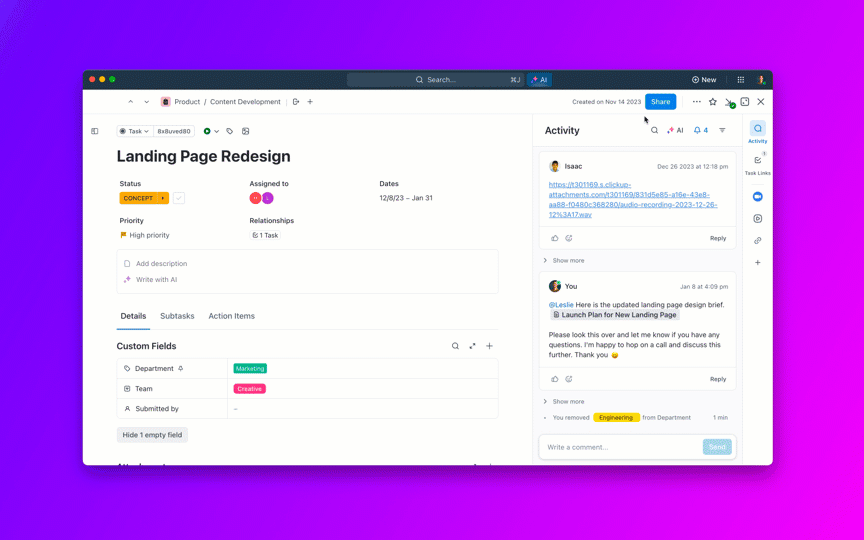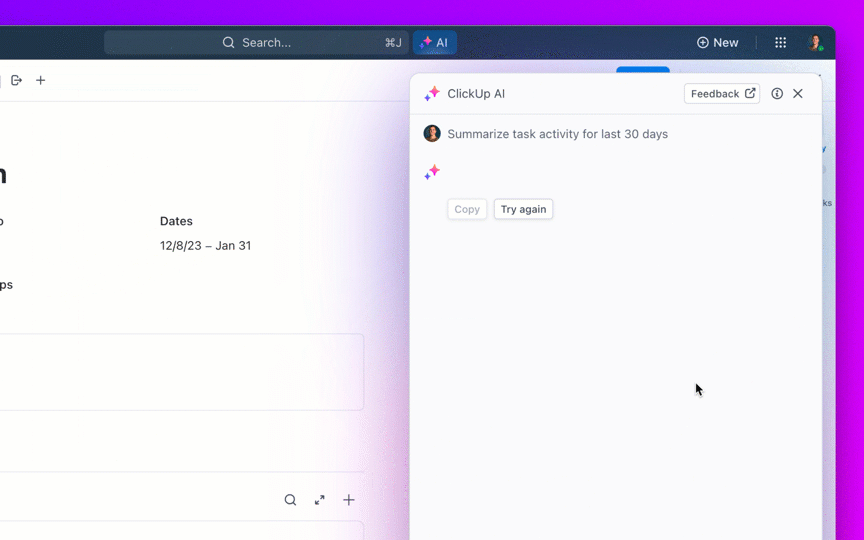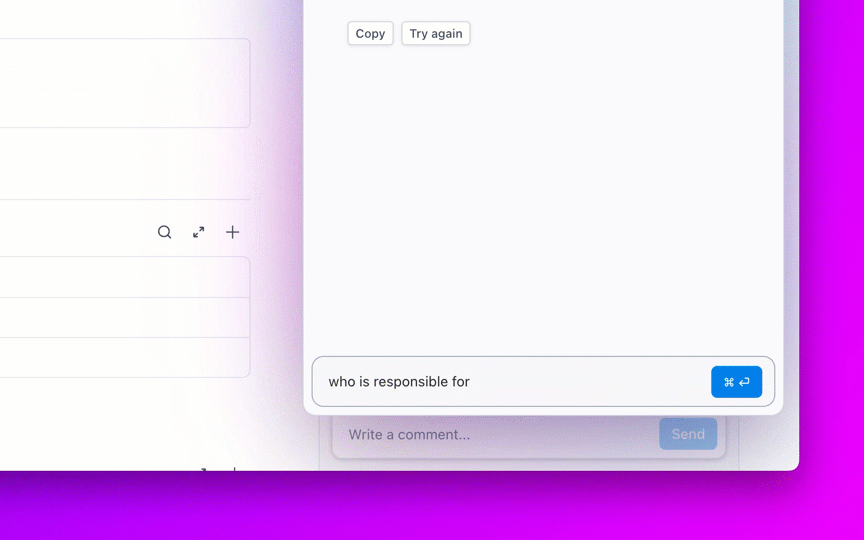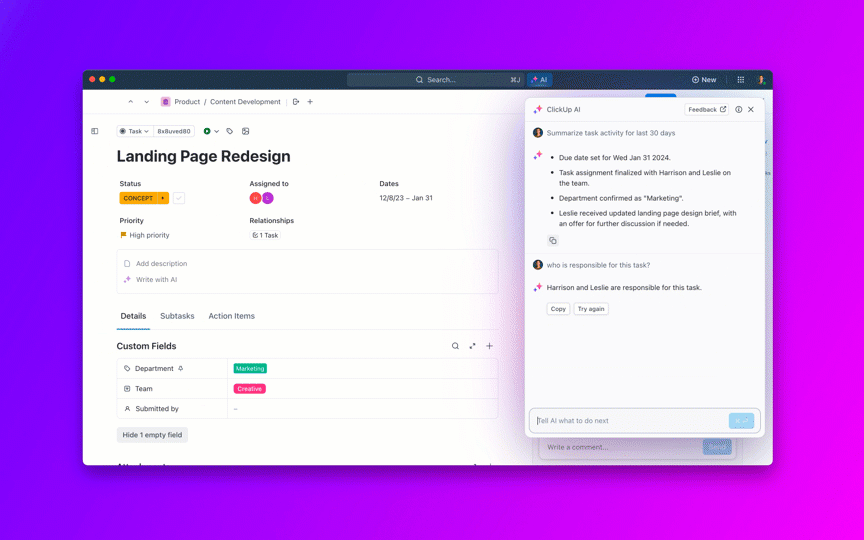

La maggior parte dei team che esplorano modelli di IA open source scoprono che LLaMA di Meta offre una combinazione rara di potenza e flessibilità, ma la configurazione tecnica può sembrare come assemblare mobili senza istruzioni.
Questa guida ti accompagna nella creazione di un chatbot LLaMA funzionale partendo da zero, coprendo tutto, dai requisiti hardware e l'accesso al modello alle strategie di prompt engineering e implementazione.
Cominciamo!
Cos'è LLaMA e perché utilizzarlo per i chatbot?
Creare un chatbot con API proprietarie spesso dà la sensazione di essere vincolati al sistema di qualcun altro, con costi imprevedibili e problemi di privacy dei dati. Questo vincolo al fornitore impedisce di personalizzare realmente il modello in base alle esigenze specifiche del proprio team, con conseguenti risposte generiche e potenziali problemi di conformità.
