

Il est 3 heures du matin.
Une alarme stridente vous réveille en sursaut.
Vous vous précipitez vers votre ordinateur, attiré par la lueur de son écran. Un système critique est en panne. La panique s'installe. Ce n'est pas une scène tirée d'un thriller de science-fiction, mais un scénario cauchemardesque pour tout professionnel de l'informatique.
Mais c'est aussi une réalité. Lorsque le monde numérique s'arrête, la pression est immense.
C'est là que la gestion des incidents devient vitale.
La gestion des incidents est essentielle pour traiter et résoudre rapidement les interruptions de projet. En gérant efficacement ces perturbations, vous pouvez vous concentrer davantage sur l'obtention de résultats et l'achevement efficace de votre projet.
Dans cet article, nous explorerons le processus de gestion des incidents et partagerons les bonnes pratiques pour vous aider à mettre en œuvre un plan d'urgence solide. Cela vous permettra de gérer efficacement tout incident futur lié à vos projets.
Comprendre la gestion des incidents
Les incidents sont des perturbations ou des menaces potentielles qui ont un impact sur la qualité du service. Par exemple, une application métier qui plante ou un serveur web qui fonctionne au ralenti, entraînant des problèmes de productivité, sont considérés comme des incidents. Ces évènements peuvent aller de petits dysfonctionnements affectant quelques utilisateurs à des pannes majeures ayant un impact sur les services mondiaux.
La gestion des incidents consiste à identifier, hiérarchiser et résoudre les problèmes informatiques afin de minimiser les perturbations des opérations de l'entreprise tout en mettant en œuvre des mesures pour prévenir leur réapparition. Ce processus de prévention proactive des incidents est essentiel pour toute organisation, car les interruptions de service peuvent entraîner des pertes importantes pour l'entreprise. Une gestion efficace des incidents permet aux équipes de hiérarchiser et de résoudre rapidement les problèmes, garantissant ainsi une meilleure continuité du service.
Lorsqu'elles sont confrontées à des incidents, les équipes ont besoin d'un plan bien défini qui les aide à :
- Réagissez rapidement pour minimiser les temps d'arrêt
- Communiquez efficacement avec les clients, les parties prenantes, les propriétaires de services et les autres parties concernées.
- Collaborez de manière transparente pour accélérer la résolution des problèmes et éliminer les obstacles à leur résolution.
- Améliorez-vous continuellement en tirant les leçons des incidents et en appliquant ces enseignements pour améliorer la qualité du service et affiner les processus.
Dans ce cadre, il est également essentiel de savoir rédiger un rapport d'incident. Des rapports d'incident détaillés facilitent une analyse approfondie, identifient les causes profondes et permettent d'élaborer des stratégies préventives.
La relation entre la gestion des incidents, l'ITSM et le DevOps
La gestion des incidents est un élément central de la gestion des services informatiques (ITSM), qui garantit la disponibilité et la fiabilité des services informatiques. Parallèlement, DevOps intègre les équipes de développement et d'exploitation afin d'améliorer la collaboration et l'efficacité.
Aligner la gestion des incidents sur les principes de gestion de projet DevOps peut aider les organisations à réagir rapidement et efficacement aux incidents. Cet alignement favorise l'amélioration continue, une récupération plus rapide après les incidents et une prestation de services améliorée.
Comprendre les processus de gestion des incidents
Un processus efficace de gestion des incidents permet aux équipes informatiques d'enquêter, de documenter et de résoudre efficacement les interruptions ou les pannes de service.
Les entreprises adoptent souvent différents types de processus de gestion des incidents adaptés à leurs besoins spécifiques. Comme il n'existe pas d'approche universelle, vous trouverez des méthodologies variées d'une organisation à l'autre.
Certaines équipes adhèrent aux processus traditionnels de gestion des incidents informatiques, tels que ceux détaillés dans les certifications ITIL (Information Technology Infrastructure Library). D'autres préfèrent une approche plus orientée vers l'ingénierie de fiabilité des sites (SRE) ou DevOps.
Le flux de travail de gestion des incidents ITIL vise à réduire les temps d'arrêt et à atténuer l'impact des incidents sur la productivité des employés. À l'aide de modèles de rapports d'incidents, les équipes peuvent mettre en place un flux de travail reproductible pour consigner, diagnostiquer et résoudre les incidents tout en conservant des enregistrements complets de leurs activités.
Le cadre ITIL est principalement utilisé par les équipes informatiques qui gèrent les services au sein des entreprises. Ces équipes personnalisent souvent la couverture étendue des incidents et des processus de l'ITIL afin de l'adapter à leurs besoins.
