
AIデプロイメントプロジェクトの失敗は、チームが誤ったモデルを選択したためではなく、3か月後にはなぜそのモデルを選んだのか、セットアップを再現する方法すら誰も覚えていないことが原因です。AIプロジェクトの46%が概念実証(PoC)から本格的な導入の間に破棄されています。
このガイドでは、Hugging Faceを用いたAIデプロイの全工程(モデルの選択・テストからデプロイ管理まで)を解説します。これにより、Slackのスレッドや散在するスプレッドシートに重要な意思決定が埋もれることなく、チームは迅速に成果を出せるようになります。
Hugging Faceとは?
Hugging Faceは、機械学習アプリケーションの構築とデプロイ向けに事前学習済みAIモデル、データセット、ツールを提供するオープンソースプラットフォームかつコミュニティハブです。
これは巨大なデジタルライブラリのようなものと考えてください。一から構築するのに数か月と膨大なリソースを費やす代わりに、すぐに使えるAIモデルを見つけることができます。
機械学習エンジニアやデータサイエンティスト向けに設計されていますが、そのツールはクロスファンクショナルなプロダクト、デザイン、エンジニアリングチームによっても活用され、AIをワークフローに統合する手段として普及しています。
多くのチームにとっての核心的な課題は、AIデプロイの圧倒的な複雑さです。このプロセスには、数千の選択肢から適切なモデルを選択すること、基盤インフラの管理、実験のバージョン管理、そして技術系・非技術系のステークホルダー間の連携確保が含まれます。
Hugging Faceは、200万以上のモデルを収めた中央リポジトリ「Model Hub」を提供することでこれを簡素化します。プラットフォームのTransformersライブラリはこれらのモデルを活用する鍵であり、わずか数行のPythonコードで読み込み・使用を可能にします。
しかし、こうした強力なツールがあっても、AIデプロイメントは依然としてプロジェクト管理上の課題であり、成功を確実にするためにはモデルの選択、テスト、ロールアウトを注意深く追跡する必要があります。
📮ClickUpインサイト:知識労働者の92%が、チャット・電子メール・スプレッドシートに散在する重要な意思決定を喪失するリスクに直面しています。意思決定を統一的に記録・追跡するシステムがなければ、重要なビジネスインサイトはデジタルノイズに埋もれてしまいます。
ClickUpのタスク管理機能があれば、こうした心配は無用です。チャット、タスクコメント、ドキュメント、電子メールからワンクリックでタスクを作成!
デプロイ可能なHugging Faceモデル
Hugging Face hubの操作は、初めて使うと圧倒されるかもしれません。数十万ものモデルが存在する中で、プロジェクトに最適なモデルを見つける鍵は主要カテゴリを理解することです。モデルは、単一目的向けに設計された小型で効率的なものから、複雑な推論を処理できる大規模な汎用モデルまで範囲があります。
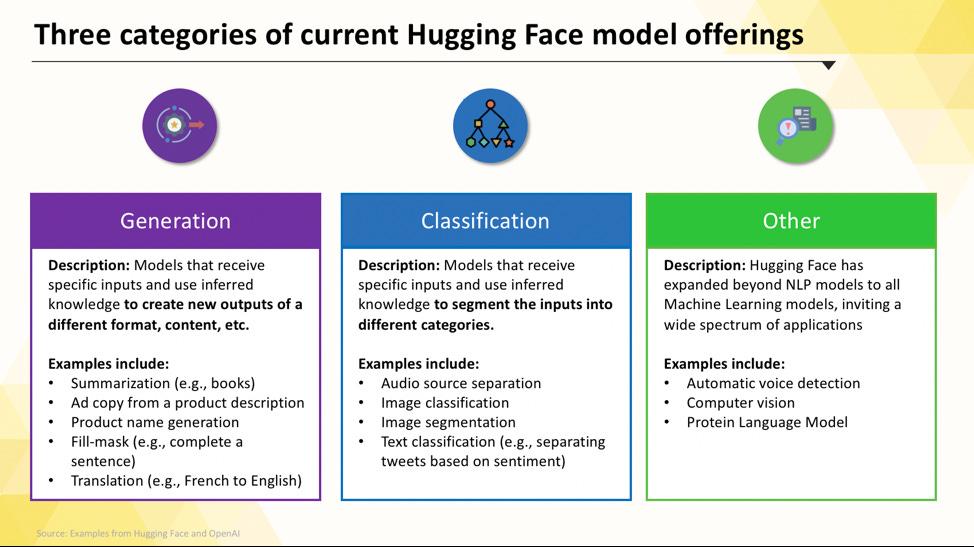
タスク特化型言語モデル
チームが単一で明確な課題を解決する必要がある場合、大規模な汎用モデルは不要なことが多々あります。そのようなモデルを実行する時間とコストは膨大になりがちで、特に小規模で特化したAIツールの方が効果的な場合にはなおさらです。そこで活躍するのがタスク特化型モデルです。
これらは特定の機能向けに訓練・最適化されたモデルです。専門性が高いため、通常はより大規模なモデルと比較してサイズが小さく、高速で、リソース効率に優れています。
これにより、速度とコストが重要な要素となる本番環境での使用に最適です。多くのモデルは標準的なCPUハードウェアでも実行可能であり、高価なGPUなしでも利用できます。
タスク特化モデルの一般的な種類には以下が含まれます:
- テキスト分類: テキストを事前定義されたラベルに分類するために使用します。例えば、顧客フィードバックを「肯定的」または「否定的」に分類したり、サポートチケットをトピック別にタグ付けしたりします。
- 感情分析:テキストの感情的トーンを判断するのに役立ち、ソーシャルメディアでのブランド監視に有用です。
- 固有表現認識:文書から人物、場所、組織などの特定エンティティを抽出し、非構造化データの構造化を支援します
- 要約機能: 長文の記事やレポートを簡潔な要約に要約し、チームの貴重な読解時間を節約します
- 翻訳: テキストを自動で別の言語に変換します
📚 こちらもご覧ください:テキストを要約する際にHugging Faceを活用する方法
大規模言語モデル
