

Un bot per il servizio clienti che apprende da ogni interazione. Un assistente commerciale che modifica la propria strategia sulla base di informazioni in tempo reale. Non si tratta solo di concetti: sono realtà, grazie agli agenti di apprendimento dell'IA.
Ma cosa rende questi agenti unici e come funziona un agente di apprendimento per ottenere questa adattabilità?
A differenza dei sistemi di IA tradizionali che funzionano con una programmazione fissa, gli agenti di apprendimento sono in continua evoluzione.
Questi agenti si adattano, migliorano e perfezionano le loro azioni nel tempo, rendendoli indispensabili per settori come quello dei veicoli autonomi e dell'assistenza sanitaria, dove flessibilità e precisione sono requisiti imprescindibili.
Pensali come un'IA che diventa più intelligente con l'esperienza, proprio come gli esseri umani.
In questo blog esploreremo i componenti chiave, i processi, i tipi e le applicazioni degli agenti di apprendimento nell'IA. 🤖
⏰ Riepilogo/riassunto in 60 secondi
Ecco una breve introduzione agli agenti di apprendimento nell'IA:
Cosa fanno: si adattano attraverso le interazioni, ad esempio i bot del servizio clienti perfezionano le risposte.
Usi principali: robotica, servizi personalizzati e sistemi intelligenti come i dispositivi domestici.
Componenti principali:
- Elemento di apprendimento: raccoglie conoscenze per migliorare le prestazioni
- Elemento prestazionale: esegue attività sulla base delle conoscenze apprese.
- Critico: valuta le azioni e fornisce feedback
- Generatore di problemi: identifica le opportunità di ulteriore apprendimento
Metodi di apprendimento:
- Apprendimento supervisionato: riconosce i modelli utilizzando dati con etichette.
- Apprendimento non supervisionato: identifica le strutture nei dati non etichettati.
- Apprendimento per rinforzo: apprende attraverso tentativi ed errori.
Impatto nel mondo reale: Migliora l'adattabilità, l'efficienza e il processo decisionale in vari settori.
⚙️ Bonus: Ti senti sopraffatto dal gergo dell'IA? Consulta il nostro glossario completo dei termini dell'IA per comprendere facilmente i concetti di base e la terminologia avanzata.
Cosa sono gli agenti di apprendimento nell'IA?
Gli agenti di apprendimento nell'IA sono sistemi che migliorano nel tempo imparando dal loro ambiente. Si adattano, prendono decisioni più intelligenti e ottimizzano le azioni sulla base di feedback e dati.
A differenza dei sistemi di IA tradizionali, che rimangono fissi, gli agenti di apprendimento sono in continua evoluzione. Ciò li rende essenziali per la robotica e i consigli personalizzati, dove le condizioni sono imprevedibili e in costante cambiamento.
🔍 Lo sapevi? Gli agenti di apprendimento operano in un ciclo di feedback: percepiscono l'ambiente, imparano dal feedback e perfezionano le loro azioni. Questo è ispirato al modo in cui gli esseri umani imparano dall'esperienza.
Componenti chiave degli agenti di apprendimento
Gli agenti di apprendimento sono generalmente composti da diversi componenti interconnessi che lavorano insieme per garantire adattabilità e miglioramento nel tempo.
Ecco alcuni componenti fondamentali di questo processo di apprendimento. 📋
Elemento di apprendimento
La responsabilità principale dell'agente è quella di acquisire conoscenze e migliorare le prestazioni analizzando dati, interazioni e feedback.
Utilizzando tecniche di IA quali l'apprendimento supervisionato, rinforzato e non supervisionato, l'agente adatta e aggiorna il proprio comportamento per migliorare la propria funzionalità.
📌 Esempio: un assistente virtuale come Siri apprende nel tempo le preferenze dell'utente, come i comandi utilizzati di frequente o accenti specifici, per fornire risposte più accurate e personalizzate.
Elemento prestazionale
Questo componente esegue attività interagendo con l'ambiente e prendendo decisioni sulla base delle informazioni disponibili. È essenzialmente il "braccio operativo" dell'agente.
📌 Esempio: nei veicoli autonomi, l'elemento prestazionale elabora i dati sul traffico e le condizioni ambientali per prendere decisioni in tempo reale, come fermarsi al semaforo rosso o evitare ostacoli.
Critico
Il critico valuta le azioni intraprese dall'elemento prestazionale e fornisce un feedback. Questo feedback aiuta l'elemento di apprendimento a identificare ciò che ha funzionato bene e ciò che necessita di miglioramenti.
