
最新のソフトウェアアップデートをリリースすると、レポートが次々と届き始めます。
突然、CSAT/NPS からロードマップの遅れまで、すべてを左右する 1 つのメトリクス、つまり「バグ解決時間」が重要になったのです。
経営陣は、これを約束を守るためのメトリクスと捉えています。予定通りに製品を出荷し、学び、収益を確保できるかどうか。実務担当者は、チケットの重複、所有権の不明確さ、エスカレーションの混乱、Slack、スプレッドシート、別々のツールに散在するコンテキストなど、現場での苦労を痛感しています。
その断片化により、サイクルが延長され、根本原因が埋もれてしまい、優先順位付けが推測作業になってしまいます。
その結果は?学習の遅れ、コミットの未達成、そしてすべてのスプリントにひそかに負担をかけるバックログです。
このガイドは、バグ解決時間の測定、ベンチマーク、短縮のためのエンドツーエンドのプレイブックであり、従来の手動プロセスと比較して AI がワークフローをどのように変化させるかを具体的に示しています。
バグ解決時間とは?
バグ解決時間は、バグが報告されてから完全に解決されるまでの、バグの修正に要した時間です。
実際には、問題が(ユーザー、QA、またはモニタリングによって)報告または検出されると時計が動き始め、修正が実装され、マージされ、検証またはリリースできる状態になった時点で時計が止まります。
例:月曜日の午前 10 時に報告された P1 クラッシュが、火曜日の午後 3 時に修正がマージされた場合、解決時間は約 29 時間となります。
これはバグの検出時間とは異なります。検出時間は、バグの発生後(アラームの発生、QA テストツールによる検出、顧客からの報告)に、そのバグを認識するまでの時間を測定するものです。
解決時間は、問題の認識から解決までの時間を測定します。具体的には、トリエイジ、再現、診断、実装、レビュー、テスト、リリース準備の段階を含みます。検出は「問題が発生していることを認識した状態」であり、解決は「問題が解決され、リリース可能な状態」です。
Teams では、境界が若干異なります。1 つを選択して一貫性を保つことで、トレンドを正確に把握することができます。
- 報告 → 解決:コードの修正がマージされ、QA の準備が整った時点で終了します。エンジニアリングのスループットに最適
- 「報告済み」→「閉じた」:QA 検証およびリリースが含まれます。顧客に影響を与える SLA に最適
- 検出 → 解決:チケットが作成される前に、モニタリング/QA によって問題が検出された時点で開始されます。生産量の多いチームに有用です。
🧠 おもしろい事実:ファイナルファンタジー XIV に発生した 、風変わりで面白いバグは、その詳細さが評価され 、読者から「2025 年の MMO で最も具体的なバグ修正」と評されました。このバグは、特定のイベントゾーンでプレイヤーがアイテムの価格を 44,442 ギルから 49,087 ギルに設定すると発生し、おそらく整数オーバーフローの不具合により、接続が切断されるというものでした。
なぜ重要なのか
解決時間は、リリースのペースを左右する要素です。解決時間が長くなったり、予測できなくなったりすると、範囲の縮小、ホットフィックス、リリースの凍結を余儀なくされます。また、ロングテール(外れ値)は平均よりもスプリントの進捗を大幅に遅らせるため、プランニングの負債が発生します。
これは顧客満足度にも直結します。顧客は、問題が迅速に認識され、予測通りに解決される場合、その問題を許容します。修正が遅れる、あるいはさらに悪いことに、修正内容が不安定な場合、エスカレーションにつながり、CSAT/NPS が低下し、契約更新が危険にさらされます。
つまり、バグの解決時間を明確かつ体系的に測定し、それを削減すれば、ロードマップとリレーションシップが改善されるということです。
バグ解決時間を測定する方法
まず、測定の開始点と終了点を明確に定義します。
ほとんどのチームは、「報告済み」→「解決済み」(修正がマージされ、検証の準備が整った状態)または「報告済み」→「閉じた」(QA によって検証され、変更がリリースまたはその他の方法で閉じた状態)のいずれかを選択しています。
1つの定義を選択し、一貫して使用することで、トレンドが意味のあるものになります。
次に、観察可能なメトリクスが必要です。その概要を見てみましょう。
注目すべきバグ追跡のメトリクス:
| 📊 メトリクス | 📌 意味するところ | 💡 メリット | 🧮 式(該当する場合) |
|---|---|---|---|
| バグ数 🐞 | 報告されたバグの総番号 | システムの健全性を一目で把握できるビューを提供します。番号が多い?調査すべき時が来たようです。 | 総バグ数 = システムに記録されたすべてのバグ {開いている + 閉じた} |
| 公開バグ 🚧 | まだ修正されていないバグ | 現在の作業負荷を表示します。優先順位付けに役立ちます。 | 開いているバグ = 総バグ数 - 閉じたバグ |
| 閉じたバグ ✅ | 解決および検証済みのバグ | 進捗状況と完了した作業を追跡します。 | 閉じたバグ = ステータスが「閉じた」または「解決済み」のバグの数 |
| バグの重大度 🔥 | バグの重大度(例:重大、重大、軽微) | 影響度に基づいてトリエイジを支援します。 | カテゴリフィールドとして追跡され、式は使用されません。フィルター/グループ化を使用してください。 |
| バグの優先度 📅 | バグの修正の緊急度 | スプリントおよびリリースのプランニングに役立ちます。 | また、通常、ランク付けされるカテゴリフィールド(P0、P1、P2 など)も含まれます。 |
| 解決までの時間 ⏱️ | バグの報告から修正までの時間 | 応答性を測定します。 | 解決までの時間 = 閉じた日付 - レポート作成日 |
| 再オープン率 🔄 | 閉じた後に再開されたバグの割合 | 修正の品質や回帰の問題を反映します。 | 再開率(%) = {再開されたバグ ÷ 閉じたバグの総数} × 100 |
| バグの漏れ 🕳️ | 本番環境に潜入したバグ | QA/ソフトウェアテストの有効性を示します。 | 漏れ率(%) = {製品バグ÷総バグ} × 100 |
| バグ密度 🧮 | コードのサイズ単位あたりのバグ数 | リスクの高いコード領域を強調表示します。 | 欠陥密度 = バグの番号 ÷ KLOC {キロ行コード} |
| 割り当て済みバグと未割り当てバグ 👥 | 所有権によるバグの配布 | 漏れのないプロセスを保証します。 | フィルター を使用:「割り当て先」が null のバグ = 未割り当て |
| オープンバグの年齢 🧓 | バグが未解決のまま残る期間 | 停滞とバックログのリスクを早期に検出します。 | バグの経過時間 = 現在の日付 - 報告された日付 |
