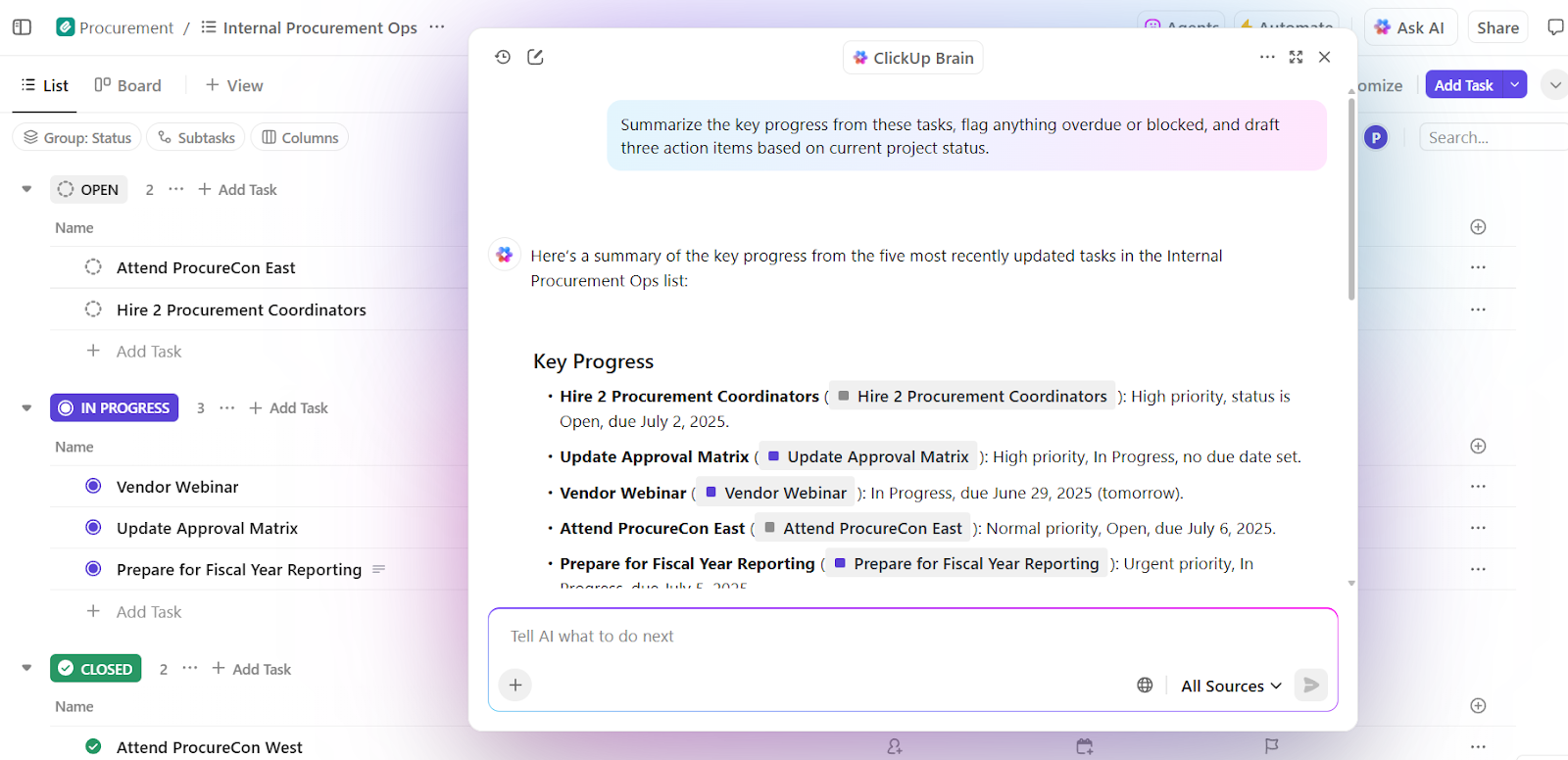

LLMが強力になるにつれ、プロンプト作成はもはや難題ではない。制約となるのはコンテキストだ。
コンテキストエンジニアリングとは、適切な情報を適切なフォーマットでLLM(大規模言語モデル)に提供することである。
コンテキストエンジニアリングが難しい理由は何か?
スタックの各層を設計し、コンテキストを捕捉して利用可能にする必要がある。コンテキストが少なすぎると、LLMは何をすべきかわからなくなる。コンテキストが多すぎると、トークンが不足する。では、どうバランスを取るか?
以下に、コンテキストエンジニアリングに関する知っておくべき全てを共有します。
AIコンテキストエンジニアリングとは何か?
AIコンテキストエンジニアリングとは、LLMや高度なAI・マルチモーダルモデルが効果的にタスクを遂行できるよう、指示と関連コンテキストを設計・最適化するプロセスである。
これはプロンプト作成の域を超えている。コンテキスト・エンジニアリングが以下を決定する:
- どの情報が表面化されるか
- どこから得られるか(記憶、ツール、データベース、文書)
- どのようにフォーマットするか(スキーマ、要約、制約)
- いつモデル推論ループに注入するか
🌟 目的:LLMのコンテキストウィンドウに提供する情報を最適化し、ノイズとなる情報をフィルタリングすること。
コンテキストがAIの応答をどう改善するのか?
コンテキストがなければ、LLMは統計的に最も可能性の高いテキストの続きを予測する。一方、優れたコンテキストエンジニアリングは以下のように出力を改善する:
- アンカリング推論:モデルは統計的推測ではなく既知の事実に基づいて応答を構築する
- 幻覚現象の低減:明確な制約条件と関連データが解決策のスペースを狭める
- 一貫性の向上:入力が類似していれば出力も類似する。コンテキストの形が安定しているためである
- コストとレイテンシの削減: 文書全体や履歴を丸ごと投入するより、ターゲットを絞ったコンテキストが効果的
ShopifyのCEO、トビ・ルトケの言葉で要約すると:
プロンプト設計よりも文脈設計という用語の方がずっと気に入っている。この言葉は中核となるスキルをより的確に表現している:LLMがタスクを合理的に解決できるよう、必要な文脈をすべて提供する技術である。
プロンプト設計よりも文脈設計という用語の方がずっと気に入っている。この言葉は中核となるスキルをより的確に表現している:LLMがタスクを合理的に解決できるよう、必要な文脈をすべて提供する技術である。
AI駆動ワークフローにおけるコンテキストエンジニアリングの役割
AI駆動型ワークフローにおいて、LLMは単独のツールではない。それらは既にデータ、ルール、状態を備えたシステム内で動作する。
コンテキストエンジニアリングにより、モデルはワークフロー内の位置と次にやることを理解できるようになる。
モデルが現在の状態、過去の行動、不足している入力を認識できれば、汎用的な助言を生成する代わりに、適切な次のステップを提案または実行できる。
これは承認ルール、コンプライアンス制約、エスカレーション経路といったビジネスロジックを明示的に提供することも意味する。これらが文脈の一部となることで、AIの判断は業務上の現実と整合性を保ち続ける。
最終的に、コンテキストエンジニアリングは各ステップで状態と決定事項を明確に引き継ぐことで、多段階かつ主体的なワークフローを実現する。
これにより、ワークフローの規模拡大に伴うエラーの連鎖を防ぎ、コンテキストの有効性を向上させます。
👀 ご存知ですか?企業のジェネレーティブAI導入の95%が失敗に終わるのは、モデルが弱いからではなく、組織がAIを実際のワークフローに統合できていないためです。
ChatGPTのような汎用AIツールは個人向けには有効だが、システムコンテキストやビジネスルール、変化する状態を学習しないため、大規模化すると機能しなくなる。つまり、AIの失敗の大半はモデル自体の問題ではなく、統合とコンテキストの失敗によるものだ。
📮ClickUpインサイト:回答者の62%が ChatGPTやClaudeのような 対話型AIツールに依存しています 。馴染み深いチャットボットインターフェースと、コンテンツ生成やデータ分析など多用途な能力が、様々な役割や業界で人気を集める理由かもしれません。 しかし、AIに質問するたびに別のタブに切り替える必要がある場合、関連する切り替えコストとコンテキスト切り替えの負担は時間とともに蓄積します。ClickUp Brainなら違います。ClickUpワークスペース内に常駐し、作業内容を把握。プレーンテキストプロンプトを理解し、タスクに極めて関連性の高い回答を提供します!ClickUpで生産性を2倍向上させましょう!
