
A maioria das equipes trata a geração de SQL como um truque de mágica. Você digita uma pergunta e obtém uma consulta.
Mas a realidade é esta: o Snowflake Cortex Analyst só funciona tão bem quanto o modelo semântico que você cria primeiro, e essa configuração não é trivial. Ao aprender a usar o Snowflake Cortex para geração de SQL, as equipes de dados agora podem transformar linguagem natural em consultas complexas e executáveis em segundos.
Este guia orienta você pelo processo de implementação, desde a definição do seu modelo semântico YAML até a consulta ao seu data warehouse usando linguagem natural, para que você compreenda tanto o potencial quanto os pré-requisitos antes de começar.
Também analisamos onde o Snowflake Cortex apresenta limitações e como o ClickUp pode dar suporte aos fluxos de trabalho mais amplos relacionados à geração de SQL.
O que é o Snowflake Cortex Analyst?
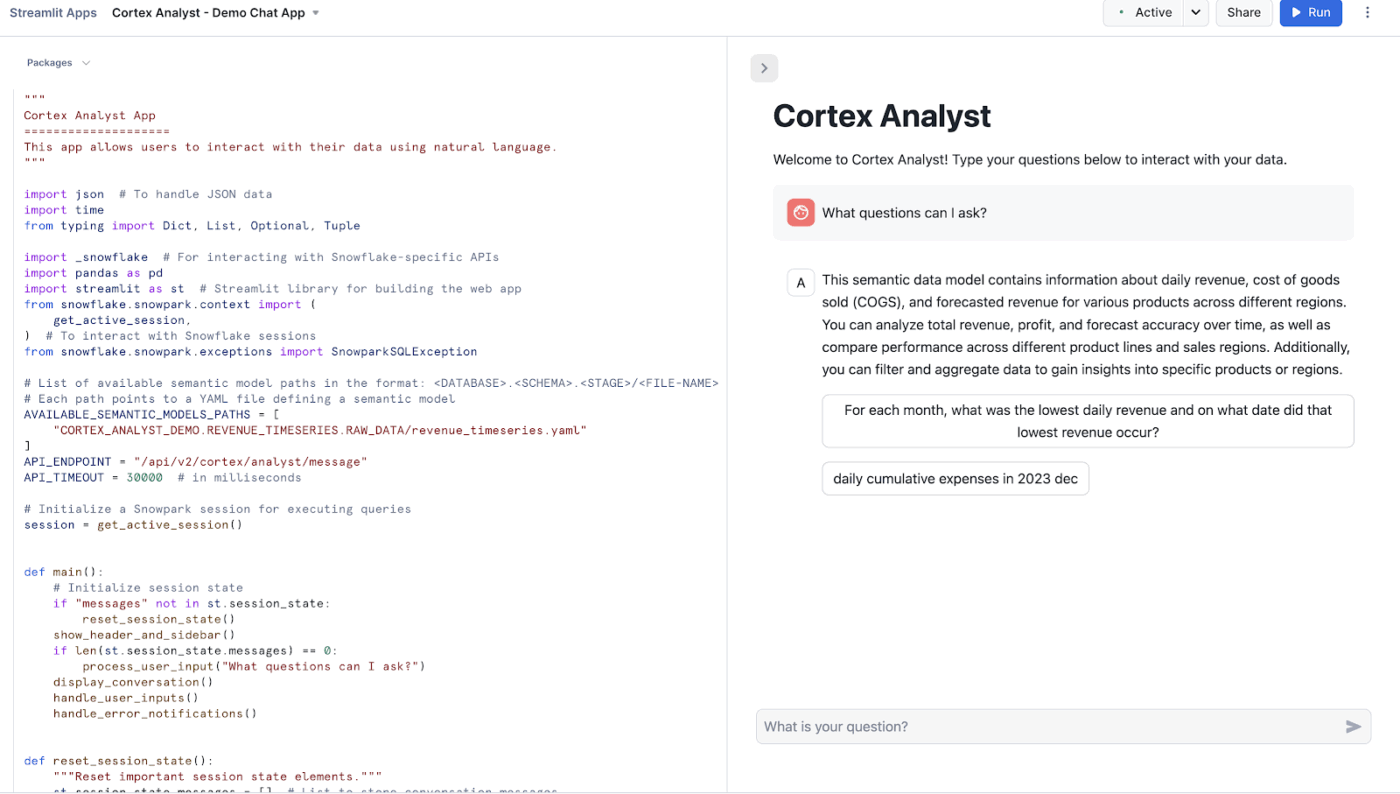
O Snowflake Cortex Analyst é um serviço totalmente gerenciado que permite criar aplicativos conversacionais com base em seus dados analíticos.
