
Die meisten Teams betrachten die SQL-Generierung wie einen Zaubertrick. Man gibt eine Frage ein und erhält eine Abfrage.
Aber hier ist die Realität: Snowflake Cortex Analyst funktioniert nur so gut wie das semantische Modell, das Sie zuvor erstellen, und dieses Setup ist nicht trivial. Wenn Datenteams lernen, wie man Snowflake Cortex für die SQL-Generierung einsetzt, können sie nun natürliche Sprache in Sekundenschnelle in komplexe, ausführbare Abfragen umwandeln.
Dieser Leitfaden führt Sie durch den tatsächlichen Implementierungsprozess, von der Definition Ihres YAML-Semantikmodells bis hin zur Abfrage Ihres Data Warehouse mithilfe natürlicher Sprache, damit Sie sowohl die Leistungsfähigkeit als auch die Voraussetzungen verstehen, bevor Sie beginnen.
Wir schauen uns auch an, wo Snowflake Cortex Grenzen stößt und wie ClickUp die umfassenderen Workflows rund um die SQL-Generierung unterstützen kann.
Was ist Snowflake Cortex Analyst?
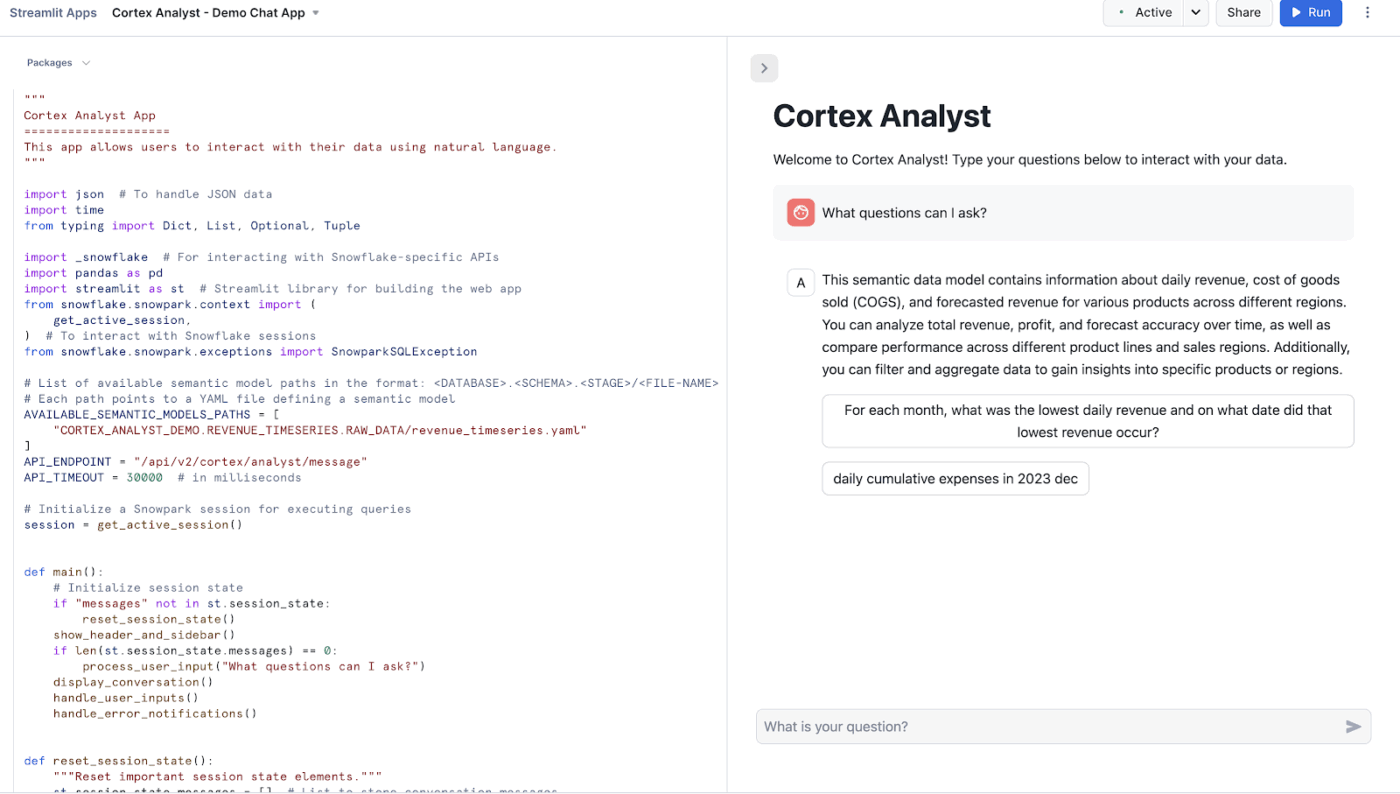
Snowflake Cortex Analyst ist ein vollständig verwalteter Dienst, mit dem Sie dialogorientierte Anwendungen auf Basis Ihrer Analysedaten erstellen können.
