
La plupart des gens pensent qu'ils doivent choisir entre utiliser des outils d'IA puissants ou préserver la confidentialité de leurs données. Mais vous pouvez en réalité avoir les deux. Exécuter l'IA localement signifie que les données ne quittent jamais votre matériel. Vous gardez un contrôle total sur vos informations tout en effectuant l'automatisation de vos tâches les plus répétitives.
Ce guide vous montre comment utiliser l'IA locale pour assurer la sécurité de vos flux de travail à l'aide d'outils tels qu'Ollama. Vous apprendrez à sélectionner des modèles open source adaptés aux spécifications de votre matériel. Vous découvrirez également comment créer des flux de travail automatisés qui traitent les documents privés en local.
Nous examinerons également la centralisation des flux de travail dans un espace unifié tel que ClickUp. 😎
Qu'est-ce que l'IA locale ?
L'IA locale signifie que vous exécutez des modèles linguistiques de grande envergure (LLM) entièrement sur votre propre matériel, comme votre ordinateur portable ou un serveur sur site, au lieu d'envoyer vos données vers des services cloud externes. Cette solution convient à toute équipe traitant des informations sensibles, qu'il s'agisse des services d'ingénierie et de conception de produits ou des services juridiques et financiers.
Avec la plupart des outils d'IA basés sur le cloud, vos requêtes, vos documents et vos données sont transférés vers des serveurs tiers. Vous perdez ainsi le contrôle sur la manière dont ces informations sont traitées, stockées ou utilisées.
À l'inverse, l'IA locale conserve vos données au sein de votre environnement. Vous gardez ainsi le contrôle total de la sécurité et de la protection des données pour vos flux de travail.
Bien sûr, il y a un compromis à faire. La mise en place d'une IA locale nécessite davantage d'efforts techniques et un investissement initial en matériel. Cependant, cela élimine complètement votre dépendance vis-à-vis des fournisseurs externes. Grâce à l'inférence sur appareil, vos informations restent exactement là où vous le souhaitez.
Pourquoi l'IA locale est-elle importante pour la sécurité des flux de travail en équipe ?
🔎 Le saviez-vous ? Seul 1 consommateur sur 10 est prêt à partager des informations sensibles, telles que des données financières, de communication ou biométriques, avec des systèmes basés sur l'IA.
Cette hésitation reflète une réalité de plus en plus courante pour les équipes B2B. Avec l'IA basée sur le cloud, vous confiez en effet la propriété intellectuelle de votre entreprise à un tiers. Pour les équipes juridiques, financières ou RH, cela engendre une responsabilité considérable.
L'IA locale change la donne en transférant l'IA sur votre propre matériel. Voici pourquoi cela est important pour vos opérations quotidiennes :
- Éliminez les fuites de données : empêchez que du code propriétaire ou des contrats clients privés ne soient utilisés pour entraîner un modèle public que vos concurrents pourraient exploiter
- Respectez la conformité réglementaire : restez dans les limites du RGPD ou de la loi HIPAA, car les données sensibles ne franchissent jamais de frontières internationales et ne transitent jamais par un serveur tiers
- Éliminez la dépendance à Internet : effectuez des analyses de données complexes ou des tâches de conception lors d'une panne ou dans des environnements hautement sécurisés où l'accès au cloud est restreint
- Gérez vos coûts de manière prévisible : évitez l'augmentation des frais d'API à mesure que votre équipe s'agrandit, puisque votre seul coût est le matériel que vous possédez déjà
En intégrant l'IA locale à vos outils existants, vous pouvez automatiser votre travail sans compromettre votre sécurité.
⚠️ Cependant, il est important de garder à l'esprit que ce problème peut s'aggraver. Votre équipe pourrait vouloir adopter plusieurs Outils d'IA, ce qui entraînerait une prolifération incontrôlée de ces outils, sans supervision ni stratégie. Cela peut se traduire par un gaspillage d'argent, une duplication des efforts et des risques pour la sécurité.
Au final, cela élargit votre modèle de menaces de sécurité et rend le suivi du travail plus difficile.
📮ClickUp Insight : Les équipes peu performantes sont 4 fois plus susceptibles de jongler avec plus de 15 outils, tandis que les équipes hautement performantes maintiennent leur efficacité en limitant leur boîte à outils à 9 plateformes ou moins. Mais pourquoi ne pas utiliser une seule plateforme ? En tant qu'application tout-en-un pour le travail, ClickUp regroupe vos tâches, projets, documents, wikis, chats et appels sur une seule plateforme, le tout avec des flux de travail alimentés par l'IA. Prêt à travailler plus intelligemment ? ClickUp convient à toutes les équipes, offre une visibilité sur le travail et vous permet de vous concentrer sur l'essentiel pendant que l'IA s'occupe du reste.
De quoi avez-vous besoin pour exécuter l'IA locale ?
Vous n'avez pas besoin d'un superordinateur spécialisé pour exécuter l'IA localement. Les récentes évolutions dans la conception des modèles vous permettent de vous lancer avec le matériel dont vous disposez déjà. Il suffit simplement qu'il réponde à quelques critères spécifiques.
Configuration matérielle requise
C'est votre matériel qui détermine la taille et la vitesse des modèles d'IA que vous pouvez utiliser. Si une machine puissante vous permet d'exécuter des modèles de raisonnement plus complexes, les modèles plus petits sont désormais étonnamment performants.