Ele utiliza um agente especializado de conversão de texto para SQL para transformar perguntas em linguagem natural em consultas precisas e executáveis. Esse serviço preenche a lacuna entre estruturas de dados complexas e usuários de negócios que precisam de respostas sem precisar escrever código.
Os principais recursos incluem:
- Oferecendo uma interface de alta precisão para interagir com dados estruturados
- Usando modelos semânticos para compreender sua lógica de negócios e terminologia específicas
- Oferecendo uma API REST para fácil integração em aplicativos personalizados ou ferramentas de BI
- Preservando a privacidade dos dados ao processar solicitações dentro dos limites de segurança do Snowflake
📮 ClickUp Insight: 88% dos participantes da nossa pesquisa usam IA para suas tarefas pessoais, mas mais de 50% evitam usá-la no trabalho. Quais são as três principais barreiras? Falta de integração perfeita, lacunas de conhecimento ou preocupações com segurança.
Mas e se a IA já estivesse integrada ao seu espaço de trabalho e fosse segura? O ClickUp Brain, o assistente de IA integrado do ClickUp, torna isso realidade. Ele compreende comandos em linguagem simples, resolvendo as três principais preocupações relacionadas à adoção de IA, ao mesmo tempo em que conecta seu chat, tarefas, documentos e conhecimento em todo o espaço de trabalho.
Encontre respostas e insights com um único clique!
Pré-requisitos para a geração de SQL do Snowflake Cortex
Começar a usar o Snowflake Cortex sem a configuração correta leva à frustração. Você pode obter resultados imprecisos, perder tempo com o diagnóstico de problemas e concluir erroneamente que a ferramenta está com defeito, quando o verdadeiro problema é uma base fraca.
Para evitar isso, você precisa primeiro estabelecer três elementos fundamentais.
1. Configure seu banco de dados e suas tabelas
Sua IA é tão inteligente quanto os dados aos quais tem acesso. Se o esquema do seu banco de dados for um labirinto de nomes de colunas enigmáticos, como cust_dat_v2_final, tanto seus analistas quanto a IA terão dificuldade em entendê-lo.
Essa confusão faz com que a IA gere junções incorretas ou extraia dados das colunas erradas, e sua equipe perde horas apenas tentando decifrar o esquema antes mesmo de poder escrever uma consulta.
Comece garantindo que seu software de data warehouse contenha as tabelas que você deseja que o Cortex Analyst consulte. Sempre que possível, use nomes de colunas claros e descritivos. Por exemplo, uma coluna chamada customer_lifetime_value é muito mais intuitiva tanto para humanos quanto para IA do que clv_01.
Para prosseguir com a configuração, sua função no Snowflake precisará das seguintes permissões:
- UTILIZAÇÃO: No banco de dados e no esquema que contêm suas tabelas
- SELECT: Nas tabelas que você deseja que o Cortex Analyst consulte
- CREATE STAGE: No esquema, necessário para carregar seu arquivo de modelo semântico
📖 Leia também: Como usar o Snowflake Cortex para inteligência de negócios
2. Crie seu arquivo de modelo semântico
O maior obstáculo em qualquer ferramenta de conversão de texto para SQL é que a IA não fala a linguagem específica da sua empresa. Ela não sabe, por si só, que “ARR” significa “Receita Anual Recorrente” ou que a tabela de clientes se une à tabela de pedidos pelo campo customer_id.
