
ハグリングフェイス要約スクリプトを構築する開発者のほとんどが同じ壁にぶつかる:要約はターミナル上では完璧に動作する。しかし、本来サポートすべき実際の仕事との接続はほとんど実現しない。
このガイドでは、Hugging FaceのTransformersライブラリを用いたテキスト要約器の構築手順を解説します。さらに、チームがタスク・プロジェクト・意思決定と接続する要約を必要とする場合、完璧な実装でさえも解決策よりも多くの問題を生み出す理由を明らかにします。
テキスト要約とは何か?
チームは情報に溺れています。長大な文書、延々と続くミーティング議事録、難解な研究論文、手作業で消化するのに何時間もかかる四半期報告書に直面しています。この絶え間ない情報過多は意思決定を遅らせ、生産性を低下させます。
テキスト要約とは、自然言語処理(NLP)を用いてコンテンツを要約し、最も重要な情報を保持した短く一貫性のあるバージョンに凝縮するプロセスです。あらゆる文書に対する即席のエグゼクティブブリーフと捉えてください。このNLP要約技術は一般的に以下の2つのアプローチのいずれかを使用します:
抽出型要約: この手法は、ソーステキストから直接最も重要な文を特定して抽出することで機能します。まるでハイライターが自動的に要点を拾い上げてくれるようなものです。最終的な要約は元の文の集合体となります。
抽象化要約:このより高度な手法は、テキストの核心的な意味を捉えるために全く新しい文章を生成します。情報を言い換えることで、人間が長い話を自分の言葉で説明するのと同じように、より流暢で人間らしい要約の結果を生み出します。
この結果は至る所で見られます。ミーティングメモをアクションアイテムに凝縮し、顧客フィードバックをトレンドに集約し、プロジェクト文書の概要を素早く作成するために活用されています。目標は常に同じです:一語一語読むことなく、本質的な情報を得ることにあります。
📮 ClickUpインサイト: ビジネスパーソンは1日平均30分以上を業務関連情報の検索に費やしています。電子メールやSlackのスレッド、散在するファイルを掘り起こすだけで年間120時間以上が失われている計算です。ワークスペースに組み込まれたインテリジェントなAIアシスタントがこれを変えます。ClickUpBrainは適切な文書、会話、タスク詳細を数秒で抽出することで即座の洞察と回答を提供。検索を止め、作業を開始できます。
💫 実際の結果: QubicaAMFのようなチームは、時代遅れのナレッジ管理プロセスを排除することで、ClickUpを活用し週に5時間以上、年間で1人あたり250時間以上を再獲得しました。
テキスト要約にHugging Faceを使う理由とは?
カスタムテキスト要約モデルをゼロから構築するのは膨大な作業です。トレーニングには巨大なデータセット、強力で高価な計算リソース、そして機械学習の専門家チームが必要です。この高い参入障壁が、ほとんどのエンジニアリングチームやプロダクトチームを最初から遠ざけています。
Hugging Faceはこの課題を解決するプラットフォームです。オープンソースのコミュニティ兼データサイエンスプラットフォームであり、数千もの事前学習済みモデルへのアクセスを提供することで、開発者にとってLLM要約を民主化します。ゼロから構築する代わりに、すでに99%完成した強力なモデルから始められます。
多くの開発者がハグリングフェイスを選ぶ理由はこちら:🛠️
事前学習済みモデルのアクセス:Hugging Face Hubは、Google、Meta、OpenAIなどの企業が訓練した200万以上の公開モデルを収めた大規模リポジトリです。これらの最先端のチェックポイントを自身のプロジェクトにダウンロードして使用できます。
簡素化されたパイプラインAPI: パイプライン機能は、テキスト前処理、モデル推論、出力フォーマットといった複雑なステップを、わずか数行のコードで処理する高レベルAPIです。
モデルの多様性: 選択肢は一つに限定されません。BART、T5、Pegasusなど、それぞれ異なる強み、サイズ、性能特性を持つ幅広いアーキテクチャから選択できます。
フレームワークの柔軟性: Transformersライブラリは、最も普及している2つの深層学習フレームワークであるPyTorchとTensorFlowとシームレスに連携します。チームが既に慣れている方を選択できます。
コミュニティサポート: 充実したドキュメント、公式コース、活発な開発者コミュニティにより、チュートリアルを見つけたり、問題に直面した際にサポートを受けたりすることが容易です。
Hugging Faceは開発者にとって非常に強力ですが、コードベースのソリューションであることを忘れてはいけません。実装と維持には技術的専門知識が必要です。単に仕事を要約したいだけの非技術チームには、必ずしも最適な選択肢とは言えません。
🧐 ご存知でしたか? Hugging FaceのTransformersライブラリは、数行のコードで最先端のNLPモデルを利用することを主流にしました。これが、要約するプロトタイプがしばしばここから始まる理由です。
ハグリングフェイス トランスフォーマーとは?