📌 Esempio: in un sistema di raccomandazione, il critico analizza le interazioni degli utenti (come clic o salti) per determinare quali suggerimenti hanno ottenuto un esito positivo e aiuta l'elemento di apprendimento a perfezionare le raccomandazioni future.
Generatore di problemi
Questo componente incoraggia l'esplorazione suggerendo nuovi scenari o azioni che l'agente può testare.
Spinge l'agente oltre la sua zona di comfort, garantendo un miglioramento continuo. L'agente impedisce inoltre risultati subottimali ampliando l'intervallo delle sue esperienze.
📌 Esempio: nell'IA per l'e-commerce, il generatore di problemi potrebbe suggerire strategie di marketing personalizzate o simulare modelli di comportamento dei clienti. Questo aiuta l'IA a perfezionare il proprio approccio per fornire raccomandazioni su misura per le diverse preferenze degli utenti.
Il processo di apprendimento negli agenti di apprendimento
Gli agenti di apprendimento si basano principalmente su tre categorie chiave per adattarsi e migliorare. Queste sono state descritte di seguito. 👇
1. Apprendimento supervisionato
L'agente apprende da set di dati con etichette, in cui ogni input corrisponde a un output specifico.
Questo metodo richiede un grande volume di dati accuratamente etichettati per l'addestramento ed è ampiamente utilizzato in applicazioni quali il riconoscimento delle immagini, la traduzione linguistica e il rilevamento delle frodi.
📌 Esempio: un sistema di filtraggio delle e-mail impara a classificare le e-mail come spam o meno sulla base dei dati storici. L'elemento di apprendimento identifica i modelli tra gli input (contenuto delle e-mail) e gli output (etichette di classificazione) per effettuare previsioni accurate.
2. Apprendimento non supervisionato
I modelli o le relazioni nascosti nei dati emergono man mano che l'agente analizza le informazioni senza etichette esplicite. Questo approccio funziona bene per rilevare anomalie, creare sistemi di raccomandazione e ottimizzare la compressione dei dati.
Aiuta anche a identificare intuizioni che potrebbero non avere una visibilità immediata con i dati etichettati.
📌 Esempio: la segmentazione dei clienti nel marketing può raggruppare gli utenti in base al loro comportamento per progettare campagne mirate. L'attenzione è rivolta alla comprensione della struttura e alla formazione di cluster o associazioni.
3. Apprendimento per rinforzo
A differenza di quanto descritto sopra, l'apprendimento per rinforzo (RL) prevede che gli agenti agiscano in un ambiente per massimizzare i premi cumulativi nel tempo.
L'agente apprende attraverso tentativi ed errori, ricevendo feedback sotto forma di ricompense o penalità.
🔔 Ricorda: la scelta del metodo di apprendimento dipende dal problema, dalla disponibilità dei dati e dalla complessità dell'ambiente. L'apprendimento per rinforzo è fondamentale per le attività che non prevedono una supervisione diretta, poiché utilizza cicli di feedback per adattare le azioni.
Tecniche di apprendimento rinforzato
- Iterazione delle politiche: ottimizza le aspettative di ricompensa apprendendo direttamente una politica che mappa gli stati alle azioni.
- Iterazione di valore: determina le azioni ottimali calcolando il valore di ciascuna coppia stato-azione.
- Metodi Monte Carlo: simula diversi scenari futuri per prevedere i risultati delle azioni, particolarmente utile in ambienti dinamici e probabilistici.
Esempi di applicazioni RL nel mondo reale
- Guida autonoma: gli algoritmi RL addestrano i veicoli a navigare in sicurezza, ottimizzare i percorsi e adattarsi alle condizioni del traffico imparando continuamente da ambienti simulati.
- AlphaGo e IA: l'apprendimento per rinforzo ha permesso ad AlphaGo di Google di sconfiggere i campioni umani imparando le strategie ottimali per giochi complessi come il Go.
- Prezzi dinamici: le piattaforme di e-commerce utilizzano l'apprendimento rinforzato (RL) per adeguare le strategie di prezzo in base ai modelli di domanda e alle azioni della concorrenza, al fine di massimizzare i ricavi.
🧠 Curiosità: gli agenti di apprendimento hanno sconfitto campioni umani in giochi come gli scacchi e Starcraft, dimostrando la loro adattabilità e intelligenza.
Approcci di apprendimento Q e reti neurali
Il Q-learning è un algoritmo RL ampiamente utilizzato in cui gli agenti apprendono il valore di ciascuna coppia stato-azione attraverso l'esplorazione e il feedback. L'agente costruisce una tabella Q, una matrice che assegna ricompense attese alle coppie stato-azione.
Sceglie l'azione con il valore Q più alto e perfeziona la sua tabella in modo iterativo per migliorare la precisione.
