
Cybervorfälle entwickeln sich rasend schnell. Ransomware verbreitet sich innerhalb von Minuten, KI-generierte Phishing-Angriffe umgehen Filter, und ein einziger Fehltritt kann zu einer umfassenden Sicherheitsverletzung eskalieren, noch bevor sich die Teams überhaupt über die Lage abstimmen können. Der Druck ist real, ebenso wie die Kosten.
Laut dem Cost of a Data Breach Report von IBM belaufen sich die Kosten weltweit im Durchschnitt auf 4,44 Millionen US-Dollar, wobei Verzögerungen bei der Reaktion und mangelnde Koordination diese Zahl noch weiter in die Höhe treiben.
Inmitten dieses Chaos brauchen Teams Klarheit. Ein Incident-Response-Playbook gibt Ihrem Team ein gemeinsames Skript an die Hand, wenn es chaotisch wird. Es legt fest, wer zuerst handelt, welche Schritte zu befolgen sind und wie die Kommunikation während der Entwicklung der Situation eng gehalten wird.
In diesem Blogbeitrag erfahren Sie, wie Sie ein Incident-Response-Playbook erstellen, das auf die heutigen Bedrohungen zugeschnitten ist. Wir untersuchen reale Szenarien, klare Reaktionsmaßnahmen und ClickUp, den weltweit ersten konvergierten KI-Arbeitsbereich als System, das Ihr Team auch unter Druck nutzen kann.
Was ist ein Leitfaden für die Reaktion auf Incidents?
Ein Incident-Response-Playbook ist ein strukturierter, schrittweiser Leitfaden, der Sicherheitsteams dabei hilft, bestimmte Arten von Cybervorfällen konsistent und effizient zu bewältigen. Es legt genau fest, was zu erledigen ist, wer für die einzelnen Maßnahmen verantwortlich ist und wie man ohne Verwirrung oder Verzögerungen von der Erkennung zur Eindämmung und Wiederherstellung gelangt.
Betrachten Sie es als einen einsatzbereiten Plan für reale Szenarien wie Phishing-Angriffe, Ransomware-Infektionen oder Datenlecks.
🧠 Wissenswertes: Der erste Computervirus war nicht bösartig. Im Jahr 1971 bewegte sich ein Programm namens Creeper zwischen Computern hin und her, nur um die Nachricht „I’m the creeper, catch me if you can“ anzuzeigen. Dies führte zur Erstellung des ersten Antivirenprogramms namens Reaper.
Handbuch zur Reaktion auf Incidents vs. Plan vs. Runbook
Die Begriffe im Zusammenhang mit Dokumenten zur Sicherheit werden häufig verwechselt. Diese Verwirrung führt zu echten Problemen, wenn Teams ihre Standardarbeitsanweisungen erstellen. Das Ergebnis sind entweder sehr allgemeine Pläne, denen konkrete Schritte fehlen, oder übermäßig technische Handbücher, die die Führungskräfte verwirren.
Hier sehen Sie, wie sich diese drei Dokumente unterscheiden.
| Dokument | Umfang | Detailgrad | Wann es zum Einsatz kommt | Wer nutzt es | Format |
| Plan | Unternehmensweite Strategie | Übergeordnete Richtlinien | Vor dem Auftreten von Incidents | Führung und Recht | Richtliniendokument |
| Leitfaden | Szenariospezifische Reaktion | Taktische Schritte-für-Schritte-Maßnahmen | Bei einem bestimmten Incident-Typ | Incident-Response-Team | Workflow mit Entscheidungsbaum |
| Runbook | Einzelnes technisches Verfahren | Detaillierte automatisierte Schritte | Während einer bestimmten Aufgabe | Technische Einsatzkräfte | Checkliste oder Skript |
Alle drei Komponenten müssen zusammenwirken. Ein Plan ohne Playbooks ist zu vage, um darauf zu reagieren. Ein Playbook ohne Runbooks überlässt die technische Umsetzung der Improvisation.
📮 ClickUp Insight: 53 % der Unternehmen verfügen über keine KI-Governance oder nur über informelle Richtlinien.
Und wenn Menschen nicht wissen, wohin ihre Daten gelangen – oder ob ein tool ein Compliance-Risiko darstellen könnte –, zögern sie.
Wenn ein KI-Tool außerhalb vertrauenswürdiger Systeme betrieben wird oder unklare Datenpraktiken aufweist, reicht die Befürchtung „Was, wenn das nicht sicher ist?“ aus, um die Einführung sofort zu stoppen.
Das ist bei der vollständig regulierten Umgebung mit Sicherheit von ClickUp nicht der Fall. ClickUp AI entspricht den Vorschriften der DSGVO, HIPAA und SOC 2 und ist nach ISO 42001 zertifiziert, wodurch sichergestellt wird, dass Ihre Daten vertraulich, geschützt und verantwortungsbewusst verwaltet werden.
Drittanbietern von KI ist es untersagt, ClickUp-Kundendaten für Trainingszwecke zu verwenden oder zu speichern, und die Unterstützung mehrerer Modelle unterliegt einheitlichen Berechtigungen, Datenschutzkontrollen und strengen Sicherheitsstandards. Hier wird die KI-Governance Teil des ClickUp-Workspaces selbst, sodass Teams KI vertrauensvoll und ohne zusätzliches Risiko nutzen können.
Wichtige Schlüsselelemente eines Leitfadens für die Reaktion auf Incidents
Jedes effektive Handbuch für die Reaktion auf Incidents weist denselben grundlegenden Aufbau auf. Bevor Sie mit der Erstellung beginnen, müssen Sie wissen, was darin enthalten sein soll.
Auslöser und Klassifizierung von Incidents
Auslöser sind die spezifischen Bedingungen, die das Playbook aktivieren. Dies kann beispielsweise ein SIEM-Alarm wegen ungewöhnlicher Anmeldemuster oder ein Bericht eines Benutzers über eine verdächtige E-Mail sein. Verknüpfen Sie Ihre Auslöser mit einem System zur Klassifizierung von Incidents, damit Ihr Team weiß, wie schnell es handeln muss.
- Schweregrad 1: Kritisch: Aktive Datenexfiltration oder Ransomware-Verschlüsselung in Bearbeitung
- Schweregrad 2: Hoch: Bestätigter Angriff ohne aktive Ausbreitung
- Schweregrad 3: Mittel: Verdächtige Aktivität, die untersucht werden muss
- Schweregrad 4: Niedrig: Verstoß gegen Richtlinien oder geringfügige Anomalie
Die Klassifizierung bestimmt, welche Maßnahmen ausgelöst werden und wie schnell dies geschieht. Ohne sie reagieren Teams entweder übermäßig auf Warnmeldungen mit niedriger Priorität oder zu zurückhaltend auf echte Bedrohungen.
📖 Lesen Sie auch: Möglichkeiten zur Verbesserung der Cybersicherheit im Projektmanagement
Rollen und Verantwortlichkeiten
Ein Playbook ist nutzlos, wenn niemand weiß, wer wofür zuständig ist. Definieren Sie die Schlüsselrollen, die in jedem Playbook enthalten sein sollten.
