
La mayoría de los equipos ven la generación de SQL como un truco de magia. Escribes una pregunta y obtienes una consulta.
Pero esta es la realidad: Snowflake Cortex Analyst solo funciona tan bien como el modelo semántico que se cree primero, y esa configuración no es sencilla. Al aprender a utilizar Snowflake Cortex para la generación de SQL, los equipos de datos ahora pueden transformar el lenguaje natural en consultas complejas y ejecutables en cuestión de segundos.
Esta guía le guía a través del proceso de implementación real, desde la definición de su modelo semántico YAML hasta la consulta de su almacén de datos utilizando lenguaje natural, para que comprenda tanto el potencial como los requisitos previos antes de empezar.
También analizaremos las limitaciones de Snowflake Cortex y cómo ClickUp puede ofrecer compatibilidad con los flujos de trabajo más amplios relacionados con la generación de SQL.
¿Qué es Snowflake Cortex Analyst?
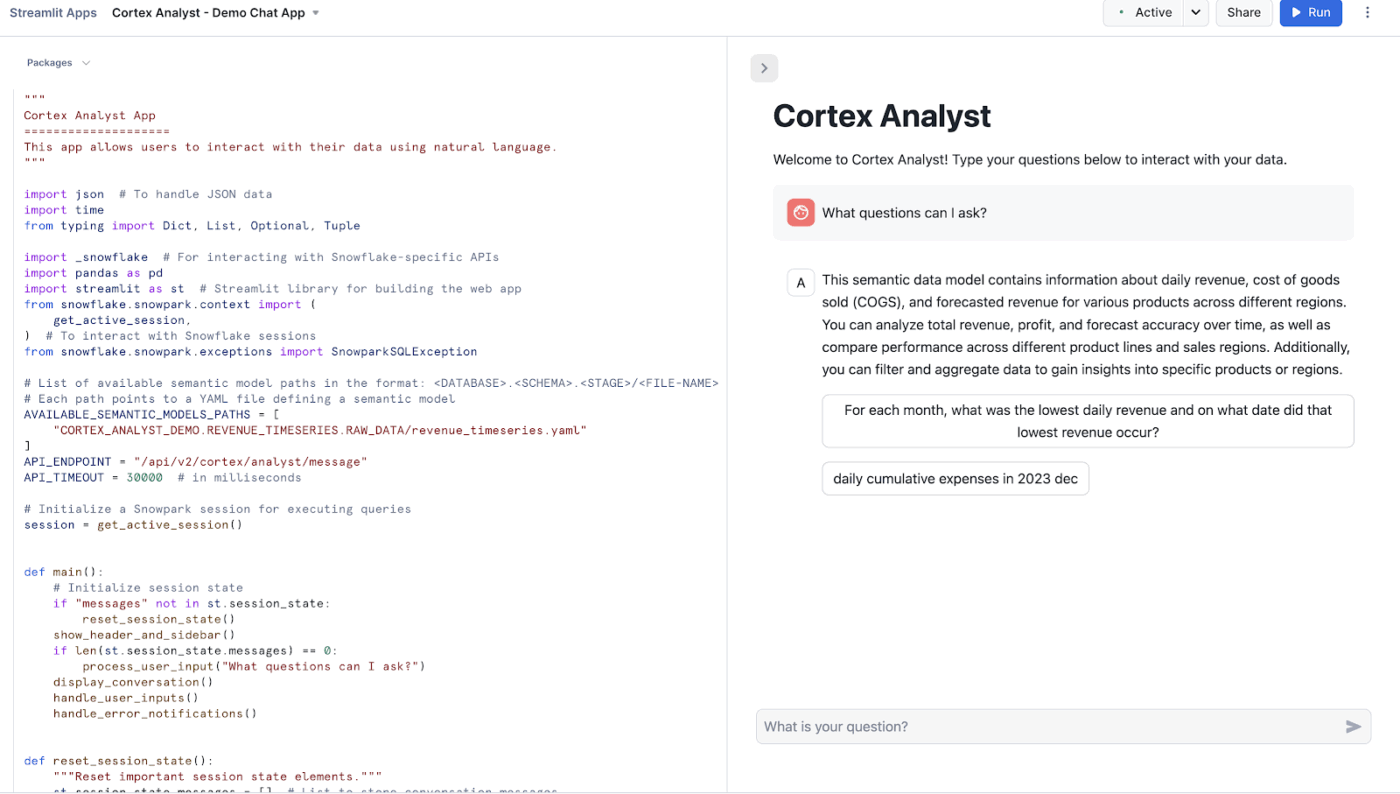
Snowflake Cortex Analyst es un servicio totalmente gestionado que le permite crear aplicaciones conversacionales basadas en sus datos analíticos.
