kepemimpinan.
- Posting 'Pengumuman' atau pembaruan untuk menyiarkan status insiden tingkat tinggi di seluruh perusahaan.
- Tag rekan tim, lampirkan tangkapan layar, dan lampirkan log langsung di obrolan, menjaga konteks teknis tetap dekat.
Langkah #6: Uji, audit, dan sempurnakan jalur eskalasi Anda
Kebijakan eskalasi harus berkembang seiring dengan sistem Anda. Berikut adalah hal-hal yang harus Anda lakukan secara rutin:
| Aktivitas | Apa yang perlu diuji atau ditinjau | Mengapa hal ini penting |
| Latihan siaga (triwulanan) | Simulasikan insiden P1 dan P2, verifikasi waktu dan rute eskalasi. | Memastikan otomatisasi dan jalur eskalasi berfungsi dengan baik di bawah tekanan. |
| Validasi jalur eskalasi | Periksa apakah ada eskalasi yang buntu atau pemilik yang tidak teridentifikasi. | Mencegah insiden terhenti tanpa visibilitas |
| Penghargaan & timer proses penyelesaian | Bandingkan timer yang dikonfigurasi dengan MTTA dan MTTR aktual. | Menjaga waktu eskalasi tetap realistis dan efektif. |
| Penilaian kelelahan peringatan | Identifikasi tim respons yang menerima peringatan berlebihan atau berulang. | Mengurangi kelelahan dan kehilangan peringatan kritis. |
| Ketepatan tingkat keparahan dan prioritas | Periksa apakah insiden telah diklasifikasikan dengan benar. | Meningkatkan rute pengalihan, kecepatan respons, dan akurasi eskalasi. |
| Tindak lanjut pasca insiden | Pastikan tindakan yang diidentifikasi dalam retrospeksi diselesaikan. | Mencegah insiden berulang dan kegagalan sistemik. |
Alat & Integrasi untuk Otomatisasi Eskalasi
Bagian ini akan memandu Anda melalui perangkat lunak manajemen insiden yang membantu Anda mendeteksi insiden lebih cepat, meneruskannya secara instan, dan menjaga semua tim tetap terinformasi tanpa perlu tindak lanjut manual.
1. ClickUp (Terbaik untuk mengintegrasikan eskalasi lintas fungsi ke dalam satu ruang kerja insiden yang terhubung)
Metode eskalasi tradisional memaksa tim untuk mengelola email, spreadsheet, obrolan, dan catatan yang tersebar, sehingga hampir tidak mungkin untuk mendapatkan gambaran yang jelas dan real-time tentang apa yang sedang terjadi.
Perangkat Lunak Manajemen Tugas ClickUp untuk Manajemen Eskalasi menghilangkan kerumitan dengan mengonsolidasikan semua detail eskalasi ke dalam satu ruang kerja yang terorganisir.
Mari kita lihat beberapa fitur perangkat lunak manajemen aset IT yang menjadikan ClickUp sebagai pilihan utama bagi tim yang mengelola eskalasi volume tinggi dan alur kerja insiden yang kompleks.
Kerjakan sesuai cara Anda
Visualisasikan tugas Anda dari berbagai sudut pandang untuk menyesuaikan kebutuhan operasional Anda dengan ClickUp Views:
- Gunakan Tampilan Daftar ClickUp agar pemimpin SRE dapat mengurutkan insiden berdasarkan tingkat keparahan, sisa waktu SLA, atau grup piket untuk triase cepat.
- Gunakan tampilan papan ClickUp untuk memungkinkan manajer teknik memvisualisasikan serah terima dan tanggung jawab tim selama proses eskalasi.
- ClickUp Gantt View untuk pemimpin program untuk memetakan tonggak penyelesaian dan ketergantungan antar layanan.
- ClickUp Workload View untuk penjadwal piket yang memastikan insinyur tidak kelebihan beban selama jendela insiden dengan volume tinggi.
Ubah diskusi rapat menjadi tindakan
Selama proses eskalasi dan tinjauan insiden, mencatat diskusi dan poin tindakan secara andal dapat menjadi tantangan. ClickUp AI Notetaker secara otomatis bergabung dalam pertemuan yang dijadwalkan di Google Calendar, Outlook, Zoom, atau Teams, merekam dan menerjemahkan percakapan.
Setelah pertemuan:
- Akses transkrip yang dapat dicari dan ringkasan tindakan.
- Pastikan kejelasan dengan menggunakan catatan yang disimpan di ClickUp Docs. Hal ini memudahkan untuk menghubungkan kembali ke tugas insiden atau laporan retrospektif.
- Tanyakan pertanyaan kepada ClickUp AI tentang konten rapat untuk mengklarifikasi keputusan atau mengidentifikasi tindak lanjut yang terlewat.
Hubungkan dengan alat yang sudah ada dalam stack teknologi Anda
Di balik layar, integrasi ClickUp dan ekosistem Webhooks memastikan konektivitas yang mulus dengan sisa sistem Anda.
Platform ini terintegrasi secara native dengan alat seperti Slack, GitHub, Zoom, dan lainnya, serta mendukung Webhooks melalui API Publiknya untuk menyiarkan peristiwa (perbaruan tugas dan perubahan status) ke layanan eksternal atau alur kerja otomatisasi. Hal ini memudahkan untuk memicu alur kerja, menyinkronkan data, atau mengeskalasi insiden antar sistem tanpa perlu pengalihan manual.
