
Projekty szkoleniowe AI rzadko kończą się niepowodzeniem na poziomie modelu. Problemy pojawiają się, gdy eksperymenty, dokumentacja i aktualizacje dla interesariuszy są rozproszone między zbyt wieloma narzędziami.
Ten przewodnik przeprowadzi Cię przez proces szkolenia modeli za pomocą Databricks DBRX — LLM, który jest nawet dwukrotnie bardziej wydajny obliczeniowo niż inne wiodące modele — przy jednoczesnym utrzymaniu porządku w pracy w ClickUp.
Od ustawień i dostosowywania po dokumentację i aktualizacje między zespołami — zobaczysz, jak pojedynczy, zintegrowany obszar roboczy pomaga wyeliminować rozproszenie kontekstu i pozwala zespołowi skupić się na tworzeniu, a nie wyszukiwaniu. 🛠
Czym jest DBRX?
DBRX to potężny, otwartoźródłowy model języka (LLM) zaprojektowany specjalnie do szkolenia i wnioskowania modeli AI w przedsiębiorstwach. Ponieważ jest to oprogramowanie open source na licencji Databricks Open Model License, Twój zespół ma pełny dostęp do wag i architektury modelu, co pozwala na sprawdzanie, modyfikowanie i wdrażanie go na własnych warunkach.
Dostępne są dwie wersje: DBRX Base do głębokiego wstępnego szkolenia oraz DBRX Instruct do zadań wymagających wykonywania gotowych instrukcji.
Architektura DBRX i projekt mieszanki ekspertów
DBRX rozwiązuje zadania przy użyciu architektury Mixture-of-Experts (MoE). W przeciwieństwie do tradycyjnych dużych modeli językowych, które wykorzystują wszystkie swoje miliardy parametrów do każdego obliczenia, DBRX aktywuje tylko ułamek swoich całkowitych parametrów (najbardziej odpowiednich ekspertów) dla danego zadania.
Pomyśl o tym jak o zespole wyspecjalizowanych ekspertów; zamiast angażować wszystkich w rozwiązywanie każdego problemu, system inteligentnie kieruje każde zadanie do najbardziej wykwalifikowanych osób o odpowiednich parametrach.
Nie tylko skraca to czas reakcji, ale także zapewnia najwyższą wydajność i wyniki, jednocześnie znacznie obniżając koszty obliczeniowe.
Oto krótki przegląd jego kluczowych specyfikacji:
- Łączna liczba parametrów: 132 mld we wszystkich ekspertach
- Aktywne parametry: 36B na przejście do przodu
- Liczba ekspertów: łącznie 16 (MoE Top-4 routing), z czego 4 aktywni dla dowolnego tokenu
- Okno kontekstowe: 32 tys. tokenów
Specyfikacje danych szkoleniowych i tokenów DBRX
Wydajność modelu LLM zależy od jakości danych, na których został wyszkolony. DBRX został wstępnie wyszkolony na ogromnym zbiorze danych zawierającym 12 bilionów tokenów, starannie wyselekcjonowanym przez zespół Databricks przy użyciu zaawansowanych narzędzi do przetwarzania danych. Właśnie dlatego osiągnął tak dobre wyniki w branżowych testach porównawczych.
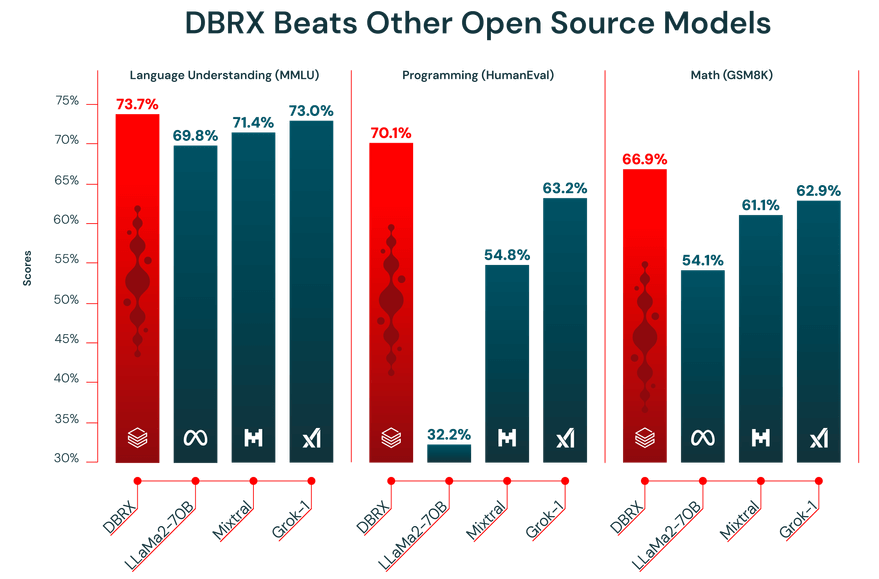
Dodatkowo DBRX oferuje okno kontekstowe o pojemności 32 000 tokenów. Jest to ilość tekstu, którą model może uwzględnić jednocześnie. Duże okno kontekstowe jest niezwykle pomocne w przypadku złożonych zadań, takich jak podsumowywanie długich raportów, przeglądanie obszernych dokumentów prawnych lub tworzenie zaawansowanych systemów generowania wspomaganego wyszukiwaniem (RAG), ponieważ pozwala modelowi zachować kontekst bez skracania lub pomijania informacji.
