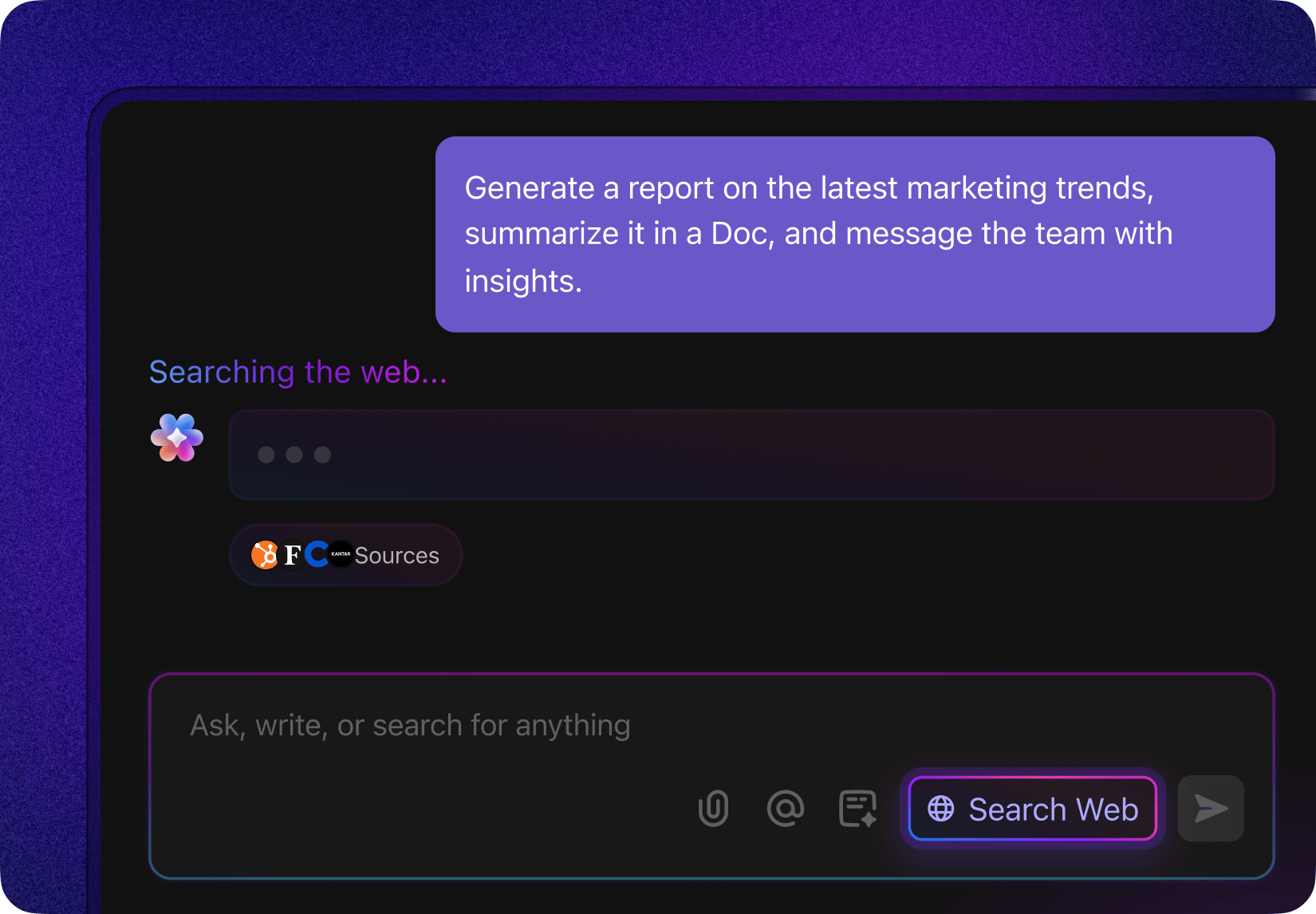

U weet zeker dat het document bestaat. U hebt het vorige week nog gezien.
Maar nadat u elke denkbare combinatie van trefwoorden hebt geprobeerd – 'marketingresultaten Q3', 'prestaties derde kwartaal', 'marketingrapport oktober' – blijft de zoekbalk van uw bedrijf leeg. Deze frustrerende zoektocht naar informatie is een klassiek teken van een verouderde trefwoordzoekopdracht.
Deze systemen vinden alleen exacte woordovereenkomsten en missen wat u eigenlijk bedoelt. Cohere lost dit probleem effectief op door een intelligente zoeklaag te bieden die de verbinding tussen uw systemen herstelt.
Dus als u zich afvraagt 'Hoe gebruik ik Cohere voor Enterprise Search?', dan hebben wij het antwoord voor u. In deze handleiding wordt alles uitgelegd.
Wat is Cohere AI en waarom is het belangrijk voor Enterprise Search?
Cohere is een AI-platform dat grote taalmodellen (LLM's) bouwt, speciaal voor gebruik binnen ondernemingen. Voor interne zoekopdrachten betekent dit dat er niet langer alleen op trefwoorden wordt gezocht, maar dat er sprake is van semantisch, intelligent zoeken dat intentie, context en betekenis begrijpt.
