
La plupart des équipes considèrent la génération de SQL comme un tour de magie. Vous tapez une question et obtenez une requête.
Mais voici la réalité : Snowflake Cortex Analyst ne fonctionne aussi bien que le modèle sémantique que vous créez au préalable, et l'installation n'est pas anodine. En apprenant à utiliser Snowflake Cortex pour la génération de requêtes SQL, les équipes chargées des données peuvent désormais transformer le langage naturel en requêtes complexes et exécutables en quelques secondes.
Ce guide vous accompagne tout au long du processus de mise en œuvre, de la définition de votre modèle sémantique YAML à la requête de votre entrepôt de données en langage naturel, afin que vous compreniez à la fois la puissance de cet outil et ses prérequis avant de vous lancer.
Nous examinons également les limites de Snowflake Cortex et la manière dont ClickUp peut fournir l'assistance pour les flux de travail plus larges liés à la génération de requêtes SQL.
Qu'est-ce que Snowflake Cortex Analyst ?
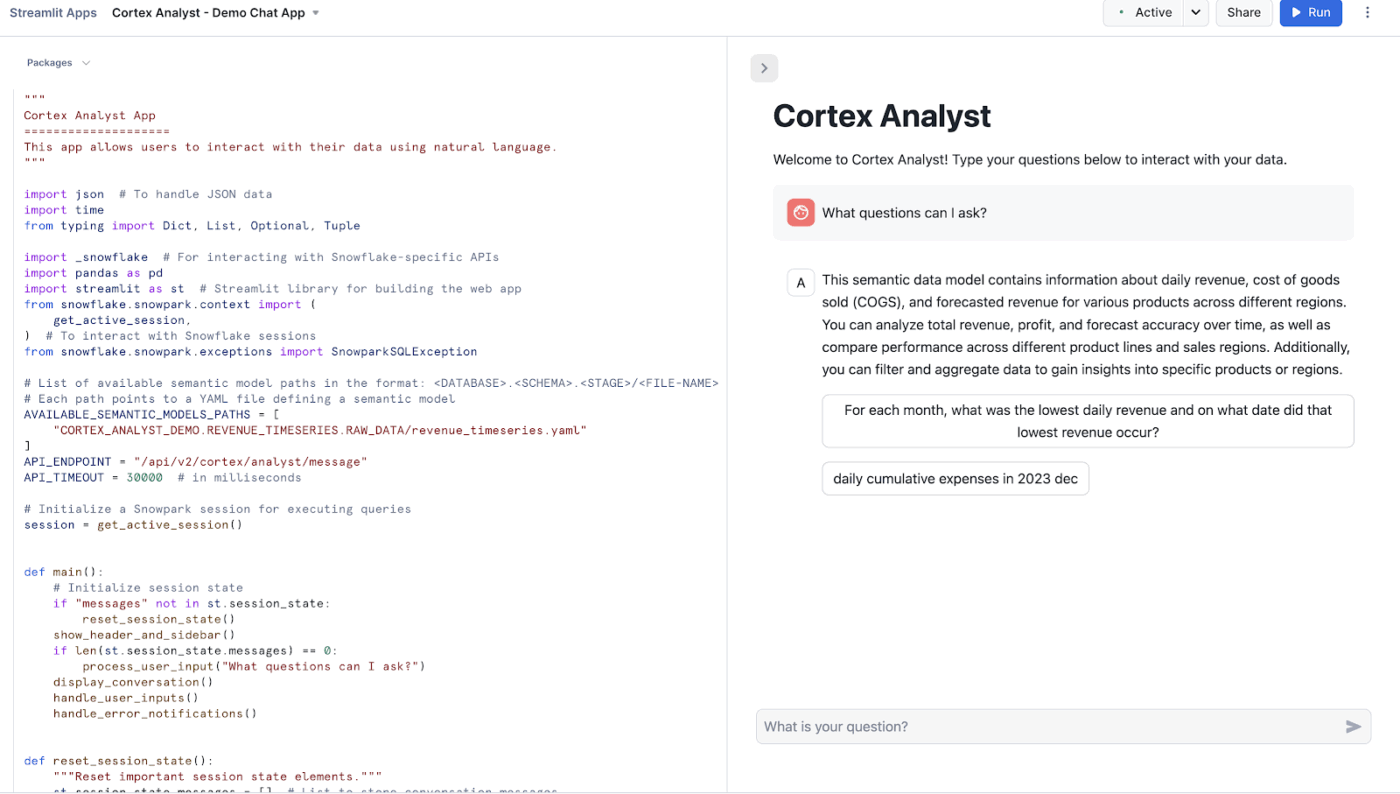
Snowflake Cortex Analyst est un service entièrement géré qui vous permet de créer des applications conversationnelles à partir de vos données analytiques.
