
LLaMAを検討するほとんどの企業チームは同じ段階で立ち往生します:モデル重みをダウンロードし、ターミナル画面を見つめながら、次に何をすべきか全く見当がつかないことに気づくのです。
この課題は広く見られる現象です——88%の企業が少なくとも1つの機能でAIを活用している一方で、組織全体に拡大できているのはわずか7%に過ぎません。
本ガイドでは、ユースケースに適したモデルサイズの選択から自社データを用いた微調整まで、完全なプロセスを解説します。これにより、実際のビジネス状況を理解する実用的なAIソリューションを展開できます。
LLaMAとは何か?なぜ企業向けAIにとって重要なのか?
LLaMA(Large Language Model Meta AIの略称)はMetaが開発したオープンソースの言語モデル群です。大まかに言えば、GPTやGeminiといったモデルと同様のコア機能(言語理解、テキスト生成、情報横断的な推論)をやっています。最大の違いは、企業がそれをどのように活用できるかという点にあります。
LLaMAはオープンソースのため、企業はブラックボックスAPIを介したみなしぎみでのみ利用する必要はありません。自社インフラ上で実行し、内部データで微調整を行い、展開方法や場所を制御できます。
企業にとってこれは非常に大きな意味を持ちます。特に、データのプライバシー、コンプライアンス、コスト予測可能性が新規性よりも重要視される場合にはなおさらです。
この柔軟性により、LLaMAは単なるスタンドアロンのチャットボットとして追加するのではなく、ワークフローに深く組み込まれたAIを求めるチームにとって特に魅力的です。組織外に機密データを送信することなく、内部ナレッジアシスタント、カスタマーサポート自動化、開発者ツール、製品に直接組み込まれたAI機能などを実現できます。
要するに、LLaMAが企業向けAIにおいて重要なのは、チームにデプロイ方法、カスタム化、実際のビジネスシステムへのAI統合に関する選択肢を与えるからです。そしてAIが実験段階から日常業務へと移行するにつれ、このレベルの制御は「あれば便利なもの」から「必須要件」へと変化していきます。
企業アプリケーション向けLLaMA導入の手順
1. 企業のユースケースを定義する
ダウンロード前に、AIが真のインパクトをもたらす具体的なワークフローを特定しましょう。AIユースケースとモデルサイズの適合が鍵です。単純なタスクには効率的な80億パラメータモデルが、複雑な推論には700億パラメータ以上の大規模モデルが適しています。
貴社のビジネスに最適なAIアプリケーションを見極めるため、様々な企業機能や業界における実用的なAI活用事例の概要をご覧ください:
一般的な開始点には以下が含まれます:
- 文書処理:長文レポートの要約や契約書からの重要情報抽出
- コード支援:定型コードの生成、レガシーシステムの解説、最適化の提案
- ナレッジ検索:Retrieval-Augmented Generation(RAG)技術を用いて社内文書を検索し、従業員の質問に回答する
- コンテンツ生成: 初期段階のコミュニケーション文書やマーケティングコピーの起草
2. 前提条件と依存関係の設定
次に、ハードウェアとソフトウェアを準備します。モデルサイズによって必要なリソースが異なります。LLaMA 8Bモデルには約15GBのVRAMを搭載したGPUが必要ですが、70Bモデルには131GB以上が必要です。
ソフトウェアスタックにはPython 3.8以上、PyTorch、CUDAドライバー、Hugging Faceエコシステム(transformers、accelerate、bitsandbytes)を含める必要があります。
3. LLaMAモデルの重み値にアクセスしてダウンロードする
モデル重みはMeta公式LlamaダウンロードページまたはHugging Faceモデルhubから 入手可能です。商用利用を許可するLlama 3コミュニティライセンスに同意する必要があります。セットアップに応じて、safetensorsフォーマットまたはGGUFフォーマットで重みをダウンロードします。
4. 開発環境の設定
重みをダウンロードしたら、環境設定を行います。必要なPythonライブラリ(transformers、accelerate、量子化処理用のbitsandbytesなど)をインストールします。量子化処理はモデルのメモリ使用量を削減するプロセスです。
