
IT-Ausfälle können ohne Achtung auftreten.
Von Serverausfällen bis hin zu Cyberangriffen – ohne einen soliden Wiederherstellungsplan könnte Ihr Geschäft mit stundenlangen Ausfallzeiten, Datenverlusten und erheblichen finanziellen Schäden konfrontiert sein, wobei 54 % der schwerwiegenden Ausfälle Kosten von über 100.000 US-Dollar verursachen.
Dieser Blog führt Sie durch die Erstellung eines umfassenden IT-Notfallwiederherstellungsplans, der Ihre Systeme schützt, klare Wiederherstellungsziele definiert und sicherstellt, dass Ihr Team genau weiß, was zu erledigen ist, wenn etwas schiefgeht.
Was ist ein IT-NotfallwiederherstellungsPlan?
Wenn Ihre Server gerade jetzt ausfallen würden, wüsste Ihr Team dann genau, was zu erledigen ist? 🛠️
Ein IT-Notfallwiederherstellungsplan (Disaster Recovery, DR) ist Ihre dokumentierte Strategie zur Wiederherstellung von IT-Systemen und Daten nach einer Störung – von Naturkatastrophen bis hin zu Cyberangriffen. Es handelt sich im Wesentlichen um Ihr Playbook, um die Technologie wieder online zu bringen, wenn etwas schiefgeht.
💡 DR vs. Geschäftskontinuität
Disaster Recovery (DR) konzentriert sich speziell auf die Wiederherstellung Ihrer IT-Infrastruktur und Daten. Business Continuity (BC) ist umfassender und zielt darauf ab, Ihr gesamtes Geschäft während und nach einer Krise betriebsbereit zu halten, selbst wenn die IT ausfällt. Betrachten Sie DR als einen wichtigen Bestandteil Ihrer gesamten BC-Strategie.
💡 DR vs. Geschäftskontinuität
Disaster Recovery (DR) konzentriert sich speziell auf die Wiederherstellung Ihrer IT-Infrastruktur und Daten. Business Continuity (BC) ist umfassender und zielt darauf ab, Ihr gesamtes Geschäft während und nach einer Krise betriebsbereit zu halten, selbst wenn die IT ausfällt. Betrachten Sie DR als einen wichtigen Bestandteil Ihrer gesamten BC-Strategie.
Ihr NotfallwiederherstellungsPlan ist wichtig, denn Ausfallzeiten kosten mehr als nur Geld. Jede Minute, in der Ihre Systeme offline sind, kann das Vertrauen Ihrer Kunden untergraben, den Betrieb stören und sogar zu Strafen wegen Nichteinhaltung von Vorschriften führen. Ein umfassender DR-Plan ist Ihr Fahrplan zur Ausfallsicherheit.
Ein guter Plan umfasst:
- Backup-Verfahren für Daten: Wie und wo Sie Kopien wichtiger Informationen speichern, damit Sie diese wiederherstellen können.
- Schritte zur Systemwiederherstellung: Die genaue Reihenfolge, um Dienste in der richtigen Reihenfolge wieder online zu bringen.
- Teamverantwortlichkeiten: Wer erledigt was während eines Incidents, um Verwirrung zu vermeiden?
- Kommunikationsprotokolle: Wie Sie die Beteiligten, von Ihrem Team bis zu Ihren Kunden, auf dem Laufenden halten.
- Wiederherstellungsziele: Ihre spezifischen Ziele hinsichtlich der Geschwindigkeit, mit der Systeme wiederhergestellt werden müssen, und des akzeptablen Datenverlusts.
Häufige IT-Notfallszenarien und deren Auswirkungen
Katastrophen sind nicht nur Hollywood-Szenarien, sondern passieren Unternehmen jeden Tag. Wenn Sie wissen, wovor Sie sich schützen müssen, können Sie eine viel stärkere Verteidigung aufbauen.
Naturkatastrophen und physische Schäden
Ereignisse wie Überschwemmungen, Brände, Erdbeben und größere Stromausfälle können ganze Rechenzentren innerhalb weniger Minuten zerstören. Als beispielsweise ein großes Rechenzentrum in Nashville von einer Überschwemmung heimgesucht wurde, verloren einige Unternehmen Daten aus mehreren Wochen und standen vor einer monatelangen Wiederherstellung. Der beste Schutz dagegen ist geografische Redundanz, d. h. die Verteilung Ihrer Infrastruktur auf mehrere physische Standorte, sodass ein einzelnes Ereignis nicht alles lahmlegen kann.
Cyberangriffe und Datenkompromittierung
Ransomware, Distributed-Denial-of-Service-Angriffe (DDoS) und Datenverletzungen unterscheiden sich von physischen Katastrophen. Sie sind oft schwerer zu erkennen, können sich unbemerkt über Verbindungen ausbreiten und sind häufig das Einzelziel Ihrer Backup-Systeme, was die Wiederherstellung besonders schwierig macht. Die Häufigkeit und Raffinesse dieser Cyberangriffe nimmt in allen Branchen weiter zu. Ransomware ist mittlerweile für 44 % aller bestätigten Sicherheitsverletzungen verantwortlich und stellt damit eine der größten Bedrohungen dar.
Hardwareausfälle und Datenverlust
Manchmal fallen selbst die am besten getesteten und bewährten Backup-Systeme aus. Serverabstürze, Ausfälle des Speichers und Fehlfunktionen von Netzwerkgeräten können ohne Vorwarnung auftreten. Selbst wenn Sie über redundante (Backup-)Systeme verfügen, können diese dennoch gleichzeitig ausfallen, wenn sie gemeinsame Komponenten oder Stromquellen nutzen und somit einen Single Point of Failure bilden.
👀 Wussten Sie schon: Im Oktober 2025 kam es bei AWS zu einem größeren Ausfall, als ein Fehler im internen DNS-Verwaltungssystem für Amazon DynamoDB dazu führte, dass die Auflösung von Domainnamen in der Datencenter-Region US-EAST-1 fehlschlug. Dieser „kleine” technische Defekt war der Auslöser für eine Kettenreaktion von Ausfällen bei Dutzenden von AWS-Diensten und legte weltweit Hunderte von beliebten Apps und Plattformen lahm – von Messaging- und Social-Media-Apps bis hin zu Banken, Gaming-Websites und mehr. Für viele Menschen führte der Ausfall dazu, dass ein Großteil des Internets vorübergehend „verschwand”, was deutlich machte, wie anfällig unsere digitale Infrastruktur ist, wenn so viel von einer Handvoll Cloud-Anbietern abhängt.
Softwarefehler und Dienstunterbrechungen
Eine beschädigte Datenbank, ein fehlgeschlagenes Software-Update oder ein einfacher Fehler in der Konfiguration können ganze Plattformen zum Erliegen bringen. Sie werden vielleicht feststellen, dass eine falsch konfigurierte Codezeile eine Kettenreaktion in verbundenen Systemen auslösen und zu einem großflächigen Ausfall mit weitreichenden Auswirkungen führen kann. Ein ordnungsgemäßes Änderungsmanagement und spezielle Testumgebungen sind Ihre besten Verbündeten, um diese Risiken zu minimieren.
