
De meeste teams beschouwen het genereren van SQL als een goocheltruc. Je typt een vraag in en krijgt een query.
Maar dit is de realiteit: Snowflake Cortex Analyst werkt slechts zo goed als het semantische model dat u eerst bouwt, en die installatie is niet eenvoudig. Door te leren hoe ze Snowflake Cortex kunnen gebruiken voor het genereren van SQL, kunnen datateams nu binnen enkele seconden natuurlijke taal omzetten in complexe, uitvoerbare queries.
Deze handleiding leidt u door het daadwerkelijke implementatieproces, van het definiëren van uw YAML-semantische model tot het queryen van uw datawarehouse met behulp van natuurlijke taal, zodat u zowel de kracht als de vereisten begrijpt voordat u begint.
We bekijken ook waar Snowflake Cortex tekortschiet en hoe ClickUp de bredere werkstroom rondom SQL-generatie kan ondersteunen.
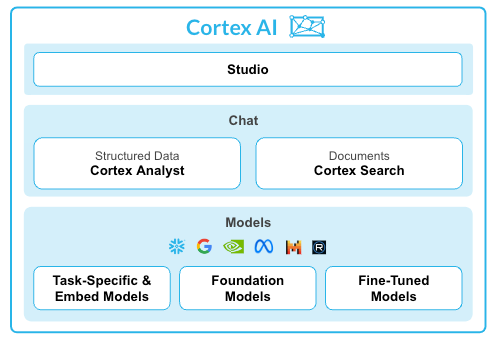
Wat is Snowflake Cortex Analyst?
Snowflake Cortex Analyst is een volledig beheerde service waarmee u conversatiegerichte applicaties kunt bouwen op basis van uw analytische gegevens.
Het maakt gebruik van een gespecialiseerde tekst-naar-SQL-agent om vragen in natuurlijke taal om te zetten in nauwkeurige, uitvoerbare query's. Deze service overbrugt de kloof tussen complexe gegevensstructuren en zakelijke gebruikers die antwoorden nodig hebben zonder code te schrijven.
Belangrijke functies zijn onder meer:
- Een zeer nauwkeurige interface bieden voor interactie met gestructureerde gegevens
- Semantische modellen gebruiken om uw specifieke bedrijfslogica en terminologie te begrijpen
- Met een REST API voor eenvoudige integratie in aangepaste applicaties of BI-tools
- Gegevensprivacy waarborgen door verzoeken te verwerken binnen de grenzen van de veiligheid van Snowflake
📮 ClickUp Insight: 88% van de respondenten in onze enquête gebruikt AI voor persoonlijke taken, maar meer dan 50% schrikt ervoor terug om het op het werk te gebruiken. De drie belangrijkste belemmeringen? Gebrek aan naadloze integratie, kennislacunes of bezorgdheid over de veiligheid.
Maar wat als AI al in je werkruimte is ingebouwd en al veilig is? ClickUp Brain, de ingebouwde AI-assistent van ClickUp, maakt dit mogelijk. Het begrijpt opdrachten in gewone taal, lost alle drie de zorgen rond AI-implementatie op en maakt tegelijkertijd de verbinding tussen je chat, taken, documenten en kennis in de hele werkruimte mogelijk.
Vind antwoorden en inzichten met één enkele klik!
Vereisten voor Snowflake Cortex SQL-generatie
Zonder de juiste installatie aan de slag gaan met Snowflake Cortex leidt tot frustratie. U kunt onnauwkeurige resultaten krijgen, tijd verspillen aan het oplossen van problemen en ten onrechte concluderen dat de tool niet werkt, terwijl het echte probleem een zwakke basis is.
Om dit te voorkomen, moet u eerst drie basiselementen op orde hebben.
1. Stel uw database en tabellen in
Uw AI is slechts zo slim als de gegevens waartoe deze toegang heeft. Als uw databaseschema een doolhof is van cryptische kolomnamen zoals cust_dat_v2_final, zullen zowel uw analisten als de AI moeite hebben om er wijs uit te worden.
Deze verwarring leidt ertoe dat de AI onjuiste joins genereert of gegevens uit de verkeerde kolommen haalt, waardoor uw team uren verspilt aan het ontcijferen van het schema voordat ze zelfs maar een query kunnen schrijven.
