
La maggior parte degli sviluppatori che creano uno script di riepilogo/riassunto Hugging Face si scontrano con lo stesso ostacolo: il riepilogo funziona perfettamente nel loro terminale, ma raramente effettua la connessione al lavoro reale che dovrebbe supportare.
Questa guida ti accompagna nella creazione di un riassuntore di testo con la libreria Transformers di Hugging Face, quindi ti mostra perché anche un'implementazione impeccabile può creare più problemi di quanti ne risolva quando il tuo team ha bisogno di riassunti che siano effettivamente collegati ad attività, progetti e decisioni.
Che cos'è la sintesi dei testi?
I team sono sommersi dalle informazioni. Ti trovi di fronte a documenti lunghi, trascrizioni di riunioni infinite, articoli di ricerca complessi e relazioni trimestrali che richiedono ore per essere analizzati manualmente. Questo costante sovraccarico di informazioni rallenta il processo decisionale e riduce la produttività.
La riassunzione dei testi è il processo che utilizza l'elaborazione del linguaggio naturale (NLP) per condensare questi contenuti in una versione breve e coerente che conservi le informazioni più importanti. Considerala come una riassunzione esecutiva istantanea di qualsiasi documento. Questa tecnologia di riassunzione NLP utilizza generalmente uno dei due approcci seguenti:
Riepilogo estrattivo: questo metodo funziona identificando ed estraendo le frasi più importanti direttamente dal testo originale. È come avere un evidenziatore che seleziona automaticamente i punti chiave per te. Il riepilogo finale è una raccolta di frasi originali.
Riassunto astratto: questo metodo più avanzato genera frasi completamente nuove per catturare il significato fondamentale del testo di partenza. Parafrasa le informazioni, ottenendo un riepilogo/riassunto più fluido e simile a quello umano, proprio come una persona spiegherebbe una lunga storia con parole proprie.
I risultati di questo approccio sono visibili ovunque. Viene utilizzato per condensare gli appunti delle riunioni in elementi concreti, sintetizzare il feedback dei clienti in tendenze e creare rapide panoramiche della documentazione del progetto. L'obiettivo è sempre lo stesso: ottenere le informazioni essenziali senza leggere ogni singola parola.
📮 ClickUp Insight: Il professionista medio trascorre più di 30 minuti al giorno alla ricerca di informazioni relative al lavoro. Si tratta di oltre 120 ore all'anno perse a setacciare email, thread di Slack e file sparsi. Un assistente IA intelligente integrato nella tua area di lavoro può cambiare questa situazione. ClickUp Brain fornisce approfondimenti e risposte immediate facendo emergere i documenti, le conversazioni e i dettagli delle attività giusti in pochi secondi, così puoi smettere di cercare e iniziare a lavorare.
💫 Risultati reali: team come QubicaAMF hanno recuperato più di 5 ore alla settimana utilizzando ClickUp, oltre 250 ore all'anno a persona, eliminando processi di gestione delle conoscenze obsoleti.
Perché utilizzare Hugging Face per la sintesi di testi?
Creare da zero un modello personalizzato per la sintesi del testo è un'impresa titanica. Richiede enormi set di dati per l'addestramento, risorse computazionali potenti e costose e un team di esperti di machine learning. Queste elevate barriere all'ingresso impediscono alla maggior parte dei team di ingegneri e di prodotto di mettersi all'opera.
Hugging Face è la piattaforma che risolve questo problema. Si tratta di una piattaforma open source di community e data science che ti dà accesso a migliaia di modelli pre-addestrati, democratizzando efficacemente la funzione di riepilogamento/riassunto LLM per gli sviluppatori. Invece di partire da zero, puoi iniziare con un modello potente che è già al 99% del lavoro.
Ecco perché così tanti sviluppatori si affidano a Hugging Face: 🛠️
Accesso al modello pre-addestrato: Hugging Face Hub è un enorme repository di oltre 2 milioni di modelli pubblici addestrati da aziende come Google, Meta e OpenAI. Puoi scaricare e utilizzare questi checkpoint all'avanguardia per i tuoi progetti.
API pipeline semplificata: la funzione pipeline è un'API di alto livello che gestisce tutti i passaggi complessi, come la pre-elaborazione del testo, l'inferenza del modello e la formattazione dell'output, in poche righe di codice.
Varietà di modelli: non sei vincolato a un'unica opzione. Puoi scegliere tra un ampio intervallo di architetture come BART, T5 e Pegasus, ciascuna con diversi punti di forza, dimensioni e caratteristiche prestazionali.