| 重複バグ 🧬 | 重複レポートの番号 | 受付プロセスにおけるエラーをハイライト表示します。 | 重複率 = 重複件数÷総バグ件数×100 |
| MTTD(平均検出時間) 🔎 | バグやインシデントの検出に要する平均時間 | 測定、監視、および意識向上の効率を評価します。 | MTTD = Σ(検出時間 - 発生時間)÷ バグの番号 |
| MTTR(平均解決時間) 🔧 | バグの検出から完全な修正までの平均時間 | エンジニアリングの対応力と修正時間を追跡します。 | MTTR = Σ(解決時間 - 検出時間)÷ 解決したバグの番号 |
| MTTA(平均承認時間) 📬 | 検出からバグの作業開始までの時間 | チームの対応力やアラートへの対応力を示します。 | MTTA = Σ(認識時間 - 検出時間)÷ バグの番号 |
| MTBF(平均故障間隔) 🔁 | 1つの障害が解決された後、次の障害が発生するまでの時間 | 時間の経過に伴う安定性を示します。 | MTBF = 総稼働時間÷障害発生回数 |
⚡️ テンプレートアーカイブ:バグ追跡用の 15 種類の無料バグレポートテンプレートとフォーム
バグ解決時間に影響を与える要因
解決時間は、多くの場合「エンジニアのコード作成の速さ」と同一視されます。
しかし、それはプロセスの一部に過ぎません。
バグ解決時間は、受付時の品質、システム全体のフロー効率、依存関係のリスクの合計です。これらのいずれかが不安定になると、サイクルタイムが延長され、予測可能性が低下し、エスカレーションが激化します。
受付の品質が全体を左右する
明確な再現ステップ、環境の詳細、ログ、バージョン/ビルド情報が記載されていないレポートは、余分なやり取りを余儀なくします。複数のチャネル(サポート、QA、モニタリング、Slack)から重複したレポートが送信されると、ノイズが増え、所有権が分散してしまいます。
適切なコンテキストを早期に把握し、重複を排除することで、後々のタスクの引き継ぎや確認のための連絡が大幅に削減されます。
優先順位付けとルーティングにより、バグに対処する担当者と対応時期を決定
顧客やビジネスへの影響と関連付けられていない(または時間の経過とともに変化している)重大度ラベルは、キューの混乱の原因となります。最も注目度の高いチケットが優先的に処理され、影響の大きい欠陥は放置されたままになってしまうからです。
コンポーネント/所有者ごとにルーティングルールを明確にし、単一の「真実のキュー」により、P0/P1 の仕事が「最近のものや雑多なもの」に埋もれることを防ぎます。
所有権と引き継ぎは、目に見えないキラーです。
バグがモバイル、バックエンド認証、プラットフォームチームのいずれに属するかが不明な場合、そのバグはバウンスされます。バウンスされるたびにコンテキストがリセットされます。
タイムゾーンもこれをさらに複雑にします。1 日の終わりに、所有者が指定されていないバグが報告された場合、その再現が開始されるまでに 12~24 時間も失われる可能性があります。オンコールまたは毎週の DRI により、「誰が何を所有するか」を厳密に定義することで、このようなずれを排除することができます。
再現性は可観測性に依存します
ログが散在したり、相関 ID が欠落したり、クラッシュトレースが不足したりすると、診断は推測作業になってしまいます。特定のフラグ、テナント、またはデータ形状でのみ発生するバグは、開発環境では再現が困難です。
エンジニアが、生産環境と同様の安全なデータにアクセスできない場合、数時間ではなく数日かけて、計測、再導入、待機という作業を行うことになってしまいます。
環境とデータの整合性が正確性を保ちます
「私のマシンでは動作する」は、通常「本番データは異なる」を意味します。開発/ステージングが本番環境(設定、サービス、サードパーティのバージョン)から乖離しているほど、幽霊を追いかけることに費やす時間が増えます。データのスナップショット、シードスクリプト、パリティチェックを安全に行うことで、そのギャップを縮小できます。
作業中 (WIP) と重点事項が実際の処理能力を向上
過負荷のチームは、一度に多くのバグに対応し、注意が散漫になり、タスクとミーティングの間で忙殺されます。コンテキストの切り替えにより、目に見えない作業時間が追加されます。
作業中のリミットを可視化し、新しい作業を開始する前に手掛けている作業を完了させることを重視することで、一人のヒーローの努力よりも早く中央値を下げることができます。
コードレビュー、CI、QA のスピードは、従来のボトルネックです。
ビルド時間の遅延、不安定なテスト、不明確なレビューSLAは、本来迅速に修正できる問題を遅らせます。10分のパッチが、レビューアの待機や数時間に及ぶパイプラインへの割り当てで2日間かかることもあります。
同様に、バッチテストや手動のスモークテストに依存する QA キューは、「報告」から「解決」までの時間が短い場合でも、「報告」から「閉じた」までの時間を 1 日以上延長する原因となります。
依存関係がキューを拡大
チーム間の変更(スキーマ、プラットフォームの移行、SDK の更新)、ベンダーのバグ、アプリストアのレビュー(モバイル)は、待機状態を引き起こします。明示的な「ブロック/一時停止」の追跡がない場合、これらの待機は平均値を目に見えない形で膨らませ、実際のボトルネックがどこにあるかを隠してしまいます。
リリースモデルとロールバック戦略は重要です。
手動ゲートによる分厚なリリーストレインで出荷する場合、解決済みのバグも次のトレインが出発するまで放置されます。Feature Flags、Canary リリース、およびホットフィックスレーンを使用すると、修正のデプロイをフルリリースサイクルから切り離すことができるため、特に P0/P1 インシデントのテールを短縮できます。
アーキテクチャと技術的負債が上限を決定する
緊密な結合、テストの継ぎ目の欠如、不透明なレガシーモジュールは、単純な修正を危険なものにします。チームは、追加のテストやレビューの時間を増やすことでこれを補いますが、その結果、サイクルが長くなります。一方、優れた契約テストを備えたモジュール式のコードを使用すると、隣接するシステムに影響を与えることなく、迅速に対応することができます。
コミュニケーションとステータスの衛生状態が予測可能性に影響を与える
曖昧な更新情報(「調査中」など)は、関係者が ETA を問い合わせたり、サポートがチケットを再開したり、製品がエスカレーションされたりすると、再作業が発生します。ステータスの移行、再現方法と根本原因に関するメモ、および ETA の掲載を明確にすることで、顧客離れの減少とエンジニアリングチームの集中力の維持を実現します。
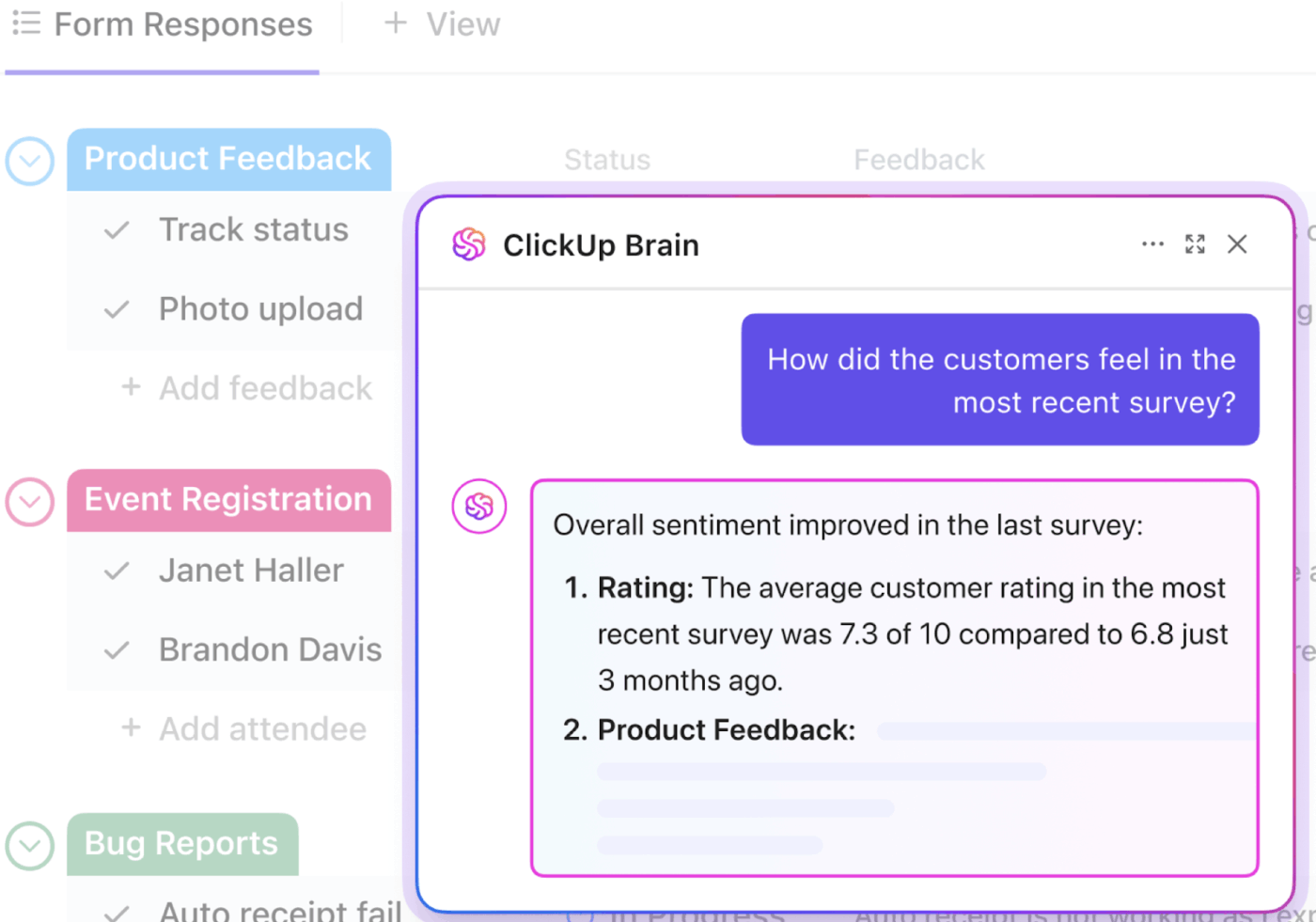
📮ClickUp Insight: 平均的なビジネスパーソンは、1 日 30 分以上、仕事に関連する情報を探して過ごしています。これは、電子メール、Slack のスレッド、散在するファイルを探して過ごす時間で、1 年間に 120 時間以上にも上ります。