Zorg er eerst voor dat uw datawarehouse-software de tabellen bevat die u door Cortex Analyst wilt laten queryen. Gebruik waar mogelijk duidelijke, beschrijvende kolomnamen. Een kolom met de naam customer_lifetime_value is bijvoorbeeld veel intuïtiever voor zowel mensen als AI dan clv_01.
Om door te gaan met de installatie, heeft uw Snowflake-rol de volgende toestemmingen nodig:
- GEBRUIK: Op de database en het schema waarin uw tabellen staan
- SELECT: Op de tabellen die u door Cortex Analyst wilt laten queryen
- CREATE FASE: Op het schema, dat nodig is om uw semantische modelbestand te uploaden
2. Maak uw semantische modelbestand
De grootste hindernis bij elke tekst-naar-SQL-tool is dat de AI de unieke taal van uw bedrijf niet spreekt. De AI weet niet automatisch dat 'ARR' staat voor 'Annual Recurring Revenue' of dat de tabel met uw klanten via het veld customer_id wordt gekoppeld aan uw bestellingentabel.
Zonder deze context zou de AI SQL kunnen genereren die technisch geldig is, maar logisch onjuist, waardoor u antwoorden krijgt die er correct uitzien, maar gevaarlijk misleidend zijn.
Het semantische model is de oplossing. Het is een YAML-bestand dat fungeert als uw aangepaste 'vertaallaag' en Cortex Analyst de specifieke woordenschat en logica van uw bedrijf bijbrengt. Het opstellen en onderhouden van dit bestand is een gezamenlijke inspanning van data-engineers die ETL-tools gebruiken om het schema te kennen, en bedrijfsanalisten die de terminologie beheersen.
Uw semantische modelbestand moet de volgende sleutelonderdelen bevatten:
| Component | Doel |
| Tabel | Geeft een lijst met elke tabel met een beschrijving in gewone taal van het doel ervan |
| Kolommen | Definieert het semantische type van elke kolom (zoals categorie of statistiek) en kan steekproefwaarden bevatten |
| Relationships | Geeft aan hoe tabellen via joins met elkaar worden verbonden, waardoor giswerk voor de AI wordt geëlimineerd |
| Geverifieerde queries | Bevat voorbeeldparen van vragen en SQL-query's die als krachtige richtlijnen dienen voor de LLM |
3. Configureer Cortex Search Service (optioneel)
Soms zitten de antwoorden die u nodig hebt verborgen in ongestructureerde tekst, zoals productbeschrijvingen, supporttickets of transcripties van telefoongesprekken. Standaard SQL-queries kunnen deze gegevens niet verwerken, waardoor u vaak het 'waarom' achter het 'wat' mist.
U kunt hier optioneel Snowflake Cortex Search Service toevoegen. Dit is een search-as-a-service- laag waarmee u tegelijkertijd zowel uw gestructureerde tabellen als uw ongestructureerde tekstgegevens kunt queryen met behulp van AI-agenten voor data-analyse.
U moet Cortex Search configureren als uw analisten vragen moeten stellen waarvoor context uit tekst moet worden gehaald voordat SQL wordt gegenereerd. U kunt bijvoorbeeld eerst zoeken naar alle productrecensies die de zin 'batterijprobleem' bevatten en vervolgens een SQL-query genereren om de verkoopgegevens voor alleen die producten samen te voegen.
Voor het genereren van pure SQL voor gestructureerde tabellen is deze service niet nodig.
🠠 Leuk weetje: In het begin van de jaren 70 ontwikkelden IBM-onderzoekers Donald Chamberlin en Raymond Boyce de ‘Structured English Query Language’. Ze moesten de naam veranderen in SQL omdat ‘SEQUEL’ al als handelsmerk was geregistreerd door een Brits vliegtuigbedrijf.
Stapsgewijze handleiding voor het genereren van SQL met Cortex Analyst
U hebt het voorbereidende werk gedaan, maar nu staart u naar een leeg scherm en weet u niet precies hoe de werkstroom eruitziet. Hoe zet u een vraag in uw hoofd om in een uitvoerbare SQL-query? Als het workflowbeheer onduidelijk is, blijven nieuwe tools vaak ongebruikt en is de investering in de installatie verspild.
Het praktische proces is verfrissend eenvoudig. Hier volgt een nadere toelichting!
