
AI-projecten voor training mislukken zelden op modelniveau. Ze lopen vast wanneer experimenten, documentatie en updates voor belanghebbenden verspreid zijn over te veel tools.
Deze gids leidt je door het trainen van modellen met Databricks DBRX, een LLM die tot twee keer zo rekenkrachtig is als andere toonaangevende modellen, terwijl het werk eromheen georganiseerd blijft in ClickUp.
Van installatie en afstemming tot documentatie en teamoverschrijdende updates: je zult zien hoe één enkele, geconvergeerde werkruimte contextversnippering helpt voorkomen en ervoor zorgt dat je team zich kan concentreren op bouwen in plaats van zoeken. 🛠
Wat is DBRX?
DBRX is een krachtig, open-source groot taalmodel (LLM) dat speciaal is ontworpen voor het trainen en infereren van AI-modellen voor ondernemingen. Omdat het open source is onder de Databricks Open Model License, heeft uw team volledige toegang tot de gewichten en architectuur van het model, zodat u het naar eigen inzicht kunt inspecteren, wijzigen en implementeren.
Het is verkrijgbaar in twee varianten: DBRX Base voor diepgaande pre-training en DBRX Instruct voor kant-en-klare taken waarbij instructies worden opgevolgd.
DBRX-architectuur en 'mixture-of-experts'-ontwerp
DBRX lost taken op met behulp van een Mixture-of-Experts (MoE)-architectuur. In tegenstelling tot traditionele grote taalmodellen die al hun miljarden parameters gebruiken voor elke afzonderlijke berekening, activeert DBRX slechts een fractie van zijn totale parameters (de meest relevante experts) voor een bepaalde Taak.
Zie het als een team van gespecialiseerde experts; in plaats van dat iedereen aan elk probleem werkt, wijst het systeem elke taak op intelligente wijze toe aan de meest gekwalificeerde parameters.
Dit verkort niet alleen de responstijd, maar levert ook topprestaties en -resultaten op, terwijl de rekenkosten aanzienlijk worden verlaagd.
Hier volgt een kort overzicht van de belangrijkste specificaties:
- Totaal aantal parameters: 132 miljard voor alle experts
- Actieve parameters: 36B per forward pass
- Aantal experts: 16 in totaal (MoE Top-4 routing), waarvan 4 actief voor een bepaald token
- Contextvenster: 32K tokens
DBRX-trainingsgegevens en tokenspecificaties
De prestaties van een LLM zijn slechts zo goed als de gegevens waarop deze is getraind. DBRX is vooraf getraind op een enorme dataset van 12 biljoen tokens, die zorgvuldig is samengesteld door het Databricks-team met behulp van hun geavanceerde gegevensverwerkingstools. Dat is precies waarom het zo goed presteerde op industriële benchmarks.
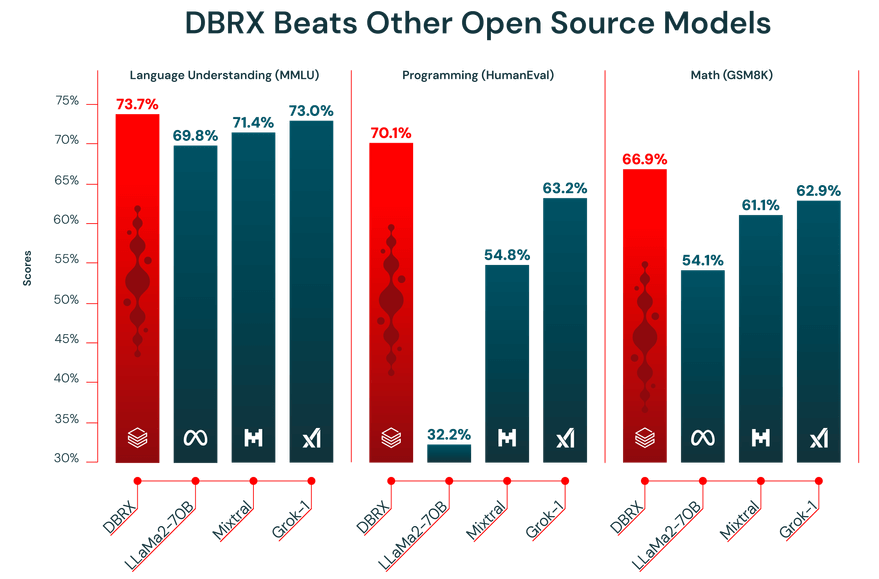
Bovendien heeft DBRX een contextvenster van 32.000 tokens als functie. Dit is de hoeveelheid tekst die het model in één keer kan verwerken. Een groot contextvenster is erg handig voor complexe taken zoals het samenvatten van lange rapporten, het doorzoeken van uitgebreide juridische documenten of het bouwen van geavanceerde RAG-systemen (Retrieval-Augmented Generation), omdat het model hierdoor de context kan behouden zonder informatie af te kappen of te vergeten.