- GPU avec VRAM : une carte NVIDIA dédiée dotée d'au moins 12 Go de VRAM constitue actuellement la solution idéale pour la plupart des équipes. Elle vous permet d'exécuter à grande vitesse des modèles de taille moyenne tels que Llama 3.3 (8 milliards de paramètres) ou Mistral Small.
- Mémoire vive (RAM) : si vous ne disposez pas d'un GPU haut de gamme, la mémoire vive de votre ordinateur prendra le relais. 32 Go vous offrent une marge suffisante pour exécuter un modèle tout en gardant votre navigateur et vos outils de gestion de projet ouverts
- Mémoire unifiée (pour les utilisateurs de Mac) : si vous utilisez un Mac équipé d'une puce de la série M (M2, M3 ou M4), votre RAM et la mémoire de votre GPU sont partagées. Cela rend les Mac particulièrement efficaces pour l'IA locale, car le modèle peut accéder à l'ensemble de la mémoire disponible
- Stockage rapide : les modèles sont des fichiers volumineux, dont l'intervalle de taille varie souvent entre 5 Go et 50 Go. L'utilisation d'un SSD NVMe est indispensable pour éviter de longs délais d'attente lors du chargement d'un nouveau modèle
🔎 Le saviez-vous ? Construire un PC coûte aujourd'hui nettement plus cher qu'il y a quelques mois seulement. Auparavant, un kit de mémoire DDR5 de 32 Go coûtait moins de 130 dollars, mais aujourd'hui, ces mêmes kits dépassent les 400 dollars. Cette évolution a fait des 32 Go le nouveau minimum requis pour tout travail sérieux en IA locale, car vous avez besoin d'une marge suffisante pour exécuter des modèles sans que les performances de votre système ne s'effondrent.
Configuration logicielle requise
Le logiciel sert de passerelle entre votre matériel et l'IA. Vous n'avez plus besoin d'être développeur pour le faire fonctionner.
- Système d'exploitation : Bien que Linux soit l'environnement natif de l'IA, Windows et macOS sont désormais tout aussi performants. Les utilisateurs de Windows peuvent utiliser WSL2 pour bénéficier d'un environnement similaire à Linux, même si de nombreux outils s'exécutent désormais directement sous Windows
- Gestionnaires de modèles : des outils comme Ollama ou LM Studio constituent le point de départ le plus simple. Ils se chargent de la quantification, c'est-à-dire de la compression du modèle afin qu'il s'adapte automatiquement à votre matériel.
- Pilotes : Vous aurez besoin des derniers pilotes pour votre matériel, tels que le dernier pilote CUDA pour les cartes NVIDIA. La plupart des programmes d'installation modernes vérifient cela pour vous lors de l'installation.
Options LLM open source
Nous assistons à une explosion de modèles open-source que vous pouvez télécharger gratuitement. Ceux-ci sont développés par des entreprises telles que Meta (Llama), Mistral et Alibaba (Qwen). Contrairement aux systèmes fermés, ces modèles vous permettent de voir exactement comment ils fonctionnent et où vont vos données.
Lorsque vous choisissez un grand modèle linguistique, vérifiez la licence du logiciel. La plupart utilisent Apache 2.0 ou MIT, ce qui vous permet de les utiliser pour vos opérations d'entreprise sans frais d'abonnement mensuels. Comme ces modèles résident sur votre matériel, ils s'intègrent directement à vos flux de travail privés.
Vous pouvez par exemple utiliser un modèle local pour rédiger des e-mails internes, résumer des comptes-rendus de réunion ou analyser des ensembles de données propriétaires. Cela vous permet de conserver les détails les plus sensibles de vos projets et vos notes stratégiques sur votre propre machine.
🧠 Anecdote : Les puces de la série M d'Apple offrent un avantage architectural unique aux équipes soucieuses de la confidentialité. La mémoire unifiée du Mac permet à l'IA de utiliser l'ensemble de la mémoire vive du système comme s'il s'agissait d'une mémoire graphique dédiée.
Cela signifie qu'un MacBook équipé de 128 Go de RAM peut exécuter des modèles volumineux et très sophistiqués qui nécessiteraient normalement un matériel spécialisé pour l'entreprise coûtant plus de 10 000 dollars.
Les meilleurs modèles d'IA locale pour les flux de travail en équipe
Pour trouver le modèle qui vous convient, comparez les atouts du modèle aux tâches de votre équipe et aux capacités de votre matériel.
Modèles polyvalents
Ce sont les outils indispensables de votre installation locale. Utilisez-les pour rédiger des e-mails, résumer les avancées d'un projet ou trouver des idées créatives.
- Llama 4 Scout (17B) : Dispose d'une fonctionnalité de fenêtre de contexte de 10 millions de tokens, ce qui vous permet de traiter des milliers de pages de texte à la fois
- Mistral Small 4 : utilise une architecture de type « mixture-of-experts », ce qui signifie qu'il n'active qu'une fraction de ses paramètres pour chaque tâche
- Qwen 3.5 (7B) : Offre des performances supérieures en toutes circonstances si votre équipe gère de la documentation technique en plusieurs langues
Modèles de raisonnement et d'utilisation d'outils
Utilisez-les lorsque vous avez besoin que les agents LLM résolvent des problèmes en plusieurs étapes, suivent une logique complexe ou agissent en tant qu'agents autonomes au sein de vos flux de travail.