Integrasikan semua alat AI Anda
Untuk membawa otomatisasi dan konteks ke level berikutnya, ClickUp BrainGPT menghadirkan kecerdasan buatan kontekstual di seluruh alur kerja eskalasi Anda. Ini adalah aplikasi kecerdasan buatan kontekstual yang memahami tugas Anda, dokumen, dan konteks historis.
Dengan Enterprise Search dan Connected Apps, Anda dapat dengan cepat mengakses informasi dari ruang kerja Anda, Slack, Google Drive, GitHub, dan lainnya. Selama panggilan insiden langsung, fitur Talk-to-Text di ClickUp memungkinkan Anda mendikte catatan eskalasi atau instruksi tanpa menggunakan tangan, memastikan tidak ada yang terlewat.
Anda juga dapat mensistematisasikan tugas-tugas yang dapat diulang dengan Custom AI Prompts dan Saved Prompts, seperti: ‘Ringkas semua insiden yang belum terselesaikan dan rekomendasikan tindakan eskalasi.’
Fitur terbaik ClickUp
- Prioritaskan masalah kritis: Gunakan Prioritas Tugas ClickUp untuk menyoroti eskalasi yang mendesak atau berdampak tinggi.
- Organisir urutan eskalasi yang kompleks: Atur Ketergantungan Tugas ClickUp untuk menghubungkan tugas-tugas terkait (misalnya, ‘Menunggu’ atau ‘Menghalangi’) sehingga langkah-langkah eskalasi menghindari tindakan prematur atau kemacetan.
- Pecah insiden menjadi bagian-bagian yang dapat ditindaklanjuti: Pecah eskalasi menjadi tugas-tugas yang lebih detail dan bagikan ke tim-tim dengan menggunakan Subtugas Bersarang.
- Pantau kecepatan penyelesaian dengan akurat: Catat dan pantau berapa lama tugas eskalasi membutuhkan waktu untuk diakui dan diselesaikan menggunakan fitur Pelacakan Waktu Proyek ClickUp.
Batasan ClickUp
- Dengan begitu banyak fitur, tampilan, dan opsi penyesuaian, tim sering menghadapi kurva pembelajaran sebelum semuanya terasa intuitif.
Harga ClickUp
[Tabel harga]
Ulasan dan penilaian ClickUp
- G2: 4. 7/5 (10.300+ ulasan)
- Capterra: 4.6/5 (4.400+ ulasan)
Apa yang dikatakan pengguna nyata tentang ClickUp?
Ulasan ini benar-benar menggambarkan semuanya:
ClickUp mengumpulkan semua tugas, proyek, dan komunikasi saya dalam satu tempat, sehingga sangat mudah untuk tetap terorganisir. Saya menyukai betapa fleksibelnya semuanya—mulai dari tampilan, alur kerja, hingga dasbor—sehingga saya dapat mengatur ruang kerja sesuai kebutuhan. Kemampuan untuk berkolaborasi secara real-time, menugaskan tugas, dan melacak kemajuan tanpa perlu berganti alat adalah keuntungan besar.
ClickUp mengumpulkan semua tugas, proyek, dan komunikasi saya dalam satu tempat, sehingga sangat mudah untuk tetap terorganisir. Saya menyukai betapa fleksibelnya semuanya—mulai dari tampilan, alur kerja, hingga dasbor—sehingga saya dapat mengatur ruang kerja sesuai kebutuhan. Kemampuan untuk berkolaborasi secara real-time, menugaskan tugas, dan melacak kemajuan tanpa perlu berganti alat adalah keuntungan besar.
📮 ClickUp Insight: 21% orang mengatakan lebih dari 80% waktu kerja mereka dihabiskan untuk tugas-tugas berulang. Dan 20% lainnya mengatakan tugas-tugas berulang menghabiskan setidaknya 40% waktu mereka.
Itu hampir setengah dari waktu kerja (41%) yang dihabiskan untuk tugas-tugas yang tidak memerlukan banyak pemikiran strategis atau kreativitas (seperti email tindak lanjut 👀).
Super Agents ClickUp membantu menghilangkan rutinitas yang membosankan. Bayangkan pembuatan tugas, pengingat, pembaruan, catatan rapat, penulisan email, dan bahkan pembuatan alur kerja end-to-end! Semua itu (dan lebih banyak lagi) dapat diotomatisasi dengan cepat menggunakan ClickUp, aplikasi serba guna untuk pekerjaan Anda.
💫 Hasil Nyata: Lulu Press menghemat 1 jam per hari per karyawan dengan menggunakan ClickUp Automations—mengakibatkan peningkatan efisiensi kerja sebesar 12%.
2. PagerDuty (Terbaik untuk pemberitahuan real-time dan respons piket yang cerdas)
PagerDuty adalah platform manajemen insiden IT berbasis cloud dan platform operasi digital yang membantu tim mendeteksi, merespons, dan menyelesaikan insiden kritis seperti gangguan layanan atau ancaman keamanan dengan cepat. Platform ini memberikan pemimpin SRE, DevOps, dan dukungan teknis jalur yang jelas dari deteksi hingga penyelesaian, didukung oleh otomatisasi, triase berbasis AI, dan alur kerja yang terintegrasi secara mendalam.
