
Les sinistres informatiques peuvent survenir sans avertissement.
Des pannes de serveur aux cyberattaques, sans plan de reprise solide, votre entreprise pourrait être confrontée à des heures d'indisponibilité, à la perte de données et à de graves préjudices financiers, 54 % des pannes graves coûtant plus de 100 000 dollars américains.
Ce blog vous guide dans l'élaboration d'un plan complet de reprise après sinistre informatique qui protège vos systèmes, définit des objectifs de reprise clairs et garantit que votre équipe sait exactement quoi faire en cas de problème.
Qu'est-ce qu'un plan de reprise après sinistre informatique ?
Si vos serveurs tombaient en panne maintenant, votre équipe saurait-elle exactement quoi faire ? 🛠️
Un plan de reprise après sinistre informatique (DR) est votre stratégie documentée pour restaurer les systèmes et les données informatiques après toute perturbation, qu'il s'agisse d'une catastrophe naturelle ou d'une cyberattaque. Il s'agit essentiellement de votre plan d'action pour remettre la technologie en ligne lorsque les choses tournent mal.
💡 Reprise après sinistre ou continuité des activités de l'entreprise ?
La reprise après sinistre (DR) se concentre spécifiquement sur la restauration de votre infrastructure informatique et de vos données. La continuité des activités (BC) est plus large et vise à maintenir l'ensemble de votre entreprise opérationnelle pendant et après une crise, même en cas de panne informatique. Considérez la DR comme un élément clé de votre stratégie globale de BC.
💡 Reprise après sinistre ou continuité des activités de l'entreprise ?
La reprise après sinistre (DR) se concentre spécifiquement sur la restauration de votre infrastructure informatique et de vos données. La continuité des activités (BC) est plus large et vise à maintenir l'ensemble de votre entreprise opérationnelle pendant et après une crise, même en cas de panne informatique. Considérez la DR comme un élément clé de votre stratégie globale de BC.
Votre plan de reprise après sinistre est important, car les temps d'arrêt ont un coût qui va bien au-delà de l'aspect financier. Chaque minute d'indisponibilité de vos systèmes peut éroder la confiance de vos clients, perturber vos opérations et même entraîner des amendes pour non-conformité. Un plan de reprise après sinistre complet est votre feuille de route vers la résilience.
Un bon forfait couvre les aspects suivants :
- Procédures de sauvegarde des données : comment et où stocker les copies des informations critiques afin de pouvoir les restaurer.
- Étapes de restauration du système : la séquence exacte pour remettre les services en ligne dans le bon ordre.
- Responsabilités de l'équipe : qui fait quoi lors d'un incident afin d'éviter toute confusion ?
- Protocoles de communication : comment informer les parties prenantes, de votre équipe à vos clients.
- Objectifs de reprise : vos objectifs spécifiques concernant la rapidité avec laquelle les systèmes doivent être rétablis et le niveau acceptable de perte de données.
Scénarios courants de sinistres informatiques et leur impact
Les catastrophes ne sont pas seulement des scénarios hollywoodiens ; elles touchent les entreprises tous les jours. Comprendre ce que vous protégez vous aide à mettre en place une défense beaucoup plus solide.
Catastrophes naturelles et dommages physiques
Des évènements tels que les inondations, les incendies, les tremblements de terre et les coupures de courant majeures peuvent détruire des centres de données entiers en quelques minutes. Lorsqu'une inondation majeure a frappé un centre de données de Nashville, par exemple, certaines entreprises ont perdu des semaines de données et ont dû faire face à des mois de récupération. La meilleure protection contre cela est la redondance géographique, qui consiste à répartir votre infrastructure sur plusieurs emplacements physiques afin qu'un seul évènement ne puisse pas tout détruire.
Cyberattaques et compromission des données
Les ransomwares, les attaques par déni de service distribué (DDoS) et les violations de données sont différents des sinistres physiques. Ils sont souvent plus difficiles à détecter, peuvent se propager silencieusement à travers les systèmes connectés et ciblent fréquemment vos systèmes de sauvegarde, ce qui rend la reprise particulièrement difficile. La fréquence et la sophistication de ces cyberattaques continuent d'augmenter dans tous les secteurs, les ransomwares représentant désormais 44 % de toutes les violations confirmées, ce qui en fait une menace majeure.
📖 Pour en savoir plus : 10 façons de réduire les risques liés à la sécurité dans la gestion de projet
Pannes matérielles et perte de données
Parfois, même les systèmes de sauvegarde les plus testés et les plus fiables tombent en panne. Les pannes de serveur, les défaillances de stockage et les dysfonctionnements des équipements réseau peuvent survenir sans avertissement. Même si vous disposez de systèmes redondants (de sauvegarde), ceux-ci peuvent tout de même tomber en panne simultanément s'ils partagent des composants ou des sources d'alimentation communs, créant ainsi un point de défaillance unique.
👀 Le saviez-vous ? En octobre 2025, AWS a subi une panne majeure lorsqu'un bug dans son système interne de gestion DNS pour Amazon DynamoDB a provoqué l'échec de la résolution des noms de domaine dans la région du centre de données US-EAST-1. Ce « petit » défaut technique a déclenché une défaillance en cascade sur des dizaines de services AWS et a mis hors service des centaines d'applications et de plateformes populaires dans le monde entier, des applications de messagerie et de réseaux sociaux aux banques, en passant par les sites de jeux, etc. Pour de nombreuses personnes, cette panne a temporairement fait « disparaître » une grande partie d'Internet, soulignant à quel point notre infrastructure numérique est fragile lorsqu'elle est si dépendante de quelques prestataires de cloud.
Erreurs logicielles et interruption de service
Une base de données corrompue, une mise à jour logicielle échouée ou une simple erreur de configuration peuvent mettre à mal des plateformes entières. Vous remarquerez peut-être qu'une ligne de code mal configurée peut se répercuter sur tous les systèmes connectés, provoquant une panne généralisée avec un rayon d'action important. Une gestion adéquate des changements et des environnements de test dédiés sont vos meilleurs alliés pour minimiser ces risques.
