

AI zmieniła to, co inżynierowie powinni dokumentować samodzielnie. GitHub Copilot, Cursor i Mintlify mogą generować dokumenty pierwszego rzędu: opisy parametrów, podsumowania funkcji i szkielety plików README. Nie potrafią jednak opisać warstwy intencji: podjętej decyzji, zaakceptowanego kompromisu, istotnego ograniczenia oraz opcji odrzuconej przez zespół.
Kod pokazuje zachowanie. Rzadko zachowuje uzasadnienie. To uzasadnienie zazwyczaj znajduje się w wątku na Slacku, komentarzu do zgłoszenia, przeglądzie incydentów lub w czyjejś pamięci.
Badanie programistów przeprowadzone przez Stack Overflow w 2024 roku wykazało, że 61% profesjonalnych programistów spędza ponad 30 minut dziennie na szukaniu odpowiedzi w pracy, a co czwarty poświęca na to ponad godzinę. Oczywiście niektóre wyszukiwania są nieuniknione. Jednak prawdziwą stratą jest kontekst sprintu, który nigdy nie trafił do dokumentu.
Ten przewodnik pokazuje, co inżynierowie powinni napisać samodzielnie, w czym może pomóc AI oraz jak sprawić, by dokumentacja kodu pozostała przydatna po zakończeniu sprintu.
TL;DR
AI może przygotować szkic warstwy mechanicznej dokumentacji: docstringi, typy parametrów, podsumowania funkcji i szkielety plików README. Inżynierowie nadal muszą opisać warstwę intencji: decyzje, kompromisy, ograniczenia i odrzucone opcje stojące za kodem.
Inżynierowie nadal powinni to robić samodzielnie, w dokumentach dotyczących decyzji architektonicznych, opisach PR oraz komentarzach wyjaśniających dodawanych wraz z kodem. Warstwa intencji zapobiega sytuacji, w której kolejny programista próbuje odtworzyć decyzje na podstawie nazw zmiennych, komunikatów commitów i starych PR-ów. AI może teraz tworzyć szkice rutynowych elementów: typów parametrów, opisów zwracanych wartości oraz podstawowych podsumowań funkcji.
Co tak naprawdę powinna wyjaśniać dokumentacja kodu?
Dokumentacja kodu powinna pomóc kolejnemu programiście zrozumieć, co robi kod, jak z niego bezpiecznie korzystać i dlaczego został zbudowany w ten sposób. Pojawia się ona w dwóch miejscach: wewnątrz plików źródłowych jako komentarze i docstringi oraz poza plikami źródłowymi jako pliki README, dokumentacja API, instrukcje obsługi i notatki dotyczące architektury.
Większość baz kodu staje się trudna do odczytania po zniknięciu kontekstu decyzji. Pierwotny programista mógł dokonać mądrego kompromisu. Kolejny programista widzi jedynie artefakt, a nie uzasadnienie.
W wyniku każdy nowy członek zespołu musi samodzielnie odtwarzać intencje na podstawie nazw zmiennych, komunikatów commitów i starych PR-ów. Spowalnia to wdrażanie nowych pracowników, przeglądy, debugowanie oraz przyszłe zmiany w tym samym obszarze.
Dobra dokumentacja odpowiada na cztery pytania:
- Dla kogo jest ten kod? Dla wewnętrznych programistów, współpracowników oprogramowania open source, zewnętrznych użytkowników API czy użytkowników końcowych
- Jakie problemy rozwiązuje? Potrzeby biznesowe lub techniczne stojące za modułem
- Dlaczego wybrano to podejście? Rozważane alternatywy i zaakceptowane kompromisy
- Gdzie znajdują się powiązane elementy? Moduły z zależnością, usługi nadrzędne, decyzje architektoniczne, zgłoszenia i instrukcje operacyjne
Pytanie „dlaczego” zasługuje na największą uwagę ze strony ludzi.
Wyszukiwanie informacji to już teraz spore obciążenie w pracy umysłowej, nie tylko w inżynierii. Badanie ClickUp dotyczące zarządzania wiedzą pokazało, że 57% pracowników traci czas na szukanie informacji związanych z pracą w wewnętrznych dokumentach lub bazach wiedzy. Kiedy nie mogą znaleźć tego, czego potrzebują, 1 na 6 osób ucieka się do osobistych rozwiązań: przeglądania starych e-maili, notatek lub zrzutów ekranu.
Z dokumentacją kodu jest tak samo: jeśli programiści nie mogą znaleźć wyjaśnienia, to równie dobrze mogłoby ono nie istnieć.