Er nutzt einen speziellen Text-zu-SQL-Agenten, um Fragen in natürlicher Sprache in präzise, ausführbare Abfragen umzuwandeln. Dieser Dienst schließt die Lücke zwischen komplexen Datenstrukturen und Benutzern des Geschäfts, die Antworten benötigen, ohne selbst Code schreiben zu müssen.
Zu den wichtigsten Funktionen gehören:
- Bereitstellung einer hochpräzisen Schnittstelle für die Interaktion mit strukturierten Daten
- Nutzung semantischer Modelle zum Verständnis Ihrer spezifischen Geschäftslogik und Terminologie
- Mit einer REST-API für die einfache Integration in benutzerdefinierte Anwendungen oder BI-Tools
- Wahrung des Datenschutzes durch die Verarbeitung von Anfragen innerhalb der Snowflake-Sicherheitsgrenzen
📮 ClickUp Insight: 88 % unserer Umfrageteilnehmer nutzen KI für ihre privaten Aufgaben, doch über 50 % scheuen sich davor, sie bei der Arbeit einzusetzen. Die drei größten Hindernisse? Fehlende nahtlose Integration, Wissenslücken oder Bedenken hinsichtlich der Sicherheit.
Aber was wäre, wenn KI bereits in Ihrem Workspace integriert und sicher wäre? ClickUp Brain, der integrierte KI-Assistent von ClickUp, macht dies möglich. Er versteht Eingaben in einfacher Sprache, löst alle drei Bedenken hinsichtlich der KI-Einführung und stellt gleichzeitig eine Verbindung zwischen Ihrem Chat, Ihren Aufgaben, Dokumenten und Ihrem Wissen im gesamten Workspace her.
Finden Sie Antworten und Erkenntnisse mit nur einem Klick!
Voraussetzungen für die SQL-Generierung mit Snowflake Cortex
Wenn Sie sich ohne das richtige Setup an Snowflake Cortex wagen, führt dies zu Frustration. Sie erhalten möglicherweise ungenaue Ergebnisse, verschwenden Zeit mit der Fehlerbehebung und kommen fälschlicherweise zu dem Schluss, dass das Tool nicht funktioniert, obwohl das eigentliche Problem in einer schwachen Grundlage liegt.
Um dies zu vermeiden, müssen Sie zunächst drei grundlegende Elemente einrichten.
1. Richten Sie Ihre Datenbank und Tabellen ein
Ihre KI ist nur so intelligent wie die Daten, auf die sie zugreifen kann. Wenn Ihr Datenbankschema ein Labyrinth aus kryptischen Spaltennamen wie „cust_dat_v2_final“ ist, werden sowohl Ihre Analysten als auch die KI Schwierigkeiten haben, darin einen Sinn zu erkennen.
Diese Verwirrung führt dazu, dass die KI falsche Verknüpfungen generiert oder Daten aus den falschen Spalten abruft, und Ihr Team verschwendet Stunden damit, das Schema zu entschlüsseln, bevor es überhaupt eine Abfrage schreiben kann.
Stellen Sie zunächst sicher, dass Ihre Data-Warehouse-Software die Tabellen enthält, die Cortex Analyst abfragen soll. Verwenden Sie nach Möglichkeit klare, aussagekräftige Spaltennamen. Beispielsweise ist eine Spalte mit dem Namen „customer_lifetime_value“ sowohl für Menschen als auch für KI weitaus intuitiver als „clv_01“.
Um mit dem Setup fortzufahren, benötigt Ihre Snowflake-Rolle die folgenden Berechtigungen:
- VERWENDUNG: In der Datenbank und dem Schema, die Ihre Tabellen enthalten
- SELECT: Für die Tabellen, die Cortex Analyst abfragen soll
- CREATE PHASE: Im Schema, das zum Hochladen Ihrer semantischen Modelldatei erforderlich ist
📖 Lesen Sie auch: So nutzen Sie Snowflake Cortex für Business Intelligence
2. Erstellen Sie Ihre semantische Modelldatei
Die größte Hürde bei jedem Text-zu-SQL-Tool besteht darin, dass die KI die spezifische Sprache Ihres Unternehmens nicht versteht. Sie weiß nicht von vornherein, dass „ARR“ für „Annual Recurring Revenue“ steht oder dass die Kundentabelle über das Feld „customer_id“ mit Ihrer Auftragstabelle verknüpft ist.
Ohne diesen Kontext könnte die KI SQL generieren, das zwar technisch gültig, aber logisch falsch ist, und Ihnen Antworten liefern, die zwar korrekt aussehen, aber gefährlich irreführend sind.