Utiliza un agente especializado de conversión de texto a SQL para convertir preguntas en lenguaje natural en consultas precisas y ejecutables. Este servicio tiende un puente entre las estructuras de datos complejas y los usuarios empresariales que necesitan respuestas sin tener que escribir código.
Entre las principales funciones se incluyen:
- Ofrece una interfaz de gran precisión para interactuar con datos estructurados
- Uso de modelos semánticos para comprender su lógica empresarial y terminología específicas
- Ofrece una API REST para facilitar la integración en aplicaciones personalizadas o herramientas de BI
- Mantener la privacidad de los datos al procesar las solicitudes dentro del perímetro de seguridad de Snowflake
📮 ClickUp Insight: El 88 % de los encuestados utiliza la IA para sus tareas personales, pero más del 50 % evita usarla en el trabajo. ¿Cuáles son las tres principales barreras? La falta de una integración fluida, las lagunas de conocimiento o las preocupaciones de seguridad.
Pero, ¿y si la IA estuviera integrada en tu entorno de trabajo y ya fuera segura? ClickUp Brain, el asistente de IA integrado de ClickUp, lo hace realidad. Entiende las indicaciones en lenguaje sencillo, resolviendo las tres preocupaciones relacionadas con la adopción de la IA, al tiempo que conecta tu chat, tus tareas, tus documentos y tus conocimientos en todo el entorno de trabajo.
¡Encuentre respuestas y información con un solo clic!
Requisitos previos para la generación de SQL con Snowflake Cortex
Lanzarse a usar Snowflake Cortex sin la configuración adecuada puede resultar frustrante. Podrías obtener resultados inexactos, perder tiempo solucionando problemas y llegar a la conclusión errónea de que la herramienta no funciona, cuando el verdadero problema es una base deficiente.
Para evitarlo, primero debe contar con tres elementos fundamentales.
1. Configura tu base de datos y tus tablas
Tu IA es tan inteligente como los datos a los que tiene acceso. Si el esquema de tu base de datos es un laberinto de nombres de columnas crípticos como cust_dat_v2_final, tanto tus analistas como la IA tendrán dificultades para entenderlo.
Esta confusión hace que la IA genere uniones incorrectas o extraiga datos de las columnas equivocadas, y su equipo pierde horas solo intentando descifrar el esquema antes incluso de poder escribir una consulta.
Empiece por asegurarse de que su software de almacén de datos contiene las tablas que desea que Cortex Analyst realice consultas. Siempre que sea posible, utilice nombres de columna claros y descriptivos. Por ejemplo, una columna llamada customer_lifetime_value resulta mucho más intuitiva tanto para las personas como para la IA que clv_01.
Para continuar con la configuración, su rol de Snowflake necesitará los siguientes permisos:
- USO: En la base de datos y el esquema que contienen sus tablas
- SELECT: En las tablas que desea que Cortex Analyst realice consultas
- CREATE FASE: En el esquema, que es necesario para cargar su archivo de modelo semántico
📖 Lea también: Cómo utilizar Snowflake Cortex para la inteligencia empresarial en la empresa
2. Crea tu archivo de modelo semántico
El mayor obstáculo de cualquier herramienta de conversión de texto a SQL es que la IA no habla el lenguaje específico de su empresa. No sabe de forma innata que «ARR» significa «ingresos recurrentes anuales» o que la tabla de clientes se une a la tabla de pedidos mediante el campo customer_id.