Flessibilità del framework: la libreria Transformers funziona perfettamente con i due framework di deep learning più popolari, PyTorch e TensorFlow. Puoi utilizzare quello con cui il tuo team ha già familiarità.
Supporto della community: grazie alla documentazione completa, ai corsi ufficiali e a una community attiva di sviluppatori, è facile trovare tutorial e ottenere aiuto quando si incontrano problemi.
Sebbene Hugging Face sia incredibilmente potente per gli sviluppatori, è importante ricordare che si tratta di una soluzione basata su codice. Richiede competenze tecniche per l'implementazione e la manutenzione. Questo non è sempre l'ideale per i team non tecnici che hanno solo bisogno di riepilogare il proprio lavoro.
🧐 Lo sapevi? La libreria Transformers di Hugging Face ha reso mainstream l'uso di modelli NLP all'avanguardia con poche righe di codice, motivo per cui i prototipi per la riepilogazione/riassunzione spesso partono da lì.
Cosa sono i trasformatori Hugging Face?
Hai deciso di utilizzare Hugging Face, ma qual è la tecnologia che lo rende possibile? La tecnologia di base è un'architettura chiamata Transformer. Quando è stata introdotta in un articolo del 2017 intitolato "Attention Is All You Need", ha rivoluzionato il campo dell'NLP.
Prima dei Transformers, i modelli faticavano a comprendere il contesto delle frasi lunghe. L'innovazione chiave del Transformer è il meccanismo di attenzione, che consente al modello di valutare l'importanza delle diverse parole nel testo di input durante l'elaborazione di una parola specifica. Questo lo aiuta a cogliere le dipendenze a lungo raggio e a comprendere il contesto, fondamentale per creare riassunti coerenti.
La libreria Hugging Face Transformers è un pacchetto Python che rende incredibilmente facile l'utilizzo di questi modelli complessi. Non è necessario avere un dottorato in machine learning. La libreria semplifica il lavoro più complesso.
I tre componenti fondamentali che devi conoscere
- Tokenizzatori: i modelli non comprendono le parole, ma i numeri. Un tokenizzatore prende il testo inserito e lo converte in una sequenza di token numerici, un processo chiamato tokenizzazione, che il modello è in grado di elaborare.
- Modelli: si tratta delle reti neurali preaddestrate. Per riepilogare/riassumere, si tratta in genere di modelli sequenza-sequenza con una struttura encoder-decoder. L'encoder legge il testo di input per creare una rappresentazione numerica e il decoder utilizza tale rappresentazione per generare il riassunto.
- Pipeline: questo è il modo più semplice per utilizzare un modello. Una pipeline raggruppa un modello preaddestrato con il suo tokenizer corrispondente e gestisce per te tutti i passaggi di pre-elaborazione dell'input e post-elaborazione dell'output.
Due dei modelli più popolari per il riassunto sono BART e T5. BART (Bidirectional and Auto-Regressive Transformer) è particolarmente efficace nel riassunto astratto, producendo riassunti che si leggono in modo molto naturale. T5 (Text-to-Text Transfer Transformer) è un modello versatile che inquadra ogni attività di NLP come un problema di testo-testo, rendendolo un potente tuttofare.
🎥 Guarda questo video per vedere un confronto tra i migliori riassuntori PDF basati sull'IA e scopri quali strumenti forniscono i riassunti più rapidi e accurati senza perdere il contesto.
Come creare un riassuntore di testo con Hugging Face
Sei pronto a creare il tuo esempio di riassuntore? Tutto ciò che ti serve è una conoscenza di base di Python, un editor di codice come VS Code e una connessione Internet. L'intero processo richiede solo quattro passaggi. In pochi minuti avrai un riassuntore funzionante.
Passaggio 1: installa le librerie necessarie
Per prima cosa, devi installare le librerie necessarie. La principale è transformers. Avrai anche bisogno di un framework di deep learning come PyTorch o TensorFlow. Per questo esempio useremo PyTorch.
Apri il tuo terminale o prompt dei comandi ed esegui il seguente comando:

Alcuni modelli, come T5, richiedono anche la libreria sentencepiece per il loro tokenizer. È consigliabile installarla.

💡 Suggerimento professionale: crea un ambiente virtuale Python prima di installare questi pacchetti. In questo modo le dipendenze del tuo progetto rimarranno isolate e si eviteranno conflitti con altri progetti presenti sul tuo computer.
Passaggio 2: carica il modello e il tokenizer
Il modo più semplice per iniziare è utilizzare la funzione pipeline. Questa gestisce automaticamente il caricamento del modello e del tokenizer corretti per l'attività di riepilogamento/riassunto.
