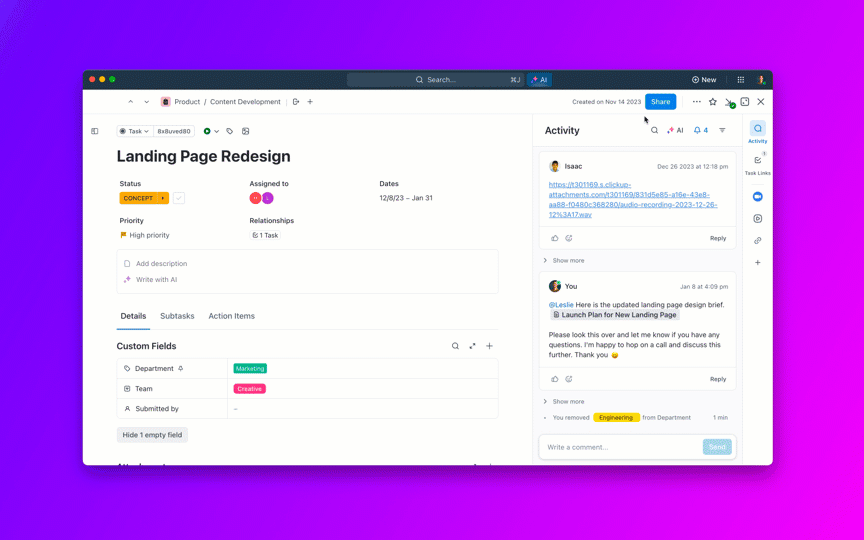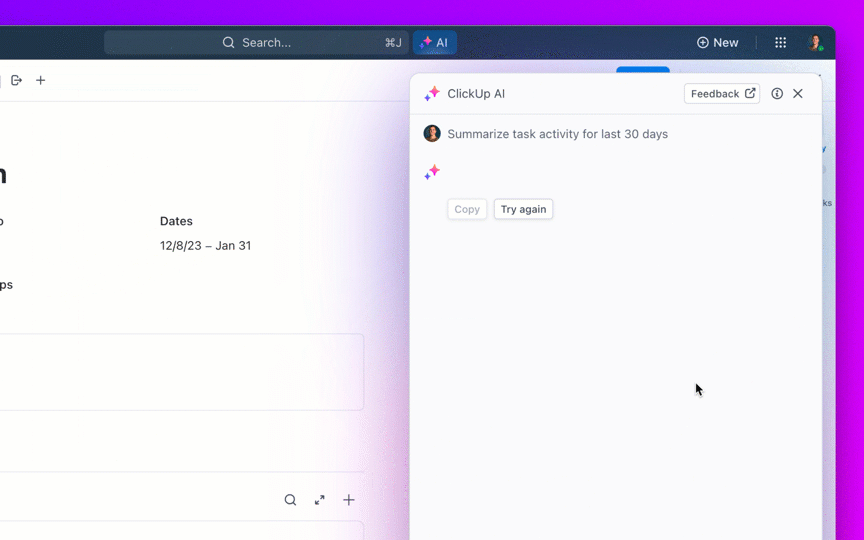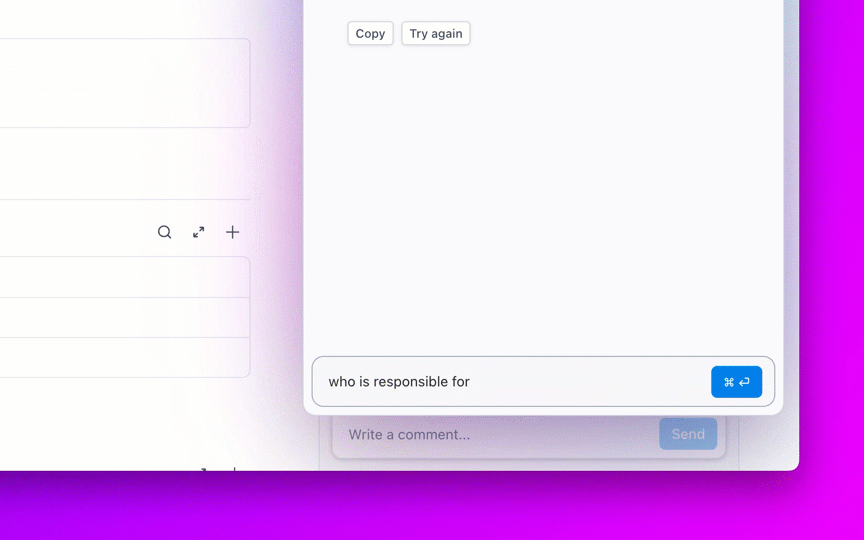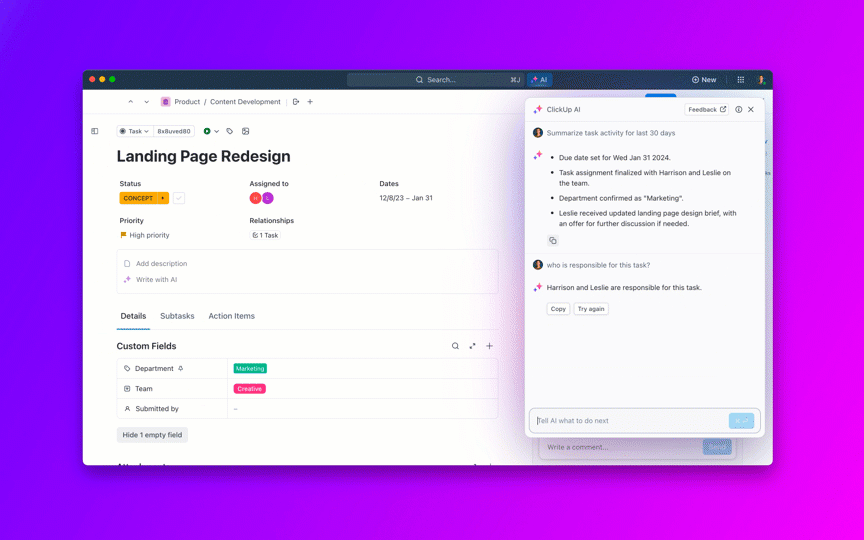

La mayoría de los equipos que exploran modelos de IA de código abierto descubren que LLaMA de Meta ofrece una combinación poco común de potencia y flexibilidad, pero la configuración técnica puede parecer como montar muebles sin instrucciones.
Esta guía le muestra cómo crear un chatbot LLaMA funcional desde cero, cubriendo todo, desde los requisitos de hardware y el acceso al modelo hasta la ingeniería de indicaciones y las estrategias de implementación.
¡Manos a la obra!
¿Qué es LLaMA y por qué utilizarlo para chatbots?
Crear un chatbot con API propietarias a menudo da la sensación de estar atrapado en el sistema de otra persona, enfrentándose a costes impredecibles y cuestiones relacionadas con la privacidad de los datos. Esta dependencia del proveedor significa que no se puede personalizar realmente el modelo para las necesidades únicas de su equipo, lo que da lugar a respuestas genéricas y posibles problemas de cumplimiento normativo.
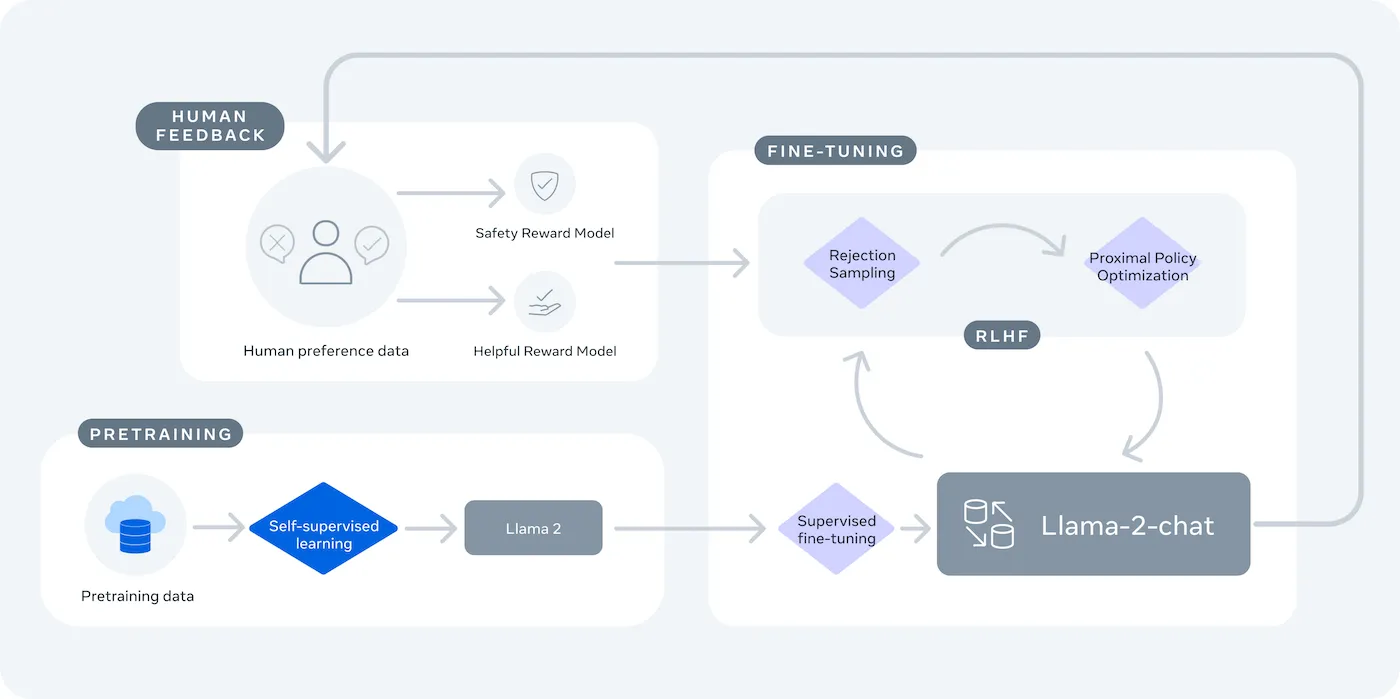
LLaMA (Large Language Model Meta IA) es la familia de modelos de lenguaje de peso abierto de Meta, y ofrece una potente alternativa. Está diseñado tanto para uso comercial como para investigación, y le ofrece un control que los modelos cerrados no proporcionan.
