
Vous êtes sûr que le document existe. Vous l'avez vu la semaine dernière.
Mais après avoir essayé toutes les combinaisons de mots-clés possibles (« résultats marketing T3 », « performances troisième trimestre », « rapport marketing octobre »), la barre de recherche de votre entreprise reste vide. Cette recherche d'informations frustrante est un signe classique d'une recherche par mots-clés obsolète.
Ces systèmes ne trouvent que les correspondances exactes et passent à côté de ce que vous voulez réellement dire. Cohere résout efficacement ce problème en fournissant une couche de recherche intelligente qui établit la connexion entre vos systèmes.
Si vous vous demandez comment utiliser Cohere pour la recherche d'entreprise, nous avons la solution. Ce guide vous explique tout.
Qu'est-ce que Cohere IA et pourquoi est-ce important pour la recherche d'entreprise ?
Cohere est une plateforme d'IA qui crée des modèles linguistiques à grande échelle (LLM) spécialement destinés à une utilisation en entreprise. Pour la recherche interne, cela signifie passer d'une recherche basée sur des mots-clés à une recherche sémantique et intelligente qui comprend l'intention, le contexte et le sens.
La plupart des outils de recherche d'entreprise s'appuient encore sur la correspondance littérale des mots-clés. Si les mots exacts n'apparaissent pas dans le titre ou le corps d'un document, le résultat est souvent manqué. Cohere change cela en permettant aux systèmes de recherche de comprendre ce que l'utilisateur recherche réellement, et pas seulement ce qu'il a tapé.
Les équipes qui tentent de créer elles-mêmes un moteur de recherche basé sur l'IA passent généralement des mois à assembler des bases de données vectorielles, à intégrer des pipelines et à reclasser des modèles. Même après tout ce travail, la recherche est souvent peu performante, car elle se trouve dans un système distinct de celui où le travail est réellement effectué, déconnectée des tâches, des documents et des flux de travail.
Un outil de recherche d'entreprise puissant tel que Cohere utilise la génération augmentée par la récupération (RAG) pour combiner la recherche intelligente et l'IA. Cette approche transforme vos connaissances internes en une ressource accessible instantanément.
Dans le cas de Cohere, l'outil convertit les documents en intégrations, des représentations numériques de la signification. Lorsqu'un utilisateur recherche « rapport trimestriel sur les revenus », le système récupère des documents conceptuellement pertinents tels que « Résultats financiers du quatrième trimestre » ou « Résumé des bénéfices », même si ces mots-clés exacts ne sont pas présents.
C'est pourquoi Cohere est important pour la recherche d'entreprise. Il réduit la complexité de la mise en œuvre, améliore la précision des résultats et permet une recherche qui fonctionne de la même manière que les employés pensent et posent des questions dans les systèmes de travail modernes.
📮ClickUp Insight : Plus de la moitié des employés (57 %) perdent du temps à rechercher des informations liées au travail dans les documents internes ou la base de connaissances de l'entreprise.
Et quand ils n'y parviennent pas ? 1 personne sur 6 a recours à des solutions de contournement personnelles, fouillant dans d'anciens e-mails, notes ou captures d'écran juste pour reconstituer le puzzle.
ClickUp Brain élimine la recherche en fournissant des réponses instantanées, alimentées par l'IA, extraites de l'ensemble de votre environnement de travail et des applications tierces intégrées, afin que vous obteniez ce dont vous avez besoin sans difficulté.
Principales fonctionnalités de Cohere pour la recherche d'entreprise
Lorsque vous évaluez des solutions de recherche basées sur l'IA, le battage marketing peut rendre difficile l'identification des fonctionnalités qui résolvent réellement vos problèmes. Les promesses génériques d'une « recherche plus intelligente » n'aident pas vos équipes d'ingénieurs et de produits à prendre des décisions éclairées.
En réalité, un système de recherche fiable repose sur un ensemble de modèles d'IA distincts qui fonctionnent ensemble.
Cohere propose plusieurs modèles que vous pouvez utiliser indépendamment ou combiner pour créer une architecture de recherche sophistiquée. Comprendre ces fonctionnalités essentielles est la première étape pour concevoir un système qui répond aux besoins spécifiques de votre équipe.
Intégration pour la recherche vectorielle sémantique
La plus grande frustration avec les anciens systèmes de recherche est leur incapacité à trouver des informations conceptuellement liées. Vous recherchez « guide d'intégration des employés » et vous passez à côté du document au titre « Checklist pour le premier jour des nouveaux employés ». Cela se produit parce que le système fait correspondre les mots, et non le sens.
