

Es ist 3 Uhr morgens.
Ein durchdringender Alarm weckt Sie aus dem Schlaf.
Sie springen auf und werden vom Leuchten Ihres Computerbildschirms angezogen. Ein kritisches System ist ausgefallen. Panik macht sich breit. Dies ist keine Szene aus einem Science-Fiction-Thriller, sondern ein Alptraumszenario für jeden IT-Experten.
Aber es ist auch Realität. Wenn die digitale Welt zum Stillstand kommt, ist der Druck enorm.
Hier wird das Incident Management zu einer wichtigen Stütze.
Das Incident Management ist der Schlüssel zur schnellen Behebung und Lösung von Projektunterbrechungen. Durch ein effizientes Management dieser Störungen können Sie sich mehr auf die Erzielung von Ergebnissen und das effektive Abschließen Ihres Projekts konzentrieren.
In diesem Artikel untersuchen wir den Prozess des Vorfallmanagements und geben Ihnen Best Practices frei, mit denen Sie einen robusten Notfallplan implementieren können. So können Sie sicher sein, dass Sie alle zukünftigen Projektvorfälle effektiv bewältigen können.
Incident Management verstehen
Incidents sind Störungen oder potenzielle Bedrohungen, die sich auf die Servicequalität auswirken. Beispiele hierfür sind eine abgestürzte Geschäftsanwendung oder ein langsam laufender Server, die zu Problemen bei der Produktivität führen. Diese Ereignisse können von kleineren Störungen, von denen nur wenige Benutzer betroffen sind, bis hin zu größeren Ausfällen reichen, die sich auf globale Dienste auswirken.
Das Incident Management ist der Prozess der Identifizierung, Priorisierung und Lösung von IT-Problemen, um Störungen des Geschäftsbetriebs zu minimieren und gleichzeitig Maßnahmen zur Vermeidung künftiger Vorkommen zu ergreifen. Dieser Prozess der proaktiven Incident-Prävention ist für jedes Unternehmen von entscheidender Bedeutung, da Serviceausfälle zu erheblichen Geschäftsverlusten führen können. Ein effizientes Incident Management ermöglicht es Teams, Probleme schnell zu priorisieren und zu lösen und so eine bessere Servicekontinuität zu gewährleisten.
Bei der Bearbeitung von Incidents benötigen Teams einen klar definierten Plan, der ihnen dabei hilft:
- Reagieren Sie umgehend , um Ausfallzeiten zu minimieren.
- Kommunizieren Sie effektiv mit Kunden, Stakeholdern, Service-Eigentümern und anderen relevanten Parteien.
- Nahtlose Zusammenarbeit zur Beschleunigung der Problemlösung und Beseitigung von Hindernissen
- Verbessern Sie sich kontinuierlich, indem Sie aus Incidents lernen und diese Erkenntnisse nutzen, um die Servicequalität zu steigern und Prozesse zu optimieren.
In diesem Zusammenhang ist es auch wichtig zu wissen, wie man einen Incident-Bericht verfasst. Detaillierte Incident-Berichte erleichtern eine gründliche Analyse, identifizieren die Ursachen und helfen bei der Entwicklung von Präventionsstrategien.
Die Beziehung zwischen Incident Management, ITSM und DevOps
Das Incident Management ist ein zentraler Bestandteil des IT Service Managements (ITSM) und stellt sicher, dass IT-Services verfügbar und zuverlässig bleiben. DevOps integriert Entwicklungs- und Betriebsteams, um die Zusammenarbeit und Effizienz zu verbessern.
Die Abstimmung des Incident-Managements auf die DevOps-Projektmanagement-Prinzipien kann Unternehmen dabei helfen, schnell und effektiv auf Incidents zu reagieren. Diese Abstimmung fördert die kontinuierliche Verbesserung, eine schnellere Wiederherstellung nach Incidents und eine verbesserte Servicebereitstellung.
Incident-Management-Prozesse verstehen
Ein effektiver Incident-Management-Prozess ermöglicht es IT-Teams, Serviceunterbrechungen oder -ausfälle effizient zu untersuchen, zu dokumentieren und zu beheben.
Verschiedene Unternehmen wenden oft unterschiedliche Arten von Incident-Management-Prozessen an, die auf ihre spezifischen Bedürfnisse zugeschnitten sind. Da es keinen einheitlichen Ansatz gibt, finden Sie in verschiedenen Organisationen unterschiedliche Methoden.
Einige Teams halten sich an traditionelle IT-basierte Incident-Management-Prozesse, wie sie beispielsweise in den ITIL-Zertifizierungen (Information Technology Infrastructure Library) beschrieben sind. Andere bevorzugen einen eher auf Site Reliability Engineering (SRE) oder DevOps ausgerichteten Ansatz.
