
Desastres de TI podem ocorrer sem aviso prévio.
De falhas no servidor a ataques cibernéticos — e sem um plano de recuperação sólido, sua empresa pode enfrentar horas de tempo de inatividade, perda de dados e sérios danos financeiros, com 54% das interrupções graves custando mais de US$ 100.000.
Este blog orienta você na criação de um plano abrangente de recuperação de desastres de TI que protege seus sistemas, define objetivos claros de recuperação e garante que sua equipe saiba exatamente o que fazer quando algo der errado.
O que é um plano de recuperação de desastres de TI?
Se seus servidores travassem agora, sua equipe saberia exatamente o que fazer? 🛠️
Um plano de recuperação de desastres (DR) de TI é sua estratégia documentada para restaurar sistemas e dados de TI após qualquer interrupção, desde desastres naturais até ataques cibernéticos. É essencialmente seu manual para colocar a tecnologia de volta online quando algo der errado.
💡 DR x Continuidade dos negócios
A recuperação de desastres (DR) se concentra especificamente na restauração da sua infraestrutura de TI e dos seus dados. A continuidade dos negócios (BC) é mais ampla, com o objetivo de manter toda a sua empresa operacional durante e após uma crise, mesmo que a TI esteja inoperante. Pense na DR como uma parte essencial da sua estratégia geral de BC.
💡 DR x Continuidade dos negócios
A recuperação de desastres (DR) se concentra especificamente na restauração da sua infraestrutura de TI e dos seus dados. A continuidade dos negócios (BC) é mais ampla, com o objetivo de manter toda a sua empresa operacional durante e após uma crise, mesmo que a TI esteja inoperante. Pense na DR como uma parte essencial da sua estratégia geral de BC.
Seu plano de recuperação de desastres é importante porque o tempo de inatividade custa mais do que apenas dinheiro. Cada minuto em que seus sistemas ficam offline pode minar a confiança do cliente, interromper as operações e até mesmo levar a multas por não conformidade. Um plano abrangente de DR é o seu roteiro para a resiliência.
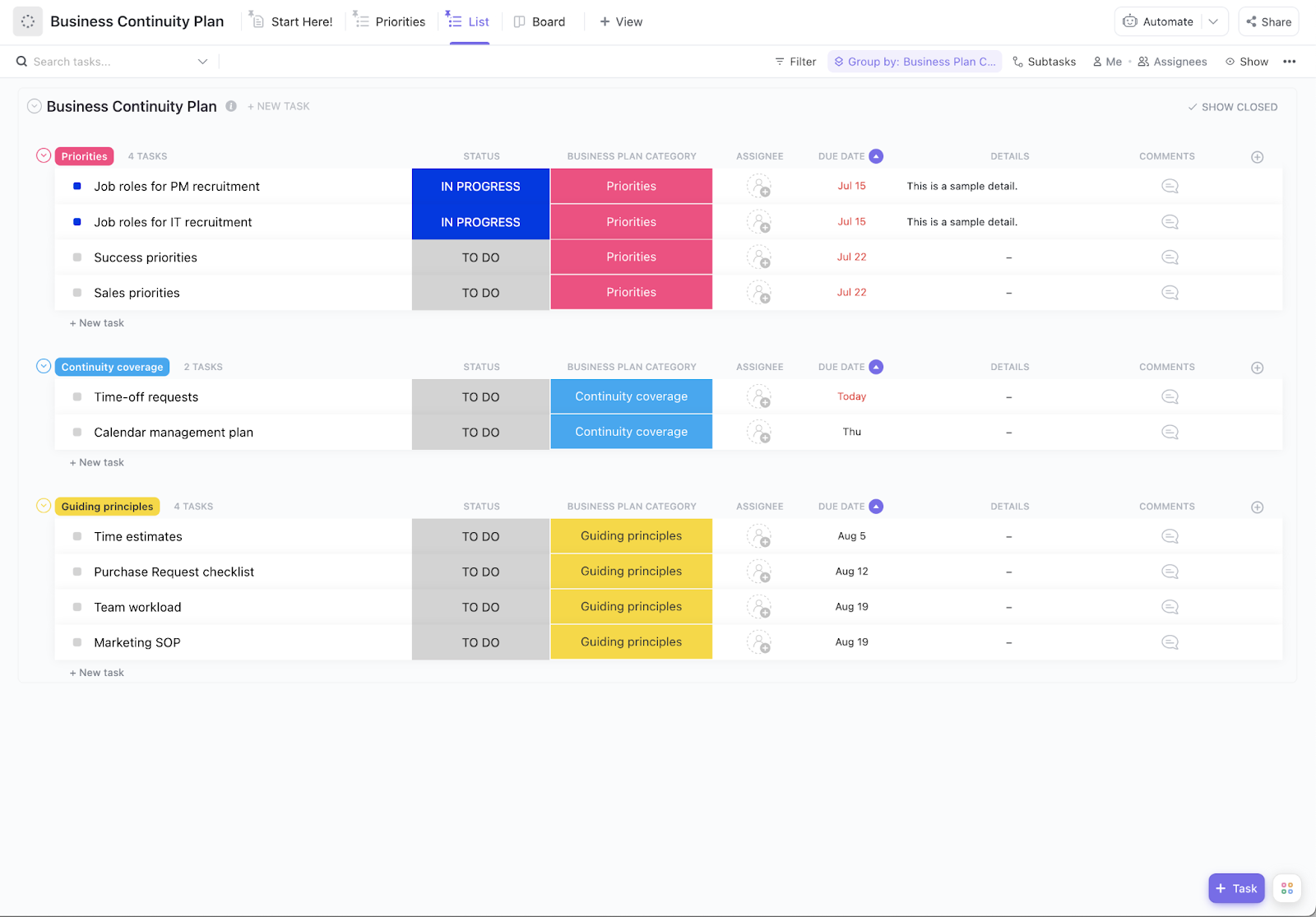
Um ótimo plano abrange:
- Procedimentos de backup de dados: como e onde armazenar cópias de informações críticas para que você possa restaurá-las
- Etapas de restauração do sistema: a sequência exata para colocar os serviços de volta online na ordem correta
- Responsabilidades da equipe: quem faz o quê durante um incidente para evitar confusão
- Protocolos de comunicação: como você manterá as partes interessadas informadas, desde sua equipe até seus clientes
- Objetivos de recuperação: suas metas específicas sobre a rapidez com que os sistemas devem retornar e quanto de perda de dados é aceitável.