Erreurs humaines et mauvaises configurations
Les suppressions accidentelles, les configurations incorrectes et les modifications non autorisées restent l'une des causes les plus courantes des pannes informatiques. Une seule commande erronée ou un fichier supprimé peut déclencher des heures d'indisponibilité et une dégradation du service. Si la formation et les contrôles d'accès sont utiles, ils ne peuvent toutefois pas éliminer totalement les erreurs humaines.
📮ClickUp Insight : 92 % des employés utilisent des méthodes incohérentes pour suivre les éléments à mener, ce qui entraîne des décisions manquées et des retards dans l'exécution.
Que vous envoyiez des notes de suivi ou utilisiez des feuilles de calcul, le processus est souvent dispersé et inefficace. Grâce aux fonctionnalités de gestion des tâches de ClickUp, vous n'aurez plus jamais à vous en soucier. Créez des tâches à partir du chat, des commentaires sur les tâches ClickUp, des documents et des e-mails en un seul clic !
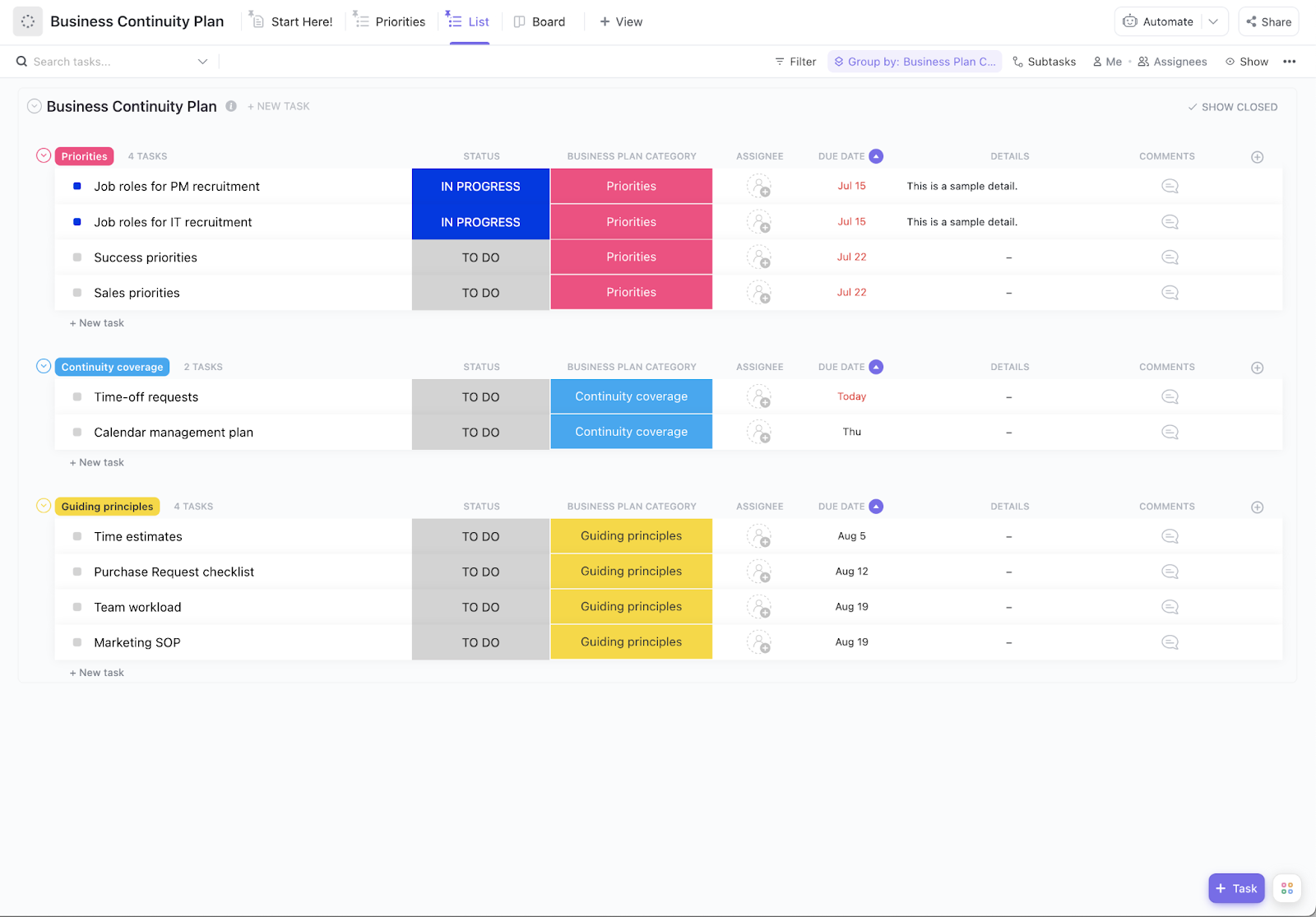
Éléments clés d'un plan de reprise après sinistre informatique
Un plan de reprise après sinistre solide est votre guide complet pour vous remettre en ligne. Chacun de ces éléments s'appuie sur les autres pour créer une protection complète pour votre entreprise.
Évaluation et hiérarchisation des risques
Tout d'abord, vous devez savoir à quoi vous avez affaire. Une évaluation des risques consiste à identifier vos vulnérabilités et à évaluer la probabilité et l'impact de chaque menace potentielle. Vous pouvez organiser cela dans une matrice des risques afin de voir quelles sont les menaces les plus graves.
Votre évaluation doit couvrir les points suivants :
- Systèmes critiques: ce qui doit absolument continuer à fonctionner pour que votre entreprise puisse opérer.
- Sensibilité des données : quelles informations nécessitent le plus haut niveau de protection (comme les données clients) ?