🎥 Obejrzyj to wideo, aby zobaczyć, jak usprawniona koordynacja projektów może zmienić cykl pracy przy szkoleniu AI i wyeliminować utrudnienia związane z przełączaniem się między niepołączonymi narzędziami. 👇🏽
Jak uzyskać dostęp do DBRX i skonfigurować go
DBRX oferuje dwie podstawowe ścieżki dostępu, z których obie zapewniają pełny dostęp do wag modelu na korzystnych warunkach komercyjnych. Możesz korzystać z Hugging Face, aby uzyskać maksymalną elastyczność, lub uzyskać do niego bezpośredni dostęp poprzez Databricks, aby uzyskać bardziej zintegrowane doświadczenie.
Uzyskaj dostęp do DBRX poprzez Hugging Face.
Dla zespołów, które cenią sobie elastyczność i są już zaznajomione z ekosystemem Hugging Face, dostęp do DBRX poprzez hub jest idealnym rozwiązaniem. Pozwala to na integrację modelu z istniejącymi cyklami pracy opartymi na transformatorach.
Oto jak zacząć:
- Utwórz lub zaloguj się na swoje konto Hugging Face.
- Przejdź do karty modelu DBRX w hubie i zaakceptuj warunki licencji.
- Zainstaluj bibliotekę transformatorów wraz z niezbędnymi zależnościami, takimi jak accelerate.
- Użyj klasy AutoModelForCausalLM w skrypcie Python, aby załadować model DBRX.
- Skonfiguruj potok wnioskowania, pamiętając, że DBRX wymaga znacznej ilości pamięci GPU (VRAM) do skutecznego działania.
📖 Więcej informacji: Jak skonfigurować temperaturę LLM
Uzyskaj dostęp do DBRX poprzez Databricks.
Jeśli Twój zespół już korzysta z Databricks do inżynierii danych lub uczenia maszynowego, najłatwiejszym sposobem jest dostęp do DBRX za pośrednictwem tej platformy. Eliminuje to problemy związane z ustawieniami i zapewnia wszystkie narzędzia potrzebne do MLOps dokładnie tam, gdzie już pracujesz.
Aby rozpocząć, wykonaj następujące kroki w obszarze roboczym Databricks:
- Przejdź do sekcji Model Garden lub Mosaic AI.
- Wybierz DBRX Base lub DBRX Instruct, w zależności od swoich potrzeb.
- Skonfiguruj punkt końcowy obsługi dla dostępu do API lub skonfiguruj środowisko notebooka do interaktywnego użytkowania.
- Rozpocznij testowanie wnioskowania za pomocą próbkowych podpowiedzi, aby upewnić się, że wszystko działa poprawnie, zanim zwiększysz skalę szkolenia lub wdrożenia modelu AI.
Takie podejście zapewnia płynny dostęp do narzędzi takich jak MLflow do śledzenia eksperymentów i Unity Catalog do zarządzania modelami.
📮 ClickUp Insight: Przeciętny profesjonalista spędza ponad 30 minut dziennie na wyszukiwaniu informacji związanych z pracą — to ponad 120 godzin rocznie straconych na przeszukiwanie wiadomości e-mail, wątków na Slacku i rozproszonych plików.
Inteligentny asystent AI wbudowany w Twój obszar roboczy może to zmienić. Poznaj ClickUp Brain.
Zapewnia natychmiastowe wgląd i odpowiedzi, wyświetlając odpowiednie dokumenty, rozmowy i szczegóły zadań w ciągu kilku sekund — dzięki czemu możesz przestać szukać i zacząć pracować.
Jak dostosować DBRX i trenować niestandardowe modele AI
Gotowy model, bez względu na to, jak potężny, nigdy nie zrozumie unikalnych niuansów Twojej działalności. Ponieważ DBRX jest oprogramowaniem typu open source, możesz go dostosować, aby stworzyć niestandardowy model, który będzie mówił językiem Twojej firmy lub wykonywał określone zadania, które chcesz mu powierzyć.
Oto trzy popularne sposoby, dzięki którym możesz to zrobić:
1. Dostosuj DBRX za pomocą zestawów danych Hugging Face
Dla zespołów, które dopiero zaczynają lub pracują nad typowymi zadaniami, publiczne zbiory danych z Hugging Face Hub są doskonałym źródłem informacji. Są one wstępnie sformatowane i łatwe do załadowania, co oznacza, że nie musisz spędzać godzin na przygotowywaniu danych.