Sem esse contexto, a IA pode gerar um SQL tecnicamente válido, mas logicamente incorreto, fornecendo respostas que parecem corretas, mas são perigosamente enganosas.
O modelo semântico é a solução. Trata-se de um arquivo YAML que funciona como sua “camada de tradução” personalizada, ensinando ao Cortex Analyst o vocabulário e a lógica específicos do seu negócio. A criação e a manutenção desse arquivo são um esforço colaborativo entre engenheiros de dados, que utilizam ferramentas ETL para conhecer o esquema, e analistas de negócios, que conhecem a terminologia.
Seu arquivo de modelo semântico deve conter estes componentes principais:
| Componente | Objetivo |
| Tabelas | Lista cada tabela com uma descrição em linguagem simples de sua finalidade |
| Colunas | Define o tipo semântico de cada coluna (como categoria ou métrica) e pode incluir valores de exemplo |
| Relações | Especifica como as tabelas se conectam por meio de junções, eliminando qualquer margem para suposições por parte da IA |
| Consultas verificadas | Apresenta exemplos de pares de perguntas e SQL que servem como guias úteis para o LLM |
3. Configure o Cortex Search Service (opcional)
Às vezes, as respostas de que você precisa estão ocultas em textos não estruturados, como descrições de produtos, tickets de suporte ou transcrições de chamadas. As consultas SQL padrão não conseguem acessar esses dados, o que significa que muitas vezes você perde o “porquê” por trás do “o quê”.
Opcionalmente, você pode adicionar o Snowflake Cortex Search Service aqui. Trata-se de uma camada de pesquisa como serviço que permite consultar tanto suas tabelas estruturadas quanto seus dados de texto não estruturados, utilizando agentes de IA para análise de dados simultaneamente.
Você deve configurar o Cortex Search se seus analistas precisarem fazer perguntas que exijam a extração de contexto do texto antes de gerar o SQL. Por exemplo, você poderia primeiro pesquisar todas as avaliações de produtos que contenham a frase “problema com a bateria” e, em seguida, gerar uma consulta SQL para agregar os dados de vendas apenas desses produtos.
Para geração de SQL puro em tabelas estruturadas, este serviço não é necessário.
🧠 Curiosidade: No início da década de 1970, os pesquisadores da IBM Donald Chamberlin e Raymond Boyce criaram a “Structured English Query Language”. Eles tiveram que mudar o nome para SQL porque “SEQUEL” já era uma marca registrada de uma empresa aeronáutica britânica.
Guia passo a passo para gerar SQL com o Cortex Analyst
Você já fez o trabalho de preparação, mas agora está diante de uma tela em branco, sem saber ao certo qual é o fluxo de trabalho real. Como transformar uma pergunta na sua cabeça em uma consulta SQL executável? Quando o gerenciamento do fluxo de trabalho não é claro, novas ferramentas muitas vezes ficam sem uso, e o investimento na configuração é desperdiçado.
O processo prático é surpreendentemente simples. Veja mais detalhes aqui!
Passo 1: Prepare seus dados no Snowflake
Antes de mais nada, seus dados estruturados precisam estar no Snowflake. Cada aplicação do Cortex Analyst é direcionada a uma única tabela ou a uma visualização composta por uma ou mais tabelas. Certifique-se de que suas tabelas estejam criadas e preenchidas.
Se você estiver carregando a partir de arquivos simples:
- Carregue seus arquivos de dados (por exemplo, CSVs) para um Snowflake Stage
- Use o comando COPY INTO para carregar dados do estágio para suas tabelas
- Verifique se os dados foram carregados com sucesso antes de prosseguir
📖 Leia também: Como usar o Snowflake Cortex para análise empresarial
Etapa 2: Crie um modelo semântico (ou visão semântica)
Esta é a etapa de configuração mais importante. O poder do Cortex Analyst vem da combinação de grandes modelos de linguagem (LLMs) com modelos semânticos, um arquivo YAML que acompanha o esquema do seu banco de dados e codifica o contexto de negócios.