Sin este contexto, la IA podría generar un código SQL técnicamente válido pero lógicamente erróneo, lo que le proporcionaría respuestas que parecen correctas pero que son peligrosamente engañosas.
El modelo semántico es la solución. Se trata de un archivo YAML que actúa como su «capa de traducción» personalizada, enseñando a Cortex Analyst el vocabulario y la lógica específicos de su empresa. La creación y el mantenimiento de este archivo es un esfuerzo colaborativo entre los ingenieros de datos, que utilizan herramientas ETL para conocer el esquema, y los analistas de negocio, que conocen la terminología.
Su archivo de modelo semántico debe contener estos componentes clave:
| Componente | Objetivo |
| Tablas | Lista de las tablas con una descripción en lenguaje sencillo de su finalidad |
| Columnas | Define el tipo semántico de cada columna (como categoría o métrica) y puede incluir valores de muestra |
| Relaciones | Especifica cómo se conectan las tablas mediante uniones, eliminando cualquier conjetura para la IA |
| Consultas verificadas | Proporciona ejemplos de pares de preguntas y SQL que sirven como guías muy útiles para el LLM |
3. Configura Cortex Search Service (opcional)
A veces, las respuestas que necesita se ocultan en texto no estructurado, como descripciones de productos, tickets de soporte o transcripciones de llamadas. Las consultas SQL estándar no pueden acceder a estos datos, lo que significa que a menudo se pierde el «por qué» detrás del «qué».
Si lo desea, puede añadir aquí Snowflake Cortex Search Service. Se trata de una capa de búsqueda como servicio que le permite realizar consultas tanto en sus tablas estructuradas como en sus datos de texto no estructurados utilizando al mismo tiempo agentes de IA para el análisis de datos.
Debe configurar Cortex Search si sus analistas necesitan formular preguntas que requieran extraer contexto del texto antes de generar SQL. Por ejemplo, primero podría buscar todas las reseñas de productos que contengan la frase «problema con la batería» y, a continuación, generar una consulta SQL para agregar los datos de ventas únicamente de esos productos.
Para la generación de SQL puro en tablas estructuradas, este servicio no es necesario.
🧠 Dato curioso: A principios de la década de 1970, los investigadores de IBM Donald Chamberlin y Raymond Boyce crearon el «Structured English Query Language». Tuvieron que cambiar el nombre a SQL porque «SEQUEL» ya era una marca registrada de una empresa aeronáutica británica.
Guía paso a paso para generar SQL con Cortex Analyst
Ya ha terminado el trabajo preliminar, pero ahora se encuentra ante una pantalla en blanco, sin saber muy bien cuál es el flujo de trabajo real. ¿Cómo pasa de una pregunta en su cabeza a una consulta SQL ejecutable? Cuando la gestión del flujo de trabajo no está clara, las nuevas herramientas suelen quedar sin usar y la inversión en su configuración se desperdicia.
El proceso práctico es sorprendentemente sencillo. ¡Echemos un vistazo más de cerca!
Paso n.º 1: Prepara tus datos en Snowflake
Antes de nada, sus datos estructurados deben estar almacenados en Snowflake. Cada aplicación de Cortex Analyst apunta a una sola tabla o a una vista compuesta por una o más tablas. Asegúrese de que sus tablas estén creadas y pobladas.
Si está cargando datos desde archivos planos:
- Sube tus archivos de datos (por ejemplo, CSV) a una fase de Snowflake
- Utilice el comando COPY INTO para cargar datos desde la fase a sus tablas
- Comprueba que los datos se hayan cargado de forma correcta antes de continuar
Paso n.º 2: Crea un modelo semántico (o vista semántica)
Este es el paso más importante de la configuración. La potencia de Cortex Analyst proviene de la combinación de modelos de lenguaje a gran escala (LLM) con modelos semánticos, un archivo YAML que se aloja junto al esquema de su base de datos y codifica el contexto de la empresa.
