
かつては、ビジネス成果を予測するには、データサイエンスチームと数か月にわたるモデル開発、そして「うまくいくことを祈る」ことしかありませんでした。
しかし、マッキンゼーの調査によると、現在では企業の78%が少なくとも1つのビジネス機能でAIを活用しており、その時間は数ヶ月から、ほぼ瞬時に得られるインサイトへと短縮されました。
こうした変化に伴い、予測モデルを迅速にリリースしなければならないというプレッシャーはかつてないほど高まっています。
IBM Watsonxは、予測モデルの構築とデプロイのプロセスを、開発チームが数分で実行できる統合されたブラウザベースのワークフローに集約します。しかし、スピードだけでは不十分です。これらのモデルが生成する予測が、その影響を受ける経営層のワークフローと接続しなければ、真のインパクトを生み出すことはできません。
このガイドでは、最初のデータセットのアップロードやモデルのトレーニングから、ライブAPIとしてのデプロイ、そして最も重要な点として、生成されたインサイトをClickUpなどのツールにおける経営陣のワークフローに接続させるまでの全フェーズを網羅しています。🔨
Watsonxでのモデル構築方法と、その出力を実運用に活かし、チーム全体で予測結果に基づいたアクションにつなげる方法を学びます。
Watsonxでのモデル構築方法と、その出力を実運用に活かし、チーム全体で予測結果に基づいたアクションにつなげる方法を学びます。
IBM Watsonxとは何か、また予測分析をどのようにサポートするのか?
ビジネス向けにAIモデルを運用する場合、モデルのトレーニングは1つの場所で、データ管理は別の場所で、ガバナンスやコンプライアンス対応はさらに別のツールで行うことになるかもしれません。
IBM Watsonxは、IBMが提供する企業向けAIおよびデータプラットフォームであり、こうした断片化の問題を技術的な側面から解決するために設計されています。これは基本的に、ビジネス内でAIを構築、トレーニング、実行するためのAI製品スイートであり、すべてがばらばらだったり実験的だったりするといった印象を与えることなく利用できます。
このプラットフォームは、単一のプロジェクトワークスペースを提供することで、分断されたワークフローの問題を解決します。環境を離れることなく、データのアップロード、実験の実行、モニタリングの設定を行うことができます。
Watsonxスイートには、主に3つのコンポーネントが含まれています:
- Watsonx.ai: AutoAIまたはカスタムノートブックを使用して予測モデルを構築・トレーニングする
- Watsonx. data: レイクハウス・アーキテクチャにおいて、複数のデータソースにまたがるデータを接続し、準備する
