
Los desastres de TI pueden ocurrir sin advertencia.
Desde fallos en los servidores hasta ciberataques, sin un plan de recuperación sólido, su empresa podría enfrentarse a horas de tiempo de inactividad, pérdida de datos y graves daños financieros, ya que el 54 % de las interrupciones graves cuestan más de 100 000 dólares estadounidenses.
Este blog le guía a través de la creación de un plan integral de recuperación ante desastres de TI que proteja sus sistemas, defina objetivos de recuperación claros y garantice que su equipo sepa exactamente qué hacer cuando surjan problemas.
¿Qué es un plan de recuperación ante desastres de TI?
Si sus servidores se bloquearan ahora mismo, ¿sabría su equipo exactamente qué hacer? 🛠️
Un plan de recuperación ante desastres (DR) de TI es su estrategia documentada para restaurar los sistemas y datos de TI después de cualquier interrupción, desde desastres naturales hasta ciberataques. Es, en esencia, su manual para volver a poner en marcha la tecnología cuando las cosas van mal.
💡 DR frente a continuidad de la empresa
La recuperación ante desastres (DR) se centra específicamente en restaurar su infraestructura de TI y sus datos. La continuidad del negocio (BC) es más amplia y tiene como objetivo mantener toda su empresa operativa durante y después de una crisis, incluso si la TI está inactiva. Piense en la DR como una parte clave de su estrategia general de BC.
💡 DR frente a continuidad de la empresa
La recuperación ante desastres (DR) se centra específicamente en restaurar su infraestructura de TI y sus datos. La continuidad del negocio (BC) es más amplia y tiene como objetivo mantener toda su empresa operativa durante y después de una crisis, incluso si la TI está inactiva. Piense en la DR como una parte clave de su estrategia general de BC.
Su plan de recuperación ante desastres es importante porque el tiempo de inactividad cuesta más que solo dinero. Cada minuto que sus sistemas están fuera de línea puede erosionar la confianza de los clientes, interrumpir las operaciones e incluso dar lugar a multas por incumplimiento. Un plan de recuperación ante desastres completo es su hoja de ruta hacia la resiliencia.
Un buen plan incluye:
- Procedimientos de copia de seguridad de datos: cómo y dónde almacenar copias de la información crítica para poder restaurarla.
- Pasos para la restauración del sistema: la secuencia exacta para restablecer los servicios en el orden correcto.
- Responsabilidades del equipo: quién hace qué durante una incidencia para evitar confusiones.
- Protocolos de comunicación: cómo informar a las partes interesadas, desde su equipo hasta sus clientes.
- Objetivos de recuperación: sus metas específicas sobre la rapidez con la que deben recuperarse los sistemas y la cantidad de pérdida de datos que es aceptable.
Escenarios comunes de desastres informáticos y su impacto
Los desastres no son solo escenarios de Hollywood, sino que ocurren a las empresas todos los días. Comprender contra qué se está protegiendo le ayuda a construir una defensa mucho más sólida.
Desastres naturales y daños físicos
Eventos como inundaciones, incendios, terremotos y cortes de energía importantes pueden destruir centros de datos enteros en cuestión de minutos. Por ejemplo, cuando una gran inundación afectó a un centro de datos de Nashville, algunas empresas perdieron semanas de datos y se enfrentaron a meses de recuperación. La mejor protección contra esto es la redundancia geográfica, lo que significa distribuir su infraestructura en múltiples ubicaciones físicas para que un solo evento no pueda afectar todo.
Ciberataques y compromiso de datos
El ransomware, los ataques de denegación de servicio distribuido (DDoS) y las violaciones de datos son diferentes de los desastres físicos. A menudo son más difíciles de detectar, pueden propagarse silenciosamente a través de los sistemas conectados y, con frecuencia, también se dirigen a los sistemas de copia de seguridad, lo que hace que la recuperación sea especialmente difícil. La frecuencia y la sofisticación de estos ciberataques siguen aumentando en todos los sectores, y el ransomware representa ahora el 44 % de todas las violaciones confirmadas, lo que lo convierte en una de las principales amenazas.
📖 Más información: 10 formas de reducir los riesgos de seguridad en la gestión de proyectos
Fallos de hardware y pérdida de datos
A veces, incluso los sistemas de copia de seguridad más probados y fiables fallan. Los fallos del servidor, los fallos de almacenamiento y los fallos de funcionamiento de los equipos de red pueden producirse sin advertencia. Incluso si dispone de sistemas redundantes (de copia de seguridad), estos pueden fallar al mismo tiempo si realizan un uso compartido de componentes o fuentes de alimentación, lo que crea un único punto de fallo.
👀 ¿Sabías que... En octubre de 2025, AWS sufrió una importante interrupción del servicio cuando un error en su sistema interno de gestión de DNS para Amazon DynamoDB provocó un fallo en la resolución de nombres de dominio en la región del centro de datos US-EAST-1. Este «pequeño» defecto técnico fue el desencadenante de un fallo en cadena en docenas de servicios de AWS y dejó fuera de servicio a cientos de aplicaciones y plataformas populares en todo el mundo, desde aplicaciones de mensajería y redes sociales hasta bancos, sitios de juegos y mucho más. Para muchas personas, la interrupción del servicio hizo que gran parte de Internet «desapareciera» temporalmente, lo que puso de relieve lo frágil que es nuestra infraestructura digital cuando hay una gran dependencia de un puñado de proveedores de servicios en la nube.
