
Większość zespołów badających modele AI typu open source odkrywa, że LLaMA firmy Meta oferuje rzadkie połączenie mocy i elastyczności, ale ustawienia techniczne mogą przypominać składanie mebli bez instrukcji.
Ten przewodnik przeprowadzi Cię przez proces tworzenia funkcjonalnego chatbota LLaMA od podstaw, obejmujący wszystko, od wymagań sprzętowych i dostępu do modeli po inżynierię podpowiedzi i strategie wdrażania.
Zacznijmy!
Czym jest LLaMA i dlaczego warto używać go w chatbotach?
Tworzenie chatbota przy użyciu zastrzeżonych interfejsów API często sprawia wrażenie, jakbyś był uzależniony od systemu innej firmy, narażony na nieprzewidywalne koszty i problemy związane z prywatnością danych. Ta zależność od dostawcy oznacza, że nie możesz naprawdę dostosować modelu do unikalnych potrzeb swojego zespołu, co prowadzi do generycznych odpowiedzi i potencjalnych problemów związanych z przestrzeganiem przepisów.
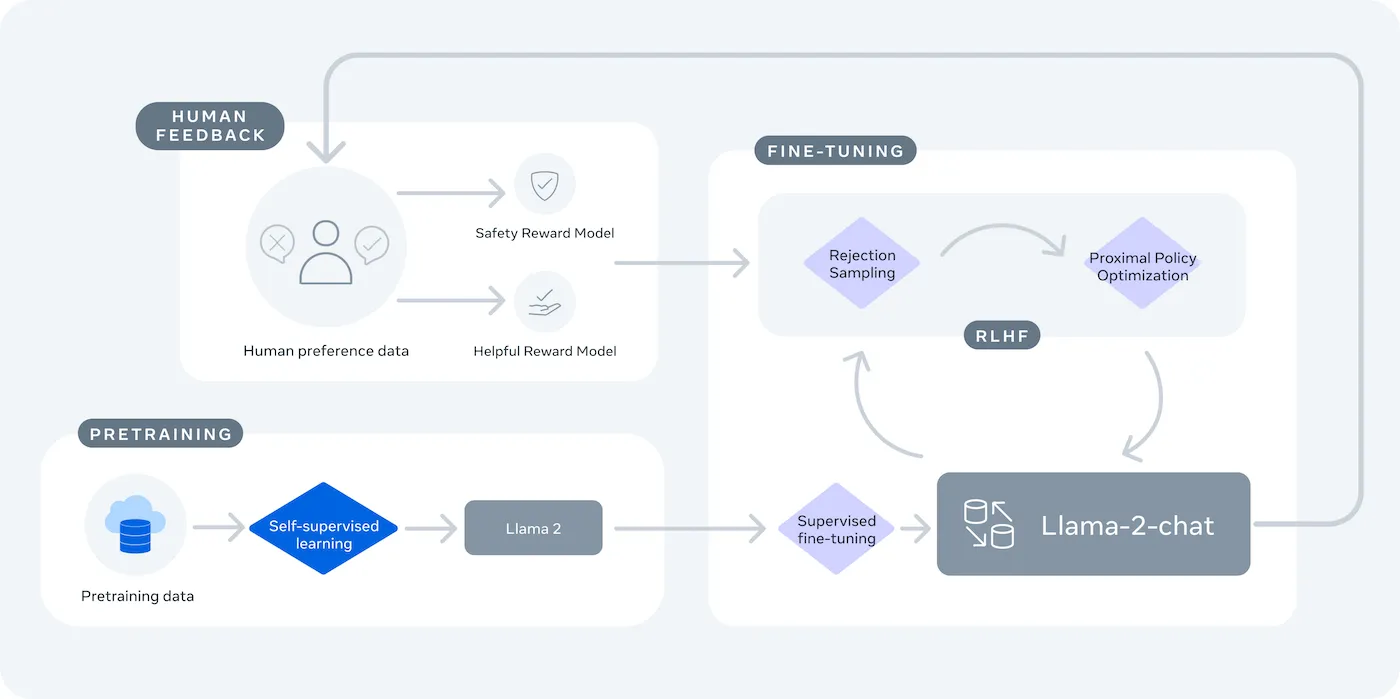
LLaMA (Large Language Model Meta AI) to rodzina otwartych modeli językowych firmy Meta, która stanowi potężną alternatywę. Została zaprojektowana zarówno do celów badawczych, jak i komercyjnych, zapewniając kontrolę, której nie dają modele zamkniętego typu.