ワークスペースに組み込まれたインテリジェントな AI アシスタントが、その状況を一変させます。ClickUp Brain をご利用ください。適切なドキュメント、会話、タスクの詳細を数秒で表示して、即座に洞察と答えを提供するため、検索作業から解放され、すぐに仕事に取り掛かることができます。
💫 実際の結果:QubicaAMF などのチームは、ClickUp を使用することで、時代遅れの知識管理プロセスを排除し、毎週 5 時間以上、年間では 1 人あたり 250 時間以上の時間を節約しています。四半期ごとに 1 週間分の生産性が向上したら、あなたのチームは何ができるか想像してみてください。
解決時間が遅れることを示す先行指標
❗️「認識までの時間」の増加、および 12 時間以上所有者が決定しないチケットの多発
❗️「レビュー/CI での時間」のスライスが増加し、テストの不安定さが頻繁に発生しています。
❗️受付時の重複率が高く、チーム間で重大度ラベルに一貫性がない
❗️外部依存関係が指定されていない「ブロック」の状態にある複数のバグ
❗️再発生率の上昇(修正が再現できない、完了の定義が曖昧)
組織によって、これらの要因に対する認識は異なります。経営幹部は、学習サイクルの損失や収益機会の損失として、オペレーターは、優先順位付けの混乱や所有権の不明確さとして、それぞれ認識しています。
受付、フロー、依存関係を調整することで、曲線全体(中央値と P90)を低下させることができます。
より良いバグレポートの作成方法について詳しく知りたい方は、こちらをご覧ください。👇🏼
バグ解決時間の業界ベンチマーク
バグ解決のベンチマークは、リスク許容度、リリースモデル、および変更のリリース速度によって変化します。
ここでは、中央値 (P50) を使用して一般的なフローを把握し、P90 を使用して、重大度と発生元 (顧客、QA、モニタリング) ごとに約束事項と SLA を設定することができます。
では、その内容を詳しく見ていきましょう:
| 🔑 キーワード | 📝 説明 | 💡 なぜ重要なのか |
|---|---|---|
| P50(中央値) | 中間値:バグの修正の 50% はこれよりも早く、50% はこれよりも遅い | 👉 通常のまたは最も一般的な解決時間を反映します。通常のパフォーマンスを理解するのに適しています。 |
| P90(90パーセンタイル) | バグの 90% はこの時間内に修正されます。10% だけがそれ以上の時間がかかります。 | 👉 最悪の場合(ただし現実的な)の限界を表します。外部への約束の設定に役立ちます。 |
| SLAs(サービスレベル契約) | 問題への対応速度に関する、社内のコミットメントや顧客へのコミットメント | 👉 例:「P1 のバグは 90% の場合、48 時間以内に解決しています。信頼と説明責任の構築に役立ちます |
| 深刻度と原因別 | 2 つの重要な側面からメトリクスをセグメント化します。• 重大度 (例:P0、P1、P2)• ソース (例:顧客、QA、モニタリング) | 👉 より正確な追跡と優先順位付けが可能になり、重大なバグに迅速に対応できます。 |
以下は、成熟したチームがしばしばターゲットとする業界に基づく方向性の範囲です。これを出発点として、お客様の状況に合わせて調整してください。
SaaS
常時稼働で CI/CD に対応しているため、ホットフィックスも一般的です。重大な問題 (P0/P1) は、多くの場合、1 営業日以内の対応、P90 は 24~48 時間以内の対応を目指しています。重要度の低い問題 (P2+) は、通常、3~7 日で対応、P90 は 10~14 日で対応しています。堅牢な機能フラグと自動テストを備えたチームは、対応が早い傾向があります。
ECプラットフォーム
コンバージョンとカートのフローは収益に直結するため、その基準はより高くなっています。P0/P1 の問題は通常、数時間以内に(ロールバック、フラグ、設定の変更など)軽減され、同じ日に完全に解決されます。P90 は、ピークシーズンでも 1 日以内、または 12 時間以内に解決されるのが一般的です。P2+ の問題は、多くの場合 2~5 日で解決され、P90 は 10 日以内に解決されます。
エンタープライズソフトウェア
検証の負荷が大きくなり、顧客の変更ウィンドウが長くなると、開発ペースが鈍化します。P0/P1 では、チームは 4~24 時間以内に回避策、1~3 営業日以内に修正、P90 では 5 営業日以内に修正をターゲットとしています。P2+ のアイテムは、顧客のロールアウトスケジュールに応じて、2~4 週間を中央値とするリリーストレインにバッチ処理されることがよくあります。
ゲームおよびモバイルアプリ
ライブサービスのバックエンドは SaaS と同様に動作します(フラグとロールバックは数分から数時間、P90 は当日中)。クライアントの更新はストアのレビューによって制約されます。P0/P1 では多くの場合、サーバー側の手段を即座に使用し、1~3 日以内にクライアントパッチをリリースします。P90 は、レビューを迅速化して 1 週間以内にリリースします。P2+ の修正は、通常、次のスプリントまたはコンテンツのドロップにスケジュールされます。
銀行/フィンテック
リスクとコンプライアンスのゲートにより、「迅速な緩和、慎重な変更」というパターンが推進されます。P0/P1 は迅速に緩和され(フラグ、ロールバック、数分から数時間以内のトラフィックのシフト)、1~3 日で完全に修正されます。P90 は 1 週間以内に、変更管理を含めて修正されます。P2+ は、セキュリティ、監査、CAB レビューに合格するまで 2~6 週間かかることがよくあります。
番号がこれらの範囲外にある場合は、「エンジニアリングのスピード」が根本的な問題であると判断する前に、受付の品質、ルーティング/所有権、コードレビュー、QA のスループット、依存関係の承認を確認してください。
🌼 ご存知でしたか?2024 年の Stack Overflow のアンケートによると、開発者はコーディング作業において AI を信頼できるパートナーとしてますます活用しています。なんと 82% が、実際にコードの記述に AI を使用しています。まさにクリエイティブな協力者といえるでしょう。行き詰まったり、解決策を探したりする場合、67.5% が AI に答えの検索を頼り、半数以上 (56.7%) がデバッグやヘルプの取得に AI を活用しています。
また、AI ツールは、プロジェクトの文書化 (40.1%) や、合成データやコンテンツの作成 (34.8%) にも役立つことがわかりました。新しいコードベースに興味がありますか?3 分の 1 近く(30.9%)が、AI を使用してその知識の習得に役立てています。コードのテストは、依然として多くの場合手作業による骨の折れる作業ですが、27.2% がこの分野でも AI を導入しています。コードレビュー、プロジェクトプランニング、予測分析などの他の分野では AI の導入率は低いものの、AI がソフトウェア開発のあらゆるフェーズに着実に浸透していることは明らかです。