Il utilise un agent spécialisé de conversion texte-SQL pour transformer les questions en langage naturel en requêtes précises et exécutables. Ce service comble le fossé entre les structures de données complexes et les utilisateurs professionnels de l’entreprise qui ont besoin de réponses sans avoir à écrire de code.
Les principales fonctionnalités sont les suivantes :
- Fournir une interface très précise pour interagir avec des données structurées
- Utilisation de modèles sémantiques pour comprendre votre logique d’entreprise et votre terminologie spécifiques
- Offre une API REST pour une intégration facile dans des applications personnalisées ou des outils BI
- Préserver la confidentialité des données en traitant les requêtes au sein de la zone de sécurité Snowflake
📮 ClickUp Insight : 88 % des personnes interrogées dans notre sondage utilisent l'IA pour leurs tâches personnelles, mais plus de 50 % hésitent à l'utiliser au travail. Les trois principaux obstacles ? L'absence d'intégration transparente, le manque de connaissances ou les préoccupations en matière de sécurité.
Mais que se passerait-il si l'IA était intégrée à votre environnement de travail et était déjà sécurisée ? ClickUp Brain, l'assistant IA intégré de ClickUp, fait de cela une réalité. Il comprend les invites en langage naturel, résolvant ainsi les trois principaux obstacles à l'adoption de l'IA tout en établissant la connexion entre votre chat, vos tâches, vos documents et vos connaissances à travers l'environnement de travail.
Trouvez des réponses et des informations en un seul clic !
Prérequis pour la génération de SQL avec Snowflake Cortex
Se lancer dans Snowflake Cortex sans une installation adéquate est source de frustration. Vous risquez d'obtenir des résultats inexacts, de perdre du temps à résoudre des problèmes et de conclure à tort que l'outil est défectueux, alors que le véritable problème réside dans une base insuffisante.
Pour éviter cela, vous devez d'abord mettre en place trois éléments fondamentaux.
1. Configurez votre base de données et vos tables
L'intelligence de votre IA dépend de la qualité des données auxquelles elle a accès. Si le schéma de votre base de données est un véritable labyrinthe de noms de colonnes cryptiques tels que cust_dat_v2_final, vos analystes et votre IA auront du mal à s'y retrouver.
Cette confusion conduit l'IA à générer des jointures incorrectes ou à extraire des données des mauvaises colonnes, et votre équipe perd des heures à essayer de déchiffrer le schéma avant même de pouvoir écrire une requête.
Commencez par vous assurer que votre logiciel d'entrepôt de données contient les tables que vous souhaitez que Cortex Analyst effectue pour vous des requêtes. Dans la mesure du possible, utilisez des noms de colonnes clairs et descriptifs. Par exemple, une colonne nommée customer_lifetime_value est bien plus intuitive, tant pour les humains que pour l'IA, que clv_01.
Pour procéder à l'installation, votre rôle Snowflake devra disposer des permissions suivantes :
- UTILISATION : Sur la base de données et le schéma contenant vos tables
- SELECT : Sur les tables que vous souhaitez que Cortex Analyst présente sous forme de requête
- CREATE ÉTAPE : Sur le schéma, ce qui est nécessaire pour charger votre fichier de modèle sémantique
📖 À lire également : Comment utiliser Snowflake Cortex pour la Business Intelligence
2. Créez votre fichier de modèle sémantique
Le principal obstacle avec tout outil de conversion texte-SQL est que l'IA ne parle pas le langage propre à votre entreprise. Elle ne sait pas d'emblée que « ARR » signifie « chiffre d'affaires annuel récurrent » ou que la table de vos clients est jointe à votre table de commandes via le champ customer_id.