- Incident Commander: Ist für die gesamte Reaktion verantwortlich und trifft Entscheidungen zur Eskalation
- Technischer Leiter: Leitet die praktische Untersuchung und Eindämmung
- Leiter Kommunikation: Verwaltet interne Updates und externe Benachrichtigungen
- Rechtsbeauftragter: Berät zu regulatorischen Verpflichtungen und zur Beweissicherung
- Führungskraft als Sponsor: Genehmigt wichtige Entscheidungen wie Systemabschaltungen
Weisen Sie Rollen nach Funktion zu, statt nur nach Namen. Da Mitarbeiter in Urlaub gehen oder das Unternehmen verlassen können, benötigt jede Rolle einen Hauptverantwortlichen und ein Backup.
Verfahren zur Erkennung, Eindämmung und Wiederherstellung
Dies ist der operative Kern des Playbooks. Durch Erkennung und Analyse wird überprüft, ob es sich bei dem Auslöser um einen echten Incident handelt, und es werden erste Indikatoren für eine Kompromittierung gesammelt.
Die Eindämmung umfasst sofortige Maßnahmen, um die Ausbreitung des Incidents zu verhindern. Dazu gehören die Isolierung betroffener Systeme, das Blockieren bösartiger IP-Adressen und die Deaktivierung kompromittierter Konten. Sie müssen zwischen kurzfristiger Eindämmung, um den Schaden zu begrenzen, und langfristiger Eindämmung zur Gewährleistung der Stabilität unterscheiden.
Durch die Beseitigung und Wiederherstellung wird die Bedrohung vollständig beseitigt, indem Malware entfernt und Schwachstellen gepatcht werden. In dieser Phase wird der normale Betrieb der Systeme wiederhergestellt, und es werden Validierungstests durchgeführt, um sicherzustellen, dass die Bedrohung tatsächlich beseitigt wurde.
🔍 Wussten Sie schon? Eine der größten Bedrohungen für die Sicherheit aller Zeiten begann mit einem Passwortproblem. Im Jahr 2012 kam es bei LinkedIn zu einem massiven Datenleck, unter anderem weil Passwörter mit veralteten Hash-Verfahren gespeichert wurden, wodurch Millionen von Konten leicht zu knacken waren.
Kommunikations- und Eskalationsprotokolle
Neben der technischen Reaktion erfordern Vorfälle eine koordinierte Kommunikation. Die interne Eskalation legt fest, wann der Einsatzleiter die Geschäftsleitung und den Rechtsbeistand hinzuzieht.
Die externe Kommunikation legt fest, wer mit Kunden, Aufsichtsbehörden oder der Presse spricht. Viele Compliance-Rahmenwerke sehen verbindliche Zeitleisten für Benachrichtigungen vor, auf die Ihr Leitfaden Bezug nehmen sollte.
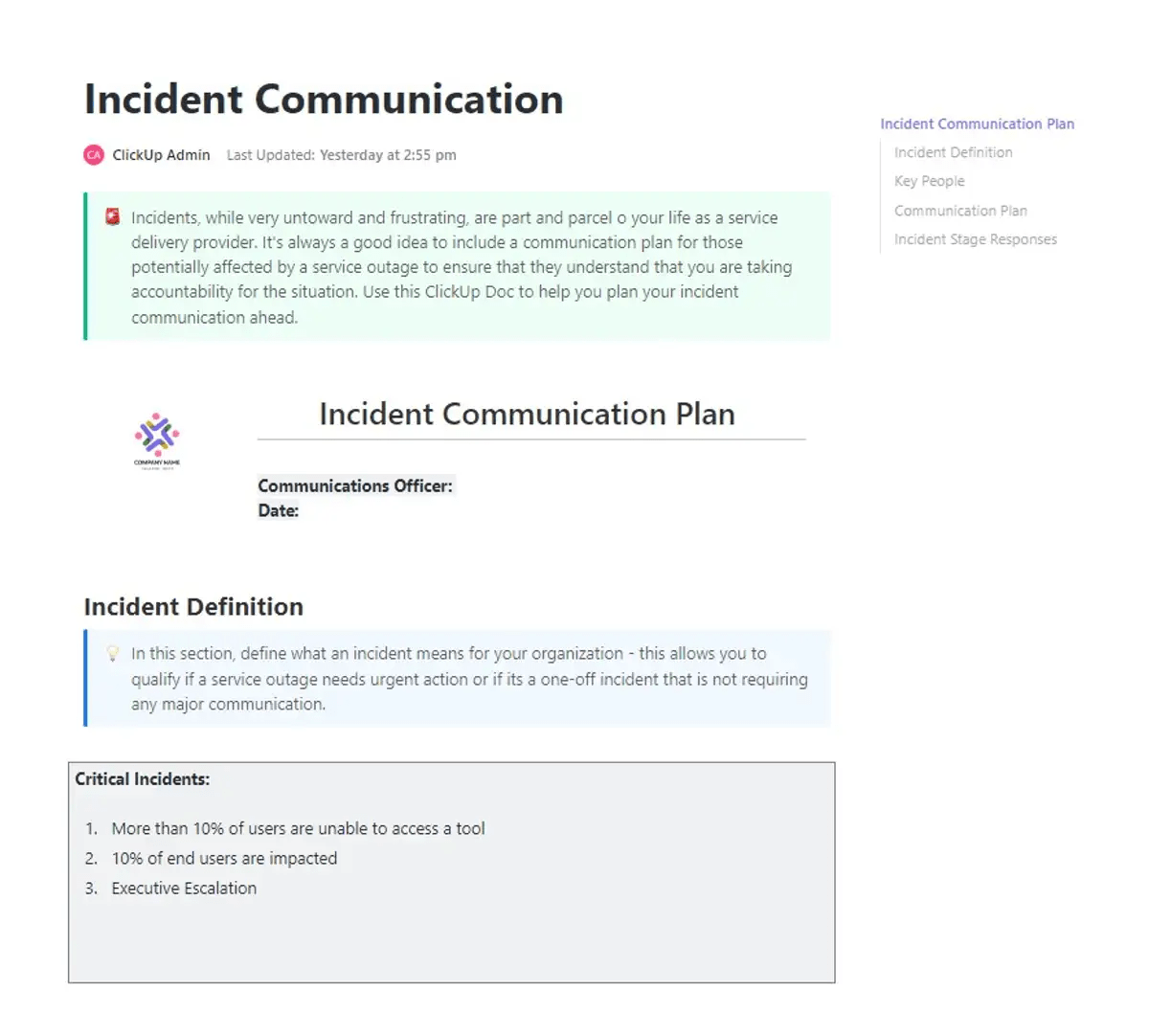
⚡ Vorlagenarchiv: Wenn Incidents auftreten, ist das größte Risiko oft die Verwirrung, die darauf folgt. Verzögerte Updates, unklare Eigentümerschaft und uneinheitliche Kommunikation können die Reaktionszeiten verlangsamen und die Auswirkungen verstärken. Genau hier bietet die ClickUp-Vorlage für einen Plan bei Incidents einen echten Wert.
