

Ein Kundenservice-Bot, der aus jeder Interaktion lernt. Ein Verkaufsassistent, der seine Strategie auf der Grundlage von Echtzeit-Erkenntnissen anpasst. Das sind nicht nur Konzepte – dank /AI-Lernagenten sind sie Realität.
Aber was macht diese Agenten so einzigartig und wie funktioniert ein Lernagent, um diese Anpassungsfähigkeit zu erreichen?
Im Gegensatz zu herkömmlichen KI-Systemen, die mit fester Programmierung arbeiten, entwickeln sich Lernagenten weiter.
Sie passen sich an, verbessern und verfeinern ihre Handlungen im Laufe der Zeit und sind damit unverzichtbar für Branchen wie autonome Fahrzeuge und das Gesundheitswesen, in denen Flexibilität und Präzision unverzichtbar sind.
Stellen Sie sich diese Agenten als KI vor, die mit zunehmender Erfahrung intelligenter wird, genau wie Menschen.
In diesem Blogbeitrag werden wir die Schlüssel-Komponenten, Prozesse, Arten und Anwendungen von Lernagenten in der KI untersuchen. 🤖
⏰ 60-Sekunden-Zusammenfassung
Hier finden Sie eine kurze Einführung in Lernagenten in der KI:
Was sie tun: Sie passen sich durch Interaktionen an, z. B. indem benutzerdefinierte Kundendienst-Bots ihre Antworten verfeinern.
Wichtigste Anwendungsbereiche: Robotik, personalisierte Dienste und intelligente Systeme wie Heimgeräte.
Kernkomponenten:
- Lernelement: Sammelt Wissen, um die Leistung zu verbessern.
- Leistungselement: Führt Aufgaben auf der Grundlage des erlernten Wissens aus.
- Kritiker: Bewertet Handlungen und gibt Feedback.
- Problemgenerator: Identifiziert Möglichkeiten für weiteres Lernen.
Lernmethoden:
- Überwachtes Lernen: Erkennt Muster anhand von Daten mit Beschreibung.
- Unüberwachtes Lernen: Identifiziert Strukturen in unbeschrifteten Daten.
- Verstärkendes Lernen: Lernt durch Versuch und Fehler.
Auswirkungen in der Praxis: Verbessert die Anpassungsfähigkeit, Effizienz und Entscheidungsfindung in verschiedenen Branchen.
⚙️ Bonus: Fühlen Sie sich von der KI-Fachsprache überfordert? Schauen Sie sich unser umfassendes Glossar mit KI-Begriffen an, um grundlegende Konzepte und fortgeschrittene Terminologie leicht zu verstehen.
Was sind Lernagenten in der KI?
Lernende Agenten in der KI sind Systeme, die sich im Laufe der Zeit verbessern, indem sie aus ihrer Umgebung lernen. Sie passen sich an, treffen intelligentere Entscheidungen und optimieren ihre Handlungen auf der Grundlage von Feedback und Daten.
Im Gegensatz zu herkömmlichen KI-Systemen, die unverändert bleiben, entwickeln sich Lernagenten kontinuierlich weiter. Dies macht sie unverzichtbar für die Robotik und personalisierte Empfehlungen, wo die Bedingungen unvorhersehbar sind und sich ständig ändern.
🔍 Wussten Sie schon? Lernagenten arbeiten in einer Feedbackschleife – sie nehmen ihre Umgebung wahr, lernen aus Feedback und verfeinern ihre Handlungen. Dies ist inspiriert von der Art und Weise, wie Menschen aus Erfahrungen lernen.
Schlüsselkomponenten von Lernagenten
Lernagenten bestehen in der Regel aus mehreren miteinander verbundenen Komponenten, die zusammenarbeiten, um Anpassungsfähigkeit und kontinuierliche Verbesserung zu gewährleisten.
Hier sind einige wichtige Komponenten dieses Lernprozesses. 📋
Lernelement
Die Hauptaufgabe des Agenten besteht darin, Wissen zu erwerben und die Leistung durch die Analyse von Daten, Interaktionen und Feedback zu verbessern.
Mithilfe von KI-Techniken wie überwachtem, verstärktem und unüberwachtem Lernen passt der Agent sein Verhalten an und aktualisiert es, um seine Funktion zu verbessern.
📌 Beispiel: Ein virtueller Assistent wie Siri lernt im Laufe der Zeit die Vorlieben des Benutzers kennen, z. B. häufig verwendete Befehle oder bestimmte Akzente, um genauere und personalisierte Antworten zu geben.
Leistungselement
Diese Komponente führt Aufgaben aus, indem sie mit der Umgebung interagiert und auf der Grundlage der verfügbaren Informationen Entscheidungen trifft. Sie ist im Wesentlichen der „Aktionsarm” des Agenten.
📌 Beispiel: In autonomen Fahrzeugen verarbeitet das Leistungselement Verkehrsdaten und Umgebungsbedingungen, um Echtzeitentscheidungen zu treffen, z. B. an einer roten Ampel anzuhalten oder Hindernissen auszuweichen.