Errores de software e interrupción del servicio
Una base de datos dañada, una actualización de software fallida o un simple error de configuración pueden inutilizar plataformas enteras. Es posible que observe que un código mal configurado puede propagarse por los sistemas conectados, provocando una interrupción generalizada con un gran radio de alcance. Una gestión adecuada de los cambios y unos entornos de prueba específicos son sus mejores aliados para minimizar estos riesgos.
Errores humanos y configuraciones incorrectas
Las eliminaciones accidentales, las configuraciones incorrectas y los cambios no autorizados siguen siendo una de las causas más comunes de interrupciones de TI. Un solo comando incorrecto o un archivo eliminado pueden ser desencadenantes de horas de tiempo de inactividad y degradación del servicio. Si bien la capacitación y los controles de acceso ayudan, no pueden eliminar por completo los errores humanos.
📮ClickUp Insight: El 92 % de los trabajadores utiliza métodos inconsistentes para realizar el seguimiento de los elementos pendientes, lo que da como resultado decisiones erróneas y retrasos en la ejecución.
Ya sea que envíe notas de seguimiento o utilice hojas de cálculo, el proceso suele ser disperso e ineficiente. Con las funciones de gestión de tareas de ClickUp, nunca tendrá que preocuparse por esto. Cree tareas desde el chat, los comentarios de tareas de ClickUp, los documentos y los correos electrónicos con un solo clic.
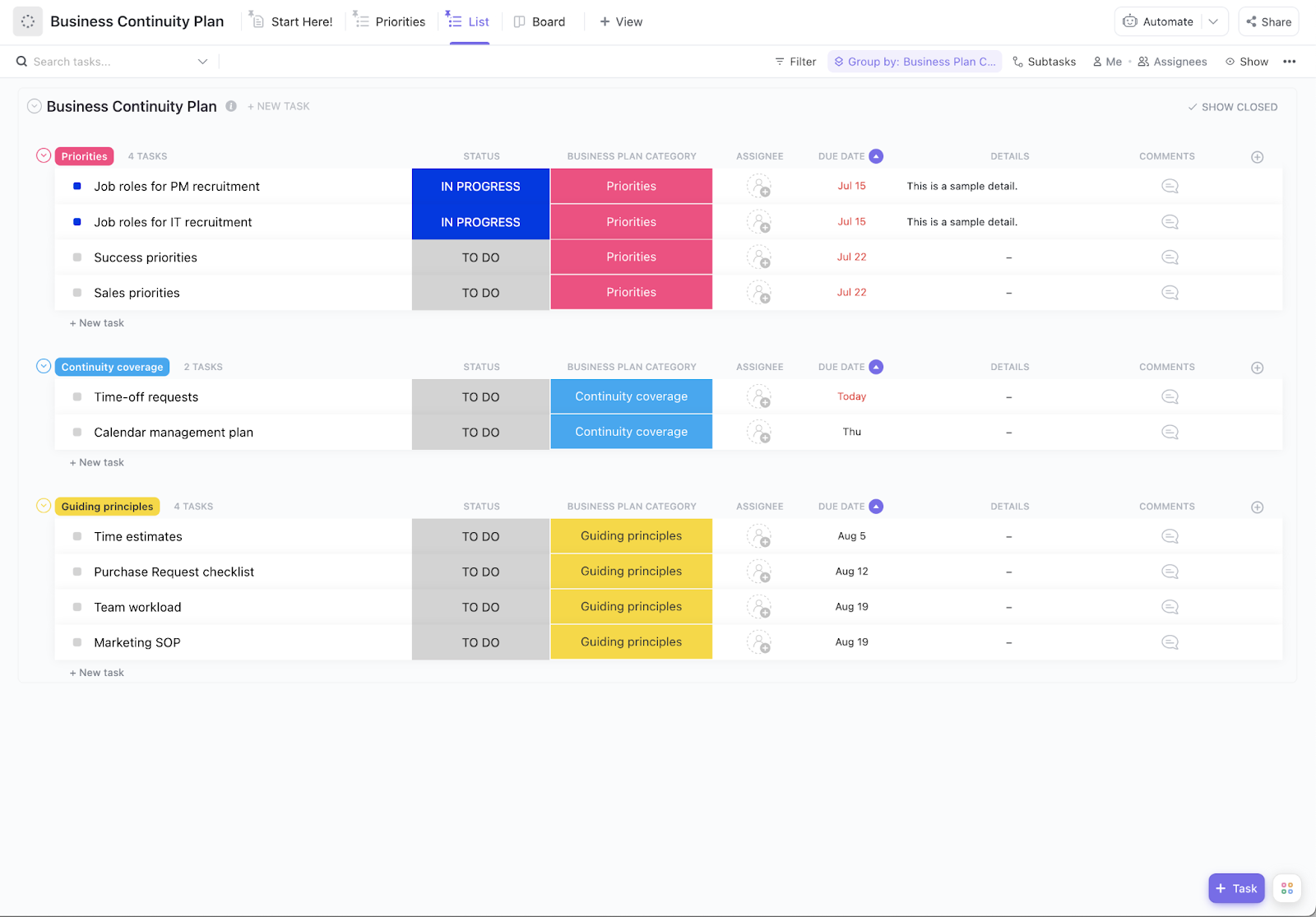
Componentes clave de un plan de recuperación ante desastres de TI
Un plan de recuperación ante desastres sólido es su guía completa para volver a estar en línea. Cada uno de estos componentes se complementa con los demás para crear una protección integral para su empresa.