De meeste zoekfuncties voor ondernemingen zijn nog steeds gebaseerd op letterlijke trefwoordovereenkomsten. Als de exacte woorden niet in de titel of tekst van een document voorkomen, wordt het resultaat vaak gemist. Cohere brengt hier verandering in door zoekmachines in staat te stellen te begrijpen wat een gebruiker daadwerkelijk zoekt, en niet alleen wat hij heeft getypt.
Teams die zelf een AI-aangedreven zoekfunctie willen bouwen, zijn meestal maanden bezig met het samenstellen van vector-databases, het inbedden van pijplijnen en het herschikken van modellen. Zelfs na al dat werk presteert de zoekfunctie vaak ondermaats, omdat deze in een apart systeem draait, los van de taken, documenten en werkstroom waar het werk daadwerkelijk plaatsvindt.
Een krachtige zoekfunctie voor ondernemingen zoals Cohere maakt gebruik van retrieval-augmented generation (RAG) om slimme zoekopdrachten te combineren met AI. Deze aanpak maakt uw interne kennis direct toegankelijk.
In het geval van Cohere zet de tool documenten om in embeddings, numerieke weergaven van betekenis. Wanneer iemand zoekt naar 'kwartaalrapportage', haalt het systeem conceptueel relevante documenten op, zoals 'Financiële resultaten Q4' of 'Winstoverzicht', zelfs als die exacte trefwoorden niet aanwezig zijn.
Daarom is Cohere zo belangrijk voor enterprise search. Het vermindert de complexiteit van de implementatie, verbetert de nauwkeurigheid van de resultaten en maakt zoekopdrachten mogelijk die aansluiten bij de manier waarop werknemers daadwerkelijk denken en vragen stellen binnen moderne werksystemen.
📮ClickUp Insight: Meer dan de helft van alle werknemers (57%) verspilt tijd met het doorzoeken van interne documenten of de kennisbank van het bedrijf om werkgerelateerde informatie te vinden.
En als dat niet lukt? 1 op de 6 neemt zijn toevlucht tot persoonlijke workarounds: oude e-mails, aantekeningen of schermafbeeldingen doorzoeken om alles bij elkaar te puzzelen.
ClickUp Brain maakt zoeken overbodig door direct AI-aangedreven antwoorden te geven die uit uw hele ClickUp-werkruimte en geïntegreerde apps van derden worden gehaald, zodat u zonder gedoe krijgt wat u nodig hebt.
Belangrijkste Cohere-functies voor Enterprise Search
Wanneer u AI-zoekoplossingen evalueert, kan de marketinghype het moeilijk maken om te bepalen welke mogelijkheden daadwerkelijk uw problemen oplossen. Algemene beloften van 'slimmer zoeken' helpen uw engineering- en productteams niet om weloverwogen beslissingen te nemen.
De realiteit is dat een betrouwbaar zoeksysteem afhankelijk is van een reeks verschillende AI-modellen die samenwerken.
Cohere biedt verschillende modellen die u afzonderlijk kunt gebruiken of kunt combineren om een geavanceerde zoekarchitectuur te bouwen. Inzicht in deze kernfuncties is de eerste stap naar het ontwerpen van een systeem dat voldoet aan de specifieke behoeften van uw team.
Embedden voor semantische vectorzoekopdrachten
Het grootste minpunt van oude zoeksystemen is dat ze niet in staat zijn om conceptueel gerelateerde informatie te vinden. U zoekt naar 'onboardinggids voor werknemers' en mist het document met de titel 'Checklist voor de eerste dag van nieuwe werknemers'. Dit gebeurt omdat het systeem woorden met elkaar vergelijkt, niet de betekenis.
Het Embed-model, met neurale zoekfunctie, lost dit op door tekst om te zetten in vectoren: lange lijsten met getallen die de semantische betekenis weergeven. Dit proces, embedding genaamd, stelt het systeem in staat om documenten te identificeren die conceptueel vergelijkbaar zijn, zelfs als ze geen gemeenschappelijke trefwoorden hebben. In wezen begrijpt uw zoekfunctie automatisch synoniemen en verwante ideeën.
Dit zijn de sleutelaspecten van het Embed-model van Cohere:
- Multimodale ondersteuning: De nieuwste versie, Embed 4, kan zowel tekst als afbeeldingen verwerken, waardoor u in één keer in verschillende soorten content kunt zoeken.
- Meertalige mogelijkheden: u kunt informatie zoeken in documenten in verschillende talen zonder deze eerst te hoeven vertalen.
- Dimensionaliteitsopties: u kunt de grootte van uw vectoren kiezen. Hogere dimensies leggen meer nuances vast, maar vereisen meer opslagruimte en verwerkingskracht.