🎥 Bekijk deze video om te zien hoe gestroomlijnde projectcoördinatie uw AI-trainingswerkstroom kan transformeren en de wrijving van het schakelen tussen losstaande tools kan elimineren. 👇🏽
Toegang krijgen tot DBRX en de instellingen ervan
DBRX biedt twee primaire toegangsroutes, die beide volledige toegang bieden tot de modelgewichten onder permissieve commerciële voorwaarden. U kunt Hugging Face gebruiken voor maximale flexibiliteit of rechtstreeks toegang krijgen via Databricks voor een meer geïntegreerde ervaring.
Krijg toegang tot DBRX via Hugging Face
Voor teams die flexibiliteit belangrijk vinden en al vertrouwd zijn met het Hugging Face-ecosysteem, is toegang tot DBRX via de hub de ideale oplossing. Hiermee kunt u het model integreren in uw bestaande op transformers gebaseerde werkstroom.
Zo gaat u aan de slag:
- Maak een Hugging Face-account aan of log in op je bestaande account.
- Ga naar de DBRX-modelkaart op de hub en accepteer de licentievoorwaarden.
- Installeer de transformers-bibliotheek samen met de nodige afhankelijkheden, zoals accelerate.
- Gebruik de AutoModelForCausalLM-klasse in uw Python-script om het DBRX-model te laden.
- Configureer uw inferentiepijplijn en houd er rekening mee dat DBRX aanzienlijk GPU-geheugen (VRAM) vereist voor een effectieve werking.
📖 Lees meer: Hoe LLM-temperatuur configureren
Krijg toegang tot DBRX via Databricks
Als uw team al Databricks gebruikt voor data-engineering of machine learning, is toegang tot DBRX via het platform de gemakkelijkste manier. Het voorkomt problemen bij de installatie en biedt u alle tools die u nodig hebt voor MLOps, precies daar waar u al werkt.
Volg deze stappen binnen uw Databricks-werkruimte om aan de slag te gaan:
- Ga naar de Model Garden of de Mosaic AI-sectie.
- Selecteer DBRX Base of DBRX Instruct, afhankelijk van uw behoeften.
- Configureer een serving-eindpunt voor API-toegang of stel een notebookomgeving in voor interactief gebruik.
- Begin met het testen van inferentie met voorbeeldprompts om te controleren of alles correct werkt voordat je de training of implementatie van je AI-model opschaalt.
Deze aanpak biedt je naadloze toegang tot tools zoals MLflow om experimenten bij te houden en de Unity Catalog voor modelbeheer.
📮 ClickUp Insight: De gemiddelde professional besteedt meer dan 30 minuten per dag aan het zoeken naar werkgerelateerde informatie. Dat komt neer op meer dan 120 uur per jaar die verloren gaat aan het doorzoeken van e-mails, Slack-threads en verspreide bestanden.
Een intelligente AI-assistent die in uw werkruimte is ingebouwd, kan daar verandering in brengen. Maak kennis met ClickUp Brain.
Het levert direct inzichten en antwoorden door binnen enkele seconden de juiste documenten, gesprekken en Taakdetails naar boven te halen, zodat je kunt stoppen met zoeken en aan het werk kunt gaan.
Hoe u DBRX kunt finetunen en aangepaste AI-modellen kunt trainen
Een kant-en-klaar model, hoe krachtig ook, zal nooit de unieke nuances van uw business begrijpen. Omdat DBRX open source is, kunt u het nauwkeurig afstemmen om een aangepast model te creëren dat de taal van uw business spreekt of een specifieke taak uitvoert die u wilt laten uitvoeren.
Hier zijn drie veelgebruikte manieren om dit te doen:
1. DBRX verfijnen met datasets van Hugging Face
Voor teams die net beginnen of aan veelvoorkomende taken werken, zijn openbare datasets van Hugging Face hub een geweldige bron. Ze zijn vooraf geformatteerd en gemakkelijk te laden, wat betekent dat je geen uren hoeft te besteden aan het voorbereiden van je gegevens.