Los modelos LLaMA vienen en diferentes tamaños, medidos en parámetros (por ejemplo, 7B, 13B, 70B). Piensa en los parámetros como una medida de la complejidad y la potencia del modelo: los modelos más grandes son más capaces, pero requieren más recursos computacionales.
He aquí algunas razones por las que podrías utilizar un chatbot LLaMA:
- Privacidad de los datos: cuando ejecuta un modelo en su propia infraestructura, los datos de sus conversaciones nunca salen de su entorno. Esto es fundamental para los equipos que manejan información confidencial.
- Personalización: puede ajustar un modelo LLaMA a los documentos o datos internos de su empresa. Esto le ayuda a comprender su contexto específico y a proporcionar respuestas mucho más relevantes.
- Previsibilidad de costes: tras la configuración inicial del hardware, no tendrá que preocuparse por los cargos por token de la API. Sus costes serán fijos y previsibles.
- Sin límites de velocidad: la capacidad de su chatbot está limitada por su propio hardware, no por las cuotas de un proveedor. Puede ampliarlo según sea necesario.
La principal desventaja es la comodidad a cambio del control. LLaMA requiere una configuración más técnica que una API plug-and-play. Para los chatbots de producción, los equipos suelen utilizar LLaMA 2 o la más reciente LLaMA 3, que ofrece un razonamiento mejorado y puede manejar más texto a la vez.
