

Es gibt zwei Arten von KI-Assistenten: solche, die alles bis zur letzten Woche wissen, und solche, die wissen, was vor einer Minute passiert ist.
Wenn Sie den ersten KI-Assistenten fragen: „Ist mein Flug noch verspätet?“, antwortet er möglicherweise auf der Grundlage des gestrigen Flugplans und könnte falsch liegen. Der zweite Assistent, der mit sekundengenauen Daten arbeitet, überprüft Live-Updates und gibt Ihnen die richtige Antwort.
Der zweite Assistent ist das, was wir als Live-Wissen bezeichnen, in Aktion.
Und es bildet die Grundlage für agentenbasierte KI-Systeme – solche, die nicht nur Fragen beantworten, sondern handeln, entscheiden, koordinieren und sich anpassen. Hier liegt der Schwerpunkt auf Autonomie, Anpassungsfähigkeit und zielorientiertem Denken .
In diesem Blogbeitrag untersuchen wir, was Live-Wissen im Zusammenhang mit KI bedeutet, warum es wichtig ist, wie es funktioniert und wie Sie es in realen Workflows einsetzen können.
Unabhängig davon, ob Sie im operativen Bereich, im Produktmanagement, im Support oder in der Führungsebene tätig sind, bietet Ihnen dieser Artikel die Grundlage, um die richtigen Fragen zu stellen, Systeme zu bewerten und zu verstehen, wie Live-Wissen Ihre Technologie und Ihre Geschäftsergebnisse verändern kann. Lassen Sie uns eintauchen.
Was ist Live-Wissen in der agentenbasierten KI?
Live-Wissen bezieht sich auf Informationen, die in Echtzeit verfügbar und aktuell sind und einem KI-System in dem Moment zur Verfügung stehen, in dem es handeln muss.
Dieser Begriff wird in der Regel im Zusammenhang mit agentenbasierter und umgebungsbezogener KI verwendet – KI-Agenten, die Ihre Mitarbeiter, Ihr Wissen, Ihre Arbeit und Ihre Prozesse so gut kennen, dass sie nahtlos und proaktiv im Hintergrund arbeiten können.
Live-Wissen bedeutet, dass sich die KI nicht nur auf den Datensatz stützt, mit dem sie trainiert wurde, oder auf den Wissensstand zum Zeitpunkt der Bereitstellung. Stattdessen lernt sie kontinuierlich dazu, baut Verbindungen zu aktuellen Datenströmen auf und passt ihre Aktionen an das an, was gerade tatsächlich geschieht.
Wenn wir dies im Zusammenhang mit KI-Agenten (d. h. Systemen, die handeln oder Entscheidungen treffen) diskutieren, ermöglicht Live-Wissen ihnen, Veränderungen in ihrer Umgebung wahrzunehmen, neue Informationen zu integrieren und entsprechende Folgeschritte zu wählen.
Wie es sich von statischen Trainingsdaten und traditionellen Wissensdatenbanken unterscheidet
Die meisten herkömmlichen KI-Systeme werden anhand eines festen Datensatzes – wie Text, Bilder oder Protokolle – trainiert und dann eingesetzt. Ihr Wissen ändert sich nicht, es sei denn, Sie trainieren sie neu oder aktualisieren sie.
Das ist so, als würde man ein in den 90er Jahren veröffentlichtes Buch über Computer lesen und versuchen, ein MacBook aus dem Jahr 2025 zu benutzen.
Herkömmliche Wissensdatenbanken (z. B. das FAQ-Repository Ihres Unternehmens oder eine statische Datenbank mit Produktspezifikationen) werden zwar in bestimmten Zeiträumen aktualisiert, sind jedoch nicht dafür ausgelegt, kontinuierlich neue Informationen zu streamen und sich anzupassen.
Live-Wissen unterscheidet sich dadurch, dass es kontinuierlich und dynamisch ist – Ihr Agent arbeitet auf der Grundlage eines Live-Feeds, anstatt sich auf eine zwischengespeicherte Kopie zu verlassen.
Kurz gesagt:
- Statisches Training = „Was das Modell zum Zeitpunkt seiner Erstellung wusste“
- Live-Wissen = „was das Modell in Echtzeit über die sich verändernde Welt weiß“
Die Beziehung zwischen Live-Wissen und Agentenautonomie
Agentische KI-Systeme sind so konzipiert, dass sie mehr zu erledigen haben als nur Fragen zu beantworten.
Sie können:
- Maßnahmen koordinieren
- Planen Sie mehrstufige Workflows
- Arbeiten Sie mit minimalem menschlichem Aufwand.
Um dies effektiv zu erledigen, benötigen sie ein tiefes Verständnis des aktuellen Zustands, einschließlich des Status von Systemen, der neuesten Metriken, des Kundenkontexts und externer Ereignisse. Genau das bietet Live-Wissen.
Damit kann der Agent erkennen, wenn sich die Bedingungen ändern, seinen Entscheidungsweg anpassen und entsprechend der aktuellen Situation des Geschäfts oder der Umgebung handeln.
Wie Live-Wissen unübersichtliche Workflows und unzusammenhängende Workflows behebt
Live-Wissen – also die vernetzte Echtzeit-Verbindung zu Informationen über alle Ihre tools hinweg – löst direkt alltägliche Probleme, die durch die Zersplitterung der Arbeit entstehen. Aber was ist das überhaupt?
Stellen Sie sich vor, Sie arbeiten an einem Projekt und benötigen das neueste Kundenfeedback, aber dieses ist in einem E-Mail-Thread vergraben, während der Projektplan in einem separaten Tool und die Designdateien in einer weiteren App befinden. Ohne Live-Wissen verschwenden Sie Zeit damit, zwischen Plattformen zu wechseln, Teamkollegen nach Updates zu fragen oder sogar wichtige Details zu übersehen.
Live-Wissen bietet Ihnen das beste Szenario, in dem Sie sofort nach Feedback suchen und es finden, den aktuellen Status des Projekts einsehen und auf die neuesten Designs zugreifen können – alles an einem Ort, unabhängig davon, wo sich die Daten befinden.
Beispielsweise kann ein Marketingmanager gleichzeitig auf Kampagnenergebnisse aus Analysetools zugreifen, kreative Assets von einer Designplattform überprüfen und Teamdiskussionen aus Chat-Apps einsehen. Ein Support-Mitarbeiter kann die gesamte Historie eines Kunden – E-Mails, Tickets und Chat-Protokolle – einsehen, ohne zwischen verschiedenen Systemen umzuschalten.
Das bedeutet weniger Zeitaufwand für die Suche nach Informationen, weniger verpasste Updates und schnellere, sicherere Entscheidungen. Kurz gesagt: Live-Wissen schafft eine Verbindung zwischen Ihrer verstreuten digitalen Welt und macht die tägliche Arbeit reibungsloser und mit höherer Produktivität.
Als weltweit erster konvergierter KI-Workspace bietet der Live Intelligence KI-Agent von ClickUp all dies und noch einiges mehr. Sehen Sie ihn hier in Aktion. 👇🏼
📖 Weiterlesen: KI im Wissensmanagement: Vorteile, Anwendungsfälle und tools
Schlüsselkomponenten, die Live-Wissenssysteme ermöglichen
Hinter jedem Live-Wissenssystem verbirgt sich ein unsichtbares Netzwerk aus beweglichen Teilen: Es ruft kontinuierlich Daten ab, erstellt Verbindungen zwischen Datenquellen und lernt aus den Ergebnissen. Diese Komponenten arbeiten zusammen, um sicherzustellen, dass Informationen nicht nur im Speicher gespeichert werden, sondern während der Arbeit fließen, aktualisiert werden und sich anpassen.
Praktisch gesehen basiert Live-Wissen auf einer Mischung aus Datenbewegung, Integrationsintelligenz, kontextbezogenem Gedächtnis und feedbackgesteuertem Lernen. Jeder Teil hat eine bestimmte Rolle dabei, Ihren Workspace auf dem Laufenden zu halten und proaktiv statt reaktiv zu gestalten.
Eine der größten Herausforderungen in dynamischen Organisationen ist die Arbeitsausbreitung. Wenn Teams neue Tools und Prozesse einführen, kann Wissen schnell über Plattformen, Kanäle und Formate hinweg fragmentiert werden. Ohne ein System, das diese verstreuten Informationen vereinheitlicht und sichtbar macht, gehen wertvolle Erkenntnisse verloren und Teams verschwenden Zeit mit der Suche oder doppelten Arbeit. Live-Wissen begegnet der Arbeitsausbreitung direkt, indem es Informationen aus allen Quellen kontinuierlich integriert und verbindet und so sicherstellt, dass Wissen unabhängig von seiner Herkunft zugänglich, aktuell und umsetzbar bleibt. Dieser einheitliche Ansatz verhindert Fragmentierung und ermöglicht es Teams, smarter statt härter zu arbeiten.