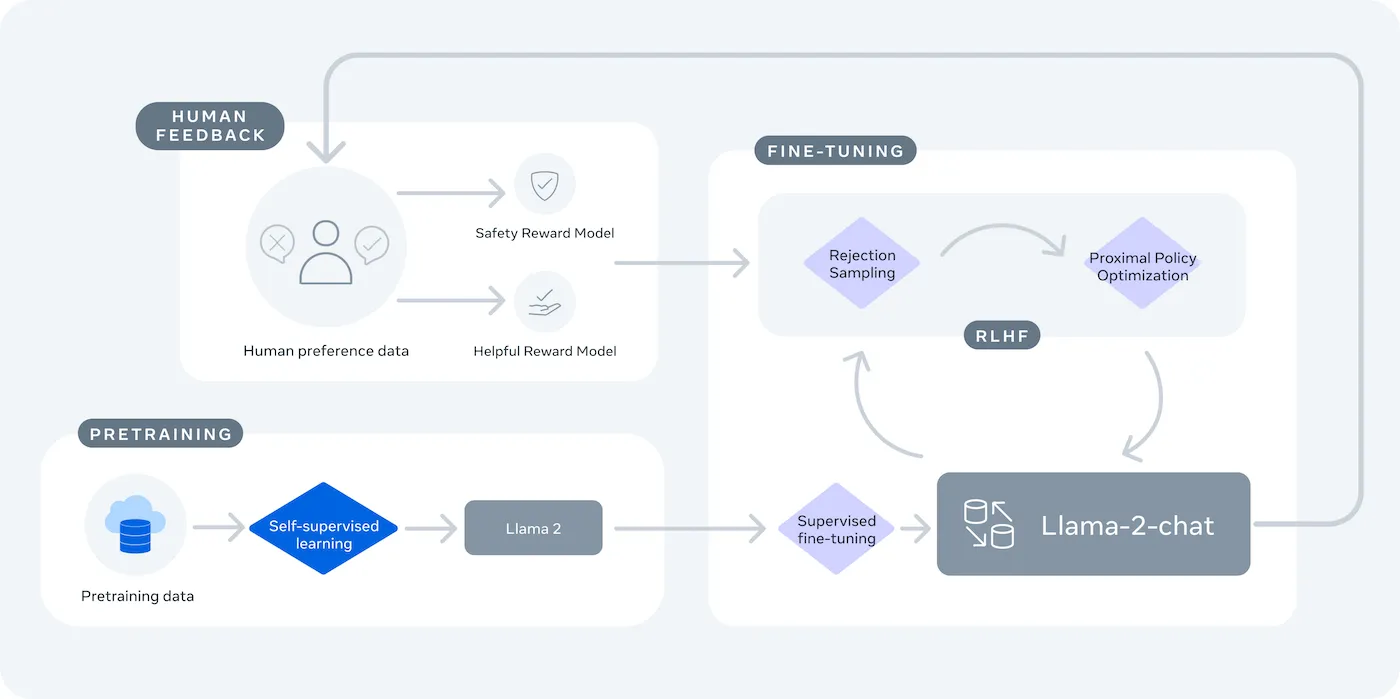
LLaMA (Large Language Model Meta IA) è la famiglia di modelli linguistici open-weight di Meta e offre una potente alternativa. È progettato sia per la ricerca che per l'uso commerciale, offrendoti il controllo che i modelli chiusi non garantiscono.
I modelli LLaMA sono disponibili in diverse dimensioni, misurate in parametri (ad esempio, 7B, 13B, 70B). Considera i parametri come una misura della complessità e della potenza del modello: i modelli più grandi sono più capaci ma richiedono maggiori risorse computazionali.
Ecco perché potresti utilizzare un chatbot LLaMA:
- Privacy dei dati: quando esegui un modello sulla tua infrastruttura, i dati delle conversazioni non lasciano mai il tuo ambiente. Questo è fondamentale per i team che gestiscono informazioni sensibili.
- Personalizzazione: puoi ottimizzare un modello LLaMA sui documenti o sui dati interni della tua azienda. Questo lo aiuta a comprendere il tuo contesto specifico e a fornire risposte molto più pertinenti.
- Prevedibilità dei costi: dopo la configurazione iniziale dell'hardware, non dovrai più preoccuparti dei costi API per token. I tuoi costi diventeranno fissi e prevedibili.
- Nessun limite di frequenza: la capacità del tuo chatbot è limitata dal tuo hardware, non dalle quote del fornitore. Puoi scalare in base alle tue esigenze.
Il compromesso principale è la praticità a fronte del controllo. LLaMA richiede una configurazione più tecnica rispetto a un'API plug-and-play. Per i chatbot di produzione, i team utilizzano in genere LLaMA 2 o il più recente LLaMA 3, che offre un ragionamento migliorato ed è in grado di gestire più testo contemporaneamente.