Las vistas semánticas son ahora el método recomendado por Snowflake para Cortex Analyst. Almacenan métricas empresariales, relaciones y definiciones directamente dentro de Snowflake. Los archivos de modelos semánticos YAML heredados siguen funcionando, pero Snowflake orienta las nuevas implementaciones hacia las vistas semánticas.
Su modelo semántico o vista debe incluir:
- Descripciones de tablas y columnas: Explicaciones en lenguaje sencillo sobre el significado de cada campo
- Métricas empresariales: definiciones de campos calculados como ingresos, tasa de abandono o tasa de conversión
- Filtros y sinónimos: Términos alternativos que los usuarios podrían utilizar (por ejemplo, «cancelado» correlacionado con un valor de estado específico)
- Consultas verificadas: El repositorio de consultas verificadas de Snowflake almacena pares aprobados de preguntas y SQL. Cuando la pregunta de un usuario se asemeja a una de esas entradas, Cortex Analyst puede hacer referencia a ella durante la generación de SQL.
🤝 Recordatorio: Snowflake recomienda no utilizar más de 10 tablas ni más de 50 columnas seleccionadas para obtener un rendimiento óptimo en el flujo de trabajo de Snowsight.
Paso n.º 3: Carga el modelo semántico en una fase de Snowflake
Si utiliza un modelo semántico basado en YAML, debe prepararlo para que Cortex Analyst pueda hacer referencia a él en tiempo de ejecución.
- Sube tu archivo .yaml a una fase interna de Snowflake (por ejemplo, RAW_DATA)
- Comprueba que el archivo aparece en la fase a través de la interfaz de usuario de Snowsight o mediante el comando LIST @stage_name
- Toma nota de la ruta de la fase; la necesitarás en tus llamadas a la API o en la configuración de la aplicación.
Si utiliza una vista semántica, este paso se gestiona de forma nativa dentro de Snowflake y no es necesario realizar ninguna carga por separado.
🔍 ¿Sabías que...? NULL en SQL no significa cero ni vacío. Representa datos desconocidos o faltantes, lo que da lugar a comportamientos poco intuitivos, como comparaciones que no devuelven ni verdadero ni falso.
Paso n.º 4: Envía una pregunta en lenguaje natural a través de la API REST
Ahora comienza la generación de SQL propiamente dicha. La API REST genera una consulta SQL para una pregunta determinada utilizando un modelo semántico o una vista semántica proporcionados en la solicitud.
Estructura tu solicitud de API con:
- mensajes; una matriz que contiene la pregunta del usuario con el rol: «usuario»
- Una referencia a su modelo semántico o vista semántica
- Tu modelo preferido (o déjalo en «auto» para que Cortex realice la selección más adecuada)
Podrás mantener conversaciones de varios turnos en las que podrás hacer preguntas de seguimiento basadas en consultas anteriores.
Paso n.º 5: Analizar la respuesta de la API
Cada mensaje de una respuesta puede contener varios bloques de contenido de diferentes tipos. Los tres valores que se admiten actualmente para el campo «type» son: texto, sugerencias y SQL.
Esto es lo que significa cada tipo:
- SQL: Cortex ha generado correctamente una consulta; esto es lo que ejecutará
- texto: Una explicación o respuesta en lenguaje natural que acompaña al SQL
- sugerencias: El tipo de contenido «sugerencias» solo se incluye en una respuesta si la pregunta del usuario era ambigua y Cortex Analyst no pudo devolver una instrucción SQL para esa consulta. Utilícelas para aclarar o precisar la pregunta
🔍 ¿Sabías que...? El orden en el que escribes el SQL no es el orden en el que se ejecuta. Aunque escribas SELECT primero, las bases de datos procesan en realidad FROM y WHERE antes de realizar la selección de las columnas. Esto confunde tanto a los principiantes como a los usuarios experimentados.
