
La plupart des projets de déploiement d'IA échouent non pas parce que les équipes ont choisi le mauvais modèle, mais parce que trois mois plus tard, personne ne se souvient pourquoi elles l'ont choisi ni comment reproduire l'installation. 46 % des projets d'IA sont abandonnés entre la phase de validation du concept et leur adoption à grande échelle.
Ce guide vous explique comment utiliser Hugging Face pour le déploiement de l'IA, de la sélection et du test des modèles à la gestion du processus de déploiement, afin que votre équipe puisse livrer plus rapidement sans perdre de décisions cruciales dans les fils de discussion Slack et les feuilles de calcul éparpillées.
Qu'est-ce que Hugging Face ?
Hugging Face est une plateforme open source et un hub communautaire qui fournit des modèles d'IA pré-entraînés, des ensembles de données et des outils pour créer et déployer des applications d'apprentissage automatique.
Considérez-le comme une immense bibliothèque numérique où vous pouvez trouver des modèles d'IA prêts à l'emploi au lieu de passer des mois et d'investir des ressources considérables pour les créer à partir de zéro.
Conçu pour les ingénieurs en apprentissage automatique et les scientifiques des données, ses outils sont de plus en plus utilisés par des équipes interfonctionnelles de produit, de conception et d'ingénierie pour intégrer l'IA dans leurs flux de travail.
Le saviez-vous ? 63 % des organisations ne disposent pas de pratiques adéquates en matière de gestion des données pour l'IA. Cela entraîne souvent des retards dans les projets et un gaspillage de ressources.
Le principal défi pour de nombreuses équipes réside dans la complexité même du déploiement de l'IA. Le processus implique de sélectionner le bon modèle parmi des milliers d'options, de gérer l'infrastructure sous-jacente, de versionner les expériences et de s'assurer que les parties prenantes techniques et non techniques sont alignées.
Hugging Face simplifie ce processus en fournissant son Model Hub, un référentiel central contenant plus de 2 millions de modèles. La bibliothèque de transformateurs de la plateforme est la clé qui débloque ces modèles, vous permettant de les charger et de les utiliser en quelques lignes de code Python seulement.
Cependant, même avec ces outils puissants, le déploiement de l'IA reste un défi en matière de gestion de projet, qui nécessite un suivi minutieux de la sélection, des tests et du déploiement des modèles pour garantir sa réussite.
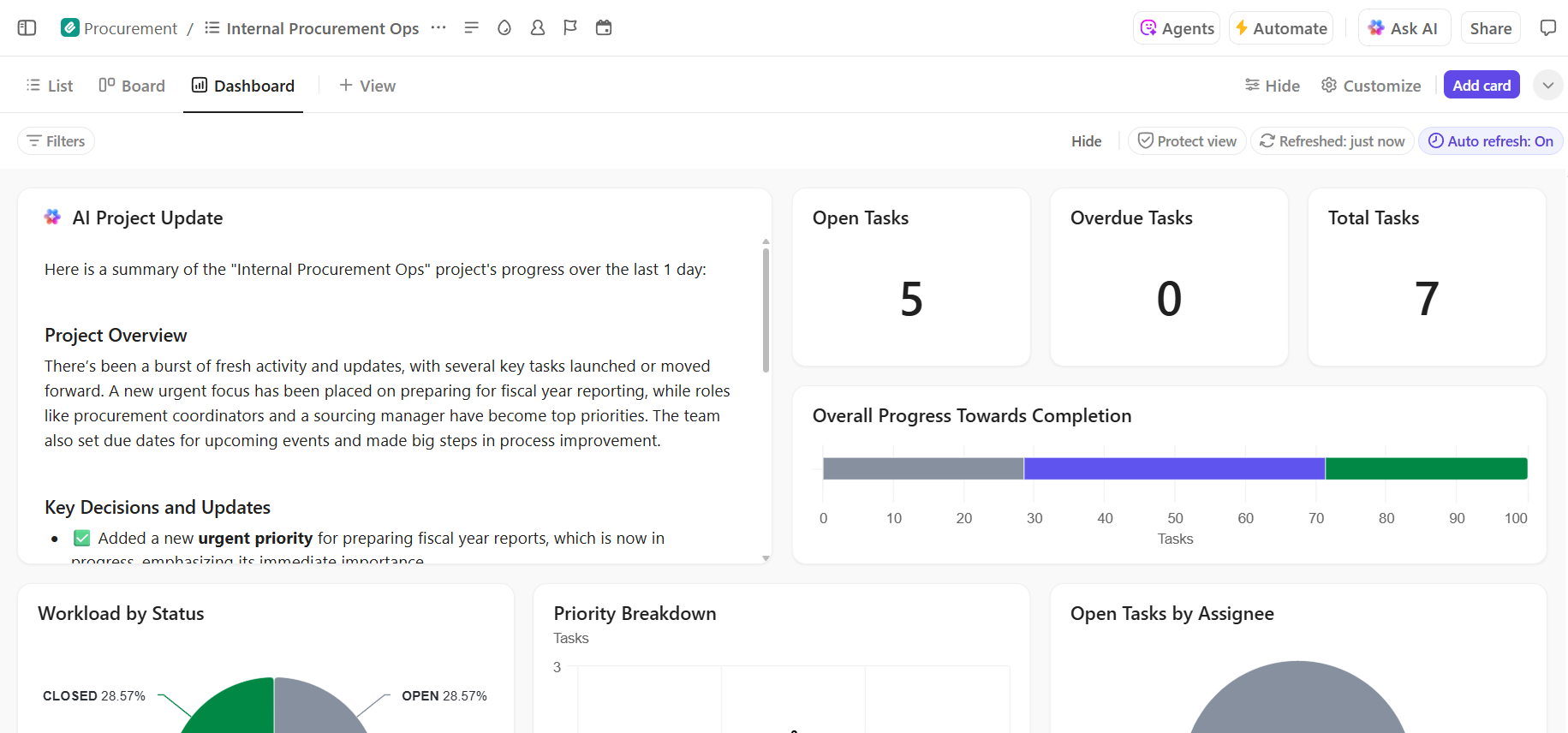
📮ClickUp Insight : 92 % des travailleurs du savoir risquent de perdre des décisions importantes dispersées dans des chats, des e-mails et des feuilles de calcul. Sans un système unifié pour saisir et suivre les décisions, les informations essentielles de l’entreprise se perdent dans le bruit numérique.