📌 Esempio: un drone alimentato dall'IA che impara a consegnare pacchi in modo efficiente utilizza il Q-learning per valutare i percorsi. Lo fa assegnando ricompense per le consegne puntuali e penalità per i ritardi o le collisioni. Nel tempo, affina la sua tabella Q per scegliere i percorsi di consegna più efficienti e sicuri.
Tuttavia, le tabelle Q diventano poco pratiche in ambienti complessi con spazi di stato ad alta dimensionalità.
Qui avviene il passaggio alle reti neurali, che approssimano i valori Q invece di memorizzarli esplicitamente. Questo cambiamento consente all'apprendimento per rinforzo di affrontare problemi più complessi.
Le reti Deep Q (DQN) vanno oltre, sfruttando il deep learning per elaborare dati grezzi e non strutturati come immagini o input dei sensori. Queste reti possono mappare direttamente le informazioni sensoriali alle azioni, aggirando la necessità di un'ampia ingegnerizzazione delle caratteristiche.
📌 Esempio: nelle auto a guida autonoma, i DQN elaborano i dati dei sensori in tempo reale per apprendere strategie di guida, come il cambio di corsia o l'evitamento di ostacoli, senza regole preprogrammate.
Questi metodi avanzati consentono agli agenti di adattare le loro capacità di apprendimento a attività che richiedono un'elevata potenza di calcolo e adattabilità.
⚙️ Bonus: impara a creare e perfezionare una base di conoscenze IA che semplifica la gestione delle informazioni, migliora il processo decisionale e aumenta la produttività del team.
Il processo di apprendimento degli agenti valorizza l'elaborazione di strategie per un processo decisionale intelligente in tempo reale. Ecco alcuni aspetti chiave che aiutano il processo decisionale:
- Esplorazione vs. sfruttamento: gli agenti bilanciano l'esplorazione di nuove azioni per trovare strategie migliori e lo sfruttamento di azioni conosciute per massimizzare i risultati.
- Processo decisionale multi-agente: in impostazioni collaborative o competitive, gli agenti interagiscono e adattano le strategie in base a obiettivi di condivisione o tattiche antagonistiche.
- Compromessi strategici: gli agenti imparano anche a stabilire le priorità degli obiettivi in base al contesto, ad esempio bilanciando velocità e precisione in un sistema di consegna.
🎤 Avviso podcast: consulta il nostro elenco curato di podcast popolari sull'IA per approfondire la tua comprensione del funzionamento degli agenti di apprendimento.
Tipi di agenti IA
Gli agenti di apprendimento nell'intelligenza artificiale sono disponibili in vari moduli, ciascuno adattato a attività e sfide specifiche.
Esploriamo i loro meccanismi di funzionamento, le loro caratteristiche uniche e alcuni esempi reali. 👀
Agenti riflessi semplici
Tali agenti rispondono direttamente agli stimoli sulla base di regole predefinite. Utilizzano un meccanismo condizione-azione (if-then) per scegliere le azioni in base all'ambiente attuale senza considerare la storia o il futuro.
Caratteristiche
- Funziona su un sistema logica-condizione-azione.
- Non si adatta ai cambiamenti né apprende dalle azioni passate.
- Funziona al meglio in ambienti trasparenti e prevedibili.
Esempio
Un termostato funziona come un semplice agente riflessivo, accendendo il riscaldamento quando la temperatura scende al di sotto di una soglia prestabilita e spegnendolo quando sale. Prende decisioni basandosi esclusivamente sulle letture della temperatura attuale.
🧠 Curiosità: alcuni esperimenti assegnano agli agenti di apprendimento bisogni simulati come la fame o la sete, incoraggiandoli a sviluppare comportamenti orientati agli obiettivi e ad apprendere come soddisfare questi "bisogni" in modo efficace.
Agenti riflessivi basati su modelli
Questi agenti mantengono un modello interno del mondo che consente loro di considerare gli effetti delle loro azioni. Inoltre, deducono lo stato dell'ambiente al di là di ciò che possono percepire immediatamente.
Caratteristiche
- Utilizza un modello memorizzato dell'ambiente per il processo decisionale.
- Stima lo stato attuale per gestire ambienti parzialmente osservabili.
- Offre maggiore flessibilità e adattabilità rispetto ai semplici agenti riflessi.
Esempio
Un'auto a guida autonoma Tesla utilizza un agente basato su modelli per navigare sulle strade. Rileva gli ostacoli visibili e prevede il movimento dei veicoli vicini, compresi quelli nei punti ciechi, utilizzando sensori avanzati e dati in tempo reale. Ciò consente all'auto di prendere decisioni di guida precise e informate, migliorando la sicurezza e l'efficienza.