Het proces is vrij eenvoudig:
- Zoek een dataset op de hub die past bij uw taak (bijv. instructies volgen, samenvatten).
- Laad het met behulp van de datasetbibliotheek
- Zorg ervoor dat de gegevens worden geformatteerd in instructie-responsparen.
- Configureer uw trainingsscript met hyperparameters zoals leersnelheid en batchgrootte.
- Start de trainingstaak en zorg ervoor dat je gedurende een periode regelmatig checkpoints opslaat.
- Evalueer het verfijnde model op een apart validatieset om de verbetering te meten.
2. DBRX verfijnen met lokale datasets
Meestal krijg je de beste resultaten door te finetunen met je eigen gegevens. Zo kun je het model de specifieke terminologie, stijl en domeinkennis van je bedrijf aanleren. Houd er wel rekening mee dat dit alleen loont als je gegevens schoon en goed voorbereid zijn en voldoende volume hebben.
Volg deze stappen om uw interne gegevens voor te bereiden:
- Gegevensverzameling: verzamel hoogwaardige voorbeelden uit uw interne wiki's, documenten en databases.
- Formaatconversie: Structureer uw gegevens in een consistent instructie-responsformaat, vaak als JSON-regels.
- Kwaliteitsfiltering: verwijder alle voorbeelden van lage kwaliteit, dubbele voorbeelden of irrelevante voorbeelden.
- Validatiesplit: reserveer een klein deel van uw gegevens (meestal 10-15%) om de prestaties van het model te evalueren.
- Privacybeoordeling: verwijder of maskeer alle persoonlijk identificeerbare informatie (PII) of gevoelige gegevens.
3. DBRX verfijnen met StreamingDataset
Als je dataset uiteindelijk te groot is om in het geheugen van je machine te passen, geen zorgen, je kunt de Streaming Dataset-bibliotheek van Databricks gebruiken. Hiermee kun je gegevens rechtstreeks vanuit de opslagruimte van de cloud streamen terwijl het model wordt getraind, in plaats van alles in één keer in het geheugen te laden.
Zo kunt u dit doen:
- Gegevensvoorbereiding: Maak je trainingsgegevens schoon en structureer ze, en sla ze vervolgens op in een streambaar format zoals JSONL of CSV in cloudopslagruimte.
- Conversie van streamingformat: Converteer je dataset naar een streamingvriendelijk format, zoals Mosaic Data Shard (MDS), zodat deze tijdens de training efficiënt kan worden gelezen.
- Training loader installatie: Configureer uw training loader zodat deze naar de externe dataset verwijst en definieer een lokale cache voor tijdelijke opslagruimte.
- Modelinitialisatie: start het DBRX-fijnafstemmingsproces met behulp van een trainingsframework dat StreamingDataset ondersteunt, zoals LLM Foundry.
- Streaming-gebaseerde training: voer de trainingstaak uit terwijl de gegevens tijdens de training in batches worden gestreamd, in plaats van volledig in het geheugen te worden geladen.
- Checkpointing en herstel: hervat de training naadloos als een run wordt onderbroken, zonder gegevens te dupliceren of over te slaan.
- Evaluatie en implementatie: valideer de prestaties van het verfijnde model en implementeer het met behulp van uw favoriete serving- of inferentie-installatie.
💡Pro-tip: in plaats van helemaal vanaf nul een DBRX-trainingsplan op te stellen, kun je beter beginnen met ClickUp's AI en Machine Learning Projects Roadmap Sjabloon en deze aanpassen aan de behoeften van je team. Deze sjabloon biedt een duidelijke structuur voor het plannen van datasets, trainingsfasen, evaluatie en implementatie, zodat je je kunt concentreren op het organiseren van je werk in plaats van het structureren van een werkstroom.
DBRX-gebruiksscenario's voor het trainen van AI-modellen
Het is één ding om een krachtig model te hebben, maar het is iets heel anders om precies te weten waar het uitblinkt.
Als je geen duidelijk beeld hebt van de sterke punten van een model, kun je gemakkelijk tijd en middelen verspillen aan pogingen om het te laten werken waar het simpelweg niet past. Dit leidt tot ondermaatse resultaten en frustratie.
De unieke architectuur en trainingsgegevens van DBRX maken het bijzonder geschikt voor verschillende sleutelgebruiksscenario's binnen ondernemingen. Als je deze sterke punten kent, kun je het model afstemmen op je bedrijfsdoelstellingen en je rendement op investering maximaliseren.
