
De meeste teams die open-source AI-modellen onderzoeken, ontdekken dat Meta's LLaMA een zeldzame combinatie van kracht en flexibiliteit biedt, maar de technische installatie kan aanvoelen als het in elkaar zetten van meubels zonder instructies.
Deze gids leidt u door het bouwen van een functionele LLaMA-chatbot vanaf nul, waarbij alles aan bod komt, van hardwarevereisten en modeltoegang tot prompt engineering en implementatiestrategieën.
Laten we aan de slag gaan!
Wat is LLaMA en waarom zou je het gebruiken voor chatbots?
Het bouwen van een chatbot met eigen API's voelt vaak alsof je vastzit aan het systeem van iemand anders, met onvoorspelbare kosten en vragen over gegevensprivacy. Deze vendor lock-in betekent dat je het model niet echt kunt aanpassen aan de unieke behoeften van je team, wat leidt tot generieke reacties en mogelijke complianceproblemen.
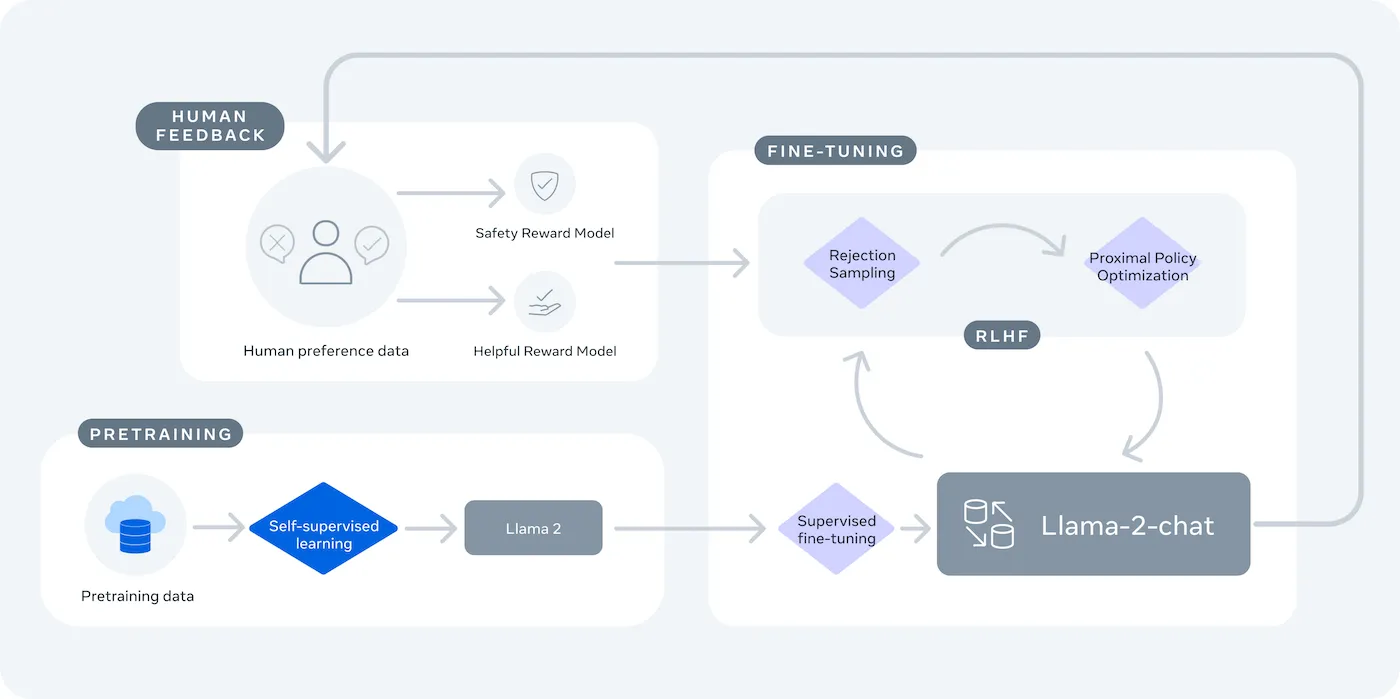
LLaMA (Large Language Model Meta AI) is Meta's familie van open-weight taalmodellen en biedt een krachtig alternatief. Het is ontworpen voor zowel onderzoek als commercieel gebruik en geeft u de controle die gesloten modellen niet bieden.
