
I progetti di addestramento dell'IA raramente falliscono a livello di modello. Incontrano difficoltà quando gli esperimenti, la documentazione e gli aggiornamenti delle parti interessate sono sparsi su troppi strumenti.
Questa guida ti illustra come addestrare i modelli con Databricks DBRX, un LLM che offre un'efficienza di calcolo doppia rispetto ad altri modelli leader, mantenendo il lavoro correlato organizzato in ClickUp.
Dalla configurazione e messa a punto alla documentazione e agli aggiornamenti tra i team, vedrai come un unico spazio di lavoro convergente aiuta a eliminare la dispersione di contesto e mantiene il tuo team concentrato sulla creazione, non sulla ricerca. 🛠
Cos'è DBRX?
DBRX è un potente modello linguistico di grandi dimensioni (LLM) open source progettato specificamente per l'addestramento e l'inferenza dei modelli di IA per l'azienda. Poiché è open source sotto la Databricks Open Model License, il tuo team ha pieno accesso ai pesi e all'architettura del modello, consentendoti di ispezionarlo, modificarlo e implementarlo secondo le tue esigenze.
È disponibile in due varianti: DBRX Base per il pre-addestramento approfondito e DBRX Instruct per attività di esecuzione di istruzioni pronte all'uso.
Architettura DBRX e progettazione mixture-of-experts
DBRX risolve le attività utilizzando un'architettura Mixture-of-Experts (MoE). A differenza dei tradizionali modelli linguistici di grandi dimensioni che utilizzano tutti i loro miliardi di parametri per ogni singolo calcolo, DBRX attiva solo una parte dei suoi parametri totali (gli esperti più rilevanti) per ogni dato compito.
Pensalo come un team di esperti specializzati: invece di far lavorare tutti su ogni problema, il sistema indirizza in modo intelligente ogni attività ai parametri corrispondenti più qualificati.
Questo non solo riduce i tempi di risposta, ma offre anche prestazioni e risultati di alto livello, riducendo significativamente i costi di calcolo.
Ecco una rapida panoramica delle sue specifiche principali:
- Parametri totali: 132 miliardi tra tutti gli esperti
- Parametri attivi: 36B per passaggio in avanti
- Numero di esperti: 16 in totale (MoE Top-4 routing), con 4 attivi per ogni token
- Finestra di contesto: 32K token
Dati di addestramento DBRX e specifiche dei token
Le prestazioni di un LLM dipendono dalla qualità dei dati su cui è stato addestrato. DBRX è stato pre-addestrato su un enorme set di dati da 12 trilioni di token, accuratamente curato dal team Databricks utilizzando i propri strumenti avanzati di elaborazione dei dati. È proprio per questo che ha ottenuto ottimi risultati nei benchmark di settore.
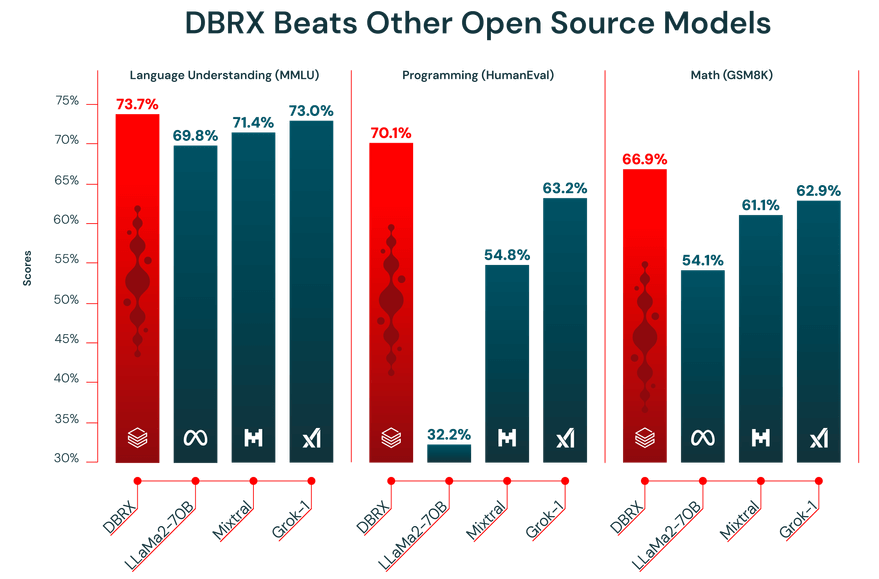
Inoltre, DBRX dispone di una finestra di contesto da 32.000 token. Questa è la quantità di testo che il modello può considerare contemporaneamente. Una finestra di contesto di grandi dimensioni è estremamente utile per attività complesse come riepilogare lunghi rapporti, esaminare documenti legali di grandi dimensioni o creare sistemi avanzati di generazione aumentata dal recupero (RAG), poiché consente al modello di mantenere il contesto senza troncature o perdite di informazioni.