プロジェクトによっては、単純な分類や要約以上の機能が必要になる場合があります。創造的なマーケティングコピーを生成したり、コードを書いたり、複雑なユーザー質問に会話形式で回答できるAIが必要になるかもしれません。こうしたシナリオでは、大規模言語モデル(LLM)が有効な選択肢となるでしょう。
LLM(大規模言語モデル)とは、インターネット上の膨大なテキストやデータを用いて訓練された数十億のパラメーターを持つモデルです。この大規模な訓練により、ニュアンスや文脈、複雑な推論を理解する能力を獲得しています。Hugging Faceで利用可能な人気のオープンソースLLMには、Llama、Mistral、Falconファミリーのモデルが含まれます。
この強力な性能の代償として、膨大な計算リソースが必要となります。これらのモデルをデプロイするには、大容量メモリ(VRAM)を備えた高性能GPUがほぼ必須です。
よりアクセスしやすくするため、量子化などの技術を活用できます。これにより、性能をわずかに犠牲にしながらモデルのサイズを縮小でき、性能の低いハードウェアでも実行可能になります。
📚 関連記事:AIにおけるLLMエージェントとは?その仕組みを解説
テキストから画像生成モデルとマルチモーダルモデル
データはテキストだけとは限りません。マーケティングキャンペーン用の画像生成、ミーティング音声の文字起こし、ビデオコンテンツの理解など、チームが直面する課題は多岐にわたります。こうした異なるデータタイプを横断的に処理するマルチモーダルモデルこそが、まさにここで不可欠となるのです。
最も人気のあるマルチモーダルモデルはテキストから画像を生成するモデルです。Stable Diffusionのようなモデルは拡散法と呼ばれる技術を用い、シンプルなプロンプトから驚くべきビジュアルを創出します。しかしその可能性は画像生成だけにとどまりません。
Hugging Faceからデプロイ可能なその他の一般的なマルチモーダルモデルには以下が含まれます:
- 画像キャプション生成: 画像のテキストを自動生成。アクセシビリティ向上やコンテンツ管理に最適です。
- 音声認識:OpenAIのWhisperなどのモデルで、音声データをテキストに変換します。
- ビジュアル質問応答: 画像について質問し、テキストベースの回答を得られます。例:「この写真の車はどんな色ですか?」
LLMと同様に、これらのモデルは計算負荷が高く、効率的に実行するには通常GPUが必要です。
📚 こちらもご覧ください:驚異的なビジュアルを生成する50以上のAI画像プロンプト
これらの異なるAIモデルが実際のビジネスアプリケーションにどう応用されるかを知るには、様々な業界や機能分野における実世界のAI活用事例をまとめたこの概要をご覧ください。
御社のAI成熟度はどの程度ですか?
316名の専門家を対象としたアンケートから、真のAI変革にはAI機能の導入だけでは不十分であることが明らかになりました。AI成熟度診断テストで自社の現状を把握し、スコア向上のためにやることを確認しましょう。
AIデプロイメントのためのHugging Face設定方法
最初のモデルをデプロイする前に、ローカル環境とHugging Faceアカウントを正しくセットアップする必要があります。チームメンバー間で設定が統一されていないと「私の環境では動くのに」という典型的な問題が発生し、よくある悩みとなります。このプロセスを標準化するために数分かけることで、後々のトラブルシューティングに要する時間を大幅に節約できます。
- Hugging Faceアカウントを作成し、アクセストークンを生成するまず、Hugging Faceのウェブサイトで無料アカウントに登録します。ログイン後、プロフィールに移動し、「設定」をクリックし、「アクセストークン」タブを選択します。最低でも「read」許可を持つ新しいトークンを生成してください。モデルをダウンロードする際に必要です。
- 必要なPythonライブラリをインストールするターミナルを開き、必要なコアライブラリをインストールします。必須の2つはtransformersとhuggingface_hubです。pipを使用してインストールできます:pip install transformers huggingface_hub
- 認証の設定アクセストークンを使用するには、コマンドラインでhuggingface-cli loginを実行し、プロンプトが表示されたらトークンを貼り付けるか、システム環境変数として設定します。コマンドラインログインが最も簡単な開始方法です。
- セットアップの確認すべてが正常に動作していることを確認する最良の方法は、簡単なコードを実行することです。transformersライブラリのpipeline機能を使用して基本モデルを読み込んでみてください。エラーなく実行されれば、準備完了です。
