
Cyberincidenten ontwikkelen zich razendsnel. Ransomware verspreidt zich binnen enkele minuten, door AI gegenereerde phishing-berichten glippen langs filters en één enkele misstap kan escaleren tot een grootschalige inbreuk nog voordat teams zich kunnen afstemmen over wat er aan de hand is. De druk is reëel, en dat geldt ook voor de kosten.
Volgens IBM's Cost of a Data Breach Report bedraagt het wereldwijde gemiddelde 4,44 miljoen dollar, waarbij vertragingen bij de respons en slechte coördinatie dat nummer nog verder opdrijven.
Te midden van de chaos hebben teams behoefte aan duidelijkheid. Een incidentresponshandboek biedt uw team een gezamenlijk draaiboek voor als het misgaat. Het beschrijft wie als eerste actie onderneemt, welke stappen moeten worden gevolgd en hoe de communicatie strak kan worden gehouden terwijl de situatie zich ontwikkelt.
In deze blogpost leer je hoe je een incidentresponshandboek opstelt dat is afgestemd op de bedreigingen van vandaag. We bekijken praktijkscenario's, duidelijke responsmaatregelen en ClickUp, 's werelds eerste Converged AI-werkruimte, als een systeem dat je team onder druk kan gebruiken.
Wat is een incidentresponshandboek?
Een incidentresponshandboek is een gestructureerde, stapsgewijze gids die beveiligingsteams helpt om specifieke soorten cyberincidenten op een consistente en efficiënte manier aan te pakken. Het beschrijft precies wat er moet gebeuren wanneer zich een incident voordoet, wie verantwoordelijk is voor elke actie en hoe de overgang van detectie naar beheersing en herstel kan plaatsvinden zonder verwarring of vertragingen.
Zie het als een kant-en-klaar actieplan voor praktijksituaties zoals phishingaanvallen, ransomware-infecties of datalekken.
🧠 Leuk weetje: Het eerste computervirus was niet kwaadaardig. In 1971 verspreidde een programma met de naam Creeper zich tussen computers om alleen maar het bericht “I’m the creeper, catch me if you can” weer te geven. Dit leidde tot het aanmaken van het eerste antivirusprogramma, genaamd Reaper.
Handleiding voor incidentrespons versus plan versus runbook
Mensen halen de terminologie voor documentatie over veiligheid voortdurend door elkaar. Deze verwarring leidt tot echte problemen wanneer teams hun standaardprocedures opstellen. Het resultaat is ofwel algemene plannen zonder concrete stappen, ofwel te technische handleidingen die het management in verwarring brengen.
Dit zijn de verschillen tussen deze drie documenten.
| Document | Reikwijdte | Detailniveau | Wanneer wordt het gebruikt? | Voor wie is dit bedoeld? | Format |
| Abonnement | Organisatiebrede strategie | Beleid op hoog niveau | Vóór incidenten | Leiderschap en juridische zaken | Beleidsdocument |
| Handleiding | Scenario-specifieke respons | Tactische stapsgewijze acties | Tijdens een specifiek type incident | Incidentresponsteam | Werkstroom met beslissingsboom |
| Runbook | Enkele technische procedure | Gedetailleerde geautomatiseerde stappen | Tijdens een specifieke taak | Technische hulpverleners | Checklist of script |
Deze drie moeten samenwerken. Een plan zonder draaiboeken is te vaag om naar te handelen. Een draaiboek zonder runbooks laat de technische uitvoering over aan improvisatie.
📮 ClickUp Insight: 53% van de organisaties heeft geen AI-governance of alleen informele richtlijnen.
En wanneer mensen niet weten waar hun gegevens naartoe gaan – of dat een tool een compliance-risico kan opleveren – aarzelen ze.
Als een AI-tool buiten vertrouwde systemen staat of onduidelijke gegevenspraktijken hanteert, is de angst voor "Wat als dit niet veilig is?" voldoende om de implementatie meteen te stoppen.
Dat is niet het geval met de volledig gereguleerde, veilige omgeving van ClickUp. ClickUp AI voldoet aan de AVG, HIPAA en SOC 2 en is ISO 42001-gecertificeerd, waardoor uw gegevens privé, beschermd en verantwoord beheerd worden.
Externe AI-providers mogen geen ClickUp-klantgegevens gebruiken voor training of opslaan, en ondersteuning voor meerdere modellen werkt onder uniforme toestemmingen, privacycontroles en strikte normen voor veiligheid. Hier wordt AI-governance onderdeel van de werkruimte zelf, zodat teams AI met vertrouwen kunnen gebruiken, zonder extra risico's.
Belangrijkste onderdelen van een incidentresponshandboek
Elk effectief incidentresponsplan heeft hetzelfde deel van de basisstructuur. Voordat u begint met het opstellen ervan, moet u weten wat erin moet staan.
Triggercriteria en classificatie van incidenten
Triggers zijn de specifieke voorwaardes die het draaiboek activeren. Dit kan een SIEM-waarschuwing zijn voor afwijkende inlogpatronen of een gebruiker die een verdachte e-mail rapporteert. Koppel uw triggers aan een classificatiesysteem voor incidenten, zodat uw team weet hoe snel het moet handelen.
- Ernst 1: Kritiek: Actieve gegevensdiefstal of ransomware-versleuteling in uitvoering
- Ernst 2: Hoog: Bevestigde inbreuk zonder actieve verspreiding
- Ernst 3: Gemiddeld: Verdachte activiteit die nader onderzoek vereist
- Ernst 4: Laag: Overtreding van het beleid of kleine afwijking
De classificatie bepaalt welke acties worden geactiveerd en hoe snel. Zonder deze classificatie reageren teams ofwel overdreven op waarschuwingen met lage prioriteit, ofwel te zwak op echte bedreigingen.