- Dépendances : quels autres systèmes ou processus sont affectés lorsque chaque système tombe en panne ?
📖 En savoir plus : Comment mettre en œuvre la gestion de l'infrastructure informatique
Analyse de l'impact sur l'activité et criticité
Ensuite, déterminez le coût réel des temps d'arrêt. Une analyse d'impact sur l'activité (BIA) vous aide à déterminer l'impact financier et opérationnel d'une panne pour chaque système. Cela vous permet de classer vos systèmes par niveau de criticité afin de hiérarchiser vos efforts de reprise.
| Critique | Moins d'une heure | Traitement des paiements, bases de données clients |
| Élevé | Une à quatre heures | E-mail, outils de communication interne |
| Moyen | Quatre à 24 heures | Environnements de développement, outils de rapports |
| Faible | Plus de 24 heures | Systèmes d'archivage, serveurs de test hors production |
Objectifs RTO et RPO
Ces deux acronymes sont au cœur de votre stratégie de reprise.
- Objectif de temps de reprise (RTO) : il s'agit du temps maximal pendant lequel vous pouvez vous permettre qu'un système soit hors service. Il répond à la question suivante : « Dans quel délai devons-nous rétablir le système ? »
- Objectif de point de reprise (RPO) : il s'agit de la quantité maximale de données que vous pouvez vous permettre de perdre, mesurée en temps. Il répond à la question suivante : « Quelle quantité de données pouvons-nous perdre sans subir de préjudice majeur ? »
Par exemple, votre système d’e-mail interne peut avoir un RTO de quatre heures, mais votre base de données e-commerce destinée aux clients peut avoir un RPO de seulement 15 minutes, ce qui signifie que vous ne pouvez pas perdre plus de 15 minutes de données de transactions.
Forfait de sauvegarde et de reprise des données
Votre plan de sauvegarde est votre filet de sécurité ultime. Une bonne pratique courante est la règle 3-2-1 : conservez au moins trois copies de vos données importantes, stockez-les sur deux types de supports différents et conservez l'une de ces copies hors site.
Vous aurez également le choix entre différents types de sauvegarde :
- Sauvegardes complètes : copie intégrale de toutes les données, généralement à faire chaque semaine ou chaque mois.
- Sauvegardes incrémentielles : ne sauvegardez que les modifications apportées depuis la dernière sauvegarde, quel que soit son type.
- Sauvegardes différentielles : sauvegarde toutes les modifications apportées depuis la dernière sauvegarde complète.
Plus important encore, vous devez tester régulièrement votre processus de restauration des sauvegardes. Une sauvegarde non testée n'est qu'un espoir, pas un plan.
💟 Bonus : Capturez les détails essentiels lors d'incidents très stressants en utilisant la fonction de reconnaissance vocale de ClickUp Brain MAX, afin de ne jamais manquer d'informations importantes, même lorsque la saisie au clavier n'est pas pratique. Il vous suffit d'énoncer vos observations et de laisser l'IA se charger de la documentation.
Plan de communication et mises à jour des parties prenantes
En cas de sinistre, un plan de communication clair est essentiel. Votre plan doit définir les chaînes de notifications, la fréquence des mises à jour et les canaux à utiliser pour chaque type d'incident.
Différents groupes ont besoin d'informations différentes :
- Équipes internes : ont besoin de détails techniques et d’éléments spécifiques à prendre.
- Clients : vous devez connaître le statut du service et savoir quand vous pensez qu'il sera rétabli.
- Fournisseurs : leur intervention peut être nécessaire pour l’assistance ou les escalades.
- Organismes de réglementation : peuvent exiger des notifications officielles en fonction de votre secteur d'activité.
Des outils tels que ce modèle de plan de communication prêt à l'emploi de ClickUp peuvent vous aider à agir plus rapidement grâce à un protocole établi en cas de crise.

Programme de test et de formation
Un plan que vous ne testez jamais est un plan voué à l'échec. Des tests réguliers permettent de révéler les lacunes et les faiblesses avant qu'une véritable catastrophe ne survienne.
Prévoyez différents types de tests tout au long de l'année :
- Exercices sur table : votre équipe passe en revue un scénario de catastrophe sur papier afin de vérifier la logique du plan.
- Basculements partiels : vous testez la reprise de composants ou de services spécifiques non critiques.
- Tests de reprise après sinistre complets : vous effectuez un basculement complet vers vos systèmes de sauvegarde (le test ultime).
Après chaque test, mettez à jour votre documentation et formez immédiatement les nouveaux membres de l'équipe aux procédures.
📖 En savoir plus : Comment élaborer des politiques et des procédures informatiques efficaces
Étapes pour créer un plan de reprise après sinistre informatique
L'élaboration de votre plan de reprise après sinistre ne doit pas nécessairement être une tâche fastidieuse.
Voici comment vous pouvez vous y prendre, étape par étape. 🙌
Étape 1 : Dressez l'inventaire des actifs
Vous ne pouvez pas protéger ce que vous ne connaissez pas. Commencez par dresser une liste des actifs qui répertorie tous les éléments matériels, logiciels, référentiels de données et dépendances système de votre environnement. Veillez à inclure les coordonnées des fournisseurs, les clés de licence et les détails de configuration afin de pouvoir vous y référer rapidement lors d'une reprise.

Le modèle ITAM de ClickUp regroupe la gestion des incidents, la gestion des problèmes, la gestion des changements, des solutions simples de gestion des actifs et la gestion des connaissances. Notre modèle ITSM Known Errors simplifie le suivi des erreurs connues dans vos systèmes. Explorez tous nos modèles informatiques dès que votre objectif change.
Personnalisez vos flux de travail comme vous le souhaitez pour chaque étape de l'ITAM, du déploiement et de la configuration à la maintenance et à la mise hors service.