Paso n.º 6: Ejecuta el SQL generado en Snowflake
Una vez que tenga el bloque SQL de la respuesta, ejecútelo en su almacén virtual de Snowflake. La consulta SQL generada se ejecuta en su almacén virtual de Snowflake para generar el resultado final. Los datos permanecen dentro de los límites de gobernanza de Snowflake.
Aspectos clave que debe tener en cuenta en el momento de la ejecución:
- Cortex Analyst se integra completamente con las políticas de control de acceso basado en roles (RBAC) de Snowflake, lo que garantiza que las consultas SQL generadas y ejecutadas cumplan con todos los controles de acceso establecidos.
- Si un usuario no tiene acceso a una tabla, la consulta fallará al ejecutarse, igual que ocurriría con un código SQL escrito a mano.
- En esta fase se aplican los costes de computación del almacén, independientemente de las tarifas de uso propias de Cortex Analyst.
Paso n.º 7: Perfeccionar y repetir
No siempre se garantiza obtener una consulta perfecta a la primera. A continuación te explicamos cómo mejorar los resultados con el tiempo:
- Añade consultas verificadas a tu modelo semántico para las preguntas que surgen repetidamente
- Enriquezca su modelo semántico con mejores descripciones, sinónimos y filtros cuando Cortex malinterprete un término
- Utilice conversaciones de varios turnos para continuar, por ejemplo, «Ahora filtra eso por región»; las conversaciones de varios turnos permiten formular preguntas de seguimiento que se basan en consultas anteriores.
- Supervise el uso a través de CORTEX_ANALYST_USAGE_HISTORY y el historial de consultas de Snowflake para detectar patrones en consultas fallidas o inexactas
🧠 Dato curioso: Una sola condición JOIN que falte puede causar problemas graves. Olvidar una condición JOIN puede generar un producto cartesiano, multiplicando drásticamente las filas y, en ocasiones, provocando fallos en los sistemas.
Buenas prácticas para la precisión de Snowflake Text-to-SQL
La calidad de su modelo semántico determina directamente la precisión de las consultas que genera. A continuación le presentamos las buenas prácticas para mejorar la precisión. 🛠️
- Añade consultas verificadas a tu modelo semántico: esto es lo más eficaz que puedes hacer. Incluye muchos ejemplos de pares pregunta-SQL que reflejen cómo tu equipo formula realmente las preguntas.
- Utilice nombres descriptivos para las columnas y las tablas: El modelo funciona mejor cuando los nombres de las columnas y las tablas son autoexplicativos. Si no puede cambiar el esquema, añada descripciones claras en su archivo YAML para cualquier nombre de columna críptico.
- Incluya valores de muestra: añadir datos de muestra para columnas categóricas (como estado o región) ayuda al modelo a comprender las opciones de filtro válidas disponibles
- Prueba con casos extremos: Durante el desarrollo, formula deliberadamente preguntas ambiguas o complicadas para identificar en qué puntos tu modelo semántico necesita más contexto o aclaraciones.
- Iterar sobre su modelo semántico: Considere su modelo semántico como un documento vivo. Debe actualizarse continuamente mediante un proceso iterativo basado en qué consultas tienen éxito y cuáles fallan
ClickUp: una alternativa más sencilla a Snowflake Cortex
Snowflake Cortex funciona bien cuando los equipos desean generar SQL y ejecutar consultas en datos estructurados. Los equipos definen esquemas, correlacionan relaciones y escriben consultas para extraer información. Esa configuración tiene sentido en entornos con gran volumen de datos, especialmente cuando los analistas se encargan de la elaboración de informes.
Sin embargo, muchos equipos no necesitan una capa SQL completa para responder a las preguntas operativas cotidianas. Los gestores de producto, los jefes de programa y los equipos de operaciones suelen querer respuestas rápidas relacionadas con el trabajo en curso.
ClickUp ofrece una vía más accesible. Los equipos formulan preguntas en lenguaje sencillo, revisan paneles en tiempo real y actúan en función de la información obtenida sin necesidad de escribir SQL ni crear modelos semánticos.