📖 Lees ook: Manieren om de cyberbeveiliging in projectmanagement te verbeteren
Rollen en verantwoordelijkheden
Een draaiboek heeft geen zin als niemand weet wie waarvoor verantwoordelijk is. Bepaal welke belangrijke rollen in elk draaiboek moeten voorkomen.
- Incidentcommandant: Is verantwoordelijk voor de algehele respons en neemt beslissingen over escalatie
- Technisch leider: Geeft leiding aan het praktische onderzoek en de beheersing
- Communicatiemanager: Beheert interne updates en externe notificaties
- Juridisch contactpersoon: Adviseert over wettelijke verplichtingen en het bewaren van bewijsmateriaal
- Uitvoerende sponsor: Keurt belangrijke beslissingen goed, zoals het stilleggen van systemen
Wijs rollen toe op basis van functie in plaats van alleen op naam. Mensen kunnen op vakantie gaan of het bedrijf verlaten, dus elke rol heeft een primaire en een back-up nodig.
Procedures voor detectie, beheersing en herstel
Dit is de operationele kern van het draaiboek. Detectie en analyse bevestigen of de trigger een echt incident is en verzamelen de eerste indicatoren van een inbreuk.
Beheersing omvat onmiddellijke maatregelen om te voorkomen dat het incident zich verder verspreidt. Dit omvat het isoleren van getroffen systemen, het blokkeren van kwaadaardige IP-adressen en het uitschakelen van gecompromitteerde accounts. U moet onderscheid maken tussen kortetermijnbeheersing om de schade te beperken en langetermijnbeheersing voor stabiliteit.
Uitroeiing en herstel verwijderen de dreiging volledig door malware te verwijderen en kwetsbaarheden te patchen. Deze fase herstelt de normale werking van systemen en omvat validatietests om te garanderen dat de dreiging daadwerkelijk verdwenen is.
🔍 Wist u dat? Een van de grootste dreigingen voor de veiligheid ooit begon met een wachtwoordprobleem. In 2012 kreeg LinkedIn te maken met een grootschalig datalek, deels omdat wachtwoorden werden opgeslagen met verouderde hash-methoden, waardoor miljoenen accounts gemakkelijk te kraken waren.
Communicatie- en escalatieprotocollen
Incidenten vereisen naast de technische respons ook gecoördineerde communicatie. Interne escalatie bepaalt wanneer de incidentcommandant het directieteam en de juridische adviseur inschakelt.
Externe communicatie bepaalt wie er met klanten, toezichthouders of de pers communiceert. Veel compliance-kaders hebben verplichte tijdlijnen voor notificaties waarnaar uw draaiboek moet verwijzen.
⚡ Sjabloonarchief: Wanneer zich incidenten voordoen, is het grootste risico vaak de verwarring die daarop volgt. Vertraagde updates, onduidelijke eigendommen en versnipperde communicatie kunnen de reactietijden vertragen en de impact vergroten. Dat is precies waar de ClickUp-sjabloon voor een communicatieplan bij incidenten echte waarde biedt.
Dit sjabloon biedt teams een kant-en-klaar raamwerk om onder druk duidelijk te communiceren. U kunt rollen definiëren, communicatiekanalen in kaart brengen en ervoor zorgen dat de juiste belanghebbenden op het juiste moment worden geïnformeerd. Het centraliseert alles, van contactpunten tot escalatiepaden, zodat teams op één lijn blijven wanneer het er echt toe doet.
Hoe stelt u een incidentresponshandboek op (stap voor stap)
Een beveiligingsincident zonder plan is een crisis. Een beveiligingsincident met een draaiboek is een proces. Hier leest u hoe u er een opstelt dat standhoudt onder druk. 👀
Stap 1: Bepaal de reikwijdte en doelstellingen
Bepaal, voordat u ook maar één procedure opstelt, wat het draaiboek wel en niet omvat.
Scope creep gaat ten koste van de bruikbaarheid. Een draaiboek dat elk mogelijk scenario probeert te behandelen, voldoet uiteindelijk aan geen enkel scenario, en hulpverleners verspillen tijd met het zoeken naar richtlijnen die ofwel niet bestaan ofwel niet van toepassing zijn op hun situatie.
Begin met het beantwoorden van vier vragen:
- Welke soorten incidenten vallen hieronder: ransomware, datalekken, bedreigingen van binnenuit, DDoS-aanvallen, phishing, account-overnames, inbreuken in de toeleveringsketen, of al het bovenstaande
- Op welke systemen en omgevingen het draaiboek van toepassing is: Cloudinfrastructuur, on-premises servers, hybride omgevingen, SaaS-platforms, OT/ICS-systemen of specifieke bedrijfsonderdelen met unieke risicoprofielen
- Wat succes inhoudt: Een target gemiddelde detectietijd (MTTD) van minder dan 60 minuten, een gemiddelde responstijd (MTTR) van minder dan vier uur, of het voldoen aan SOC 2, ISO 27001 of HIPAA
- Wie is verantwoordelijk voor het draaiboek: Een aangewezen persoon of team dat verantwoordelijk is voor het up-to-date houden ervan, de verdeling onder de juiste personen en het plannen van evaluaties
Het afbakenen van de scope klinkt eenvoudig, totdat je er daadwerkelijk mee aan de slag gaat. Teams lopen in deze fase vaak vast omdat de input verspreid is over eerdere incidenten, losse aantekeningen en de verwachtingen van belanghebbenden.