Étape 2 : Classer les services critiques
Identifiez maintenant les actifs qui sont essentiels à la mission et ceux qui sont simplement utiles. Créez des cartes de dépendance des services qui montrent comment vos systèmes sont connectés et dépendent les uns des autres. Accordez une attention particulière aux services destinés aux clients qui ont un impact direct sur les revenus ou l'expérience utilisateur.
🎥 Regardez cette présentation pratique qui montre comment élaborer un plan structuré et de haut niveau à l'aide des puissantes fonctionnalités de ClickUp, de la définition des objectifs à l'attribution des tâches et au suivi des progrès.
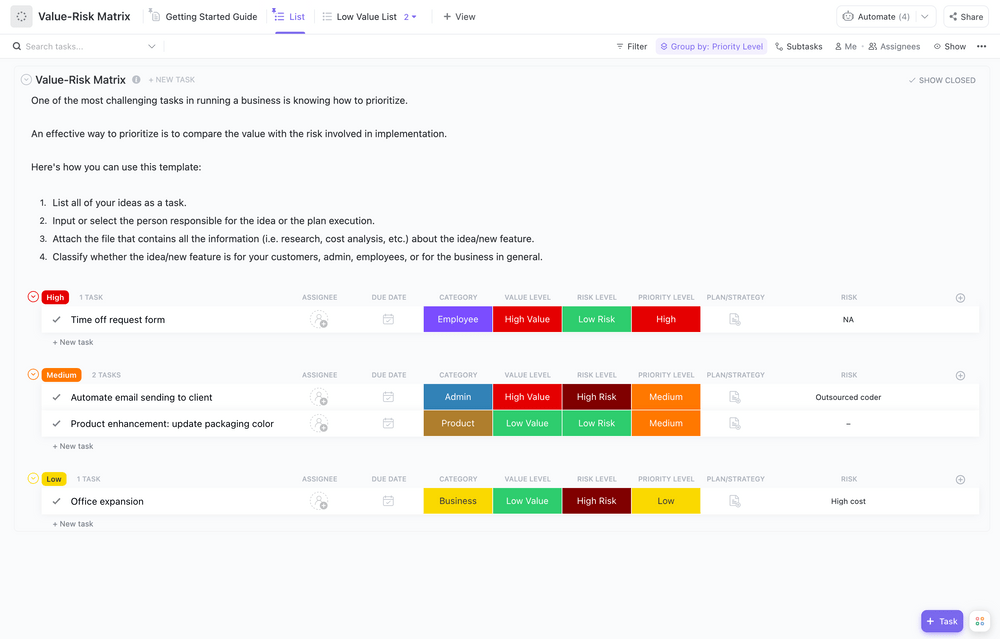
Étape 3 : Évaluer les risques et les menaces
Évaluez les risques et les menaces en analysant la probabilité et l'impact de chaque type de menace dans votre situation spécifique. Tenez compte des risques géographiques (êtes-vous situé dans une zone sismique ou inondable ?) et des menaces spécifiques à votre secteur d'activité (comme les changements réglementaires ou les cyberattaques ciblées). Consignez tout dans un registre des risques afin de pouvoir le suivre au fil du temps.

Le modèle de Tableau blanc d'évaluation des risques ClickUp apporte une dimension visuelle à votre processus d'évaluation des risques. Il facilite l'évaluation et la catégorisation des risques, incitant votre équipe à partager ses idées et à collaborer dans un format visuel et attrayant.
Ce modèle vous permet de :
- Évaluez les catégories de risques et les impacts potentiels.
- Analysez les données pour identifier les domaines potentiellement préoccupants.
- Déterminez les mesures préventives à mettre en place pour réduire l'exposition aux risques.
Grâce à ses fonctionnalités qui vous permettent de dessiner, d'écrire et d'ajouter des notes autocollantes, ce modèle de tableau blanc de gestion des risques est idéal pour évaluer les risques de votre projet.
Étape 4 : Définir les cibles RTO et RPO
Travaillez directement avec les parties prenantes de votre entreprise pour définir ce qu'elles considèrent comme un temps d'arrêt et une perte de données acceptables pour chaque niveau de service que vous avez identifié précédemment. Vous devrez trouver un équilibre entre le coût d'une reprise plus rapide et l'impact sur l'activité : tout ne nécessite pas une reprise instantanée sans perte de données. Obtenez l'accord de la direction sur ces cibles.
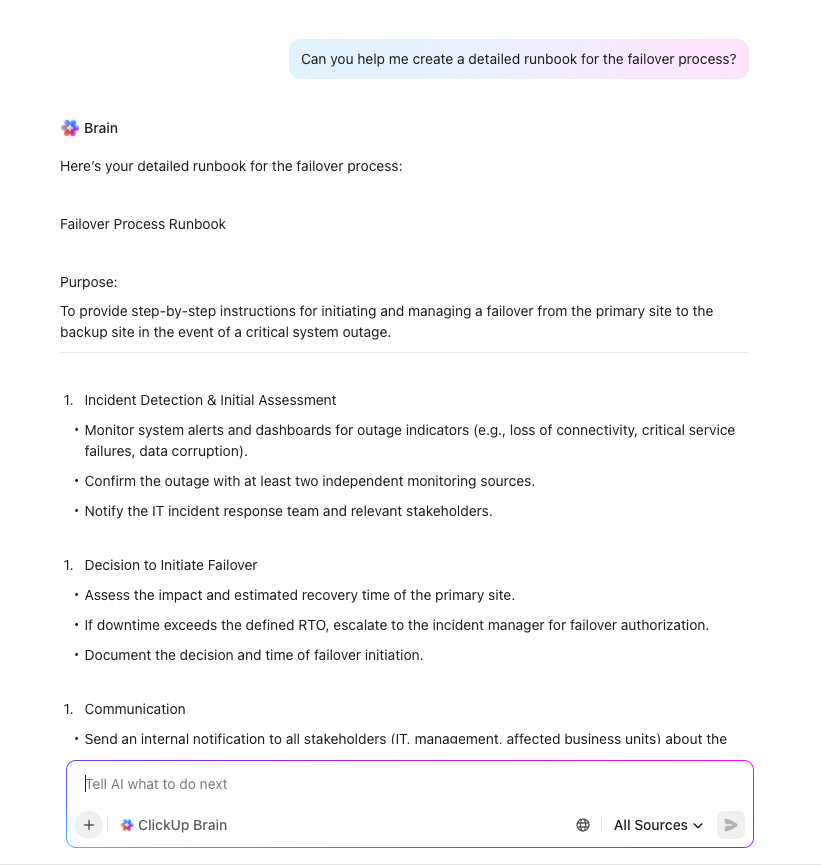
Étape 5 : Définir les chemins de sauvegarde et de basculement
Une fois vos cibles fixées, vous pouvez désormais concevoir vos solutions techniques. Créez des stratégies de sauvegarde adaptées au RPO de chaque système et planifiez des procédures de basculement détaillées, y compris des sites de traitement alternatifs et des méthodes d'accès d'urgence. Ajoutez des schémas de réseau et des guides d'exécution étape par étape pour garantir une exécution sans faille.