Hub上のモデルの一部は「ゲート付き」であることに注意してください。つまり、トークンでアクセスするには、モデルページでライセンス条項に同意する必要があります。
また、誰がどの認証情報を持っているか、どの環境設定が使用されているかを追跡することは、それ自体がプロジェクト管理のタスクであり、チームの規模が大きくなるほど重要度が増すことを覚えておいてください。
🌟 Hugging Faceモデルをより広範なソフトウェアシステムに統合する場合、ClickUpのソフトウェア統合テンプレートがワークフローの可視化と多段階の技術的統合の追跡を支援します。
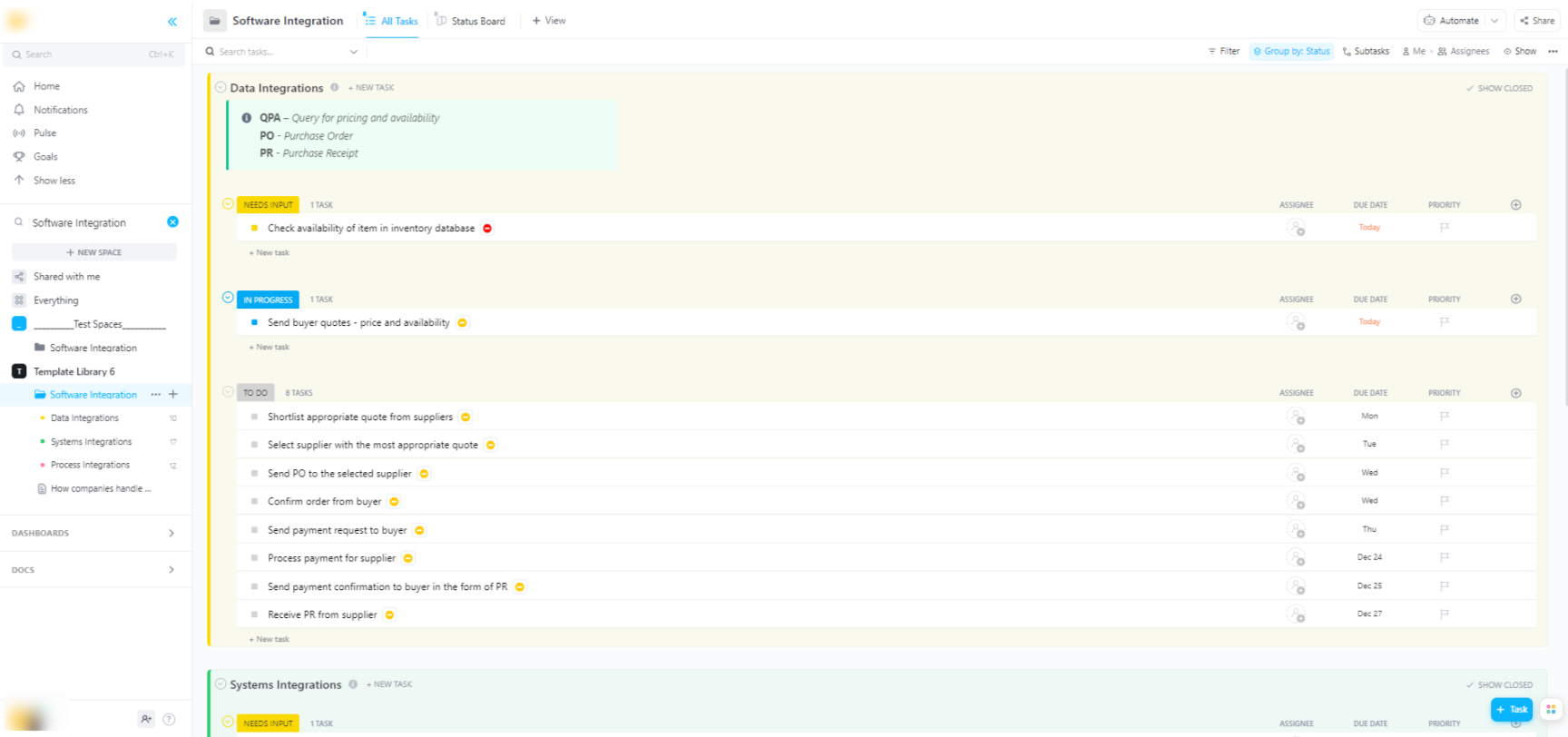
このテンプレートは、以下の操作を簡単に行えるシステムを提供します:
- 異なるソフトウェアソリューション間の接続を可視化する
- チームメンバーにタスクを作成・割り当て、円滑なコラボレーションを実現
- 統合に関連するすべてのタスクを一箇所に整理する
Hugging Faceモデルのデプロイメントオプション
ローカル環境でモデルをテストしたら、次に考えるべきは「どこに配置するか」です。他者が利用可能な本番環境にモデルをデプロイすることは重要なステップですが、選択肢は複雑です。誤った方法を選択すると、パフォーマンスの低下、コストの増加、ユーザートラフィックへの対応不能といった問題が生じる可能性があります。
選択は、想定トラフィックや予算、迅速なプロトタイプ構築かスケーラブルな本番環境対応アプリケーションかの有無など、具体的な要件によって異なります。
Hugging Face スペース
デモや社内ツールを迅速に作成する必要がある場合、Hugging Face Spacesが最適な選択肢となることが多いです。Spacesは機械学習アプリケーションをホストするための無料プラットフォームであり、チームや関係者と共有できるプロトタイプ構築に最適です。
GradioやStreamlitといった人気フレームワークでアプリのユーザーインターフェースを構築できます。これにより、わずか数行のPythonコードでインタラクティブなデモを簡単に作成できます。
スペースの作成は、お好みのSDKを選択し、コードを格納したGitリポジトリを接続し、ハードウェアを選択するだけの簡単さです。基本的なアプリには無料のCPU環境が提供されますが、より負荷の高いモデルには有料のGPUハードウェアへアップグレード可能です。
以下のリミットに留意してください:
- 高トラフィックAPI向けではありません: スペースはデモ用に設計されており、数千の同時APIリクエストを処理するものではありません
- コールドスタート: スペースが非アクティブ状態の場合、リソース節約のため「スリープ状態」に移行することがあり、次にアクセスする最初のユーザーに遅延が生じます
- Gitベースのワークフロー: アプリケーションコード全体をGitリポジトリで管理。バージョン管理に最適です
Hugging Face Inference API
既存アプリケーションにモデルを統合する際は、APIの利用が一般的です。Hugging Face Inference APIを使えば、基盤インフラを自ら管理することなくモデルを実行できます。データを含むHTTPリクエストを送信するだけで、予測結果が返ってきます。
サーバー管理やスケーリング、メンテナンスを避けたい場合に最適なアプローチです。Hugging Faceはこのサービスにおいて主に2つのプランを提供しています:
- 無料推論API: これはレートリミット付きの共有インフラストラクチャオプションであり、開発やテストに最適です。トラフィックが少ないユースケースや、導入初期段階にぴったりです。
- 推論エンドポイント: 実稼働アプリケーションでは、推論エンドポイントの利用が推奨されます。これは専用で自動スケーリングするインフラを提供する有料サービスであり、高負荷時でもアプリケーションの高速性と信頼性を保証します。
APIの使用には、リクエストヘッダーに認証トークンを含め、モデルのエンドポイントURLにJSONペイロードを送信します。
クラウドプラットフォームへのデプロイ
Amazon Web Services(AWS)、Google Cloud Platform(GCP)、Microsoft Azureなどの主要クラウドプロバイダーで既に大規模な環境を構築しているチームにとって、それらへのデプロイが最も合理的な選択肢となる場合があります。このアプローチでは最大の制御が可能となり、既存のクラウドサービスやセキュリティプロトコルとの統合を実現できます。