- Llama 4 Maverick : Il est multimodal de manière native. Cela le rend idéal pour les équipes qui doivent analyser des diagrammes complexes ou des feuilles de calcul financières, où le contexte visuel est tout aussi important que le texte.
- Phi-4 (14B) : Optimisé pour les STEM et le raisonnement logique. Utilisez-le pour la validation de données ou des tâches mathématiques complexes qui nécessitent généralement des modèles beaucoup plus volumineux et coûteux.
- DeepSeek-R1 : affiche sa chaîne de raisonnement interne, ce qui vous aide à vérifier sa logique pour les analyses à enjeux élevés. Idéal pour la recherche approfondie et la planification stratégique
Modèles spécifiques à une tâche
Parfois, un outil spécialisé est plus efficace qu'un assistant généraliste. Ces modèles sont optimisés pour une partie spécifique de votre flux de travail.
- Qwen 3-Coder-Next : Comprend la logique à l'échelle du référentiel, ce qui lui permet de suggérer des corrections de bogues ou de refactoriser le code sur plusieurs fichiers. Le tout en respectant les guides de style spécifiques de votre équipe
- Voxtral Mini : Identifie les différents intervenants dans un enregistrement et transforme les enregistrements de réunions privées en texte consultable. Fonctionne entièrement hors ligne, ce qui permet d'éviter les fuites de données.
- Nomic Embed v1.5 : Transforme vos documents privés en données mathématiques pour la recherche sémantique. Cela vous permet d'effectuer des recherches dans la base de connaissances interne de votre équipe en fonction du sens plutôt que de simples mots-clés
📚 À lire également : Moteurs de recherche LLM : la recherche d'informations pilotée par l'IA
Outils populaires pour exécuter l'IA locale
Vous n'avez plus besoin d'être ingénieur logiciel pour exécuter des modèles sur votre propre machine. Plusieurs applications conviviales se chargent désormais de l'installation technique à votre place en quelques minutes.
Ollama et OpenWebUI
Ollama est la solution idéale si vous recherchez rapidité et flexibilité. Il fonctionne en arrière-plan et gère votre bibliothèque de modèles via une interface simple.
Bien qu'il s'agisse à la base d'un outil simple, la plupart des utilisateurs l'associent à OpenWebUI. Cela ajoute une interface de chat soignée dans votre navigateur, dont l'apparence et le fonctionnement rappellent les outils cloud que vous connaissez déjà. Cela crée également une passerelle locale permettant à d'autres applications de votre ordinateur de communiquer en toute sécurité avec vos modèles d'IA.
LM Studio
Si vous préférez une application de bureau traditionnelle, LM Studio est une excellente alternative. Il fonctionne comme une boutique d'applications dédiée à l'IA. Vous pouvez l'utiliser pour rechercher, télécharger et discuter avec un nouveau modèle en quelques clics seulement.
L'application intègre une fonctionnalité de détection du matériel, ce qui lui permet de configurer automatiquement vos paramètres en fonction de votre GPU ou de votre RAM. Cela en fait un excellent point de départ si vous souhaitez tester différents modèles sans jamais toucher à une ligne de code.
GPT4All
Pour les équipes qui se concentrent exclusivement sur la confidentialité et l'analyse de documents, GPT4All est une solution fiable et simple. Elle fonctionne sur presque tous les ordinateurs, y compris les anciens ordinateurs portables qui ne disposent pas nécessairement d'une carte graphique dédiée.
Sa fonctionnalité la plus utile est la possibilité de discuter directement avec vos fichiers locaux. Vous pouvez indiquer à l'application un dossier sur votre disque dur, et l'IA répondra à vos questions concernant ces documents spécifiques. Le tout sans jamais les télécharger sur un serveur tiers.
📚 À lire également : Les meilleurs agents IA pour les utilisateurs sans code
Comment configurer l'IA locale pour des flux de travail sécurisés
Ce guide pratique utilise Ollama, car il s'agit d'un outil largement pris en charge pour créer des flux de travail IA locaux et sécurisés.
Étape 1 : Installez Ollama
Téléchargez le programme d'installation depuis le site officiel pour votre système d'exploitation spécifique. Alors que les versions antérieures de Windows nécessitaient une installation manuelle du sous-système Linux, la version actuelle s'installe comme une application native.