LLaMA-modellen zijn er in verschillende groottes, gemeten in parameters (bijv. 7B, 13B, 70B). Beschouw parameters als een maatstaf voor de complexiteit en kracht van het model: grotere modellen zijn krachtiger, maar vereisen meer rekenkracht.
Dit zijn enkele redenen waarom u een LLaMA-chatbot zou kunnen gebruiken:
- Gegevensprivacy: wanneer u een model op uw eigen infrastructuur uitvoert, blijven uw gesprekken altijd binnen uw omgeving. Dit is van cruciaal belang voor teams die met gevoelige informatie werken.
- Aanpassing: U kunt een LLaMA-model aangepast afstemmen op de interne documenten of gegevens van uw bedrijf. Hierdoor begrijpt het uw specifieke context beter en kan het veel relevantere antwoorden geven.
- Kostenvoorspelbaarheid: Na de eerste hardware-installatie hoeft u zich geen zorgen te maken over API-kosten per token. Uw kosten worden vast en voorspelbaar.
- Geen limieten: De capaciteit van uw chatbot wordt beperkt door uw eigen hardware, niet door de quota van een leverancier. U kunt naar behoefte opschalen.
De belangrijkste afweging is gemak versus controle. LLaMA vereist meer technische installatie dan een plug-and-play API. Voor productiechatbots gebruiken teams doorgaans LLaMA 2 of het nieuwere LLaMA 3, dat verbeterde redenering biedt en meer tekst tegelijk kan verwerken.
Wat u nodig hebt voordat u een LLaMA-chatbot bouwt
Zonder de juiste tools aan een ontwikkelingsproject beginnen, is vragen om frustratie. Halverwege realiseer je je dat je een belangrijk stuk hardware of software mist, waardoor je voortgang wordt belemmerd en je uren tijd verspilt.
Om dit te voorkomen, verzamel je vooraf alles wat je nodig hebt. Hier is een checklist om een vlotte start te garanderen. 🛠️
Hardwarevereisten
| Modelgrootte | Minimale VRAM | Alternatieve optie |
|---|---|---|
| 7B parameters | 8 GB | Cloud GPU-Instance |
| 13 miljard parameters | 16 GB | Cloud GPU-Instance |
| 70 miljard parameters | Meerdere GPU's | Kwantificering of cloud |
Als uw lokale computer niet over een krachtige grafische processor (GPU) beschikt, kunt u clouddiensten zoals AWS of GCP gebruiken. Inference-platforms zoals Baseten en Replicate bieden ook pay-as-you-go GPU-toegang.
Softwarevereisten
- Python 3. 8+: Dit is de standaard programmeertaal voor machine learning-projecten.
- Pakketbeheerder: U hebt pip of Conda nodig om de benodigde bibliotheken voor uw project te installeren.
- Virtuele omgeving: Dit is een best practice waarmee u de afhankelijkheden van uw project geïsoleerd houdt van andere Python-projecten op uw computer.
Toegangsvereisten
- Hugging Face-account: u hebt een account nodig om de LLaMA-modelgewichten te downloaden.
- Meta-goedkeuring: u moet de licentieovereenkomst van Meta accepteren om toegang te krijgen tot LLaMA-modellen, die doorgaans binnen enkele uren worden goedgekeurd.
- API-sleutels: deze zijn alleen nodig als u besluit om een gehost inferentie-eindpunt te gebruiken in plaats van het model lokaal uit te voeren.
Voor deze handleiding gebruiken we het LangChain-framework. Dit vereenvoudigt veel van de complexe aspecten van het bouwen van een chatbot, zoals het beheren van prompts en geschiedenis van gesprekken.
{kind=link}
Hoe u stap voor stap een chatbot bouwt met LLaMA
Het kan overweldigend zijn om alle technische onderdelen van een chatbot – het model, de prompt, het geheugen – met elkaar te verbinden. Je raakt gemakkelijk verdwaald in de code, wat leidt tot bugs en een chatbot die niet werkt zoals verwacht. Deze stapsgewijze handleiding splitst het proces op in eenvoudige, beheersbare delen.
