

Sei un responsabile di reparto alla ricerca della persona perfetta per svolgere un’attività specifica. Con una grande quantità di dati aziendali, trovare la persona più adatta è quasi impossibile, soprattutto se la tua attività è urgente.
Inoltre, chi ha il tempo di chiedere a tutti se hanno conoscenze sufficienti su un'area specifica?
Ma cosa succederebbe se potessi semplicemente chiedere a un sistema: "A chi è stata assegnata più spesso [attività]?" e ottenere una risposta immediata e accurata basata su dati reali? Questo è ciò che fanno i sistemi di recupero delle informazioni.
Questi sistemi setacciano montagne di dati per trovare esattamente ciò di cui hai bisogno.
Ora, estendi questa idea a un database globale: un sistema IR organizza grandi quantità di dati, aiutandoti a trovare le risposte più pertinenti in pochi secondi. Questa guida esplorerà diversi modelli di recupero delle informazioni, il loro funzionamento e il ruolo delle tecnologie IA in un sistema IR.
⏰ Riepilogo/riassunto in 60 secondi
📌 I sistemi di recupero delle informazioni (IR) aiutano a trovare informazioni rilevanti da grandi raccolte di dati, funzionando come un assistente virtuale che setaccia i dati per trovare ciò di cui hai bisogno.
📌 I sistemi IR hanno componenti chiave: database, indicizzatore, interfaccia di ricerca, processore di query, modelli di recupero e meccanismi di classificazione/punteggio.
📌 Vengono utilizzati quattro modelli IR principali: booleano (utilizza operatori AND/OR/NOT), Spazio vettoriale (rappresenta i documenti come vettori), Probabilistico (utilizza approcci statistici) e Interdipendenza dei termini (analizza le relazioni tra i termini).
📌 L'apprendimento automatico e l'elaborazione del linguaggio naturale migliorano i sistemi IR ottimizzando il riconoscimento dei modelli, il posizionamento dei risultati e la comprensione del contesto.
📌 Le sfide principali includono la privacy dei dati, la scalabilità e il mantenimento della qualità dei dati durante l'elaborazione di grandi set di dati.
Che cos'è il recupero delle informazioni (IR)?
Il recupero delle informazioni (IR) significa semplicemente trovare le informazioni giuste da grandi raccolte di dati, come biblioteche digitali, database o archivi Internet.
È come avere un assistente virtuale che setaccia montagne di dati per fornirti esattamente ciò di cui hai bisogno. *
A prima vista, l'utente inserisce una query, spesso utilizzando parole chiave o frasi, per cercare informazioni specifiche. Dietro le quinte, tecniche e algoritmi avanzati analizzano le stringhe di ricerca e le abbinano ai dati pertinenti.
Anziché identificare una sola risposta, i sistemi IR forniscono diversi oggetti, ciascuno con diversi gradi di rilevanza rispetto alla tua query. Inoltre, sono utilizzati ovunque e hanno molteplici applicazioni (ne parleremo presto 🔔).
💡Suggerimento professionale: hai bisogno di trovare la persona più qualificata per un'attività? Inserisci termini specifici come "analisi del rapporto commerciale Q1 e Q2 attività assegnate a" nel sistema di recupero delle informazioni. In questo modo, il sistema filtra rapidamente i dati irrilevanti e individua chi se ne è occupato maggiormente.
Applicazioni dell'IR in diversi campi
Dall'assistenza sanitaria all'e-commerce, i sistemi IR vengono utilizzati in numerosi campi per gestire e classificare i dati. Ecco alcuni esempi 👇
Assistenza sanitaria
Nel settore sanitario, i sistemi IR scansionano i database delle cartelle cliniche e dei documenti di ricerca per aiutare medici e ricercatori a trovare le informazioni più rilevanti. Come risultato, accelerano la diagnosi delle malattie, identificano le opzioni terapeutiche e trovano gli studi più pertinenti utilizzando feedback rilevanti.