Grâce aux fonctionnalités de gestion des tâches de ClickUp, vous n'aurez plus jamais à vous soucier de cela. Créez des tâches à partir de chats, de commentaires sur des tâches, de documents et d'e-mails en un seul clic !
📚 À lire également : Les meilleures alternatives à Hugging Face pour les LLM, le NLP et les flux de travail d'IA
Modèles Hugging Face que vous pouvez déployer
La navigation dans le Hub Hugging Face peut sembler intimidante lorsque vous débutez. Avec des centaines de milliers de modèles, la clé est de comprendre les principales catégories afin de trouver celui qui convient le mieux à votre projet. Les modèles vont des options petites et efficaces conçues pour un usage unique aux modèles massifs et polyvalents capables de gérer des raisonnements complexes.
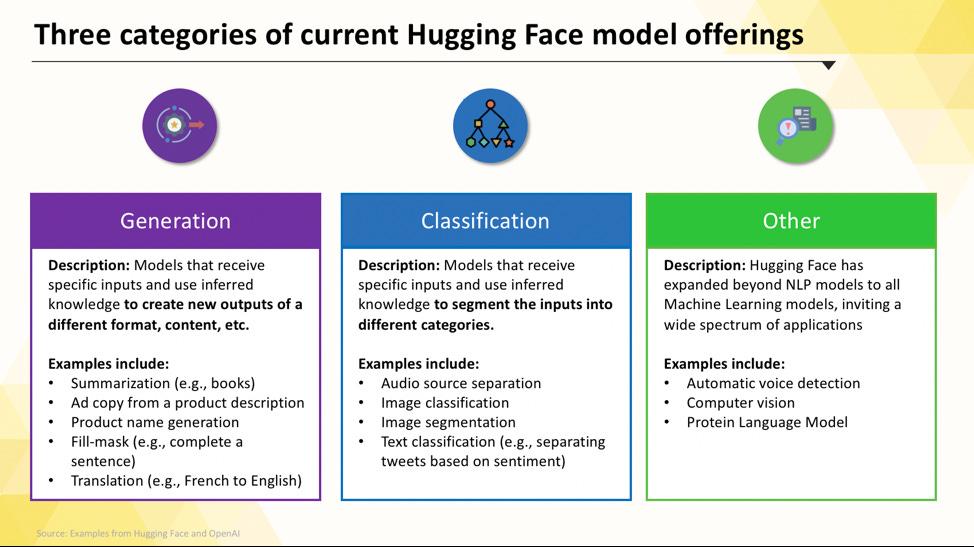
Modèles linguistiques spécifiques à une tâche
Lorsque votre équipe doit résoudre un problème unique et bien défini, vous n'avez souvent pas besoin d'un modèle généraliste de grande envergure. Le temps et le coût nécessaires pour exécuter un tel modèle peuvent être prohibitifs, surtout lorsqu'un outil d'IA plus petit et plus ciblé serait plus efficace. C'est là que les modèles spécifiques à une tâche entrent en jeu.
Il s'agit de modèles qui ont été formés et optimisés pour une fonction particulière. Comme ils sont spécialisés, ils sont généralement plus petits, plus rapides et plus économes en ressources que leurs homologues plus volumineux.
Cela les rend idéales pour les environnements de production où la vitesse et le coût sont des facteurs importants. Beaucoup peuvent même fonctionner sur du matériel CPU standard, ce qui les rend accessibles sans GPU coûteux.
Les types courants de modèles spécifiques à une tâche comprennent :
- Classification de texte : utilisez cette fonctionnalité pour classer le texte dans des libellés prédéfinis, par exemple en triant les commentaires des clients dans des catégories « positifs » ou « négatifs » ou en marquant les tickets d'assistance par sujet.
- Analyse des sentiments : cela vous aide à déterminer la tonalité émotionnelle d'un texte, ce qui est utile pour surveiller votre marque sur les réseaux sociaux.
- Reconnaissance d'entités nommées : extrayez des entités spécifiques telles que des personnes, des lieux et des organisations à partir de documents afin de structurer des données non structurées.
- Résumé : résumez de longs articles ou rapports en résumés concis, ce qui permettra à votre équipe de gagner un temps précieux en lecture.
- Traduction : Convertissez automatiquement du texte d'une langue à une autre.
📚 À lire également : Comment utiliser Hugging Face pour résumer un texte
Modèles linguistiques de grande taille
Parfois, votre projet nécessite plus qu'une simple classification ou résumation. Vous pourriez avoir besoin d'une IA capable de générer des textes marketing créatifs, d'écrire du code ou de répondre à des questions complexes des utilisateurs de manière conversationnelle. Dans ces cas-là, vous vous tournerez probablement vers un modèle linguistique à grande échelle (LLM).
Les LLM sont des modèles comportant des milliards de paramètres entraînés à partir d'énormes quantités de textes et de données provenant d'Internet. Cet entraînement intensif leur permet de comprendre les nuances, le contexte et les raisonnements complexes. Parmi les LLM open source populaires disponibles sur Hugging Face, on trouve les modèles des familles Llama, Mistral et Falcon.
Le compromis pour cette puissance est les ressources informatiques importantes qu'ils nécessitent. Le déploiement de ces modèles nécessite presque toujours des GPU puissants avec beaucoup de mémoire (VRAM).
Pour les rendre plus accessibles, vous pouvez utiliser des techniques telles que la quantification, qui réduit la taille du modèle à un coût minime en termes de performances, ce qui lui permet de fonctionner sur du matériel moins puissant.
📚 À lire également : Que sont les agents LLM dans l'IA et comment fonctionnent-ils ?
Modèles de texte-image et multimodaux
Vos données ne se limitent pas toujours au texte. Votre équipe peut avoir besoin de générer des images pour une campagne marketing, de transcrire l'audio d'une réunion ou de comprendre le contenu d'une vidéo. C'est là que les modèles multimodaux, conçus pour travailler avec différents types de données, deviennent essentiels.