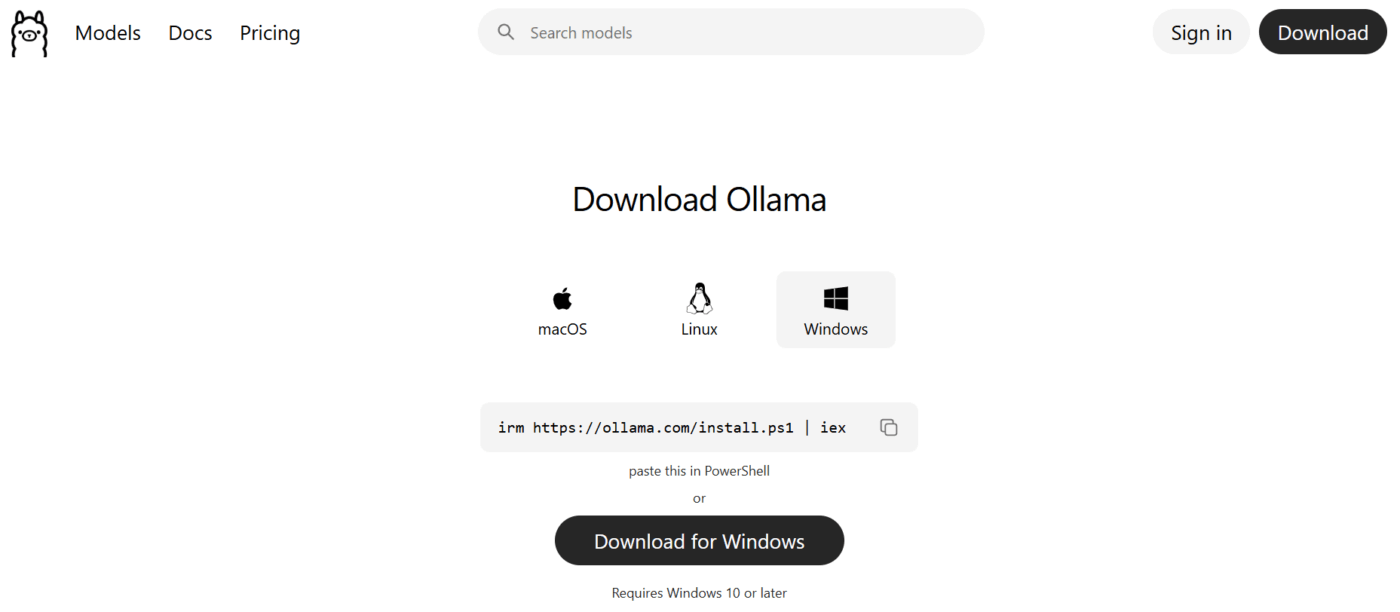
L'installation ne devrait prendre que quelques minutes. Une fois l'installation terminée, ouvrez votre terminal ou votre invite de commande et tapez ollama --version pour vérifier que tout est prêt.
Étape 2 : Téléchargez et exécutez un modèle
Pour commencer à utiliser une IA, vous devez en extraire les poids vers votre machine. Pour votre premier test, essayez un modèle compact mais puissant comme Llama 3.2 (3B) ou la dernière version de Mistral.
Utilisez la commande ollama run llama3.2 pour lancer le téléchargement.
Selon votre débit Internet, cela prend généralement quelques minutes. Une fois le téléchargement terminé, vous pouvez saisir une invite directement dans le terminal pour obtenir une réponse immédiate du modèle stocké sur votre disque dur.
Étape 3 : Effectuez la connexion à votre outil de flux de travail
La véritable valeur de l'IA locale réside dans son intégration à vos tâches quotidiennes. Lorsque Ollama est en cours d'exécution, il démarre automatiquement un serveur local à l'adresse http://localhost:11434. Cela crée une passerelle sécurisée permettant à d'autres applications de communiquer avec votre modèle.
Ce serveur étant compatible avec les protocoles OpenAI standard, vous pouvez le connecter à des plateformes d'automatisation ou à des scripts internes en modifiant simplement l'adresse de l'API. Vous pouvez, par exemple, rediriger un outil de recherche de documents local vers cette adresse. Cela lui permet de résumer des fichiers privés sans jamais envoyer ce texte vers le cloud.
📖 À lire également : Comment rationaliser l'orchestration des flux de travail pour gagner en efficacité
Bonnes pratiques de sécurité pour les flux de travail d'IA locale
L'exécution locale de l'IA constitue une étape majeure en matière de confidentialité. Cependant, le stockage local des données implique que vous êtes désormais responsable de leur protection. Bien que vous ayez éliminé le risque de violation de sécurité dans le cloud par un tiers, vous devez tout de même sécuriser votre matériel et la manière dont votre équipe interagit avec les modèles.
Suivez ces bonnes pratiques :
- Isolation du réseau : Limitez l'accès aux API aux réseaux internes de confiance afin que votre serveur IA reste inaccessible depuis l'Internet public
- Validation des entrées : Nettoyez toutes les données avant de les envoyer au modèle. Cela permet de bloquer les instructions malveillantes cachées dans les documents ou les e-mails.
- Contrôles d'accès : mettez en place une authentification sur votre terminal IA afin de vérifier que seuls les utilisateurs autorisés peuvent déclencher des actions de modèle
- Journalisation des audits : conservez une trace de toutes les interactions avec les modèles afin de faciliter les enquêtes en matière de conformité et de sécurité
- Isolation des conteneurs : exécutez vos modèles dans des environnements sandboxés tels que Docker. Cela empêche une éventuelle faille de sécurité d'atteindre les fichiers système essentiels de votre infrastructure.
- Mises à jour régulières : installez les derniers correctifs pour des outils tels qu'Ollama afin de rester protégé contre les vulnérabilités récemment découvertes
- Limite de fréquence : pour empêcher qu'un seul utilisateur ou script ne surcharge votre serveur de requêtes, mettez en place une limite de fréquence afin de contrôler le nombre de requêtes pouvant être effectuées au cours d'une période donnée
🔎 Le saviez-vous ? Les manipulations par invite ne sont plus une menace théorique. Un récent sondage de Gartner a révélé que 32 % des entreprises ont subi une attaque malveillante par invite sur leurs applications /IA au cours de l'année dernière. Ces attaques peuvent manipuler votre modèle local afin qu'il génère des résultats biaisés ou non autorisés.