🔍 Lo sapevi? Il concetto di agenti di apprendimento spesso imita i comportamenti osservati negli animali, come l'apprendimento per tentativi ed errori o l'apprendimento basato sulla ricompensa.
Funzioni dell'agente software e dell'assistente virtuale
Questi agenti operano in ambienti digitali e svolgono attività specifiche in modo autonomo.
Gli assistenti virtuali come Siri o Alexa elaborano gli input degli utenti utilizzando l'elaborazione del linguaggio naturale (NLP) ed eseguono azioni come rispondere a query o controllare dispositivi intelligenti.
Caratteristiche
- Semplifica le attività quotidiane come la pianificazione, l'impostazione di promemoria o il controllo dei dispositivi.
- Migliora continuamente utilizzando algoritmi di apprendimento e dati di interazione con l'utente.
- Funziona in modo asincrono, rispondendo in tempo reale o quando viene triggerato.
Esempio
Alexa può riprodurre musica, impostare promemoria e controllare dispositivi domestici intelligenti interpretando i comandi vocali, effettuando la connessione a sistemi basati su cloud ed eseguendo le azioni appropriate.
🔍 Lo sapevi? Gli agenti basati sull'utilità, che si concentrano sulla massimizzazione dei risultati valutando diverse azioni, spesso lavorano insieme agli agenti basati sull'apprendimento nell'IA. Gli agenti di apprendimento perfezionano le loro strategie nel tempo sulla base dell'esperienza e possono utilizzare il processo decisionale basato sull'utilità per fare scelte più intelligenti.
Sistemi multi-agente e applicazioni della teoria dei giochi
Questi sistemi sono costituiti da più agenti interagenti che cooperano, competono o lavorano in modo indipendente per raggiungere obiettivi individuali o collettivi.
Inoltre, i principi della teoria dei giochi spesso guidano il loro comportamento in scenari competitivi.
Caratteristiche
- Richiede coordinamento o negoziazione tra gli agenti.
- Funziona bene in ambienti dinamici e di distribuzione.
- Simula o gestisce sistemi complessi come le catene di approvvigionamento o il traffico urbano.
Esempio
Nel sistema di automazione del magazzino di Amazon, i robot (agenti) lavorano in modo collaborativo per prelevare, smistare e trasportare gli elementi. Questi robot comunicano tra loro per evitare collisioni e garantire operazioni fluide. I principi della teoria dei giochi aiutano a gestire priorità concorrenti, come il bilanciamento tra velocità e risorse, per garantire che il sistema funzioni in modo efficiente.
Applicazioni degli agenti di apprendimento
Gli agenti di apprendimento hanno trasformato numerosi settori migliorando l'efficienza e il processo decisionale.
Ecco alcune applicazioni chiave. 📚
Robotica e automazioni
Gli agenti di apprendimento sono al centro della robotica moderna e consentono ai robot di operare in modo autonomo e adattivo in ambienti dinamici.
A differenza dei sistemi tradizionali che richiedono una programmazione dettagliata per ogni attività, gli agenti di apprendimento consentono ai robot di migliorarsi autonomamente attraverso l'interazione e il feedback.
Come funziona
I robot dotati di agenti di apprendimento utilizzano tecniche come l'apprendimento per rinforzo per interagire con l'ambiente circostante e valutare i risultati delle loro azioni. Nel tempo perfezionano il loro comportamento, concentrandosi sulla massimizzazione dei premi e sull'evitare le penalità.
Le reti neurali portano questo concetto ancora più avanti, consentendo ai robot di elaborare dati complessi come input visivi o layout spaziali, facilitando un processo decisionale sofisticato.
Esempi
- Veicoli autonomi: in agricoltura, gli agenti di apprendimento consentono ai trattori autonomi di navigare nei campi, adattarsi alle diverse condizioni del suolo e ottimizzare i processi di semina o raccolta. Utilizzano dati in tempo reale per migliorare l'efficienza e ridurre gli sprechi.
- Robot industriali: nella produzione, i bracci robotici dotati di agenti di apprendimento perfezionano i loro movimenti per migliorare la precisione, l'efficienza e la sicurezza, come nelle linee di assemblaggio automobilistiche.
Simulazione e modelli basati su agenti
Gli agenti di apprendimento alimentano simulazioni che offrono un modo economico e gratis per studiare sistemi complessi.
Questi sistemi replicano le dinamiche del mondo reale, prevedono i risultati e ottimizzano le strategie modellando agenti con comportamenti distinti e capacità di adattamento.