🎥 Guarda questo video per scoprire come un coordinamento dei progetti ottimizzato può trasformare il tuo flusso di lavoro di addestramento dell'IA ed eliminare l'attrito causato dal passaggio da uno strumento all'altro. 👇🏽
Come accedere e configurare DBRX
DBRX offre due modalità di accesso principali, entrambe con accesso completo ai pesi del modello a condizioni commerciali permissive. Puoi utilizzare Hugging Face per la massima flessibilità o accedervi direttamente tramite Databricks per un'esperienza più integrata.
Accedi a DBRX tramite Hugging Face
Per i team che apprezzano la flessibilità e hanno già familiarità con l'ecosistema Hugging Face, l'accesso a DBRX tramite l'hub è la soluzione ideale. Consente di integrare il modello nei flussi di lavoro esistenti basati su trasformatori.
Ecco come iniziare:
- Crea o accedi al tuo account Hugging Face
- Accedi alla scheda del modello DBRX sull'hub e accetta i termini della licenza.
- Installa la libreria dei trasformatori insieme alle dipendenze necessarie come accelerate.
- Usa la classe AutoModelForCausalLM nel tuo script Python per caricare il modello DBRX.
- Configura la tua pipeline di inferenza, tenendo presente che DBRX richiede una notevole quantità di memoria GPU (VRAM) per funzionare in modo efficace.
📖 Per saperne di più: Come configurare la temperatura LLM
Accedi a DBRX tramite Databricks
Se il tuo team utilizza già Databricks per l'ingegneria dei dati o l'apprendimento automatico, accedere a DBRX attraverso la piattaforma è il modo più semplice. Elimina le difficoltà di configurazione e ti fornisce tutti gli strumenti necessari per MLOps proprio dove stai già lavorando.
Segui questi passaggi all'interno della tua area di lavoro Databricks per iniziare:
- Vai alla sezione Model Garden o Mosaic IA.
- Scegliete DBRX Base o DBRX Instruct, a seconda delle vostre esigenze.
- Configura un endpoint di servizio per l'accesso alle API o imposta un ambiente notebook per un utilizzo interattivo.
- Inizia a testare l'inferenza con prompt di esempio per assicurarti che tutto funzioni correttamente prima di scalare l'addestramento o l'implementazione del tuo modello di IA.
Questo approccio ti offre un accesso senza soluzione di continuità a strumenti come MLflow per il monitoraggio degli esperimenti e Unity Catalog per la governance dei modelli.
📮 Approfondimento ClickUp: in media, un professionista trascorre più di 30 minuti al giorno alla ricerca di informazioni relative al lavoro, ovvero oltre 120 ore all'anno perse a setacciare email, thread Slack e file sparsi.
Un assistente IA intelligente integrato nella tua area di lavoro può cambiare tutto questo. Entra in ClickUp Brain.
Fornisce informazioni e risposte immediate facendo emergere i documenti, le conversazioni e i dettagli delle attività giusti in pochi secondi, così puoi smettere di cercare e iniziare a lavorare.
Come ottimizzare DBRX e addestrare modelli di IA personalizzati
Un modello standard, per quanto potente, non potrà mai comprendere le sfumature uniche delle attività aziendali. Poiché DBRX è open source, puoi ottimizzarlo per creare un modello personalizzato che parli la lingua della tua azienda o svolga un'attività specifica che desideri gli venga assegnata.
Ecco tre modi comuni da fare:
1. Ottimizza DBRX con i set di dati Hugging Face
Per i team che hanno appena iniziato o che lavorano su attività comuni, i set di dati pubblici di Hugging Face Hub sono una risorsa eccellente. Sono preformattati e facili da caricare, il che significa che non dovrai passare ore a preparare i tuoi dati.
Il processo è piuttosto semplice:
- Trova un set di dati sull'hub che corrisponda alla tua attività (ad esempio, seguire istruzioni, riepilogare/riassumere).