Le type de modèle multimodal le plus populaire est le modèle texte-image, qui génère des images à partir d'un texte. Des modèles tels que Stable Diffusion utilisent une technique appelée diffusion pour créer des visuels époustouflants à partir de simples instructions. Mais les possibilités vont bien au-delà de la génération d'images.
Voici d'autres modèles multimodaux courants que vous pouvez déployer à partir de Hugging Face :
- Légende d'image : générez automatiquement du texte descriptif pour les images, ce qui est idéal pour l'accessibilité et la gestion du contenu.
- Reconnaissance vocale : transcrivez des enregistrements audio en texte écrit à l'aide de modèles tels que Whisper d'OpenAI.
- Réponse visuelle à des questions : posez des questions sur une image et obtenez une réponse sous forme de texte, par exemple « De quelle couleur est la voiture sur cette photo ? ».
Tout comme les LLM, ces modèles sont très gourmands en ressources informatiques et nécessitent généralement un GPU pour fonctionner efficacement.
📚 À lire également : Plus de 50 suggestions d'images IA pour créer des visuels époustouflants
Pour découvrir comment ces différents types de modèles d'IA se traduisent en applications commerciales pratiques pour les entreprises, regardez cet aperçu des cas d'utilisation concrets de l'IA dans divers secteurs et fonctions.
Quel est le niveau de maturité de votre organisation en matière d'IA ?
Notre sondage mené auprès de 316 professionnels révèle que la véritable transformation IA nécessite plus que la simple adoption de fonctionnalités IA. Répondez à l'évaluation de maturité IA pour connaître le niveau de votre organisation et découvrir ce que vous pouvez faire pour améliorer votre score.
Comment configurer Hugging Face pour le déploiement de l'IA
Avant de pouvoir déployer votre premier modèle, vous devez configurer correctement votre environnement local et votre compte Hugging Face. Il est fréquent que les équipes soient frustrées lorsque différents membres ont des installations incohérentes, ce qui conduit au problème classique « ça marche sur ma machine ». Prendre quelques minutes pour standardiser ce processus permet d'économiser des heures de dépannage par la suite.
- Créez un compte Hugging Face et générez un jeton d'accès. Commencez par créer un compte gratuit sur le site web de Hugging Face. Une fois connecté, accédez à votre profil, cliquez sur « Paramètres », puis allez dans l'onglet « Jetons d'accès ». Générez un nouveau jeton avec au moins les permissions « lecture » ; vous en aurez besoin pour télécharger des modèles.
- Installez les bibliothèques Python requises. Ouvrez votre terminal et installez les bibliothèques principales dont vous aurez besoin. Les deux bibliothèques essentielles sont transformers et huggingface_hub. Vous pouvez les installer à l'aide de pip : pip install transformers huggingface_hub
- Configurez l'authentification. Pour utiliser votre jeton d'accès, vous pouvez soit vous connecter via la ligne de commande en exécutant huggingface-cli login et en collant votre jeton lorsque vous y êtes invité, soit le définir comme variable d'environnement dans votre système. La connexion via la ligne de commande est souvent le moyen le plus simple de commencer.
- Vérifiez l'installation. La meilleure façon de confirmer que tout fonctionne est d'exécuter un simple bout de code. Essayez de charger un modèle de base à l'aide de la fonction pipeline de la bibliothèque transformers. Si elle s'exécute sans erreur, vous êtes prêt à commencer.
N'oubliez pas que certains modèles du hub sont « verrouillés », ce qui signifie que vous devez accepter leurs conditions de licence sur la page du modèle avant de pouvoir y accéder avec votre jeton.
N'oubliez pas non plus que le suivi des identifiants et des configurations environnementales utilisés est une tâche de gestion de projet à part entière, qui devient d'autant plus cruciale que votre équipe s'agrandit.
🌟 Si vous intégrez des modèles Hugging Face dans des systèmes logiciels plus larges, le modèle d'intégration logicielle de ClickUp vous aide à visualiser les flux de travail et à suivre les intégrations techniques en plusieurs étapes.
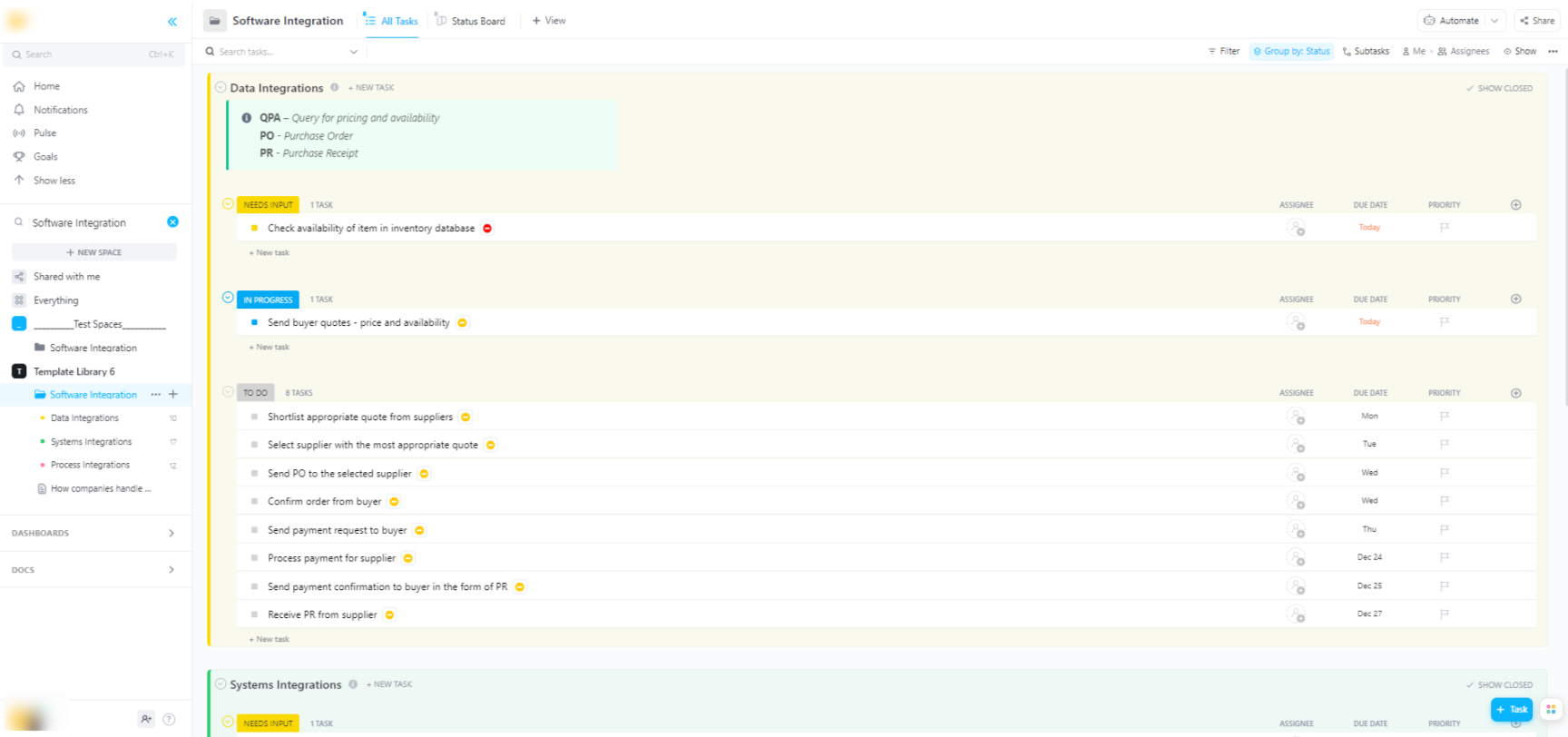
Le modèle vous fournit un système facile à suivre qui vous permet de :
- Visualisez les connexions entre différentes solutions logicielles.