Cosa ti serve prima di creare un chatbot LLaMA
Affrontare un progetto di sviluppo senza gli strumenti giusti è fonte di frustrazione. A metà strada, ti rendi conto che ti manca un componente hardware o software fondamentale, compromettendo i tuoi progressi e sprecando ore del tuo tempo.
Per evitare questo inconveniente, raccogli tutto ciò che ti serve in anticipo. Ecco una lista di controllo per garantire un avvio senza intoppi. 🛠️
Requisiti hardware
| Dimensione del modello | VRAM minima | Opzione alternativa |
|---|---|---|
| 7 miliardi di parametri | 8 GB | Istanza GPU cloud |
| 13 miliardi di parametri | 16 GB | Istanza GPU cloud |
| 70 miliardi di parametri | GPU multiple | Quantizzazione o cloud |
Se il tuo computer locale non dispone di una scheda grafica (GPU) sufficientemente potente, puoi utilizzare servizi cloud come AWS o GCP. Anche piattaforme di inferenza come Baseten e Replicate offrono accesso GPU con pagamento a consumo.
Requisiti software
- Python 3. 8+: questo è il linguaggio di programmazione standard per i progetti di machine learning.
- Gestore di pacchetti: avrai bisogno di pip o Conda per installare le librerie necessarie per il tuo progetto.
- Ambiente virtuale: si tratta di una best practice che mantiene le dipendenze del tuo progetto isolate dagli altri progetti Python presenti sul tuo computer.
Requisiti di accesso
- Account Hugging Face: avrai bisogno di un account per scaricare i pesi del modello LLaMA.
- Approvazione Meta: per accedere ai modelli LLaMA è necessario accettare il contratto di licenza di Meta, che di solito viene approvato entro poche ore.
- Chiavi API: sono necessarie solo se si decide di utilizzare un endpoint di inferenza ospitato invece di eseguire il modello localmente.
Per questa guida utilizzeremo il framework LangChain, che semplifica molte delle parti complesse della creazione di un chatbot, come la gestione dei prompt e della cronologia delle conversazioni.
{kind=link}
Come creare un chatbot con LLaMA passaggio dopo passaggio
Collegare tutti gli elementi tecnici di un chatbot (il modello, il prompt, la memoria) può sembrare un compito arduo. È facile perdersi nel codice, causando bug e un chatbot che non funziona come previsto. Questa guida passo passo suddivide il processo in parti semplici e gestibili.
Questo approccio funziona sia che tu stia eseguendo il modello sul tuo computer sia che tu stia utilizzando un servizio in hosting.
Passaggio 1: installa i pacchetti richiesti
Per prima cosa, devi installare le librerie Python principali. Apri il terminale ed esegui questo comando:
pip install langchain transformers accelerate torch
Se utilizzi un servizio ospitato come Baseten per l'inferenza, dovrai anche installare il suo kit di sviluppo software (SDK) specifico:
pip install baseten
Ecco cosa da fare per ciascuno di questi pacchetti:
- Langchain: un framework che aiuta a creare applicazioni con modelli linguistici di grandi dimensioni, compresa la gestione delle catene di conversazione e della memoria.
- Transformers: la libreria Hugging Face per caricare ed eseguire il modello LLaMA.
- Accelerate: una libreria che aiuta a ottimizzare il caricamento del modello sulla CPU e sulla GPU.
- Torch: la libreria PyTorch, che fornisce la potenza di backend per i calcoli del modello.
Se stai eseguendo il modello localmente su una macchina con una GPU NVIDIA, assicurati di aver installato e configurato correttamente CUDA. Ciò consente al modello di utilizzare la GPU per prestazioni molto più veloci.
Passaggio 2: ottieni l'accesso ai modelli LLaMA
Prima di poter scaricare il modello, è necessario ottenere l'accesso ufficiale da Meta tramite Hugging Face.
- Crea un account su huggingface.co
- Vai alla pagina del modello, ad esempio meta-llama/Llama-2-7b-chat-hf
- Clicca su "Accedi al repository" e accetta i termini di licenza di Meta.