Diese Vorlage bietet Teams ein einsatzbereites Rahmenwerk, um auch unter Druck klar zu kommunizieren. Sie können Rollen definieren, Kommunikationskanäle festlegen und sicherstellen, dass die richtigen Beteiligten zum richtigen Zeitpunkt informiert werden. Es zentralisiert alles von Kontaktstellen bis hin zu Eskalationswegen, sodass Teams in kritischen Situationen aufeinander abgestimmt bleiben.
So erstellen Sie ein Playbook für die Reaktion auf Incidents (Schritt für Schritt)
Ein Sicherheitsincident ohne Plan ist eine Krise. Ein Sicherheitsincident mit einem Playbook ist ein Prozess. So erstellen Sie ein Playbook, das auch unter Druck funktioniert. 👀
Schritt 1: Definieren Sie den Umfang und die Ziele
Bevor Sie auch nur eine einzige Vorgehensweise festlegen, sollten Sie klären, was das Playbook abdeckt und was nicht.
Scope Creep beeinträchtigt die Benutzerfreundlichkeit. Ein Leitfaden, der versucht, jedes mögliche Szenario abzudecken, wird letztendlich keinem davon gerecht, und die Einsatzkräfte verschwenden Zeit damit, nach Anweisungen zu suchen, die entweder nicht vorhanden sind oder nicht auf ihre Situation zutreffen.
Beantworten Sie zunächst vier Fragen:
- Welche Arten von Incidents fallen darunter: Ransomware, Datenlecks, Insider-Bedrohungen, DDoS-Angriffe, Phishing, Kontoübernahmen, Kompromittierungen der Lieferkette oder alle oben genannten
- Für welche Systeme und Umgebungen das Playbook gilt: Cloud-Infrastruktur, lokale Server, Hybridumgebungen, SaaS-Plattformen, OT/ICS-Systeme oder bestimmte Geschäftsbereiche mit spezifischen Risikoprofilen
- So sieht Erfolg aus: Ein Einzelziel für die durchschnittliche Erkennungszeit (MTTD) von unter 60 Minuten, ein Einzelziel für die durchschnittliche Reaktionszeit (MTTR) von unter vier Stunden oder die Einhaltung der Standards SOC 2, ISO 27001 oder HIPAA
- Wer ist für das Playbook verantwortlich: Eine namentlich benannte Person oder ein Team, das dafür zuständig ist, die Richtigkeit des Playbooks sicherzustellen, es an die richtigen Personen zu verteilen und Überprüfungen zu planen
Den Umfang zu definieren klingt einfach, bis man sich daran macht, es zu erledigen. Teams kommen in dieser Phase oft nicht weiter, da die Informationen über vergangene Incidents, verstreute Notizen und die Erwartungen der Beteiligten verteilt sind.
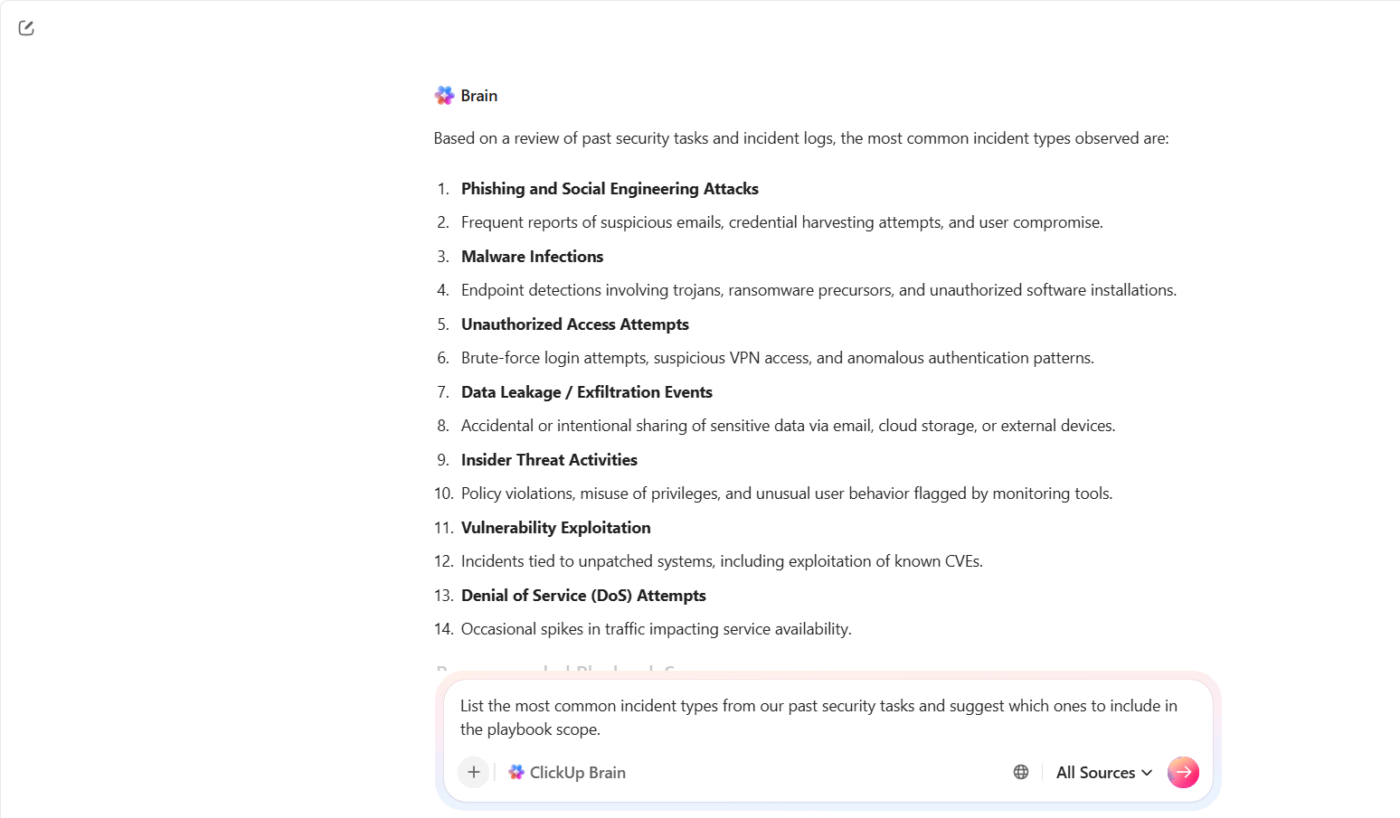
ClickUp Brain hilft Ihnen dabei, diesen Kontext zusammenzuführen und in einen nutzbaren Ausgangspunkt zu verwandeln. Sie fangen nicht bei Null an. Sie bauen auf dem auf, was Ihr Team bereits weiß.