Das semantische Modell ist die Lösung. Es handelt sich um eine YAML-Datei, die als Ihre benutzerdefinierte „Übersetzungsschicht“ fungiert und Cortex Analyst das spezifische Vokabular und die Logik Ihres Geschäfts beibringt. Der Aufwand für die Erstellung und Pflege dieser Datei ist eine gemeinsame Aufgabe von Dateningenieuren, die mithilfe von ETL-Tools das Schema kennen, und Business-Analysten, die mit der Terminologie vertraut sind.
Ihre Semantikmodelldatei sollte folgende Schlüsselkomponenten enthalten:
| Komponente | Zweck |
| Tabellen | Die Liste zeigt jede Tabelle mit einer Beschreibung ihres Zwecks in einfacher Sprache auf |
| Spalten | Definiert den semantischen Typ jeder Spalte (z. B. Kategorie oder Metriken) und kann Beispielwerte enthalten |
| Beziehungen | Legt fest, wie Tabellen über Joins miteinander verbunden werden, wodurch für die KI jegliches Rätselraten entfällt |
| Verifizierte Abfragen | Enthält Beispielpaare aus Fragen und SQL-Anweisungen, die als nützliche Anleitungen für das LLM dienen |
3. Konfigurieren Sie den Cortex Search Service (optional)
Manchmal sind die Antworten, die Sie benötigen, in unstrukturierten Texten verborgen, wie beispielsweise Produktbeschreibungen, Support-Tickets oder Gesprächsprotokollen. Standard-SQL-Abfragen können diese Daten nicht auswerten, was bedeutet, dass Ihnen oft das „Warum“ hinter dem „Was“ fehlt.
Optional können Sie hier den Snowflake Cortex Search Service hinzufügen. Dabei handelt es sich um eine Search-as-a-Service- Ebene, mit der Sie sowohl Ihre strukturierten Tabellen als auch Ihre unstrukturierten Texte mithilfe von KI-Agenten für die Datenanalyse gleichzeitig abfragen können.
Sie sollten Cortex Search konfigurieren, wenn Ihre Analysten Fragen stellen müssen, für die vor der Generierung von SQL Kontextinformationen aus dem Text abgerufen werden müssen. Sie könnten beispielsweise zunächst nach allen Produktbewertungen suchen, die den Ausdruck „Batterieproblem“ enthalten, und dann eine SQL-Abfrage generieren, um die Verkaufsdaten nur für diese Produkte zusammenzufassen.
Für die reine SQL-Generierung für strukturierte Tabellen ist dieser Dienst nicht erforderlich.
🧠 Wissenswertes: In den frühen 1970er Jahren entwickelten die IBM-Forscher Donald Chamberlin und Raymond Boyce die „Structured English Abfrage Language“. Sie mussten den Namen in SQL ändern, da „SEQUEL“ bereits von einem britischen Flugzeughersteller als Marke geschützt war.
Schritt-für-Schritt-Anleitung zur SQL-Generierung mit Cortex Analyst
Sie haben die Vorbereitungsarbeit erledigt, sitzen nun aber vor einem leeren Bildschirm und sind sich über den tatsächlichen Workflow unsicher. Wie gelangen Sie von einer Frage in Ihrem Kopf zu einer ausführbaren SQL-Abfrage? Wenn der Workflow unklar ist, bleiben neue Tools oft ungenutzt, und die Investition in das Setup ist verschwendet.
Der praktische Ablauf ist erfreulich unkompliziert. Hier ein genauerer Blick darauf!
Schritt 1: Bereiten Sie Ihre Daten in Snowflake vor
Zunächst müssen Ihre strukturierten Daten in Snowflake vorhanden sein. Jede Cortex Analyst-Anwendung ist entweder auf eine einzelne Tabelle oder auf eine Ansicht ausgerichtet, die aus einer oder mehreren Tabellen besteht. Stellen Sie sicher, dass Ihre Tabellen erstellt und mit Population gefüllt sind.
Wenn Sie Daten aus Flatfiles laden:
- Laden Sie Ihre Datendateien (z. B. CSV-Dateien) in eine Snowflake-Phase hoch
- Verwenden Sie den Befehl COPY INTO, um Daten aus der Phase in Ihre Tabellen zu laden
- Überprüfen Sie, ob der Ladevorgang erfolgreich war, bevor Sie fortfahren
📖 Lesen Sie auch: So nutzen Sie Snowflake Cortex für Enterprise-Analysen
Schritt 2: Erstellen Sie ein semantisches Modell (oder eine semantische Ansicht)
Dies ist der wichtigste Schritt beim Setup. Die Leistungsfähigkeit von Cortex Analyst beruht auf der Kombination von großen Sprachmodellen (LLMs) mit semantischen Modellen – einer YAML-Datei, die neben Ihrem Datenbankschema liegt und den geschäftlichen Kontext kodiert.