Modele LLaMA są dostępne w różnych rozmiarach, mierzonych w parametrach (np. 7B, 13B, 70B). Parametry można traktować jako miarę złożoności i mocy modelu — większe modele mają większe możliwości, ale wymagają więcej zasobów obliczeniowych.
Oto dlaczego warto korzystać z chatbota LLaMA:
- Privatność danych: Kiedy uruchamiasz model na własnej infrastrukturze, dane rozmów nigdy nie opuszczają Twojego środowiska. Ma to kluczowe znaczenie dla zespołów zajmujących się poufnymi informacjami.
- Dostosowanie: Możesz dostosować model LLaMA do wewnętrznych dokumentów lub danych swojej firmy. Pomaga to zrozumieć konkretny kontekst i zapewnić znacznie bardziej trafne odpowiedzi.
- Przewidywalność kosztów: po wstępnych ustawieniach sprzętu nie musisz martwić się o opłaty za tokeny API. Twoje koszty stają się stałe i przewidywalne.
- Brak ograniczeń szybkości: Obciążenie Twojego chatbota jest ograniczone jedynie przez Twój sprzęt, a nie limity dostawcy. Możesz skalować go zgodnie z potrzebami.
Głównym kompromisem jest wygoda kontroli. LLaMA wymaga bardziej technicznych ustawień niż API typu plug-and-play. W przypadku chatbotów produkcyjnych zespoły zazwyczaj używają LLaMA 2 lub nowszego LLaMA 3, który oferuje ulepszone rozumowanie i może obsługiwać więcej tekstu jednocześnie.
Co jest potrzebne przed stworzeniem chatbota LLaMA
Rozpoczęcie projektu programistycznego bez odpowiednich narzędzi to prosta droga do frustracji. W połowie projektu zdajesz sobie sprawę, że brakuje Ci kluczowego elementu sprzętu lub oprogramowania, co hamuje postępy i powoduje stratę wielu godzin.
Aby tego uniknąć, zbierz wszystko, czego potrzebujesz, z wyprzedzeniem. Oto lista kontrolna, która zapewni płynny start. 🛠️
Wymagania sprzętowe
| Rozmiar modelu | Minimalna pamięć VRAM | Opcja alternatywna |
|---|---|---|
| 7 miliardów parametrów | 8 GB | Instancja GPU w chmurze |
| 13 miliardów parametrów | 16 GB | Instancja GPU w chmurze |
| 70 miliardów parametrów | Wiele procesorów graficznych | Kwantyzacja lub chmura |
Jeśli Twój lokalny komputer nie ma wystarczająco wydajnego procesora graficznego (GPU), możesz skorzystać z usług w chmurze, takich jak AWS lub GCP. Platformy wnioskowania, takie jak Baseten i Replicate, oferują również dostęp do GPU w modelu płatności zgodnie z rzeczywistym użyciem.
Wymagania dotyczące oprogramowania
- Python 3. 8+: Jest to standardowy język programowania dla projektów związanych z uczeniem maszynowym.
- Menedżer pakietów: Do zainstalowania bibliotek niezbędnych do realizacji projektu potrzebny będzie pip lub Conda.
- Środowisko wirtualne: Jest to najlepsza praktyka, która pozwala odizolować zależności projektu od innych projektów Python na komputerze.
Wymagania dotyczące dostępu
- Konto Hugging Face: Aby pobrać wagi modelu LLaMA, potrzebujesz konta.
- Zatwierdzenie Meta: Aby uzyskać dostęp do modeli LLaMA, należy zaakceptować umowę licencyjną Meta, która zazwyczaj jest zatwierdzana w ciągu kilku godzin.
- Klucze API: Są one niezbędne tylko wtedy, gdy zdecydujesz się używać hostowanego punktu końcowego wnioskowania zamiast uruchamiania modelu lokalnie.
W tym przewodniku wykorzystamy framework LangChain. Upraszcza on wiele złożonych aspektów tworzenia chatbota, takich jak zarządzanie podpowiedziami i historią rozmów.
{kind=link}
Jak krok po kroku stworzyć chatbota za pomocą LLaMA
Połączenie wszystkich elementów technicznych chatbota — modelu, podpowiedzi, pamięci — może wydawać się przytłaczające. Łatwo jest zgubić się w kodzie, co prowadzi do błędów i chatbota, który nie działa zgodnie z oczekiwaniami. Ten przewodnik krok po kroku dzieli proces na proste, łatwe do opanowania części.