Deze aanpak werkt zowel als u het model op uw eigen computer uitvoert als wanneer u een gehoste service gebruikt.
Stap 1: Installeer de vereiste pakketten
Eerst moet u de belangrijkste Python-bibliotheken installeren. Open uw terminal en voer dit commando uit:
pip install langchain transformers accelerate torch
Als u een gehoste service zoals Baseten gebruikt voor inferentie, moet u ook de specifieke softwareontwikkelingskit (SDK) installeren:
pip install baseten
Dit is wat elk van deze pakketten doet:
- Langchain: Een framework dat helpt bij het bouwen van applicaties met grote taalmodellen, inclusief het beheren van gesprekken en geheugen.
- Transformers: De Hugging Face-bibliotheek voor het laden en uitvoeren van het LLaMA-model
- Accelerate: een bibliotheek die helpt bij het optimaliseren van de manier waarop het model op uw CPU en GPU wordt geladen.
- Torch: De PyTorch-bibliotheek, die de backend-kracht levert voor de berekeningen van het model.
Als u het model lokaal uitvoert op een machine met een NVIDIA GPU, zorg er dan voor dat CUDA correct is geïnstalleerd en geconfigureerd. Hierdoor kan het model de GPU gebruiken voor veel snellere prestaties.
Stap 2: Krijg toegang tot LLaMA-modellen
Voordat u het model kunt downloaden, moet u officiële toegang krijgen van Meta via Hugging Face.
- Maak een account aan op huggingface.co
- Ga naar de pagina van het model, bijvoorbeeld meta-llama/Llama-2-7b-chat-hf
- Klik op 'Toegang tot opslagplaats' en ga akkoord met de licentievoorwaarden van Meta.
- Genereer een nieuwe toegangstoken in de instellingen van uw Hugging Face-account.
- Voer in uw terminal huggingface-cli login uit en plak uw token om de verificatie van uw machine uit te voeren.
Goedkeuring verloopt doorgaans snel. Zorg ervoor dat u een modelvariant kiest met 'chat' in de naam, aangezien deze specifiek zijn getraind voor conversatietaakken.
Stap 3: Laad het LLaMA-model
Nu kunt u het model in uw code laden. Afhankelijk van uw hardware hebt u twee belangrijke opties.
Als u over een voldoende krachtige GPU beschikt, kunt u het model lokaal laden:
Als uw hardware een limiet heeft, kunt u een gehoste inferentieservice gebruiken:
Het commando device_map="auto" geeft de transformers-bibliotheek de opdracht om het model automatisch te verdelen over alle beschikbare GPU's.
Als u nog steeds te weinig geheugen hebt, kunt u een techniek genaamd kwantisering gebruiken om de grootte van het model te verkleinen, hoewel dit de prestaties enigszins kan verminderen.
Stap 4: Maak een promptsjabloon
LLaMA-chatmodellen zijn getraind om een specifiek format voor prompts te verwachten. Een promptsjabloon zorgt ervoor dat uw invoer correct is gestructureerd.
Laten we dit format eens nader bekijken:
- <
>: Dit gedeelte bevat de systeemprompt, die het model zijn kerninstructies geeft en zijn persoonlijkheid definieert. - [INST]: Dit markeert het begin van de vraag of instructie van de gebruiker.
- [/INST]: Dit geeft aan het model aan dat het tijd is om een reactie te genereren.
Houd er rekening mee dat verschillende versies van LLaMA mogelijk iets andere sjablonen gebruiken. Controleer altijd de documentatie van het model op Hugging Face voor het juiste format.
Stap 5: Stel de chatbotketen in
Vervolgens maakt u een verbinding tussen uw model en promptsjabloon met behulp van LangChain. Deze keten bevat ook geheugen om het gesprek bij te houden.
LangChain biedt verschillende soorten geheugen:
- ConversationBufferMemory: Dit is de eenvoudigste optie. Hiermee wordt de volledige geschiedenis van de gesprekken opgeslagen.
