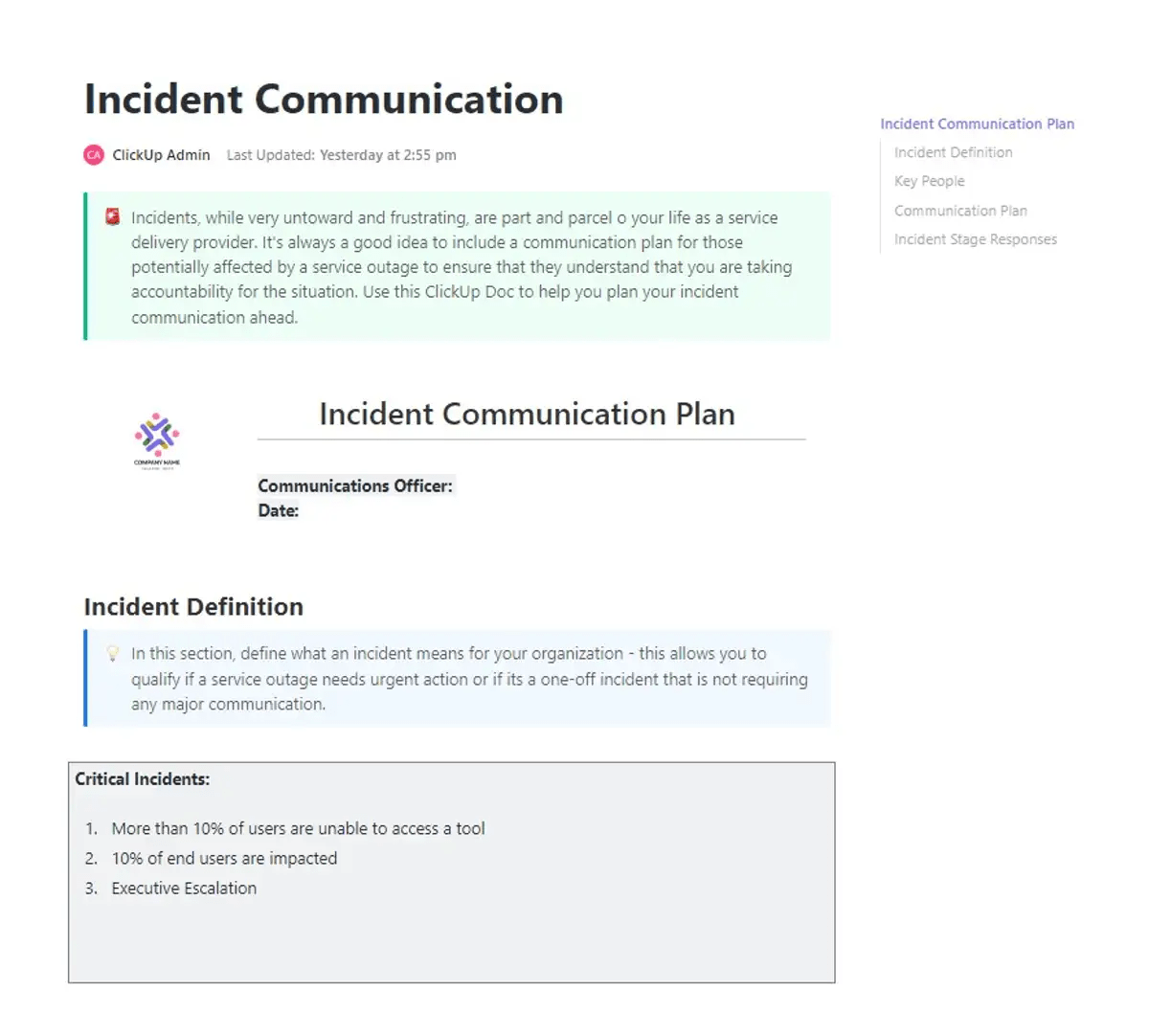

Les incidents cybernétiques se déroulent à un rythme effréné. Les ransomwares se propagent en quelques minutes, les tentatives de phishing générées par l'IA échappent aux filtres, et une seule erreur peut dégénérer en une violation à grande échelle avant même que les équipes aient le temps de se mettre d'accord sur ce qui se passe. La pression est réelle, tout comme le coût.
Le rapport Cost of a Data Breach Report d'IBM estime le coût moyen mondial à 4,44 millions de dollars, un nombre que les retards d'intervention et le manque de coordination ne font qu'alourdir.
Au cœur de ce chaos, les équipes ont besoin de clarté. Un guide d'intervention en cas d'incident fournit à votre équipe un plan d'action commun lorsque la situation devient chaotique. Il précise qui doit agir en premier, les étapes à suivre et comment maintenir une communication étroite à mesure que la situation évolue.
Dans cet article de blog, vous apprendrez à élaborer un guide d'intervention en cas d'incident adapté aux menaces actuelles. Nous explorons des scénarios concrets, des mesures d'intervention claires et ClickUp, le premier environnement de travail convergent basé sur l'IA au monde, un système que votre équipe peut utiliser même sous pression.
Qu'est-ce qu'un guide d'intervention en cas d'incident ?
Un guide d'intervention en cas d'incident est un document structuré, étape par étape, qui aide les équipes de sécurité à gérer des types spécifiques de cyberincidents de manière cohérente et efficace. Il décrit précisément ce qu'il faut faire lorsqu'un incident se produit, qui est responsable de chaque action, et comment passer de la détection à la maîtrise et à la reprise sans confusion ni retard.
Considérez-le comme un plan d'action prêt à l'emploi pour des scénarios concrets tels que les attaques par hameçonnage, les infections par ransomware ou les violations de données.
🧠 Anecdote : Le premier « virus » informatique n'était pas malveillant. En 1971, un programme appelé Creeper se propageait d'un ordinateur à l'autre dans le seul but d'afficher le message « Je suis le Creeper, attrape-moi si tu peux ». Cela a conduit à la création du premier antivirus, appelé Reaper.
Guide d'intervention en cas d'incident, plan d'intervention et manuel d'intervention : quelle est la différence ?
