

Il existe deux types d'assistants IA : ceux qui savent tout jusqu'à la semaine dernière et ceux qui savent ce qui s'est passé il y a une minute.
Si vous demandez au premier assistant IA « Mon vol est-il toujours retardé ? », il vous répondra peut-être en se basant sur l'horaire d'hier, ce qui pourrait être erroné. Le deuxième assistant, alimenté par des données actualisées à la seconde près, vérifie les mises à jour en direct et vous donne la bonne réponse.
Le deuxième assistant est ce que nous appelons la connaissance en temps réel, vue en action.
Elle constitue la base des systèmes d'IA agentique, qui ne se contentent pas de répondre à des questions, mais agissent, décident, coordonnent et s'adaptent. Ici, l'accent est mis sur l'autonomie, l'adaptabilité et le raisonnement axé sur les objectifs .
Dans cet article, nous explorerons ce que signifie la connaissance en temps réel dans le contexte de l'IA, pourquoi elle est importante, comment elle fonctionne et comment vous pouvez l'utiliser dans des flux de travail réels.
Que vous travailliez dans les opérations, les produits, l’assistance ou la direction, cet article vous donne les bases nécessaires pour poser les bonnes questions, évaluer les systèmes et comprendre comment les connaissances en temps réel pourraient transformer votre technologie et vos résultats d’entreprise. Plongeons-nous dans le vif du sujet.
Qu'est-ce que les connaissances en temps réel dans l'IA agentielle ?
Les connaissances en temps réel désignent les informations disponibles en temps réel, à jour et accessibles à un système d'IA au moment où il doit agir.
Ce terme est généralement utilisé dans le contexte de l'IA agentielle et ambiante, c'est-à-dire des agents IA qui connaissent si bien vos collaborateurs, vos connaissances, votre travail et vos processus qu'ils peuvent fonctionner de manière transparente et proactive en arrière-plan.
La connaissance en temps réel signifie que l'IA ne se fie pas uniquement à l'ensemble de données sur lequel elle a été formée ou à l'instantané des connaissances au moment du déploiement. Au contraire, elle continue d'apprendre, établit des connexions avec les flux de données actuels et ajuste ses actions en fonction de ce qui se passe réellement à ce moment-là.
Dans le contexte des agents IA (c'est-à-dire des systèmes qui agissent ou prennent des décisions), les connaissances en temps réel leur permettent de détecter les changements dans leur environnement, d'intégrer de nouvelles informations et de choisir les étapes suivantes en conséquence.
En quoi cela diffère-t-il des données d'entraînement statiques et des bases de connaissances traditionnelles ?
La plupart des systèmes d'IA traditionnels sont formés à partir d'un ensemble de données fixe (texte, images ou journaux, par exemple), puis déployés. Leurs connaissances ne changent pas, sauf si vous les reformiez ou les mettiez à jour.
C'est comme lire un livre sur les ordinateurs publié dans les années 90 et essayer d'utiliser un MacBook de 2025.
Les bases de connaissances traditionnelles (par exemple, le référentiel de FAQ de votre entreprise ou une base de données statique contenant les spécifications des produits) peuvent faire l'objet de mises à jour périodiques, mais elles ne sont pas conçues pour diffuser en continu de nouvelles informations et s'adapter.
Les connaissances en temps réel se distinguent par leur caractère continu et dynamique : votre agent fonctionne à partir d'un flux en direct plutôt que d'une copie mise en cache.
En bref :
- Formation statique = « ce que le modèle savait lorsqu'il a été créé »
- Connaissances en temps réel = « ce que le modèle sait à mesure que le monde change, en temps réel ».
La relation entre les connaissances en temps réel et l'autonomie des agents
Les systèmes d'IA agentique sont conçus pour faire plus que simplement répondre à une question.
Ils peuvent :
- Coordonnez les actions
- Planifiez des flux de travail en plusieurs étapes
- Fonctionnez avec un minimum d'intervention humaine
Pour y parvenir efficacement, ils doivent avoir une compréhension approfondie de la situation actuelle, notamment du statut des systèmes, des derniers indicateurs commerciaux, du contexte client et des évènements externes. C'est exactement ce qu'offre la connaissance en temps réel.
Grâce à cela, l'agent peut détecter les changements de conditions, adapter son processus décisionnel et agir en fonction de la réalité actuelle de l'entreprise ou de l'environnement.
Comment les connaissances en temps réel remédient à la prolifération du travail et aux flux de travail déconnectés
La connaissance en direct, c'est-à-dire l'accès connecté en temps réel à l'information sur tous vos outils, résout directement les problèmes quotidiens causés par la dispersion au travail. Mais qu'est-ce que c'est exactement ?
Imaginez que vous travaillez sur un projet et que vous avez besoin des derniers commentaires du client, mais ceux-ci sont enfouis dans un fil de discussion par e-mail, tandis que le plan du projet se trouve dans un autre outil et que les fichiers de conception sont dans une autre application encore. Sans connaissances en temps réel, vous perdez du temps à passer d'une plateforme à l'autre, à demander des mises à jour à vos collègues, voire à manquer des détails importants.
Les connaissances en temps réel offrent le scénario idéal où vous pouvez rechercher et trouver instantanément ces commentaires, consulter le dernier statut du projet et accéder aux dernières conceptions, le tout en un seul endroit, quel que soit l'emplacement des données.
Par exemple, un responsable marketing peut simultanément accéder aux résultats d'une campagne à partir d'outils d'analyse, examiner les ressources créatives d'une plateforme de conception et consulter les discussions de l'équipe à partir d'applications de chat. Un agent d'assistance peut consulter l'historique complet d'un client (e-mails, tickets et journaux de chat) sans avoir à activer/désactiver des systèmes.
Vous passez ainsi moins de temps à rechercher des informations, vous manquez moins de mises à jour et vous prenez des décisions plus rapides et plus sûres. En bref, les connaissances en temps réel assurent la connexion de votre univers numérique dispersé, rendant votre travail quotidien plus fluide et plus productif.
En tant que premier environnement de travail IA convergent au monde, l'agent IA Live Intelligence de ClickUp offre tout cela et bien plus encore. Découvrez-le en action ici. 👇🏼
📖 En savoir plus : La gestion des connaissances par l'IA : avantages, cas d'utilisation et Outils d'IA
Composants clés qui permettent les systèmes de connaissances en temps réel
Derrière chaque système de connaissances en temps réel se cache un réseau invisible de composants mobiles : il collecte en permanence des données, effectue des connexions entre des sources de données et apprend des résultats. Ces composants fonctionnent ensemble pour garantir que les informations ne restent pas simplement au sein du stockage, mais circulent, se mettent à jour et s'adaptent au fur et à mesure que le travail avance.
Concrètement, les connaissances en temps réel reposent sur une combinaison de transfert de données, d'intelligence d'intégration, de mémoire contextuelle et d'apprentissage basé sur le retour d'information. Chaque élément joue un rôle spécifique pour que votre environnement de travail reste informé et proactif plutôt que réactif.
L'un des plus grands défis des organisations dynamiques est la prolifération du travail. À mesure que les équipes adoptent de nouveaux outils et processus, les connaissances peuvent rapidement se fragmenter entre les plateformes, les canaux et les formats. Sans un système permettant d'unifier et de mettre en évidence ces informations dispersées, des informations précieuses sont perdues et les équipes perdent du temps à rechercher ou à dupliquer le travail. Les connaissances en temps réel remédient directement à la prolifération du travail en intégrant et en effectuant en permanence des connexions avec les informations provenant de toutes les sources, garantissant ainsi que les connaissances restent accessibles, à jour et exploitables, quelle que soit leur origine. Cette approche unifiée empêche la fragmentation et permet aux équipes de travailler plus intelligemment, sans pour autant travailler plus dur.