適切な設定でモデルを読み込み、カスタマイズに進む前に簡単なテストプロンプトを実行し、すべてが正しく動作していることを確認してください。
💡専任の機械学習インフラチームがいない場合、このプロセス全体が実現不可能になる可能性があります。ClickUp Brainならデプロイの複雑さを完全に回避。チームが既に活動しているワークスペース内で、文章作成支援やタスク自動化といったAI機能を直接提供します。モデルのダウンロードやGPUプロビジョニングは不要です。
企業データ向けにLLaMAをカスタムする方法
ベースとなるLLaMAモデルの使用は良い出発点ですが、御社の固有の略語、プロジェクト名、内部プロセスを理解することはできません。その結果、汎用的で役に立たない応答が生じ、実際のビジネス課題を解決できません。
企業向けAIはカスタマイズによって真価を発揮します——独自の用語体系やナレッジベースでモデルを訓練することで。
ドメイン固有のトレーニングデータを準備する
カスタムAIの成功は、モデルのサイズや計算能力よりも、トレーニングデータの品質に大きく依存します。まずは社内情報の収集とクリーニングから始めましょう。
- 内部文書:製品仕様書、プロセスガイド、ポリシー文書を収集する
- 過去のコミュニケーション記録:電子メールテンプレート、サポートチケットの応答、ミーティング要約を収集する
- 専門用語集:用語集、略語の定義、業界固有の言語をまとめてください
収集した情報を、教師あり微調整用の指示-応答ペアにフォーマットします。例えば、指示が「このサポートチケットを要約してください」であれば、応答は簡潔で明確な要約となります。このステップは、モデルにデータを用いた特定のタスクの実行方法を教える上で極めて重要です。
📮 ClickUpインサイト:平均的なビジネスパーソンは1日30分以上を仕事関連情報の検索に費やしています。電子メールやSlackのスレッド、散らばったファイルを掘り起こすことで、年間120時間以上が失われている計算です。ワークスペースに組み込まれたインテリジェントなAIアシスタントが、この状況を変えます。
ClickUp Brainが登場。適切な文書、会話、タスク詳細を瞬時に抽出し、即座に洞察と回答を提供します。検索作業を止め、すぐに仕事を開始できます。
💫 実証済み結果:QubicaAMFのようなチームは、旧式のナレッジ管理プロセスを排除することで、ClickUpを活用し週5時間以上(年間1人あたり250時間超)の時間を創出しました。四半期ごとに1週間分の生産性が追加されたら、あなたのチームが何を創造できるか想像してみてください!
ビジネスコンテキストでLLaMAを微調整する
ファインチューニングとは、LLaMAの既存知識を特定のユースケースに適応させるプロセスであり、これによりドメイン固有タスクの精度が劇的に向上します。モデルを一から訓練する代わりに、パラメーターのごく一部のみを更新するパラメータ効率の良い手法を利用できるため、時間と計算リソースを節約できます。
一般的な微調整手法には以下が含まれます:
- LoRA(低ランク適応法): モデル全体ではなく小さな「アダプター」マトリックスを学習させる手法で、非常に効率的です
- QLoRA: LoRAと量子化を組み合わせ、48GB GPU 1台でのファインチューニングを可能にしつつ、フルファインチューニングと同等の性能を実現します
- 完全な微調整:モデルの全パラメーターを更新する手法。最高レベルのカスタムが可能だが、膨大な計算リソースを必要とする
📚 関連記事:企業向け生成AIツールが仕事を変革する
モデル性能の評価と反復改善
カスタマイズしたモデルが実際に機能しているかどうかの確認方法とは?AI評価は単純な精度スコアを超え、実世界の有用性を測定する必要があります。本番環境のユースケースを反映した評価データセットを作成し、応答品質、事実の正確性、レイテンシーなど、ビジネスにとって重要なメトリクスを追跡しましょう。
- 定性的評価: 人間によるレビューアが、出力のトーン、有用性、正確性を評価する
- 定量メトリクス:BLEUスコアやパープレクシティなどの自動化による評価指標を活用し、大規模環境での性能を追跡する
- 運用監視:デプロイ後は、ユーザーフィードバックとエラー率を追跡し、改善点を特定する
💡この反復的なトレーニングと評価のプロセス自体がプロジェクトとなる可能性があります。スプレッドシートに埋もれることなく、ClickUpで直接AI開発ライフサイクルを管理しましょう。