Lo que necesita antes de crear un chatbot LLaMA
Lanzarse a un proyecto de desarrollo sin las herramientas adecuadas es una receta para la frustración. Llegas a la mitad y te das cuenta de que te falta una pieza clave de hardware o software, lo que descarrila tu progreso y te hace perder horas de tu tiempo.
Para evitarlo, reúne todo lo que necesitas por adelantado. Aquí tienes una lista de control para garantizar un comienzo sin problemas. 🛠️
Requisitos de hardware
| Tamaño del modelo | VRAM mínima | Opción alternativa |
|---|---|---|
| 7 mil millones de parámetros | 8 GB | Instancia de GPU en la nube |
| 13 000 millones de parámetros | 16 GB | Instancia de GPU en la nube |
| 70 000 millones de parámetros | Múltiples GPU | Cuantificación o nube |
Si tu equipo local no tiene una unidad de procesamiento gráfico (GPU) lo suficientemente potente, puedes utilizar servicios en la nube como AWS o GCP. Las plataformas de inferencia como Baseten y Replicate también ofrecen acceso a GPU de pago por uso.
Requisitos de software
- Python 3. 8+: Este es el lenguaje de programación estándar para proyectos de aprendizaje automático.
- Gestor de paquetes: Necesitará pip o Conda para instalar las bibliotecas necesarias para su proyecto.