一般的なワークフローでは、Dockerを使用してモデルとその依存関係を「コンテナ化」し、そのコンテナをクラウドコンピューティングサービスにデプロイします。各クラウドプロバイダーには、このプロセスを簡素化するサービスや統合機能があります:
- AWS SageMaker: Hugging Faceモデルのトレーニングとデプロイをネイティブに統合
- Google Cloud Vertex AI: hubから管理対象エンドポイントへモデルをデプロイ可能
- Azure Machine Learning: Hugging Faceモデルのインポートと提供を実現するツールを提供します
この方法はより多くのセットアップとDevOpsの専門知識を必要としますが、環境を完全に制御する必要がある大規模な企業グレードのデプロイメントにおいては、往々にして最適な選択肢となります。
📚 こちらもご覧ください:ワークフロー自動化:ワークフローを自動化して生産性を向上させる
推論のためのHugging Faceモデルの実行方法
Hugging FaceでAIをデプロイする際、「推論の実行」とは、学習済みモデルを用いて新規の未見データに対して予測を行うプロセスを指します。これはモデルがデプロイ目的の仕事を実行する瞬間です。このステップを正しく行うことが、応答性が高く効率的なアプリケーション構築の鍵となります。
チームにとって最大の悩みは、遅いまたは非効率な推論コードを書くことです。これはユーザー体験の悪化や運用コストの高騰につながります。幸い、transformersライブラリは推論を実行する複数の方法を提供しており、それぞれが簡便性と制御性の間でトレードオフを持っています。
- パイプラインAPI: 最も簡単で一般的な導入方法です。pipeline()機能は複雑な処理を抽象化し、データ前処理・モデルフォワーディング・後処理を自動実行します。感情分析など多くの標準タスクでは、たった1行のコードで予測結果を取得できます。
- AutoModel + AutoTokenizer: 推論プロセスをより細かく制御する必要がある場合、AutoModelクラスとAutoTokenizerクラスを直接使用できます。これにより、テキストのトークン化方法や、モデルの生の出力を人間が読める予測値に変換する方法を手動で処理できます。このアプローチは、カスタムタスクを扱う場合や、特定の事前処理・事後処理ロジックを実装する必要がある場合に有用です。
- バッチ処理: 効率を最大化するには、特にGPU上で、入力を1つずつ処理するのではなくバッチ単位で処理すべきです。モデルにバッチ単位の入力を単一のフォワードパスで送信する方が、個々の入力を個別に送信するよりも大幅に高速です。
推論コードのパフォーマンス監視はデプロイライフサイクルの重要な要素です。レイテンシ(予測にかかる時間)やスループット(1秒あたりの予測処理数)といったメトリクスの追跡には、特に異なるチームメンバーが新しいモデルバージョンを実験する場合、調整と明確なドキュメントが不可欠です。
📚 こちらもご覧ください:AIチームが活用すべき最高のコラボレーションツール
ステップバイステップの例:Hugging Faceモデルのデプロイ
シンプルな感情分析モデルのデプロイを完全な例で解説します。以下のステップに従えば、モデルの選択からテスト可能なエンドポイントの稼働までを完了できます。
- モデルを選択: Hugging Face hubにアクセスし、左側のフィルターで「テキスト分類」を行うモデルを検索します。 distilbert-base-uncased-finetuned-sst-2-english が良い出発点です。モデルカードを読み、その性能と使用方法を理解しましょう。
- 依存関係のインストール: ローカルPython環境に、必要なライブラリがインストールされていることを確認してください。このモデルでは、transformersとtorchのみが必要です。以下のコマンドを実行してください:pip install transformers torch
- ローカル環境でテスト: デプロイ前に、必ずモデルがご自身のマシンで期待通りに動作することを確認してください。パイプラインを使用してモデルを読み込む小さなPythonスクリプトを作成し、サンプル文でテストします。例:classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")classifier("ClickUp is the best production efficiency platform!")