Les gens confondent constamment la terminologie relative à la documentation de sécurité. Cette confusion engendre de réels problèmes lorsque les équipes élaborent leurs procédures opérationnelles standard. Vous vous retrouvez alors avec des plans généraux dépourvus d’étapes concrètes ou des guides trop techniques qui déconcertent la direction.
Voici en quoi ces trois documents diffèrent.
| Document | Portée | Niveau de détail | Quand l'utiliser | À qui s'adresse-t-il ? | Mettre en forme |
| Planifier | Stratégie à l'échelle de l'organisation | Politiques générales | Avant les incidents | Direction et aspects juridiques | Document de politique |
| Guide | Réponse adaptée à chaque scénario | Mesures tactiques étape par étape | Lors d'un type d'incident spécifique | Équipe d'intervention en cas d'incident | Flux de travail sous forme d'arbre de décision |
| Guide opérationnel | Procédure technique unique | Étapes d'automatisation détaillées | Au cours d'une tâche spécifique | Intervenants techniques | Checklist ou script |
Ces trois éléments doivent fonctionner de concert. Un plan sans guide d'intervention est trop vague pour être mis en œuvre. Un guide d'intervention sans guide d'exécution laisse l'exécution technique au hasard.
📮 ClickUp Insight : 53 % des organisations ne disposent d'aucune gouvernance en matière d'IA ou ne disposent que de directives informelles.
Et lorsque les utilisateurs ne savent pas où vont leurs données — ou si un outil risque de créer un risque de non-conformité —, ils hésitent.
Si un outil d'IA se trouve en dehors des systèmes de confiance ou si ses pratiques en matière de données ne sont pas claires, la crainte de se demander « Et si ce n'était pas sûr ? » suffit à bloquer son adoption.
Ce n'est pas le cas avec l'environnement sécurisé et entièrement réglementé de ClickUp. ClickUp AI est conforme au RGPD, à la loi HIPAA et à la norme SOC 2, et détient la certification ISO 42001, garantissant ainsi la confidentialité, la sécurité et la gestion responsable de vos données.
Il est interdit aux fournisseurs tiers d'IA de s'entraîner sur les données des clients ClickUp ou de les conserver, et l'assistance multimodèle fonctionne selon des permissions unifiées, des contrôles de confidentialité et des normes de sécurité strictes. Ici, la gouvernance de l'IA fait partie intégrante de l'environnement de travail lui-même, ce qui permet aux équipes d'utiliser l'IA en toute confiance, sans risque supplémentaire.
Éléments clés d'un guide d'intervention en cas d'incident
Tout guide de réponse aux incidents efficace repose sur la même structure de base. Avant de commencer à l'élaborer, vous devez savoir ce qu'il doit contenir.
Critères de déclenchement et classification des incidents
Les déclencheurs sont les conditions spécifiques qui activent le guide. Il peut s'agir d'une alerte SIEM signalant des schémas de connexion anormaux ou d'un utilisateur signalant un e-mail suspect. Associez vos déclencheurs à un système de classification des incidents afin que votre équipe sache à quelle vitesse elle doit agir.
- Gravité 1 : Critique : Exfiltration de données en cours ou chiffrement par ransomware en cours
- Gravité 2 : Élevée : Compromission confirmée sans propagation active
- Gravité 3 : Moyenne : Activité suspecte nécessitant une enquête
- Gravité 4 : Faible : Violation de la politique ou anomalie mineure
La classification détermine quelles actions doivent être déclenchées et à quelle vitesse. Sans elle, les équipes risquent soit de réagir de manière excessive à des alertes de faible priorité, soit de ne pas réagir suffisamment face à de réelles menaces.
📖 À lire également : Comment améliorer la cybersécurité dans la gestion de projet
Rôles et responsabilités
Un guide d'intervention ne sert à rien si personne ne sait qui est responsable de quoi. Définissez les rôles clés qui doivent figurer dans chaque guide d'intervention.
- Responsable des incidents : supervise l'ensemble de la réponse et prend les décisions d'escalade
- Responsable technique : Dirige les opérations pratiques d'investigation et de confinement
- Responsable de la communication : Gère les mises à jour internes et les notifications externes
- Liaison juridique : Conseille sur les obligations réglementaires et la conservation des preuves
- Responsable de projet : Approuve les décisions importantes telles que les arrêts de système
Attribuez les rôles en fonction des fonctions plutôt que simplement en fonction des noms des personnes. Les employés peuvent partir en vacances ou quitter l'entreprise ; chaque rôle doit donc avoir un titulaire et une sauvegarde.
Procédures de détection, de confinement et de reprise
Il s'agit du cœur opérationnel du guide. La détection et l'analyse permettent de vérifier si le déclencheur correspond à un véritable incident et de recueillir les premiers indicateurs de compromission.
Le confinement implique des mesures immédiates visant à empêcher la propagation de l'incident. Cela comprend l'isolation des systèmes affectés, le blocage des adresses IP malveillantes et la désactivation des comptes compromis. Vous devez faire la distinction entre le confinement à court terme, destiné à endiguer la situation, et le confinement à long terme, visant à assurer la stabilité.
L'éradication et la reprise permettent d'éliminer complètement la menace grâce à la suppression des logiciels malveillants et à la correction des vulnérabilités. Cette phase rétablit le fonctionnement normal des systèmes et comprend des tests de validation visant à s'assurer que la menace a bien disparu.
🔍 Le saviez-vous ? L'une des plus grandes menaces de sécurité jamais enregistrées a commencé par un problème de mot de passe. En 2012, LinkedIn a subi une violation massive en partie parce que les mots de passe étaient stockés à l'aide de méthodes de hachage obsolètes, rendant des millions de comptes faciles à pirater.
Protocoles de communication et d'escalade
Les incidents nécessitent une communication coordonnée parallèlement à l'intervention technique. L'escalade interne détermine à quel moment le responsable des incidents doit informer l'équipe de direction et le service juridique.
La communication externe détermine qui s'adresse aux clients, aux autorités de régulation ou à la presse. De nombreux cadres de conformité prévoient des échéanciers de notifications obligatoires auxquels votre guide doit se référer.
⚡ Archives de modèles : Lorsqu'un incident survient, le plus grand risque réside souvent dans la confusion qui s'ensuit. Des mises à jour tardives, des responsabilités floues et une communication dispersée peuvent ralentir les délais d'intervention et amplifier l'impact. C'est précisément là que le modèle de plan de communication en cas d'incident de ClickUp apporte une réelle valeur ajoutée.