Der ITIL-Workflow für das Incident Management konzentriert sich darauf, Ausfallzeiten zu reduzieren und die Auswirkungen von Incidents auf die Produktivität der Mitarbeiter zu minimieren. Mithilfe von Vorlagen für Vorfallberichte können Teams einen wiederholbaren Workflow zur Protokollierung, Diagnose und Behebung von Incidents einrichten und gleichzeitig umfassende Aufzeichnungen über ihre Aktivitäten führen.
Das ITIL-Framework wird vor allem von IT-Teams verwendet, die Services innerhalb von Unternehmen verwalten. Diese Teams passen die umfassende Abdeckung von Incidents und Prozessen durch ITIL häufig benutzerdefiniert an ihre Bedürfnisse an.
ITIL ist besonders hilfreich, um eine Kultur der proaktiven Fehlerbehebung zu schaffen. Seine strukturierten Prozesse helfen Teams dabei, Incidents und Maßnahmen konsistent zu verfolgen, die Berichterstellung und Analyse zu verbessern und letztendlich zu robusteren Services und effektiveren Teams zu führen.
KI und maschinelles Lernen im Incident Management
Die Integration von KI und maschinellem Lernen in das Incident Management verändert die Art und Weise, wie Teams mit Vorfällen umgehen. KI-gestützte Tools können große Datenmengen analysieren, um potenzielle Vorfälle vorherzusagen, bevor sie eintreten, und ermöglichen so vorbeugende Maßnahmen.
Algorithmen für maschinelles Lernen können Muster und Anomalien erkennen, die menschlichen Analysten möglicherweise entgehen, und liefern so tiefere Einblicke in die Ursachen und mögliche Lösungen. Diese Technologien können auch Routineaufgaben wie die Protokollierung von Incidents und die Erstdiagnose automatisieren, wodurch personelle Ressourcen für komplexere Problemlösungen frei werden.
Hochverfügbarkeit und Ausfallzeiten im Incident Management
Die Minimierung von Ausfallzeiten ist für ein effektives Incident Management von entscheidender Bedeutung. Hohe Verfügbarkeit stellt sicher, dass Systeme jederzeit betriebsbereit und zugänglich sind, wodurch das Risiko von Dienstunterbrechungen minimiert wird. Redundanz, Failover-Mechanismen und Lastenausgleich werden eingesetzt, um eine hohe Verfügbarkeit zu erreichen.
Die Reduzierung von Ausfallzeiten ist entscheidend für die Aufrechterhaltung der Produktivität und Kundenzufriedenheit. Incident-Management-Prozesse müssen robuste Pläne für schnelle Reaktionen und Wiederherstellungen umfassen, um die Dauer und Auswirkungen von Ausfällen zu minimieren.
Der IT-Incident-Management-Prozess im Detail
Das Incident-Management umfasst die effiziente Identifizierung, Protokollierung, Kategorisierung, Priorisierung und Lösung von Incidents.
Wenn Sie diese Schritte verstehen, können Sie einen systematischen Ansatz für das Management von Incidents sicherstellen, Ausfallzeiten minimieren und zukünftige Vorkommen verhindern.
Schritte im IT-Incident-Management-Prozess
1. Identifizieren und protokollieren Sie den Incident
Vorfälle können verschiedene Ursachen haben, darunter Mitarbeiter, Kunden, Lieferanten oder Überwachungssysteme. Der erste Schritt besteht darin, den Vorfall zu identifizieren und zu protokollieren. Diese Protokolle, die oft als Incident-Tickets bezeichnet werden, umfassen in der Regel:
- Name der Person, die den Bericht über den Incident erstellt hat
- Datum und Uhrzeit der Meldung des Incidents
- Eine Beschreibung des Incidents mit detaillierten Angaben zu Fehlfunktionen oder Ausfällen
- Zu Zwecken der Nachverfolgung wird eine eindeutige Nummer vergeben.
2. Kategorisieren Sie den Incident
Es ist entscheidend, jedem Incident eine logische und intuitive Kategorie (und gegebenenfalls eine Unterkategorie) zuzuweisen. Diese Kategorisierung hilft bei der Analyse von Daten hinsichtlich Trends und Mustern, was für ein effektives Problemmanagement und die zukünftige Vorfallprävention unerlässlich ist.
3. Priorisieren Sie den Incident
Jeder Incident muss aufgrund seiner Auswirkungen auf das Geschäft, der Anzahl der betroffenen Personen, der relevanten SLAs und der potenziellen finanziellen, sicherheitsrelevanten und Compliance-Auswirkungen priorisiert werden.
Die zuständigen Teams legen die relative Priorität fest, indem sie den Incident mit anderen offenen Incidents vergleichen. Die Festlegung von Schweregrad und Prioritätsstufen im Voraus ist eine Best Practice, die es Incident Managern ermöglicht, die Priorität schnell zu beurteilen.