Sans ce contexte, l'IA pourrait générer du code SQL techniquement valide mais logiquement erroné, vous fournissant ainsi des réponses qui semblent correctes mais qui sont dangereusement trompeuses.
Le modèle sémantique est la solution. Il s'agit d'un fichier YAML qui fait office de « couche de traduction » personnalisée, enseignant à Cortex Analyst le vocabulaire et la logique spécifiques à votre entreprise. La création et la maintenance de ce fichier relèvent d'un effort collaboratif entre les ingénieurs de données, qui utilisent des outils ETL pour connaître le schéma, et les analystes métier, qui connaissent la terminologie.
Votre fichier de modèle sémantique doit contenir les clés suivantes :
| Composant | Objectif |
| Tables | Fait la liste de chaque table avec une description en langage clair de son objectif |
| Colonnes | Définit le type sémantique de chaque colonne (comme la catégorie ou les indicateurs) et peut inclure des échantillons de valeurs |
| Relations | Spécifie comment les tables sont reliées par des jointures, éliminant ainsi toute approximation pour l'IA |
| Requêtes vérifiées | Fournit des exemples de paires question-SQL qui constituent des guides très utiles pour le LLM |
3. Configurer Cortex Search Service (facultatif)
Parfois, les réponses dont vous avez besoin se cachent dans des textes non structurés, tels que des descriptions de produits, des tickets d'assistance ou des transcriptions d'appels. Les requêtes SQL standard ne peuvent pas exploiter ces données, ce qui signifie que vous passez souvent à côté du « pourquoi » derrière le « quoi ».
Vous pouvez également ajouter ici Snowflake Cortex Search Service. Il s'agit d'une couche de recherche en tant que service qui vous permet de lancer des requêtes sur vos tables structurées et vos données textuelles non structurées à l'aide d'agents IA pour l'analyse des données.
Vous devez configurer Cortex Search si vos analystes ont besoin de poser des questions qui nécessitent d'extraire le contexte du texte avant de générer du code SQL. Par exemple, vous pourriez d'abord rechercher tous les avis sur les produits contenant l'expression « problème de batterie », puis générer une requête SQL pour agréger les données de vente uniquement pour ces produits.
Pour la génération de SQL pur à partir de tables structurées, ce service n'est pas nécessaire.
🧠 Anecdote : Au début des années 1970, les chercheurs d'IBM Donald Chamberlin et Raymond Boyce ont créé le « Structured English Query Language ». Ils ont dû changer le nom en SQL car « SEQUEL » était déjà une marque déposée par un constructeur aéronautique britannique.
Guide étape par étape pour générer du code SQL avec Cortex Analyst
Vous avez effectué le travail préparatoire, mais vous vous retrouvez désormais face à un écran vide, ne sachant pas exactement comment procéder. Comment passer d'une question dans votre tête à une requête SQL exécutable ? Lorsque la gestion du flux de travail n'est pas claire, les nouveaux outils restent souvent inutilisés et l'investissement consacré à l'installation est gaspillé.
Le processus pratique est d'une simplicité rafraîchissante. Voyons cela de plus près !
Étape n° 1 : Préparez vos données dans Snowflake
Avant toute chose, vos données structurées doivent être stockées dans Snowflake. Chaque application Cortex Analyst est orientée vers une seule table ou une vue composée d'une ou plusieurs tables. Assurez-vous que vos tables sont créées et renseignées.
Si vous effectuez un chargement à partir de fichiers plats :
- Importez vos fichiers de données (par exemple, des fichiers CSV) vers une étape Snowflake
- Utilisez la commande COPY INTO pour charger les données de l'étape dans vos tables
- Vérifiez que la charge des données a été réussie avant de passer à l'étape suivante
📖 À lire également : Comment utiliser Snowflake Cortex pour l'analyse de l'entreprise
Étape n° 2 : Créez un modèle sémantique (ou une vue sémantique)
Il s'agit de l'étape d'installation la plus importante. La puissance de Cortex Analyst repose sur la combinaison de grands modèles linguistiques (LLM) et de modèles sémantiques, un fichier YAML qui accompagne votre schéma de base de données et encode le contexte de l'entreprise.