Ce modèle offre aux équipes un cadre prêt à l'emploi pour communiquer clairement en situation de crise. Vous pouvez définir les rôles, mapper les canaux de communication et vous assurer que les bonnes parties prenantes sont informées au bon moment. Il centralise tout, des points de contact aux procédures d'escalade, afin que les équipes restent coordonnées lorsque cela compte le plus.
Comment élaborer un guide d'intervention en cas d'incident (étape par étape)
Un incident de sécurité sans plan est une crise. Un incident de sécurité avec un guide d'intervention est un processus. Voici comment en élaborer un qui résiste à la pression. 👀
Étape n° 1 : Définir le périmètre et les objectifs
Avant de rédiger la moindre procédure, déterminez ce que le guide couvre et ce qu'il ne couvre pas.
La dérive des objectifs nuit à la facilité d'utilisation. Un guide qui tente de couvrir tous les scénarios possibles finit par n'en traiter aucun correctement, et les intervenants perdent du temps à chercher des conseils qui n'existent pas ou ne s'appliquent pas à leur situation.
Commencez par répondre à quatre questions :
- Quels types d'incidents sont concernés : ransomware, violations de données, menaces internes, attaques DDoS, hameçonnage, piratage de comptes, compromission de la chaîne d'approvisionnement, ou tout ce qui précède
- À quels systèmes et environnements ce guide s'applique-t-il ? Infrastructure cloud, serveurs sur site, environnements hybrides, plateformes SaaS, systèmes OT/ICS ou unités opérationnelles spécifiques présentant des profils de risque particuliers
- Réussite : un temps de détection moyen (MTTD) inférieur à 60 minutes, un temps de réponse moyen (MTTR) inférieur à quatre heures, ou la conformité aux normes SOC 2, ISO 27001 ou HIPAA
- Qui est responsable du guide : Une personne ou une équipe désignée chargée d'en garantir l'exactitude, de le diffuser aux personnes concernées et d'organiser des revues
Définir le périmètre semble simple jusqu'à ce que l'on s'y mette. Les équipes bloquent souvent à cette étape, car les informations proviennent d'incidents passés, de notes éparses et des attentes des parties prenantes.
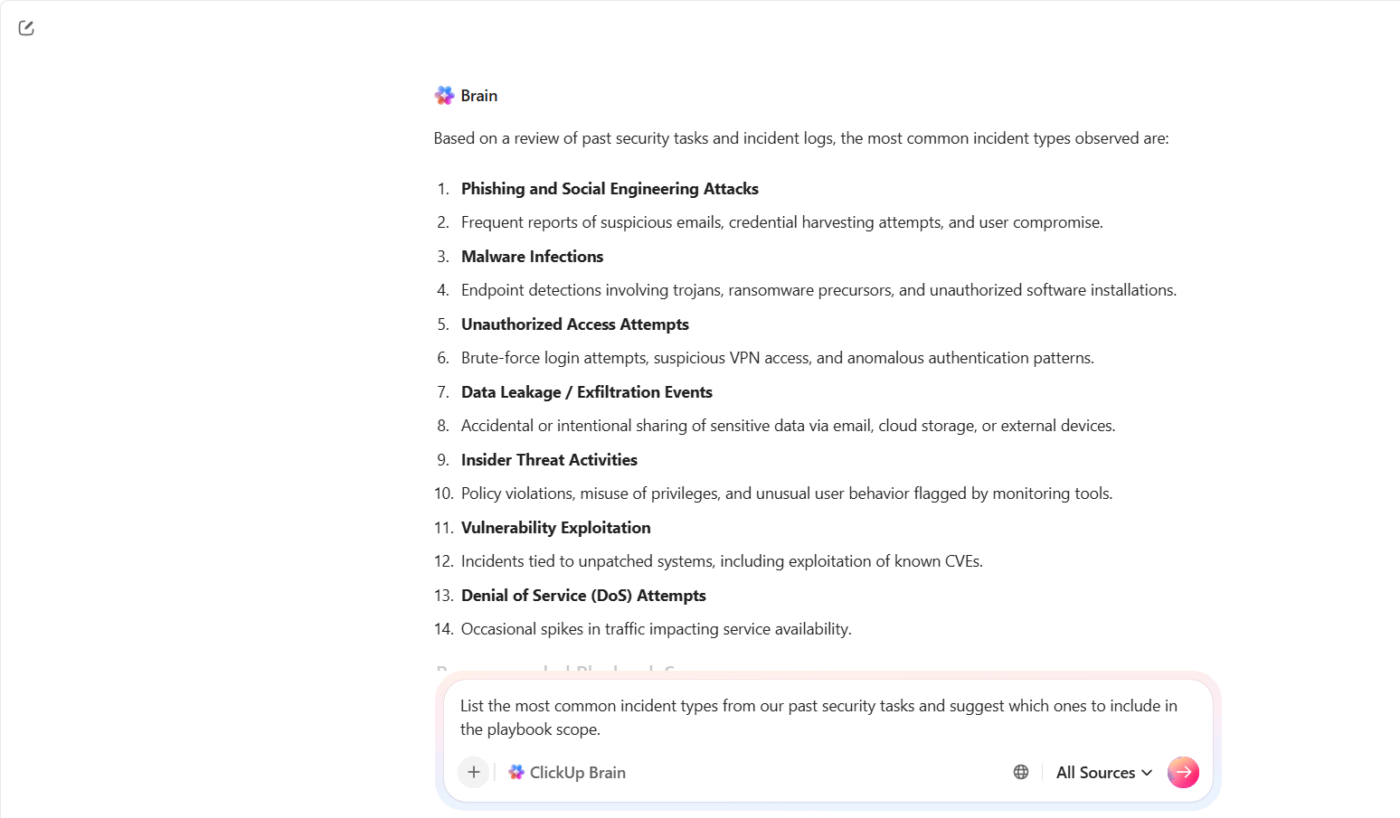
ClickUp Brain vous aide à rassembler toutes ces informations et à en faire un point de départ concret. Vous ne partez pas d'une page blanche. Vous vous appuyez sur ce que votre équipe sait déjà.