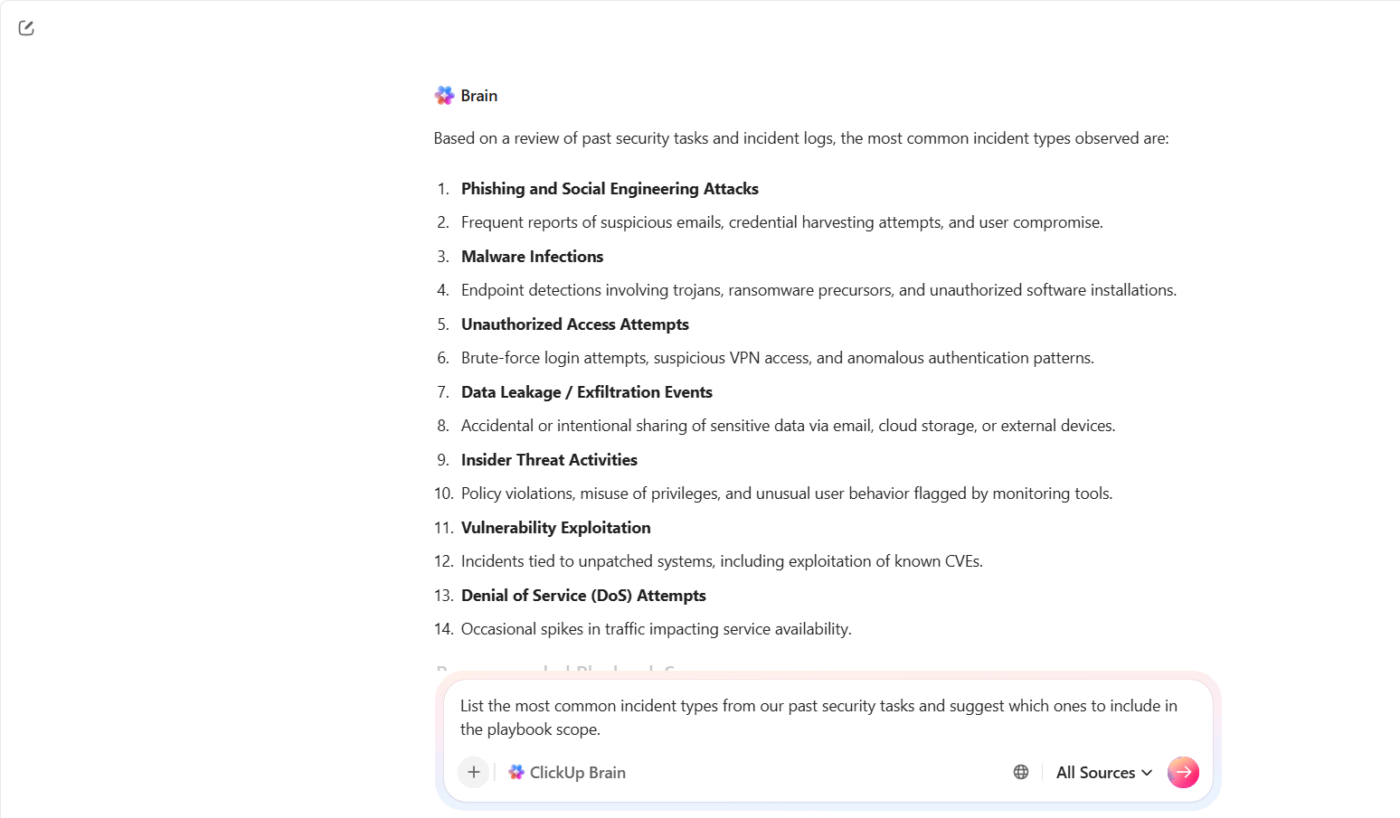
ClickUp Brain helpt je die context samen te brengen en om te zetten in een bruikbaar uitgangspunt. Je begint niet met een leeg blad. Je bouwt voort op wat je team al weet.
Stel bijvoorbeeld dat uw team voor veiligheid het afgelopen kwartaal meerdere incidenten met phishing en account-overnames heeft afgehandeld. In plaats van elk geval handmatig te bekijken, kunt u ClickUp Brain vragen: ‘Maak een lijst van de meest voorkomende incidenttypes uit onze eerdere taken voor veiligheid en stel voor welke daarvan in het draaiboek moeten worden opgenomen.’
Stap 2: Identificeer en classificeer soorten incidenten
Niet alle incidenten zijn hetzelfde. Een verkeerd geconfigureerde S3-bucket en een actieve ransomware-aanval vereisen totaal verschillende reacties, verschillende teamleden en verschillende escalatieprocedures.
Door in een vroeg stadium een classificatiesysteem op te zetten, kunnen hulpverleners vanaf de eerste melding snelle, consistente beslissingen nemen zonder bij elke melding te hoeven wachten op goedkeuring van het management.
Een standaard vierdelig ernstmodel werkt als volgt:
- Kritiek (P1): Actieve inbreuk, gegevensdiefstal of systeemwijde compromittering — onmiddellijke reactie vereist
- Hoog (P2): Vermoedelijke inbraak, diefstal van inloggegevens of aanzienlijke verstoring van de dienstverlening
- Medium (P3): Malware gedetecteerd maar ingeperkt, beleidsschending met risico op blootstelling van gegevens
- Laag (P4): Mislukte inlogpogingen, kleine beleidsschendingen, informatieve waarschuwingen
Breng elk type incident in kaart met een ernstniveau, zodat hulpverleners snel beslissingen kunnen nemen zonder elke melding te escaleren.
Zodra u hebt bepaald wat binnen het toepassingsgebied valt, ligt de volgende uitdaging bij consistentie. Verschillende hulpverleners interpreteren dezelfde waarschuwing vaak op verschillende manieren, wat besluitvorming vertraagt en onnodige escalaties veroorzaakt.