Proces jest dość prosty:
- Znajdź w hubie zbiór danych pasujący do Twojego zadania (np. wykonywanie instrukcji, streszczanie).
- Załaduj go, korzystając z biblioteki zestawów danych.
- Upewnij się, że dane są formatowane w pary instrukcja-odpowiedź.
- Skonfiguruj skrypt szkoleniowy za pomocą hiperparametrów, takich jak tempo uczenia się i rozmiar partii.
- Uruchom zadanie szkoleniowe, pamiętając o okresowym zapisywaniu punktów kontrolnych.
- Oceń dopracowany model na oddzielnym zestawie walidacyjnym, aby zmierzyć poprawę.
2. Dostosuj DBRX za pomocą lokalnych zestawów danych
Najlepsze wyniki zazwyczaj osiąga się poprzez dostosowanie modelu do własnych danych. Pozwala to nauczyć model specyficznej terminologii, stylu i wiedzy branżowej Twojej firmy. Należy jednak pamiętać, że jest to opłacalne tylko wtedy, gdy dane są czyste, dobrze przygotowane i mają wystarczającą objętość.
Wykonaj następujące kroki, aby przygotować dane wewnętrzne:
- Gromadzenie danych: Zbierz wysokiej jakości przykłady z wewnętrznych stron wiki, dokumentów i baz danych.
- Konwersja formatu: uporządkuj swoje dane w spójnym formacie instrukcja-odpowiedź, często jako linie JSON.
- Filtrowanie jakości: Usuń wszystkie przykłady niskiej jakości, duplikaty lub nieistotne przykłady.
- Podział walidacyjny: Odłóż niewielką część danych (zazwyczaj 10–15%) w celu oceny wydajności modelu.
- Kontrola prywatności: Usuń lub zamaskuj wszelkie dane osobowe (PII) lub dane wrażliwe.
3. Dostosuj DBRX za pomocą StreamingDataset
Jeśli Twój zbiór danych okaże się zbyt duży, aby zmieścić się w pamięci komputera, nie martw się — możesz skorzystać z biblioteki Streaming Dataset firmy Databricks. Pozwala ona na strumieniowe przesyłanie danych bezpośrednio z pamięci w chmurze podczas szkolenia modelu, zamiast ładowania ich wszystkich jednocześnie do pamięci.
Oto jak to zrobić:
- Przygotowanie danych: Oczyść i uporządkuj dane szkoleniowe, a następnie zapisz je w formacie umożliwiającym strumieniowe przesyłanie, takim jak JSONL lub CSV, w pamięci masowej w chmurze.
- Konwersja formatu strumieniowego: przekonwertuj zbiór danych na format przyjazny dla strumieniowania, taki jak Mosaic Data Shard (MDS), aby można go było efektywnie odczytywać podczas szkolenia.
- Ustawienia modułu ładującego szkolenia: Skonfiguruj moduł ładujący szkolenia tak, aby wskazywał zdalny zestaw danych i zdefiniuj lokalną pamięć podręczną do tymczasowego przechowywania danych.
- Inicjalizacja modelu: Rozpocznij proces dostrajania DBRX, korzystając z frameworka szkoleniowego z wsparciem StreamingDataset, takiego jak LLM Foundry.
- Szkolenie oparte na strumieniowaniu: Uruchom zadanie szkoleniowe podczas strumieniowego przesyłania danych w partiach podczas szkolenia, zamiast ładować je w całości do pamięci.
- Kontrolowanie i odzyskiwanie: płynne wznawianie szkolenia w przypadku przerwania działania, bez powielania lub pomijania danych.
- Ocena i wdrożenie: Zweryfikuj wydajność dopracowanego modelu i wdroż go, korzystając z preferowanych ustawień serwowania lub wnioskowania.
💡Wskazówka dla profesjonalistów: zamiast tworzyć plan szkolenia DBRX od podstaw, zacznij od szablonu planu projektów AI i uczenia maszynowego ClickUp i dostosuj go do potrzeb swojego zespołu. Zapewnia on przejrzystą strukturę planowania zestawów danych, faz szkolenia, oceny i wdrażania, dzięki czemu możesz skupić się na organizacji pracy, a nie na tworzeniu struktury cyklu pracy.
Przykłady zastosowań DBRX do szkolenia modeli AI
Posiadanie potężnego modelu to jedno, ale zupełnie inną sprawą jest dokładna wiedza o tym, gdzie najlepiej się sprawdza.
Kiedy nie masz jasnego obrazu mocnych stron modelu, łatwo jest poświęcić czas i zasoby na próby dostosowania go do sytuacji, w której po prostu nie pasuje. Prowadzi to do słabych wyników i frustracji.