Cenários comuns de desastres de TI e impacto
Desastres não são apenas cenários de Hollywood; eles acontecem nas empresas todos os dias. Entender o que você está protegendo ajuda a construir uma defesa muito mais forte.
Desastres naturais e danos físicos
Eventos como inundações, incêndios, terremotos e grandes quedas de energia podem destruir data centers inteiros em questão de minutos. Quando uma grande inundação atingiu um data center em Nashville, por exemplo, algumas empresas perderam semanas de dados e enfrentaram meses de recuperação. A melhor proteção contra isso é a redundância geográfica, que significa distribuir sua infraestrutura por vários locais físicos para que um único evento não possa derrubar tudo.
Ataques cibernéticos e comprometimento de dados
Ransomware, ataques distribuídos de negação de serviço (DDoS) e violações de dados são diferentes de desastres físicos. Eles costumam ser mais difíceis de detectar, podem se espalhar silenciosamente por sistemas conectados e frequentemente têm como alvo também seus sistemas de backup, tornando a recuperação especialmente desafiadora. A frequência e a sofisticação desses ataques cibernéticos continuam a aumentar em todos os setores, com o ransomware agora representando 44% de todas as violações confirmadas, tornando-os uma das principais ameaças.
Falhas de hardware e perda de dados
Às vezes, mesmo os sistemas de backup mais testados e confiáveis simplesmente quebram. Falhas no servidor, falhas de armazenamento e mau funcionamento do equipamento de rede podem ocorrer sem aviso prévio. Mesmo que você tenha sistemas redundantes (backup), eles ainda podem falhar ao mesmo tempo se compartilharem componentes ou fontes de alimentação comuns, criando um único ponto de falha.
👀 Você sabia? Em outubro de 2025, a AWS sofreu uma grande interrupção quando um bug em seu sistema interno de gerenciamento de DNS para Amazon DynamoDB causou falha na resolução de nomes de domínio na região do data center US-EAST-1. Esse “pequeno” defeito técnico provocou uma falha em cascata em dezenas de serviços da AWS e derrubou centenas de aplicativos e plataformas populares em todo o mundo — desde aplicativos de mensagens e redes sociais até bancos, sites de jogos e muito mais. Para muitas pessoas, a interrupção fez com que grande parte da Internet “desaparecesse” temporariamente, destacando o quão frágil é nossa infraestrutura digital quando tanto depende de um punhado de provedores de nuvem.
Erros de software e interrupção do serviço
Um banco de dados corrompido, uma atualização de software com falha ou um simples erro de configuração podem derrubar plataformas inteiras. Você pode perceber que uma linha de código mal configurada pode se espalhar pelos sistemas conectados, criando uma interrupção generalizada com um grande raio de ação. O gerenciamento adequado de mudanças e ambientes de teste dedicados são seus melhores aliados para minimizar esses riscos.
Erros humanos e configurações incorretas
Exclusões acidentais, configurações incorretas e alterações não autorizadas continuam sendo uma das causas mais comuns de interrupções de TI. Um único comando errado ou um arquivo excluído pode causar horas de tempo de inatividade e degradação do serviço. Embora o treinamento e os controles de acesso ajudem, eles não podem eliminar totalmente os erros humanos.
📮ClickUp Insight: 92% dos funcionários usam métodos inconsistentes para acompanhar itens de ação, o que resulta em decisões perdidas e execução atrasada.
Seja enviando notas de acompanhamento ou usando planilhas, o processo costuma ser disperso e ineficiente. Com os recursos de gerenciamento de tarefas do ClickUp, você nunca mais precisará se preocupar com isso. Crie tarefas a partir de bate-papos, comentários de tarefas do ClickUp, documentos e e-mails com um único clique!
Componentes principais de um plano de recuperação de desastres de TI
Um plano de DR sólido é o seu manual completo para voltar a ficar online. Cada um destes componentes complementa os outros para criar uma proteção abrangente para a sua empresa.
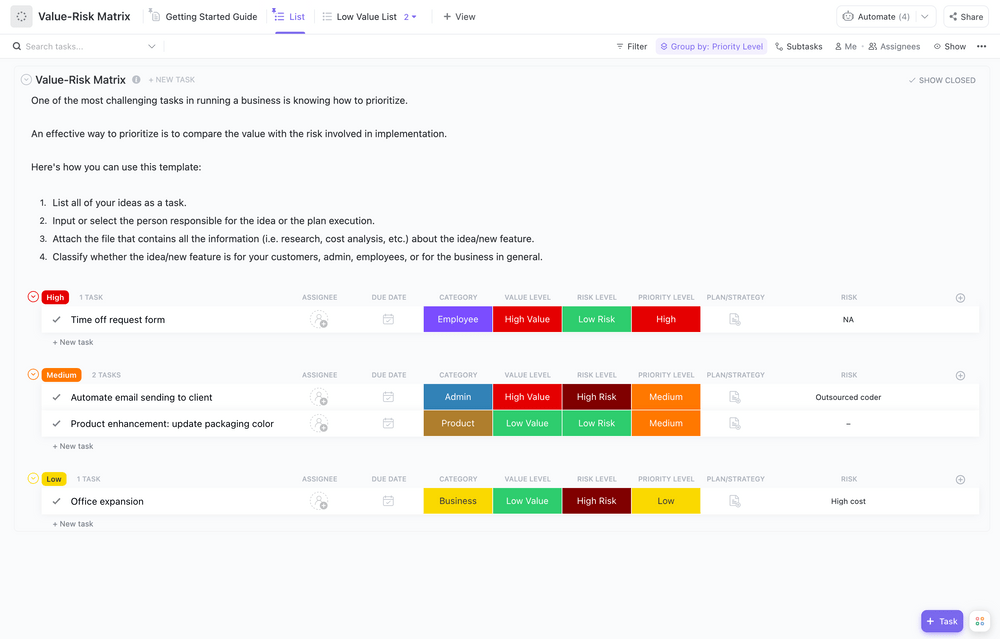
Avaliação e priorização de riscos
Primeiro, você precisa saber o que está enfrentando. Uma avaliação de riscos é o processo de identificar suas vulnerabilidades e avaliar a probabilidade e o impacto de cada ameaça potencial. Você pode organizar isso em uma matriz de riscos para ver quais ameaças são mais graves.