4. Reagieren Sie auf den Incident
Die Reaktionsphase umfasst mehrere Schlüsselmaßnahmen:
- Erstdiagnose: Im Idealfall diagnostiziert und behebt das Support-Team an vorderster Front den Incident. Ist dies nicht möglich, protokolliert es alle relevanten Informationen und leitet den Incident an das Team der nächsten Ebene weiter.
- Eskalation: Das nachfolgende Team setzt den Diagnoseprozess fort. Wenn es den Incident nicht lösen kann, eskaliert es ihn.
- Kommunikation: Regelmäßige Updates werden an betroffene interne und externe Stakeholder freigegeben.
- Untersuchung und Diagnose: Diese Phase dauert so lange, bis die Art des Incidents identifiziert ist. Die Teams können externe Ressourcen oder Mitglieder aus anderen Abteilungen hinzuziehen, um die Lösung zu unterstützen.
- Lösung und Wiederherstellung: Nach der Diagnose führt das Team die erforderlichen Schritte zur Lösung des Incidents durch. Die Wiederherstellung umfasst die Zeit, die für die vollständige Wiederherstellung des Betriebs erforderlich ist, da einige Korrekturen, wie z. B. Bug-Patches, auch nach der Lösung noch getestet und bereitgestellt werden müssen.
- Abschluss: Wenn der Incident eskaliert wurde, wird er zum Abschluss an den Service Desk zurückgeleitet. Nur Mitarbeiter des Service Desks können Incidents abschließen, um Qualität und Kundenzufriedenheit sicherzustellen.
Incident Management für DevOps- und SRE-Teams
DevOps- und SRE-Ansätze haben immense Popularität erlangt, insbesondere mit dem Aufkommen von ständig verfügbaren Cloud-Diensten, weltweit zugänglichen Webanwendungen, Microservices und Software-as-a-Service-Lösungen (SaaS).
Moderne Software, die für den privaten und beruflichen Gebrauch unverzichtbar ist, wird selten auf einem lokalen Server gehostet. Stattdessen werden diese Anwendungen in der Regel in Rechenzentren bereitgestellt und bedienen Tausende oder Millionen von Benutzern weltweit. Agilität und Schnelligkeit sind für die Teams, die für die Wartung dieser Dienste verantwortlich sind, von entscheidender Bedeutung. Jede Ausfallzeit kann weitreichende Folgen haben und zahlreiche Unternehmen gleichzeitig beeinträchtigen.
Die Philosophie „you build it, you run it“ bietet agilen Teams die nötige Flexibilität. Allerdings kann sie auch zu Unklarheiten hinsichtlich der Verantwortlichkeiten führen. DevOps-Teams können zwar mit weniger starren Entwicklungsprozessen erfolgreich sein, dennoch ist es unerlässlich, die wichtigsten Praktiken des Incident Managements zu standardisieren:
Geteilte Bereitschaftsdienstpflichten
Im Gegensatz zu herkömmlichen Modellen, bei denen bestimmte Mitglieder des Teams als Bereitschaftsexperten benannt werden, arbeiten DevOps-Teams in der Regel mit einem rotierenden Bereitschaftsdienstplan. Dieser Ansatz stellt sicher, dass alle Mitglieder des Teams für die Reaktion auf Incidents verantwortlich sind, auch für solche, die außerhalb der regulären Arbeitszeiten auftreten können.
Vertrautheit fördert die Lösung
Im Mittelpunkt der DevOps-Philosophie steht die Überzeugung, dass die Ingenieure, die einen Dienst entwickelt haben, am besten in der Position sind, auftretende Probleme zu lösen. Dieses Prinzip unterstreicht die Mentalität „Wer etwas entwickelt, betreibt es auch“, wonach diejenigen, die mit der Architektur und den Feinheiten des Dienstes am besten vertraut sind, sich um Ausfälle und Störungen kümmern.
Schnelligkeit und Verantwortlichkeit
DevOps-Teams müssen Software schnell entwickeln und bereitstellen. Diese Geschwindigkeit bringt jedoch eine zusätzliche Verantwortung mit sich. Das Wissen, dass sie Incidents beheben müssen, motiviert Ingenieure dazu, hochwertigen, zuverlässigen Code zu erstellen.
Die Ursachenanalyse (Root Cause Analysis, RCA) ist ebenfalls ein wesentlicher Bestandteil des DevOps-Incident-Managements. Bei der RCA werden die zugrunde liegenden Ursachen von Incidents identifiziert, sodass Teams praktische Lösungen implementieren und eine Wiederholung verhindern können.