Par exemple, supposons que votre équipe de sécurité ait géré plusieurs incidents de phishing et de prise de contrôle de compte au cours du dernier trimestre. Au lieu d'examiner manuellement chaque cas, vous pouvez demander à ClickUp Brain : « Répertoriez les types d'incidents les plus courants parmi nos tâches de sécurité passées et suggérez ceux à inclure dans le champ d'application du guide. »
Étape n° 2 : Identifiez et classez les types d'incidents
Tous les incidents ne se valent pas. Un compartiment S3 mal configuré et une attaque active par ransomware nécessitent des réponses, des équipes et des procédures d'escalade totalement différentes.
La mise en place précoce d'un système de classification permet aux intervenants de prendre des décisions rapides et cohérentes dès la première alerte, sans avoir à attendre l'approbation de la direction à chaque intervention.
Un modèle standard de gravité à quatre niveaux fonctionne comme suit :
- Critique (P1) : Violation active, exfiltration de données ou compromission à l'échelle du système — une réponse immédiate est requise
- Élevé (P2) : intrusion présumée, vol d'identifiants ou perturbation importante du service
- Moyen (P3) : Malware détecté mais maîtrisé, violation de la politique avec risque d'exposition des données
- Faible (P4) : tentatives de connexion infructueuses, violations mineures des politiques, alertes d'information
Mappez chaque type d'incident à un niveau de gravité afin que les intervenants puissent prendre des décisions rapides sans avoir à escalader chaque appel.
Une fois que vous avez défini ce qui relève de son champ d'application, le défi suivant porte sur la cohérence. Les différents intervenants interprètent souvent la même alerte de différentes manières, ce qui ralentit la prise de décision et entraîne des escalades inutiles.
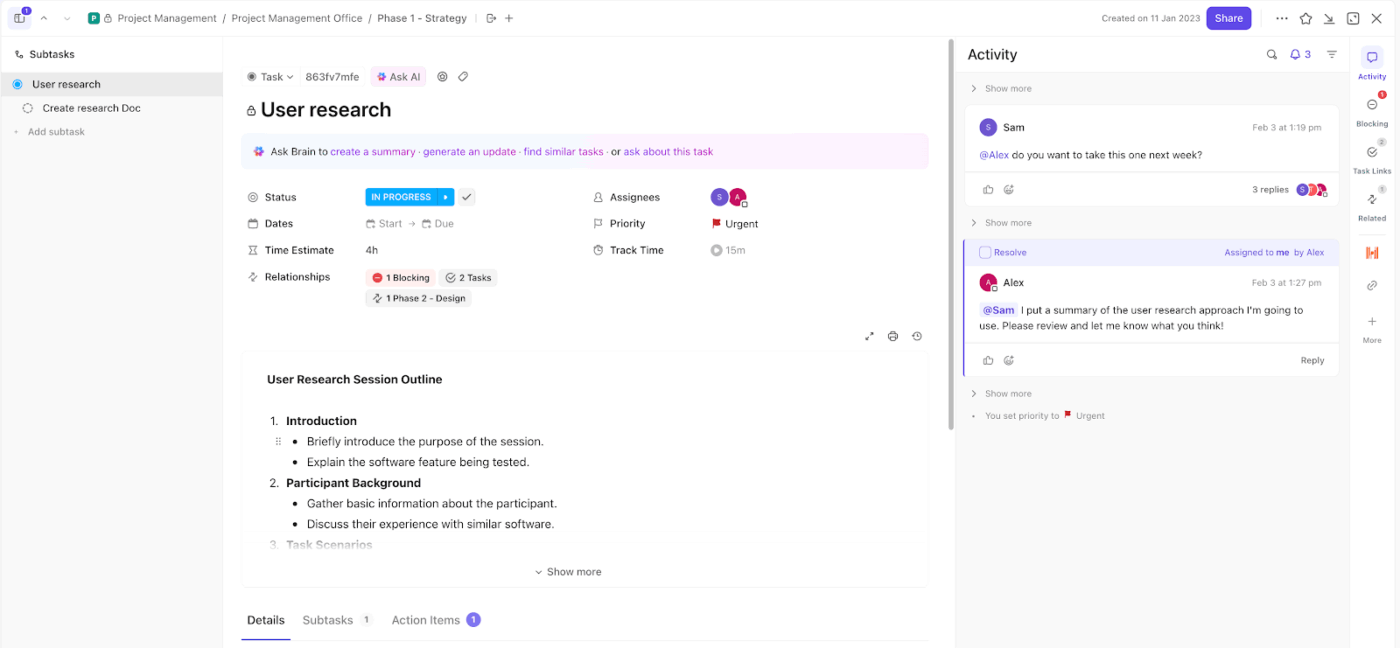
Commencez par utiliser les tâches ClickUp comme unique unité d'exécution. Chaque incident devient une tâche, ce qui signifie que rien ne passe inaperçu dans des canaux non suivis comme les e-mails ou le chat.
Par exemple, supposons que votre outil de surveillance signale un vol potentiel d'identifiants. Vous créez une tâche avec le titre « Compromission possible des identifiants – compte financier ». Cette tâche devient alors le point central pour l'enquête, les mises à jour et la résolution.
