![Jak szkolić Gemini na podstawie własnych danych w [rok]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Według najnowszych badań przeprowadzonych wśród przedsiębiorstw 73% organizacji twierdzi, że ich modele AI nie rozumieją terminologii i kontekstu specyficznego dla danej firmy, co prowadzi do wyników wymagających znacznej ręcznej korekty. Staje się to jednym z największych wyzwań związanych z wdrażaniem AI.
Duże modele językowe, takie jak Google Gemini, są już szkolone na ogromnych publicznych zbiorach danych. Większość firm nie potrzebuje szkolenia nowego modelu, ale nauczania Gemini kontekstu swojej działalności: dokumentów, cykli pracy, klientów i wiedzy wewnętrznej.
Ten przewodnik przeprowadzi Cię przez zakończony proces szkolenia modelu Gemini firmy Google na podstawie własnych danych. Omówimy wszystko, od przygotowania zestawów danych w prawidłowym formacie JSONL po uruchamianie zadań dostrajania w Google AI Studio.
Sprawdzimy również, czy zintegrowany obszar roboczy z wbudowaną AI może zaoszczędzić Ci tygodnie czasu potrzebnego na ustawienia.
Czym jest dostosowywanie Gemini i dlaczego ma znaczenie?
Dostosowywanie Gemini to proces szkolenia modelu podstawowego Google na podstawie własnych danych.
Potrzebujesz AI, która rozumie Twoją działalność, ale gotowe modele udzielają ogólnych odpowiedzi, które nie trafiają w sedno. Oznacza to, że tracisz czas na ciągłe poprawianie wyników, ponowne wyjaśnianie terminologii stosowanej w Twojej firmie i frustrację, gdy AI po prostu tego nie rozumie.
Te ciągłe zmiany spowalniają pracę Twojego zespołu i podważają obietnicę wydajności AI.
Dostosowanie Gemini pozwala stworzyć niestandardowy model Gemini, który uczy się konkretnych wzorców, tonu i wiedzy dziedzinowej, dzięki czemu może dokładniej reagować na unikalne przypadki użycia. Takie podejście sprawdza się najlepiej w przypadku spójnych, powtarzalnych zadań, w których model bazowy wielokrotnie zawodzi.
Czym różni się dostosowywanie od inżynierii podpowiedzi
Inżynieria podpowiedzi polega na przekazywaniu modelowi tymczasowych instrukcji opartych na sesji za każdym razem, gdy wchodzisz z nim w interakcję. Po zakończeniu rozmowy model zapomina o kontekście.
To podejście osiąga swoje granice, gdy Twój przypadek użycia wymaga specjalistycznej wiedzy, której model bazowy po prostu nie posiada. Możesz podać tylko określoną liczbę instrukcji, zanim model będzie musiał faktycznie nauczyć się Twoich wzorców.
Natomiast dostrajanie trwale modyfikuje zachowanie modelu poprzez zmianę jego wewnętrznych wag na podstawie przykładów szkoleniowych, dzięki czemu zmiany pozostają aktywne we wszystkich przyszłych sesjach.
Dostosowywanie nie jest szybkim rozwiązaniem sporadycznych problemów związanych z AI; wymaga znacznej inwestycji czasu i danych. Ma największy sens w konkretnych scenariuszach, w których model bazowy konsekwentnie nie spełnia oczekiwań i potrzebne jest trwałe rozwiązanie.
Rozważ dostosowanie, gdy potrzebujesz, aby AI opanowała:
- Specjalistyczna terminologia: w Twojej branży używa się żargonu, który model konsekwentnie błędnie interpretuje lub nie potrafi poprawnie wykorzystać.
- Spójny format wyjściowy: za każdym razem potrzebujesz odpowiedzi o bardzo specyficznej strukturze, np. generowanie raportów lub fragmentów kodu.
- Wiedza specjalistyczna: model nie posiada wiedzy na temat Twoich niszowych produktów, procesów wewnętrznych ani zastrzeżonych cykli pracy.
- Głos marki: Chcesz, aby wszystkie wyniki generowane przez AI idealnie pasowały do głosu, stylu i osobowości Twojej marki.
| Aspekt | Inżynieria podpowiedzi | Precyzyjne dostosowywanie |
| Czym jest | Tworzenie lepszych instrukcji w podpowiedzi, aby kierować zachowaniem modelu | Dalsze szkolenie modelu na podstawie własnych przykładów |
| Jakie zmiany | Dane wejściowe przesyłane do modelu | Wagi wewnętrzne modelu |
| Szybkość wdrożenia | Natychmiastowy — działa od razu | Powolny — wymaga przygotowania zbioru danych i czasu na szkolenie |
| Złożoność techniczna | Niski — nie jest wymagana wiedza z zakresu uczenia maszynowego | Średni do wysokiego — wymaga potoków ML |
| Wymagane dane | Kilka dobrych przykładów w oknie podpowiedzi | Setki lub tysiące przykładów z etykietami |
| Spójność wyników | Średni — różni się w zależności od podpowiedzi | Wysoki — zachowanie jest wbudowane w model |
| Najlepsze dla | Jednorazowe zadania, eksperymenty, szybka iteracja | Powtarzalne zadania wymagające spójnych wyników |
Inżynieria podpowiedzi kształtuje to, co mówisz do modelu. Dostrajanie kształtuje sposób myślenia modelu.