Come funziona
Gli agenti di apprendimento nelle simulazioni osservano il loro ambiente, testano le azioni e adattano le loro strategie per massimizzare l'efficacia. Imparano e migliorano continuamente nel tempo, consentendo loro di ottimizzare i risultati.
Le simulazioni sono molto efficaci nella gestione della catena di approvvigionamento, nella pianificazione urbana e nello sviluppo della robotica.
Esempi
- Gestione del traffico: agenti simulati modellano il flusso del traffico nelle città. Ciò consente ai ricercatori di testare interventi come nuove strade o tariffe di congestione prima della loro implementazione.
- Epidemiologia: nelle simulazioni di pandemia, gli agenti di apprendimento imitano il comportamento umano per valutare la diffusione delle malattie. Aiutano anche a valutare l'efficacia delle misure di contenimento, come il distanziamento sociale.
💡 Suggerimento professionale: ottimizza la pre-elaborazione dei dati nell'apprendimento automatico dell'IA per migliorare l'accuratezza e l'efficienza degli agenti di apprendimento. Un input di alta qualità garantisce un processo decisionale più affidabile.
Sistemi intelligenti
Gli agenti di apprendimento guidano i sistemi intelligenti consentendo l'elaborazione dei dati in tempo reale e l'adattamento al comportamento e alle preferenze degli utenti.
Dagli elettrodomestici intelligenti ai dispositivi di pulizia autonomi, questi sistemi trasformano il modo in cui gli utenti interagiscono con la tecnologia, rendendo le attività quotidiane più efficienti e personalizzate.
Come funziona
Dispositivi come Roomba utilizzano sensori integrati e agenti di apprendimento per mappare il layout della casa, evitare ostacoli e ottimizzare i percorsi di pulizia. Raccolgono e analizzano costantemente dati, come le aree che richiedono una pulizia frequente o la disposizione dei mobili, migliorando le loro prestazioni ad ogni utilizzo.
Esempi
- Dispositivi domestici intelligenti: i termostati come Nest imparano gli orari e le preferenze di temperatura degli utenti. Regolano automaticamente le impostazioni per risparmiare energia mantenendo il comfort.
- Aspirapolvere robotici: Roomba raccoglie molti dati al secondo. Questo gli permette di imparare a muoversi tra i mobili e identificare le aree più trafficate per una pulizia efficiente.
Questi sistemi intelligenti mettono in evidenza le applicazioni pratiche degli agenti di apprendimento nella vita quotidiana, come la semplificazione dei flussi di lavoro e l'automazione delle attività ripetitive per una maggiore efficienza.
🔍 Lo sapevi? Roomba raccoglie oltre 230.400 punti dati al secondo per mappare la tua casa.
Forum Internet e assistenti virtuali
Gli agenti di apprendimento sono fondamentali per migliorare le interazioni online e l'assistenza digitale. Consentono ai forum e agli assistenti virtuali di offrire esperienze personalizzate.
Come funziona
Gli agenti di apprendimento moderano le discussioni nei forum e identificano e rimuovono spam o contenuti dannosi. È interessante notare che raccomandano anche argomenti rilevanti agli utenti in base alla loro cronologia di navigazione.
Gli assistenti virtuali basati sull'IA come Alexa e Google Assistant utilizzano agenti di apprendimento per elaborare input in linguaggio naturale, migliorando nel tempo la loro comprensione contestuale.
Esempi
- Forum Internet: i bot di moderazione di Reddit utilizzano agenti di apprendimento per scansionare i post alla ricerca di violazioni delle regole o linguaggio offensivo. Tale igiene basata sull'IA mantiene le comunità online sicure e coinvolgenti.
- Assistenti virtuali: Alexa apprende le preferenze dell'utente, come le playlist preferite o i comandi smart home utilizzati di frequente, per fornire un'assistenza personalizzata e proattiva.
⚙️ Bonus: impara come utilizzare l'IA sul posto di lavoro per aumentare la produttività e semplificare le attività con agenti intelligenti.
Sfide nello sviluppo degli agenti di apprendimento
Lo sviluppo di agenti di apprendimento comporta sfide tecniche, etiche e pratiche, tra cui la progettazione di algoritmi, i requisiti computazionali e l'implementazione nel mondo reale.
Esaminiamo alcune delle sfide chiave che lo sviluppo dell'IA deve affrontare nel corso della sua evoluzione. 🚧
Equilibrio tra esplorazione e sfruttamento
Gli agenti di apprendimento devono affrontare il dilemma di trovare un equilibrio tra esplorazione e sfruttamento.
Sebbene algoritmi come epsilon-greedy possano essere d'aiuto, il raggiungimento del giusto equilibrio dipende in larga misura dal contesto. Inoltre, un'esplorazione eccessiva può avere come risultato l'inefficienza, mentre un eccessivo affidamento allo sfruttamento può produrre soluzioni non ottimali.