- Entorno virtual: se trata de una buena práctica que mantiene las dependencias de su proyecto aisladas de otros proyectos Python en su máquina.
Requisitos de acceso
- Cuenta de Hugging Face: Necesitará una cuenta para descargar los pesos del modelo LLaMA.
- Aprobación de Meta: Debe aceptar el acuerdo de licencia de Meta para obtener acceso a los modelos LLaMA, que normalmente se aprueba en unas pocas horas.
- Claves de API: solo son necesarias si decide utilizar un punto final de inferencia alojado en lugar de ejecutar el modelo localmente.
Para esta guía, utilizaremos el marco LangChain. Simplifica muchas de las partes complejas de la creación de un chatbot, como la gestión de las indicaciones y el historial de conversaciones.
{kind=link}
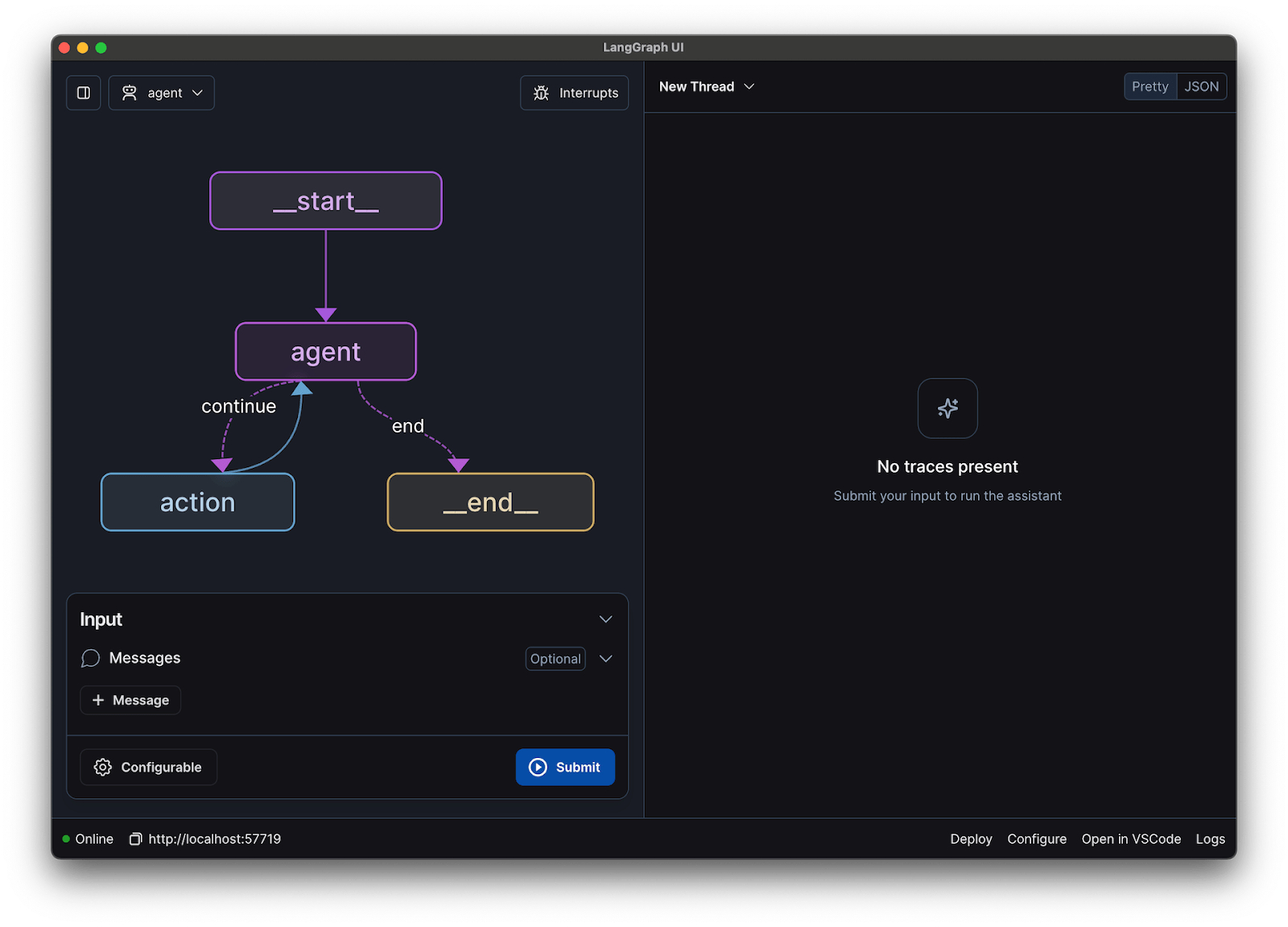
Cómo crear un chatbot con LLaMA paso a paso
Conectar todas las piezas técnicas de un chatbot (el modelo, la indicación, la memoria) puede resultar abrumador. Es fácil perderse en el código, lo que provoca errores y un chatbot que no funciona como se esperaba. Esta guía paso a paso desglosa el proceso en partes sencillas y manejables.