Stap 1: Bereid uw gegevens voor in Snowflake
Allereerst moeten uw gestructureerde gegevens in Snowflake staan. Elke Cortex Analyst-toepassing is gericht op ofwel een enkele tabel, ofwel een weergave die uit een of meer tabellen bestaat. Zorg ervoor dat uw tabellen zijn aangemaakt en voorzien van een populatie.
Als u gegevens uit platte bestanden laadt:
- Upload uw gegevensbestanden (bijv. CSV's) naar een Snowflake fase
- Gebruik het COPY INTO-commando om gegevens vanuit de fase in uw tabellen te laden
- Controleer of de gegevens succesvol zijn geladen voordat u verdergaat
Stap 2: Bouw een semantisch model (of semantische weergave)
Dit is de belangrijkste stap in de installatie. De kracht van Cortex Analyst komt voort uit de combinatie van grote taalmodellen (LLM's) met semantische modellen, een YAML-bestand dat naast uw databaseschema staat en de zakelijke context codeert.
Semantic Views zijn nu de door Snowflake aanbevolen methode voor Cortex Analyst. Ze slaan bedrijfsstatistieken, relaties en definities rechtstreeks op in Snowflake. Verouderde YAML-bestanden voor semantische modellen werken nog steeds, maar Snowflake richt nieuwe implementaties op Semantic Views.
Uw semantische model of weergave moet het volgende bevatten:
- Tabel- en kolombeschrijvingen: Uitleg in gewone taal over de betekenis van elk veld
- Business-statistieken: Definities voor berekende velden zoals omzet, churn of conversieratio
- Filters en synoniemen: Alternatieve termen die gebruikers zouden kunnen gebruiken (bijv. ‘geannuleerd’, in kaart gebracht als een specifieke statuswaarde)
- Geverifieerde queries: De Verified Query Opslagplaats van Snowflake bevat goedgekeurde vraag-en-SQL-paren. Wanneer een vraag van een gebruiker lijkt op een van die invoeren, kan Cortex Analyst hiernaar verwijzen tijdens het genereren van SQL
🤝 Vriendelijke herinnering: Snowflake raadt aan om niet meer dan 10 tabellen en niet meer dan 50 geselecteerde kolommen te gebruiken voor optimale prestaties in de Snowsight-werkstroom.
Stap 3: Upload het semantische model naar een Snowflake-fase
Als u een op YAML gebaseerd semantisch model gebruikt, moet dit in fasen worden geïmplementeerd, zodat Cortex Analyst er tijdens de uitvoering naar kan verwijzen.
- Upload uw .yaml-bestand naar een interne Snowflake-fase (bijv. RAW_DATA)
- Controleer of het bestand in de fase verschijnt via de Snowsight-gebruikersinterface of met het commando LIST @stage_name
- Noteer het fasepad; u zult hiernaar verwijzen in uw API-aanroepen of app-configuratie
Als u een Semantic View gebruikt, wordt deze stap native binnen Snowflake afgehandeld en is er geen aparte upload nodig.
🔍 Wist u dat? NULL in SQL betekent niet nul of leeg. Het staat voor onbekende of ontbrekende gegevens, wat leidt tot onintuïtief gedrag, zoals vergelijkingen die noch waar, noch onwaar opleveren.
Stap 4: Stuur een vraag in natuurlijke taal via de REST API
Nu begint de daadwerkelijke SQL-generatie. De REST API genereert een SQL-query voor een bepaalde vraag met behulp van een semantisch model of een semantische weergave die in het verzoek is opgegeven.
Structureer uw API-verzoek met:
- berichten; een array met uw vraag van de gebruiker met rol: “gebruiker”
- Een verwijzing naar uw semantische model of semantische weergave
- Uw voorkeursmodel (of laat het op 'auto' staan zodat Cortex het beste model selecteert)
U kunt gesprekken voeren die uit meerdere beurten bestaan, waarbij u vervolgvragen kunt stellen die voortbouwen op eerdere queries.
Stap 5: De API-respons parseren
Elk bericht in een reactie kan meerdere inhoudsblokken van verschillende typen bevatten. Drie waarden die momenteel worden ondersteund voor het veld type zijn: tekst, suggesties en SQL.