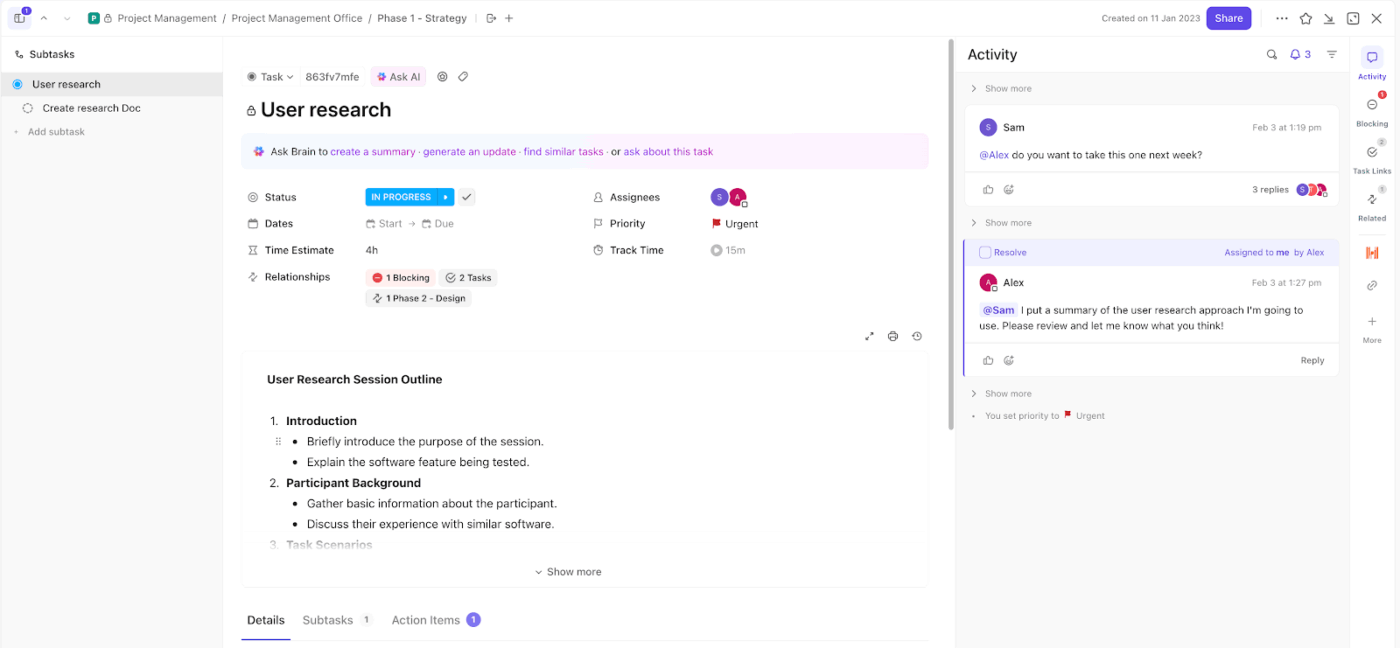
Begin met ClickUp-taken als uw enige uitvoeringseenheid. Elk incident wordt een Taak, wat betekent dat er niets door ongemonitorde kanalen zoals e-mail of chat glipt.
Stel bijvoorbeeld dat uw monitoringtool een mogelijke diefstal van inloggegevens signaleert. U maakt een Taak aan met de titel ‘Mogelijke inbreuk op inloggegevens – financiële account’. Die Taak wordt nu het centrale punt voor onderzoek, updates en oplossing.
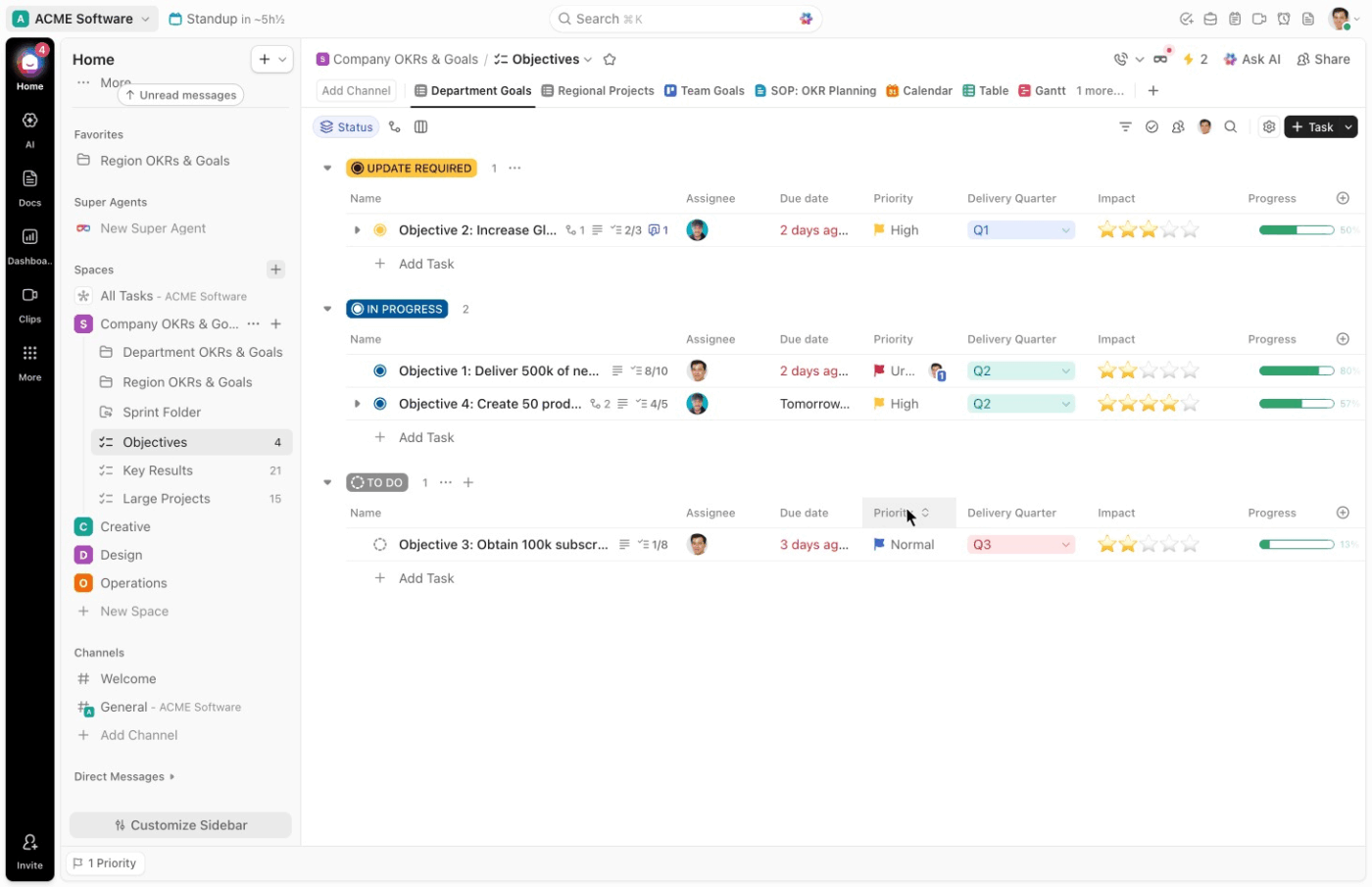
Vervolgens bieden de aangepaste velden in ClickUp je de structuur die nodig is voor snelle classificatie. Je kunt velden instellen zoals:
- Type incident: Phishing, ransomware, DDoS, bedreiging van binnenuit
- Ernstniveau: P1, P2, P3, P4
- Betrokken systemen: Cloud, on-premise, SaaS, eindpunt
- Gegevensgevoeligheid: Hoog, gemiddeld, laag
Stap 3: Stel incident-specifieke responsprocedures op
Dit vormt de operationele kern van het draaiboek.