Es handelt sich um einen proaktiven Ansatz, der unmittelbare Probleme angeht und das Gesamtsystem stärkt, wodurch die Wahrscheinlichkeit künftiger schwerwiegender Incidents verringert und die Ausfallsicherheit der Dienste verbessert wird.
Durch die Aufrechterhaltung eines kontinuierlichen und kohärenten Flows bei der Vorfallsbearbeitung können DevOps-Teams Flexibilität und Struktur in Einklang bringen. Dadurch sind sie gut vorbereitet, um Vorfälle schnell und effektiv zu bearbeiten, was zu zuverlässigeren und robusteren Softwarediensten führt.
Rollen im Incident Management
Auch wenn Unternehmen ihre Rollen und Verantwortlichkeiten je nach ihren spezifischen Anforderungen anpassen können, sind die folgenden Rollen in IT-Incident-Management-Teams am weitesten verbreitet:
- Endbenutzer/Anfragender: Diese Person ist in der Regel von einer Dienstunterbrechung betroffen und dafür verantwortlich, den Incident-Management-Prozess durch Einreichen eines Incident-Tickets zu initiieren.
- Tier-1-Service-Desk: Der Tier-1-Service-Desk ist die erste Anlaufstelle für Anfragende. Techniker bearbeiten grundlegende Probleme und Anfragen. Ihr Fachwissen umfasst häufige Probleme wie Passwortzurücksetzungen und Probleme der Verbindung wie WLAN-Probleme.
- Tier-2-Service-Desk: Techniker dieser Ebene verfügen über fortgeschrittenere Fähigkeiten und Kenntnisse als diejenigen der Tier-1-Ebene. Sie befassen sich mit komplexeren Problemen und bearbeiten Eskalationen aus der Tier-1-Ebene. Ihre Rolle umfasst die Lösung komplizierter technischer Probleme und die Sicherstellung einer effektiven Behebung von Incidents.
- Service Desk der Stufe 3 und höher: Diese Stufe umfasst Spezialisten mit fundierten Kenntnissen in bestimmten Bereichen der IT-Infrastruktur, wie z. B. Hardwarewartung oder Support für Server.
- Incident Manager: Der Incident Manager überwacht den Incident-Management-Prozess, bewertet dessen Wirksamkeit, schlägt Verbesserungen vor und sorgt für die Einhaltung der festgelegten Verfahren.
- Prozessverantwortlicher: Der Prozessverantwortliche überwacht und optimiert den Incident-Management-Prozess. Er analysiert, passt an und verbessert den Prozess, um sicherzustellen, dass er mit den Unternehmenszielen übereinstimmt und das Incident Management optimal unterstützt.
Diese Rollen tragen gemeinsam zu einem gut strukturierten und effizienten Prozess zur Identifizierung und Verwaltung von Incidents bei, der eine schnelle und effektive Lösung von Incidents gewährleistet und gleichzeitig den Ansatz kontinuierlich verbessert.
Tools und Ressourcen für ein effektives Incident Management
Der Einsatz der richtigen tools und Ressourcen für das Incident Management kann die Effizienz und Effektivität des Incident-Management-Prozesses erheblich steigern.
Webbrowser, insbesondere Google Chrome, spielen eine zentrale Rolle beim Incident Management. Die Vielseitigkeit und Kompatibilität von Chrome mit verschiedenen webbasierten Incident-Management-Softwareprogrammen machen es zu einem unverzichtbaren Tool für IT-Teams. Seine umfangreiche Bibliothek an Erweiterungen, wie Entwicklertools, Bug-Tracker und Leistungsmonitore, ermöglicht Echtzeit-Diagnosen und Fehlerbehebungen.
Darüber hinaus hilft das Abrufen von Artefakten wie Cache-Daten, Verlauf, Downloads usw. durch Browser-Forensik den Teams, mögliche Quellen für Virenangriffe und bösartigen Code zu identifizieren.
Chrome lässt sich außerdem nahtlos in ClickUp integrieren, eine hoch bewertete Software für Produktivität und Incident-Management, die von Teams in kleinen und großen Unternehmen verwendet wird.
Hier sind einige der wesentlichen Vorteile der Verwendung von ClickUp für das Incident Management:
1. Zentralisierte Nachverfolgung von Incidents
ClickUp fasst alle Informationen zu Incidents auf einer einzigen Plattform zusammen. Durch diesen zentralisierten Ansatz sind alle Incident-Berichte, Aktualisierungen und Lösungen an einem Ort verfügbar, wodurch das Risiko von Informationsverlusten verringert wird und sichergestellt ist, dass die Mitglieder des Teams jederzeit auf die aktuellsten Daten zugreifen können.