Chociaż ten artykuł skupia się na Gemini, zrozumienie alternatywnych podejść do dostosowywania AI może dać fajną perspektywę na różne metody osiągania podobnych celów.
Wideo pokazuje , jak stworzyć niestandardowy model GPT, który jest kolejnym popularnym podejściem do dostosowywania AI do konkretnych zastosowań:
📖 Przeczytaj również: Jak zostać inżynierem podpowiedzi
Jak przygotować dane szkoleniowe dla Gemini
Większość projektów związanych z dostosowywaniem kończy się niepowodzeniem jeszcze przed rozpoczęciem, ponieważ Teams nie doceniają procesu przygotowania danych. Firma Gartner przewiduje, że 60% projektów związanych z AI zostanie porzuconych z powodu nieodpowiednich danych gotowych do wykorzystania w AI.
Możesz spędzić tygodnie na nieprawidłowym gromadzeniu i formatowaniu danych, a mimo to szkolenie zakończy się niepowodzeniem lub powstanie bezużyteczny model. Jest to często najbardziej czasochłonna część całego procesu, ale prawidłowe wykonanie tego zadania jest najważniejszym czynnikiem decydującym o powodzeniu.
W tym przypadku bardzo ważna jest zasada „garbage in, garbage out” (co włożysz, to wyjdzie). Jakość Twojego niestandardowego modelu będzie bezpośrednio odzwierciedlać jakość danych, na których go trenujesz.
Wymagania dotyczące formatu zbioru danych
Gemini wymaga, aby dane szkoleniowe były w określonym formacie o nazwie JSONL, co oznacza JSON Lines. W pliku JSONL każda linia jest zakończonym, samodzielnym obiektem JSON, który reprezentuje jeden przykład szkoleniowy. Taka struktura ułatwia systemowi przetwarzanie dużych zbiorów danych, linia po linii.
Każdy przykład szkoleniowy musi zawierać dwa kluczowe pola:
- text_input: Jest to podpowiedź lub pytanie, które zadajesz modelowi.
- wynik: Jest to idealna, doskonała odpowiedź, której chcesz nauczyć model.
Dla wygody Google AI Studio akceptuje również pliki w formacie CSV i konwertuje je do wymaganej struktury JSONL.
Może to nieco ułatwić wstępne wprowadzanie danych, jeśli Twój zespół czuje się bardziej komfortowo pracując w arkuszach kalkulacyjnych.
Zalecenia dotyczące rozmiaru zbioru danych
Chociaż jakość jest ważniejsza od ilości, nadal potrzebujesz minimalnej liczby przykładów, aby model mógł rozpoznawać i uczyć się wzorców. Rozpoczęcie pracy z zbyt małą liczbą przykładów spowoduje, że model nie będzie w stanie uogólniać ani działać niezawodnie.
Oto kilka ogólnych wskazówek dotyczących rozmiaru zbioru danych:
- Minimalna wykonalność: w przypadku prostych, bardzo specyficznych zadań wyniki można zacząć obserwować już po około 100–500 wysokiej jakości przykładach.
- Lepsze wyniki: w przypadku bardziej złożonych lub zróżnicowanych wyników, dążenie do uzyskania od 500 do 1000 przykładów pozwoli uzyskać bardziej solidny i niezawodny model.
- Malejące zyski: W pewnym momencie samo dodanie większej ilości powtarzających się danych nie poprawi znacząco wydajności. Skup się na różnorodności i jakości, a nie na samej ilości.
Zebranie setek wysokiej jakości przykładów stanowi poważne wyzwanie dla większości zespołów. Przed przystąpieniem do procesu dostosowywania należy odpowiednio zaplanować fazę gromadzenia danych.
📮 ClickUp Insight: Przeciętny profesjonalista spędza ponad 30 minut dziennie na wyszukiwaniu informacji związanych z pracą — to ponad 120 godzin rocznie straconych na przeszukiwanie wiadomości e-mail, wątków na Slacku i rozproszonych plików.