- Watsonxのガバナンス: モデルのパフォーマンスを追跡し、公平性ルールを適用する
特に予測分析に関しては、watsonx.ai が主な操作画面となります。これには、アルゴリズムを自動的に選択し、候補となるモデルをランク付けするノーコードの実験ビルダー「AutoAI」が含まれています。
このガイドの残りの部分では、watsonx.ai 内の AutoAI ワークフローに焦点を当てます。これは、実用的な予測モデルを迅速に立ち上げるための最速の方法です。
Watsonxでの予測モデル構築ステップバイステップガイド
このフローガイドでは、すでにIBM Cloudアカウントをお持ちで、Watsonxプロジェクトが作成済みであることを前提としています。ローカル環境のセットアップは一切不要で、すべてのフローをブラウザ上で直接完了できます。フローは以下の通りです:
ステップ1:データの準備とアップロード
まず、データをCSVファイルなどの表フォーマットに整理します。このファイルには、予測したい対象を明確に指定したターゲット列が必要です。また、モデルが学習するための入力となる機能列も必要です。
データをアップロードするには、Watsonxプロジェクトに移動し、「アセット」タブを開きます。そこから、CSVファイルを直接アップロードするか、watsonx.data 経由でデータソースに接続できます。
開始する前に、よくあるデータの問題に十分注意してください:
- 欠損値: 高い精度を確保するため、アップロード前に重要な列の大きな欠損を整理してください
- ターゲット列の型: 分類モデルのターゲットはカテゴリ型、回帰モデルのターゲットは数値型であることを確認してください
ステップ2:AutoAI を使用した予測モデルのトレーニング
ここからモデルのトレーニングが始まります。プロジェクトワークスペースから、「新しいAutoAI実験を作成」をクリックします。
アップロードしたデータセットを選択し、ターゲットの列を指定します。その後、実験の種類や、トレーニング用とテスト用のデータ分割方法などのオプション設定を構成できます。
実験を実行して、AutoAIにパイプラインのリーダーボードを自動的に生成させます。このリーダーボードは、精度やF1スコアなど、選択したメトリクスに基づいて候補モデルをランク付けします。
リーダーボードの各行は、機械学習アルゴリズムと特徴量エンジニアリングの固有の組み合わせを表しています。通常、上位にランクインしているパイプラインは、AutoAIが特定のデータセットに対して推奨するものです。
ランキング上位のパイプラインが自動的に最適な選択肢になるとは限りません。無条件に1位のものを選ぶのではなく、上位2~3つのパイプラインを比較してみる価値があります。各パイプラインをクリックして詳細を確認することで、どの機能が最も重要か、あるいは交差マトリックスを用いてモデルがどのような誤りを犯しているかなどを確認できます。