Nehmen wir zum Beispiel an, Ihr Sicherheitsteam hat im letzten Quartal mehrere Phishing- und Account-Takeover-Incidents bearbeitet. Anstatt jeden Fall manuell zu überprüfen, können Sie ClickUp Brain anweisen: „Liste die häufigsten Incident-Typen aus unseren vergangenen Sicherheitsaufgaben auf und schlage vor, welche davon in den Umfang des Playbooks aufgenommen werden sollten.“
Schritt 2: Identifizieren und klassifizieren Sie Incident-Typen
Nicht alle Incidents sind gleich. Ein falsch konfigurierter S3-Bucket und ein aktiver Ransomware-Angriff erfordern völlig unterschiedliche Reaktionen, unterschiedliche Mitglieder des Teams und unterschiedliche Eskalationswege.
Durch die frühzeitige Einrichtung eines Klassifizierungssystems können die Einsatzkräfte bereits ab der ersten Warnmeldung schnelle und einheitliche Entscheidungen treffen, ohne bei jedem Einsatz auf die Genehmigung der Führungskräfte warten zu müssen.
Ein standardmäßiges vierstufiges Schweregradsmodell funktioniert wie folgt:
- Kritisch (P1): Aktiver Sicherheitsverstoß, Datenexfiltration oder systemweite Kompromittierung – sofortige Reaktion erforderlich
- Hoch (P2): Verdacht auf Eindringen, Diebstahl von Zugangsdaten oder erhebliche Dienstunterbrechung
- Mittel (P3): Malware erkannt, aber eingedämmt; Richtlinienverstoß mit Risiko der Datenpreisgabe
- Niedrig (P4): Fehlgeschlagene Anmeldeversuche, geringfügige Richtlinienverstöße, informative Warnmeldungen
Ordnen Sie jedem Vorfallstyp eine Schweregradstufe zu, damit die Einsatzkräfte schnelle Entscheidungen treffen können, ohne jeden Anruf eskalieren zu müssen.
Sobald Sie den Anwendungsbereich definiert haben, liegt die nächste Herausforderung in der Konsistenz. Verschiedene Einsatzkräfte interpretieren denselben Alarm oft unterschiedlich, was Entscheidungen verlangsamt und unnötige Eskalationen verursacht.
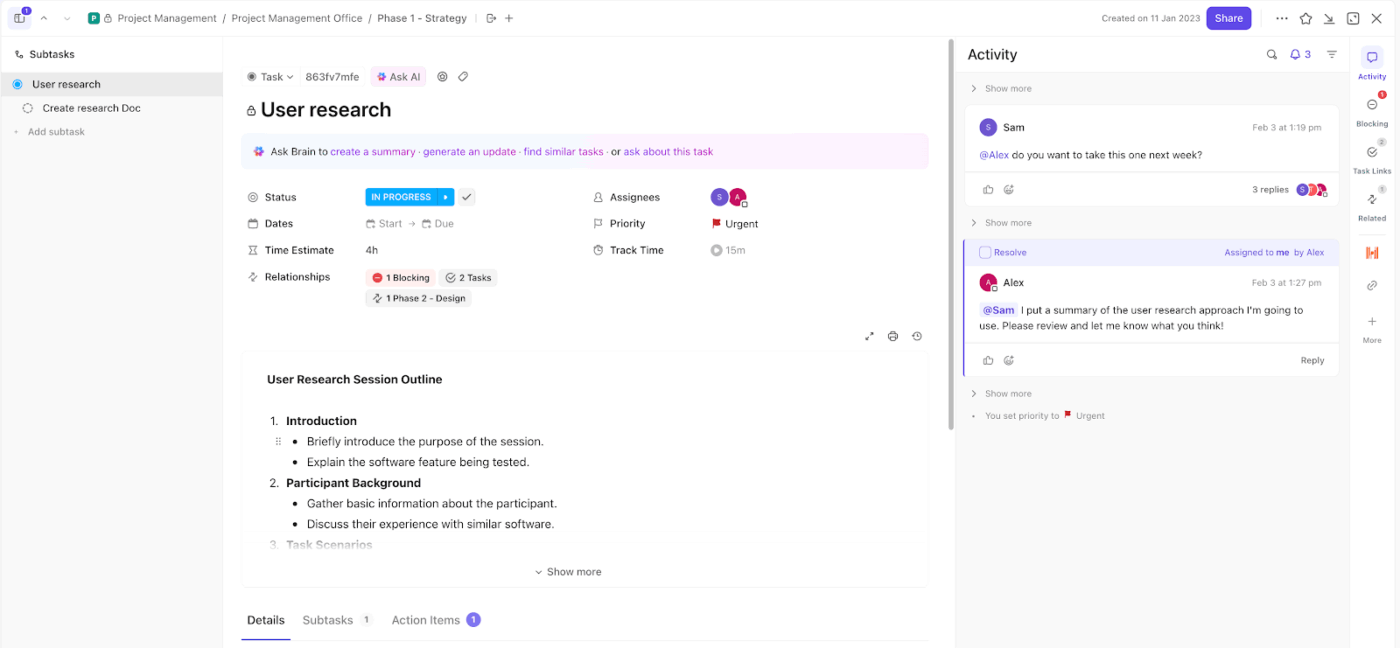
Beginnen Sie mit ClickUp-Aufgaben als Ihrer zentralen Ausführungseinheit. Jeder Incident wird zu einer Aufgabe, sodass nichts durch unüberwachte Kanäle wie E-Mail oder Chat unter den Tisch fällt.
Nehmen wir zum Beispiel an, Ihr Überwachungstool meldet einen möglichen Diebstahl von Anmeldedaten. Sie erstellen eine Aufgabe mit dem Titel „Mögliche Kompromittierung von Anmeldedaten – Finanzkonto“. Diese Aufgabe wird nun zur zentralen Anlaufstelle für Untersuchungen, Aktualisierungen und die Behebung des Problems.