Nel tuo script Python, importa la pipeline e inizializzala in questo modo:

Qui specifichiamo due cose:
L'attività: diciamo alla pipeline che vogliamo eseguire la "riassunzione".
Il modello: scegliamo un checkpoint specifico pre-addestrato dall'Hugging Face Hub. facebook/bart-large-cnn è una scelta popolare addestrata su articoli di notizie e funziona bene per la sintesi generica. Per un test più rapido, è possibile utilizzare un modello più piccolo come t5-small.
La prima volta che esegui questo codice, scaricherà i pesi del modello dall'hub, operazione che potrebbe richiedere alcuni minuti. Successivamente, il modello verrà memorizzato nella cache del tuo computer locale per un caricamento immediato.
Passaggio 3: crea la funzione di sintesi
Per rendere il tuo codice pulito e riutilizzabile, è meglio racchiudere la logica di riassunto in una funzione. Questo rende anche più facile sperimentare con parametri diversi.
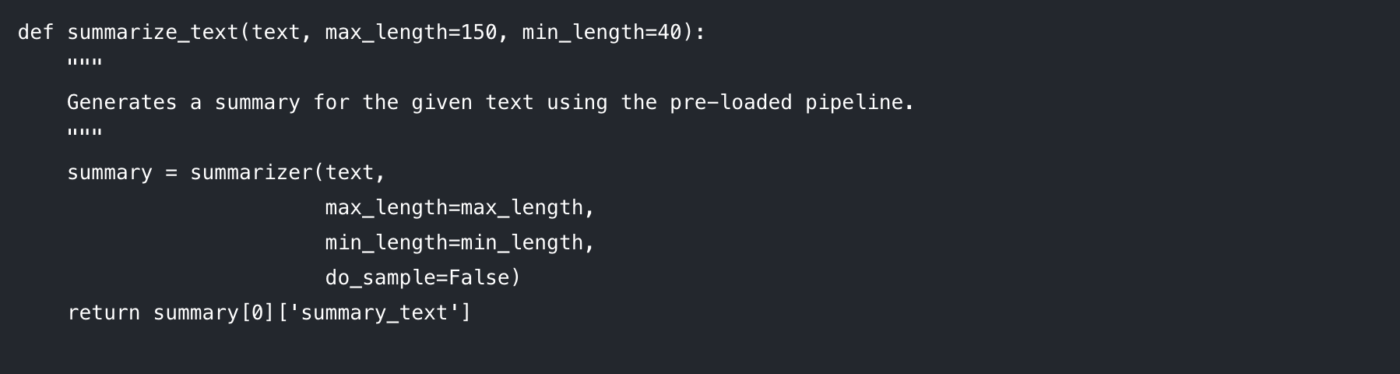
Analizziamo i parametri che puoi controllare:
max_length: imposta il numero massimo di token (approssimativamente, parole) per il riassunto di output.
min_length: imposta il numero minimo di token per impedire al modello di generare riassunti eccessivamente brevi o vuoti.
do_sample: quando impostato su False, il modello utilizza un metodo deterministico (come la ricerca beam) per generare il riepilogo/riassunto più probabile. Impostandolo su True si introduce la casualità, che può produrre risultati più creativi ma meno prevedibili.
La regolazione di questi parametri è fondamentale per ottenere la qualità di output desiderata.
Passaggio 4: genera il tuo riepilogo/riassunto
Ora viene la parte divertente. Passa il tuo testo alla funzione e stampa il risultato. 🤩

Dovresti vedere una versione condensata dell'articolo stampata sulla tua console. Se riscontri dei problemi, ecco alcune soluzioni rapide:
Il testo inserito è troppo lungo: il modello potrebbe generare un errore se l'input supera la lunghezza massima (spesso 512 o 1024 token). Aggiungi truncation=True all'interno della chiamata summarizer() per tagliare automaticamente gli input lunghi.
Il riepilogo/riassunto è troppo generico: prova ad aumentare il parametro num_beams (ad esempio, num_beams=4). In questo modo il modello cercherà in modo più approfondito un riepilogo/riassunto migliore, ma potrebbe essere leggermente più lento.
Questo approccio basato sul codice è fantastico per gli sviluppatori che creano app personalizzate. Ma cosa succede quando è necessario integrarlo nel lavoro quotidiano di un team? È qui che iniziano a manifestarsi i limiti.
Limiti di Hugging Face per la sintesi di testi
Hugging Face è un'ottima opzione quando si desidera flessibilità e controllo. Ma una volta che si prova a utilizzarlo per flussi di lavoro reali in team (non solo un notebook demo), emergono rapidamente alcune sfide prevedibili.