- Créez et attribuez des tâches aux membres de votre équipe pour une collaboration plus fluide.
- Organisez toutes les tâches liées à l'intégration en un seul endroit.
Options de déploiement pour les modèles Hugging Face
Une fois que vous avez testé un modèle localement, la question suivante est : où va-t-il être hébergé ? Le déploiement d'un modèle dans un environnement de production où il peut être utilisé par d'autres est une étape cruciale, mais les options peuvent prêter à confusion. Choisir la mauvaise voie peut entraîner des performances lentes, des coûts élevés ou une incapacité à gérer le trafic des utilisateurs.
Votre choix dépendra de vos besoins spécifiques, tels que le trafic prévu, votre budget et le fait que vous développiez un prototype rapide ou une application évolutive et prête à être mise en production.
Hugging Face Espaces
Si vous avez besoin de créer rapidement une démo ou un outil interne, Hugging Face Espaces est souvent le meilleur choix. Espaces est une plateforme gratuite d'hébergement d'applications d'apprentissage automatique, parfaite pour créer des prototypes que vous pouvez partager avec votre équipe ou vos parties prenantes.
Vous pouvez créer l'interface utilisateur de votre application à l'aide de frameworks populaires tels que Gradio ou Streamlit, qui facilitent la création de démos interactives en quelques lignes de Python.
Pour créer un espace, il suffit de sélectionner votre SDK préféré, de réaliser une connexion avec un référentiel Git et de choisir votre matériel. Espaces propose un niveau CPU gratuit pour les applications de base, mais vous pouvez passer à un matériel GPU payant pour les modèles plus exigeants.
Gardez à l'esprit les limites suivantes :
- Ne convient pas aux API à fort trafic : Espaces est conçu pour les démonstrations, et non pour traiter des milliers de requêtes API simultanées.
- Démarrages à froid : si votre espace est inactif, il peut « se mettre en veille » pour économiser des ressources, ce qui entraîne un retard pour le premier utilisateur qui y accède à nouveau.
- Flux de travail basé sur Git : tout le code de votre application est géré via un référentiel Git, ce qui est idéal pour le contrôle des versions.
API d'inférence Hugging Face
Lorsque vous devez intégrer un modèle dans une application existante, vous souhaiterez probablement utiliser une API. L'API Hugging Face Inference vous permet d'exécuter des modèles sans avoir à gérer vous-même l'infrastructure sous-jacente. Il vous suffit d'envoyer une requête HTTP avec vos données pour obtenir une prédiction.
Cette approche est idéale lorsque vous ne souhaitez pas vous occuper des serveurs, de la mise à l'échelle ou de la maintenance. Hugging Face propose deux niveaux principaux pour ce service :
- API d'inférence gratuite : il s'agit d'une option d'infrastructure partagée à limite de fréquence, idéale pour le développement et les tests. Elle est parfaite pour les cas d'utilisation à faible trafic ou lorsque vous débutez.
- Points de terminaison d'inférence : pour les applications de production, vous devrez utiliser des points de terminaison d'inférence. Il s'agit d'un service payant qui vous fournit une infrastructure dédiée et auto-évolutive, garantissant la rapidité et la fiabilité de votre application, même en cas de charge importante.
L'utilisation de l'API implique l'envoi d'une charge utile JSON à l'URL du point de terminaison du modèle avec votre jeton d'authentification dans l'en-tête de la requête.
Déploiement sur plateforme cloud
Pour les équipes qui sont déjà très présentes sur un grand fournisseur de cloud comme Amazon Web Services (AWS), Google Cloud Platform (GCP) ou Microsoft Azure, le déploiement sur ces plateformes peut être le choix le plus logique. Cette approche vous donne le plus de contrôle et vous permet d'intégrer le modèle à vos services cloud et protocoles de sécurité existants.
Le flux de travail général consiste à « conteneuriser » votre modèle et ses dépendances à l'aide de Docker, puis à déployer ce conteneur sur un service de calcul cloud. Chaque fournisseur de cloud propose des services et des intégrations qui simplifient ce processus :
- AWS SageMaker : offre une intégration native pour la formation et le déploiement des modèles Hugging Face.
- Google Cloud Vertex IA : vous permet de déployer des modèles depuis le hub vers des points de terminaison gérés.