To podejście sprawdza się niezależnie od tego, czy model jest uruchamiany na własnym komputerze, czy też korzystasz z usługi hostowanej.
Krok 1: Zainstaluj wymagane pakiety
Najpierw musisz zainstalować podstawowe biblioteki Python. Otwórz terminal i uruchom następującą komendę:
pip install langchain transformers accelerate torch
Jeśli korzystasz z hostowanej usługi, takiej jak Baseten, do wnioskowania, musisz również zainstalować jej specjalny zestaw narzędzi programistycznych (SDK):
pip install baseten
Oto, co każdy z tych pakietów robi:
- Langchain: framework pomagający tworzyć aplikacje z wykorzystaniem dużych modeli językowych, w tym zarządzanie łańcuchami konwersacji i pamięcią.
- Transformatory: biblioteka Hugging Face do ładowania i uruchamiania modelu LLaMA.
- Accelerate: biblioteka, która pomaga zoptymalizować sposób ładowania modelu do procesora i karty graficznej.
- Torch: Biblioteka PyTorch, która zapewnia zaplecze obliczeniowe dla modelu.
Jeśli model jest uruchamiany lokalnie na komputerze z procesorem graficznym NVIDIA, upewnij się, że CUDA jest zainstalowana i poprawnie skonfigurowana. Dzięki temu model może korzystać z procesora graficznego, co znacznie przyspiesza jego działanie.
Krok 2: Uzyskaj dostęp do modeli LLaMA
Zanim będziesz mógł pobrać model, musisz uzyskać oficjalny dostęp od Meta za pośrednictwem Hugging Face.
- Załóż konto na stronie huggingface.co
- Przejdź do strony modelu, na przykład meta-llama/Llama-2-7b-chat-hf.
- Kliknij „Uzyskaj dostęp do repozytorium” i zaakceptuj warunki licencji Meta.
- W ustawieniach konta Hugging Face wygeneruj nowy token dostępu.
- W terminalu uruchom huggingface-cli login i wklej swój token, aby uwierzytelnić swoje urządzenie.
Zatwierdzenie następuje zazwyczaj szybko. Upewnij się, że wybierasz wariant modelu z nazwą zawierającą słowo „chat”, ponieważ zostały one specjalnie przeszkolone do zadań związanych z konwersacją.
Krok 3: Załaduj model LLaMA
Teraz możesz załadować model do swojego kodu. Masz dwie główne opcje w zależności od sprzętu.
Jeśli dysponujesz wystarczająco wydajną kartą graficzną, możesz załadować model lokalnie:
Jeśli masz limit sprzętu, możesz skorzystać z hostowanej usługi wnioskowania:
Komenda device_map="auto" nakazuje bibliotece transformers automatyczną dystrybucję modelu na wszystkie dostępne procesory graficzne.
Jeśli nadal brakuje Ci pamięci, możesz użyć techniki zwanej kwantyzacją, aby zmniejszyć rozmiar modelu, choć może to nieznacznie obniżyć jego wydajność.
Krok 4: Utwórz szablon podpowiedzi
Modele czatu LLaMA są szkolone tak, aby oczekiwały określonego formatu podpowiedzi. Szablon podpowiedzi zapewnia prawidłową strukturę wprowadzanych danych.
Przyjrzyjmy się bliżej temu formatowi:
- <
>: Ta sekcja zawiera podpowiedź systemową, która przekazuje modelowi podstawowe instrukcje i definiuje jego osobowość. - [INST]: Oznacza początek pytania lub instrukcji użytkownika.
- [/INST]: Sygnalizuje modelowi, że nadszedł czas na wygenerowanie odpowiedzi.
Pamiętaj, że różne wersje LLaMA mogą używać nieco innych szablonów. Zawsze sprawdzaj dokumentację modelu na Hugging Face, aby upewnić się, że format jest prawidłowy.
Krok 5: Skonfiguruj łańcuch chatbotów
Następnie wykonasz połączenie swojego modelu i szablonu podpowiedzi w łańcuch konwersacyjny za pomocą LangChain. Łańcuch ten będzie również zawierał pamięć do śledzenia rozmowy.
LangChain oferuje kilka rodzajów pamięci:
- ConversationBufferMemory: Jest to najprostsza opcja. Przechowuje całą historię rozmów.
- ConversationSummaryMemory: Aby zaoszczędzić przestrzeń, ta opcja okresowo podsumowuje starsze fragmenty rozmowy.