Este enfoque funciona tanto si ejecuta el modelo en su propio equipo como si utiliza un servicio alojado.
Paso 1: Instale los paquetes necesarios.
En primer lugar, debe instalar las bibliotecas principales de Python. Abra su terminal y ejecute este comando:
pip install langchain transformers accelerate torch
Si utiliza un servicio alojado como Baseten para la inferencia, también deberá instalar su kit de desarrollo de software (SDK) específico:
pip install baseten
Esto es lo que hace cada uno de estos paquetes:
- Langchain: un marco que ayuda a crear aplicaciones con grandes modelos de lenguaje, incluida la gestión de cadenas de conversación y memoria.
- Transformers: la biblioteca Hugging Face para cargar y ejecutar el modelo LLaMA.
- Accelerate: una biblioteca que ayuda a optimizar la forma en que el modelo se carga en la CPU y la GPU.
- Torch: La biblioteca PyTorch, que proporciona la potencia de backend para los cálculos del modelo.
Si ejecuta el modelo localmente en una máquina con una GPU NVIDIA, asegúrese de tener CUDA instalado y configurado correctamente. Esto permite que el modelo utilice la GPU para obtener un rendimiento mucho más rápido.
Paso 2: Obtenga acceso a los modelos LLaMA.
Antes de poder descargar el modelo, debe obtener acceso oficial de Meta a través de Hugging Face.
- Crea una cuenta en huggingface.co
- Vaya a la página del modelo, por ejemplo, meta-llama/Llama-2-7b-chat-hf.
- Haga clic en «Acceder al repositorio» y acepte los términos de la licencia de Meta.
- En los ajustes de su cuenta de Hugging Face, genere un nuevo token de acceso.
- En su terminal, ejecute huggingface-cli login y pegue su token para realizar la autenticación de su máquina.
La aprobación suele ser rápida. Asegúrate de elegir una variante del modelo que incluya «chat» en el nombre, ya que estas han sido entrenadas específicamente para tareas de conversación.
Paso 3: Cargar el modelo LLaMA
Ahora puede cargar el modelo en su código. Tiene dos opciones principales, dependiendo de su hardware.
Si dispone de una GPU lo suficientemente potente, puede cargar el modelo localmente:
Si su hardware tiene un límite, puede utilizar un servicio de inferencia alojado:
El comando device_map="auto" indica a la biblioteca de transformadores que realice automáticamente la distribución del modelo entre todas las GPU disponibles.
Si aún así se queda sin memoria, puede utilizar una técnica llamada cuantificación para reducir el tamaño del modelo, aunque esto puede reducir ligeramente su rendimiento.
Paso 4: Crear una plantilla de indicaciones
Los modelos de chat LLaMA están entrenados para esperar un formato específico para las indicaciones. Una plantilla de indicaciones garantiza que su entrada esté estructurada correctamente.
Analicemos este formato:
- <
>: Esta sección contiene la indicación del sistema, que proporciona al modelo sus instrucciones básicas y define su personalidad. - [INST]: Indica el comienzo de la pregunta o instrucción del usuario.
- [/INST]: Esto indica al modelo que es el momento de generar una respuesta.
Ten en cuenta que las diferentes versiones de LLaMA pueden utilizar plantillas ligeramente diferentes. Comprueba siempre la documentación del modelo en Hugging Face para conocer el formato correcto.
Paso 5: Configurar la cadena de chatbots
A continuación, conectará su modelo y su plantilla de indicaciones en una cadena conversacional utilizando LangChain. Esta cadena también incluirá memoria para realizar el seguimiento de la conversación.
LangChain ofrece varios tipos de memoria:
- ConversationBufferMemory: Esta es la opción más sencilla. Almacena todo el historial de conversaciones.
- ConversationSummaryMemory: para ahorrar espacio, esta opción resume periódicamente las partes más antiguas de la conversación.