Voici une présentation des blocs fondamentaux qui rendent cela possible et de la manière dont ils s'appliquent dans la pratique :
| Composant | Ce qu'il fait | Comment ça marche ? |
|---|---|---|
| Pipelines de données | Intégrez en permanence de nouvelles données dans le système. | Les pipelines de données utilisent des API, des flux d'évènements et des webhooks pour extraire ou pousser de nouvelles informations à partir de plusieurs outils et environnements. |
| Couches d'intégration | Connectez les données provenant de différents systèmes internes et externes dans une vue unifiée. | Les couches d'intégration synchronisent les informations entre les applications telles que les CRM, les bases de données et les capteurs IoT, éliminant ainsi les silos et les doublons. |
| Systèmes contextuels et mémoriels | Aidez l'IA à se souvenir de ce qui est pertinent et à oublier ce qui ne l'est pas. | Ces systèmes créent une « mémoire de travail » pour les agents, leur permettant de conserver le contexte des discussions, actions ou flux de travail récents tout en supprimant les données obsolètes. |
| Mécanismes de récupération et de mise à jour | Permettez aux systèmes d'accéder aux informations les plus récentes au moment où vous en avez besoin. | Les outils de recherche effectuent des requêtes sur les données juste avant qu'une réponse ou une décision ne soit prise, garantissant ainsi l'utilisation des mises à jour les plus récentes. Les bases de données internes sont mises à jour automatiquement avec les nouvelles informations. |
| Boucles de rétroaction | Permettez l'apprentissage et l'amélioration continus à partir des résultats | Les mécanismes de rétroaction réexaminent les actions passées à l'aide de nouvelles données, comparent les résultats attendus aux résultats réels et ajustent les modèles internes en conséquence. |
Ensemble, ces composants font passer l'IA d'une « connaissance à un moment donné » à une « compréhension continue en temps réel ».
Pourquoi les connaissances en temps réel sont-elles importantes pour les agents IA ?
Les systèmes /IA ne sont efficaces que dans la mesure où les connaissances sur lesquelles ils s'appuient sont fiables.
Dans les flux de travail modernes, ces connaissances changent à chaque instant. Qu'il s'agisse de l'évolution du sentiment des clients, des données sur les produits ou des performances opérationnelles en temps réel, les informations statiques perdent rapidement leur pertinence.
C'est là que les connaissances en temps réel deviennent essentielles.
Les connaissances en temps réel permettent aux agents IA de passer du statut de répondeurs passifs à celui de solveurs de problèmes adaptatifs. Ces agents se synchronisent en permanence avec les conditions du monde réel, détectent les changements dès qu'ils se produisent et ajustent leur raisonnement en temps réel. Cette capacité rend l'IA plus sûre, plus fiable et plus alignée sur les objectifs humains dans des systèmes complexes et dynamiques.
Limites des connaissances statiques dans les environnements dynamiques
Lorsque les systèmes d'IA utilisent uniquement des données statiques (c'est-à-dire celles dont ils disposaient au moment de leur formation ou de leur dernière mise à jour), ils risquent de prendre des décisions qui ne correspondent plus à la réalité. Par exemple, les prix du marché ont changé, les performances des serveurs se sont détériorées ou la disponibilité des produits a évolué.
Si un agent ne remarque pas ces changements et n'en tient pas compte, il peut produire des réponses inexactes, des actions inappropriées ou, pire encore, introduire des risques.
Des recherches indiquent que, à mesure que les systèmes deviennent de plus en plus autonomes, le recours à des données obsolètes devient une vulnérabilité importante. Les bases de connaissances IA peuvent aider à combler cette lacune. Regardez cette vidéo pour en savoir plus à leur sujet. 👇🏼
🌏 Lorsque les chatbots ne disposent pas des connaissances en temps réel adéquates :
L'assistant virtuel alimenté par l'IA d'Air Canada a fourni à un client des informations incorrectes concernant la politique de la compagnie aérienne en matière de voyages pour cause de décès. Le client, Jake Moffatt, était en deuil de sa grand-mère et a utilisé le chatbot pour se renseigner sur les tarifs avec réduction.
Le chatbot lui a indiqué à tort qu'il pouvait acheter un billet au prix plein et demander un remboursement de la réduction pour décès dans les 90 jours. Se fiant à ce conseil, Moffatt a réservé des vols coûteux. Cependant, la politique réelle d'Air Canada exigeait que la réduction pour décès soit demandée avant le voyage et ne pouvait être appliquée rétroactivement.
Scénarios réels dans lesquels les connaissances en temps réel sont essentielles
Air Canada n'est qu'un exemple parmi d'autres. Voici d'autres scénarios dans lesquels les connaissances en temps réel peuvent faire la différence :
- Agents du service clientèle : un assistant IA qui ne peut pas vérifier le dernier statut d'expédition ou l'état des stocks fournira des réponses médiocres ou manquera des occasions de faire un suivi.
- Agents financiers : les cours boursiers, les taux de devises ou les indicateurs économiques changent à chaque seconde. Un modèle sans données en temps réel sera en décalage avec les réalités du marché.
- Agents de santé : les données de surveillance des patients (fréquence cardiaque, tension artérielle, résultats de laboratoire) peuvent évoluer rapidement. Les agents qui n'accèdent pas aux données récentes risquent de passer à côté d'avertissements.
- Agents DevOps ou opérationnels : indicateurs système, incidents, comportement des utilisateurs... Les changements peuvent s'accélérer rapidement. Les agents ont besoin d'une connaissance en temps réel pour notifier, remédier ou escalader au bon moment.
Zillow a mis fin à son entreprise de revente immobilière (Zillow Offers) après que son modèle d'IA pour l'évaluation des prix des maisons n'ait pas réussi à prédire avec précision l'évolution rapide du marché immobilier pendant la pandémie, entraînant des pertes financières massives dues au surcoût des propriétés. Cela met en évidence le risque de dérive du modèle lorsque les indicateurs économiques changent rapidement.
Impact sur la prise de décision et la précision des agents
Lorsque les connaissances en temps réel sont intégrées, les agents deviennent plus fiables, plus précis et plus réactifs. Ils peuvent éviter les décisions « obsolètes », réduire la latence dans la détection des changements et réagir de manière appropriée.
Ils renforcent également la confiance : les utilisateurs savent que l'agent « sait ce qui se passe ».
Du point de vue de la prise de décision, les connaissances en temps réel garantissent que les « données » utilisées par l'agent pour planifier et mettre en œuvre ses étapes sont valides à ce moment précis. Cela permet d'obtenir de meilleurs résultats, de réduire le nombre d'erreurs et d'améliorer l'agilité des processus.
Valeur commerciale et avantages concurrentiels
Pour les organisations, le passage des connaissances statiques aux connaissances en temps réel dans les agents IA débloque plusieurs avantages :
- Réaction plus rapide au changement : lorsque votre IA sait ce qui se passe actuellement, vous pouvez agir plus rapidement.
- Interaction personnalisée et actualisée : l'expérience client s'améliore lorsque les réponses reflètent le contexte le plus récent.
- Résilience opérationnelle : les systèmes qui détectent rapidement les anomalies ou les changements peuvent atténuer les risques.
- Différenciation concurrentielle : si vos agents peuvent s'adapter en temps réel et que les autres ne le peuvent pas, vous gagnez en rapidité et en perspicacité.
En résumé, les connaissances en temps réel constituent une capacité stratégique pour les organisations qui cherchent à garder une longueur d'avance sur le changement.
Comment fonctionne Live Knowledge : composants principaux
Les connaissances en temps réel sont synonymes de flux de travail, de sensibilisation et d'adaptabilité en temps réel.
Lorsque le flux de connaissances se produit en temps réel, cela aide les équipes à prendre des décisions plus rapides et plus intelligentes.
Voici comment fonctionnent les systèmes de connaissances en temps réel en coulisses, grâce à trois couches clés : les sources de données en temps réel, les méthodes d'intégration et l'architecture des agents.
Composant 1 : Sources de données en temps réel
Tout système de connaissances en temps réel commence par ses entrées : les données qui affluent en permanence depuis vos outils, vos applications et vos flux de travail quotidiens. Ces entrées peuvent provenir de pratiquement n'importe quel endroit où vous travaillez : un client qui soumet un ticket d'assistance dans Zendesk, un commercial qui met à jour ses notes de vente dans Salesforce ou un développeur qui publie un nouveau code sur GitHub.