コンテキストエンジニアリングはどのように機能するのか?
コンテキストエンジニアリングは、情報がモデルに到達する前に段階的に形作ることによって機能する。
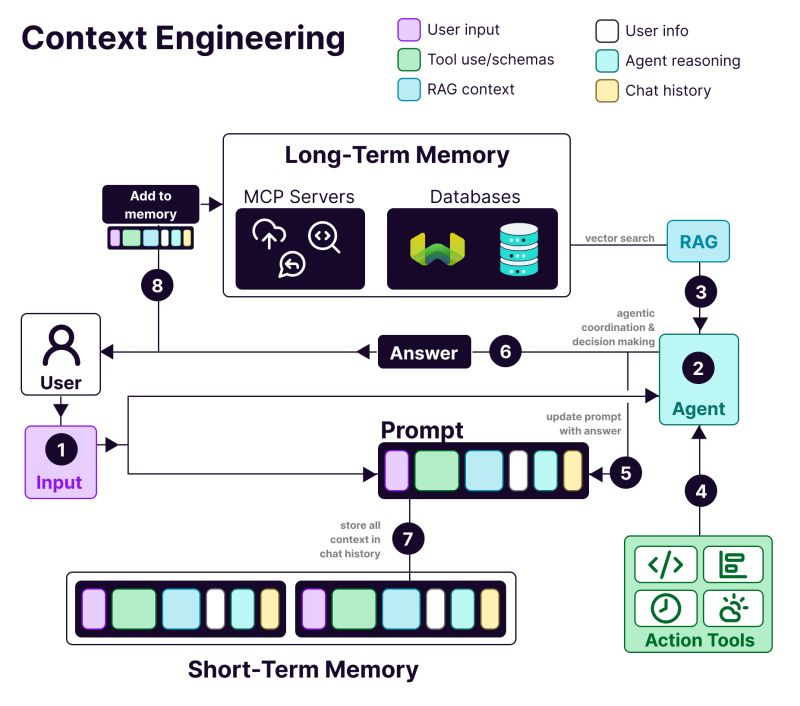
コンテキスト設計システムの構造には以下が含まれる:
- 𝗨𝘀𝗲𝗿 i𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻: 嗜好、履歴、およびパーソナライゼーションデータ
- T𝗼𝗼𝗹 u𝘀𝗲: API、計算ツール、検索エンジン——LLMがやることに必要なものは何でも
- 𝗥𝗔𝗚 c𝗼𝗻𝘁𝗲𝘅𝘁: Weaviateのようなベクトルデータベースから情報を取得
- 𝗨𝘀𝗲𝗿 i𝗻𝗽𝘂𝘁: 実際のクエリまたは手元のタスク
- 𝗔𝗴𝗲𝗻𝘁 r𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴: LLMの思考プロセスと意思決定の連鎖
- 𝗖𝗵𝗮𝘁 h𝗶𝘀𝘁𝗼𝗿𝘆: 連続性を提供する過去のやり取り
⭐ ボーナス:AIツールを活用して生産性を最大化する方法とは?
AIシステムにおけるコンテキストエンジニアリングの利点
AIアプリケーション構築時にコンテキストエンジニアリングが必要な理由は以下の通りです:
より正確な出力
意思決定に関連するコンテキストを提供することで曖昧さが軽減される。モデルは確率的な推測に頼るのではなく、既知の事実・制約・状態の範囲内で推論を行う。
大規模環境における一貫した動作
安定したコンテキスト構造は再現性のある出力を生み出す。類似した入力は類似した判断につながる——生産ワークフローに不可欠な特性だ。
コストとレイテンシの削減
ターゲットを絞った圧縮コンテキストはトークンの無駄遣いを防ぐ。システムは完全な履歴や文書を繰り返し読み込むことなく、より迅速に応答する。
より安全な自動化
コンテキストはビジネスルールと許可を符号化する。これによりAIはポリシー違反やリスクの高い行動をトリガーしないまま行動できる。
より優れたマルチステップワークフロー
クリーンなコンテキスト引き継ぎは、ステップ間で状態を保持する。ワークフローが複雑化したり自律性を増しても、エラーが累積することはない。
デバッグと反復の容易化
構造化されたコンテキストは失敗の可視性を高める。モデルを責める代わりに、欠落・陳腐化・誤順位付けされた入力にエラーの原因を特定できる。
より強力な企業導入
ワークフローの文脈を尊重するAIシステムは信頼性を感じさせる——これがパイロット運用と企業内導入ツールの決定的な違いだ。
📚 詳細はこちら:リアルタイムデータを活用したAIの活用方法
👀 ご存知ですか?コンテキストを認識するAIは生産性に直接影響します。ボストン・コンサルティング・グループの調査によると、コミュニケーションチームだけでも生成AIを活用することで現在の時間の26~36%を削減可能であり、コンテキストを理解する再設計されたワークフローと自律システムを導入すれば、生産性向上率は50%に迫る可能性があります。
AIコンテキストエンジニアリング vs プロンプトエンジニアリング
プロンプト設計:ChatGPTに新機能発表電子メールの作成を依頼する。単一タスクの指示書を作成しているのだ。
コンテキストエンジニアリング:カスタマーサービスボットを構築している。過去のチケットを記憶し、ユーザーアカウント詳細にアクセスし、会話履歴を維持する必要がある。
AI研究者アンドレイ・カーパシーが説明しているように:
人々はプロンプトを、日常的にLLMに与える短いタスク説明と結びつけて考える。しかし産業レベルのLLMアプリにおいては、コンテキストエンジニアリングとは、次のステップに必要な情報をコンテキストウィンドウに正確に充填する繊細な技術と科学なのである。
人々はプロンプトを、日常的にLLMに与える短いタスク説明と結びつけて考える。しかし産業レベルのLLMアプリにおいては、コンテキストエンジニアリングとは、次のステップに必要な情報をコンテキストウィンドウに正確に充填する繊細な技術と科学なのである。
「プロンプト設計」より「コンテキスト設計」に賛成。
人々はプロンプトを、日常的にLLMに与える短いタスク説明と結びつけて考えがちだ。しかし産業レベルのLLMアプリでは、コンテキストエンジニアリングこそがコンテキストウィンドウを埋める繊細な技術と科学なのだ…https://t.co/Ne65F6vFcf
— Andrej Karpathy (@karpathy)2025年6月25日
「プロンプト設計」より「コンテキスト設計」に賛成。
人々はプロンプトを、日常的にLLMに与える短いタスク説明と結びつけて考えがちだ。しかし産業レベルのLLMアプリでは、コンテキストエンジニアリングこそがコンテキストウィンドウを埋める繊細な技術と科学なのだ…https://t.co/Ne65F6vFcf
— Andrej Karpathy (@karpathy)2025年6月25日
| アプローチ | 重点を置く点 | 最適な用途 |
| プロンプトエンジニアリング | モデル向けの指示と出力フォーマットの設計 | 単発タスク、コンテンツ生成、フォーマット固有の出力 |
| コンテキストエンジニアリング | モデルに関連データ、状態、制約条件を供給する | 会話型AI、文書分析ツール、コーディングアシスタント |
| 両方を同時に | 明確な指示とシステムレベルの文脈を組み合わせる | 一貫性と信頼性を必要とする本番環境向けAIアプリケーション |
ほとんどのアプリケーションでは、プロンプトエンジニアリングとコンテキストエンジニアリングを組み合わせて使用します。コンテキストエンジニアリングシステムにおいても、よく書かれたプロンプトは依然として必要です。