ITIL est particulièrement utile pour créer une culture de dépannage proactif. Ses processus structurés aident les équipes à assurer un suivi cohérent des incidents et des actions, améliorant ainsi les rapports et l'analyse, ce qui se traduit finalement par des services plus robustes et des équipes plus efficaces.
L'IA et l'apprentissage automatique dans la gestion des incidents
L'intégration de l'IA et du machine learning dans la gestion des incidents transforme la manière dont les équipes traitent les incidents. Les outils basés sur l'IA peuvent analyser de grandes quantités de données afin de prédire les incidents potentiels avant qu'ils ne se produisent, permettant ainsi de prendre des mesures préventives.
Les algorithmes d'apprentissage automatique peuvent identifier des modèles et des anomalies que les analystes humains pourraient manquer, offrant ainsi des informations plus approfondies sur les causes profondes et les solutions potentielles. Ces technologies peuvent également automatiser les tâches routinières, telles que l'enregistrement des incidents et les diagnostics initiaux, libérant ainsi les ressources humaines pour la résolution de problèmes plus complexes.
Haute disponibilité et temps d'arrêt dans la gestion des incidents
Il est essentiel de réduire au minimum les temps d'arrêt pour une gestion efficace des incidents. La haute disponibilité garantit que les systèmes sont opérationnels et accessibles à tout moment, minimisant ainsi le risque d'interruption de service. La redondance, les mécanismes de basculement et l'équilibrage de charge sont utilisés pour atteindre une haute disponibilité.
Réduire les temps d'arrêt est essentiel pour maintenir la productivité et la satisfaction des clients. Les processus de gestion des incidents doivent inclure des plans solides pour une réponse et une reprise rapides afin de minimiser la durée et l'impact des pannes.
Processus de gestion des incidents informatiques en détail
La gestion des incidents consiste à identifier, enregistrer, classer, hiérarchiser et résoudre efficacement les incidents.
Comprendre ces étapes permet d'adopter une approche systématique de la gestion des incidents, de réduire les temps d'arrêt et de prévenir les occurrences futures.
Étapes du processus de gestion des incidents informatiques
1. Identifiez et consignez l'incident
Les incidents peuvent provenir de diverses sources, notamment des employés, des clients, des fournisseurs ou des systèmes de surveillance. La première étape consiste à identifier et à enregistrer l'incident. Ces registres, souvent appelés tickets d'incident, comprennent généralement :
- Le nom de la personne qui signale l'incident
- La date et l'heure auxquelles l'incident a été signalé
- Une description de l'incident détaillant ce qui ne fonctionne pas ou est en panne
- Un nombre d'identification unique est attribué à des fins de suivi.
2. Catégorisez l'incident
Il est essentiel d'attribuer à chaque incident une catégorie logique et intuitive (et une sous-catégorie, si nécessaire). Cette catégorisation facilite l'analyse des données pour identifier les tendances et les schémas, ce qui est essentiel pour une gestion efficace des problèmes et la prévention des incidents futurs.
3. Hiérarchisez les incidents
Chaque incident doit être classé par ordre de priorité en fonction de son impact sur l'entreprise, du nombre de personnes concernées, des accords de niveau de service (SLA) applicables et des implications potentielles en matière financière, de sécurité et de conformité.
Les équipes responsables déterminent sa priorité relative en la comparant à d'autres incidents ouverts. Il est recommandé de déterminer à l'avance les niveaux de gravité et de priorité, ce qui permet aux gestionnaires d'incidents d'évaluer rapidement les priorités.
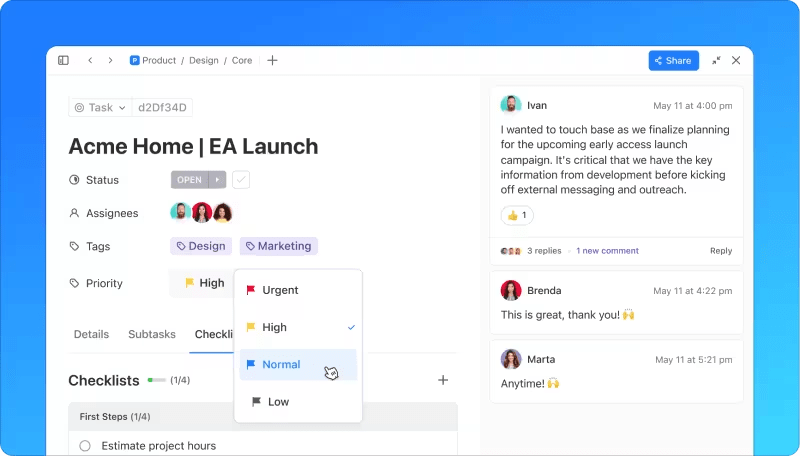
4. Réagir à l'incident
La phase de réponse comprend plusieurs actions clés :
- Diagnostic initial : dans l'idéal, l'équipe d'assistance de première ligne diagnostique et résout l'incident. Si elle n'y parvient pas, elle consigne toutes les informations pertinentes et les transmet à l'équipe de niveau supérieur.