Kritiker
Der Kritiker bewertet die vom Leistungselement durchgeführten Aktionen und gibt Feedback. Dieses Feedback hilft dem Lernelement dabei, zu erkennen, was gut funktioniert hat und was verbessert werden muss.
📌 Beispiel: In einem Empfehlungssystem analysiert der Kritiker die Interaktionen der Benutzer (wie Klicks oder Überspringen), um zu ermitteln, welche Vorschläge erfolgreich waren, und hilft dem Lernelement dabei, zukünftige Empfehlungen zu verfeinern.
Problemgenerator
Diese Komponente regt zur Erkundung an, indem sie neue Szenarien oder Aktionen vorschlägt, die der Agent testen kann.
Dadurch wird der Agent aus seiner Komfortzone herausgedrängt, was eine kontinuierliche Verbesserung gewährleistet. Der Agent verhindert außerdem suboptimale Ergebnisse, indem er den Bereich seiner Erfahrung erweitert.
📌 Beispiel: In der E-Commerce-KI könnte der Problemgenerator personalisierte Marketingstrategien vorschlagen oder benutzerdefinierte Kundenverhaltensmuster simulieren. Dies hilft der KI, ihren Ansatz zu verfeinern, um Empfehlungen zu liefern, die auf unterschiedliche Benutzerpräferenzen zugeschnitten sind.
Der Lernprozess in Lernagenten
Lernagenten stützen sich in erster Linie auf drei Schlüsselkategorien, um sich anzupassen und zu verbessern. Diese sind im Folgenden beschrieben. 👇
1. Überwachtes Lernen
Der Agent lernt aus Datensätzen mit Beschreibung, wobei jede Eingabe einer bestimmten Ausgabe entspricht.
Diese Methode erfordert eine große Menge genau beschriebener Daten für das Training und wird häufig in Anwendungen wie Bilderkennung, Sprachübersetzung und Betrugserkennung eingesetzt.
📌 Beispiel: Ein E-Mail-Filtersystem lernt anhand von Verlaufsdaten, E-Mails als Spam oder nicht als Spam zu klassifizieren. Das Lernelement identifiziert Muster zwischen Eingaben (E-Mail-Inhalt) und Ausgaben (Beschreibungen der Klassifizierung), um genaue Vorhersagen zu treffen.
2. Unüberwachtes Lernen
Verborgene Muster oder Beziehungen in Daten werden sichtbar, wenn der Agent Informationen ohne explizite Beschreibungen analysiert. Dieser Ansatz eignet sich gut für die Erkennung von Anomalien, die Erstellung von Empfehlungssystemen und die Optimierung der Datenkomprimierung.
Außerdem hilft es dabei, Erkenntnisse zu gewinnen, die mit Beschreibungen der Daten möglicherweise nicht sofort sichtbar sind.
📌 Beispiel: Die Kundensegmentierung im Marketing kann Benutzer anhand ihres Verhaltens gruppieren, um gezielte Kampagnen zu entwerfen. Der Schwerpunkt liegt auf dem Verständnis der Struktur und der Bildung von Clustern oder Assoziationen.
3. Verstärkendes Lernen
Im Gegensatz dazu handelt es sich beim verstärkenden Lernen (RL) um Agenten, die in einer Umgebung Maßnahmen ergreifen, um die kumulativen Belohnungen im Laufe der Zeit zu maximieren.
Der Agent lernt durch Versuch und Irrtum und erhält Feedback in Form von Belohnungen oder Strafen.
🔔 Denken Sie daran: Die Wahl der Lernmethode hängt vom Problem, der Datenverfügbarkeit und der Komplexität der Umgebung ab. Verstärkendes Lernen ist für Aufgaben ohne direkte Überwachung von entscheidender Bedeutung, da es Feedback-Schleifen nutzt, um Aktionen anzupassen.
Verstärkendes Lernen
- Policy Iteration: Optimiert die Belohnungserwartungen, indem direkt eine Policy gelernt wird, die Zustände auf Aktionen abbildet.
- Wertiteration: Bestimmt optimale Aktionen, indem der Wert jedes Zustands-Aktions-Paares berechnet wird.
- Monte-Carlo-Methoden: Simuliert mehrere Zukunftsszenarien, um Handlungsbelohnungen vorherzusagen, besonders nützlich in dynamischen und probabilistischen Umgebungen.
Beispiele für RL-Anwendungen aus der Praxis
- Autonomes Fahren: RL-Algorithmen trainieren Fahrzeuge darin, sicher zu navigieren, Routen zu optimieren und sich an die Verkehrsbedingungen anzupassen, indem sie kontinuierlich aus simulierten Umgebungen lernen.
- AlphaGo und Spiel-KI: Durch verstärktes Lernen gelang es Googles AlphaGo, menschliche Champions zu besiegen, indem es optimale Strategien für komplexe Spiele wie Go erlernte.
- Dynamische Preisgestaltung: E-Commerce-Plattformen nutzen RL, um ihre Preisstrategien auf der Grundlage von Nachfragemustern und Maßnahmen der Wettbewerber anzupassen und so ihren Umsatz zu maximieren.