Koszt popełnienia błędu jest wysoki. Jeden z komentujących na r/AskProgramming opisał cykl pracy RPA, w którym nieudokumentowany przycisk omal nie był wyzwalaczem automatycznego naliczenia opłat bankowych i wysłania pism do klientów.
Wyszukiwanie informacji to już teraz spore obciążenie w pracy umysłowej, nie tylko w inżynierii. Badanie ClickUp dotyczące zarządzania wiedzą pokazało, że 57% pracowników traci czas na szukanie informacji związanych z pracą w wewnętrznych dokumentach lub bazach wiedzy. Kiedy nie mogą znaleźć tego, czego potrzebują, 1 na 6 osób ucieka się do własnych rozwiązań: przeglądania starych e-maili, notatek lub zrzutów ekranu.
Z dokumentacją kodu jest tak samo: jeśli programiści nie mogą znaleźć wyjaśnienia, to równie dobrze mogłoby ono nie istnieć.
Koszt popełnienia błędu jest wysoki. Jeden z komentujących na r/AskProgramming opisał cykl pracy RPA, w którym nieudokumentowany przycisk był wyzwalaczem dla automatyzacji bankowej i wywoływania pism do klientów.
Jakie są główne rodzaje dokumentacji kodu?
Pięć głównych typów to komentarze w tekście, docstringi, pliki README, wewnętrzne wiki oraz zewnętrzna dokumentacja API. Każdy z nich jest przeznaczony dla innego czytelnika w innym momencie. Mieszanie ich utrudnia pisanie dokumentacji i korzystanie z niej. Plik README, który brzmi jak docstring, zniechęca nowych współpracowników. Docstring, który brzmi jak strona wiki, staje się zbędnym balastem w plikach źródłowych.
Komentarze w tekście i ciągi dokumentacyjne
Komentarze w tekście kodu powinny wyjaśniać nieoczywiste rozumowanie. Komentarz przekształcający x = x + 1 na „zwiększ x” nic nie wnosi. Komentarz mówiący „przesunięcie dla odpowiedzi API indeksowanej od zera” ma swoje uzasadnienie, ponieważ kod nie może pokazać tego zewnętrznego ograniczenia. Komentarze w tekście kodu należy zarezerwować dla nieoczywistej logiki w treści funkcji.
Docstringi to ustrukturyzowane opisy dołączone do funkcji, klas lub modułów. Obejmują one parametry, wartości zwracane, wyjątki i przykłady użycia. Każdy język ma swoje własne konwencje. Postępuj zgodnie z konwencjami obowiązującymi w danym języku: PEP 257 dla docstringów w Pythonie, Javadoc dla Javy oraz JSDoc dla JavaScriptu i TypeScriptu.
Porównaj te dwa przykłady:
Słaby docstring:
Silny docstring:
Drugi nazywa funkcję w jasny sposób, dokumentuje jej parametry i ujawnia założenie: przepływ realizacji transakcji wykorzystuje stawkę podatku w wysokości 8,25%.
Pliki README, wiki i dokumenty zewnętrzne
Plik README powinien odpowiadać na pięć pytań w następującej kolejności: Czym zajmuje się ten projekt? Jak go zainstalować? Jak z niego korzystać? Jak wnieść swój wkład? Gdzie uzyskać pomoc? Jeśli nowy współpracownik nie może szybko znaleźć ścieżki ustawień, plik README jest albo przeładowany, albo źle uporządkowany.
Wiki i bazy wiedzy sprawdzają się najlepiej w przypadku zawartości obejmującej wiele repozytoriów lub usług: decyzji architektonicznych, przewodników wdrożeniowych i instrukcji operacyjnych. Wiki, do której nikt nie umieszcza linków w kodzie, staje się kolejnym problemem związanym z wyszukiwaniem.
Dokumentacja zewnętrzna obejmuje referencje API, przewodniki SDK oraz dokumenty przeznaczone dla użytkowników. Służy ona odbiorcom Twojego kodu, a nie współpracownikom. Dokumenty zewnętrzne wymagają więcej szczegółów dotyczących ustawień, jaśniejszych kroków uwierzytelniania oraz struktury w stylu referencyjnym, ponieważ czytelnik może w ogóle nie znać Twojego kodu źródłowego.