Unikalna architektura i dane szkoleniowe DBRX sprawiają, że wyjątkowo dobrze nadaje się on do kilku kluczowych zastosowań w Enterprise. Znajomość tych mocnych stron pomoże Ci dostosować model do celów biznesowych i zmaksymalizować zwrot z inwestycji.
Generowanie tekstu i tworzenie zawartości
DBRX Instruct jest precyzyjnie dostosowany do wykonywania instrukcji i generowania wysokiej jakości tekstu. Dzięki temu jest to potężne narzędzie do automatyzacji szerokiego zakresu zadań związanych z zawartością. Jego duże okno kontekstowe stanowi znaczną zaletę, umożliwiając obsługę długich dokumentów bez utraty wątku.
Możesz go używać do:
- Dokumentacja techniczna: Generuj i udoskonalaj instrukcje obsługi produktów, odniesienia do API i przewodniki dla użytkowników.
- Zawartość marketingowa: szkice wpisów na blogu, biuletyny e-mailowe i aktualizacje w mediach społecznościowych.
- Generowanie raportów: Podsumowuj złożone wyniki analizy danych i twórz zwięzłe streszczenia wykonawcze.
- Tłumaczenie i lokalizacja: Dostosuj istniejącą zawartość do nowych rynków i odbiorców.
Generowanie kodu i zadania związane z debugowaniem
Znaczna część danych szkoleniowych DBRX zawierała kod, dzięki czemu jest to wydajne wsparcie LLM dla programistów. Może pomóc w przyspieszeniu cykli rozwoju poprzez automatyzację powtarzalnych zadań związanych z kodowaniem i pomoc w rozwiązywaniu złożonych problemów.
Oto kilka sposobów, w jakie Twój zespół inżynierów może to wykorzystać:
- Autouzupełnianie kodu: automatyczne generowanie treści funkcji na podstawie komentarzy lub ciągów dokumentacyjnych.
- Wykrywanie błędów: analizuj fragmenty kodu, aby zidentyfikować potencjalne błędy lub nieścisłości logiczne.
- Wyjaśnienie kodu: Przetłumacz złożone algorytmy lub starszą wersję kodu na prosty język angielski.
- Generowanie testów: Twórz testy jednostkowe na podstawie sygnatury funkcji i oczekiwanego zachowania.
RAG i aplikacje o długim kontekście
Generowanie wspomagane wyszukiwaniem (RAG) to potężna technika, która opiera odpowiedzi modelu na prywatnych danych Twojej firmy. Jednak systemy RAG często borykają się z modelami, które mają małe okna kontekstowe, co wymusza agresywne dzielenie danych na fragmenty, co może spowodować utratę ważnego kontekstu. Okno kontekstowe 32K DBRX stanowi doskonałą podstawę dla solidnych aplikacji RAG.
Dzięki temu możesz tworzyć potężne narzędzia wewnętrzne, takie jak:
- Wyszukiwanie w Enterprise: Stwórz chatbota, który odpowiada na pytania pracowników, korzystając z wewnętrznej bazy wiedzy.
- Obsługa klienta: Stwórz agenta, który generuje odpowiedzi wsparcia technicznego oparte na dokumentacji produktu.
- Pomoc badawcza: Opracuj narzędzie, które może syntetyzować informacje z setek stron artykułów naukowych.
- Sprawdzanie zgodności: automatyczna weryfikacja treści marketingowych pod kątem wewnętrznych wytycznych dotyczących marki lub dokumentów regulacyjnych.
Jak zintegrować szkolenie DBRX z cyklem pracy Twojego zespołu
Udany projekt szkolenia modeli AI to coś więcej niż tylko kod i obliczenia. To wspólny wysiłek inżynierów ML, analityków danych, menedżerów produktu i interesariuszy.
Gdy współpraca ta jest rozproszona między notebookami Jupyter, kanałami Slack i oddzielnymi narzędziami do zarządzania projektami, powstaje rozproszenie kontekstu, czyli sytuacja, w której kluczowe informacje o projekcie są rozproszone między zbyt wieloma narzędziami.
ClickUp rozwiązuje ten problem. Zamiast korzystać z wielu narzędzi, otrzymujesz jedną zintegrowaną przestrzeń roboczą AI, w której zarządzanie projektami, dokumentacja i komunikacja współistnieją, dzięki czemu Twoje eksperymenty pozostają połączone od planowania, przez realizację, aż po ocenę.
Nigdy nie tracisz z oczu eksperymentów i postępów.
Podczas przeprowadzania wielu eksperymentów najtrudniejszą częścią nie jest szkolenie modelu, ale śledzenie zmian, które zaszły w trakcie procesu. Która wersja zestawu danych została użyta, która szybkość uczenia się była najlepsza lub które uruchomienie zostało wysłane?