Hugging Faceを使うことに決めたが、実際にやることとは何か?その中核技術はトランスフォーマーと呼ばれるアーキテクチャだ。2017年の論文「Attention Is All You Need」で発表された時、この技術は自然言語処理(NLP)のフィールドを完全に変えた。
トランスフォーマーが登場する以前、モデルは長い文の文脈を理解するのに苦労していました。トランスフォーマーの重要な革新点は注意機構であり、これによりモデルは特定の単語を処理する際に、入力テキスト内の異なる単語の重要度を評価できるようになります。これは長距離依存関係を捉え、文脈を理解するのに役立ち、一貫性のある要約を作成する上で極めて重要です。
Hugging Face Transformersライブラリは、複雑なモデルを驚くほど簡単に使えるPythonパッケージです。機械学習の博士号は必要ありません。このライブラリが面倒な処理を抽象化してくれます。
知っておくべき3つの核心的な構成要素
- トークナイザー: モデルは単語を理解しません。番号を理解します。トークナイザーは入力テキストを受け取り、モデルが処理可能な番号トークンの列(トークナイゼーションと呼ばれるプロセス)に変換します。
- モデル: これらは事前学習済みニューラルネットワークそのものです。要約では、通常エンコーダ-デコーダ構造を持つシーケンス間モデルが用いられます。エンコーダが入力テキストを読み取り数値表現を生成し、デコーダがその表現を用いて要約を生成します。
- パイプライン: モデルを使用する最も簡単な方法です。パイプラインは事前学習済みモデルと対応するトークン・トークナイザーをバンドルし、入力の前処理と出力の後処理の全ステップを自動的に処理します。
要約で最も人気のあるモデルはBARTとT5の2つです。BART(双方向自己回帰トランスフォーマー)は抽象的要約に特に優れ、非常に自然な読み口の要約を生成します。T5(テキスト間転送トランスフォーマー)は汎用性の高いモデルで、あらゆるNLPタスクをテキスト間変換問題として捉えるため、強力なオールラウンダーとなっています。
🎥 こちらのビデオで、最高のAI PDF要約ツールを比較検証。文脈を損なわずに最速かつ最も正確な要約を提供するツールを学びましょう。
ハグリングフェイスでテキスト要約器を構築する方法
独自のサマライザー例を作成する準備はできましたか?必要なのは基本的なPython知識、VS Codeのようなコードエディター、そしてインターネット接続だけです。全工程はたった4ステップ。数分で動作するサマライザーが完成します。
ステップ1: 必要なライブラリをインストールする
まず、必要なライブラリをインストールする必要があります。主なものはtransformersです。また、PyTorchやTensorFlowなどの深層学習フレームワークも必要です。この例ではPyTorchを使用します。
ターミナルまたはコマンドプロンプトを開き、次のコマンドを実行してください:

T5などの一部のモデルでは、トークン化のためにsentencepieceライブラリも必要です。こちらもお勧めします。

💡 プロのコツ: パッケージをインストールする前にPython仮想環境を作成しましょう。これによりプロジェクトの依存関係が分離され、マシン上の他のプロジェクトとの競合を防げます。
ステップ2: モデルとトークン・トークナイザーを読み込む
最も簡単な始め方はパイプライン機能を使用することです。要約タスクに適したモデルとトークン化機能の読み込みを自動的に処理します。
Pythonスクリプト内でパイプラインをインポートし、以下のように初期化します:

ここでは、次の2点を指定しています:
タスク: パイプラインに「要約する」ことを指示します。
モデルについて: Hugging Face hubから特定の事前学習済みモデルチェックポイントを選択します。facebook/bart-large-cnnはニュース記事で訓練された人気モデルで、汎用的な要約に効果的です。迅速なテストにはt5-smallのような小型モデルも使用可能です。