📖 Lees meer: AI Enterprise Search Use Cases
Herschik voor verbeterde relevantie van resultaten
Soms levert een zoekopdracht een lijst met relevante documenten op, maar staat het belangrijkste document verstopt op de tweede pagina. Hierdoor moeten gebruikers de resultaten doorzoeken, wat tijd kost en ervoor zorgt dat ze hun vertrouwen in het zoeksysteem verliezen.
Dit is een rangschikkingsprobleem. Het systeem heeft de juiste informatie gevonden, maar heeft deze niet correct geprioriteerd.
Het Rerank-model van Cohere lost dit op met een proces in twee fasen. Eerst gebruikt u een snelle zoekmethode (zoals semantisch zoeken) om een grote set potentieel relevante documenten te verzamelen. Vervolgens geeft u die lijst door aan het Rerank-model, dat een rekenintensievere cross-encoderarchitectuur gebruikt om elk document te analyseren aan de hand van uw specifieke query en ze opnieuw te rangschikken voor maximale relevantie.
Dit is vooral handig in situaties waarin precisie van cruciaal belang is, zoals wanneer een supportmedewerker het juiste antwoord voor een klant zoekt of een lid van het team naar een specifiek gedeelte in een document zoekt. Hoewel dit een kleine hoeveelheid verwerkingstijd toevoegt, is de verbetering in de kwaliteit van de resultaten vaak de moeite waard.
📖 Lees meer: Voorbeelden en use cases van workflowautomatisering
Enterprise Search-gebruiksscenario's voor teams
Abstracte AI-mogelijkheden zijn interessant, maar ze worden pas nuttig als u ze toepast om echte zakelijke problemen op te lossen. Een succesvolle implementatie van enterprise search begint met het identificeren van deze specifieke pijnpunten. 👀
Hier zijn een paar praktische scenario's waarin teams door Cohere aangedreven zoekopdrachten kunnen toepassen:
- Zoeken in kennisbanken: help medewerkers antwoorden te vinden in interne documentatie, wiki's, kennisbanken van de klantenservice en standaardwerkprocedures (SOP's) .
- Klantenservice: stel medewerkers in staat om snel relevante helpartikelen en eerdere ticketoplossingen te vinden terwijl ze in gesprek zijn met een klant. Uit analyse van McKinsey blijkt dat de productiviteit met 30-45% toeneemt wanneer generatieve AI wordt toegepast op werkstroomen van de klantenservice.
- Juridisch en compliance: doorzoek miljoenen contracten, beleidsdocumenten en regelgevingsdocumenten met semantisch begrip om specifieke clausules of precedenten te vinden.
- Onderzoek en ontwikkeling: stel ingenieurs in staat om relevant eerder werk, octrooien en technische documentatie te vinden om dubbel werk te voorkomen.
- HR en onboarding: Breng relevante beleidsregels, trainingsmateriaal, voorbeelden van werkstroom en procedures voor nieuwe medewerkers naar voren, zodat zij zelf antwoorden kunnen vinden.
- Sales enablement: help verkopers de juiste casestudy's, concurrentie-informatie en productinformatie te vinden om deals sneller te sluiten.
De rode draad is dat effectief zoeken binnen ondernemingen moet worden geïntegreerd in de bestaande werkstroom. Een op zichzelf staande zoekbalk is niet voldoende. Uw team moet informatie kunnen vinden en daar onmiddellijk op kunnen reageren zonder van tool te hoeven wisselen.
🛠️ Toolkit: Creëer een interne hub die uw team daadwerkelijk zal gebruiken. Het sjabloon voor de Knowledge Base van ClickUp houdt alles – van how-to's tot SOP's – overzichtelijk georganiseerd en gemakkelijk doorzoekbaar, zodat niemand hoeft te raden waar de informatie zich bevindt.

Hoe u Cohere instelt voor Enterprise Search
De overstap van het evalueren van AI-zoekopdrachten naar de daadwerkelijke implementatie ervan kan intimiderend zijn. Vooral als uw team nog niet bekend is met grote taalmodellen.
Hoewel de complexiteit van uw installatie afhankelijk is van uw schaalgrootte en bestaande technologiestack, zijn de belangrijkste stappen voor het bouwen van een door Cohere aangedreven zoeksysteem altijd hetzelfde. Dit gedeelte biedt een praktische handleiding voor uw technische team.
Vereisten en API-toegang
Voordat u code gaat schrijven, moet u uw tools en toegang op orde hebben. Deze eerste installatie helpt om problemen met de veiligheid en obstakels later te voorkomen.
Dit is wat u nodig hebt om aan de slag te gaan:
- Cohere API-account: Meld u aan op de Cohere-website om uw API-sleutels te verkrijgen.
- Ontwikkelomgeving: De meeste teams gebruiken Python, maar er zijn ook SDK's beschikbaar voor andere talen.
- Vector-database: u hebt een plek nodig om uw document-embeddings op te slaan, zoals Pinecone, Weaviate, Qdrant of een beheerde service zoals Amazon OpenSearch.
- Documentcorpus: verzamel de content die u doorzoekbaar wilt maken (bijv. pdf's, tekstbestanden, databaserecords).