Limiti dei token e grattacapi causati dai documenti lunghi
La maggior parte dei modelli per il riassunto ha una lunghezza massima di input fissa. Ad esempio, facebook/bart-large-cnn è configurato con max_position_embeddings = 1024. Ciò significa che i documenti più lunghi spesso richiedono il troncamento o la suddivisione in blocchi.
Se hai solo bisogno di una base di riferimento rapida, puoi abilitare il troncamento nella pipeline e andare avanti. Ma se hai bisogno di riepiloghi/riassunti fedeli di documenti lunghi, in genere finisci per creare una logica di suddivisione in blocchi e poi fare un secondo passaggio, un "riepilogo dei riepiloghi", per unire i risultati. Si tratta di un lavoro ingegneristico aggiuntivo ed è facile ottenere risultati incoerenti.
Rischio di allucinazioni (e il costo della verifica)
I modelli astrattivi a volte possono generare allucinazioni, creando testi che sembrano plausibili ma che in realtà sono errati. Per gli usi aziendali critici, questo crea un problema: ogni riepilogo/riassunto deve essere verificato manualmente. A quel punto, non stai realmente risparmiando tempo, ma stai solo spostando il lavoro in una parte diversa del processo.
Mancanza di consapevolezza del contesto
Un modello Hugging Face conosce solo il testo che gli viene fornito. Non ha alcuna comprensione degli obiettivi del tuo progetto, delle persone coinvolte o di come un documento sia correlato a un altro, poiché manca dell'intelligenza contestuale dei sistemi moderni. Non è in grado di dirti se un riepilogo/riassunto di una chiamata di un cliente contraddice il documento dei requisiti del progetto, perché vive in modo isolato.
Overhead di integrazione (il problema dell'"ultimo miglio")
Generare un riepilogo/riassunto è solitamente la parte facile. La vera difficoltà è ciò che viene dopo.
Dove va a finire il riassunto? Chi lo vede? Come si trasforma in un'attività attuabile? Come lo colleghi al lavoro che lo ha generato?
Risolvere quell'ultimo ostacolo significa creare integrazioni personalizzate e codice di collegamento. Ciò comporta un lavoro aggiuntivo per gli sviluppatori e spesso crea un flusso di lavoro macchinoso per tutti gli altri.
Barriera tecnica e manutenzione continua
Un approccio basato su Python è accessibile principalmente a chi sa scrivere codice. Ciò crea un ostacolo pratico per i team di marketing, commerciali e di operazioni, il che significa che la sua adozione rimane limitata.
Include anche la manutenzione continua: gestione delle dipendenze, aggiornamento delle librerie e mantenimento del funzionamento di Tutto mentre le API e i modelli evolvono. Quello che inizia come un vantaggio immediato può diventare silenziosamente un altro sistema da gestire.
📮 ClickUp Insight: il 42% delle interruzioni sul lavoro deriva dal dover destreggiarsi tra piattaforme, gestire e-mail e passare da una riunione all'altra. E se fosse possibile eliminare queste costose interruzioni? ClickUp unisce i tuoi flussi di lavoro (e le chat) in un'unica piattaforma semplificata. Avvia e gestisci le tue attività da chat, documenti, lavagne online e altro ancora, mentre le funzionalità basate sull'intelligenza artificiale mantengono il contesto connesso, ricercabile e gestibile.
Il problema più grande: la proliferazione del contesto
Anche se il tuo script per la sintesi funziona perfettamente, il tuo team può comunque perdere tempo perché il risultato è scollegato dal luogo in cui si svolge effettivamente il lavoro.
Questo è il cosiddetto "context sprawl", ovvero quando i team perdono ore a cercare informazioni, passando da un'app all'altra e cercando file su piattaforme non collegate tra loro.