Menschliche Fehler und Fehlkonfigurationen
Versehentliche Löschungen, falsche Konfigurationen und unbefugte Änderungen gehören nach wie vor zu den häufigsten Ursachen für IT-Ausfälle. Ein einziger falscher Befehl oder eine gelöschte Datei kann der Auslöser für stundenlange Ausfallzeiten und eine Verschlechterung der Dienstqualität sein. Schulungen und Zugriffskontrollen sind zwar hilfreich, können menschliche Fehler jedoch nicht vollständig ausschließen.
📮ClickUp Insight: 92 % der Mitarbeiter verwenden uneinheitliche Methoden für die Nachverfolgung von Aktionselementen, was das Ergebnis versäumter Entscheidungen und verzögerter Ausführung ist.
Ob Sie nun Follow-up-Notizen versenden oder Tabellenkalkulationen verwenden, der Prozess ist oft unübersichtlich und ineffizient. Mit den Funktionen für die Aufgabenverwaltung von ClickUp müssen Sie sich darüber keine Gedanken mehr machen. Erstellen Sie Aufgaben aus Chats, ClickUp-Aufgabenkommmentaren, Dokumenten und E-Mails mit einem einzigen Klick!
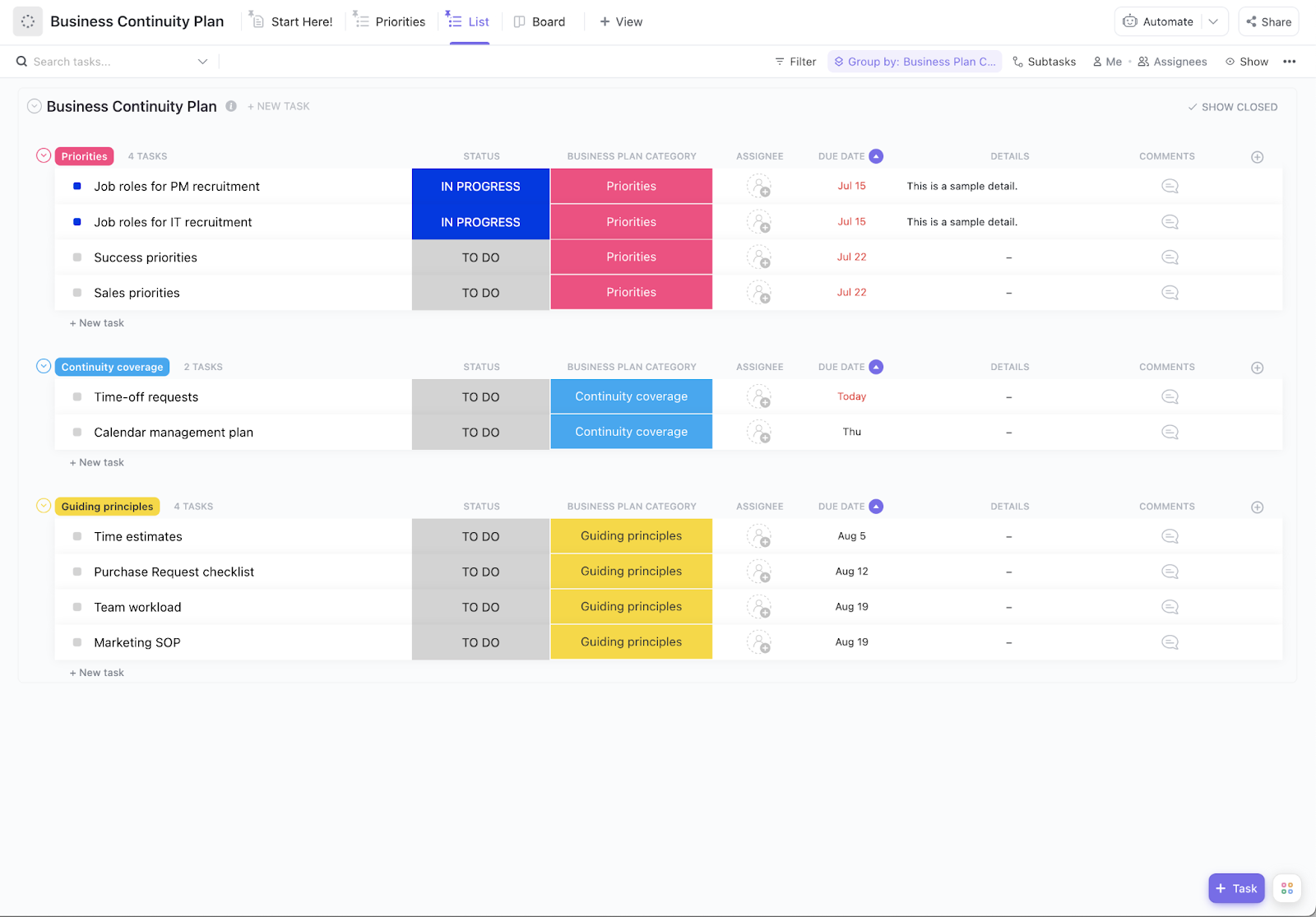
Wichtige Schlüsselkomponenten eines IT-Notfallwiederherstellungsplans
Ein solider DR-Plan ist Ihr umfassendes Playbook für die Wiederherstellung Ihrer Online-Verfügbarkeit. Jede dieser Komponenten baut auf den anderen auf, um einen umfassenden Schutz für Ihr Geschäft zu schaffen.
Risikobewertung und Priorisierung
Zunächst müssen Sie wissen, womit Sie es zu tun haben. Eine Risikobewertung ist der Prozess der Identifizierung Ihrer Schwachstellen und der Bewertung der Wahrscheinlichkeit und der Auswirkungen jeder potenziellen Bedrohung. Sie können dies in einer Matrix organisieren, um zu sehen, welche Bedrohungen am schwerwiegendsten sind.
Ihre Bewertung sollte Folgendes umfassen:
- Kritische Systeme: Was muss unbedingt laufen, damit Ihr Geschäft funktionieren kann?
- Datenempfindlichkeit: Welche Informationen benötigen den höchsten Schutz (z. B. Kundendaten)?
- Abhängigkeiten: Welche anderen Systeme oder Prozesse fallen aus, wenn ein System ausfällt?
📖 Weiterlesen: So implementieren Sie IT-Infrastrukturmanagement
Geschäftliche Auswirkungsanalyse und Kritikalität
Ermitteln Sie anschließend die tatsächlichen Kosten von Ausfallzeiten. Mithilfe einer Business Impact Analysis (BIA) können Sie die finanziellen und betrieblichen Auswirkungen eines Ausfalls für jedes System bestimmen. Auf diese Weise können Sie Ihre Systeme nach Kritikalitätsstufen klassifizieren, um den Aufwand für Ihre Wiederherstellungsmaßnahmen zu priorisieren.
| Kritisch | Weniger als eine Stunde | Zahlung, Kundendatenbanken |
| Hoch | Ein bis vier Stunden | E-Mail, interne Kommunikationstools |
| Mittel | Vier bis 24 Stunden | Entwicklungsumgebungen, Berichterstellungstools |
| Niedrig | 24+ Stunden | Archivierungssysteme, Testserver außerhalb der Produktion |
RTO- und RPO-Ziele
Diese beiden Akronyme bilden den Kern Ihrer Wiederherstellungsstrategie.