Sua avaliação deve abranger:
- Sistemas críticos: o que precisa permanecer em funcionamento para que sua empresa opere
- Sensibilidade dos dados: quais informações precisam do mais alto nível de proteção (como dados de clientes)
- Dependências: quais outros sistemas ou processos são afetados quando cada sistema falha
Análise de impacto nos negócios e criticidade
Em seguida, calcule o custo real do tempo de inatividade. Uma análise de impacto nos negócios (BIA) ajuda a determinar o impacto financeiro e operacional de uma interrupção para cada sistema. Isso permite classificar seus sistemas em níveis de criticidade para priorizar seus esforços de recuperação.
| Crítico | Menos de uma hora | Processamento de pagamentos, bancos de dados de clientes |
| Alto | De uma a quatro horas | E-mail, ferramentas de comunicação interna |
| Médio | De quatro a 24 horas | Ambientes de desenvolvimento, ferramentas de relatórios |
| Baixo | Mais de 24 horas | Sistemas de arquivo, servidores de teste que não são de produção |
Objetivos de RTO e RPO
Essas duas siglas são o cerne da sua estratégia de recuperação.
- Objetivo de tempo de recuperação (RTO): é o tempo máximo que você pode permitir que um sistema fique inoperante. Ele responde à pergunta: “Com que rapidez precisamos que isso volte a funcionar?”
- Objetivo de ponto de recuperação (RPO): é a quantidade máxima de dados que você pode perder, medida em tempo. Ele responde à pergunta: “Quantos dados podemos perder sem grandes prejuízos?”
Por exemplo, seu sistema de e-mail interno pode ter um RTO de quatro horas, mas seu banco de dados de comércio eletrônico voltado para o cliente pode ter um RPO de apenas 15 minutos, o que significa que você não pode perder mais do que 15 minutos de dados de transações.
Plano de backup e recuperação de dados
Seu plano de backup é sua rede de segurança definitiva. Uma prática recomendada comum é a regra 3-2-1: mantenha pelo menos três cópias dos seus dados importantes, armazene-as em dois tipos diferentes de mídia e mantenha uma dessas cópias fora do local.
Você também poderá escolher entre diferentes tipos de backup:
- Backups completos: uma cópia completa de todos os dados, geralmente feita semanal ou mensalmente.
- Backups incrementais: faça backup apenas das alterações feitas desde o último backup de qualquer tipo.
- Backups diferenciais: faz backup de todas as alterações feitas desde o último backup completo
Mais importante ainda, você deve testar seu processo de restauração de backup regularmente. Um backup não testado é apenas uma esperança, não um plano.
💟 Bônus: Capture detalhes críticos durante incidentes de alto estresse usando o recurso de conversão de voz em texto do ClickUp Brain MAX, para que você nunca perca informações importantes, mesmo quando digitar não for prático. Basta falar suas observações e deixar que a IA cuide da documentação.
Plano de comunicação e atualizações para as partes interessadas
Quando ocorre um desastre, um plano de comunicação claro é fundamental. Seu plano deve definir cadeias de notificação, a frequência com que você fornecerá atualizações e quais canais você usará para cada tipo de incidente.
Grupos diferentes precisam de informações diferentes:
- Equipes internas: Precisam de detalhes técnicos e itens de ação específicos
- Clientes: Precisam saber o status do serviço e quando esperam que ele seja resolvido.
- Fornecedores: pode ser necessário envolvê-los para obter suporte ou escalar problemas
- Órgãos reguladores: podem exigir notificações formais, dependendo do seu setor.
Ferramentas como este modelo de plano de comunicação pronto para uso da ClickUp podem ajudá-lo a agir mais rapidamente com um protocolo estabelecido durante uma crise.

Programa de testes e treinamento
Um plano que você nunca testa é um plano que irá falhar. Testes regulares revelam lacunas e pontos fracos antes que um desastre real aconteça.
Programe diferentes tipos de testes ao longo do ano:
- Exercícios simulados: sua equipe analisa um cenário de desastre no papel para verificar a lógica do plano.
- Failovers parciais: você testa a recuperação de componentes ou serviços específicos e não críticos.
- Testes completos de DR: você executa um failover completo para seus sistemas de backup (o teste definitivo).
Após cada teste, atualize sua documentação e treine imediatamente os novos membros da equipe sobre os procedimentos.
Etapas para criar um plano de recuperação de desastres de TI
Criar seu plano de DR não precisa ser uma tarefa difícil.
Veja como você pode fazer isso passo a passo. 🙌
Etapa 1: crie um inventário de ativos
Você não pode proteger o que não sabe que tem. Comece criando um inventário de ativos que liste todos os hardwares, softwares, repositórios de dados e dependências de sistema em seu ambiente. Certifique-se de incluir contatos de fornecedores, chaves de licença e detalhes de configuração para referência rápida durante uma recuperação.

O modelo ITAM da ClickUp reúne gerenciamento de incidentes, gerenciamento de problemas, gerenciamento de mudanças, soluções simples de gerenciamento de ativos e gerenciamento de conhecimento. Nosso modelo ITSM Known Errors simplifica o rastreamento de erros conhecidos em seus sistemas. Explore todos os nossos modelos de TI assim que sua finalidade mudar.
Personalize seus fluxos de trabalho no estilo que desejar para cada etapa do ITAM, desde a implantação e configuração até a manutenção e a aposentadoria.
Etapa 2: classifique os serviços críticos
Agora, identifique quais desses ativos são essenciais para a missão e quais são apenas desejáveis. Crie mapas de dependência de serviços que mostrem como seus sistemas se conectam e dependem uns dos outros. Preste atenção especial a quaisquer serviços voltados para o cliente que afetem diretamente a receita ou a experiência do usuário.
🎥 Assista a este tutorial prático que demonstra como criar um plano estruturado e de alto nível usando os poderosos recursos do ClickUp — desde a definição de metas até a atribuição de tarefas e o acompanhamento do progresso.
Etapa 3: Avalie riscos e ameaças
Avalie os riscos e ameaças avaliando a probabilidade e o impacto de cada tipo de ameaça para sua situação específica. Considere seus riscos geográficos (você está em uma zona sísmica ou planície aluvial?) e quaisquer ameaças específicas do setor (como mudanças regulatórias ou ataques cibernéticos direcionados). Documente tudo em um registro de riscos para que você possa acompanhá-lo ao longo do tempo.