- Escalade : l'équipe suivante poursuit le processus de diagnostic. Si elle ne parvient pas à résoudre l'incident, elle le fait remonter à un niveau supérieur.
- Communication : les mises à jour régulières sont partagées avec les parties prenantes internes et externes concernées.
- Enquête et diagnostic : cette phase se poursuit jusqu'à ce que la nature de l'incident soit identifiée. Les équipes peuvent faire appel à des ressources externes ou à des membres d'autres services pour les aider à résoudre le problème.
- Résolution et rétablissement : une fois le diagnostic posé, l'équipe met en œuvre les étapes nécessaires pour résoudre l'incident. Le rétablissement correspond au temps nécessaire pour que les opérations soient entièrement rétablies, car certaines corrections, comme les correctifs de bogues, peuvent nécessiter des tests et un déploiement même après la résolution.
- Clôture : si l'incident a été escaladé, il est renvoyé au service d'assistance pour être clôturé. Seuls les employés du service d'assistance peuvent clôturer les incidents, garantissant ainsi la qualité et la satisfaction du client.
Gestion des incidents pour les équipes DevOps et SRE
Les approches DevOps et SRE ont gagné en popularité, en particulier avec l'essor des services cloud toujours disponibles, des applications web accessibles dans le monde entier, des microservices et des solutions SaaS (Software-as-a-Service).
Les logiciels modernes, indispensables à usage personnel et professionnel, sont rarement hébergés sur un serveur local. Au contraire, ces applications sont généralement déployées dans des centres de données, au service de milliers, voire de millions d'utilisateurs à travers le monde. L'agilité et la rapidité sont essentielles pour les équipes chargées de la maintenance de ces services. Tout temps d'arrêt peut avoir des conséquences considérables, affectant simultanément de nombreuses organisations.
La philosophie « vous le construisez, vous le gérez » offre aux équipes agiles la flexibilité nécessaire. Mais elle peut également brouiller les lignes de responsabilité. Si les équipes DevOps peuvent prospérer grâce à des processus de développement moins rigides, il est essentiel de normaliser les pratiques fondamentales de gestion des incidents :
Responsabilités partagées en matière d'astreinte
Contrairement aux modèles traditionnels où certains membres de l'équipe sont désignés comme experts de garde, les équipes DevOps adoptent généralement un système de rotation des gardes. Cette approche garantit que tous les membres de l'équipe sont responsables de la réponse aux incidents, y compris ceux qui peuvent survenir en dehors des heures de travail normales.
La familiarité favorise la résolution
Au cœur de la philosophie DevOps se trouve la conviction que les ingénieurs qui ont développé un service sont les mieux placés pour résoudre les problèmes lorsqu'ils surviennent. Ce principe met en avant la mentalité « vous le construisez, vous le gérez », selon laquelle ce sont ceux qui connaissent le mieux l'architecture et les subtilités du service qui s'occupent des pannes et des perturbations.
Rapidité et responsabilité
Les équipes DevOps doivent créer et déployer des logiciels rapidement. Mais cette rapidité s'accompagne d'une responsabilité supplémentaire. Sachant qu'ils devront résoudre les incidents, les ingénieurs sont motivés à produire un code fiable et de haute qualité.
L'analyse des causes profondes (RCA) est également essentielle dans la gestion des incidents DevOps. La RCA consiste à identifier les causes sous-jacentes des incidents, ce qui permet aux équipes de mettre en œuvre des solutions pratiques et d'éviter une période d'incidents prolongée.
Il s'agit d'une approche proactive qui permet de résoudre les problèmes immédiats et de renforcer l'ensemble du système, réduisant ainsi le risque d'incidents majeurs à l'avenir et améliorant la résilience des services.
En maintenant un flux continu et cohérent dans les pratiques de gestion des incidents, les équipes DevOps peuvent trouver le juste équilibre entre flexibilité et structure. Cela leur permet d'être bien préparées à traiter les incidents rapidement et efficacement, ce qui se traduit par des services logiciels plus fiables et plus robustes.