- Wiederherstellungszeitziel (Recovery Time Objective, RTO): Dies ist die maximale Zeit, die Sie sich für einen Systemausfall leisten können. Es beantwortet die Frage: „Wie schnell muss das System wieder online sein?“
- Recovery Point Objective (RPO): Dies ist die maximale Datenmenge, deren Verlust Sie sich leisten können, gemessen in Zeit. Es beantwortet die Frage: „Wie viele Daten können wir ohne größeren Schaden verlieren?“
Beispielsweise könnte Ihr internes E-Mail-System eine RTO von vier Stunden haben, während Ihre kundenorientierte E-Commerce-Datenbank eine RPO von nur 15 Minuten hat, was bedeutet, dass Sie nicht mehr als 15 Minuten an Daten zu Transaktionen verlieren dürfen.
Daten-Backup- und Wiederherstellungs-Plan
Ihr Backup-Plan ist Ihr ultimatives Sicherheitsnetz. Eine gängige Best Practice ist die 3-2-1-Regel: Bewahren Sie mindestens drei Kopien Ihrer wichtigen Daten auf, speichern Sie diese auf zwei verschiedenen Medientypen und bewahren Sie eine dieser Kopien außerhalb Ihres Unternehmens auf.
Außerdem können Sie zwischen verschiedenen Typen von Backups wählen:
- Vollständige Backups: Eine vollständige Kopie aller Daten, die in der Regel wöchentlich oder monatlich erledigt wird.
- Inkrementelle Backups: Es werden nur Änderungen seit dem letzten Backup jeglicher Art gesichert.
- Differential-Backups: Sichert alle Änderungen, die seit dem letzten vollständigen Backup vorgenommen wurden.
Am wichtigsten ist, dass Sie Ihren Backup-Wiederherstellungsprozess regelmäßig testen. Ein ungetestetes Backup ist nur eine Hoffnung, kein Plan.
💟 Bonus: Erfassen Sie wichtige Details während stressiger Incidents mit der Sprach-zu-Text-Funktion von ClickUp Brain MAX, damit Sie keine wichtigen Informationen verpassen, selbst wenn das Tippen nicht möglich ist. Sprechen Sie einfach Ihre Beobachtungen und überlassen Sie die Dokumentation der KI.
Kommunikationsplan und Updates für Stakeholder
Wenn eine Katastrophe eintritt, ist ein klarer Kommunikationsplan das Alles. Ihr Plan muss Benachrichtigungsketten, die Häufigkeit von Updates und die für jede Art von Incident zu verwendenden Kanäle festlegen.
Verschiedene Gruppen benötigen unterschiedliche Informationen:
- Interne Teams: Benötigen technische Details und konkrete Elemente
- Kunden: Sie müssen den Status des Dienstes kennen und wissen, wann mit einer Lösung zu rechnen ist.
- Anbieter: Möglicherweise müssen sie unterstützt oder bei Eskalationen hinzugezogen werden.
- Aufsichtsbehörden: Je nach Branche können formelle Benachrichtigungen erforderlich sein.
Tools wie diese gebrauchsfertige Vorlage für einen Kommunikationsplan von ClickUp können Ihnen helfen, in Krisensituationen dank eines festgelegten Protokolls schneller zu handeln.

Test- und Schulungsprogramm
Ein Plan, den Sie nie testen, ist ein Plan, der scheitern wird. Regelmäßige Tests decken Lücken und Schwachstellen auf, bevor eine echte Katastrophe eintritt.
Planen Sie verschiedene Arten von Tests über das ganze Jahr hinweg:
- Tabletop-Übungen: Ihr Team geht ein Katastrophenszenario auf dem Papier durch, um die Logik des Plans zu überprüfen.
- Teilweise Failovers: Sie testen die Wiederherstellung bestimmter, nicht kritischer Komponenten oder Dienste.
- Vollständige DR-Tests: Sie schließen ein vollständiges Failover auf Ihre Backup-Systeme ab (der ultimative Test).
Aktualisieren Sie nach jedem Test Ihre Dokumentation und schulen Sie neue Mitglieder des Teams umgehend in den Verfahren.
📖 Weiterlesen: Wie man effektive IT-Richtlinien und -Verfahren entwickelt
Schritte zur Erstellung eines IT-Notfallwiederherstellungsplans
Die Erstellung Ihres DR-Plans muss keine überwältigende Aufgabe sein.
So können Sie Schritt für Schritt vorgehen. 🙌
Schritt 1: Erstellen Sie ein Inventar Ihrer Ressourcen
Sie können nicht schützen, was Sie nicht kennen. Beginnen Sie mit der Erstellung einer Liste aller Hardwarekomponenten, Softwareprogramme, Repositorys und Systemabhängigkeiten in Ihrer Umgebung. Achten Sie darauf, dass Sie die Kontaktdaten der Anbieter, Lizenzschlüssel und Konfigurationsdetails für eine schnelle Referenz während der Wiederherstellung angeben.

Die ClickUp-ITAM-Vorlage vereint Incident Management, Problem Management, Change Management, einfache Asset-Management-Lösungen und Knowledge Management. Unsere ITSM-Vorlage für bekannte Fehler vereinfacht die Nachverfolgung bekannter Fehler in Ihren Systemen. Entdecken Sie alle unsere IT-Vorlagen, sobald sich Ihr Zweck ändert.
Passen Sie Ihre Workflows für jede ITAM-Phase benutzerdefiniert an, von der Bereitstellung und Konfiguration bis hin zur Wartung und Außerbetriebnahme.
Schritt 2: Kritische Dienste klassifizieren
Identifizieren Sie nun, welche dieser Ressourcen geschäftskritisch sind und welche nur „nice to have“ sind. Erstellen Sie Service-Abhängigkeitskarten, die zeigen, wie Ihre Systeme miteinander verbunden sind und voneinander abhängen. Achten Sie besonders auf alle kundenorientierten Dienste, die sich direkt auf den Umsatz oder die Benutzererfahrung auswirken.
🎥 Sehen Sie sich diese praktische Anleitung an, die zeigt, wie Sie mit den leistungsstarken Features von ClickUp einen strukturierten, übergeordneten Plan erstellen können – von der Festlegung von Zielen über die Zuweisung von Aufgaben bis hin zur Nachverfolgung des Fortschritts.