Le modèle Embed, avec recherche neuronale, résout ce problème en convertissant le texte en vecteurs, de longues listes de nombres qui capturent la signification sémantique. Ce processus, appelé intégration, permet au système d'identifier des documents conceptuellement similaires, même s'ils ne partagent aucun mot-clé commun. En substance, votre outil de recherche comprend automatiquement les synonymes et les idées connexes.
Voici les principaux aspects du modèle d'intégration de Cohere :
- Assistance multimodale : la dernière version, Embed 4, peut traiter à la fois du texte et des images, ce qui vous permet d'effectuer des recherches simultanées dans différents types de contenu.
- Fonctionnalités multilingues : vous pouvez rechercher des informations dans des documents rédigés dans différentes langues sans avoir à les traduire au préalable.
- Options de dimensionnalité : vous pouvez choisir la taille de vos vecteurs. Les dimensions plus élevées capturent davantage de nuances, mais nécessitent plus d'espace de stockage et de puissance de traitement.
📖 En savoir plus : Cas d'utilisation de la recherche d'entreprise par IA
Reclassement pour améliorer la pertinence des résultats
Parfois, une recherche renvoie une liste de documents pertinents, mais le plus important se trouve enfoui dans la deuxième page. Cela oblige les utilisateurs à passer au crible les résultats, ce qui leur fait perdre du temps et leur confiance dans le système de recherche.
Il s'agit d'un problème de classement. Le système a trouvé les bonnes informations, mais n'a pas réussi à les classer correctement par ordre de priorité.
Le modèle Rerank de Cohere résout ce problème grâce à un processus en deux étapes. Tout d'abord, vous utilisez une méthode de recherche rapide (comme la recherche sémantique) pour rassembler un grand nombre de documents potentiellement pertinents. Ensuite, vous transmettez cette liste au modèle Rerank, qui utilise une architecture d'encodeurs croisés plus gourmande en ressources informatiques pour analyser chaque document par rapport à votre requête spécifique et les réorganiser afin d'obtenir une pertinence maximale.
Cela s'avère particulièrement utile dans les situations à haut risque où la précision est essentielle, par exemple lorsqu'un agent d'assistance trouve la bonne réponse pour un client ou qu'un membre de l'équipe recherche une section spécifique dans un document. Bien que cela ajoute un léger temps de traitement, l'amélioration de la qualité des résultats en vaut souvent la peine.
📖 En savoir plus : Exemples et cas d'utilisation de l'automatisation des flux de travail
Cas d'utilisation de la recherche d'entreprise pour les équipes
Les capacités de l'IA abstraite sont intéressantes, mais elles ne deviennent utiles que lorsque vous les appliquez pour résoudre des problèmes commerciaux concrets. Une mise en œuvre réussie de la recherche d'entreprise commence par l'identification de ces points faibles spécifiques. 👀
Voici quelques scénarios pratiques dans lesquels les équipes peuvent appliquer la recherche optimisée par Cohere :
- Recherche dans la base de connaissances: aidez vos employés à trouver des réponses dans la documentation interne, les wikis, la base de connaissances du service client et les procédures opératoires normalisées (SOP) .
- Service client : permettez aux agents de trouver rapidement les articles d'aide pertinents et les résolutions de tickets antérieures lorsqu'ils sont en ligne avec un client. Une analyse de McKinsey montre que l'application de l'IA générative aux flux de travail du service client permet de gagner 30 à 45 % en productivité.
- Juridique et conformité : recherchez des millions de contrats, de politiques et de documents réglementaires grâce à la compréhension sémantique afin de trouver des clauses ou des précédents spécifiques.
- Recherche et développement : permettez aux ingénieurs de trouver des travaux antérieurs, des brevets et de la documentation technique pertinente afin d'éviter la duplication des efforts.
- RH et intégration : présentez les politiques, les supports de formation, les exemples de flux de travail et les procédures pertinents pour les nouvelles recrues afin qu'elles puissent trouver elles-mêmes les réponses à leurs questions.
- Aide à l'équipe commerciale : aidez les commerciaux à trouver les bonnes études de cas, les informations sur la concurrence et les informations sur les produits afin de conclure plus rapidement les ventes.
Le fil commun est qu'une recherche d'entreprise efficace doit être intégrée à la gestion existante des flux de travail. Une barre de recherche autonome ne suffit pas. Votre équipe doit être en mesure de trouver des informations et d'agir immédiatement sans avoir à changer d'outil.
🛠️ Boîte à outils : créez un hub interne que votre équipe utilisera réellement. Le modèle de base de connaissances de ClickUp permet de tout organiser de manière claire et facile à rechercher, des modes d'emploi aux procédures opératoires normalisées, afin que personne ne se demande où se trouvent les informations.