Rôles dans la gestion des incidents
Bien que les organisations puissent adapter leurs rôles et responsabilités en fonction de leurs besoins spécifiques, voici quelques-uns des rôles les plus courants au sein des équipes de gestion des incidents informatiques :
- Utilisateur final/demandeur : il s'agit généralement de la personne qui subit une interruption de service et qui est chargée de lancer le processus de gestion des incidents en soumettant un ticket d'incident.
- Service d'assistance de niveau 1 : le service d'assistance de niveau 1 est le premier point de contact pour les demandeurs. Les techniciens traitent les problèmes et les demandes de base. Leur expertise couvre les problèmes courants tels que la réinitialisation des mots de passe et les problèmes de connexion comme les problèmes Wi-Fi.
- Service d'assistance de niveau 2 : les techniciens de ce niveau possèdent des compétences et des connaissances plus avancées que ceux du niveau 1. Ils traitent des problèmes plus complexes et gèrent les escalades provenant du niveau 1. Leur rôle consiste à résoudre des problèmes techniques complexes et à garantir une résolution efficace des incidents.
- Service d'assistance de niveau 3 et supérieur : ce niveau comprend des spécialistes possédant une expertise approfondie dans des domaines spécifiques de l'infrastructure informatique, tels que la maintenance du matériel ou l'assistance pour les serveurs.
- Responsable des incidents : le responsable des incidents supervise le processus de gestion des incidents, évalue son efficacité, suggère des améliorations et veille au respect des procédures établies.
- Responsable du processus : le responsable du processus supervise et affine le processus de gestion des incidents. Il analyse, ajuste et améliore le processus afin de s'assurer qu'il correspond aux objectifs de l'organisation et fournit une assistance optimale aux efforts de gestion des incidents.
Ces rôles contribuent collectivement à un processus d'identification et de gestion des incidents bien structuré et efficace, garantissant une résolution rapide et efficace des incidents tout en améliorant continuellement l'approche.
À lire également : Comment rédiger un bon rapport de bug (avec exemples et modèles)
Outils et ressources pour une gestion efficace des incidents
L'utilisation des outils et ressources appropriés pour la gestion des incidents peut considérablement améliorer l'efficacité et l'efficience du processus de gestion des incidents.
Les navigateurs Web, en particulier Google Chrome, jouent un rôle essentiel dans la gestion des incidents. La polyvalence de Chrome et sa compatibilité avec divers logiciels de gestion des incidents basés sur le Web en font un outil indispensable pour les équipes informatiques. Sa vaste bibliothèque d'extensions, telles que des outils de développement, des outils de suivi des bogues et des moniteurs de performances, permet d'effectuer des diagnostics et des dépannages en temps réel.
De plus, la récupération d'artefacts tels que les données de cache, l'historique, les téléchargements, etc. , grâce à l'analyse forensic du navigateur, aide les équipes à identifier les sources possibles d'attaques virales et de codes malveillants.
Chrome s'intègre également de manière transparente à ClickUp, un logiciel de productivité et de gestion des incidents ayant une très bonne évaluation, utilisé par les équipes des petites et grandes entreprises.
Voici quelques-uns des avantages significatifs liés à l'utilisation de ClickUp pour la gestion des incidents :
1. Suivi centralisé des incidents
ClickUp regroupe toutes les informations relatives aux incidents sur une seule plateforme. Cette approche centralisée garantit que tous les rapports d'incidents, les mises à jour et les résolutions sont accessibles en un seul endroit, ce qui réduit le risque de perte d'informations et permet aux membres de l'équipe d'avoir les données les plus récentes à portée de main.
2. Collaboration en temps réel
Les fonctionnalités de collaboration de ClickUp facilitent la communication entre les membres de l'équipe. Les utilisateurs peuvent commenter directement les tâches, partager des fichiers et mettre à jour le statut des incidents en temps réel grâce à la vue Chat de ClickUp. Cette fonctionnalité est particulièrement utile pour les équipes travaillant à différents emplacements ou dans différents fuseaux horaires, car elle permet à chacun de rester informé et aligné.

3. Gestion automatisée des flux de travail
ClickUp Automations permet de créer des flux de travail automatisés qui déclenchent des actions spécifiques en fonction de conditions prédéfinies. Par exemple, lorsqu'un incident est signalé, des notifications automatisées peuvent être envoyées aux membres de l'équipe concernés et des tâches peuvent être attribuées en fonction du type d'incident. Cela réduit les efforts manuels et accélère la résolution des incidents.