- Caricalo utilizzando la libreria dei set di dati
- Assicurati che i dati siano formattati in coppie istruzione-risposta.
- Configura il tuo script di addestramento con iperparametri come il tasso di apprendimento e la dimensione del batch.
- Avvia il processo di addestramento, assicurandoti di salvare periodicamente i checkpoint.
- Valuta il modello ottimizzato su un set di validazione separato per misurare il miglioramento.
2. Ottimizza DBRX con set di dati locali
Di solito si ottengono i risultati migliori ottimizzando il modello con i propri dati proprietari. Ciò consente di insegnare al modello la terminologia, lo stile e le conoscenze specifiche della tua azienda. Tieni presente che questo approccio è efficace solo se i tuoi dati sono puliti, ben preparati e in quantità sufficiente.
Segui questi passaggi per preparare i tuoi dati interni:
- Raccolta dati: raccogli esempi di alta qualità dai tuoi wiki interni, documenti e database.
- Conversione del formato: strutturate i vostri dati in un formato coerente di istruzioni-risposte, spesso come righe JSON.
- Filtraggio della qualità: rimuovi tutti gli esempi di bassa qualità, duplicati o irrilevanti.
- Divisione di convalida: metti da parte una piccola parte dei tuoi dati (in genere il 10-15%) per valutare le prestazioni del modello.
- Revisione della privacy: rimuovi o maschera qualsiasi informazione di identificazione personale (PII) o dato sensibile.
3. Ottimizza DBRX con StreamingDataset
Se il tuo set di dati risulta troppo grande per essere contenuto nella memoria del tuo computer, non preoccuparti: puoi utilizzare la libreria Streaming Dataset di Databricks. Ti consente di trasmettere i dati direttamente dall’archiviazione cloud mentre il modello è in fase di addestramento, invece di caricarli tutti in memoria contemporaneamente.
Ecco come puoi farlo:
- Preparazione dei dati: pulisci e struttura i tuoi dati di addestramento, quindi archiviali in un formato riproducibile come JSONL o CSV nell'archiviazione cloud.
- Conversione del formato di streaming: converti il tuo set di dati in un formato adatto allo streaming, come Mosaic Data Shard (MDS), in modo che possa essere letto in modo efficiente durante l'addestramento.
- Configurazione del caricatore di addestramento: configura il tuo caricatore di addestramento in modo che punti al set di dati remoto e definisci uno spazio di archiviazione locale per l'archiviazione temporanea dei dati.
- Inizializzazione del modello: avvia il processo di ottimizzazione DBRX utilizzando un framework di addestramento che offre supporto per StreamingDataset, come LLM Foundry.
- Addestramento basato su streaming: esegui il processo di addestramento mentre i dati vengono trasmessi in batch durante l'addestramento, anziché caricarli interamente nella memoria.
- Checkpointing e ripristino: riprendi l'addestramento senza interruzioni se un'esecuzione viene interrotta, senza duplicare o saltare dati.
- Valutazione e implementazione: convalida le prestazioni del modello ottimizzato e implementalo utilizzando la tua configurazione di servizio o inferenza preferita.
💡Suggerimento professionale: invece di creare un piano di addestramento DBRX da zero, inizia con il modello di roadmap per progetti di IA e machine learning di ClickUp e modificalo in base alle esigenze del tuo team. Fornisce una struttura chiara per la pianificazione dei set di dati, le fasi di addestramento, la valutazione e l'implementazione, così puoi concentrarti sull'organizzazione del tuo lavoro piuttosto che sulla strutturazione di un flusso di lavoro.
Casi d'uso di DBRX per l'addestramento di modelli di IA
Una cosa è avere un modello potente, un'altra è sapere esattamente dove eccelle.
Quando non si ha un quadro chiaro dei punti di forza di un modello, è facile sprecare tempo e risorse cercando di farlo funzionare dove semplicemente non è adatto. Ciò porta a risultati scadenti e frustrazione.
L'architettura unica e i dati di addestramento di DBRX lo rendono particolarmente adatto a diversi casi d'uso aziendali chiave. Conoscere questi punti di forza ti aiuta ad allineare il modello ai tuoi obiettivi aziendali e a massimizzare il ritorno sull'investimento.
Generazione di testo e creazione di contenuti
DBRX Instruct è ottimizzato per seguire le istruzioni e generare testi di alta qualità. Questo lo rende uno strumento potente per automatizzare un'ampia gamma di attività relative ai contenuti. La sua ampia finestra di contesto è un vantaggio significativo, che gli consente di gestire documenti lunghi senza perdere il thread del discorso.