ステップ3:予測モデルのデプロイ
最適なパイプラインを選択したら、それをプロジェクト内のモデルとして保存します。その後、保存したモデルをデプロイメントスペースにプロモートする必要があります。デプロイメントスペースとは、本番環境の作業負荷用に特別に設計された独立した環境のことです。
オンライン展開とバッチ展開のどちらかを選択できます。オンライン展開では、オンデマンドで予測を行うためのリアルタイムREST APIが利用できます。バッチ展開では、設定されたスケジュールに従って大規模なデータセットのスコアリングが行われます。
組み込みの「テスト」タブを使用して、サンプル入力ペイロードを送信します。これにより、下流システムに統合する前に予測出力を検証できます。デプロイにより、外部アプリケーションが呼び出すためのAPIエンドポイントとスコアリングURLが生成されます。
ステップ4:モデルのパフォーマンスを監視・評価する
履歴データで学習させたモデルは、現実世界のパターンが変化するにつれて、時間の経過とともに精度が低下することがあります。この精度の低下は「ドリフト」と呼ばれ、時間の経過とともにモデルの品質を徐々に低下させる可能性があります。
実環境でのモデルのパフォーマンスを継続的に追跡し、問題が顕在化する前に検知するには、Watson OpenScaleコンポーネントを通じてモニタリングを有効にし、デプロイメントをモニタリングツールにリンクさせ、精度と正確性に関する品質閾値を設定してください。
予測に機密性の高い属性が含まれる場合は、公平性を確保するためにフェアネスモニターを設定してください。
このシステムは、特定の結果をもたらした機能を正確に示す、予測ごとの説明を生成できます。そこから、これらの監視ダッシュボードを毎月確認し、品質が低下した場合はモデルを再トレーニングするように設定できます。
このセクションを締めくくる前に、このプロセスの各ステップには異なる担当者が関与していることを理解しておくことが重要です。実行状況を追跡するシステムがなければ、プロセスはすぐに遅延し、制御不能に陥る恐れがあります。
- データアナリストは、データセットをアップロードする前に、そのクリーニングと検証を行う責任があります
- 機械学習エンジニアがAutoAIの実験を実行し、上位のパイプラインを比較します
- モデル展開とAPIのセットアップは、同じエンジニア(またはML Opsスペシャリスト)が担当します
- データサイエンティストやAIリーダーは、パフォーマンスを監視し、ドリフトレポートを確認し、再トレーニングが必要なタイミングを判断します