Comment configurer Cohere pour la recherche d'entreprise
Passer de l'évaluation de la recherche IA à sa mise en œuvre effective peut sembler intimidant. Surtout si votre équipe n'est pas familiarisée avec les grands modèles linguistiques.
Bien que la complexité de votre installation dépende de votre taille et de votre infrastructure technologique existante, les étapes fondamentales pour créer un système de recherche optimisé par Cohere sont les mêmes. Cette section fournit un guide pratique pour aider votre équipe technique.
Conditions préalables et accès à l'API
Avant d'écrire le moindre code, vous devez mettre en place vos outils et vos accès. Cette installation initiale permet d'éviter les problèmes de sécurité et les obstacles ultérieurs.
Voici ce dont vous aurez besoin pour commencer :
- Compte API Cohere : inscrivez-vous sur le site web de Cohere pour obtenir vos clés API.
- Environnement de développement : la plupart des équipes utilisent Python, mais des SDK sont disponibles pour d'autres langages.
- Base de données vectorielle : vous aurez besoin d'un espace pour stocker les intégrations de vos documents, comme Pinecone, Weaviate, Qdrant ou un service géré comme Amazon OpenSearch.
- Corpus de documents : rassemblez le contenu que vous souhaitez rendre consultable (par exemple, fichiers PDF, fichiers de texte, enregistrements de bases de données).
Vous pouvez également accéder aux modèles Cohere via Amazon Bedrock, ce qui peut simplifier la facturation et la sécurité si votre entreprise travaille déjà dans l'écosystème AWS.
Générez des intégrations avec Cohere Embed
L'étape suivante consiste à convertir vos documents en vecteurs consultables. Ce processus implique de préparer votre contenu, puis de le traiter à l'aide du modèle Cohere Embed.
La manière dont vous préparez vos documents, en particulier la manière dont vous les divisez en petits morceaux, a un impact considérable sur la qualité de la recherche. C'est ce qu'on appelle votre stratégie de découpage.
Les stratégies de segmentation courantes comprennent :
- Morceaux de taille fixe : la méthode la plus simple, mais elle peut diviser de manière maladroite des phrases ou des idées en leur milieu.
- Segmentation sémantique : une méthode plus avancée qui respecte la structure du document, comme la coupure à la fin des paragraphes ou des sections.
- Morceaux qui se chevauchent : cette approche inclut une petite quantité de texte répété entre les morceaux afin de préserver le contexte d'un morceau à l'autre.
Une fois vos documents fragmentés, vous les envoyez par lots à l'API Embed afin de générer les représentations vectorielles. Il s'agit généralement d'un processus unique pour vos documents existants, les documents nouveaux ou mis à jour étant intégrés au fur et à mesure de leur création.
📖 En savoir plus : Qu'est-ce qu'un moteur de recherche interne ? Les meilleurs outils et leur fonctionnement
Stockez et effectuez des requêtes sur des vecteurs
Vos vecteurs nouvellement créés ont besoin d'un emplacement. Une base de données vectorielle est une base de données spécialisée conçue pour stocker et effectuer des requêtes sur les intégrations en fonction de leur similitude.
Le processus de requête fonctionne comme suit :
- Un utilisateur saisit une requête de recherche.
- Votre application envoie cette requête au même modèle Cohere Embed afin de la convertir en vecteur.
- Ce vecteur de requête est envoyé à la base de données, qui trouve les vecteurs de documents les plus similaires.
- La base de données renvoie les documents correspondants, que vous pouvez ensuite afficher à l'utilisateur.
Lorsque vous choisissez une base de données vectorielle, vous devez également réfléchir à l'indicateur de similarité à utiliser. La similarité cosinus est la plus courante pour la recherche basée sur le texte, mais d'autres options existent pour différents cas d'utilisation.
| Indicateur de similarité | Idéal pour |
|---|---|
| Similitude cosinus | Recherche de texte à usage général |
| Produit scalaire | Lorsque l'amplitude des vecteurs est importante |
| Distance euclidienne | Données spatiales ou géographiques |
Mettez en œuvre le reclassement pour obtenir de meilleurs résultats.
Pour de nombreuses applications, les résultats de votre base de données vectorielle sont suffisants. Mais lorsque vous avez besoin du meilleur résultat possible, il est judicieux d'ajouter une étape de reclassement.
Cela est particulièrement important lorsque votre recherche alimente un système RAG, car la qualité de la réponse générée dépend fortement de la qualité du contexte récupéré.