Servizio clienti personalizzato
Le tecniche di recupero delle informazioni rendono il supporto clienti più rapido e accurato. Ad esempio, gli agenti possono digitare domande degli utenti come "politica di rimborso" nel sistema aziendale per recuperare risposte immediate.
I chatbot IA e gli help desk basati sul recupero delle informazioni fanno un passaggio avanti, offrendo soluzioni in tempo reale senza il coinvolgimento umano. Ecco perché spesso le tue domande ricevono una risposta in pochi secondi!
Piattaforme di e-commerce
I sistemi IR rendono lo shopping online un gioco da ragazzi. Analizzano i database e abbinano il comportamento dei clienti per consigliare prodotti che ti piaceranno.
Ad esempio, Amazon utilizza l'IR per suggerire elementi in base alla cronologia delle ricerche e agli acquisti precedenti, aiutandoti a trovare esattamente ciò di cui hai bisogno.
Componenti di un sistema di recupero delle informazioni
Ora sappiamo cos'è il recupero delle informazioni e come funziona. Analizziamo gli elementi fondamentali di un sistema IR. →
1. Database
Tutto inizia con il database. Si tratta di una raccolta di dati correlati tra loro, come documenti di testo, email, pagine web, immagini e video. Quando inserisci una determinata query, il sistema IR effettua una ricerca tra questi risultati del database per recuperare le informazioni più rilevanti per le tue esigenze.
2. Indicizzatore
Prima che il sistema possa recuperare qualsiasi cosa, l'indicizzatore organizza i dati. È come preparare un catalogo di biblioteca per velocizzare la ricerca. L'indicizzatore elabora i documenti:
- Tokenizzazione: suddivisione dei contenuti in parti più piccole, come la suddivisione delle frasi in parole o frasi (chiamate token).
- Stemming: semplificazione delle parole alla loro forma base (ad esempio, "running" diventa "run").
- Rimozione delle parole inutili: salta le parole di riempimento come "e", "o" e "il" per concentrarti sulla query principale.
- Estrazione delle parole chiave: identificazione delle parole chiave principali nel testo
- Estrazione dei metadati: ricavare dettagli aggiuntivi come l'autore, la data di pubblicazione o il titolo.
3. Interfaccia di ricerca
L'interfaccia di ricerca funge da gateway per il sistema IR. È qui che digiti la tua query utilizzando semplici parole chiave o filtri più dettagliati. Progettata per essere facile da usare, ti consente di comunicare facilmente le tue esigenze di accesso alle informazioni e ottenere i risultati pertinenti che stai cercando.
4. Processore di query
Una volta premuto "Cerca", il processore di query prende il controllo. Affina il tuo input applicando le tecniche elencate nella sezione indicizzatore. Inoltre, gestisce anche operatori booleani come "AND", "OR" e "NOT" per rendere la tua query più intelligente.
5. Modelli di recupero
È qui che avviene la magia. Il sistema confronta la tua query con i documenti indizzati utilizzando modelli di recupero. Questi metodi decidono come abbinare la tua query ai dati memorizzati. Alcuni dei nomi più comuni includono:
- Modelli booleani
- Modelli di spazio vettoriale
- Modelli probabilistici
- E molto altro ancora... (di cui parleremo più avanti)
6. Classificazione e punteggio
Una volta individuati i potenziali risultati corrispondenti, il sistema li classifica in base alla rilevanza. Ogni documento ottiene un punteggio utilizzando metodi come TF-IDF (Term Frequency-Inverse Document Frequency) o altri algoritmi. Ciò garantisce che il risultato più rilevante appaia in cima alla lista.
7. Presentazione o visualizzazione
Infine, ti vengono presentati i risultati. In genere, il sistema mostra un elenco ordinato di documenti di testo con funzionalità/funzioni aggiuntive come snippet, filtri o opzioni di ordinamento. Ciò rende più facile selezionare il documento più pertinente. Tuttavia, il numero di risultati visualizzati può variare in base alle tue preferenze, alla query o alle impostazioni di sistema.
🔍Lo sapevi?: I sistemi tradizionali di recupero delle informazioni si basavano principalmente su database strutturati e sulla corrispondenza di parole chiave di base. Il risultato? Gravi problemi di pertinenza e personalizzazione.