これを管理するための体系的な方法がないと、すぐに散在するメモやSlackのメッセージ、電子メール、あるいは記憶に頼るようになってしまい、そこで遅延やステップの抜けが発生します。その結果、タスク管理が極めて重要になります。
これらのステップを個別に管理するのではなく、ClickUpタスクでは次のようなシステムを提供します:
- すべてのステップが追跡可能なタスクになります
- 各タスクは適切な担当者に割り当てられます
- ワークフロー全体を通じて進捗状況の可視性が高まります
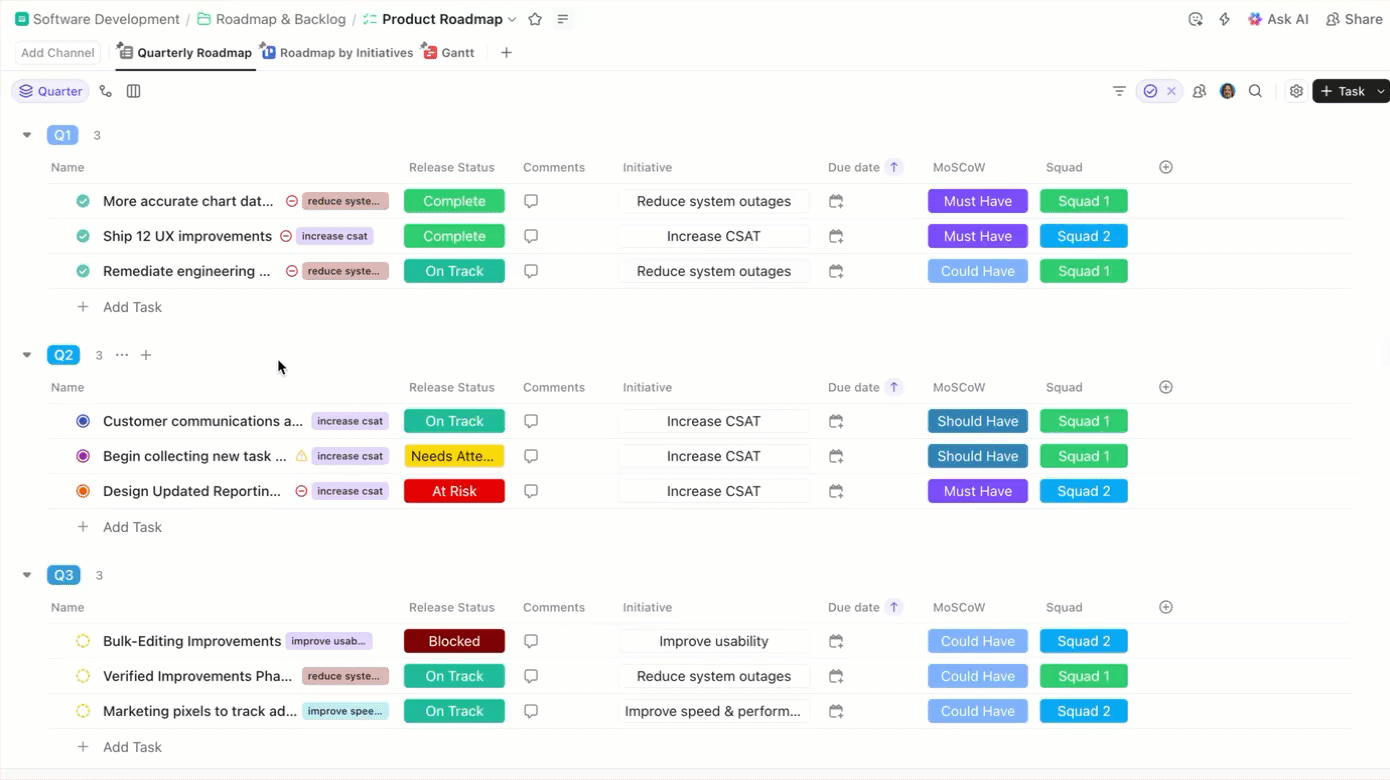
それだけではありません。各タスクの実行をサポートするコンテキストや構造化データも、すべて備わっています。
- カスタムフィールドには、モデルバージョン、データセットのソース、評価メトリクス、デプロイメントの種類、再トレーニングの頻度などの構造化データを記録できます。
- ClickUp Docsには、データ準備ガイドライン、モデルの前提条件、実験メモ、デプロイ手順などのサポートドキュメントを保存できます
これにより、タスクは漠然とした「やるべきこと」ではなく、文脈が明確に反映された仕事単位となり、明確で、担当者が割り当てられ、すぐに実行できる状態になります。
しかし、単にタスクを追跡するだけでは終わりません。これらのタスクは単発の作業ではなく、一定レベルの反復的な手作業を常に必要とする継続的なワークフローなのです。
例:
- モデルの精度が閾値を下回った場合、再トレーニングを担当する担当者を割り当てる必要があります
- OpenScaleがドリフトを検知した場合、そのアラートは明確な所有者がいるタスクに変換する必要があります
- テスト中にデプロイに失敗した場合は、その内容をログに記録し、担当者を割り当て、迅速に解決する必要があります
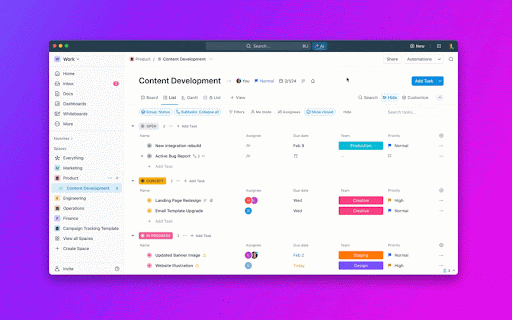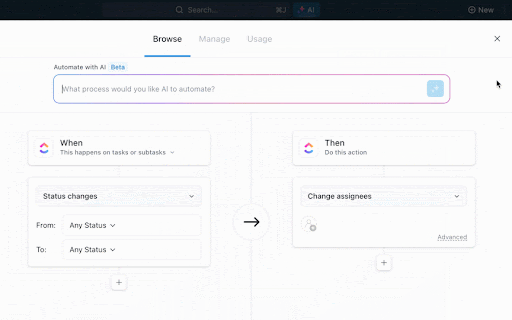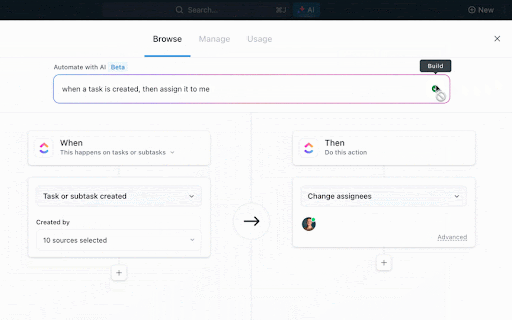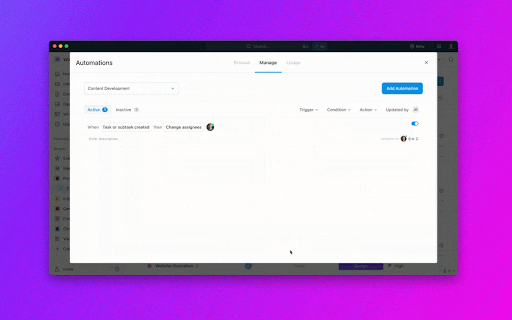
ClickUp自動化は、あらかじめ定義された条件に基づいて自動アクションをトリガーすることで、これらのワークフロー間の手動での引き継ぎを排除し、さらに一歩進んだ機能を提供します。
新しいデータセットがアップロードされると、検証タスクが自動的に作成され、データアナリストに割り当てられます。タスクが「準備完了」とマークされると、モデルトレーニングタスクが自動的に機械学習エンジニアに割り当てられます。トレーニングが完了すると、MLオペレーションスペシャリスト向けのデプロイメントタスクがトリガーされます。