Les vues sémantiques constituent désormais la méthode recommandée par Snowflake pour Cortex Analyst. Elles stockent les indicateurs d’entreprise, les relations et les définitions directement au sein de Snowflake. Les anciens fichiers de modèles sémantiques YAML fonctionnent toujours, mais Snowflake oriente les nouvelles implémentations vers les vues sémantiques.
Votre modèle sémantique ou votre vue doit inclure :
- Descriptions des tableaux et des colonnes : explications en langage clair de la signification de chaque champ
- Indicateurs métier : définitions des champs calculés tels que le chiffre d'affaires, le taux de désabonnement ou le taux de conversion
- Filtres et synonymes : termes alternatifs que les utilisateurs pourraient utiliser (par exemple, « annulé » mappé vers une valeur de statut spécifique)
- Requêtes vérifiées : le référentiel de requêtes vérifiées de Snowflake stocke les paires question-SQL approuvées. Lorsqu'une question d'un utilisateur ressemble à l'une de ces entrées, Cortex Analyst peut s'y référer lors de la génération de requêtes SQL.
🤝 Rappel amical : Snowflake recommande de ne pas utiliser plus de 10 tables et de ne pas sélectionner plus de 50 colonnes pour obtenir des performances optimales dans le flux de travail Snowsight.
Étape n° 3 : Importez le modèle sémantique vers une étape Snowflake
Si vous utilisez un modèle sémantique basé sur YAML, celui-ci doit être déployé afin que Cortex Analyst puisse y faire référence lors de l'exécution.
- Téléchargez votre fichier .yaml vers une étape interne de Snowflake (par exemple, RAW_DATA)
- Vérifiez que le fichier apparaît dans l'étape via l'interface utilisateur Snowsight ou à l'aide de la commande LIST @stage_name
- Notez le chemin d'accès à l'étape ; vous y ferez référence dans vos appels API ou dans la configuration de votre application
Si vous utilisez une vue sémantique, cette étape est gérée en natif dans Snowflake et aucun téléchargement séparé n'est nécessaire.
🔍 Le saviez-vous ? En SQL, NULL ne signifie pas zéro ou vide. Il représente des données inconnues ou manquantes, ce qui entraîne des comportements contre-intuitifs, comme des comparaisons qui ne renvoient ni vrai ni faux.
Étape n° 4 : Envoyez une question en langage naturel via l'API REST
La génération SQL proprement dite commence maintenant. L'API REST génère une requête SQL pour une question donnée à l'aide d'un modèle sémantique ou d'une vue sémantique fourni(e) dans la requête.
Structurez votre requête API avec :
- Messages ; un tableau contenant la question de l'utilisateur avec le rôle : « utilisateur »
- Une référence à votre modèle sémantique ou à votre vue sémantique
- Votre modèle préféré (ou laissez le paramètre sur « auto » pour que Cortex effectue la sélection)
Vous pouvez mener des discussions en plusieurs étapes, au cours desquelles vous pouvez poser des questions complémentaires qui s'appuient sur les requêtes précédentes.
Étape n° 5 : Analyser la réponse de l'API
Chaque message d'une réponse peut comporter plusieurs blocs de contenu de types différents. Les trois valeurs actuellement prises en charge pour le champ « type » sont : texte, suggestions et SQL.
Voici ce que signifie chaque type :
- SQL : Cortex a généré une requête avec succès ; voici ce que vous allez exécuter
- texte : Une explication ou une réponse en langage naturel accompagnant le code SQL
- suggestions : Le type de contenu « suggestion » n'est inclus dans une réponse que si la question de l'utilisateur était ambiguë et que Cortex Analyst n'a pas pu renvoyer d'instruction SQL pour cette requête. Utilisez-les pour clarifier ou affiner la question
🔍 Le saviez-vous ? L'ordre dans lequel vous écrivez le code SQL n'est pas celui dans lequel il s'exécute. Même si vous écrivez SELECT en premier, les bases de données traitent en réalité les clauses FROM et WHERE avant de réaliser la sélection des colonnes. Cela sème la confusion tant chez les débutants que chez les utilisateurs expérimentés.