Hier finden Sie eine Übersicht über die wichtigsten Blöcke, die dies ermöglichen, und wie sie in der Praxis zum Einsatz kommen:
| Komponente | Was es zu erledigen hat | So funktioniert es |
|---|---|---|
| Datenpipelines | Führen Sie kontinuierlich neue Daten in das System ein. | Datenpipelines verwenden APIs, Ereignisströme und Webhooks, um neue Informationen aus mehreren Tools und Umgebungen abzurufen oder zu übertragen. |
| Integrationsschichten | Verbinden Sie Daten aus verschiedenen internen und externen Systemen in einer einheitlichen Ansicht. | Integrationsschichten übernehmen die Synchronisierung von Informationen zwischen Apps wie CRMs, Datenbanken und IoT-Sensoren und beseitigen so Silos und Duplikate. |
| Kontext- und Speichersysteme | Helfen Sie der KI dabei, sich an relevante Informationen zu erinnern und unwichtige zu vergessen. | Diese Systeme schaffen ein „Arbeitsgedächtnis“ für Agenten, das es ihnen ermöglicht, den Kontext aus aktuellen Unterhaltungen, Aktionen oder Workflows zu behalten und gleichzeitig veraltete Daten zu entfernen. |
| Abruf- und Aktualisierungsmechanismen | Ermöglichen Sie Systemen den Zugriff auf die neuesten Informationen, sobald diese benötigt werden. | Abfrage-Tools fragen Daten unmittelbar vor einer Antwort oder Entscheidung ab und stellen so sicher, dass die aktuellsten Updates verwendet werden. Interne Speicher werden automatisch mit neuen Erkenntnissen aktualisiert. |
| Feedback-Schleifen | Ermöglichen Sie kontinuierliches Lernen und Verbesserungen anhand von Ergebnissen. | Feedback-Mechanismen überprüfen vergangene Aktionen anhand neuer Daten, vergleichen erwartete mit tatsächlichen Ergebnissen und passen interne Modelle entsprechend an. |
Zusammen verwandeln diese Komponenten eine KI von „Wissen zu einem bestimmten Zeitpunkt“ in „kontinuierliches Echtzeit-Verständnis“.
Warum Live-Wissen für KI-Agenten wichtig ist
KI-Systeme sind nur so gut wie das Wissen, auf dem sie basieren.
In modernen Workflows ändert sich dieses Wissen minütlich. Ob es sich um sich verändernde Kundenstimmungen, sich weiterentwickelnde Produktdaten oder operative Leistungen in Echtzeit handelt – statische Informationen verlieren schnell an Relevanz.
Hier kommt Live-Wissen ins Spiel.
Live-Wissen ermöglicht es KI-Agenten, sich von passiven Reagierern zu anpassungsfähigen Problemlösern zu entwickeln. Diese Agenten führen eine kontinuierliche Synchronisierung mit den realen Bedingungen durch, erkennen Veränderungen, sobald sie auftreten, und passen ihre Schlussfolgerungen in Echtzeit an. Diese Fähigkeit macht KI sicherer, zuverlässiger und besser auf menschliche Ziele in komplexen, dynamischen Systemen abgestimmt.
Limitationen statischen Wissens in dynamischen Umgebungen
Wenn KI-Systeme nur statische Daten verwenden (d. h. das, was sie zum Zeitpunkt des Trainings oder der letzten Aktualisierung wussten), laufen sie Gefahr, Entscheidungen zu treffen, die nicht mehr der Realität entsprechen. Beispielsweise haben sich die Marktpreise geändert, die Server-Leistung hat sich verschlechtert oder die Produktverfügbarkeit ist anders.
Wenn ein Agent diese Änderungen nicht bemerkt und berücksichtigt, kann dies zu ungenauen Antworten, unangemessenen Handlungen oder schlimmer noch – zu Risiken führen.
Untersuchungen zeigen, dass mit zunehmender Autonomie von Systemen die Abhängigkeit von veralteten Daten zu einer erheblichen Schwachstelle wird. KI-Wissensdatenbanken können dabei helfen, diese Lücke zu schließen. Sehen Sie sich dieses Video an, um weitere Informationen darüber zu erhalten. 👇🏼
🌏 Wenn Chatbots nicht über das richtige Live-Wissen verfügen:
Der KI-gestützte virtuelle Assistent von Air Canada lieferte einem Kunden falsche Informationen über die Reiseregelungen der Fluggesellschaft im Trauerfall. Der Kunde, Jake Moffatt, trauerte um den Tod seiner Großmutter und nutzte den Chatbot, um sich nach Rabatten bei Flugtarifen zu erkundigen.
Der Chatbot informierte ihn fälschlicherweise, dass er ein Ticket zum Vollpreis kaufen und innerhalb von 90 Tagen eine Rückerstattung des Trauerrabatts beantragen könne. Aufgrund dieser Auskunft buchte Moffatt teure Flüge. Die tatsächlichen Richtlinien von Air Canada sahen jedoch vor, dass ein ermäßigter Trauerrabatt vor Reiseantritt beantragt werden musste und nicht rückwirkend geltend gemacht werden konnte.
Reale Szenarien, in denen Live-Wissen entscheidend ist
Air Canada ist nur ein Beispiel. Hier sind weitere Szenarien, in denen Live-Wissen einen Unterschied machen kann:
- Kundendienstmitarbeiter: Ein KI-Assistent, der den aktuellen Status des Versands oder des Lagerbestandes nicht überprüfen kann, gibt schlechte Antworten oder verpasst Gelegenheiten zur Nachverfolgung.
- Finanzagenten: Aktienkurse, Währungswechselkurse oder Wirtschaftsindikatoren ändern sich von Sekunde zu Sekunde. Ein Modell ohne Live-Daten hinkt der Marktrealität hinterher.
- Agenten im Gesundheitswesen: Patientenüberwachungsdaten (Herzfrequenz, Blutdruck, Laborergebnisse) können sich schnell ändern. Agenten, die keinen Zugriff auf aktuelle Daten haben, können Warnsignale übersehen.
- DevOps- oder Betriebsagenten : Systemmetriken, Incidents, Benutzerverhalten – Änderungen in diesen Bereichen können sich schnell ausweiten. Agenten benötigen Live-Informationen, um zum richtigen Zeitpunkt Benachrichtigungen zu versenden, Abhilfemaßnahmen zu ergreifen oder Eskalationen vorzunehmen.
Zillow stellte sein Hausverkaufsgeschäft (Zillow Offers) ein, nachdem sein KI-Modell zur Preisermittlung für Häuser die rasanten Veränderungen auf dem Immobilienmarkt während der Pandemie nicht genau vorhersagen konnte, was zu massiven finanziellen Verlusten durch überhöhte Immobilienpreise führte. Dies verdeutlicht das Risiko von Modellabweichungen, wenn sich die Wirtschaftsindikatoren schnell ändern.
Auswirkungen auf die Entscheidungsfindung und Genauigkeit von Agenten
Durch die Integration von Live-Wissen werden Agenten zuverlässiger, genauer und zeitnaher. Sie können „veraltete” Entscheidungen vermeiden, Verzögerungen bei der Erkennung von Änderungen reduzieren und angemessen reagieren.
Außerdem schaffen sie Vertrauen: Die Benutzer wissen, dass der Agent „weiß, was los ist“.
Aus Sicht der Entscheidungsfindung stellt Live-Wissen sicher, dass die „Eingaben“ für die Planungs- und Handlungsschritte des Agenten für den jeweiligen Moment gültig sind. Dies führt zu besseren Ergebnissen, weniger Fehlern und agileren Prozessen.
Wert des Geschäfts und Wettbewerbsvorteile
Für Unternehmen bietet der Übergang von statischem zu Live-Wissen in KI-Agenten mehrere Vorteile:
- Schnellere Reaktion auf Veränderungen: Wenn Ihre KI weiß, was gerade passiert, können Sie schneller handeln.
- Personalisierte und aktuelle Interaktion: Das Kundenerlebnis verbessert sich, wenn die Antworten den aktuellen Kontext widerspiegeln.
- Operative Resilienz: Systeme, die Anomalien oder Veränderungen schnell erkennen, können Risiken mindern.
- Wettbewerbsvorteil: Wenn Ihre Agenten sich in Echtzeit anpassen können und andere nicht, gewinnen Sie an Geschwindigkeit und Erkenntnissen.