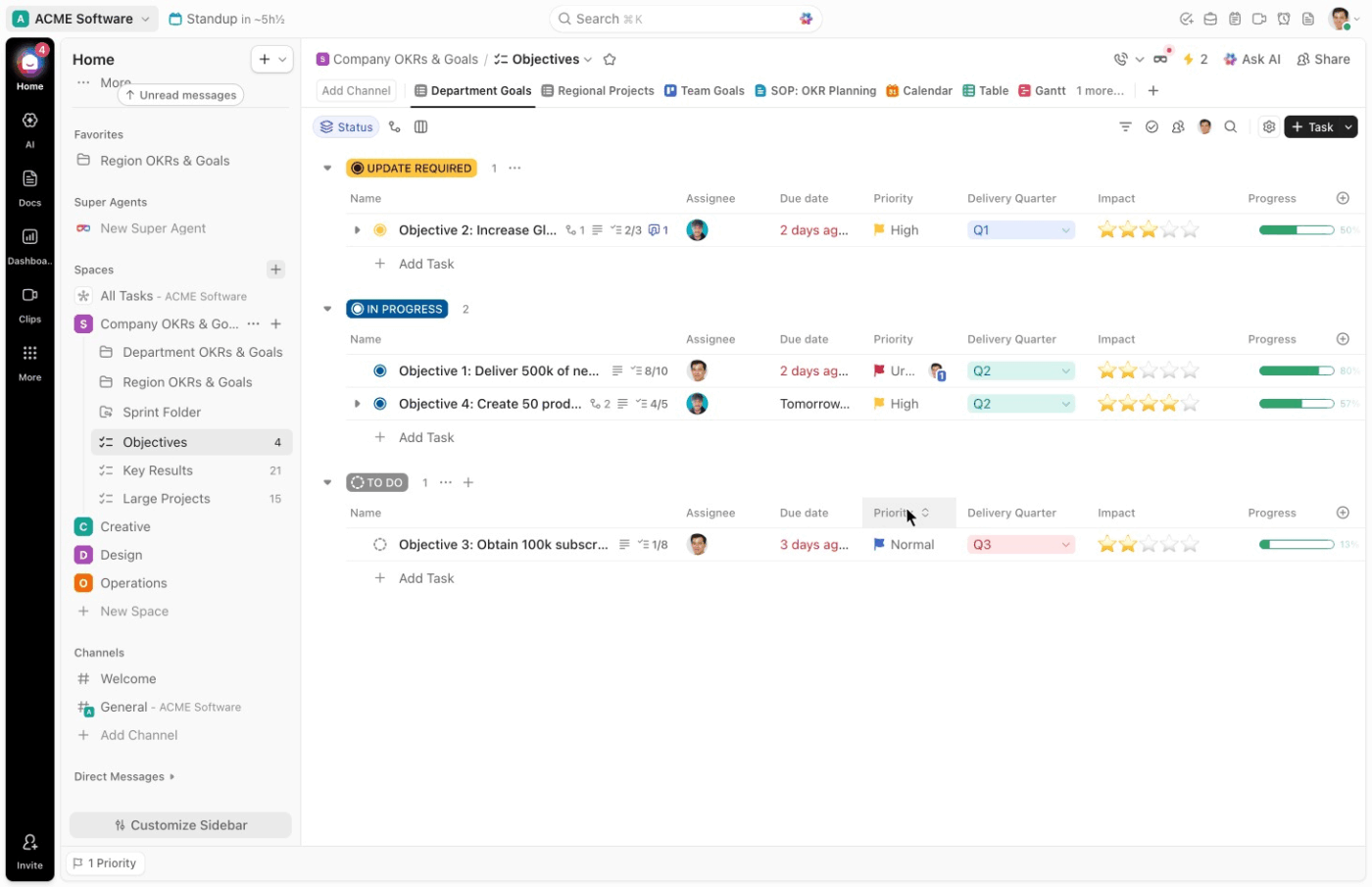
À partir de là, les champs personnalisés de ClickUp vous fournissent la structure nécessaire pour une classification rapide. Vous pouvez configurer des champs tels que :
- Type d'incident : hameçonnage, ransomware, DDoS, menace interne
- Niveau de gravité : P1, P2, P3, P4
- Systèmes concernés : Cloud, sur site, SaaS, terminaux
- Sensibilité des données : Élevée, moyenne, faible
Étape n° 3 : Rédigez des procédures d'intervention spécifiques à chaque incident
Il s'agit du cœur opérationnel du guide.
Pour chaque type d'incident, rédigez une procédure dédiée suffisamment détaillée pour qu'un intervenant puisse la suivre sous pression sans avoir à improviser. Les consignes génériques sont souvent ignorées lorsque les systèmes sont hors service.
Chaque procédure doit inclure :
- Déclencheur : l'alerte ou le rapport spécifique qui déclenche la réponse
- Étapes initiales de triage : les premières mesures prises par l'intervenant dans les 15 minutes, adaptées au type d'incident
- Checklist pour la collecte de preuves : journaux, vidages de mémoire, captures réseau et en-têtes d'e-mails — tout ce qui est nécessaire avant que les mesures de confinement ne les détruisent
- Mesures de confinement : étapes spécifiques et concrètes
- Critères d'escalade : les conditions qui déclenchent l'escalade vers la direction, le service juridique ou un prestataire externe spécialisé dans la gestion des incidents
- Modèles de communication : ébauches pré-rédigées pour les mises à jour internes et les notifications aux clients
Une procédure de gestion des ransomwares n'a rien à voir avec une procédure de gestion du phishing. Rédigez-les séparément en tenant compte des spécificités de chaque scénario.

Avec ClickUp Docs, vous pouvez structurer chaque procédure d'incident de manière à répondre précisément aux questions que se pose un intervenant sur le moment. Par exemple, imaginons que vous documentiez un scénario de ransomware.
Le document peut guider l'intervenant de la manière suivante :
- Ce qui a déclenché cela : « Alerte de chiffrement des terminaux détectée via l'EDR »
- Ce qu'il faut faire dans les 15 premières minutes : Isoler la machine affectée, désactiver l'accès au réseau, confirmer l'étendue de la propagation
- Éléments à recueillir avant la confinement : Journaux système, processus actifs, modifications récentes des fichiers
- Dans quelles conditions faut-il signaler l'incident à un niveau supérieur : propagation du chiffrement sur plusieurs terminaux ou accès à des lecteurs partagés
- Ce qu'il faut communiquer : une alerte interne à la direction de la sécurité et une mise à jour préparée à l'intention des équipes concernées
ClickUp Documents renforce encore cette approche grâce à une intégration directe dans l'exécution :
- Associez cette procédure aux tâches liées aux incidents dans ClickUp, afin que les intervenants puissent consulter les instructions au moment précis où ils doivent agir.
- Ajoutez des checklists dans chaque section afin que les étapes critiques ne soient pas omises en cas de pression.