È stato allora che le moderne tecnologie di IA hanno trasformato il recupero di testi attraverso:
- Apprendimento automatico (ML): aiuta i sistemi IR ad apprendere dai modelli di comportamento degli utenti e a migliorare i risultati di ricerca nel tempo.
- Reti neurali profonde: algoritmi in grado di elaborare dati non strutturati (come immagini o video) e scoprire relazioni complesse.
- Elaborazione del linguaggio naturale (NLP): consente ai sistemi di comprendere il significato e il contesto delle query per fornire supporto al riconoscimento delle immagini e all'analisi del sentiment, rendendo l'accesso alle informazioni più versatile.
Modelli di recupero delle informazioni
Esistono diversi sistemi IR che semplificano il processo di ricerca dei documenti pertinenti. Diamo un'occhiata a quelli più utilizzati:
1. Teoria degli insiemi e modelli booleani
Il modello booleano è una delle tecniche di recupero delle informazioni più semplici. Ecco come funziona:
- AND: Recupera i documenti contenenti tutti i termini della query. Ad esempio, una ricerca di "gatto AND cane" restituirà i documenti che contengono menzioni di entrambi su un motore di ricerca.
- OR: Trova i documenti che contengono uno qualsiasi dei termini nella query. Per "gatto OR cane", recupera i documenti che contengono una menzione di gatto, cane o entrambi.
- NOT: Esclude i documenti che contengono un termine specifico. Ad esempio, "gatto AND NOT cane" restituisce i documenti che contengono una menzione del gatto ma non del cane.
Questo modello utilizza il concetto di "bag of words" (insieme di parole), in cui viene creata una matrice 2D. In questa matrice:
- Le colonne rappresentano i documenti
- Le righe rappresentano i termini della query
A ogni cella viene assegnato un valore di 1 (se il termine è presente) o 0 (se non lo è).

✅ Pro
- Facile da comprendere e implementare
- Recupera i documenti che corrispondono esattamente ai termini della query
❌ Contro
- I modelli booleani non classificano i documenti in base alla rilevanza, quindi tutti i risultati sono considerati ugualmente importanti.
- Si concentra sulla corrispondenza esatta dei termini, quindi i risultati possono variare in base al significato o al contesto della query.
2. Modelli di spazio vettoriale
Un modello Vector Space è un modello algebrico che rappresenta sia i documenti che le query come vettori in uno spazio multidimensionale. Ecco come funziona:
1. Viene creata una matrice termine-documento, in cui le righe sono i termini e le colonne sono i documenti.
2. Viene formato un vettore di query basato sui termini di ricerca dell'utente.
3. Il sistema calcola un punteggio numerico utilizzando una misura chiamata similarità coseno, che determina quanto il vettore di query corrisponda ai vettori dei documenti.

Come sistema di recupero delle informazioni, i documenti vengono quindi classificati in base a questi punteggi, con quelli con il punteggio più alto che risultano i più rilevanti.
✅ Pro
- Recupera gli elementi anche se solo alcuni termini corrispondono
- Variazioni nell'uso dei termini e nella lunghezza dei documenti, adattandosi a diversi tipi di documenti
❌ Contro
- Vocabolari e raccolte di documenti più grandi rendono i calcoli di similarità molto dispendiosi in termini di risorse.
3. Modelli probabilistici
Questo modello adotta un approccio statistico, utilizzando la probabilità per stimare la pertinenza di un documento rispetto alla query. Esso tiene conto di:
- Frequenza dei termini nel documento
- Con quale frequenza i termini compaiono insieme (occorrenza)
- Lunghezza del documento e numero totale di termini di query
Il sistema tratta il processo di recupero come un evento probabilistico, classificando i documenti archiviati in base alla loro probabilità di rilevanza. Questo approccio aggiunge profondità valutando gli oggetti di dati oltre la semplice presenza di termini di base.
✅ Pro
- Si adatta bene a varie applicazioni, tra cui analisi di affidabilità e valutazioni del flusso di carico.