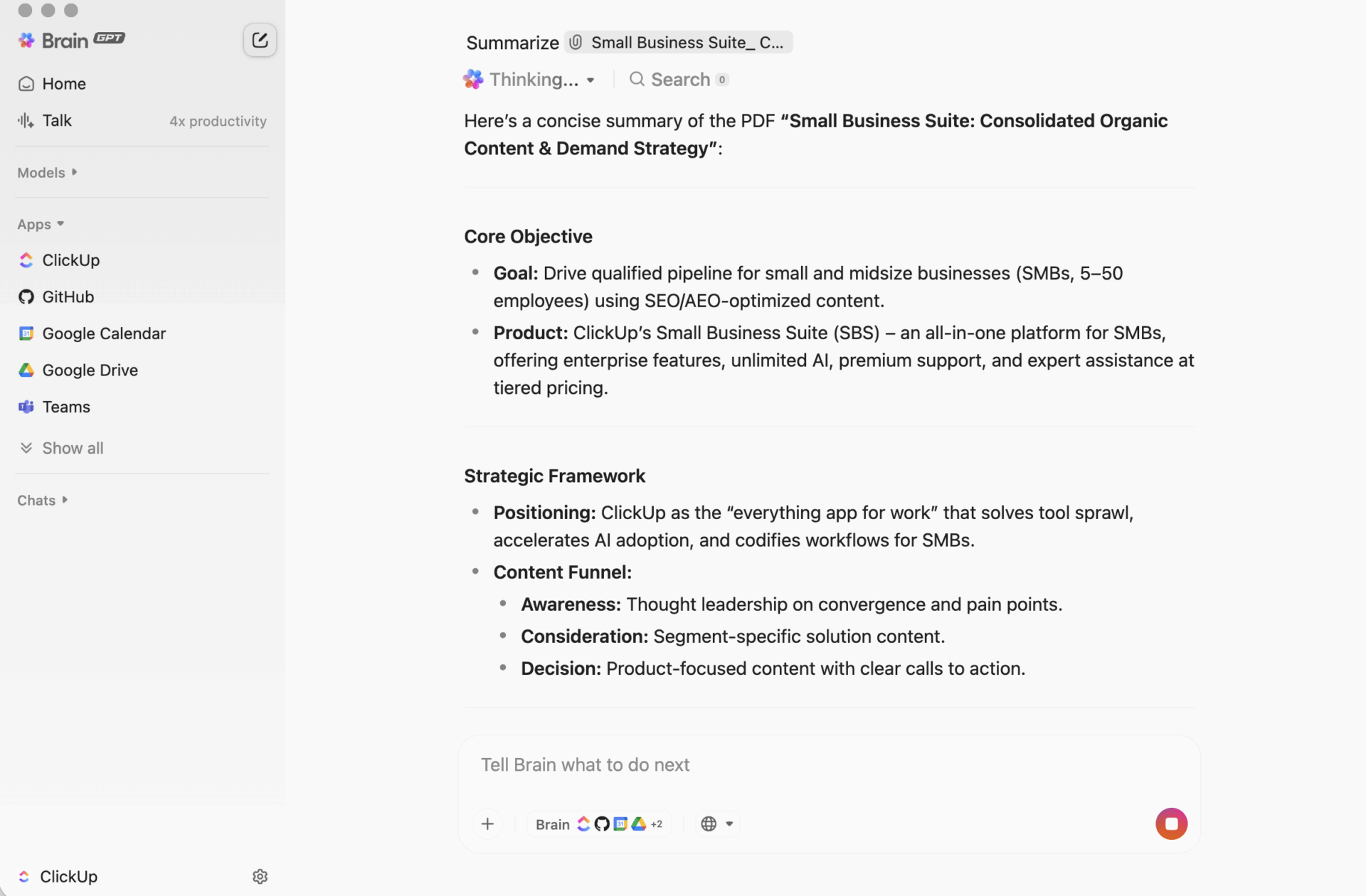
È qui che uno spazio di lavoro convergente cambia le regole del gioco. Invece di generare riassunti in un unico posto e cercare di "trasferirli nel lavoro" in un secondo momento, un sistema convergente mantiene insieme progetti, documenti e conversazioni, con ClickUp Brain integrato come livello di intelligenza. I tuoi riassunti rimangono collegati alle attività e ai documenti, quindi il passo successivo è ovvio e il passaggio di consegne è immediato.
Riassunti che si trasformano in azioni con ClickUp
Uno script di riepilogo/riassunto può funzionare perfettamente e tuttavia deludere il tuo team in un modo fastidioso: il riassunto finisce per trovarsi in un luogo separato dal lavoro.
Questo divario crea una dispersione del contesto, in cui le informazioni sono sparse tra documenti, thread di chat, attività e "note rapide" in strumenti che non sono collegati tra loro. Le persone dedicano più tempo a cercare il riepilogo/riassunto che a utilizzarlo. Il vero vantaggio non è solo generare un riepilogo/riassunto, ma mantenerlo collegato alle decisioni, ai titolari e ai passi successivi dove il lavoro viene effettivamente svolto.
Questo è ciò che rende ClickUp Brain diverso dagli altri. Riassume attività, documenti e conversazioni all'interno dello stesso spazio di lavoro in cui si trovano i tuoi progetti, in modo che il tuo team possa comprendere qualcosa e agire di conseguenza senza dover passare da uno strumento all'altro.