これにより、各ステップは手動での引き継ぎなしに次へとスムーズに進行します。タスクは自動的に作成、割り当て、コンテキスト情報が追加されるため、ワークフロー全体が途切れることなく進行し続けます。
チーム向け予測分析のユースケース
チームが予測分析を活用する最も一般的な方法は以下の通りです:
- 需要予測: 今後1四半期の製品需要を予測し、運用チームが早めに在庫を確保して品切れを防ぐことができます
- 顧客離反予測: 既存顧客の離反リスクに基づいてスコア付けを行い、リスクの高いアカウントを顧客維持ワークフローに振り分けます
- プロジェクトのリスク評価: スコープの変更など、過去の傾向に基づいて、納期に遅れる可能性のあるプロジェクトを特定します。
- セールスパイプラインの予測: 成約の見込みが高い案件を予測し、営業チームに信頼性の高い予測を提供します
- ITインシデントの予測: ログのパターンに基づいて、障害が発生する可能性の高いインフラストラクチャコンポーネントを特定します
これらすべてにおいて重要なのは、これらの予測の価値は、その出力が、チームがすでに意思決定を行っているツールに直接反映されて初めて、何倍にも高まるという点です。
🎯 おすすめ: 得られたインサイトを、ClickUpのような統合型AIワークスペースに取り込みましょう。
ClickUpを使えば、モデルのトレーニングワークフローを管理するだけではありません。日常業務も同一の場所で実行できるため、予測結果がチーム横断的な実際の仕事に直接トリガーとなります。
- マーケティングにおいては、購入意欲の高いセグメントを予測することで、キャンペーンタスクを自動的に作成できます
- 営業においては、リードスコアリングの結果を基に、優先順位付けされたアウトリーチタスクに転換できます
- 運用においては、リスク予測(解約や障害など)がトリガーとなり、フォローアップや介入を行うことができます
各チームは、MLチームがトレーニングやデプロイを行うのと同じように、ClickUpタスク内で独自のワークフローを構築できます。システムは同じですが、ユースケースが異なるだけです。
その利点は実行だけにとどまりません。ClickUpダッシュボードを使えば、以下のことが可能です:
- 予測インサイト(例:高リスクセグメントと低リスクセグメントの比較)を可視化する
- それらのインサイトから作成されたタスクが、各チームでどのように進捗しているかを追跡する
- チーム横断的な作業負荷の監視
- 予測が実際にどのような結果につながっているかを確認する
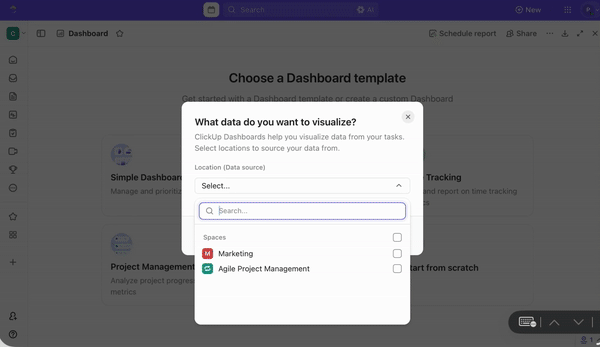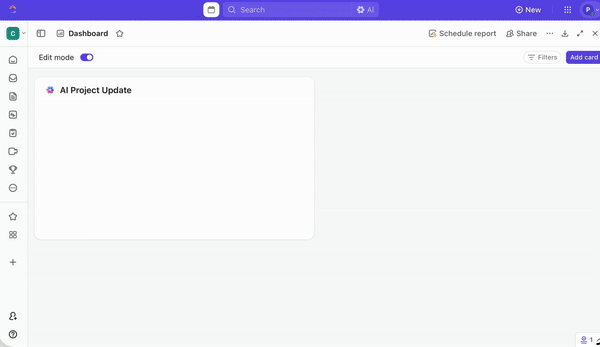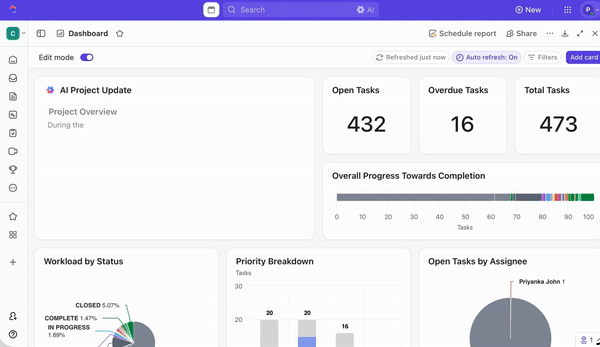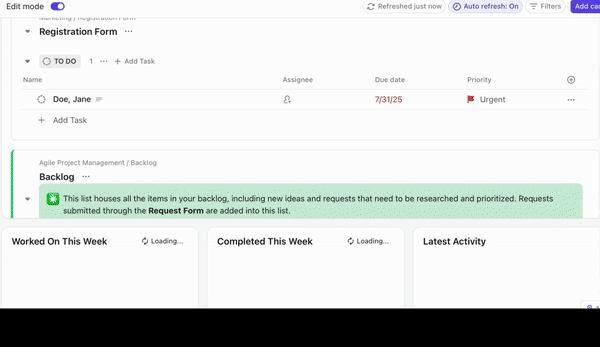