違いは、それらのプロンプトが慎重に管理された背景情報と共に機能する点だ。毎回最初から始める必要はない。
📮 ClickUpインサイト: 回答者の半数以上が毎日3つ以上のツールに入力しており、「AIスプロール」と断片化したワークフローに悩まされている。
アプリ間でコンテキストが行き来するだけで、生産的に見えても実際にはエネルギーを消耗しているだけ。Brain MAXが全てを統合:一度話すだけで、更新内容・タスク・メモがClickUpの適切な場所に正確に配置される。切り替えも混乱も不要——シームレスで集中化された生産性を実現。
AIコンテキストエンジニアリングの応用例
AIコンテキストエンジニアリングが既に実装されている主な領域は以下の通り👇
カスタマーサポートとヘルプデスクの自動化
ほとんどのチャットボットは各メッセージを新規として扱い、ユーザーに何度も同じことを繰り返させる。
コンテキストエンジニアリングにより、AIはユーザーの履歴、過去のやり取り、購入記録、製品ドキュメントを参照できる。これにより、問題を既に把握しているチームメイトのように応答する。
📌 実例:Codaのサポートチームは、過去のメッセージの理解や製品ドキュメント参照を必要とする技術的な製品質問に対応しています。サポートをスケールさせるため、彼らはIntercom Finを活用しています。Finは回答前にドキュメントと過去の会話を参照し、高いCSATを維持しながら顧客質問の50~70%を自律的に解決します。
AIライティングと職場生産性アシスタント
AIライティングツールが持つ価値は、あなたが取り組んでいる内容、その重要性、既存の知見を理解した場合のみです。この文脈が欠けると、下書きの時間を節約できても、大幅な書き直しと手作業による調整が依然として必要となります。
ここで文脈設計AIが成果を変える。タスクの状態、文書、過去の決定、チームの慣習にAIを根付かせることで、ライティングアシスタントは汎用的な文章生成からワークフローを意識したサポートへと進化する。
📌 実例: ClickUpのネイティブAI「ClickUp Brain」は、ワークスペースレベルでコンテキストエンジニアリングを適用しています。ユーザーにプロンプトへ背景情報を貼り付けるよう求める代わりに、タスク、ドキュメント、コメント、優先度、タイムラインから直接コンテキストを抽出します。
重要な能力は文脈に基づく意思決定である。進行中のプロジェクトをチームのキャパシティや過去のパフォーマンスと併せて評価し、実行可能な洞察を導き出す。
そこでまず、Brainは負荷過多・遅延・ボトルネックを検知します。問題を要約するとともに、タスクの再配分・タイムラインの更新・優先度の見直しといった具体的な改善策を提案します。
これらの判断は実際のワークスペースの文脈に基づいているため、出力結果は即座に活用可能です。背景の再説明や優先度の説明、現実との手動調整は不要です。
ClickUp Brainを利用するチームは、完全な統合率が2.26倍高く、AIへの不満スコアが最低(27.1%)であると報告しています。
営業とCRMインテリジェンス
営業ワークフローは電子メール、ミーティング、CRM、スプレッドシートにまたがる。コンテキストがなければ、AIは取引の進捗や買い手の意図を理解できない。
コンテキストエンジニアリングは、AIに購買担当者の会話内容、タイムライン、コミュニケーションのトーン、過去の関与状況を可視化させます。これにより、洞察の抽出、停滞した取引の検知、適切な次の一手の提案が可能になります。
📌 実例:Microsoftの営業チームは「Copilot for Sales」を活用している。このツールはOutlook、Teams通話、CRM更新、メモからコンテキストを抽出し、適切な洞察を提供しフォローアップ案を作成する。社内チームでは成約率が20%向上し、営業担当者1人あたりの収益が9.4%増加。コンテキスト駆動型AIがパフォーマンスをいかに増幅させるかを示している。
医療・臨床AIアシスタント
医療判断は患者の病歴、検査結果、処方箋、医師のメモに依存するが、こうした情報はしばしば分断されたシステムに分散している。これにより医師はデータの再入力に多くの時間を費やし、重要な詳細を見落とすリスクを負う。医師は仕事時間の40%近くを事務作業に費やすこともある。
AIコンテキストエンジニアリングはこれらのデータポイントを接続します。正確な要約の提供、文書作成のサポート、関連する病歴の強調表示、潜在的なリスクや次のステップの提示を通じて、臨床医をサポートします。
📌 実例:アトリウム・ヘルスはMicrosoftと共同開発したNuance DAX Copilotを活用し、過去の記録とリアルタイムの会話に基づいて診療記録を自動作成。その結果、臨床医は1日あたり30~40分の記録作業時間を削減。12の医療専門分野を対象とした研究では、患者の安全性を損なうことなくプロバイダーの効率性と満足度が向上したことが報告されている。
人事・採用アシスタント
採用判断は、スキル、面接フィードバック、職務適性、過去の採用データといったコンテキストに依存します。AIコンテキストエンジニアリングにより、履歴書、職務内容、面接記録、過去のパターンを分析し、優れた候補者をより迅速に特定できます。
📌 実例:マイクロンの企業チームは、Eightfold AIを活用している。この人材インテリジェンスプラットフォームは、履歴書・役割要件・社内キャリアパス・過去の採用実績を分析し、職務適性を予測する。スキルと潜在能力に基づき候補者を評価する結果、人材パイプラインが拡大。最小限の採用チームで月8名分の追加採用を実現した。
コンテキストエンジニアリングをサポートするツールとプラットフォーム
コンテキストエンジニアリングを大規模に実装するのに役立つツールはどれか?