Tekstgeneratie en contentaanmaak
DBRX Instruct is nauwkeurig afgestemd op het volgen van instructies en het genereren van hoogwaardige tekst. Dit maakt het een krachtig hulpmiddel voor de automatisering van een breed bereik aan inhoudgerelateerde taken. Het grote contextvenster is een belangrijk voordeel, waardoor het lange documenten kan verwerken zonder de thread kwijt te raken.
Je kunt het gebruiken voor:
- Technische documentatie: genereer en verfijn producthandleidingen, API-referenties en gebruikershandleidingen.
- Marketingcontent: conceptblogposts, e-mailnieuwsbrieven en updates voor sociale media
- Rapportage: Vat complexe gegevensbevindingen samen en maak beknopte samenvattingen voor het management.
- Vertaling en lokalisatie: Pas bestaande content aan voor nieuwe markten en doelgroepen.
Codegeneratie en debugging-taken
Een aanzienlijk deel van de trainingsgegevens van DBRX bestond uit code, waardoor het een krachtige LLM-ondersteuning voor ontwikkelaars is. Het kan helpen om ontwikkelingscyclusen te versnellen door repetitieve codetaaken te automatiseren en te helpen bij het oplossen van complexe problemen.
Hier zijn een paar manieren waarop uw engineeringteam hiervan gebruik kan maken:
- Codeaanvulling: genereer automatisch functielichamen op basis van opmerkingen of docstrings
- Bugdetectie: analyseer codefragmenten om mogelijke fouten of logische tekortkomingen te identificeren.
- Uitleg van de code: Vertaal complexe algoritmen of verouderde code naar eenvoudig Engels.
- Testgeneratie: maak unit-tests op basis van de handtekening en het verwachte gedrag van een functie.
RAG en toepassingen met een lange context
Retrieval-Augmented Generation (RAG) is een krachtige techniek die de reacties van een model baseert op de privégegevens van uw bedrijf. RAG-systemen hebben echter vaak moeite met modellen met kleine contextvensters, waardoor agressieve gegevensverdeling nodig is, waardoor belangrijke context verloren kan gaan. Het 32K-contextvenster van DBRX vormt een uitstekende basis voor robuuste RAG-toepassingen.
Hiermee kunt u krachtige interne tools bouwen, zoals:
- Enterprise search: maak een chatbot die vragen van medewerkers beantwoordt met behulp van uw interne kennisbank.
- Klantenservice: bouw een agent die ondersteuningsreacties genereert op basis van uw productdocumentatie.
- Onderzoeksassistentie: Ontwikkel een tool die informatie uit honderden pagina's aan onderzoeksrapporten kan samenvatten.
- Controle op naleving: Controleer automatisch marketingteksten aan de hand van interne merkrichtlijnen of regelgevingsdocumenten.
Hoe u DBRX-training kunt integreren in de werkstroom van uw team
Een succesvol AI-modeltrainingsproject omvat meer dan alleen code en rekenkracht. Het is een gezamenlijke inspanning van ML-ingenieurs, datawetenschappers, productmanagers en belanghebbenden.
Wanneer deze samenwerking verspreid is over Jupyter-notebooks, Slack-kanalen en afzonderlijke tools voor projectmanagement, creëert u context sprawl, een situatie waarin cruciale projectinformatie verspreid is over te veel tools.
ClickUp lost dat op. In plaats van met meerdere tools te jongleren, krijg je één geconvergeerde AI-werkruimte waar projectmanagement, documentatie en communicatie samenkomen, zodat je experimenten verbonden blijven van planning tot uitvoering tot evaluatie.
Blijf nooit het overzicht houden over experimenten en voortgang
Bij het uitvoeren van meerdere experimenten is het moeilijkste niet het trainen van het model, maar het bijhouden van wat er tijdens het proces is veranderd. Welke datasetversie is gebruikt, welke leersnelheid presteerde het beste of welke run is verzonden?