Comment mettre en place des flux de travail IA sécurisés pour votre équipe
Une fois votre serveur local opérationnel, vous pouvez l'intégrer à votre travail quotidien. Cela transforme un simple outil en un moteur de productivité privé. La manière la plus efficace d'y parvenir est d'utiliser la génération augmentée par la recherche (RAG).
Ce processus effectue la connexion de votre IA locale à une base de données privée contenant vos propres fichiers. Vous pouvez répondre à des questions en tenant compte du contexte spécifique de votre entreprise sans jamais télécharger le moindre octet vers le cloud.
Vous pouvez également concevoir des flux de travail « human-in-the-loop » dans lesquels le travail de l'IA est vérifié par des membres de l'équipe humaine. Cela garantit la précision tout en accélérant considérablement votre production.
Voici quelques exemples concrets :
- Analyse de documents : résumez les rapports internes ou les commentaires des clients pour en extraire instantanément les informations clés
- Génération de brouillons : créez des premières versions d'e-mails ou de mises à jour de projet que les membres de l'équipe pourront peaufiner
- Classification des données : catégorisez automatiquement les tâches entrantes en fonction du contenu spécifique de la demande
- Préparation de la réunion : générez des points de discussion en analysant les fichiers de projet associés stockés sur votre disque dur local
- Révision de code : obtenez des commentaires sur votre code source propriétaire sans exposer votre propriété intellectuelle à des tiers
📮ClickUp Insight : Notre sondage sur la maturité de l'IA montre que l'accès à l'IA au travail reste limité : 36 % des personnes n'y ont aucun accès, et seules 14 % déclarent que la plupart des employés peuvent réellement l'expérimenter. Lorsque l'IA est soumise à des permissions, nécessite des outils supplémentaires ou des installations complexes, les équipes n'ont même pas la possibilité de l'essayer dans leur travail quotidien.
ClickUp Brain élimine tous ces obstacles en intégrant l'IA directement dans l'environnement de travail que vous utilisez déjà. Vous pouvez exploiter plusieurs modèles d'IA, générer des images, écrire ou déboguer du code, effectuer des recherches sur le Web, résumer des documents, et bien plus encore, sans changer d'outil ni perdre votre concentration.
C'est votre partenaire d'IA ambiante, facile à utiliser et accessible à tous les membres de l'équipe.
Limites de l'utilisation de l'IA locale pour les flux de travail basés sur l'IA
L'IA locale est un outil puissant, mais ce n'est pas une solution miracle à tous les problèmes. Comprendre ses limites vous aide à déterminer quand effectuer une tâche sur votre propre matériel et quand utiliser le cloud. Pour certaines équipes, les compromis techniques et financiers peuvent l'emporter sur les avantages en matière de confidentialité.
- Limites des capacités : les modèles propriétaires haut de gamme conservent encore un léger avantage en matière de raisonnement complexe et de nuances créatives par rapport aux versions open source