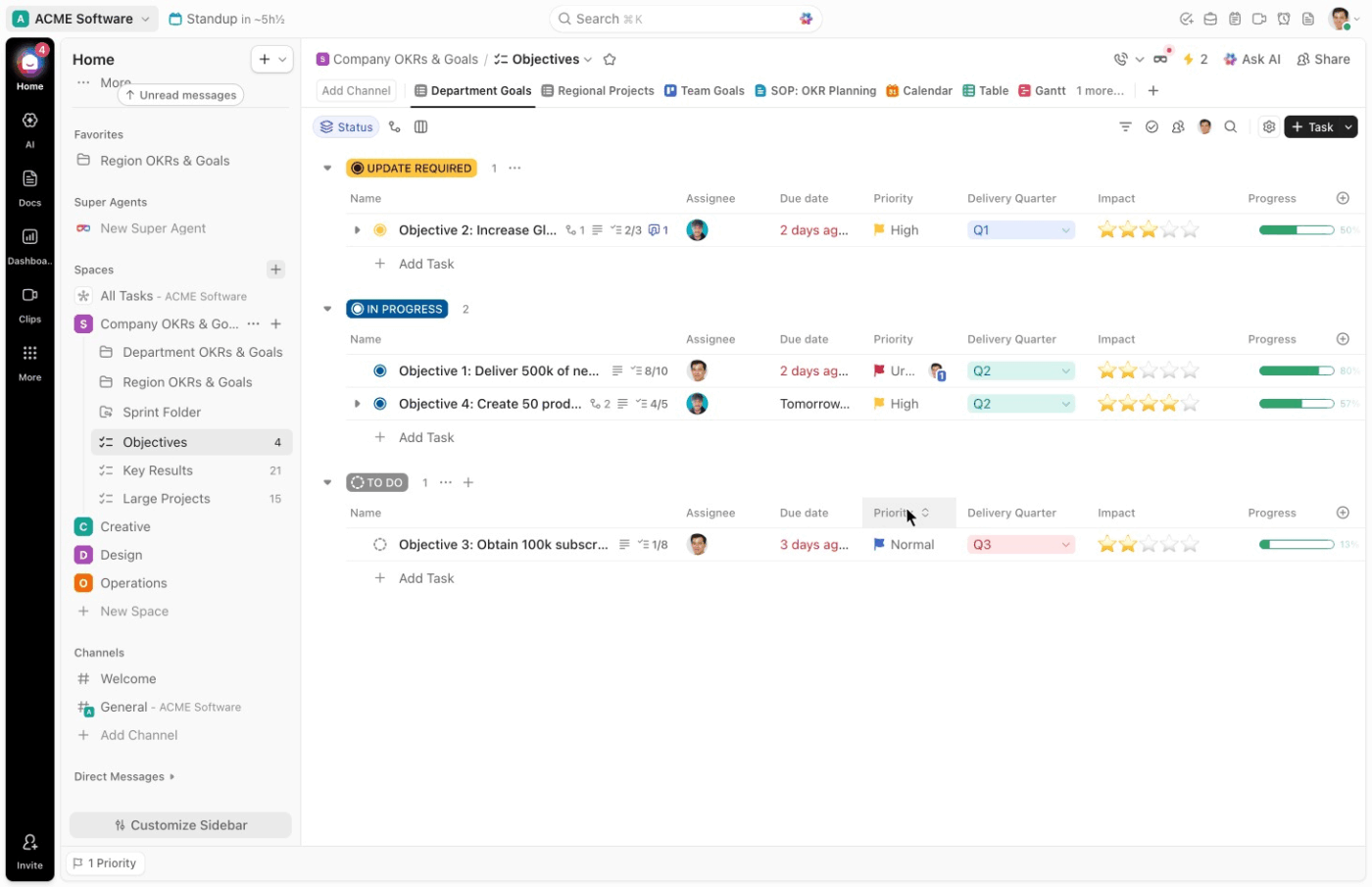
Anschließend bieten Ihnen benutzerdefinierte Felder in ClickUp die erforderliche Struktur für eine schnelle Klassifizierung. Sie können Felder wie die folgenden einrichten:
- Art des Incidents: Phishing, Ransomware, DDoS, Insider-Bedrohung
- Schweregrad: P1, P2, P3, P4
- Betroffene Systeme: Cloud, On-Premise, SaaS, Endgeräte
- Datensensibilität: Hoch, mittel, niedrig
Schritt 3: Erstellen Sie incidentspezifische Reaktionsverfahren
Dies ist der operative Kern des Playbooks.
Erstellen Sie für jeden Incident-Typ eine eigene Vorgehensweise, die so konkret ist, dass ein Einsatzkraft sie auch unter Druck befolgen kann, ohne improvisieren zu müssen. Allgemeine Anweisungen werden bei Systemausfällen oft ignoriert.
Jedes Verfahren sollte Folgendes umfassen:
- Auslöser: Die spezifische Warnmeldung oder der Bericht, der die Reaktion auslöst
- Erste Triage-Schritte: Die ersten Maßnahmen, die ein Incident Responder innerhalb von 15 Minuten ergreift, zugeschnitten auf die Art des Vorfalls
- Checkliste zur Beweissicherung: Protokolle, Speicherauszüge, Netzwerk-Captures und E-Mail-Kopfzeilen – alles, was benötigt wird, bevor es durch Eindämmungsmaßnahmen zerstört wird
- Eindämmungsmaßnahmen: Konkrete, umsetzbare Schritte
- Eskalationskriterien: Die Bedingungen, die als Auslöser für eine Eskalation an Führungskräfte, Rechtsberater oder einen externen IR-Anbieter dienen
- Kommunikationsvorlagen: Vorgefertigte Entwürfe für interne Updates und Kundenbenachrichtigungen
Ein Verfahren für Ransomware unterscheidet sich grundlegend von einem Verfahren für Phishing. Erstellen Sie diese separat und gehen Sie dabei auf die Besonderheiten jedes einzelnen Szenarios ein.

Mit ClickUp Docs können Sie jedes Incident-Verfahren so strukturieren, dass es genau die Fragen beantwortet, mit denen eine Einsatzkraft in diesem Moment konfrontiert ist. Als Beispiel nehmen wir an, Sie dokumentieren ein Ransomware-Szenario.
Das Dokument kann den Einsatzkräften wie folgt als Leitfaden dienen:
- Auslöser: „Über EDR erkannter Alarm zur Endpunktverschlüsselung“
- Was in den ersten 15 Minuten geschehen muss: Isolieren Sie den betroffenen Rechner, sperren Sie den Netzwerkzugang und ermitteln Sie das Ausmaß der Ausbreitung.
- Was muss vor der Eindämmung erfasst werden: Systemprotokolle, aktive Prozesse, aktuelle Dateiänderungen
- Unter welchen Bedingungen ist eine Eskalation erforderlich: Verschlüsselung, die sich über mehrere Endgeräte ausbreitet, oder Zugriff auf gemeinsam genutzte Laufwerke
- Was kommuniziert werden muss: Interner Alarm an die Leitung der Sicherheit und ein vorbereiteter Statusbericht für die betroffenen Teams
ClickUp Docs verstärkt dies noch durch die direkte Integration in die Ausführung:
- Fügen Sie die Vorgehensweise zu den Incident-Aufgaben in ClickUp hinzu, damit die Einsatzkräfte die Anleitung genau im richtigen Moment aufrufen können
- Fügen Sie in jedem Abschnitt Checklisten hinzu, damit wichtige Schritte unter Druck nicht übersehen werden.
- Weisen Sie Mitgliedern des Teams bei einer Eskalation bestimmte Maßnahmen zu, ohne das Dokument zu verlassen
- Überarbeiten Sie die Anweisungen unmittelbar nach der Lösung, damit zukünftige Reaktionen ohne Verzögerung verbessert werden
Schritt 4: Legen Sie Kommunikationsprotokolle und Standards für die Beweissicherung fest
Zwei Bereiche, die bei der Entwicklung von Playbooks oft vernachlässigt werden und bei einem tatsächlichen Incident zu ernsthaften Problemen führen: die Kommunikation im Team und der Umgang mit Beweismitteln.