- Nelle impostazioni del tuo account Hugging Face, genera un nuovo token di accesso.
- Nel tuo terminale, esegui huggingface-cli login e incolla il tuo token per effettuare l'autenticazione del tuo dispositivo.
L'approvazione è solitamente rapida. Assicurati di scegliere una variante del modello con "chat" nel nome, poiché queste sono state specificamente addestrate per attività di conversazione.
Passaggio 3: carica il modello LLaMA
Ora puoi caricare il modello nel tuo codice. Hai due opzioni principali a seconda del tuo hardware.
Se disponi di una GPU sufficientemente potente, puoi caricare il modello localmente:
Se il tuo hardware ha un limite, puoi utilizzare un servizio di inferenza ospitato:
Il comando device_map="auto" indica alla libreria dei trasformatori di effettuare automaticamente la distribuzione del modello su tutte le GPU disponibili.
Se la memoria continua a non essere sufficiente, puoi utilizzare una tecnica chiamata quantizzazione per ridurre la dimensione del modello, anche se ciò potrebbe comportare una leggera riduzione delle prestazioni.
Passaggio 4: crea un modello di prompt
I modelli di chat LLaMA sono addestrati per aspettarsi un formato specifico per i prompt. Un modello di prompt garantisce che il tuo input sia strutturato correttamente.
Analizziamo questo formato:
- <
>: questa sezione contiene il prompt di sistema, che fornisce al modello le istruzioni fondamentali e ne definisce la personalità. - [INST]: Indica l'inizio della domanda o dell'istruzione dell'utente.
- [/INST]: Questo segnala al modello che è il momento di generare una risposta.
Tieni presente che versioni diverse di LLaMA potrebbero utilizzare modelli leggermente diversi. Controlla sempre la documentazione del modello su Hugging Face per verificare il formato corretto.
Passaggio 5: configura la catena del chatbot
Successivamente, collegherai il tuo modello e il modello di prompt in una catena conversazionale utilizzando LangChain. Questa catena includerà anche una memoria per tenere traccia della conversazione.
LangChain offre diversi tipi di memoria:
- ConversationBufferMemory: questa è l'opzione più semplice. Memorizza l'intera cronologia delle conversazioni.
- ConversationSummaryMemory: per risparmiare spazio, questa opzione riepiloga periodicamente le parti più vecchie della conversazione.
- ConversationBufferWindowMemory: mantiene in memoria solo gli ultimi scambi, il che è utile per evitare che il contesto diventi troppo lungo.
Per i test, ConversationBufferMemory è un ottimo punto di partenza.
Passaggio 6: esegui il ciclo del chatbot
Infine, puoi creare un semplice ciclo per interagire con il tuo chatbot dal terminale.
In un'applicazione reale, sostituiresti questo ciclo con un endpoint API utilizzando un framework come FastAPI o Flask. Puoi anche trasmettere in streaming la risposta del modello all'utente, rendendo il chatbot molto più veloce.
Puoi anche regolare parametri come la temperatura per controllare la casualità delle risposte. Una temperatura bassa (ad esempio 0,2) rende l'output più deterministico e fattuale, mentre una temperatura più alta (ad esempio 0,8) incoraggia una maggiore creatività.
Come testare il tuo chatbot LLaMA
Hai creato un chatbot che fornisce risposte, ma è pronto per gli utenti reali? L'implementazione di un bot non testato può portare a imbarazzanti fallimenti, come fornire informazioni errate o generare contenuti inappropriati, che possono danneggiare la reputazione della tua azienda.
Un piano di test sistematico è la soluzione a questa incertezza. Assicura che il tuo chatbot sia robusto, affidabile e sicuro.
Test funzionali:
- Casi limite: verifica come il bot gestisce input vuoti, messaggi molto lunghi e caratteri speciali.
- Verifica della memoria: assicurati che il chatbot ricordi il contesto durante più turni di una conversazione.
- Istruzioni da seguire: verifica che il bot rispetti le regole impostate nel prompt di sistema.