- Investissement matériel : pour obtenir des performances élevées sur des modèles volumineux, il faut des GPU coûteux dotés d'une mémoire VRAM importante. Cela peut représenter un coût initial élevé pour les petites équipes
- Frais de maintenance : vous êtes responsable de toutes les mises à jour logicielles, du dépannage matériel et de l'application des correctifs de sécurité sans l'aide de l'équipe d'assistance d'un fournisseur, prestataire
- Compétences techniques : L'optimisation d'un environnement local nécessite des connaissances pratiques en matière de quantification des modèles et de configuration des serveurs
- Gestion de la sécurité : contrairement aux services cloud, les modèles locaux ne disposent pas de modération intégrée. Vous devez mettre en place vos propres filtres de contenu et mesures de protection.
- Consommation électrique : L'exécution de modèles d'IA à grande échelle sur vos propres serveurs ou postes de travail peut augmenter considérablement votre consommation d'électricité et vos besoins en refroidissement
De nombreuses équipes adoptent une approche hybride : l'IA locale pour les données sensibles, l'IA dans le cloud pour les tâches moins sensibles nécessitant une puissance maximale. Voici un bref aperçu comparatif des deux approches :
| Factor | IA locale | IA dans le cloud |
|---|---|---|
| Confidentialité des données | Contrôle total | Données envoyées au fournisseur, prestataire |
| Complexité de l'installation | Higher | Réduire |
| Coûts récurrents | Matériel + électricité | Frais par jeton |
| Capacités des modèles | Bon, en progrès | À la pointe de la technologie |
| Maintenance | Autogéré | Géré par le fournisseur, prestataire |
Comment ClickUp fournit l'assistance pour les flux de travail sécurisés basés sur l'IA
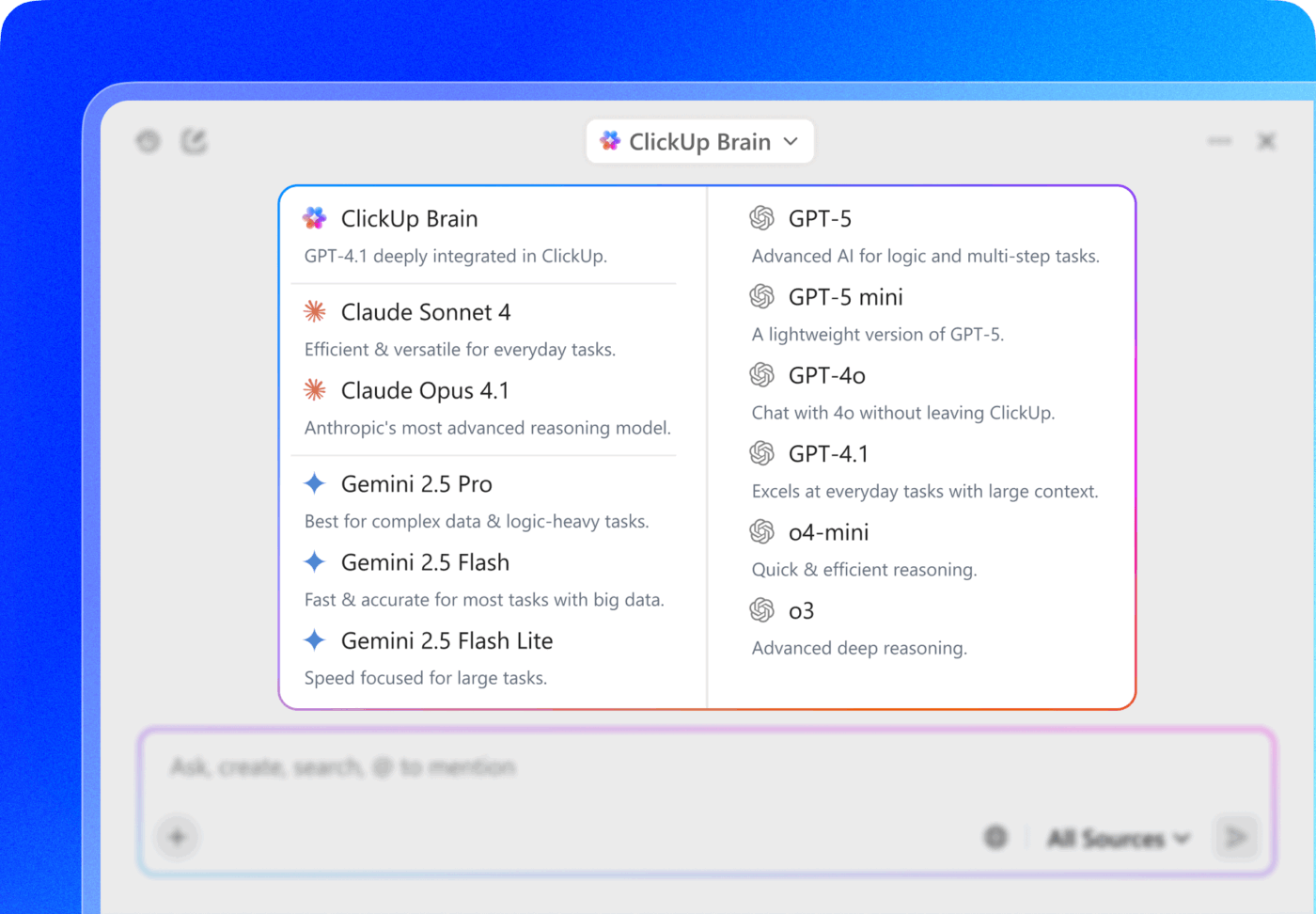
Aujourd'hui, la plupart des équipes sont confrontées à un dilemme : utiliser une IA cloud puissante et s'inquiéter de la destination de leurs données, ou mettre en place des modèles locaux et gérer les coûts associés. ClickUp contourne ce dilemme en agissant comme un espace de travail IA convergent, où l'IA est déjà intégrée au système dans lequel vous travaillez.
ClickUp Brain est la couche d'IA directement intégrée à l'environnement de travail ClickUp, conçue pour comprendre vos tâches, vos documents et la communication de votre équipe en un seul endroit. Elle offre une assistance IA avec un contexte complet — sans outils séparés, sans intégrations fragiles.
Pour les équipes qui souhaitent mettre en place des flux de travail IA sécurisés, cette combinaison de contexte et de contrôle fait toute la différence entre l'expérimentation et l'adoption effective.
🌟 ClickUp est également conforme à la norme SOC 2 et respecte les normes ISO 42001 en matière de gestion responsable de l'IA. Cela garantit que vos données ne sont jamais utilisées pour entraîner des modèles tiers, ce qui vous permet d'automatiser votre travail avec la même confiance que dans le cadre d'une installation sur site.
Accédez à des flux de travail de recherche et autonomes avec ClickUp Brain
Une fois vos données sécurisées au sein de l'environnement de travail, ClickUp Brain extrait de la valeur de vos tâches et de vos documents en temps réel.