ClickUp sprawia, że proces ten jest niezwykle łatwy. W zadaniach ClickUp możesz śledzić każdy przebieg szkolenia osobno, a w ramach zadań możesz używać pól niestandardowych do rejestrowania:
- Wersja zestawu danych
- Hiperparametry
- Wariant modelu (DBRX Base vs DBRX Instruct)
- Status szkolenia (w kolejce, w trakcie, ocena, wdrożone)
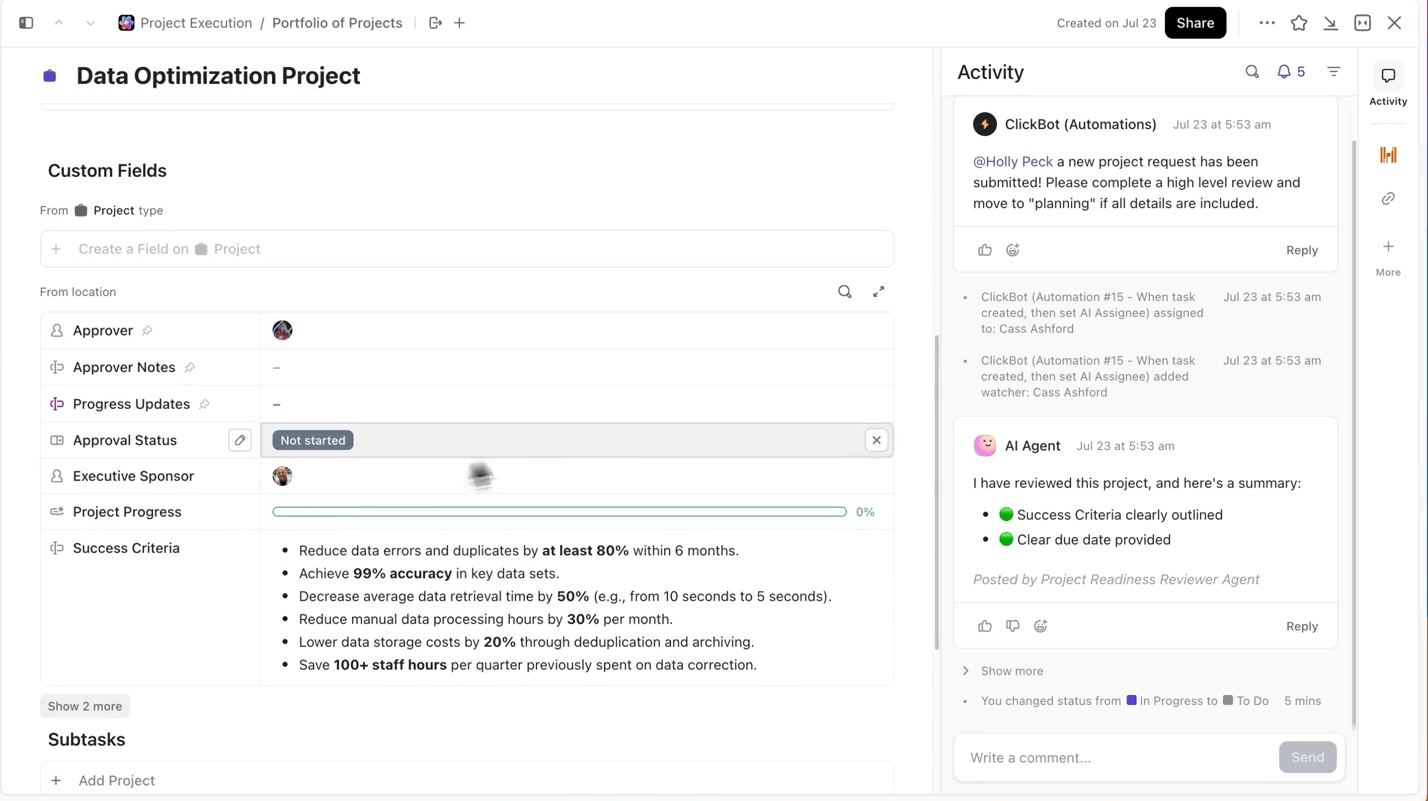
W ten sposób każdy udokumentowany eksperyment można wyszukać, łatwo porównać z innymi i powtórzyć.
Przechowuj dokumentację modelu powiązaną z pracą
Nie musisz przeskakiwać między notatnikami Jupyter, plikami README lub wątkami Slack, aby zrozumieć kontekst zadania eksperymentu.
Dzięki ClickUp Docs możesz uporządkować architekturę modelu, skrypty przygotowujące dane lub wskaźniki oceny i zapewnić do nich dostęp , dokumentując je w przeszukiwalnym dokumencie , który zawiera bezpośrednie połączone linki do zadań eksperymentalnych, z których pochodzą.

💡Wskazówka dla profesjonalistów: Prowadź aktualny opis projektu w ClickUp Docs, zawierający szczegółowe informacje na temat każdej decyzji, od architektury po wdrożenie, aby nowi członkowie zespołu mogli zawsze szybko zapoznać się ze szczegółami projektu bez konieczności przeglądania starych wątków.