2. Zusammenarbeit in Echtzeit
Die Kollaborationsfunktionen von ClickUp ermöglichen eine nahtlose Kommunikation zwischen den Teammitgliedern. Mit der ClickUp-Chat-Ansicht können Benutzer direkt zu Aufgaben Kommentare abgeben, Dateien freigeben und den Status von Incidents in Echtzeit aktualisieren. Diese Funktion ist besonders für Teams von Vorteil, die an verschiedenen Standorten oder in unterschiedlichen Zeitzonen arbeiten, da sie dafür sorgt, dass alle auf dem Laufenden bleiben und sich abstimmen können.

3. Automatisiertes Workflow-Management
ClickUp Automatisierung hilft Ihnen dabei, automatisierte Workflows zu erstellen, die bestimmte Aktionen basierend auf vordefinierten Bedingungen auslösen. Wenn beispielsweise ein Incident gemeldet wird, können automatisierte Benachrichtigungen an die zuständigen Teammitglieder gesendet und Aufgaben basierend auf der Art des Incidents zugewiesen werden. Dies reduziert den manuellen Aufwand und beschleunigt die Lösung von Incidents.
4. Integrierte Berichterstellung und Analyse
Die Plattform bietet leistungsstarke Tools für die Berichterstellung und Analyse, mit denen Sie Vorfalltrends und Metriken überwachen können. Teams können detaillierte Berichte zur Priorisierung von Incidents, zur Lösungsdauer von Incidents, zu Wiederholungsraten und anderen Schlüssel-Metriken erstellen. Dieser datengestützte Ansatz hilft dabei, Muster zu erkennen, die Wirksamkeit von Reaktionsstrategien zu bewerten und fundierte Entscheidungen zur Verbesserung der Vorfallmanagementprozesse zu treffen.
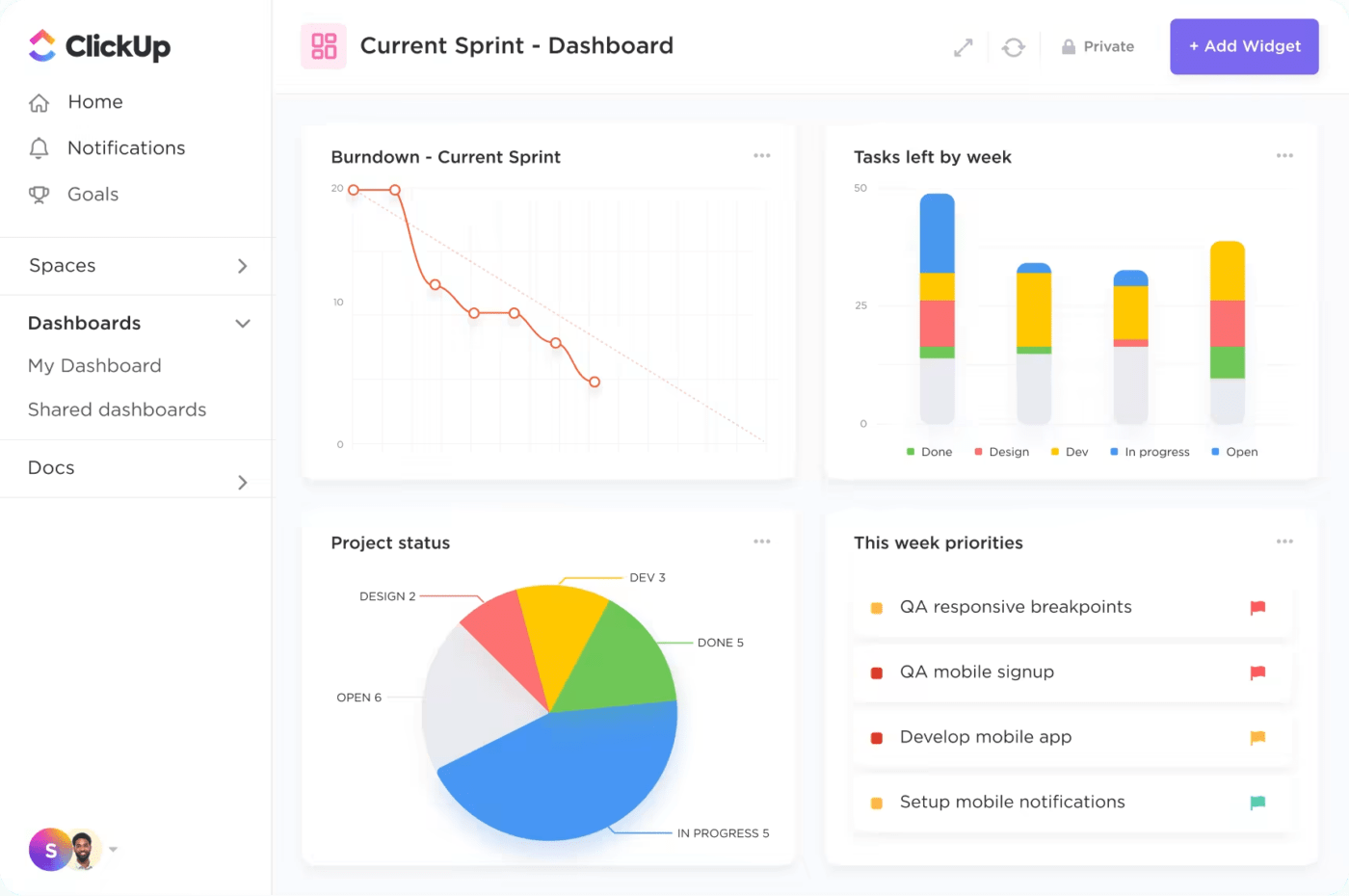
5. Anpassbare Dashboards
Die Plattform ermöglicht Ihnen die Erstellung benutzerdefinierter Dashboards, die wichtige Metriken und KPIs zum Vorfallmanagement anzeigen. ClickUp-Dashboards bieten eine visuelle Übersicht über laufende Vorfälle, anstehende Aufgaben und die Leistung der Teams, sodass Manager den aktuellen Stand des Vorfallmanagements schnell beurteilen und etwaige Probleme beheben können.