Étape 6 : Attribuer les rôles et les niveaux d'escalade
Définissez la structure de votre équipe de reprise après sinistre en attribuant des responsabilités et des pouvoirs décisionnels clairs. Créez des listes de contacts complètes avec le personnel principal et le personnel de sauvegarde pour chaque rôle. Une matrice RACI (Responsible, Accountable, Consulted, Informed) est un excellent outil pour éliminer toute confusion lors d'un incident très stressant.
Étape 7 : Documenter et communiquer le plan
Documentez et communiquez le plan à l'aide de procédures claires et détaillées que tous les membres de votre équipe peuvent suivre, même sous pression. Il est essentiel de stocker cette documentation dans un emplacement facilement accessible, distinct de votre infrastructure principale. Assurez-vous que chaque membre de l'équipe sait exactement où trouver le plan en cas de crise.
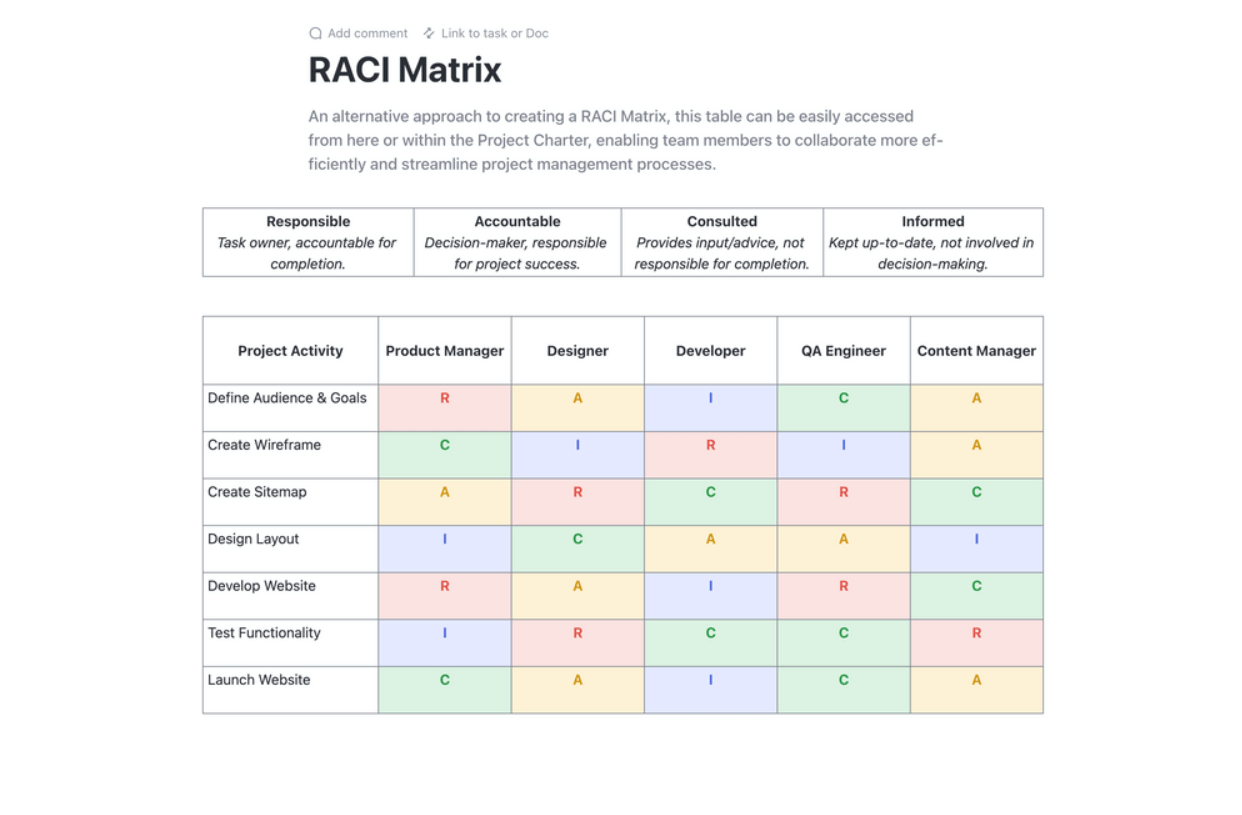
Rationalisez la planification de vos projets grâce au modèle de planification RACI de ClickUp. Ce modèle de document change la donne en proposant un diagramme clair qui permet de définir les rôles et les responsabilités de l'équipe par rapport aux tâches du projet. Adoptez le cadre RACI (Responsible, Accountable, Consulted, and Informed) pour mettre tout le monde sur la même longueur d'onde, garantir la responsabilité et l'alignement avec les objectifs organisationnels.