U kunt ook toegang krijgen tot de modellen van Cohere via Amazon Bedrock, wat de facturering en veiligheid kan vereenvoudigen als uw bedrijf al binnen het AWS-ecosysteem werkt.
Genereer embeddings met Cohere Embed
De volgende stap is het omzetten van uw documenten in doorzoekbare vectoren. Dit proces omvat het voorbereiden van uw content en deze vervolgens door het Cohere Embed-model te halen.
De manier waarop u uw documenten voorbereidt, en met name hoe u ze in kleinere stukken opsplitst, heeft een enorme invloed op de zoekresultaten. Dit wordt uw chunkingstrategie genoemd.
Veelgebruikte chunking-strategieën zijn onder meer:
- Vastgrootte chunks: De eenvoudigste methode, maar deze kan zinnen of ideeën op een onhandige manier in tweeën splitsen.
- Semantische chunking: een geavanceerdere methode die rekening houdt met de documentstructuur, zoals het splitsen aan het einde van alinea's of secties.
- Overlappende stukken: Bij deze aanpak wordt een kleine hoeveelheid tekst tussen stukken herhaald om de context over de grenzen heen te behouden.
Zodra uw documenten zijn opgedeeld, stuurt u ze in batches naar de Embed API om de vectorrepresentaties te genereren. Dit is meestal een eenmalig proces voor uw bestaande documenten, waarbij nieuwe of bijgewerkte documenten worden ingebed zodra ze worden aangemaakt.
Vectoren opslaan en queryen
Uw nieuw aangemaakte vectoren hebben een thuis nodig. Een vectordatabase is een gespecialiseerde database die is ontworpen om embeddings op basis van hun gelijkenis op te slaan en op te vragen.
De query-procedure werkt als volgt:
- Een gebruiker typt een zoekquery in
- Uw applicatie stuurt die query naar hetzelfde Cohere Embed-model om deze om te zetten in een vector.
- De queryvector wordt naar de database gestuurd, die de meest vergelijkbare documentvectoren vindt.
- De database retourneert de overeenkomende documenten, die u vervolgens aan de gebruiker kunt tonen.
Bij het kiezen van een vectordatabase moet u ook overwegen welke gelijkenismeting u wilt gebruiken. Cosinusgelijkenis wordt het meest gebruikt voor tekstgebaseerd zoeken, maar er zijn ook andere opties voor verschillende gebruikssituaties.
| Overeenkomstmaatstaf | Het meest geschikt voor |
|---|---|
| Cosinusgelijkenis | Algemene zoekopdrachten voor tekst |
| Dot Product | Wanneer de grootte van vectoren belangrijk is |
| Euclidische afstand | Ruimtelijke of geografische gegevens |
Implementeer herrangschikking voor betere resultaten
Voor veel toepassingen zijn de resultaten uit uw vectordatabase goed genoeg. Maar wanneer u het allerbeste resultaat bovenaan wilt hebben, is het slim om een herschikkingsstap toe te voegen.
Dit is vooral belangrijk wanneer uw zoekfunctie een RAG-systeem aanstuurt, aangezien de kwaliteit van het gegenereerde antwoord sterk afhankelijk is van de kwaliteit van de opgehaalde context.
De herrangschikkingspijplijn is eenvoudig:
- Haal een grotere set van initiële kandidaten uit uw vectordatabase (bijvoorbeeld de top 50 resultaten).
- Geef de oorspronkelijke query van de gebruiker en deze lijst met kandidaten door aan de Cohere Rerank API.
- De API retourneert dezelfde lijst met documenten, maar dan opnieuw gerangschikt op basis van een nauwkeurigere relevantiescore.
- Toon de beste resultaten uit de opnieuw gerangschikte lijst aan de gebruiker.
Om de impact van het opnieuw rangschikken te meten, kunt u offline evaluatiestatistieken bijhouden, zoals nDCG (Normalized Discounted Cumulative Gain) en MRR (Mean Reciprocal Rank).
💫 Bekijk deze walkthrough voor een visueel overzicht van de implementatie van Enterprise Search-mogelijkheden, waarin de belangrijkste concepten en praktische overwegingen worden gedemonstreerd:
Best practices voor Cohere-aangedreven Enterprise Search
Het bouwen van een zoeksysteem is slechts de eerste stap. Het onderhouden en verbeteren van de kwaliteit ervan in de loop van de tijd is wat een succesvol project onderscheidt van een mislukt project. Als gebruikers een paar slechte ervaringen hebben, verliezen ze hun vertrouwen en stoppen ze met het gebruik van de tool. 🛠️
Hier zijn enkele lessen die zijn geleerd uit succesvolle implementaties van enterprise search:
- Begin met hybride zoeken: vertrouw niet alleen op semantisch zoeken. Combineer het met een traditioneel algoritme voor zoeken op trefwoorden, zoals BM25. Zo profiteert u van het beste van twee werelden: semantisch zoeken vindt conceptueel gerelateerde items, terwijl zoeken op trefwoorden ervoor zorgt dat u nog steeds exacte overeenkomsten kunt vinden voor productcodes of specifieke namen.