📖 詳細:品質保証に AI を利用する方法
バグ解決時間の短縮方法
バグの解決を迅速化するには、受付からリリースまでの各段階における摩擦を排除することが重要です。
最大のメリットは、最初の 30 分間(受付の整理、適切な所有者の決定、優先度の決定)をスマートにし、その後のループ(再現、レビュー、検証)を圧縮することで得られます。
システムとして連携する 9 つの戦略をご紹介します。AI が各ステップを加速し、ワークフローが 1 か所に整理されるため、経営陣は予測可能性を獲得し、実務担当者はフローを実現できます。
1. インプットを中央集約化し、ソースからコンテキストを捕捉します。
Slack のスレッド、サポートチケット、スプレッドシートからコンテキストを再構築すると、バグの解決時間が長くなります。サポート、QA、モニタリングなど、すべてのレポートを、コンポーネント、重大度、環境、アプリのバージョン/ビルド、再現手順、予想と実際、添付ファイル (ログ/HAR/スクリーン) を収集する構造化されたテンプレートを使用して、単一のキューに集約します。
AI は、長いレポートを自動的に要約し、添付ファイルから再現手順や環境の詳細を抽出し、重複の可能性のあるものをフラグ付けするため、一貫性のある充実した記録からトリアージを開始できます。
注目すべきメトリクス: MTTA(数時間ではなく数分以内に認識)、重複率、「情報が必要」の所要時間。

2. AI 支援の優先順位付けとルーティングにより MTTA を大幅に短縮
最も迅速な修正は、適切な担当者にすぐに割り当てられるものです。
シンプルなルールと AI を使用して、重大度を分類し、コンポーネント/コード領域ごとに所有者を特定し、SLA クロックで自動的に割り当てます。P0/P1 とその他すべてに明確なスイムレーンを設定し、「所有者」を明確にします。
自動化により、フィールドから優先度を設定し、コンポーネントごとにチームにルーティングし、SLA タイマーを開始し、オンコールエンジニアに通知することができます。AI は、過去のパターンに基づいて、重大度と所有者を提案することができます。トリアージが 30 分間の議論ではなく 2~5 分の処理で済むようになると、MTTA が短縮され、MTTR もそれに追随して短縮されます。
注目すべきメトリクス: MTTA、初回対応品質(最初のコメントで適切な情報が要求されているか)、バグごとの引き継ぎ回数。
実際の運用例はこちらです:
3. 明確な SLA 階層により、ビジネスへの影響度に応じて優先順位付け
「最も大きな声が勝つ」という状況は、キューを予測不能にし、CSAT/NPSや更新率を監視する経営陣との信頼を損ないます。
その代わりに、重大度、頻度、影響を受ける ARR、機能の重要度、更新/リリースまでの期間などを総合したスコアを採用し、SLA 階層(例:P0:1~2 時間以内に緩和、1 日以内に解決、P1:当日、P2:スプリント内)で裏付けます。
作業中 (WIP) リミットを設定して P0/P1 レーンを可視化し、作業が滞らないよう管理します。
注目すべきメトリクス: 階層別の P50/P90 解決率、SLA 違反率、CSAT/NPS との相関関係。
💡プロのヒント: ClickUpのタスクの優先度、カスタムフィールド、および依存関係フィールド を使用すると、影響度スコアを計算し、バグをアカウント、フィードバック、またはロードマップのアイテムにリンクすることができます。さらに、 ClickUp の目標を使用すると、SLA の遵守を企業レベルの目標に結び付けることができ、調整に関する経営陣の懸念に直接対応することができます。
4. 再現と診断を一度の作業で完了させる
「ログを送っていただけますか?」という余分なやり取りは、解決時間を長引かせる原因になります。
「良好」の状態を標準化します。ビルド/コミットに必要なフィールド、環境、再現ステップ、予想と実績、およびログ、クラッシュダンプ、HAR ファイルなどの添付ファイルなどです。クライアント/サーバーのテレメトリを計測し、クラッシュ ID とリクエスト ID をトレースにリンクできるようにします。
Sentry(または類似のツール)を導入してスタックトレースを取得し、その問題をバグに直接リンクします。AI はログとトレースを読み取って、考えられる障害領域を提案し、最小限の再現手順を生成することで、1 時間の目視作業を数分の集中作業に変えます。
一般的なバグのクラスに関するランブックを保存することで、エンジニアはゼロから作業を開始する必要がなくなります。
注目すべきメトリクス:「情報待ち」に費やした時間、初回で再現された割合、再現できないために再オープンとなった割合。
📖 詳細はこちら:ソフトウェア開発における AI の活用方法(ユースケースとツール)
5. コードレビューとテストループの短縮
大規模な PR は作業を停滞させます。外科的パッチ、トランクベースの開発、機能フラグを採用して、修正を安全にリリースできるようにしましょう。コードの所有権に応じてレビュー担当者を事前に割り当ててアイドル時間を回避し、チェックリスト(テストの更新、テレメトリの追加、キルスイッチのフラグ)を使用して品質を確実に確保しましょう。
自動化により、バグは PR オープン時に「レビュー中」に、マージ時に「解決済み」に移動します。AI は、レビューに焦点を当てるために、ユニットテストを提案したり、リスクの高い差分を強調表示したりすることができます。
注目すべきメトリクス:「レビュー中」の所要時間、バグ修正 PR の変更失敗率、P90 レビューのレイテンシー。
ClickUp のGitHub/GitLab統合機能を使用すると、解決ステータスを同期させることができます。自動化機能により、「完了の定義」を強制的に適用することができます。
📖 詳細:AI を使用してタスクを自動化する方法
6. 検証を並行化し、QA 環境のパリティを実現
検証は、数日後に、あるいは顧客がまったく使用していない環境で開始すべきではありません。
「QA 準備完了」の状態を厳格に維持:報告されたケースと一致するシードデータを使用して、本番環境と同様の環境で検証されたフラグ駆動型のホットフィックス。
可能であれば、QA が即座に検証できるように、バグブランチから一時的な環境を設定します。その後、AI がバグの説明と過去の回帰からテストケースを生成します。
注目すべきメトリクス:「QA/検証」にかかった時間、QA から開発に戻ったバウンス率、マージ後の閉じたまでの平均時間。

📖 詳細はこちら:効果的なテストケースの書き方
7. ステータスを明確に伝達して、調整の負担を軽減