Inteligentny asystent AI wbudowany w Twój obszar roboczy może to zmienić. Poznaj ClickUp Brain. Zapewnia on natychmiastowe informacje i odpowiedzi, wyświetlając odpowiednie dokumenty, rozmowy i szczegóły zadań w ciągu kilku sekund — dzięki czemu możesz przestać szukać i zacząć pracować.
💫 Rzeczywiste wyniki: zespoły takie jak QubicaAMF odzyskały ponad 5 godzin tygodniowo dzięki ClickUp — to ponad 250 godzin rocznie na osobę — eliminując przestarzałe procesy zarządzania wiedzą. Wyobraź sobie, co Twój zespół mógłby osiągnąć, mając dodatkowy tydzień wydajności w każdym kwartale!
Najlepsze praktyki dotyczące jakości danych
Niespójne lub sprzeczne przykłady mogą wprowadzić model w błąd, co spowoduje, że wyniki będą niepewne i nieprzewidywalne. Aby tego uniknąć, dane szkoleniowe muszą być starannie wyselekcjonowane i oczyszczone. Jeden zły przykład może zniweczyć efekty nauki na podstawie wielu dobrych przykładów.
Postępuj zgodnie z poniższymi wytycznymi, aby zapewnić wysoką jakość danych:
- Spójność: Wszystkie przykłady powinny mieć ten sam format, styl i ton. Jeśli chcesz, aby AI była formalna, wszystkie przykłady wyjściowe powinny być formalne.
- Różnorodność: Twój zbiór danych powinien obejmować pełny zakres danych wejściowych, z którymi model prawdopodobnie spotka się w rzeczywistym użyciu. Nie trenuj go tylko na łatwych przypadkach.
- Dokładność: Każdy przykładowy wynik musi być idealny. Powinien to być dokładnie taki wynik, jaki chcesz uzyskać z modelu, bez żadnych błędów ani literówek.
- Czystość: Przed rozpoczęciem szkolenia należy usunąć zduplikowane przykłady, poprawić wszystkie błędy ortograficzne i gramatyczne oraz rozwiązać wszelkie sprzeczności w danych.
Zdecydowanie zaleca się, aby przykłady szkoleniowe zostały sprawdzone i zatwierdzone przez kilka osób. Świeże spojrzenie często pozwala wychwycić błędy lub niespójności, które mogły zostać przeoczone.
Jak dostosować Gemini krok po kroku
Proces dostosowywania Gemini obejmuje kilka kroków technicznych na platformach Google. Jedna błędna konfiguracja może spowodować stratę wielu godzin cennego czasu szkoleniowego i zasobów obliczeniowych, zmuszając Cię do rozpoczęcia procesu od nowa. Ten praktyczny przewodnik ma na celu ograniczenie prób i błędów, prowadząc Cię przez cały proces od początku do końca. 🛠️
Zanim zaczniesz, potrzebujesz konta Google Cloud z włączoną funkcją rozliczeń i dostępem do Google AI Studio. Zarezerwuj co najmniej kilka godzin na wstępne ustawienia i pierwsze zadanie szkoleniowe, a także dodatkowy czas na testowanie i iterację modelu.
Krok 1: Skonfiguruj Google AI Studio
Google AI Studio to internetowy interfejs, w którym można zarządzać całym procesem dostosowywania. Zapewnia on przyjazny dla użytkownika sposób przesyłania danych, konfigurowania szkolenia i testowania niestandardowego modelu bez konieczności pisania kodu.
Najpierw przejdź do strony ai.google.dev i zaloguj się na swoje konto Google.
Musisz zaakceptować Warunki usługi i utworzyć nowy projekt w Google Cloud Console, jeśli jeszcze go nie masz. Upewnij się, że włączyłeś niezbędne interfejsy API zgodnie z podpowiedziami platformy.
Krok 2: Prześlij zestaw danych szkoleniowych
Po skonfigurowaniu przejdź do sekcji dostosowywania w Google AI Studio. Tutaj rozpoczniesz proces tworzenia niestandardowego modelu.
Wybierz opcję „Utwórz dostrojony model” i wybierz model bazowy. Gemini 1. 5 Flash to popularny i ekonomiczny wybór do dostrajania.
Następnie prześlij plik JSONL lub CSV zawierający przygotowany zestaw danych szkoleniowych. Platforma zweryfikuje plik pod kątem zgodności z wymaganiami formatowania, sygnalizując wszelkie typowe błędy, takie jak brakujące pola lub nieprawidłowa struktura.
Krok 3: Skonfiguruj ustawienia dostrajania
Po załadowaniu i sprawdzeniu danych skonfigurujesz parametry szkolenia. Te ustawienia, znane jako hiperparametry, kontrolują sposób, w jaki model uczy się na podstawie danych.