Gestione dei costi computazionali elevati
L'addestramento di agenti di apprendimento sofisticati richiede spesso risorse computazionali estese. Ciò è più applicabile in ambienti con dinamiche complesse o ampi spazi stato-azione.
Ricorda che algoritmi come l'apprendimento per rinforzo con reti neurali, come il Deep Q-Learning, richiedono una notevole potenza di elaborazione e memoria. Avrai bisogno di aiuto per rendere pratico l'apprendimento in tempo reale per applicazioni con risorse limitate.
Superare la scalabilità e il transfer learning
Scalare gli agenti di apprendimento per operare in modo efficace in ambienti grandi e multidimensionali rimane una sfida. Il trasferimento dell'apprendimento, in cui gli agenti applicano le conoscenze da un dominio all'altro, è ancora agli inizi.
Ciò ha limitato la loro capacità di generalizzare tra attività o ambienti diversi.
📌 Esempio: un agente IA addestrato per gli scacchi avrebbe difficoltà con il Go a causa delle regole e degli obiettivi molto diversi, evidenziando la sfida del trasferimento di conoscenze tra domini diversi.
Qualità e disponibilità dei dati
Le prestazioni degli agenti di apprendimento sono fortemente dipendenti dalla qualità e dalla diversità dei dati di addestramento.
Dati insufficienti o distorti possono portare a un apprendimento incompleto o errato e avere come risultato decisioni subottimali o non etiche. Inoltre, la raccolta di dati reali per la formazione può essere costosa e richiedere molto tempo.
⚙️ Bonus: Esplora i corsi sull'IA per migliorare la tua comprensione degli altri agenti.
Strumenti e risorse per gli agenti di apprendimento
Gli sviluppatori e i ricercatori si affidano a vari strumenti per costruire e addestrare gli agenti di apprendimento. Framework come TensorFlow, PyTorch e OpenAI Gym offrono un'infrastruttura di base per l'implementazione di algoritmi di apprendimento automatico.
Questi strumenti aiutano anche a creare ambienti simulati. Alcune app di IA semplificano e migliorano questo processo.
Per gli approcci tradizionali di apprendimento automatico, strumenti come Scikit-learn rimangono affidabili ed efficaci.
Per la gestione dei progetti di ricerca e sviluppo nell'ambito dell'IA, ClickUp offre molto più della semplice gestione delle attività: funge da hub centralizzato per organizzare le attività, effettuare il monitoraggio dello stato e consentire una collaborazione fluida tra i team.
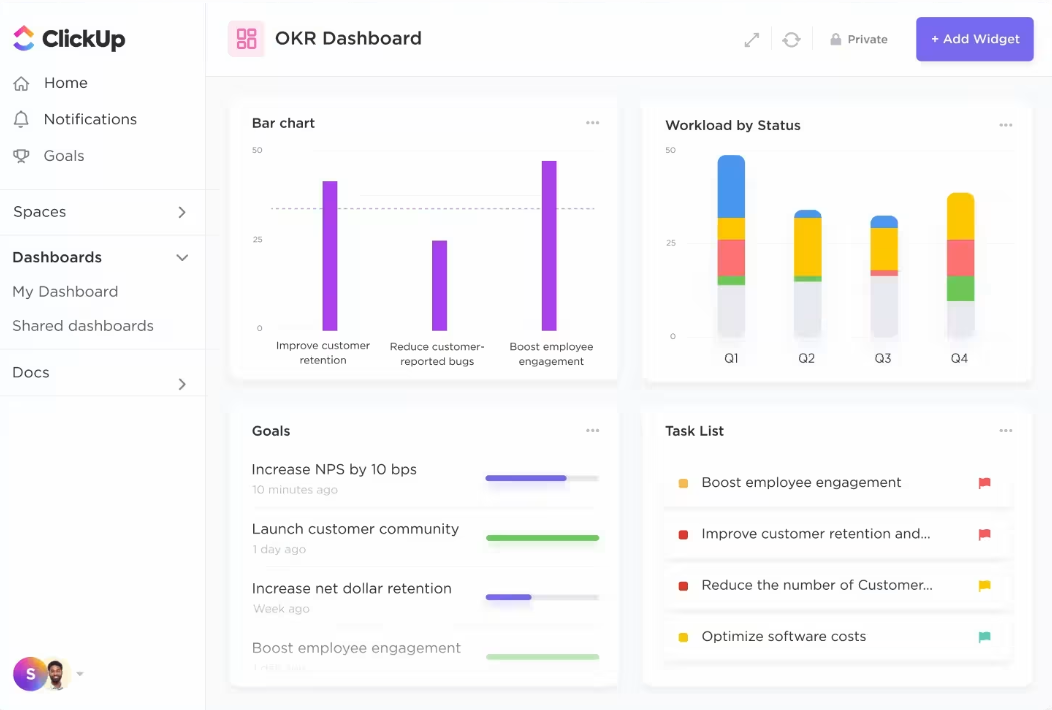
ClickUp per la gestione dei progetti di IA riduce il lavoro richiesto per valutare lo stato delle attività e assegnare i compiti.