Étape 8 : Tester, examiner et améliorer
Enfin, planifiez des tests trimestriels pour valider vos procédures et identifier les lacunes éventuelles. Consignez toutes les leçons tirées de chaque test et de chaque incident réel, et utilisez-les pour mettre à jour votre plan. Créez un système de suivi systématique des améliorations afin de vous assurer que tous les problèmes identifiés sont résolus.
🌼 Le saviez-vous ? En 2017, GitLab a subi une panne majeure de sa base de données. Au cours de la reprise, ils ont découvert que plusieurs de leurs méthodes de sauvegarde avaient échoué silencieusement pendant plusieurs jours. Cet incident a enseigné à l'ensemble du secteur technologique une leçon cruciale : la validation des sauvegardes n'est pas négociable. Une sauvegarde non testée n'est pas vraiment une sauvegarde.
🌼 Le saviez-vous ? En 2017, GitLab a subi une panne majeure de sa base de données. Au cours de la reprise, ils ont découvert que plusieurs de leurs méthodes de sauvegarde avaient échoué silencieusement pendant plusieurs jours. Cet incident a enseigné à l'ensemble du secteur technologique une leçon cruciale : la validation des sauvegardes n'est pas négociable. Une sauvegarde non testée n'est pas vraiment une sauvegarde.
Stratégies et solutions de reprise après sinistre
Toutes les entreprises n'ont pas besoin de la même approche en matière de reprise après sinistre. Explorons les options qui s'offrent à vous en fonction de votre budget, de vos besoins en matière de reprise et des ressources disponibles.
Approche de sauvegarde et de restauration
Il s'agit de la méthode la plus simple et la plus rentable. Elle consiste à effectuer des sauvegardes régulières vers un emplacement hors site (comme le cloud ou un centre de données secondaire), puis à les restaurer manuellement en cas de besoin. Cette approche est idéale pour les systèmes non critiques qui peuvent tolérer un RTO plus long, car la reprise peut prendre des heures, voire des jours.
Haute disponibilité et redondance
Cette stratégie vise à éliminer les points de défaillance uniques en utilisant plusieurs systèmes actifs. Des techniques telles que l'équilibrage de charge, le clustering de serveurs et le stockage RAID garantissent que si un composant tombe en panne, un autre prend immédiatement le relais. Bien que plus coûteuse à mettre en place et à entretenir, cette approche permet de réduire les temps d'arrêt à quelques secondes ou minutes, ce qui la rend idéale pour les services critiques.
Options de réplication et de basculement
La réplication consiste à copier les données en temps quasi réel vers un site secondaire, ce qui garantit une perte de données minimale en cas de sinistre.
- Réplication synchrone : écrit les données simultanément sur les sites principal et secondaire, garantissant ainsi une perte de données nulle. Cependant, elle nécessite une bande passante élevée et peut ralentir votre système principal.
- Réplication asynchrone : les données sont d'abord écrites sur le site principal, puis copiées sur le site secondaire avec un léger décalage. Cette méthode est moins coûteuse et a moins d'impact sur les performances, mais elle comporte un faible risque de perte de données.
Reprise après sinistre basée sur le cloud et DRaaS
La reprise après sinistre en tant que service (DRaaS) est devenue un choix populaire pour de nombreuses entreprises. Elle offre une tarification à l'utilisation, une distribution géographique instantanée et une automatisation de la reprise sans avoir à créer et à maintenir vos propres sites de reprise après sinistre physiques. La reprise après sinistre dans le cloud élimine les dépenses d'investissement considérables liées à un centre de données de sauvegarde tout en offrant une évolutivité plus rapide et une plus grande flexibilité que les approches traditionnelles de sites chauds, tièdes ou froids.
Comment ClickUp rationalise la planification de la reprise après sinistre informatique
La gestion d'un plan de reprise après sinistre à partir de feuilles de calcul, de documents et de chaînes d'e-mails dispersés crée un risque de sinistre en soi.
Ce type de dispersion du travail, la fragmentation du travail entre plusieurs outils déconnectés qui ne communiquent pas entre eux, et la dispersion du contexte, lorsque les équipes perdent des heures à rechercher des informations dispersées entre différentes applications et plateformes, entraînent une confusion, des informations obsolètes et des temps de réponse lents alors que chaque seconde compte.
Avec ClickUp Converged AI Workspace, une plateforme unique et sécurisée qui regroupe toutes vos applications professionnelles, vos données et vos flux de travail, avec une IA contextuelle comme couche d'intelligence, et qui combine la gestion de projet, la documentation et la communication d'équipe. Ne jonglez plus entre plusieurs plateformes et regroupez votre planification de reprise après sinistre, vos tests et vos interventions en cas d'incident dans un système unifié.
Documentation centralisée sur la reprise après sinistre avec ClickUp Docs et assistance IA intégrée
Assurez-vous que votre équipe dispose toujours d'une source unique de documents fiables grâce à ClickUp Docs.
Élaborez l'intégralité de votre plan de reprise après sinistre dans un espace collaboratif où chacun peut contribuer en temps réel lors d'un incident. Liez directement les documents aux tâches et projets liés à l'incident pour une navigation fluide, et intégrez des diagrammes ou des guides pratiques afin de conserver les informations essentielles à portée de main.
Mieux encore, vous pouvez protéger vos documents afin d'empêcher toute modification en cours et utiliser les permissions granulaires de ClickUp pour contrôler qui peut afficher ou modifier les procédures de reprise sensibles. Chaque modification est suivie dans l'historique du document, ce qui vous offre une piste d'audit complète.
Création de plans optimisés par l'IA avec ClickUp Brain
Accélérez la planification de la reprise après sinistre et éliminez les lacunes critiques grâce à ClickUp Brain, votre assistant IA contextuel qui comprend l'ensemble de votre environnement de travail. Contrairement aux outils d'IA génériques, ClickUp Brain exploite les tâches, les documents et les flux de travail réels de votre organisation pour fournir une assistance précise et concrète aux initiatives de reprise après sinistre.