4. Rapports et analyses intégrés
La plateforme fournit des outils de reporting et d'analyse robustes qui permettent de surveiller les tendances en matière d'incidents et les indicateurs de performance. Les équipes peuvent générer des rapports détaillés sur la hiérarchisation des incidents, les délais de résolution des incidents, les taux de récurrence et d'autres indicateurs de performance clés. Cette approche basée sur les données permet d'identifier des tendances, d'évaluer l'efficacité des stratégies de réponse et de prendre des décisions éclairées pour améliorer les processus de gestion des incidents.
5. Tableaux de bord personnalisables
La plateforme vous permet de créer des tableaux de bord personnalisés qui affichent les indicateurs clés de performance (KPI) et les mesures critiques de gestion des incidents. Les tableaux de bord ClickUp offrent une vue d'ensemble visuelle des incidents en cours, des tâches en attente et des performances de l'équipe, permettant ainsi aux responsables d'évaluer rapidement l'état actuel de la gestion des incidents et de résoudre tout problème.
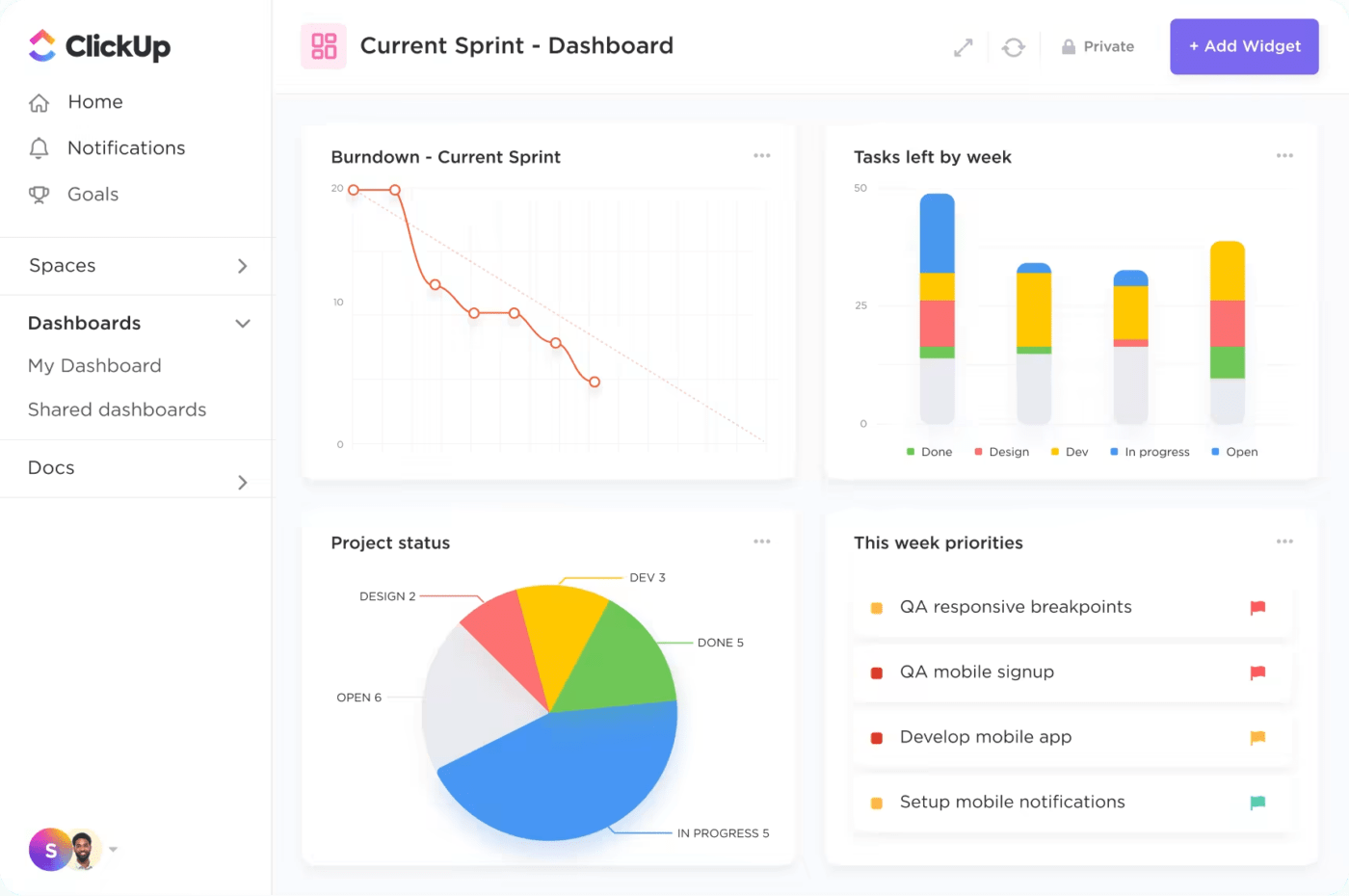
6. Modèles prédéfinis
ClickUp propose une gamme de modèles informatiques personnalisables conçus pour la gestion des incidents. Ces modèles aident également les utilisateurs à documenter les bugs.