- デプロイの作成: この例では、迅速かつ簡単なデプロイのためにHugging Face Spacesを使用します。新しいスペースを作成し、Gradio SDKを選択し、モデルを読み込み、それとの対話のためのシンプルなGradioインターフェースを定義するapp.pyファイルを作成します。
- デプロイの確認: スペースが稼働したら、インタラクティブなインターフェースでテストできます。また、スペースのエンドポイントに直接APIリクエストを送信し、JSONレスポンスを取得することで、プログラム的に動作していることを確認できます。
これらのステップを完了すると、稼働中のモデルが得られます。プロジェクトの次の段階では、モデルの使用状況を監視し、更新プランを立て、人気が高まった場合にインフラを拡張する可能性があります。
データ準備から本番環境へのデプロイまで、複数のフェーズを跨ぐ複雑なAIデプロイプロジェクトを管理するチーム向けに、ClickUpの「ソフトウェアプロジェクト管理アドバンストテンプレート」が包括的な構造を提供します。
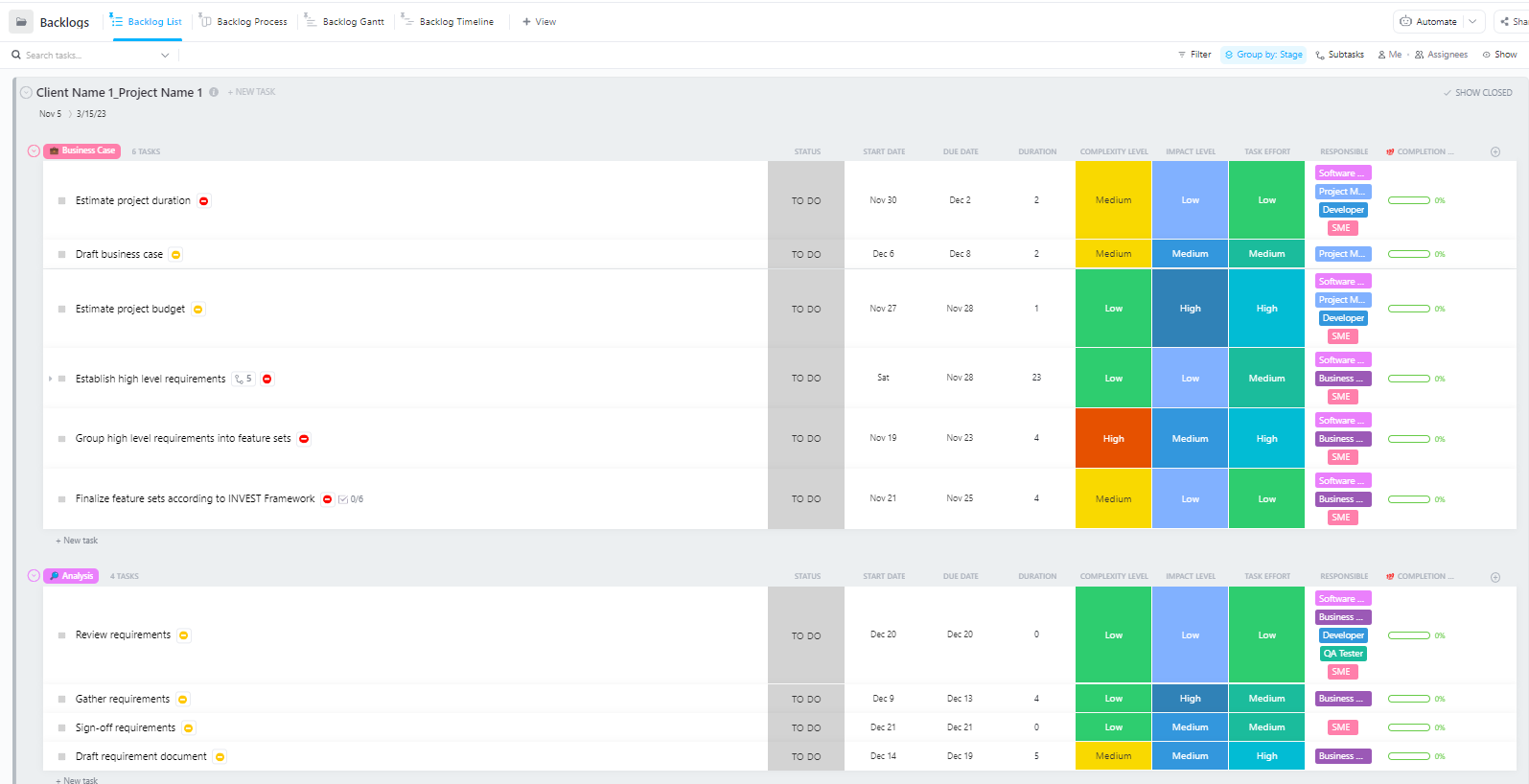
このテンプレートはチームに次のことを支援します:
- 複数のマイルストーン、タスク、リソース、依存関係を持つプロジェクトを管理する
- ガントチャートとタイムラインでプロジェクト進捗を可視化
- チームメンバーとシームレスに連携し、成功裏に完了させる
Hugging Faceデプロイメントにおけるよくある課題とその解決方法
明確なプランがあっても、デプロイ中にいくつかの障害に直面する可能性があります。意味不明なエラーメッセージを見つめるのは非常に苛立たしく、チームの進捗を停滞させかねません。以下に最も一般的な課題と解決策を紹介します。🛠️
🚨問題:「モデルに認証が必要です」
- 原因: ライセンス条項への同意が必要な「制限付き」モデルにアクセスしようとしています
- 解決策: hub上のモデルページにアクセスし、ライセンス契約書を読み、同意してください。使用するトークンに「read」許可が付与されていることを確認してください。
🚨問題:「CUDAメモリ不足」
- 原因: 読み込もうとしているモデルが、GPUのメモリ(VRAM)容量を超えています。
- 解決策: 最速の修正策は、モデルの小型バージョンまたは量子化バージョンを使用することです。また、推論時のバッチサイズを縮小することも試みられます。