Valutazione della qualità:
- Pertinenza: la risposta risponde effettivamente alla domanda dell'utente?
- Accuratezza: le informazioni fornite sono corrette?
- Coerenza: la conversazione ha un flusso logico?
- Sicurezza: il bot rifiuta di rispondere a richieste inappropriate o dannose?
Test delle prestazioni:
- Latenza: misura il tempo necessario al bot per iniziare a rispondere e completare la risposta.
- Utilizzo delle risorse: monitora la quantità di memoria GPU utilizzata dal modello durante l'inferenza.
- Concorrenza: verifica le prestazioni del sistema quando più utenti interagiscono contemporaneamente con esso.
Inoltre, fai attenzione ai problemi comuni dell'LLM come le allucinazioni (affermare con sicurezza informazioni false), lo spostamento di contesto (perdere di vista l'argomento in una conversazione lunga) e la ripetizione. Registrare tutte le conversazioni di prova è un ottimo modo per individuare schemi ricorrenti e risolvere i problemi prima che raggiungano i tuoi utenti.
📚 Leggi anche: La differenza tra test funzionali e test non funzionali
Casi d'uso di LLaMA Chatbot per i team
Una volta superate le fasi di messa a punto e implementazione, LLaMA diventa particolarmente utile quando viene applicato ai problemi quotidiani del team, piuttosto che a dimostrazioni astratte di IA. In genere i team non hanno bisogno di un "chatbot", ma di un accesso più rapido alle conoscenze, meno passaggi manuali e meno lavoro ripetitivo.
Assistente interno per la conoscenza
Ottimizzando LLaMA sulla documentazione interna, sui wiki e sulle FAQ, oppure abbinandolo a una knowledge base basata su RAG, i team possono porre domande in linguaggio naturale e ottenere risposte precise e contestualizzate. Ciò elimina l'attrito della ricerca su strumenti dispersi, mantenendo i dati sensibili completamente interni, anziché inviarli ad API di terze parti.
🌟 Enterprise Search in ClickUp e l'agente Ambient Answers predefinito forniscono risposte contestuali dettagliate alle tue domande utilizzando le conoscenze presenti nell'area di lavoro di ClickUp.
Assistente per la revisione del codice del codice
Una volta addestrato sul tuo codice base e sulle tue guide di stile, LLaMA può fungere da assistente per la revisione contestuale del codice. Anziché best practice generiche, gli sviluppatori ricevono suggerimenti in linea con le convenzioni del team, le decisioni architetturali e i modelli storici.
🌟 Un assistente per la revisione del codice basato su LLaMA può evidenziare problemi, suggerire miglioramenti o spiegare codice sconosciuto. Codegen di ClickUp fa un passo avanti agendo all'interno del flusso di lavoro di sviluppo, creando richieste pull, applicando refactoring o aggiornando i file direttamente in risposta a tali intuizioni. Il risultato è meno copia-incolla e meno passaggi interrotti tra il "pensare" e il "fare".
Triage del supporto clienti
LLaMA può essere addestrato per la classificazione delle intenzioni, in modo da comprendere le query dei clienti in arrivo e indirizzarle al team o al flusso di lavoro appropriato. Le domande più comuni possono essere gestite automaticamente, mentre i casi più complessi vengono inoltrati agli agenti umani con il contesto allegato, riducendo i tempi di risposta senza compromettere la qualità.
Potresti anche creare un Super Agente di Triage utilizzando il linguaggio naturale all'interno dell'area di lavoro di ClickUp. Ulteriori informazioni
Riassunto delle riunioni e follow-up
Utilizzando le trascrizioni delle riunioni come input, LLaMA è in grado di estrarre decisioni, elementi da intraprendere e punti chiave della discussione. Il vero valore emerge quando questi output confluiscono direttamente negli strumenti di gestione delle attività, trasformando le conversazioni in lavoro tracciabile.