Par exemple, le modèle de rapport d'incident informatique ClickUp permet aux équipes informatiques de documenter, de suivre et de résoudre les incidents rapidement et efficacement. Cela améliore non seulement la rapidité du service, mais aide également les entreprises à identifier les tendances à long terme auxquelles elles peuvent remédier afin d'améliorer leur infrastructure informatique globale.
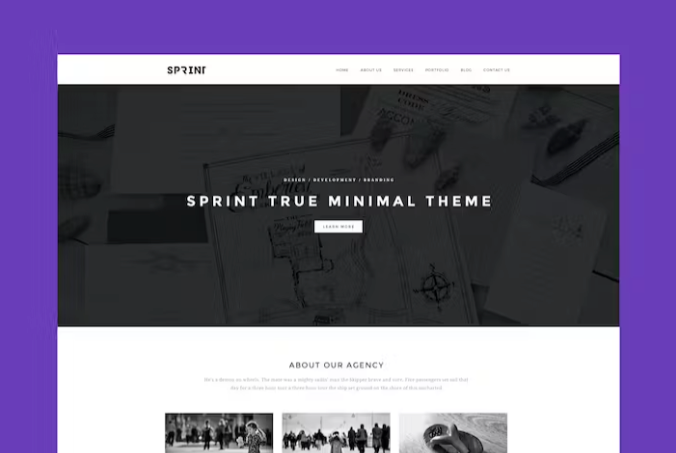
Ce modèle facilite les tâches suivantes :
- Documentez et signalez les incidents avec précision.
- Suivez la résolution des problèmes en temps réel
- Identifiez les schémas récurrents dans les problèmes signalés dans les rapports afin de résoudre les problèmes de manière proactive.
Il comprend des éléments essentiels tels qu'une description détaillée, une checklist, des sous-tâches et des champs personnalisables. Cette flexibilité garantit que le modèle peut être adapté à vos processus et procédures organisationnels, permettant ainsi de créer un rapport d'incident informatique complet.
Vous pouvez également utiliser le modèle de plan d'action en cas d'incident ClickUp, qui simplifie l'élaboration de plans d'action complets en cas d'incident (IAP) pour les entreprises.
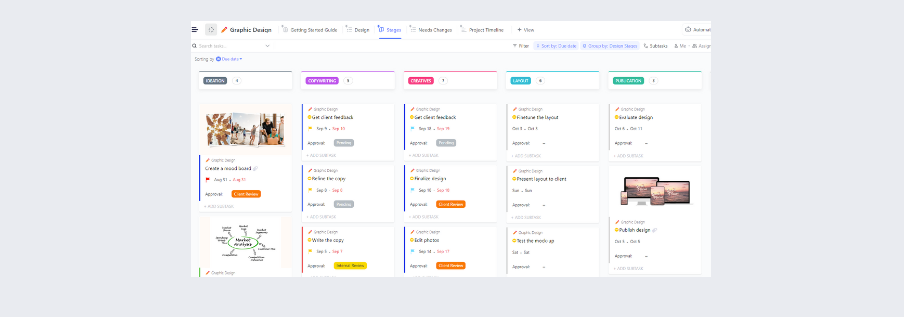
Ce modèle comprend systématiquement toutes les informations essentielles, vous aidant ainsi à établir des registres fiables des activités liées aux incidents et à mettre en œuvre des stratégies de réponse efficaces.
La fonctionnalité du modèle comporte des sections codées par couleur pour une documentation organisée :
- Résumé de la situation : fournit un aperçu concis de l'incident et du plan d'action global.
- Plan d'exécution : détaille les objectifs et les stratégies de gestion des incidents.
- Coordonnées de l'équipe chargée des incidents : liste les coordonnées des personnes impliquées dans la réponse.
- Liste d'organisation des incidents : décrit les rôles et responsabilités des équipes chargées des opérations, de la planification, de la logistique et des finances.