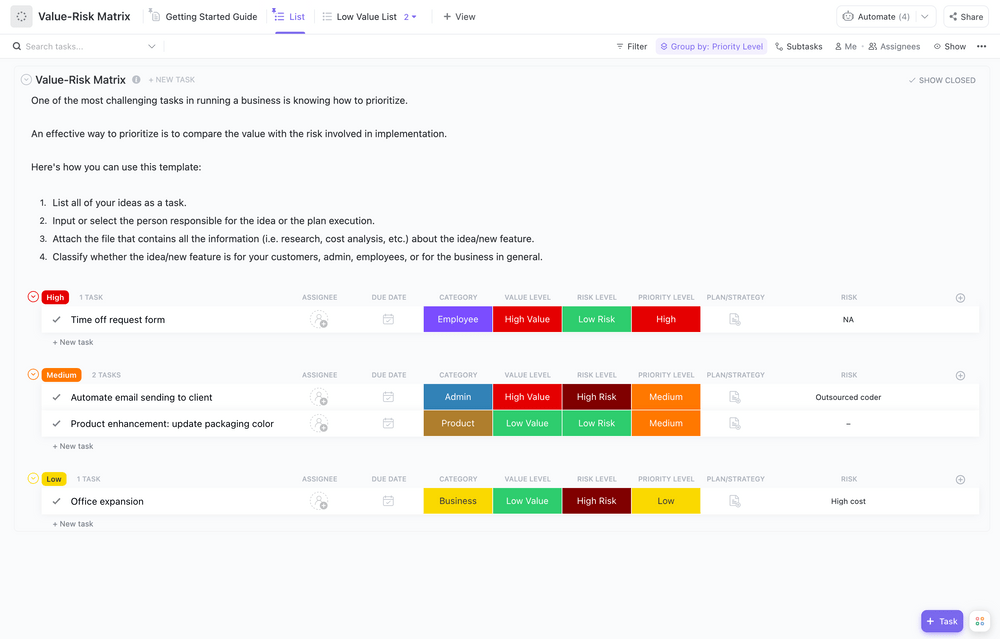
Schritt 3: Risiken und Bedrohungen bewerten
Bewerten Sie Risiken und Bedrohungen, indem Sie die Wahrscheinlichkeit und die Auswirkungen jeder Art von Bedrohung für Ihre spezifische Situation bewerten. Berücksichtigen Sie Ihre geografischen Risiken (befinden Sie sich in einem Erdbebengebiet oder einer Überschwemmungszone?) und alle branchenspezifischen Bedrohungen (wie regulatorische Änderungen oder gezielte Cyberangriffe). Dokumentieren Sie alles in einem Risikoregister, damit Sie es im Laufe der Zeit verfolgen können.

Die ClickUp-Vorlage „Risikobewertung“ für Whiteboards schafft eine visuelle Dimension für Ihren Risikobewertungsprozess. Sie hilft bei der Bewertung und Kategorisierung von Risiken und inspiriert Ihr Team dazu, Erkenntnisse freizugeben und in einem ansprechenden und visuellen Format zusammenzuarbeiten.
Mit dieser Vorlage können Sie:
- Bewerten Sie Risikokategorien und potenzielle Auswirkungen.
- Analysieren Sie Daten, um potenzielle Problembereiche zu identifizieren.
- Legen Sie vorbeugende Maßnahmen fest, um das Risiko zu verringern.
Mit Features zum Zeichnen, Schreiben und Hinzufügen von Haftnotizen eignet sich diese Whiteboard-Vorlage für das Risikomanagement perfekt zur Bewertung der Risiken Ihres Projekts.
Schritt 4: Festlegen der RTO- und RPO-Einzelziele
Arbeiten Sie direkt mit Ihren Stakeholdern zusammen, um zu definieren, was sie als akzeptable Ausfallzeit und Datenverlust für jede zuvor identifizierte Serviceebene betrachten. Sie müssen die Kosten für eine schnellere Wiederherstellung gegen die Auswirkungen auf das Geschäft abwägen – nicht alles erfordert eine sofortige Wiederherstellung ohne Datenverlust. Holen Sie sich die Zustimmung der Geschäftsleitung zu diesen Einzelzielen ein.
Schritt 5: Backup- und Failover-Pfade definieren
Nachdem Sie Ihre Einzelziele festgelegt haben, können Sie nun Ihre technischen Lösungen entwerfen. Erstellen Sie Backup-Strategien, die auf das RPO jedes Systems zugeschnitten sind, und planen Sie detaillierte Failover-Verfahren, einschließlich alternativer Verarbeitungsstandorte und Notfallzugriffsmethoden. Fügen Sie Netzwerkdiagramme und Schritt-für-Schritt-Anleitungen hinzu, um die Ausführung kinderleicht zu machen.
Schritt 6: Rollen und Eskalationen zuweisen
Definieren Sie die Struktur Ihres DR-Teams mit klaren Verantwortlichkeiten und Entscheidungsbefugnissen. Erstellen Sie umfassende Kontaktlisten mit Haupt- und Backup-Personal für jede Rolle. Eine RACI-Matrix (Responsible, Accountable, Consulted, Informed) ist ein hervorragendes Tool, um Verwirrung während eines stressigen Incidents zu vermeiden.
Schritt 7: Dokumentieren und kommunizieren Sie den Plan
Dokumentieren und kommunizieren Sie den Plan mit klaren, schrittweisen Verfahren, die jeder in Ihrem Team auch unter Druck befolgen kann. Es ist wichtig, diese Dokumentation an einem leicht zugänglichen Speicherort aufzubewahren, der von Ihrer primären Infrastruktur getrennt ist. Stellen Sie sicher, dass jedes Mitglied des Teams genau weiß, wo es den Plan im Krisenfall finden kann.
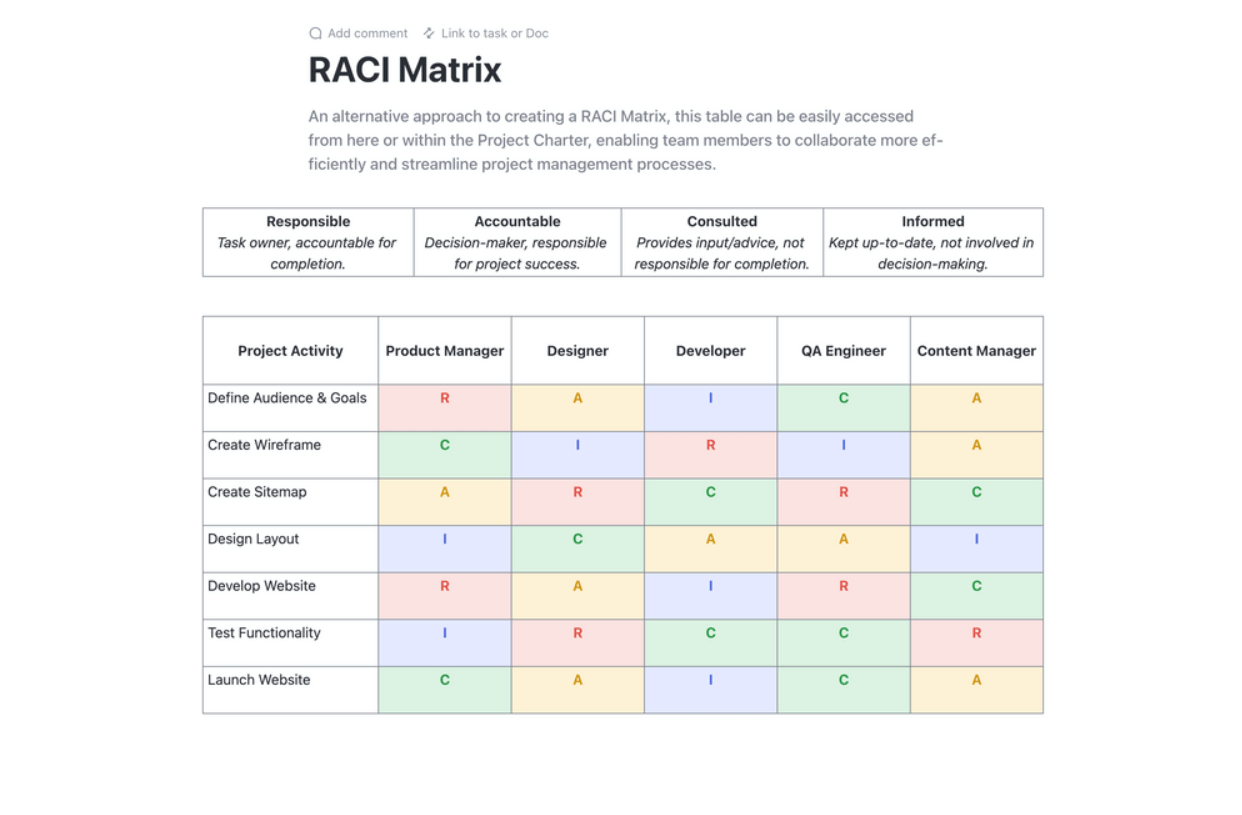
Optimieren Sie Ihre Projektplanung mit der RACI-Planungsvorlage von ClickUp. Diese Dokumentvorlage ist ein echter Game-Changer und bietet ein übersichtliches Diagramm zur Definition der Rollen und Verantwortlichkeiten des Teams in Bezug auf die Projektaufgaben. Nutzen Sie das RACI-Framework (Responsible, Accountable, Consulted und Informed), um alle auf den gleichen Stand zu bringen und so die Verantwortlichkeit und Ausrichtung auf die Unternehmensziele sicherzustellen.