1. LangChain(コンテキストをプログラムで組み立てるのに最適)
LangChainは、コンテキストをプログラム的に組み立て、更新し、ルーティングする必要があるAIシステム構築のためのオープンソースのオーケストレーションフレームワークです。
AIエージェントツールは、開発者が静的なプロンプトに依存する代わりに、LLMをツール、データソース、メモリ、制御ロジックと接続することを支援します。
Core LangChainは連鎖処理と検索を担当し、LangGraphは複雑な多ステップ推論のための状態保持型グラフベースワークフローを実現します。
DeepAgentsはこの基盤を拡張し、プラン機能・サブエージェント・永続的コンテキストを備えた自律エージェントの長期実行をサポートします。
これらのコンポーネントが一体となり、LangChainはコンテキストエンジニアリングの制御層として機能します。コンテキストをいつ取得するか、どのように進化させるか、そしてエージェントワークフロー全体でどこへフローするかを決定するのです。
LangChainの優れた機能
- 監視ツールで実行状況を把握し、モデル呼び出し・レイテンシ・エラー・コンテキストフローをエンドツーエンドで追跡。デバッグとパフォーマンス分析に活用する
- 組み込みのテストフレームワークを用いてモデル動作を体系的に評価する。これにより正しさを測定し、出力を比較し、ベンチマークに対する変更を検証できる。
- バージョン管理、ロールアウト制御、チェーンとエージェントの本番環境対応実行をサポートするマネージド環境で、ワークフローを大規模に展開する
LangChainの制限事項
- このツールは初心者にとって習得が難しく、数日ごとに更新されるドキュメントは圧倒されるほど膨大だ
LangChainの価格設定
- 開発者: Free
- プラス:$39/ユーザー/月
- 企業向け: カスタム価格設定
LangChainの評価とレビュー
- G2: 4. 7/5, (30件以上のレビュー)
- Capterra: 評価とレビューが不足しています
実際のユーザーはLangChainについてどう言っているのか?
Redditのユーザーによれば:
いくつかの方法を試した結果、最終的に気に入ったのはlanggraphワークフローを用いた標準的なツール呼び出しだ。つまり、決定論的なワークフローをエージェントとしてラップし、メインのLLMがツールとして呼び出すようにする。こうすることで、メインのLLMは真に動的なUXを提供しつつ、重いことをワークフローに委譲し、その出力を適切にメインのLLMに戻すことができる。
いくつかの方法を試した結果、最終的に気に入ったのはlanggraphワークフローを用いた標準的なツール呼び出しだ。つまり、決定論的なワークフローをエージェントとしてラップし、メインのLLMがツールとして呼び出すようにする。こうすることで、メインのLLMは真に動的なUXを提供しつつ、重いことをワークフローに委譲し、その出力を適切にメインのLLMに戻すことができる。
2. OpenAI API(コンテクストAI APIは構造化されたコンテキスト、ツール呼び出し、システムレベルの制御を提供する)
OpenAI APIは、多様なアプリケーションを支える高度な生成AIモデルにアクセスするための汎用インターフェースです。
開発者はこれを活用し、言語理解と生成を製品に統合する。要約、翻訳、コード支援、推論もサポートする。
APIはチャット、埋め込み、機能呼び出し、モデレーション、マルチモーダル入力をサポートし、モデルとの構造化された対話を可能にします。OpenAIは認証、スケーリング、バージョン管理を処理するため、迅速なプロトタイピングに最適です。
使いやすさは、APIが複雑なモデル動作をシンプルで信頼性の高いエンドポイントに抽象化していることに起因する。
OpenAI APIの優れた機能
- テキスト、コード、マルチモーダル入力にわたり、自然言語タスクと推論のためのコンテキストを意識した出力を生成する
- 意味検索、クラスタリング、ベクトルベースの検索ワークフローを強化する豊富な埋め込みデータを作成する
- 構造化された呼び出しを通じて機能やツールを起動し、モデルが外部システムやサービスと相互作用できるようにする
OpenAI APIのリミット
- 長期記憶機能は備えていない。APIはデフォルトでステートレスである
OpenAI APIの価格設定
GPT-5.2
- 入力: $1.750 / 100万トークン
- キャッシュ済み入力: $0.175 / 100万トークン
- 出力: $14.000 / 100万トークン
GPT-5.2 Pro
- 入力: $21.00 / 100万トークン
- キャッシュされた入力: 利用不可
- 出力: $168.00 / 100万トークン
GPT-5 Mini
- 入力: $0.250 / 100万トークン
- キャッシュ済み入力: $0.025 / 100万トークン
- 出力: $2.000 / 100万トークン
OpenAI APIの評価とレビュー
- G2: レビューが不足している
- Capterra: レビューが不足しています
実際のユーザーはOpenAI APIについてどう言っているのか?
Redditのユーザーによれば:
OpenAIのAPIは他のAPIと同様であるため、技術的な観点からは学習曲線はゼロであるべきだ。すべてのエンドポイント、パラメーター、例の応答は十分に文書化されている。基本的な開発経験があれば、コースは必要ないはずだ。 Pythonを学ぶべきという上記の意見には同意します。Pythonライブラリには作業を容易にする関連情報が全て揃っています。JSを使い続けたい場合はノードライブラリもあります。最大の学習曲線は、それらを戦略的に活用する方法でしょう。コードで構築を試みる前に、プレイグラウンドでシステムメッセージ、ユーザープロンプト、パラメーターを試しに使ってみてください(機能する例を見つければ、プレイグラウンドからサンプルコードを取得できるはずです)。
OpenAIのAPIは他のAPIと同様であるため、技術的な観点からは学習曲線はゼロであるべきだ。すべてのエンドポイント、パラメーター、例は十分に文書化されている。基本的な開発経験があれば、コースは必要ないはずだ。 Pythonを学ぶべきという上記の意見には同意します。Pythonライブラリには作業を容易にする関連情報が全て揃っています。JSを使い続けたい場合はNodeライブラリもあります。最大の学習曲線は、それらを戦略的に活用する方法でしょう。コードで構築を試みる前に、プレイグラウンドでシステムメッセージ、ユーザープロンプト、パラメーターを試しに使ってみてください(機能する例を見つければ、プレイグラウンドからサンプルコードを取得できるはずです)。
3. LlamaIndex(検索拡張生成システムに最適)
LlamaIndexは、大規模言語モデルが外部データにアクセスし活用できるように設計されたオープンソースのデータフレームワークです。
構造化データと非構造化データを、LLMが効率的に推論できる表現に変換するコネクタ、インデックス、クエリインターフェースを提供します。
深いカスタムインフラなしでRAGシステムを構築できる。検索、ベクトル化、関連性ランキングを抽象化する。
これは主に、実データに基づく意味検索、要約、質問応答などのユースケースに用いられる。
LlamaIndexの主な機能
- 異種データソースを検索可能な構造にインデックス化し、LLMが効果的にクエリを実行できるようにする
- ベクトル検索とクエリプランを活用し、戦略的にコンテキストを抽出することで、正確な証拠注入を実現する
- 推論の効率性と関連性を保つため、コンテキストを圧縮・要約する
LlamaIndexの価格設定
- Free
- スターター: 月額50ドル
- プロ:月額500ドル
- 企業:カスタム価格設定
LlamaIndexの評価とレビュー
- G2: レビューが不足している
- Capterra: レビューが不足しています
実際のユーザーはLlamaIndexについてどう言っているのか?