🧠 Wissenswertes: Lernende Agenten haben menschliche Champions in Spielen wie Schach und Starcraft besiegt und damit ihre Anpassungsfähigkeit und Intelligenz unter Beweis gestellt.
Q-Lernen und neuronale Netzwerke
Q-Learning ist ein weit verbreiteter RL-Algorithmus, bei dem Agenten den Wert jedes Zustands-Aktions-Paares durch Erkundung und Feedback lernen. Der Agent erstellt eine Q-Tabelle, eine Matrix, die den Zustands-Aktions-Paaren erwartete Belohnungen zuweist.
Er wählt die Aktion mit dem höchsten Q-Wert aus und verfeinert seine Tabelle iterativ, um die Genauigkeit zu verbessern.
📌 Beispiel: Eine KI-gestützte Drohne, die lernt, Pakete effizient zuzustellen, nutzt Q-Learning, um Routen zu bewerten. Dazu vergibt sie Belohnungen für pünktliche Lieferungen und Strafen für Verspätungen oder Kollisionen. Mit der Zeit verfeinert sie ihre Q-Tabelle, um die effizientesten und sichersten Lieferwege auszuwählen.
In komplexen Umgebungen mit hochdimensionalen Zustandsräumen sind Q-Tabellen jedoch unpraktisch.
Hier kommen neuronale Netze zum Einsatz, die Q-Werte approximieren, anstatt sie explizit zu speichern. Diese Veränderung ermöglicht es dem verstärkenden Lernen, komplexere Probleme anzugehen.
Deep Q-Netzwerke (DQNs) gehen noch einen Schritt weiter und nutzen Deep Learning, um rohe, unstrukturierte Daten wie Bilder oder Sensoreingaben zu verarbeiten. Diese Netzwerke können sensorische Informationen direkt in Aktionen umsetzen, ohne dass umfangreiches Feature Engineering erforderlich ist.
📌 Beispiel: In selbstfahrenden Autos verarbeiten DQNs Echtzeit-Sensordaten, um Fahrstrategien wie Spurwechsel oder Hindernisvermeidung ohne vorprogrammierte Regeln zu erlernen.
Diese fortschrittlichen Methoden ermöglichen es Agenten, ihre Lernfähigkeiten auf Aufgaben zu skalieren, die eine hohe Rechenleistung und Anpassungsfähigkeit erfordern.
⚙️ Bonus: Erfahren Sie, wie Sie eine KI-Wissensdatenbank erstellen und verfeinern können, die das Informationsmanagement optimiert, die Entscheidungsfindung verbessert und die Produktivität Ihrer Teams steigert.
Der Lernprozess für Agenten legt Wert auf die Entwicklung von Strategien für intelligente Entscheidungen in Echtzeit. Hier sind die Schlüsselaspekte, die die Entscheidungsfindung unterstützen:
- Erkundung vs. Nutzung: Agenten balancieren die Erkundung neuer Aktionen, um bessere Strategien zu finden, und die Nutzung bekannter Aktionen, um den Ertrag zu maximieren.
- Entscheidungsfindung mit mehreren Agenten: In kooperativen oder kompetitiven Einstellungen interagieren Agenten und passen ihre Strategien auf der Grundlage gemeinsamer Ziele oder gegnerischer Taktiken an.
- Strategische Kompromisse: Agenten lernen auch, Ziele je nach Kontext zu priorisieren, beispielsweise indem sie Geschwindigkeit und Genauigkeit in einem Liefersystem gegeneinander abwägen.
🎤 Podcast-Hinweis: Sehen Sie sich unsere kuratierte Liste beliebter KI-Podcasts an, um Ihr Verständnis für die Funktionsweise von Lernagenten zu vertiefen.
Arten von KI-Agenten
Lernagenten in der künstlichen Intelligenz gibt es in verschiedenen Formen, die jeweils auf bestimmte Aufgaben und Herausforderungen zugeschnitten sind.
Lassen Sie uns ihre Funktionsweise, ihre einzigartigen Eigenschaften und Beispiele aus der Praxis erkunden. 👀
Einfache Reflex-Agenten
Solche Agenten reagieren direkt auf Reize basierend auf vordefinierten Regeln. Sie verwenden einen Mechanismus für Bedingungen und Aktionen (wenn-dann) , um Aktionen basierend auf der aktuellen Umgebung auszuwählen, ohne die Vergangenheit oder Zukunft zu berücksichtigen.
Eigenschaften
- Arbeitet mit einem logikbasierten System für Bedingungen und Aktionen.
- Passt sich nicht an Veränderungen an und lernt nicht aus vergangenen Handlungen.
- Funktioniert am besten in transparenten und vorhersehbaren Umgebungen.
Beispiel
Ein Thermostat hat die Funktion eines einfachen Reflexagents, indem es die Heizung einschaltet, wenn die Temperatur unter einen festgelegten Schwellenwert fällt, und sie ausschaltet, wenn sie steigt. Es trifft Entscheidungen ausschließlich auf der Grundlage der aktuellen Temperaturmessungen.