ClickUp BrainGPT: interagisci con i riassunti utilizzando il linguaggio naturale
Su desktop, BrainGPT è l'interfaccia conversazionale per ClickUp Brain. Invece di aprire script, notebook o strumenti di IA esterni, il tuo team può chiedere ciò di cui ha bisogno in un linguaggio semplice, direttamente in ClickUp.
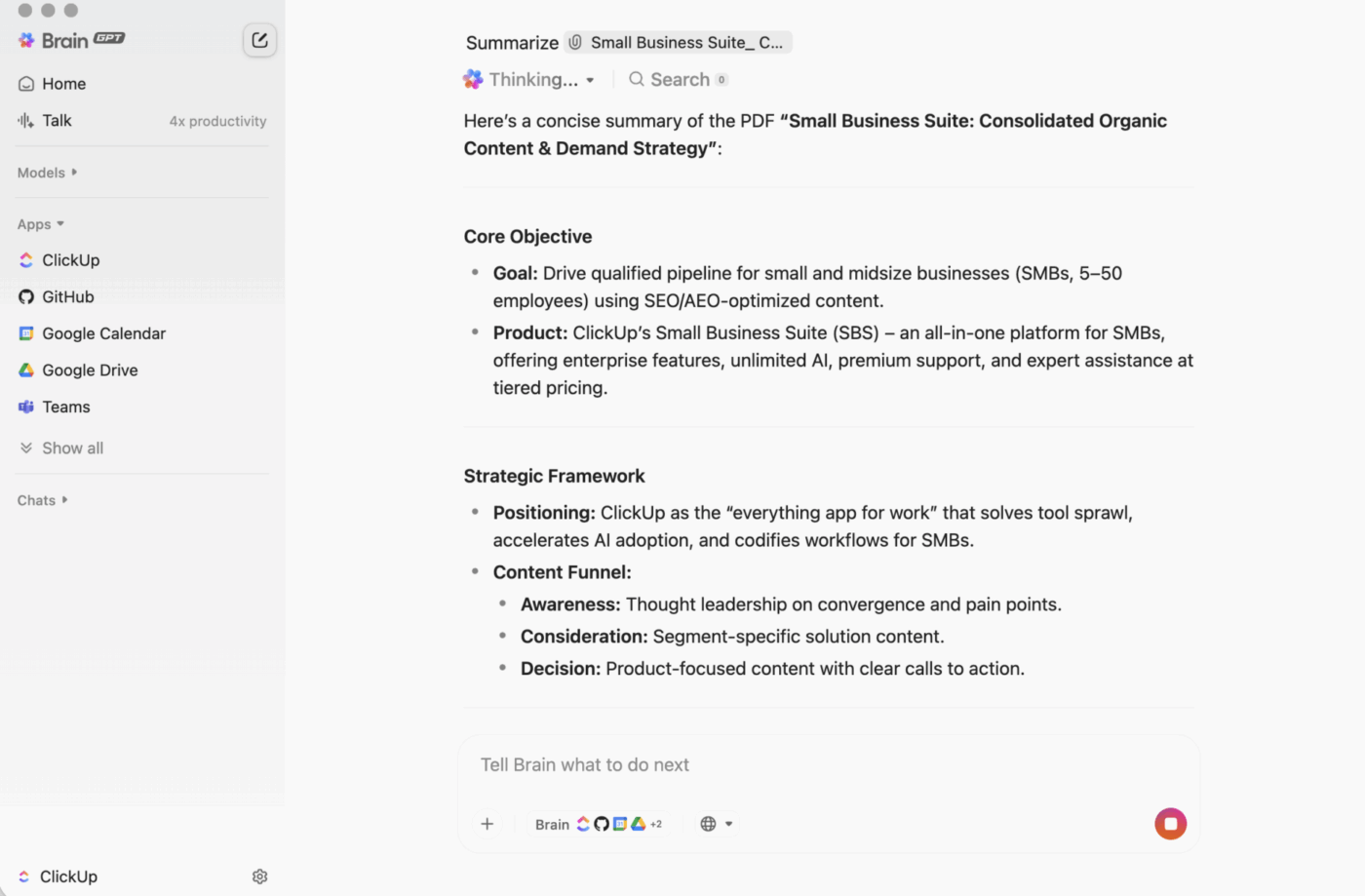
Puoi digitare (o utilizzare la funzione di riconoscimento vocale) per:
- Riassumi una lunga descrizione di un'attività, una thread di commenti o un documento.
- Continua con domande come "Quali sono i prossimi passaggi?" o "Chi ne è responsabile?".