正直なところ、langchainやllamaindexのような生成AIフレームワークの大半はあまり優れておらず、コードを複雑にするだけだと思う。シンプルなPythonを使う方が良い。
正直なところ、langchainやllamaindexのような生成AIフレームワークの大半はあまり優れておらず、コードを複雑にするだけだと思う。シンプルなPythonを使う方が良い。
4. ClickUp BrainGPT(ワークスペースAIアシスタントとして最適)
このリストのツールのほとんどは、特定のコンテキストエンジニアリングを支援します。プロンプトの作成、データの取得、ワークフローの調整などを行います。
ClickUp Brainは異なるアプローチを取ります。世界初の統合型AIワークスペースとして、ClickUpはプロジェクト、タスク、ドキュメント、コミュニケーションを単一プラットフォームに統合し、コンテキストを認識するAIを内蔵しています。
その方法はこちら👇
あなたとあなたの仕事を理解するAIと協働する
ClickUp Brainは、あなたの仕事の文脈を理解します。
ClickUpタスク、ドキュメント、コメント、依存関係、ステータス、タイムライン、所有権からコンテキストを抽出します。ワークスペースデータに基づく質問をするたびに、背景を貼り付けたりプロジェクトの経緯を説明したりする必要はありません。
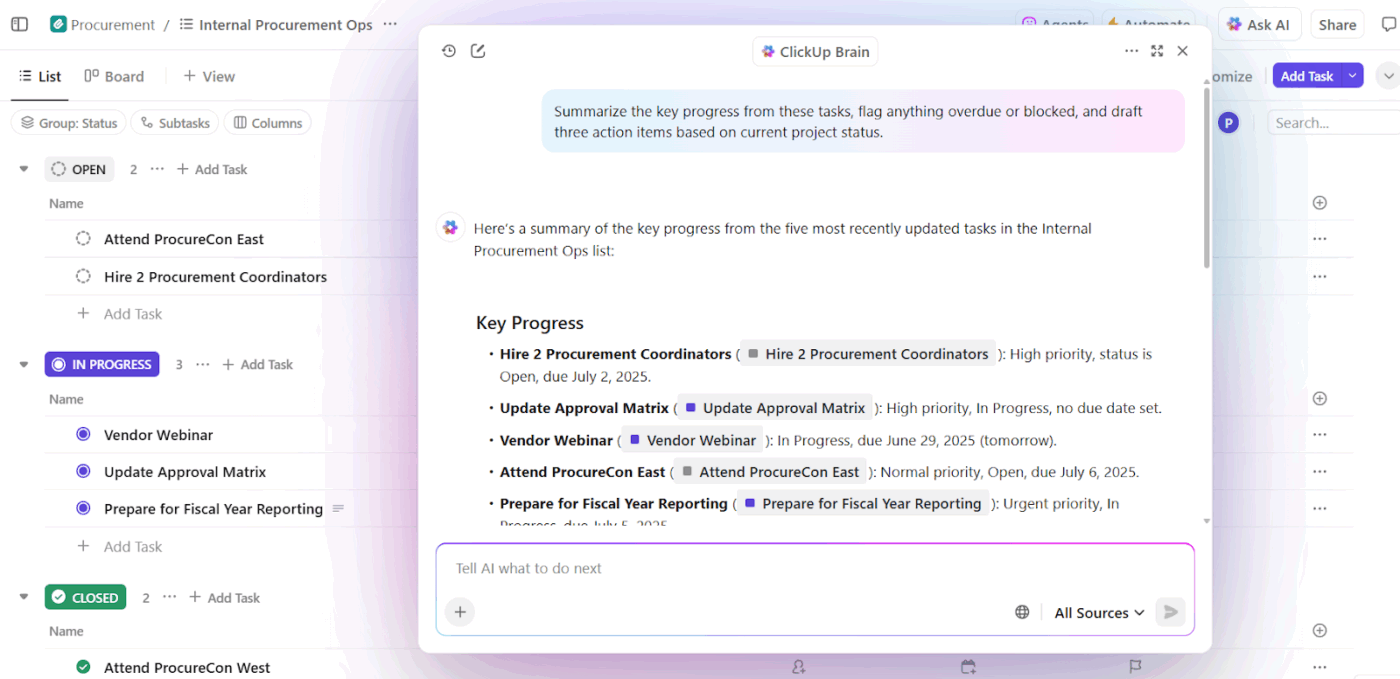
📌 例えば、マネージャーが「第3四半期キャンペーンの進捗を遅らせている要因は?」と尋ねた場合、ワークスペースをスキャンし、以下のような具体的な障害要因を抽出します:
- 未割り当てタスク
- 承認待ち
- 停滞したレビュー
- アセット待ちの依存関係
アクション所有者と時間的影響を示すブロッカーレポートを取得します。
実行と既に整合したAIライティング
ClickUp BrainはAIライティングアシスタントとして機能しますが、決定的な違いがあります:チームが構築している内容を理解した上で文章を生成するのです。
PMやマーケターがClickUpドキュメント内でローンチメッセージを起草する際、Brainは以下が可能です:
- 既存の製品コンテキストを用いて価値提案を定義する
- 異なる対象層に合わせたメッセージを設計する
- トーン、明瞭さ、ポジション目標に合わせてコンテンツを書き換える
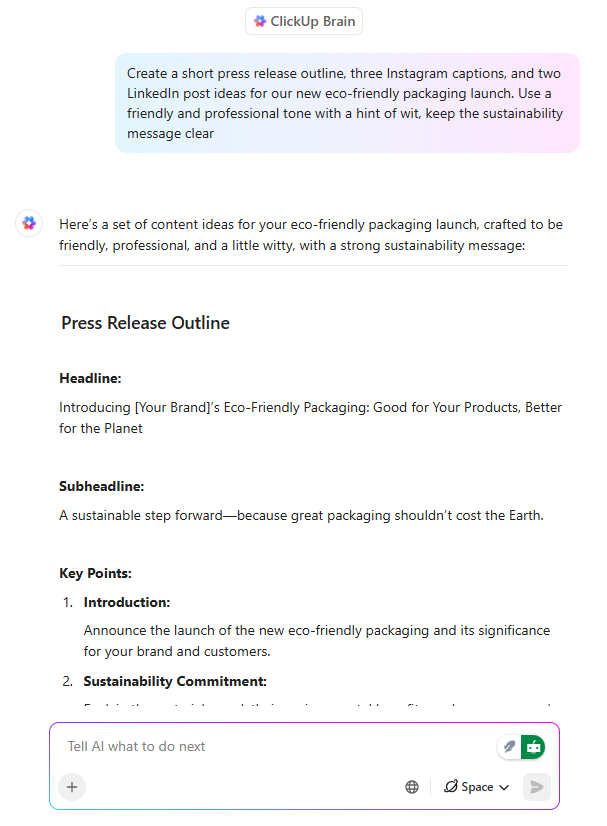
さらに重要なのは、文書がタスク・タイムライン・承認プロセスと常に接続されていることだ。ドキュメントと仕事の間に乖離が生じない。後からコンテンツを再解釈する必要がなくなるため、大幅な時間節約につながる。
💡 プロのコツ: ClickUp Brain内で直接、ChatGPT、Claude、Geminiファミリーの複数AIモデルから選択しましょう!