Legen Sie im Hinblick auf die Kommunikation folgende Parameter im Voraus fest:
- Primäre und Backup-Kanäle
- Zeitleiste für Benachrichtigungen
- Anforderungen an die externe Offenlegung
- Eine einzige Quelle der Wahrheit
Das Playbook sollte unter anderem Folgendes festlegen:
- Was Sie erfassen sollten: Systemereignisprotokolle, Protokolle der Authentifizierung, Speicherabbilder, Netzwerk-Flows und Screenshots der Angreiferaktivitäten
- So erfassen Sie die Daten: Schreibgeschützte forensische Image-Erstellung, Schreibsperren und ein Protokoll aller Erfassungsvorgänge mit Zeitstempel und dem Namen der Person, die den Vorgang durchgeführt hat
- Wo es gespeichert werden sollte: In einer separaten, zugriffskontrollierten Umgebung, die von den betroffenen Systemen isoliert ist
- Wer hat Zugriff darauf: Beschränkt auf namentlich genannte Ermittler und genehmigt durch den Rechts- und Compliance-Beauftragten
Wenn sich ein Incident ereignet, ist die Kommunikation oft über verschiedene Tools verstreut. Updates landen in Slack, Entscheidungen werden in Telefonkonferenzen getroffen und wichtige Details gehen in Threads unter, die niemand mehr aufruft. Diese mangelnde Struktur sorgt für Verwirrung, verzögert die Eskalation und erschwert die Nachbetrachtung nach dem Incident unnötig.
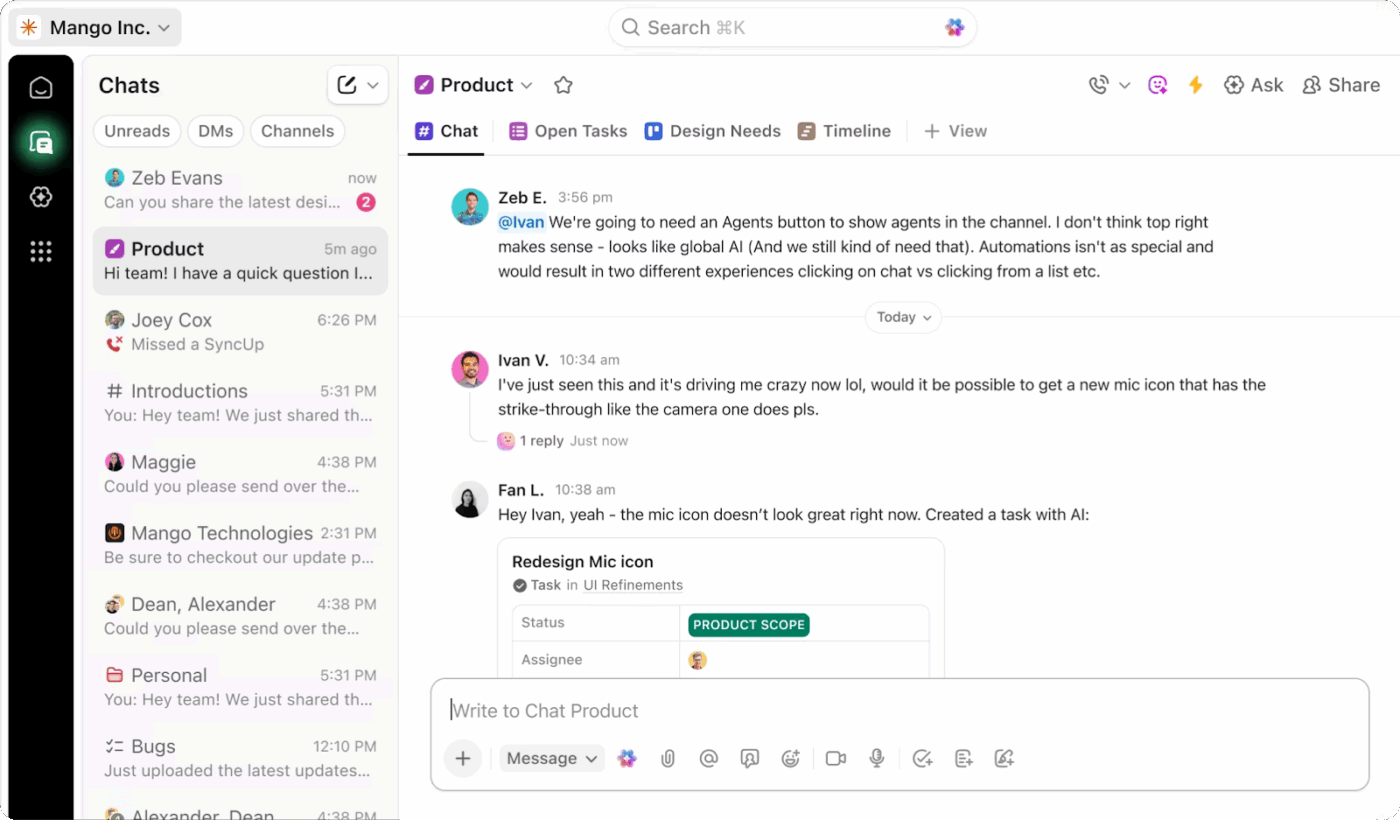
ClickUp Chat bietet Ihnen einen eigenen, verknüpften Kanal, in dem die Kommunikation zu Incidents fokussiert, mit guter Sichtbarkeit und leicht nachvollziehbar bleibt.
Sie können es als Ihre primäre Kommunikationsplattform für die Incident Response einrichten, die direkt mit der Arbeit, die nachverfolgt wird, verknüpft ist. Diese Verbindung verändert die Art und Weise, wie Teams in Stresssituationen zusammenarbeiten.
🚀 Der Vorteil von ClickUp: Machen Sie jeden Incident zu einer Lernerfahrung – mit der Vorlage für Incident-Response-Berichte von ClickUp.
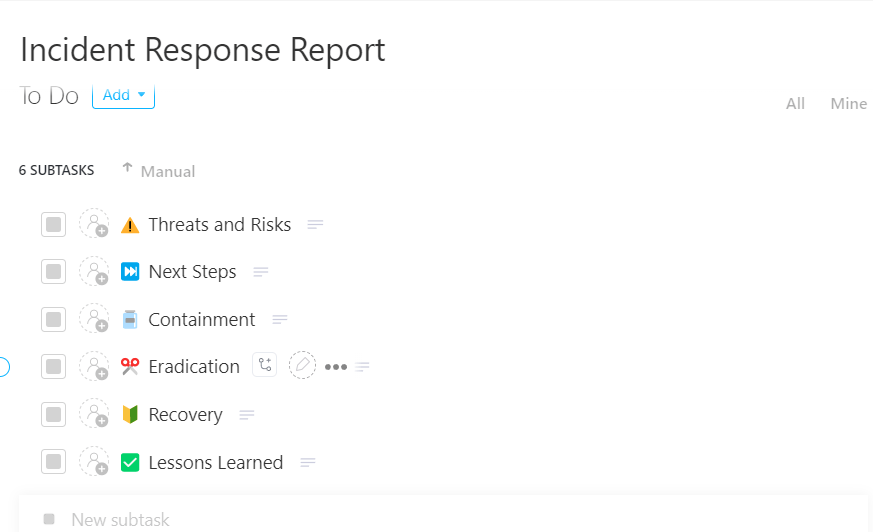
Erfassen Sie jeden Incident lückenlos und übersichtlich mit der ClickUp-Vorlage für Incident-Reaktionsberichte
Als einsatzbereites, aufgabenbasiertes System konzipiert, ermöglicht es Ihnen, Incidents von Anfang bis Ende an einem Ort zu erfassen, zu verfolgen und zu verwalten, sodass nichts zwischen verschiedenen Tools oder Teams verloren geht.