❌ Contro
- Si basa su ipotesi relative alle relazioni tra i dati, che possono portare a risultati fuorvianti.
4. Modelli di interdipendenza dei termini
A differenza dei modelli più semplici, i modelli di interdipendenza dei termini si concentrano sulle relazioni tra i termini piuttosto che sulla loro frequenza. Questi modelli analizzano come le parole e le frasi sono correlate tra loro per migliorare l'accuratezza dei risultati.
Utilizzano uno dei due approcci seguenti:
- Modalità immanente: esplora le relazioni all'interno del testo stesso.
- Modalità trascendente: considera dati o contesti esterni per dedurre relazioni
Questo metodo è particolarmente utile per cogliere le sfumature di significato, come i sinonimi o le frasi specifiche del contesto.
✅ Pro
- Cattura le sfumature linguistiche considerando le relazioni tra i termini
- Migliora le prestazioni di recupero comprendendo le dipendenze dei termini e il contesto
❌ Contro
- Richiede dati approfonditi per modellare accuratamente le relazioni tra i termini, che potrebbero non essere sempre disponibili.
Ecco fatto! Questi sono alcuni dei sistemi di recupero delle informazioni più comunemente utilizzati, con i loro pro e contro.
➡️ Per saperne di più: 4 alternative e concorrenti di Spotlight Search
Recupero delle informazioni vs. query dei dati
Sebbene questi due termini sembrino quasi identici, funzionano in modo diverso. Mettiamo quindi a confronto IR e Data Querying per vedere come si differenziano in termini di scopo, casi d'uso ed esempi:
| Aspetto | Ricerca delle informazioni (IR) | Interrogazione dei dati |
| Definizione | Funziona come un motore di ricerca che setaccia tonnellate di dati per fornirti i risultati più pertinenti. | Immagina di porre una domanda specifica a un database in un linguaggio che esso comprende (come SQL). |
| Obiettivo/Scopo | Ti aiuta a trovare informazioni o risorse accurate e pertinenti sui motori di ricerca, in modo facile e veloce. | Estrai dati precisi in modo da poter analizzare, aggiornare o elaborare i numeri. |
| Casi d'uso | Utilizzato per ricerche sul web, consigli di e-commerce, biblioteche digitali, approfondimenti sanitari e altro ancora. | Ottimo per attività come la gestione delle scorte nell'e-commerce, l'analisi delle finanze e l'ottimizzazione delle catene di approvvigionamento. |
| Esempio | Cerca "I migliori laptop tra 800 e 1000 dollari" su Google per ottenere risultati classificati | Esegui una query sul tuo sistema di inventario con "SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000" per trovare ciò che è disponibile in magazzino. |
Il ruolo dell'apprendimento automatico e dell'NLP nel recupero delle informazioni
I sistemi IR sono come cacciatori di tesori per i dati: setacciano enormi quantità di informazioni per trovare esattamente ciò che stai cercando. Ma quando ML e NLP uniscono le forze, questi sistemi diventano più intelligenti, più veloci e molto più precisi.
Pensa al ML come al cervello dietro i sistemi IR. 🧠
Aiuta il sistema ad apprendere, adattarsi e migliorare i risultati ogni volta che cerchi informazioni. Ecco come funziona:
- Individuazione dei modelli: il ML studia ciò su cui gli utenti cliccano, ciò che ignorano e ciò che leggono più a lungo. Quindi utilizza queste informazioni per mostrarti i risultati più pertinenti la volta successiva.
- Risultati di classificazione: ML recupera le informazioni e le classifica. Ciò significa che i risultati migliori e più utili vengono visualizzati nella parte superiore della ricerca.
- Adattarsi al tempo: con ogni query, il ML migliora. Rileva le tendenze, affina la sua comprensione e gestisce facilmente anche le domande più complesse.
Ad esempio, se oggi cerchi "i migliori laptop economici" e interagisci con risultati specifici, il ML saprà dare la priorità a opzioni simili quando in seguito cercherai "notebook convenienti". Combinando l'IA con il ML, i motori di ricerca web possono persino prevedere ciò di cui potresti aver bisogno in futuro.