Zusammenfassend lässt sich sagen, dass Live-Wissen eine strategische Fähigkeit für Unternehmen ist, die Veränderungen immer einen Schritt voraus sein wollen.
So funktioniert Live Knowledge: Kernkomponenten
Live-Wissen steht für Live-Workflows, Bewusstsein und Anpassungsfähigkeit.
Wenn Wissen in Echtzeit fließt, können Teams schnellere und intelligentere Entscheidungen treffen.
So funktionieren Live-Wissenssysteme hinter den Kulissen, angetrieben von drei Schlüsselkomponenten: Echtzeit-Datenquellen, Integrationsmethoden und Agentenarchitektur.
Komponente 1: Echtzeit-Datenquellen
Jedes Live-Wissenssystem beginnt mit seinen Eingaben: den Daten, die ständig aus Ihren Tools, Apps und täglichen Workflows eingehen. Diese Eingaben können von praktisch überall kommen, wo Sie arbeiten: von einem Kunden, der ein Support-Ticket in Zendesk einreicht, einem Vertriebsmitarbeiter, der Deal-Notizen in Salesforce aktualisiert, oder einem Entwickler, der neuen Code auf GitHub hochlädt.
Selbst automatisierte Systeme liefern Signale: IoT-Sensoren melden die Leistung von Geräten, Marketing-Dashboards liefern Live-Kampagnen-Metriken und Finanzplattformen aktualisieren Umsatzzahlen in Echtzeit.
Zusammen bilden diese vielfältigen Datenströme die Grundlage für Live-Wissen: einen kontinuierlichen, miteinander verbundenen Informationsfluss, der widerspiegelt, was gerade in Ihrem gesamten Geschäftsökosystem geschieht. Wenn ein KI-System sofort auf diese Eingaben zugreifen und sie interpretieren kann, geht es über die passive Datenerfassung hinaus und wird zu einem Echtzeit-Mitarbeiter, der Teams dabei hilft, schneller zu handeln, sich anzupassen und Entscheidungen zu treffen.
APIs und Webhooks
APIs und Webhooks sind das Bindeglied des modernen Workspaces. APIs ermöglichen einen strukturierten Datenaustausch auf Abruf.
Mit ClickUp Integrations können Sie beispielsweise in Sekundenschnelle Updates von Slack oder Salesforce abrufen. Webhooks gehen noch einen Schritt weiter, indem sie bei Änderungen automatisch Updates übertragen und Ihre Daten ohne manuelle Synchronisierung auf dem neuesten Stand halten. Zusammen beseitigen sie „Informationsverzögerungen“ und stellen sicher, dass Ihr System immer die aktuellen Ereignisse widerspiegelt.
Datenbankverbindungen
Echtzeit-Datenbankverbindungen ermöglichen es Modellen, Betriebsdaten zu überwachen und auf deren Entwicklung zu reagieren. Ob es sich um Kundenerkenntnisse aus einem CRM-System oder Berichte über den Fortschritt aus Ihrem Projektmanagement-Tool handelt – diese direkte Pipeline stellt sicher, dass Ihre KI-Entscheidungen auf aktuellen, genauen Informationen basieren.
Stream-Verarbeitungssysteme
Stream-Verarbeitungstechnologien wie Kafka und Flink wandeln rohe Ereignisdaten in sofortige Erkenntnisse um. Das kann Echtzeit-Warnmeldungen bedeuten, wenn ein Projekt ins Stocken gerät, automatische Workload-Verteilung oder die Identifizierung von Workflow-Engpässen, bevor sie zu Hindernissen werden. Diese Systeme geben Teams einen Pulse über ihre Abläufe, während diese sich entwickeln.
Externe Wissensdatenbanken
Kein System kann isoliert erfolgreich sein. Die Verbindung zu externen Wissensquellen – Produktdokumentationen, Forschungsbibliotheken oder öffentlichen Datensätzen – verschafft Live-Systemen einen globalen Kontext.
Das bedeutet, dass Ihr KI-Assistent nicht nur versteht, was in Ihrem Workspace geschieht, sondern auch, warum dies im Gesamtkontext wichtig ist.
📖 Weiterlesen: Wie man wissensbasierte Agenten in der KI einsetzt
Komponente 2: Methoden zur Wissensintegration
Sobald die Daten fließen, besteht der nächste Schritt darin, sie in eine lebendige, atmende Wissenschicht zu integrieren, die sich kontinuierlich weiterentwickelt.
Dynamische Kontexteinbindung
Der Kontext ist die geheime Zutat, die Rohdaten in aussagekräftige Erkenntnisse verwandelt. Durch dynamische Kontexteinbindung können KI-Systeme genau dann die relevantesten und aktuellsten Informationen – wie aktuelle Projektupdates oder Prioritäten des Teams – einbeziehen, wenn Entscheidungen getroffen werden. Das ist so, als hätten Sie einen Assistenten, der genau im richtigen Moment genau das parat hat, was Sie brauchen.
Sehen Sie, wie Brain Agent dies innerhalb von ClickUp umsetzt:
Echtzeit-Abrufmechanismen
Die herkömmliche KI-Suche stützt sich auf gespeicherte Informationen. Die Echtzeit-Suche geht noch einen Schritt weiter, indem sie Verbindungen kontinuierlich scannt und aktualisiert und nur die aktuellsten und relevantesten Inhalte anzeigt.
Wenn Sie beispielsweise ClickUp Brain um eine Zusammenfassung des Projekts bitten, durchsucht es nicht alte Dateien, sondern zieht neue Erkenntnisse aus den neuesten Live-Daten.
Aktualisierungen des Wissensgraphen
Wissensgraphen bilden Beziehungen zwischen Personen, Aufgaben, Zielen und Ideen ab. Durch die Aktualisierung dieser Graphen in Echtzeit wird sichergestellt, dass sich Abhängigkeiten parallel zu Ihren Workflows weiterentwickeln. Wenn sich Prioritäten verschieben oder neue Aufgaben hinzukommen, gleicht der Graph diese automatisch aus und bietet Teams eine klare, stets genaue Ansicht der Verbindungen ihrer Arbeit.
Ansätze für kontinuierliches Lernen
Durch kontinuierliches Lernen können sich KI-Modelle auf der Grundlage von Benutzer-Feedback und sich ändernden Mustern anpassen. Jeder Kommentar, jede Korrektur und jede Entscheidung wird zu Trainingsdaten, die dem System helfen, die tatsächliche Arbeitsweise Ihres Teams besser zu verstehen.
Komponente 3: Agentenarchitektur für Live-Wissen
Die letzte und oft komplexeste Ebene ist die Art und Weise, wie KI-Agenten Wissen verwalten, speichern und priorisieren, um Kohärenz und Reaktionsfähigkeit zu gewährleisten.
Speicherverwaltungssysteme
Genau wie Menschen muss auch KI wissen, was sie sich merken und was sie vergessen muss. Speichersysteme schaffen ein Gleichgewicht zwischen Kurzzeitgedächtnis und Langzeitspeicher, indem sie wichtige Zusammenhänge (wie aktuelle Ziele oder Client-Präferenzen) bewahren und gleichzeitig irrelevante Informationen herausfiltern. So bleibt das System leistungsfähig und wird nicht überlastet.
Optimierung des Kontextfensters
Kontextfenster definieren, wie viele Informationen eine KI auf einmal „sehen” kann. Wenn diese Fenster optimiert sind, können Agenten lange, komplexe Interaktionen verwalten, ohne wichtige Details aus den Augen zu verlieren. In der Praxis bedeutet dies, dass Ihre KI die gesamte Projektgeschichte und alle Unterhaltungen abrufen kann – nicht nur die letzten paar Nachrichten –, was genauere und relevantere Antworten ermöglicht.
Doch mit der zunehmenden Einführung von KI-Tools und -Agenten in Unternehmen entsteht eine neue Herausforderung: die KI-Ausbreitung. Wissen, Aktionen und Kontext können über verschiedene Bots und Plattformen hinweg fragmentiert werden, was zu inkonsistenten Antworten, doppelter Arbeit und verpassten Erkenntnissen führt. Live-Wissen begegnet diesem Problem, indem es Informationen vereinheitlicht und Kontextfenster über alle KI-Systeme hinweg optimiert, sodass jeder Agent aus einer einzigen, aktuellen Quelle der Wahrheit schöpft. Dieser Ansatz verhindert Fragmentierung und versetzt Ihre KI in die Lage, konsistenten, umfassenden Support zu leisten.