🚨問題:「trust_remote_code エラー」
- 原因: Hub上のモデルの中にはカスタムコードの実行が必要なものが存在し、セキュリティ上の理由からライブラリはデフォルトでこれを実行しません
- 解決策: モデルを読み込む際に `trust_remote_code=True` を追加することで回避できます。ただし、安全性を確保するため、常にソースコードを事前に確認してください。
🚨問題: 「トークン化プロセスの不一致」
- 原因: 使用しているトークン化アルゴリズムがモデルの学習に使用されたものと完全に一致しないため、入力が不正確になり、パフォーマンスが低下しています。
- 解決策: トークナイザーは常にモデル本体と同じモデルチェックポイントから読み込みます。例: AutoTokenizer.from_pretrained("model-name")
🚨問題:「レートリミット超過」
- 原因: 無料の推論APIに対して期間中に過剰なリクエストを送信しました
- 解決策:本番環境では専用の推論エンドポイントへアップグレードしてください。開発環境では、同じリクエストを複数回送信しないようキャッシュを実装できます。
どの解決策がどの問題に有効かを追跡することは極めて重要です。こうした知見を記録する一元的な場所がなければ、チームは同じ問題を何度も繰り返し解決することになりがちです。
📮 ClickUpインサイト: 従業員の4人に1人が、業務の文脈を構築するためだけに4つ以上のツールを使用しています。重要な詳細が電子メールに埋もれ、Slackのスレッドで展開され、別のツールに文書化されるため、チームは仕事を遂行する代わりに情報の探索に時間を浪費せざるを得ません。
ClickUpは全ワークフローを単一プラットフォームに統合。ClickUp電子メールプロジェクト管理、ClickUpチャット、ClickUpドキュメント、ClickUp Brainなどの機能で、すべてが接続・同期され瞬時にアクセス可能に。「仕事のための仕事」に別れを告げ、生産性の高い時間を取り戻しましょう。
💫 実証済み結果:ClickUpを活用することで、チームは毎週5時間以上(年間1人あたり250時間以上)を、時代遅れのナレッジ管理プロセスから解放できます。四半期ごとに1週間分の生産性が追加されたら、チームが何を創出できるか想像してみてください!