Ora parliamo di NLP. Aiuta i sistemi IR a capire cosa intendi, non solo le parole che digiti. In parole semplici:
- Comprende il contesto: l'NLP sa che quando dici "jaguar" potresti riferirti all'animale o all'auto, e lo capisce in base al resto della tua query.
- Gestisce linguaggi complessi: che la tua query sia semplice ("voli economici") o dettagliata ("voli diretti per Tokyo sotto i 500 dollari"), l'NLP assicura che il sistema comprenda e fornisca i risultati corretti.
Insieme, NLP e IR rendono la ricerca intuitiva, come parlare con qualcuno che ti capisce al volo. Ciò significa meno scorrimento, meno frustrazione e più momenti in cui pensi: "Wow, è proprio quello che mi serviva!".
Il ruolo di ClickUp nel recupero delle informazioni
ClickUp, l'app completa per il lavoro, migliora la gestione dei dati con i modelli IR.
La sua IA integrata identifica e abbina in modo unico i risultati alla query dell'utente, portando la tecnologia intelligente a un livello superiore.
E per rendere il tutto ancora più interessante, la funzione Connected Search di ClickUp ti consente di avere tutto ciò di cui hai bisogno "immediatamente" a portata di mano. Ciò significa che:
- Cerca qualsiasi cosa: a chi piace sfogliare email e sistemi di gestione delle conoscenze per individuare file importanti? Trova qualsiasi file in pochi secondi utilizzando l'opzione Ricerca connessa. Meglio ancora, cerca i file nelle tue app connesse e accedi a tutto in un unico posto.
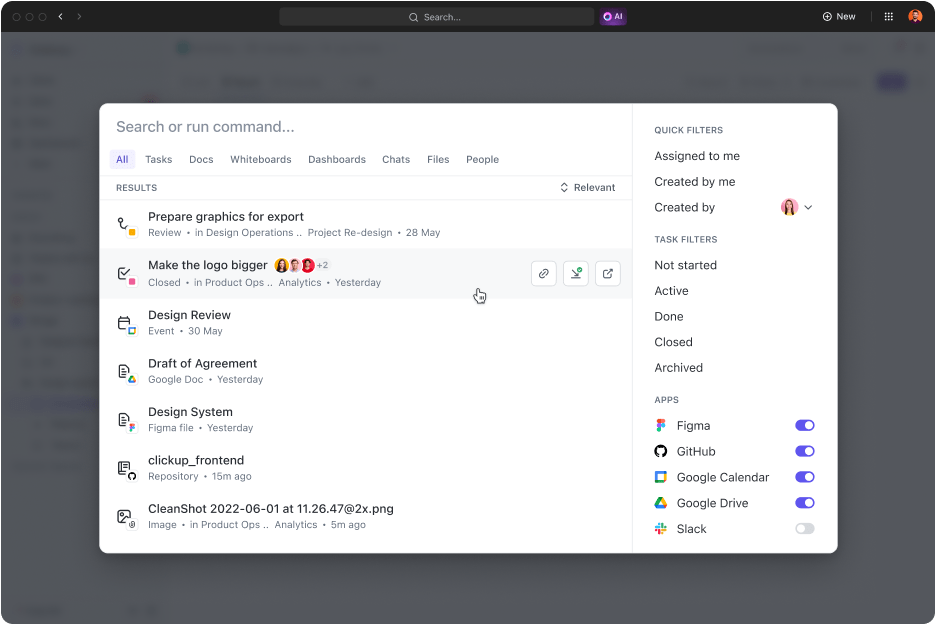
- Collega le tue app preferite: ClickUp offre alcune delle migliori integrazioni che estendono le sue capacità di ricerca ad app di terze parti come Google Drive, Slack, Dropbox, Figma e altre ancora.

- Affina i risultati: più lo usi, più diventa bravo a capire cosa stai cercando, fornendoti risultati su misura per te.