🧠 Wissenswertes: In einigen Experimenten werden Lernagenten simulierte Bedürfnisse wie Hunger oder Durst zugewiesen, um sie dazu anzuregen, zielgerichtete Verhaltensweisen zu entwickeln und zu lernen, wie sie diese „Bedürfnisse” effektiv befriedigen können.
Modellbasierte Reflex-Agenten
Diese Agenten verfügen über ein internes Modell der Welt, das es ihnen ermöglicht, die Auswirkungen ihrer Handlungen zu berücksichtigen. Außerdem schließen sie auf den Zustand der Umgebung, der über das hinausgeht, was sie unmittelbar wahrnehmen können.
Eigenschaften
- Nutzt ein gespeichertes Modell der Umgebung für die Entscheidungsfindung.
- Schätzt den aktuellen Zustand, um teilweise beobachtbare Umgebungen zu bewältigen.
- Bietet im Vergleich zu einfachen Reflexagenten eine größere Flexibilität und Anpassungsfähigkeit.
Beispiel
Ein selbstfahrendes Auto von Tesla nutzt einen modellbasierten Agenten, um sich auf Straßen zu navigieren. Es erkennt sichtbare Hindernisse und sagt die Bewegungen von Fahrzeugen in der Nähe voraus, einschließlich derjenigen im toten Winkel, mithilfe fortschrittlicher Sensoren und Echtzeitdaten. So kann das Auto präzise und fundierte Fahrentscheidungen treffen, was die Sicherheit und Effizienz erhöht.
🔍 Wussten Sie schon? Das Konzept der Lernagenten ahmt oft Verhaltensweisen nach, die bei Tieren beobachtet werden, wie beispielsweise Lernen durch Versuch und Irrtum oder belohnungsbasiertes Lernen.
Funktionen von Software-Agenten und virtuellen Assistenten
Diese Agenten arbeiten in digitalen Umgebungen und führen bestimmte Aufgaben autonom aus.
Virtuelle Assistenten wie Siri oder Alexa verarbeiten Eingaben der Benutzer mithilfe von Natural Language Processing (NLP) und führen Aktionen wie die Beantwortung von Abfragen oder die Steuerung von Smart Devices aus.
Eigenschaften
- Vereinfacht alltägliche Aufgaben wie Terminplanung, Einstellung von Erinnerungen oder Steuern von Geräten.
- Kontinuierliche Verbesserung durch Lernalgorithmen und Daten aus der Interaktion mit den Benutzern
- Arbeitet asynchron und reagiert in Echtzeit oder bei Auslösern.
Beispiel
Alexa kann Musik abspielen, Erinnerungen einstellen und Smart-Home-Geräte steuern, indem sie Sprachbefehle interpretiert, eine Verbindung zu cloudbasierten Systemen herstellt und entsprechende Aktionen ausführt.
🔍 Wussten Sie schon? Nutzenorientierte Agenten, die sich auf die Maximierung von Ergebnissen durch die Bewertung verschiedener Aktionen konzentrieren, arbeiten in der KI häufig mit lernbasierten Agenten zusammen. Lernende Agenten verfeinern ihre Strategien im Laufe der Zeit auf der Grundlage von Erfahrungen und können nutzenorientierte Entscheidungsfindung einsetzen, um intelligentere Entscheidungen zu treffen.
Multi-Agenten-Systeme und Anwendungen der Spieltheorie
Diese Systeme bestehen aus mehreren interagierenden Agenten, die zusammenarbeiten, miteinander konkurrieren oder unabhängig voneinander arbeiten, um individuelle oder kollektive Ziele zu erreichen.
Darüber hinaus leiten Prinzipien der Spieltheorie häufig ihr Verhalten in Wettbewerbsszenarien.
Eigenschaften
- Erfordert Koordination oder Verhandlung zwischen den Agenten.
- Funktioniert gut in dynamischen und verteilten Umgebungen.
- Simuliert oder verwaltet komplexe Systeme wie Lieferketten oder den städtischen Verkehr.
Beispiel
Im Lagerautomationssystem von Amazon arbeiten Roboter (Agenten) zusammen, um Elemente zu kommissionieren, zu sortieren und zu transportieren. Diese Roboter kommunizieren miteinander, um Kollisionen zu vermeiden und einen reibungslosen Betrieb zu gewährleisten. Prinzipien der Spieltheorie helfen dabei, konkurrierende Prioritäten wie das Gleichgewicht zwischen Geschwindigkeit und Ressourcen zu verwalten, um einen effizienten Betrieb des Systems sicherzustellen.
Anwendungen von Lernagenten
Lernagenten haben zahlreiche Branchen durch die Verbesserung der Effizienz und Entscheidungsfindung verändert.
Hier sind einige wichtige Anwendungen. 📚
Robotik und Automatisierung
Lernende Agenten sind das Herzstück der modernen Robotik und ermöglichen es Robotern, in dynamischen Umgebungen autonom und anpassungsfähig zu agieren.