Najważniejsze klucze, które zobaczysz, to:
- Epoki: Określają, ile razy model będzie trenowany na całym zbiorze danych. Większa liczba epok może prowadzić do lepszego uczenia się, ale także stwarza ryzyko nadmiernego dopasowania.
- Tempo uczenia się: kontroluje, jak agresywnie model dostosowuje swoje wagi na podstawie podanych przykładów.
- Rozmiar partii: określa, ile przykładów szkoleniowych jest przetwarzanych razem w jednej grupie.
Przy pierwszej próbie najlepiej zacząć od ustawień domyślnych zalecanych przez Google AI Studio. Platforma upraszcza te złożone decyzje, dzięki czemu jest dostępna nawet dla osób, które nie są ekspertami w dziedzinie uczenia maszynowego.
Krok 4: Uruchom zadanie dostosowywania
Po skonfigurowaniu ustawień możesz rozpocząć proces dostosowywania. Serwery Google zaczną przetwarzać Twoje dane i dostosowywać parametry modelu. Proces szkolenia może trwać od kilku minut do kilku godzin, w zależności od wielkości zbioru danych i wybranego modelu.
Postęp zadania można monitorować bezpośrednio w panelu Google AI Studio. Ponieważ zadanie jest wykonywane na serwerach Google, można bezpiecznie zamknąć przeglądarkę i wrócić później, aby sprawdzić status. Jeśli zadanie zakończy się niepowodzeniem, prawie zawsze wynika to z problemu z jakością lub formatowaniem danych szkoleniowych.
Krok 5: Przetestuj swój niestandardowy model
Po zakończeniu szkolenia Twój niestandardowy model będzie gotowy do testowania. ✨
Dostęp do niego można uzyskać za pośrednictwem interfejsu playground w Google AI Studio.
Zacznij od wysłania mu podpowiedzi podobnych do przykładów szkoleniowych, aby zweryfikować jego dokładność. Następnie przetestuj go na skrajnych przypadkach i nowych wariantach, których wcześniej nie widział, aby ocenić jego zdolność do uogólniania.
- Dokładność: Czy generuje dokładnie takie wyniki, do jakich został przeszkolony?
- Uogólnienie: Czy model poprawnie obsługuje nowe dane wejściowe, które są podobne, ale nie identyczne z danymi szkoleniowymi?
- Spójność: Czy odpowiedzi są wiarygodne i przewidywalne w przypadku wielu prób z tą samą podpowiedzią?
Jeśli wyniki nie będą satysfakcjonujące, prawdopodobnie będziesz musiał wrócić do poprzedniego etapu, poprawić dane szkoleniowe, dodając więcej przykładów lub naprawiając niespójności, a następnie ponownie przeszkolić model.
📖 Przeczytaj również: Jak najlepiej wykorzystać AI do wprowadzania innowacji i zwiększania wydajności
Najlepsze praktyki dotyczące szkolenia Gemini na danych niestandardowych
Samo wykonanie kroków technicznych nie gwarantuje uzyskania doskonałego modelu. Wiele zespołów kończy ten proces, ale jest rozczarowanych wynikami, ponieważ nie stosują strategii optymalizacji wykorzystywanych przez doświadczonych praktyków. To właśnie odróżnia model funkcjonalny od modelu o wysokiej wydajności.
Nic dziwnego, że raport Deloitte „State of Generative AI in the Enterprise” wykazał, iż dwie trzecie firm twierdzi, że 30% lub mniej ich eksperymentów z generatywną sztuczną inteligencją zostanie w pełni wdrożonych w ciągu sześciu miesięcy.
Zastosowanie tych najlepszych praktyk pozwoli Ci zaoszczędzić czas i uzyskać znacznie lepsze wyniki.
- Zacznij od małej skali, a następnie zwiększaj ją: przed przystąpieniem do pełnego szkolenia przetestuj swoje podejście na niewielkim podzbiorze danych (np. 100 przykładach). Pozwoli to zweryfikować format danych i szybko ocenić wydajność bez marnowania czasu.
- Wersjonuj swoje zbiory danych: podczas dodawania, usuwania lub edytowania przykładów szkoleniowych zapisuj każdą wersję swojego zbioru danych. Pozwoli to na śledzenie zmian, odtwarzanie wyników i przywrócenie poprzedniej wersji, jeśli nowa działa gorzej.
- Test przed i po: Przed rozpoczęciem dostosowywania ustal punkt odniesienia, oceniając wydajność modelu bazowego w zakresie kluczowych zadań. Pozwoli to obiektywnie zmierzyć, jak dużą poprawę przyniosły wysiłki dostosowujące.