Evaluación y priorización de riesgos
En primer lugar, debe saber a qué se enfrenta. Una evaluación de riesgos es el proceso de identificar sus vulnerabilidades y evaluar la probabilidad y el impacto de cada amenaza potencial. Puede organizar esto en una matriz de riesgos para ver qué amenazas son más graves.
Su evaluación debe abarcar:
- Sistemas críticos: lo que debe seguir funcionando sin falta para que su empresa pueda operar.
- Sensibilidad de los datos: ¿Qué información necesita el mayor nivel de protección (como los datos de los clientes)?
- Dependencias: ¿Qué otros sistemas o procesos se ven afectados cuando falla cada sistema?
📖 Más información: Cómo implementar la gestión de la infraestructura de TI
Análisis del impacto en la empresa y criticidad
A continuación, calcule el coste real del tiempo de inactividad. Un análisis del impacto en la empresa (BIA) le ayuda a determinar el impacto financiero y operativo de una interrupción del servicio para cada sistema. Esto le permite clasificar sus sistemas en niveles de criticidad para priorizar sus esfuerzos de recuperación.
| Crítico | Menos de una hora. | Procesamiento de pagos, bases de datos de clientes |
| Alto | De una a cuatro horas. | Correo electrónico, herramientas de comunicación interna |
| Medio | De cuatro a veinticuatro horas. | Entornos de desarrollo, herramientas de elaboración de informes |
| Bajo | Más de 24 horas | Sistemas de archivo, servidores de pruebas que no son de producción. |
Objetivos de RTO y RPO
Estas dos siglas son el núcleo de su estrategia de recuperación.
- Objetivo de tiempo de recuperación (RTO): es el tiempo máximo que puede permitirse que un sistema esté inactivo. Responde a la pregunta: «¿Con qué rapidez necesitamos que vuelva a estar en línea?».
- Objetivo de punto de recuperación (RPO): es la cantidad máxima de datos que puede permitirse perder, medida en tiempo. Responde a la pregunta: «¿Cuántos datos podemos perder sin sufrir daños importantes?».
Por ejemplo, su sistema de correo electrónico interno puede tener un RTO de cuatro horas, pero su base de datos de comercio electrónico orientada al cliente puede tener un RPO de solo 15 minutos, lo que significa que no puede perder más de 15 minutos de datos de transacciones.
Plan de copia de seguridad y recuperación de datos
Su plan de copia de seguridad es su última red de seguridad. Una buena práctica habitual es la regla 3-2-1: mantenga al menos tres copias de sus datos importantes, almacénelas en dos tipos de soportes diferentes y guarde una de esas copias fuera de las instalaciones.
También podrá elegir entre diferentes tipos de copias de seguridad:
- Copias de seguridad completas: una copia completa de todos los datos, que suele ser terminada semanal o mensualmente.
- Copias de seguridad incrementales: solo se copian los cambios realizados desde la última copia de seguridad de cualquier tipo.
- Copias de seguridad diferenciales: realiza una copia de seguridad de todos los cambios realizados desde la última copia de seguridad completa.
Y lo más importante: debe probar regularmente su proceso de restauración de copias de seguridad. Una copia de seguridad sin probar es solo una esperanza, no un plan.
💟 Bonificación: Capture detalles críticos durante incidencias de alto estrés utilizando la función de conversión de voz a texto de ClickUp Brain MAX, para que nunca se pierda información importante, incluso cuando no sea práctico escribir. Solo tiene que expresar sus observaciones y dejar que la IA se encargue de la documentación.
Plan de comunicación y actualizaciones para las partes interesadas
Cuando se produce un desastre, es fundamental contar con un plan de comunicación claro. Su plan debe definir las cadenas de notificación, la frecuencia con la que proporcionará actualizaciones y los canales que utilizará para cada tipo de incidencia.
Los diferentes grupos necesitan información diferente:
- Equipos internos: necesitan detalles técnicos y elementos específicos.
- Clientes: Necesitan conocer el estado del servicio y cuándo se espera que se resuelva.
- Proveedores: puede ser necesario contar con ellos para obtener soporte o escalar incidencias.
- Organismos reguladores: pueden exigir notificaciones formales en función de su sector.
Herramientas como esta plantilla de plan de comunicación lista para usar de ClickUp pueden ayudarle a actuar con mayor rapidez gracias a un protocolo establecido durante una crisis.

Programa de pruebas y formación
Un plan que nunca se prueba es un plan que fracasará. Las pruebas periódicas revelan las deficiencias y debilidades antes de que se produzca un desastre real.
Programe diferentes tipos de pruebas a lo largo del año:
- Ejercicios de simulación: su equipo repasa un escenario de desastre sobre el papel para comprobar la lógica del plan.
- Conmutaciones por error parciales: comprueba la recuperación de componentes o servicios específicos no críticos.
- Pruebas completas de recuperación ante desastres: se ejecuta una conmutación por error completa a los sistemas de copia de seguridad (la prueba definitiva).