Étape n° 6 : Exécutez le code SQL généré dans Snowflake
Une fois que vous disposez du bloc SQL issu de la réponse, exécutez-le sur votre entrepôt virtuel Snowflake. La requête SQL générée est exécutée dans votre entrepôt virtuel Snowflake afin de produire le résultat final. Les données restent dans les limites de la gouvernance de Snowflake.
Points clés à connaître au moment de l'exécution :
- Cortex Analyst s'intègre pleinement aux politiques de contrôle d'accès basé sur les rôles (RBAC) de Snowflake, garantissant ainsi que les requêtes SQL générées et exécutées respectent tous les contrôles d'accès établis.
- Si un utilisateur n'a pas accès à une table, la requête échouera lors de son exécution, tout comme ce serait le cas avec du code SQL écrit manuellement.
- Des frais de calcul liés à l'entrepôt de données s'appliquent à cette étape, indépendamment des frais d'utilisation propres à Cortex Analyst.
Étape n° 7 : Affiner et itérer
Il n'est pas toujours garanti d'obtenir une requête parfaite dès le premier essai. Voici comment améliorer les résultats au fil du temps :
- Ajoutez des requêtes vérifiées à votre modèle sémantique pour les questions qui reviennent régulièrement
- Enrichissez votre modèle sémantique avec de meilleures descriptions, des synonymes et des filtres lorsque Cortex interprète mal un terme
- Utilisez les discussions à plusieurs tours pour approfondir, par exemple : « Filtrez maintenant par région ». Les discussions à plusieurs tours permettent de poser des questions complémentaires qui s'appuient sur les requêtes précédentes.
- Surveillez l'utilisation via CORTEX_ANALYST_USAGE_HISTORY et l'historique des requêtes Snowflake pour identifier les schémas récurrents dans les requêtes ayant échoué ou étant inexactes
🧠 Anecdote : Une seule condition JOIN manquante peut entraîner des problèmes considérables. Oublier une condition JOIN peut générer un produit cartésien, multipliant considérablement le nombre de lignes et provoquant parfois le plantage des systèmes.
Bonnes pratiques pour optimiser la précision de la conversion texte-SQL dans Snowflake
La qualité de votre modèle sémantique détermine directement la précision des requêtes qu'il génère. Voici les bonnes pratiques qui permettent d'améliorer cette précision. 🛠️
- Ajoutez des requêtes vérifiées à votre modèle sémantique : c'est la mesure la plus efficace à faire. Intégrez de nombreux exemples de paires question-SQL qui reflètent la manière dont votre équipe pose réellement ses questions.
- Utilisez des noms de colonnes et de tables descriptifs : le modèle fonctionne mieux lorsque les noms de colonnes et de tables sont explicites. Si vous ne pouvez pas modifier le schéma, ajoutez des descriptions claires dans votre fichier YAML pour tout nom de colonne obscur.
- Inclure des échantillons de valeurs : L'ajout d'échantillons de données pour les colonnes catégorielles (telles que le statut ou la région) aide le modèle à comprendre les options de filtrage valides disponibles
- Testez avec des cas limites : pendant le développement, posez intentionnellement des questions ambiguës ou complexes afin d'identifier les points où votre modèle sémantique a besoin de plus de contexte ou de précisions.
- Itérez sur votre modèle sémantique : Considérez votre modèle sémantique comme un document évolutif. Il doit être mis à jour en permanence grâce à un processus itératif basé sur les requêtes qui aboutissent et celles qui échouent
ClickUp : une alternative plus simple à Snowflake Cortex
Snowflake Cortex est particulièrement adapté lorsque les équipes souhaitent générer du code SQL et exécuter des requêtes sur des données structurées. Les équipes définissent des schémas, mapperont les relations et rédigent des requêtes pour extraire des informations. Cette installation est particulièrement pertinente pour les environnements riches en données, notamment lorsque les analystes sont responsables de la création des rapports.
Cependant, de nombreuses équipes n'ont pas besoin d'une couche SQL complète pour répondre aux questions opérationnelles quotidiennes. Les chefs de produit, les responsables de programme et les équipes opérationnelles souhaitent souvent obtenir des réponses rapides en lien avec leur travail en cours.