- Powtarzaj nieudane próby: gdy Twój niestandardowy model generuje błędną lub źle sformatowaną odpowiedź, nie denerwuj się. Dodaj ten konkretny przypadek niepowodzenia jako nowy, poprawiony przykład do danych szkoleniowych na potrzeby kolejnej iteracji.
- Dokumentuj proces: Prowadź dziennik każdego przebiegu szkolenia, odnotowując wersję użytego zestawu danych, hiperparametry i wyniki. Dokumentacja ta jest nieoceniona dla zrozumienia, co działa, a co nie działa w dłuższej perspektywie czasowej.
Zarządzanie tymi iteracjami, wersjami zestawów danych i dokumentacją wymaga solidnego zarządzania projektami. Scentralizowanie tych zadań na platformie zaprojektowanej z myślą o ustrukturyzowanych cyklach pracy może zapobiec chaotycznemu przebiegowi procesu.
Typowe wyzwania podczas szkolenia Gemini
Zespoły często poświęcają dużo czasu i zasobów na dostosowywanie, ale potem napotykają przewidywalne przeszkody, które prowadzą do zmarnowanego wysiłku i frustracji. Znajomość tych typowych pułapek z wyprzedzeniem może pomóc w płynniejszym przejściu przez ten proces.
Oto niektóre z najczęstszych wyzwań i sposoby ich rozwiązania:
- Nadmierne dopasowanie: Dzieje się tak, gdy model doskonale zapamiętuje przykłady szkoleniowe, ale nie potrafi uogólnić nowych, nieznanych danych wejściowych. Aby to naprawić, możesz zwiększyć różnorodność danych szkoleniowych, rozważyć zmniejszenie liczby epok lub sprawdzić alternatywne metody, takie jak generowanie wspomagane odzyskiwaniem.
- Niespójne wyniki: Jeśli model udziela różnych odpowiedzi na bardzo podobne pytania, prawdopodobnie wynika to z faktu, że dane szkoleniowe zawierają sprzeczne lub niespójne przykłady. Aby rozwiązać te konflikty, konieczne jest dokładne oczyszczenie danych.
- Odchylenie formatu: Czasami model zaczyna działać zgodnie z pożądaną strukturą wyjściową, ale z czasem „odchyla się” od niej. Rozwiązaniem jest dołączenie wyraźnych instrukcji dotyczących formatu do wyników przykładów szkoleniowych, a nie tylko do zawartości.
- Powolne cykle iteracji: Gdy każde uruchomienie szkolenia trwa wiele godzin, znacznie spowalnia to możliwość eksperymentowania i wprowadzania ulepszeń. Najpierw przetestuj swoje pomysły na mniejszych zestawach danych, aby uzyskać szybszą informację zwrotną przed uruchomieniem pełnego zadania szkoleniowego.
- Wąskie gardło w gromadzeniu danych: Często najtrudniejszą częścią jest wąskie gardło w gromadzeniu danych, czyli po prostu zebranie wystarczającej liczby wysokiej jakości przykładów. Zacznij od wykorzystania najlepszych istniejących treści — takich jak zgłoszenia do wsparcia technicznego, teksty marketingowe lub dokumenty techniczne — i rozszerzaj je w miarę możliwości.
Te wyzwania są kluczowym powodem, dla którego wiele zespołów ostatecznie poszukuje alternatyw dla ręcznego procesu dostrajania.
📮ClickUp Insight: 88% respondentów naszej ankiety korzysta z AI do zadań osobistych, ale ponad 50% unika używania jej w pracy. Trzy główne przeszkody? Brak płynnej integracji, braki w wiedzy lub obawy dotyczące bezpieczeństwa. A co, jeśli sztuczna inteligencja jest wbudowana w Twój obszar roboczy i jest już bezpieczna? ClickUp Brain, wbudowany asystent AI ClickUp, sprawia, że staje się to rzeczywistością. Rozumie podpowiedzi w prostym języku, rozwiązując wszystkie trzy problemy związane z wdrażaniem sztucznej inteligencji, jednocześnie tworząc połączenie między czatem, zadaniami, dokumentami i wiedzą w całym obszarze roboczym. Znajdź odpowiedzi i spostrzeżenia za pomocą jednego kliknięcia!
Dlaczego ClickUp jest mądrzejszą alternatywą
Precyzyjne dostosowywanie Gemini jest potężnym narzędziem, ale jest to również rozwiązanie zastępcze.
W tym artykule pokazaliśmy, że dostosowywanie sprowadza się ostatecznie do jednego: nauczenia AI rozumienia kontekstu Twojej firmy. Problem polega na tym, że dostosowywanie odbywa się pośrednio. Przygotowujesz zestawy danych, tworzysz przykłady, ponownie trenujesz modele i utrzymujesz potoki, aby AI mogła zbliżyć się do sposobu działania Twojego zespołu.