Jeśli zespół nie ma jeszcze ustalonej struktury, zacznij od szablonu dokumentacji technicznej zawierającego notatki dotyczące architektury i ustawień lub szablonu dokumentacji projektu obejmującego cele, właścicieli, kamienie milowe i decyzje. Dostosuj sekcje zamiast wymyślać format od podstaw.
| Typ | Główna grupa docelowa | Częstotliwość aktualizacji | Typowa lokalizacja |
|---|---|---|---|
| Komentarze w tekście | Programiści analizujący konkretną ścieżkę kodu | Kiedy zmienia się zachowanie kodu | Pliki źródłowe |
| Ciągi dokumentacyjne | Programiści wywołujący funkcję, klasę lub moduł | Kiedy zmienia się interfejs | Pliki źródłowe |
| README | Nowi współpracownicy i oceniający | W przypadku każdej większej aktualizacji lub zmiany w projekcie | Katalog główny repozytorium |
| Wiki lub baza wiedzy | Zespoły wewnętrzne i interesariusze z różnych zespołów | W miarę zmian decyzji lub procesów | Wiki repozytorium lub wspólna baza wiedzy |
| Zewnętrzna dokumentacja API | Użytkownicy API i użytkownicy końcowi | W zależności od wydania lub wersji API | Platforma dokumentacyjna |
Jak obecnie wygląda proces tworzenia dokumentacji?
Wykorzystaj AI do tworzenia tych części, które jest w stanie sporządzić. Poświęć czas na podejmowanie decyzji, analizę ograniczeń i kompromisów.
Sztuczna inteligencja może obecnie przygotować większość rutynowych zadań: typy parametrów, opisy zwracanych wartości oraz podstawowe podsumowania funkcji. Praca człowieka związana z dokumentacją dzieli się na dwie kategorie.
Najpierw pisz kod samodokumentujący się
Najlepszą dokumentacją jest kod, który prawie jej nie potrzebuje. Opisowe nazwy, funkcje o jednym przeznaczeniu i spójne konwencje zmniejszają obciążenie związane z dokumentacją, zanim jeszcze napiszesz pierwszy komentarz.
Kod samodokumentujący się ułatwia odczytanie zachowania. Rzadko wyjaśnia jednak uzasadnienie tego zachowania. Nazwy pomagają programistom zidentyfikować, co dana funkcja robi. Dokumentacja powinna wyjaśniać to, czego nie da się przekazać za pomocą nazwy.
Przed dodaniem komentarza zadaj sobie pytanie, czy zmiana nazwy zmiennej lub wyodrębnienie funkcji nie sprawi, że komentarz stanie się zbędny. Jeśli odpowiedź brzmi „tak”, najpierw przeprowadź refaktoryzację. Jasna nazwa pozwala uniknąć komentarzy, które jedynie tłumaczą nieodpowiednie nazewnictwo.
Wcześniej:
Po:
Zrefaktoryzowana wersja przekazuje te same informacje wyłącznie poprzez nazewnictwo. Jedynym przydatnym komentarzem byłoby teraz wyjaśnienie, dlaczego niektóre role są wykluczone, co jest decyzją polityczną, której sam kod nie jest w stanie wyrazić.
Napisz warstwę intencji (część, której AI nie jest w stanie stworzyć)
Wdrożenie ma widoczność w kodzie. Zamiar znika, chyba że ktoś go zapisze. Kod rzadko zachowuje informacje o tym, dlaczego dokonano kompromisu, jakie ograniczenia wpłynęły na projekt lub która alternatywa została odrzucona.
Dobrze oddaje to powszechna zasada wśród programistów: dokumentuj „dlaczego”, a nie „co”. Najwyżej oceniony komentarz na r/coding:
Widzę, że to rozgałęzienie warunkowe rozdziela użytkowników na czerwonych i niebieskich. Powiedz mi, dlaczego użytkownicy są tak klasyfikowani i dlaczego rozdzielamy ich w ten sposób.
Widzę, że ten warunek rozgałęzia się między użytkownikami z grupy czerwonej i niebieskiej. Powiedz mi, dlaczego użytkownicy są tak klasyfikowani i dlaczego rozgałęziamy się między nimi.
Komentarz do commitu może pomóc podczas przeglądu, ale nie jest dobrym długoterminowym miejscem na uzasadnienie projektu, ponieważ przyszli czytelnicy rzadko znajdują go w momencie, gdy go potrzebują.
Will Larson, były dyrektor ds. technologii w Calm i autor książki An Elegant Puzzle, napisał o wartości rejestrów decyzji architektonicznych, ponieważ pozwalają one zachować uzasadnienie inżynieryjne poza bazą kodu.
Dokumenty ADR są przydatne, ponieważ zapewniają stałe miejsce na uzasadnienie projektu. Jeśli Twój zespół nie ma ustalonego formatu, skorzystaj z prostego szablonu ADR: decyzja, kontekst, rozważane opcje, kompromisy i konsekwencje.