Genera y perfecciona SQL más rápido
Snowflake Cortex se centra en generar consultas SQL a partir de conjuntos de datos estructurados dentro de un entorno de almacén de datos. Esto funciona bien cuando sus datos ya se encuentran en Snowflake y tiene los esquemas correlacionados.

ClickUp Brain ofrece compatibilidad con la generación de SQL de una forma más flexible y centrada en la ejecución. Los equipos generan, perfeccionan y almacenan consultas SQL directamente dentro de su entorno de trabajo de ClickUp, donde ya tienen lugar los análisis, los debates y las decisiones.
Imaginemos que un analista de productos trabaja en una tarea de análisis de retención dentro de ClickUp. En lugar de cambiar de herramienta para escribir consultas, le pregunta a ClickUp Brain:
📌 Prueba esta indicación: Escribe una consulta SQL para calcular la retención de siete días de los usuarios agrupados por cohorte de registro.
ClickUp Brain genera una consulta estructurada que incluye agrupación por cohortes, filtros de fecha y lógica de retención. El analista pega la consulta en Snowflake u otro almacén de datos y la ejecuta de inmediato.
Esto ayuda a:
- Escriba uniones entre varias tablas, como usuarios, pedidos y eventos
- Convierte preguntas sobre productos en inglés sencillo en lógica SQL lista para su ejecución
- Depura consultas erróneas y explica problemas, como uniones incorrectas o condiciones que faltan.
- Reescribe las consultas para mejorar el rendimiento o la legibilidad
Por ejemplo, durante la revisión de un experimento de crecimiento, un especialista en marketing pregunta: «Escribe una consulta SQL para comparar las tasas de conversión entre dos páginas de destino durante los últimos 14 días».
ClickUp Brain genera la consulta utilizando agregación condicional y filtros de fecha. El equipo la ejecuta en Snowflake y valida los resultados del experimento.
📌 Prueba esta indicación: Corrige esta consulta SQL en la que la unión duplica filas y explica el problema.
ClickUp Brain identifica el problema de la unión, corrige la consulta y explica cómo se produjeron las filas duplicadas debido a condiciones de unión incorrectas.
Sustituya la elaboración de informes basada en SQL
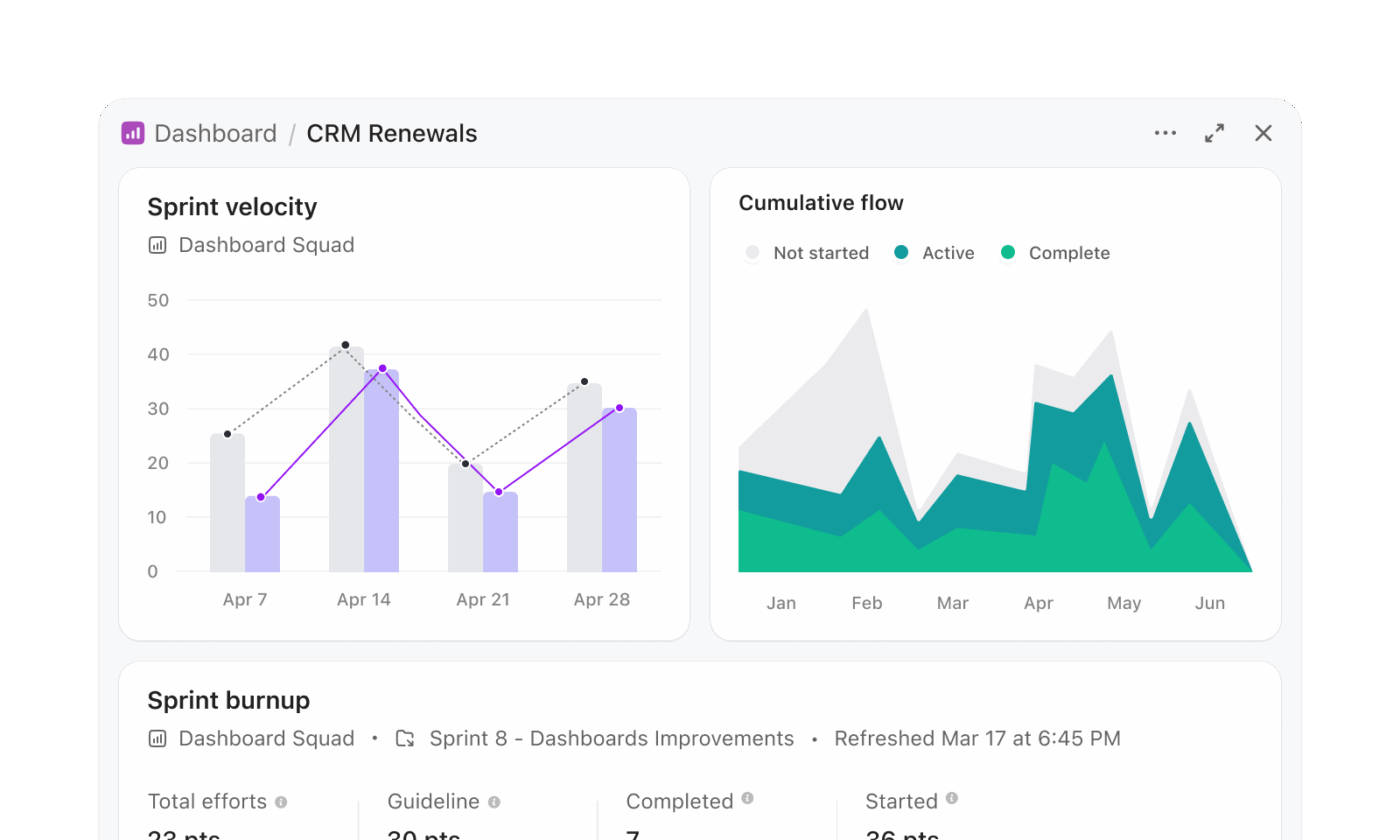