Fitur seperti Jeli Incident Analysis, PagerDuty Analytics, dan Runbook Automation membantu tim mengurangi waktu henti, menghilangkan tugas rutin, dan belajar dari setiap insiden.
Fitur terbaik PagerDuty
- Otomatiskan rute insiden dengan fitur bawaan Pengelolaan Piket dan kebijakan eskalasi dinamis Escalation Policies.
- Percepat proses triase menggunakan AIOps, yang menyaring kebisingan peringatan, mengkorelasikan peristiwa, dan menyoroti sinyal yang sebenarnya.
- Jaga agar pemangku kepentingan internal dan eksternal tetap selaras dengan Stakeholder Comms, Status Update Templates, dan Status Pages.
- Sinkronkan alat-alat Anda dengan lebih dari 700 integrasi dan API yang dapat diperluas menggunakan sistem pemantauan, pencatatan, CI/CD, dan dukungan.
Batasan PagerDuty
- Volume peringatan yang tinggi jika integrasi dan ambang batas cerdas tidak disesuaikan, yang dapat menyebabkan kebisingan dan kelelahan.
- Peringatan ganda atau berulang mungkin terjadi selama lonjakan, sehingga membuat konfirmasi menjadi lebih sulit di bawah tekanan.
Harga PagerDuty
- Gratis
- Profesional: $25/bulan per pengguna
- Bisnis: $49/bulan per pengguna
- Enterprise: harga khusus
Ulasan dan penilaian PagerDuty
- G2: 4.5/5 (900+ ulasan)
- Capterra: 4.6/5 (200+ ulasan)
Apa yang dikatakan pengguna nyata tentang PagerDuty?
Seperti yang dikatakan oleh seorang pengguna nyata:
PagerDuty membuat pemberitahuan insiden menjadi cepat dan andal. Ia mengirimkan pemberitahuan yang tepat pada waktu yang tepat dan menjaga tim kami tetap terorganisir. […] PagerDuty terkadang terasa berisik ketika pemberitahuan tidak difilter dengan baik. Beberapa pengaturan agak rumit bagi pengguna baru.
PagerDuty membuat pemberitahuan insiden menjadi cepat dan andal. Ia mengirimkan pemberitahuan yang tepat pada waktu yang tepat dan menjaga tim kami tetap terorganisir. […] PagerDuty terkadang terasa berisik ketika pemberitahuan tidak difilter dengan baik. Beberapa pengaturan agak rumit bagi pengguna baru.
💡 Tips Pro: Buat pengecualian, bahkan dalam jalur eskalasi yang jelas. Biarkan gangguan kritis, peringatan keamanan, atau insiden di lingkungan yang diatur langsung diteruskan ke penanggap senior atau spesialis.
3. GLPi (Pilihan terbaik untuk pengelolaan aset end-to-end dan operasi layanan yang selaras dengan ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) adalah platform manajemen layanan TI (ITSM) dan manajemen aset TI (ITAM) sumber terbuka yang lengkap. Tim dapat memantau infrastruktur mereka secara end-to-end (perangkat keras, perangkat lunak, lisensi, dan perangkat jaringan) serta mengelola insiden, permintaan layanan, dan perubahan menggunakan proses yang selaras dengan ITIL.
Semua kontrak dan dokumen Anda, termasuk garansi dan perjanjian layanan, tetap terorganisir dengan rapi, sehingga tidak tersebar di berbagai sistem. Jika Anda mengelola pusat data, GLPi bahkan memungkinkan Anda untuk memvisualisasikan tata letak, jalur kabel, dan penggunaan energi, sehingga Anda selalu tahu apa yang terjadi di balik layar.
Fitur terbaik GLPi
- Gunakan plugin GLPI Inventory, OCS Inventory, atau FusionInventory untuk secara otomatis mendeteksi dan mendokumentasikan aset IT baru.
- Otomatiskan tugas-tugas berulang, penugasan tiket, pemberitahuan, dan acara berulang untuk mengurangi pekerjaan manual.
- Bangun basis pengetahuan untuk FAQ, dokumentasi, dan artikel yang terhubung dengan tiket untuk layanan mandiri dan dukungan teknisi.
- Hubungkan dengan Azure/Entra, Centreon, Google, OAuth2, dan webhooks untuk mensinkronkan data, memicu alur kerja, dan meningkatkan CMDB Anda.
Batasan GLPi
- Kompatibilitas plugin dapat terganggu antar versi, menyebabkan beban pemeliharaan.
- Fitur pelaporan, analitik, dan ekspor terasa terbatas dan memerlukan perbaikan.
Harga GLPi
- Harga khusus
Ulasan dan penilaian GLPi
- G2: 4. 6/5 (30+ ulasan)
- Capterra: 4.5/5 (40+ ulasan)
Apa yang dikatakan pengguna nyata tentang GLPi?