Schritt 8: Testen, überprüfen und verbessern
Planen Sie schließlich vierteljährliche Tests, um Ihre Verfahren zu validieren und etwaige Lücken zu identifizieren. Dokumentieren Sie alle aus den einzelnen Tests und realen Incidents gewonnenen Erkenntnisse und nutzen Sie diese, um Ihren Plan zu aktualisieren. Richten Sie ein systematisches System zur Nachverfolgung von Verbesserungen ein, um sicherzustellen, dass alle festgestellten Probleme behoben werden.
🌼 Wussten Sie schon: Im Jahr 2017 kam es bei Gitlab zu einem schwerwiegenden Datenbankausfall. Während der Wiederherstellung stellte sich heraus, dass mehrere ihrer Backup-Methoden seit Tagen unbemerkt versagt hatten. Dieser Incident lehrte die gesamte Tech-Branche eine wichtige Lektion: Die Validierung von Backups ist unverzichtbar. Ein ungetestetes Backup ist kein echtes Backup.
🌼 Wussten Sie schon: Im Jahr 2017 kam es bei Gitlab zu einem schwerwiegenden Datenbankausfall. Während der Wiederherstellung stellte sich heraus, dass mehrere ihrer Backup-Methoden seit Tagen unbemerkt versagt hatten. Dieser Incident lehrte die gesamte Tech-Branche eine wichtige Lektion: Die Validierung von Backups ist unverzichtbar. Ein ungetestetes Backup ist kein echtes Backup.
Strategien und Lösungen für die Notfallwiederherstellung
Nicht jedes Unternehmen benötigt denselben DR-Ansatz. Lassen Sie uns Ihre Optionen auf der Grundlage Ihres Budgets, Ihrer Wiederherstellungsanforderungen und Ihrer verfügbaren Ressourcen untersuchen.
Ansatz für Backup und Wiederherstellung
Dies ist die einfachste und kostengünstigste Methode. Dabei werden regelmäßig Backups an einem externen Speicherort (z. B. in der Cloud oder in einem sekundären Rechenzentrum) erstellt und bei Bedarf manuell wiederhergestellt. Dieser Ansatz eignet sich am besten für nicht kritische Systeme, die eine längere RTO tolerieren können, da die Wiederherstellung Stunden oder sogar Tage dauern kann.
Hohe Verfügbarkeit und Redundanz
Diese Strategie zielt darauf ab, einzelne Fehlerquellen durch den Einsatz mehrerer aktiver Systeme zu beseitigen. Techniken wie Lastenausgleich, Server-Clustering und RAID-Speicher sorgen dafür, dass bei Ausfall einer Komponente sofort eine andere übernimmt. Dieser Ansatz ist zwar in der Einrichtung und Wartung teurer, kann jedoch Ausfallzeiten auf wenige Sekunden oder Minuten minimieren und ist daher ideal für kritische Dienste.
Replikations- und Failover-Optionen
Bei der Replikation werden Daten nahezu in Echtzeit an einen sekundären Standort kopiert, wodurch der Datenverlust im Katastrophenfall auf ein Minimum reduziert wird.
- Synchrone Replikation: Schreibt Daten gleichzeitig an den primären und sekundären Standort und garantiert so null Datenverlust. Dies erfordert jedoch eine hohe Bandbreite und kann Ihr primäres System verlangsamen.
- Asynchrone Replikation: Die Daten werden zuerst an den primären Standort geschrieben und dann mit einer geringen Verzögerung an den sekundären Standort kopiert. Diese Methode ist kostengünstiger und hat weniger Auswirkungen auf die Leistung, jedoch besteht ein geringes Risiko für Datenverluste.
Cloud-basierte Notfallwiederherstellung und DRaaS
Disaster Recovery as a Service (DRaaS) ist für viele Unternehmen zu einer beliebten Wahl geworden. Es bietet Pay-as-you-go-Preise, sofortige geografische Verteilung und automatisierte Wiederherstellungsorchestrierung, ohne dass Sie eigene physische DR-Standorte aufbauen und warten müssen. Cloud-DR eliminiert die enormen Kapitalkosten eines Backup-Rechenzentrums und bietet gleichzeitig eine schnellere Skalierung und mehr Flexibilität als herkömmliche Hot-, Warm- oder Cold-Site-Ansätze.
Wie ClickUp die IT-Notfallwiederherstellungsplanung optimiert
Die Verwaltung eines DR-Plans über verstreute Tabellenkalkulationen, Dokumente und E-Mail-Ketten hinweg birgt ein eigenes Katastrophenrisiko.
Diese Art von Arbeitsausbreitung, die Fragmentierung der Arbeit über mehrere, nicht miteinander verbundene Tools, die nicht miteinander kommunizieren, und die Kontextverbreitung, bei der Teams Stunden damit verschwenden, nach Informationen zu suchen, die über verschiedene Apps und Plattformen verstreut sind, führen zu Verwirrung, veralteten Informationen und langsamen Reaktionszeiten, wenn jede Sekunde zählt.