- タスク内でミーティングメモを要約するには、高速で軽量なモデルを使用する
- ドキュメント、タスク、ダッシュボードを横断したキャンペーン実績を分析する際は、推論能力を重視したモデルに切り替える
真の戦略とは?モデル選択をClickUpの接続コンテキスト(タスク、コメント、ドキュメント、カスタムフィールド)と組み合わせること。そうすればモデルは単なる「賢さ」を超え、実際のワークスペース環境の中で機能するようになる。
手動作業の負担を軽減するコンテキスト連動型タスク自動化
AI搭載タスク機能により、ClickUpはコンテキストをアクションに変換します。主な機能は以下の通りです:
- ClickUpチャットの議論をタスクに変換する
- 既存のタスクタイトルから、範囲に基づいてサブタスクとタスク説明を生成する
- 仕事が停滞した際の次のステップを提案する
- 実際のプロジェクト状態を用いて定型更新を自動化する
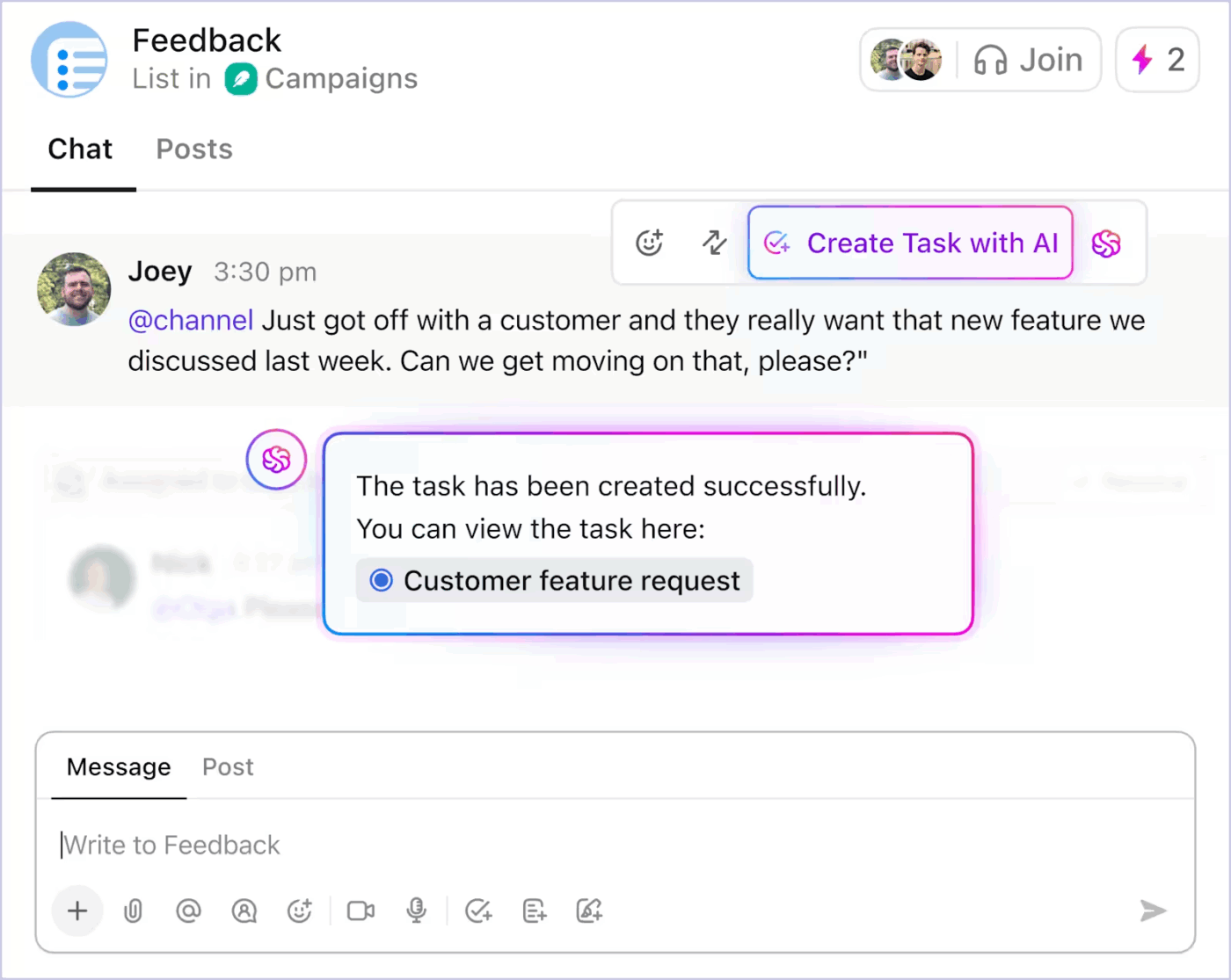
ClickUpのAI搭載タスク自動化で雑務を削減する方法はこちら👇
自動化はリアルタイムのコンテキストによって駆動されるため、チームは意図を構造に変換する時間を削減できる。仕事は絶え間ない手動介入なしに前進する。
AIエージェントに重労働を任せよう
ClickUp Super Agentsは、単一のクエリを超え、自律的な複数ステップの実行へと、ClickUpのコンテキストAIを拡張します。
特定のプロンプトを待つ代わりに、これらの自動化AIエージェントはワークスペース内でユーザーに代わって行動します。ユーザーが定義したコンテキストと目標に基づき、タスク、ルール、成果を処理していくのです。
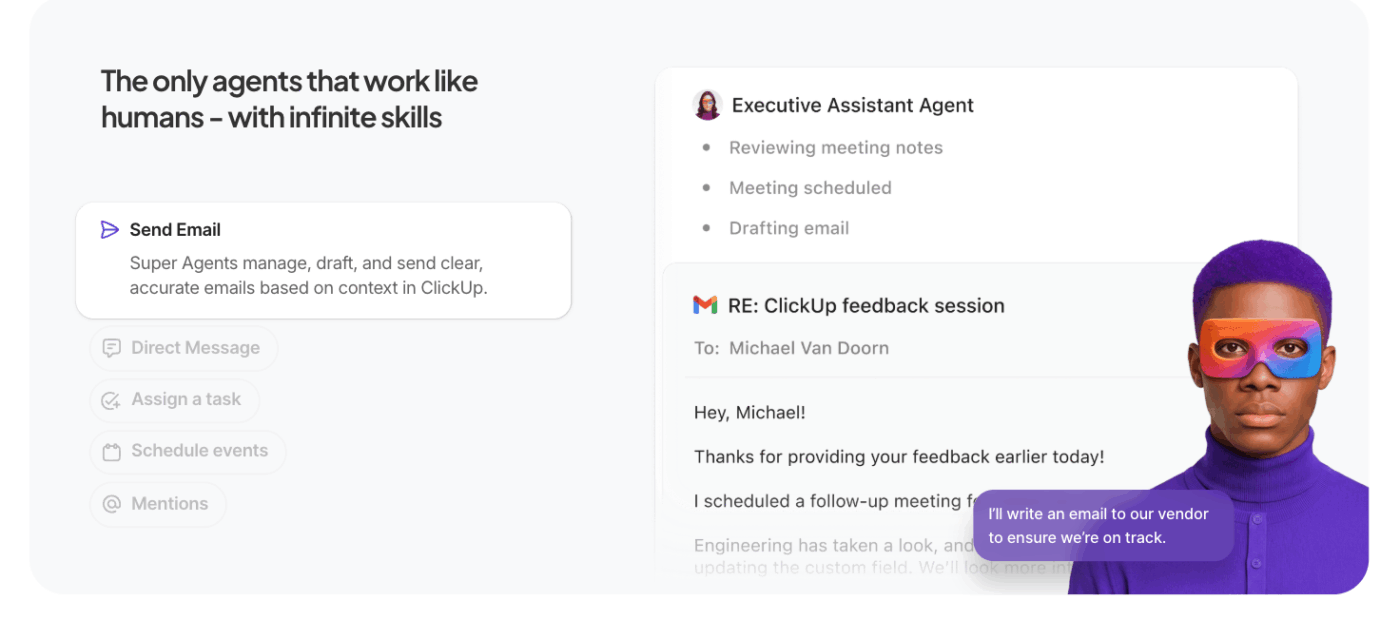
通常のエージェントとの違い:
- 能動的なタスク実行:エージェントはワークスペースのコンテキスト(タスク、依存関係、タイムライン)を解釈し、手動指示なしにステータス更新、サブタスク作成、所有者への通知といった一連の処理を実行する
- 目標指向型ワークフロー:高次元の目標(例:「第3四半期キャンペーンの障害を解決する」)を定義すると、エージェントがプランを立て、コンテキストを取得し、作業を前進させるアクションを実行します
- 持続的なコンテキストと記憶: エージェントはステップ間で状態を維持し、既に完了した処理と残された処理を推論できるようにする。これにより精度が向上し、冗長な仕事が削減される
- ワークスペースツールとの連携: ClickUpタスク、ドキュメント、コメントや接続ツールと連動し、システム横断でワークフローを完了する。文脈を欠いた行動提案ではなく、システム全体を調整する。
📚 さらに読む:モデルベース反射エージェントとは何か
ClickUpの主な機能
- デスクトップと接続アプリにAIを導入ClickUp Brain MAX:ワークスペース全体の検索、音声テキスト変換、主要AIモデルの切り替えが可能。タスク・ドキュメント・チャットへのアクションを、フローを中断せずに実行
- 企業サーチで即座に答えを見つけよう: タスク、ドキュメント、コメント、ファイル、接続されたツールを横断検索。重要なコンテキストが埋もれたりサイロ化したりすることはありません
- アイデアを素早く形に:音声入力で: メモやプラン、進捗を口述し、集中力や勢いを損なうことなく、構造化された仕事内容に変換
- 手作業を削減するClickUpダッシュボード:実際のワークスペースのコンテキストと状態変化に基づき、タスク更新・割り当て・フォローアップを自動でトリガー
- ClickUpチャットで議論を実行可能なものに: 決定事項、フィードバック、承認をタスクと直接連携させて会話し、会話が実行に結びつくようにする
- ミーティングをSyncUpsに置き換える: 非同期の更新情報を共有し、AI生成の要約を取得し、定期的な通話なしでチームを連携させ続ける