O modelo de quadro branco de avaliação de riscos do ClickUp cria uma dimensão visual para o seu processo de avaliação de riscos. Ele auxilia na avaliação e categorização de riscos, inspirando sua equipe a compartilhar insights e colaborar em um formato envolvente e visual.
Este modelo permite que você:
- Avalie as categorias de risco e os impactos potenciais
- Analise os dados para identificar possíveis áreas de preocupação
- Determine medidas preventivas para reduzir a exposição ao risco.
Com recursos que permitem desenhar, escrever e adicionar notas adesivas, este modelo de quadro branco para gerenciamento de riscos é perfeito para avaliar os riscos do seu projeto.
Etapa 4: definir metas de RTO e RPO
Trabalhe diretamente com as partes interessadas da sua empresa para definir o que elas consideram tempo de inatividade e perda de dados aceitáveis para cada nível de serviço identificado anteriormente. Você precisará equilibrar o custo de uma recuperação mais rápida com o impacto nos negócios — nem tudo precisa de uma recuperação instantânea e sem perda de dados. Obtenha a aprovação da diretoria para essas metas.
Etapa 5: definir caminhos de backup e failover
Com suas metas definidas, agora você pode projetar suas soluções técnicas. Crie estratégias de backup personalizadas para o RPO de cada sistema e planeje procedimentos detalhados de failover, incluindo locais de processamento alternativos e métodos de acesso de emergência. Inclua diagramas de rede e manuais passo a passo para tornar a execução infalível.
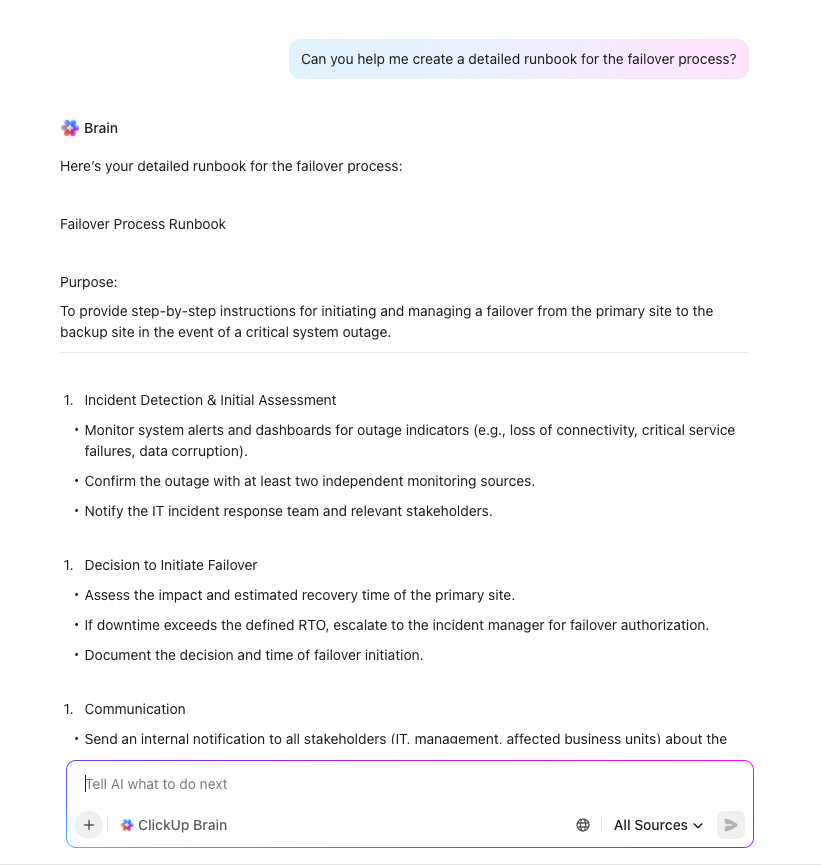
Etapa 6: Atribuir funções e escalonamento
Defina a estrutura da sua equipe de DR com responsabilidades e autoridade de tomada de decisão claras. Crie listas de contatos abrangentes com o pessoal principal e de backup para cada função. Uma matriz RACI (Responsável, Prestação de contas, Consultado, Informado) é uma ótima ferramenta para eliminar a confusão durante um incidente de alto estresse.
Etapa 7: Documente e comunique o plano
Documente e comunique o plano com procedimentos claros e passo a passo que qualquer pessoa da sua equipe possa seguir, mesmo sob pressão. É fundamental armazenar essa documentação em um local altamente acessível, separado da sua infraestrutura principal. Certifique-se de que todos os membros da equipe saibam exatamente onde encontrar o plano durante uma crise.
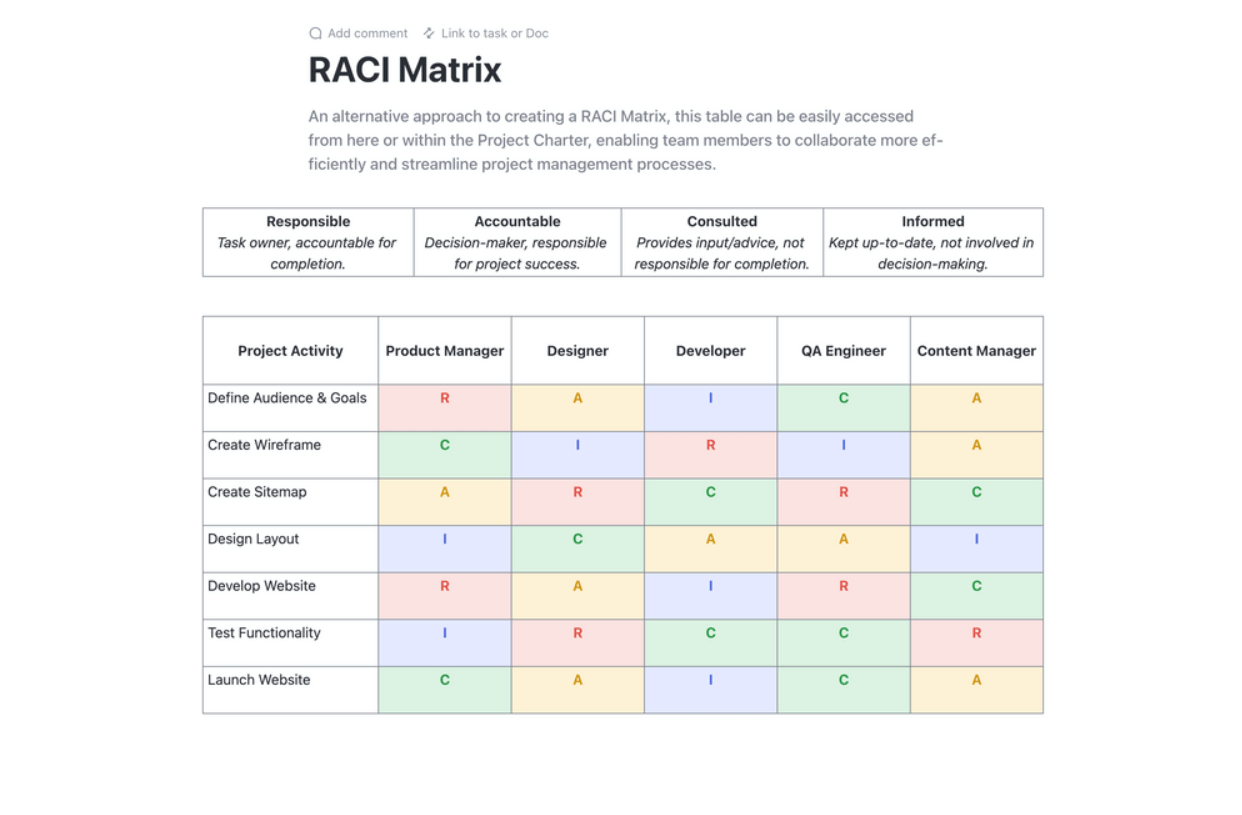
Otimize o planejamento do seu projeto com o modelo de planejamento RACI do ClickUp. Esse modelo de documento é revolucionário, oferecendo um gráfico claro para definir as funções e responsabilidades da equipe em relação às tarefas do projeto. Adote a estrutura RACI (Responsável, Prestação de contas, Consultado e Informado) para que todos estejam em sintonia, garantindo a prestação de contas e o alinhamento com os objetivos organizacionais.