Im Gegensatz zu herkömmlichen Systemen, die für jede Aufgabe eine detaillierte Programmierung erfordern, ermöglichen Lernagenten Robotern, sich durch Interaktion und Feedback selbst zu verbessern.
So funktioniert es
Mit Lernagenten ausgestattete Roboter nutzen Techniken wie verstärktes Lernen, um mit ihrer Umgebung zu interagieren und die Ergebnisse ihrer Handlungen zu bewerten. Sie verfeinern ihr Verhalten im Laufe der Zeit und konzentrieren sich dabei darauf, Belohnungen zu maximieren und Strafen zu vermeiden.
Neuronale Netze gehen noch einen Schritt weiter und ermöglichen es Robotern, komplexe Daten wie visuelle Eingaben oder räumliche Layouts zu verarbeiten, was eine differenzierte Entscheidungsfindung erleichtert.
Beispiele
- Autonome Fahrzeuge: In der Landwirtschaft ermöglichen Lernagenten autonomen Traktoren, sich auf Feldern zu bewegen, sich an unterschiedliche Bodenbedingungen anzupassen und Pflanz- oder Harvest-Prozesse zu optimieren. Sie nutzen Echtzeitdaten, um die Effizienz zu verbessern und Verschwendung zu reduzieren.
- Industrieroboter: In der Fertigung optimieren mit Lernagenten ausgestattete Roboterarme ihre Bewegungen, um Präzision, Effizienz und Sicherheit zu verbessern, beispielsweise in Automobilmontagelinien.
📖 Lesen Sie auch: KI-Hacks, die Sie schneller, smarter und besser machen
Simulation und agentenbasierte Modelle
Lernagenten ermöglichen Simulationen, die eine kostengünstige und kostenlose Möglichkeit bieten, komplexe Systeme zu untersuchen.
Diese Systeme replizieren reale Dynamiken, sagen Ergebnisse voraus und optimieren Strategien, indem sie Agenten mit unterschiedlichen Verhaltensweisen und Anpassungsfähigkeiten modellieren.
So funktioniert es
Lernende Agenten in Simulationen beobachten ihre Umgebung, testen Handlungen und passen ihre Strategien an, um ihre Effektivität zu maximieren. Sie lernen kontinuierlich dazu und verbessern sich im Laufe der Zeit, wodurch sie Ergebnisse optimieren können.
Simulationen sind äußerst effektiv im Lieferkettenmanagement, in der Stadtplanung und in der Roboterentwicklung.
Beispiele
- Verkehrsmanagement: Simulierte Agenten modellieren den Verkehrsflow in Städten. So können Forscher Maßnahmen wie neue Straßen oder Staugebühren vor der Umsetzung testen.
- Epidemiologie: In Pandemiesimulationen ahmen Lernagenten menschliches Verhalten nach, um die Ausbreitung von Krankheiten zu bewerten. Außerdem helfen sie dabei, die Wirksamkeit von Eindämmungsmaßnahmen wie Social Distancing zu bewerten.
💡 Profi-Tipp: Optimieren Sie die Datenvorverarbeitung im KI-Maschinellen Lernen, um die Genauigkeit und Effizienz von Lernagenten zu verbessern. Hochwertige Eingaben sorgen für zuverlässigere Entscheidungen.
Intelligente Systeme
Lernagenten treiben intelligente Systeme an, indem sie die Echtzeit-Datenverarbeitung und die Anpassung an das Verhalten und die Präferenzen der Benutzer ermöglichen.
Von intelligenten Haushaltsgeräten bis hin zu autonomen Reinigungsgeräten verändern diese Systeme die Art und Weise, wie Benutzer mit Technologie interagieren, und machen alltägliche Aufgaben effizienter und persönlicher.
So funktioniert es
Geräte wie der Roomba verwenden integrierte Sensoren und Lernagenten, um das Layout zu erfassen, Hindernissen auszuweichen und Reinigungswege zu optimieren. Sie sammeln und analysieren ständig Daten – beispielsweise zu Bereichen, die häufig gereinigt werden müssen, oder zur Platzierung von Möbeln – und verbessern so mit jedem Einsatz ihre Leistung.
Beispiele
- Smart-Home-Geräte: Thermostate wie Nest lernen die Zeitpläne und Temperaturvorlieben der Benutzer. Sie passen die Einstellungen automatisch an, um Energie zu sparen und gleichzeitig den Komfort zu gewährleisten.
- Roboterstaubsauger: Der Roomba sammelt pro Sekunde viele Datenpunkte. Dadurch lernt er, sich um Möbel herum zu bewegen und stark frequentierte Bereiche für eine effiziente Reinigung zu identifizieren.
Diese intelligenten Systeme zeigen die praktischen Anwendungen von Lernagenten im Alltag auf, beispielsweise die Rationalisierung von Workflows und die Automatisierung wiederholender Aufgaben zur Steigerung der Effizienz.
🔍 Wussten Sie schon? Roomba sammelt über 230.400 Datenpunkte pro Sekunde, um eine Karte Ihres Zuhauses zu erstellen.