Skoncentruj swoją dokumentację na następujących kategoriach:
- Decyzje projektowe i alternatywy: „W tym przepływie płatności wybraliśmy pamięć podręczną typu write-through zamiast write-back, ponieważ spójność danych ma większe znaczenie niż opóźnienie zapisu”.
- Znane ograniczenia: dług techniczny, ograniczenia skalowalności, tymczasowe rozwiązania lub obszary wymagające przyszłego uporządkowania
- Założenia: Oczekiwane formaty danych wejściowych, wymagania środowiskowe lub zależności od elementów wyższego poziomu, których kod nie wymusza
- Referencje: Linki do odpowiednich zgłoszeń, dokumentów RFC lub protokołów decyzji architektonicznych (ADR), które wyjaśniają szerszy kontekst
Różne konteksty wymagają różnych miejsc. Docstringi oddają intencje na poziomie funkcji. Komentarze w kodzie zajmują się uzasadnieniem na poziomie linii. Opisy PR dostarczają kontekstu na poziomie zmian. ADR zajmują się decyzjami na poziomie systemu. Komunikaty commit również pomagają, ale nie powinny być jedynym zapisem ważnej decyzji.
Typowy antywzorzec: dokumentowanie działania algorytmu sortowania linia po linii. Prawdziwym pytaniem jest, dlaczego zastosowano niestandardowe sortowanie zamiast biblioteki standardowej. W przypadku niestandardowych ścieżek kodu należy udokumentować decyzję stojącą za implementacją.
Jakie są najważniejsze najlepsze praktyki w zakresie dokumentacji?
Pięć praktyk sprawia, że dokumentacja ma większe szanse pozostać przydatna po zakończeniu sprintu. Większość innych porad dotyczących dokumentacji opiera się na tym, że te nawyki są najpierw wdrażane.
- Dokumentuj podczas pisania kodu, a nie po. Kontekst szybko się zmienia. Do następnego sprintu zapomnisz, którą alternatywę odrzuciłeś i dlaczego. Napisz komentarz wyjaśniający w tym samym commitie co kod, bo inaczej w ogóle go nie napiszesz
- Stosuj spójny przewodnik stylistyczny. Wybierz jeden format docstringów, taki jak styl Google, styl NumPy, Javadoc lub JSDoc, i egzekwuj go podczas przeglądu kodu lub lintingu. Spójność ma większe znaczenie niż sam wybór formatu. Wspólny przewodnik stylistyczny eliminuje pytanie „jak to sformatować?” i umożliwia automatyczny linting
- Traktuj dokumentację jako część przeglądu kodu. Dodaj sprawdzanie dokumentacji do swojej listy kontrolnej przeglądu PR. Jeśli PR zmienia zachowanie, recenzent powinien sprawdzić, czy dokumentacja odzwierciedla tę zmianę. Dokumentacja Google dotycząca praktyk inżynieryjnych wymaga od recenzentów sprawdzenia, czy kod jest odpowiednio udokumentowany. Stosuj tę samą zasadę wewnętrznie: jeśli PR zmienia zachowanie, recenzenci powinni sprawdzić, czy komentarze, docstringi, pliki README i instrukcje nadal są zgodne
- Usuń nieaktualną dokumentację. Przestarzałe dokumenty wyrządzają realne szkody, ponieważ kierują czytelników w stronę niewłaściwej implementacji, API lub procesu. Sprawdzaj dokumentację co kwartał lub przed każdą większą aktualizacją. Wyznacz osobę odpowiedzialną za własność dokumentów, aby dokumentacja nie była obowiązkiem wszystkich, a tym samym nikogo.
- Przykłady powinny być gotowe do uruchomienia. Przykłady kodu powinny być łatwe do skopiowania, uruchomienia i przetestowania. To najbezpieczniejszy sposób na wykrycie odchyleń, zanim zrobią to użytkownicy
Jakich narzędzi należy używać do generowania dokumentacji kodu?
Narzędzia do dokumentacji dzielą się na dwie grupy: tradycyjne generatory i asystentów AI. Pełnią one różne funkcje.