- ConversationBufferWindowMemory: przechowuje w pamięci tylko kilka ostatnich wymian, co jest przydatne w zapobieganiu zbyt długiemu kontekstowi.
Do testowania świetnie nadaje się ConversationBufferMemory.
Krok 6: Uruchom pętlę chatbota
Na koniec możesz utworzyć prostą pętlę, aby komunikować się z chatbotem z terminala.
W rzeczywistym zastosowaniu pętlę tę należy zastąpić punktem końcowym API przy użyciu frameworka takiego jak FastAPI lub Flask. Można również przesyłać strumieniowo odpowiedź modelu z powrotem do użytkownika, co sprawia, że chatbot działa znacznie szybciej.
Możesz również dostosować parametry, takie jak temperatura, aby kontrolować losowość odpowiedzi. Niska temperatura (np. 0,2) sprawia, że wynik jest bardziej deterministyczny i oparty na faktach, podczas gdy wyższa temperatura (np. 0,8) sprzyja większej kreatywności.
📚 Przeczytaj również: Agent AI a chatbot: kluczowe różnice i który z nich jest odpowiedni dla Ciebie?
Jak przetestować chatbota LLaMA
Stworzyłeś chatbota, który udziela odpowiedzi, ale czy jest on gotowy do obsługi prawdziwych użytkowników? Wdrożenie niesprawdzonego bota może prowadzić do żenujących niepowodzeń, takich jak podawanie nieprawidłowych informacji lub generowanie nieodpowiedniej zawartości, co może zaszkodzić reputacji Twojej firmy.
Rozwiązaniem tej niepewności jest systematyczny plan testów. Dzięki niemu Twój chatbot będzie solidny, niezawodny i bezpieczny.
Testowanie funkcjonalne:
- Przypadki skrajne: sprawdź, jak bot radzi sobie z pustymi danymi wejściowymi, bardzo długimi wiadomościami i znakami specjalnymi.
- Weryfikacja pamięci: upewnij się, że chatbot zapamiętuje kontekst wielu tur rozmowy.
- Postępuj zgodnie z instrukcjami: Sprawdź, czy bot przestrzega zasad ustawionych w systemie.
Ocena jakości:
- Trafność: Czy odpowiedź faktycznie odpowiada na pytanie użytkownika?
- Dokładność: Czy dostarczane informacje są poprawne?
- Spójność: Czy przepływ rozmowy jest logiczny?
- Bezpieczeństwo: Czy bot odmawia odpowiedzi na nieodpowiednie lub szkodliwe prośby?
Testowanie wydajności:
- Opóźnienie: zmierz, ile czasu zajmuje botowi rozpoczęcie odpowiedzi i jej zakończenie.
- Wykorzystanie zasobów: monitoruj ilość pamięci GPU wykorzystywanej przez model podczas wnioskowania.
- Współbieżność: sprawdź, jak system działa, gdy wielu użytkowników korzysta z niego jednocześnie.
Zwróć też uwagę na typowe problemy związane z LLM, takie jak halucynacje (pewne podawanie fałszywych informacji), dryf kontekstowy (utrata wątku w długiej rozmowie) i powtarzanie się. Rejestrowanie wszystkich rozmów testowych to świetny sposób na wykrycie wzorców i naprawienie problemów, zanim dotrą one do użytkowników.
📚 Przeczytaj również: Różnica między testowaniem funkcjonalnym a testowaniem niefunkcjonalnym
Przykłady zastosowań chatbota LLaMA dla Teams
Po opanowaniu mechanizmów dostrajania i wdrażania LLaMA staje się najbardziej wartościowa, gdy jest stosowana do rozwiązywania codziennych problemów zespołu, a nie do abstrakcyjnych demonstracji AI. Zespoły zazwyczaj nie potrzebują „chatbota”; potrzebują szybszego dostępu do wiedzy, mniejszego nakładu pracy ręcznej i mniej powtarzalnych zadań.
Wewnętrzny asystent wiedzy
Dzięki dostosowaniu LLaMA do wewnętrznej dokumentacji, stron wiki i często zadawanych pytań — lub połączeniu go z bazą wiedzy opartą na RAG — zespoły mogą zadawać pytania w języku naturalnym i uzyskiwać precyzyjne, uwzględniające kontekst odpowiedzi. Eliminuje to konieczność przeszukiwania rozproszonych narzędzi, jednocześnie zapewniając pełną poufność danych, które nie są wysyłane do zewnętrznych interfejsów API.