Ma to sens w przypadku specjalistycznych zastosowań. Jednak dla większości zespołów prawdziwym celem nie jest sama personalizacja Gemini. Cel jest prostszy:
Potrzebujesz AI, która rozumie Twoją pracę.
W tym zakresie ClickUp stosuje zasadniczo inne — i inteligentniejsze — podejście.
Zintegrowany obszar roboczy ClickUp AI zapewnia Twojemu zespołowi sztuczną inteligencję, która natychmiast rozumie kontekst Twojej pracy — bez konieczności wykonywania żmudnych zadań. Zamiast szkolić sztuczną inteligencję, aby nauczyła się Twojego kontekstu w późniejszym czasie, pracujesz z ClickUp Brain, zintegrowanym asystentem AI, w którym Twój kontekst już istnieje.
Twoje zadania, dokumenty, komentarze, historia projektów i decyzje są natywnie połączone. Nie ma potrzeby szkolenia AI na podstawie Twoich danych, ponieważ znajduje się ona już tam, gdzie odbywa się Twoja praca, korzystając z istniejącego ekosystemu zarządzania wiedzą.
| Aspekt | Dostosowywanie Gemini | ClickUp Brain |
|---|---|---|
| Czas ustawień | Przygotowanie danych trwa od kilku dni do kilku tygodni. | Natychmiastowe — działa z istniejącymi danymi obszaru roboczego |
| Źródło kontekstu | Ręcznie wyselekcjonowane przykłady szkoleniowe | Automatyczny dostęp do wszystkich połączonych zadań |
| Konserwacja | Przeprowadź ponowne szkolenie, gdy zmienią się Twoje potrzeby. | Ciągła aktualizacja wraz z rozwojem Twojego obszaru roboczego |
| Wymagane umiejętności techniczne | Umiarkowane do wysokiego | Brak |
Ponieważ ClickUp jest Twoim systemem pracy, ClickUp Brain działa w ramach połączonego wykresu danych. Nie ma rozproszenia AI między niepołączonymi narzędziami, nie ma kruchych procesów szkoleniowych i nie ma ryzyka, że model przestanie być zsynchronizowany z rzeczywistym sposobem pracy Twojego zespołu.
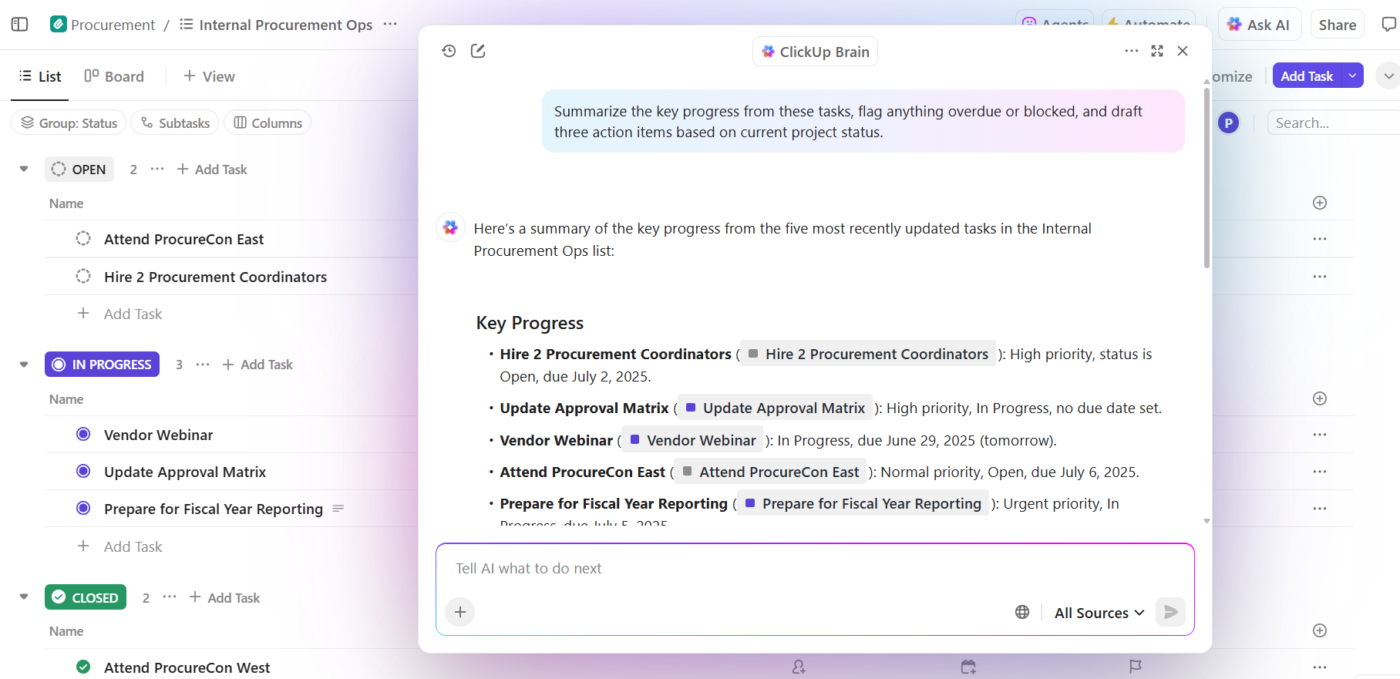
Oto jak wygląda to w praktyce:
- Zadawaj pytania dotyczące swoich projektów: ClickUp Brain przeszukuje obszar roboczy w poszukiwaniu zadań, dokumentów, komentarzy i aktualizacji, aby odpowiedzieć na pytania, korzystając z rzeczywistych danych projektowych, a nie ogólnej wiedzy szkoleniowej.