Después de cada prueba, actualice su documentación y forme inmediatamente a los nuevos miembros del equipo en los procedimientos.
📖 Más información: Cómo desarrollar políticas y procedimientos de TI eficaces
Pasos para crear un plan de recuperación ante desastres de TI
Crear su plan de recuperación ante desastres no tiene por qué ser una tarea abrumadora.
A continuación le mostramos cómo puede abordarlo paso a paso. 🙌
Paso 1: Crear el inventario de activos
No se puede proteger lo que no se conoce. Empiece por crear una lista de activos que incluya todos los componentes de hardware, software, repositorios de datos y dependencias del sistema de su entorno. Asegúrese de incluir los datos de contacto de los proveedores, las claves de licencia y los detalles de configuración para poder consultarlos rápidamente durante la recuperación.

La plantilla ITAM de ClickUp reúne la gestión de incidencias, la gestión de problemas, la gestión de cambios, soluciones sencillas de gestión de activos y la gestión del conocimiento. Nuestra plantilla de errores conocidos de ITSM simplifica el seguimiento de los errores conocidos en sus sistemas. Explore todas nuestras plantillas de TI tan pronto como cambie su propósito.
Personalice sus flujos de trabajo con el estilo que desee para cada fase de ITAM, desde la implementación y la configuración hasta el mantenimiento y la retirada.
Paso 2: Clasificar los servicios críticos
Ahora, identifique cuáles de esos activos son críticos para la misión y cuáles son simplemente deseables. Cree mapas de dependencia de servicios que muestren cómo se conectan y dependen entre sí sus sistemas. Preste especial atención a los servicios de cara al cliente que afectan directamente a los ingresos o a la experiencia del usuario.
🎥 Vea este práctico tutorial que muestra cómo crear un plan estructurado y de alto nivel utilizando las potentes funciones de ClickUp, desde el establecimiento de metas hasta la asignación de tareas y el seguimiento del progreso.
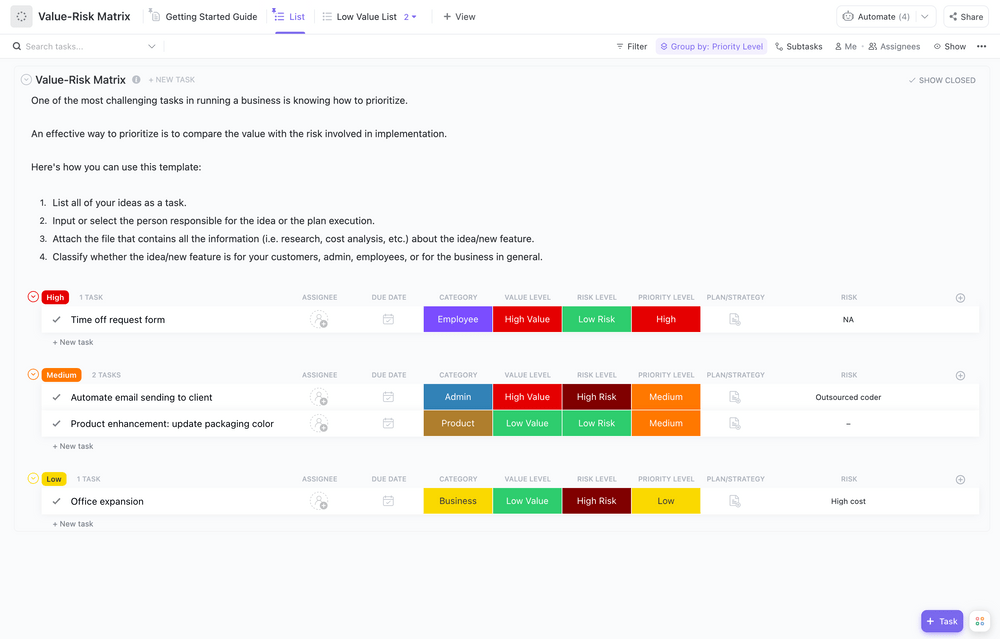
Paso 3: Evaluar los riesgos y las amenazas
Evalúe los riesgos y las amenazas analizando la probabilidad y el impacto de cada tipo de amenaza en su situación específica. Tenga en cuenta los riesgos geográficos (¿se encuentra en una zona sísmica o en una llanura inundable?) y cualquier amenaza específica del sector (como cambios normativos o ciberataques selectivos). Documente todo en un registro de riesgos para poder realizar un seguimiento a lo largo del tiempo.

La plantilla de pizarra para evaluación de riesgos de ClickUp crea una dimensión visual para su proceso de evaluación de riesgos. Ayuda a evaluar y categorizar los riesgos, lo que anima a su equipo a compartir ideas y colaborar en un formato atractivo y visual.
Esta plantilla le permite:
- Evalúe las categorías de riesgo y los posibles impactos.
- Analice los datos para identificar posibles áreas de preocupación.
- Determine las medidas preventivas para reducir la exposición al riesgo.
Con funciones que le permiten dibujar, escribir y añadir notas adhesivas, esta plantilla de pizarra para la gestión de riesgos es perfecta para evaluar los riesgos de su proyecto.