Même les systèmes d'automatisation fournissent des signaux : les capteurs IoT fournissent des rapports sur les performances des équipements, les tableaux de bord marketing fournissent des indicateurs en direct sur les campagnes et les plateformes financières actualisent les chiffres d'affaires en temps réel.
Ensemble, ces divers flux de données constituent la base des connaissances en temps réel : un flux d'informations continu et interconnecté qui reflète ce qui se passe actuellement dans votre écosystème d'entreprise. Lorsqu'un système d'IA peut accéder à ces données et les interpréter instantanément, il va au-delà de la collecte passive de données et devient un collaborateur en temps réel qui aide les équipes à agir, à s'adapter et à prendre des décisions plus rapidement.
API et webhook
Les API et les webhooks sont le tissu conjonctif de l'environnement de travail moderne. Les API permettent un partage structuré et à la demande des données.
Par exemple, les intégrations ClickUp vous aident à récupérer les mises à jour de Slack ou Salesforce en quelques secondes. Les webhooks vont encore plus loin en poussant automatiquement les mises à jour lorsqu'un changement survient, ce qui permet de garder vos données à jour sans avoir besoin de synchronisation manuelle. Ensemble, ils éliminent le « décalage d'information » et garantissent que votre système reflète toujours ce qui se passe à l'instant présent.
Connexions à la base de données
Les connexions en temps réel aux bases de données permettent aux modèles de surveiller les données opérationnelles et de réagir à leur évolution. Qu'il s'agisse d'informations sur les clients provenant d'un CRM ou de mises à jour sur l'avancement de vos projets provenant de votre outil de gestion de projet, ce pipeline direct garantit que vos décisions IA sont fondées sur des informations en temps réel et précises.
Systèmes de traitement de flux
Les technologies de traitement de flux telles que Kafka et Flink convertissent les données brutes des évènements en informations instantanées. Cela peut se traduire par des alertes en temps réel lorsqu'un projet est bloqué, un équilibrage automatique de la charge de travail ou l'identification des goulots d'étranglement dans le flux de travail avant qu'ils ne deviennent des obstacles. Ces systèmes permettent aux équipes de suivre leurs opérations au fur et à mesure qu'elles se déroulent.
Bases de connaissances externes
Aucun système ne peut prospérer de manière isolée. La connexion à des sources de connaissances externes (documents sur les produits, bibliothèques de recherche ou ensembles de données publiques) donne aux systèmes en direct un contexte global.
Cela signifie que votre assistant IA comprend non seulement ce qui se passe dans votre environnement de travail, mais aussi pourquoi cela est important dans le contexte global.
📖 En savoir plus : Comment utiliser les agents basés sur la connaissance dans l'IA
Composante 2 : méthodes d'intégration des connaissances
Une fois le flux de données en place, l'étape suivante consiste à les intégrer dans une couche de connaissances vivante et évolutive qui se développe en permanence.
Injection dynamique de contexte
Le contexte est l'ingrédient secret qui transforme les données brutes en informations significatives. L'injection dynamique de contexte permet aux systèmes IA d'intégrer les informations les plus pertinentes et les plus récentes, telles que les dernières mises à jour d'un projet ou les priorités de l'équipe, au moment précis où les décisions sont prises. C'est comme avoir un assistant qui se souvient exactement de ce dont vous avez besoin au moment idéal.
Découvrez comment Brain Agent y parvient dans ClickUp :
Mécanismes de récupération en temps réel
La recherche IA traditionnelle s'appuie sur des informations stockées. La recherche en temps réel va plus loin en analysant et en actualisant en permanence les sources en connexion, afin de ne faire apparaître que le contenu le plus récent et le plus pertinent.
Par exemple, lorsque vous demandez à ClickUp Brain un résumé de projet, il ne fouille pas dans d'anciens fichiers, mais extrait des informations récentes à partir des dernières données en temps réel.
Mises à jour du graphe de connaissances
Les graphiques de connaissances mappent les relations entre les personnes, les tâches, les objectifs et les idées. La mise à jour en temps réel de ces graphiques garantit que les dépendances évoluent parallèlement à vos flux de travail. À mesure que les priorités changent ou que de nouvelles tâches sont ajoutées, le graphique se rééquilibre automatiquement, offrant aux équipes une vue claire et toujours précise des liens entre les différentes tâches.
Approches d'apprentissage continu
L'apprentissage continu permet aux modèles d'IA de s'adapter en fonction des commentaires des utilisateurs et de l'évolution des modèles. Chaque commentaire, correction et décision devient une donnée d'entraînement, aidant le système à mieux comprendre le fonctionnement réel de votre équipe.
Composante 3 : architecture d'agent pour les connaissances en temps réel
La dernière couche, souvent la plus complexe, concerne la manière dont les agents IA gèrent, mémorisent et hiérarchisent les connaissances afin de garantir la cohérence et la réactivité.
Systèmes de gestion de la mémoire
Tout comme les êtres humains, l'IA doit savoir ce qu'il faut retenir et ce qu'il faut oublier. Les systèmes de mémoire équilibrent la mémoire à court terme et le stockage à long terme, en conservant le contexte essentiel (tel que les objectifs en cours ou les préférences des clients) tout en filtrant les informations non pertinentes. Cela permet au système de rester performant et de ne pas être surchargé.
Optimisation de la fenêtre contextuelle
Les fenêtres contextuelles définissent la quantité d'informations qu'une IA peut « voir » à la fois. Lorsque ces fenêtres sont optimisées, les agents peuvent gérer des interactions longues et complexes sans perdre de vue les détails importants. En pratique, cela signifie que votre IA peut se souvenir de l'historique complet d'un projet et de toutes les discussions, et pas seulement des derniers messages, ce qui lui permet de fournir des réponses plus précises et plus pertinentes.
Cependant, à mesure que les organisations adoptent davantage d'outils et d'agents IA, un nouveau défi apparaît : la prolifération de l'IA. Les connaissances, les actions et le contexte peuvent se fragmenter entre différents robots et plateformes, ce qui entraîne des réponses incohérentes, des doublons dans le travail et des informations manquantes. Les connaissances en temps réel remédient à ce problème en unifiant les informations et en optimisant les fenêtres contextuelles dans tous les systèmes IA, garantissant ainsi que chaque agent s'appuie sur une source unique et actualisée. Cette approche empêche la fragmentation et permet à votre IA de fournir une assistance cohérente et complète.
Hiérarchisation des informations
Toutes les connaissances ne méritent pas la même attention. La hiérarchisation intelligente garantit que l'IA se concentre sur ce qui compte vraiment : les tâches urgentes, les dépendances changeantes ou les changements majeurs en matière de performances. En filtrant les données en fonction de leur impact, le système évite la surcharge d'informations et améliore la clarté.
Stratégies de mise en cache
La rapidité favorise l'adoption. La mise en cache des informations fréquemment consultées, telles que les commentaires récents, les mises à jour des tâches ou les indicateurs de performance, permet une récupération instantanée tout en réduisant la charge du système. Cela signifie que votre équipe bénéficie d'une collaboration fluide et en temps réel, sans décalage entre l'action et l'information.
Les connaissances en temps réel transforment le travail réactif en travail proactif. Lorsque les données en temps réel, l'apprentissage continu et l'architecture d'agents intelligents sont réunis, vos systèmes cessent de prendre du retard.
C'est la base pour des décisions plus rapides, moins d'angles morts et un écosystème IA plus connecté.
📮ClickUp Insight : 18 % des personnes interrogées dans le cadre de notre sondage souhaitent utiliser l'IA pour organiser leur vie à l'aide de calendriers, de tâches et de rappels. 15 % souhaitent que l'IA se charge des tâches routinières et du travail administratif.