ClickUpでAIデプロイメントプロジェクトを管理する方法
Hugging Faceを用いたAIデプロイでは、モデルのパッケージ化・ホスティング・提供が容易になりますが、実環境でのデプロイに伴う調整のオーバーヘッドは解消されません。チームは依然として、テスト中のモデルを追跡し、設定を調整し、意思決定を文書化し、MLエンジニアからプロダクト・運用チームまで全員が同じ認識を共有する必要があります。
エンジニアリングチームが様々なモデルをテストしている間、プロダクトチームは要件を定義し、ステークホルダーは進捗を問い合わせています。こうした情報はSlack、電子メール、スプレッドシート、様々なドキュメントに散在してしまいます。
この仕事の拡散——相互に連携しない複数のツールに仕事活動が分散する現象——は混乱を招き、全員の作業効率を低下させます。
世界初の統合型AIワークスペース「ClickUp」が、プロジェクト管理・ドキュメント管理・チームコミュニケーションを単一ワークスペースに統合することで、ここが重要な役割を果たします。
この統合は特にAIデプロイメントプロジェクトにおいて価値があります。技術系と非技術系のステークホルダーが、5つの異なるツールを使い分けることなく、共有された可視性を必要とする場面で効果を発揮します。
更新情報をチケットやドキュメント、チャットスレッドに散らかす代わりに、チームはデプロイのライフサイクル全体を一元管理できます。
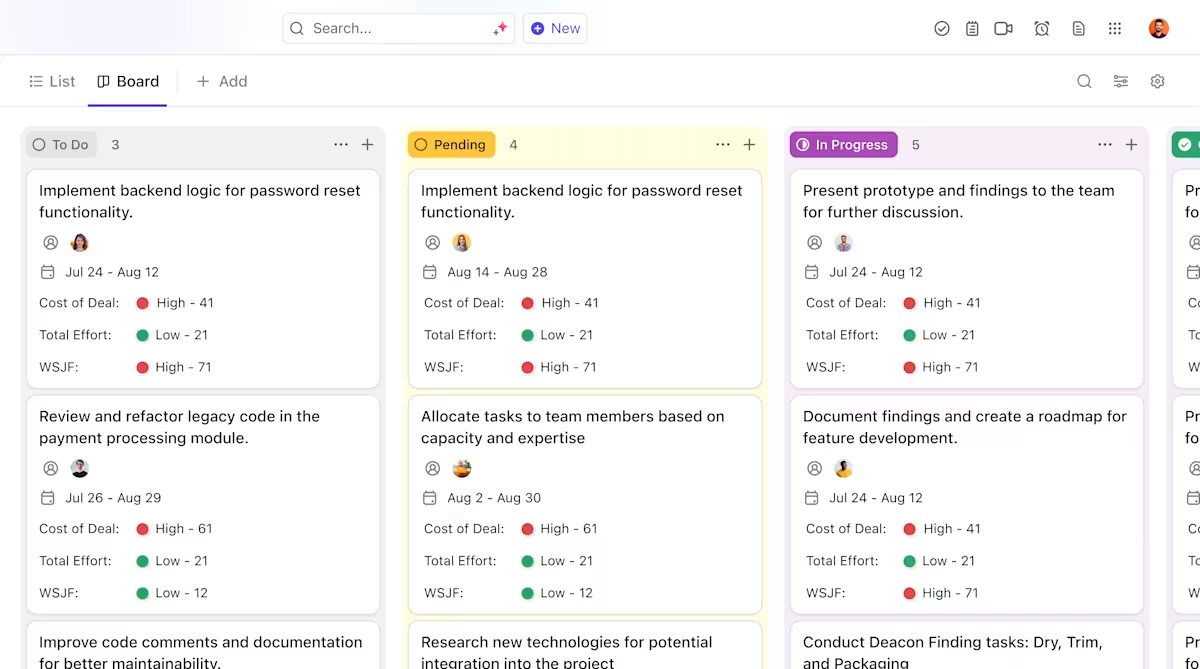
ClickUpがAIデプロイメントプロジェクトをサポートする方法:
- モデルライフサイクル全体での明確な所有権と追跡:ClickUpタスクを活用し、Hugging Faceモデルの評価、テスト、ステージング、本番環境までの進捗を追跡。カスタムステータス、所有者、障害要因をチーム全体で可視化
- 一元化された、常に最新のデプロイメントドキュメント:ClickUp Docsでデプロイメント手順書、環境設定、トラブルシューティングガイドを管理。ドキュメントはモデルと共に進化し、検索・参照が容易な状態を維持します。Docsはタスクと接続しているため、関連する仕事のすぐ横にドキュメントが存在します。
- 仕事の拡散なしにコンテキストに沿った共同作業を実現:議論、決定、更新をタスクやドキュメントに直接紐付け、散在するSlackスレッドや電子メール、連携しないプロジェクトツールへの依存を減らします。
- デプロイ進捗のエンドツーエンド可視性:ClickUpダッシュボードでリアルタイムの進捗とボトルネックを可視化し、デプロイパイプラインを監視、リスクを早期に特定、チームのキャパシティを調整