- Cerca a modo tuo: accedi alla ricerca connessa e cerca rapidamente i file PDF da qualsiasi punto della tua area di lavoro. Ad esempio, puoi avviare una ricerca dal Centro di comando, dalla barra delle azioni globali o dal tuo desktop.
- Crea comandi di ricerca personalizzati: aggiungi comandi di ricerca personalizzati come scorciatoie ai link, archiviazione di testo per un uso successivo e altro ancora per semplificare il tuo flusso di lavoro.
E se esistesse un modo per automatizzare le attività noiose, lavorare più velocemente e portare a termine più cose in meno tempo?
ClickUp Brain, l'assistente IA integrato, rende tutto questo realtà. È l'assistente definitivo per la gestione dei dati: intelligente, veloce e sempre pronto ad aiutarti.
In breve 👇
- Hub di conoscenza all-in-one: non affidarti più alle email e ai messaggi per gli aggiornamenti. Chiedi qualsiasi cosa sui tuoi compiti, documenti o persone e rilassati mentre ClickUp Brain mappa le risposte in base al contesto dall'interno e dalle app collegate.

- Trova più rapidamente ciò che ti serve: ClickUp Brain classifica i risultati in modo intelligente, come un sistema IR avanzato. Assegna la priorità ai file rilevanti, suggerisce attività correlate e ti aiuta persino a scoprire carichi di lavoro nascosti nei tuoi dati.
- Automatizza le attività: Brain automatizza la generazione di report o il monitoraggio delle scadenze attraverso i suoi strumenti di IA. È un assistente personale che ti libera tempo per decisioni più importanti, mantenendo tutto sotto controllo.
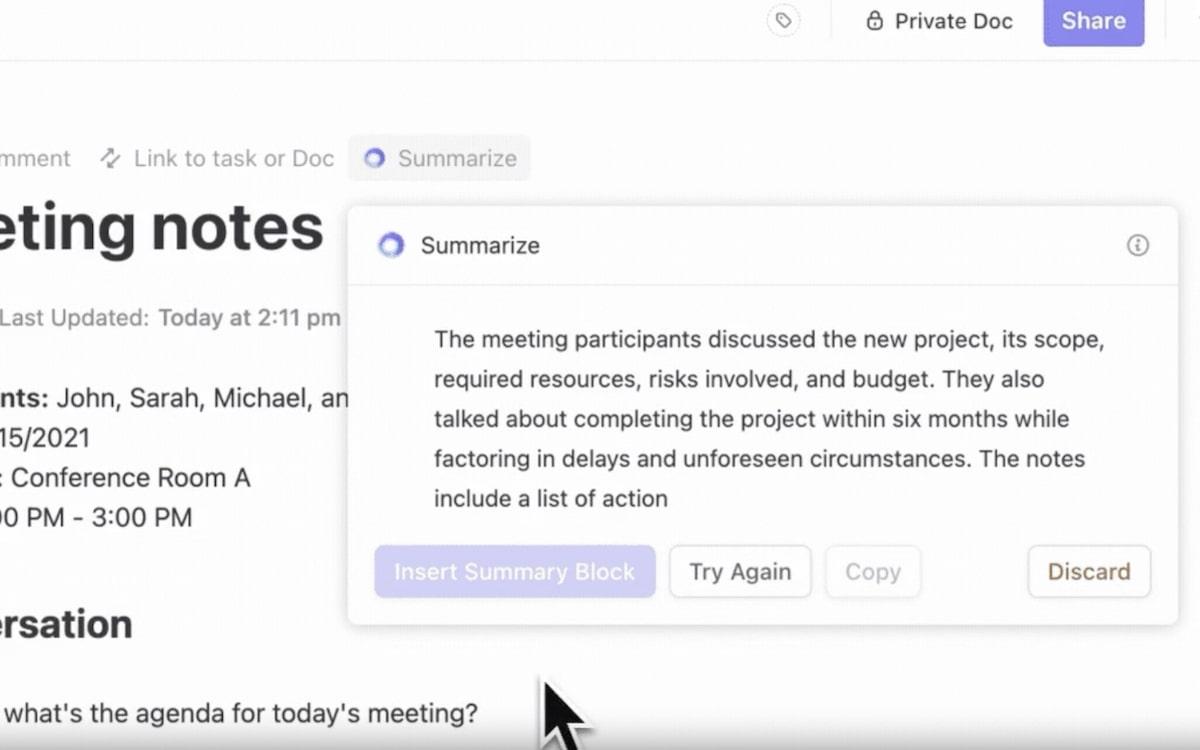
- Ricerca sensibile al contesto: grazie alla NLP, comprende la tua domanda, anche se la tua query è complessa o vaga. Ad esempio, cercando "rapporto sulle vendite del primo trimestre" otterrai il rapporto esatto collegato alla tua attività.