Inilah yang dikatakan oleh salah satu pengguna:
Sistem manajemen aset IT dan tiket dukungan sumber terbuka yang sangat dapat disesuaikan dengan komunitas pendukung yang besar. Antarmuka pengguna agak rumit bagi pemula. Plugin tidak selalu didukung dari versi lama ke versi baru.
Sistem manajemen aset IT dan tiket dukungan sumber terbuka yang sangat dapat disesuaikan dengan komunitas pendukung yang besar. Antarmuka pengguna agak rumit bagi pemula. Plugin tidak selalu didukung dari versi lama ke versi baru.
4. Splunk On-Call (Terbaik untuk mengarahkan peringatan pemantauan langsung ke insinyur)
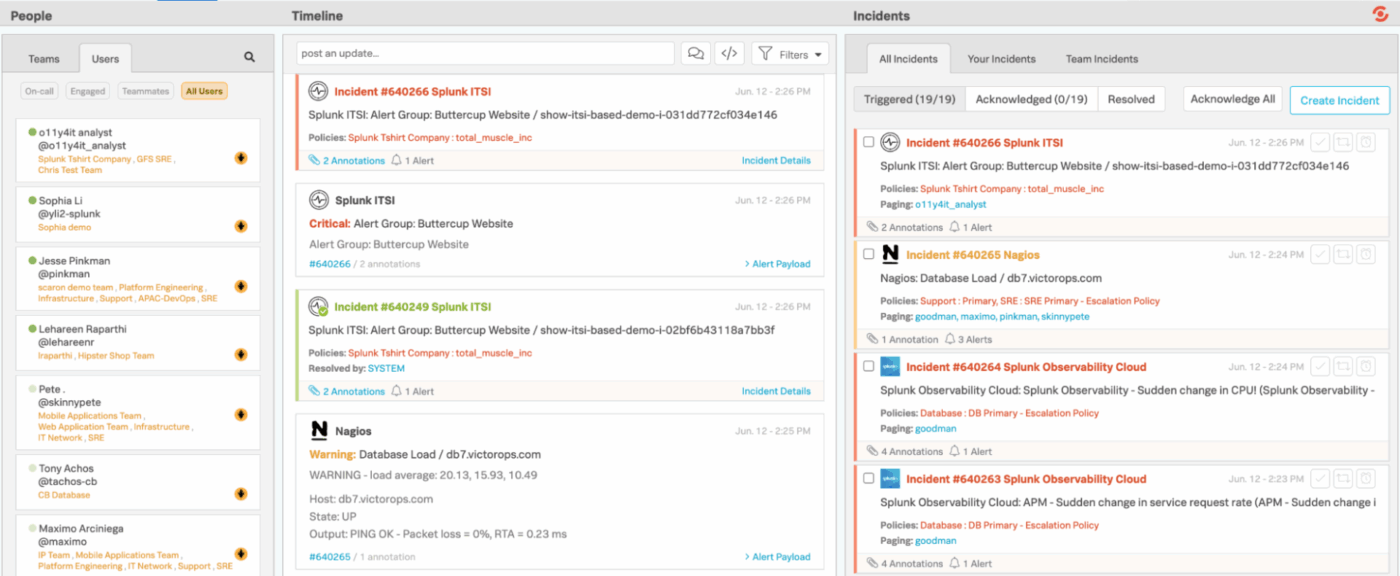
Splunk On-Call memberikan tim teknik dan tim piket cara yang lebih cepat dan efisien untuk mengelola insiden, menghilangkan kebutuhan akan alur kerja tiket tradisional yang lambat. Alih-alih mengirimkan peringatan ke antrean umum, Splunk On-Call terintegrasi langsung dengan sistem pemantauan dan observabilitas Anda, secara otomatis mengarahkan masalah ke orang yang tepat berdasarkan jadwal, aturan, dan konteks.
Integrasi mobile dan chat memudahkan untuk mengonfirmasi, mengalihkan, atau menyelesaikan insiden dari mana saja. Dan di balik layar, Splunk On-Call mencatat secara detail tren, pola yang terbukti, dan perilaku eskalasi.
Fitur terbaik Splunk On-Call
- Perluas kemampuan platform menggunakan lebih dari 1.000 integrasi dan add-on yang telah diverifikasi dari Splunk dan komunitas yang lebih luas.
- Bangun dasbor kustom dan laporan visual untuk memantau volume peringatan, kesehatan insiden, kinerja penanggap, dan beban kerja tim.
- Dengan cepat saring insiden berdasarkan aktivitas Anda sendiri, insiden tim, atau semua yang terjadi di seluruh organisasi.
- Beralih antara tampilan Triggered, Acknowledged, dan Resolved untuk melihat status masing-masing insiden.
Batasan Splunk On-Call
- Penjadwalan shift di antara beberapa tim dapat menjadi rumit jika aturan tidak ditentukan sebelumnya.
- Kemampuan terbatas untuk menghasilkan laporan insiden yang rinci dan terperinci berdasarkan tanggal.
Harga Layanan On-Call Splunk
- Harga khusus
Ulasan dan penilaian Splunk On-Call
- G2: 4. 6/5 (40+ ulasan)
- Capterra: 4.5/5 (30+ ulasan)
Apa yang dikatakan pengguna nyata tentang Splunk On-Call?