Internetforen und virtuelle Assistenten
Lernagenten tragen entscheidend zur Verbesserung von Online-Interaktionen und digitaler Unterstützung bei. Sie ermöglichen Foren und virtuellen Assistenten, personalisierte Erfahrungen zu bieten.
So funktioniert es
Lernagenten moderieren Diskussionen in Foren und identifizieren und entfernen Spam oder schädliche Inhalte. Interessanterweise empfehlen sie den Benutzern auch relevante Themen auf der Grundlage ihres Browserverlaufs.
Virtuelle KI-Assistenten wie Alexa und Google Assistant verwenden Lernagenten, um Eingaben in natürlicher Sprache zu verarbeiten und so ihr Kontextverständnis im Laufe der Zeit zu verbessern.
Beispiele
- Internetforen: Die Moderations-Bots von Reddit verwenden Lernagenten, um Beiträge auf Regelverstöße oder beleidigende Sprache zu überprüfen. Diese KI-basierte Hygiene sorgt für Sicherheit und Attraktivität in Online-Communities.
- Virtuelle Assistenten: Alexa lernt die Vorlieben der Benutzer, wie z. B. Favoriten in Playlists oder häufig verwendete Smart-Home-Befehle, um personalisierte und proaktive Unterstützung zu bieten.
⚙️ Bonus: Erfahren Sie, wie Sie KI an Ihrem Arbeitsplatz einsetzen können, um die Produktivität zu steigern und Aufgaben mit intelligenten Agenten zu optimieren.
Herausforderungen bei der Entwicklung von Lernagenten
Die Entwicklung von Lernagenten ist mit technischen, ethischen und praktischen Herausforderungen verbunden, darunter Algorithmusdesign, Rechenanforderungen und die Umsetzung in der Praxis.
Werfen wir einen Blick auf einige der Schlüssel-Herausforderungen, denen sich die KI-Entwicklung im Laufe ihrer Weiterentwicklung gegenübersieht. 🚧
Ausgewogenheit zwischen Erforschung und Nutzung
Lernagenten stehen vor dem Dilemma, Exploration und Exploitation in Einklang zu bringen.
Algorithmen wie Epsilon-Greedy können zwar hilfreich sein, doch hängt das Erreichen der richtigen Balance stark vom Kontext ab. Darüber hinaus kann eine übermäßige Exploration das Ergebnis von Ineffizienz sein, während eine übermäßige Abhängigkeit von Exploitation zu suboptimalen Lösungen führen kann.
Verwaltung hoher Rechenkosten
Das Training anspruchsvoller Lernagenten erfordert oft umfangreiche Rechenressourcen. Dies gilt insbesondere für Umgebungen mit komplexer Dynamik oder großen Zustands-Aktions-Spaces.
Denken Sie daran, dass Algorithmen wie das verstärkende Lernen mit neuronalen Netzen, beispielsweise Deep Q-Learning, erhebliche Rechenleistung und Speicherplatz erfordern. Sie benötigen Unterstützung, um Echtzeitlernen für Anwendungen mit begrenzten Ressourcen praktikabel zu machen.
Skalierbarkeit und Transferlernen überwinden
Die Skalierung von Lernagenten, damit sie in großen, mehrdimensionalen Umgebungen effektiv arbeiten können, bleibt eine Herausforderung. Transferlernen, bei dem Agenten Wissen aus einem Bereich auf einen anderen übertragen, steckt noch in den Kinderschuhen.
Dies hat ihre Fähigkeit eingeschränkt, über Aufgaben oder Umgebungen hinweg zu generalisieren.
📌 Beispiel: Ein für Schach trainierter KI-Agent hätte aufgrund der völlig unterschiedlichen Regeln und Ziele Schwierigkeiten mit Go, was die Herausforderung des domänenübergreifenden Wissenstransfers verdeutlicht.
Datenqualität und -verfügbarkeit
Die Leistung von Lernagenten ist stark von der Qualität und Vielfalt der Trainingsdaten abhängig.
Unzureichende oder verzerrte Daten können zu unvollständigem oder fehlerhaftem Lernen führen und als Ergebnis suboptimale oder unethische Entscheidungen zur Folge haben. Darüber hinaus kann das Sammeln von Daten aus der realen Welt für Trainingszwecke kostspielig und zeitaufwendig sein.
⚙️ Bonus: Entdecken Sie KI-Kurse, um Ihr Verständnis für andere Agenten zu vertiefen.
Tools und Ressourcen für Lernagenten
Entwickler und Forscher nutzen verschiedene Tools, um Lernagenten zu erstellen und zu trainieren. Frameworks wie TensorFlow, PyTorch und OpenAI Gym bieten eine grundlegende Infrastruktur für die Implementierung von Algorithmen für maschinelles Lernen.
Diese Tools helfen auch bei der Erstellung simulierter Umgebungen. Einige KI-Apps vereinfachen und verbessern diesen Prozess ebenfalls.
Für traditionelle Ansätze des maschinellen Lernens sind Tools wie Scikit-learn nach wie vor zuverlässig und effektiv.