Etapa 8: Teste, analise e melhore
Por fim, programe testes trimestrais para validar seus procedimentos e identificar quaisquer lacunas. Documente todas as lições aprendidas em cada teste e quaisquer incidentes reais e use-as para atualizar seu plano. Crie um sistema de acompanhamento de melhorias sistemático para garantir que quaisquer problemas encontrados sejam resolvidos.
🌼 Você sabia? Em 2017, o GitLab sofreu uma grande interrupção no banco de dados. Durante a recuperação, eles descobriram que vários de seus métodos de backup estavam falhando silenciosamente há dias. Esse incidente ensinou uma lição crucial para toda a indústria de tecnologia: a validação do backup é imprescindível. Um backup não testado não é realmente um backup.
🌼 Você sabia? Em 2017, o GitLab sofreu uma grande interrupção no banco de dados. Durante a recuperação, eles descobriram que vários de seus métodos de backup estavam falhando silenciosamente há dias. Esse incidente ensinou uma lição crucial para toda a indústria de tecnologia: a validação do backup é imprescindível. Um backup não testado não é realmente um backup.
Estratégias e soluções de recuperação de desastres
Nem todas as organizações precisam da mesma abordagem de DR. Vamos explorar suas opções com base no seu orçamento, necessidades de recuperação e recursos disponíveis.
Abordagem de backup e restauração
Este é o método mais simples e econômico. Envolve fazer backups regulares para um local externo (como a nuvem ou um data center secundário) e, em seguida, restaurá-los manualmente quando necessário. Essa abordagem é ideal para sistemas não críticos que podem tolerar um RTO mais longo, pois a recuperação pode levar horas ou até dias.
Alta disponibilidade e redundância
Essa estratégia visa eliminar pontos únicos de falha usando vários sistemas ativos. Técnicas como balanceamento de carga, clustering de servidores e armazenamento RAID garantem que, se um componente falhar, outro assuma instantaneamente. Embora seja mais caro de configurar e manter, essa abordagem pode minimizar o tempo de inatividade para apenas segundos ou minutos, tornando-a ideal para serviços críticos.
Opções de replicação e failover
A replicação envolve a cópia de dados quase em tempo real para um site secundário, o que garante perda mínima de dados durante um desastre.
- Replicação síncrona: grava dados nos sites primário e secundário ao mesmo tempo, garantindo zero perda de dados. No entanto, requer alta largura de banda e pode tornar seu sistema primário mais lento.
- Replicação assíncrona: grava os dados primeiro no site principal e, em seguida, os copia para o site secundário com um pequeno atraso. É mais econômica e tem menos impacto no desempenho, mas você aceita um pequeno risco de perda de dados.
Recuperação de desastres baseada em nuvem e DRaaS
A Recuperação de Desastres como Serviço (DRaaS) tornou-se uma opção popular para muitas empresas. Ela oferece preços pré-pagos, distribuição geográfica instantânea e orquestração automatizada da recuperação, sem a necessidade de construir e manter seus próprios sites físicos de DR. A DR na nuvem elimina a enorme despesa de capital de um data center de backup, ao mesmo tempo em que oferece escalabilidade mais rápida e maior flexibilidade do que as abordagens tradicionais de sites quentes, mornos ou frios.
Como o ClickUp simplifica o planejamento de recuperação de desastres de TI
Gerenciar um plano de DR em planilhas, documentos e cadeias de e-mails dispersos cria seu próprio risco de desastre.
Esse tipo de expansão do trabalho, a fragmentação do trabalho em várias ferramentas desconectadas que não se comunicam entre si e a expansão do contexto, quando as equipes perdem horas procurando informações espalhadas por aplicativos e plataformas, leva à confusão, informações desatualizadas e tempos de resposta lentos quando cada segundo conta.
Com o ClickUp Converged AI Workspace — uma plataforma única e segura onde todos os seus aplicativos, dados e fluxos de trabalho coexistem com IA contextual como camada de inteligência — que combina gerenciamento de projetos, documentação e comunicação em equipe. Pare de lidar com várias plataformas e reúna seu planejamento de DR, testes e resposta a incidentes em um sistema unificado.
Documentação centralizada de DR com o ClickUp Docs e assistência integrada de IA.