Puoi utilizzarlo per:
- Documentazione tecnica: genera e perfeziona manuali dei prodotti, riferimenti API e guide per gli utenti.
- Contenuti di marketing: bozze di post per blog, newsletter via email e aggiornamenti sui social media.
- Generazione di report: riepiloga i risultati di dati complessi e crea riassunti esecutivi concisi.
- Traduzione e localizzazione: adattare i contenuti esistenti a nuovi mercati e pubblici
Generazione di codice e attività di debug
Una parte significativa dei dati di addestramento di DBRX includeva codice, rendendolo un valido supporto LLM per gli sviluppatori. Può aiutare ad accelerare i cicli di sviluppo automatizzando le attività di codifica ripetitive e assistendo nella risoluzione di problemi complessi.
Ecco alcuni modi in cui il tuo team di ingegneri può sfruttarlo:
- Completamento del codice: genera automaticamente i corpi delle funzioni dai commenti o dalle stringhe di documentazione.
- Rilevamento dei bug: analizza frammenti di codice per identificare potenziali errori o difetti logici.
- Spiegazione del codice: traduci algoritmi complessi o codice legacy in un linguaggio semplice.
- Generazione di test: crea test unitari basati sulla firma di una funzione e sul comportamento previsto.
RAG e applicazioni a contesto lungo
La generazione aumentata dal recupero (RAG) è una tecnica potente che basa le risposte di un modello sui dati privati della tua azienda. Tuttavia, i sistemi RAG spesso hanno difficoltà con modelli che hanno finestre di contesto ridotte, costringendo a un chunking aggressivo dei dati che può far perdere contesti importanti. La finestra di contesto da 32K di DBRX lo rende una base eccellente per applicazioni RAG robuste.
Questo ti consente di creare potenti strumenti interni, come ad esempio:
- Ricerca aziendale: crea un chatbot che risponda alle domande dei dipendenti utilizzando la tua knowledge base interna.
- Supporto clienti: crea un agente che generi risposte di supporto basate sulla documentazione del tuo prodotto.
- Assistenza alla ricerca: sviluppa uno strumento in grado di sintetizzare le informazioni contenute in centinaia di pagine di articoli di ricerca.
- Verifica della conformità: verifica automaticamente i testi di marketing rispetto alle linee guida interne del marchio o ai documenti normativi.
Come integrare la formazione DBRX nel flusso di lavoro del tuo team
Un progetto di addestramento di modelli IA di successo non riguarda solo il codice e l'elaborazione. È uno sforzo collaborativo che coinvolge ingegneri ML, data scientist, product manager e stakeholder.
Quando questa collaborazione è dispersa tra notebook Jupyter, canali Slack e strumenti di project management separati, si crea una dispersione di contesto, una situazione in cui le informazioni critiche del progetto sono sparse su troppi strumenti.
ClickUp risolve questo problema. Invece di destreggiarti tra più strumenti, avrai a disposizione un unico spazio di lavoro AI convergente in cui la project management, la documentazione e la comunicazione convivono, in modo che i tuoi esperimenti rimangano collegati dalla pianificazione all'esecuzione fino alla valutazione.
Non perdere mai il monitoraggio degli esperimenti e dello stato
Quando si eseguono più esperimenti, la parte più difficile non è addestrare il modello, ma il monitoraggio di ciò che è cambiato durante il processo. Quale versione del set di dati è stata utilizzata, quale tasso di apprendimento ha funzionato meglio o quale esecuzione è stata distribuita?