🌟 L'AI Meeting Notetaker di ClickUp non si limita a prendere appunti durante le riunioni, ma redige riepiloghi, genera azioni da intraprendere e collega gli appunti delle riunioni ai tuoi documenti e alle tue attività.
Redazione e iterazione di documenti
I team possono utilizzare LLaMA per generare bozze preliminari di report, proposte o documentazione sulla base di modelli esistenti ed esempi passati. Ciò consente di concentrare il lavoro richiesto sulla revisione e il perfezionamento anziché sulla creazione da zero, accelerando la consegna senza abbassare gli standard.
🌟 ClickUp Brain può generare rapidamente bozze per la documentazione, mantenendo tutte le tue conoscenze lavorative nel contesto. Provalo oggi stesso.
I chatbot basati su LLaMA sono più efficaci quando sono integrati nei flussi di lavoro esistenti (documentazione, project management e comunicazione del team) piuttosto che quando funzionano come strumenti autonomi.
È qui che l'integrazione diretta dell'IA nella tua area di lavoro fa la differenza. Invece di creare uno strumento separato, puoi portare l'IA conversazionale dove il tuo team già opera.
Ad esempio, puoi creare un bot LLaMA personalizzato che funga da assistente di conoscenza. Tuttavia, se risiede al di fuori del tuo strumento di project management, il tuo team dovrà cambiare contesto per porgli una domanda. Ciò crea attrito e rallenta il lavoro di tutti.
Elimina questo cambio di contesto utilizzando un'IA che fa già parte del tuo flusso di lavoro.
Fai domande sui tuoi progetti, attività e documenti senza mai uscire da ClickUp utilizzando ClickUp Brain. Basta digitare @brain in qualsiasi commento di attività o nella chat di ClickUp per ottenere una risposta immediata e contestualizzata. È come avere un membro del team che conosce perfettamente il tuo intero spazio di lavoro. 🤩
Questo trasforma il chatbot da una novità a una parte fondamentale del motore di produttività del tuo team.
Limiti dell'utilizzo di LLaMA per la creazione di chatbot
Creare un chatbot LLaMA può essere stimolante, ma spesso i team vengono colti alla sprovvista da complessità nascoste. Il modello open source "gratis" può rivelarsi più costoso e difficile da gestire del previsto, portando a un'esperienza utente scadente e a un ciclo di manutenzione costante che consuma risorse.
È importante comprendere i limiti prima di commit.
- Complessità tecnica: l'impostazione e la manutenzione di un modello LLaMA richiedono conoscenze relative all'infrastruttura di apprendimento automatico.
- Requisiti hardware: l'esecuzione di modelli più grandi e potenti richiede hardware GPU costoso e i costi del cloud possono aumentare rapidamente.
- Limiti della finestra contestuale: i modelli LLaMA hanno una memoria limitata ( 4K token per LLaMA 2 ). La gestione di documenti o conversazioni lunghi richiede strategie di suddivisione complesse.
- Nessuna protezione di sicurezza integrata: sei responsabile dell'implementazione dei tuoi filtri per i contenuti e delle misure di sicurezza.
- Manutenzione continua: man mano che vengono rilasciati nuovi modelli, sarà necessario aggiornare i sistemi e i modelli ottimizzati potrebbero richiedere un nuovo addestramento.
I modelli self-hosted hanno in genere una latenza maggiore rispetto alle API commerciali altamente ottimizzate. Si tratta di oneri operativi che le soluzioni gestite risolvono per te.
📮ClickUp Insight: l'88% dei partecipanti al nostro sondaggio utilizza l'IA per le proprie attività personali, ma oltre il 50% evita di utilizzarla sul lavoro. I tre principali ostacoli? Mancanza di integrazione perfetta, lacune di conoscenza o preoccupazioni relative alla sicurezza.
Ma cosa succede se l'IA è integrata nel tuo spazio di lavoro ed è già sicura? ClickUp Brain, l'assistente IA integrato di ClickUp, rende tutto questo realtà. Comprende i prompt in linguaggio semplice, risolvendo tutte e tre le preoccupazioni relative all'adozione dell'IA e collegando chat, attività, documenti e conoscenze in tutto lo spazio di lavoro. Trova risposte e approfondimenti con un solo clic!