適切な更新を行うことで、3 件のステータス確認と 1 件のエスカレーションを回避できます。
アップデートを製品のように扱う:短く、具体的で、対象者(サポート、経営陣、顧客)を意識したものにする。P0/P1 の対応リズム(例えば、問題が解決するまで 1 時間ごと、その後 4 時間ごと)を確立し、情報源を 1 つに統一する。
AI は、タスクの履歴から、重大度やチーム別のライブステータスなど、顧客に安全なアップデートや社内要約を起草することができます。製品担当ディレクターなどの経営幹部は、バグをイニシアチブに集約することで、重要な品質作業が納期の約束に支障をきたすかどうかを確認することができます。
注目すべきメトリクス:P0/P1 のステータス更新間の時間、コミュニケーションに関するステークホルダーの CSAT。
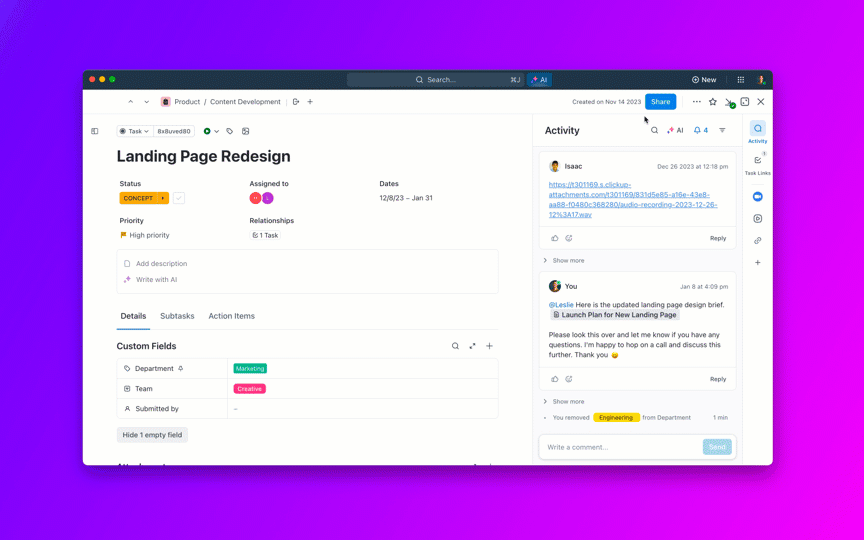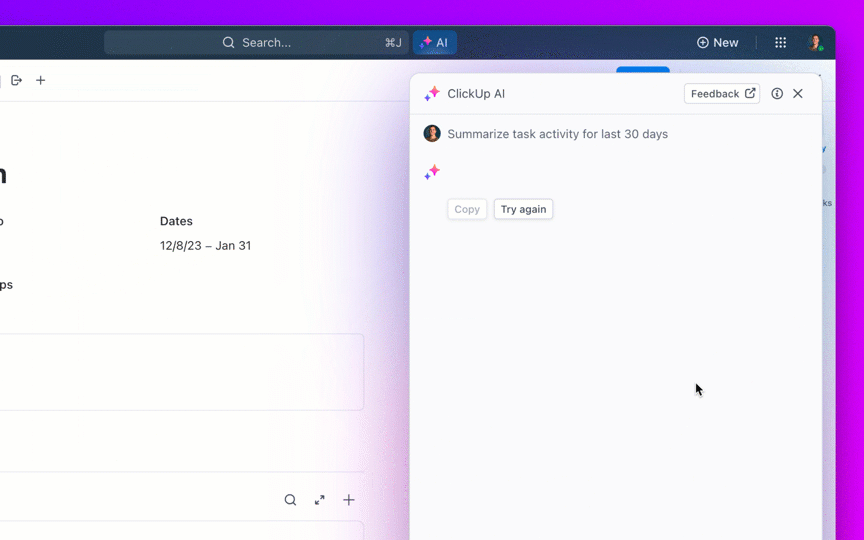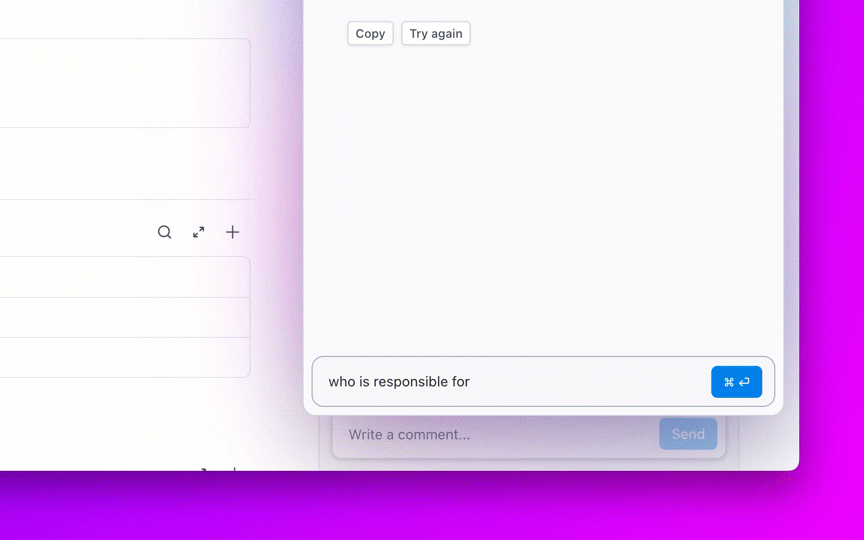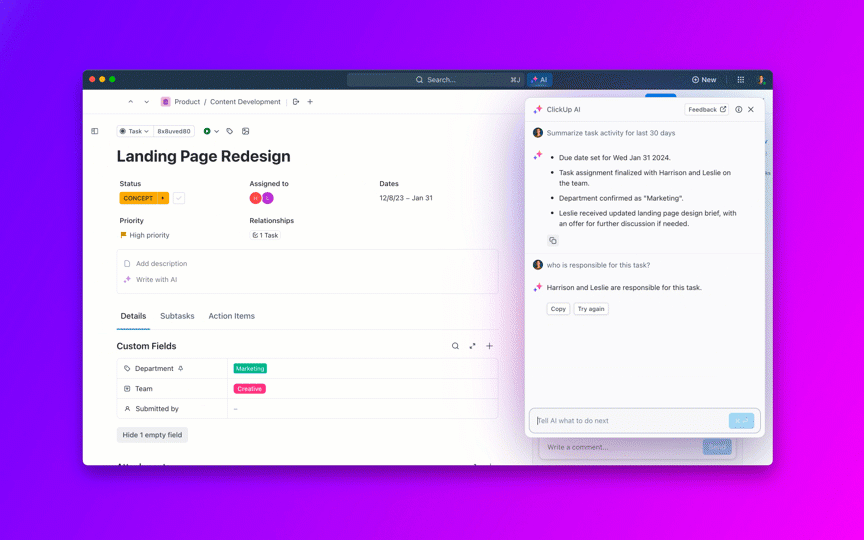
8. バックログの老化を管理し、「永遠に未解決」を防止します。
増え続ける古いバックログは、スプリントごとに静かに負担となっています。
経過ポリシー(例:P2 > 30 日でレビューをトリガー、P3 > 90 日で正当な理由が必要)を設定し、毎週「経過トリアージ」をスケジュールして、重複をマージし、廃止されたレポートを閉じ、価値の低いバグを製品バックログアイテムに変換します。
AI を使用して、バックログをテーマ(例:「認証トークンの有効期限」、「画像アップロードの不安定さ」)ごとにクラスタリングすることで、テーマ別の修正週間をスケジュールし、一連の欠陥を一度に解消することができます。
注目すべきメトリクス:バックログの年齢別件数、重複/廃止として閉じた問題の割合、テーマ別バーンダウン速度。
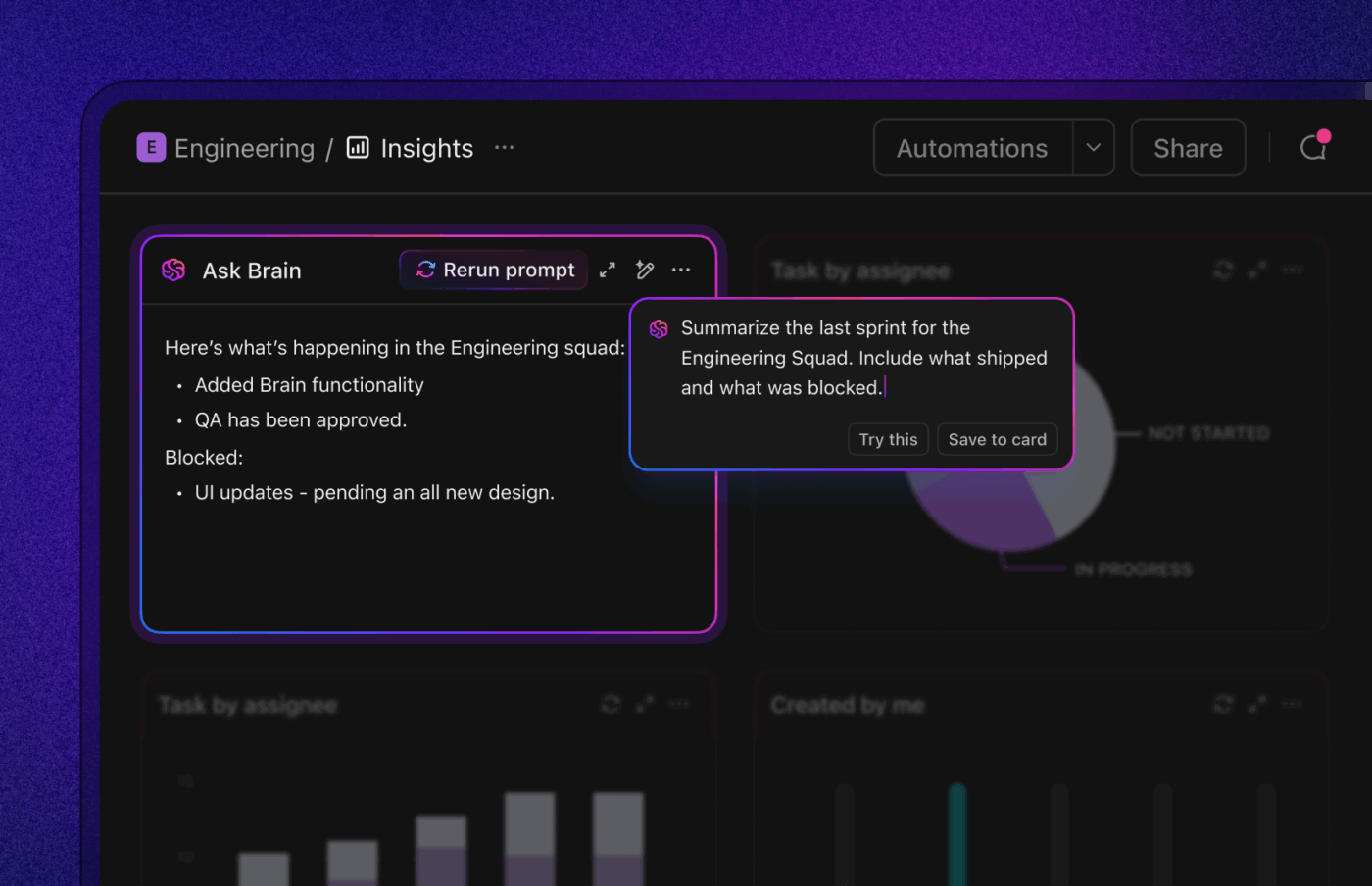
9. 根本原因と予防策でループを閉じる
同じ種類の不具合が繰り返し発生する場合、MTTRの改善はより大きな問題をかくしている可能性があります。
P0/P1 および高頻度の P2 について、迅速かつ責任の所在を明確にした根本原因分析を行い、根本原因(仕様ギャップ、テストギャップ、ツールギャップ、統合の不整合)にタグを付け、影響を受けるコンポーネントやインシデントにリンクし、フォローアップタスク(ガード、テスト、リントルール)を完了まで追跡します。
AI は、RCA の要約を作成し、変更履歴に基づいて予防的なテストやリントルールを提案することができます。このようにして、火事場対応から火事の発生そのものを減らすことができるのです。
注目すべきメトリクス: 再発生率、回帰率、再発までの時間、および予防措置が完了した RCA の割合。

これらの変更を組み合わせることで、エンドツーエンドのプロセスが短縮されます:より迅速な承認、より明確なトリエイジ、より適切な優先順位付け、レビューとQAでの遅延の減少、およびより明確なコミュニケーション。経営陣はCSAT/NPSと売上高に連動した予測可能性を得られ、実務担当者はコンテキスト切り替えの少ない落ち着いたキューを得られます。
📖 詳細はこちら:根本原因分析の実施方法
バグ解決時間の短縮に役立つ AI ツール
AI は、受付、優先順位付け、ルーティング、修正、検証など、あらゆるステップで解決時間を短縮します。
しかし、真のメリットは、ツールがコンテキストを理解し、手助けを必要とせずに仕事を進行させるようになったときに実現します。
レポートを自動的に充実させる(再現ステップ、環境、重複)機能、影響度に応じて優先順位付け、適切な所有者にルーティング、明確な更新案の作成、コード、CI、可観測性との緊密な統合機能を備えたシステムを探してください。
最高のツールは、エージェントのようなワークフローもサポートしています。SLA を監視し、レビュー担当者に通知し、滞っているアイテムをエスカレーションし、関係者に結果を要約するボットです。バグ解決を改善する AI ツールをご紹介します。
1. ClickUp(コンテキスト AI、自動化、エージェントワークフローに最適)
効率的でインテリジェントなバグ解決ワークフローをお探しなら、仕事のためのすべてを備えたアプリ「ClickUp」が、AI、自動化、エージェントによるワークフロー支援を 1 つにまとめます。
ClickUp Brain は、長いバグスレッドを要約し、添付ファイルから再現手順や環境の詳細を抽出し、重複の可能性のあるものをフラグ付けし、次のアクションを提案することで、適切なコンテキストを即座に表示します。Slack、チケット、ログをいちいち確認する代わりに、チームは、すぐに行動に移せる、明確で充実した記録を入手できます。
ClickUp の自動化機能とオートパイロットエージェントにより、手作業による管理を必要とせずに作業を円滑に進めることができます。バグは自動的に適切なチームに割り当てられ、所有者が指定され、SLA と期日が設定されます。また、作業の進捗に応じてステータスが更新され、関係者にタイムリーに通知が送信されます。

これらのエージェントは、問題の優先順位付けと分類、類似のレポートのクラスタリング、過去の修正事例の参照による対処方法の提案、緊急性の高いアイテムのエスカレーションも行うことができるため、ボリュームが急増しても MTTA および MTTR を短縮することができます。
🛠️ すぐに使えるツールキットをお探しですか?ClickUp のバグおよび問題追跡テンプレートは、サポート、エンジニアリング、製品チームがソフトウェアのバグや問題を簡単に把握できるように設計された 、ClickUp for Software の強力なソリューションです。リスト、ボード、作業量、フォーム、タイムラインなどのカスタマイズ可能なビューにより、チームはバグ追跡プロセスを最適な方法で視覚化して管理できます。
テンプレートの 20 種類のカスタムステータスと 7 種類のカスタムフィールドにより、ワークフローをカスタマイズして、すべての問題を発見から解決まで確実に追跡することができます。組み込みの自動化機能により、反復的なタスクが処理されるため、貴重な時間を節約し、手作業による努力を削減できます。
💟 ボーナス:Brain MAX は 、スマートで実用的な機能によりバグの解決を加速するように設計された、AI 搭載のデスクトップコンパニオンです 。
バグを発見したら、Brain MAX の音声入力機能を使って問題点を口頭で入力するだけで、そのメモが即座に文字に変換され、新規または既存のバグチケットに添付されます。Enterprise Search は、ClickUp、GitHub、Google Drive、Slack などの接続されたすべてのツールを徹底的に検索し、関連するバグレポート、エラーログ、コードスニペット、ドキュメントを表示するため、アプリを切り替えることなく、必要なコンテキストをすべて入手できます。