Dit is wat elk type betekent:
- SQL: Cortex heeft met succes een query gegenereerd; dit is wat u gaat uitvoeren
- tekst: Een uitleg of antwoord in natuurlijke taal bij de SQL
- suggesties: Het content-type 'suggestie' wordt alleen in een antwoord opgenomen als de vraag van de gebruiker dubbelzinnig was en Cortex Analyst geen SQL-instructie voor die query kon retourneren. Gebruik deze om de vraag te verduidelijken of te verfijnen
🔍 Wist u dat? De volgorde waarin u SQL schrijft, is niet de volgorde waarin het wordt uitgevoerd. Ook al schrijft u SELECT als eerste, databases verwerken in feite FROM en WHERE voordat ze kolommen selecteren. Dit brengt zowel beginners als ervaren gebruikers in verwarring.
Stap 6: Voer de gegenereerde SQL uit in Snowflake
Zodra u het SQL-blok uit het antwoord hebt ontvangen, voert u dit uit in uw Snowflake Virtual Warehouse. De gegenereerde SQL-query wordt uitgevoerd in uw Snowflake Virtual Warehouse om de uiteindelijke uitvoer te genereren. De gegevens blijven binnen de governance-grenzen van Snowflake.
Belangrijke zaken om te weten op het moment van uitvoering:
- Cortex Analyst is volledig geïntegreerd met het op rollen gebaseerde toegangsbeheer (RBAC) van Snowflake, waardoor wordt gegarandeerd dat gegenereerde en uitgevoerde SQL-queries voldoen aan alle vastgestelde toegangsregels
- Als een gebruiker geen toegang heeft tot een tabel, mislukt de query bij de uitvoering, net zoals dat het geval zou zijn bij handgeschreven SQL
- In deze fase zijn er kosten voor warehouse-rekenkracht van toepassing, los van de gebruiksvergoedingen van Cortex Analyst zelf
Stap 7: Verfijn en herhaal
Het is niet altijd gegarandeerd dat u bij de eerste poging een perfecte query krijgt. Hier leest u hoe u de resultaten in de loop van de tijd kunt verbeteren:
- Voeg geverifieerde queries toe aan uw semantische model voor vragen die herhaaldelijk terugkomen
- Verrijk uw semantische model met betere beschrijvingen, synoniemen en filters wanneer Cortex een term verkeerd interpreteert
- Gebruik gesprekken met meerdere beurtwisselingen om door te vragen, bijvoorbeeld: ‘Filter dat nu op regio’. Gesprekken met meerdere beurtwisselingen maken vervolgvragen mogelijk die voortbouwen op eerdere queries.
- Monitor het gebruik via CORTEX_ANALYST_USAGE_HISTORY en de Snowflake-querygeschiedenis om patronen te ontdekken in mislukte of onnauwkeurige query's
🧠 Leuk weetje: Eén ontbrekende JOIN-voorwaarde kan enorme problemen veroorzaken. Het vergeten van een join-voorwaarde kan een Cartesisch product opleveren, waardoor het aantal rijen enorm toeneemt en systemen soms crashen.
Best practices voor de nauwkeurigheid van Snowflake Text-to-SQL
De kwaliteit van uw semantische model bepaalt rechtstreeks de nauwkeurigheid van de queries die het genereert. Hier zijn de best practices die de nauwkeurigheid verbeteren. 🛠️
- Voeg geverifieerde queries toe aan uw semantische model: Dit is het meest effectieve wat u kunt doen. Neem tal van voorbeelden van vragen en SQL-query's op die weerspiegelen hoe uw team daadwerkelijk vragen stelt
- Gebruik beschrijvende kolom- en tabelnamen: Het model presteert beter wanneer kolom- en tabelnamen voor zichzelf spreken. Als u het schema niet kunt wijzigen, voeg dan duidelijke beschrijvingen toe in uw YAML-bestand voor cryptische kolomnamen
- Voeg voorbeeldwaarden toe: Door voorbeeldgegevens toe te voegen voor categorische kolommen (zoals status of regio) helpt u het model de beschikbare geldige filteropties te begrijpen
- Test met randgevallen: Stel tijdens de ontwikkeling bewust dubbelzinnige of lastige vragen om te achterhalen waar uw semantische model meer context of verduidelijking nodig heeft
- Herhaal uw semantische model: Beschouw uw semantische model als een levend document. Het moet voortdurend worden bijgewerkt via een iteratief proces op basis van welke query's slagen en welke mislukken
ClickUp: een eenvoudiger alternatief voor Snowflake Cortex
Snowflake Cortex werkt goed wanneer teams SQL willen genereren en query's willen uitvoeren op gestructureerde data. Teams definiëren schema's, brengen relaties in kaart en schrijven query's om inzichten te verkrijgen. Die installatie is zinvol voor data-intensieve omgevingen, vooral wanneer analisten verantwoordelijk zijn voor de rapportage.