Priorisierung von Informationen
Nicht jedes Wissen verdient die gleiche Aufmerksamkeit. Intelligente Priorisierung sorgt dafür, dass sich die KI auf das Wesentliche konzentriert: dringende Aufgaben, sich ändernde Abhängigkeiten oder wichtige Leistungsänderungen. Durch die Filterung nach Auswirkungen verhindert das System eine Datenüberflutung und sorgt für mehr Klarheit.
Caching-Strategien
Geschwindigkeit treibt die Akzeptanz voran. Das Zwischenspeichern häufig abgerufener Informationen wie aktuelle Kommentare, Aktualisierungen für Aufgaben oder Metriken ermöglicht einen sofortigen Abruf und reduziert gleichzeitig die Systemlast. Das bedeutet, dass Ihr Team eine reibungslose Zusammenarbeit in Echtzeit ohne Verzögerungen zwischen Aktion und Erkenntnis erlebt.
Live-Wissen verwandelt Arbeit von reaktiv zu proaktiv. Wenn Echtzeitdaten, kontinuierliches Lernen und intelligente Agentenarchitektur zusammenkommen, bleiben Ihre Systeme nicht mehr zurück.
Dies ist die Grundlage für schnellere Entscheidungen, weniger blinde Flecken und eine besser vernetzte KI- Umgebung.
📮ClickUp Insight: 18 % der Befragten unserer Umfrage möchten KI nutzen, um ihr Leben mithilfe von Kalendern, Aufgaben und Erinnerungen zu organisieren. Weitere 15 % möchten, dass KI Routineaufgaben und Verwaltungsarbeiten übernimmt.
Zu erledigen ist es für eine KI erforderlich, die Prioritätsstufen für jede Aufgabe in einem Workflow zu verstehen, die notwendigen Schritte zur Erstellung oder Anpassung von Aufgaben auszuführen und automatisierte Workflows einzurichten.
Die meisten Tools haben einen oder zwei dieser Schritte umgesetzt. ClickUp hat jedoch Benutzern dabei geholfen, mit unserer Plattform ClickUp Brain MAX mehr als fünf Apps zu konsolidieren!
Arten von Live-Wissenssystemen
In diesem Abschnitt befassen wir uns mit den verschiedenen Architekturmuster für die Bereitstellung von Live-Wissen an KI-Agenten – wie der Daten-Flow aussieht, wann der Agent Updates erhält und welche Kompromisse damit verbunden sind.
Pull-basierte Systeme
In einem Pull-basierten Modell fragt der Agent Daten ab, wenn er sie benötigt. Stellen Sie sich das wie einen Schüler vor, der mitten im Unterricht die Hand hebt und fragt: „Wie ist das aktuelle Wetter?“ oder „Wie lautet der aktuelle Lagerbestand?“ Der Agent dient als Auslöser für eine Abfrage an eine Live-Quelle (API, Datenbank) und verwendet das Ergebnis für seinen nächsten Schritt der Schlussfolgerung.
👉🏽 Warum pull-basiert? Dies ist effizient, wenn der Agent nicht ständig Live-Daten benötigt. Sie vermeiden es, alle Daten kontinuierlich zu streamen, was kostspielig oder unnötig sein könnte. Außerdem haben Sie mehr Kontrolle: Sie entscheiden genau, was wann abgerufen wird.
👉🏽 Nachteile: Es kann zu Latenzzeiten kommen – wenn die Datenanfrage Zeit in Anspruch nimmt, wartet der Agent möglicherweise und reagiert langsamer. Außerdem besteht die Gefahr, dass Sie Aktualisierungen zwischen den Abfragen verpassen (wenn Sie nur in regelmäßigen Abständen überprüfen). Beispielsweise ruft ein Mitarbeiter des Kundensupports die API für den Versandstatus möglicherweise nur ab, wenn ein Kunde fragt: „Wo ist meine Bestellung?“, anstatt einen konstanten Live-Feed der Versandereignisse zu pflegen.
Push-basierte Systeme
Anstatt darauf zu warten, dass der Agent nachfragt, pusht das System Updates an den Agenten, sobald sich etwas ändert. Das ist wie bei einem Nachrichten-Abonnement: Wenn ein Ereignis passiert, werden Sie sofort benachrichtigt. Für einen KI-Agenten, der Live-Wissen nutzt, bedeutet dies, dass er immer über den aktuellen Kontext verfügt, während sich Ereignisse entwickeln.
👉🏽 Warum push-basiert? Es bietet minimale Latenz und hohe Reaktionsfähigkeit, da der Agent Änderungen sofort erkennt, sobald sie auftreten. Dies ist in Hochgeschwindigkeits- oder Hochrisikosituationen (z. B. Finanzhandel, Systemzustandsüberwachung) von großem Wert.
👉🏽 Nachteile: Die Wartung kann teurer und komplexer sein. Der Agent erhält möglicherweise viele irrelevante Updates, die gefiltert und priorisiert werden müssen. Außerdem benötigen Sie eine robuste Infrastruktur, um kontinuierliche Datenströme zu verarbeiten. Beispielsweise erhält ein DevOps-KI-Agent Webhook-Benachrichtigungen, wenn die CPU-Auslastung des Servers einen Schwellenwert überschreitet, und leitet eine Skalierungsmaßnahme ein.
Hybride Ansätze
In der Praxis kombinieren die meisten robusten Live-Wissenssysteme sowohl Pull- als auch Push-Ansätze. Der Agent abonniert wichtige Ereignisse (Push) und ruft bei Bedarf gelegentlich umfassendere Kontextdaten ab (Pull).
Dieses Hybridmodell hilft dabei, ein Gleichgewicht zwischen Reaktionsfähigkeit und Kosten/Komplexität herzustellen. In einem Vertriebsagenten-Szenario könnte die KI beispielsweise Push-Benachrichtigungen erhalten, wenn ein Lead ein Angebot öffnet, und gleichzeitig CRM-Daten zur Historie dieses Kunden abrufen, um die nächste Kontaktaufnahme vorzubereiten.
Ereignisgesteuerte Architekturen
Sowohl Push- als auch Hybridsysteme basieren auf dem Konzept einer ereignisgesteuerten Architektur.
Hier ist das System um Ereignisse herum strukturiert (Geschäftstransaktionen, Sensorwerte, Benutzerinteraktionen), die Logik-Flows, Entscheidungen oder Statusaktualisierungen auslösen.
Laut Branchenanalysen werden Streaming-Plattformen und „Streaming Lakehouses “ zu Ausführungsebenen für agentenbasierte KI – wodurch die Grenze zwischen Verlaufsdaten und Live-Daten aufgehoben wird.
In solchen Systemen werden Ereignisse über Pipelines weitergeleitet, mit Kontext angereichert und an Agenten weitergeleitet, die sie auswerten, darauf reagieren und möglicherweise neue Ereignisse auslösen.
Der Live-Knowledge-Agent wird so zu einem Knoten in einer Echtzeit-Feedbackschleife: Wahrnehmen → Denken → Handeln → Aktualisieren.
👉🏽 Warum das wichtig ist: Bei ereignisgesteuerten Systemen ist Live-Wissen nicht nur ein Add-On, sondern wird zu einem integralen Bestandteil der Art und Weise, wie der Agent die Realität wahrnimmt und beeinflusst. Wenn ein Ereignis eintritt, aktualisiert der Agent sein Weltmodell und reagiert entsprechend.
👉🏽 Kompromisse: Es erfordert die Berücksichtigung von Parallelität, Latenz, Ereignisreihenfolge, Fehlerbehandlung (was passiert, wenn ein Ereignis verloren geht oder verzögert wird?) und „Was-wäre-wenn“-Logik für nicht vorhersehbare Szenarien.
Implementierung von Live-Wissen: Technische Ansätze
Der Aufbau von Live-Wissen erfordert eine sich ständig weiterentwickelnde technische Intelligenz. Hinter den Kulissen verknüpfen Unternehmen APIs, Streaming-Architekturen, Kontext-Engines und adaptive Lernmodelle miteinander, um Informationen aktuell und nutzbar zu halten.
In diesem Abschnitt untersuchen wir, wie diese Systeme zum Leben erweckt werden: die Technologien, die Echtzeit-Bewusstsein ermöglichen, die Architekturmuster, die es skalierbar machen, und die praktischen Schritte, die Teams unternehmen, um von statischem Wissen zu kontinuierlicher Live-Intelligenz überzugehen.
Retrieval-Augmented Generation (RAG) mit Live-Datenquellen
Ein weit verbreiteter Ansatz ist die Kombination eines großen Sprachmodells (LLM) mit einem Live-Retrieval-System, das oft als RAG bezeichnet wird.