Seorang pengguna merangkumnya seperti ini:
Kemampuan untuk menangani insiden, eskalasi, dan mengambil alih tugas dari rekan tim melalui aplikasi seluler sungguh luar biasa. […] Saya ingin dapat menjadwalkan pengalihan dan mengubah jadwal reguler melalui aplikasi seluler untuk perubahan jadwal darurat.
Kemampuan untuk menangani insiden, eskalasi, dan mengambil alih tugas dari rekan tim melalui aplikasi seluler sungguh luar biasa. […] Saya ingin dapat menjadwalkan pengalihan dan mengubah jadwal reguler melalui aplikasi seluler untuk perubahan jadwal darurat.
🔍 Tahukah Anda? Logika 'mengalihkan ke orang yang tepat jika tingkat pertama gagal' berakar dari sistem telepon awal: ketika operator manual tidak dapat menghubungkan panggilan, sistem akan mengalihkan (atau mengeskalasi) panggilan tersebut ke operator lain atau sistem telepon lainnya.
5. ServiceNow (Terbaik untuk mengoordinasikan skala perusahaan dengan otomatisasi yang didukung AI)
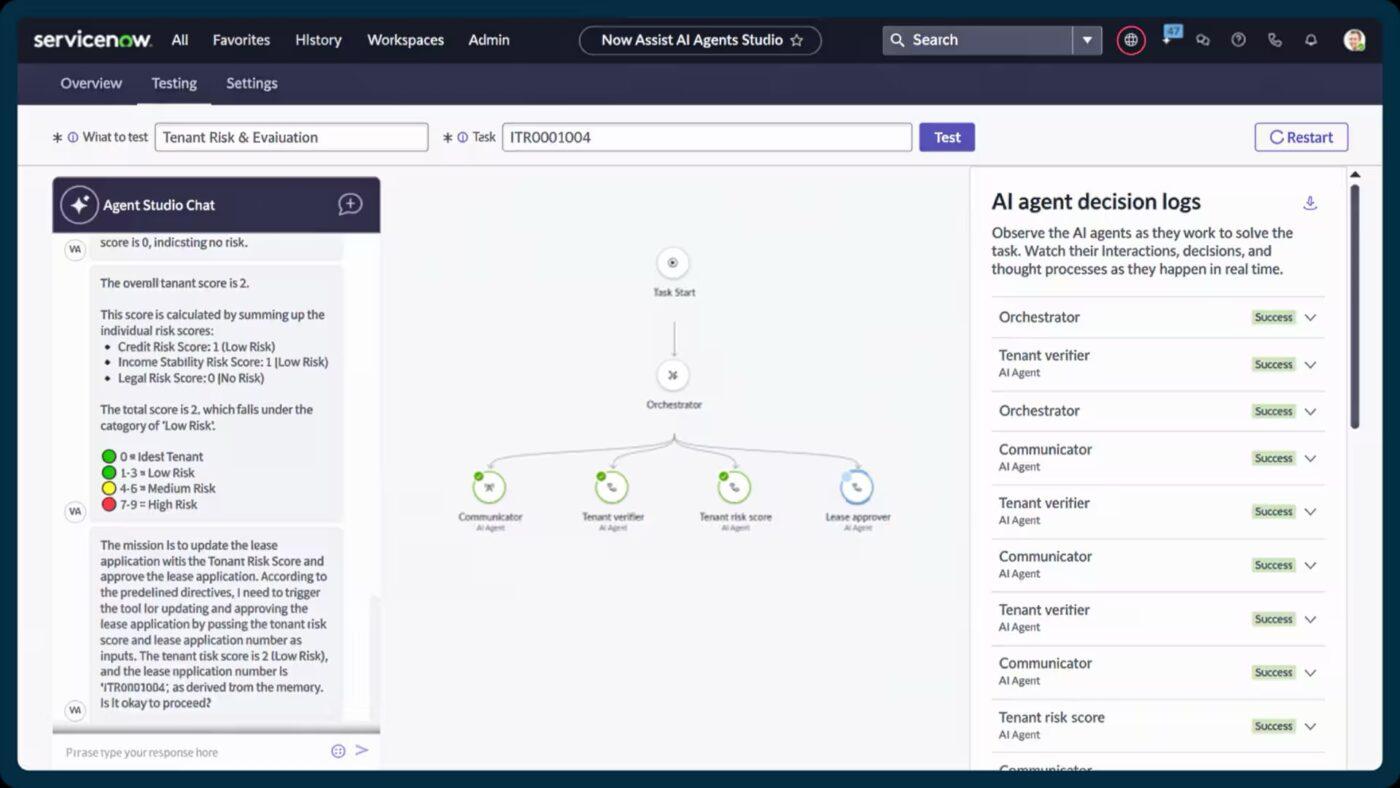
ServiceNow secara otomatis mengklasifikasikan, memprioritaskan, dan merutekan insiden begitu insiden tersebut dilaporkan. Dengan fitur seperti Now Assist untuk rekomendasi tiket insiden otomatis dan pembangkitan konten cerdas, tim respons dapat menyelesaikan masalah lebih cepat dan dengan konteks yang lebih lengkap.