Veel teams hebben echter geen volledige SQL-laag nodig om alledaagse operationele vragen te beantwoorden. Productmanagers, programmaleiders en operationele teams willen vaak snelle antwoorden die aansluiten bij hun lopende werk.
ClickUp biedt een toegankelijkere manier. Teams stellen vragen in gewone taal, bekijken live dashboards en ondernemen actie op basis van inzichten zonder SQL te schrijven of semantische modellen te bouwen.
Genereer en verfijn SQL sneller
Snowflake Cortex richt zich op het genereren van SQL-query's op basis van gestructureerde datasets binnen een datawarehouse-omgeving. Dat werkt goed wanneer uw data al in Snowflake staat en u schema's hebt in kaart gebracht.

ClickUp Brain ondersteunt het genereren van SQL op een flexibelere, uitvoeringsgerichte manier. Teams genereren, verfijnen en slaan SQL-query's rechtstreeks op in hun werkruimte, waar analyse, discussies en beslissingen al plaatsvinden.
Stel dat een productanalist in ClickUp werkt aan een retentieanalyse-taak. In plaats van van tool te wisselen om query's te schrijven, vraagt hij ClickUp Brain:
📌 Probeer deze prompt eens: Schrijf een SQL-query om de retentie over zeven dagen te berekenen voor gebruikers gegroepeerd per cohorte van aanmeldingen.
ClickUp Brain genereert een gestructureerde query met cohortgroepering, datumfilters en retentielogica. De analist plakt de query in Snowflake of een ander datawarehouse en voert deze direct uit.
Het helpt:
- Schrijf joins tussen meerdere tabellen, zoals gebruikers, bestellingen en gebeurtenissen
- Zet productvragen in gewoon Engels om in SQL-logica die klaar is voor uitvoering
- Debug defecte queries en leg problemen uit, zoals onjuiste joins of ontbrekende voorwaarden
- Herschrijf queries voor betere prestaties of leesbaarheid
Bijvoorbeeld: tijdens een evaluatie van een groeiexperiment vraagt een marketeer: ‘Schrijf een SQL-query om de conversiepercentages van twee landingspagina's in de afgelopen 14 dagen te vergelijken’.
ClickUp Brain genereert de query met behulp van voorwaardelijke aggregatie en datumfilters. Het team voert deze uit in Snowflake en valideert de experimentresultaten.