ClickUp offre une approche plus accessible. Les équipes posent des questions en langage clair, consultent des tableaux de bord en temps réel et agissent sur la base des informations obtenues sans avoir à écrire de code SQL ni à créer de modèles sémantiques.
Générez et affinez vos requêtes SQL plus rapidement
Snowflake Cortex se concentre sur la génération de requêtes SQL à partir d'ensembles de données structurés au sein d'un environnement d'entrepôt. Cela fonctionne bien lorsque vos données se trouvent déjà dans Snowflake et que vous disposez de schémas définis.

ClickUp Brain prend en charge la génération de requêtes SQL de manière plus flexible et axée sur l'exécution. Les équipes génèrent, affinent et stockent leurs requêtes SQL directement au sein de leur environnement de travail, là où s'effectuent déjà les analyses, les discussions et les prises de décision.
Imaginons qu'un analyste produit travaille sur une tâche d'analyse de fidélisation dans ClickUp. Au lieu de changer d'outil pour rédiger des requêtes, il demande à ClickUp Brain :
📌 Essayez ces instructions : Écrivez une requête SQL pour calculer le taux de rétention sur sept jours des utilisateurs regroupés par cohorte d'inscription.
ClickUp Brain génère une requête structurée qui inclut le regroupement par cohorte, des filtres de date et une logique de rétention. L'analyste colle la requête dans Snowflake ou un autre entrepôt de données et l'exécute immédiatement.
Cela permet de :
- Écrivez des jointures entre plusieurs tables, telles que les utilisateurs, les commandes et les évènements
- Convertissez des questions sur les produits formulées en anglais courant en logique SQL prête à être exécutée
- Déboguez les requêtes défectueuses et expliquez les problèmes, tels que les jointures incorrectes ou les conditions manquantes
- Réécrivez vos requêtes pour améliorer leurs performances ou leur lisibilité
Par exemple, lors d'une analyse d'expérience de croissance, un responsable marketing demande : « Écrivez une requête SQL pour comparer les taux de conversion entre deux pages de destination au cours des 14 derniers jours ».
ClickUp Brain génère la requête à l'aide d'agrégations conditionnelles et de filtres de date. L'équipe l'exécute dans Snowflake et valide les résultats de l'expérience.