Ini menggabungkan manajemen insiden, perubahan, dan aset. Dengan cara ini, Anda mendapatkan pandangan real-time tentang bagaimana layanan terhubung, di mana kemacetan terjadi, dan komponen mana yang mungkin berkontribusi pada gangguan berulang.
Fitur terbaik ServiceNow
- Tugaskan, rute, dan pantau tugas lapangan melalui Field Service Management dan Dispatcher Workspace
- Berdayakan karyawan dan pelanggan dengan portal layanan mandiri yang didukung oleh AI Search dan agen virtual.
- Gunakan alur kerja bawaan dan alat low-code di App Engine untuk memperluas atau menyesuaikan proses layanan.
- Otomatiskan tugas-tugas berulang dan alur kerja di seluruh tim dengan Flow Designer dan Automation Engine.
Batasan ServiceNow
- Opsi antarmuka pengguna (UI) dan branding portal terasa ketinggalan zaman atau membatasi.
- Ketergantungan yang tinggi pada tenaga ahli atau konsultan untuk implementasi.
Harga ServiceNow
- Harga khusus
Ulasan dan penilaian ServiceNow
- G2: 4. 4/5 (3.300+ ulasan)
- Capterra: 4.5/5 (300+ ulasan)
Apa yang dikatakan pengguna nyata tentang ServiceNow?
Begini cara seorang pengguna menjelaskannya:
[…] Alur kerja yang sudah dibangun sebelumnya merupakan fitur unggulan bagi saya, karena mereka menyederhanakan proses dan menghemat waktu yang signifikan, meminimalkan kebutuhan konfigurasi khusus, dan memungkinkan alur kerja yang lebih lancar dan efisien. […] Selain itu, saya mengalami kesulitan dalam mengintegrasikan solusi kustom saya ke dalam sistem Manajemen Layanan Pelanggan, yang memerlukan banyak iterasi.
[…] Alur kerja yang sudah dibangun sebelumnya merupakan fitur unggulan bagi saya, karena mereka menyederhanakan proses dan menghemat waktu yang signifikan, meminimalkan kebutuhan konfigurasi khusus, dan memungkinkan alur kerja yang lebih lancar dan efisien. […] Selain itu, saya mengalami kesulitan dalam mengintegrasikan solusi kustom saya ke dalam sistem Manajemen Layanan Pelanggan, yang memerlukan banyak iterasi.
Praktik Terbaik dan Tata Kelola
Berikut adalah beberapa praktik terbaik yang memastikan otomatisasi tetap akurat, menghindari kelelahan akibat peringatan berlebihan, dan sesuai dengan harapan bisnis dan regulasi.
- Tentukan kriteria eskalasi yang tidak dapat dinegosiasikan: Hubungkan pemicu dengan sinyal yang dapat diukur, seperti pelanggaran SLO, lonjakan anomali, dampak pada tingkat pelanggan, atau sensitivitas regulasi.
- Tetapkan kejelasan peran di setiap tingkatan: Gunakan peta RACI sederhana untuk setiap tingkatan eskalasi agar tanggung jawab tidak pernah ambigu selama insiden yang mendesak.
- Terapkan tata kelola piket dinamis: Sesuaikan secara otomatis jalur eskalasi selama akhir pekan, hari libur, batas kapasitas, dan serah terima untuk mengurangi kelelahan dan mencegah notifikasi yang tidak terbalas.
- Tambahkan titik pemeriksaan manual untuk skenario berisiko tinggi: Meskipun menggunakan otomatisasi, wajibkan konfirmasi manual untuk insiden yang melibatkan paparan data pelanggan, transaksi pembayaran, atau alur kerja yang diatur.
- Jaga jejak audit lengkap: Simpan catatan yang tidak dapat diubah tentang siapa yang dihubungi, kapan mereka mengonfirmasi, langkah otomatis apa yang dijalankan, dan keputusan apa yang diambil.
🧠 Fakta Menarik: Keluhan tertulis tertua yang diketahui di dunia diukir pada tablet tanah liat sekitar tahun 1750 SM. Ini pada dasarnya merupakan eskalasi status proyek awal. Seorang pelanggan bernama Nanni menulis kepada pedagang Ea-nāṣir, marah karena tembaga yang diterimanya berkualitas lebih rendah dari yang dijanjikan dan utusannya diperlakukan dengan buruk.
Tantangan Umum dan Cara Mengatasinya
Meskipun memiliki kebijakan eskalasi yang jelas, tim sering menghadapi hambatan operasional yang memperlambat respons insiden atau menimbulkan kebingungan.