ClickUp rende questo processo estremamente semplice. Puoi effettuare il monitoraggio di ogni ciclo di addestramento separatamente in attività di ClickUp e, all'interno delle attività, puoi utilizzare i campi personalizzati per registrare:
- Versione del set di dati
- Iperparametri
- Variante del modello (DBRX Base vs DBRX Instruct)
- Stato dell'addestramento (in coda, in esecuzione, in fase di valutazione, implementato)
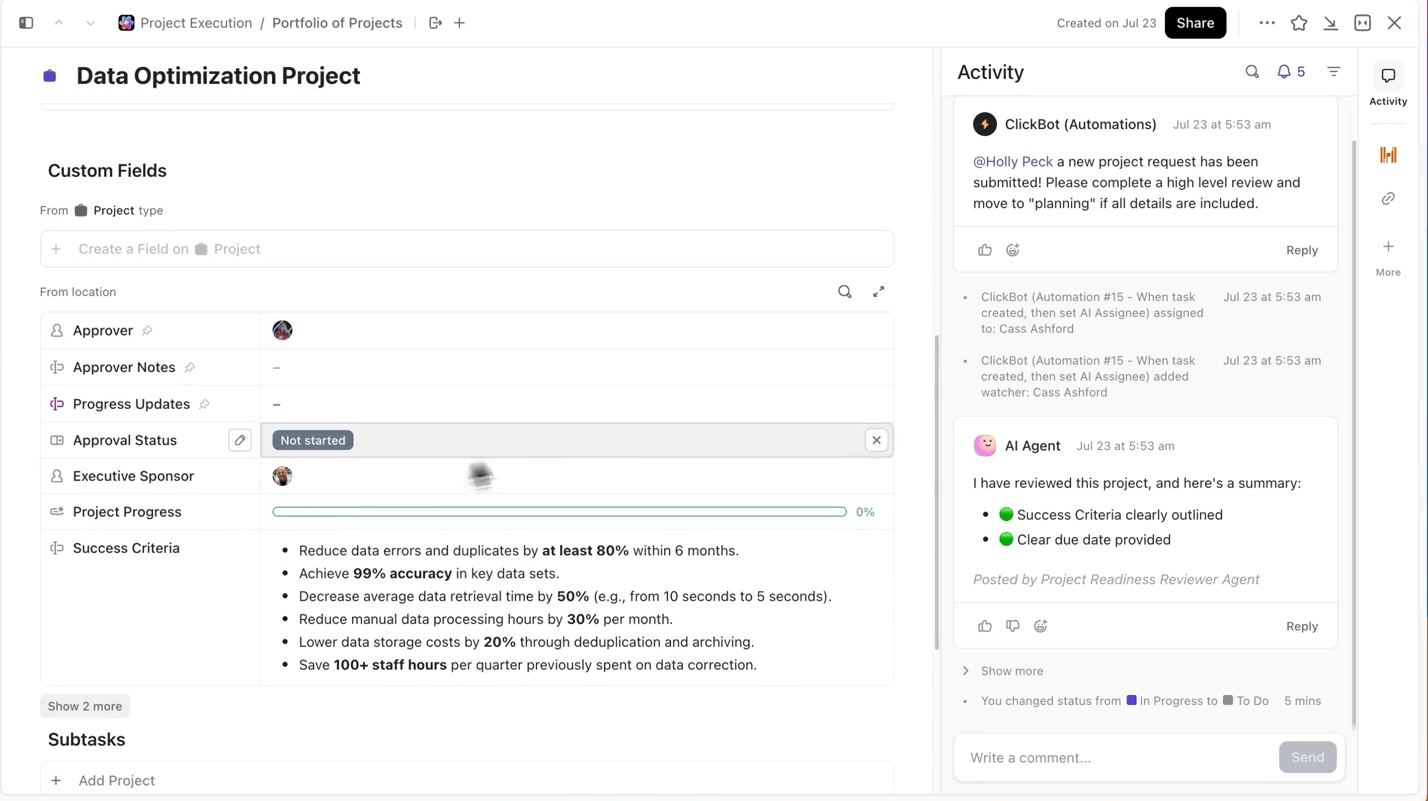
In questo modo, ogni esperimento documentato è ricercabile, facile da confrontare con altri e riproducibile.
Mantieni la documentazione dei modelli collegata al lavoro
Non è necessario passare dai notebook Jupyter ai file README o ai thread Slack per comprendere il contesto dell'attività di un esperimento.
Con ClickUp Docs, puoi mantenere l'architettura del modello, gli script di preparazione dei dati o le metriche di valutazione organizzati e accessibili documentandoli in un documento ricercabile che si collega direttamente alle attività sperimentali da cui provengono.

💡Suggerimento professionale: mantieni un brief di progetto aggiornato in ClickUp Docs che descriva in dettaglio ogni decisione, dall'architettura alla distribuzione, in modo che i nuovi membri del team possano sempre essere aggiornati sui dettagli del progetto senza dover cercare tra i vecchi thread.