📌 Essayez cette invitation : Corrigez cette requête SQL dans laquelle la jointure duplique des lignes et expliquez le problème.
ClickUp Brain identifie le problème de jointure, corrige la requête et explique comment des lignes en double sont apparues en raison de conditions de jointure incorrectes.
Remplacez les rapports basés sur SQL
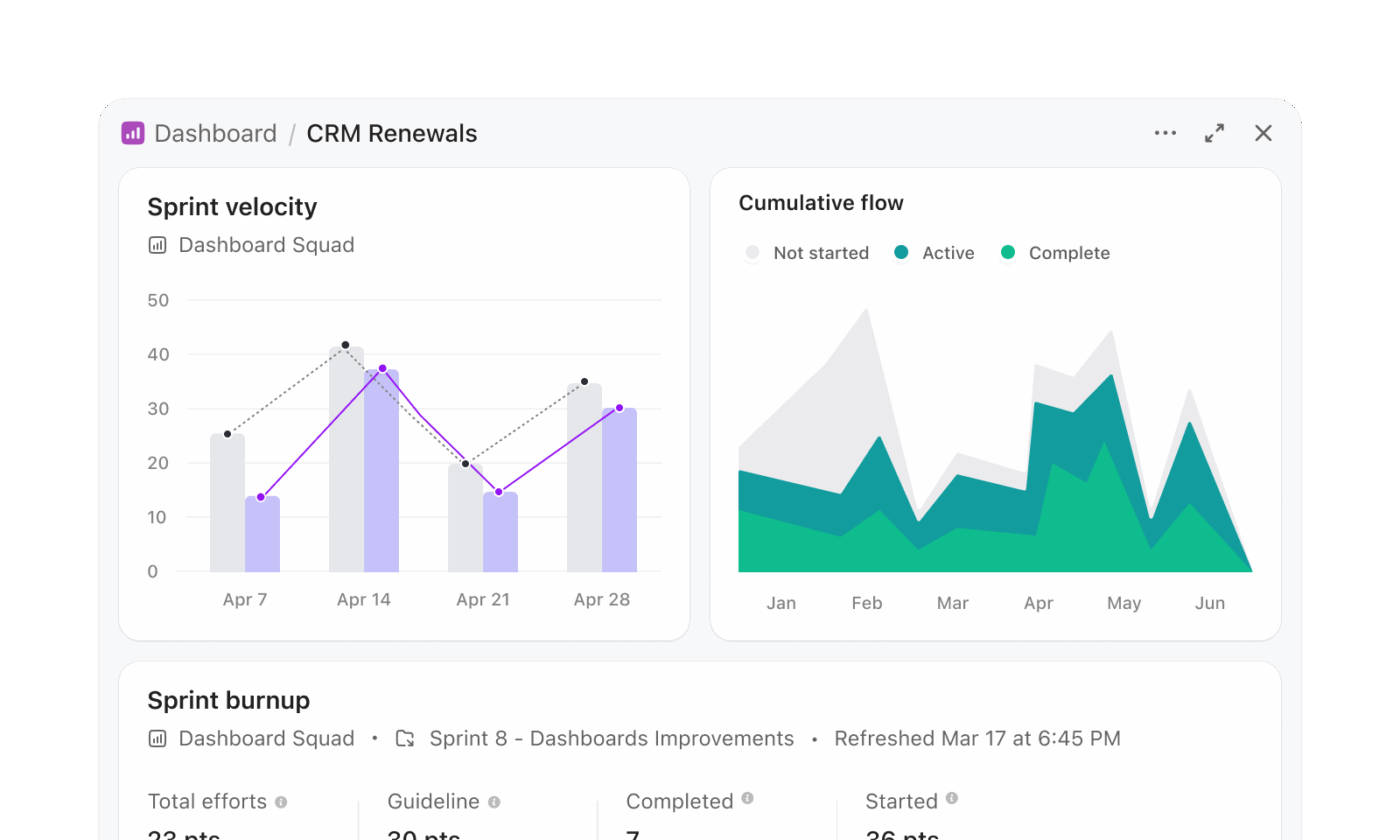
Les flux de travail Snowflake Cortex impliquent souvent la génération de SQL, l'exécution de requêtes et la visualisation des résultats dans une couche distincte. Les tableaux de bord ClickUp suppriment ce processus en plusieurs étapes et présentent les informations directement à partir du travail en temps réel.
Une équipe de gestion de programme chargée du suivi de l'état de préparation d'une version peut créer un tableau de bord sans avoir à écrire de requêtes. Par exemple, un tableau de bord de version peut inclure :
- Une carte de liste de tâches filtrée pour afficher les tâches en retard dans toutes les équipes produit
- Une carte de charge de travail qui présente la distribution des tâches entre les ingénieurs
- Un diagramme à barres comparant les tâches achevées et les tâches en attente par sprint
- Une carte de calcul permettant de suivre le temps moyen d'exécution
Imaginons qu'un chef de projet consulte ce tableau de bord avant une réunion de lancement. Il constate immédiatement que les services backend affichent des taux de retard plus élevés. Il ouvre la carte de la liste des tâches et examine précisément les tâches à l'origine du risque.
Un utilisateur réel de ClickUp partage :
ClickUp nous permet de nous transmettre RAPIDEMENT les projets, de vérifier FACILEMENT leur statut et offre à notre responsable une vue d'ensemble de notre charge de travail à tout moment sans qu'elle ait à nous interrompre. Nous avons certainement gagné une journée par semaine grâce à ClickUp, voire plus. Le nombre d'e-mails a CONSIDÉRABLEMENT diminué.
ClickUp nous permet de nous transmettre RAPIDEMENT des projets, de vérifier FACILEMENT leur statut et offre à notre responsable une vue d'ensemble de notre charge de travail à tout moment sans qu'elle ait à nous interrompre. Nous avons certainement gagné une journée par semaine grâce à ClickUp, voire plus. Le nombre d'e-mails a CONSIDÉRABLEMENT diminué.