- Azure Machine Learning : fournit des outils pour importer et exploiter les modèles Hugging Face.
Bien que cette méthode nécessite davantage d'installation et d'expertise en DevOps, elle constitue souvent la meilleure option pour les déploiements à grande échelle et de niveau entreprise où vous avez besoin d'un contrôle total sur l'environnement.
📚 À lire également : Automatisation des flux de travail : automatisez vos flux de travail pour booster votre productivité
Comment exécuter les modèles Hugging Face pour l'inférence
Lorsque vous utilisez Hugging Face pour le déploiement de l'IA, « l'inférence » est le processus qui consiste à utiliser votre modèle entraîné pour faire des prédictions sur des données nouvelles et inconnues. C'est le moment où votre modèle accomplit le travail pour lequel vous l'avez déployé. Il est essentiel de bien maîtriser cette étape pour créer une application réactive et efficace.
La plus grande frustration pour les équipes est d'écrire un code d'inférence lent ou inefficace, ce qui peut entraîner une mauvaise expérience pour les utilisateurs et des coûts opérationnels élevés. Heureusement, la bibliothèque transformers offre plusieurs façons d'exécuter l'inférence, chacune avec ses propres compromis entre simplicité et contrôle.
- API Pipeline : C'est la manière la plus simple et la plus courante de commencer. La fonction pipeline() élimine la plupart des complexités en gérant pour vous le prétraitement des données, le transfert des modèles et le post-traitement. Pour de nombreuses tâches standard telles que l'analyse des sentiments, vous pouvez obtenir une prédiction avec une seule ligne de code.
- AutoModel + AutoTokenizer : lorsque vous avez besoin d'un contrôle accru sur le processus d'inférence, vous pouvez utiliser directement les classes AutoModel et AutoTokenizer. Cela vous permet de gérer manuellement la tokenisation de votre texte et la conversion des résultats bruts du modèle en prédictions lisibles par l'homme. Cette approche est utile lorsque vous travaillez sur une tâche personnalisée ou que vous devez mettre en œuvre une logique de pré- ou post-traitement spécifique.
- Traitement par lots : pour optimiser l'efficacité, en particulier sur un GPU, vous devez traiter les entrées par lots plutôt qu'une par une. L'envoi d'un lot d'entrées via le modèle en un seul passage est nettement plus rapide que l'envoi individuel de chaque entrée.
La surveillance des performances de votre code d'inférence est un élément clé du cycle de vie du déploiement. Le suivi d'indicateurs tels que la latence (le temps nécessaire à une prédiction) et le débit (le nombre de prédictions que vous pouvez effectuer par seconde) nécessite une coordination et une documentation claire, en particulier lorsque différents membres de l'équipe testent de nouvelles versions du modèle.
📚 À lire également : Les meilleurs outils de collaboration pour les équipes d'IA
Exemple étape par étape : déployer un modèle Hugging Face
Passons en revue un exemple complet de déploiement d'un modèle simple d'analyse des sentiments. En suivant ces étapes, vous passerez du choix d'un modèle à la mise en place d'un point de terminaison testable et opérationnel.
- Sélectionnez votre modèle : rendez-vous sur Hugging Face Hub et utilisez les filtres situés à gauche pour rechercher des modèles permettant d'effectuer une « classification de texte ». Un bon point de départ est distilbert-base-uncased-finetuned-sst-2-english. Lisez sa carte pour comprendre ses performances et son utilisation.
- Installez les dépendances : dans votre environnement Python local, assurez-vous que les bibliothèques nécessaires sont installées. Pour ce modèle, vous aurez simplement besoin de transformers et torch. Exécutez pip install transformers torch
- Testez localement : avant le déploiement, assurez-vous toujours que le modèle fonctionne comme prévu sur votre machine. Écrivez un petit script Python pour charger le modèle à l'aide du pipeline et testez-le avec un échantillon de phrase. Par exemple : classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") suivi de classifier("ClickUp est la meilleure plateforme de productivité !")
- Créer un déploiement : pour cet exemple, nous utiliserons Hugging Face Espaces pour un déploiement rapide et facile. Créez un nouvel espace, sélectionnez le SDK Gradio et créez une application app.py qui charge votre modèle et définit une interface Gradio simple pour interagir avec lui.
- Vérifiez le déploiement : une fois votre espace opérationnel, vous pouvez utiliser l'interface interactive pour le tester. Vous pouvez également envoyer une requête API directe au point de terminaison de l'espace pour obtenir une réponse JSON, confirmant ainsi qu'il fonctionne correctement au niveau programmatique.
Une fois ces étapes franchies, vous disposez d'un modèle opérationnel. La phase suivante du projet consisterait à surveiller son utilisation, à planifier les mises à jour et, éventuellement, à adapter l'infrastructure si le modèle rencontre un franc succès.
Pour les équipes qui gèrent des projets complexes de déploiement d'IA en plusieurs phases, de la préparation des données au déploiement en production, le modèle avancé de gestion de projet logiciel de ClickUp offre une structure complète.