修正の調整が必要ですか?Brain MAX を使用すると、バグを適切な開発者に割り当て、ステータス更新の自動リマインダーを設定し、進捗状況を追跡することができます。
2. Sentry(エラーの捕捉に最適)
Sentry は 、エラー、トレース、ユーザーセッションを 1 か所に収集することで、MTTD と再現時間を短縮します 。AI による問題のグループ化によりノイズが削減され、「疑わしいコミット」および所有権ルールにより、コードの所有者が特定されるため、ルーティングが瞬時に行われます。セッションリプレイにより、エンジニアは正確なユーザーパスとコンソール/ネットワークの詳細情報を入手できるため、何度もやり取りを繰り返すことなく再現することができます。
Sentry AI の機能は、問題のコンテキストを要約し、一部のスタックでは、問題のあるコードを参照する自動修正パッチを提案します。実用的な効果としては、重複チケットの削減、割り当ての迅速化、レポートから実用的なパッチまでの道のりの短縮などが挙げられます。
3. GitHub Copilot(コードのレビューを迅速に行うのに最適)
Copilot は 、エディター内の修正ループを加速します 。スタックトレースを説明し、ターゲットを絞ったパッチを提案し、修正を確定するためのユニットテストを作成し、再現スクリプトの骨組みを作成します。
Copilot Chat は、失敗したコードを検証し、より安全なリファクタリングを提案し、コードレビューを迅速化するコメントや PR 説明を生成します。必要なレビューや CI と組み合わせることで、特に再現が明確な、範囲が限定されたバグの場合、「診断 → 実装 → テスト」にかかる時間を大幅に短縮します。
4. Snyk by DeepCode AI(パターンの検出に最適)
DeepCode のAI 搭載の静的解析は、コードや PR 作成時に欠陥やセキュリティ上の問題のあるパターンを検出します。問題のあるフローを強調表示し、その原因を説明し、コードベースのイディオムに合った安全な修正を提案します。
マージ前にリグレッションを検出し、開発者に安全なパターンを指導することで、新しいバグの発生率を低減し、レビューでは発見が難しい複雑なロジックエラーの修正を迅速化します。IDE および PR との統合により、この作業が仕事場に近い場所で実行できます。
5. DatadogのWatchdogとAIOps(ログ分析に最適)
Datadog の Watchdog は、ML を使用して、ログ、メトリクス、トレース、および実際のユーザーモニタリング全体の異常を表面化します。スパイクをデプロイマーカー、インフラストラクチャの変更、およびトポロジーと関連付けて、考えられる根本原因を提示します。
顧客に影響を与える欠陥については、検出から数分、アラートのノイズを削減する自動グループ化、そして調査すべき具体的な手掛かりを得ることができます。空白の状態から始めるのではなく、「このデプロイがこれらのサービスに影響を与え、このエンドポイントでエラー率が上昇した」という情報から始めることで、優先順位付けの時間が短縮されます。
⚡️ テンプレートアーカイブ:Excel および ClickUp での無料の問題追跡およびログテンプレート
6. New Relic AI(傾向の特定と要約に最適)
New Relic のエラー受信トレイは、サービスやバージョン間で類似のエラーをクラスタ化し、AI アシスタントが影響を要約し、考えられる原因を強調表示し、関連するトレース/トランザクションにリンクします。
導入の相関関係とエンティティの変更インテリジェンスにより、最近のリリースが問題の原因であるかどうかがすぐにわかります。分散システムの場合、そのコンテキストにより、チーム間の連絡に費やす時間が大幅に短縮され、確固たる仮説を立ててバグを適切な所有者に確実に伝達することができます。
7. Rollbar(自動化されたワークフローに最適)
Rollbar は、重複をグループ化し、発生の傾向を追跡するインテリジェントなフィンガープリント機能を備えた、リアルタイムのエラー監視を専門としています。AI による要約と根本原因のヒントにより、チームは影響の範囲(影響を受けるユーザー、影響を受けるバージョン)を把握でき、テレメトリとスタックトレースにより、迅速な再現の手がかりを得ることができます。
Rollbar のワークフロールールは、タスクの自動作成、重大度のタグ付け、所有者へのルーティングを行い、煩雑なエラーストリームを、コンテキストが添付された優先順位付きキューに変換します。
8. PagerDuty AIOps およびランブックの自動化(低タッチ診断のベスト)
PagerDuty は、イベント相関と ML ベースのノイズ低減機能を使用して、アラートストームを実用的なインシデントに集約します。
ダイナミックルーティングにより、問題は即座に適切な担当者に割り当てられ、ランブックの自動化により、人間が対応する前に診断や緩和措置(サービスの再起動、デプロイのロールバック、機能フラグの切り替え)を開始することができます。バグの解決時間に関しては、MTTA の短縮、P0 の緩和措置の迅速化、アラート疲労による時間の損失の削減につながります。
その共通点は、すべてのステップで自動化と AI を活用していることです。早期に検出し、よりスマートにルーティングし、コードに早く到達し、エンジニアの作業を遅らせることなくステータスを伝達することで、バグ解決時間を大幅に短縮することができます。
📖 詳細:DevOps で AI を使用する方法
バグ解決に AI を使用した実例
AI はついに実験室から飛び出しました。実環境でのバグ解決時間を短縮しています。
さっそく見てみましょう!
| ドメイン / 組織 | AI の活用方法 | 影響/メリット |
|---|---|---|
| Ubisoft | 10 年分の社内コードでトレーニングされた AI ツール「 Commit Assistant」を開発。コーディング段階でバグを予測・防止します。 | 時間とコストの大幅な削減を目指します。従来、ゲーム開発費の 70% はバグの修正に費やされていました。 |
| Razer (Wyvrn Platform) | バグの検出を自動化し、QA レポートを生成する AI 搭載の QA Copilot(Unreal および Unity と統合)をリリースしました。 | バグの検出率を最大 25% 向上させ、QA 時間を半分に短縮します。 |
| Google / DeepMind および Project Zero | FFmpeg や ImageMagick などのオープンソースソフトウェアのセキュリティ脆弱性を自律的に検出する AI ツール「Big Sleep」を導入しました。 | 20 件のバグを特定し、そのすべてが人間の専門家によって検証され、パッチの適用が予定されています。 |