ClickUp maakt dit proces supergemakkelijk voor je. Je kunt elke trainingsrun afzonderlijk bijhouden in ClickUp-taaken, en binnen taaken kun je aangepaste velden gebruiken om het volgende te registreren:
- Datasetversie
- Hyperparameters
- Modelvariant (DBRX Base vs DBRX Instruct)
- Trainingsstatus (in wachtrij, bezig, evalueren, geïmplementeerd)
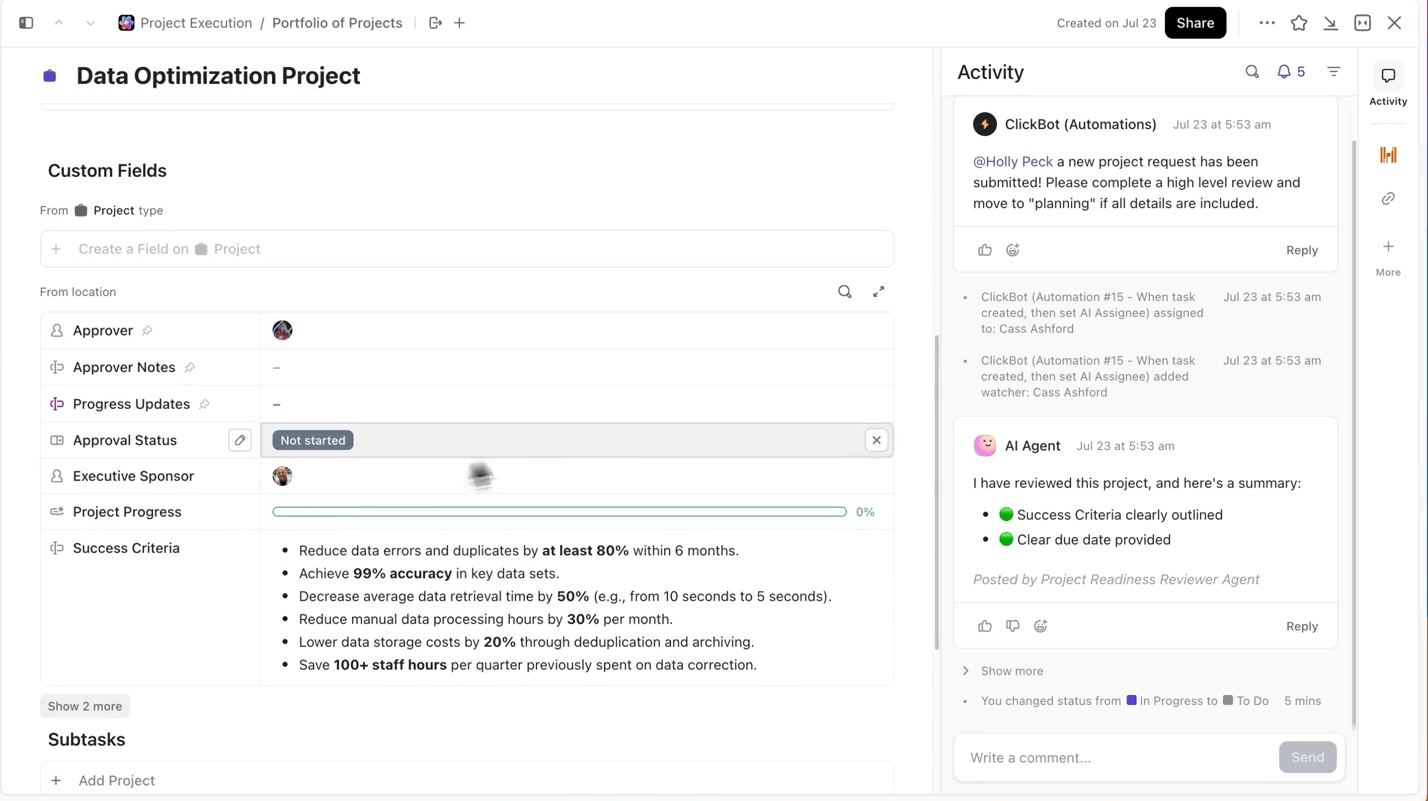
Op die manier is elk gedocumenteerd experiment doorzoekbaar, gemakkelijk te vergelijken met andere experimenten en reproduceerbaar.
Houd modeldocumentatie gekoppeld aan het werk
Je hoeft niet te schakelen tussen Jupyter-notebooks, README-bestanden of Slack-threads om de context van een experiment-taak te begrijpen.
Met ClickUp Docs kunt u uw modelarchitectuur, scripts voor gegevensvoorbereiding of evaluatiestatistieken georganiseerd en toegankelijk houden door ze te documenteren in een doorzoekbaar document dat rechtstreeks gekoppeld is aan de experimenttaken waaruit ze afkomstig zijn.

💡Pro-tip: Houd een actueel projectoverzicht bij in ClickUp Docs waarin elke beslissing, van architectuur tot implementatie, gedetailleerd wordt beschreven, zodat nieuwe leden van het team altijd op de hoogte zijn van de projectdetails zonder oude threads te hoeven doorzoeken.