Offri agli stakeholder visibilità in tempo reale
I dashboard di ClickUp mostrano in tempo reale lo stato di avanzamento degli esperimenti e il carico di lavoro del team. I
Invece di compilare manualmente gli aggiornamenti o inviare email, i dashboard si aggiornano automaticamente in base ai dati presenti nelle tue attività. In questo modo, gli stakeholder possono controllare in qualsiasi momento lo stato delle cose e non dovranno mai interromperti con domande del tipo "a che punto siamo?".
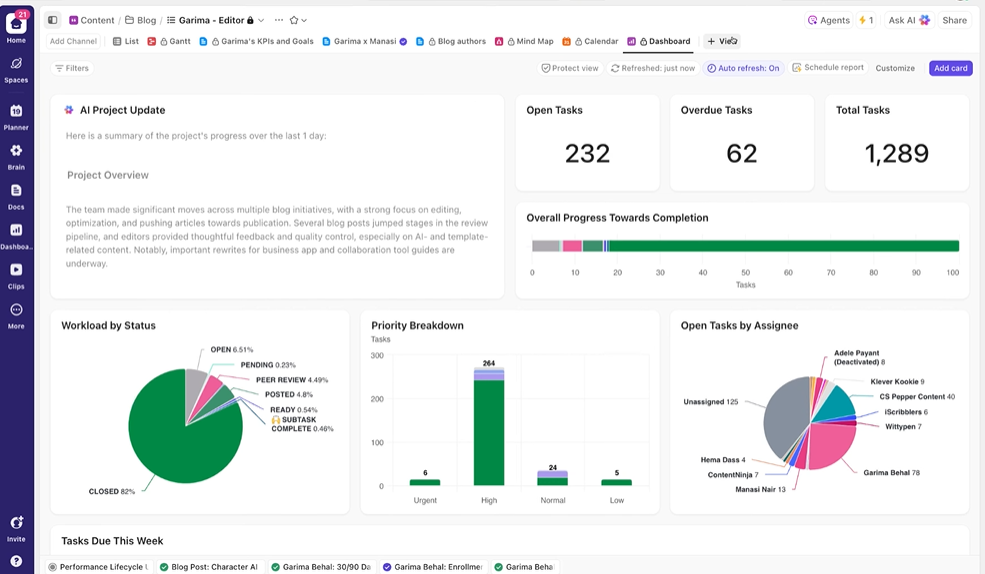
In questo modo, potrai concentrarti sull'esecuzione degli esperimenti invece di dover effettuare costantemente la reportistica manuale.
Trasforma l'IA nel tuo assistente intelligente per i progetti
Non è necessario scavare manualmente tra settimane di dati di addestramento per ottenere un riepilogo/riassunto degli esperimenti effettuati fino a quel momento. Basta effettuare una menzione di @Brain in qualsiasi commento relativo a un'attività di ClickUp e ClickUp Brain ti fornirà l'aiuto necessario con il contesto completo dei tuoi progetti passati e in corso.
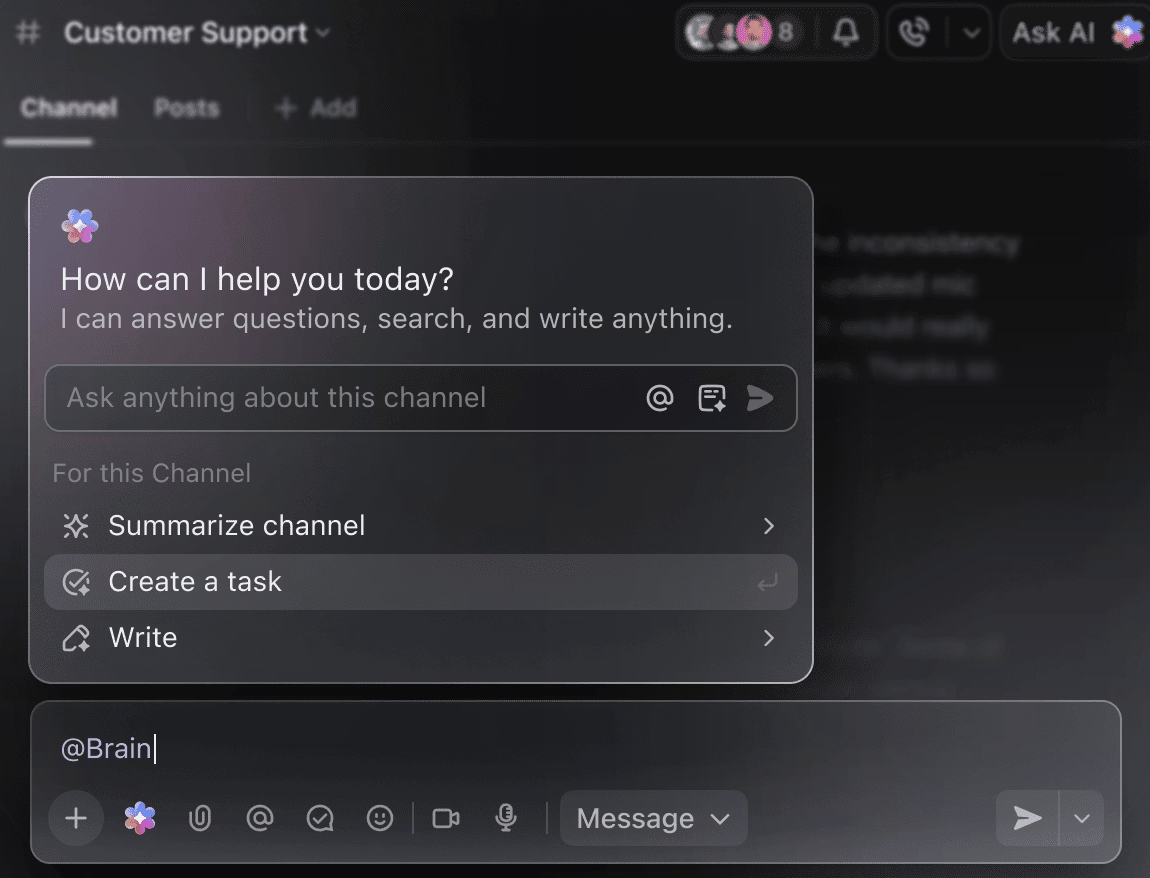
Puoi chiedere a Brain di "Riassumere gli esperimenti della scorsa settimana in 5 punti chiave" o "Redigere un documento con gli ultimi risultati degli iperparametri" e ottenere immediatamente un risultato perfetto.
🧠 Il vantaggio di ClickUp: i Super Agent di ClickUp vanno ben oltre: possono automatizzare interi flussi di lavoro in base a trigger definiti dall'utente, non solo rispondere alle sue domande. Con i super agenti, puoi creare automaticamente una nuova attività di addestramento DBRX ogni volta che viene caricato un set di dati, avvisare il tuo team e collegare i documenti pertinenti quando l'addestramento termina o raggiunge un checkpoint, nonché generare un riepilogo settimanale dei progressi e inviarlo agli stakeholder senza che tu debba fare nulla.