🌟 Wyszukiwanie korporacyjne w ClickUp oraz gotowy agent Ambient Answers zapewniają szczegółowe, kontekstowe odpowiedzi na pytania, korzystając z wiedzy zawartej w obszarze roboczym ClickUp.
Pomocnik w przeglądaniu kodu
Po przeszkoleniu na podstawie własnej bazy kodu i przewodników stylistycznych LLaMA może pełnić rolę asystenta do kontekstowej weryfikacji kodu. Zamiast ogólnych najlepszych praktyk programiści otrzymują sugestie zgodne z konwencjami zespołu, decyzjami architektonicznymi i historycznymi wzorcami.
🌟 Narzędzie do przeglądu kodu oparte na LLaMA może wykrywać problemy, sugerować ulepszenia lub wyjaśniać nieznany kod. Codegen firmy ClickUp idzie o krok dalej, działając w ramach cyklu pracy — tworząc pull requesty, stosując refaktoryzację lub aktualizując pliki bezpośrednio w odpowiedzi na te spostrzeżenia. Wynikiem jest mniej kopiowania i wklejania oraz mniej nieudanych przekazów między „myśleniem” a „działaniem”.
Segregacja zgłoszeń do obsługi klienta
LLaMA może zostać przeszkolona w zakresie klasyfikacji intencji, aby rozumieć przychodzące zapytania klientów i kierować je do odpowiedniego zespołu lub cyklu pracy. Niestandardowe pytania mogą być obsługiwane automatycznie, natomiast skrajne przypadki są eskalowane do agentów ludzkich wraz z dołączonym kontekstem, co skraca czas odpowiedzi bez utraty jakości.
Możesz również po prostu zbudować Triage Super Agent, używając języka naturalnego w swoim obszarze roboczym ClickUp. Dowiedz się więcej
Podsumowanie spotkania i dalsze działania
Wykorzystując transkrypcje spotkań jako dane wejściowe, LLaMA może wyodrębnić decyzje, elementy do wykonania i kluczowe punkty dyskusji. Prawdziwa wartość pojawia się, gdy wyniki te przepływają bezpośrednio do narzędzi do zarządzania zadaniami, przekształcając rozmowy w śledzone zadania.
🌟 AI Meeting Notetaker od ClickUp nie tylko sporządza notatki ze spotkań, ale także tworzy podsumowania, generuje zadania do wykonania i łączy notatki ze spotkań z dokumentami i zadaniami.
Tworzenie i iteracja dokumentów
Zespoły mogą używać LLaMA do generowania pierwszych wersji raportów, propozycji lub dokumentacji na podstawie istniejących szablonów i przykładów z przeszłości. Dzięki temu wysiłek skupia się na przeglądaniu i udoskonalaniu, a nie na tworzeniu pustej strony, co przyspiesza dostarczanie wyników bez obniżania standardów.
🌟 ClickUp Brain może szybko generować szkice dokumentacji, zachowując kontekst całej wiedzy o miejscu pracy. Wypróbuj już dziś.
Chatboty oparte na LLaMA są najbardziej skuteczne, gdy są wbudowane w istniejące cykle pracy — dokumentację, zarządzanie projektami i komunikację zespołową — zamiast działać jako samodzielne narzędzia.
Właśnie w tym przypadku bezpośrednia integracja sztucznej inteligencji z Twoim obszarem roboczym ma ogromne znaczenie. Zamiast tworzyć oddzielne narzędzie, możesz wprowadzić konwersacyjną sztuczną inteligencję do miejsca, w którym już działa Twój zespół.
Możesz na przykład stworzyć niestandardowego bota LLaMA, który będzie pełnił funkcję asystenta wiedzy. Jeśli jednak znajduje się on poza narzędziem do zarządzania projektami, Twój zespół będzie musiał przełączać się między kontekstami, aby zadać mu pytanie. Powoduje to tarcia i spowalnia pracę wszystkich.
Wyeliminuj konieczność przełączania się między kontekstami, korzystając ze AI, która jest już częścią Twojego cyklu pracy.