- Attribuez des actions spécifiques aux membres de l'équipe lors de l'escalade sans quitter le document
- Affinez les instructions immédiatement après la résolution afin d'améliorer sans délai les interventions futures
Étape n° 4 : Définissez des protocoles de communication et des normes en matière de preuves
Deux aspects souvent négligés lors de l'élaboration d'un guide et qui peuvent entraîner de graves problèmes lors d'un incident réel : la manière dont l'équipe communique et la manière dont les preuves sont traitées.
En matière de communication, définissez ces paramètres à l'avance :
- Canaux principaux et de sauvegarde
- Échéanciers de notifications
- Obligations de divulgation externe
- Une source unique d'informations fiables
Le guide doit préciser, sur la base de preuves :
- Éléments à collecter : journaux d'évènements système, journaux d'authentification, images mémoire, données de flux réseau et captures d'écran de l'activité des attaquants
- Comment collecter ces données : images forensiques en lecture seule, dispositifs de blocage d'écriture et journal de toutes les opérations de collecte, avec horodatage et nom de la personne qui les a effectuées
- Où le stocker : dans un environnement distinct, à accès contrôlé et isolé des systèmes affectés
- Qui peut y accéder : Réservé aux enquêteurs désignés et approuvé par le responsable des relations juridiques et de la conformité
Lorsqu'un incident survient, la communication est souvent fragmentée entre différents outils. Les mises à jour sont publiées sur Slack, les décisions sont prises lors d'appels téléphoniques et les détails essentiels se perdent dans des fils de discussion que personne ne consulte plus. Ce manque de structure engendre de la confusion, retarde l'escalade et rend les analyses post-incident plus difficiles qu'elles ne devraient l'être.
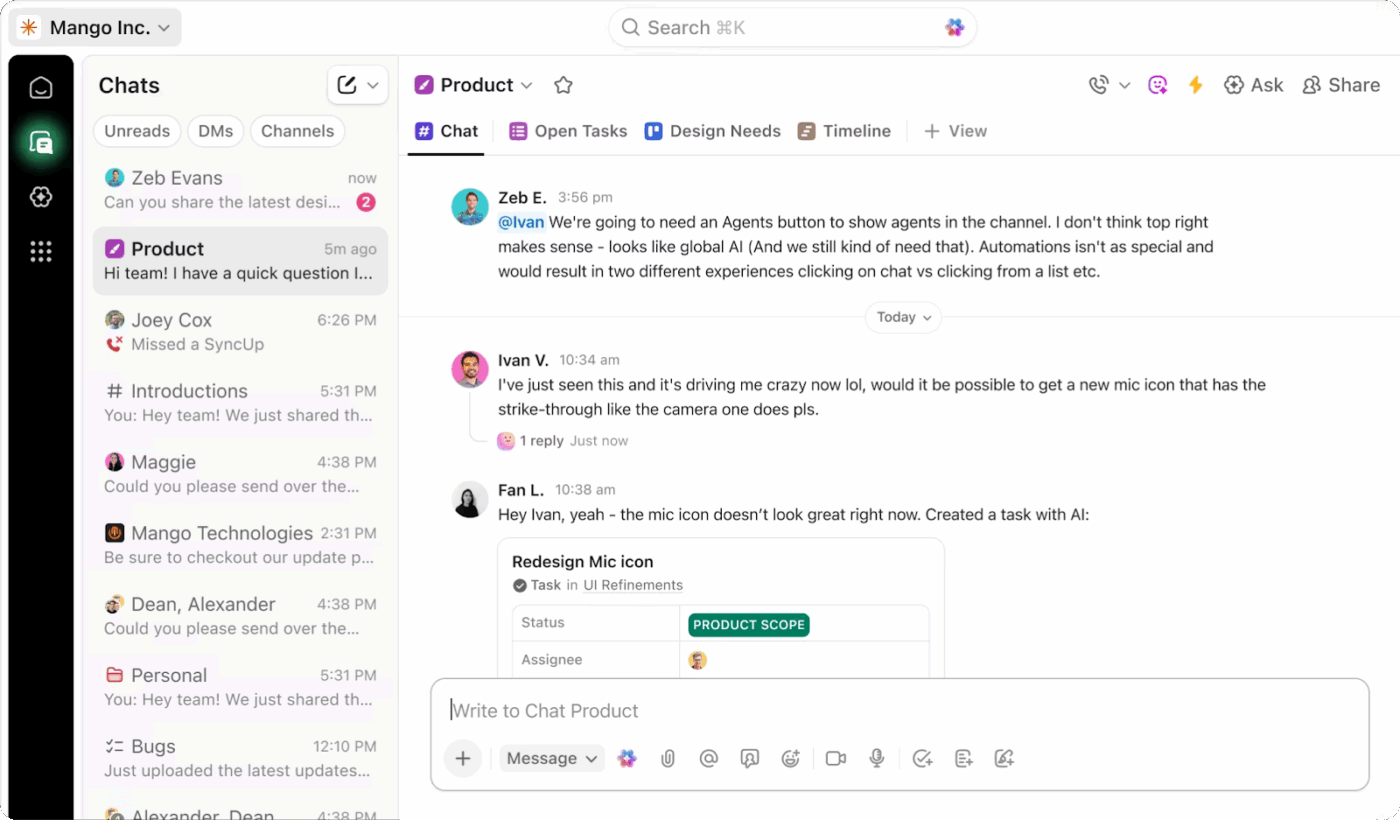
ClickUp Chat vous offre un canal dédié et contextualisé où la communication relative aux incidents reste ciblée, visible et facile à suivre.
Vous pouvez le configurer comme votre principal canal de communication pour la gestion des incidents, directement lié au travail en cours de suivi. Cette connexion transforme la manière dont les équipes se coordonnent dans les situations de forte pression.
🚀 L'avantage ClickUp : Transformez chaque incident en opportunité d'apprentissage grâce au modèle de rapport de réponse aux incidents de ClickUp.