Errori comuni da evitare
Intraprendere un progetto di addestramento DBRX è entusiasmante, ma alcuni errori comuni possono compromettere i tuoi progressi. Evitare questi errori ti farà risparmiare tempo, denaro e molta frustrazione.
- Sottovalutare i requisiti hardware: DBRX è potente, ma anche ingombrante. Cercare di eseguirlo su hardware inadeguato porterà a errori di memoria insufficiente e al fallimento dei lavori di addestramento. Tieni presente che DBRX (132B) richiede almeno 264 GB di VRAM per l'inferenza a 16 bit, ovvero circa 70-80 GB quando si utilizza la quantizzazione a 4 bit.
- Saltare i controlli sulla qualità dei dati: se i dati in entrata sono scadenti, anche quelli in uscita lo saranno. La messa a punto su un set di dati disordinato e di bassa qualità insegnerà al modello solo a produrre risultati disordinati e di bassa qualità.
- Ignorare i limiti di lunghezza del contesto: sebbene la finestra di contesto di 32K di DBRX sia generosa, non è infinita. L'inserimento di input nel modello che superano questo limite avrà come risultato un troncamento silenzioso e prestazioni scadenti.
- Utilizzo di Base quando Instruct è appropriato: DBRX Base è un modello grezzo e pre-addestrato destinato a un ulteriore addestramento su larga scala. Per la maggior parte delle attività che richiedono l'esecuzione di istruzioni, è consigliabile iniziare con DBRX Instruct, che è già stato ottimizzato per tale scopo.
- Separazione del lavoro di formazione dal coordinamento del progetto: quando il monitoraggio degli esperimenti avviene in uno strumento e il piano del progetto in un altro, si creano silos di informazioni. Utilizza una piattaforma integrata come ClickUp per garantire la sincronizzazione tra il lavoro tecnico e il coordinamento del progetto.