Paso 4: Ajuste objetivos de RTO y RPO
Trabaje directamente con las partes interesadas de su empresa para definir lo que consideran un tiempo de inactividad y una pérdida de datos aceptables para cada nivel de servicio que haya identificado anteriormente. Deberá equilibrar el coste de una recuperación más rápida con el impacto en el negocio, ya que no todo necesita una recuperación instantánea y sin pérdida de datos. Obtenga la aprobación de la dirección para estos objetivos.
Paso 5: Defina las rutas de copia de seguridad y conmutación por error.
Una vez establecidos sus objetivos, ya puede diseñar sus soluciones técnicas. Cree estrategias de copia de seguridad adaptadas al RPO de cada sistema y planifique procedimientos de conmutación por error detallados, incluidos sitios de procesamiento alternativos y métodos de acceso de emergencia. Incluya diagramas de red y manuales paso a paso para que la ejecución sea infalible.
Paso 6: Asignar roles y escalar
Defina la estructura de su equipo de recuperación ante desastres con responsabilidades y autoridad para la toma de decisiones claras. Cree listas de contactos completas con el personal principal y de copia de seguridad para cada rol. Una matriz RACI (Responsable, Acuarable, Consultado, Informado) es una excelente herramienta para eliminar la confusión durante una incidencia de alto estrés.
Paso 7: Documentar y comunicar el plan
Documente y comunique el plan con procedimientos claros y detallados que cualquier miembro de su equipo pueda seguir, incluso bajo presión. Es fundamental almacenar esta documentación en una ubicación fácilmente accesible, separada de su infraestructura principal. Asegúrese de que todos los miembros del equipo sepan exactamente dónde encontrar el plan durante una crisis.
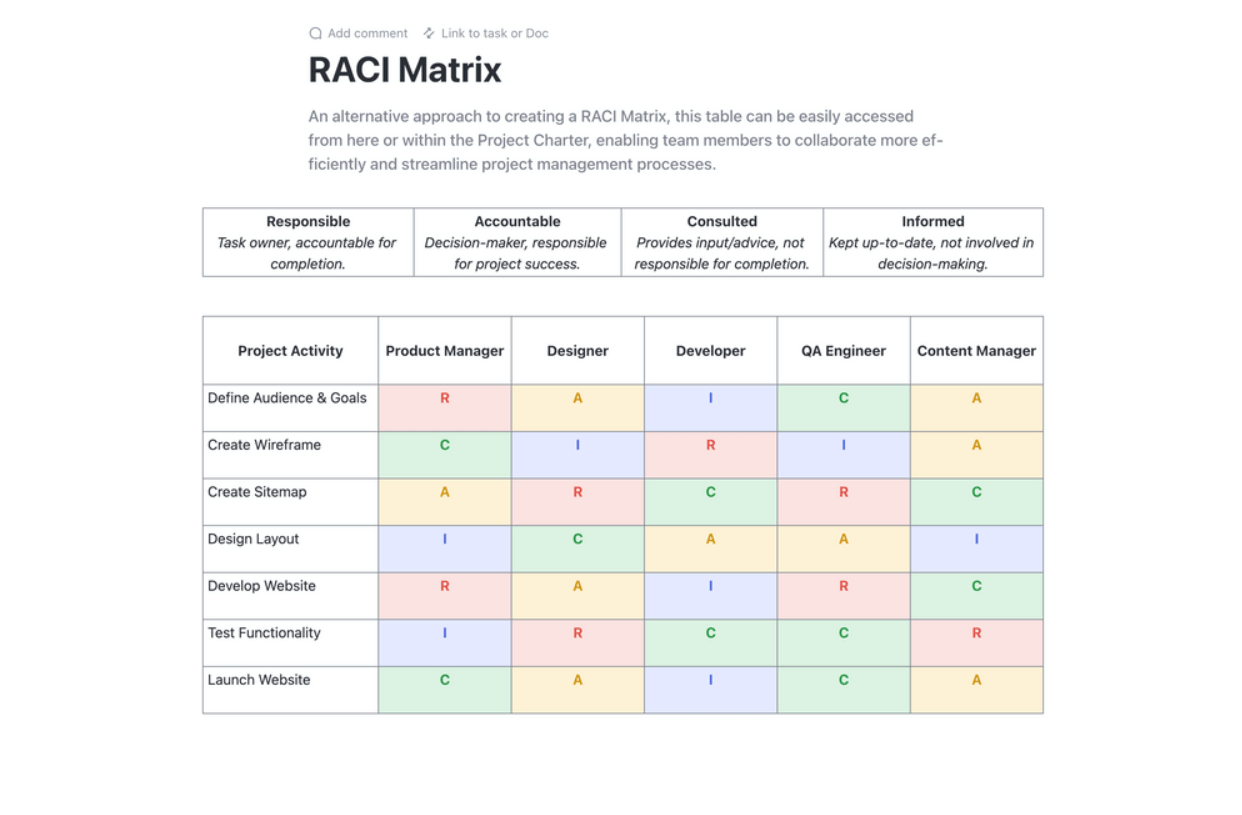
Optimice la planificación de sus proyectos con la plantilla de planificación RACI de ClickUp. Esta plantilla de documento supone un gran cambio, ya que ofrece un gráfico claro para definir los roles y responsabilidades del equipo en relación con las tareas del proyecto. Adopte el marco RACI (Responsable, Acuartillado, Consultado e Informado) para que todos estén en sintonía, garantizando la responsabilidad y la alineación con las metas de la organización.