このコードを初めて実行すると、hubからモデルの重みデータをダウンロードします。これには数分かかる場合があります。その後、モデルはローカルマシンにキャッシュされ、即座に読み込まれるようになります。
ステップ3: 要約機能の作成
コードをクリーンで再利用可能な状態にするには、要約ロジックを機能でラップするのが最適です。これにより、様々なパラメーターを簡単に試すことも可能になります。
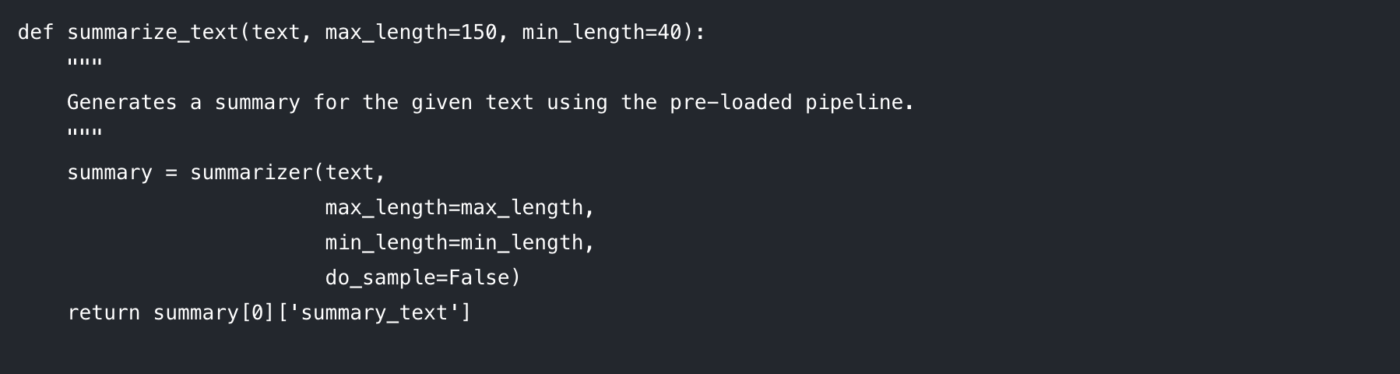
制御可能なパラメーターを分解してみましょう:
max_length: 出力要約の最大トークン数(おおよそ単語数)を設定します。
min_length: モデルの生成する要約が過度に短くなったり空になったりするのを防ぐため、最小トークン数を設定します。
do_sample: Falseに設定すると、モデルはビーム検索などの決定論的手法で最も可能性の高い要約を生成します。Trueに設定するとランダム性が導入され、より創造的だが予測困難な結果を生む可能性があります。
これらのパラメーターを調整することが、望む出力品質を得るための鍵となります。
ステップ4: 要約を生成する
さあ、楽しい部分です。テキストを機能に渡して結果を出力しましょう。🤩

コンソールに記事の要約バージョンが表示されるはずです。問題が発生した場合の対処法は以下の通りです:
入力テキストが長すぎる場合:入力がモデルの最大長(通常512または1024トークン)を超えるとエラーが発生する可能性があります。長い入力を自動的に切り詰めるには、summarizer()呼び出し内にtruncation=Trueを追加してください。
要約が一般的すぎる場合: num_beams パラメーターの値を上げることを試してみてください(例:num_beams=4)。これによりモデルはより良い要約を徹底的に探索しますが、処理速度が若干低下する可能性があります。
このコードベースのアプローチは、カスタムアプリを構築する開発者にとって素晴らしいものです。しかし、これをチームの日常の仕事に統合する必要がある場合はどうなるでしょうか?そこでリミットが明らかになり始めます。
テキスト要約におけるHugging Faceの限界
柔軟性と制御性を求めるならHugging Faceは優れた選択肢です。しかし実際のチームワークフロー(単なるデモノートブックではない)で活用しようとすると、予想通りの課題がすぐに現れます。
トークンリミットと長文処理の課題
ほとんどの要約モデルには固定の最大入力長が設定されています。例としてfacebook/bart-large-cnnはmax_position_embeddings = 1024で構成されています。これは長いドキュメントでは切り詰めやチャンク分割が必要になることを意味します。
簡易なベースラインが必要な場合は、パイプラインで切り詰め処理を有効にして次に進めます。しかし、長文を忠実に要約する必要がある場合、通常はチャンキングロジックを構築し、結果を統合するための「要約の要約」という二次処理をやることになります。これは追加のエンジニアリング作業であり、出力結果に一貫性が欠けやすいのです。
幻覚リスク(および検証コスト)
抽象化モデルは時に幻覚を起こし、一見妥当に聞こえるが事実誤認のテキストを生成することがあります。ビジネスクリティカルな用途ではこれが問題となります:すべての要約を手動で検証する必要が生じるのです。この時点で、実際には時間を節約しているわけではなく、仕事をプロセスの別の段階に移しているに過ぎません。
文脈認識の欠如
Hugging Faceモデルが認識できるのは、与えられたテキストのみです。プロジェクトの目標や関係者、文書間の関連性といった現代システムが持つ文脈理解能力を欠いているため、顧客との通話から作成した要約がプロジェクト要件ドキュメントと矛盾しているかどうかを判断できません。モデルは孤立した状態で動作するためです。
統合オーバーヘッド(「ラストマイル」問題)
要約を生成するのは通常、簡単な部分です。本当の難関はその後にあるのです。
要約はどこに表示されるのか?誰が閲覧するのか?どのように実行可能なタスクへ変換されるのか?それをトリガーとした仕事とどう接続するのか?