- Trascurare la valutazione prima dell'implementazione: un modello che funziona bene sui dati di addestramento potrebbe fallire clamorosamente nel mondo reale. Convalida sempre il tuo modello ottimizzato su un set di test riservato prima di implementarlo in produzione.
- Trascurare la complessità della messa a punto: poiché DBRX è un modello Mixture-of-Experts, gli script di messa a punto standard potrebbero richiedere librerie specializzate come Megatron-LM o PyTorch FSDP per gestire la frammentazione dei parametri su più GPU.
DBRX rispetto ad altre piattaforme di addestramento dell'IA
La scelta di una piattaforma di addestramento IA comporta un compromesso fondamentale: controllo contro praticità. I modelli proprietari, basati solo su API, sono facili da usare ma vincolano l'utente all'ecosistema di un fornitore.
I modelli aperti come DBRX offrono un controllo completo, ma richiedono maggiori competenze tecniche e infrastrutture. Questa scelta può lasciarti bloccato, insicuro su quale percorso supporti effettivamente i tuoi obiettivi a lungo termine: una sfida che molti team affrontano durante l'adozione dell'IA.
Questa tabella illustra le differenze principali per aiutarti a prendere una decisione informata.
| Pesi | Apri (Personalizzato) | Proprietario | Apri (Personalizzato) | Proprietario |
| Messa a punto | Controllo totale | Basato su API | Controllo totale | Basato su API |
| Self-hosting | Sì | No | Sì | No |
| Licenza | Modello aperto DB | Termini OpenAI | Comunità Llama | Termini antropici |
| Contesto | 32K | 128K – 1M | 128K | 200.000 - 1 milione |
DBRX è la scelta giusta quando hai bisogno di un controllo completo sul modello, devi ospitarlo autonomamente per motivi di sicurezza o conformità, o desideri la flessibilità di una licenza commerciale permissiva. Se non disponi di un'infrastruttura GPU dedicata o se dai più valore alla velocità di immissione sul mercato che alla personalizzazione approfondita, le alternative basate su API potrebbero essere più adatte.
Inizia ad addestrare in modo più intelligente con ClickUp
DBRX ti offre una base pronta per l'uso nell'azienda per la creazione di applicazioni IA personalizzate, con la trasparenza e il controllo che non ottieni dai modelli proprietari. La sua efficiente architettura MoE mantiene bassi i costi di inferenza e il suo design aperto semplifica la messa a punto. Ma una tecnologia potente è solo metà dell'equazione.
Il vero esito positivo deriva dall'allineamento del lavoro tecnico con il flusso di lavoro collaborativo del tuo team. L'addestramento dei modelli di IA è un lavoro di squadra ed è fondamentale garantire la sincronizzazione degli esperimenti, della documentazione e della comunicazione con le parti interessate. Quando riunisci tutto in un unico spazio di lavoro convergente e riduci la dispersione del contesto, puoi fornire modelli migliori e più veloci.
Inizia gratis con ClickUp per coordinare i tuoi progetti di addestramento dell'IA in un unico spazio di lavoro. ✨
Domande frequenti
Puoi monitorare l'addestramento utilizzando strumenti ML standard come TensorBoard, Weights & Biases o MLflow. Se stai effettuando l'addestramento all'interno dell'ecosistema Databricks, MLflow è integrato in modo nativo per un monitoraggio continuo degli esperimenti.
Sì, DBRX può essere integrato nelle pipeline MLOps standard. Contenendo il modello in un container, è possibile distribuirlo utilizzando piattaforme di orchestrazione come Kubeflow o flussi di lavoro CI/CD personalizzati.
DBRX Base è il modello pre-addestrato di base destinato ai team che desiderano eseguire un pre-addestramento continuo specifico per dominio o una messa a punto approfondita dell'architettura. DBRX Instruct è una versione ottimizzata per seguire le istruzioni, che lo rende un punto di partenza migliore per la maggior parte dello sviluppo di applicazioni.
La differenza principale è il controllo. DBRX offre pieno accesso ai pesi del modello per una personalizzazione approfondita e l'auto-hosting, mentre GPT-4 è un servizio solo API.
I pesi del modello DBRX sono disponibili gratis con la licenza Databricks Open Model License. Tuttavia, i costi dell'infrastruttura di calcolo necessaria per eseguire o ottimizzare il modello sono a carico dell'utente.