Zapewnij interesariuszom widoczność w czasie rzeczywistym
Pulpity ClickUp pokazują postępy eksperymentów i obciążenie pracą zespołu w czasie rzeczywistym. I
Zamiast ręcznie kompilować aktualizacje lub wysyłać e-maile, pulpity nawigacyjne aktualizują się automatycznie na podstawie danych zawartych w zadaniach. Dzięki temu interesariusze mogą w dowolnym momencie sprawdzić, na jakim etapie są prace, i nie muszą przerywać Ci pytaniami typu „jak wygląda status?”.
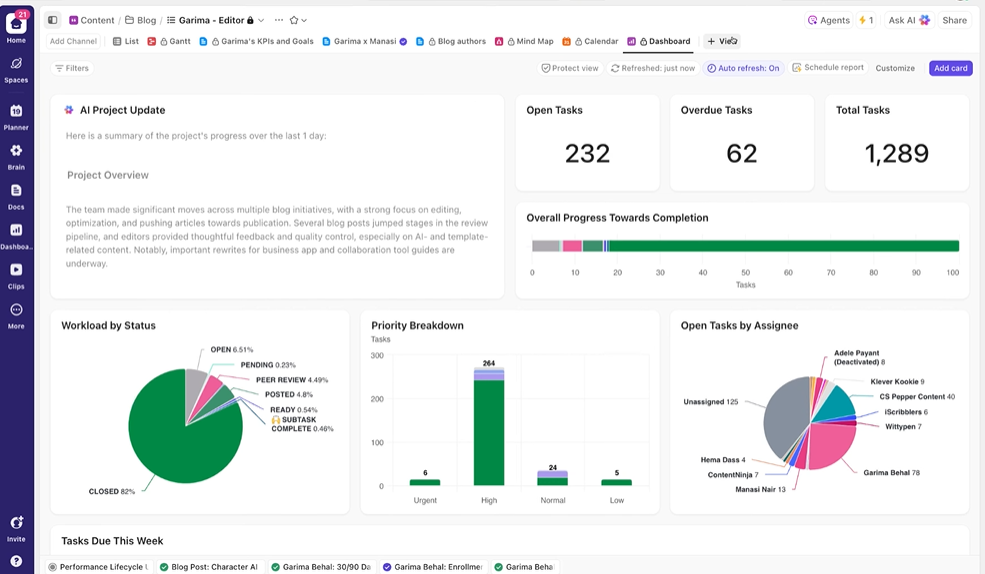
W ten sposób możesz skupić się na przeprowadzaniu eksperymentów, zamiast ciągle ręcznie prowadzić raportowanie na ich temat.
Zmień AI w swojego inteligentnego pomocnika w projektach.
Nie musisz ręcznie przeglądać tygodni danych szkoleniowych, aby uzyskać podsumowanie dotychczasowych eksperymentów. Wystarczy zrobić wzmiankę o @Brain w dowolnym komentarzu do zadania, a ClickUp Brain zapewni Ci potrzebną pomoc wraz z pełnym kontekstem dotyczącym przeszłych i bieżących projektów.
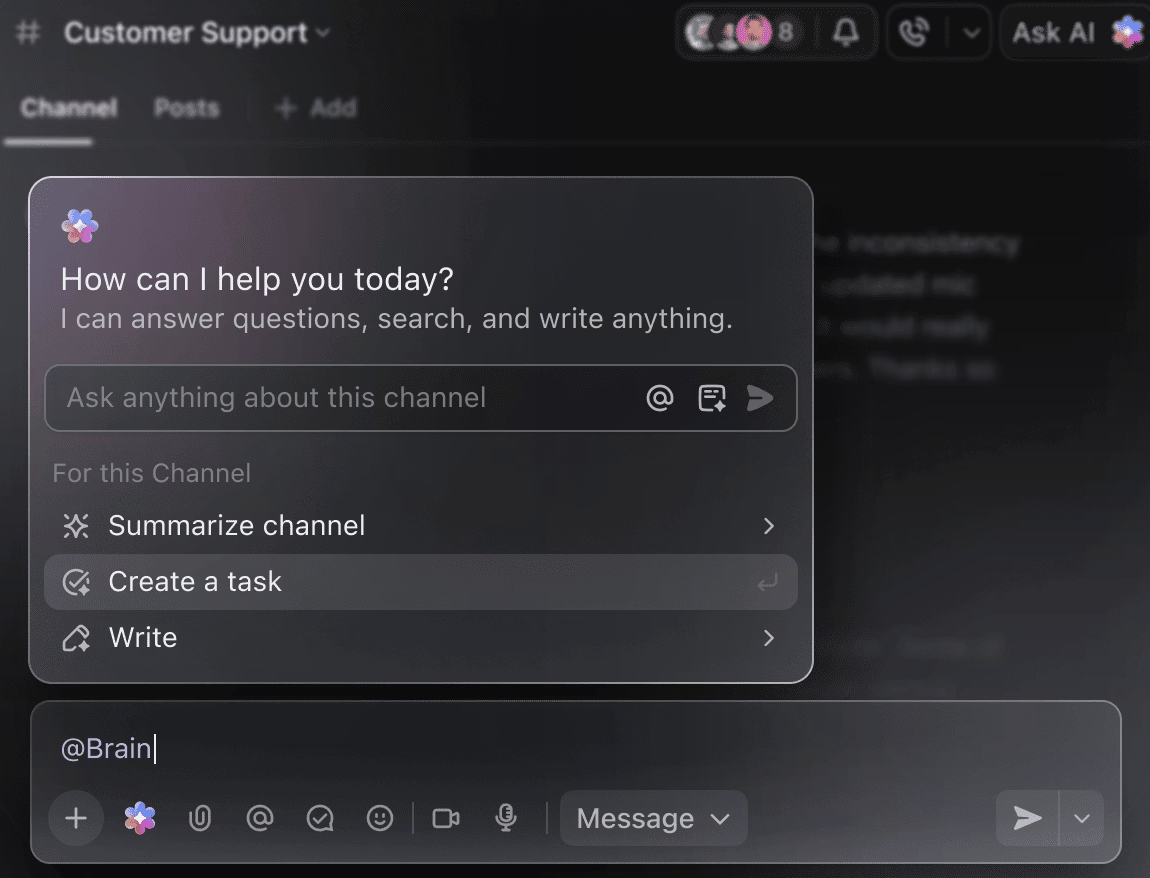
Możesz poprosić Brain o „Podsumowanie eksperymentów z ostatniego tygodnia w 5 punktach” lub „Sporządzenie dokumentu z najnowszymi wynikami hiperparametrów” i natychmiast uzyskać dopracowany wynik.
🧠 Zalety ClickUp: Super agenci ClickUp idą o krok dalej — mogą zautomatyzować całe cykle pracy w oparciu o zdefiniowane przez Ciebie wyzwalacze, a nie tylko odpowiadać na pytania. Dzięki superagentom możesz automatycznie tworzyć nowe zadania szkoleniowe DBRX po każdym przesłaniu zestawu danych, powiadamiać swój zespół i połączone dokumenty po zakończeniu szkolenia lub osiągnięciu punktu kontrolnego, a także generować cotygodniowe podsumowanie postępów i przesyłać je do interesariuszy bez konieczności wykonywania jakichkolwiek czynności.
Typowe błędy, których należy unikać