6. Vorgefertigte Vorlagen
ClickUp bietet einen Bereich anpassbarer IT-Vorlagen, die speziell für das Incident Management entwickelt wurden. Diese Vorlagen helfen Benutzern auch dabei, Fehler zu dokumentieren.
Als Beispiel dient die ClickUp-Vorlage für IT-Incidents , mit der IT-Teams Incidents schnell und effizient dokumentieren, verfolgen und beheben können. Dies verbessert nicht nur die Servicegeschwindigkeit, sondern hilft Unternehmen auch dabei, langfristige Trends zu erkennen, die sie zur Verbesserung ihrer gesamten IT-Infrastruktur nutzen können.
Mit dieser Vorlage ist es ganz einfach:
- Dokumentieren und melden Sie Incidents genau
- Verfolgen Sie den Fortschritt der Problemlösung in Echtzeit
- Identifizieren Sie Muster in gemeldeten Problemen, um proaktiv Lösungen zu finden.
Er enthält wichtige Komponenten wie eine detaillierte Beschreibung, eine Checkliste, Unteraufgaben und anpassbare Felder. Dank dieser Flexibilität lässt sich die Vorlage an die Prozesse und Verfahren Ihres Unternehmens anpassen, sodass Sie einen umfassenden IT-Incident-Bericht erstellen können.
Sie können auch die ClickUp-Vorlage für Vorfallaktionspläne verwenden, die die Entwicklung umfassender Vorfallaktionspläne (IAPs) für Unternehmen vereinfacht.
Diese Vorlage enthält systematisch alle wichtigen Informationen und hilft Ihnen dabei, zuverlässige Aufzeichnungen über Aktivitäten im Zusammenhang mit Incidents zu erstellen und effektive Reaktionsstrategien zu implementieren.
Die Vorlage enthält farbcodierte Abschnitte für eine übersichtliche Dokumentation:
- Zusammenfassung der Situation: Bietet einen prägnanten Überblick über den Incident und den allgemeinen Plan.
- Ausführungsplan: Enthält detaillierte Ziele und Strategien für das Management des Incidents.
- Kontaktdaten des Incident-Teams: Liste der Kontaktdaten der Mitarbeiter, die an der Reaktion beteiligt sind.
- Liste zur Organisation von Incidents: Beschreibt die Rollen und Verantwortlichkeiten der Teams für Betrieb, Planung, Logistik und Finanzen.
- Liste zur Zuweisung von Incidents: Weist Vorgesetzten und Mitgliedern der Teams bestimmte Aufgaben zu.
- Karte/Zusammenfassung der Situation: Enthält grafische Darstellungen des Vorfallortes oder der Region.
- Genehmigung des Plans für Incidents: Erfasst Details wie den Namen der Person, die den Plan übermittelt, das Datum der Übermittlung und die erforderlichen Signaturen.
Mithilfe dieser Vorlage können Unternehmen alle für die IAP-Genehmigung erforderlichen Details effizient zusammenstellen und eine gut koordinierte und gründliche Incident-Response-Maßnahme einleiten.
Best Practices für das Incident Management
Ein effektives Incident Management basiert auf Best Practices, die eine schnelle und effektive Lösung gewährleisten.
Legen Sie mit SLAs klare Erwartungen fest
Service Level Agreements (SLAs) spielen eine wichtige Rolle, indem sie klare Erwartungen daran formulieren, wie schnell Teams Incidents je nach Schweregrad bearbeiten sollten.