Tradycyjne generatory analizują skomentowane fragmenty kodu źródłowego i tworzą przeglądalne referencje. Wybór odpowiedniego generatora zależy zazwyczaj od używanego języka programowania.
| Narzędzie | Język/ekosystem | Co generuje |
|---|---|---|
| Javadoc | Java | Dokumentacja API na podstawie komentarzy w dokumentacji |
| JSDoc | JavaScript/TypeScript | Dokumentacja API na podstawie opatrzonych adnotacjami komentarzy |
| Sphinx | Python (ofertuje wsparcie dla innych języków za pośrednictwem wtyczek) | Kompletne strony dokumentacji z reStructuredText lub Markdown |
| Doxygen | C, C++, Java, Python i inne | Dokumentacja referencyjna obejmująca różne języki |
| Godoc | Przejdź | Dokumentacja pakietu na podstawie komentarzy w kodzie źródłowym |
Jakość wyników zależy całkowicie od twoich docstringów. One formatują i publikują to, co napisałeś. Nie wymyślają brakujących intencji.
Asystenci oparci na sztucznej inteligencji stanowią dodatkowy poziom. GitHub Copilot, Cursor i Windsurf mogą tworzyć komentarze i ciągi dokumentacyjne bezpośrednio w edytorze. Mintlify pomaga generować i utrzymywać dokumentację dla programistów na podstawie kodu i istniejącej dokumentacji. Swimm skupia się na powiązaniu dokumentacji wewnętrznej ze zmianami w kodzie. ReadMe i GitBook pomagają zespołom publikować referencje API i dokumentację dla programistów, często z funkcjami wyszukiwania lub tworzenia treści wspomaganymi przez AI.
Badanie Stack Overflow wykazało, że dokumentacja była najczęściej wymienianą kategorią automatyzacji opartej na AI , pojawiającą się w około 33,9% otwartych odpowiedzi programistów. Narzędzia te sprawdzają się najlepiej, gdy kod źródłowy już jasno przedstawia zachowanie.