À faire, une IA doit être capable de comprendre les niveaux de priorité de chaque tâche dans un flux de travail, d'exécuter les étapes nécessaires pour créer ou ajuster des tâches, et de mettre en place des flux de travail d'automatisation.
La plupart des outils ont mis en place une ou deux de ces étapes. Cependant, ClickUp a aidé les utilisateurs à consolider plus de 5 applications à l'aide de notre plateforme avec ClickUp Brain MAX!
Types de systèmes de connaissances en temps réel
Dans cette section, nous allons nous pencher sur les différents modèles architecturaux permettant de fournir des connaissances en temps réel aux agents IA : comment se fait le flux de données, quand l'agent reçoit des mises à jour et les compromis impliqués.
Systèmes basés sur la demande
Dans un modèle basé sur la demande, l'agent demande des données lorsqu'il en a besoin. Imaginez un élève qui lève la main en plein cours : « Quel temps fait-il actuellement ? » ou « Quel est le dernier état des stocks ? » L'agent déclenche une requête vers une source en temps réel (API, base de données) et utilise le résultat dans l'étape suivante de son raisonnement.
👉🏽 Pourquoi utiliser une approche « pull » ? Elle est efficace lorsque l'agent n'a pas besoin de données en temps réel à chaque instant. Vous évitez ainsi de devoir stocker en continu toutes les données, ce qui pourrait s'avérer coûteux ou inutile. Elle offre également un meilleur contrôle : vous décidez exactement quoi récupérer et quand.
👉🏽 Compromis : cela peut entraîner une latence : si la demande de données prend du temps, l'agent peut attendre et répondre plus lentement. De plus, vous risquez de manquer des mises à jour entre les sondages (si vous ne vérifiez que périodiquement). Par exemple, un agent du service client peut ne consulter l'API de statut d'expédition que lorsqu'un client demande « Où en est ma commande ? », plutôt que de maintenir un flux en direct constant des évènements d'expédition.
Systèmes basés sur la technologie « push »
Ici, au lieu d'attendre que l'agent demande, le système pousse les mises à jour vers l'agent dès qu'un changement survient. C'est comme s'abonner à une alerte d'actualité : quand un évènement se produit, vous en êtes immédiatement informé. Pour un agent IA qui utilise les connaissances en temps réel, cela signifie qu'il dispose toujours d'un contexte à jour au fur et à mesure que les évènements se déroulent.
👉🏽 Pourquoi utiliser une approche push ? Elle offre une latence minimale et une réactivité élevée, car l'agent est informé des changements dès qu'ils se produisent. Cela s'avère précieux dans les contextes à haute vitesse ou à haut risque (par exemple, les transactions financières, la surveillance de l'état des systèmes).
👉🏽 Compromis : la maintenance peut être plus coûteuse et plus complexe. L'agent peut recevoir de nombreuses mises à jour non pertinentes, qui doivent être filtrées et classées par ordre de priorité. Vous avez également besoin d'une infrastructure robuste pour gérer les flux continus. Par exemple, un agent IA DevOps reçoit des alertes webhook lorsque l'utilisation du processeur du serveur dépasse un certain seuil et lance une action de mise à l'échelle.
Approches hybrides
Dans la pratique, les systèmes de connaissances en temps réel les plus robustes combinent les approches « pull » et « push ». L'agent s'abonne aux évènements critiques (push) et récupère occasionnellement des données contextuelles plus larges lorsque cela est nécessaire (pull).
Ce modèle hybride permet de trouver un équilibre entre réactivité et coût/complexité. Par exemple, dans le cas d'un agent commercial, l'IA peut recevoir des notifications push lorsqu'un prospect ouvre une proposition, tout en extrayant les données CRM sur l'historique de ce client afin de préparer sa prochaine prise de contact.
Architectures orientées évènements
Le concept d'architecture événementielle est à la base des systèmes push et hybrides.
Ici, le système est structuré autour d'évènements (transactions commerciales, lectures de capteurs, interactions des utilisateurs) qui déclenchent des flux logiques, des décisions ou des mises à jour d'état.
Selon les analyses du secteur, les plateformes de streaming et les « streaming lakehouses » deviennent des couches d'exécution pour l'IA agentique, effaçant ainsi la frontière entre les données historiques et les données en temps réel.
Dans de tels systèmes, les évènements se propagent à travers des pipelines, s'enrichissent de contexte et alimentent des agents qui raisonnent, agissent, puis émettent éventuellement de nouveaux évènements.
L'agent de connaissances en temps réel devient ainsi un nœud dans une boucle de rétroaction en temps réel : percevoir → raisonner → agir → mettre à jour.
👉🏽 Pourquoi est-ce important ? Avec les systèmes événementiels, les connaissances en temps réel ne sont pas seulement un module complémentaire, elles font partie intégrante de la façon dont l'agent perçoit et influence la réalité. Lorsqu'un évènement se produit, l'agent met à jour son modèle du monde et réagit en conséquence.
👉🏽 Compromis : cela nécessite une conception tenant compte de la concurrence, de la latence, de l'ordre des évènements, de la gestion des pannes (que se passe-t-il en cas de perte ou de retard d'un évènement ?) et d'une logique « que se passerait-il si » pour les scénarios imprévus.
Mise en œuvre des connaissances en temps réel : approches techniques
La création de connaissances en temps réel implique une intelligence artificielle en constante évolution. En coulisses, les organisations combinent des API, des architectures de streaming, des moteurs contextuels et des modèles d'apprentissage adaptatifs afin de garantir la fraîcheur et l'exploitabilité des informations.
Dans cette section, nous examinerons comment ces systèmes prennent vie : les technologies qui alimentent la connaissance en temps réel, les modèles architecturaux qui la rendent évolutive et les étapes pratiques que les équipes prennent pour passer d'une connaissance statique à une intelligence continue et en temps réel.
Génération augmentée par la récupération (RAG) avec des sources de données en temps réel
Une approche largement utilisée consiste à combiner un modèle linguistique à grande échelle (LLM) avec un système de recherche en direct, souvent appelé RAG.
Dans les cas d'utilisation du RAG, lorsque l'agent doit répondre, il effectue d'abord une étape de récupération : il effectue une requête auprès de sources externes à jour (bases de données vectorielles, API, documents). Ensuite, le LLM utilise les données récupérées (dans son invite ou son contexte) pour générer la sortie.
Pour les connaissances en temps réel, les sources de récupération ne sont pas des archives statiques, mais des flux en direct continuellement mis à jour. Cela garantit que les résultats du modèle reflètent l'état actuel du monde.
Étapes de mise en œuvre :
- Identifiez les sources en direct (API, flux, bases de données)
- Indexez-les ou rendez-les consultables (base de données vectorielle, graphe de connaissances, magasin relationnel).
- À chaque activation d'un agent : récupérez les enregistrements récents pertinents, insérez-les dans l'invite/les instructions.
- Générer une réponse
- Vous pouvez également mettre à jour la mémoire ou les bases de connaissances avec les nouvelles informations découvertes.
Serveurs MCP et protocoles en temps réel
De nouvelles normes, telles que le Model Context Protocol (MCP), visent à définir la manière dont les modèles interagissent avec les systèmes en direct : points de terminaison de données, Outils d'IA, appels et mémoire contextuelle.
Selon un livre blanc, le MCP pourrait jouer pour l'IA le rôle que le HTTP a joué autrefois pour le web (connecter les modèles aux outils et aux données).
Concrètement, cela signifie que votre architecture d'agents pourrait comporter :
- Un serveur MCP qui traite les requêtes entrantes provenant de la couche modèle ou agent.
- Une couche de services qui effectue la connexion aux outils internes/externes, aux API et aux flux de données en direct.
- Une couche de gestion du contexte qui conserve l'état, la mémoire et les données récentes pertinentes.
En standardisant l'interface, vous rendez le système modulaire : les agents peuvent connecter différentes sources de données, différents outils et différents graphiques de mémoire.
Mises à jour de la base de données vectorielle
Lorsqu'il s'agit de connaissances en temps réel, de nombreux systèmes maintiennent une base de données vectorielle (embeddings) dont le contenu est continuellement mis à jour.