➡️ Per saperne di più: Che cos'è un sistema di gestione del lavoro e come implementarlo?
Sfide e prospettive future nel recupero delle informazioni
Il mondo del recupero delle informazioni consiste nel dare un senso a grandi quantità di dati, ma anche i sistemi IR più avanzati incontrano qualche ostacolo lungo il percorso.
Esploriamo le sfide comuni e le interessanti tendenze che stanno dando forma al futuro di questa disciplina scientifica essenziale:
- Privacy e sicurezza dei dati: affinché un modello IR fornisca risultati oggettivi, spesso è necessario accedere a dati sensibili. Tuttavia, proteggere i dati degli utenti non è un gioco da ragazzi per le risorse di recupero delle informazioni.
- Scalabilità e prestazioni: quando gli utenti effettuano ricerche in grandi set di dati, la gestione di una raccolta di contenuti in aumento può sovraccaricare anche i modelli di recupero più robusti. La sfida consiste nel garantire un recupero efficiente senza compromettere la pertinenza dei risultati di ricerca.
- Qualità dei dati e comprensione contestuale: query ambigue o metadati mal organizzati possono portare a discrepanze, rendendo difficile per il sistema identificare in modo univoco l'intenzione dell'utente.
Tendenze emergenti e progressi nella tecnologia IR
Nonostante i numerosi ostacoli, i recenti progressi tecnologici ci hanno permesso di costruire sistemi più intelligenti ed efficienti.
I moderni sistemi di recupero delle informazioni utilizzano ora metodi avanzati come l'analisi basata su grafici per interpretare i numeri, il testo e il contesto, i metadati e le relazioni tra i punti dati.
Cosa significa questo per gli utenti? Consente un recupero dei testi più preciso e un'analisi dettagliata, soprattutto in campi come la ricerca e le industrie che trattano grandi quantità di dati.
In combinazione con le tecnologie del web semantico, si concentra sulle stringhe di ricerca e sull'intento dell'utente. Questi sistemi possono andare oltre le corrispondenze letterali e recuperare documenti altamente pertinenti, anche per query utente complesse nel processo di recupero delle informazioni.
Ad esempio, cercando "vantaggi del lavoro da remoto" è possibile ottenere risultati relativi alla produttività, alla salute mentale e all'equilibrio tra vita lavorativa e vita privata, tutto perché il sistema comprende le connessioni.
Recupera rapidamente i documenti con la gestione dei dati di ClickUp
Cercare quel documento importante tra file, app e strumenti infiniti è estenuante. Immagina di provare ad analizzare i documenti recuperati come ricercatore, studente, professionista IT o data scientist: diventa solo un miscuglio di informazioni sovraccariche.
Ma con ClickUp non perderai mai più tempo a cercare informazioni.
È la soluzione all-in-one che riunisce tutto il tuo lavoro in un unico posto. Con funzionalità/funzioni come Connected Search e ClickUp Brain, non importa dove si trovano i tuoi dati: ClickUp ti consente di trovarli, gestirli e agire su di essi con facilità.
Perché accontentarti di qualcosa di "solo ok" quando puoi avere qualcosa di "fantastico"? Prova ClickUp gratis e scopri come trasforma il tuo flusso di lavoro in qualcosa di audace, efficiente e decisamente inarrestabile!