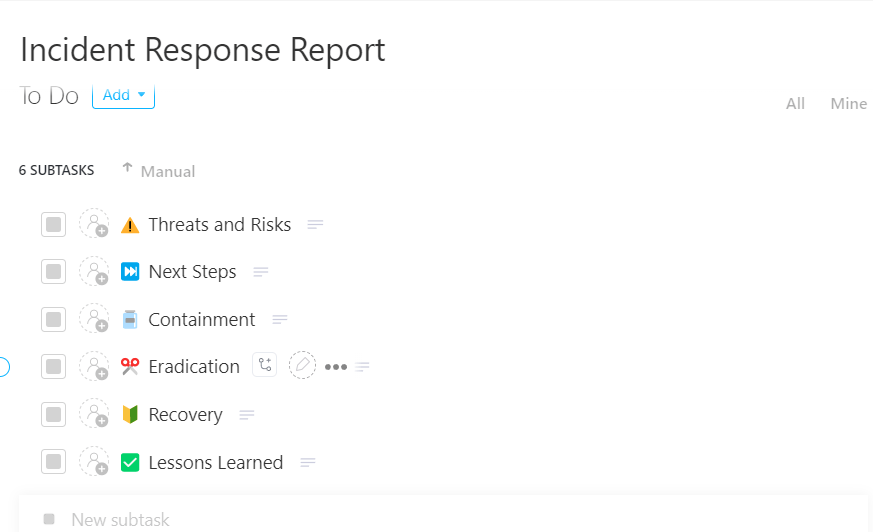
Enregistrez chaque incident avec clarté et sans aucune lacune à l'aide du modèle de rapport de réponse aux incidents ClickUp
Conçu comme un système prêt à l'emploi basé sur des tâches, il vous permet d'enregistrer, de suivre et de gérer les incidents de A à Z en un seul endroit, afin qu'aucune information ne se perde entre les outils ou les équipes.
Étape n° 5 : Tester, intégrer et établir une fréquence de révision
Un guide qui n'a jamais été testé n'est qu'un ensemble d'hypothèses. Avant de le considérer comme opérationnel, validez-le à l'aide d'exercices structurés et intégrez-le aux outils que votre équipe utilise au quotidien.
Pour les tests, effectuez les exercices par ordre d'intensité :
- Exercice sur table : un animateur présente un scénario simulé et l'équipe discute des décisions à prendre à voix haute
- Exercice fonctionnel : L'équipe exécute des étapes spécifiques dans un environnement contrôlé, comme l'isolation d'un terminal de test
- Simulation complète : Une équipe rouge met en œuvre un scénario d'attaque réaliste tandis que l'équipe d'intervention réagit en temps réel
Pour l'intégration des outils, mappez directement le guide à vos identifiants d'alerte SIEM, aux actions de confinement EDR, aux flux de travail de création de tickets et aux procédures de transfert vers des prestataires externes spécialisés dans la réponse aux incidents. Les intervenants doivent passer de l'alerte à la procédure puis à l'action sans changer de contexte.
Comment ClickUp peut vous aider
La réalisation d'exercices sur table et de simulations met souvent en évidence la même lacune. Les équipes connaissent les étapes en théorie, mais la mise en œuvre est ralentie car aucun système ne guide activement la réponse en temps réel.

Les agents IA de ClickUp comblent cette lacune. Ils observent l'activité au niveau des tâches, des champs et des flux de travail, puis agissent selon la logique que vous définissez. Cela les rend particulièrement utiles lorsque vous testez et mettez en œuvre votre guide.
Commencez par voir comment cela se déroule lors d'un exercice sur table.
Supposons que votre animateur présente une attaque de phishing qui dégénère en compromission des identifiants. Pendant que votre équipe discute des prochaines étapes, un agent IA peut :
- Générez une checklist structurée pour la réponse aux incidents, alignée sur votre procédure de lutte contre le phishing
- Suggérez les actions suivantes en fonction de champs de tâches tels que « type d'incident » et « gravité ».
- Rédigez une note interne en utilisant les détails des tâches en cours
Cela permet d'ancrer les discussions dans les étapes concrètes de mise en œuvre.
💡 Conseil de pro : Pour la maintenance continue, organisez vos revues autour de trois déclencheurs :
- Un audit complet annuel accompagné d'un exercice sur table portant sur toute procédure non testée au cours des 12 derniers mois
- Après chaque incident majeur, tant que les détails sont encore frais
- Vérification trimestrielle des changements de personnel et d'outils
Attribuez un propriétaire désigné à chaque cycle grâce à la fonctionnalité « Multiple Assignees » de ClickUp. Sans responsabilisation, les révisions sont négligées et le guide devient discrètement un handicap.
Exemples de guides d'intervention en cas d'incident par type de menace
Voici à quoi ressemble le processus d'élaboration d'un guide lorsqu'il est appliqué aux types de menaces les plus courants.
Guide d'intervention en cas d'incident lié à un ransomware
- Déclencheur : alerte de détection au niveau des terminaux signalant une activité de chiffrement de fichiers ou des modifications inhabituelles des extensions de fichiers
- Contenir immédiatement : isolez immédiatement les systèmes affectés du réseau et désactivez les lecteurs partagés
- Mesures clés : Identifiez la variante du ransomware, déterminez l'étendue du chiffrement et préservez les preuves numériques
- Récupération : effectuez une restauration à partir de sauvegardes saines après avoir vérifié qu'elles ne sont pas compromises, puis appliquez un correctif à l'entrée
- Après l'incident : consignez l'échéancier de l'attaque et vérifiez l'intégrité des procédures de sauvegarde
🔍 Le saviez-vous ? L'un des premiers hackers était un lanceur d'alerte. Dans les années 1980, un groupe connu sous le nom de Chaos Computer Club a révélé des failles de sécurité dans les systèmes bancaires afin de démontrer leur vulnérabilité, plutôt que de les exploiter à des fins lucratives.
Guide d'intervention en cas d'incident de phishing
- Déclencheur : un utilisateur signale un e-mail suspect ou la détection d'une page visant à récupérer des identifiants
- Mesures immédiates : Mettez l'e-mail en quarantaine dans toutes les boîtes de réception et bloquez le domaine de l'expéditeur.