Semantic Views sind nun die von Snowflake empfohlene Methode für Cortex Analyst. Sie speichern Metriken, Beziehungen und Definitionen direkt in Snowflake. Ältere YAML-Dateien für semantische Modelle funktionieren weiterhin, aber Snowflake empfiehlt für neue Implementierungen die Verwendung von Semantic Views.
Ihr semantisches Modell oder Ihre Ansicht sollte Folgendes enthalten:
- Tabellen- und Spaltenbeschreibungen: Erklärungen in einfacher Sprache zur Bedeutung der einzelnen Felder
- Metriken: Definitionen für berechnete Felder wie Umsatz, Abwanderungsrate oder Konversionsrate
- Filter und Synonyme: Alternative Begriffe, die Benutzer verwenden könnten (z. B. „storniert“, dem einem bestimmten Wert des Status zugeordnet ist)
- Verifizierte Abfragen: Das Verified Query Repository von Snowflake speichert genehmigte Frage-SQL-Paare. Wenn eine Benutzerabfrage einem dieser Einträge ähnelt, kann Cortex Analyst bei der SQL-Generierung darauf zurückgreifen.
🤝 Freundliche Erinnerung: Snowflake empfiehlt, für einen optimalen Workflow im Snowsight nicht mehr als 10 Tabellen und nicht mehr als 50 ausgewählte Spalten zu verwenden.
Schritt 3: Laden Sie das semantische Modell in eine Snowflake-Phase hoch
Wenn Sie ein YAML-basiertes semantisches Modell verwenden, muss dieses bereitgestellt werden, damit Cortex Analyst zur Laufzeit darauf zugreifen kann.
- Laden Sie Ihre .yaml-Datei in eine interne Snowflake-Phase hoch (z. B. RAW_DATA)
- Überprüfen Sie über die Snowsight-Benutzeroberfläche oder den Befehl LIST @stage_name, ob die Datei in der Phase angezeigt wird.
- Notieren Sie sich den Pfad der Phase; Sie werden ihn in Ihren API-Aufrufen oder in der Konfiguration der App benötigen.
Wenn Sie eine Semantic View verwenden, wird dieser Schritt nativ in Snowflake abgewickelt, sodass kein separater Upload erforderlich ist.
🔍 Wussten Sie schon? NULL bedeutet in SQL nicht Null oder leer. Es steht für unbekannte oder fehlende Daten, was zu nicht intuitivem Verhalten führt, wie zum Beispiel Vergleichen, die weder „wahr“ noch „falsch“ zurückgeben.
Schritt 4: Senden Sie eine Frage in natürlicher Sprache über die REST-API
Nun beginnt die eigentliche SQL-Generierung. Die REST-API generiert anhand eines in der Anfrage bereitgestellten semantischen Modells oder einer semantischen Ansicht eine SQL-Abfrage für eine bestimmte Frage.
Strukturieren Sie Ihre API-Anfrage mit:
- Nachrichten; ein Array, das Ihre Benutzerfrage mit der Rolle „Benutzer“ enthält
- Ein Verweis auf Ihr semantisches Modell oder Ihre semantische Ansicht
- Ihr bevorzugtes Modell (oder lassen Sie die Einstellung auf „Auto“, damit Cortex die beste Auswahl macht)
Sie können mehrstufige Unterhaltungen führen, in denen Sie Folgefragen stellen können, die auf früheren Abfragen aufbauen.
Schritt 5: Die API-Antwort analysieren
Jede Nachricht in einer Antwort kann mehrere Blöcke mit unterschiedlichen Inhalten enthalten. Derzeit werden für das Feld „type“ drei Werte unterstützt: Text, suggestions und SQL.
Hier erfahren Sie, was die einzelnen Typen bedeuten:
- SQL: Cortex hat einen Erfolg bei der Generierung einer Abfrage erzielt; diese werden Sie ausführen
- Text: Eine Erklärung oder Antwort in natürlicher Sprache, die der SQL-Abfrage beigefügt ist
- Vorschläge: Der Inhaltstyp „Vorschlag“ wird nur dann in eine Antwort aufgenommen, wenn die Frage des Benutzers mehrdeutig war und Cortex Analyst keine SQL-Anweisung für diese Abfrage zurückgeben konnte. Verwenden Sie diese, um die Frage zu präzisieren oder zu verfeinern
🔍 Wussten Sie schon? Die Reihenfolge, in der Sie SQL schreiben, entspricht nicht der Reihenfolge, in der es ausgeführt wird. Auch wenn Sie SELECT zuerst schreiben, verarbeiten Datenbanken tatsächlich FROM und WHERE, bevor sie Spalten auswählen. Dies verwirrt sowohl Anfänger als auch erfahrene Benutzer.