- Investeer in datakwaliteit en -hygiëne: uw zoekresultaten zijn slechts zo goed als uw data. Schone, goed gestructureerde documenten met duidelijke koppen en alinea's leveren veel betere embeddings op.
- Verdeel zorgvuldig: De manier waarop u uw documenten in delen verdeelt, is van cruciaal belang. In plaats van willekeurige limieten voor tekens te gebruiken, kunt u beter proberen de delen af te stemmen op de logische structuur van uw documenten, zoals alinea's of secties.
- Metadatafiltering toevoegen: Semantisch zoeken is krachtig, maar soms weten gebruikers al wat ze zoeken. Laat hen resultaten filteren op metadata zoals datum, afdeling of documenttype voordat het semantisch zoeken begint.
- Monitor en herhaal: let goed op wat uw gebruikers zoeken, op welke resultaten ze klikken en welke queries geen resultaten opleveren. Deze gegevens zijn van onschatbare waarde voor het identificeren van hiaten in de content en het verbeteren van uw systeem.
- Ga op een elegante manier om met fouten: geen enkel zoeksysteem is perfect. Wanneer een zoekopdracht slechte resultaten oplevert, bied dan nuttige alternatieven aan, zoals het voorstellen van alternatieve queries of het aanbieden van hulp door een menselijke expert.
Beperkingen van Cohere voor Enterprise Search
Hoewel Cohere krachtige AI-modellen biedt, is het geen plug-and-play-oplossing (niet helemaal).
Het bouwen van een productieklaar enterprise search-oplossing brengt aanzienlijke uitdagingen met zich mee die teams vaak onderschatten. Het is cruciaal om deze beperkingen te begrijpen om een weloverwogen beslissing te kunnen nemen en dure verrassingen achteraf te voorkomen.
Het grootste probleem is dat u een set tools krijgt, geen afgewerkt product. Hierdoor blijft uw team verantwoordelijk voor het bouwen en onderhouden van de volledige infrastructuur rond zoeken als een dienst.
Hier zijn enkele sleutel-limieten waarmee u rekening moet houden:
| Uitdaging | Waarom dit een probleem wordt |
|---|---|
| Vereist gespecialiseerde expertise | U hebt ervaren AI- en data-engineers nodig om het systeem te bouwen, te beheren en te onderhouden. Dit is niet iets wat de meeste teams zomaar kunnen opzetten of bezitten. |
| Aangepaste integraties vereist | De modellen maken niet automatisch verbinding met uw bestaande tools. Elke databron moet handmatig worden aangesloten en onderhouden. |
| Veel onderhoud nodig | Zoekindexen moeten voortdurend worden vernieuwd naarmate de content verandert of modellen worden bijgewerkt, wat extra operationeel werk met zich meebrengt. |
| Niet verbonden met uw werkruimte | De AI begrijpt taal, maar bevindt zich niet op de plek waar uw team daadwerkelijk werkt, waardoor er een kloof ontstaat tussen zoeken en uitvoeren. |
| Contextwisselingen zijn onvermijdelijk | Mensen vinden informatie op één plek en schakelen vervolgens over naar andere tools om ermee aan de slag te gaan, wat ten koste gaat van de productiviteit en acceptatie. |
📖 Lees meer: Gratis sjablonen voor kennisbanken in Word & ClickUp
Hoe u ClickUp kunt gebruiken als alternatief voor Enterprise Search
Inmiddels zou de afweging duidelijk moeten zijn.
Enterprise Search is krachtig, maar als u het zelf bouwt, moet u ook zorgen voor ingestiepijplijnen, chunkingstrategieën, het vernieuwen van embeddings, logica voor het opnieuw rangschikken en voortdurend onderhoud. Dat is een langdurige investering in infrastructuur, geen uitrol van een functie.
Als 's werelds eerste geconvergeerde AI-werkruimte verwijdert ClickUp die hele laag door AI-aangedreven zoeken native te maken voor de werkruimte zelf.
Dit is belangrijk omdat de meeste zoekproblemen niet echt zoekproblemen zijn. Het zijn problemen met versnipperd werk . Wanneer werk verspreid is over verschillende tools, zijn teams gedwongen om voortdurend op zoek te gaan naar context. Het resultaat is tijdverlies, dubbel werk en beslissingen die worden genomen zonder volledige zichtbaarheid.
ClickUp pakt dat probleem bij de bron aan door werk, context en intelligentie samen te brengen in één werkruimte. Laten we eens kijken hoe dat in de praktijk werkt.
Krijg contextbewuste antwoorden uit de hele werkruimte met ClickUp Brain.