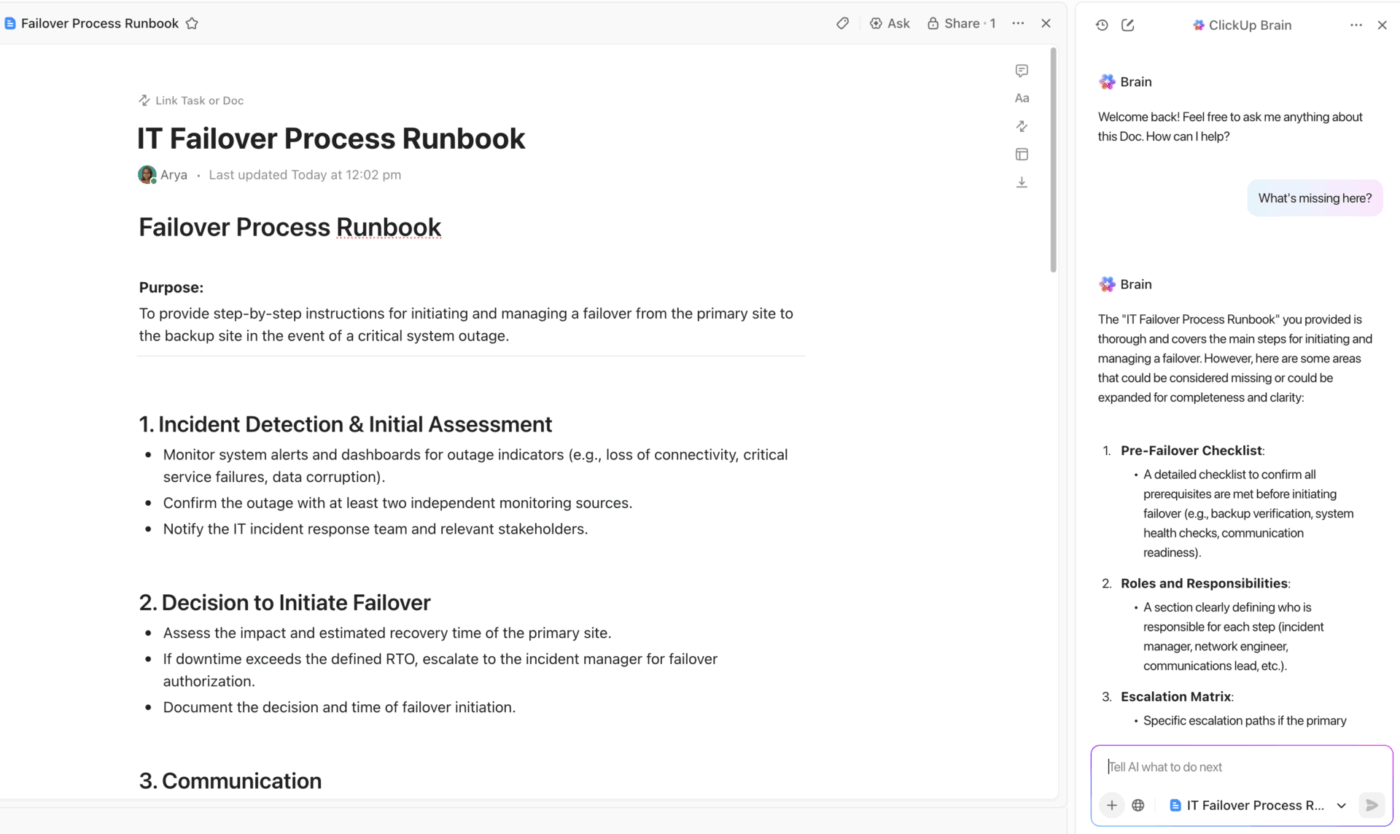
Garanta que sua equipe sempre tenha uma única fonte de verdade com o ClickUp Docs.
Crie todo o seu plano de recuperação de desastres em um espaço colaborativo onde todos podem contribuir em tempo real durante um incidente. Vincule documentos diretamente a tarefas e projetos de incidentes para uma navegação perfeita e incorpore diagramas ou manuais de operações para manter as informações críticas exatamente onde você precisa delas.
O melhor de tudo é que você pode proteger seus documentos para evitar edições acidentais e usar as permissões granulares do ClickUp para controlar quem pode visualizar ou alterar procedimentos confidenciais de recuperação. Todas as alterações são rastreadas no histórico do documento, fornecendo uma trilha de auditoria completa.
Criação de planos com inteligência artificial usando o ClickUp Brain
Acelere o planejamento de recuperação de desastres e elimine lacunas críticas com o ClickUp Brain — seu assistente de IA contextual que entende todo o seu espaço de trabalho. Ao contrário das ferramentas genéricas de IA, o ClickUp Brain aproveita as tarefas, documentos e fluxos de trabalho reais da sua organização para oferecer suporte preciso e prático para iniciativas de DR.
Basta enviar uma solicitação ao ClickUp Brain, como “Crie uma lista de verificação de recuperação de desastres para nossa plataforma de comércio eletrônico”, e receba instantaneamente um modelo abrangente e personalizado que se alinha aos seus sistemas, processos e necessidades de conformidade. Ele pode ajudá-lo com:
- Consciência contextual: o ClickUp Brain tem acesso à estrutura, ao conteúdo e às permissões do seu espaço de trabalho. Ele pode consultar tarefas, documentos, comentários e até mesmo aplicativos conectados, fornecendo respostas e ações personalizadas para o seu trabalho real, e não apenas sugestões genéricas.
- Solução de problemas e orientação: Solucione problemas instantaneamente, obtenha instruções passo a passo ou solicite as melhores práticas sobre qualquer recurso do ClickUp. O Brain pode guiá-lo por processos complexos, automatizar tarefas repetitivas e ajudar a resolver bloqueios.
- Automação e aceleração do fluxo de trabalho: use agentes de IA pré-construídos ou personalizados para automatizar fluxos de trabalho de várias etapas, triar solicitações ou gerenciar trabalhos recorrentes, economizando horas todas as semanas.
- Pesquisa profunda: encontre informações ocultas em qualquer lugar do seu espaço de trabalho, incluindo tarefas, documentos e ferramentas integradas, mesmo que sejam antigas ou difíceis de localizar com a pesquisa padrão.
- Resumos e atualizações em tempo real: gere atualizações de projetos, resumos de reuniões ou relatórios de progresso instantaneamente, extraindo dados do espaço de trabalho em tempo real.
- Simplificação da documentação técnica: converta documentos técnicos complexos em procedimentos ou listas de verificação claras e práticos que sua equipe pode seguir, mesmo sob pressão.
- Inteligência multimodelo: escolha entre os principais modelos de IA (OpenAI GPT-4.1, GPT-5, Claude, Gemini e muito mais) para obter os melhores resultados em qualquer tarefa, sem necessidade de assinaturas separadas.