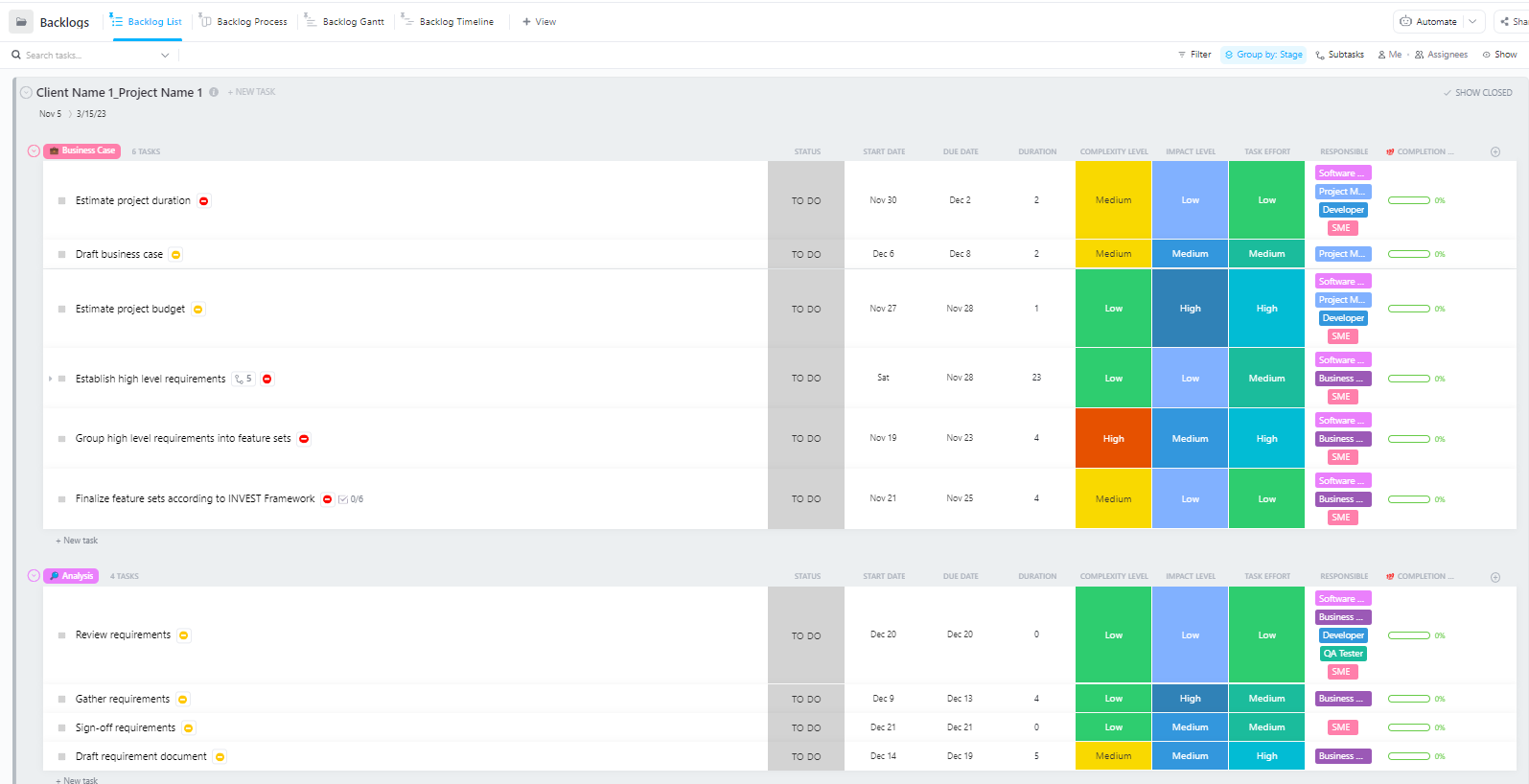
Ce modèle aide les équipes à :
- Gérez des projets comportant plusieurs jalons, tâches, ressources et dépendances.
- Visualisez la progression du projet à l'aide de diagrammes de Gantt et d'échéanciers.
- Collaborez en toute transparence avec vos coéquipiers pour garantir la réussite de vos projets.
Problèmes courants liés au déploiement de Hugging Face et comment les résoudre
Même avec un plan clair, vous risquez de rencontrer quelques obstacles lors du déploiement. Se retrouver face à un message d'erreur cryptique peut être extrêmement frustrant et freiner la progression de votre équipe. Voici quelques-uns des défis les plus courants et comment les surmonter. 🛠️
🚨Problème : « Le modèle nécessite une authentification »
- Cause : vous essayez d'accéder à un modèle « fermé » qui vous oblige à accepter ses conditions de licence.
- Solution : rendez-vous sur la page du modèle sur le hub, lisez et acceptez le contrat de licence. Assurez-vous que le jeton d'accès que vous utilisez dispose des permissions de « lecture ».
🚨Problème : « CUDA out of memory » (mémoire CUDA insuffisante)
- Cause : le modèle que vous essayez de charger est trop volumineux pour la mémoire de votre GPU (VRAM).
- Solution : la solution la plus rapide consiste à utiliser une version plus petite du modèle ou une version quantifiée. Vous pouvez également essayer de réduire la taille du lot pendant l'inférence.
🚨Problème : « erreur trust_remote_code »
- Cause : certains modèles du hub nécessitent un code personnalisé pour fonctionner et, pour des raisons de sécurité, la bibliothèque ne l'exécute pas par défaut.
- Solution : vous pouvez contourner ce problème en ajoutant trust_remote_code=True lorsque vous chargez le modèle. Cependant, vous devez toujours vérifier le code source au préalable pour vous assurer qu'il est sûr.
🚨Problème : « Incompatibilité du tokenizer »
- Cause : le tokeniseur que vous utilisez n'est pas exactement celui avec lequel le modèle a été entraîné, ce qui entraîne des entrées incorrectes et des performances médiocres.
- Solution : chargez toujours le tokenizer à partir du même point de contrôle que le modèle lui-même. Par exemple, AutoTokenizer. from_pretrained("nom-du-modèle")
🚨Problème : « Limite de fréquence dépassée »
- Cause : vous avez effectué trop de requêtes vers l'API d'inférence gratuite en période courte.
- Solution : pour une utilisation en production, passez à un point de terminaison d'inférence dédié. Pour le développement, vous pouvez mettre en place une mise en cache afin d'éviter d'envoyer plusieurs fois la même requête.
Le suivi des solutions qui fonctionnent pour quels problèmes est essentiel. Sans un endroit centralisé pour documenter ces conclusions, les équipes finissent souvent par résoudre le même problème encore et encore.
📮 ClickUp Insight : 1 employé sur 4 utilise au moins quatre outils différents pour créer un contexte de travail. Une information clé peut être enfouie dans un e-mail, développée dans un fil de discussion Slack et documentée dans un outil distinct, ce qui oblige les équipes à perdre du temps à rechercher des informations au lieu de se concentrer sur leur travail.