必要なことは、棒グラフ、円グラフ、折れ線グラフ、進捗トラッカーなど、お好みのウィジェットを選ぶことです。こうすることで、モデルが特定のツールに閉じ込められたり、実行が別のツールで行われたりすることがなくなり、すべてが一箇所で接続して機能します。
得られた知見は、単に意思決定の参考になるだけでなく、意思決定のトリガーとなり、担当者が割り当てられ、進捗が追跡され、実際に完了されます。
💡 プロのヒント:ClickUp Brainをワークスペース全体で利用できる組み込みAIアシスタントとして活用できます。
これは独立したツールではなく、ClickUpワークスペース内に組み込まれたインテリジェンス層です。つまり、タスク、データ、ワークフローに関するコンテキストがすでに備わっているということです。
つまり、単にタスクを追跡するだけでなく、AIアシスタントがあなたのそばで働き、状況を把握し、次にやることを迅速に進める手助けをしてくれます。
たとえば、チームメイトに話しかけるのと同じように、タスクのコメントで @Brain をメンションして、次のように尋ねることができます:
- 「最新のドリフトレポートを要約し、注意が必要な点を強調してください。」
- 「過去30日間でモデルのパフォーマンスにどのような変化があったか?」
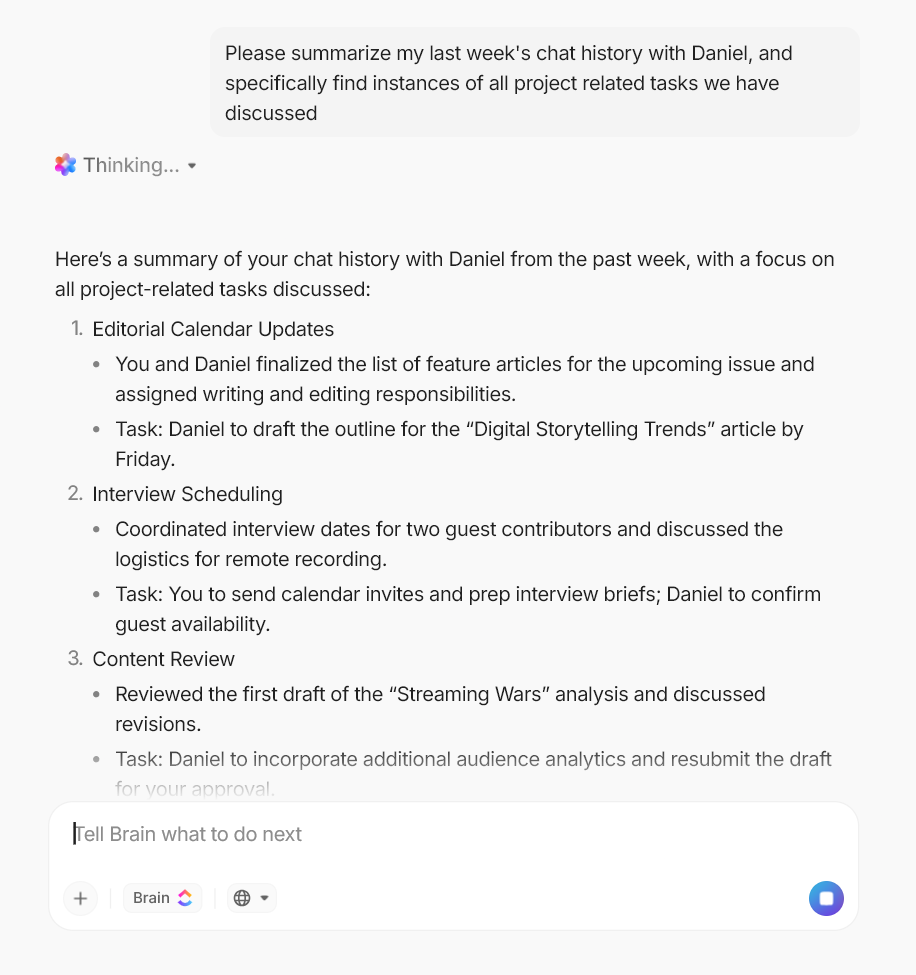
ワークスペースのデータを活用し、明確で即座な回答を提供します。また、作業の生成も可能です。次のようなリクエストが可能です:
- モデルが再デプロイされた理由を説明する簡単な更新情報をステークホルダー向けに作成する
- 最近のパフォーマンス低下を踏まえた再トレーニングプランを策定する
- トレーニング前に新しいデータセットを検証するためのチェックリストを作成する
ClickUpは統合ワークスペースを提供しているため、チームはコミュニケーションと実行のために別々のツールを切り替える必要もありません。
モデルの精度低下について会話したり、フラグが立てられたドリフトアラートを確認したり、デプロイの失敗後のステップを決定したりする場合でも、すべての会話をClickUpチャット内で直接行うことができます。
しかし、もっと重要なのは、それらの会話がただ放置されるわけではないということです。
議論を確実に行動につなげるには、「コメントの割り当て」機能をご利用ください。会話の途中で、特定のチームメンバーにメッセージを割り当てることができ、即座に明確なアクションアイテムに変えることができます。
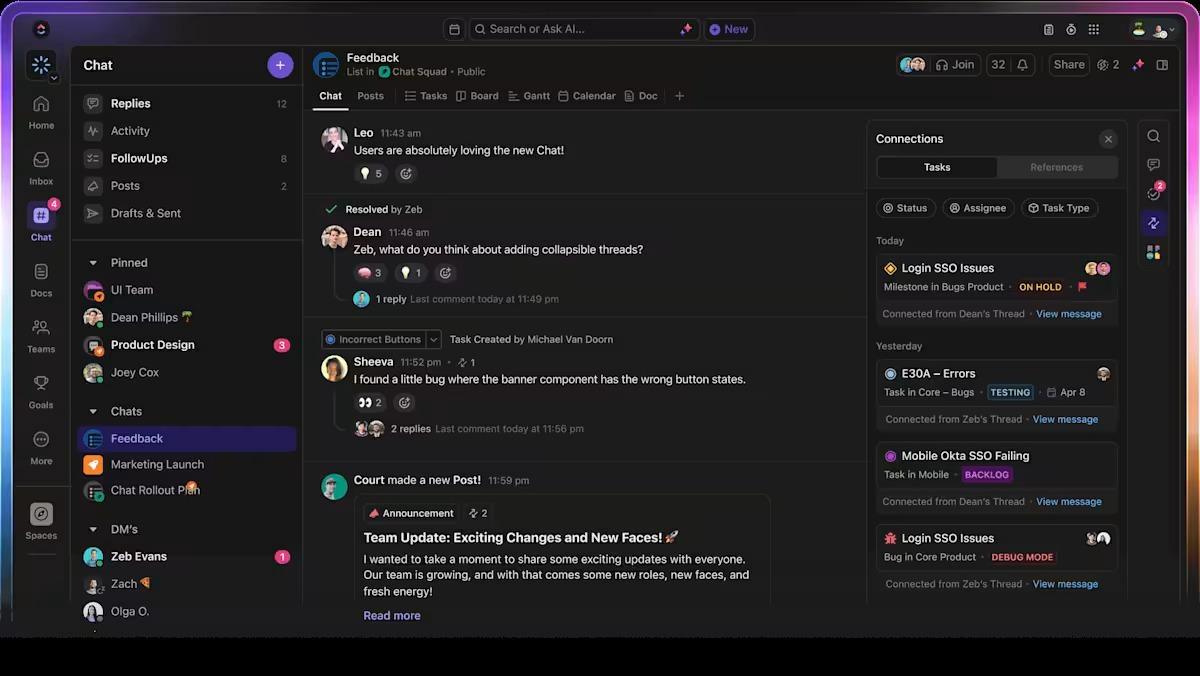