Schrijf voor elk type incident een specifieke procedure die zo gedetailleerd is dat een hulpverlener deze onder druk kan volgen zonder te improviseren. Algemene richtlijnen worden genegeerd wanneer systemen uitvallen.
Elke procedure moet het volgende bevatten:
- Trigger: De specifieke waarschuwing of melding die de respons in gang zet
- Eerste triagestappen: De eerste acties die een incidentbeheerder binnen 15 minuten onderneemt, afgestemd op het type incident
- Checklist voor het verzamelen van bewijsmateriaal: logbestanden, geheugendumps, netwerkgegevens en e-mailkopteksten – alles wat nodig is voordat het door inperkingsmaatregelen wordt vernietigd
- Beheersingsmaatregelen: Specifieke, uitvoerbare stappen
- Escalatiecriteria: De voorwaarden die de escalatie triggeren naar leidinggevenden, juridische adviseurs of een externe IR-leverancier
- Communicatiesjablonen: Kant-en-klare concepten voor interne updates en notificaties voor klanten
Een procedure voor ransomware lijkt in niets op een procedure voor phishing. Schrijf ze apart op, met de specificiteit die elk scenario vereist.

Met ClickUp Docs kunt u elke incidentprocedure zo structureren dat deze precies de vragen beantwoordt waarmee een incidentbeheerder op dat moment wordt geconfronteerd. Stel bijvoorbeeld dat u een ransomware-scenario documenteert.
Het document kan de hulpverlener als volgt begeleiden:
- Wat was de trigger hiervoor: ‘Waarschuwing voor endpoint-versleuteling gedetecteerd via EDR’
- Wat er in de eerste 15 minuten moet gebeuren: Isoleer de getroffen machine, schakel netwerktoegang uit, controleer de omvang van de verspreiding
- Wat moet worden vastgelegd vóór het indammen: Systeemlogboeken, actieve processen, recente bestandswijzigingen
- Voor welke voorwaarden is escalatie nodig: Verspreiding van versleuteling over meerdere eindpunten of toegang tot gedeelde schijven
- Wat moet worden gecommuniceerd: Een interne waarschuwing aan het team voor veiligheid en een voorbereide update voor de getroffen teams
ClickUp Documents versterkt dit nog verder door directe integratie in de uitvoering:
- Koppel de procedure aan incidenten in ClickUp, zodat hulpverleners de richtlijnen op het exacte moment van actie kunnen openen
- Voeg checklists toe aan elke sectie, zodat cruciale stappen onder druk niet over het hoofd worden gezien
- Wijs tijdens escalatie specifieke acties toe aan teamleden zonder het document te verlaten
- Pas de instructies direct na het oplossen van het incident aan, zodat toekomstige reacties zonder vertraging worden verbeterd
Stap 4: Stel communicatieprotocollen en bewijsstandaarden vast
Twee aspecten die bij het opstellen van een draaiboek vaak onderbelicht blijven en tijdens een daadwerkelijk incident voor ernstige problemen zorgen: hoe het team communiceert en hoe bewijsmateriaal wordt behandeld.
Definieer met betrekking tot communicatie van tevoren de volgende parameters:
- Primaire en back-upkanalen
- Tijdlijnen voor notificaties
- Vereisten inzake externe openbaarmaking
- Eén enkele bron van waarheid
Op basis van bewijsmateriaal moet het draaiboek het volgende specificeren:
- Wat u moet verzamelen: Systeemlogboeken, logboeken voor verificatie, geheugenafbeeldingen, netwerkstromingsgegevens en schermafbeeldingen van de activiteiten van de aanvaller
- Hoe u dit verzamelt: Forensische imaging (alleen-lezen), schrijfblokkers en een logboek van elke verzamelactie met een tijdstempel en de naam van de persoon die deze heeft uitgevoerd
- Waar moet u het opslaan: Een aparte omgeving met toegangsbeheer, geïsoleerd van de getroffen systemen
- Wie heeft toegang: Beperkt tot aangewezen onderzoekers en goedgekeurd door de juridische en compliance-contactpersoon
Wanneer zich een incident voordoet, is de communicatie vaak versnipperd over verschillende tools. Updates komen binnen via Slack, beslissingen worden genomen tijdens telefoongesprekken en belangrijke details raken begraven in threads die niemand meer terugleest. Dat gebrek aan structuur zorgt voor verwarring, vertraagt de escalatie en maakt evaluaties na het incident moeilijker dan nodig is.