As Visualizações Semânticas são agora o método recomendado pelo Snowflake para o Cortex Analyst. Elas armazenam métricas de negócios, relações e definições diretamente dentro do Snowflake. Os arquivos de modelo semântico YAML legados ainda funcionam, mas o Snowflake direciona novas implementações para as Visualizações Semânticas.
Seu modelo semântico ou visualização deve incluir:
- Descrições de tabelas e colunas: Explicações em linguagem simples sobre o significado de cada campo
- Métricas de negócios: Definições para campos calculados, como receita, rotatividade ou taxa de conversão
- Filtros e sinônimos: termos alternativos que os usuários podem usar (por exemplo, “cancelado” mapeado para um valor de status específico)
- Consultas verificadas: O Repositório de Consultas Verificadas do Snowflake armazena pares aprovados de perguntas e SQL. Quando a pergunta de um usuário se assemelha a uma dessas entradas, o Cortex Analyst pode consultá-la durante a geração de SQL
🤝 Lembrete: O Snowflake sugere usar no máximo 10 tabelas e no máximo 50 colunas selecionadas para obter o melhor desempenho no fluxo de trabalho do Snowsight.
Etapa 3: Carregue o modelo semântico em um estágio do Snowflake
Se você estiver usando um modelo semântico baseado em YAML, ele precisa ser preparado para que o Cortex Analyst possa consultá-lo em tempo de execução.
- Carregue seu arquivo .yaml para um estágio interno do Snowflake (por exemplo, RAW_DATA)
- Confirme se o arquivo aparece no estágio por meio da interface do usuário do Snowsight ou do comando LIST @stage_name
- Anote o caminho da etapa; você precisará consultá-lo em suas chamadas de API ou na configuração do aplicativo
Se você estiver usando uma Visualização Semântica, essa etapa é tratada nativamente no Snowflake, e não é necessário fazer nenhum upload separado.
🔍 Você sabia? NULL no SQL não significa zero ou vazio. Representa dados desconhecidos ou ausentes, o que leva a comportamentos contraintuitivos, como comparações que não retornam nem verdadeiro nem falso.
Etapa 4: Envie uma pergunta em linguagem natural por meio da API REST
Agora começa a geração do SQL propriamente dita. A API REST gera uma consulta SQL para uma determinada pergunta usando um modelo semântico ou uma visão semântica fornecida na solicitação.
Estruture sua solicitação de API com:
- mensagens; uma matriz contendo a pergunta do usuário com a função: “usuário”
- Uma referência ao seu modelo semântico ou visão semântica
- Seu modelo preferido (ou deixe como “auto” para que o Cortex selecione o melhor)
Você pode ter conversas com várias trocas de mensagens, nas quais é possível fazer perguntas complementares com base em consultas anteriores.
Etapa 5: Analise a resposta da API
Cada mensagem em uma resposta pode ter vários blocos de conteúdo de diferentes tipos. Os três valores atualmente suportados para o campo “type” são: texto, sugestões e SQL.
Veja o que cada tipo significa:
- SQL: O Cortex gerou uma consulta com sucesso; é isso que você irá executar
- texto: Uma explicação ou resposta em linguagem natural que acompanha o SQL
- sugestões: O tipo de conteúdo “sugestão” só é incluído em uma resposta se a pergunta do usuário for ambígua e o Cortex Analyst não conseguir retornar uma instrução SQL para essa consulta. Use-as para esclarecer ou refinar a pergunta
🔍 Você sabia? A ordem em que você escreve o SQL não é a ordem em que ele é executado. Mesmo que você escreva SELECT primeiro, os bancos de dados, na verdade, processam FROM e WHERE antes de selecionar as colunas. Isso confunde tanto usuários iniciantes quanto experientes.