Los flujos de trabajo de Snowflake Cortex suelen implicar la generación de SQL, la ejecución de consultas y la visualización de resultados en una capa separada. Los paneles de ClickUp eliminan ese proceso de varios pasos y presentan información directamente desde el trabajo en tiempo real.
Un equipo de gestión de programas que realiza el seguimiento de la preparación de lanzamientos puede crear un panel sin necesidad de escribir consultas. Por ejemplo, un panel de lanzamientos puede incluir:
- Una tarjeta de lista de tareas filtrada para mostrar las tareas vencidas de todos los equipos de producto
- Una tarjeta de carga de trabajo que muestra la distribución de tareas entre los ingenieros
- Un gráfico de barras que compara las tareas completadas con las pendientes por sprint
- Una tarjeta de cálculo que realiza el seguimiento del tiempo medio de finalización
Supongamos que el responsable de un programa revisa este panel antes de una reunión de lanzamiento. Inmediatamente observa que los servicios de backend muestran mayores índices de retraso. Abre la tarjeta de la lista de tareas y examina las tareas concretas que están generando el riesgo.
Un usuario real de ClickUp comparte su experiencia:
ClickUp nos permite pasarnos proyectos entre nosotros RÁPIDAMENTE, comprobar FÁCILMENTE el estado de los proyectos y ofrece a nuestra supervisora una visión de nuestra carga de trabajo en cualquier momento sin que tenga que interrumpirnos. Sin duda, hemos ahorrado un día a la semana usando ClickUp, si no más. El número de correos electrónicos se ha reducido CONSIDERABLEMENTE.
ClickUp nos permite pasarnos proyectos entre nosotros RÁPIDAMENTE, comprobar FÁCILMENTE el estado de los proyectos y ofrece a nuestra supervisora una visión de nuestra carga de trabajo en cualquier momento sin que tenga que interrumpirnos. Sin duda, hemos ahorrado un día a la semana usando ClickUp, si no más. El número de correos electrónicos se ha reducido CONSIDERABLEMENTE.
Actúa en función de los insights sin necesidad de pipelines
Snowflake Cortex se centra en generar información a partir de los datos. Los equipos siguen teniendo que interpretar los resultados y ser los desencadenantes de acciones por separado.