Paso 8: Pruebe, revise y mejore
Por último, programe pruebas trimestrales para validar sus procedimientos e identificar cualquier deficiencia. Documente todas las lecciones aprendidas de cada prueba y de cualquier incidencia real, y utilícelas para actualizar su plan. Cree un sistema de seguimiento de mejoras sistemático para garantizar que se resuelvan todos los problemas que encuentre.
🌼 ¿Sabías que... En 2017, GitLab sufrió una importante interrupción de su base de datos. Durante la recuperación, descubrieron que varios de sus métodos de copia de seguridad habían estado fallando silenciosamente durante días. Esta incidencia enseñó a toda la industria tecnológica una lección crucial: la validación de las copias de seguridad no es negociable. Una copia de seguridad sin probar no es realmente una copia de seguridad.
🌼 ¿Sabías que... En 2017, GitLab sufrió una importante interrupción de su base de datos. Durante la recuperación, descubrieron que varios de sus métodos de copia de seguridad habían estado fallando silenciosamente durante días. Esta incidencia enseñó a toda la industria tecnológica una lección crucial: la validación de las copias de seguridad no es negociable. Una copia de seguridad sin probar no es realmente una copia de seguridad.
Estrategias y soluciones de recuperación ante desastres
No todas las organizaciones necesitan el mismo enfoque de recuperación ante desastres. Exploremos sus opciones en función de su presupuesto, sus necesidades de recuperación y los recursos disponibles.
Enfoque de copia de seguridad y restauración
Este es el método más sencillo y rentable. Consiste en realizar copias de seguridad periódicas en una ubicación externa (como la nube o un centro de datos secundario) y restaurarlas manualmente cuando sea necesario. Este enfoque es el más adecuado para sistemas no críticos que pueden tolerar un RTO más largo, ya que la recuperación puede llevar horas o incluso días.
Alta disponibilidad y redundancia
Esta estrategia tiene como objetivo eliminar los puntos únicos de fallo mediante el uso de múltiples sistemas activos. Técnicas como el equilibrio de carga, la agrupación de servidores y el almacenamiento RAID garantizan que, si un componente falla, otro lo sustituya al instante. Aunque su configuración y mantenimiento son más costosos, este enfoque puede reducir el tiempo de inactividad a solo unos segundos o minutos, lo que lo hace ideal para servicios críticos.
Opciones de replicación y conmutación por error
La replicación consiste en copiar datos casi en tiempo real a un sitio secundario, lo que garantiza una pérdida mínima de datos durante un desastre.
- Replicación sincrónica: escribe datos en los sitios primario y secundario al mismo tiempo, lo que garantiza que no se pierdan datos. Sin embargo, requiere un gran ancho de banda y puede ralentizar su sistema primario.
- Replicación asíncrona: escribe los datos primero en el sitio principal y luego los copia al sitio secundario con un ligero retraso. Es menos costosa y tiene menos impacto en el rendimiento, pero se acepta un pequeño riesgo de pérdida de datos.
Recuperación ante desastres basada en la nube y DRaaS
La recuperación ante desastres como servicio (DRaaS) se ha convertido en una opción muy popular para muchas empresas. Ofrece precios de pago por uso, distribución geográfica instantánea y automatización de la recuperación sin necesidad de crear y mantener sus propios sitios físicos de recuperación ante desastres. La recuperación ante desastres en la nube elimina el enorme gasto de capital que supone un centro de datos de copia de seguridad, al tiempo que proporciona una escalabilidad más rápida y una mayor flexibilidad que los enfoques tradicionales de sitios activos, inactivos o en espera.
Cómo ClickUp optimiza la planificación de la recuperación ante desastres de TI
Gestionar un plan de recuperación ante desastres a través de hojas de cálculo, documentos y cadenas de correo electrónico dispersos crea su propio riesgo de desastre.
Este tipo de dispersión del trabajo, la fragmentación del trabajo en múltiples herramientas desconectadas que no se comunican entre sí y la dispersión del contexto, cuando los equipos pierden horas buscando información dispersa en aplicaciones y plataformas, conduce a confusión, información desactualizada y tiempos de respuesta lentos cuando cada segundo cuenta.
Con ClickUp Converged AI Workspace, una plataforma única y segura en la que todas sus aplicaciones de trabajo, datos y flujos de trabajo conviven con la IA contextual como capa de inteligencia, que combina la gestión de proyectos, la documentación y la comunicación del equipo. Deje de hacer malabarismos con múltiples plataformas y reúna su planificación de recuperación ante desastres, pruebas y respuesta a incidencias en un sistema unificado.
Documentación centralizada de recuperación ante desastres con ClickUp Docs y asistencia integrada con IA.
Asegúrese de que su equipo siempre disponga de una única fuente de información veraz con ClickUp Docs.
Cree todo su plan de recuperación ante desastres en un espacio colaborativo en el que todos puedan contribuir en tiempo real durante una incidencia. Vincule documentos directamente a tareas y proyectos relacionados con incidencias para facilitar la navegación, e incorpore diagramas o manuales de procedimientos para tener la información crítica justo donde la necesita.
Lo mejor de todo es que puede proteger sus documentos para evitar ediciones accidentales y utilizar los permisos granulares de ClickUp para controlar quién puede tener vista o cambiar los procedimientos de recuperación confidenciales. Cada cambio se registra en el historial del documento, lo que le proporciona un registro de auditoría completo.