Etapa 6: Execute o SQL gerado no Snowflake
Depois de obter o bloco de SQL da resposta, execute-o no seu armazém virtual do Snowflake. A consulta SQL gerada é executada no seu armazém virtual do Snowflake para gerar o resultado final. Os dados permanecem dentro dos limites de governança do Snowflake.
Pontos importantes a saber no momento da execução:
- O Cortex Analyst integra-se totalmente às políticas de controle de acesso baseado em funções (RBAC) do Snowflake, garantindo que as consultas SQL geradas e executadas cumpram todos os controles de acesso estabelecidos
- Se um usuário não tiver acesso a uma tabela, a consulta falhará na execução, assim como aconteceria com um SQL escrito manualmente
- Nesta fase, aplicam-se os custos de computação do data warehouse, independentemente das tarifas de uso do Cortex Analyst
Etapa 7: Refine e itere
Nem sempre é garantido obter uma consulta perfeita na primeira tentativa. Veja como melhorar os resultados ao longo do tempo:
- Adicione consultas verificadas ao seu modelo semântico para perguntas que surgem repetidamente
- Enriqueça seu modelo semântico com descrições, sinônimos e filtros melhores quando o Cortex interpretar um termo incorretamente
- Use conversas com várias trocas de mensagens para dar continuidade, por exemplo, “Agora filtre isso por região”; conversas com várias trocas de mensagens permitem perguntas complementares que se baseiam em consultas anteriores
- Monitore o uso por meio do CORTEX_ANALYST_USAGE_HISTORY e do histórico de consultas do Snowflake para identificar padrões em consultas com falha ou imprecisas
🧠 Curiosidade: Uma condição JOIN ausente pode causar problemas graves. Esquecer uma condição JOIN pode gerar um produto cartesiano, multiplicando drasticamente as linhas e, às vezes, causando falhas no sistema.
Práticas recomendadas para a precisão do Snowflake Text-to-SQL
A qualidade do seu modelo semântico determina diretamente a precisão das consultas que ele gera. Aqui estão as práticas recomendadas para melhorar a precisão. 🛠️
- Adicione consultas verificadas ao seu modelo semântico: Essa é a ação mais impactante que você pode realizar. Inclua diversos pares de perguntas e consultas SQL que reflitam a forma como sua equipe realmente faz perguntas
- Use nomes descritivos para colunas e tabelas: O modelo tem melhor desempenho quando os nomes das colunas e tabelas são autoexplicativos. Se não for possível alterar o esquema, adicione descrições claras no seu arquivo YAML para quaisquer nomes de colunas enigmáticos
- Inclua valores de exemplo: Adicionar dados de exemplo para colunas categóricas (como status ou região) ajuda o modelo a compreender as opções de filtro válidas disponíveis
- Teste com casos extremos: Durante o desenvolvimento, faça perguntas ambíguas ou complexas de propósito para identificar onde seu modelo semântico precisa de mais contexto ou esclarecimentos
- Itere seu modelo semântico: Trate seu modelo semântico como um documento vivo. Ele deve ser atualizado continuamente por meio de um processo iterativo baseado em quais consultas são bem-sucedidas e quais falham
ClickUp: uma alternativa mais simples ao Snowflake Cortex
O Snowflake Cortex funciona bem quando as equipes desejam gerar SQL e executar consultas em dados estruturados. As equipes definem esquemas, mapeiam relações e escrevem consultas para extrair insights. Essa configuração faz sentido para ambientes com grande volume de dados, especialmente quando os analistas são responsáveis pelos relatórios.
Muitas equipes, no entanto, não precisam de uma camada SQL completa para responder a perguntas operacionais do dia a dia. Gerentes de produto, líderes de programa e equipes de operações geralmente querem respostas rápidas relacionadas ao trabalho em andamento.
O ClickUp oferece um caminho mais acessível. As equipes fazem perguntas em linguagem simples, analisam painéis em tempo real e agem com base nas informações obtidas sem precisar escrever SQL ou criar modelos semânticos.