Le processus de reclassement est simple :
- Récupérez un ensemble plus large de candidats initiaux à partir de votre base de données vectorielle (par exemple, les 50 premiers résultats).
- Transmettez la requête initiale de l'utilisateur et cette liste de candidats à l'API Cohere Rerank.
- L'API renvoie la même liste de documents, mais réorganisée en fonction d'un score de pertinence plus précis.
- Affichez les meilleurs résultats de la liste reclassée à l'utilisateur.
Pour mesurer l'impact du reclassement, vous pouvez suivre des indicateurs d'évaluation hors ligne, tels que le nDCG (gain cumulatif normalisé actualisé) et le MRR (rang réciproque moyen).
💫 Pour un aperçu visuel de la mise en œuvre des fonctionnalités de recherche d'entreprise, regardez cette présentation qui illustre les concepts clés et les considérations pratiques :
Bonnes pratiques pour la recherche d'entreprise optimisée par Cohere
La création d'un système de recherche n'est que la première étape. C'est la maintenance et l'amélioration de sa qualité au fil du temps qui font la différence entre un projet de réussite et un projet raté. Si les utilisateurs ont quelques mauvaises expériences, ils perdront confiance et cesseront d'utiliser l'outil. 🛠️
Voici quelques enseignements tirés de la mise en œuvre réussie de la recherche d'entreprise :
- Commencez par la recherche hybride : ne vous fiez pas uniquement à la recherche sémantique. Combinez-la avec un algorithme de recherche par mot-clé traditionnel, tel que BM25. Vous bénéficierez ainsi du meilleur des deux mondes : la recherche sémantique trouve des éléments conceptuellement liés, tandis que la recherche par mot-clé vous permet de trouver des correspondances exactes pour les codes produit ou les noms spécifiques.
- Investissez dans l'hygiène et la qualité des données: la qualité de vos résultats de recherche dépend de celle de vos données. Des documents propres, bien structurés, avec des titres et des paragraphes clairs produisent des intégrations de bien meilleure qualité.
- Divisez judicieusement : la manière dont vous divisez vos documents en morceaux est essentielle. Au lieu d'utiliser des limites de caractères arbitraires, essayez d'aligner les morceaux avec la structure logique de vos documents, comme les paragraphes ou les sections.
- Ajoutez un filtrage par métadonnées : la recherche sémantique est puissante, mais parfois, les utilisateurs savent déjà ce qu'ils recherchent. Permettez-leur de filtrer les résultats par métadonnées telles que la date, le service ou le type de document avant que la recherche sémantique ne se lance.
- Surveillez et itérez : soyez attentif à ce que vos utilisateurs recherchent, aux résultats sur lesquels ils cliquent et aux requêtes qui ne donnent aucun résultat. Ces données sont précieuses pour identifier les lacunes en matière de contenu et améliorer votre système.
- Gérez les échecs avec élégance : aucun système de recherche n'est parfait. Lorsqu'une recherche donne de mauvais résultats, fournissez des solutions de rechange utiles, comme suggérer d'autres requêtes ou proposer de contacter un expert humain.
📖 En savoir plus : Recherche personnalisée : améliorez la productivité et l'expérience sur le lieu de travail
Limites de Cohere pour la recherche d'entreprise
Bien que Cohere soit un fournisseur de modèles d'IA puissants, il ne s'agit pas d'une solution prête à l'emploi (pas exactement).
La mise en place d'une solution de recherche d'entreprise prête à l'emploi s'accompagne de défis importants que les équipes sous-estiment souvent. Il est essentiel de comprendre ces limites pour prendre une décision éclairée et éviter des surprises coûteuses à l'avenir.
Le principal problème est que vous obtenez un ensemble d'outils, et non un produit fini. Votre équipe est donc chargée de créer et de maintenir l'ensemble de l'infrastructure autour de la recherche en tant que service.
Voici quelques-unes des principales limites à prendre en compte :
| Défi | Pourquoi cela pose-t-il problème ? |
|---|---|
| Nécessite une expertise spécialisée | Vous avez besoin d'ingénieurs expérimentés en IA et en données pour créer, exploiter et assurer la maintenance du système. Ce n'est pas quelque chose que la plupart des équipes peuvent mettre en place ou posséder à la légère. |
| Intégrations personnalisées requises | Les modèles ne se connectent pas automatiquement à vos outils existants. Chaque source de données doit être connectée et soumise à une maintenance manuelle. |
| Maintenance continue élevée | Les index de recherche doivent être constamment actualisés à mesure que le contenu change ou que les modèles sont mis à jour, ce qui ajoute un travail opérationnel continu. |
| Non connecté à votre environnement de travail | L'IA comprend le langage, mais elle n'est pas présente là où votre équipe travaille réellement, ce qui crée un décalage entre la recherche et l'exécution. |
| Le changement de contexte est inévitable | Les utilisateurs trouvent les informations à un seul endroit, puis changent d'outil pour les exploiter, ce qui nuit à la productivité et à l'adoption. |
📖 En savoir plus : Modèles gratuits de base de connaissances dans Word et ClickUp
Comment utiliser ClickUp comme alternative à la recherche d'entreprise
À présent, le compromis devrait être évident.