Les intégrations représentent de nouveaux documents, des points de données en temps réel et des états d'entités. La récupération est donc actualisée. Par exemple, lorsque de nouvelles données de capteurs arrivent, vous les convertissez en intégration et les insérez dans le magasin de vecteurs, afin que les requêtes suivantes en tiennent compte.
Considérations relatives à la mise en œuvre :
- À quelle fréquence réintégrez-vous les données en temps réel ?
- Comment supprimer les intégrations obsolètes ?
- Comment éviter la saturation du magasin de vecteurs et garantir la vitesse des requêtes ?
Modèles d'orchestration API
Les agents appellent rarement une seule API ; ils invoquent souvent plusieurs points de terminaison en séquence ou en parallèle. Les implémentations de connaissances en temps réel nécessitent une orchestration. Par exemple :
- Étape 1 : Vérifiez l'API d'inventaire en direct
- Étape 2 : si les stocks sont faibles, vérifiez l'API ETA du fournisseur.
- Étape 3 : Générer un message personnalisé basé sur les résultats combinés
Cette couche d'orchestration peut inclure la mise en cache, la logique de réessai, la limite de fréquence, les solutions de secours et l'agrégation des données. La conception de cette couche est essentielle pour la stabilité et les performances.
Utilisation des outils et appel des fonctions
Dans la plupart des cadres d'IA, les agents utilisent des outils pour agir.
Un outil est simplement une fonction prédéfinie que l'agent peut appeler, telle que get_stock_price(), check_server_status() ou fetch_customer_order().
Les frameworks LLM modernes rendent cela possible grâce à l'appel de fonctions, où le modèle décide quel outil utiliser, transmet les paramètres appropriés et reçoit une réponse structurée qu'il peut analyser.
Les agents de connaissances en temps réel vont encore plus loin. Au lieu d'utiliser des données statiques ou simulées, leurs outils se connectent directement à des sources en temps réel : bases de données en direct, API et flux d'évènements. L'agent peut récupérer les résultats actuels, les interpréter dans leur contexte et agir ou réagir immédiatement. Ce pont entre le raisonnement et les données du monde réel est ce qui transforme un modèle passif en un système adaptatif et continuellement conscient.
Étapes de mise en œuvre :
- Définissez les fonctions des outils qui englobent les sources de données en direct (API, bases de données).
- Assurez-vous que l'agent peut sélectionner l'outil à appeler et produire des arguments.
- Capturez les résultats des outils et intégrez-les dans le contexte de raisonnement.
- Assurez la journalisation, la gestion des erreurs et la repli (que se passe-t-il si l'outil tombe en panne ?)
📖 En savoir plus : MCP vs RAG vs agents IA
Cas d'utilisation et applications
La connaissance en temps réel passe rapidement du concept à l'avantage concurrentiel.
De la coordination de projets en temps réel au service client adaptatif et à la maintenance prédictive, les organisations constatent déjà des gains tangibles en termes de rapidité, de précision et de prévoyance.
Vous trouverez ci-dessous quelques-unes des applications les plus intéressantes de la connaissance en temps réel aujourd'hui et la manière dont elle redéfinit ce que signifie réellement le « travail intelligent » dans la pratique.
Agents du service clientèle disposant d'un inventaire des produits en temps réel
Dans le commerce de détail, un chatbot d'assistance relié aux systèmes d'inventaire et d'expédition en temps réel peut répondre à des questions telles que « Ce produit est-il en stock ? », « Quand sera-t-il expédié ? » ou « Puis-je bénéficier d'une livraison express ? ».
Au lieu de se fier à des données FAQ statiques (qui peuvent indiquer « rupture de stock » même lorsque le stock vient d'arriver), l'agent lance des requêtes sur les API d'inventaire et d'expédition en temps réel.
Agents financiers avec flux de données de marché
Les flux de travail financiers exigent une récupération immédiate des informations.
Un agent IA connecté à des API de données de marché (cours boursiers, taux de devises, indicateurs économiques) peut surveiller les changements en direct et soit alerter les traders humains, soit agir de manière autonome dans le cadre de paramètres définis.
La couche de connaissances en temps réel est ce qui distingue un simple tableau de bord analytique (rapports statiques) d'un agent autonome qui détecte une baisse soudaine de valeur et déclenche une couverture ou une transaction.
L'assistante virtuelle de Bank of America, « Erica », démontre avec succès l'intérêt d'utiliser des données en temps réel pour les agents IA dans le secteur financier. Elle traite chaque année des centaines de millions d'interactions avec les clients en accédant aux informations sur les comptes courants, en fournissant des conseils personnalisés et instantanés sur les finances, en aidant à effectuer des transactions et en gérant les budgets.
Agents de santé avec surveillance des patients
Dans le domaine de la santé, les connaissances en temps réel impliquent la connexion aux capteurs des patients, aux appareils médicaux, aux dossiers médicaux électroniques (DME) et à la transmission en continu des signes vitaux.
Un agent IA peut surveiller en temps réel la fréquence cardiaque, le taux d'oxygène et les résultats d'analyses d'un patient, les comparer à des seuils ou des modèles, et alerter les cliniciens ou prendre les mesures recommandées (par exemple, signaler l'aggravation de la condition du patient). Les systèmes d'avertissement précoce alimentés par l'analyse des données en temps réel permettent déjà d'identifier la septicémie ou l'insuffisance cardiaque beaucoup plus tôt que les approches traditionnelles.
Nvidia, par exemple, développe une plateforme d'agents IA d'entreprise qui alimente des agents spécifiques à certaines tâches, dont un conçu pour l'Hôpital d'Ottawa afin d'aider les patients 24 heures sur 24. L'agent guidera les patients tout au long des étapes de préparation préopératoire, de rétablissement postopératoire et de rééducation.
Comme l'explique Kimberly Powell, vice-présidente et directrice générale de Nvidia Healthcare, l'objectif est de libérer du temps pour les cliniciens tout en améliorant l'expérience des patients.
Agents DevOps avec indicateurs de système
Dans les opérations informatiques, les agents de connaissances en temps réel surveillent les journaux, la télémétrie, les évènements liés à l'infrastructure et les API de statut des services. En cas de pics de latence, de prolifération d'erreurs ou d'épuisement des ressources, l'agent peut déclencher une correction : redémarrer un service, augmenter la capacité ou rediriger le trafic. Comme l'agent reste informé de l'état du système en temps réel, il peut agir plus efficacement et réduire les temps d'arrêt.
Équipe commerciale avec intégration CRM
Dans l’équipe commerciale, les connaissances en temps réel consistent à lier un agent au CRM, aux plateformes de communication et aux activités récentes des prospects.
Imaginez un agent commercial qui surveille le moment où un prospect ouvre une proposition, puis invite le représentant à agir : « Votre proposition a été affichée. Souhaitez-vous planifier un suivi dès maintenant ? » L'agent peut extraire des données d'engagement en temps réel, le contexte du prospect, les taux de réussite historiques, le tout de manière dynamique, afin de formuler des suggestions personnalisées et opportunes. Cela permet de passer d'une approche générique à une action contextuelle.
JPMorgan Chase a exploité les agents IA lors d'une récente crise boursière afin de fournir des conseils plus rapidement, de servir davantage de clients et d'augmenter ses ventes. Son assistant « Coach » basé sur l'IA a aidé les conseillers financiers à obtenir des informations jusqu'à 95 % plus rapidement, permettant à l'entreprise d'augmenter son chiffre d'affaires brut d'environ 20 % entre 2023 et 2024 et de cibler une augmentation de 50 % du nombre de clients au cours des 3 à 5 prochaines années.
Débloquez l'intelligence en direct pour votre organisation avec ClickUp
Les équipes d'aujourd'hui ont besoin de plus que des outils statiques. Elles ont besoin d'un environnement de travail qui comprend, connecte et accélère activement le travail. ClickUp est le premier environnement de travail IA convergent, conçu pour fournir des informations en temps réel en intégrant les connaissances, l'automatisation et la collaboration dans une plateforme unique et unifiée.