これにより、会話が埋もれてしまったり、「こうやること」だけで終わったりするのではなく、ClickUpチャット内で最初から最後まで実際に実行され、追跡されるタスクとなります。
🎥 ビジネスにおけるAIアプリケーションの全体像をより深く理解するために、組織がさまざまな機能や業界でAIをどのように活用しているかを紹介する、実世界のAI活用事例の概要動画をご覧ください。 ✨
IBM Watsonxを用いた予測分析の制限事項
どのツールにも一長一短があり、Watsonxも例外ではありません。確かに強力なツールですが、このプラットフォームにコミットする前に、以下の制限事項について考慮してください:
- 習得の難易度: デプロイメントスペースやガバナンスモニターの設定には、クラウドプラットフォームの概念を十分に理解している必要があります。そのため、チームにクラウドツールやインフラストラクチャの経験がまだ少ない場合は、適していない可能性があります。
- 手動によるデータ管理: このプラットフォームでは、生データのクリーニングや構造化という最も困難な作業は自動化されていません。そのため、信頼性の高い結果を得るには、チームが依然として膨大な量のデータ準備作業を手動で行う必要があります。
- コンピューティングコスト: IBM Watsonxでのトレーニング実験および本番環境のホスティングは、使用量に応じた課金体系となっています。そのため、作業負荷が増加すると、スケールアップに伴いクラウドリソースが急速に消費され、コストも高くなる可能性があります。
- ワークフローの統合: 予測に基づいてアクションを起こすには、外部のプロジェクト管理ツールとの接続が必要です
- ガバナンスの複雑さ: 公平性およびドリフトの監視設定には複数のステップが必要であり、小規模なチームにとっては負担に感じられる
これらのリミットは、補完的なツールを導入すべき箇所を浮き彫りにしているに過ぎません。これは、予測パイプラインのアクション側において特に当てはまります。
📮 ClickUp Insight: アンケート回答者の88%が個人的なタスクにAIを活用している一方で、50%以上が仕事での利用をためらっています。主な障壁は3つ。シームレスな統合の欠如、知識の不足、そしてセキュリティへの懸念です。
しかし、もしAIがワークスペースに組み込まれていて、すでにセキュリティ対策が施されているとしたらどうでしょうか? ClickUpの組み込みAIアシスタント「ClickUp Brain」なら、それが現実になります。このアシスタントは平易な言葉でのプロンプトを理解し、AI導入に関する3つの懸念事項をすべて解決すると同時に、ワークスペース全体のチャット、タスク、ドキュメント、ナレッジを接続します。ワンクリックで答えや洞察を見つけましょう!