In RAG-Anwendungsfällen führt der Agent, wenn er antworten muss, zunächst einen Abrufschritt durch: Er führt eine Abfrage auf aktuellen externen Datenquellen (Vektordatenbanken, APIs, Dokumente) durch. Anschließend verwendet das LLM die abgerufenen Daten (in seiner Eingabeaufforderung oder seinem Kontext), um die Ausgabe zu generieren.
Bei Live-Wissen handelt es sich bei den Abrufquellen nicht um statische Archive, sondern um kontinuierlich aktualisierte Live-Feeds. Dadurch wird sichergestellt, dass die Ergebnisse des Modells den aktuellen Stand der Welt widerspiegeln.
Implementierungsschritte:
- Identifizieren Sie Live-Quellen (APIs, Streams, Datenbanken)
- Indexieren oder machen Sie sie abfragbar (Vektordatenbank, Wissensgraph, relationaler Speicher)
- Bei jeder Agentenaktivierung: Abrufen aktueller relevanter Datensätze, Einfügen in die Eingabeaufforderung/den Kontext
- Antwort generieren
- Optional können Sie Speicher oder Wissensspeicher mit neu entdeckten Fakten aktualisieren.
MCP-Server und Echtzeitprotokolle
Neuere Standards wie das Model Context Protocol (MCP) zielen darauf ab, zu definieren, wie Modelle mit Live-Systemen interagieren: Datenendpunkte, KI-Tools, Aufrufe und kontextbezogenes Gedächtnis.
Laut einem Whitepaper könnte MCP für KI die Rolle spielen, die HTTP einst für das Web gespielt hat (Verbindung von Modellen mit Tools und Daten).
In der Praxis bedeutet dies, dass Ihre Agentenarchitektur möglicherweise Folgendes umfasst:
- Ein MCP-Server, der eingehende Anfragen aus der Modell- oder Agentenschicht verarbeitet.
- Eine Service-Ebene, die interne/externe Tools, APIs und Live-Datenströme miteinander verbindet.
- Eine Kontextmanagement-Ebene, die Status, Speicher und relevante aktuelle Daten verwaltet.
Durch die Standardisierung der Schnittstelle machen Sie das System modular – Agenten können verschiedene Datenquellen, Tools und Speichergraphen einbinden.
Aktualisierungen der Vektordatenbank
Im Umgang mit Live-Wissen unterhalten viele Systeme eine Vektordatenbank (Embeddings), deren Inhalt kontinuierlich aktualisiert wird.
Einbettungen repräsentieren neue Dokumente, Live-Datenpunkte und Entitätszustände. So sind die Abfragen immer aktuell. Beispiel: Wenn neue Sensordaten eintreffen, wandeln Sie diese in eine Einbettung um und fügen sie in den Vektorspeicher ein, sodass sie bei nachfolgenden Abfragen berücksichtigt werden.
Überlegungen zur Implementierung:
- Wie oft binden Sie Live-Daten neu ein?
- Wie lassen Sie veraltete Einbettungen verfallen?
- Wie vermeiden Sie eine Überlastung des Vektorspeichers und gewährleisten eine hohe Geschwindigkeit bei Abfragen?
API-Orchestrierungsmuster
Agenten rufen selten eine einzelne API auf, sondern oft mehrere Endpunkte nacheinander oder parallel. Live-Wissen-Implementierungen erfordern eine Orchestrierung. Beispiel:
- Schritt 1: Überprüfen Sie die Live-Bestands-API
- Schritt 2: Wenn der Lagerbestand niedrig ist, überprüfen Sie die ETA-API des Lieferanten.
- Schritt 3: Generieren Sie benutzerdefinierte Mitteilungen für den Kunden auf der Grundlage der kombinierten Ergebnisse.
Diese Orchestrierungsebene kann Caching, Wiederholungslogik, Ratenlimit, Fallbacks und Datenaggregation umfassen. Die Gestaltung dieser Ebene ist entscheidend für Stabilität und Leistung.
Tool-Nutzung und Aufruf der Funktion
In den meisten KI-Frameworks verwenden Agenten Tools, um Maßnahmen zu ergreifen.
Ein Tool ist einfach eine vordefinierte Funktion, die der Agent aufrufen kann, z. B. get_stock_price(), check_server_status() oder fetch_customer_order().
Moderne LLM-Frameworks ermöglichen dies durch Funktionsaufrufe, bei denen das Modell entscheidet, welches Tool verwendet werden soll, die richtigen Parameter übergibt und eine strukturierte Antwort erhält, die es auswerten kann.
Live-Wissensagenten gehen noch einen Schritt weiter. Anstelle von statischen oder simulierten Daten verbinden sich ihre Tools direkt mit Echtzeitquellen – Live-Datenbanken, APIs und Ereignisströmen. Der Agent kann aktuelle Ergebnisse abrufen, sie im Kontext interpretieren und sofort handeln oder reagieren. Diese Brücke zwischen Schlussfolgerungen und realen Daten verwandelt ein passives Modell in ein anpassungsfähiges, kontinuierlich informiertes System.
Implementierungsschritte:
- Definieren Sie Tool-Funktionen, die Live-Datenquellen (APIs, Datenbanken) umfassen.
- Stellen Sie sicher, dass der Agent die Auswahl treffen kann, welches tool er aufruft und welche Argumente er erzeugt.
- Erfassen Sie tool-Ausgaben und integrieren Sie sie in den Kontext der Argumentation.
- Sorgen Sie für Protokollierung, Fehlerbehandlung und Fallback (was passiert, wenn das tool ausfällt?).
📖 Weiterlesen: MCP vs. RAG vs. KI-Agenten
Anwendungsfälle und Anwendungen
Live-Wissen entwickelt sich schnell vom Konzept zum Wettbewerbsvorteil.
Von der Echtzeit-Projektkoordination über adaptiven Kundensupport bis hin zur vorausschauenden Wartung – Unternehmen profitieren bereits jetzt von konkreten Vorteilen in Bezug auf Geschwindigkeit, Genauigkeit und Vorausschau.
Im Folgenden finden Sie einige der überzeugendsten Beispiele dafür, wie Live-Wissen heute angewendet wird und wie es die Bedeutung von „intelligenter Arbeit” in der Praxis neu definiert.
Kundendienstmitarbeiter mit Live-Produktbestand
Im Einzelhandel kann ein Support-Chatbot, der mit Live-Bestands- und Versandsystemen verbunden ist, Fragen wie „Ist dieser Artikel vorrätig?“, „Wann wird er versandt?“ oder „Kann ich eine Expresslieferung erhalten?“ beantworten.
Anstatt sich auf statische FAQ-Daten zu verlassen (die möglicherweise „nicht vorrätig“ anzeigen, obwohl gerade neue Ware eingetroffen ist), führt der Agent eine Echtzeit-Abfrage des Bestands- und Versand-APIs durch.
Finanzagenten mit Marktdaten-Feeds
Finanzielle Workflows erfordern einen sofortigen Informationsabruf.
Ein KI-Agent, der mit Marktdaten-APIs (Aktienkurse, Wechselkurse, Wirtschaftsindikatoren) verbunden ist, kann Live-Veränderungen überwachen und entweder menschliche Händler benachrichtigen oder innerhalb definierter Parameter autonom handeln.
Die Live-Wissensschicht unterscheidet ein einfaches Analyse-Dashboard (statische Berichte) von einem autonomen Agenten, der einen plötzlichen Wertverlust erkennt und einen Auslöser für eine Absicherung oder einen Handel auslöst.
Der virtuelle Assistent „Erica” der Bank of America demonstriert erfolgreich den Wert der Nutzung von Echtzeitdaten für KI-Agenten im Finanzsektor. Er wickelt jährlich Hunderte Millionen von Interaktionen mit Clients ab, indem er auf aktuelle Kontoinformationen zugreift, personalisierte und sofortige Finanzberatung bietet, bei Transaktionen hilft und Budgets verwaltet.
Agenten im Gesundheitswesen mit Patientenüberwachung
Im Gesundheitswesen bedeutet Live-Wissen die Verbindung mit Patientensensoren, medizinischen Geräten, elektronischen Gesundheitsakten (EHR) und der Übertragung von Vitalparametern.
Ein KI-Agent kann die Herzfrequenz, den Sauerstoffgehalt und die Laborergebnisse eines Patienten in Echtzeit überwachen, sie mit Schwellenwerten oder Mustern vergleichen und Ärzte alarmieren oder empfohlene Maßnahmen ergreifen (z. B. die Bedingung eskalieren). Frühwarnsysteme, die auf Live-Datenanalysen basieren, helfen bereits dabei, Sepsis oder Herzinsuffizienz deutlich früher als mit herkömmlichen Ansätzen zu erkennen.