ClickUp rassemble l'ensemble de votre flux de travail sur une plateforme unifiée. Grâce à des fonctionnalités telles que ClickUp Email Gestion de projet, ClickUp Chat, ClickUp Docs et ClickUp Brain, tout reste connecté, synchronisé et accessible instantanément. Dites adieu au « travail autour du travail » et récupérez votre temps de productivité.
💫 Résultats concrets : grâce à ClickUp, les équipes gagnent plus de 5 heures par semaine, soit plus de 250 heures par an et par personne, en éliminant les processus de gestion des connaissances obsolètes. Imaginez ce que votre équipe pourrait accomplir avec une semaine supplémentaire de productivité chaque trimestre !
Comment gérer les projets de déploiement d'IA dans ClickUp
L'utilisation de Hugging Face pour le déploiement de l'IA facilite le packaging, l'hébergement et la mise à disposition des modèles, mais elle n'élimine pas les coûts de coordination liés au déploiement dans le monde réel. Les équipes doivent toujours suivre les modèles en cours de test, s'accorder sur les configurations, documenter les décisions et veiller à ce que tout le monde, des ingénieurs ML aux équipes produit et opérations, soit sur la même longueur d'onde.
Lorsque votre équipe d'ingénieurs teste différents modèles, que votre équipe produit définit les exigences et que les parties prenantes demandent des mises à jour, les informations se retrouvent dispersées entre Slack, les e-mails, les feuilles de calcul et divers documents.
Cette dispersion du travail, c'est-à-dire la fragmentation des activités professionnelles entre plusieurs outils déconnectés qui ne communiquent pas entre eux, crée de la confusion et ralentit tout le monde.
C'est là que ClickUp, le premier espace de travail IA convergent au monde, joue un rôle clé en réunissant la gestion de projet, la documentation et la communication d'équipe dans un seul et même environnement de travail.
Cette convergence est particulièrement utile pour les projets de déploiement d'IA, où les parties prenantes techniques et non techniques ont besoin d'une visibilité partagée sans avoir à utiliser cinq outils différents.
Au lieu de disperser les mises à jour entre les tickets, les documents et les fils de discussion, les équipes peuvent gérer l'ensemble du cycle de vie du déploiement en un seul endroit.
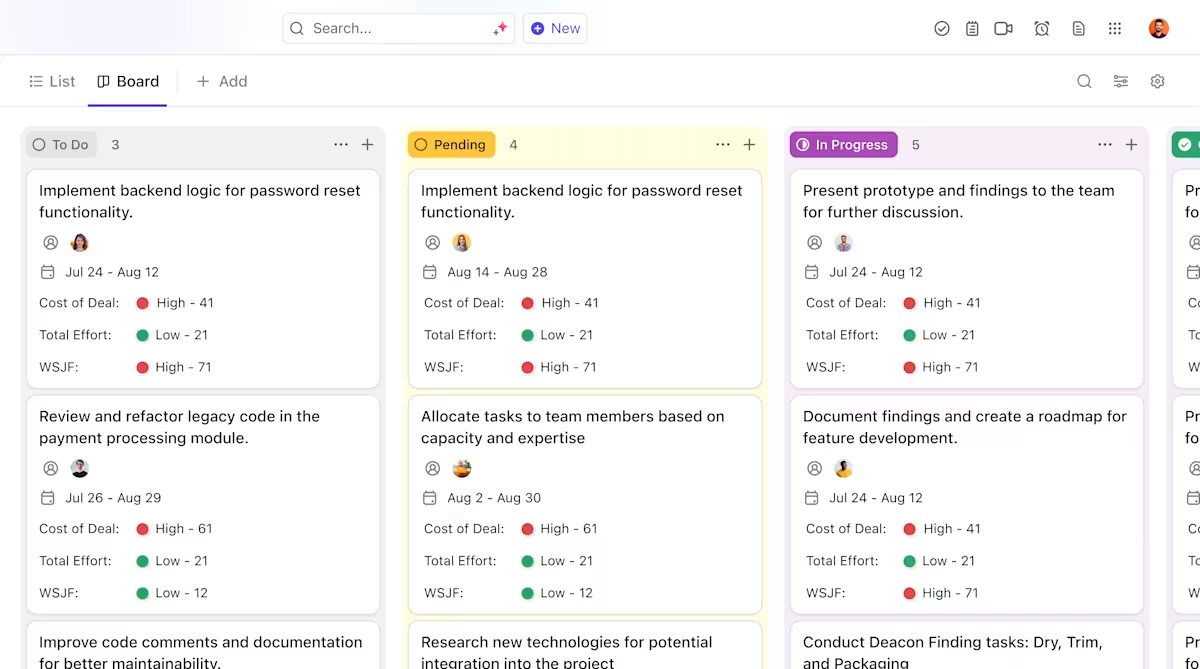
Voici comment ClickUp peut vous fournir de l'assistance dans votre projet de déploiement d'IA :
- Propriété claire et suivi tout au long du cycle de vie des modèles : utilisez les tâches ClickUp pour suivre les modèles Hugging Face tout au long de leur évaluation, test, mise en place et production, avec des statuts personnalisés, des propriétaires et des bloqueurs visibles par toute l'équipe.
- Documentation centralisée et évolutive sur le déploiement : conservez les runbooks de déploiement, les configurations d'environnement et les guides de dépannage dans ClickUp Docs, afin que la documentation évolue en même temps que vos modèles et reste facile à rechercher et à consulter. Comme les documents sont liés aux tâches, votre documentation est directement associée au travail auquel elle se rapporte.
- Collaboration contextuelle sans dispersion du travail : liez directement les discussions, les décisions et les mises à jour aux tâches et aux documents, afin de réduire la dépendance aux fils de discussion Slack dispersés, aux e-mails et aux outils de projet déconnectés.
- Visibilité de bout en bout sur la progression du déploiement : surveillez le pipeline de déploiement, identifiez les risques à un stade précoce et équilibrez les capacités de l'équipe à l'aide des tableaux de bord ClickUp qui affichent en temps réel la progression et les goulots d'étranglement.
- Intégration et rappel des décisions plus rapides grâce à l'IA intégrée : utilisez ClickUp Brain pour résumer les longs documents de déploiement, mettre en évidence les informations pertinentes issues des déploiements passés et aider les nouveaux membres de l'équipe à se mettre à niveau sans avoir à fouiller dans le contexte historique.