- ConversationBufferWindowMemory: mantiene solo los últimos intercambios en la memoria, lo que resulta útil para evitar que el contexto se alargue demasiado.
Para realizar pruebas, ConversationBufferMemory es un buen punto de partida.
Paso 6: Ejecuta el bucle del chatbot.
Por último, puede crear un bucle sencillo para interactuar con su chatbot desde el terminal.
En una aplicación real, sustituirías este bucle por un punto final de API utilizando un marco como FastAPI o Flask. También puedes transmitir la respuesta del modelo al usuario, lo que hace que el chatbot parezca mucho más rápido.
También puede ajustar parámetros como la temperatura para controlar la aleatoriedad de las respuestas. Una temperatura baja (por ejemplo, 0,2) hace que el resultado sea más determinista y factual, mientras que una temperatura más alta (por ejemplo, 0,8) fomenta una mayor creatividad.
📚 Lea también: Agente de IA frente a chatbot: diferencias clave y cuál es el más adecuado para usted.
Cómo probar su chatbot LLaMA
Ha creado un chatbot que da respuestas, pero ¿está listo para usuarios reales? Implementar un bot sin probar puede provocar fallos embarazosos, como proporcionar información incorrecta o generar contenido inapropiado, lo que puede dañar la reputación de su empresa.
Un plan de pruebas sistemático es la solución a esta incertidumbre. Garantiza que su chatbot sea robusto, fiable y seguro.
Pruebas funcionales:
- Casos extremos: comprueba cómo gestiona el bot las entradas vacías, los mensajes muy largos y los caracteres especiales.
- Verificación de memoria: asegúrate de que el chatbot recuerde el contexto a lo largo de múltiples turnos en una conversación.
- Instrucciones a seguir: Comprueba si el bot cumple las reglas que has establecido en el sistema.
Evaluación de la calidad:
- Relevancia: ¿La respuesta realmente responde a la pregunta del usuario?
- Precisión: ¿Es correcta la información que proporciona?
- Coherencia: ¿La conversación fluye de forma lógica?
- Seguridad: ¿El bot se niega a responder a solicitudes inapropiadas o perjudiciales?
Pruebas de rendimiento:
- Latencia: mida cuánto tiempo tarda el bot en empezar a responder y en terminar su respuesta.
- Uso de recursos: supervise cuánta memoria GPU utiliza el modelo durante la inferencia.
- Concurrencia: comprueba el rendimiento del sistema cuando varios usuarios interactúan con él al mismo tiempo.
Además, ten cuidado con los problemas comunes de LLM, como las alucinaciones (afirmar con seguridad información falsa), la deriva del contexto (perder el hilo del tema en una conversación larga) y la repetición. Registrar todas las conversaciones de prueba es una forma estupenda de detectar patrones y solucionar problemas antes de que lleguen a tus usuarios.
Casos de uso de LLaMA Chatbot para equipos
Una vez superados los aspectos técnicos del ajuste y la implementación, LLaMA resulta más valioso cuando se aplica a los problemas cotidianos del equipo, y no a demostraciones abstractas de IA. Por lo general, los equipos no necesitan «un chatbot», sino un acceso más rápido al conocimiento, menos traspasos manuales y menos trabajo repetitivo.
Asistente de conocimiento interno
Al ajustar LLaMA en la documentación interna, wikis y preguntas frecuentes, o al combinarlo con una base de conocimientos basada en RAG, los equipos pueden formular preguntas en lenguaje natural y obtener respuestas precisas y contextuales. Esto elimina la fricción de buscar en herramientas dispersas, al tiempo que mantiene los datos confidenciales totalmente internos, en lugar de enviarlos a API de terceros.
🌟 La búsqueda empresarial en ClickUp y el agente Ambient Answers preconfigurado proporcionan respuestas contextuales detalladas a tus preguntas utilizando el conocimiento de tu entorno de trabajo de ClickUp.
Ayudante para la revisión del código
Cuando se entrena con su propio código base y guías de estilo, LLaMA puede actuar como un asistente de revisión de código contextual. En lugar de buenas prácticas genéricas, los desarrolladores obtienen sugerencias que se alinean con las convenciones del equipo, las decisiones arquitectónicas y los patrones históricos.
🌟 Un asistente de revisión de código basado en LLaMA puede detectar problemas, sugerir mejoras o explicar código desconocido. Codegen de ClickUp va un paso más allá al actuar dentro del flujo de trabajo de desarrollo, creando solicitudes de validación, aplicando refactorizaciones o actualizando archivos directamente en respuesta a esa información. El resultado es menos copiar y pegar y menos traspasos fallidos entre «pensar» y «hacer».