Comme l'IA est intégrée, elle évite le décalage contextuel qui ralentit les installations locales. Vous pouvez lui poser des questions qui nécessitent une vue d'ensemble de l'historique de votre projet pour obtenir une réponse précise :
- Identifiez les décisions finales issues d'un long dossier technique sans avoir à faire défiler les différentes versions
- Rédigez des mises à jour destinées aux parties prenantes à partir des commentaires sur les tâches et des changements de statut
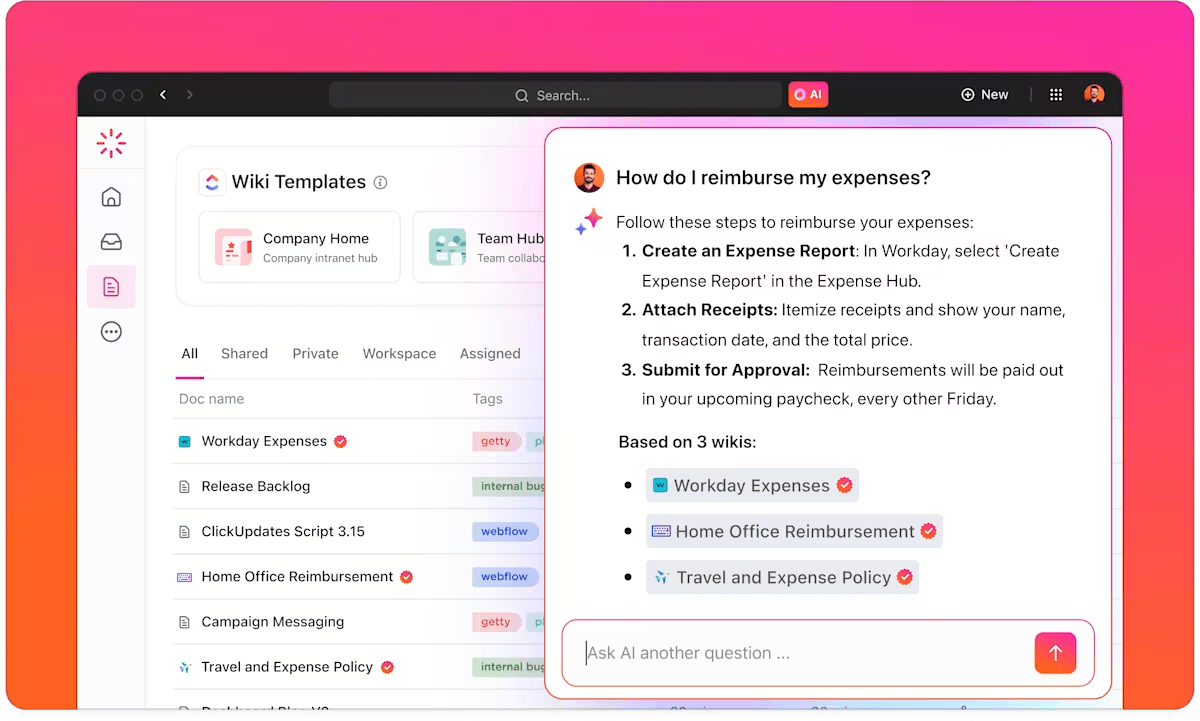
ClickUp Brain génère des réponses basées sur les données de votre espace de travail en analysant le contenu spécifique de vos documents, tâches et discussions. Ainsi, à mesure que votre projet évolue, l'IA dispose toujours du contexte le plus récent.
Cela permet à votre équipe de s'appuyer sur des informations sans avoir à réexpliquer manuellement l'historique du projet ni à transférer des données entre des outils déconnectés.
💡Conseil de pro : Vous pouvez étendre encore davantage le contexte de votre environnement de travail en utilisant Enterprise AI Search pour extraire des informations de tous vos outils externes.
Par exemple, posez une question complexe telle que « Montre-moi toutes les transactions en cours dans le pipeline », et ClickUp Brain effectuera une recherche dans toutes vos applications connectées, notamment Slack, Google Drive et Gmail, pour vous fournir une réponse fiable en temps réel, accompagnée de sources.
Cela transforme les données fragmentées sur plusieurs plateformes en une seule couche d'informations consultable, où vous pouvez trouver n'importe quel fichier, message ou tâche sans jamais quitter votre environnement de travail.
Gérez vos tâches de manière intelligente grâce à l'automatisation et à l'IA
ClickUp Brain ne se contente pas d'apporter une aide passive : il intervient activement au sein de votre système de gestion des tâches. Il peut :
- Générez des tâches à partir de notes de réunion ou de documents
- Décomposez les livrables volumineux en sous-tâches
- Suggérer des propriétaires de tâches en fonction de l'activité passée
- Proposer des échéances en fonction du contexte du projet
Il peut également mettre à jour le statut des tâches, résumer de longs fils de commentaires en étapes claires à suivre et signaler les obstacles avant qu'ils ne ralentissent l'exécution.

Associé à ClickUp Automatisation, cela devient un système en boucle fermée : l'IA peut déclencher des flux de travail (comme l'attribution de tâches, la notification des parties prenantes ou la mise à jour des priorités) en fonction des changements au sein de votre environnement de travail.
Par exemple, lorsqu'un document est finalisé, des tâches peuvent être créées et attribuées automatiquement sans que personne n'ait à transférer manuellement les données d'un outil à l'autre.
💟 Bonus : Faites de ClickUp Brain MAX votre « mémoire décisionnelle ».
Utilisez-la pour :
- Résumez les longs fils de discussion en décisions claires et en étapes suivantes
- Mettez à jour les documents en indiquant « ce qui a changé et pourquoi » après chaque jalon clé
- Générez des journaux de décision hebdomadaires à partir des tâches, des réunions et des mises à jour
Au fil du temps, cela crée une base de connaissances institutionnelles évolutive à laquelle Brain MAX peut se référer. Ainsi, au lieu de répondre aux requêtes de manière isolée, il commence à répondre en tenant compte des décisions, des priorités et des schémas passés.
C'est là que l'IA passe du statut d'outil utile à celui d'outil fiable, en particulier dans les flux de travail IA sécurisés où le contexte et la traçabilité sont essentiels.