| カリフォルニア大学バークレー校の研究者 | CyberGymというベンチマークを使用して、AI モデルが 188 件のオープンソースプロジェクトを分析し、15 件の未知の「ゼロデイ」バグを含む 17 件の脆弱性を発見し、概念実証のエクスプロイトを生成しました。 | 脆弱性の検出と自動化されたエクスプロイトの校正における AI の進化する能力をご紹介します。 |
| Spur(イエール大学発スタートアップ) | 平易な言語で記述されたテストケースの説明を、自動化されたウェブサイトテストルーチンに変換するAI エージェントを開発しました。これは、事実上、自己作成型の QA ワークフローです。 | 最小限の人為的な介入で自律的なテストを実現します。 |
| Android バグレポートの自動再現 | NLP + 強化学習を使用して、バグ報告の言語を解釈し、Android のバグを再現するためのステップを生成しました。 | 67% の精度、77% の再現率、74% のバグ報告の再現を達成し、従来の方法よりも優れたパフォーマンスを発揮しています。 |
バグ解決時間の測定におけるよくある間違い
測定が間違っていると、改善プランも間違ったものになってしまいます。
バグ解決ワークフローにおける「悪い数字」の多くは、曖昧な定義、一貫性のないワークフロー、および表面的な分析に起因しています。
まず、開始/停止の定義、待機や再開の処理方法などの基本から始め、顧客が体験したとおりにデータを読み取ります。これには以下が含まれます。
❌ 境界が曖昧: 同じダッシュボードで「報告済み→解決済み」と「報告済み→閉じた」が混在している(または月ごとに切り替わっている)と、傾向が意味をなさなくなります。境界を 1 つ選び、文書化し、チーム全体で適用してください。両方必要な場合は、明確なラベルを付けて別々のメトリクスとして公開してください。
❌ 平均値のみのアプローチ:平均値に依存すると、少数の長時間の異常値によるキューの現実が隠れてしまいます。「一般的な」時間には中央値 (P50) を使用し、予測可能性/SLA には P90 を使用し、キャパシティプランニングには平均値を使用してください。単一の番号だけでなく、常に分布を確認してください。
❌ セグメンテーションなし:すべてのバグをまとめて処理すると、P0 インシデントと外観上の問題である P3 が混在してしまいます。重大度、ソース(顧客、QA、モニタリング)、コンポーネント/チーム、および「新規」と「回帰」でセグメント化します。P0/P1 P90 はステークホルダーが感じるものであり、P2+ 中央値はエンジニアリングがプランのベースとするものです。
❌ 「一時停止」時間を無視:顧客からのログ、外部ベンダー、リリースウィンドウを待っていますか?ブロック/一時停止を最優先のステータスとして追跡しないと、解決時間が議論の対象になります。カレンダー時間とアクティブ時間の両方をレポートすることで、ボトルネックが可視化され、議論が不要になります。
❌ 時間の正規化のギャップ:タイムゾーンが混在したり、業務時間とカレンダーの時間を途中で切り替えたりすると、比較が正確でなくなります。タイムスタンプを 1 つのゾーン(または UTC)に正規化し、SLA を業務時間またはカレンダー時間で測定するかを一度決定し、それを一貫して適用してください。
❌ 不正確な受付と重複: 環境/ビルド情報の欠落やチケットの重複は、対応時間を延長し、所有権を混乱させます。受付時に必要なフィールドを標準化し、自動的に情報を充実させ(ログ、バージョン、デバイス)、対応時間をリセットせずに重複を削除します。重複は「新しい」問題としてではなく、リンクされている問題として閉じます。
❌ 一貫性のないステータスモデル: 独自のステータス(「QA 準備完了」、「レビュー待ち 2」など)は、ステータスに費やした時間を隠蔽し、ステータスの移行の信頼性を低下させます。標準的なワークフロー(新規 → 優先順位付け → 進行中 → レビュー中 → 解決済み → 閉じた)を定義し、パスから外れたステータスを監査します。
❌ ステータスに要した時間が不明: 単一の「合計時間」の番号だけでは、仕事がどこで滞っているのか把握できません。トリアージ、レビュー中、ブロック、QA に費やした時間を記録して確認します。コードレビューの P90 が実装の P90 を大幅に上回っている場合、その解決策は「コーディングのスピードアップ」ではなく、レビューのキャパシティのブロックを解除することです。
🧠 興味深い事実:DARPA の最新の AI サイバーチャレンジでは、サイバーセキュリティの自動化における画期的な飛躍が紹介されました。このコンテストでは、人間の介入なしに、ソフトウェアの脆弱性を自律的に検出、悪用、パッチ適用を行う AI システムが紹介されました。優勝チーム「Team Atlanta」は、注入されたバグの 77% を発見し、その 61% をパッチで修正するという素晴らしい成果を上げ、AI が欠陥を発見するだけでなく、積極的に修正する能力も備えていることを実証しました。
❌ 再オープンを見逃す: 再オープンを新しいバグとして扱うと、時計がリセットされ、MTTR が過大評価されます。再オープン率と「安定的なクローズまでの時間」(最初のレポートからすべてのサイクルにわたる最終的なクローズまでの時間)を追跡します。再オープンが増加している場合は、通常、再現性が低い、テストのギャップがある、または完了の定義が曖昧であることが考えられます。
❌ MTTA の排除:チームは MTTR にこだわって MTTA (認識/所有権確認時間) を無視しがちです。MTTA が長い場合は、解決に時間がかかることを示す早期の警告です。MTTA を測定し、重大度に応じて SLA を設定し、ルーティング/エスカレーションを自動化して、MTTA を短縮しましょう。
❌ ガードレールのない AI/自動化: レビューなしで AI に重大度を設定したり、重複を閉じたりすると、エッジケースが誤分類され、メトリクスが静かに歪む可能性があります。AI を提案に使用し、P0/P1 では人間の確認を義務付け、モデルのパフォーマンスを毎月監査して、データの信頼性を維持しましょう。
これらの継ぎ目を強化することで、解決時間チャートはついに現実を反映したものになります。そこから、改善はさらに進みます。インテイクの改善により MTTA が短縮され、状態が明確になることで真のボトルネックが明らかになり、セグメント化された P90 により、リーダーは約束を確実に果たすことができます。
⚡️ テンプレートアーカイブ:ソフトウェアテスト用 10 種類のテストケーステンプレート
バグ解決を改善するためのベストプラクティス
要点をまとめると、以下のポイントを押さえておきましょう!