- Seguro e sensível a permissões: o Brain só acessa informações que você já tem permissão para ver, mantendo padrões rígidos de privacidade e conformidade.
- Interface conversacional: use @brain em comentários ou bate-papos para obter insights contextuais, redigir respostas ou acionar automações sem sair do seu fluxo de trabalho.
- Prompts personalizados e fluxos de trabalho salvos: salve e reutilize prompts para necessidades recorrentes, garantindo consistência e economizando tempo para toda a sua equipe.
💡Dica profissional: nunca perca uma lição das suas reuniões de análise de incidentes, registrando todos os detalhes com o ClickUp AI Notetaker. Ele pode participar das suas reuniões virtuais, transcrever toda a discussão e gerar automaticamente uma lista de itens de ação a partir das lições aprendidas. Isso cria um histórico de incidentes pesquisável, para que você possa consultar rapidamente eventos passados e suas resoluções.

Fluxos de trabalho de DR automatizados com o ClickUp Automations
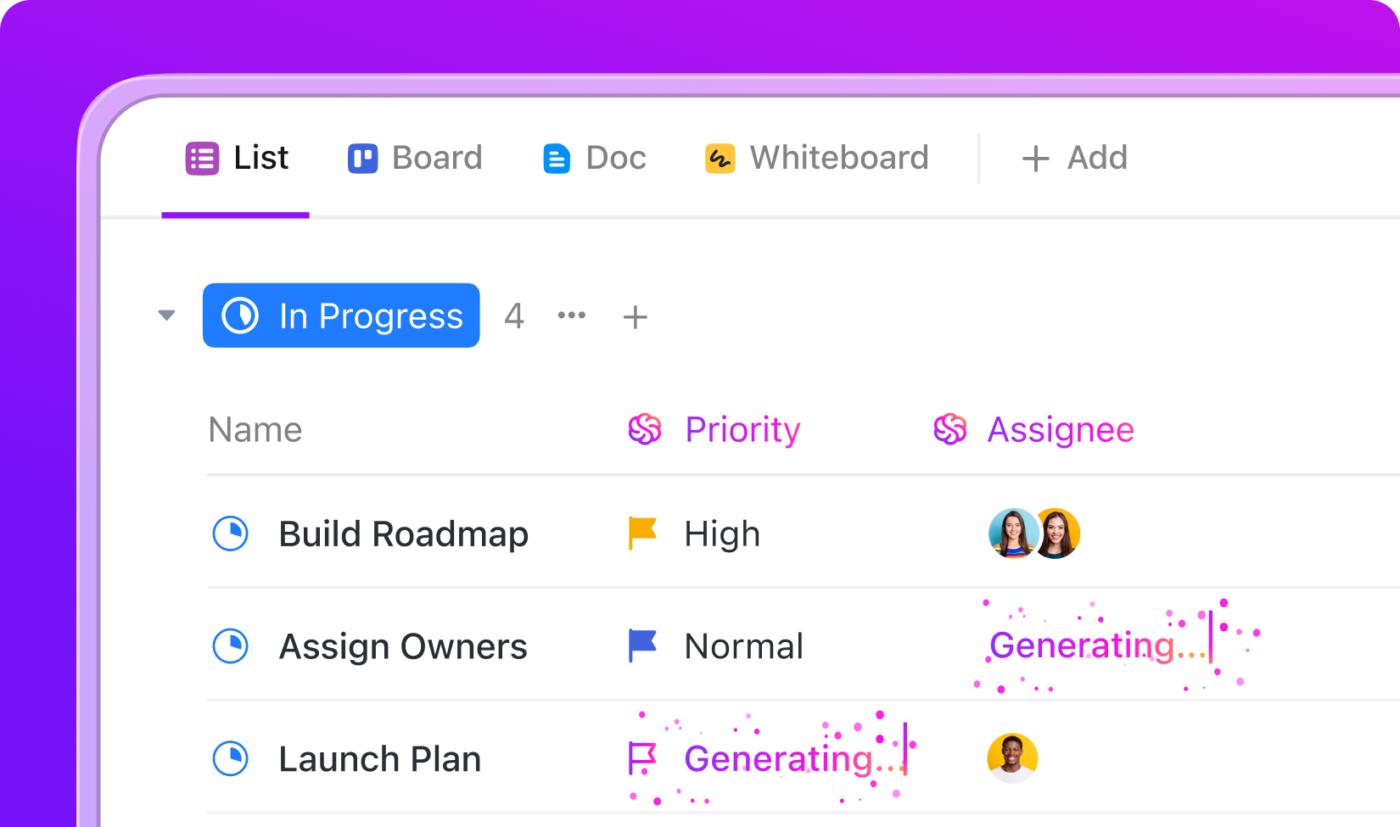
Imagine que sua equipe está enfrentando uma interrupção repentina — cada segundo conta e você não pode se dar ao luxo de perder uma única etapa. Com os agentes e automações de IA do ClickUp, você não precisa se apressar ou confiar na memória. Assim que um incidente é declarado, a IA do ClickUp entra em ação, orientando sua equipe e lidando com o trabalho pesado para que você possa se concentrar em resolver o problema.
Veja como isso funciona em um cenário real:
- Quando alguém marca uma tarefa como “Incidente declarado”, o ClickUp Agent cria automaticamente uma lista de verificação com as etapas de resposta, atribui-as às pessoas certas e inicia um cronômetro para acompanhar o tempo necessário para a recuperação.
- Se o incidente for marcado como “crítico”, um agente pode enviar instantaneamente um e-mail de alerta para sua equipe de liderança e configurar uma sala de bate-papo especial — sua “sala de guerra” — para que todos possam se comunicar em um único lugar.
- A IA pode acessar relatórios de incidentes anteriores e documentação relevante, para que sua equipe tenha tudo o que precisa ao alcance dos dedos.
Veja o fluxo de trabalho aqui:
Com os agentes de IA do ClickUp, você conta com um colega de equipe digital confiável que ajuda sua equipe a manter a calma, a organização e a eficácia, mesmo sob pressão.