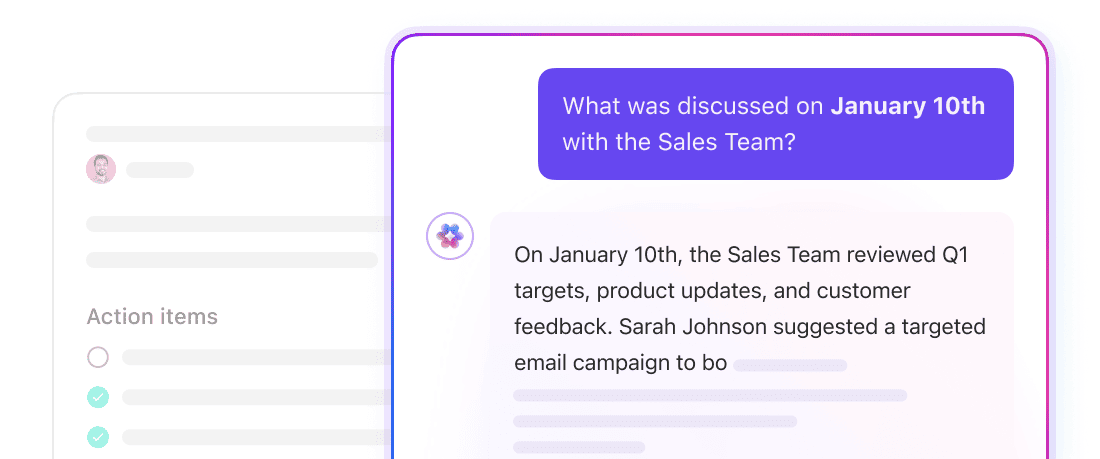
ClickUp Brain is een contextuele AI-laag die in uw hele werkruimte actief is. Het kan vragen beantwoorden, informatie samenvatten en relevant werk naar voren brengen, omdat het al toegang heeft tot de onderliggende structuur van uw werkruimte: ClickUp-taaken, ClickUp-documenten, ClickUp-comments en meer.
U hoeft hier geen chunkgroottes te definiëren of embeddings te beheren. Brain gebruikt het native datamodel van ClickUp om te begrijpen hoe informatie met elkaar verbonden is. Stel een vraag als "Wat blokkeert de lancering in het vierde kwartaal?" en Brain kan context halen uit taken, opmerkingen en documenten die aan dat initiatief zijn gekoppeld.
ClickUp Brain ondersteunt ook meerdere AI-modellen, waardoor u verschillende verzoeken kunt koppelen aan het meest geschikte model voor redeneren, samenvatten of genereren. Zo voorkomt u dat uw werkstroom wordt beperkt door de sterke punten of beperkingen van één enkel model.
Wanneer u externe context nodig hebt, kan Brain rechtstreeks vanuit de ClickUp-werkruimte zoeken op internet en samengevatte resultaten weergeven zonder dat u ClickUp hoeft te verlaten of een apart browsertabblad hoeft te openen.
Zoek, navigeer en voer uit met ClickUp Enterprise Search