- Mesures clés : imposez la réinitialisation des mots de passe et révoquez immédiatement les sessions actives si des identifiants ont été transmis
- Communication : Informez les utilisateurs concernés et envoyez une alerte de sensibilisation à l'ensemble de l'organisation sans semer la panique
- Restauration : Vérifiez qu'il ne reste aucun accès persistant et mettez à jour les règles de filtrage des e-mails
Guide d'intervention en cas d'accès non autorisé
- Déclencheur : activité de connexion anormale, alerte d'escalade de privilèges ou accès à des ressources sensibles
- Confinement immédiat : désactivez le compte compromis, mettez fin aux sessions actives et restreignez l'accès
- Actions clés : Déterminez comment l'accès a été obtenu et auditez toutes les actions effectuées par le compte compromis
- Restauration : réinitialisez les identifiants de tous les comptes potentiellement affectés et renforcez les contrôles d'accès
- Après l'incident : Réalisez un audit complet des accès et mettez à jour les politiques de privilèges minimaux
Bonnes pratiques pour les guides d'intervention en cas d'incident
Voici les bonnes pratiques qui distinguent les équipes capables de résoudre les incidents de manière efficace de celles qui, six heures plus tard, sont toujours réunies dans une salle de crise à se disputer pour savoir à qui incombe la responsabilité de la restauration. Maîtrisez ces principes et tout le reste deviendra plus facile. 🔥
Décrivez ce qu'il faut faire, et non ce qu'il faut envisager
La plupart des guides regorgent d'étapes telles que « évaluer la gravité de la situation » ou « identifier les parties prenantes concernées ». Ce ne sont pas des étapes. Ce sont des rappels à faire du travail de réflexion.
Un guide pratique vous indique les mesures à prendre, et non pas simplement qu'une action est nécessaire. Remplacez « évaluer l'impact sur les clients » par « vérifier le tableau de bord des sessions actives et coller le nombre dans le canal dédié aux incidents ». Tout réside dans la précision.
Séparer la personne chargée de trouver la solution de celle chargée de gérer l'incident
Lorsque l'ingénieur le plus expérimenté de l'équipe doit à la fois rechercher la cause première du problème, répondre aux questions de la direction et décider qui page, ces trois tâches sont mal gérées.
Votre guide doit imposer une séparation stricte : une personne est chargée de l'enquête, une autre de la gestion de l'incident. Le responsable des incidents ne prend aucune décision technique. Il délègue, débloque et communique. Cela peut sembler être une charge supplémentaire jusqu'à ce que cela vous fasse gagner deux heures pour la première fois.
🔍 Le saviez-vous ? Pas moins de 91 % des grandes entreprises ont déjà modifié leurs stratégies de cybersécurité en raison de l'instabilité géopolitique, faisant des tensions mondiales un facteur déterminant dans leurs décisions en matière de cyberdéfense.
Effectuez l'analyse rétrospective tant que les gens sont encore en colère
Les meilleures analyses rétrospectives ont lieu dans les 48 heures, car la frustration est encore vive. L'ingénieur qui estimait que le seuil d'alerte était trop élevé le fera savoir dès le deuxième jour.
Au dixième jour, ils sont déjà passés à autre chose et la réunion se transforme en une reconstitution polie de l'échéancier plutôt qu'en une discussion franche sur ce qui n'a pas fonctionné.
Testez le guide en essayant de le contourner
La seule façon fiable de savoir si votre guide fonctionne est de l'utiliser alors qu'il n'y a pas d'urgence. Organisez une simulation. Choisissez un scénario de défaillance réaliste, remettez le guide à quelqu'un sans préparation préalable et observez où il hésite.
Chaque hésitation est une faille. Chaque question posée est une étape manquante. Un guide qui n'a jamais été testé en conditions réelles n'est jamais achevé.
Un responsable des opérations partage son avis sur l'utilisation de ClickUp:
ClickUp s'est révélé être un excellent outil pour assurer l'organisation et la coordination de notre équipe. Il facilite la gestion des projets, l'attribution des tâches et le suivi des progrès, le tout en un seul endroit. J'apprécie particulièrement sa flexibilité : on peut personnaliser les flux de travail, créer des modèles et adapter la plateforme aux différents processus de l'équipe.
Cela s'est avéré très utile pour mettre en place des systèmes reproductibles pour des éléments tels que les procédures opératoires normalisées (SOP), les évaluations de performance et le suivi de projet. Le fait de créer des connexions entre les tâches, les documents et la communication permet de réduire les allers-retours et de s'assurer que tout le monde est sur la même longueur d'onde.
Créez et gérez des guides d'intervention en cas d'incident avec ClickUp
Garder les guides opérationnels et accessibles au moment où cela compte est un défi de taille. La plupart des équipes se retrouvent avec une documentation dispersée entre les wikis, Google Docs et les signets Slack. Lorsqu’un incident survient, personne ne sait avec certitude quelle version est à jour ni où se trouve la matrice d’escalade.
Éliminez la prolifération des outils et les changements de contexte grâce à ClickUp. Grâce à cet environnement de travail convergent, votre documentation de guide d'intervention, vos flux de travail de réponse et la communication au sein de votre équipe se trouvent tous au même endroit.
Que vous élaboriez votre premier guide ou que vous regroupiez des documents épars, ClickUp offre à votre équipe un espace unique pour planifier, réagir et s'améliorer. Inscrivez-vous gratuitement dès aujourd'hui !
Foire aux questions (FAQ)
1. Quelle est la différence entre un guide d'intervention en cas d'incident et un guide opérationnel ?
Un guide couvre l'ensemble du cycle de vie de la réponse pour un type d'incident spécifique. En revanche, un manuel d'exécution est une procédure technique plus ciblée visant à achever une tâche unique dans le cadre de cette réponse.
2. À quelle fréquence devez-vous mettre à jour votre guide d'intervention en cas d'incident ?
Réviser et mettre à jour les guides au moins une fois par trimestre. Vous devez également les mettre à jour après chaque incident réel et après chaque exercice sur table.
4. Peut-on utiliser un modèle de guide d'intervention en cas d'incident comme point de départ ?
Certes, les modèles issus de référentiels tels que le NIST ou la CISA vous offrent une structure éprouvée. Les modèles ClickUp sont également très utiles. Cela vous permet de personnaliser la base en fonction de votre environnement plutôt que de partir d'une page blanche.
5. Les petites équipes ont-elles besoin d'un guide d'intervention en cas d'incident ?
On peut affirmer que les petites équipes ont davantage besoin de guides d'intervention, car elles ont moins de marge d'erreur. Un guide d'intervention simple pour vos principaux scénarios de menace vaut bien mieux que d'improviser une réponse.