- Liste d'attribution des incidents : attribue des tâches spécifiques aux superviseurs et aux membres de l'équipe.
- Map/résumé de la situation : comprend des représentations graphiques du site ou de la région où s'est produit l'incident.
- Approbation du plan d'intervention pour incident : enregistre des informations telles que le nom de la personne qui soumet le plan, la date d'envoi et les signatures requises.
En utilisant ce modèle, les entreprises peuvent compiler efficacement toutes les informations nécessaires à l'approbation du plan d'action en cas d'incident (IAP) et mettre en place une réponse coordonnée et complète.
À lire également : 10 façons de réduire les risques liés à la sécurité informatique dans la gestion de projet
Bonnes pratiques en matière de gestion des incidents
Une gestion efficace des incidents repose sur des bonnes pratiques qui garantissent une résolution rapide et efficace.
Définissez des attentes claires avec les SLA
Les accords de niveau de service (SLA) jouent un rôle important en définissant clairement les attentes quant à la rapidité avec laquelle les équipes doivent traiter les incidents en fonction de leur gravité.
Les SLA définissent des délais de réponse et de résolution spécifiques, qui permettent de hiérarchiser les incidents et guident les équipes dans la gestion efficace de leur charge de travail. Cette approche structurée vous aide à concentrer vos ressources là où elles sont le plus nécessaires, afin d'aligner la résolution des incidents sur les priorités de l'entreprise et de minimiser les temps d'arrêt.
Appliquez régulièrement des correctifs pour prévenir les incidents.
Une autre pratique essentielle consiste à appliquer régulièrement des correctifs, ce qui permet de prévenir les incidents en corrigeant les vulnérabilités avant qu'elles ne puissent être exploitées. Il s'agit d'un processus continu qui corrige les failles de sécurité des logiciels et des systèmes, rendant plus difficile pour les pirates d'exploiter les faiblesses connues.
Cette pratique est un élément fondamental du cadre de gestion des risques liés à la cybersécurité, car elle protège l'infrastructure informatique contre les menaces émergentes et réduit le risque de violations. Sans correctifs opportuns, les vulnérabilités restent ouvertes et peuvent entraîner des problèmes de sécurité importants.
Donnez la priorité à la surveillance des centres de données
La gestion des centres de données joue également un rôle essentiel dans la gestion des incidents. Une gestion adéquate garantit que les aspects physiques et virtuels du centre de données sont bien entretenus. Cela inclut la supervision des contrôles environnementaux, des alimentations électriques et de la sécurité physique.
Les systèmes de surveillance en temps réel sont essentiels à cet égard, car ils permettent de détecter et de résoudre les problèmes avant qu'ils ne s'aggravent. Une gestion efficace des centres de données, associée à un cadre de gestion des risques de cybersécurité bien mis en œuvre, permet de détecter les problèmes à un stade précoce, ce qui contribue à éviter les perturbations majeures et à maintenir la stabilité des opérations informatiques.
Avantages et défis de la gestion des incidents
Les incidents peuvent ralentir la progression des projets et épuiser des ressources précieuses, entraînant souvent des perturbations opérationnelles importantes et une perte potentielle de données critiques. Cela souligne l'importance vitale d'une gestion efficace des incidents.
Les principaux avantages de la gestion des incidents sont les suivants :
1. Amélioration de la prévention des incidents
La prévention des incidents consiste à identifier et à atténuer de manière proactive les problèmes potentiels avant qu'ils ne s'aggravent. Des systèmes efficaces de gestion des incidents permettent aux organisations de mettre en œuvre des mesures préventives et de surveiller en permanence les performances du système, réduisant ainsi la fréquence et la gravité des incidents.
2. Processus de changement rationalisé
Un processus de changement bien géré garantit que les employés mettent en œuvre les mises à jour et les modifications de manière systématique, en suivant les procédures établies. L'utilisation de procédures opératoires normalisées (SOP) pour la gestion du changement permet de normaliser les procédures, d'assurer la cohérence et de réduire le risque d'erreurs.
3. Résolution et clôture efficaces des incidents
Un processus de résolution clairement défini garantit que les équipes traitent rapidement les incidents et prennent toutes les mesures nécessaires pour résoudre le problème. Une fois résolus, les incidents sont officiellement fermés avec une documentation complète et des mesures de suivi. Cette approche structurée améliore l'efficacité opérationnelle et fournit un enregistrement précieux pour l'analyse post-incident et l'amélioration continue, contribuant ainsi à affiner les stratégies de gestion des incidents au fil du temps.