Mit ClickUp Converged AI Workspace – einer einzigen, sicheren Plattform, auf der alle Ihre Arbeitsanwendungen, Daten und Workflows zusammen mit kontextbezogener KI als Intelligenzschicht zusammenlaufen – kombinieren Sie Projektmanagement, Dokumentation und Teamkommunikation. Schluss mit dem Jonglieren zwischen mehreren Plattformen: Bringen Sie Ihre DR-Planung, Tests und Incident Response in einem einheitlichen System zusammen.
Zentralisierte DR-Dokumentation mit ClickUp Docs und integrierter KI-Unterstützung
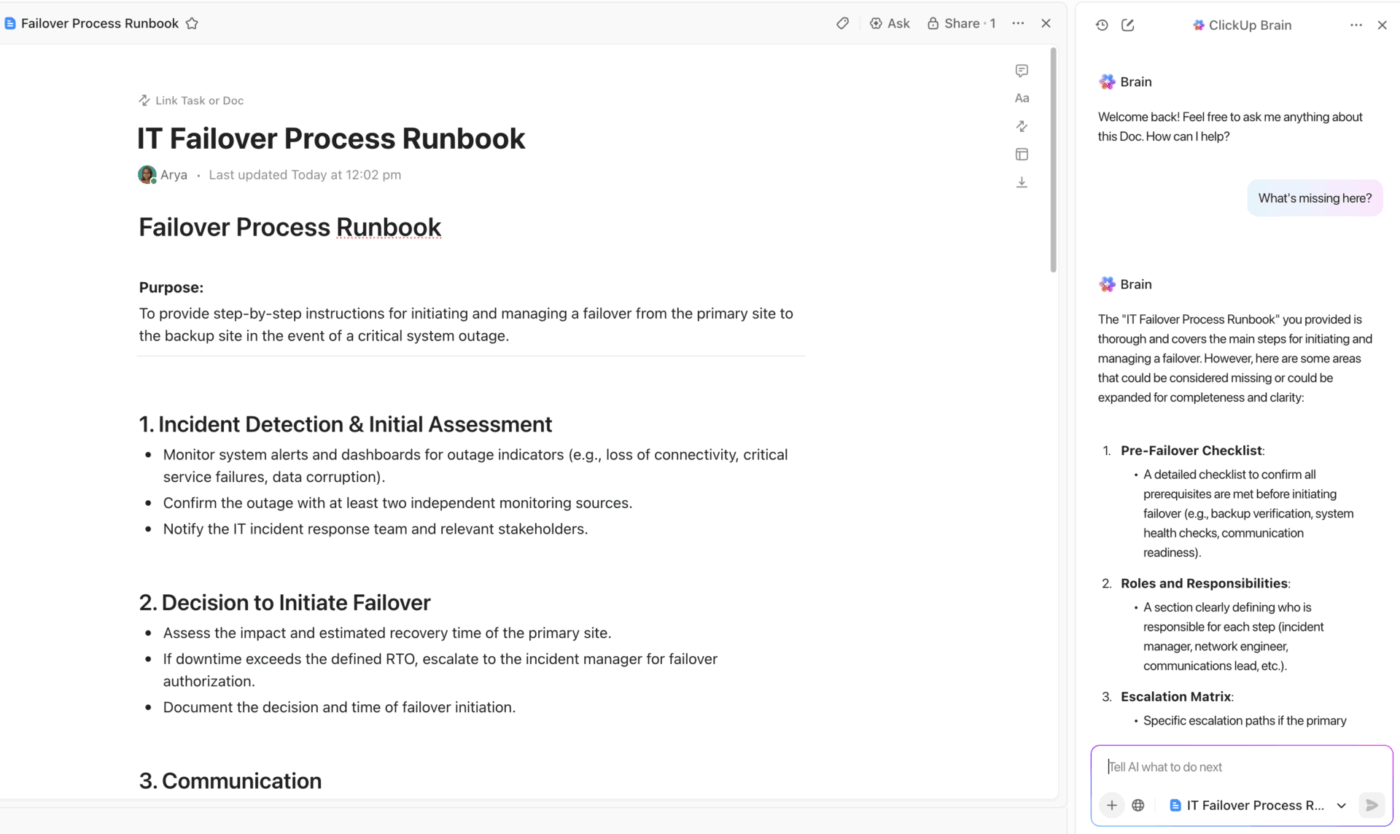
Stellen Sie mit ClickUp Docs sicher, dass Ihr Team immer über eine einzige zuverlässige Informationsquelle verfügt.
Erstellen Sie Ihren gesamten Notfallwiederherstellungsplan in einem kollaborativen Bereich, in dem jeder während eines Incidents in Echtzeit Beiträge leisten kann. Verknüpfen Sie Dokumente direkt mit Incident-Aufgaben und Projekten, um eine nahtlose Navigation zu ermöglichen, und betten Sie Diagramme oder Runbooks ein, damit wichtige Informationen genau dort verfügbar sind, wo Sie sie benötigen.
Das Beste daran ist, dass Sie Ihre Dokumente vor versehentlichen Bearbeitungen schützen und mithilfe detaillierter ClickUp-Berechtigungen steuern können, wer sensible Wiederherstellungsverfahren einsehen oder ändern darf. Jede Änderung wird im Verlauf des Dokuments nachverfolgt, sodass Sie über einen vollständigen Prüfpfad verfügen.
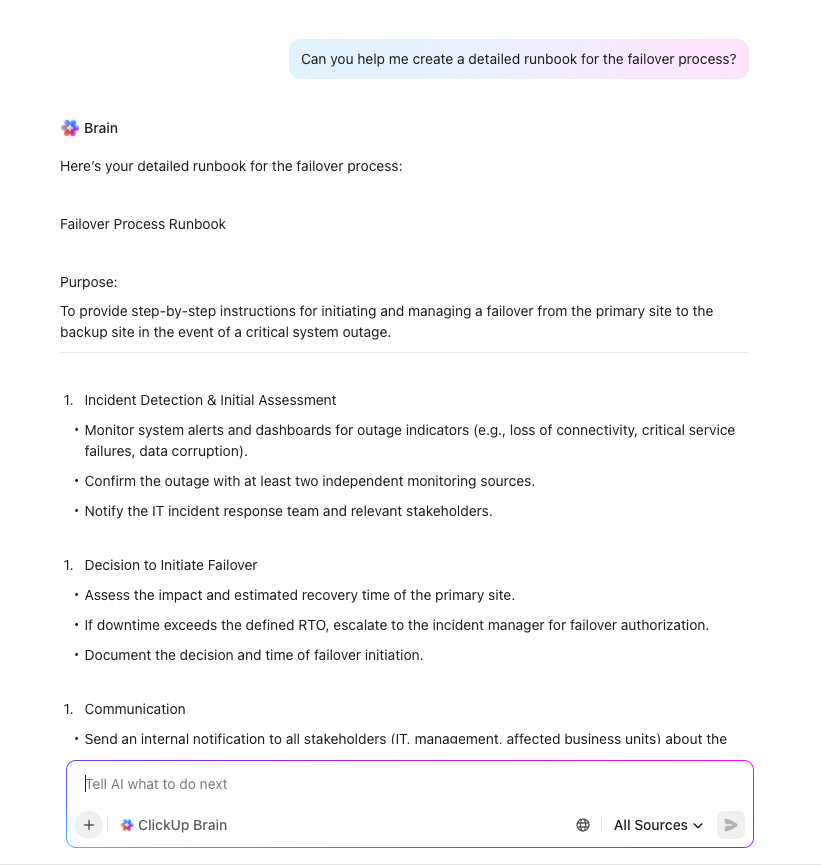
KI-gestützte Erstellung von Plänen mit ClickUp Brain
Beschleunigen Sie die Disaster-Recovery-Planung und beseitigen Sie kritische Lücken mit ClickUp Brain – Ihrem kontextbezogenen KI-Assistenten, der Ihren gesamten Arbeitsbereich versteht. Im Gegensatz zu generischen KI-Tools nutzt ClickUp Brain die tatsächlichen Aufgaben, Dokumente und Workflows Ihres Unternehmens, um präzise und umsetzbare Unterstützung für DR-Initiativen zu bieten.