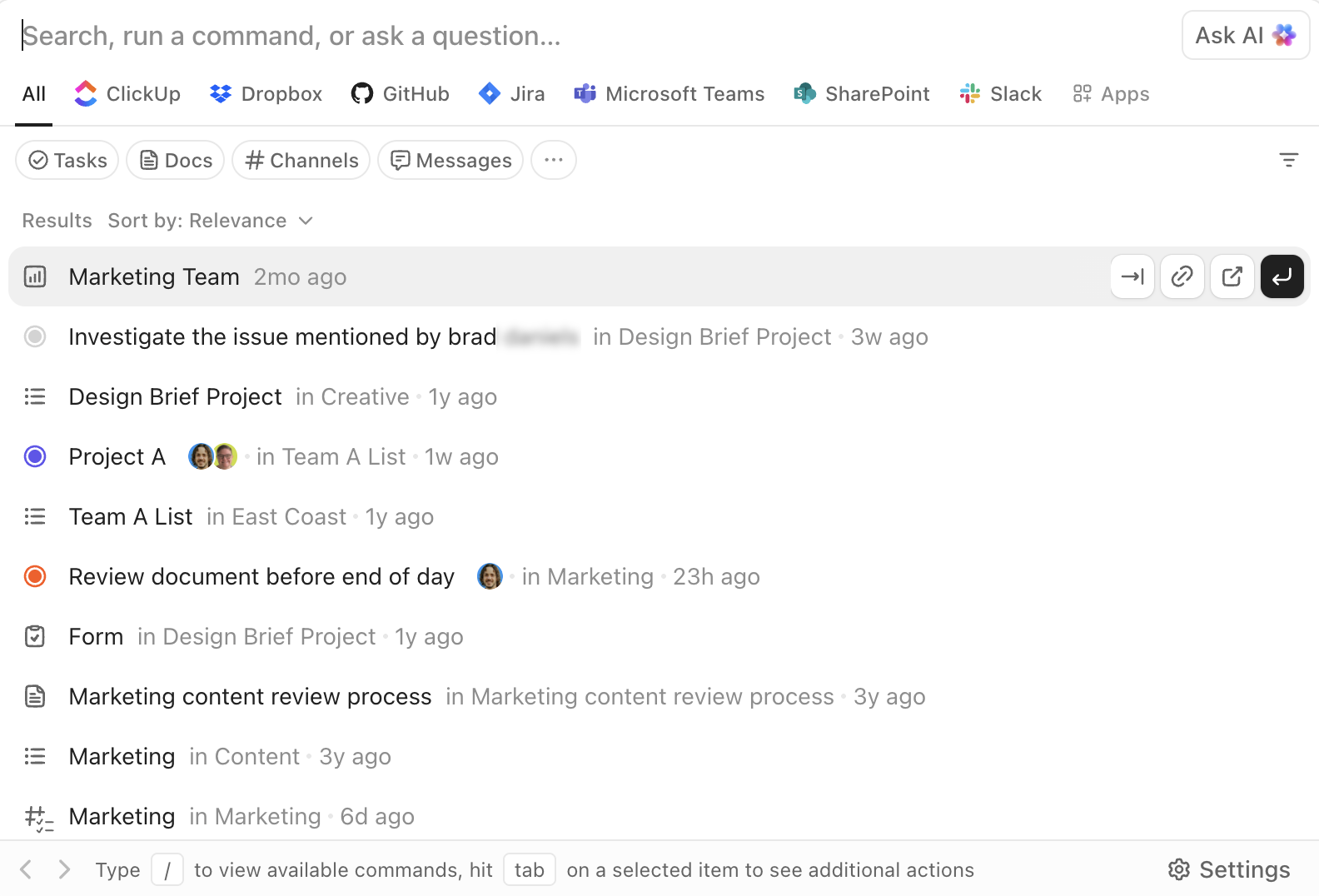
ClickUp's Enterprise Search is overal in de werkruimte toegankelijk. Hiermee kunt u zoeken in taken, documenten, opmerkingen en bijlagen, maar ook in gekoppelde apps van derden, zoals Google Drive, Slack, GitHub en meer, afhankelijk van uw integraties.
De AI Command Bar verandert zoeken in een uitvoeringslaag. U kunt rechtstreeks vanuit dezelfde interface naar items springen, taken aanmaken, statussen wijzigen, eigenaren toewijzen of specifieke weergaven openen. Dit is niet alleen 'zoeken en lezen', maar 'zoeken en handelen'.
Omdat zoeken is geïntegreerd in de gebruikersinterface van de werkruimte, zijn de resultaten altijd bruikbaar. U hoeft informatie niet apart op te halen en vervolgens van tool te wisselen om deze te gebruiken. De werkstroom blijft ononderbroken.
Verminder de wildgroei aan tools met ClickUp BrainGPT
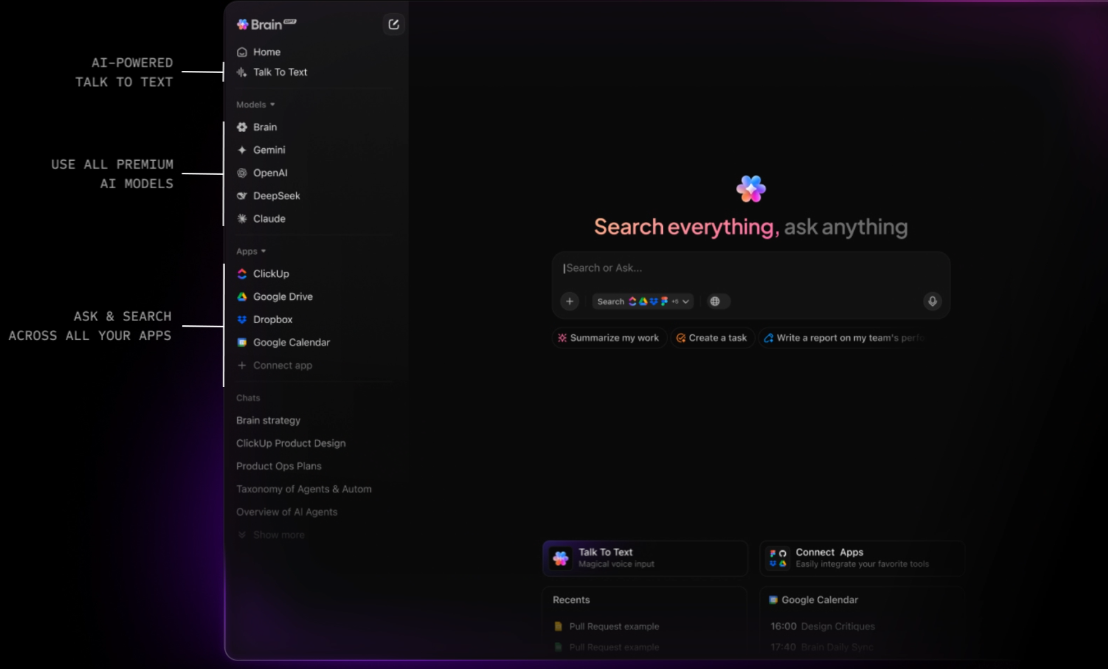
ClickUp BrainGPT breidt de zoekmogelijkheden uit tot buiten de browser en biedt een zelfstandige desktop-app en Chrome-extensie. Het maakt rechtstreeks verbinding met uw ClickUp-werkruimte en toont dezelfde contextuele intelligentie zonder dat u eerst ClickUp of een van uw verbonden apps hoeft te openen.