Für die Verwaltung von KI-Forschungs- und Entwicklungsprojekten bietet ClickUp mehr als nur Aufgabenmanagement – es fungiert als zentraler hub für die Organisation von Aufgaben, die Nachverfolgung von Fortschritten und die nahtlose Zusammenarbeit zwischen Teams.
ClickUp für KI-Projektmanagement reduziert den manuellen Aufwand für die Bewertung des Status der Aufgaben und die Zuweisung von Aufgaben.
Anstatt jede Aufgabe manuell zu überprüfen oder herauszufinden, wer verfügbar ist, übernimmt die KI die schwere Arbeit. Sie kann den Fortschritt automatisch aktualisieren, Engpässe identifizieren und die beste Person für jede Aufgabe basierend auf ihrer Workload und ihren Fähigkeiten vorschlagen.
Auf diese Weise verbringen Sie weniger Zeit mit mühsamen Verwaltungsaufgaben und haben mehr Zeit für das Wesentliche – die Weiterentwicklung Ihrer Projekte.
Hier sind einige herausragende KI-gestützte Features. 🤩
ClickUp Brain
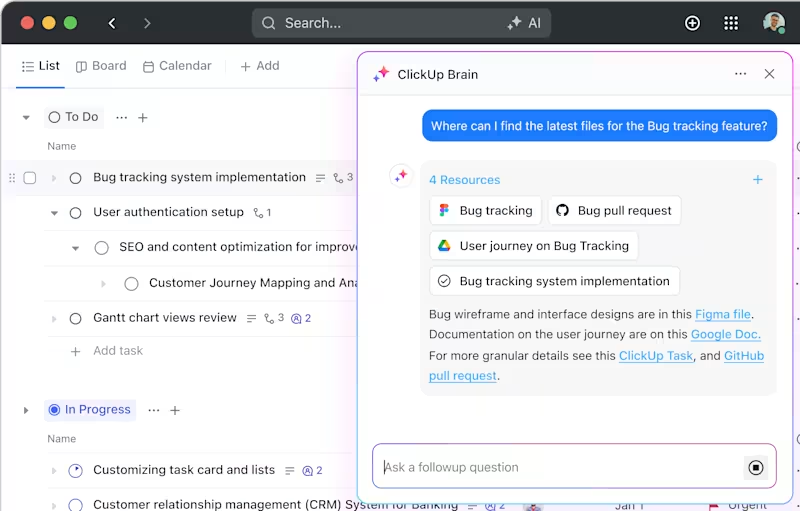
ClickUp Brain, ein in die Plattform integrierter KI-gestützter Assistent, vereinfacht selbst die komplexesten Projekte. Er unterteilt umfangreiche Studien in überschaubare Aufgaben und Unteraufgaben und hilft Ihnen so, organisiert zu bleiben und den Überblick zu behalten.
Benötigen Sie schnellen Zugriff auf Versuchsergebnisse oder Dokumentationen? Geben Sie einfach eine Abfrage ein, und ClickUp Brain findet in Sekundenschnelle alles, was Sie brauchen. Sie können sogar Folgefragen auf der Grundlage vorhandener Daten stellen, sodass Sie das Gefühl haben, einen persönlichen Assistenten zu haben.
Außerdem verknüpft er Aufgaben automatisch mit relevanten Ressourcen, wodurch Sie Zeit und Aufwand sparen.
Nehmen wir an, Sie führen eine Studie darüber durch, wie sich Reinforcement-Learning-Agenten im Laufe der Zeit verbessern.
Sie durchlaufen mehrere Phasen: Literaturrecherche, Datenerhebung, Experimentieren und Analyse. Mit ClickUp Brain können Sie die Anweisung „Teile diese Studie in Aufgaben auf“ geben, woraufhin automatisch Unteraufgaben für jede Phase erstellt werden.
Sie können ihn dann bitten, relevante Artikel zum Q-Lernen oder Datensätze zur Agentenleistung abzurufen, was er sofort tut. Während Sie die Aufgaben bearbeiten, kann ClickUp Brain bestimmte Forschungsartikel oder Versuchsergebnisse direkt mit den Aufgaben verknüpfen, sodass alles übersichtlich bleibt.
Ob bei Forschungsprojekten oder alltäglichen Projekten – ClickUp Brain sorgt dafür, dass Sie smarter statt härter arbeiten.