📌 Probeer deze prompt eens: Corrigeer deze SQL-query waarbij de join rijen dupliceert en leg uit wat het probleem is.
ClickUp Brain identificeert het join-probleem, corrigeert de query en legt uit hoe dubbele rijen zijn ontstaan door onjuiste join-voorwaarden.
Vervang SQL-gestuurde rapportage
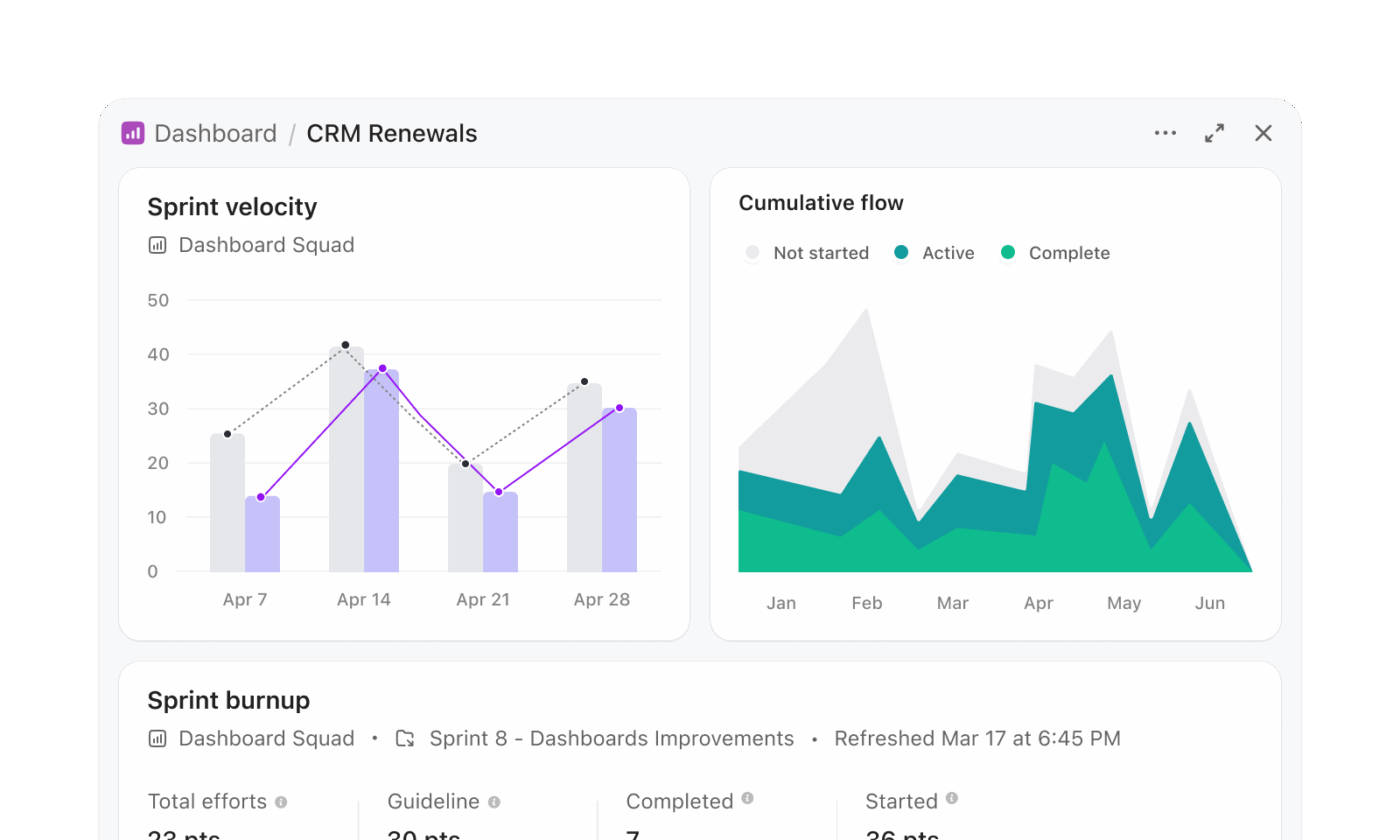
Snowflake Cortex-werkstroomen omvatten vaak het genereren van SQL, het uitvoeren van queries en het visualiseren van resultaten in een aparte laag. ClickUp Dashboards maken een einde aan dat meerstappenproces en presenteren inzichten rechtstreeks vanuit live werk.
Een programmamanagementteam dat de gereedheid voor een release bijhoudt, kan een dashboard bouwen zonder query's te schrijven. Een releasedashboard kan bijvoorbeeld het volgende bevatten:
- Een taaklijstkaart die is gefilterd om achterstallige taken van alle productteams weer te geven
- Een werklastkaart die de taakverdeling onder engineers weergeeft
- Een staafdiagram waarin voltooide taken worden vergeleken met taken in behandeling per Sprint
- Een berekeningskaart die de gemiddelde voltooiingstijd bijhoudt
Stel dat een programmaleider dit dashboard bekijkt vóór een releasevergadering. Hij ziet meteen dat de backend-services hogere vertragingen vertonen. Hij opent de lijst met taken en bekijkt welke taken precies het risico veroorzaken.
Een echte ClickUp-gebruiker deelt:
Met ClickUp kunnen we SNEL projecten aan elkaar doorgeven, GEMAKKELIJK de status van projecten controleren en geeft het onze leidinggevende op elk moment inzicht in onze werklast zonder dat ze ons hoeft te onderbreken. We hebben zeker één dag per week bespaard door ClickUp te gebruiken, zo niet meer. Het aantal e-mails is AANZIENLIJK verminderd.
Met ClickUp kunnen we SNEL projecten aan elkaar doorgeven, GEMAKKELIJK de status van projecten controleren en geeft het onze leidinggevende op elk moment inzicht in onze werklast zonder dat ze ons hoeft te onderbreken. We hebben zeker één dag per week bespaard door ClickUp te gebruiken, zo niet meer. Het aantal e-mails is AANZIENLIJK verminderd.