Il suffit de demander à ClickUp Brain de « créer une checklist de reprise après sinistre pour notre plateforme de commerce électronique » pour recevoir instantanément un modèle complet et personnalisé, adapté à vos systèmes, processus et besoins en matière de conformité. Il peut vous aider à :
- Connaissance du contexte : ClickUp Brain a accès à la structure, au contenu et aux permissions de votre environnement de travail. Il peut référencer des tâches, des documents, des commentaires et même des applications connectées, fournissant ainsi des réponses et des actions adaptées à votre travail réel, et pas seulement des suggestions génériques.
- Dépannage et conseils : dépannez instantanément les problèmes, obtenez des instructions étape par étape ou demandez les bonnes pratiques pour n'importe quelle fonctionnalité de ClickUp. Brain peut vous guider à travers des processus complexes, automatiser des tâches répétitives et vous aider à résoudre les blocages.
- Automatisation et accélération des flux de travail : utilisez des agents IA prédéfinis ou personnalisés pour automatiser les flux de travail en plusieurs étapes, trier les demandes ou gérer le travail récurrent, et ainsi gagner plusieurs heures chaque semaine.
- Recherche approfondie : trouvez des informations enfouies n'importe où dans votre environnement de travail, y compris des tâches, des documents et des outils intégrés, même si elles datent de plusieurs années ou sont difficiles à localiser avec une recherche standard.
- Résumés et mises à jour en temps réel : générez instantanément des mises à jour de projet, des résumés de réunion ou des rapports d'avancement à partir des données en direct de l'environnement de travail.
- Simplification de la documentation technique : convertissez des documents techniques complexes en procédures ou checklists claires et exploitables que votre équipe peut suivre, même sous pression.
- Intelligence multimodèle : choisissez parmi les meilleurs modèles d'IA (OpenAI GPT-4. 1, GPT-5, Claude, Gemini, etc.) pour obtenir les meilleurs résultats dans toutes les tâches, sans abonnement supplémentaire.
- Sécurisé et respectueux des autorisations : Brain n'accède qu'aux informations que vous êtes déjà autorisé à consulter, en respectant des normes strictes en matière de confidentialité et de conformité.
- Interface de discussion : utilisez @brain dans les commentaires ou lors de la discussion pour obtenir des informations contextuelles, rédiger des réponses ou déclencher des automatisations sans quitter votre flux de travail.
- Invites personnalisées et flux de travail enregistrés : enregistrez et réutilisez les invitations et les instructions pour les besoins récurrents, afin de garantir la cohérence et de gagner du temps pour toute votre équipe.
💡Conseil de pro : ne manquez jamais une leçon tirée de vos réunions d'analyse des incidents en capturant chaque détail avec ClickUp AI Notetaker. Cet outil peut participer à vos réunions virtuelles, transcrire l'intégralité de la discussion et générer automatiquement une liste d'éléments à réaliser à partir des leçons apprises. Cela permet de créer un historique des incidents consultable, afin que vous puissiez rapidement vous référer aux évènements passés et à leurs résolutions.

Flux de travail de reprise après sinistre automatisé avec ClickUp Automatisations
Imaginez que votre équipe soit confrontée à une panne soudaine : chaque seconde compte et vous ne pouvez vous permettre de manquer une seule étape. Grâce aux agents IA et aux automatisations de ClickUp, vous n'avez plus besoin de vous précipiter ou de vous fier à votre mémoire. Dès qu'un incident est signalé, l'IA de ClickUp se met en action, guide votre équipe et se charge des tâches fastidieuses afin que vous puissiez vous concentrer sur la résolution du problème.
Voici comment cela fonctionne dans un scénario réel :
- Lorsqu'une personne marque une tâche comme « Incident déclaré », ClickUp Agent crée automatiquement une checklist des étapes à suivre, les attribue aux personnes concernées et lance un chronomètre pour suivre le temps nécessaire à la reprise.
- Si l'incident est marqué comme « critique », un agent peut instantanément envoyer un e-mail d'alerte à votre équipe de direction et créer une salle de discussion spéciale, votre « salle de crise », afin que tout le monde puisse communiquer au même endroit.
- L'IA peut extraire les rapports d'incidents passés et la documentation pertinente, afin que votre équipe dispose de tout ce dont elle a besoin à portée de main.
Consultez le flux de travail ici :
Avec ClickUp AI Agents, vous disposez d'un coéquipier numérique fiable qui aide votre équipe à rester calme, organisée et efficace, même lorsque la pression est forte.