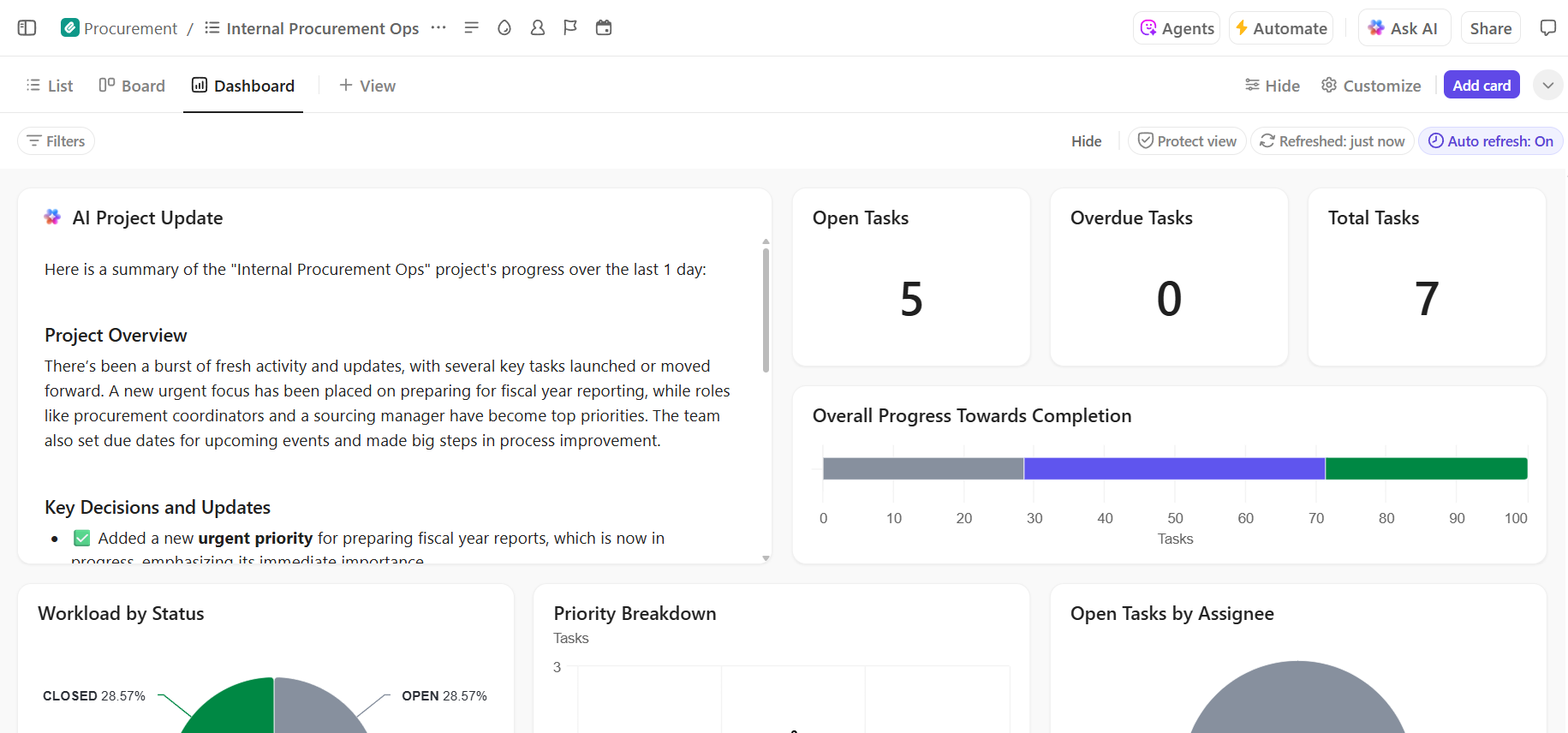
📚 À lire également : Comment réaliser l'automatisation des processus grâce à l'IA pour des flux de travail plus rapides et plus intelligents
Gérez votre projet de déploiement d'IA en toute simplicité dans ClickUp.
La réussite du déploiement de Hugging Face repose sur des bases techniques solides et une gestion de projet claire et organisée. Si les défis techniques peuvent être surmontés, ce sont souvent les problèmes de coordination et de communication qui causent l'échec des projets.
En établissant un flux de travail clair sur une plateforme unique, votre équipe peut livrer plus rapidement et éviter la frustration liée à la dispersion du contexte, lorsque les équipes perdent des heures à rechercher des informations, à passer d'une application à l'autre et à répéter les mises à jour sur plusieurs plateformes.
ClickUp, l'application tout-en-un pour le travail, regroupe la gestion de vos projets, votre documentation et la communication de votre équipe en un seul endroit afin de vous offrir une source unique et fiable pour l'ensemble du cycle de vie de votre déploiement d'IA.
Regroupez vos projets de déploiement d'IA et éliminez le chaos lié aux outils. Commencez dès aujourd'hui avec ClickUp, gratuitement.
Foire aux questions (FAQ)
Oui, Hugging Face propose une offre gratuite généreuse qui comprend l'accès au Model Hub, à des espaces alimentés par CPU pour les démonstrations et à une API d'inférence à limite de fréquence pour les tests. Pour les besoins de production nécessitant du matériel dédié ou des limites plus élevées, des forfaits payants sont disponibles.
Espaces est conçu pour héberger des applications interactives avec une interface visuelle, ce qui le rend idéal pour les démonstrations et les outils internes. L'API Inference fournit un accès programmatique aux modèles, vous permettant de les intégrer à vos applications via de simples requêtes HTTP.
Absolument. Grâce à des démonstrations interactives hébergées sur Hugging Face Espaces, les membres non techniques de l'équipe peuvent tester les modèles et donner leur avis sans écrire une seule ligne de code.
Les principales limitations de l'offre gratuite sont les limites de fréquence de l'API Inference, l'utilisation de matériel CPU partagé pour les Espaces, qui peut être lent, et les « démarrages à froid », où les applications inactives mettent un certain temps à se réveiller. /