Gere e refine SQL mais rapidamente
O Snowflake Cortex se concentra na geração de consultas SQL a partir de conjuntos de dados estruturados dentro de um ambiente de data warehouse. Isso funciona bem quando seus dados já estão no Snowflake e você tem esquemas mapeados.

O ClickUp Brain oferece suporte à geração de SQL de maneira mais flexível e focada na execução. As equipes geram, refinam e armazenam consultas SQL diretamente dentro de seu espaço de trabalho, onde já ocorrem análises, discussões e decisões.
Suponha que um analista de produtos esteja trabalhando em uma tarefa de análise de retenção no ClickUp. Em vez de trocar de ferramenta para escrever consultas, ele pergunta ao ClickUp Brain:
📌 Experimente este prompt: Escreva uma consulta SQL para calcular a retenção de sete dias para usuários agrupados por coorte de inscrição.
O ClickUp Brain gera uma consulta estruturada que inclui agrupamento por coorte, filtros de data e lógica de retenção. O analista cola a consulta no Snowflake ou em outro data warehouse e a executa imediatamente.
Isso ajuda a:
- Escreva junções entre várias tabelas, como usuários, pedidos e eventos
- Converta perguntas sobre produtos em inglês simples em lógica SQL pronta para execução
- Depure consultas com erros e explique problemas, como junções incorretas ou condições ausentes
- Reescreva consultas para obter melhor desempenho ou legibilidade
Por exemplo, durante uma análise de experimento de crescimento, um profissional de marketing pergunta: “Escreva uma consulta SQL para comparar as taxas de conversão entre duas páginas de destino nos últimos 14 dias”.
O ClickUp Brain gera a consulta usando agregação condicional e filtros de data. A equipe a executa no Snowflake e valida os resultados do experimento.
📌 Experimente este prompt: Corrija esta consulta SQL em que a junção duplica linhas e explique o problema.
O ClickUp Brain identifica o problema de junção, corrige a consulta e explica como as linhas duplicadas ocorreram devido a condições de junção incorretas.