La recherche d'entreprise est puissante, mais la créer soi-même implique de gérer les pipelines d'ingestion, les stratégies de segmentation, les actualisations des intégrations, la logique de reclassement et la maintenance continue. Il s'agit d'un engagement infrastructurel à long terme, et non d'un simple déploiement de fonctionnalités.
En tant que premier environnement de travail IA convergent au monde, ClickUp supprime toute cette couche en intégrant la recherche alimentée par l'IA à l'environnement de travail lui-même.
Cela est important, car la plupart des problèmes de recherche ne sont pas vraiment des problèmes de recherche. Il s'agit plutôt de problèmes liés à la dispersion du travail . Lorsque le travail est dispersé entre différents outils déconnectés, les équipes sont obligées de rechercher constamment le contexte. Le résultat est une perte de temps, une duplication des efforts et des décisions prises sans visibilité totale.
ClickUp s'attaque à ce problème à la source en regroupant le travail, le contexte et l'intelligence dans un seul environnement de travail. Voyons comment cela fonctionne dans la pratique.
Obtenez des réponses contextuelles à partir de l'ensemble des environnements de travail avec ClickUp Brain.
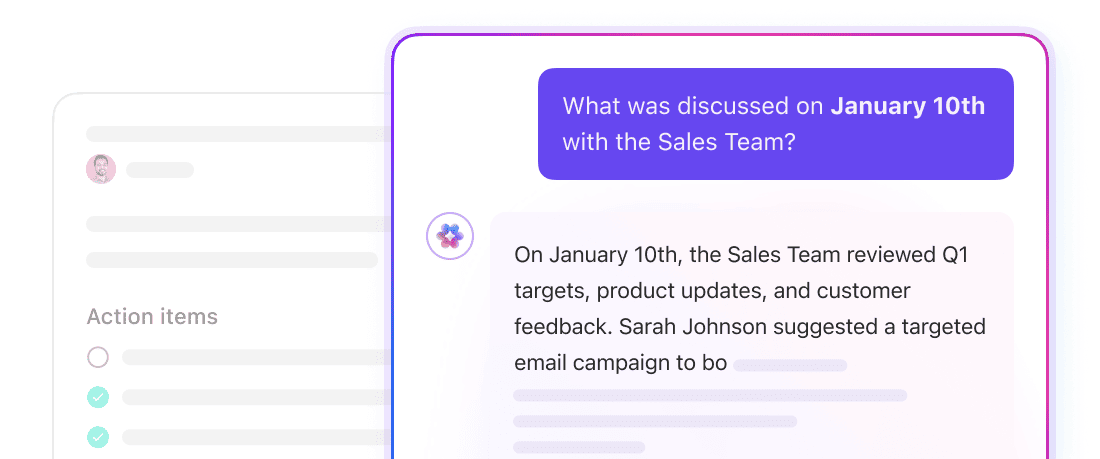
ClickUp Brain est une couche d'IA contextuelle qui fonctionne dans tout votre environnement de travail. Elle peut répondre à des questions, résumer des informations et faire ressortir les tâches pertinentes, car elle a déjà accès à la structure sous-jacente de votre environnement de travail : ClickUp Tasks, ClickUp Docs, ClickUp Comments, etc.
Il n'est pas nécessaire de définir la taille des blocs ni de gérer les intégrations. Brain utilise le modèle de données natif de ClickUp pour comprendre comment les informations sont reliées entre elles. Posez une question telle que « Qu'est-ce qui bloque le lancement du quatrième trimestre ? » et Brain peut extraire le contexte à partir des tâches, des commentaires et des documents liés à cette initiative.
ClickUp Brain prend également en charge plusieurs modèles d'IA en arrière-plan, ce qui vous permet d'exploiter différentes requêtes vers le modèle le plus approprié pour le raisonnement, la résumation ou la génération. Cela évite de limiter vos flux de travail aux forces ou aux limites d'un seul modèle.
Lorsque vous avez besoin d'un contexte externe, Brain peut effectuer des recherches sur le Web directement depuis l'environnement de travail, et vous fournir des résultats résumés sans que vous ayez à quitter ClickUp ou à ouvrir un onglet de navigateur séparé.