Schritt 6: Führen Sie die generierte SQL-Anfrage in Snowflake aus
Sobald Sie den SQL-Block aus der Antwort erhalten haben, führen Sie ihn in Ihrem virtuellen Snowflake-Warehouse aus. Die generierte SQL-Abfrage wird in Ihrem virtuellen Snowflake-Warehouse ausgeführt, um die endgültige Ausgabe zu erzeugen. Die Daten verbleiben innerhalb der Governance-Grenzen von Snowflake.
Wichtige Informationen zur Ausführungszeit:
- Cortex Analyst ist vollständig in die rollenbasierten Zugriffskontrollrichtlinien (RBAC) von Snowflake integriert und stellt sicher, dass die generierten und ausgeführten SQL-Abfragen alle festgelegten Zugriffskontrollen einhalten.
- Wenn ein Benutzer keinen Zugriff auf eine Tabelle hat, schlägt die Abfrage bei der Ausführung fehl, genau wie bei handgeschriebener SQL
- In dieser Phase fallen Rechenkosten für das Warehouse an, die von den Nutzungsgebühren für Cortex Analyst getrennt sind.
Schritt 7: Verfeinern und iterieren
Es ist nicht immer garantiert, dass die Abfrage auf Anhieb perfekt ist. So verbessern Sie die Ergebnisse im Laufe der Zeit:
- Fügen Sie verifizierte Abfragen zu Ihrem semantischen Modell hinzu, um Fragen zu beantworten, die immer wieder auftauchen
- Erweitern Sie Ihr semantisches Modell mit besseren Beschreibungen, Synonymen und Filtern, wenn Cortex einen Begriff falsch interpretiert
- Nutzen Sie mehrstufige Unterhaltungen für Folgeanfragen, zum Beispiel „Filtern Sie das jetzt nach Region“ – mehrstufige Unterhaltungen ermöglichen Folgefragen, die auf vorherigen Abfragen aufbauen
- Überwachen Sie die Nutzung über CORTEX_ANALYST_USAGE_HISTORY und den Snowflake-Abfrageverlauf, um Muster in fehlgeschlagenen oder ungenauen Abfragen zu erkennen
🧠 Wissenswertes: Eine fehlende JOIN-Bedingung kann massive Probleme verursachen. Das Vergessen einer JOIN-Bedingung kann zu einem kartesischen Produkt führen, wodurch sich die Anzahl der Zeilen drastisch vervielfacht und Systeme manchmal abstürzen.
Best Practices für die Genauigkeit von Snowflake Text-to-SQL
Die Qualität Ihres semantischen Modells bestimmt direkt die Genauigkeit der Abfragen, die es generiert. Hier finden Sie die Best Practices zur Verbesserung der Genauigkeit. 🛠️
- Fügen Sie verifizierte Abfragen zu Ihrem semantischen Modell hinzu: Dies ist der wirkungsvollste Schritt, den Sie unternehmen können. Nehmen Sie zahlreiche Beispiele für Paare aus Fragen und SQL-Abfragen auf, die widerspiegeln, wie Ihr Team tatsächlich Fragen stellt.
- Verwenden Sie aussagekräftige Spalten- und Tabellennamen: Das Modell liefert bessere Ergebnisse, wenn Spalten- und Tabellennamen selbsterklärend sind. Wenn Sie das Schema nicht ändern können, fügen Sie in Ihrer YAML-Datei klare Beschreibungen für alle kryptischen Spaltennamen hinzu.
- Beispielwerte einfügen: Das Hinzufügen von Beispielwerten für kategoriale Spalten (wie Status oder Region) hilft dem Modell, die verfügbaren gültigen Filteroptionen zu verstehen
- Testen Sie mit Randfällen: Stellen Sie während der Entwicklung bewusst mehrdeutige oder knifflige Fragen, um festzustellen, wo Ihr semantisches Modell mehr Kontext oder Klarstellung benötigt.
- Iterieren Sie Ihr semantisches Modell: Betrachten Sie Ihr semantisches Modell als ein lebendiges Dokument. Es sollte kontinuierlich durch einen iterativen Prozess aktualisiert werden, der darauf basiert, welche Abfragen erfolgreich sind und welche fehlschlagen.
ClickUp: Eine einfachere Alternative zu Snowflake Cortex
Snowflake Cortex eignet sich besonders gut, wenn Teams SQL generieren und Abfragen über strukturierte Daten hinweg ausführen möchten. Teams definieren Schemata, ordnen Beziehungen zu und schreiben Abfragen, um Erkenntnisse zu gewinnen. Dieses Setup ist sinnvoll für datenintensive Umgebungen, insbesondere wenn Analysten für die Berichterstellung verantwortlich sind.