- ConversationSummaryMemory: Om ruimte te besparen, vat deze optie periodiek oudere delen van het gesprek samen.
- ConversationBufferWindowMemory: hiermee worden alleen de laatste paar uitwisselingen in het geheugen bewaard, wat handig is om te voorkomen dat de context te lang wordt.
Voor het testen is ConversationBufferMemory een uitstekende plek om te beginnen.
Stap 6: Voer de chatbot-lus uit
Ten slotte kunt u een eenvoudige lus maken om vanaf de terminal met uw chatbot te communiceren.
In een praktijktoepassing zou u deze lus vervangen door een API-eindpunt met behulp van een framework zoals FastAPI of Flask. U kunt ook de reactie van het model terugstreamen naar de gebruiker, waardoor de chatbot veel sneller aanvoelt.
U kunt ook parameters zoals temperatuur aanpassen om de willekeurigheid van de reacties te beïnvloeden. Een lage temperatuur (bijv. 0,2) maakt de output meer deterministisch en feitelijk, terwijl een hogere temperatuur (bijv. 0,8) meer creativiteit stimuleert.
Hoe u uw LLaMA-chatbot kunt testen
Je hebt een chatbot gebouwd die antwoorden geeft, maar is deze klaar voor echte gebruikers? Het implementeren van een ongeteste bot kan leiden tot gênante mislukkingen, zoals het verstrekken van onjuiste informatie of het genereren van ongepaste content, wat de reputatie van je bedrijf kan schaden.
Een systematisch testplan is de oplossing voor deze onzekerheid. Het zorgt ervoor dat uw chatbot robuust, betrouwbaar en veilig is.
Functionele tests:
- Uitzonderingsgevallen: test hoe de bot omgaat met lege invoer, zeer lange berichten en speciale tekens.
- Geheugenverificatie: zorg ervoor dat de chatbot de context onthoudt tijdens meerdere gespreksbeurten.
- Instructies volgen: Controleer of de bot zich houdt aan de instellingen die u in de systeemprompt hebt gedaan.
Kwaliteitsevaluatie:
- Relevantie: Beantwoordt het antwoord daadwerkelijk de vraag van de gebruiker?
- Nauwkeurigheid: Is de informatie die de provider verstrekt correct?
- Coherentie: Verloopt het gesprek logisch?
- Veiligheid: Weigert de bot ongepaste of schadelijke verzoeken te beantwoorden?
Prestatietests:
- Latentie: Meet hoe lang het duurt voordat de bot begint te reageren en zijn reactie voltooit.
- Resourcegebruik: Controleer hoeveel GPU-geheugen het model gebruikt tijdens inferentie.
- Concurrency: Test hoe het systeem presteert wanneer meerdere gebruikers tegelijkertijd ermee communiceren.
Let ook op veelvoorkomende LLM-problemen zoals hallucinaties (het vol vertrouwen geven van onjuiste informatie), contextverschuiving (het bijhouden van het onderwerp in een lang gesprek) en herhaling. Het loggen van alle testgesprekken is een uitstekende manier om patronen te ontdekken en problemen op te lossen voordat ze uw gebruikers bereiken.
LLaMA Chatbot-gebruiksscenario's voor teams
Zodra u de mechanica van het afstemmen en implementeren achter de rug hebt, wordt LLaMA het meest waardevol wanneer het wordt toegepast op alledaagse teamproblemen – niet op abstracte AI-demo's. Teams hebben doorgaans geen 'chatbot' nodig; ze hebben behoefte aan snellere toegang tot kennis, minder handmatige overdrachten en minder repetitief werk.
Interne kennisassistent
Door LLaMA af te stemmen op interne documentatie, wiki's en veelgestelde vragen, of door het te koppelen aan een op RAG gebaseerde kennisbank, kunnen teams vragen in natuurlijke taal stellen en nauwkeurige, contextbewuste antwoorden krijgen. Dit neemt de wrijving weg van het zoeken in verspreide tools, terwijl gevoelige gegevens volledig intern blijven en niet naar API's van derden worden verzonden.