この「ラストマイル」を解決するには、カスタム統合とグルーコードの構築が必要です。これにより開発者の初期作業が増加し、他の関係者にとっては煩雑なワークフローを生み出すことが多々あります。
技術的障壁と継続的なメンテナンス
Pythonベースのアプローチは、主にコードが書ける人々にアクセス可能です。これはマーケティング、営業、運用チームにとって実用的な障壁となり、採用が限定的である状態を意味します。
継続的なメンテナンスも必要です:依存関係の管理、ライブラリの更新、APIやモデルの進化に合わせてすべてを正常に動作させること。手軽な解決策として始まったものが、いつの間にか手のかかるシステムへと変貌する可能性があります。
📮 ClickUpインサイト:仕事の妨げの42%は、複数のプラットフォームの切り替え、電子メール管理、ミーティング間の移動が原因です。こうしたコストのかかる中断をなくせたら? ClickUpはワークフロー(とチャット)を単一の合理化されたプラットフォームに統合します。チャット、ドキュメント、ホワイトボードなどからタスクを開始・管理しながら、AI搭載機能が文脈を連携させ、検索可能かつ管理しやすく保ちます。
より大きな問題:文脈の拡散
たとえ要約スクリプトが完璧に機能しても、出力結果が実際の仕事現場から切り離されているため、チームは時間を浪費する可能性があります。
それがコンテキストの拡散です。チームが情報を検索し、アプリを切り替え、連携されていないプラットフォーム間でファイルを探し回るのに何時間も浪費する状態です。
ここで統合ワークスペースがゲームチェンジャーとなる。要約を別場所で生成し後から「作業に組み込む」のではなく、統合システムはプロジェクト・ドキュメント・会話を一元管理し、ClickUp Brainをインテリジェンス層として組み込む。要約はタスクやDocsと常時接続しているため、次のステップが明確で、引き継ぎが即時に行える。
ClickUpで行動につながる要約
サマライゼーションスクリプトは完璧に機能していても、チームにとって厄介な形で失敗することがあります。つまり、要約が仕事とは切り離された場所に存在してしまうのです。
このギャップが文脈の拡散を生み出します。情報はドキュメント、チャットスレッド、タスク、そして接続しないツール内の「クイックメモ」に散在します。人々は要約を活用するよりも、それを探す時間の方が長くなります。真の価値は単に要約を生成することではありません。その要約を、実際の仕事が行われる場所である意思決定、所有者、次のステップに紐づけた状態で維持することにあるのです。
これがClickUp Brainの差別化ポイントです。タスク・文書・会話をプロジェクトが存在する同じワークスペース内で要約するため、チームはツールを切り替えることなく内容を理解し、即座に行動に移せます。

ClickUp BrainGPT:自然言語で要約と対話する
デスクトップでは、BrainGPTがClickUp Brainの会話型インターフェースです。スクリプトやノートブック、外部AIツールを開く代わりに、チームは必要なことを平易な言葉で直接ClickUp内で尋ねられます。
入力(または音声入力)で以下が可能です:
- 長いタスク説明、コメントスレッド、またはドキュメントを要約する
- フォローアップとして「次のステップは?」や「担当者は誰?」といった質問を投げかけましょう。
- 要約をアクションに変える:所有者や期日を設定したタスクとして作成する
ClickUp Brainはワークスペース内で動作するため、出力はリアルタイムの文脈(タスク説明、コメント、サブタスク、リンクされているドキュメント、プロジェクト構造)に基づいています。別のツールにテキストを貼り付けて重要な情報を見落とさないか心配する必要はありません。
なぜコードベースの要約ワークフローよりも優れているのか(ほとんどのチームにとって)
開発者主導のワークフローは強力な要約を生成できる。問題はその後発生する——誰かが要約結果を実際の仕事現場へコピーし、タスクへ変換し、進捗を追跡しなければならない段階だ。
ClickUp Brainがそのループを閉じる:
コーディング不要チームの誰もが、何もインストールしたりコードを書いたりすることなく、ドキュメントやタスクスレッド、散らかったコメント群を要約できます。
文脈を認識する要約ClickUp Brainは、人々が忘れがちな要素を含めることができます:コメントの中に埋もれた決定事項、返信でメンションされた障害要因、「完了」の意味を変えるサブタスクなど。
要約は仕事現場に存在するタスク内で進捗を確認したり、ClickUp Docsの先頭に要約を追加したり、別の「要約ドキュメント」を作成せずに議論を素早くまとめられます。誰も確認しないドキュメントを作る必要はありません。
ツールの乱立を減らす個別のスクリプト、Jupyterノートブック、APIキー、または一人だけが理解できるワークフローは必要ありません。ドキュメント、タスク、要約機能はすべて同一システム内に統合されます。
これが統合ワークスペースの実用的な利点です:要約、アクション、コラボレーションが事後的に継ぎ接ぎされるのではなく、同時に実現されるのです。
これが統合ワークスペースの実用的な利点です:要約する、アクションを行う、コラボレーションを行うが、事後的に継ぎ接ぎされるのではなく、同時に実現されるのです。
実際の現場での活用事例
チームがよく使うパターンをいくつか紹介します:
- コメントスレッドを要約する:長文の議論があるタスクを開き、AIオプションをクリックするだけで、変更点と重要なポイントの迅速な要約を取得できます
- ドキュメントを要約する:ClickUpドキュメントを開き、「Ask AI」でページの要約を生成。誰でも素早く内容を把握できます
- アクションアイテムの抽出:要約を取得し、次のステップを直ちに担当者や期日付きのタスクに変換。引き継ぎ時の勢いが失われないようにする
| 機能 | Hugging Face (コードベース) | ClickUp Brain |
|---|---|---|
| 必要なセットアップ | Python環境、ライブラリ、コード | なし、組み込み |
| 文脈認識 | テキストのみ(入力する内容) | ワークスペース全体の文脈(タスク、ドキュメント、コメント、サブタスク) |
| ワークフロー統合 | 手動でのエクスポート/インポート | 要約はタスクや更新情報に変換可能 |
| 必要な技術スキル | 開発者レベル | チームの誰にでも |
| メンテナンス | 継続的なモデルとコードのメンテナンス | 自動更新 |
要約から実行へ:スーパーエージェントで実現する
要約は有用です。難しいのは、特に量が増えた時に、一貫して実行に移されるようにすることです。
そこで登場するのがClickUpスーパーエージェントです。同じワークスペース内で、要約された情報を利用し、トリガーや条件に基づいて作業を前進させることができます。
Super Agentsを活用すれば、チームは以下が可能になります:
- スケジュールに沿った変更の要約(週次プロジェクト総括、日次ステータスロールアップ)
- アクションアイテムを抽出し、所有者を割り当てることを自動化
- 停滞した仕事をフラグ付けする(レビューで滞留中のタスク、未回答のスレッド、期限切れの次ステップ)
- 手動レポート作成なしで リーダーシップの可視性を高く保つ
要約が静的なテキストとして留まるのではなく、エージェントが要約をプランへと変え、プランを進捗へと導くことを支援します。
仕事が行われる場所で生きる要約
カスタムアプリや特注のパイプライン、モデル動作の完全な制御が必要な場合、Hugging Face Transformersは最適です。
しかし多くのチームにとって、より大きな問題は「これを要約できるか?」ではなく、「これを要約し、担当者と期限、可視性を伴う具体的な仕事に即座に変換できるか?」である。
チームの生産性と迅速な実行力を目標とするなら、ClickUp Brainが文脈に沿った要約を提供します。仕事現場その場で、「要点はこれ」から「次にやるべきこと」への明確な道筋を示します。
セットアップを飛ばして、実際の仕事現場で要約を始めませんか?ClickUpを無料で始め、Brainに面倒な作業を任せましょう。