AI traci na skuteczności, gdy wyjaśnienie zależy od decyzji podjętych poza bazą kodu: wątku na Slacku, spotkania planistycznego, zgłoszenia lub przeglądu incydentu. Potrafi ona podsumować działanie funkcji. Nie jest jednak w stanie określić, które ograniczenie podlegało negocjacji, która opcja została odrzucona ani dlaczego zaakceptowano dany kompromis.
Praktyczny cykl pracy:
- Pozwól AI przygotować szkielet: podsumowanie funkcji, parametry, wartości zwracane i typowe wyjątki
- Porównaj to z rzeczywistym zachowaniem kodu
- Dodaj uzasadnienie: decyzję, ograniczenie, założenie lub odrzuconą alternatywę
- Napisz ADR dla decyzji na poziomie systemu
- Nie publikuj dokumentów wygenerowanych przez AI bez ich sprawdzenia
Gdzie ClickUp się sprawdza, a gdzie nie
ClickUp nie jest generatorem dokumentacji na poziomie kodu. Nie zastąpi Javadoc, Sphinx, JSDoc ani Godoc. Pomaga w tworzeniu dokumentacji związanej z kodem: plików README, instrukcji obsługi, przewodników dla nowych pracowników, ADR i dzienników decyzji, które powinny pozostawać połączone z zadaniami, zgłoszeniami i sprintami, w wyniku których powstały.
ClickUp Docs pozwala tworzyć te dokumenty równolegle z pracą inżynierską, a ClickUp Brain może stworzyć dokument na podstawie kontekstu zadania lub projektu, a następnie programiści mogą dodać uzasadnienie decyzji, ograniczenia i kompromisy.
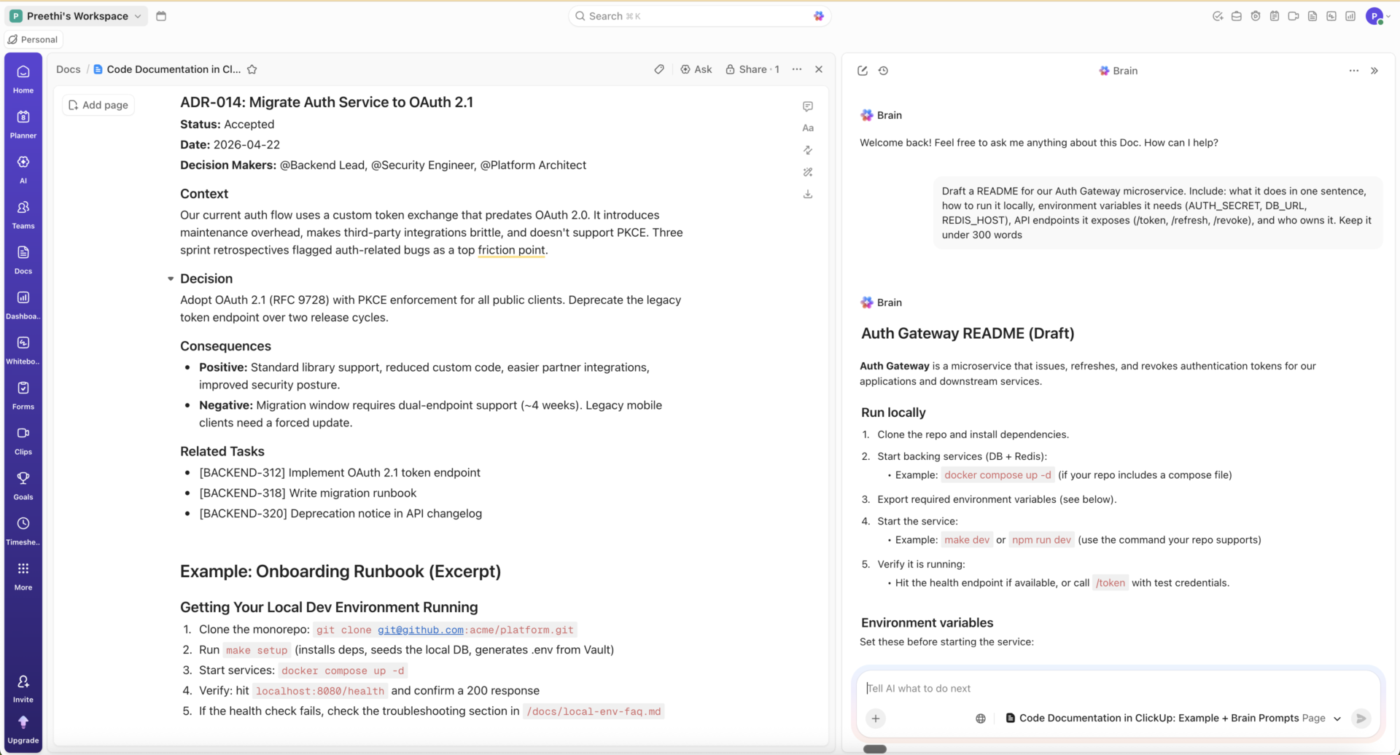
Dla zespołów inżynierów oznacza to mniej czasu spędzonego na przeszukiwaniu rozproszonych dokumentów, czatów i zgłoszeń, a więcej czasu na utrwalanie decyzji, które te narzędzia zazwyczaj ukrywają.
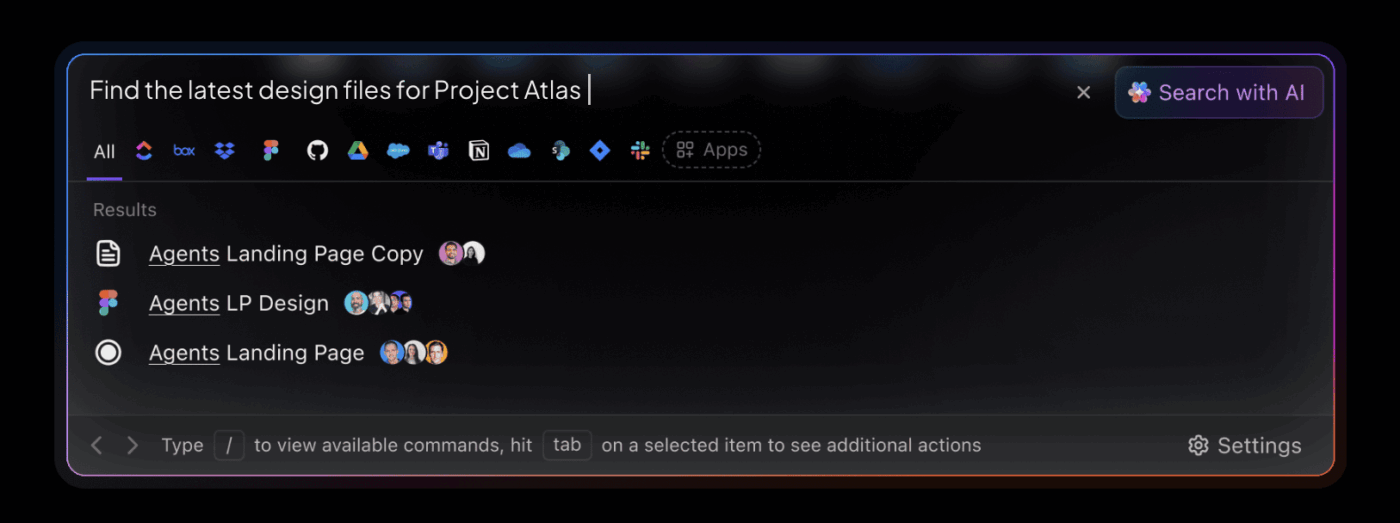
Jeśli Twoim problemem jest to, że „nasza dokumentacja jest zakończona pod względem technicznym, ale nikt nie może jej znaleźć”, to jest to problem z wykrywalnością. Pomocne może być połączone obszar roboczy.