Clasificación del soporte al cliente
LLaMA puede entrenarse para la clasificación de intenciones con el fin de comprender las consultas entrantes de los clientes y dirigirlas al equipo o flujo de trabajo adecuado. Las preguntas comunes pueden gestionarse automáticamente, mientras que los casos extremos se escalan a agentes humanos con el contexto adjunto, lo que reduce los tiempos de respuesta sin sacrificar la calidad.
También puede crear un superagente de triaje utilizando lenguaje natural dentro de su entorno de trabajo de ClickUp. Más información
Resumen de reuniones y seguimiento
Utilizando transcripciones de reuniones como entrada, LLaMA puede extraer decisiones, elementos de acción y puntos clave de debate. El valor real surge cuando estos resultados fluyen directamente a las herramientas de gestión de tareas, convirtiendo las conversaciones en trabajo rastreable.
🌟 El tomador de notas de reuniones con IA de ClickUp no solo toma notas de las reuniones, sino que redacta resúmenes, genera tareas pendientes y enlaza las notas de las reuniones con tus documentos y tareas.
Redacción e iteración de documentos
Los equipos pueden utilizar LLaMA para generar borradores de informes, propuestas o documentación basados en plantillas existentes y ejemplos anteriores. Esto permite pasar del esfuerzo dedicado a la creación de páginas en blanco a la revisión y el perfeccionamiento, lo que acelera la entrega sin reducir los estándares.
🌟 ClickUp Brain puede generar rápidamente borradores para documentación, manteniendo todo el conocimiento de su lugar de trabajo en contexto. Pruébelo hoy mismo.
Los chatbots con tecnología LLaMA son más eficaces cuando se integran en los flujos de trabajo existentes (documentación, gestión de proyectos y comunicación del equipo) que cuando funcionan como herramientas independientes.
Aquí es donde la integración directa de la IA en su entorno de trabajo marca la diferencia. En lugar de crear una herramienta independiente, puede llevar la IA conversacional al lugar donde ya opera su equipo.
Por ejemplo, puede crear un bot LLaMA personalizado para que actúe como asistente de conocimientos. Pero si se encuentra fuera de su herramienta de gestión de proyectos, su equipo tendrá que cambiar de contexto para hacerle una pregunta. Esto crea fricciones y ralentiza el trabajo de todos.
Elimine este cambio de contexto utilizando una IA que ya forma parte de su flujo de trabajo.
Haz preguntas sobre tus proyectos, tareas y documentos sin salir de ClickUp utilizando ClickUp Brain. Solo tienes que escribir @brain en cualquier comentario de tarea o en ClickUp Chat para obtener una respuesta instantánea y contextualizada. Es como tener un miembro del equipo que conoce a la perfección todo tu entorno de trabajo. 🤩
Esto transforma el chatbot de una novedad a una parte fundamental del motor de productividad de su equipo.
Limitaciones del uso de LLaMA para crear chatbots
Crear un chatbot LLaMA puede ser muy gratificante, pero los equipos a menudo se ven sorprendidos por complejidades ocultas. El modelo de código abierto «gratis» puede acabar siendo más caro y difícil de gestionar de lo esperado, lo que da lugar a una mala experiencia de usuario y a un ciclo de mantenimiento constante que agota los recursos.
Es importante comprender los límites antes de realizar la confirmación.
- Complejidad técnica: la configuración y el mantenimiento de un modelo LLaMA requieren conocimientos sobre infraestructura de aprendizaje automático.
- Requisitos de hardware: ejecutar los modelos más grandes y potentes requiere un hardware GPU caro, y los costes de la nube pueden acumularse rápidamente.
- Limitaciones de la ventana de contexto: los modelos LLaMA tienen un límite en la memoria ( 4K tokens para LLaMA 2 ). El manejo de documentos o conversaciones largos requiere estrategias de fragmentación complejas.
- Sin medidas de seguridad integradas: usted es responsable de implementar sus propias medidas de filtrado de contenido y seguridad.
- Mantenimiento continuo: a medida que se lancen nuevos modelos, tendrás que actualizar tus sistemas, y es posible que los modelos ajustados requieran un nuevo entrenamiento.
Los modelos autohospedados también suelen tener una latencia mayor que las API comerciales altamente optimizadas. Todas estas son cargas operativas que las soluciones gestionadas se encargan de manejar por usted.