Invece di controllare manualmente ogni attività o capire chi è disponibile, l'IA fa il lavoro pesante. Può aggiornare automaticamente lo stato, identificare i colli di bottiglia e suggerire la persona più adatta per ogni attività in base al carico di lavoro e alle competenze.
In questo modo, dedicherai meno tempo alle noiose attività amministrative e più tempo a ciò che conta davvero: portare avanti i tuoi progetti.
Ecco alcune funzionalità/funzioni basate sull'IA che spiccano. 🤩
ClickUp Brain
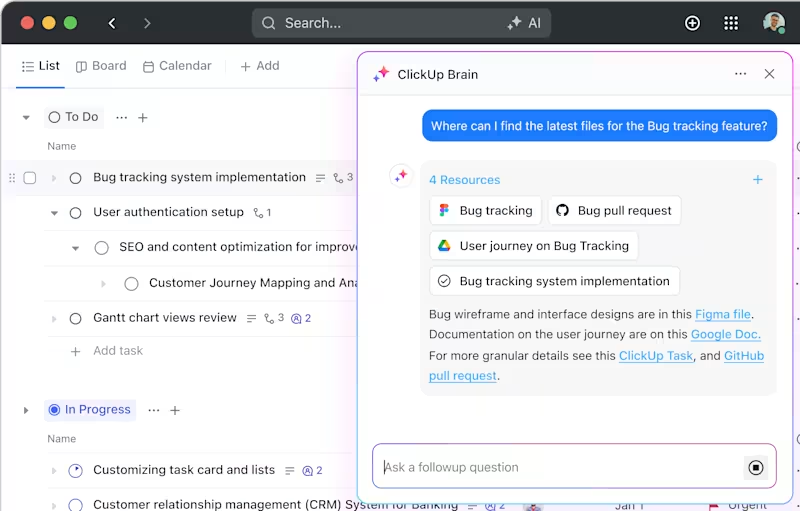
ClickUp Brain, un assistente basato sull'IA integrato nella piattaforma, semplifica anche i progetti più complessi. Suddivide studi approfonditi in attività e attività secondarie gestibili, aiutandoti a rimanere organizzato e in linea con gli obiettivi.
Hai bisogno di accedere rapidamente ai risultati sperimentali o alla documentazione? Basta digitare una query e ClickUp Brain recupera tutto ciò di cui hai bisogno in pochi secondi. Ti permette anche di porre domande di approfondimento basate sui dati esistenti, facendoti sentire come se avessi un assistente personale.
Inoltre, collega automaticamente le attività alle risorse pertinenti, consentendoti di risparmiare tempo e lavoro richiesto.
Supponiamo che tu stia conducendo uno studio su come gli agenti di apprendimento rinforzato migliorano nel tempo.
Ci sono diverse fasi: revisione della letteratura, raccolta dei dati, sperimentazione e analisi. Con ClickUp Brain, puoi chiedere di "suddividere questo studio in attività" e il programma creerà automaticamente delle attività secondarie per ogni fase.
Puoi quindi chiedergli di recuperare articoli pertinenti sul Q-learning o di recuperare set di dati sulle prestazioni dell'agente, cosa che fa istantaneamente. Mentre svolgi le attività, ClickUp Brain può collegare articoli di ricerca specifici o risultati di esperimenti direttamente alle attività, mantenendo tutto organizzato.
Che si tratti di affrontare progetti di ricerca o progetti quotidiani, ClickUp Brain ti garantisce un lavoro più intelligente, non più difficile.