Les défis de la gestion des incidents
Malgré ses avantages, la gestion des incidents pose souvent plusieurs défis.
1. Difficulté à identifier les causes profondes
L'un des principaux défis consiste à identifier la cause profonde d'un incident, en particulier lorsqu'il s'agit de problèmes complexes impliquant plusieurs composants du système et des interdépendances.
Pour diagnostiquer avec précision la cause sous-jacente, il faut mener une enquête approfondie et souvent faire appel à une collaboration interfonctionnelle. Les procédures opératoires normalisées (SOP) peuvent aider à créer des procédures normalisées pour l'analyse des causes profondes, mais la mise en œuvre efficace de ces procédures nécessite des outils et des méthodologies avancés.
Stanley Security a été confronté à un défi similaire lors de la gestion de ses processus de réponse aux incidents. En tant que leader mondial des solutions de sécurité, Stanley Security traite divers incidents sur différents systèmes et dans différentes régions.
Auparavant, les équipes marketing de l'entreprise utilisaient des outils tels qu'Excel et l'e-mail pour la communication interne et la gestion des tâches. La pandémie de COVID-19 a mis en évidence la nécessité de disposer d'outils de gestion de projet plus intégrés et plus évolutifs afin de supprimer les cloisonnements et d'améliorer la productivité.
ClickUp a fourni un environnement de travail unifié pour les équipes internationales, facilitant la communication et l'organisation des documents, ainsi que des procédures opératoires normalisées, dans une base de données mondiale. Cette harmonisation a permis aux équipes de collaborer plus efficacement et de partager les bonnes pratiques. En conséquence, Stanley Security a amélioré son travail d'équipe de 80 %, économisant plus de 8 heures par semaine en réunions et mises à jour. L'entreprise a également constaté une réduction de 50 % du temps consacré à la création et au partage de rapports.
2. Périodicité des incidents
Un autre défi consiste à empêcher la récurrence des incidents. Cela nécessite une compréhension approfondie des problèmes sous-jacents et la mise en œuvre de mesures préventives efficaces. Il est essentiel d'identifier les schémas et les tendances des incidents passés afin d'élaborer des stratégies visant à atténuer les risques futurs.
ClickUp relève ce défi en fournissant des outils intégrés de rapports et d'analyse qui offrent des informations sur les indicateurs d'incidents et les tendances de performance. Cette approche basée sur les données facilite l'identification des problèmes récurrents et aide à élaborer des stratégies de prévention ciblées.

La solution informatique et PMO de ClickUp peut vous aider dans ce domaine :
- Créez des statuts personnalisés (par exemple, « Fermé », « En attente », « Travail en cours ») et des champs (par exemple, « Demandeur », « Service ») pour classer et gérer efficacement les incidents.
- Suivez et surveillez les incidents en temps réel, en garantissant des mises à jour rapides et des vérifications de statut.
- Joignez les pièces jointes pertinentes, les captures d'écran ou les journaux aux incidents pour analyse. Créez une base de connaissances pour trouver une solution commune aux incidents.
- Générez des rapports sur la fréquence des incidents, le temps de résolution et les causes profondes afin d'identifier les tendances et d'améliorer la réponse.
- Connectez ClickUp à d'autres outils informatiques pour obtenir une vue d'ensemble des incidents.
Maîtriser la gestion des incidents pour une réussite optimale des projets
Maîtriser la gestion des incidents ne consiste pas seulement à réagir aux problèmes, mais aussi à créer un environnement résilient et agile où les interruptions sont rapidement gérées et les objectifs du projet atteints avec un impact minimal.
L'adoption de ces stratégies aidera votre équipe à éviter les problèmes potentiels et garantira le bon déroulement et la réussite de vos projets.
Avec ClickUp, vous bénéficiez d'une plateforme tout-en-un qui intègre la gestion des incidents à la gestion des projets et des opérations informatiques. Le suivi en temps réel, les flux de travail automatisés et les outils collaboratifs de ClickUp permettent à votre équipe de traiter et de résoudre rapidement les problèmes tout en maintenant vos projets sur la bonne voie. Qu'il s'agisse de gérer les opérations quotidiennes ou de naviguer parmi les exigences complexes d'un projet, ClickUp offre la visibilité et le contrôle nécessaires pour obtenir des résultats exceptionnels.
Prêt à améliorer votre gestion des incidents et la réussite de vos projets ? Inscrivez-vous dès aujourd'hui à ClickUp et transformez votre gestion des incidents !