Recherche d'entreprise unifiée : des connaissances en temps réel à portée de main
Trouvez instantanément des réponses, quel que soit l'endroit où se trouvent les informations. La recherche d'entreprise de ClickUp relie les tâches, les documents, les chats et les outils tiers intégrés dans une seule barre de recherche alimentée par l'IA. Les requêtes en langage naturel renvoient des résultats riches en contexte, rassemblant des données structurées et non structurées afin que vous puissiez prendre des décisions plus rapidement.
- Effectuez des recherches dans les tâches, les documents, les chats et les outils tiers intégrés à l'aide d'une seule barre de recherche alimentée par l'IA.
- Utilisez des requêtes en langage naturel pour récupérer des données structurées et non structurées à partir de toutes les sources de données tierces connectées.
- Affichez instantanément les politiques, les mises à jour de projet, les fichiers et l'expertise en la matière avec des résultats riches en contexte.
- Indexez et effectuez la connexion des informations provenant de Google Drive, Slack et d'autres plateformes pour obtenir une vue d'ensemble.
Effectuez l'automatisation, l'orchestration et la raison à travers les flux de travail grâce aux agents IA
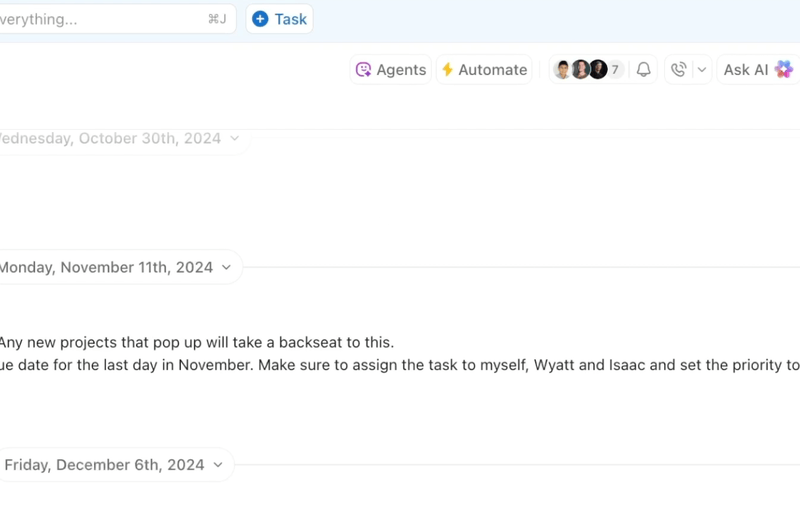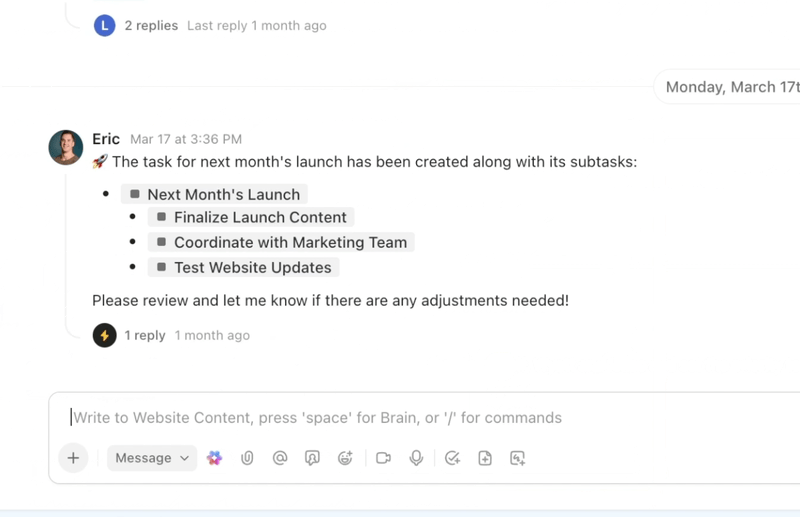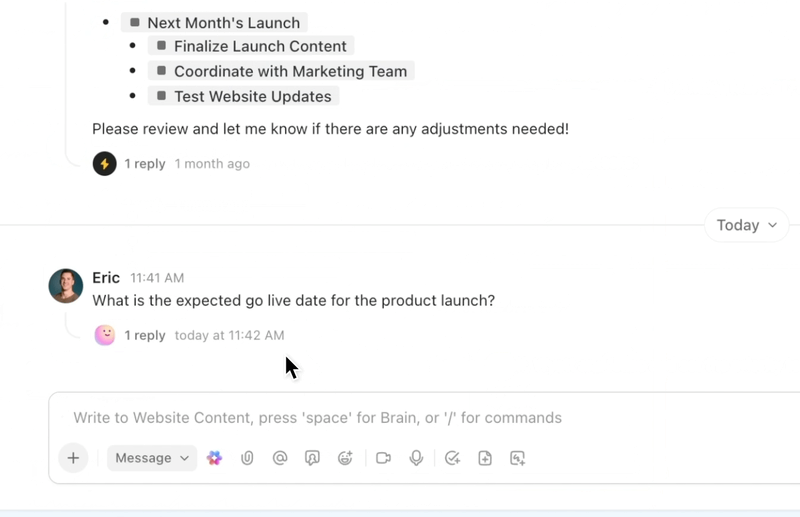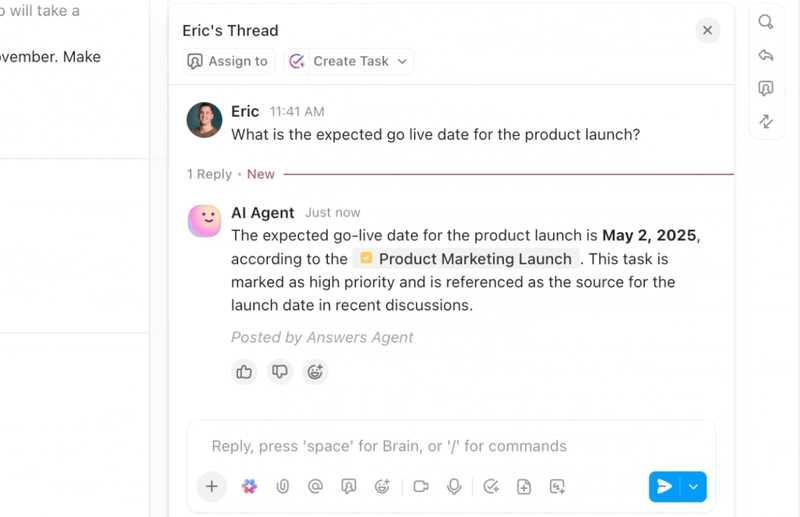
Automatisez les tâches répétitives et orchestrez des processus complexes grâce à des agents IA intelligents qui agissent comme des coéquipiers numériques. Les agents IA de ClickUp exploitent les données et le contexte de l'environnement de travail en temps réel, ce qui leur permet de raisonner, d'agir et de s'adapter à l'évolution des besoins de l'entreprise.
- Déployez des agents IA personnalisables qui automatisent les tâches, trient les demandes et exécutent des flux de travail en plusieurs étapes.
- Résumez les réunions, générez du contenu, mettez à jour les tâches et déclenchez des automatisations basées sur des données en temps réel.
- Adaptez vos actions en fonction du contexte, des dépendances et de la logique métier grâce à des capacités de raisonnement avancées.