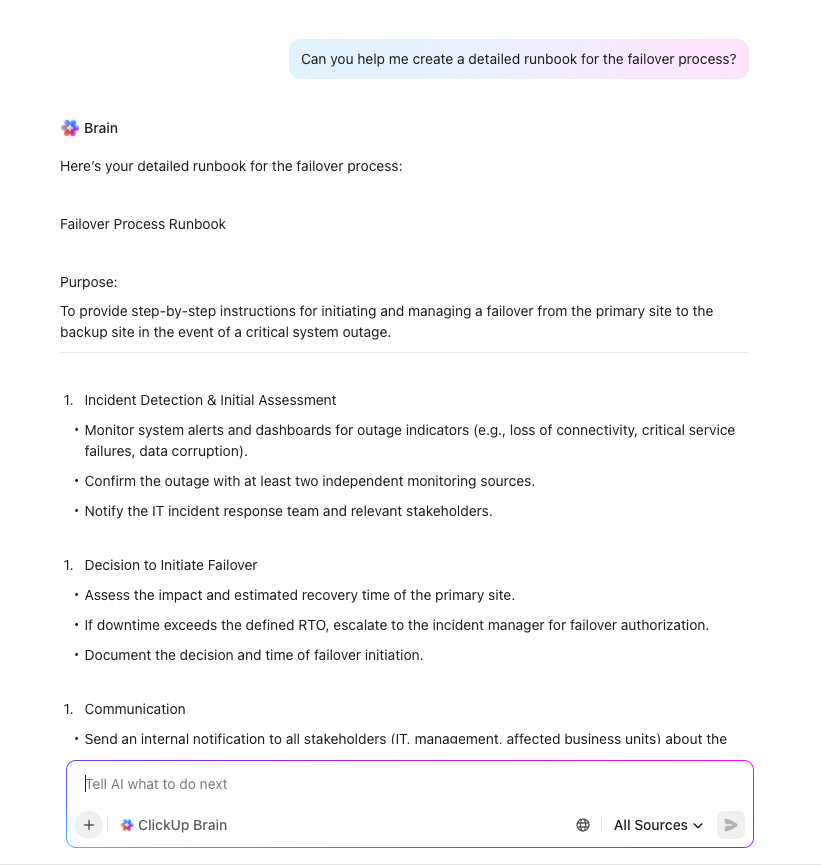
Creación de planes impulsada por IA con ClickUp Brain.
Acelere la planificación de la recuperación ante desastres y elimine las deficiencias críticas con ClickUp Brain, su asistente de IA contextual que comprende todo su entorno de trabajo. A diferencia de las herramientas de IA genéricas, ClickUp Brain aprovecha las tareas, los documentos y los flujos de trabajo reales de su organización para ofrecer un apoyo preciso y práctico a las iniciativas de recuperación ante desastres.
Solo tiene que hacer una indicación a ClickUp Brain algo como «Crear una lista de control de recuperación ante desastres para nuestra plataforma de comercio electrónico» y recibirá al instante una plantilla completa y personalizada que se adapta a sus sistemas, procesos y necesidades de cumplimiento. Le puede ayudar con:
- Conciencia contextual: ClickUp Brain tiene acceso a la estructura, el contenido y los permisos de su entorno de trabajo. Puede hacer referencia a tareas, documentos, comentarios e incluso aplicaciones conectadas, proporcionando respuestas y acciones adaptadas a su trabajo real, no solo sugerencias genéricas.
- Solución de problemas y orientación: Solucione problemas al instante, obtenga instrucciones paso a paso o solicite las buenas prácticas sobre cualquier función de ClickUp. Brain puede guiarle a través de procesos complejos, realizar automatizaciones de tareas repetitivas y ayudarle a resolver obstáculos.
- Automatización y aceleración del flujo de trabajo: utilice agentes de IA predefinidos o personalizados para automatizar flujos de trabajo de varios pasos, clasificar solicitudes o gestionar tareas recurrentes, lo que le permitirá ahorrar horas cada semana.
- Búsqueda profunda: encuentre información oculta en cualquier lugar de su entorno de trabajo, incluidas tareas, documentos y herramientas integradas, incluso si tiene años de antigüedad o es difícil de localizar con la búsqueda estándar.
- Resúmenes y actualizaciones en tiempo real: genere actualizaciones de proyectos, resúmenes de reuniones o informes de progreso al instante, a partir de los datos del entorno de trabajo en tiempo real.
- Simplificación de la documentación técnica: convierta documentos técnicos complejos en procedimientos o listas de control claros y prácticos que su equipo pueda seguir, incluso bajo presión.
- Inteligencia multimodelo: elija entre los principales modelos de IA (OpenAI GPT-4. 1, GPT-5, Claude, Gemini y más) para obtener los mejores resultados en cualquier tarea, sin necesidad de suscripciones adicionales.
- Seguridad y sensibilidad a los permisos: Brain solo accede a la información que usted ya tiene permiso para ver, manteniendo estrictos estándares de privacidad y cumplimiento normativo.
- Interfaz de conversación: utilice @brain en los comentarios o al chatear para obtener información contextual, redactar respuestas o desencadenar automatizaciones sin salir de su flujo de trabajo.