Geef belanghebbenden realtime zichtbaarheid
ClickUp-dashboards tonen de voortgang van experimenten en de werklast van het team in realtime. I
In plaats van handmatig updates samen te stellen of e-mails te versturen, worden dashboards automatisch bijgewerkt op basis van de gegevens in uw taken. Zo kunnen belanghebbenden op elk moment inchecken, zien hoe de zaken ervoor staan en hoeven ze u nooit te storen met vragen als "wat is de status?".
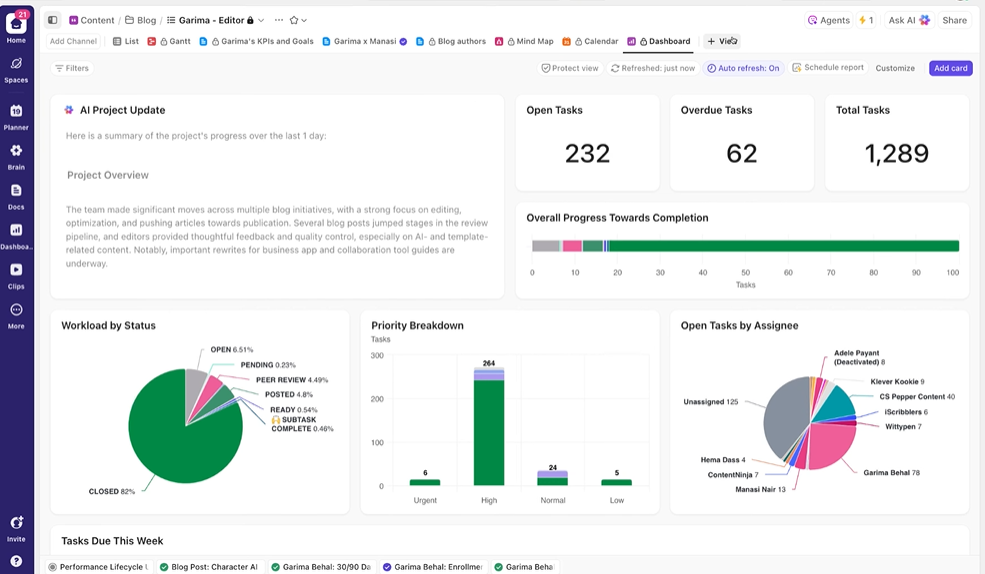
Op deze manier kunt u zich concentreren op het uitvoeren van experimenten in plaats van voortdurend handmatig rapportage uit te brengen.
Maak van AI je slimme projectassistent
Je hoeft niet handmatig weken aan trainingsgegevens door te spitten om een overzicht te krijgen van de experimenten tot nu toe. Vermeld gewoon @Brain in een opmerking bij een taak en ClickUp Brain geeft je de hulp die je nodig hebt met volledige context over je eerdere en lopende projecten.
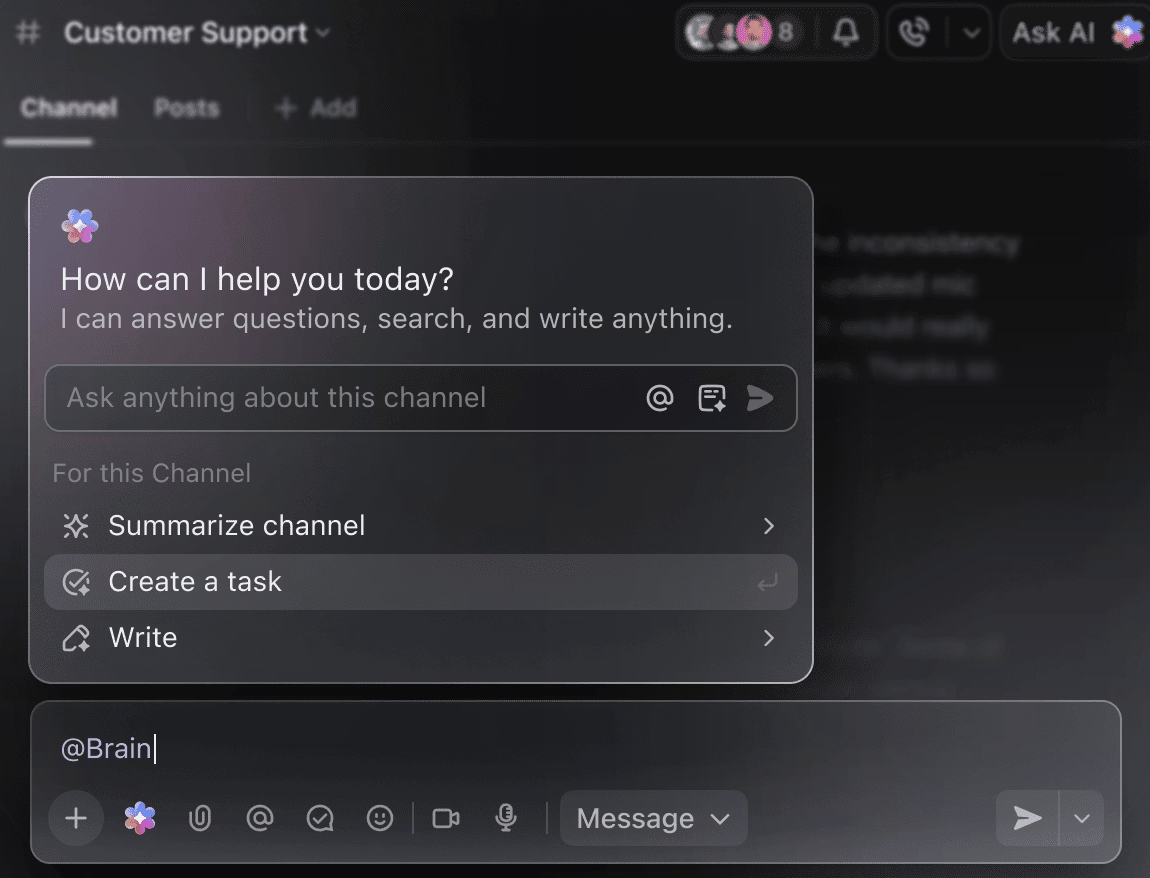
Je kunt Brain vragen om 'de experimenten van vorige week in 5 punten samen te vatten' of 'een document op te stellen met de nieuwste hyperparameterresultaten', en je krijgt direct een gepolijste output.
🧠 Het voordeel van ClickUp: De Super Agents van ClickUp gaan nog een stap verder: ze kunnen volledige werkstroomautomatisering uitvoeren op basis van door u gedefinieerde triggers, en niet alleen uw vragen beantwoorden. Met superagenten kunt u automatisch een nieuwe DBRX-trainingstaak aanmaken wanneer een dataset wordt geüpload, uw team op de hoogte brengen en relevante documenten koppelen wanneer de training is voltooid of een checkpoint heeft bereikt, en een wekelijks voortgangsrapport genereren en naar belanghebbenden sturen zonder dat u daar iets voor hoeft te doen.