Viele Teams benötigen jedoch keine vollständige SQL-Ebene, um alltägliche operative Fragen zu beantworten. Produktmanager, Programmleiter und Betriebsteams wünschen sich oft schnelle Antworten, die sich auf die aktuelle Arbeit beziehen.
ClickUp bietet einen einfacheren Weg. Teams stellen Fragen in einfacher Sprache, überprüfen Live-Dashboards und handeln auf der Grundlage der gewonnenen Erkenntnisse, ohne SQL-Abfragen schreiben oder semantische Modelle erstellen zu müssen.
SQL schneller generieren und verfeinern
Snowflake Cortex konzentriert sich auf die Generierung von SQL-Abfragen aus strukturierten Datensätzen innerhalb einer Warehouse-Umgebung. Das funktioniert gut, wenn Ihre Daten bereits in Snowflake gespeichert sind und Sie über festgelegte Schemata verfügen.

ClickUp Brain unterstützt die SQL-Generierung auf flexiblere, ausführungsorientierte Weise. Teams erstellen, verfeinern und speichern SQL-Abfragen direkt in ihrem Workspace, wo bereits Analysen, Diskussionen und Entscheidungen stattfinden.
Angenommen, ein Produktanalyst arbeitet in ClickUp an einer Kundenbindungsanalyse. Anstatt das Tool zu wechseln, um Abfragen zu schreiben, fragt er ClickUp Brain:
📌 Probieren Sie diesen Befehl aus: Schreiben Sie eine SQL-Abfrage, um die 7-Tage-Retention für Benutzer zu berechnen, gruppiert nach Kohorte der Anmeldung.
ClickUp Brain generiert eine strukturierte Abfrage, die Kohortengruppierungen, Datumsfilter und Retentionslogik enthält. Der Analyst fügt die Abfrage in Snowflake oder ein anderes Data Warehouse ein und führt sie sofort aus.
Es hilft dabei:
- Schreiben Sie Joins über mehrere Tabellen hinweg, z. B. Benutzer, Bestellungen und Ereignisse
- Wandeln Sie Produktfragen in einfachem Englisch in ausführbare SQL-Logik um
- Beheben Sie fehlerhafte Abfragen und erklären Sie Probleme wie falsche Verknüpfungen oder fehlende Bedingungen
- Schreiben Sie Abfragen um, um die Leistung oder Lesbarkeit zu verbessern
Beispielsweise fragt ein Marketingmitarbeiter während der Auswertung eines Wachstumsexperiments: „Erstellen Sie eine SQL-Abfrage, um die Konversionsraten zweier Landingpages in den letzten 14 Tagen zu vergleichen.“
ClickUp Brain generiert die Abfrage mithilfe von bedingten Aggregationen und Datumsfiltern. Das Team führt sie in Snowflake aus und validiert die Versuchsergebnisse.
📌 Probieren Sie diesen Befehl aus: Korrigieren Sie diese SQL-Abfrage, bei der der Join Zeilen dupliziert, und erklären Sie das Problem.