Nvidia entwickelt beispielsweise eine KI-Agentenplattform für Unternehmen, die aufgabenspezifische Agenten unterstützt – darunter einen, der für das Ottawa Hospital entwickelt wurde, um Patienten rund um die Uhr zu unterstützen. Der Agent begleitet Patienten durch die Vorbereitung auf die Operation, die Genesung nach der Operation und die Rehabilitation.
Wie Kimberly Powell, Vice President und General Manager für den Gesundheitsbereich bei Nvidia, erklärt, besteht das Ziel darin, Ärzten Zeit zu sparen und gleichzeitig die Patientenerfahrung zu verbessern.
DevOps-Agenten mit Systemmetriken
Im IT-Betrieb überwachen Live-Wissensagenten Protokolle, Telemetriedaten, Infrastrukturereignisse und Service-Status-APIs. Bei Latenzspitzen, einer Zunahme von Fehlern oder einer Erschöpfung der Ressourcen kann der Agent als Auslöser Abhilfemaßnahmen auslösen – einen Dienst neu starten, zusätzliche Kapazitäten bereitstellen oder den Datenverkehr umleiten. Da der Agent stets über den aktuellen Systemstatus informiert ist, kann er effektiver handeln und Ausfallzeiten reduzieren.
Vertriebsmitarbeiter mit CRM-Integration
Im Vertrieb bedeutet Live-Wissen, einen Agenten mit dem CRM, Kommunikationsplattformen und den aktuellen Lead-Aktivitäten zu verknüpfen.
Stellen Sie sich einen Vertriebsassistenten vor, der überwacht, wann ein potenzieller Kunde ein Angebot öffnet, und dann den Vertriebsmitarbeiter darauf hinweist: „Ihr Angebot wurde gerade angesehen. Möchten Sie jetzt einen Folgetermin vereinbaren?“ Der Agent kann Live-Interaktionsdaten, Lead-Kontext und historische Gewinnraten dynamisch abrufen, um zeitnahe, personalisierte Vorschläge zu erstellen. Dadurch wird die Kundenansprache von einer generischen zu einer kontextbezogenen Maßnahme.
JPMorgan Chase nutzte KI-Agenten während einer kürzlichen Marktkrise, um schneller Beratung anzubieten, mehr Clients zu bedienen und den Umsatz zu steigern. Der KI-gesteuerte „Coach”-Assistent half Finanzberatern dabei, Erkenntnisse bis zu 95 % schneller zu gewinnen, wodurch das Unternehmen seinen Bruttoumsatz zwischen 2023 und 2024 um ~20 % steigern und ein Einzelziel für eine 50-prozentige Zunahme der Client-Zahl in den nächsten 3 bis 5 Jahren anstreben konnte.
Entfesseln Sie Live-Intelligenz für Ihr Unternehmen mit ClickUp
Heutige Teams brauchen mehr als statische Tools. Sie brauchen einen Workspace, der ihre Arbeit aktiv versteht, verbindet und beschleunigt. ClickUp ist der erste konvergierte KI-Workspace, der entwickelt wurde, um Live-Intelligenz zu liefern, indem Wissen, Automatisierung und Zusammenarbeit in einer einzigen, einheitlichen Plattform integriert werden.
Einheitliche Enterprise-Suche: Echtzeitwissen auf Knopfdruck
Finden Sie sofort Antworten, unabhängig davon, wo sich die Informationen befinden. Die Enterprise-Suche von ClickUp verbindet Aufgaben, Dokumente, Chats und integrierte Tools von Drittanbietern in einer einzigen, KI-gestützten Suchleiste. Abfragen in natürlicher Sprache liefern kontextreiche Ergebnisse und führen strukturierte und unstrukturierte Daten zusammen, sodass Sie schneller Entscheidungen treffen können.
- Durchsuchen Sie Aufgaben, Dokumente, Chats und integrierte Tools von Drittanbietern mit einer einzigen KI-gestützten Suchleiste.
- Verwenden Sie natürliche Sprachabfragen, um strukturierte und unstrukturierte Daten aus allen verbundenen Drittanbieter-Datenquellen abzurufen.
- Zeigen Sie Richtlinien, Projektaktualisierungen, Dateien und Fachwissen mit kontextreichen Ergebnissen sofort an.
- Indizieren und erstellen Sie Verbindungen zu Informationen aus Google Drive, Slack und anderen Plattformen für eine ganzheitliche Ansicht.
Automatisierung, Koordinierung und Argumentation über Workflows hinweg mit KI-Agenten
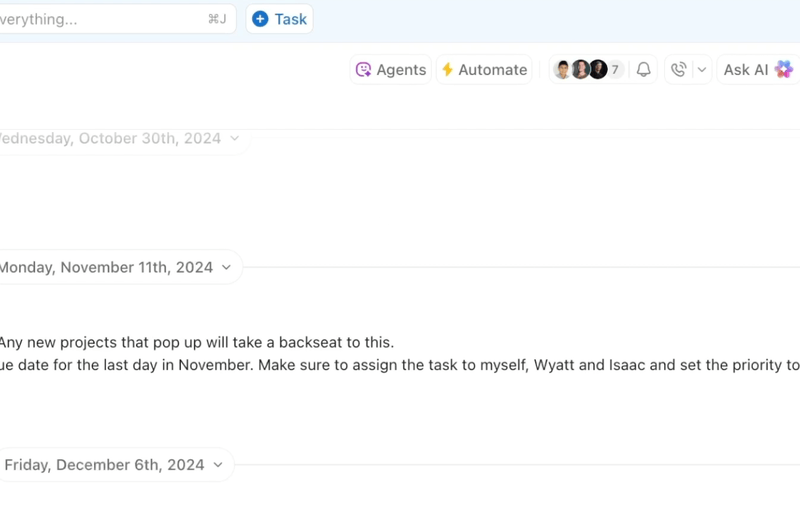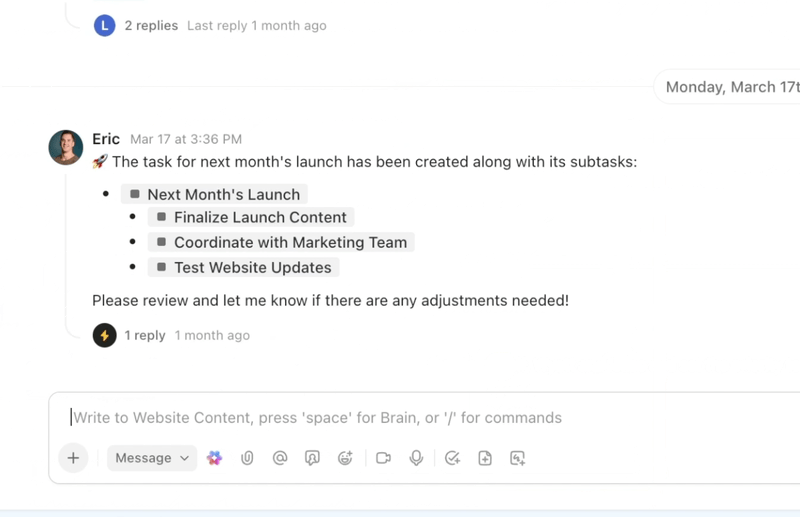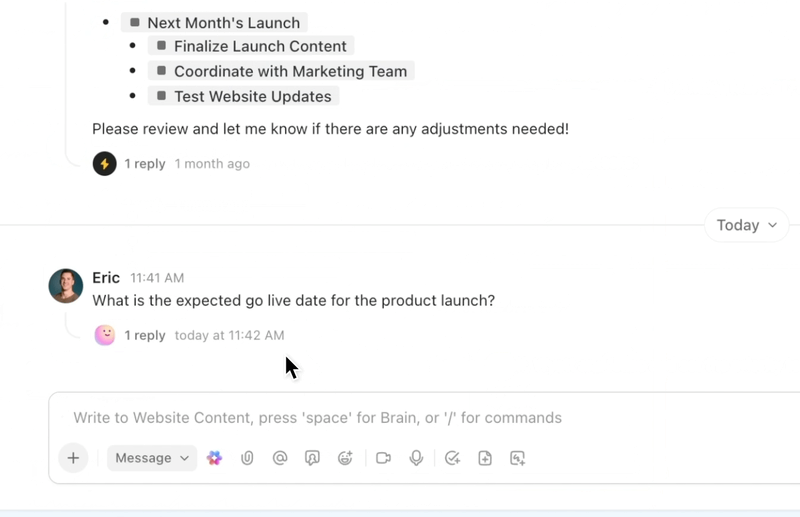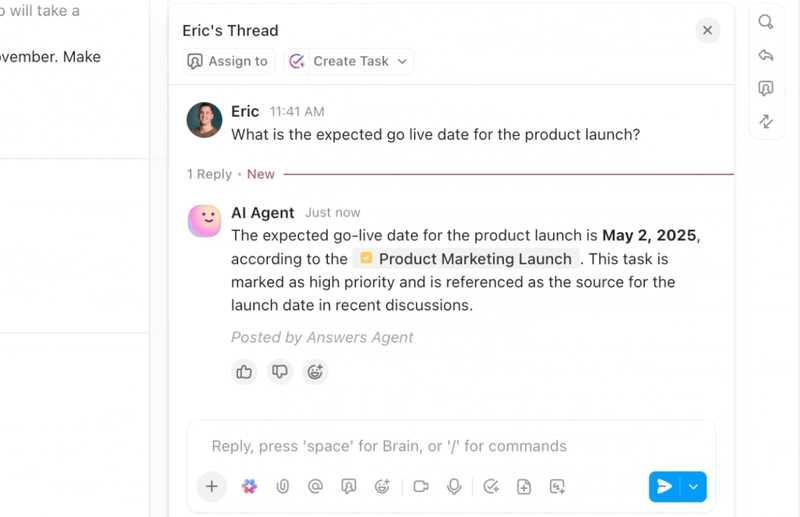
Automatisieren Sie wiederholende Aufgaben und koordinieren Sie komplexe Prozesse mit intelligenten KI-Agenten, die als digitale Teamkollegen fungieren. Die KI-Agenten von ClickUp nutzen Echtzeit-Workspace-Daten und -Kontexte, um zu argumentieren, Maßnahmen zu ergreifen und sich an veränderte Geschäftsanforderungen anzupassen.