- Generuj zawartość z kontekstem: ClickUp Brain ma już bezpieczny dostęp do Twoich zadań, plików, komentarzy i historii projektów. Może tworzyć dokumenty, podsumowania i aktualizacje statusu, które odnoszą się do Twojej rzeczywistej pracy, osi czasu i priorytetów. Koniec z rozproszeniem kontekstu, w wyniku którego zespoły tracą godziny na wyszukiwanie informacji w różnych aplikacjach i plikach.
- Automatyzacja z zrozumieniem: Dzięki ClickUp Automations możesz stworzyć automatyzację, która inteligentnie reaguje na kontekst projektu, taki jak terminy, własność i zmiany statusu, a nie tylko statyczne reguły. AI może nawet stworzyć je za Ciebie, bez konieczności pisania kodu.
💡Wskazówka dla profesjonalistów: Wykorzystaj prawdziwą moc AI w swoim obszarze roboczym ClickUp dzięki ClickUp Super Agents.
Super agenci to współpracownicy ClickUp oparci na sztucznej inteligencji — skonfigurowani jako „użytkownicy” AI, którzy współpracują z Twoim zespołem w obszarze roboczym. Są oni otoczeni i kontekstowi, można im przypisywać zadania, dokonywać wzmianek o nich w komentarzach, wywoływać ich za pomocą zdarzeń lub harmonogramów lub kierować za pomocą czatu — tak jak w przypadku ludzkich współpracowników.
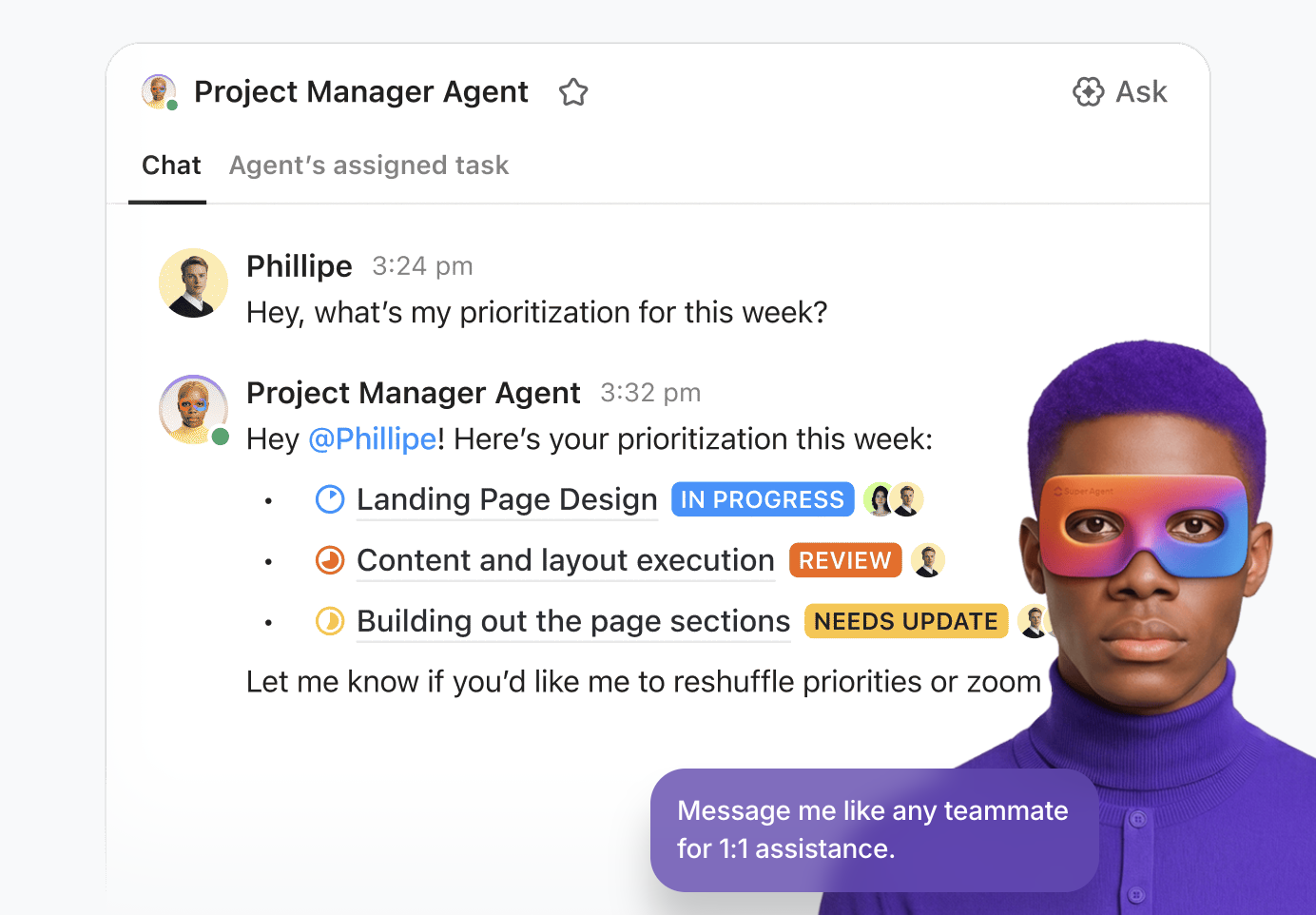
Możesz je tworzyć i wdrażać za pomocą wizualnego kreatora bez kodowania, który umożliwia:
- Określ wydarzenie początkowe, takie jak wiadomość lub zmiana statusu zadania.
- Określ zasady operacyjne, w tym sposób podsumowywania danych, delegowania zadań lub dostosowywania priorytetów.
- Wykonuj działania zewnętrzne za pomocą zintegrowanych narzędzi i rozszerzeń.
- Dostarcz wsparcie, wykonując połączenie agenta z odpowiednimi bazami wiedzy.
Dowiedz się więcej o Super Agents z poniższego wideo.
Dostosuj swoją strategię AI: skorzystaj z ClickUp