Jeśli Twoim problemem jest to, że „nasza dokumentacja API jest nieaktualna”, to jest to problem związany z generatorem i weryfikacją. Sphinx, Javadoc, JSDoc lub Godoc pomogą bardziej niż narzędzie do zarządzania obszarem roboczym. Nie myl tych dwóch rzeczy.
Co się zmienia, gdy AI tworzy większość dokumentacji?
Na każdym z wątków r/developersIndia, r/webdev i r/AskProgramming krąży powtarzający się żart dotyczący dokumentacji inżynierskiej. Kiedy ktoś pyta, jak zespół radzi sobie z dokumentacją, najpopularniejsza odpowiedź brzmi zazwyczaj mniej więcej tak: „Ja jestem dokumentem”.
To zabawne, bo prawdziwe. Od lat rozwiązaniem w przypadku brakującej dokumentacji jest inżynier, który akurat coś pamięta.
AI zmienia punkt odniesienia. Potrafi szybko sporządzać rutynową dokumentację, co sprawia, że trudniej jest usprawiedliwić brak udokumentowanych decyzji. Kiedy AI potrafi w kilka sekund stworzyć szkielet mechanicznych części dokumentów, stwierdzenie „po prostu to zapamiętam” przestaje być akceptowalne jako system ewidencyjny.
To sprawia, że praca inżyniera skupia się na intencjach, decyzjach i kompromisach: elementach, których sama składnia nie jest w stanie wyjaśnić.
Wiele starych porad dotyczących dokumentacji zostało napisanych z myślą o cyklu pracy sprzed ery AI. Kładą one duży nacisk na opisy parametrów, sygnatury funkcji i wyczerpujące notatki dotyczące ustawień.
AI może obecnie przygotować większość tych materiałów. Jeśli inżynierowie poświęcają większość czasu na tworzenie mechanicznych podsumowań, skupiają swoją uwagę na warstwie o najniższej wartości.
Poświęć ten czas na opisanie intencji: dlaczego funkcja istnieje, którą opcję odrzuciłeś i na jakich założeniach opiera się kod. To są notatki, których będzie potrzebował Twój przyszły zespół, agenci kodujący oparci na AI oraz inżynier, który przejmie bazę kodu w 2027 roku.
Jeśli Twoim problemem związanym z dokumentacją jest rozproszony kontekst, ClickUp może pomóc w utrzymaniu historii decyzji bliżej zadań, dokumentów i projektów, które ją stworzyły.
Często zadawane pytania dotyczące dokumentacji kodu
Czym jest plik README?
Plik README przechodzi pierwszy test, gdy współpracownik może szybko znaleźć pięć rzeczy: co robi projekt, jak go zainstalować, jak z niego korzystać, jak wnieść swój wkład i gdzie uzyskać pomoc. Jeśli ustawienia są ukryte pod odznakami, notatkami dotyczącymi architektury lub szczegółami dziennika zmian, plik README jest źle uporządkowany.
Jaka jest różnica między komentarzami w kodzie a dokumentacją?
Komentarze w kodzie znajdują się wewnątrz plików źródłowych i wyjaśniają konkretne linie lub bloki. Dokumentacja zazwyczaj znajduje się poza plikami źródłowymi, w plikach README, na stronach wiki, w wygenerowanych witrynach referencyjnych lub w dokumentacji API. Komentarze pomagają kolejnemu programiście, który czyta Twoją funkcję. Dokumentacja pomaga kolejnej osobie, która próbuje korzystać z Twojego projektu, uruchamiać go lub wnieść do niego swój wkład.
Czym jest warstwa intencji w dokumentacji kodu?
Warstwa intencji to część dokumentacji kodu, która opisuje, dlaczego kod istnieje, a nie co robi: podjętą decyzję, zaakceptowany kompromis, ograniczenie, które wpłynęło na projekt, oraz opcję odrzuconą przez zespół. Kod pokazuje zachowanie; warstwa intencji zachowuje uzasadnienie. Narzędzia AI, takie jak GitHub Copilot i Mintlify, mogą tworzyć szkice warstwy mechanicznej (typy parametrów, podsumowania funkcji), ale nie potrafią wywnioskować warstwy intencji na podstawie składni. Zazwyczaj znajduje się ona w rejestrach decyzji architektonicznych, opisach PR lub komentarzach, które wyjaśniają dlaczego, a nie co.