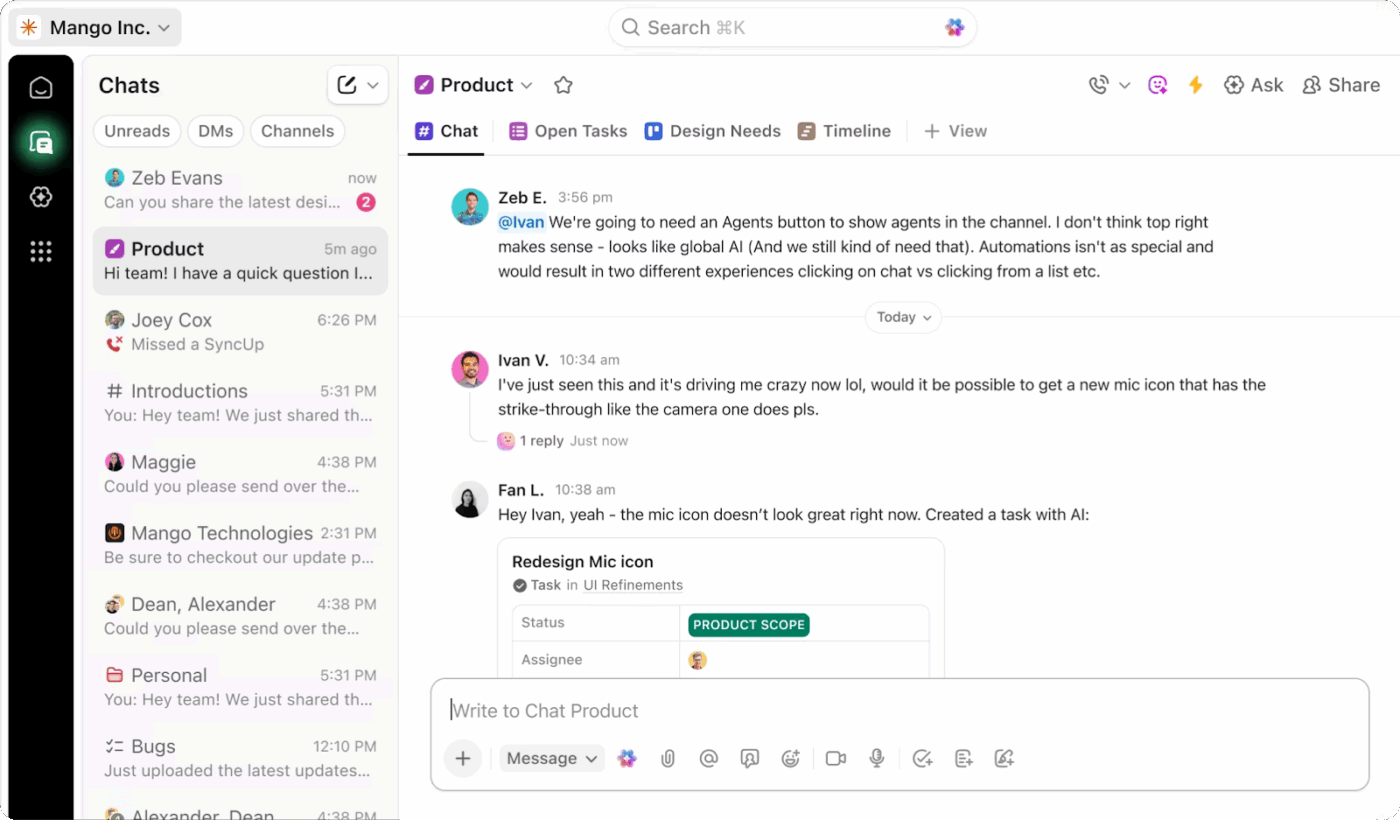
ClickUp Chat biedt je een speciaal, gekoppeld kanaal waar de communicatie over incidenten gericht, met zichtbaarheid en gemakkelijk te volgen blijft.
U kunt het instellen als uw primaire communicatielaag voor incidentrespons, direct gekoppeld aan het werk dat wordt bijgehouden. Die verbinding verandert de manier waarop teams samenwerken in stressvolle situaties.
🀚 Het voordeel van ClickUp: Maak van elk incident een leermoment met de sjabloon voor incidentresponsrapporten van ClickUp.
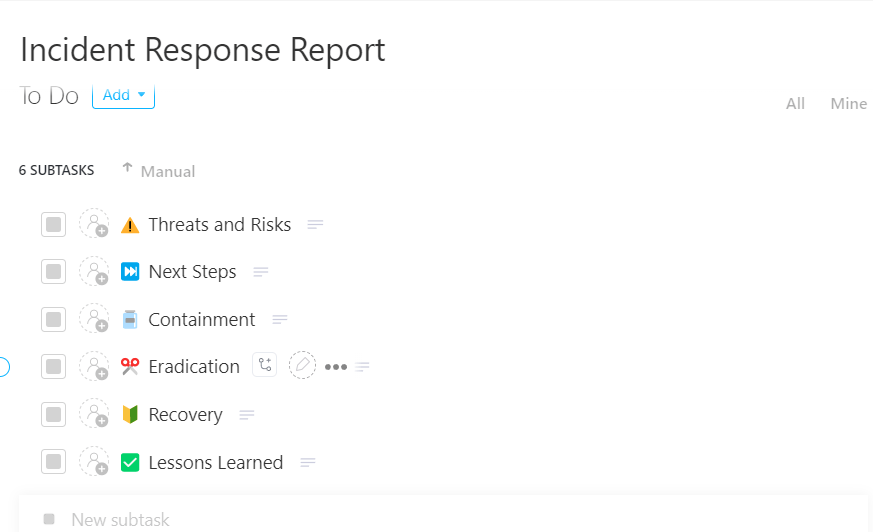
Leg elk incident duidelijk en volledig vast met behulp van de ClickUp-sjabloon voor incidentresponsrapporten
Het is opgezet als een kant-en-klaar, taakgebaseerd systeem waarmee u incidenten van begin tot eind op één plek kunt vastleggen, bijhouden en beheren, zodat er niets verloren gaat tussen tools of teams.