Recherchez, naviguez et exécutez avec ClickUp Enterprise Search.
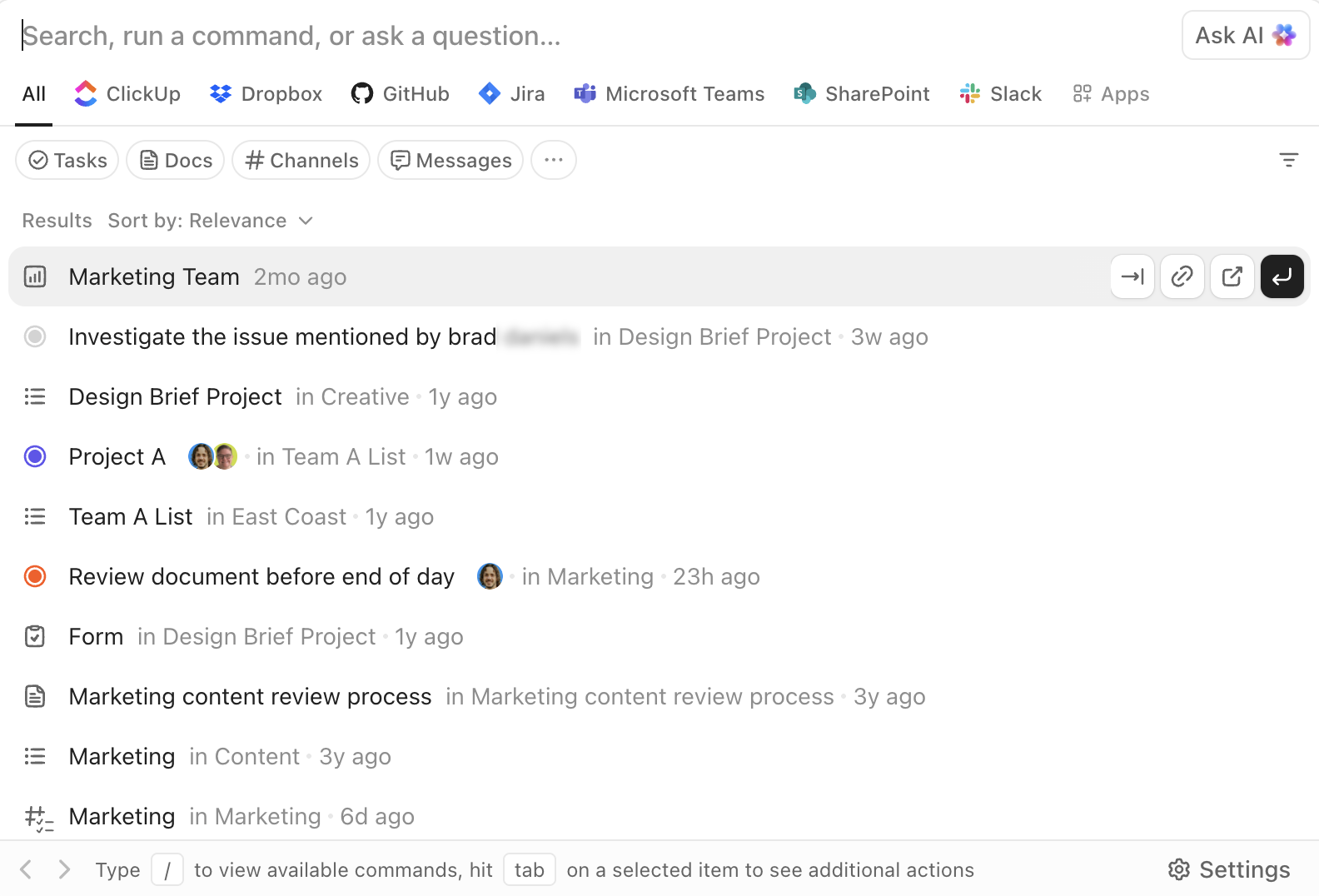
La recherche d'entreprise de ClickUp est accessible depuis n'importe où dans l'environnement de travail. Elle vous permet d'effectuer des recherches dans les tâches, les documents, les commentaires et les pièces jointes, ainsi que dans les applications tierces connectées telles que Google Drive, Slack, GitHub et bien d'autres, en fonction de vos intégrations.
La barre de commande IA transforme la recherche en une couche d'exécution. Vous pouvez accéder à des éléments, créer des tâches, modifier des statuts, attribuer des propriétaires ou ouvrir des vues spécifiques directement à partir de la même interface. Il ne s'agit pas seulement de « trouver et lire », mais aussi de « trouver et agir ».