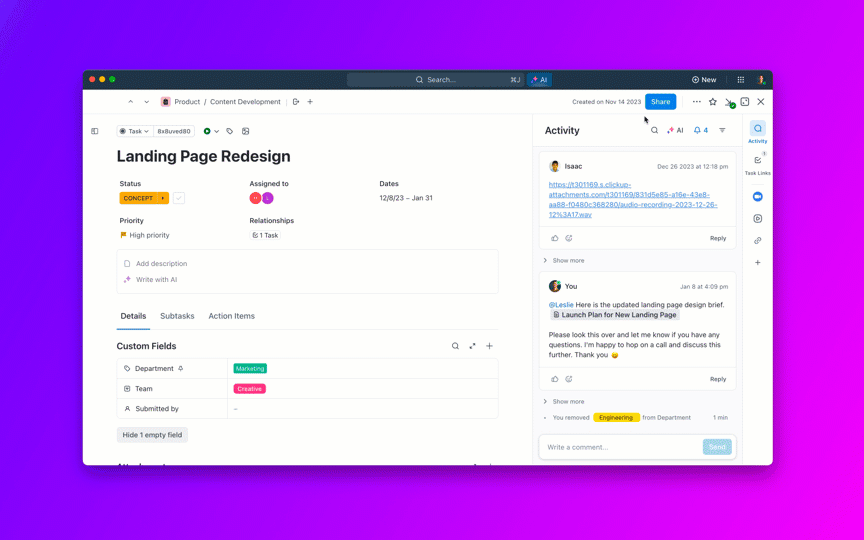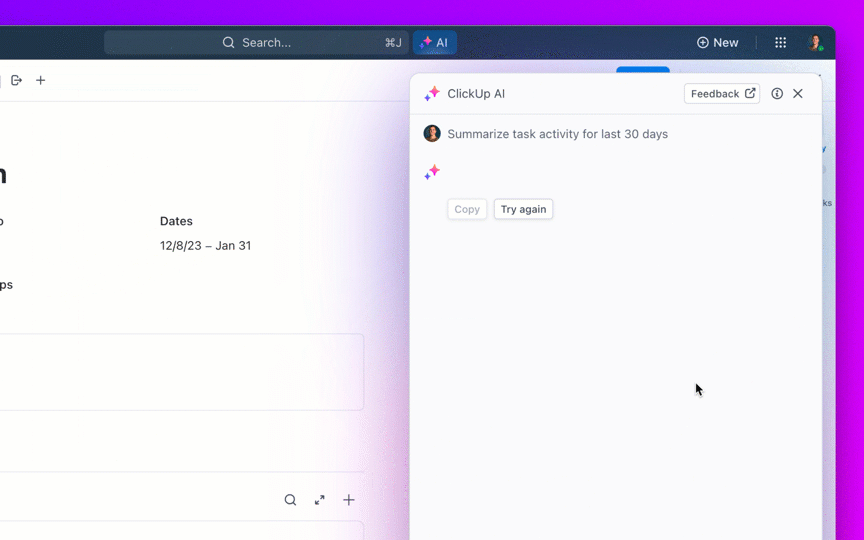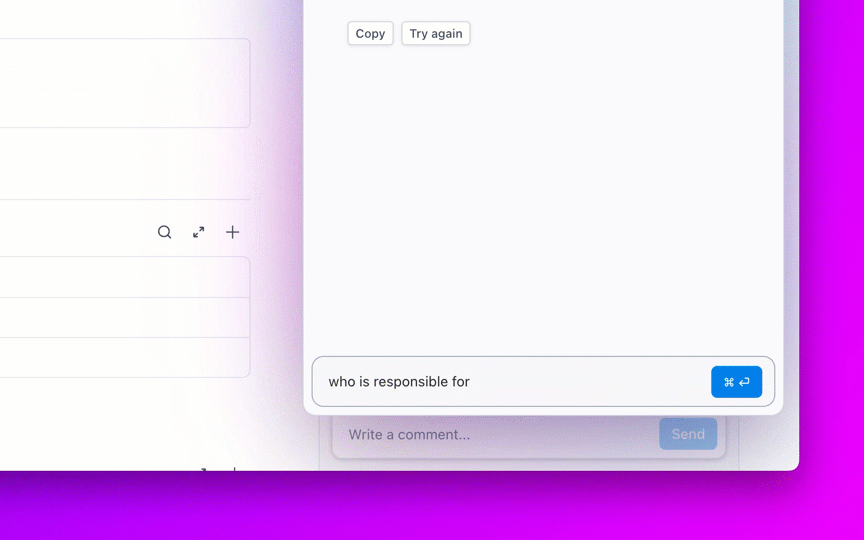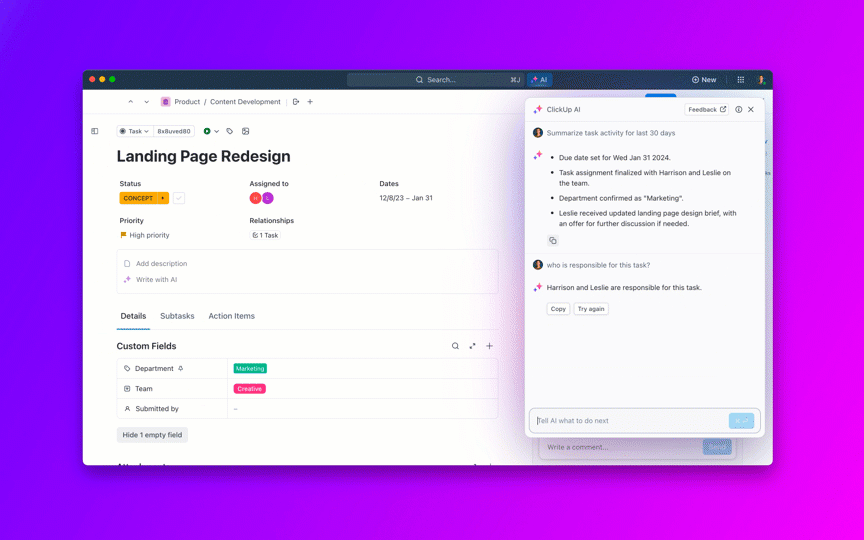
Zadawaj pytania dotyczące swoich projektów, zadań i dokumentów bez opuszczania ClickUp, korzystając z ClickUp Brain. Wystarczy wpisać @brain w dowolnym komentarzu do zadania lub czacie ClickUp, aby uzyskać natychmiastową, dostosowaną do kontekstu odpowiedź. To tak, jakbyś miał członka zespołu, który doskonale zna całą Twoją przestrzeń roboczą. 🤩
Dzięki temu chatbot przestaje być nowinką, a staje się podstawowym elementem zwiększającym wydajność Twojego zespołu.
Ograniczenia związane z wykorzystaniem LLaMA do tworzenia chatbotów
Tworzenie chatbota LLaMA może być inspirujące, ale Teams często są zaskakiwane ukrytymi złożonościami. „Free” model open source może okazać się droższy i trudniejszy w zarządzaniu niż oczekiwano, co prowadzi do słabego doświadczenia użytkownika i ciągłego, pochłaniającego zasoby cyklu konserwacji.
Przed podjęciem decyzji należy zapoznać się z limitami.
- Złożoność techniczna: Ustawienie i utrzymanie modelu LLaMA wymaga wiedzy na temat infrastruktury uczenia maszynowego.
- Wymagania sprzętowe: Uruchamianie większych, bardziej wydajnych modeli wymaga kosztownego sprzętu GPU, a koszty chmury mogą szybko wzrosnąć.