Los Superagentes de ClickUp AI cierran esa brecha y convierten los conocimientos en acciones. Funcionan como compañeros de equipo de IA que supervisan continuamente los datos del entorno de trabajo y toman medidas en función de las condiciones.
Supongamos que un gestor de programas supervisa varias iniciativas de producto. Un Super Agent puede:
- Supervise las tareas de todos los proyectos y detecte cuándo las tareas atrasadas superan un umbral definido
- Identifica patrones como retrasos repetidos en la misma fase del flujo de trabajo
- Crea una tarea que resuma los proyectos afectados y asígnala al responsable del programa
- Notifique a los propietarios de equipo cuando las tareas críticas sigan sin resolverse tras haber vencido los plazos
Por ejemplo, durante un ciclo de lanzamiento, un Super Agent detecta que más de 10 tareas de alta prioridad no han cumplido los plazos en dos equipos. Crea una tarea de ClickUp titulada «Riesgo de lanzamiento: plazos incumplidos», adjunta todas las tareas relevantes y se la asigna al gestor del programa para su revisión inmediata.
Los equipos también pueden interactuar directamente con el Super Agent: «Analiza todos los proyectos activos y destaca los riesgos de entrega para este sprint».
El Super Agent revisa los plazos, las dependencias y el estado de las tareas, y luego publica un resumen estructurado dentro del entorno de trabajo.
A continuación te explicamos cómo ajustar tu propio Super Agent en ClickUp:
Centraliza tus flujos de trabajo de datos con ClickUp
Las herramientas de conversión de texto a SQL, como Snowflake Cortex, hacen que los datos sean más accesibles. Al mismo tiempo, obtener resultados fiables sigue requiriendo un esfuerzo.
Los equipos necesitan esquemas limpios, modelos semánticos sólidos y una iteración continua para mantener la precisión de los resultados. Incluso después de generar la consulta adecuada, el trabajo no termina ahí. Alguien aún debe interpretar los resultados, compartir los conocimientos y convertirlos en decisiones.
ClickUp ofrece un enfoque diferente. En lugar de separar el análisis de la ejecución, ClickUp establece la conexión entre ambos. Los equipos generan SQL, documentan los insights, colaboran en los hallazgos y actúan en consecuencia dentro del mismo entorno de trabajo.
ClickUp Brain ayuda a redactar y perfeccionar las consultas, mientras que los paneles y los agentes de IA ayudan a los equipos a realizar el seguimiento de los resultados y a avanzar en el trabajo sin tener que cambiar de herramienta.
Snowflake Cortex te ayuda a obtener respuestas. ClickUp te ayuda a hacer algo con ellas. ¡Regístrate hoy mismo en ClickUp!
Preguntas frecuentes
Snowflake Cortex Analyst es un servicio especializado dentro de la suite más amplia de Snowflake Cortex IA. Cortex Analyst se centra específicamente en la generación de texto a SQL mediante modelos semánticos, mientras que Cortex IA incluye un intervalo más amplio de funciones de modelos de lenguaje grande (LLM), inferencia de modelos de aprendizaje automático y capacidades de búsqueda.
Sí, Cortex Analyst puede consultar tablas de Apache Iceberg gestionadas a través de Snowflake. Siempre que las tablas sean accesibles dentro de su entorno Snowflake y estén correctamente definidas en su modelo semántico, podrá generar consultas sobre ellas.
La precisión de las consultas complejas depende casi por completo de la calidad de su modelo semántico. Un modelo con relaciones entre tablas bien definidas, numerosas consultas verificadas y metadatos descriptivos producirá resultados significativamente más precisos para uniones de varias tablas y agregaciones complejas.
Los precios de Snowflake Cortex Analyst siguen el modelo basado en el consumo de Snowflake, lo que significa que se le facturará en función de los créditos de computación utilizados durante el proceso de generación de consultas. Para conocer las tarifas más actuales, consulte siempre la documentación oficial de precios de Snowflake.