Substitua relatórios baseados em SQL
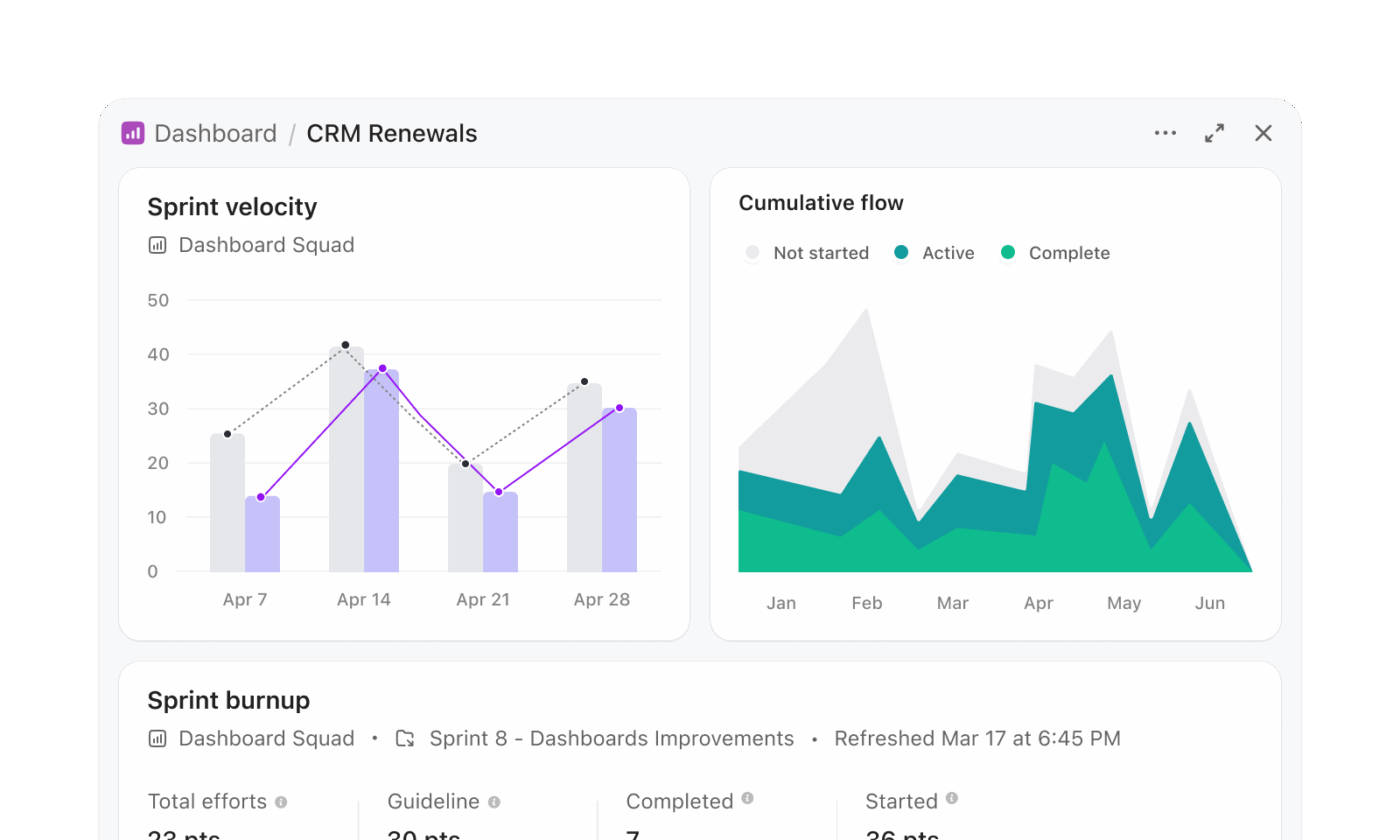
Os fluxos de trabalho do Snowflake Cortex geralmente envolvem a geração de SQL, a execução de consultas e a visualização de resultados em uma camada separada. Os painéis do ClickUp eliminam esse processo de várias etapas e apresentam insights diretamente a partir do trabalho em tempo real.
Uma equipe de gerenciamento de programas que acompanha a prontidão para lançamento pode criar um painel sem precisar escrever consultas. Por exemplo, um painel de lançamento pode incluir:
- Um cartão de lista de tarefas filtrado para mostrar tarefas vencidas em todas as equipes de produto
- Um cartão de carga de trabalho que mostra a distribuição de tarefas entre os engenheiros
- Um gráfico de barras comparando tarefas concluídas com as pendentes por sprint
- Um cartão de cálculo que monitora o tempo médio de conclusão
Suponha que um líder de programa analise este painel antes de uma reunião de lançamento. Ele percebe imediatamente que os serviços de back-end apresentam taxas de atraso mais elevadas. Ele abre o cartão da lista de tarefas e inspeciona exatamente quais tarefas estão causando risco.
Um usuário real do ClickUp compartilha:
O ClickUp nos permite passar projetos uns para os outros RAPIDAMENTE, verificar FACILMENTE o status dos projetos e dá à nossa supervisora uma visão da nossa carga de trabalho a qualquer momento, sem que ela precise nos interromper. Certamente economizamos um dia por semana usando o ClickUp, se não mais. O número de e-mails foi SIGNIFICATIVAMENTE reduzido.
O ClickUp nos permite passar projetos uns para os outros RAPIDAMENTE, verificar FACILMENTE o status dos projetos e dá à nossa supervisora uma visão geral da nossa carga de trabalho a qualquer momento, sem que ela precise nos interromper. Certamente economizamos um dia por semana usando o ClickUp, se não mais. O número de e-mails foi SIGNIFICATIVAMENTE reduzido.