- Teams Hubでチームを連携させる: チームの活動状況、所有権、優先度、キャパシティを一元的に把握し、リスクを早期に発見して仕事の再調整を迅速に行う
- ClickUpカレンダーで1日の計画を立てよう:AIが締め切り・優先度・作業量に基づき日次計画を提案。個人の集中力がチーム目標と連動します
ClickUpの制限事項
- その機能セットとカスタマイズオプションは新規ユーザーを圧倒する可能性がある
ClickUpの価格設定
ClickUpの評価とレビュー
- G2: 4. 7/5 (10,585件以上のレビュー)
- Capterra: 4. 6/5 (4,500件以上のレビュー)
実際のユーザーはClickUp AIについてどう言っているのか?
ClickUpユーザーもG2で自身の経験を共有しています:
ClickUp Brain MAXは私のワークフローに驚くべき付加価値をもたらしました。複数のLLMを単一プラットフォームで統合する仕組みにより、応答速度と信頼性が向上し、プラットフォーム全体の音声テキスト変換機能は大幅な時間節約を実現しています。また、機密情報を扱う際の安心感をもたらす企業レベルのセキュリティも高く評価しています。 […] 特に際立っているのは、ミーティングの要約、コンテンツの起草、新アイデアのブレインストーミングなど、あらゆる場面で雑音を排除し思考を明晰にしてくれる点だ。まるであらゆるニーズに適応するオールインワンのAIアシスタントを手にしているような感覚である。
ClickUp Brain MAXは私のワークフローに驚くべき付加価値をもたらしました。複数のLLMを単一プラットフォームで統合する仕組みにより、応答速度と信頼性が向上し、プラットフォーム全体の音声テキスト変換機能は大幅な時間節約を実現しています。また、機密情報を扱う際の安心感をもたらす企業レベルのセキュリティも高く評価しています。 […] 特に際立っているのは、ミーティングの要約、コンテンツの起草、新アイデアのブレインストーミングなど、あらゆる場面で雑音を排除し思考を明晰にしてくれる点だ。まるであらゆるニーズに適応するオールインワンのAIアシスタントを手にしているような感覚である。
AIコンテキストエンジニアリングにおける課題と考慮点
以下が認識すべき主要な課題です。モデルが100万トークンのコンテキストウィンドウをサポートしていても、コンテキストは制御不能になり得ます。認識すべき主要な課題は以下の通りです 👇
コンテキスト汚染
コンテキストに幻覚や誤った推論が紛れ込み、それが繰り返し参照されると、モデルはそれを事実として扱います。この汚染されたコンテキストはワークフローを誤った前提に縛り付け、それが時間とともに持続し、出力品質を低下させます。
文脈の混乱
より大きなコンテキストは魅力的だが、コンテキストが大きくなりすぎると、モデルは蓄積された履歴に過度に集中し、トレーニング中に学んだことを十分に活用しなくなる。これにより、AIは次の最適なステップを合成する代わりに、過去の詳細にループしてしまう可能性がある。
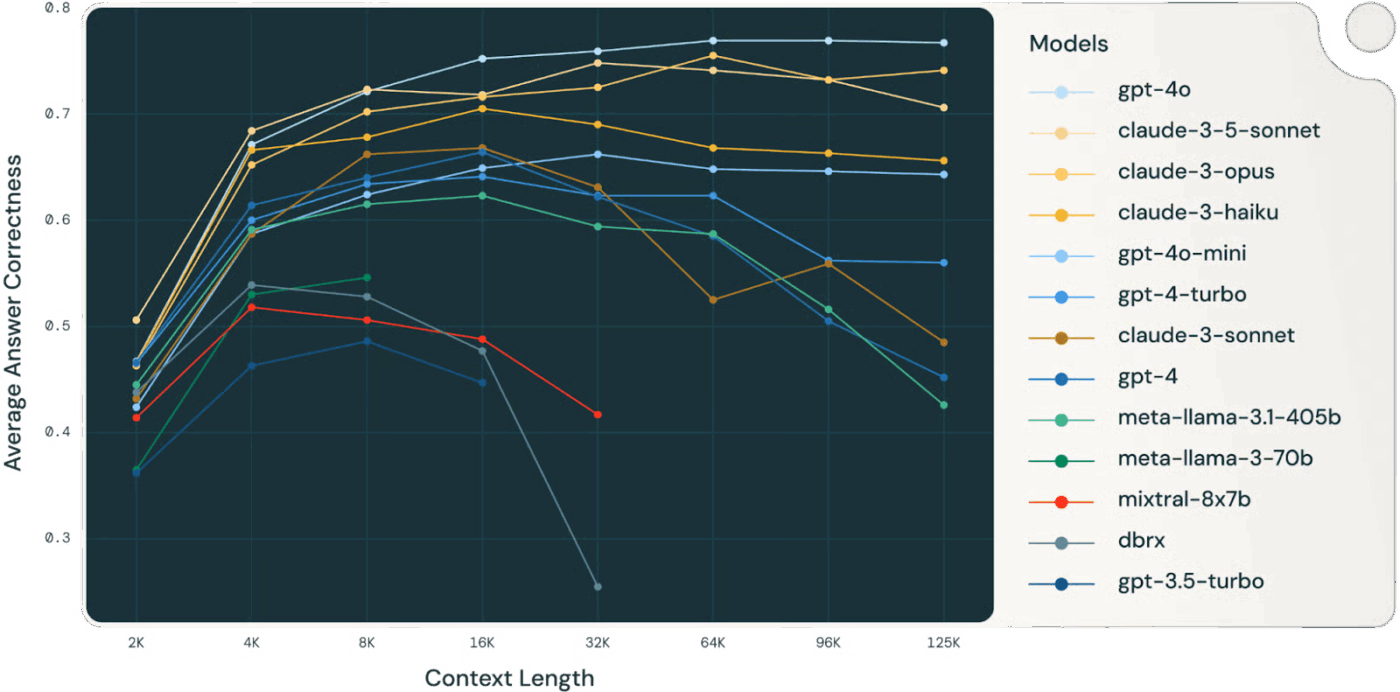
👀 ご存知ですか?Databricksの研究によると、Llama 3.1 405Bモデルの精度は、コンテキストウィンドウが満杯になるよりずっと早い32,000トークンあたりで低下し始めました。より小規模なモデルでは、さらに早い段階で性能が低下しました。
モデルは文脈が「枯渇」するずっと前に推論能力を失うことが多いため、文脈の選択と圧縮は生の文脈サイズよりも価値が高い。
📚 詳細はこちら:ワークプレイス検索とは?従業員の生産性を向上させる仕組み
コンテキストの混乱
文脈内の無関係または低シグナル情報は、重要なデータと注意を奪い合う。モデルが全ての文脈トークンを使用せざるを得ないと感じると、判断は混乱し精度が低下する——たとえ技術的に「より多くの」情報があったとしても。
コンテキストの衝突
情報が蓄積されるにつれ、新たな事実やツールの説明が以前のコンテンツと矛盾する可能性がある。矛盾するコンテキストが存在する場合、モデルは競合するシグナルを調整できず、一貫性のない、あるいは支離滅裂な出力につながる。