Geben Sie einfach eine Anfrage wie „Erstellen Sie eine Disaster-Recovery-Checkliste für unsere E-Commerce-Plattform“ in ClickUp Brain ein und Sie erhalten umgehend eine umfassende, maßgeschneiderte Vorlage, die auf Ihre Systeme, Prozesse und Compliance-Anforderungen abgestimmt ist. Das kann Ihnen dabei helfen:
- Kontextbewusstsein: ClickUp Brain hat Zugriff auf die Struktur, den Inhalt und die Berechtigungen Ihres Workspaces. Es kann auf Aufgaben, Dokumente, Kommentare und sogar verbundene Apps zugreifen und so Antworten und Maßnahmen liefern, die auf Ihre tatsächliche Arbeit zugeschnitten sind – nicht nur allgemeine Vorschläge.
- Fehlerbehebung und Anleitung: Beheben Sie Probleme sofort, erhalten Sie Schritt-für-Schritt-Anleitungen oder fragen Sie nach Best Practices für jedes ClickUp-Feature. Brain führt Sie durch komplexe Prozesse, übernimmt die Automatisierung wiederholender Aufgaben und hilft Ihnen bei der Lösung von Problemen.
- Automatisierung und Workflow-Beschleunigung: Verwenden Sie vorgefertigte oder benutzerdefinierte KI-Agenten, um mehrstufige Workflows zu automatisieren, Anfragen zu triagieren oder wiederkehrende Aufgaben zu verwalten – und so jede Woche mehrere Stunden Zeit zu sparen.
- Tiefensuche: Finden Sie Informationen, die irgendwo in Ihrem Workspace verborgen sind, darunter Aufgaben, Dokumente und integrierte Tools, selbst wenn diese schon Jahre alt oder mit der Standardsuche schwer zu finden sind.
- Echtzeit-Zusammenfassungen und -Updates: Erstellen Sie sofort Projekt-Updates, Meeting-Zusammenfassungen oder Berichte über den Fortschritt, indem Sie Live-Daten aus dem Workspace abrufen.
- Vereinfachung der technischen Dokumentation: Wandeln Sie komplexe technische Dokumente in klare, umsetzbare Verfahren oder Checklisten um, die Ihr Team auch unter Druck befolgen kann.
- Multi-Modell-Intelligenz: Wählen Sie aus führenden KI-Modellen (OpenAI GPT-4. 1, GPT-5, Claude, Gemini und mehr), um bei jeder Aufgabe die besten Ergebnisse zu erzielen – ohne separate Abonnements.
- Sicherheit und berechtigungsbasierte Zugriffssteuerung: Brain greift nur auf Informationen zu, für die Sie bereits eine Berechtigung haben, und hält dabei strenge Standards im Bereich des Datenschutzes und der Compliance ein.
- Konversationsschnittstelle: Verwenden Sie @brain in Kommentaren oder beim Chatten, um kontextbezogene Einblicke zu erhalten, Antworten zu entwerfen oder als Auslöser für Automatisierungen zu verwenden, ohne Ihren Workflow zu verlassen.
- Benutzerdefinierte Eingabeaufforderungen und gespeicherte Workflows: Speichern und verwenden Sie Eingabeaufforderungen für wiederkehrende Anforderungen erneut, um Konsistenz zu gewährleisten und Ihrem Team Zeit zu sparen.
💡Profi-Tipp: Verpassen Sie keine Lektion aus Ihren Meetings zur Überprüfung von Incidents, indem Sie mit ClickUp AI Notetaker jedes Detail festhalten. Das Tool kann an Ihren virtuellen Meetings teilnehmen, die gesamte Diskussion transkribieren und automatisch eine Liste mit Aktionspunkten aus den gewonnenen Erkenntnissen erstellen. So entsteht eine durchsuchbare Vorfallshistorie, sodass Sie schnell auf vergangene Ereignisse und deren Lösungen zurückgreifen können.

Automatisierte DR-Workflows mit ClickUp-Automatisierungen
Stellen Sie sich vor, Ihr Team ist mit einem plötzlichen Ausfall konfrontiert – jede Sekunde zählt, und Sie können es sich nicht leisten, auch nur einen einzigen Schritt zu verpassen. Mit ClickUp AI Agents und Automatisierungen müssen Sie nicht mehr hektisch handeln oder sich auf Ihr Gedächtnis verlassen. Sobald ein Incident gemeldet wird, springt die KI von ClickUp ein, leitet Ihr Team an und übernimmt die Routineaufgaben, damit Sie sich auf die Lösung des Problems konzentrieren können.
So funktioniert es in einem realen Szenario:
- Wenn jemand eine Aufgabe als „Incident gemeldet“ markiert, erstellt ClickUp Agent automatisch eine Checkliste mit Reaktionsschritten, weist diese den richtigen Personen zu und startet einen Timer, um die Nachverfolgung der Dauer der Wiederherstellung durchzuführen.
- Wenn der Incident als „kritisch“ eingestuft wird, kann ein Agent sofort eine Warn-E-Mail an Ihr Führungsteam senden und einen speziellen Chatraum – Ihren „Krisenstab“ – einrichten, damit alle an einem Ort chatten können.
- Die KI kann frühere Vorfallberichte und relevante Dokumentationen abrufen, sodass Ihr Team alles Notwendige griffbereit hat.
Sehen Sie sich hier den Workflow an:
Mit ClickUp AI Agents erhalten Sie einen zuverlässigen digitalen Teamkollegen, der Ihrem Team hilft, ruhig, organisiert und effektiv zu bleiben – selbst unter Druck.