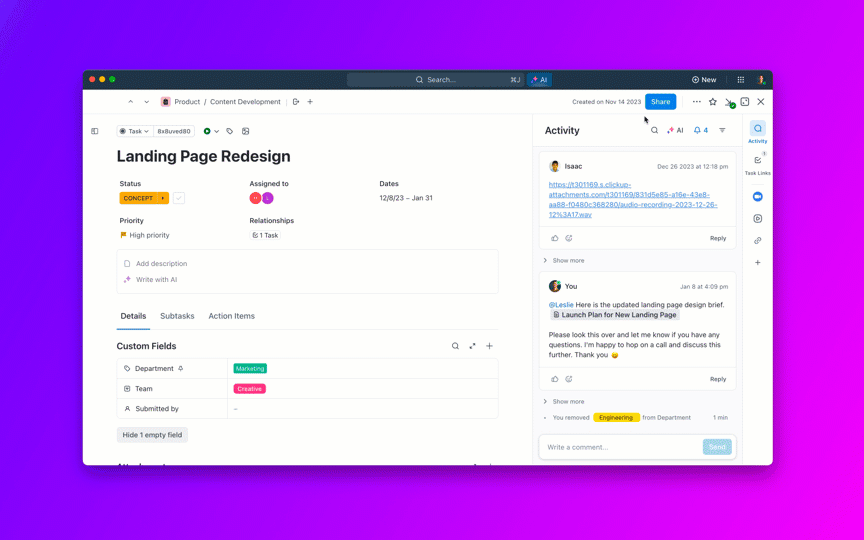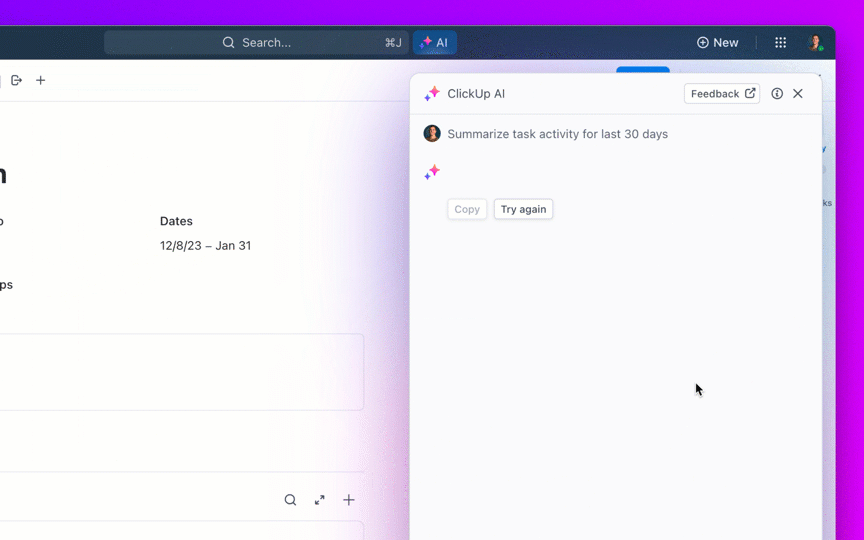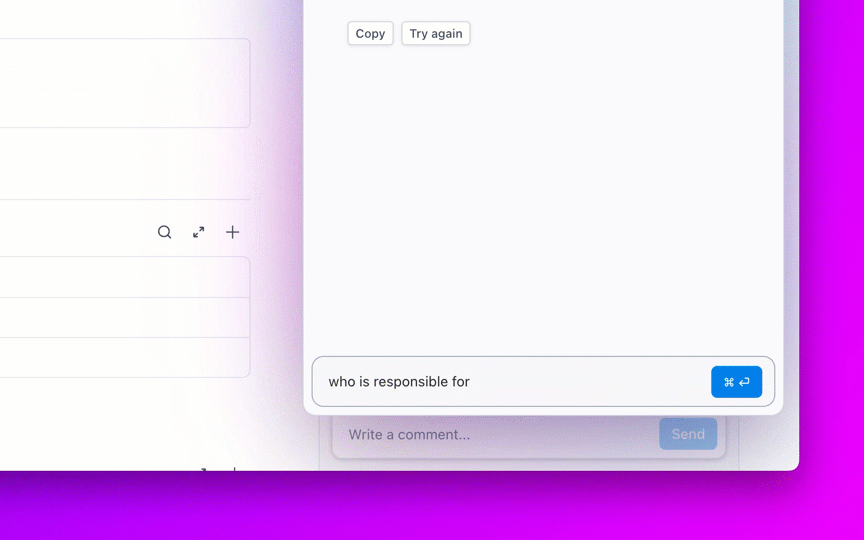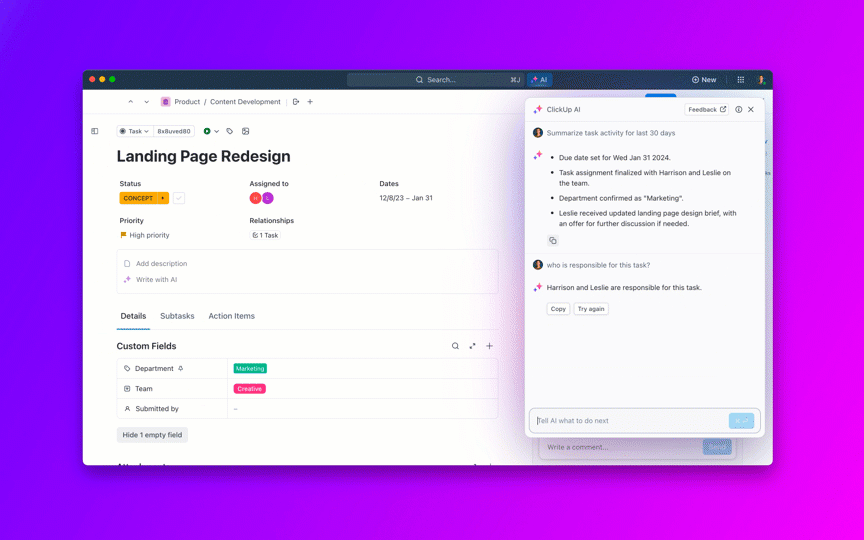
🌟 Enterprise Search in ClickUp en de vooraf gebouwde Ambient Answers -agent geven gedetailleerde contextuele antwoorden op uw vragen met behulp van kennis binnen uw ClickUp-werkruimte.
Hulp bij codebeoordeling
Wanneer LLaMA wordt getraind op basis van uw eigen codebase en stijlgidsen, kan het fungeren als een contextuele code review-assistent. In plaats van algemene best practices krijgen ontwikkelaars suggesties die aansluiten bij teamconventies, architecturale beslissingen en historische patronen.
🌟 Een op LLaMA gebaseerde code review helper kan problemen aan het licht brengen, verbeteringen voorstellen of onbekende code uitleggen. Codegen van ClickUp gaat nog een stap verder door binnen de ontwikkelingswerkstroom te werken: het creëren van pull-aanvragen, het toepassen van refactors of het direct bijwerken van bestanden in reactie op die inzichten. Het resultaat is minder kopiëren en plakken en minder mislukte overdrachten tussen 'denken' en 'doen'.
Triage van klantenservice
LLaMA kan worden getraind voor intentieclassificatie om inkomende vragen van klanten te begrijpen en deze door te sturen naar het juiste team of de juiste werkstroom. Veelvoorkomende vragen kunnen automatisch worden afgehandeld, terwijl uitzonderlijke gevallen worden doorgestuurd naar menselijke medewerkers met bijgevoegde context, waardoor de responstijden worden verkort zonder dat dit ten koste gaat van de kwaliteit.
Je kunt ook gewoon een Triage Super Agent bouwen met behulp van natuurlijke taal binnen je ClickUp-werkruimte. Meer informatie
Samenvatting van vergaderingen en follow-up
Met behulp van vergaderverslagen als input kan LLaMA beslissingen, actiepunten en belangrijke discussiepunten extraheren. De echte waarde komt naar voren wanneer deze outputs rechtstreeks in taakbeheertools worden ingevoerd, waardoor gesprekken worden omgezet in bijgehouden werk.