- 組み込みAIによる迅速なオンボーディングと意思決定の再現性:ClickUp Brainを活用し、長大なデプロイメント文書を要約、過去のデプロイメントから関連する知見を抽出、新規メンバーが過去の文脈を掘り下げることなく業務に慣れるのを支援します。
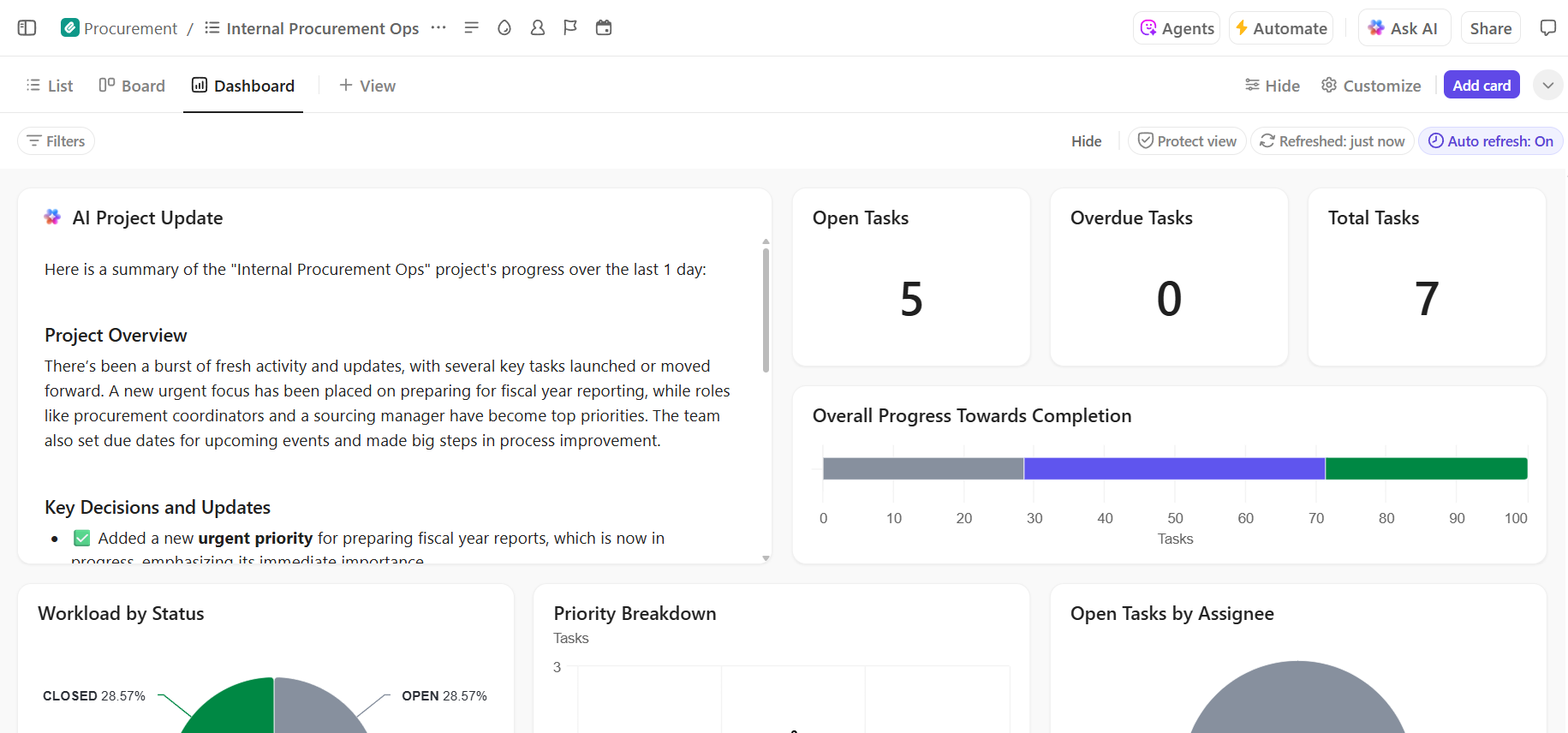
📚 こちらもご覧ください:AIでプロセスを自動化し、より迅速でスマートなワークフローを実現する方法
ClickUpでAIデプロイメントプロジェクトをシームレスに管理
Hugging Faceのデプロイ成功には、確固たる技術的基盤と明確で体系的なプロジェクト管理が不可欠です。技術的課題は解決可能ですが、プロジェクト失敗の原因は往々にして調整やコミュニケーションの断絶にあります。
単一プラットフォーム上で明確なワークフローを確立することで、チームは迅速なリリースを実現し、コンテキストの拡散によるフラストレーションを回避できます。これは、チームが情報検索に時間を浪費し、アプリを切り替え、複数のプラットフォームで更新作業を繰り返す状況です。
ClickUpは、プロジェクト管理、ドキュメント管理、チームコミュニケーションを一元化するオールインワン仕事アプリです。AIデプロイメントのライフサイクル全体において、単一の信頼できる情報源を提供します。
AIデプロイプロジェクトを統合し、ツールの混乱を解消しましょう。今すぐClickUpで無料で始められます。
よくある質問(FAQ)
はい、Hugging Faceはモデルハブへのアクセス、デモ用CPU駆動スペース、テスト用レートリミット付き推論APIを含む、充実した無料プランを提供しています。専用ハードウェアやより高いリミットが必要な本番環境では、有料プランが利用可能です。
スペースは視覚的なフロントエンドを備えたインタラクティブアプリケーションのホスティング向けに設計されており、デモや社内ツールに最適です。推論APIはモデルへのプログラムによるアクセスを提供し、シンプルなHTTPリクエストを通じてアプリケーションへの統合を可能にします。
もちろんです。Hugging Face スペースで提供されるインタラクティブなデモを通じて、技術的知識のないチームメンバーも、コードを1行も書くことなくモデルを試し、フィードバックを提供できます。
無料プランの主な制限事項は、推論APIのレートリミット、スペース機能で共有CPUハードウェアを使用することによる速度低下、および非アクティブなアプリが起動するまでの「コールドスタート」遅延です。