Echtzeit-Nachverfolgung mit ClickUp-Dashboards
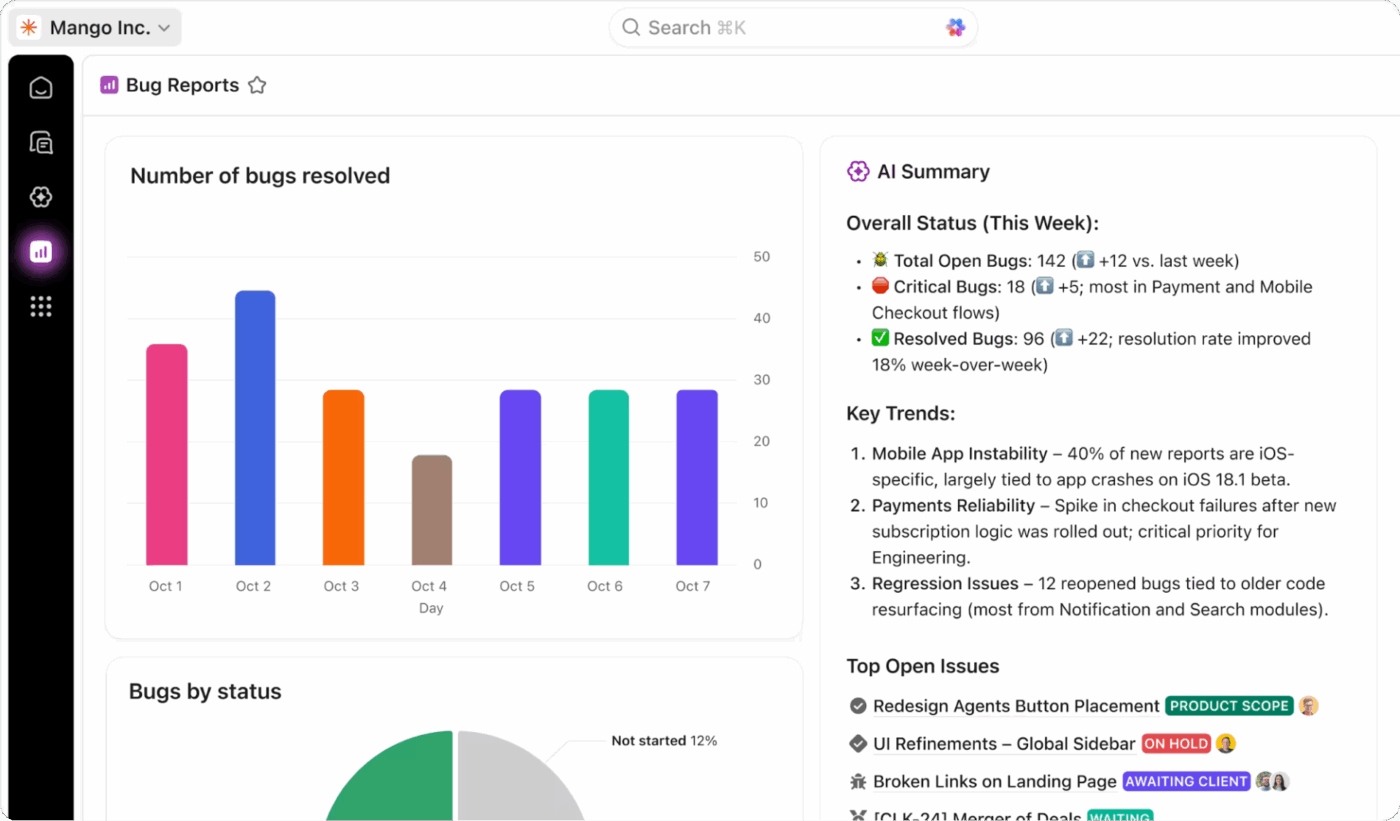
Verschaffen Sie sich eine vollständige Sichtbarkeit auf den Zustand Ihres DR-Programms, indem Sie mit ClickUp Dashboards alles in Echtzeit verfolgen. Sie können Widgets erstellen, um Ihre RTO- und RPO-Leistung während der Tests zu überwachen, die Abschlussraten der Tests zu verfolgen und Trends bei Incidents im Zeitverlauf anzuzeigen.
Fügen Sie Ihren Aufgaben benutzerdefinierte ClickUp-Felder hinzu, um die Systemkritikalität, den Wiederherstellungsstatus und die Testergebnisse zu verfolgen, und führen Sie dann alle diese Daten in einer übersichtlichen Ansicht zusammen. Diese Dashboards liefern Ihnen aussagekräftige Berichte, die dank Echtzeitdaten aus den Test- und Incident-Response-Aktivitäten Ihres Teams stets auf dem neuesten Stand sind.
📖 Weiterlesen: So erstellen Sie eine Checkliste für die Risikobewertung
Erstellen Sie noch heute Ihren DR-Plan
Jeder Tag, an dem Sie ohne DR-Plan arbeiten, ist ein Risiko, das Sie sich nicht leisten können. Katastrophen sind unvermeidlich – sei es durch Naturereignisse, Technologieausfälle oder Fehler –, aber Ihre Vorbereitung entscheidet darüber, ob sie zu kleinen Unannehmlichkeiten oder zu großen Katastrophen werden.
Ein umfassender DR-Plan erfordert ein Verständnis Ihrer Risiken, die Dokumentation klarer Verfahren und deren regelmäßige Überprüfung. Die richtigen tools machen diesen Prozess überschaubar, indem sie das Chaos verstreuter Dokumente und manueller Prozesse beseitigen.
Selbst einfache Notfallpläne sind besser als gar keine Pläne, wenn eine Katastrophe eintritt. Durch regelmäßige Tests und Aktualisierungen wird Ihr DR-Plan von einem verstaubten Dokument zu einem lebendigen System, das Ihr Geschäft wirklich schützt.
Machen Sie den ersten Schritt und beginnen Sie noch heute mit ClickUp, Ihren DR-Plan zu erstellen. Starten Sie kostenlos mit ClickUp und vereinen Sie Ihre gesamte Notfallwiederherstellungsplanung, Dokumentation und Incident Response auf einer einheitlichen Plattform. ✨
Häufig gestellte Fragen
Sie sollten Ihren DR-Plan mindestens viermal im Jahr überprüfen und ihn unmittelbar nach wesentlichen Änderungen an der Infrastruktur oder nach tatsächlichen Incidents aktualisieren. Die meisten Unternehmen führen jährlich eine umfassende, gründliche Überarbeitung durch, um alle gewonnenen Erkenntnisse zu berücksichtigen und sich an neue Technologien anzupassen.
IT-Teams, Teams der Sicherheit und Business-Continuity-Planer leiten in der Regel den Aufwand für die DR-Planung und -Tests. Sie benötigen jedoch wichtige Inputs von den Leitern der Betriebs- und Geschäftsbereiche, um sicherzustellen, dass der Plan mit den tatsächlichen Geschäftsanforderungen und Prioritäten übereinstimmt.
Verwenden Sie Stoppuhren und eindeutige Zeitstempel, um die tatsächlichen Wiederherstellungszeiten während jedes Tests mit Ihren definierten Einzelzielen zu vergleichen. Es ist wichtig, alle Abweichungen zwischen Ihren Einzelzielen und der tatsächlichen Leistung in Ihren Testberichten zu dokumentieren, um zukünftige Verbesserungen zu steuern.
Projektmanagement-Plattformen wie ClickUp eignen sich ideal für die Zentralisierung der Dokumentation, die Automatisierung von Workflows und die Nachverfolgung von Metriken für Ihr gesamtes DR-Programm. Sie können sie dann mit speziellen DR-Tools kombinieren, die die technischen Aspekte der Datenreplikation und des System-Failovers übernehmen.