- Trasforma un riepilogo/riassunto in azione creando attività da esso, con titolari e date di scadenza.
Poiché ClickUp Brain lavora all'interno del tuo spazio di lavoro, il risultato si basa sul contesto live: descrizioni delle attività, commenti, attività secondarie, documenti collegati e struttura del progetto. Non devi incollare il testo in uno strumento separato e sperare che non venga tralasciato nulla di importante.
Perché questo approccio è migliore di un flusso di lavoro di riassunto basato sul codice per la maggior parte dei team
Un flusso di lavoro creato dagli sviluppatori può generare riassunti efficaci. L'attrito emerge in seguito, quando qualcuno deve copiare il risultato nel luogo in cui si svolge il lavoro, tradurlo in attività e poi occuparsi del follow-up.
ClickUp Brain chiude il cerchio:
Non è richiesta alcuna codificaChiunque nel team può riassumere un documento, una thread di attività o una serie disordinata di commenti senza installare nulla o scrivere codice.
Riassunti sensibili al contestoClickUp Brain può includere le parti che le persone di solito dimenticano: decisioni nascoste nei commenti, ostacoli menzionati nelle risposte, attività secondarie che cambiano il significato di "terminato".
I riassunti vivono dove vive il lavoroPuoi aggiornarti all'interno di un'attività, aggiungere un riassunto nella parte superiore di ClickUp Docs o ricapitolare rapidamente una discussione senza creare un altro "documento di riassunto" che nessuno controlla.
Meno strumenti sparsi Non hai bisogno di script separati, notebook Jupyter, chiavi API o un flusso di lavoro che solo una persona capisce. I tuoi documenti, le tue attività e i tuoi riassunti rimangono tutti nello stesso sistema.
Questo è il vantaggio pratico di una area di lavoro convergente: riassumere, agire e collaborare avvengono insieme invece di essere cuciti insieme a posteriori.
Questo è il vantaggio pratico di una area di lavoro convergente: riassumere, agire e collaborare avvengono insieme invece di essere cuciti insieme a posteriori.
Come funziona nella vita reale
Ecco alcuni modelli comuni utilizzati dai team:
- Riassumi una discussione nel thread dei commenti: apri un'attività con una lunga discussione, clicca sull'opzione IA e ottieni un rapido riassunto di ciò che è cambiato e di ciò che è importante.
- Riassumi un documento: apri un documento ClickUp e utilizza "Ask IA" per generare un riepilogo/riassunto della pagina in modo che chiunque possa orientarsi rapidamente.
- Estrai gli elementi da intraprendere: prendi il riassunto e converti immediatamente i passaggi successivi in attività con assegnatari e date di scadenza, in modo che lo slancio non si esaurisca nel passaggio di consegne.
| Capacità | Hugging Face (basato su codice) | ClickUp Brain |
|---|---|---|
| Configurazione richiesta | Ambiente Python, librerie, codice | Nessuno, integrato |
| Consapevolezza del contesto | Solo testo (quello che inserisci) | Contesto completo dell'area di lavoro (attività, documenti, commenti, attività secondarie) |
| Integrazione del flusso di lavoro | Esportazione/importazione manuale | Nativo: i riassunti possono diventare attività e aggiornamenti |
| Competenze tecniche richieste | Livello sviluppatore | Chiunque nel team |
| Manutenzione | Manutenzione continua del modello e del codice | Aggiornamenti automatici |
Da riepiloghi/riassunti all'esecuzione con Super Agents
I riepiloghi/riassunti sono utili. La parte difficile è assicurarsi che si traducano costantemente in azioni concrete, soprattutto quando il volume aumenta.
È qui che entrano in gioco i ClickUp Super Agents . Possono utilizzare le informazioni riassunte e portare avanti il lavoro in base a trigger e condizioni, all'interno dello stesso spazio di lavoro.