- Setzen Sie anpassbare KI-Agenten ein, die Aufgaben automatisieren, Anfragen priorisieren und mehrstufige Workflows ausführen.
- Fassen Sie Meetings zusammen, generieren Sie Inhalte, aktualisieren Sie Aufgaben und nutzen Sie als Auslöser Automatisierungen auf der Grundlage von Echtzeitdaten.
- Passen Sie Maßnahmen anhand von Kontext, Abhängigkeiten und Geschäftslogik mithilfe fortschrittlicher Schlussfolgerungsfunktionen an.
Live-Wissensmanagement: Dynamisch, kontextbezogen und immer auf dem neuesten Stand
Verwandeln Sie statische Dokumentation in eine lebendige Wissensdatenbank. ClickUp Knowledge Management indiziert und verknüpft automatisch Informationen aus Aufgaben, Dokumenten und Unterhaltungen und sorgt so dafür, dass Ihr Wissen immer aktuell und zugänglich ist. KI-gesteuerte Vorschläge zeigen Ihnen während der Arbeit relevante Inhalte an, während intelligente Organisations- und Berechtigungseinstellungen sensible Daten sichern.
- Indizieren und verknüpfen Sie automatisch Informationen aus ClickUp Aufgaben, ClickUp Dokumenten und Unterhaltungen für eine lebendige Wissensdatenbank.
- Zeigen Sie relevante Inhalte mit KI-gesteuerten Vorschlägen an, während Sie arbeiten.
- Organisieren Sie Wissen mit detaillierten Berechtigungen für eine sichere und auffindbare Freigabe.
- Halten Sie Dokumentationen, Onboarding-Anleitungen und institutionelles Wissen stets aktuell und zugänglich.
Konvergente Zusammenarbeit: Kontextbezogen, mit Verbindungen und umsetzbar
Die Zusammenarbeit in ClickUp ist tief in Ihre Arbeit integriert.
Echtzeit-Bearbeitung, KI-gestützte Zusammenfassungen und kontextbezogene Empfehlungen sorgen dafür, dass jede Unterhaltung umsetzbar ist. ClickUp Chat, Whiteboards, Dokumente und Aufgaben sind miteinander verbunden, sodass Brainstorming, Planung und Ausführung in einem Flow erfolgen.
Es hilft Ihnen dabei:
- Arbeiten Sie in Echtzeit mit integrierten Dokumenten, Whiteboards und Aufgaben zusammen, die alle für nahtlose Workflows miteinander verknüpft sind.
- Verwandeln Sie Unterhaltungen in umsetzbare nächste Schritte mit KI-gestützten Zusammenfassungen und Empfehlungen.
- Visualisieren Sie Abhängigkeiten, Blockaden und den Status des Projekts mit Live-Updates und intelligenten Benachrichtigungen.
- Ermöglichen Sie funktionsübergreifenden Teams Brainstorming, Planung und Umsetzung in einer einheitlichen Umgebung.
ClickUp ist nicht nur ein Workspace. Es ist eine Live-Intelligenzplattform, die das Wissen Ihres Unternehmens vereint, die Automatisierung der Arbeit durchführt und Teams mit umsetzbaren Erkenntnissen versorgt – und das alles in Echtzeit.
Wir haben die besten Suchsoftwarelösungen für Unternehmen verglichen und präsentieren Ihnen hier die Ergebnisse:
Herausforderungen und Best Practices
Live-Wissen bietet zwar enorme Vorteile, birgt aber auch Risiken und Komplexität.
Im Folgenden finden Sie die wichtigsten KI-Herausforderungen, denen Unternehmen gegenüberstehen, sowie Maßnahmen zu deren Bewältigung.
| Herausforderung | Beschreibung | Best Practices |
|---|---|---|
| Latenz- und Leistungsoptimierung | Die Verbindung mit Live-Daten führt zu Latenzzeiten durch API-Aufrufe, Stream-Verarbeitung und Abrufe. Wenn die Antworten verzögert werden, leiden die Benutzererfahrung und das Vertrauen darunter. | ✅ Speichern Sie weniger wichtige Daten im Cache, um redundante Abrufe zu vermeiden. ✅ Priorisieren Sie wichtige, zeitkritische Feeds; aktualisieren Sie andere weniger häufig. ✅ Optimieren Sie den Abruf und die Kontexteinfügung, um die Wartezeit des Modells zu reduzieren. ✅ Überwachen Sie kontinuierlich die Metriken und legen Sie Leistungsschwellenwerte fest. |
| Aktualität der Daten vs. Rechenaufwand | Die Pflege von Echtzeitdaten für alle Datenquellen kann kostspielig und ineffizient sein. Nicht alle Informationen müssen sekündlich aktualisiert werden. | ✅ Daten nach Kritikalität klassifizieren (muss live sein vs. kann im Zeitraum periodisch sein)✅ Gestaffelte Aktualisierungsfrequenzen verwenden✅ Wert und Kosten abwägen – nur so oft aktualisieren, wie es sich auf Entscheidungen auswirkt |
| Sicherheit und Zugriffskontrolle | Live-Systeme haben häufig eine Verbindung zu sensiblen internen oder externen Daten (CRM, EHR, Finanzsysteme), was Risiken durch unbefugten Zugriff oder Datenlecks mit sich bringt. | ✅ Setzen Sie den geringstmöglichen Zugriff für APIs durch und Limitieren Sie die Berechtigungen von Agenten. ✅ Überprüfen Sie alle Datenabrufe, die der Agent durchführt. ✅ Wenden Sie Verschlüsselung, sichere Kanäle, Authentifizierung und Aktivitätsprotokollierung an. ✅ Verwenden Sie Anomalieerkennung, um ungewöhnliches Zugriffsverhalten zu kennzeichnen. |
| Fehlerbehandlung und Fallback-Strategien | Live-Datenquellen können aufgrund von API-Ausfallzeiten, Latenzspitzen oder fehlerhaften Daten ausfallen. Agenten müssen diese Störungen elegant bewältigen. | ✅ Implementieren Sie Wiederholungsversuche, Timeouts und Fallback-Mechanismen (z. B. zwischengespeicherte Daten, Eskalation an Menschen). ✅ Protokollieren und überwachen Sie Metriken für Fehler wie fehlende Daten oder Latenzanomalien. ✅ Sorgen Sie für eine sanfte Degradierung statt für einen stillen Ausfall. |
| Compliance und Datenverwaltung | Live-Wissen umfasst häufig regulierte oder personenbezogene Informationen, die eine strenge Überwachung und Rückverfolgbarkeit erfordern. | ✅ Klassifizieren Sie Daten nach Sensibilität und wenden Sie Aufbewahrungsrichtlinien an. ✅ Behalten Sie die Herkunft der Daten im Blick – führen Sie die Nachverfolgung von Ursprüngen, Aktualisierungen und Verwendung durch. ✅ Richten Sie eine Governance für Agentenschulungen, Speicher und Datenaktualisierungen ein. ✅ Beziehen Sie Rechts- und Compliance-Teams frühzeitig ein, insbesondere in regulierten Branchen. |
📖 Weiterlesen: Die besten Suchsoftwarelösungen für Enterprise-Unternehmen
Die Zukunft von Live-Wissen in der KI
Mit Blick auf die Zukunft wird sich Live-Wissen weiterentwickeln und die Funktion von KI-Agenten prägen – weg von der Reaktion hin zur Antizipation, weg von isolierten Agenten hin zu Netzwerken kooperierender Agenten und weg von zentralisierten Cloud-Architekturen hin zu Edge-verteilten Architekturen.