Bénéficiez d'une exécution sécurisée et contextuelle à grande échelle grâce aux Super Agents
Les Super Agents de ClickUp font évoluer ClickUp Brain d'un cran : ils ne se contentent plus d'assister le travail, mais le pilotent activement. Ces agents peuvent être configurés pour surveiller les flux de travail, prendre des mesures et orchestrer les tâches dans votre environnement de travail en fonction de règles prédéfinies et du contexte en temps réel.
Par exemple, un Super Agent peut :
- Surveillez les demandes entrantes ou les documents et convertissez-les automatiquement en tâches structurées avec des propriétaires et des échéances
- Suivez la progression des projets et signalez les risques ou les retards avant qu'ils ne s'aggravent
- Déclenchez des automatisations en plusieurs étapes lorsque certaines conditions sont remplies, par exemple pour informer les parties prenantes, mettre à jour les priorités ou créer des tâches de suivi
Ces agents s'exécutent entièrement au sein de l'espace de travail unifié de ClickUp, en tenant pleinement compte de vos tâches, de vos documents et de votre structure d'autorisations. Cela signifie que :
- Vous n'avez pas besoin d'exporter vos données vers des systèmes IA externes ou des outils d'orchestration
- Ils n'accèdent qu'aux données qu'ils sont autorisés à consulter
- Ils agissent dans les mêmes limites de permission que votre équipe
En savoir plus sur l'utilisation des Super Agents :
Bénéficiez de l'assistance de l'IA au sein même de vos documents
Avec ClickUp Docs, l'assistance IA est directement intégrée à vos flux de travail de documentation. Les équipes peuvent rédiger des briefs de projet, résumer de longs rapports, extraire des éléments à mener ou réécrire du contenu pour différents publics, le tout sans quitter la plateforme.
C'est essentiel pour la sécurité des flux de travail IA, car l'un des plus grands risques provient du copier-coller d'informations sensibles dans des outils externes. Dans ClickUp, vous minimisez les transferts de données et gardez un contrôle total sur les accès grâce aux permissions.
Verdict final : Construire votre pile d'IA privée
L'IA locale exploite l'intelligence artificielle tout en garantissant un contrôle total sur la confidentialité et la conformité des données. Cependant, cette approche nécessite un investissement important en matériel, en installation technique et en maintenance continue.
Les pratiques de sécurité restent essentielles, que vous utilisiez l'IA locale ou dans le cloud. La stratégie la plus efficace consiste souvent en une approche hybride : utiliser l'IA locale pour les opérations les plus sensibles tout en tirant parti de solutions gérées et sécurisées pour la productivité au quotidien.
Il est essentiel de peser le pour et le contre : pour de nombreuses équipes, la charge de travail liée à une solution DIY n'est peut-être pas le bon choix.
Pour ceux qui souhaitent bénéficier d'une IA de haute productivité sans avoir à supporter la charge liée à l'infrastructure, les solutions gérées telles que ClickUp Brain offrent un compromis intéressant. Elles garantissent une sécurité de niveau entreprise sans aucune complexité d'installation.
Commencez gratuitement avec ClickUp et découvrez des flux de travail sécurisés, contextuels et basés sur l'IA pour votre équipe.
Foire aux questions
Quelle est la différence entre l'IA locale et l'IA basée sur le cloud pour les flux de travail en équipe ?
L'IA locale s'exécute entièrement sur votre propre matériel, garantissant ainsi que les données ne quittent jamais votre réseau interne, tandis que l'IA basée sur le cloud envoie des instructions à des serveurs tiers pour traitement. Les installations locales offrent une souveraineté totale sur les données et un accès hors ligne, tandis que les services cloud offrent une puissance de calcul supérieure et une plus grande facilité d'utilisation, au détriment du contrôle direct des données.
Comment les équipes peuvent-elles utiliser des modèles d'IA locale avec des données de projet confidentielles ?
Les équipes peuvent utiliser l'IA locale pour traiter des documents sensibles, du code propriétaire et des dossiers financiers en orientant le modèle vers des répertoires privés sur site. Comme l'inférence s'effectue sur l'appareil, vous pouvez effectuer des tâches telles que la résumation automatisée, l'extraction de données et la recherche de connaissances internes sans risquer d'être exposé aux ensembles de formation LLM publics.
Les modèles d'IA locale sont-ils aussi performants que ChatGPT pour les tâches de travail ?
De nombreux modèles locaux open source, tels que Llama 3 et Mistral, sont désormais parfaitement capables de gérer des tâches courantes telles que la rédaction, le codage et la résumation. Alors que les modèles cloud de premier plan comme GPT-4o restent à la pointe en matière de raisonnement ultra-complexe, les modèles locaux offrent des performances comparables pour 90 % des opérations quotidiennes, tout en garantissant une confidentialité nettement supérieure.
Quels sont les avantages et les inconvénients de l'exécution de l'IA en local par rapport à l'utilisation de services d'IA dans le cloud ?
Le principal compromis consiste à choisir entre la confidentialité totale des données offerte par l'IA locale et l'évolutivité sans maintenance de l'IA dans le cloud. L'exécution de l'IA en local nécessite un investissement initial en matériel et une expertise technique, mais élimine les frais récurrents liés aux API et les risques de fuite de données. L'IA dans le cloud est plus rapide à déployer, mais implique des coûts d'abonnement permanents et une dépendance vis-à-vis des données de tiers.