Tabel ini menyoroti tantangan umum yang melampaui langkah-langkah pengaturan dasar dan menyediakan strategi praktis untuk mengatasinya.
| Tantangan ❌ | Solusi ✅ |
| Kontekstualisasi yang tidak konsisten selama serah terima | Gunakan fitur pengaitan tugas dan templat laporan insiden ClickUp untuk menjaga jejak audit lengkap mengenai detail insiden, sistem yang terdampak, dan tindakan sebelumnya di setiap tingkat eskalasi. |
| Membebani tim respons dengan peringatan prioritas rendah | Implementasikan prioritas dinamis dengan ClickUp Custom Fields dan AI Prioritize untuk menyaring insiden berdasarkan tingkat keparahan, dampak, dan ambang batas SLA. |
| Kurangnya visibilitas antar tim | Buat ruang kerja bersama, tambahkan komentar, dan buat papan tulis visual ClickUp untuk menampilkan pembaruan real-time bagi pemangku kepentingan. |
| Penundaan pengambilan keputusan selama insiden kritis | Otomatiskan pemberitahuan menggunakan fitur Suggested Actions dari ClickUp Brain Max untuk secara instan memberitahu personel yang tepat berdasarkan jenis insiden, tingkat keparahan, dan pola historis. |
| Kesulitan melacak masalah yang berulang | Manfaatkan fitur pelaporan kustom dan templat tugas berulang ClickUp untuk mengidentifikasi pola, penyebab utama, dan insiden berulang guna pencegahan proaktif. |
| Pengetahuan yang terfragmentasi selama eskalasi | Simpan SOP terpusat, runbook, dan dokumentasi insiden di ClickUp Docs, dan hubungkan dengan tugas-tugas terkait untuk referensi instan selama eskalasi langsung. |
| Tanggung jawab yang tidak selaras antar shift | Gunakan tampilan Workload dan Timeline ClickUp untuk memvisualisasikan tugas dan memastikan tidak ada tumpang tindih atau celah selama pergantian shift atau serah terima. |
| Pelacakan kepatuhan manual dan celah audit | Otomatiskan ringkasan yang siap diaudit dengan ClickUp Brain untuk mencatat semua tindakan insiden, pemberitahuan, dan penyelesaian. |
Mengukur Dampak Eskalasi Otomatis
Memantau efektivitas eskalasi otomatis memerlukan fokus pada metrik kunci terkait volume, efisiensi, dan kualitas. Indikator-indikator ini menunjukkan apakah proses eskalasi Anda lebih cepat, lebih akurat, dan kurang menyulitkan bagi tim maupun pelanggan.
Pantau metrik-metrik berikut:
- Tingkat eskalasi (volume): Persentase masalah yang diekskalasi melampaui tingkat pertama. Tingkat yang tinggi mungkin menandakan adanya celah dalam proses triase awal atau basis pengetahuan.
- Tingkat eskalasi berulang (volume): Frekuensi masalah yang sama dieskalasi berulang kali. Menandakan penyelesaian yang tidak tuntas atau hilangnya konteks.
- Waktu eskalasi (efisiensi): Durasi dari deteksi hingga eskalasi. Durasi tahap yang lebih singkat menunjukkan pengenalan otomatis yang lebih cepat terhadap masalah kritis.
- Waktu penundaan serah terima (efisiensi): Selisih waktu antara eskalasi dan saat tim berikutnya mulai bekerja untuk menyoroti gesekan dalam rute atau pemberitahuan.
- Waktu penyelesaian kasus yang ditingkatkan (efisiensi): Waktu total dari eskalasi hingga penyelesaian. Penyelesaian yang lebih cepat menunjukkan efektivitas otomatisasi.