🌟 De AI Meeting Notetaker van ClickUp maakt niet alleen aantekeningen van vergaderingen, maar stelt ook samenvattingen op, genereert actiepunten en koppelt aantekeningen aan uw documenten en taken.
Opstellen en herzien van documenten
Teams kunnen LLaMA gebruiken om eerste versies van rapporten, voorstellen of documentatie te genereren op basis van bestaande sjablonen en eerdere voorbeelden. Hierdoor verschuift de inspanning van het aanmaken van een lege pagina naar het beoordelen en verfijnen, waardoor de levering wordt versneld zonder dat de kwaliteit achteruitgaat.
🌟 ClickUp Brain kan snel concepten voor documentatie genereren, waarbij alle kennis van uw werkplek in context blijft. Probeer het vandaag nog.
Door LLaMA aangestuurde chatbots zijn het meest effectief wanneer ze worden geïntegreerd in bestaande werkstroom – documentatie, projectmanagement en teamcommunicatie – in plaats van als zelfstandige tools te worden gebruikt.
Hier maakt de directe integratie van AI in uw werkruimte het verschil. In plaats van een aparte tool te bouwen, kunt u conversationele AI integreren in de omgeving waar uw team al werkt.
U kunt bijvoorbeeld een aangepaste LLaMA-bot maken die als kennisassistent fungeert. Maar als deze buiten uw projectmanagementtool staat, moet uw team van context wisselen om een vraag te stellen. Dit zorgt voor wrijving en vertraagt iedereen.
Elimineer deze contextwisseling door een AI te gebruiken die al deel uitmaakt van uw werkstroom.
Stel vragen over uw projecten, taken en documenten zonder ClickUp te verlaten met behulp van ClickUp Brain. Typ gewoon @brain in een opmerking bij een taak of in ClickUp Chat om direct een contextgevoelig antwoord te krijgen. Het is alsof u een lid van uw team heeft dat uw hele werkruimte door en door kent. 🤩
Hierdoor verandert de chatbot van een nieuwigheid in een essentieel onderdeel van de motor voor productiviteit van uw team.
Limieten van het gebruik van LLaMA voor het bouwen van chatbots
Het bouwen van een LLaMA-chatbot kan veel mogelijkheden bieden, maar teams worden vaak overrompeld door verborgen complexiteiten. Het 'gratis' open-source model kan uiteindelijk duurder en moeilijker te beheren zijn dan verwacht, wat leidt tot een slechte gebruikerservaring en een constante, resourceverslindende onderhoudscyclus.
Het is belangrijk om de limieten te begrijpen voordat u de toewijzing accepteert.
- Technische complexiteit: Voor de instelling en het onderhouden van een LLaMA-model is kennis van machine learning-infrastructuur vereist.
- Hardwarevereisten: Voor het draaien van de grotere, krachtigere modellen is dure GPU-hardware nodig en de cloudkosten kunnen snel oplopen.
- Beperkingen van het contextvenster: LLaMA-modellen hebben een limiet aan geheugen ( 4K tokens voor LLaMA 2 ). Voor het verwerken van lange documenten of gesprekken zijn complexe chunkingstrategieën nodig.
- Geen ingebouwde veiligheidsmaatregelen: u bent zelf verantwoordelijk voor het implementeren van uw eigen content-filters en veiligheidsmaatregelen.
- Doorlopend onderhoud: wanneer er nieuwe modellen worden uitgebracht, moet u uw systemen bijwerken en moeten geoptimaliseerde modellen mogelijk opnieuw worden getraind.
Zelfgehoste modellen hebben doorgaans ook een hogere latentie dan sterk geoptimaliseerde commerciële API's. Dit zijn allemaal operationele lasten die beheerde oplossingen voor u afhandelen.
📮ClickUp Insight: 88% van de respondenten in onze enquête gebruikt AI voor persoonlijke taken, maar meer dan 50% schrikt ervoor terug om het op het werk te gebruiken. De drie belangrijkste belemmeringen? Gebrek aan naadloze integratie, kennislacunes of bezorgdheid over de veiligheid.