SLAs legen bestimmte Reaktions- und Lösungszeiten fest, die dabei helfen, Incidents zu priorisieren und Teams bei der effizienten Verwaltung ihrer Workload zu unterstützen. Dieser strukturierte Ansatz hilft Ihnen, Ressourcen dort einzusetzen, wo sie am dringendsten benötigt werden, sodass Sie die Lösung von Incidents an den Prioritäten des Geschäfts ausrichten und Ausfallzeiten minimieren können.
Wenden Sie regelmäßig Patches an, um Incidents zu verhindern.
Eine weitere wichtige Maßnahme ist das regelmäßige Patchen, das dazu beiträgt, Incidents zu verhindern, indem Schwachstellen behoben werden, bevor sie ausgenutzt werden können. Dabei handelt es sich um einen fortlaufenden Prozess, der Lücken in der Sicherheit von Software und Systemen behebt und es Angreifern erschwert, bekannte Schwachstellen auszunutzen.
Diese Vorgehensweise ist ein grundlegender Bestandteil eines Cybersicherheits-Risikomanagement-Frameworks, da sie die IT-Infrastruktur vor neuen Bedrohungen schützt und das Risiko von Sicherheitsverletzungen verringert. Ohne zeitnahe Patches bleiben Schwachstellen offen und können zu erheblichen Problemen in Bezug auf die Sicherheit führen.
Priorisieren Sie die Überwachung von Rechenzentren
Das Rechenzentrumsmanagement spielt ebenfalls eine wichtige Rolle beim Incident Management. Ein ordnungsgemäßes Management stellt sicher, dass sowohl die physischen als auch die virtuellen Aspekte des Rechenzentrums gut gewartet werden. Dazu gehören die Überwachung der Umgebungskontrollen, der Stromversorgung und der physischen Sicherheit.
Echtzeit-Überwachungssysteme sind dabei von entscheidender Bedeutung, da sie dabei helfen, Probleme zu erkennen und zu beheben, bevor sie eskalieren. Ein effektives Rechenzentrumsmanagement in Kombination mit einem gut implementierten Rahmenwerk für das Cybersicherheits-Risikomanagement ermöglicht eine frühzeitige Problemerkennung, wodurch größere Störungen vermieden und die Stabilität des IT-Betriebs aufrechterhalten werden kann.
Vorteile und Herausforderungen des Incident-Managements
Vorfälle können den Fortschritt des Projekts verlangsamen und wertvolle Ressourcen verbrauchen, was oft zu erheblichen Betriebsstörungen und potenziellen Verlusten wichtiger Daten führt. Dies unterstreicht die entscheidende Bedeutung eines effektiven Vorfallmanagements.
Zu den wichtigsten Vorteilen des Incident-Managements gehören:
1. Verbesserte Vorfallabwehr
Incident Deflection umfasst die proaktive Identifizierung und Minderung potenzieller Probleme, bevor diese zu schwerwiegenden Störungen eskalieren. Effektive Incident-Management-Systeme ermöglichen es Unternehmen, vorbeugende Maßnahmen zu ergreifen und die Systemleistung kontinuierlich zu überwachen, wodurch die Häufigkeit und Schwere von Vorfällen reduziert wird.
2. Optimierter Änderungsprozess
Ein gut verwalteter Änderungsprozess stellt sicher, dass Mitarbeiter Updates und Modifikationen systematisch und gemäß festgelegten Verfahren implementieren. Die Nutzung von Standardarbeitsanweisungen (SOP) für das Änderungsmanagement trägt zur Standardisierung von Verfahren bei, gewährleistet Konsistenz und verringert das Risiko für Fehler.
3. Effektive Lösung und Schließung von Incidents
Ein klar definierter Lösungsprozess stellt sicher, dass Teams Vorfälle umgehend bearbeiten und alle notwendigen Schritte zur Lösung des Problems unternehmen. Nach der Lösung werden Vorfälle mit vollständiger Dokumentation und Folgemaßnahmen offiziell geschlossen. Dieser strukturierte Ansatz verbessert die betriebliche Effizienz und liefert wertvolle Aufzeichnungen für die Analyse nach dem Vorfall und die kontinuierliche Verbesserung, wodurch die Strategien für das Vorfallmanagement im Laufe der Zeit verfeinert werden können.
Herausforderungen beim Incident Management
Trotz der Vorteile treten beim Incident Management häufig mehrere Herausforderungen auf.
1. Schwierigkeiten bei der Ermittlung der Ursachen
Eine große Herausforderung besteht darin, die Ursache eines Incidents zu identifizieren, insbesondere wenn es sich um komplexe Probleme handelt, die mehrere Systemkomponenten und gegenseitige Abhängigkeiten betreffen.