ClickUp-Automatisierungen
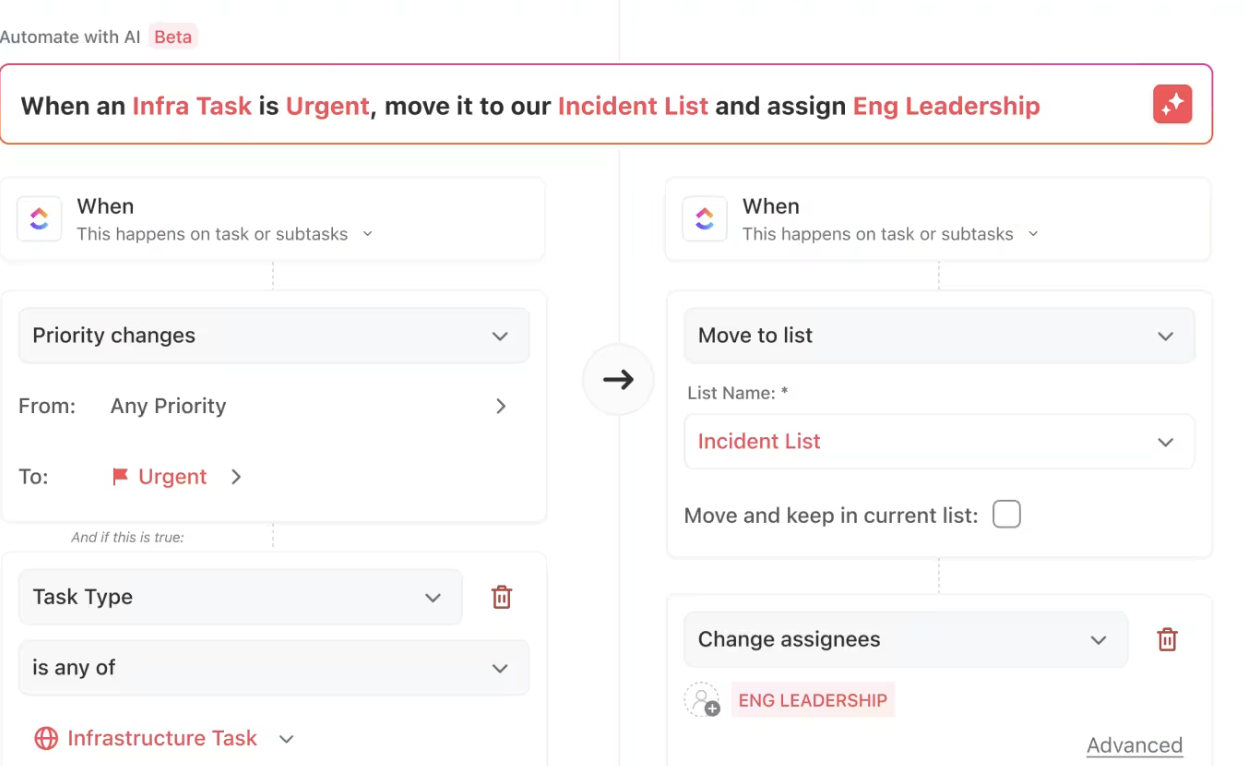
ClickUp Automatisierungen sind einfache, aber leistungsstarke Möglichkeiten, Ihren Workflow zu optimieren.
Es ermöglicht die sofortige Zuweisung von Aufgaben, sobald die Voraussetzungen fertiggestellt sind, benachrichtigt die Beteiligten über Meilensteine und meldet Verzögerungen – alles ohne manuelles Eingreifen.
Sie können auch Befehle in natürlicher Sprache verwenden, was die Verwaltung von Workflows noch einfacher macht. Sie müssen sich nicht mit komplexen Einstellungen oder Fachjargon auseinandersetzen – teilen Sie ClickUp einfach mit, was Sie benötigen, und es erstellt die Automatisierung für Sie.
Ob es darum geht, „Aufgaben in die nächste Phase zu verschieben, wenn sie als fertiggestellt markiert sind“ oder „Sarah eine Aufgabe zuzuweisen, wenn die Priorität hoch ist“ – ClickUp versteht Ihre Anfrage und richtet sie automatisch ein.
📖 Lesen Sie auch: Wie man KI für Produktivität nutzt (Anwendungsfälle und Tools)
Entwickeln Sie mit ClickUp Lernagenten wie ein Profi
Um KI-Lernagenten zu entwickeln, benötigen Sie eine fachkundige Kombination aus strukturierten Workflows und adaptiven Tools. Die zusätzliche Anforderung an technisches Fachwissen macht dies umso schwieriger, insbesondere angesichts der statistischen und datengestützten Natur solcher Aufgaben.
Erwägen Sie die Verwendung von ClickUp, um diese Projekte zu optimieren. Dieses Tool unterstützt nicht nur die Organisation, sondern fördert auch die Innovationskraft Ihres Teams, indem es vermeidbare Ineffizienzen beseitigt.
ClickUp Brain hilft Ihnen dabei, komplexe Aufgaben zu zerlegen, relevante Ressourcen sofort abzurufen und KI-gestützte Erkenntnisse zu gewinnen, damit Ihre Projekte organisiert bleiben und planmäßig verlaufen. ClickUp Automatisierungen übernehmen wiederkehrende Aufgaben wie die Aktualisierung von Statusmeldungen oder die Zuweisung neuer Aufgaben, sodass sich Ihr Team auf das Wesentliche konzentrieren kann.
Zusammen beseitigen diese Features Ineffizienzen und ermöglichen es Ihrem Team, intelligenter zu arbeiten, sodass Innovation und Fortschritt mühelos vonstattengehen.
Melden Sie sich noch heute kostenlos bei ClickUp an. ✅