Agissez sur la base d'informations sans passer par des pipelines
Snowflake Cortex se concentre sur la génération d'informations à partir des données. Les équipes doivent toujours interpréter les résultats et déclencher des actions séparément.
Les Super Agents ClickUp AI comblent ce fossé et transforment les informations en actions concrètes. Ils agissent comme des coéquipiers IA qui surveillent en permanence les données de l'environnement de travail et prennent des mesures en fonction des conditions.
Imaginons qu'un chef de projet supervise plusieurs initiatives produit. Un Super Agent peut :
- Surveillez les tâches sur l'ensemble des projets et détectez lorsque les tâches en retard dépassent un seuil défini
- Identifiez des schémas tels que des retards répétés à la même étape du flux de travail
- Créez une tâche qui résume les projets concernés et attribuez-la au responsable du programme
- Informez les propriétaires d'équipe lorsque des tâches critiques restent en suspens après les dates limites
Par exemple, au cours d'un cycle de publication, un Super Agent détecte que plus de 10 tâches à haute priorité n'ont pas respecté leurs délais dans deux équipes. Il crée une tâche ClickUp intitulée « Risque lié à la publication : délais non respectés », y joint toutes les tâches concernées et l'attribue au chef de projet pour un examen immédiat.
Les équipes peuvent également interagir directement avec le Super Agent : « Analysez tous les projets actifs et mettez en évidence les risques liés à la livraison pour ce sprint ».
Le Super Agent examine les échéances, les dépendances et le statut des tâches, puis publie un résumé structuré dans l'environnement de travail.
Voici comment configurer votre propre Super Agent dans ClickUp :
Centralisez vos flux de travail de données avec ClickUp
Les outils de conversion texte-SQL tels que Snowflake Cortex rendent les données plus accessibles. Cependant, obtenir des résultats fiables demande encore de l’effort.
Les équipes ont besoin de schémas clairs, de modèles sémantiques solides et d'itérations continues pour garantir la précision des résultats. Même après avoir généré la bonne requête, le travail ne s'arrête pas là. Il faut encore que quelqu'un interprète les résultats, partage les informations et les transforme en décisions.
ClickUp propose une approche différente. Au lieu de séparer l'analyse de l'exécution, ClickUp établit une connexion entre les deux. Les équipes génèrent du code SQL, documentent leurs conclusions, collaborent sur leurs résultats et agissent en conséquence au sein du même environnement de travail.
ClickUp Brain aide à rédiger et à affiner les requêtes, tandis que les tableaux de bord et les agents IA aident les équipes à suivre les résultats et à faire avancer le travail sans avoir à passer d'un outil à l'autre.
Snowflake Cortex vous aide à obtenir des réponses. ClickUp vous aide à les exploiter. Inscrivez-vous dès aujourd'hui sur ClickUp!
Foire aux questions
Snowflake Cortex Analyst est un service spécialisé au sein de la suite plus large Snowflake Cortex IA. Cortex Analyst se concentre spécifiquement sur la génération de requêtes SQL à partir de texte à l'aide de modèles sémantiques, tandis que Cortex IA inclut un intervalle plus large de fonctions LLM, d'inférence de modèles d'apprentissage automatique et de capacités de recherche.
Oui, Cortex Analyst peut interroger les tables Apache Iceberg gérées via Snowflake. Tant que ces tables sont accessibles au sein de votre environnement Snowflake et correctement définies dans votre modèle sémantique, vous pouvez générer des requêtes les concernant.
La précision des requêtes complexes dépend presque entièrement de la qualité de votre modèle sémantique. Un modèle présentant des relations entre tables bien définies, de nombreuses requêtes vérifiées et des métadonnées descriptives produira des résultats nettement plus précis pour les jointures multi-tables et les agrégations complexes.
La tarification de Snowflake Cortex Analyst suit le modèle de facturation à l'utilisation de Snowflake, ce qui signifie que vous êtes facturé en fonction des crédits de calcul utilisés pendant le processus de génération des requêtes. Pour connaître les tarifs les plus récents, veuillez toujours vous reporter à la documentation officielle de Snowflake relative à la tarification.