ClickUpダッシュボードでパフォーマンスメトリクスと評価結果を一元管理。ClickUpカスタムフィールドを活用し、モデルバージョン・トレーニングパラメーター・評価スコアを他のプロダクト仕事と並行して追跡。全てを整理し可視化します。🛠️
LLaMAの主要な企業向け活用事例
チームはしばしば分析麻痺に陥り、AIへの抽象的な期待から具体的な応用へと進めません。LLaMAの柔軟性は幅広い企業ワークフローに適応し、タスクの自動化と効率的な業務実現を支援します。
カスタム調整済みLLaMAモデルの主な活用事例:
- 社内ナレッジアシスタント:情報探しに時間を浪費するのはやめましょう。RAG(Retrieval-Augmented Generation)機能を備えたLLaMAを導入し、社内wiki、ポリシー文書、過去のプロジェクト通信を検索して従業員の質問に即座に回答できるチャットボットを作成します。
- カスタマーサポート自動化:チケット履歴でモデルを微調整し、自動応答文作成、問い合わせ分類、複雑な問題の適切な担当エージェントへのエスカレーションを実現。
- コード生成とレビュー:エンジニアリングチームの効率化を支援。LLaMAで定型コードを生成し、複雑なレガシーシステムを説明し、プルリクエスト内の潜在的なバグを問題化する前に特定します
- 文書処理:大量のテキストを有用な情報に変換。長大なレポートを要約する、法的契約書からの重要用語を抽出する、生の議事録から数秒で簡潔なミーティングメモを生成
- コンテンツ作成ワークフロー: ライターのブロックを克服。マーケティングコピー、製品説明、社内アナウンスメントの下書きを作成し、人間のエディターがそれを磨き上げ完成させます。
💡ClickUp Brainなら、これらのユースケースの多くをすぐに利用可能。
- タスクスレッドの要約、プロジェクト進捗報告書の作成、コンテンツ生成を、ClickUpのAI搭載ライティングアシスタントで実現
- ClickUpの企業検索と事前構築済みAmbient Answersエージェントで、ワークスペース全体から瞬時に回答を見つけられます
- ClickUp自動化で日常業務を代行するインテリジェントなワークフローを構築
企業AIにおけるLLaMA利用の制限事項
LLaMAの自社ホスティングは高度な制御を可能にする一方、課題も伴います。多くのチームは運用上の負担を過小評価し、イノベーションではなくメンテナンスに時間を取られてしまいます。「構築」の道にコミットする前に、潜在的なハードルを理解することが極めて重要です。
考慮すべき主な制限事項は以下の通りです:
- インフラ要件:大規模モデルの実行にはコストがかかり、多くの組織が保有していない強力な企業グレードのGPUが必要です
- 必要な技術的専門知識:大規模言語モデルのデプロイ、微調整、保守には、需要の高い専門的な機械学習エンジニアリングスキルが必要です
- 継続的な保守負担:これは「設定したら放置できる」ソリューションではありません。ビジネスが進化するにつれ、モデルには継続的な監視、セキュリティ更新、再トレーニングが必要です。
- 幻覚リスク:他の大規模言語モデルと同様、LLaMAも時として信憑性のあるように聞こえるが誤った情報を生成する可能性があります。企業向けアプリケーションでは、このリスクを軽減するために堅牢なガードレールと人間の監視が必要です。
- 組み込みの企業機能なし:アクセス制御、監査ログ、コンプライアンスツールなどの重要な機能は別途構築・管理が必要であり、複雑さが一層増します
💡これらの制限はClickUp Brainで回避可能です。既存ワークスペース内で管理されたAIを提供し、運用オーバーヘッドなしで企業AI機能を実現します。ClickUpなら企業レベルのセキュリティを確保し、インフラ保守を不要に。チームはコア仕事に集中できます。
📮ClickUpインサイト:アンケートの回答者の88%が個人タスクにAIを活用している一方、50%以上が仕事での利用を避けています。主な障壁は?シームレスな統合の欠如、知識不足、セキュリティ懸念の3点です。
しかし、もしAIがワークスペースに組み込まれていて、すでにセキュリティが確保されているならどうでしょう?ClickUp Brain(ClickUpの組み込みAIアシスタント)がこれを実現します。平易な言語でのプロンプトを理解し、AI導入の3つの懸念事項をすべて解決しながら、ワークスペース全体のチャット、タスク、ドキュメント、ナレッジを接続します。ワンクリックで答えと洞察を見つけましょう!