Schritt 5: Testen, integrieren und einen Überprüfungsrhythmus etablieren
Ein Handbuch, das nie getestet wurde, ist nichts weiter als eine Reihe von Annahmen. Bevor Sie es als einsatzbereit betrachten, sollten Sie es durch strukturierte Übungen validieren und mit den Tools verbinden, die Ihr Team täglich nutzt.
Führen Sie zu Testzwecken Übungen in der Reihenfolge ihrer Intensität durch:
- Tabletop-Übung: Ein Moderator stellt ein simuliertes Szenario vor, und das Team bespricht die Entscheidungen mündlich.
- Funktionsübung: Das Team führt in einer kontrollierten Umgebung bestimmte Schritte durch, beispielsweise die Isolierung eines Test-Endpunkts.
- Vollständige Simulation: Ein Red Team führt ein realistisches Angriffsszenario durch, während das IR-Team in Echtzeit reagiert
Für die Tool-Integration verknüpfen Sie das Playbook direkt mit Ihren SIEM-Alarm-IDs, EDR-Eindämmungsmaßnahmen, Ticket-Workflows und Übergabeverfahren an externe IR-Anbieter. Die Einsatzkräfte sollten ohne Kontextwechsel vom Alarm über das Verfahren zur Maßnahme übergehen.
Wie ClickUp dabei hilft
Bei Tabletop-Übungen und Simulationen zeigt sich oft dieselbe Lücke. Die Teams kennen die Schritte zwar theoretisch, doch die Umsetzung verlangsamt sich, da kein System die Reaktion in Echtzeit aktiv steuert.

ClickUp AI Agents schließen diese Lücke. Sie beobachten Aktivitäten über Aufgaben, Felder und Workflows hinweg und ergreifen dann Maßnahmen auf der Grundlage der von Ihnen definierten Logik. Das macht sie äußerst nützlich, wenn Sie Ihr Playbook testen und in den Betrieb übernehmen.
Beginnen Sie damit, wie dies im Rahmen einer Tabletop-Übung abläuft.
Angenommen, Ihr Moderator stellt einen Phishing-Angriff vor, der zu einer Kompromittierung von Anmeldedaten führt. Während Ihr Team die nächsten Schritte bespricht, kann ein KI-Agent:
- Erstellen Sie eine strukturierte Checkliste für die Reaktion, die auf Ihre Phishing-Richtlinien abgestimmt ist
- Schlagen Sie nächste Maßnahmen vor, basierend auf Feldern für Aufgaben wie „Incident-Typ“ und „Schweregrad“
- Erstellen Sie einen Entwurf für ein internes Update unter Verwendung der aktuellen Angaben zu den Aufgaben
Dadurch bleiben die Diskussionen auf den tatsächlichen Umsetzungsschritten basierend.
💡 Profi-Tipp: Für die laufende Wartung sollten Sie Überprüfungen anhand von drei Auslösern durchführen:
- Ein jährliches umfassendes Audit mit einer Tabletop-Übung zu allen Verfahren, die in den letzten 12 Monaten nicht getestet wurden
- Nach jedem schwerwiegenden Incident, solange die Details noch frisch sind
- Eine vierteljährliche Überprüfung auf personelle und toolbezogene Änderungen
Weisen Sie jedem Zyklus mit ClickUp Multiple Assignees einen namentlich genannten Verantwortlichen zu. Ohne Verantwortlichkeit werden Überprüfungen übersprungen und das Playbook wird stillschweigend zu einer Belastung.
Beispiele für Incident-Response-Playbooks nach Bedrohungsart
So sieht der Prozess zur Erstellung eines Playbooks aus, wenn er auf die gängigsten Bedrohungsarten angewendet wird.
Handbuch zur Reaktion auf Ransomware-Incidents
- Auslöser: Endpoint-Erkennungswarnung bei Dateiverschlüsselungsaktivitäten oder ungewöhnlichen Änderungen der Dateierweiterungen
- Sofortige Eindämmung: Isolieren Sie betroffene Systeme unverzüglich vom Netzwerk und deaktivieren Sie gemeinsam genutzte Laufwerke, die freigegeben sind
- Wichtige Maßnahmen: Identifizieren Sie die Ransomware-Variante, ermitteln Sie den Umfang der Verschlüsselung und sichern Sie forensische Beweise.
- Wiederherstellung: Führen Sie die Wiederherstellung aus sauberen Backups durch, nachdem Sie sichergestellt haben, dass diese nicht kompromittiert sind, und patchen Sie den Eintrag.
- Nach dem Incident: Dokumentieren Sie die Zeitleiste des Angriffs und überprüfen Sie die Verfahren zur Sicherstellung der Integrität des Backups
🔍 Wussten Sie schon? Einer der ersten Hacker war ein Whistleblower. In den 1980er Jahren deckte eine Gruppe namens Chaos Computer Club Sicherheitslücken in Bankensystemen auf, um Schwachstellen aufzuzeigen, anstatt sie aus Profitgründen auszunutzen.
Handbuch zur Reaktion auf Phishing-Incidents
- Auslöser: Ein Benutzer meldet eine verdächtige E-Mail oder eine Seite zum Sammeln von Anmeldedaten wurde entdeckt
- Sofortmaßnahmen: Die E-Mail in allen Postfächern unter Quarantäne stellen und die Absenderdomain blocken
- Wichtige Maßnahmen: Erzwingen Sie eine Passwortzurücksetzung und brechen Sie aktive Sitzungen sofort ab, wenn Anmeldedaten übermittelt wurden.
- Kommunikation: Benachrichtigen Sie betroffene Benutzer und versenden Sie eine unternehmensweite Warnmeldung, ohne Panik auszulösen
- Wiederherstellung: Stellen Sie sicher, dass kein dauerhafter Zugriff mehr besteht, und aktualisieren Sie die Regeln für den Filter der E-Mails
Handbuch für unbefugten Zugriff
- Auslöser: Ungewöhnliche Anmeldeaktivitäten, Warnung vor einer Privilegienerweiterung oder Zugriff auf sensible Ressourcen
- Sofortige Eindämmung: Deaktivieren Sie das kompromittierte Konto, beenden Sie aktive Sitzungen und beschränken Sie den Zugriff
- Wichtige Maßnahmen: Ermitteln Sie, wie der Zugriff erlangt wurde, und überprüfen Sie alle Aktionen, die über das kompromittierte Konto durchgeführt wurden.