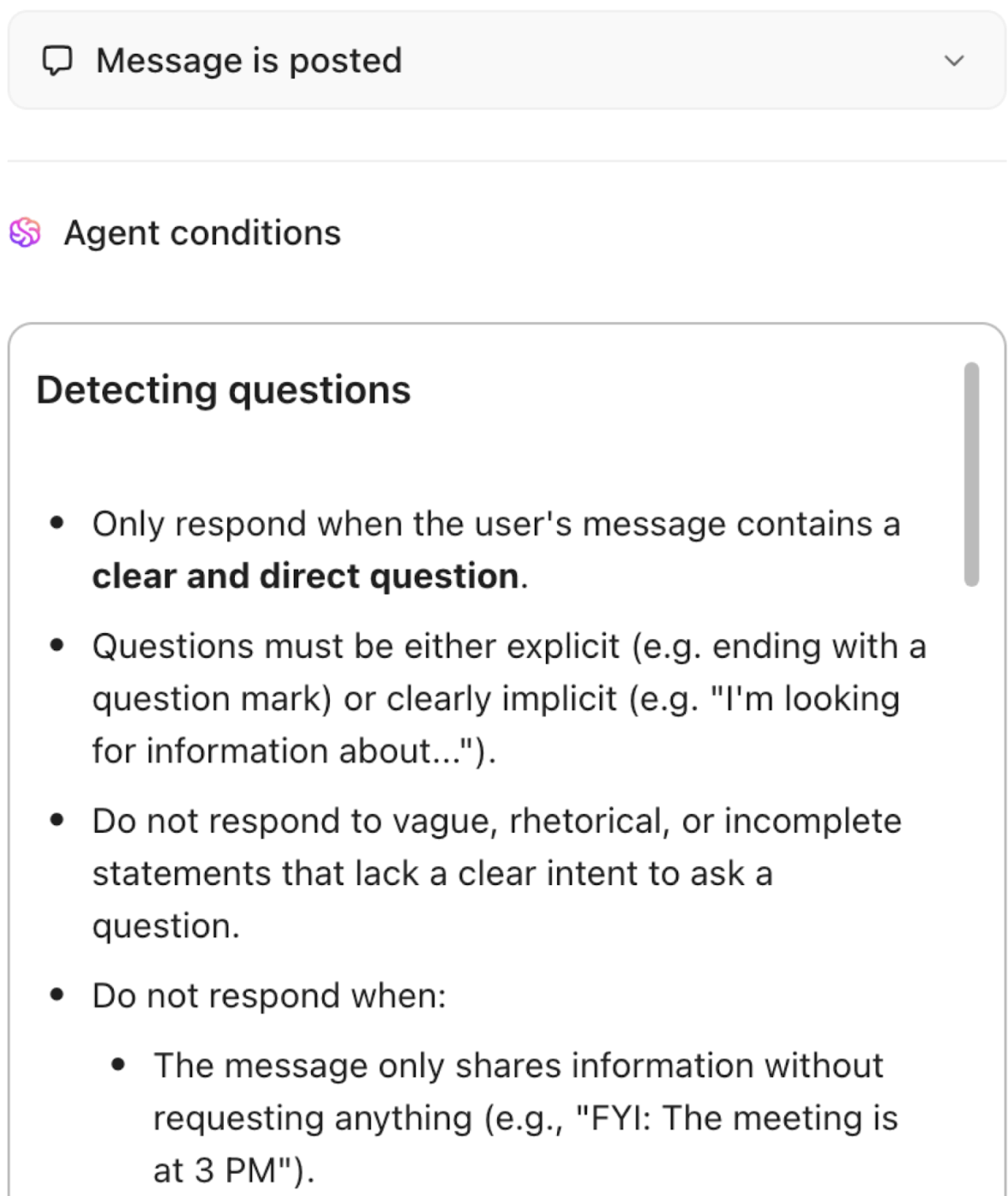
Gestion des connaissances en temps réel : dynamique, contextuelle et toujours à jour
Transformez la documentation statique en une base de connaissances vivante. ClickUp Knowledge Management indexe et lie automatiquement les informations provenant des tâches, des documents et des discussions, garantissant ainsi que les connaissances sont toujours à jour et accessibles. Des suggestions basées sur l'IA font apparaître des contenus pertinents pendant que vous travaillez, tandis qu'une organisation et des permissions intelligentes assurent la sécurité des données sensibles.
- Indexez et liez automatiquement les informations provenant de tâches ClickUp, documents ClickUp et discussions pour créer une base de connaissances vivante.
- Faites apparaître le contenu pertinent grâce à des suggestions basées sur l'IA pendant que vous travaillez.
- Organisez les connaissances à l'aide de permissions granulaires pour un partage sécurisé et facile à trouver.
- Gardez la documentation, les guides d'intégration et les connaissances institutionnelles toujours à jour et accessibles.
Collaboration convergente : contextuelle, connectée et exploitable
La collaboration dans ClickUp est profondément intégrée à votre travail.
L'édition en temps réel, les résumés générés par l'IA et les recommandations contextuelles garantissent que chaque discussion est exploitable. ClickUp Chat, Tableau blanc, Documents et Tâches sont interconnectés, ce qui permet de mener le brainstorming, la planification et l'exécution en un seul flux.
Cela vous aide à :
- Collaborez en temps réel grâce à des documents, des Tableaux blancs et des tâches intégrés, tous liés entre eux pour des flux de travail fluides.
- Transformez les discussions en étapes concrètes grâce à des résumés et des recommandations générés par l'IA.
- Visualisez les dépendances, les obstacles et le statut des projets grâce à des mises à jour en temps réel et des notifications intelligentes.
- Permettez à des équipes interfonctionnelles de réfléchir, planifier et exécuter dans un environnement unifié.
ClickUp n'est pas seulement un environnement de travail. C'est une plateforme d'intelligence en direct qui unifie les connaissances de votre organisation, effectue l'automatisation du travail et donne aux équipes des informations exploitables, le tout en temps réel.
Nous avons comparé les meilleurs logiciels de recherche d'entreprise, et voici les résultats :
Défis et bonnes pratiques
Si les connaissances en temps réel offrent de puissants avantages, elles introduisent également des risques et une certaine complexité.
Vous trouverez ci-dessous les principaux défis auxquels les organisations sont confrontées en matière d'IA, ainsi que les pratiques permettant de les atténuer.
| Défi | Description | bonnes pratiques |
|---|---|---|
| Optimisation de la latence et des performances | La connexion aux données en direct ajoute une latence due aux appels API, au traitement des flux et à la récupération. Si les réponses sont lentes, l'expérience de l'utilisateur et la confiance en pâtissent. | ✅ Mettez en cache les données moins critiques pour éviter les récupérations redondantes✅ Donnez la priorité aux flux critiques et sensibles au facteur temps ; actualisez les autres moins fréquemment✅ Optimisez la récupération et l'injection de contexte pour réduire le temps d'attente du modèle✅ Surveillez en permanence les indicateurs de latence et définissez des paramètres de performance |
| Actualité des données vs coût de calcul | La maintenance de la mise à jour en temps réel des données provenant de toutes les sources de données peut s'avérer coûteuse et inefficace. Toutes les informations ne nécessitent pas une mise à jour à chaque seconde. | ✅ Classez les données par niveau de criticité (données en temps réel vs données périodiques)✅ Utilisez des fréquences de mise à jour échelonnées✅ Équilibrez la valeur et le coût : ne procédez à des mises à jour que lorsque cela a un impact sur les décisions |
| Sécurité et contrôle d'accès | Les systèmes en direct ont souvent des connexions avec des données internes ou externes sensibles (CRM, DME, systèmes financiers), ce qui crée des risques d'accès non autorisé ou de fuite. | ✅ Appliquez un accès avec privilèges minimaux pour les API et limitez les permissions des agents✅ Auditez tous les appels de données effectués par l'agent✅ Appliquez le chiffrement, les canaux sécurisés, l'authentification et la journalisation des activités ✅ Utilisez la détection des anomalies pour signaler les comportements d'accès inhabituels |
| Gestion des erreurs et stratégies de secours | Les sources de données en direct peuvent échouer en raison d'une interruption de l'API, de pics de latence ou de données mal formées. Les agents doivent gérer ces perturbations avec élégance. | ✅ Mettez en place des mécanismes de réessai, de délai d'expiration et de repli (par exemple, données mises en cache, escalade humaine)✅ Enregistrez et surveillez les indicateurs d'erreur tels que les données manquantes ou les anomalies de latence✅ Assurez une dégradation progressive plutôt qu'une défaillance silencieuse |
| Conformité et gouvernance des données | Les connaissances en temps réel impliquent souvent des informations réglementées ou personnelles, qui nécessitent une surveillance et une traçabilité strictes. | ✅ Classez les données par niveau de sensibilité et appliquez des politiques de conservation✅ Conservez la provenance des données : suivez leur origine, leurs mises à jour et leur utilisation✅ Mettez en place une gouvernance pour la formation des agents, la mémoire et les mises à jour des données✅ Impliquez dès le début les équipes juridiques et de conformité, en particulier dans les secteurs réglementés |
📖 En savoir plus : Meilleures solutions logicielles de recherche pour l'entreprise
L'avenir des connaissances en temps réel dans l'IA
À l'avenir, les connaissances en temps réel continueront d'évoluer et de façonner le fonctionnement des agents IA, passant de la réaction à l'anticipation, des agents isolés aux réseaux d'agents collaboratifs, et du cloud centralisé aux architectures distribuées en périphérie.