ツールの過剰供給と選択問題
文脈にフィルタリングされていないツール定義が過剰に含まれると、モデルは関連性のないツールを呼び出したり、最適でないツールを優先したりする可能性がある。関連性のあるツールのみを選択的に読み込むことで、混乱を軽減し意思決定の質を向上させられる。
エンジニアリングの複雑性と保守性
効果的なコンテキスト管理には、継続的なコンテキストの剪定、要約、オフロード、隔離が必要だ。システムは履歴を圧縮するタイミングと最新情報を取得するタイミングを判断しなければならず、場当たり的なプロンプトの工夫ではなく、熟考されたインフラストラクチャが求められる。
トークン予算の規律
各トークンが動作に影響を与える。コンテキストウィンドウを大きくしても、必ずしも結果が向上するわけではない。コンテキストは管理対象リソースとして扱い、関連性と鮮度をトークンコストやモデルの注意リソースと天秤にかける必要がある。
⚠️ 統計アラート:従業員の約60%が、仕事で許可されていない公開AIツールを使用していることを認めています。多くの場合、監視が全くないプラットフォームに機密性の高い企業データを貼り付けているのです。
さらに深刻なのは、63%の組織がこうしたシャドーAI利用を監視・制限・検知するためのAIガバナンスポリシーを一切導入していない点だ。
結果?誰もAIの使用状況を監視していないため、データが漏洩している。
コンテキストエンジニアリングの未来
これは実験段階から実用段階への転換を示す。コンテキストはもはや人間が管理するものではなく、コードによって生成・管理されるようになる。それはシステム自身の構造に組み込まれた機能となる。
OpenAI開発者コミュニティに掲載されたSergeLiatko氏の優れた記事を基に、これを要約します:
コンテキストエンジニアリングはワークフローアーキテクチャへと進化する
コンテキストエンジニアリングは、自動化されたワークフローアーキテクチャへと次第に置き換わっていく。そのタスクは、適切なトークンを供給することに限定されなくなる。
効果的なコンテキスト・エンジニアリングには、変化するニーズに自動的に適応する推論、ツール、データフローの全シーケンスを調整することが含まれる。
これは、包括的なワークフロー内で適切なコンテキストを自律的に管理する動的システムを構築することを意味する。
自動化されたオーケストレーションが手動プロンプトに取って代わる
次のフロンティアは自らを組織化するAIだ。人間が各プロンプトやコンテキストバンドルを手作業で作成することなく、検索・ツール・記憶・ビジネスロジックを接続させる。あらゆるデータを明示的に供給する代わりに、システムは目標と履歴に基づき、関連するコンテキストを推論し自動的に管理する。
🧠 ClickUp Super Agentsでは既に実現しています。 彼らは常時稼働するAIチームメイトであり、人間と同様に仕事を理解し実行します。豊富な記憶(好み・直近の行動・プロジェクト履歴)を活用し過去のやり取りから継続的に学習。プロンプトを待たず、自ら行動を起こしたり問題をエスカレートしたり、洞察を提示したりできます。
エンドツーエンドの自動化こそが真の生産性向上手段となる
コンテキストエンジニアリングが進化するにつれ、生産性向上は自動化されたワークフローから生まれる。LLMはエージェントとして機能し、ツールを調整し、状態を監視し、ユーザーの細かい管理なしに多ステップロジックを実行する。
不足している文脈を手動で入力する必要はありません。システムが文脈をキュレーションし、長期記憶と推論をサポートします。
統一コンテキストがAIの仕事の効率を向上させる
AIの精度は、文脈がツール・ワークフロー・人間間で断片化する地点で崩壊する。情報が散在すると、モデルは推測を強いられる。
ClickUpのような統合型AIワークスペースはこの点で優れており、コンテキスト戦略において作業・データ・AIを一体化します。
試してみませんか?ClickUpに無料で登録しましょう。