企業向けユースケースにおける代替AIツール
数ある選択肢から適切なAIツールを選ぶことは、どのチームにとっても課題です。異なるモデル間のトレードオフを把握しようとしている一方で、誤った選択をしてリソースを浪費するのではないかと懸念しています。
これはしばしば「AIスプロール」を招く——計画性や戦略のないAIツールやプラットフォームの無秩序な拡大——チームが複数の連携しないサービスを利用することで、仕事量が減るどころか増え続ける状態である。
主要プレイヤーの概要と位置付けを簡単に説明します:
| ツール | 最適用途 | 主な考慮事項 |
|---|---|---|
| LLaMA(自社ホスティング) | 最大限の制御、データ主権の確保 | 機械学習インフラと専門知識が必要です |
| OpenAI GPT-4 | 最高性能、最小限のセットアップ | データは環境外へ流出、使用量ベースの課金 |
| Claude (Anthropic) | 長文処理タスク、安全性の重視 | GPT-4と同様のトレードオフ |
| Mistral | 欧州データ居住性、効率性 | LLaMAよりも小規模なエコシステム |
| ClickUp Brain | 統合ワークスペースAI、デプロイ不要 | 既存のワークフローにAIを導入したいチームに最適 |
複数のツールを繋ぎ合わせてニーズを満たす代わりに、作業現場に直接組み込まれたAIを活用してみませんか?これが世界初の統合型AIワークスペース「ClickUp」の中核です。プロジェクト、文書、会話、分析が共存する単一の安全なプラットフォームです。
ツールを統合し、コンテキストの拡散を解消します。これは、チームが業務に必要な情報を探すためにアプリ間を移動する時間を浪費することで生じる分断状態です。
ClickUp + コンテクストAI = 測定可能な変革
Forrester Economic Impact™調査によると、ClickUpを導入したTeamsは3年目までに384%のROIを達成し、92,400時間の業務時間を削減しました。

コンテキスト、ワークフロー、知性が一つの場所に集約されると、チームは単に仕事をするだけではありません。勝利を収めるのです。
ClickUpは、SOC 2 Type II準拠、SSO統合、SCIMプロビジョニング、詳細な許可制限など、企業導入に必要なセキュリティと管理機能も提供します。
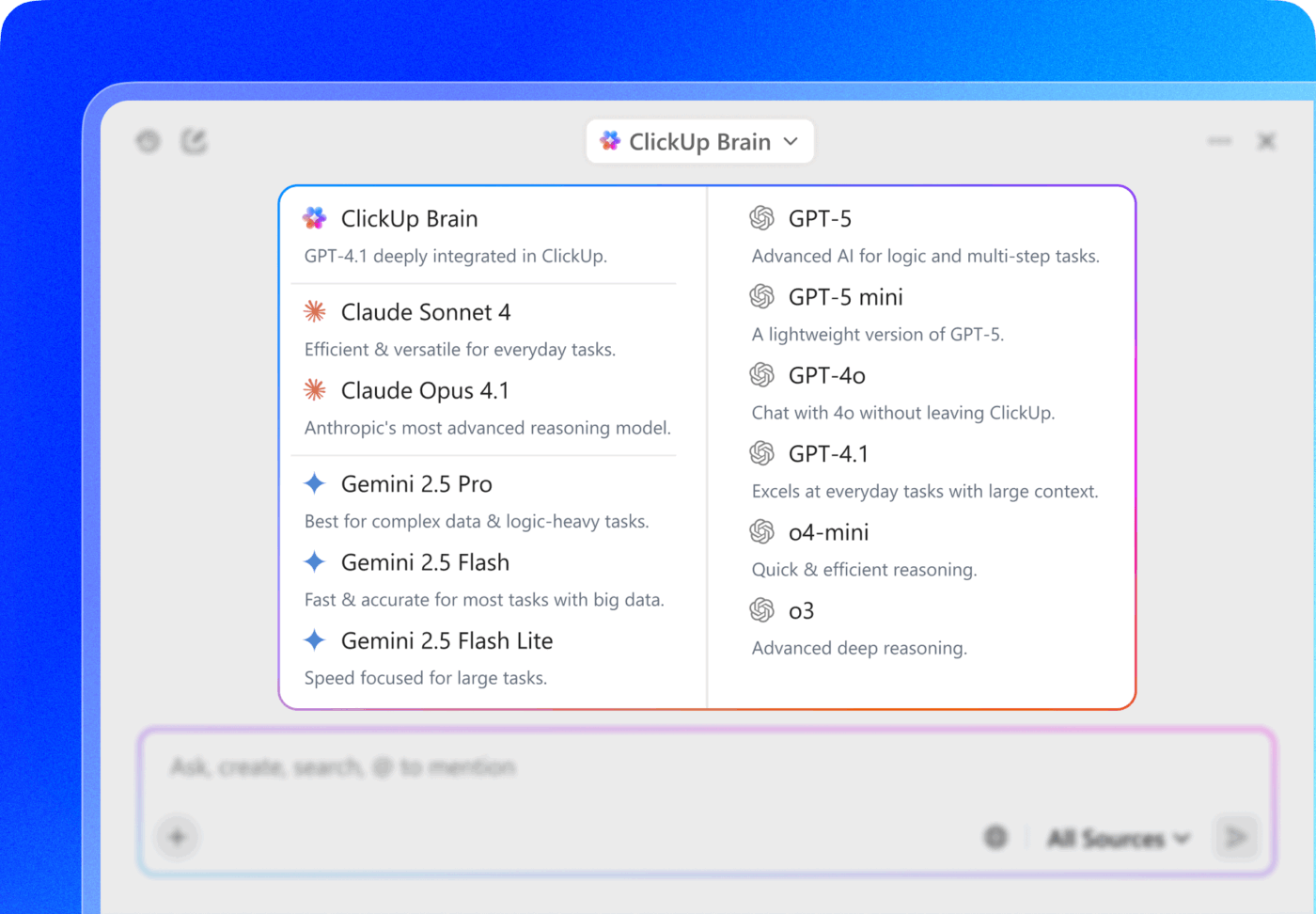