Automazioni ClickUp
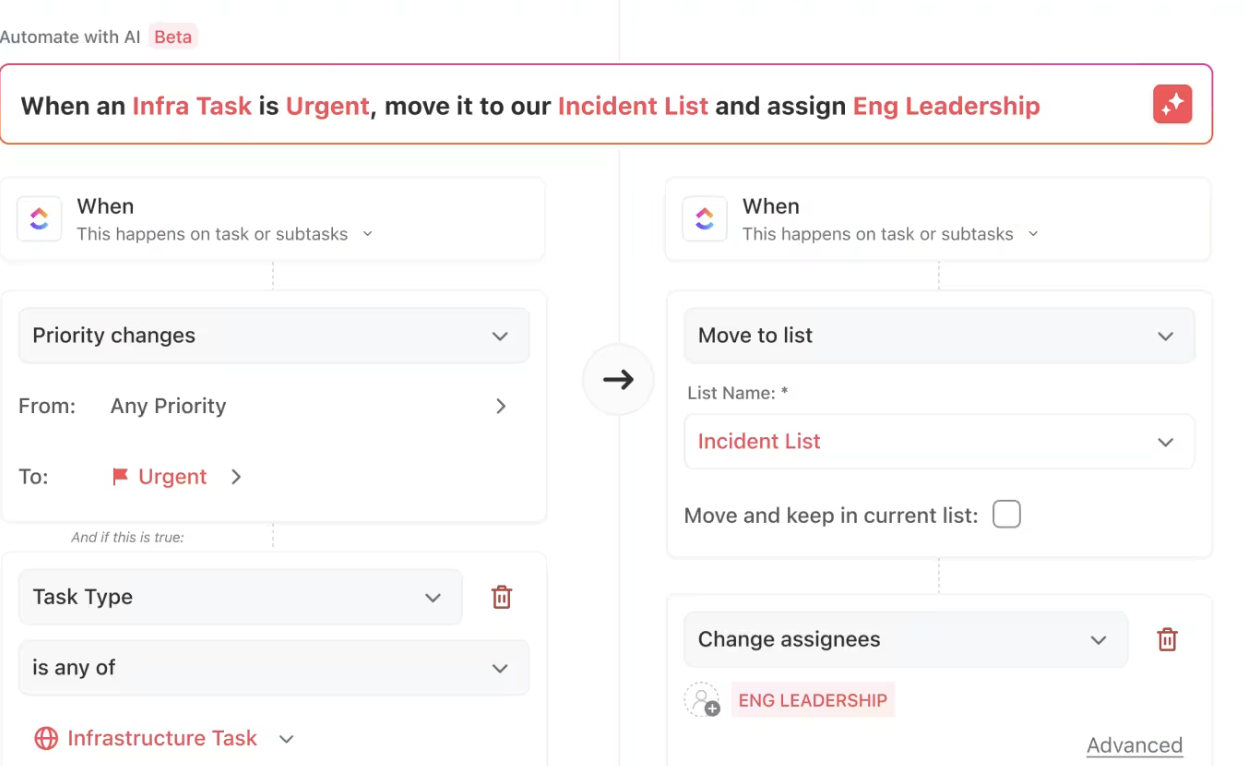
ClickUp Automations è un modo semplice ma potente per ottimizzare il tuo flusso di lavoro.
Consente l'assegnazione immediata delle attività una volta completati i prerequisiti, notifica alle parti interessate lo stato delle attività cardine e segnala eventuali ritardi, il tutto senza alcun intervento manuale.
Puoi anche utilizzare comandi in linguaggio naturale, rendendo la gestione del flusso di lavoro ancora più semplice. Non è necessario immergersi in impostazioni complesse o gergo tecnico: basta dire a ClickUp ciò di cui hai bisogno e lui creerà l'automazione per te.
Che si tratti di "spostare le attività alla fase successiva quando sono contrassegnate come completate" o "assegnare un'attività a Sarah quando la priorità è alta", ClickUp comprende la tua richiesta e la configura automaticamente.
Sviluppa agenti di apprendimento come un maestro con ClickUp
Per creare agenti di apprendimento IA, avrai bisogno di una combinazione esperta di flussi di lavoro strutturati e strumenti adattivi. La maggiore richiesta di competenze tecniche rende il tutto ancora più impegnativo, soprattutto considerando la natura statistica e basata sui dati di tali attività.
Valuta l'utilizzo di ClickUp per semplificare questi progetti. Oltre alla semplice organizzazione, questo strumento fornisce supporto all'innovazione del tuo team eliminando le inefficienze evitabili.
ClickUp Brain aiuta a scomporre compiti complessi, recuperare istantaneamente risorse pertinenti e offrire approfondimenti basati sull'IA per mantenere i tuoi progetti organizzati e in linea con gli obiettivi. Nel frattempo, ClickUp Automazioni gestisce le attività ripetitive, come l'aggiornamento degli stati o l'assegnazione di nuovi compiti, in modo che il tuo team possa concentrarsi sul quadro generale.
Insieme, queste funzionalità/funzioni eliminano le inefficienze e consentono al tuo team di lavorare in modo più intelligente, rendendo l'innovazione e il progresso più semplici.