Jak często należy aktualizować dokumentację kodu?
Aktualizuj dokumentację w tym samym pull request, który zmienia podstawowe zachowanie. Jeśli zmienia się sygnatura funkcji, docstring zmienia się w tym PR. W przypadku plików README i dokumentacji architektury przeprowadzaj audyt co najmniej raz na wydanie lub co kwartał. Nieaktualna dokumentacja jest niebezpieczna, ponieważ uczy czytelników niewłaściwego zachowania, API lub procesu.
Jakie są cztery rodzaje dokumentacji?
Powszechnie stosowany framework Diátaxis dzieli dokumentację na cztery typy: samouczki (zorientowane na naukę, dla początkujących), poradniki (zorientowane na zadania, dla użytkowników rozwiązujących konkretny problem), materiały referencyjne (zorientowane na informacje, dla użytkowników szukających szczegółów) oraz wyjaśnienia (zorientowane na zrozumienie, dla użytkowników poszukujących kontekstu). Ich mieszanie tworzy dokumentację, z której nikt nie może skorzystać. Plik README, który próbuje być pełnym samouczkiem, może ukryć ścieżkę ustawień. Strona referencyjna napisana jak esej może ukryć wywołanie API.
Jak dokumentować kod za pomocą AI?
Wykorzystaj AI do warstwy mechanicznej, a warstwę intencji napisz samodzielnie. Narzędzia takie jak GitHub Copilot, Cursor i Mintlify mogą tworzyć szkice ciągów dokumentacyjnych, opisów parametrów, wartości zwracanych i podsumowań funkcji bezpośrednio w redaktorze. Porównaj szkic z rzeczywistym zachowaniem kodu, a następnie dodaj elementy, których AI nie jest w stanie wywnioskować: uzasadnienie decyzji, ograniczenia, które do niej doprowadziły, odrzucone opcje oraz wszelkie założenia, na których opiera się kod. W przypadku decyzji na poziomie systemu napisz protokół decyzji architektonicznej. Nigdy nie publikuj dokumentów wygenerowanych przez AI bez weryfikacji przez człowieka.
Czy dokumentacja generowana przez AI jest wiarygodna?
Dokumentacja generowana przez sztuczną inteligencję jest przydatna w przypadku zadań mechanicznych, takich jak opisy parametrów, wartości zwracane i podstawowe podsumowania funkcji, ale nadal wymaga weryfikacji przez człowieka. Narzędzia takie jak GitHub Copilot, Cursor, Codeium i Mintlify dobrze sobie z tym radzą. Sztuczna inteligencja nie jest w stanie wywnioskować, dlaczego dokonano kompromisu, jakie alternatywy zostały odrzucone ani jakie ograniczenia związane z produktem, biznesem lub infrastrukturą wpłynęły na projekt. Wykorzystaj sztuczną inteligencję do stworzenia pierwszego szkicu. Samodzielnie dodaj intencje i kontekst.
Czy każda funkcja wymaga docstringu?
Nie. Publiczne interfejsy API i wszelkie funkcje, z których będą korzystać inni programiści, wymagają dokumentacji. Prywatne funkcje pomocnicze używane w jednym pliku zazwyczaj jej nie wymagają, chyba że logika działania nie jest oczywista. Nadmierna dokumentacja trywialnego kodu powoduje obciążenie związane z utrzymaniem kodu, nie zwiększając przy tym przejrzystości. Dostosuj poziom szczegółowości dokumentacji do odbiorców funkcji.
Jakie jest najlepsze narzędzie do generowania dokumentacji kodu?
Wybór odpowiedniego narzędzia zależy od używanego języka. Zespoły pracujące w Javie używają Javadoc, zespoły JavaScript i TypeScript korzystają z JSDoc, zespoły Python używają Sphinx, zespoły Go korzystają z Godoc, a Doxygen obsługuje C, C++ i kilka innych języków. Narzędzia wspomagane przez sztuczną inteligencję, takie jak Mintlify, Swimm, Copilot i Cursor, mogą pomóc w tworzeniu lub utrzymywaniu dokumentacji w różnych częściach cyklu pracy, ale nie zastępują generatorów natywnych dla danego języka.
Jak długi powinien być plik README?
Wystarczająco długi, aby szybko odpowiedzieć na podstawowe pytania: co robi projekt, jak go zainstalować, jak z niego korzystać, jak wnieść swój wkład i gdzie uzyskać pomoc. Bardziej szczegółowe informacje dotyczące ustawień, architektury i API umieść w połączonych dokumentach lub podkatalogach.