Die genaue Diagnose der zugrunde liegenden Ursache erfordert eine gründliche Untersuchung und oft auch eine funktionsübergreifende Zusammenarbeit. Standardarbeitsanweisungen (SOP) können bei der Erstellung standardisierter Verfahren zur Ursachenanalyse helfen, aber für die effektive Umsetzung dieser Verfahren sind fortschrittliche tools und Methoden erforderlich.
Stanley Security stand bei der Verwaltung seiner Incident-Response-Prozesse vor einer ähnlichen Herausforderung. Als weltweit führender Anbieter von Lösungen für die Sicherheit hat Stanley Security mit verschiedenen Incidents in unterschiedlichen Systemen und Regionen zu tun.
Bisher nutzten die Marketingteams des Unternehmens Tools wie Excel und E-Mail für die interne Kommunikation und das Aufgabenmanagement. Die durch die COVID-19-Pandemie entstandene Nachfrage nach integrierteren und skalierbareren Projektmanagement-Tools machte deutlich, dass Silos aufgebrochen und die Produktivität gesteigert werden müssen.
ClickUp stellte einen einheitlichen Arbeitsbereich für globale Teams bereit, der die Kommunikation erleichterte und Dokumente sowie SOPs in einer weltweiten Datenbank organisierte. Diese Angleichung ermöglichte es den Teams, effektiver zusammenzuarbeiten und Best Practices auszutauschen. Als Ergebnis erzielte Stanley Security eine 80-prozentige Verbesserung der Teamarbeit und sparte wöchentlich über 8 Stunden an Meetings und Updates ein. Außerdem konnte der Zeitaufwand für die Erstellung und Freigabe von Berichten um 50 % reduziert werden.
2. Wiederholung von Incidents
Eine weitere Herausforderung besteht darin, das Wiederauftreten von Incidents zu verhindern. Dies erfordert ein tiefgreifendes Verständnis der zugrunde liegenden Probleme und die Umsetzung wirksamer Präventionsmaßnahmen. Die Identifizierung von Mustern und Trends aus vergangenen Incidents ist für die Entwicklung von Strategien zur Minderung zukünftiger Risiken von entscheidender Bedeutung.
ClickUp begegnet dieser Herausforderung mit integrierten Tools für Berichterstellung und Analyse, die Einblicke in Metriken zum Incident-Verlauf und zu Leistungstrends bieten. Dieser datengestützte Ansatz erleichtert die Identifizierung wiederkehrender Probleme und hilft bei der Entwicklung gezielter Präventionsstrategien.

Die IT- und PMO-Lösung von ClickUp kann Ihnen dabei helfen:
- Erstellen Sie benutzerdefinierte Status (z. B. „Geschlossen“, „In Bearbeitung“, „In Bearbeitung“) und Felder (z. B. „Anforderer“, „Abteilung“), um Incidents effektiv zu kategorisieren und zu verwalten.
- Verfolgen und überwachen Sie Incidents in Echtzeit und sorgen Sie so für schnelle Updates und Überprüfungen des Status.
- Fügen Sie relevante Dokumente, Screenshots oder Protokolle zu Incidents hinzu, um diese zu analysieren. Erstellen Sie eine Wissensdatenbank für gängige Lösungen für Incidents.
- Erstellen Sie Berichte über die Häufigkeit von Incidents, die Lösungsdauer und die Ursachen, um Trends zu erkennen und die Reaktion zu verbessern.
- Verbinden Sie ClickUp mit anderen IT-Tools, um eine ganzheitliche Ansicht der Incidents zu erhalten.
Beherrschen Sie das Incident-Management für einen optimalen Erfolg des Projekts
Beim Incident Management geht es nicht nur darum, auf Probleme zu reagieren, sondern eine widerstandsfähige und agile Umgebung zu schaffen, in der Unterbrechungen schnell behoben und Projektziele mit minimalen Auswirkungen erreicht werden.
Durch die Umsetzung dieser Strategien kann Ihr Team potenzielle Probleme vermeiden und sicherstellen, dass Ihre Projekte reibungslos und mit Erfolg verlaufen.
Mit ClickUp profitieren Sie von einer All-in-One-Plattform, die das Vorfallmanagement mit dem Projektmanagement und dem IT-Betriebsmanagement integriert. Dank der Echtzeit-Nachverfolgung, Automatisierungen der Workflows und Tools für die Zusammenarbeit von ClickUp kann Ihr Team Probleme schnell angehen und lösen, während Ihre Projekte planmäßig voranschreiten. Ob bei der Verwaltung des Tagesgeschäfts oder der Bewältigung komplexer Projektanforderungen – ClickUp bietet die Sichtbarkeit und Kontrolle, die für außergewöhnliche Ergebnisse erforderlich sind.
Sind Sie bereit, Ihr Incident Management und Ihren Projekterfolg zu verbessern? Melden Sie sich noch heute bei ClickUp an und transformieren Sie Ihr Incident Management!