- Wiederherstellung: Setzen Sie die Anmeldedaten für alle potenziell betroffenen Konten zurück und verschärfen Sie die Zugriffskontrollen
- Nach dem Incident: Führen Sie eine umfassende Zugriffsprüfung durch und aktualisieren Sie die Richtlinien für das Prinzip der geringsten Berechtigungen
Best Practices für Incident-Response-Playbooks
Hier sind die Best Practices, die Teams, die Incidents sauber lösen, von Teams unterscheiden, die sechs Stunden später immer noch im Krisenstab sitzen und darüber streiten, wer für das Rollback verantwortlich ist. Wenn Sie diese richtig umsetzen, wird Alles einfacher. 🔥
Beschreiben Sie, was zu erledigen ist, nicht, worüber nachzudenken ist
Die meisten Playbooks sind voll von Schritten wie „die Schwere der Situation einschätzen“ oder „die zuständigen Stellen ermitteln“. Das sind keine Schritte. Es sind Erinnerungen, um nachzudenken.
Ein nützliches Playbook sagt Ihnen, welche Maßnahmen zu ergreifen sind, und nicht nur, dass Maßnahmen erforderlich sind. Ersetzen Sie „Auswirkungen auf den Kunden bewerten“ durch „Überprüfen Sie das Dashboard für aktive Sitzungen und fügen Sie die Nummer in den Incident-Kanal ein“. Konkretheit ist das A und O.
Trennen Sie die Person, die die Lösung findet, von der Person, die den Incident bearbeitet
Wenn der ranghöchste Ingenieur im Einsatz gleichzeitig die Ursache der Störung behebt, Fragen der Führungskräfte beantwortet und entscheidet, wen er benachrichtigen soll, geht alles schief.
Ihr Leitfaden sollte eine klare Aufgabenteilung vorsehen: Eine Person ist für die Untersuchung zuständig, eine andere für den Incident. Der Incident Commander trifft keine technischen Entscheidungen. Er delegiert, beseitigt Hindernisse und kommuniziert. Das mag zunächst wie Mehraufwand erscheinen, bis es Ihnen zum ersten Mal zwei Stunden Zeit spart.
🔍 Wussten Sie schon? Ganze 91 % der großen Unternehmen haben ihre Cybersicherheitsstrategien aufgrund geopolitischer Unsicherheiten bereits geändert, wodurch globale Spannungen zu einem direkten Treiber für Entscheidungen im Bereich der Cyberabwehr geworden sind.
Führen Sie die Nachbetrachtung durch, solange die Leute noch verärgert sind
Die besten Nachbesprechungen finden innerhalb von 48 Stunden statt, da die Frustration dann noch frisch ist. Der Techniker, der die Alarmschwelle für zu hoch hielt, wird dies am zweiten Tag äußern.
Am zehnten Tag haben sie das Thema bereits hinter sich gelassen, und das Meeting wird zu einer höflichen Rekonstruktion der Zeitleiste, anstatt zu einer ehrlichen Unterhaltung darüber, was schiefgelaufen ist.
Testen Sie das Playbook, indem Sie versuchen, es zu durchbrechen
Der einzige zuverlässige Weg, um herauszufinden, ob Ihr Playbook funktioniert, besteht darin, es einzusetzen, wenn noch kein echter Notfall vorliegt. Führen Sie einen Testlauf durch. Wählen Sie ein realistisches Ausfallszenario, geben Sie jemandem das Playbook ohne Vorwarnung und beobachten Sie, wo er zögert.
Jedes Zögern ist eine Lücke. Jede Frage, die gestellt wird, ist ein fehlender Schritt. Ein Playbook, das nie einem Stresstest unterzogen wurde, ist nie fertiggestellt worden.
Ein Betriebsleiter gibt seine Gedanken zur Nutzung von ClickUp frei:
ClickUp ist ein großartiges Tool, um unser Team organisiert und aufeinander abgestimmt zu halten. Es macht es einfach, Projekte zu verwalten, Aufgaben zuzuweisen und den Fortschritt an einem Ort zu verfolgen. Ich schätze besonders die Flexibilität – man kann Workflows anpassen, Vorlagen erstellen und die Plattform an unterschiedliche Teamprozesse anpassen.
Es war sehr hilfreich beim Aufbau wiederholbarer Systeme für Dinge wie Standardarbeitsanweisungen, Leistungsbeurteilungen und Nachverfolgung von Projekten. Die Verbindung von Aufgaben, Dokumenten und Kommunikation hilft, Hin- und Her-Kommunikation zu reduzieren und sorgt dafür, dass alle auf dem gleichen Stand sind.
Erstellen und verwalten Sie Playbooks für die Reaktion auf Incidents mit ClickUp
Es ist eine enorme Herausforderung, Playbooks einsatzbereit und zugänglich zu halten, wenn es darauf ankommt. Bei den meisten Teams finden sich die Unterlagen verstreut in Wikis, Google Docs und Slack-Lesezeichen. Wenn ein Incident eintritt, weiß niemand genau, welche Version aktuell ist oder wo sich die Eskalationsmatrix befindet.
Beenden Sie die Tool-Flut und den ständigen Kontextwechsel mit ClickUp. Als zentraler Workspace befinden sich Ihre Playbook-Dokumentation, Ihre Workflows und Ihre Teamkommunikation alle an genau derselben Stelle.
Ganz gleich, ob Sie Ihr erstes Playbook erstellen oder verstreute Dokumentationen zusammenführen – ClickUp bietet Ihrem Team einen zentralen Ort für Planung, Reaktion und Optimierung. Melden Sie sich noch heute kostenlos an!
Häufig gestellte Fragen (FAQ)
1. Was ist der Unterschied zwischen einem Leitfaden für die Reaktion auf Incidents und einem Runbook?
Ein Playbook deckt den gesamten Reaktionszyklus für einen bestimmten Vorfallstyp ab. Ein Runbook hingegen ist eine enger gefasste technische Vorgehensweise zum Abschließen einer einzelnen Aufgabe innerhalb dieser Reaktion.
2. Wie oft sollten Sie Ihr Handbuch für die Reaktion auf Incidents aktualisieren?
Überprüfen und aktualisieren Sie die Leitfäden mindestens vierteljährlich. Sie sollten sie außerdem nach jedem tatsächlichen Incident und nach jeder Tabletop-Übung aktualisieren.
4. Können Sie eine Vorlage für ein Incident-Response-Playbook als Ausgangspunkt verwenden?
Ja, Vorlagen aus Frameworks wie NIST oder CISA bieten Ihnen eine bewährte Struktur. Auch ClickUp-Vorlagen sind sehr hilfreich. So können Sie die Grundlage benutzerdefiniert an Ihre Umgebung anpassen, anstatt bei Null anzufangen.
5. Brauchen kleine Teams ein Playbook für die Reaktion auf Incidents?
Kleine Teams benötigen Playbooks wohl eher, da hier weniger Spielraum für Fehler besteht. Ein einfaches Playbook für Ihre wichtigsten Bedrohungsszenarien ist weitaus besser als eine improvisierte Reaktion.