Vorausschauendes Wissens-Caching
Anstatt auf Anfragen zu warten, laden Agenten proaktiv Daten vorab und speichern sie im Cache, die sie wahrscheinlich benötigen werden. Vorausschauende Caching-Modelle analysieren historische Zugriffsmuster, zeitliche Zusammenhänge (z. B. Marktöffnungszeiten) und die Absichten der Benutzer, um Dokumente, Newsfeeds oder Telemetriedaten in schnelle lokale Speicher vorab zu laden, sodass der Agent mit einer Latenz von weniger als einer Sekunde reagieren kann.
Anwendungsfälle: Ein Investmentagent lädt vor Börsenbeginn Gewinnberichte und Liquiditätsübersichten vor; ein Mitarbeiter des Kundensupports ruft vor einem geplanten Support-Anruf die aktuellen Tickets und Produktdokumente vorab ab. Untersuchungen zeigen, dass KI-gesteuertes vorausschauendes Vorabrufen und Cache-Platzierung die Trefferquoten deutlich verbessern und die Latenz in Edge- und Content-Delivery-Szenarien reduzieren.
Neue Standards und Protokolle
Interoperabilität beschleunigt den Fortschritt. Protokolle wie das Model Context Protocol (MCP) und Initiativen von Anbietern (z. B. Algolias MCP Server) schaffen standardisierte Möglichkeiten für Agenten, Live-Kontext aus externen Systemen anzufordern, einzufügen und zu aktualisieren. Standards reduzieren maßgeschneiderten Glue-Code, verbessern die Sicherheitskontrollen (klare Schnittstellen und Authentifizierung) und erleichtern die Kombination von Abrufspeichern, Speicherschichten und Schlussfolgerungsmaschinen verschiedener Anbieter. In der Praxis ermöglicht die Einführung von MCP-ähnlichen Schnittstellen den Teams, Abrufdienste auszutauschen oder neue Datenfeeds hinzuzufügen, ohne dass die Agenten großartig umgestellt werden müssen.
Integration mit Edge- und verteilten Systemen
Live-Wissen am Rand bietet zwei wesentliche Vorteile: reduzierte Latenz und verbesserter Datenschutz/Kontrolle. Geräte und lokale Gateways hosten kompakte Agenten, die lokal wahrnehmen, denken und handeln und sich selektiv mit Cloud-Repositorys synchronisieren, wenn das Netzwerk oder die Richtlinien dies zulassen.
Dieses Muster eignet sich für die Fertigung (wo Fabrikmaschinen lokale Steuerungsentscheidungen treffen), Fahrzeuge (Bordagenten, die auf Sensorfusion reagieren) und regulierte Bereiche, in denen Daten lokal bleiben müssen. Branchenumfragen und Edge-KI-Berichte sagen eine schnellere Entscheidungsfindung und eine geringere Abhängigkeit von der Cloud voraus, da Verteilung und föderierte Techniken immer ausgereifter werden.
Für Teams, die Live-Wissensstacks aufbauen, bedeutet dies, mehrschichtige Architekturen zu entwerfen, in denen kritische, latenzempfindliche Inferenz lokal ausgeführt wird, während langfristiges Lernen und umfangreiche Modellaktualisierungen zentral erfolgen.
Multi-Agenten-Wissensaustausch
Das Single-Agent-Modell weicht zunehmend kollaborativen Agenten-Ökosystemen.
Multi-Agent-Frameworks ermöglichen es mehreren spezialisierten Agenten, Situationsbewusstsein freizugeben, gemeinsame Wissensgraphen zu aktualisieren und Aktionen zu koordinieren – was sie besonders nützlich für das Flottenmanagement, Lieferketten und groß angelegte Operationen macht.
Neueste Forschungsergebnisse zu LLM-basierten Multi-Agenten-Systemen zeigen Methoden für Verteilung der Planung, Spezialisierung der Rollen und Konsensbildung zwischen Agenten auf. In der Praxis benötigen Teams gemeinsame Schemata (gemeinsame Ontologien), effiziente Pub/Sub-Kanäle für Statusaktualisierungen und eine Logik zur Konfliktlösung (wer überschreibt was und wann).
Kontinuierliches Lernen und Selbstverbesserung
Live-Wissen verbindet Abruf, Schlussfolgerung, Erinnerung, Aktion und kontinuierliches Lernen zu geschlossenen Kreisläufen. Agenten beobachten Ergebnisse, integrieren Korrektursignale und aktualisieren Erinnerungen oder Wissensgraphen, um zukünftiges Verhalten zu verbessern.
Die größten technischen Herausforderungen bestehen darin, katastrophales Vergessen zu verhindern, die Herkunft zu bewahren und die Sicherheit von Online-Updates zu gewährleisten. Aktuelle Umfragen zum kontinuierlichen Online-Lernen und zur Agentenanpassung skizzieren praktische Ansätze (episodische Speicherpuffer, Wiederholungsstrategien und eingeschränkte Feinabstimmung), die eine kontinuierliche Modellverbesserung ermöglichen und gleichzeitig Abweichungen begrenzen. Für Teams bedeutet dies, in gekennzeichnete Feedback-Pipelines, sichere Update-Richtlinien und Überwachungsmaßnahmen zu investieren, die das Modellverhalten mit realen KPIs verknüpfen.
Live-Wissen mit ClickUp in die Arbeit einbringen
Die nächste Grenze der KI in der Arbeit sind nicht nur intelligentere Modelle.
Live-Wissen ist das Bindeglied zwischen statischer Intelligenz und adaptivem Handeln und ermöglicht es KI-Agenten, mit einem Echtzeitverständnis von Projekten, Prioritäten und Fortschritten zu arbeiten. Unternehmen, die ihre KI-Systeme mit aktuellen, kontextbezogenen und vertrauenswürdigen Daten füttern können, werden das wahre Potenzial der Umgebungsintelligenz ausschöpfen: nahtlose Koordination, schnellere Ausführung und bessere Entscheidungen in jedem Team.
ClickUp wurde für diesen Wandel entwickelt. Durch die Vereinheitlichung von Aufgaben, Dokumenten, Zielen, Chats und Erkenntnissen in einem vernetzten System bietet ClickUp KI-Agenten eine lebendige, atmende Quelle der Wahrheit – keine statische Datenbank. Dank seiner kontextbezogenen und umgebungsbezogenen KI-Fähigkeiten bleiben Informationen in jedem Workflow aktuell, sodass die Automatisierung auf der Realität basiert und nicht auf veralteten Momentaufnahmen.
Da die Arbeit immer dynamischer wird, werden Tools, die den Kontext in Bewegung verstehen, den nächsten Vorsprung der Produktivität definieren. Die Mission von ClickUp ist es, dies zu ermöglichen – wo jede Aktion, jede Aktualisierung und jede Idee sofort die nächste beeinflusst und wo Teams endlich erleben, was KI leisten kann, wenn Wissen live bleibt.
Häufig gestellte Fragen
Live-Wissen steigert die Leistung, indem es den aktuellen Kontext bereitstellt: Entscheidungen basieren auf aktuellen Fakten statt auf veralteten Daten. Das führt zu genaueren Antworten, schnelleren Reaktionszeiten und einem höheren Vertrauen der Benutzer.
Viele können dies, aber nicht alle müssen es. Agenten, die in stabilen Kontexten mit geringen Veränderungen arbeiten, profitieren möglicherweise nicht so sehr davon. Aber für jeden Agenten, der mit dynamischen Umgebungen (Märkte, Kunden, Systeme) konfrontiert ist, ist Live-Wissen ein leistungsstarker Wegbereiter.
Das Testen umfasst die Simulation realer Veränderungen: Variieren Sie die Live-Eingaben, fügen Sie Ereignisse ein, messen Sie die Latenz, überprüfen Sie die Agentenausgaben und suchen Sie nach Fehlern oder veralteten Antworten. Überwachen Sie End-to-End-Workflows, Benutzerergebnisse und die Robustheit des Systems unter Live-Bedingungen.