Dostosowywanie uczy AI Twoich wzorców poprzez statyczne przykłady, ale użycie zintegrowanego oprogramowania w obszarze roboczym takim jak ClickUp eliminuje rozproszenie kontekstu, zapewniając AI aktualny, automatyczny kontekst.
To podstawa powodzenia transformacji AI: zespoły, które skupiają swoją pracę na jednej platformie, spędzają mniej czasu na szkoleniu AI, a więcej na czerpaniu z niej korzyści. Wraz z rozwojem Twojego obszaru roboczego, Twoja AI rozwija się automatycznie — bez konieczności ponownego szkolenia.
Chcesz pominąć szkolenie i zacząć korzystać z AI, która już zna Twoją pracę? Zacznij bezpłatnie korzystać z ClickUp i poznaj zalety zintegrowanego obszaru roboczego ClickUp.
Często zadawane pytania (FAQ)
Twój dostrojony model uczy się na podstawie przykładów szkoleniowych, ale podstawowy model Gemini firmy Google domyślnie nie zachowuje danych konwersacyjnych ani nie uczy się na ich podstawie. Twój model niestandardowy jest oddzielony od modelu podstawowego, który służy innym użytkownikom.
Chociaż samo szkolenie może zająć tylko kilka godzin, większą inwestycję czasu wymaga przygotowanie wysokiej jakości danych szkoleniowych. Ta faza przygotowania danych często może trwać kilka dni, a nawet tygodni, aby została wykonana prawidłowo.
Tak, możesz dostosować model bez pisania kodu, korzystając z Google AI Studio. Zapewnia ono wizualny interfejs, który obsługuje większość złożonych kwestii technicznych, ale nadal musisz zrozumieć wymagania dotyczące formatowania danych.
Instrukcje niestandardowe to tymczasowe podpowiedzi oparte na sesjach, które kierują zachowaniem modelu podczas pojedynczej rozmowy. Dostrajanie natomiast trwale dostosowuje wewnętrzne parametry modelu na podstawie przykładów szkoleniowych, powodując trwałe zmiany w jego zachowaniu.