Rastreamento em tempo real com os painéis do ClickUp
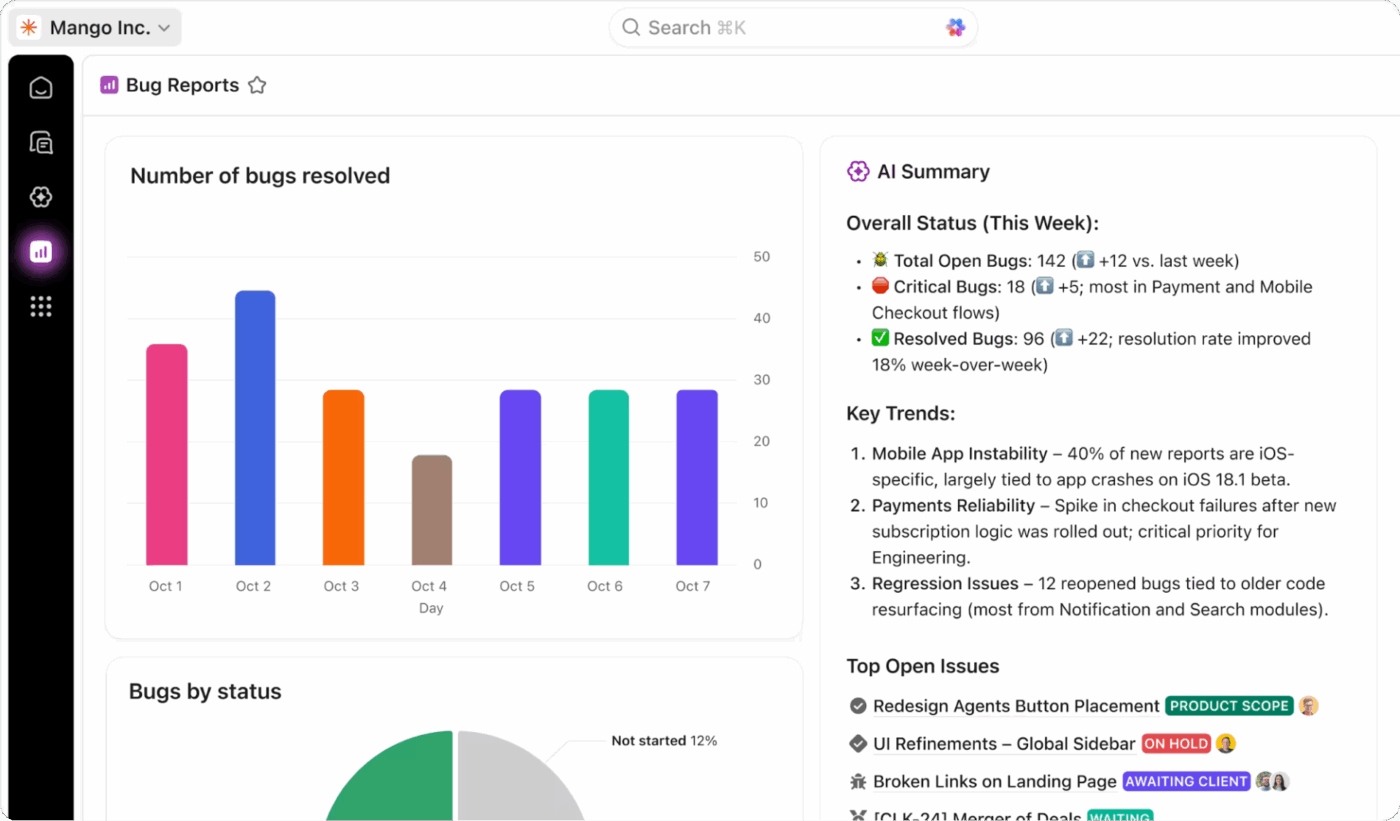
Obtenha visibilidade completa da integridade do seu programa de DR acompanhando tudo em tempo real com os painéis do ClickUp. Você pode criar widgets para monitorar o desempenho do RTO e do RPO durante os testes, acompanhar as taxas de conclusão dos testes e visualizar as tendências de incidentes ao longo do tempo.
Adicione campos personalizados do ClickUp às suas tarefas para acompanhar a criticidade do sistema, o status da recuperação e os resultados dos testes e, em seguida, reúna todos esses dados em uma visão de alto nível. Esses painéis fornecem relatórios prontos para a diretoria, sempre atualizados com dados em tempo real dos testes e das atividades de resposta a incidentes da sua equipe.
Crie seu plano de DR hoje mesmo
Cada dia que você opera sem um plano de DR é uma aposta que você não pode se dar ao luxo de perder. Desastres são inevitáveis — sejam eles naturais, falhas tecnológicas ou erros humanos —, mas é a sua preparação que determina se eles se tornarão pequenos inconvenientes ou grandes catástrofes.
Um plano de DR abrangente requer a compreensão dos riscos, a documentação de procedimentos claros e o teste regular desses procedimentos. As ferramentas certas tornam esse processo gerenciável, eliminando o caos de documentos dispersos e processos manuais.
Mesmo os planos de contingência básicos são melhores do que não ter nada quando ocorre um desastre. Testes e atualizações regulares transformarão seu plano de DR de um documento empoeirado em um sistema vivo que realmente protege seus negócios.
Dê o primeiro passo e comece a criar seu plano de DR com o ClickUp hoje mesmo. Comece gratuitamente com o ClickUp e reúna todo o seu planejamento de recuperação de desastres, documentação e resposta a incidentes em uma plataforma unificada. ✨
Perguntas frequentes
Você deve revisar seu plano de DR pelo menos quatro vezes por ano e atualizá-lo imediatamente após qualquer mudança significativa na infraestrutura ou incidentes reais. A maioria das organizações realiza uma revisão profunda e abrangente anualmente para incorporar todas as lições aprendidas e se adaptar às novas tecnologias.
As equipes de TI, segurança e planejamento de continuidade de negócios geralmente lideram os esforços de planejamento e teste de DR. No entanto, elas precisam de informações essenciais dos líderes de operações e unidades de negócios para garantir que o plano esteja alinhado com as necessidades e prioridades reais da empresa.
Use cronômetros e registros de data e hora claros para medir os tempos reais de recuperação em relação às metas definidas durante cada teste. É fundamental documentar quaisquer diferenças entre a meta e o desempenho real nos relatórios de teste para orientar melhorias futuras.
Plataformas de gerenciamento de projetos como o ClickUp são ideais para centralizar a documentação, automatizar fluxos de trabalho e acompanhar métricas para todo o seu programa de DR. Você pode então combiná-las com ferramentas especializadas de DR que lidam com os aspectos técnicos da replicação de dados e failover do sistema.