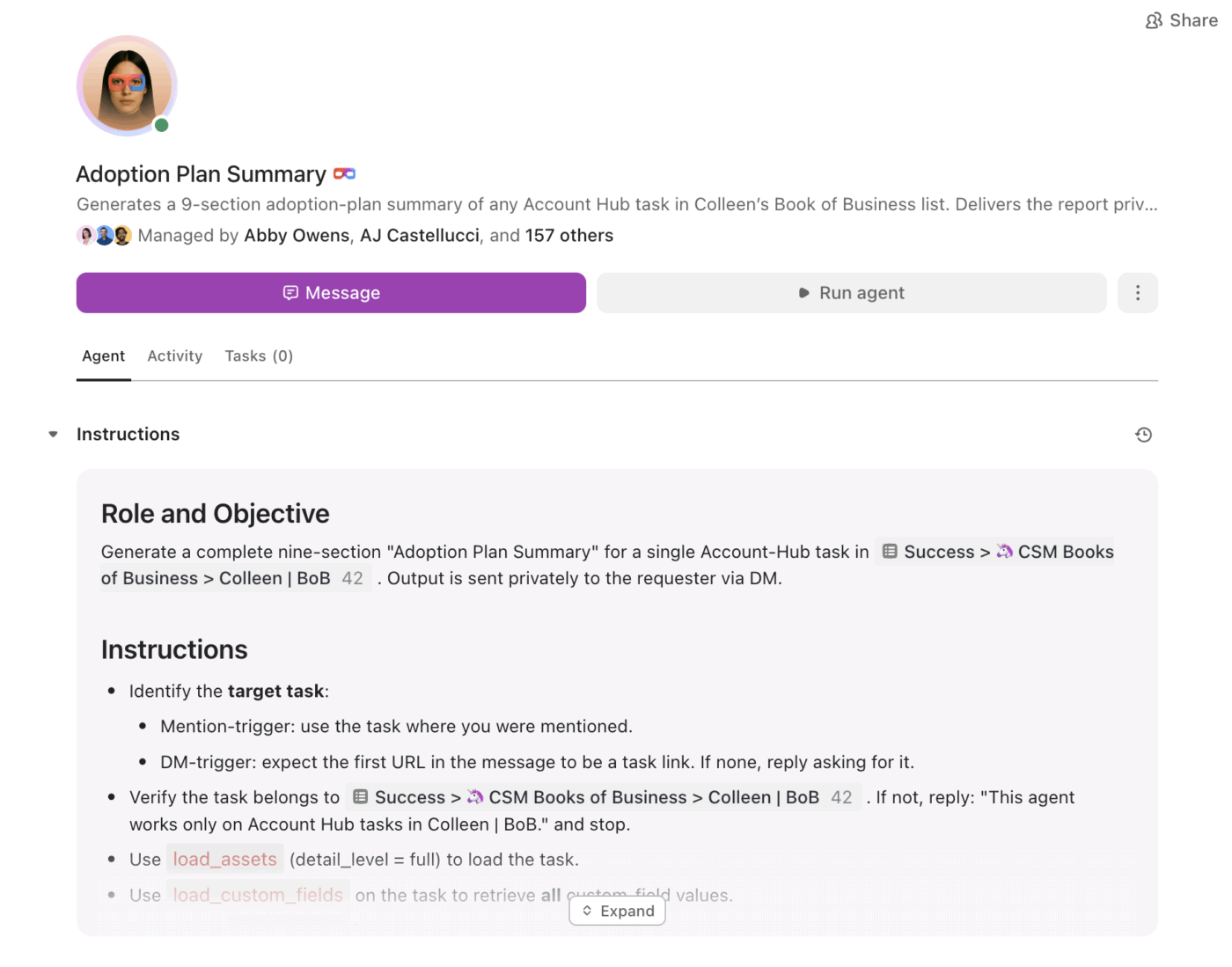
Con Super Agents, i team possono:
- Riassumi i cambiamenti secondo un programma (riepilogo settimanale del progetto, rollup quotidiano dello stato)
- Estrai automaticamente gli elementi da intraprendere e assegna i titolari.
- Segnala il lavoro in stallo (attività bloccate in fase di revisione, thread senza risposta, passaggi successivi scaduti)
- Mantieni alta la visibilità della leadership senza reportistica manuale
Invece di un riepilogo/riassunto statico sotto forma di testo, gli agenti aiutano a garantire che il riepilogo/riassunto diventi un piano e che il piano si traduca in progressi.
Riassunti che vivono dove si svolge il lavoro
I trasformatori Hugging Face sono ottimi quando hai bisogno di un'app personalizzata, una pipeline su misura o il controllo completo sul comportamento del modello.
Ma per la maggior parte dei team, il problema più grande non è "Possiamo riassumere questo?", bensì "Possiamo riassumere questo e trasformarlo immediatamente in lavoro, con titolari, scadenze e visibilità?".
Se il tuo obiettivo è la produttività del team e una rapida esecuzione, ClickUp Brain ti fornisce riassunti contestualizzati, proprio dove si svolge il lavoro, con un percorso chiaro che va dal "questo è il succo" al "questo è ciò che faremo dopo".
Sei pronto a saltare la fase di configurazione e iniziare a riassumere dove si trova effettivamente il tuo lavoro? Inizia gratis con ClickUp e lascia che Brain si occupi del lavoro pesante.