Stap 5: Test, integreer en stel een beoordelingscyclus op
Een draaiboek dat nog nooit is getest, is een verzameling aannames. Voordat u het als operationeel beschouwt, moet u het valideren door middel van gestructureerde oefeningen en het maken van een verbinding met de tools die uw team dagelijks gebruikt.
Voer voor het testen oefeningen uit in volgorde van intensiteit:
- Tabletop-oefening: Een facilitator presenteert een gesimuleerd scenario en het team bespreekt de beslissingen mondeling
- Functionele oefening: Het team voert specifieke stappen uit in een gecontroleerde omgeving, zoals het isoleren van een test-endpoint
- Volledige simulatie: Een red team voert een realistisch aanvalsscenario uit terwijl het IR-team in realtime reageert
Voor toolintegratie brengt u het draaiboek rechtstreeks in kaart met uw SIEM-alert-ID's, EDR-beheersingsacties, ticketing-werkstroomen overdrachtsprocedures naar externe IR-leveranciers. Responders moeten van alert naar procedure naar actie kunnen gaan zonder van context te wisselen.
Hoe ClickUp helpt
Het uitvoeren van tabletop-oefeningen en simulaties brengt vaak dezelfde tekortkoming aan het licht. Teams kennen de stappen in theorie, maar de uitvoering verloopt traag omdat er geen systeem is dat de respons in realtime actief begeleidt.

ClickUp AI Agents vullen de leemte op. Ze observeren activiteiten in taken, velden en werkstroomen en ondernemen vervolgens actie op basis van de logica die u definieert. Dat maakt ze zeer relevant wanneer u uw draaiboek test en in gebruik neemt.
Begin met hoe dit in de praktijk werkt tijdens een tabletop-oefening.
Stel dat uw facilitator een phishingaanval introduceert die escaleert tot het compromitteren van inloggegevens. Terwijl uw team de volgende stappen bespreekt, kan een AI-agent:
- Maak een gestructureerde checklist voor de respons die aansluit bij uw phishingprocedure
- Stel vervolgacties voor op basis van taakvelden zoals 'incidenttype' en 'ernst'
- Stel een interne update op aan de hand van de huidige details van de Taak
Zo blijven de discussies gebaseerd op concrete uitvoeringsstappen.
💡 Pro-tip: Stel voor doorlopend onderhoud beoordelingen op rond drie triggers:
- Een jaarlijkse volledige audit met een tabletop-oefening voor elke procedure die in de afgelopen 12 maanden niet is getest
- Na elk belangrijk incident, terwijl de details nog vers in het geheugen liggen
- Een driemaandelijkse controle op wijzigingen in personeel en tools
Wijs aan elke cyclus een eigenaar toe met ClickUp Multiple Assignees. Zonder verantwoordelijkheid worden beoordelingen overgeslagen en wordt het draaiboek stilletjes een last.
Voorbeelden van incidentresponshandleidingen per type bedreiging
Zo ziet het proces voor het opstellen van een draaiboek eruit wanneer het wordt toegepast op de meest voorkomende soorten bedreigingen.
Handleiding voor het reageren op ransomware-incidenten
- Trigger: Waarschuwing van endpointdetectie voor bestandsversleutelingsactiviteit of ongebruikelijke wijzigingen in bestandsextensies
- Onmiddellijke beheersing: Isoleer getroffen systemen onmiddellijk van het netwerk en schakel gedeelde schijven uit
- Belangrijkste acties: Identificeer de ransomwarevariant, bepaal de omvang van de versleuteling en bewaar forensisch bewijsmateriaal
- Herstel: Herstel de gegevens vanuit schone back-ups nadat u hebt gecontroleerd dat deze niet zijn gecompromitteerd, en patch het toegangspunt
- Na het incident: Leg de tijdlijn van de aanval vast en controleer de procedures voor de integriteit van back-ups
🔍 Wist u dat? Een van de eerste hackers was een klokkenluider. In de jaren 80 bracht een groep die bekend stond als de Chaos Computer Club fouten in de veiligheid van banksystemen aan het licht om kwetsbaarheden aan te tonen, in plaats van deze uit te buiten voor winst.
Handleiding voor de respons op phishingincidenten
- Trigger: Een gebruiker meldt een verdachte e-mail of er is een pagina voor het verzamelen van inloggegevens gedetecteerd
- Onmiddellijke maatregelen: Plaats de e-mail in quarantaine in alle mailboxen en blokkeer het domein van de afzender
- Belangrijkste acties: Dwing wachtwoordresets af en beëindig actieve sessies onmiddellijk als inloggegevens zijn ingediend
- Communicatie: Breng getroffen gebruikers op de hoogte en verstuur een organisatiebrede waarschuwing zonder paniek te veroorzaken
- Herstel: Controleer of er geen permanente toegang meer is en werk de regels voor e-mailfiltering bij
Handleiding voor ongeoorloofde toegang
- Trigger: Afwijkende inlogactiviteit, waarschuwing voor privilege-escalatie of toegang tot gevoelige bronnen
- Onmiddellijke inperking: Schakel het gecompromitteerde account uit, beëindig actieve sessies en beperk de toegang
- Belangrijkste acties: Bepaal hoe toegang is verkregen en controleer alle acties die zijn uitgevoerd via het gecompromitteerde account
- Herstel: Reset de inloggegevens voor alle mogelijk getroffen accounts en verscherp de toegangscontroles
- Na het incident: Voer een volledige toegangscontrole uit en werk het beleid voor minimale rechten bij
Best practices voor incidentresponshandleidingen
Dit zijn de best practices die het verschil maken tussen teams die incidenten vlot oplossen en teams die zes uur later nog steeds in een crisiscentrum zitten te discussiëren over wie verantwoordelijk is voor de rollback. Als je dit goed doet, wordt al het andere een stuk eenvoudiger. 🔥
Beschrijf wat er nog te doen is, niet waarover er moet worden nagedacht
De meeste draaiboeken staan vol met stappen als 'beoordeel de ernst van de situatie' of 'bepaal welke belanghebbenden erbij betrokken moeten worden'. Dit zijn geen stappen. Het zijn herinneringen om na te denken.