Aja com base em insights sem pipelines
O Snowflake Cortex se concentra na geração de insights a partir dos dados. As equipes ainda precisam interpretar os resultados e acionar ações separadamente.
Os Super Agentes de IA do ClickUp preenchem essa lacuna e transformam insights em ação. Eles atuam como colegas de equipe de IA que monitoram continuamente os dados do espaço de trabalho e tomam medidas com base nas condições.
Suponha que um gerente de programa supervisione várias iniciativas de produto. Um Super Agente pode:
- Monitore tarefas em todos os projetos e detecte quando tarefas atrasadas excederem um limite definido
- Identifique padrões, como atrasos repetidos na mesma etapa do fluxo de trabalho
- Crie uma tarefa que resuma os projetos afetados e atribua-a ao líder do programa
- Notifique os responsáveis pelas equipes quando tarefas críticas permanecerem pendentes após os prazos
Por exemplo, durante um ciclo de lançamento, um Super Agente detecta que mais de 10 tarefas de alta prioridade não cumpriram os prazos em duas equipes. Ele cria uma tarefa no ClickUp intitulada “Risco de lançamento: prazos não cumpridos”, anexa todas as tarefas relevantes e designa o gerente de programa para revisão imediata.
As equipes também podem interagir diretamente com o Super Agent: “Analise todos os projetos ativos e destaque os riscos de entrega para este sprint”.
O Super Agent analisa prazos, dependências e o status das tarefas e, em seguida, publica um resumo estruturado dentro do espaço de trabalho.
Veja como configurar seu próprio Super Agent no ClickUp:
Centralize seus fluxos de trabalho de dados com o ClickUp
Ferramentas de conversão de texto para SQL, como o Snowflake Cortex, tornam os dados mais acessíveis. Ao mesmo tempo, obter resultados confiáveis ainda exige esforço.
As equipes precisam de esquemas bem definidos, modelos semânticos robustos e iteração contínua para manter a precisão dos resultados. Mesmo depois de gerar a consulta correta, o trabalho não para por aí. Alguém ainda precisa interpretar os resultados, compartilhar insights e transformá-los em decisões.
O ClickUp traz uma abordagem diferente. Em vez de separar a análise da execução, o ClickUp conecta as duas. As equipes geram SQL, documentam insights, colaboram nas descobertas e agem com base nelas dentro do mesmo espaço de trabalho.
O ClickUp Brain ajuda a escrever e refinar consultas, enquanto os painéis e os agentes de IA ajudam as equipes a acompanhar os resultados e avançar no trabalho sem precisar alternar entre ferramentas.
O Snowflake Cortex ajuda você a obter respostas. O ClickUp ajuda você a fazer algo com elas. Inscreva-se no ClickUp hoje mesmo!
Perguntas frequentes
O Snowflake Cortex Analyst é um serviço especializado dentro do conjunto mais amplo de ferramentas de IA do Snowflake Cortex. O Cortex Analyst concentra-se especificamente na geração de texto para SQL usando modelos semânticos, enquanto o Cortex AI inclui uma gama mais ampla de funções de LLM, inferência de modelos de aprendizado de máquina e recursos de pesquisa.
Sim, o Cortex Analyst pode consultar tabelas do Apache Iceberg gerenciadas pelo Snowflake. Desde que as tabelas estejam acessíveis em seu ambiente Snowflake e devidamente definidas em seu modelo semântico, você pode gerar consultas nelas.
A precisão de consultas complexas depende quase inteiramente da qualidade do seu modelo semântico. Um modelo com relações entre tabelas bem definidas, inúmeras consultas verificadas e metadados descritivos produzirá resultados significativamente mais precisos para junções entre várias tabelas e agregações complexas.
Os preços do Snowflake Cortex Analyst seguem o modelo baseado no consumo da Snowflake, o que significa que você é cobrado com base nos créditos de computação utilizados durante o processo de geração de consultas. Para obter as tarifas mais atualizadas, consulte sempre a documentação oficial de preços da Snowflake.