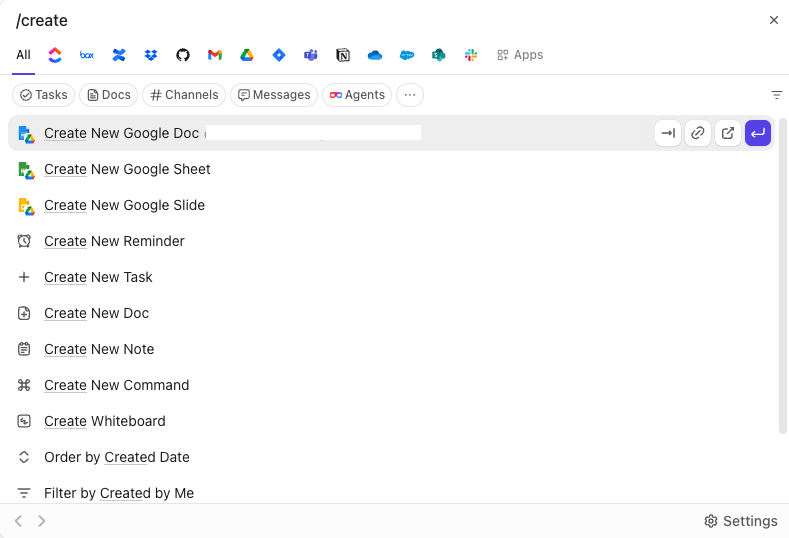
La recherche étant intégrée à l'interface utilisateur de l'environnement de travail, les résultats sont toujours exploitables. Vous ne récupérez pas les informations de manière isolée, puis changez d'outil pour les utiliser. Le flux de travail se poursuit sur place.
Réduisez la prolifération des outils avec ClickUp BrainGPT.
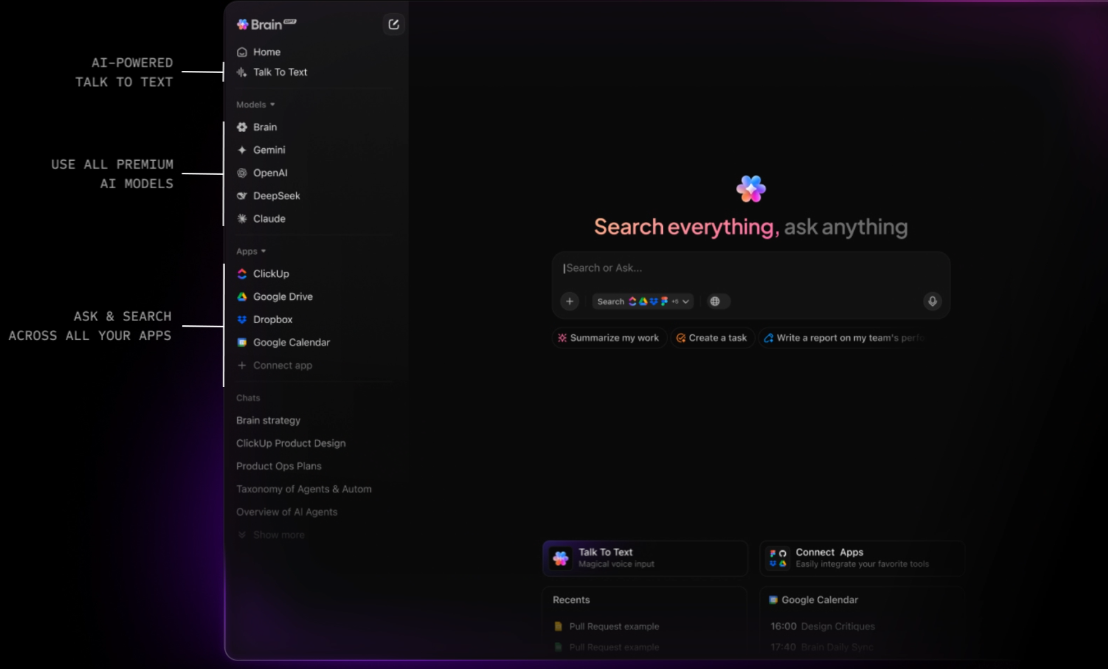
ClickUp BrainGPT étend les capacités de recherche au-delà du navigateur, en proposant une application de bureau autonome et une extension Chrome. Il effectue une connexion directe à votre environnement de travail ClickUp et affiche les mêmes informations contextuelles sans que vous ayez à ouvrir ClickUp ou l'une de vos applications connectées au préalable.