- Indicaciones personalizadas y flujos de trabajo guardados: guarde y reutilice indicaciones para necesidades recurrentes, lo que garantiza la coherencia y ahorra tiempo a todo su equipo.
💡Consejo profesional: No se pierda ninguna lección de sus reuniones de revisión de incidentes capturando cada detalle con ClickUp AI Notetaker. Puede unirse a sus reuniones virtuales, transcribir toda la discusión y generar automáticamente una lista de elementos a partir de las lecciones aprendidas. Esto crea un historial de incidentes con función de búsqueda, para que pueda consultar rápidamente los eventos pasados y sus resoluciones.

Flujos de trabajo de recuperación ante desastres automatizados con ClickUp Automatizaciones.
Imagine que su equipo se enfrenta a una interrupción repentina: cada segundo cuenta y no puede permitirse perder ni un solo paso. Con los agentes y automatizaciones de ClickUp AI, no tendrá que apresurarse ni confiar en su memoria. Tan pronto como se declara una incidencia, la IA de ClickUp entra en acción, guiando a su equipo y encargándose del trabajo pesado para que usted pueda centrarse en resolver el problema.
Así es como funciona en un escenario real:
- Cuando alguien marca una tarea como «Incidencia declarada», ClickUp Agent crea automáticamente una lista de control con los pasos de respuesta, los asigna a las personas adecuadas y pone en marcha un cronómetro para realizar el seguimiento del tiempo que se tarda en recuperar.
- Si la incidencia se marca como «crítica», un agente puede enviar instantáneamente un correo electrónico de alerta a su equipo directivo y crear una sala de chat especial, su «sala de guerra», para que todos puedan comunicarse en un solo lugar.
- La IA puede recuperar informes de incidencias anteriores y documentación relevante, para que su equipo tenga todo lo que necesita al alcance de la mano.
Vea el flujo de trabajo aquí:
Con ClickUp AI Agents, obtendrá un compañero de equipo digital fiable que ayudará a su equipo a mantener la calma, la organización y la eficacia, incluso en situaciones de presión.
Seguimiento en tiempo real con los paneles de ClickUp.
Obtenga una visibilidad completa del estado de su programa de recuperación ante desastres mediante el seguimiento de todo en tiempo real con los paneles de control de ClickUp. Puede crear widgets para supervisar el rendimiento de su RTO y RPO durante las pruebas, realizar un seguimiento de las tasas de finalización de las pruebas y ver las tendencias de incidencias a lo largo del tiempo.
Añada campos personalizados de ClickUp a sus tareas para realizar un seguimiento de la criticidad del sistema, el estado de la recuperación y los resultados de las pruebas, y luego recopile todos esos datos en una vista general. Estos paneles le proporcionan informes listos para ejecutivos que están siempre actualizados con datos en tiempo real de las pruebas y las actividades de respuesta a incidencias de su equipo.
📖 Más información: Cómo crear una lista de control para la evaluación de riesgos
Elabore hoy mismo su plan de recuperación ante desastres.
Cada día que opera sin un plan de recuperación ante desastres es una apuesta que no puede permitirse perder. Los desastres son inevitables, ya sean naturales, fallos tecnológicos o errores humanos, pero su preparación es lo que determina si se convierten en pequeños inconvenientes o en grandes catástrofes.
Un plan de recuperación ante desastres completo requiere comprender los riesgos, documentar procedimientos claros y probarlos con regularidad. Las herramientas adecuadas facilitan este proceso al eliminar el caos de los documentos dispersos y los procesos manuales.
Incluso los planes de contingencia básicos son mejores que no tener nada cuando se produce un desastre. Las pruebas y actualizaciones periódicas transformarán su plan de recuperación ante desastres de un documento obsoleto en un sistema vivo que proteja realmente su empresa.
Dé el primer paso y comience a crear su plan de recuperación ante desastres con ClickUp hoy mismo. Empiece a utilizar ClickUp de forma gratuita y reúna toda su planificación de recuperación ante desastres, documentación y respuesta a incidencias en una plataforma unificada. ✨
Preguntas frecuentes
Debe revisar su plan de recuperación ante desastres al menos cuatro veces al año y actualizarlo inmediatamente después de cualquier cambio significativo en la infraestructura o incidencia real. La mayoría de las organizaciones realizan una revisión exhaustiva y profunda cada año para incorporar todas las lecciones aprendidas y adaptarse a las nuevas tecnologías.
Los equipos de TI, los equipos de seguridad y los planificadores de continuidad del negocio suelen liderar los esfuerzos de planificación y pruebas de recuperación ante desastres. Sin embargo, necesitan aportaciones fundamentales de los responsables de operaciones y de las unidades de negocio para garantizar que el plan se ajuste a las necesidades y prioridades reales de la empresa.
Utilice cronómetros y marcas de tiempo claras para medir los tiempos de recuperación reales en comparación con los objetivos definidos durante cada prueba. Es fundamental documentar cualquier diferencia entre el objetivo y el rendimiento real en los informes de las pruebas para orientar las mejoras futuras.
Las plataformas de gestión de proyectos como ClickUp son ideales para centralizar la documentación, realizar la automatización de los flujos de trabajo y realizar el seguimiento de las métricas de todo su programa de recuperación ante desastres. A continuación, puede combinarlas con herramientas especializadas en recuperación ante desastres que se encargan de los aspectos técnicos de la replicación de datos y la conmutación por error del sistema.