Rozpoczęcie projektu szkoleniowego DBRX jest ekscytujące, ale kilka typowych pułapek może zniweczyć Twoje postępy. Unikanie tych błędów pozwoli Ci zaoszczędzić czas, pieniądze i wiele frustracji.
- Niedocenianie wymagań sprzętowych: DBRX jest potężnym narzędziem, ale również zajmuje dużo miejsca. Próba uruchomienia go na nieodpowiednim sprzęcie spowoduje błędy braku pamięci i niepowodzenie zadań szkoleniowych. Należy pamiętać, że DBRX (132B) wymaga co najmniej 264 GB pamięci VRAM dla 16-bitowej inferencji lub około 70–80 GB w przypadku kwantyzacji 4-bitowej.
- Pomijanie kontroli jakości danych: złe dane wejściowe, złe wyniki. Dostosowywanie nieuporządkowanego zestawu danych niskiej jakości spowoduje jedynie, że model będzie generował nieuporządkowane wyniki niskiej jakości.
- Ignorowanie ograniczeń długości kontekstu: Chociaż okno kontekstowe DBRX o długości 32 KB jest dość obszerne, nie jest ono nieskończone. Podanie modelu danych wejściowych przekraczających ten limit spowoduje ciche skrócenie i słabą wydajność jako wynik.
- Korzystanie z Base, gdy Instruct jest odpowiedni: DBRX Base to surowy, wstępnie wytrenowany model przeznaczony do dalszego szkolenia na dużą skalę. W przypadku większości zadań polegających na wykonywaniu instrukcji należy zacząć od DBRX Instruct, który został już dostosowany do tego celu.
- Oddzielenie pracy szkoleniowej od koordynacji projektu: Gdy śledzenie eksperymentów odbywa się w jednym narzędziu, a plan projektu w innym, powstają silosy informacyjne. Użyj zintegrowanej platformy, takiej jak ClickUp, aby zsynchronizować pracę techniczną i koordynację projektu.
- Zaniedbanie oceny przed wdrożeniem: model, który dobrze działa na danych szkoleniowych, może spektakularnie zawieść w rzeczywistym świecie. Zawsze sprawdzaj dopracowany model na oddzielnym zestawie testowym przed wdrożeniem go do produkcji.