À partir d'une seule interface, vous pouvez rechercher des tâches, des documents, des commentaires et des outils connectés, y compris Gmail et d'autres intégrations. La fonction vocale Talk-to-Text vous permet d'effectuer des recherches ou de saisir des questions instantanément, ce qui est particulièrement utile pour les recherches rapides ou le travail en déplacement.
Au lieu d'ajouter un autre produit de recherche IA à gérer, Brain GPT consolide la recherche en une seule interface qui comprend déjà votre travail.
C'est là que réside le véritable changement. ClickUp ne vous demande pas de créer une recherche d'entreprise. Cet environnement de travail convergent l'intègre directement dans le système où le travail est effectué, éliminant ainsi les frais généraux liés à l'infrastructure tout en préservant la puissance, la précision et la vitesse.
📖 En savoir plus : Principaux exemples de systèmes de gestion des connaissances
Bonus : comparaison stratégique entre une solution personnalisée et une IA native intégrée à l'environnement de travail
| Valeur fondamentale | Flexibilité maximale ; contrôle exclusif | Prêt à l'emploi ; sensible au contexte par défaut |
| Mise en œuvre | Mois : nécessite la mise en place de pipelines par les équipes d'ingénieurs. | Minutes : activez/désactivez d'un simple clic l'ensemble de l'environnement de travail. |
| Ingestion des données | Manuel : vous devez créer et assurer la maintenance d’une base de données ETL et vectorielle. | Automatique : accès en temps réel aux tâches, aux documents et au chat |
| Logique de permission | Doit être codé manuellement (risque élevé de fuites de données) | Hérité nativement de votre hiérarchie ClickUp |
| Profondeur contextuelle | Sémantique (basée sur le sens) | Opérationnel (sait qui est affecté à quoi) |
| Interface utilisateur | Vous devez concevoir et créer la barre de recherche/le chat. | Intégré (barre de recherche, documents et vues des tâches) |
| Action du flux de travail | Aucun : l'utilisateur trouve des informations, puis change d'outil pour travailler. | Élevé : trouvez des informations et convertissez-les instantanément en tâche. |
| Idéal pour | Entreprises à forte composante technologique développant des logiciels propriétaires | Teams cherchant à éliminer la « prolifération des outils » et à agir rapidement |
La recherche ne doit pas vous freiner !
La recherche sémantique n'est plus un facteur de différenciation. C'est désormais un enjeu incontournable.
Le coût réel de la recherche d'entreprise se manifeste partout ailleurs : le temps d'ingénierie nécessaire pour la créer et la maintenir, l'infrastructure requise pour garantir sa précision et les frictions créées lorsque la recherche se fait en dehors des outils où le travail est réellement effectué. Trouver le bon document n'a pas beaucoup d'importance si, pour agir, il faut encore changer de système.
C'est pourquoi le problème ne se résume pas à « améliorer la recherche ». Il s'agit d'éliminer le fossé entre l'information et l'exécution.
Lorsque la recherche est directement intégrée à l'environnement de travail, le contexte est conservé par défaut. Les réponses ne sont pas seulement récupérées, elles sont immédiatement utilisables. Les tâches peuvent être mises à jour, les décisions peuvent être documentées et le travail peut avancer sans créer un nouveau transfert.
Pour les équipes qui ne souhaitent pas passer des mois à créer et à maintenir une infrastructure de recherche personnalisée, travailler dans un environnement de travail IA convergent change complètement la donne. ClickUp offre une recherche de niveau entreprise, alimentée par l'IA, dans le cadre du système que votre équipe utilise déjà pour planifier, collaborer et exécuter.
✅ Commencez à utiliser ClickUp gratuitement.
Foire aux questions
Cohere se concentre spécifiquement sur les cas d'utilisation en entreprise, tels que la recherche, en proposant des modèles tels que Embed et Rerank, spécialement conçus pour les tâches de récupération. OpenAI fournit des modèles plus généraux et polyvalents qui peuvent être adaptés à la recherche, mais qui peuvent nécessiter davantage de réglages.
Oui, Cohere fournit des API qui permettent l'intégration avec d'autres outils ; cependant, cela nécessite des ressources de développement et d'ingénierie personnalisées. Une alternative telle que ClickUp offre une recherche IA native qui fonctionne dès son installation, éliminant ainsi tout besoin d'intégration.
Les secteurs qui disposent de vastes référentiels de documents non structurés, tels que les secteurs juridique, médical, financier et technologique, sont ceux qui tirent le plus profit de la recherche sémantique. Toute organisation confrontée à des difficultés en matière de gestion des connaissances peut constater des améliorations significatives.