Mise en cache prédictive des connaissances
Plutôt que d'attendre les demandes, les agents préchargent et mettent en cache de manière proactive les données dont ils sont susceptibles d'avoir besoin. Les modèles de mise en cache prédictive analysent les modèles d'accès historiques, le contexte temporel (par exemple, les heures d'ouverture des marchés) et l'intention des utilisateurs afin de précharger des documents, des flux d'actualités ou des données télémétriques dans des magasins locaux rapides, ce qui permet à l'agent de répondre avec une latence inférieure à la seconde.
Cas d'utilisation : un agent d'investissement précharge les rapports financiers et les aperçus de liquidité avant l'ouverture du marché ; un agent du service client précharge les tickets récents et les documents sur les produits avant un appel d'assistance programmé. Des études montrent que le préchargement prédictif et le placement en cache basés sur l'IA améliorent considérablement les taux de réussite et réduisent la latence dans les scénarios de périphérie et de diffusion de contenu.
Normes et protocoles émergents
L'interopérabilité accélérera la progression. Des protocoles tels que le Model Context Protocol (MCP) et des initiatives de fournisseurs (par exemple, le serveur MCP d'Algolia) mettent en place des méthodes standardisées permettant aux agents de demander, d'injecter et de mettre à jour le contexte en direct à partir de systèmes externes. Les normes réduisent le code de liaison sur mesure, améliorent les contrôles de sécurité (interfaces claires et authentification) et facilitent la combinaison et l'association des magasins de récupération, des couches de mémoire et des moteurs de raisonnement entre les différents fournisseurs. Concrètement, l'adoption d'interfaces de type MCP permet aux équipes d'échanger des services de récupération ou d'ajouter de nouveaux flux de données avec un minimum de retouches de la part des agents.
Intégration avec les systèmes périphériques et de distribution
Les connaissances en temps réel à la périphérie offrent deux avantages significatifs : une latence réduite et une confidentialité/un contrôle améliorés. Les appareils et les passerelles locales hébergeront des agents compacts qui détectent, raisonnent et agissent localement, se synchronisant de manière sélective avec les référentiels cloud lorsque le réseau ou la politique le permet.
Ce modèle convient à la fabrication (où les machines d'usine prennent des décisions de contrôle locales), aux véhicules (où des agents embarqués réagissent à la fusion des capteurs) et aux domaines réglementés où les données doivent rester locales. Les sondages industriels et les rapports sur l'IA de pointe prévoient une prise de décision plus rapide et une dépendance moindre au cloud à mesure que l'apprentissage distribué et les techniques fédérées arrivent à maturité.
Pour les équipes qui développent des piles de connaissances en temps réel, cela implique de concevoir des architectures à plusieurs niveaux où les inférences critiques et sensibles à la latence s'exécutent localement, tandis que l'apprentissage à long terme et les mises à jour importantes des modèles s'effectuent de manière centralisée.
Partage de connaissances multi-agents
Le modèle à agent unique cède la place à des écosystèmes d'agents collaboratifs.
Les cadres multi-agents permettent à plusieurs agents spécialisés de partager leur connaissance de la situation, de mettre à jour des graphiques de connaissances partagés et de coordonner leurs actions, ce qui les rend particulièrement utiles dans la gestion de flottes, les chaînes d'approvisionnement et les opérations à grande échelle.
Les recherches émergentes sur les systèmes multi-agents basés sur le LLM montrent des méthodes de planification distribuée, de spécialisation des rôles et de recherche de consensus entre les agents. Concrètement, les équipes ont besoin de schémas partagés (ontologies communes), de canaux pub/sub efficaces pour les mises à jour d'état et d'une logique de résolution des conflits (qui prévaut sur quoi et quand).
Apprentissage continu et amélioration personnelle
Les connaissances en temps réel fusionneront la recherche, le raisonnement, la mémoire, l'action et l'apprentissage continu en boucles fermées. Les agents observeront les résultats, intégreront les signaux correctifs et mettront à jour les mémoires ou les graphiques de connaissances afin d'améliorer les comportements futurs.
Les principaux défis techniques consistent à prévenir l'oubli catastrophique, à préserver la provenance et à garantir la sécurité des mises à jour en ligne. Des sondages récentes sur l'apprentissage continu en ligne et l'adaptation des agents décrivent des approches pratiques (tampons de mémoire épisodique, stratégies de relecture et ajustements restreints) qui permettent d'améliorer les modèles en permanence tout en limitant les dérives. Pour les équipes produit, cela implique d'investir dans des pipelines de commentaires étiquetés, des politiques de mise à jour sécurisées et une surveillance qui relie le comportement des modèles aux indicateurs de performance clés du monde réel.
Mettre les connaissances en temps réel au service de votre travail avec ClickUp
La prochaine frontière de l'IA au travail ne se limite pas à des modèles plus intelligents.
Les connaissances en temps réel font le lien entre l'intelligence statique et l'action adaptative, permettant aux agents IA de fonctionner avec une compréhension en temps réel des projets, des priorités et de la progression. Les organisations qui peuvent alimenter leurs systèmes IA avec des données récentes, contextuelles et fiables pourront débloquer tout le potentiel de l'intelligence ambiante : coordination fluide, exécution plus rapide et meilleures décisions au sein de chaque équipe.
ClickUp est conçu pour cette transition. En unifiant les tâches, les documents, les objectifs, le chat et les informations dans un système connecté, ClickUp offre aux agents IA une source d'informations vivante et dynamique, et non une base de données statique. Ses capacités d'IA contextuelle et ambiante permettent aux informations de rester à jour dans chaque flux de travail, garantissant ainsi que l'automatisation s'appuie sur la réalité et non sur des instantanés obsolètes.
À mesure que le travail devient de plus en plus dynamique, les outils qui comprennent le contexte en mouvement définiront la prochaine frontière de la productivité. La mission de ClickUp est de rendre cela possible, où chaque action, mise à jour et idée informe instantanément la suivante, et où les équipes découvrent enfin ce que l'IA peut faire lorsque les connaissances restent en temps réel.
Foire aux questions
Les connaissances en temps réel améliorent les performances en fournissant un contexte actuel : les décisions sont basées sur des faits récents plutôt que sur des données obsolètes. Cela permet d'obtenir des réponses plus précises, des temps de réaction plus rapides et une confiance accrue des utilisateurs.
Si cela est possible pour beaucoup, ce n'est pas nécessaire pour tous. Les agents qui opèrent dans des contextes stables et peu changeants peuvent ne pas en tirer autant d'avantages. Mais pour tout agent confronté à des environnements dynamiques (marchés, clients, systèmes), les connaissances en temps réel constituent un puissant catalyseur.
Les tests consistent à simuler des changements réels : varier les entrées en temps réel, injecter des évènements, mesurer la latence, vérifier les sorties des agents et rechercher les erreurs ou les réponses obsolètes. Surveillez les flux de travail de bout en bout, les résultats des utilisateurs et la robustesse du système dans des conditions réelles.