予測分析のための代替AIツール
市場には、予測モデリングのためのプラットフォームとしてWatsonx以外にも選択肢があります。技術的な熟練度によっては、他のプラットフォームの方が環境に適している場合もあります。以下のテーブルで、各プラットフォームをひと目で比較できます。
| ツール | 最適な用途 | 主な特長 |
| IBM Watsonx | ガバナンスが確保され、監査可能なAIを必要とする企業チーム | AutoAI + 組み込みのガバナンスとドリフト監視 |
| Google Vertex AI | すでにGoogle Cloudを利用しているチーム | BigQueryおよびGCPサービスとの緊密な連携 |
| Azure Machine Learning | Microsoftエコシステム企業 | Power BI および Azure DevOps へのネイティブ接続 |
| Amazon SageMaker | MLエンジニアリングリソースを備えたAWSネイティブチーム | 豊富なアルゴリズムライブラリと柔軟なノートブック環境 |
| DataRobot | 完全に自動化された機械学習を求めるビジネスアナリスト | 強力な説明可能性のデフォルト設定を備えたエンドツーエンドの自動化 |
| ClickUp Brain | プロジェクトのワークフローにAIを活用したインサイトを直接組み込む必要があるチーム | ツールを切り替えることなく、タスク、ドキュメント、ダッシュボードを横断して機能するコンテキスト認識型AI |
📮 ClickUp Insight: タスクの切り替えは、知らず知らずのうちにチームの生産性を蝕んでいます。当社の調査によると、仕事の中断の42%は、プラットフォームの切り替え、電子メールの管理、ミーティングの合間の移動に起因しています。こうした生産性を低下させる中断をなくせたらどうでしょうか?
ClickUpは、ワークフロー(およびチャット)を単一の効率的なプラットフォームに統合します。チャット、ドキュメント、ホワイトボードなどからタスクを開始・管理でき、AIを活用した機能により、コンテキストを接続し、検索・管理しやすくします!
予測するだけでなく、ClickUpで実行に移そう
IBM Watsonx を使った予測分析は、データ準備からドリフト監視まで明確なプロセスに沿って進みますが、それは最も簡単な部分です。真の課題は、それらの予測が実際にチームの働き方に変化をもたらすようにすることです。
ダッシュボードに表示されても誰も確認しない予測は、単に計算リソースの無駄に過ぎません。真の価値を引き出しているチームは、自動アラートやタスクの優先順位付けの見直しを通じて、モデルの出力を実行ワークフローに直接接続しています。
AIによるインサイト、プロジェクトの実行、チーム間のコミュニケーションがすべて1つのワークスペースに統合されている環境をお探しなら、今すぐClickUpを無料で始めてみましょう。✨
よくある質問
これは、機械学習モデルの構築、トレーニング、デプロイを行うための企業向けデータおよびAIプラットフォームです。チームはこのプラットフォームを活用し、単一のクラウド環境からデータレイクハウスの管理やAIガバナンスの監視を行っています。
AutoAIは、表形式のデータを自動的に分析し、最適な機械学習アルゴリズムを選択するノーコードツールです。機能エンジニアリングを行い、候補となるモデルをリーダーボードでランク付けするため、最も精度の高いモデルをデプロイすることができます。
このプラットフォームでは、デプロイメントスペースやガバナンスモニターを設定するために、クラウドの概念を十分に理解している必要があります。また、アップロード前の生データのクリーニングや構造化といった手動プロセスは自動化されません。