| 🧩 ベストプラクティス | 💡 意味するところ | 🚀 なぜ重要なのか |
| 堅牢なバグ追跡システムを使用 | 一元化されたバグ追跡システムを使用して、報告されたすべてのバグを追跡します。 | バグを見逃すことなく、チーム間でバグのステータスを可視化できます。 |
| 詳細なバグレポートを作成 | 視覚的なコンテキスト、OS 情報、再現手順、重大度などを含めることができます。 | 必要な情報をすべて事前に把握することで、開発者はバグをより迅速に修正できます。 |
| バグの分類と優先順位付け | 優先度マトリックスを使用して、バグを緊急度と影響度で分類します。 | チームは、まず重要なバグや緊急の問題に集中して取り組むことができます。 |
| 自動テストを活用 | CI/CDパイプライン内でテストを自動的に実行します。 | 早期検出をサポートし、リグレッションを防止します。 |
| 明確なレポート作成ガイドラインを定義 | バグの報告方法に関するテンプレートとトレーニングを提供します。 | 正確な情報とスムーズなコミュニケーションを実現します。 |
| 重要なメトリクスを追跡 | 解決時間、経過時間、および応答時間を測定します。 | 履歴データを使用して、パフォーマンスの追跡と改善が可能になります。 |
| プロアクティブなアプローチを採用 | ユーザーからの苦情を待つのではなく、積極的にテストを行ってください。 | 顧客満足度を高め、サポートの負荷を軽減します。 |
| スマートツールと機械学習を活用 | 機械学習を使用してバグを予測し、修正方法を提案します。 | 根本原因の特定とバグの修正の効率が向上します。 |
| SLAとの整合性を確保 | 解決に関する合意済みのサービスレベル契約(SLA)を順守します。 | 信頼を築き、クライアントの期待にタイムリーに応えることができます。 |
| 継続的にレビューし、改善する | 再発生バグを分析し、フィードバックを収集し、プロセスを微調整します。 | 開発プロセスとバグ管理の継続的な改善を促進します。 |
コンテキスト AI によりバグ解決が簡単
最速のバグ解決チームは、英雄的な行動に頼っていません。彼らは、明確な開始/終了の定義、クリーンな受付、ビジネスへの影響による優先順位付け、明確な所有権、サポート、QA、エンジニアリング、リリース間の緊密なフィードバックループなど、システムを設計しています。
ClickUp は、バグ解決システムのための AI 搭載の指令センターとしての役割を果たします。すべてのレポートを 1 つのキューに一元化し、構造化されたフィールドでコンテキストを標準化します。ClickUp AI が優先順位付け、要約、優先順位付けを行い、自動化によって SLA を実施し、スケジュールが遅れた場合はエスカレーションを行い、関係者の連携を維持します。バグを顧客、コード、リリースに関連付けることで、経営陣は影響を確認でき、実務者はフローを維持できます。
バグの解決時間を短縮し、ロードマップの予測可能性を高めたいとお考えの方は、ClickUp に登録して、四半期ではなく数日で成果を測定してください。
よくある質問
バグ解決時間の適切な基準とは?
「良い」番号は 1 つだけというわけではありません。それは、重大度、リリースモデル、およびリスク許容度によって異なります。「一般的な」パフォーマンスには中央値 (P50) を使用し、約束/SLA には P90 を使用し、重大度とソースによって分類します。
バグの解決とバグのクローズの違いは何ですか?
解決とは、修正が実装され (コードのマージ、構成の適用など)、チームが欠陥が対処されたとみなした時点です。終了とは、問題が検証され、正式に完了した時点です (ターゲット環境で QA 検証済み、リリース済み、または「修正不要/重複」と理由とともにマーク済みなど)。多くのチームは、報告→解決と報告→閉じたの両方を測定しています。報告→解決はエンジニアリングのスピードを反映し、報告→閉じたはエンドツーエンドの品質フローを反映します。ダッシュボードでフェーズが混在しないように、一貫した定義を使用してください。
バグ解決時間とバグ検出時間の違いは何ですか?
検出時間 (MTTD) は、モニタリング、QA、またはユーザーによって、欠陥が発生してから発見されるまでの時間です。解決時間は、検出/レポートから修正の実施 (および必要に応じて検証/リリース) までの時間です。この 2 つを合わせて、顧客への影響の期間 (検出、認識、解決、リリース) を定義します。また、MTTA(認識/割り当てにかかる時間)を追跡して、解決に時間がかかることが多いトリアージの遅延を発見することもできます。
AI はバグの解決にどのように役立つのでしょうか?
AI は、通常、時間がかかるループ(受付、優先順位付け、診断、修正、検証)を圧縮します。
- 受付と優先順位付け:長いレポートを自動的に要約し、再現手順/環境を抽出し、重複をフラグ付けし、重大度/優先度を提案することで、エンジニアは明確な状況把握から作業を開始できます(例:ClickUp AI、Sentry AI)。
- ルーティングと SLA: MTTA またはレビューの待機時間が超過した場合に、予想されるコンポーネント/所有者を予測し、タイマーを設定し、エスカレーションを行うことで、アイドル状態の「ステータス時間」を削減します(ClickUp 自動化およびエージェントのようなワークフロー)。
- 診断: 類似のエラーをクラスタ化し、最近のコミット/リリースとの関連性を分析し、スタックトレースとコードコンテキストから考えられる根本原因を指摘します(Sentry AI など)。
- 実装:リポジトリのパターンに基づいてコードの変更とテストを提案し、「記述/修正」のループを高速化します(GitHub Copilot、DeepCode による Snyk Code AI)。
- 検証とコミュニケーション:再現ステップからテストケースを作成し、リリースノートや関係者に宛てた最新情報の草案を作成し、経営陣や顧客向けにステータスを要約します(ClickUp AI)。ClickUp をコマンドセンターとして、Sentry/Copilot/DeepCode をスタックとして併用することで、チームは英雄的な努力に頼ることなく MTTA/P90 を短縮することができます。