Veelgemaakte fouten die je moet vermijden
Het starten van een DBRX-trainingsproject is spannend, maar een paar veelvoorkomende valkuilen kunnen je voortgang in de weg staan. Door deze fouten te vermijden, bespaar je tijd, geld en een hoop frustratie.
- Onderschatting van hardwarevereisten: DBRX is krachtig, maar ook groot. Als je het op ontoereikende hardware probeert uit te voeren, leidt dit tot fouten in het geheugen en mislukte trainingstaken. Houd er rekening mee dat DBRX (132B) minimaal 264 GB VRAM vereist voor 16-bits inferentie, of ongeveer 70 GB-80 GB bij gebruik van 4-bits kwantisering.
- Het overslaan van gegevenskwaliteitscontroles: Garbage in, garbage out. Het finetunen van een rommelige dataset van lage kwaliteit zal het model alleen maar leren om rommelige outputs van lage kwaliteit te produceren.
- Contextlengtebeperkingen negeren: Hoewel het contextvenster van 32K van DBRX ruim is, is het niet oneindig. Als u het model invoer geeft die deze limiet overschrijdt, zal dit resulteren in stille afkapping en slechte prestaties.
- Base gebruiken wanneer Instruct geschikt is: DBRX Base is een ruw, vooraf getraind model dat bedoeld is voor verdere, grootschalige training. Voor de meeste taken waarbij instructies moeten worden opgevolgd, kunt u het beste beginnen met DBRX Instruct, dat al voor dat doel is geoptimaliseerd.
- Het scheiden van trainingswerk en projectcoördinatie: Wanneer je experimenten in de ene tool bijhoudt en je projectplan in een andere, creëer je informatiesilo's. Gebruik een geïntegreerd platform zoals ClickUp om je technische werk en projectcoördinatie synchroniseren.