- Skor Kepuasan Pelanggan (CSAT) (kualitas): Umpan balik tentang interaksi yang ditingkatkan untuk mengukur kelancaran jalur tersebut.
- Pengalihan konteks (kualitas): Apakah agen menerima riwayat insiden lengkap untuk memastikan pelanggan tidak perlu mengulang informasi.
- Resolusi Kontak Pertama (FCR) (kualitas): Persentase masalah yang diselesaikan dalam satu interaksi.
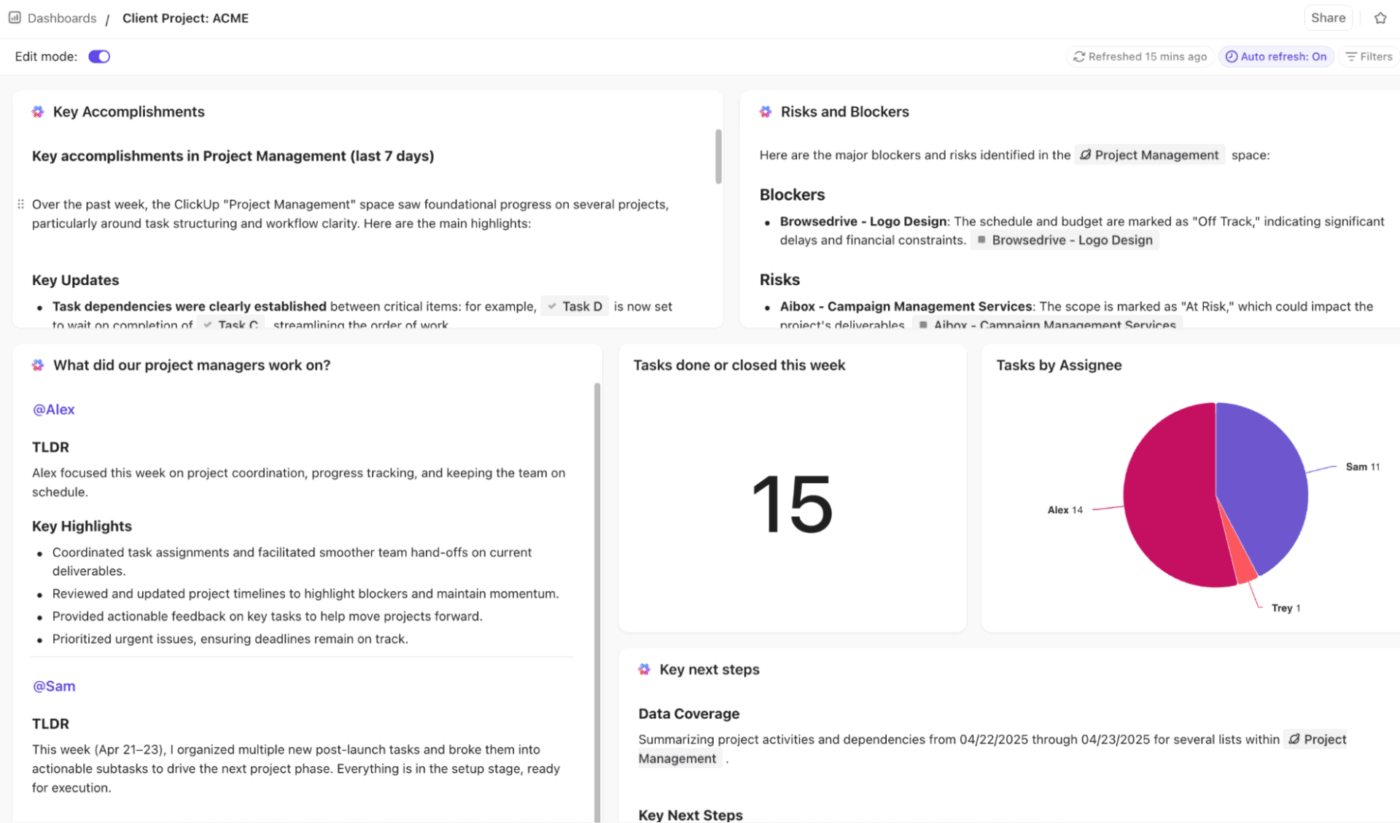
🚀 Keunggulan ClickUp: Dapatkan wawasan real-time, visual, dan didukung AI untuk semua metrik eskalasi dengan Dashboard ClickUp.
Anda dapat melacak tren eskalasi, titik penyumbatan, dan kinerja menggunakan Tabel, Pie, Bar, Line, Perhitungan, dan Kartu Laporan Waktu. Pantau tingkat eskalasi, eskalasi berulang, dan waktu eskalasi dengan kartu yang terhubung ke tugas, bidang kustom, dan status.
Untuk melangkah lebih jauh, gunakan kartu AI seperti AI Executive Summary, AI Project Update, dan AI StandUp untuk menyoroti tren, keterlambatan, dan hasil penyelesaian.
Kelola Insiden Anda Lebih Cepat dengan ClickUp
Banyak orang menganggap eskalasi insiden hanyalah tentang meneruskan tiket ke orang berikutnya, tetapi sebenarnya jauh lebih dari itu. Ini adalah sistem terstruktur di mana setiap langkah, mulai dari triase hingga penyelesaian, bekerja secara harmonis.
ClickUp menyediakan ruang kerja terpadu yang sempurna. Dengan ClickUp Automations, Anda dapat memicu peringatan, mengalihkan tugas, dan memperbarui status secara otomatis. Dan ClickUp Brain membantu memprioritaskan insiden, menghasilkan ringkasan, dan menyarankan langkah selanjutnya.
ClickUp AI Agents bertindak seperti asisten cerdas di dalam ruang kerja Anda, sementara ClickUp Dashboards memberikan tampilan real-time dari eskalasi Anda.
Daftar ke ClickUp secara gratis hari ini!
Pertanyaan yang Sering Diajukan (FAQ)
Jalur eskalasi insiden adalah urutan langkah yang telah ditentukan sebelumnya yang menentukan cara masalah diarahkan ke tim atau individu yang tepat berdasarkan tingkat keparahan, dampak, dan waktu. Hal ini memastikan insiden ditangani secara efisien dan tanggung jawab jelas. TEXT
Gunakan otomatisasi untuk insiden yang telah didefinisikan dengan jelas dan berprioritas tinggi dengan kriteria yang jelas (misalnya, gangguan layanan, pelanggaran keamanan). Simpan eskalasi manual untuk situasi ambigu atau kritis yang memerlukan penilaian manusia atau konteks tambahan.
Platform seperti ClickUp, PagerDuty, Jira Service Management, dan ServiceNow memungkinkan pengalihan otomatis, pemberitahuan, dan pembaruan. Mereka membantu tim mengurangi keterlambatan dan menjaga alur kerja insiden yang terstruktur.
Tetapkan ambang batas yang jelas untuk peringatan, prioritaskan berdasarkan tingkat keparahan, dan gunakan pemberitahuan cerdas. Batasi pemberitahuan berulang hanya untuk insiden kritis, dan manfaatkan dasbor atau alat AI untuk merangkum pembaruan daripada mengirim setiap perubahan kecil.
Tinjau kebijakan eskalasi secara berkala setidaknya setiap kuartal atau setelah insiden besar. Hal ini memastikan bahwa kriteria, tanggung jawab, dan aturan otomatisasi mencerminkan alur kerja saat ini, struktur tim, dan prioritas bisnis.