ClickUp Brain erkennt das Join-Problem, korrigiert die Abfrage und erklärt, wie es aufgrund falscher Join-Bedingungen zu doppelten Zeilen gekommen ist.
Ersetzen Sie SQL-gesteuerte Berichterstellung
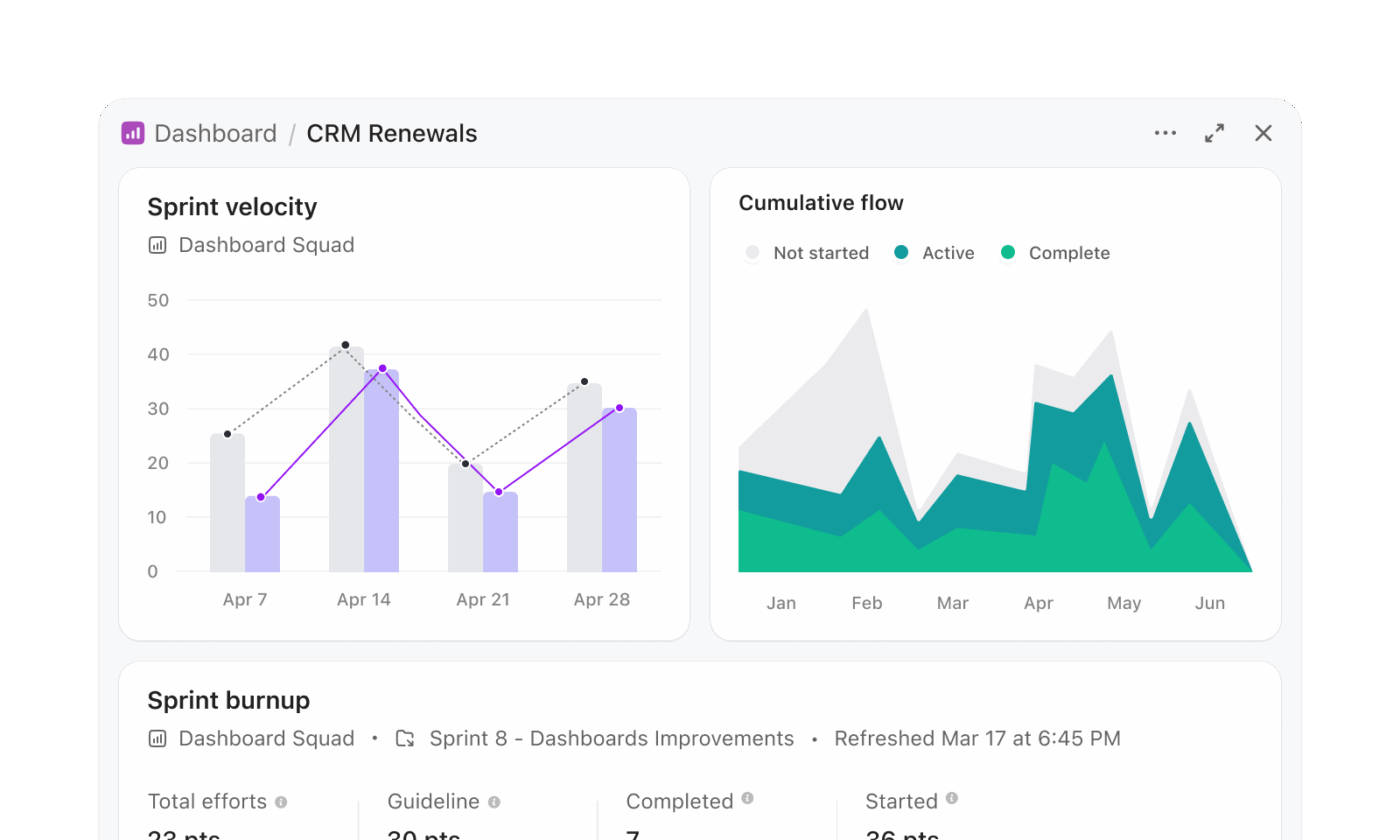
Snowflake Cortex-Workflows umfassen häufig die Generierung von SQL, die Ausführung von Abfragen und die Visualisierung der Ergebnisse in einer separaten Ebene. ClickUp-Dashboards machen diesen mehrstufigen Prozess überflüssig und präsentieren Erkenntnisse direkt aus der laufenden Arbeit.
Ein Programmmanagement-Team, das die Release-Bereitschaft nachverfolgt, kann ein Dashboard erstellen, ohne Abfragen schreiben zu müssen. Ein Release-Dashboard kann beispielsweise Folgendes enthalten:
- Eine Aufgabenlistenkarte, die so gefiltert ist, dass sie überfällige Aufgaben aller Teams anzeigt
- Eine Workload-Karte, die die Verteilung der Aufgaben unter den Ingenieuren anzeigt
- Ein Balkendiagramm, das fertiggestellte und noch ausstehende Aufgaben nach Sprint vergleicht
- Eine Berechnungskarte zur Nachverfolgung der durchschnittlichen Bearbeitungszeit
Angenommen, ein Programmleiter überprüft dieses Dashboard vor einem Release-Meeting. Er erkennt sofort, dass die Backend-Dienste höhere Verzögerungsraten aufweisen. Er öffnet die Karte der Aufgabenliste und überprüft genau die Aufgaben, die das Risiko verursachen.
Ein echter ClickUp-Benutzer gibt an:
Mit ClickUp können wir Projekte SCHNELL untereinander weitergeben, den Status von Projekten EINFACH überprüfen und unserer Vorgesetzten jederzeit einen Einblick in unsere Workload geben, ohne dass sie uns dabei stören muss. Durch die Nutzung von ClickUp haben wir sicherlich einen Tag pro Woche eingespart, wenn nicht sogar mehr. Die Anzahl der E-Mails hat sich DEUTLICH reduziert.
Mit ClickUp können wir Projekte SCHNELL untereinander weitergeben, den Status von Projekten EINFACH überprüfen und unserer Vorgesetzten jederzeit einen Einblick in unsere Workload geben, ohne dass sie uns dabei stören muss. Durch die Nutzung von ClickUp haben wir sicherlich einen Tag pro Woche eingespart, wenn nicht sogar mehr. Die Anzahl der E-Mails hat sich DEUTLICH reduziert.
Nutzen Sie Erkenntnisse ohne Pipelines
Snowflake Cortex konzentriert sich darauf, Erkenntnisse aus Daten zu gewinnen. Teams müssen die Ergebnisse weiterhin selbst interpretieren und Auslöser separat auslösen.