Maar wat als AI in uw werkruimte is ingebouwd en al veilig is? ClickUp Brain, de ingebouwde AI-assistent van ClickUp, maakt dit mogelijk. Het begrijpt prompts in gewone taal en lost alle drie de zorgen over AI-implementatie op, terwijl het uw chat, taken, documenten en kennis in de hele werkruimte met elkaar verbindt. Vind antwoorden en inzichten met één enkele klik!
Alternatieven voor LLaMA voor het bouwen van chatbots
LLaMA is slechts één optie in een zee van AI-modellen, en het kan overweldigend zijn om uit te zoeken welke voor u de juiste is.
Hieronder volgt een overzicht van de verschillende alternatieven.
Andere open-source modellen:
- Mistral: Bekend om zijn sterke prestaties, zelfs met kleinere modelgroottes, waardoor het efficiënt is.
- Falcon: Wordt geleverd met een zeer permissieve licentie, wat ideaal is voor commerciële toepassingen.
- MPT: Geoptimaliseerd voor het verwerken van lange documenten en gesprekken
Commerciële API's:
- OpenAI (GPT-4, GPT-3. 5): Algemeen beschouwd als de meest capabele grote taalmodellen, en ze zijn zeer eenvoudig te integreren.
- Anthropic (Claude): Bekend om zijn sterke veiligheidsfuncties en zeer grote contextvensters.
- Google (Gemini): Biedt krachtige multimodale mogelijkheden, waardoor het tekst, afbeeldingen en audio kan begrijpen.
U kunt deze zelf bouwen met een open-source model, betalen voor een commerciële API of gebruikmaken van een geconvergeerde AI-werkruimte die een vooraf geïntegreerde oplossing biedt met verschillende soorten AI-agents.
Bouw contextbewuste AI-assistenten met ClickUp
Door een chatbot te bouwen met LLaMA krijgt u ongelooflijk veel controle over uw gegevens, kosten en aangepaste aanpassingen. Maar die controle brengt ook verantwoordelijkheid met zich mee voor infrastructuur, onderhoud en veiligheid – zaken die beheerde API's voor u regelen. Het doel is niet alleen om een bot te bouwen, maar ook om uw team productiever te maken, en een complex technisch project kan daar soms afleidend voor zijn.
De juiste keuze hangt af van de middelen en prioriteiten van uw team. Als u ML-expertise hebt en strenge privacyvereisten, is LLaMA een fantastische optie. Als u snelheid en eenvoud vooropstelt, is een geïntegreerde tool wellicht een betere keuze.
Met ClickUp krijgt u een geconvergeerde AI-werkruimte met al uw taken, documenten en gesprekken op één plek, aangedreven door geïntegreerde AI. Het vermindert contextversnippering en helpt teams sneller en effectiever te werken, met de juiste informatie binnen handbereik dankzij aanpasbare Super Agents en contextuele AI.
Verspil geen tijd meer aan infrastructuur en profiteer vandaag nog van de voordelen van een contextbewuste AI-assistent zonder alles vanaf nul op te bouwen. Ga gratis aan de slag met ClickUp.
Veelgestelde vragen (FAQ)
De kosten zijn volledig afhankelijk van uw implementatiemethode en projectprognoses kunnen u helpen deze in te schatten. Als u uw eigen hardware gebruikt, heeft u vooraf kosten voor de GPU, maar geen doorlopende kosten per query. Cloudproviders rekenen een uurtarief op basis van GPU en modelgrootte.
Ja, de licenties voor LLaMA 2 en LLaMA 3 staan commercieel gebruik toe. U moet echter akkoord gaan met de gebruiksvoorwaarden van Meta en de vereiste bronvermelding in uw product opnemen.
LLaMA 3 is het nieuwere en krachtigere model, met betere redeneervaardigheden en een groter contextvenster (8K tokens versus 4K voor LLaMA 2). Dit betekent dat het langere gesprekken en documenten aankan, maar ook meer rekenkracht vereist om te draaien.
Hoewel Python vanwege zijn uitgebreide bibliotheken de meest gebruikte taal voor machine learning is, is het niet strikt noodzakelijk. Sommige platforms beginnen no-code of low-code oplossingen aan te bieden waarmee u een LLaMA-chatbot met een grafische interface kunt implementeren. /