Suivi en temps réel avec les tableaux de bord ClickUp
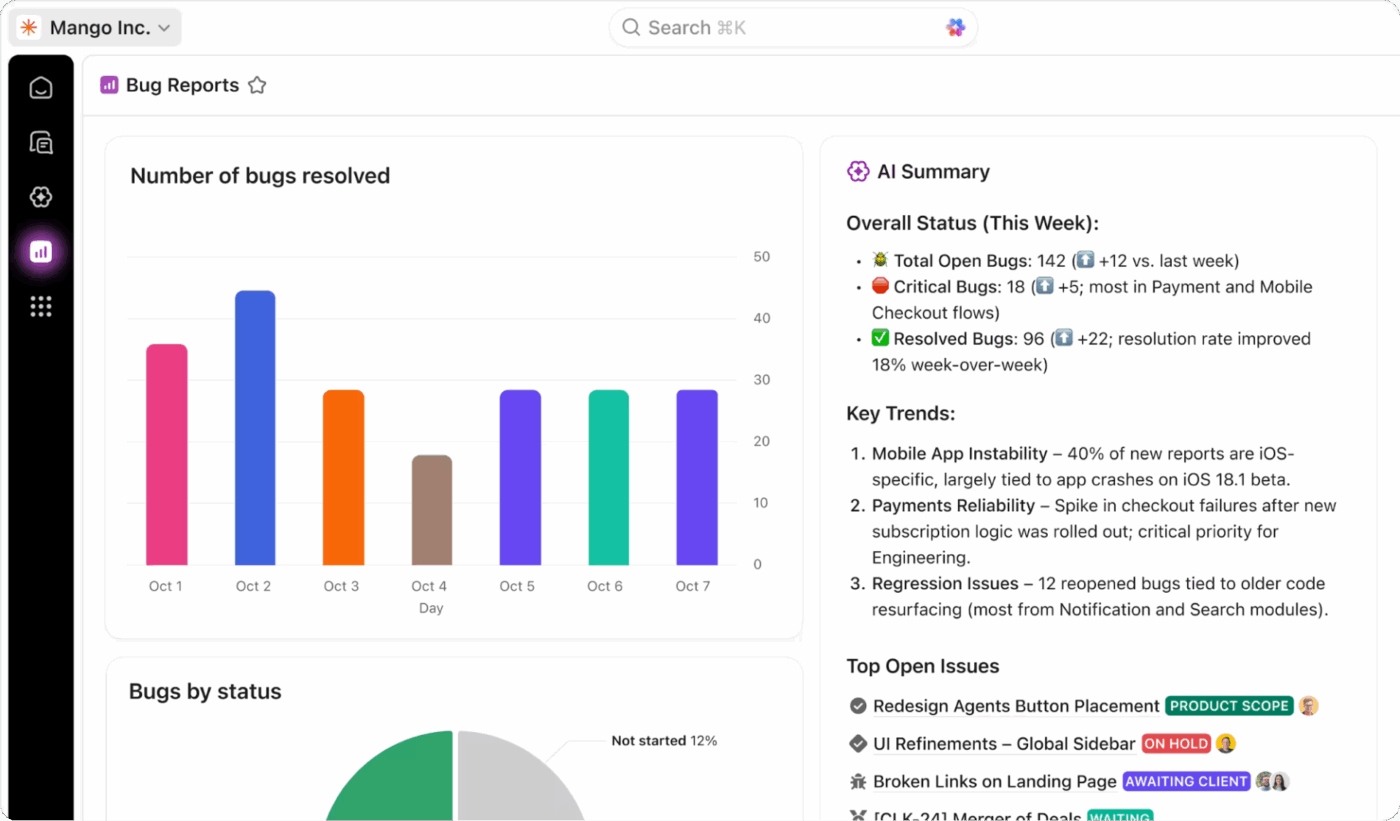
Bénéficiez d'une visibilité complète sur l'état de votre programme de reprise après sinistre en effectuant un suivi en temps réel à l'aide des tableaux de bord ClickUp. Vous pouvez créer des widgets pour surveiller les performances de vos RTO et RPO pendant les tests, suivre les taux d'achèvement des tests et afficher les tendances des incidents au fil du temps.
Ajoutez des champs personnalisés ClickUp à vos tâches pour suivre la criticité du système, l'état de la reprise et les résultats des tests, puis regroupez toutes ces données dans une vue d'ensemble. Ces tableaux de bord vous fournissent des rapports prêts à l'emploi, toujours à jour grâce aux données en temps réel issues des tests et des activités de réponse aux incidents de votre équipe.
📖 En savoir plus : Comment créer une checklist pour l'évaluation des risques
Élaborez votre plan de reprise après sinistre dès aujourd'hui
Chaque jour où vous opérez sans plan de reprise après sinistre est un pari que vous ne pouvez pas vous permettre de perdre. Les sinistres sont inévitables, qu'ils soient d'origine naturelle, technologique ou dues à des erreurs humaines, mais c'est votre préparation qui déterminera s'ils seront des inconvénients mineurs ou des catastrophes majeures.
Un plan de reprise après sinistre complet nécessite de comprendre vos risques, de documenter des procédures claires et de les tester régulièrement. Les bons outils facilitent ce processus en éliminant le chaos lié à la dispersion des documents et aux processus manuels.
Même les forfaits d'urgence les plus basiques valent mieux que rien lorsque survient une catastrophe. Des tests et des mises à jour réguliers transformeront votre forfait de reprise après sinistre, qui passera d'un document poussiéreux à un système vivant qui protège véritablement votre entreprise.
Faites la première étape et commencez dès aujourd'hui à élaborer votre plan de reprise après sinistre avec ClickUp. Commencez gratuitement avec ClickUp et regroupez tous vos plans de reprise après sinistre, votre documentation et vos interventions en cas d'incident sur une plateforme unique. ✨
Foire aux questions
Vous devez revoir votre plan de reprise après sinistre au moins quatre fois par an et le mettre à jour immédiatement après tout changement important de l'infrastructure ou incident réel. La plupart des organisations procèdent chaque année à une révision approfondie afin d'intégrer toutes les leçons apprises et de s'adapter aux nouvelles technologies.
Les équipes informatiques, les équipes de sécurité et les responsables de la continuité des activités dirigent généralement les efforts de planification et de test de reprise après sinistre. Cependant, ils ont besoin des contributions essentielles des responsables des opérations et des unités commerciales pour s'assurer que le plan correspond aux besoins et aux priorités réels de l'entreprise.
Utilisez des chronomètres et des horodatages clairs pour mesurer les temps de reprise réels par rapport à vos cibles définies lors de chaque test. Il est essentiel de documenter tout écart entre vos cibles et les performances réelles dans vos rapports de test afin d'orienter les améliorations futures.
Les plateformes de gestion de projet telles que ClickUp sont idéales pour centraliser la documentation, réaliser l'automatisation des flux de travail et effectuer le suivi des indicateurs de performance de l'ensemble de votre programme de reprise après sinistre. Vous pouvez ensuite les associer à des outils spécialisés qui gèrent les aspects techniques de la réplication des données et du basculement du système.