ClickUp Brain MAXのマルチLLMアクセスにより、検索インターフェースから直接ChatGPT、Claude、Geminiなどのプレミアムモデルを選択可能。プラットフォームが最適なモデルへ自動的にクエリをルーティングするため、複数のサブスクリプションを管理することなく、あらゆるモデルの利点を最大限に活用できます。
LLaMAでAIレイヤーを一から構築する代わりに、ClickUpでAI機能、プロジェクト管理、ドキュメント、コミュニケーションをすべて一箇所に集約した統合スタックを手に入れましょう。
ClickUpで企業AIを前進させる
LLaMAは企業チームに閉じたAI APIに代わるオープンな選択肢を提供し、大幅な制御性、コスト予測可能性、カスタマイズ性を実現します。しかし成功は技術だけでは決まりません。適切なユースケースに最適なモデルをマッチングさせ、高品質なトレーニングデータに投資し、堅牢な評価プロセスを構築することが必要です。
「自社開発か購入か」の判断は、最終的にはチームの技術力にかかっています。カスタムソリューションの構築は最大限の柔軟性を提供しますが、大きなオーバーヘッドも伴います。真の課題は単にAIにアクセスすることではなく、AIの拡散やデータサイロを増やさずに日常ワークフローに統合することです。
ClickUp BrainでLLM機能をプロジェクト管理、ドキュメント作成、チームコミュニケーションに直接導入。インフラ構築・維持の煩わしさなし。ClickUpで無料開始し、既存ワークフローにAI機能を直接組み込みましょう。🙌
よくある質問(FAQ)
はい、Llama 3コミュニティライセンスはほとんどの組織で商用利用を許可しています。月間アクティブユーザー数が7億を超える企業のみ、Metaから別途ライセンスを取得する必要があります。
LLaMAは自社ホスティングによりデータ管理の強化と予測可能なコストを実現する一方、GPT-4はセットアップの手間が少なく高い初期性能を提供します。ただし生産性向上には、ClickUp Brainのような統合ツールを通じて基盤モデルを管理せずにAI支援を活用すべきです。
LLaMAを自社でホスティングすれば、データは自社インフラに保持されるため、データ居住性には最適です。ただし、アクセス制御、監査ログ、コンテンツフィルタリングといったセキュリティ機能(通常はマネージドAIサービスに含まれる)の実装は、すべて自社で行う必要があります。
LLaMAを直接デプロイ・微調整するには高度な機械学習エンジニアリングスキルが必要です。専門知識を持たないチームは、ClickUp Brainのようなマネージドプラットフォームを通じてLLaMAベースの機能を利用できます。このプラットフォームでは、モデルデプロイや技術的な設定が一切不要でAI機能を提供します。