Handel op basis van inzichten zonder pijplijnen
Snowflake Cortex richt zich op het genereren van inzichten uit data. Teams moeten de resultaten nog steeds zelf interpreteren en afzonderlijk acties triggeren.
ClickUp AI Super Agents overbruggen die kloof en zetten inzichten om in actie. Ze fungeren als AI-teamgenoten die de gegevens in de werkruimte continu monitoren en actie ondernemen op basis van bepaalde voorwaarden.
Stel dat een programmamanager toezicht houdt op meerdere productinitiatieven. Een Super Agent kan:
- Houd taken binnen verschillende projecten in de gaten en detecteer wanneer achterstallige taken een bepaalde drempel overschrijden
- Identificeer patronen, zoals herhaaldelijke vertragingen in dezelfde werkstroomfase
- Maak een taak aan die de getroffen projecten samenvat en wijs deze toe aan de programmaleider
- Breng teameigenaren op de hoogte wanneer kritieke taken na het verstrijken van de deadline nog steeds niet zijn opgelost
Tijdens een releasecyclus detecteert een Super Agent bijvoorbeeld dat er in twee teams meer dan 10 taken met hoge prioriteit de deadline hebben gemist. Hij maakt een ClickUp-taak aan met de titel ‘Releasrisico: gemiste deadlines’, voegt alle relevante taken toe als bijlagen en wijst deze toe aan de programmamanager voor onmiddellijke beoordeling.
Teams kunnen ook rechtstreeks communiceren met de Super Agent: ‘Analyseer alle actieve projecten en markeer de opleveringsrisico's voor deze Sprint’.
De Super Agent controleert deadlines, afhankelijkheden en de status van taken en plaatst vervolgens een gestructureerd overzicht in de werkruimte.
Zo stel je je eigen Super Agent in ClickUp in:
Centraliseer uw gegevenswerkstroom met ClickUp
Text-to-SQL-tools zoals Snowflake Cortex maken data toegankelijker. Tegelijkertijd kost het nog steeds moeite om betrouwbare resultaten te verkrijgen.
Teams hebben behoefte aan schone schema's, sterke semantische modellen en voortdurende iteratie om de output nauwkeurig te houden. Zelfs nadat de juiste query is gegenereerd, houdt het werk daar niet op. Er moet nog steeds iemand de resultaten interpreteren, inzichten delen en deze omzetten in beslissingen.
ClickUp biedt een andere aanpak. In plaats van analyse en uitvoering van elkaar te scheiden, verbindt ClickUp beide. Teams genereren SQL, documenteren inzichten, werken samen aan bevindingen en ondernemen actie binnen dezelfde werkruimte.
ClickUp Brain helpt bij het schrijven en verfijnen van query's, terwijl dashboards en AI-agenten teams helpen resultaten bij te houden en werk voort te zetten zonder tussen verschillende tools te hoeven schakelen.
Snowflake Cortex helpt u antwoorden te vinden. ClickUp helpt u er iets mee te doen. Meld u vandaag nog aan voor ClickUp!
Veelgestelde vragen
Snowflake Cortex Analyst is een gespecialiseerde dienst binnen de bredere Snowflake Cortex AI-suite. Cortex Analyst is specifiek gericht op het genereren van tekst-naar-SQL met behulp van semantische modellen, terwijl Cortex AI een breder bereik aan LLM-functies, inferentie van machine learning-modellen en zoekmogelijkheden omvat.
Ja, Cortex Analyst kan query's uitvoeren op Apache Iceberg-tabellen die via Snowflake worden beheerd. Zolang de tabellen toegankelijk zijn binnen uw Snowflake-omgeving en correct zijn gedefinieerd in uw semantische model, kunt u query's op deze tabellen genereren.
De nauwkeurigheid van complexe query's hangt bijna volledig af van de kwaliteit van uw semantische model. Een model met duidelijk gedefinieerde tabelrelaties, talrijke geverifieerde query's en beschrijvende metadata levert aanzienlijk nauwkeurigere resultaten op voor joins met meerdere tabellen en complexe aggregaties.
De prijzen voor Snowflake Cortex Analyst volgen het op verbruik gebaseerde model van Snowflake, wat betekent dat u wordt gefactureerd op basis van de compute kredieten die tijdens het querygeneratieproces worden gebruikt. Raadpleeg voor de meest actuele tarieven altijd de officiële prijsdocumentatie van Snowflake.