📮ClickUp Insight: El 88 % de los encuestados utiliza la IA para sus tareas personales, pero más del 50 % evita utilizarla en el trabajo. ¿Cuáles son las tres principales barreras? La falta de una integración fluida, las lagunas de conocimiento o las preocupaciones en materia de seguridad.
Pero, ¿qué pasa si la IA está integrada en su entorno de trabajo y ya es segura? ClickUp Brain, el asistente de IA integrado de ClickUp, lo hace realidad. Entiende las indicaciones en lenguaje sencillo, resolviendo las tres preocupaciones relacionadas con la adopción de la IA, al tiempo que conecta su chat, tareas, documentos y conocimientos en todo el entorno de trabajo. ¡Encuentre respuestas e información con un solo clic!
Alternativas a LLaMA para crear chatbots
LLaMA es solo una opción entre un sinfín de modelos de IA, y puede resultar abrumador decidir cuál es el más adecuado para usted.
A continuación se muestra un desglose de las alternativas disponibles.
Otros modelos de código abierto:
- Mistral: Conocido por su gran rendimiento incluso con modelos de menor tamaño, lo que lo hace muy eficiente.
- Falcon: viene con una licencia muy permisiva, lo que es ideal para aplicaciones comerciales.
- MPT: optimizado para gestionar documentos y conversaciones largos.
API comerciales:
- OpenAI (GPT-4, GPT-3. 5): Considerados generalmente como los modelos de lenguaje grandes más capaces, son muy fáciles de integrar.
- Anthropic (Claude): Conocido por sus sólidas funciones de seguridad y sus ventanas de contexto muy amplias.
- Google (Gemini): Ofrece potentes capacidades multimodales, lo que le permite comprender texto, imágenes y audio.
Puede crearlo usted mismo con un modelo de código abierto, pagar por una API comercial o utilizar un entorno de trabajo de IA convergente que ofrezca una solución preintegrada con diferentes tipos de agentes de IA.
📚 Lea también: Cómo utilizar un chatbot para su empresa
Cree asistentes de IA sensibles al contexto con ClickUp.
Crear un chatbot con LLaMA te ofrece un control increíble sobre tus datos, costes y personalización. Pero ese control conlleva la responsabilidad de la infraestructura, el mantenimiento y la seguridad, todo lo cual gestionan las API gestionadas por ti. El objetivo no es solo crear un bot, sino hacer que tu equipo sea más productivo, y un proyecto de ingeniería complejo a veces puede distraerte de eso.
La elección adecuada depende de los recursos y las prioridades de su equipo. Si tiene experiencia en ML y necesidades estrictas de privacidad, LLaMA es una opción fantástica. Si prioriza la velocidad y la simplicidad, una herramienta integrada podría ser más adecuada.
Con ClickUp, obtienes un entorno de trabajo de IA convergente con todas tus tareas, documentos y conversaciones en un solo lugar, impulsado por IA integrada. Reduce la dispersión del contexto y ayuda a los equipos a trabajar de forma más rápida y eficaz, con la información adecuada al alcance de la mano gracias a los Super Agents personalizables y la IA contextual.
Deja de perder tiempo en infraestructura y disfruta hoy mismo de las ventajas de un asistente de IA sensible al contexto sin tener que crear nada desde cero. Empieza gratis con ClickUp.
Preguntas frecuentes (FAQ)
El coste depende totalmente de su método de implementación, y la previsión del proyecto puede ayudarle a estimarlo. Si utiliza su propio hardware, tendrá un coste inicial por la GPU, pero no habrá cuotas continuas por consulta. Los proveedores de servicios en la nube cobran una tarifa por hora basada en la GPU y el tamaño del modelo.
Sí, las licencias de LLaMA 2 y LLaMA 3 permiten el uso comercial. Sin embargo, debe aceptar las condiciones de uso de Meta y proporcionar la atribución requerida en su producto.
LLaMA 3 es el modelo más nuevo y con mayor capacidad, que ofrece mejores habilidades de razonamiento y una ventana de contexto más amplia (8K tokens frente a los 4K de LLaMA 2). Esto significa que puede manejar conversaciones y documentos más largos, pero también requiere más recursos computacionales para funcionar.
Aunque Python es el lenguaje más común para el aprendizaje automático debido a sus amplias bibliotecas, no es estrictamente necesario. Algunas plataformas están empezando a ofrecer soluciones sin código o con poco código que permiten implementar un chatbot LLaMA con una interfaz gráfica. /