- Evaluatie voor implementatie verwaarlozen: een model dat goed presteert op uw trainingsgegevens kan in de praktijk spectaculair falen. Valideer uw verfijnde model altijd op een apart testset voordat u het implementeert in de productieomgeving.
- Over het hoofd zien van de complexiteit van fine-tuning: Omdat DBRX een Mixture-of-Experts-model is, kunnen standaard fine-tuning-scripts gespecialiseerde bibliotheken zoals Megatron-LM of PyTorch FSDP vereisen om parameter-sharding over meerdere GPU's af te handelen.
DBRX versus andere AI-trainingsplatforms
Bij het kiezen van een AI-trainingsplatform moet je een fundamentele afweging maken: controle versus gemak. Eigen, API-only modellen zijn makkelijk te gebruiken, maar je zit dan vast aan het ecosysteem van een leverancier.
Open weights-modellen zoals DBRX bieden volledige controle, maar vereisen meer technische expertise en infrastructuur. Deze keuze kan je een gevoel van onzekerheid geven, omdat je niet weet welke weg daadwerkelijk bijdraagt aan je langetermijndoelen – een uitdaging waar veel teams mee te maken krijgen bij de implementatie van AI.
Deze tabel geeft een overzicht van de belangrijkste verschillen, zodat u een weloverwogen beslissing kunt nemen.
| Gewichten | Open (Aangepast) | Eigen | Open (Aangepast) | Eigen |
| Fijnafstemming | Volledige controle | API-gebaseerd | Volledige controle | API-gebaseerd |
| Zelf hosten | Ja | Nee | Ja | Nee |
| Licentie | DB Open Model | OpenAI-voorwaarden | Llama Community | Anthropic Terms |
| Context | 32K | 128K – 1M | 128K | 200.000 – 1 miljoen |
DBRX is de juiste keuze wanneer u volledige controle over het model nodig hebt, zelf moet hosten omwille van veiligheid of naleving, of de flexibiliteit van een permissieve commerciële licentie wilt. Als u geen speciale GPU-infrastructuur hebt, of als u snelheid op de markt belangrijker vindt dan diepgaande aanpassing, zijn API-gebaseerde alternatieven wellicht een betere keuze.
Begin slimmer te trainen met ClickUp
DBRX biedt je een ondernemingsklare basis voor het bouwen van aangepaste AI-toepassingen, met de transparantie en controle die je niet krijgt bij propriëtaire modellen. De efficiënte MoE-architectuur houdt de inferentiekosten laag en het open ontwerp maakt fijnafstemming eenvoudig. Maar sterke technologie is slechts de helft van het verhaal.
Echt succes komt voort uit het afstemmen van je technische werk op de gezamenlijke werkstroom van je team. Het trainen van AI-modellen is een teamsport, en het is cruciaal om experimenten, documentatie en communicatie met belanghebbenden synchroniseren. Wanneer je alles samenbrengt in één geconvergeerde werkruimte en contextversnippering tegengaat, kun je sneller betere modellen leveren.
Ga gratis aan de slag met ClickUp om uw AI-trainingsprojecten in één werkruimte te coördineren. ✨
Veelgestelde vragen
Je kunt de training monitoren met standaard ML-tools zoals TensorBoard, Weights & Biases of MLflow. Als je binnen het Databricks-ecosysteem traint, is MLflow native geïntegreerd om de experimenten naadloos bij te houden.
Ja, DBRX kan worden geïntegreerd in standaard MLOps-pijplijnen. Door het model te containeriseren, kunt u het implementeren met behulp van orchestration-platforms zoals Kubeflow of aangepaste CI/CD-werkstroomen.
DBRX Base is het fundamentele, vooraf getrainde model dat bedoeld is voor teams die domeinspecifieke voortgezette pre-training of diepgaande architecturale fijnafstemming willen uitvoeren. DBRX Instruct is een fijnafgestemde versie die is geoptimaliseerd voor het volgen van instructies, waardoor het een beter startpunt is voor de meeste applicatieontwikkeling.
Het belangrijkste verschil is controle. DBRX geeft je volledige toegang tot de modelgewichten voor diepgaande aanpassing en zelfhosting, terwijl GPT-4 een service is die alleen via API beschikbaar is.
De DBRX-modelgewichten zijn gratis beschikbaar onder de Databricks Open Model License. U bent echter zelf verantwoordelijk voor de kosten van de computerinfrastructuur die nodig is om het model uit te voeren of te verfijnen.