Vanuit één interface kunt u zoeken in taken, documenten, opmerkingen en gekoppelde tools, waaronder Gmail en andere integraties. Met de spraakgestuurde Talk-to-Text-functie kunt u direct zoekopdrachten uitvoeren of vragen vastleggen, wat vooral handig is voor snelle opzoekingen of werk onderweg.
In plaats van nog een AI-zoekproduct toe te voegen dat u moet beheren, consolideert Brain GPT het zoeken in één omgeving die uw werk al begrijpt.
Dat is de echte verandering. ClickUp vraagt u niet om een enterprise search te bouwen. Deze geconvergeerde werkruimte integreert het rechtstreeks in het systeem waar het werk plaatsvindt, waardoor infrastructuurkosten worden weggenomen en tegelijkertijd kracht, nauwkeurigheid en snelheid behouden blijven.
📖 Lees meer: Voorbeelden van de beste kennisbeheersystemen
Bonus: strategische vergelijking tussen aangepaste en native AI voor werkruimten
| Kernwaarde | Maximale flexibiliteit; eigen controle | Klaar voor uitvoering; standaard contextbewust |
| Implementatie | Maanden: Vereist dat engineeringteams pijplijnen bouwen | Minuten: met één klik schakelen voor de hele werkruimte |
| Gegevensopname | Handleiding: u moet ETL & vector DB bouwen en onderhouden | Automatisch: realtime toegang tot taken, documenten en chatten |
| Toestemminglogica | Moet handmatig worden gecodeerd (hoog risico op datalekken) | Van nature overgenomen uit uw ClickUp-hiërarchie |
| Contextuele diepgang | Semantisch (op betekenis gebaseerd) | Operationeel (weet wie aan wat is toegewezen) |
| Gebruikersinterface | U moet de zoekbalk/chatten ontwerpen en bouwen. | Ingebouwd (zoekbalk, documenten en taakweergaven) |
| Werkstroom-actie | Geen: gebruiker vindt informatie en schakelt vervolgens over naar andere tools om te werken | Hoog: vind informatie en zet deze direct om in een Taak |
| Het meest geschikt voor | Technologiegerichte bedrijven die eigen software ontwikkelen | Teams die 'tool sprawl' willen elimineren en snel willen handelen |
Zoeken mag u niet tegenhouden!
Semantisch zoeken is niet langer een onderscheidende factor. Het is een basisvereiste.
De werkelijke kosten van zoeken binnen ondernemingen komen overal naar voren: de tijd die technici nodig hebben om het op te zetten en te onderhouden, de infrastructuur die nodig is om het nauwkeurig te houden en de wrijving die ontstaat wanneer zoeken buiten de tools plaatsvindt waar het werk daadwerkelijk gebeurt. Het vinden van het juiste document maakt niet veel uit als je nog steeds van systeem moet wisselen om er iets mee te doen.
Daarom is het probleem niet alleen 'beter zoeken'. Het gaat om het dichten van de kloof tussen informatie en uitvoering.
Wanneer zoeken rechtstreeks in de werkruimte is ingebed, blijft de context standaard behouden. Antwoorden worden niet alleen opgehaald, ze zijn ook direct bruikbaar. Taaken kunnen worden bijgewerkt, beslissingen kunnen worden gedocumenteerd en het werk kan worden voortgezet zonder dat er nog een overdracht nodig is.
Voor teams die geen maanden willen besteden aan het bouwen en onderhouden van een aangepaste zoekinfrastructuur, verandert het werken in een geconvergeerde AI-werkruimte de situatie volledig. ClickUp biedt zoekfuncties op bedrijfsniveau, aangedreven door AI, als onderdeel van het systeem dat uw team al gebruikt om te plannen, samen te werken en uit te voeren.
✅ Ga gratis aan de slag met ClickUp.
Veelgestelde vragen
Cohere richt zich specifiek op gebruikssituaties voor ondernemingen, zoals zoeken, en biedt modellen zoals Embed en Rerank die speciaal zijn ontworpen voor zoekopdrachten. OpenAI biedt bredere, algemene modellen die kunnen worden aangepast voor zoekopdrachten, maar mogelijk meer afstemming vereisen.
Ja, Cohere biedt API's die integratie met andere tools mogelijk maken, maar hiervoor zijn wel aangepaste ontwikkeling en technische middelen nodig. Een alternatief zoals ClickUp biedt native AI-zoekfuncties die direct uit de doos werken, waardoor integratiewerkzaamheden overbodig zijn.
Sectoren met grote, ongestructureerde opslagplaatsen voor documenten, zoals de juridische sector, de gezondheidszorg, de financiële dienstverlening en de technologiesector, hebben het meeste baat bij semantisch zoeken. Elke organisatie die worstelt met kennisbeheer kan aanzienlijke verbeteringen realiseren.