- Pomijanie złożoności dostrajania: Ponieważ DBRX jest modelem typu „mixture-of-experts”, standardowe skrypty dostrajania mogą wymagać specjalistycznych bibliotek, takich jak Megatron-LM lub PyTorch FSDP, aby obsłużyć fragmentację parametrów na wielu procesorach graficznych.
DBRX a inne platformy szkoleniowe AI
Wybór platformy do szkolenia AI wiąże się z fundamentalnym kompromisem: kontrola kontra wygoda. Zastrzeżone modele oparte wyłącznie na API są łatwe w użyciu, ale ograniczają użytkownika do ekosystemu dostawcy.
Otwarte modele wagowe, takie jak DBRX, oferują pełną kontrolę, ale wymagają większej wiedzy technicznej i infrastruktury. Ten wybór może sprawić, że poczujesz się zagubiony, niepewny, która ścieżka faktycznie oferuje wsparcie dla Twoich długoterminowych celów — jest to wyzwanie, przed którym staje wiele zespołów podczas wdrażania AI.
W poniższej tabeli przedstawiono kluczowe różnice, które pomogą Ci podjąć świadomą decyzję.
| Wagi | Otwórz (niestandardowy) | Zastrzeżone | Otwórz (niestandardowy) | Zastrzeżone |
| Dostrajanie | Pełna kontrola | Oparte na API | Pełna kontrola | Oparte na API |
| Samodzielne hostowanie | Tak | Nie | Tak | Nie |
| Licencja | DB Open Model | Warunki OpenAI | Społeczność Llama | Terminy antropiczne |
| Kontekst | 32 tys. | 128 tys. – 1 mln | 128K | 200 tys. – 1 mln |
DBRX to właściwy wybór, gdy potrzebujesz pełnej kontroli nad modelem, musisz samodzielnie hostować ze względu na bezpieczeństwo lub zgodność z przepisami lub chcesz mieć elastyczność, jaką daje liberalna licencja komercyjna. Jeśli nie masz dedykowanej infrastruktury GPU lub wartość szybkości wprowadzenia produktu na rynek jest większa niż wartość głębokiej niestandardowej personalizacji, lepszym rozwiązaniem mogą być alternatywy oparte na API.
Rozpocznij inteligentniejsze szkolenia dzięki ClickUp
DBRX zapewnia gotową do użycia w przedsiębiorstwie podstawę do tworzenia niestandardowych aplikacji AI, oferując przejrzystość i kontrolę, których nie zapewniają modele zastrzeżone. Jego wydajna architektura MoE pozwala obniżyć koszty wnioskowania, a otwarta konstrukcja ułatwia precyzyjne dostrajanie. Jednak zaawansowana technologia to tylko połowa sukcesu.
Prawdziwe powodzenie wynika z dostosowania pracy technicznej do wspólnego cyklu pracy zespołu. Trening modeli AI to sport zespołowy, a synchronizacja eksperymentów, dokumentacji i komunikacji między interesariuszami ma kluczowe znaczenie. Gdy zgromadzisz wszystko w jednym, zintegrowanym obszarze roboczym i ograniczysz rozproszenie kontekstu, będziesz mógł szybciej dostarczać lepsze modele.
Rozpocznij bezpłatnie korzystanie z ClickUp, aby koordynować swoje projekty szkoleniowe w zakresie AI w jednym obszarze roboczym. ✨
Często zadawane pytania
Możesz monitorować szkolenie za pomocą standardowych narzędzi ML, takich jak TensorBoard, Weights & Biases lub MLflow. Jeśli szkolisz się w ekosystemie Databricks, MLflow jest natywnie zintegrowane, co zapewnia płynne śledzenie eksperymentów.
Tak, DBRX można zintegrować ze standardowymi potokami MLOps. Dzięki konteneryzacji modelu można go wdrożyć za pomocą platform orkiestracji, takich jak Kubeflow, lub niestandardowych cykli pracy CI/CD.
DBRX Base to podstawowy, wstępnie wyszkolony model przeznaczony dla zespołów, które chcą przeprowadzać ciągłe wstępne szkolenia w określonych dziedzinach lub głębokie dostrajanie architektury. DBRX Instruct to dostrojona wersja zoptymalizowana pod kątem wykonywania instrukcji, co czyni ją lepszym punktem wyjścia dla większości projektów związanych z tworzeniem aplikacji.
Główną różnicą jest kontrola. DBRX zapewnia pełny dostęp do wag modelu w celu niestandardowej personalizacji i samodzielnego hostingu, podczas gdy GPT-4 jest usługą dostępną wyłącznie poprzez API.
Wagi modelu DBRX są dostępne bezpłatnie na podstawie licencji Databricks Open Model License. Jednak użytkownik ponosi koszty infrastruktury obliczeniowej wymaganej do uruchomienia lub dostrojenia modelu.