Een nuttig draaiboek vertelt u welke actie u moet ondernemen, niet dat er actie nodig is. Vervang ‘de impact op de klant evalueren’ door ‘het dashboard met actieve sessies controleren en het nummer in het incidentkanaal plakken’. Specificiteit is waar het om draait.
Zorg ervoor dat de persoon die de oplossing vindt, niet dezelfde is als degene die het incident afhandelt
Wanneer de meest ervaren engineer in het gesprek tegelijkertijd de oorzaak aan het opsporen is, vragen van het management beantwoordt en beslist wie er moet worden opgeroepen, loopt het op alle drie de fronten mis.
Uw draaiboek moet een strikte scheiding afdwingen: één persoon is verantwoordelijk voor het onderzoek, één persoon is verantwoordelijk voor het incident. De Incident Commander neemt geen technische beslissingen. Hij of zij delegeert, lost knelpunten op en communiceert. Dit voelt als extra werk, totdat het u voor het eerst twee uur tijd bespaart.
🔍 Wist u dat? Maar liefst 91% van de grote organisaties heeft zijn cyberbeveiligingsstrategieën al aangepast vanwege geopolitieke onrust, waardoor wereldwijde spanningen een directe drijfveer zijn geworden voor beslissingen op het gebied van cyberverdediging.
Voer de evaluatie uit terwijl de mensen nog boos zijn
De beste evaluaties vinden plaats binnen 48 uur, omdat de frustratie dan nog vers is. De engineer die vond dat de waarschuwingsdrempel te hoog was, zal dat op dag twee zeggen.
Tegen dag 10 zijn ze alweer verder gegaan en wordt de vergadering een beleefde reconstructie van een tijdlijn in plaats van een openhartig gesprek over wat er mis is gegaan.
Test het draaiboek door te proberen het te doorbreken
De enige betrouwbare manier om te achterhalen of uw draaiboek werkt, is door het te gebruiken wanneer er nog niets aan de hand is. Organiseer een simulatie. Kies een realistisch storingsscenario, geef iemand het draaiboek zonder voorbereiding en kijk waar ze aarzelen.
Elke aarzeling is een lacune. Elke vraag die ze stellen is een ontbrekende stap. Een draaiboek dat nooit aan een stresstest is onderworpen, is nooit af.
Een operations manager deelt zijn ervaringen met het gebruik van ClickUp:
ClickUp is een geweldige tool geweest om ons team georganiseerd en op één lijn te houden. Het maakt het eenvoudig om projecten te beheren, taken toe te wijzen en de voortgang bij te houden, allemaal op één plek. Ik waardeer vooral de flexibiliteit: je kunt werkstroomaanpassingen doen, sjablonen maken en het platform aanpassen aan verschillende teamprocessen.
Het is erg nuttig geweest bij het opzetten van herhaalbare systemen voor zaken als SOP's, prestatiebeoordelingen en het bijhouden van projecten. Door taken, documenten en communicatie met elkaar te verbinden, wordt heen-en-weer-gepraat verminderd en blijft iedereen op één lijn.
Maak en beheer incidentresponshandleidingen met ClickUp
Het is een enorme uitdaging om playbooks operationeel en toegankelijk te houden wanneer het er echt toe doet. Bij de meeste teams is de documentatie verspreid over wiki's, Google Documenten en Slack-bladwijzers. Wanneer zich een incident voordoet, weet niemand zeker welke versie actueel is of waar de escalatiematrix zich bevindt.
Maak een einde aan deze wildgroei aan tools en contextwisselingen met ClickUp. Als geconvergeerde werkruimte bevinden je playbook-documentatie, werkstroomen en teamcommunicatie zich allemaal op precies dezelfde plek.
Of je nu je eerste draaiboek opstelt of verspreide documentatie samenbrengt, ClickUp biedt je team één centrale plek om te plannen, te reageren en te verbeteren. Meld je vandaag nog gratis aan!
Veelgestelde vragen (FAQ)
1. Wat is het verschil tussen een incidentresponshandleiding en een runbook?
Een playbook omvat de volledige responscyclus voor een specifiek type incident. Een runbook daarentegen is een meer specifieke technische procedure voor het uitvoeren van een afzonderlijke Taak binnen die respons.
2. Hoe vaak moet u uw incidentresponshandboek bijwerken?
Evalueer en werk de draaiboeken minstens elk kwartaal bij. U moet ze ook bijwerken na elk echt incident en na elke simulatieoefening.
4. Kunt u een sjabloon voor een incidentresponshandleiding als uitgangspunt gebruiken?
Ja, sjablonen van frameworks zoals NIST of CISA bieden u een beproefde structuur. Ook ClickUp-sjablonen zijn erg handig. Zo kunt u de basis aangepast aan uw omgeving in plaats van met een lege pagina te beginnen.
5. Hebben kleine teams een incidentresponshandboek nodig?
Kleine teams hebben waarschijnlijk meer behoefte aan draaiboeken, omdat er minder ruimte is voor fouten. Een eenvoudig draaiboek voor uw belangrijkste dreigingsscenario's is veel beter dan improviseren bij een reactie.