- Ograniczenia okna kontekstowego: Modele LLaMA mają limit pamięci ( 4K tokenów dla LLaMA 2 ). Obsługa długich dokumentów lub rozmów wymaga złożonych strategii dzielenia na fragmenty.
- Brak wbudowanych zabezpieczeń: użytkownik jest odpowiedzialny za wdrożenie własnych filtrów zawartości i środków bezpieczeństwa.
- Bieżąca konserwacja: W miarę pojawiania się nowych modeli konieczna będzie aktualizacja systemów, a dopracowane modele mogą wymagać ponownego szkolenia.
Modele hostowane samodzielnie mają zazwyczaj większe opóźnienia niż wysoce zoptymalizowane komercyjne interfejsy API. Są to obciążenia operacyjne, którymi zajmują się rozwiązania zarządzane.
📮ClickUp Insight: 88% respondentów naszej ankiety korzysta z AI do zadań osobistych, ale ponad 50% unika jej stosowania w pracy. Trzy główne przeszkody? Brak płynnej integracji, braki w wiedzy lub obawy dotyczące bezpieczeństwa.
A co, jeśli sztuczna inteligencja jest wbudowana w Twoje środowisko pracy i jest już bezpieczna? ClickUp Brain, wbudowany asystent AI ClickUp, sprawia, że staje się to rzeczywistością. Rozumie podpowiedzi w prostym języku, rozwiązując wszystkie trzy problemy związane z wdrożeniem sztucznej inteligencji, jednocześnie tworząc połączenie między czatem, zadaniami, dokumentami i wiedzą w całym obszarze roboczym. Znajdź odpowiedzi i spostrzeżenia za pomocą jednego kliknięcia!