ClickUp AI Super Agents schließen diese Lücke und setzen Erkenntnisse in Maßnahmen um. Sie agieren als KI-Teamkollegen, die die Daten im ClickUp-Workspace kontinuierlich überwachen und je nach Bedingung Maßnahmen ergreifen.
Angenommen, ein Programmmanager betreut mehrere Produktinitiativen. Ein Super Agent kann:
- Überwachen Sie Aufgaben über Projekte hinweg und erkennen Sie, wenn überfällige Aufgaben einen definierten Schwellenwert überschreiten
- Erkennen Sie Muster wie wiederholte Verzögerungen in derselben Workflow-Phase
- Erstellen Sie eine Aufgabe, die die betroffenen Projekte zusammenfasst, und weisen Sie diese dem Programmleiter zu
- Benachrichtigen Sie Team-Eigentümer, wenn kritische Aufgaben nach Ablauf der Fristen noch ungelöst sind
Beispielsweise erkennt ein Super Agent während eines Release-Zyklus, dass in zwei Teams mehr als 10 Aufgaben mit hoher Priorität ihre Fristen verpasst haben. Er erstellt eine ClickUp-Aufgabe mit dem Titel „Release-Risiko: verpasste Fristen“, fügt alle relevanten Aufgaben als Anhänge hinzu und weist sie dem Programmmanager zur sofortigen Überprüfung zu.
Teams können auch direkt mit dem Super Agent interagieren: „Analysiere alle aktiven Projekte und hebe die Lieferrisiken für diesen Sprint hervor“.
Der Super Agent überprüft Fristen, Abhängigkeiten und den Status der Aufgaben und veröffentlicht anschließend eine strukturierte Zusammenfassung im Workspace.
So richten Sie Ihren eigenen Super-Agenten in ClickUp ein:
Zentralisieren Sie Ihre Daten-Workflows mit ClickUp
Text-zu-SQL-Tools wie Snowflake Cortex machen Daten leichter zugänglich. Gleichzeitig erfordert es nach wie vor Aufwand, zuverlässige Ergebnisse zu erzielen.
Teams benötigen saubere Schemata, starke semantische Modelle und kontinuierliche Iteration, um die Genauigkeit der Ergebnisse zu gewährleisten. Selbst nach der Generierung der richtigen Abfrage ist die Arbeit noch nicht beendet. Es muss immer noch jemand die Ergebnisse interpretieren, Erkenntnisse freigeben und diese in Entscheidungen umsetzen.
ClickUp verfolgt einen anderen Ansatz. Anstatt Analyse und Ausführung voneinander zu trennen, stellt ClickUp eine Verbindung zwischen ihnen her. Teams generieren SQL-Abfragen, dokumentieren Erkenntnisse, arbeiten gemeinsam an den Ergebnissen und setzen diese direkt im selben Workspace um.
ClickUp Brain hilft beim Verfassen und Verfeinern von Abfragen, während Dashboards und KI-Agenten Teams dabei unterstützen, die Nachverfolgung der Ergebnisse zu gewährleisten und die Arbeit voranzubringen, ohne zwischen verschiedenen Tools hin- und herwechseln zu müssen.
Snowflake Cortex hilft Ihnen, Antworten zu finden. ClickUp hilft Ihnen, diese zu nutzen. Melden Sie sich noch heute bei ClickUp an!
Häufig gestellte Fragen
Snowflake Cortex Analyst ist ein spezialisierter Dienst innerhalb der umfassenderen Snowflake Cortex KI-Suite. Cortex Analyst konzentriert sich speziell auf die Text-zu-SQL-Generierung unter Verwendung semantischer Modelle, während Cortex KI einen breiteren Bereich an LLM-Funktionen, Inferenz von Machine-Learning-Modellen und Suchfunktionen umfasst.
Ja, Cortex Analyst kann Apache Iceberg-Tabellen abfragen, die über Snowflake verwaltet werden. Solange die Tabellen in Ihrer Snowflake-Umgebung zugänglich und in Ihrem semantischen Modell korrekt definiert sind, können Sie Abfragen für diese Tabellen generieren.
Die Genauigkeit bei komplexen Abfragen hängt fast ausschließlich von der Qualität Ihres semantischen Modells ab. Ein Modell mit klar definierten Beziehungen zwischen Tabellen, zahlreichen verifizierten Abfragen und aussagekräftigen Metadaten liefert deutlich genauere Ergebnisse bei Verknüpfungen mehrerer Tabellen und komplexen Aggregationen.
Die Preisgestaltung für Snowflake Cortex Analyst folgt dem verbrauchsbasierten Modell von Snowflake, was bedeutet, dass Ihnen die während des Prozesses der Abfragegenerierung verbrauchten Rechen-Guthaben in Rechnung gestellt werden. Die aktuellsten Preise entnehmen Sie bitte stets der offiziellen Preisdokumentation von Snowflake.