Alternative a LLaMA per la creazione di chatbot
LLaMA è solo una delle tante opzioni disponibili nel mare dei modelli di IA e può essere difficile capire quale sia quello giusto per te.
Ecco come si presenta il panorama delle alternative.
Altri modelli open source:
- Mistral: noto per le sue ottime prestazioni anche con modelli di dimensioni ridotte, che lo rendono efficiente.
- Falcon: viene fornito con una licenza molto permissiva, ottima per le applicazioni commerciali.
- MPT: ottimizzato per la gestione di documenti e conversazioni lunghi.
API commerciali:
- OpenAI (GPT-4, GPT-3. 5): generalmente considerati i modelli linguistici di grandi dimensioni più potenti, sono molto facili da integrare.
- Anthropic (Claude): noto per le sue solide funzionalità di sicurezza e le finestre di contesto molto ampie.
- Google (Gemini): offre potenti funzionalità multimodali che consentono di comprendere testi, immagini e audio.
Puoi crearlo tu stesso con un modello open source, acquistare un'API commerciale o utilizzare una zona di lavoro AI convergente che offre una soluzione preintegrata con diversi tipi di agenti IA.
📚 Leggi anche: Come utilizzare un chatbot per la tua attività aziendale
Crea assistenti IA sensibili al contesto con ClickUp
Creare un chatbot con LLaMA ti offre un controllo incredibile sui tuoi dati, sui costi e sulla personalizzazione. Ma tale controllo comporta la responsabilità dell'infrastruttura, della manutenzione e della sicurezza, tutte cose che le API gestite gestiscono per te. L'obiettivo non è solo quello di creare un bot, ma anche di rendere il tuo team più produttivo, e un progetto di ingegneria complesso a volte può distrarre da questo obiettivo.
La scelta giusta dipende dalle risorse e dalle priorità del tuo team. Se hai competenze nel campo del machine learning e requisiti di privacy rigorosi, LLaMA è un'opzione fantastica. Se dai la priorità alla velocità e alla semplicità, uno strumento integrato potrebbe essere più adatto.
Con ClickUp, ottieni uno spazio di lavoro AI convergente con tutte le tue attività, i tuoi documenti e le tue conversazioni in un unico posto, alimentato da un'intelligenza artificiale integrata. Riduce la dispersione del contesto e aiuta i team a lavorare in modo più rapido ed efficace, con le informazioni giuste a portata di mano grazie a Super Agent personalizzabili e AI contestuale.
Smetti di perdere tempo con l'infrastruttura e ottieni oggi stesso i vantaggi di un assistente IA sensibile al contesto senza dover creare nulla da zero. Inizia gratis con ClickUp.
Domande frequenti (FAQ)
Il costo dipende interamente dal metodo di implementazione e le previsioni del progetto possono aiutarti a stimarlo. Se utilizzi il tuo hardware, dovrai sostenere un costo iniziale per la GPU, ma non ci saranno costi ricorrenti per ogni query. I provider di cloud applicano una tariffa oraria basata sulla GPU e sulle dimensioni del modello.
Sì, le licenze per LLaMA 2 e LLaMA 3 consentono l'uso commerciale. Tuttavia, è necessario accettare i Termini di utilizzo di Meta e fornire l'attribuzione richiesta nel proprio prodotto.
LLaMA 3 è il modello più recente e più potente, che offre migliori capacità di ragionamento e una finestra di contesto più ampia (8K token contro i 4K di LLaMA 2). Ciò significa che è in grado di gestire conversazioni e documenti più lunghi, ma richiede anche maggiori risorse computazionali per funzionare.
Sebbene Python sia il linguaggio più comune per l'apprendimento automatico grazie alle sue librerie estese, non è strettamente necessario. Alcune piattaforme stanno iniziando a offrire soluzioni senza codice o con poco codice che consentono di implementare un chatbot LLaMA con un'interfaccia grafica. /