Alternatywy dla LLaMA do tworzenia chatbotów
LLaMA to tylko jedna z wielu opcji wśród niezliczonych modeli AI, a wybór odpowiedniego rozwiązania może być przytłaczający.
Oto jak wygląda panorama dostępnych alternatyw.
Inne modele open source:
- Mistral: Znany z wysokiej wydajności nawet przy mniejszych rozmiarach modeli, co czyni go wydajnym.
- Falcon: Posiada bardzo liberalną licencję, która doskonale nadaje się do zastosowań komercyjnych.
- MPT: Zoptymalizowany do obsługi długich dokumentów i rozmów
Komercyjne interfejsy API:
- OpenAI (GPT-4, GPT-3. 5): Powszechnie uważane za najbardziej wydajne modele językowe, które są bardzo łatwe do zintegrowania.
- Anthropic (Claude): Znany z silnych funkcji bezpieczeństwa i bardzo dużych okien kontekstowych.
- Google (Gemini): Oferuje zaawansowane funkcje multimodalne, umożliwiające rozumienie tekstu, obrazów i dźwięku.
Możesz zbudować go samodzielnie, korzystając z modelu open source, zapłacić za komercyjne API lub skorzystać ze zintegrowanego obszaru roboczego AI, który oferuje wstępnie zintegrowane rozwiązanie z różnymi typami agentów AI.
📚 Przeczytaj również: Jak wykorzystać chatbota w swojej firmie
Twórz asystentów AI rozpoznających kontekst dzięki ClickUp
Tworzenie chatbota za pomocą LLaMA zapewnia niesamowitą kontrolę nad danymi, kosztami i dostosowaniem. Jednak kontrola ta wiąże się z odpowiedzialnością za infrastrukturę, konserwację i bezpieczeństwo — wszystko to, czym zajmują się zarządzane interfejsy API. Celem nie jest tylko stworzenie bota — chodzi o zwiększenie wydajności zespołu, a złożony projekt inżynieryjny może czasami odwracać uwagę od tego celu.
Właściwy wybór zależy od zasobów i priorytetów Twojego zespołu. Jeśli masz doświadczenie w zakresie uczenia maszynowego i surowe wymagania dotyczące prywatności, LLaMA jest fantastyczną opcją. Jeśli priorytetem jest dla Ciebie szybkość i prostota, lepszym rozwiązaniem może być zintegrowane narzędzie.
Dzięki ClickUp otrzymujesz zintegrowany obszar roboczy AI, w którym wszystkie zadania, dokumenty i rozmowy znajdują się w jednym miejscu, obsługiwane przez zintegrowaną sztuczną inteligencję. Ogranicza to rozproszenie kontekstu i pomaga zespołom pracować szybciej i skuteczniej, mając pod ręką odpowiednie informacje dzięki konfigurowalnym Super Agentom i kontekstowej sztucznej inteligencji.
Nie trać czasu na infrastrukturę i już dziś ciesz się zaletami asystenta AI rozpoznającego kontekst, bez konieczności tworzenia wszystkiego od podstaw. Zacznij korzystać z ClickUp za darmo.
Często zadawane pytania (FAQ)
Koszt zależy wyłącznie od metody wdrożenia, a prognoza projektu może pomóc w jego oszacowaniu. Jeśli korzystasz z własnego sprzętu, poniesiesz koszt początkowy związany z zakupem procesora graficznego, ale nie będziesz ponosić bieżących opłat za każde zapytanie. Dostawcy usług w chmurze pobierają opłatę godzinową w oparciu o procesor graficzny i rozmiar modelu.
Tak, licencje na LLaMA 2 i LLaMA 3 pozwalają na użycie komercyjne. Musisz jednak zgodzić się na Warunki korzystania Meta i podać wymagane informacje o autorstwie w swoim produkcie.
LLaMA 3 to nowszy i bardziej wydajny model, oferujący lepsze umiejętności rozumowania i większe okno kontekstowe (8K tokenów w porównaniu z 4K w przypadku LLaMA 2). Oznacza to, że może obsługiwać dłuższe rozmowy i dokumenty, ale wymaga również większych zasobów obliczeniowych do działania.
Chociaż Python jest najpopularniejszym językiem programowania w dziedzinie uczenia maszynowego ze względu na bogate biblioteki, nie jest on bezwzględnie wymagany. Niektóre platformy zaczynają oferować rozwiązania bezkodowe lub niskokodowe, które umożliwiają wdrożenie chatbota LLaMA z interfejsem graficznym. /