
Los proyectos de entrenamiento de IA rara vez fracasan a nivel de modelo. Las dificultades surgen cuando los experimentos, la documentación y las actualizaciones de las partes interesadas se dispersan entre demasiadas herramientas.
Esta guía le muestra cómo entrenar modelos con Databricks DBRX, un LLM que es hasta dos veces más eficiente en términos de computación que otros modelos líderes, mientras mantiene el trabajo relacionado con él organizado en ClickUp.
Desde la configuración y el ajuste fino hasta la documentación y las actualizaciones entre equipos, verá cómo un único entorno de trabajo convergente ayuda a eliminar la dispersión del contexto y mantiene a su equipo centrado en crear, no en buscar. 🛠
¿Qué es DBRX?
DBRX es un potente modelo de lenguaje grande (LLM) de código abierto diseñado específicamente para el entrenamiento y la inferencia de modelos de IA de corporaciones. Al ser de código abierto bajo la licencia Databricks Open Model License, su equipo tiene acceso completo a los pesos y la arquitectura del modelo, lo que le permite inspeccionarlo, modificarlo e implementarlo según sus propios términos.
Hay dos variantes disponibles: DBRX Base para el preentrenamiento profundo y DBRX Instruct para tareas de seguimiento de instrucciones listas para usar.
Arquitectura DBRX y diseño de mezcla de expertos
DBRX resuelve tareas utilizando una arquitectura de mezcla de expertos (MoE). A diferencia de los modelos de lenguaje grandes tradicionales, que utilizan todos sus miles de millones de parámetros para cada cálculo, DBRX solo activa una fracción de sus parámetros totales (los expertos más relevantes) para cualquier tarea determinada.
Piense en ello como un equipo de expertos especializados; en lugar de que todos trabajen en todos los problemas, el sistema asigna de forma inteligente cada tarea a los parámetros más adecuados.
Esto no solo reduce el tiempo de respuesta, sino que también ofrece un rendimiento y unos resultados de primer nivel, al tiempo que reduce significativamente los costes computacionales.
A continuación, le ofrecemos un resumen de sus especificaciones clave:
- Parámetros totales: 132 000 millones en todos los expertos.
- Parámetros activos: 36B por paso hacia adelante
- Número de expertos: 16 en total (MoE Top-4 routing), con 4 activos para cualquier token dado.
- Ventana de contexto: 32 000 tokens
Especificaciones de los datos de entrenamiento y los tokens de DBRX
El rendimiento de un LLM depende de la calidad de los datos con los que se entrena. DBRX se entrenó previamente con un enorme conjunto de datos de 12 billones de tokens cuidadosamente seleccionados por el equipo de Databricks utilizando sus avanzadas herramientas de procesamiento de datos. Es precisamente por eso por lo que obtuvo unos resultados tan buenos en las pruebas de referencia del sector.
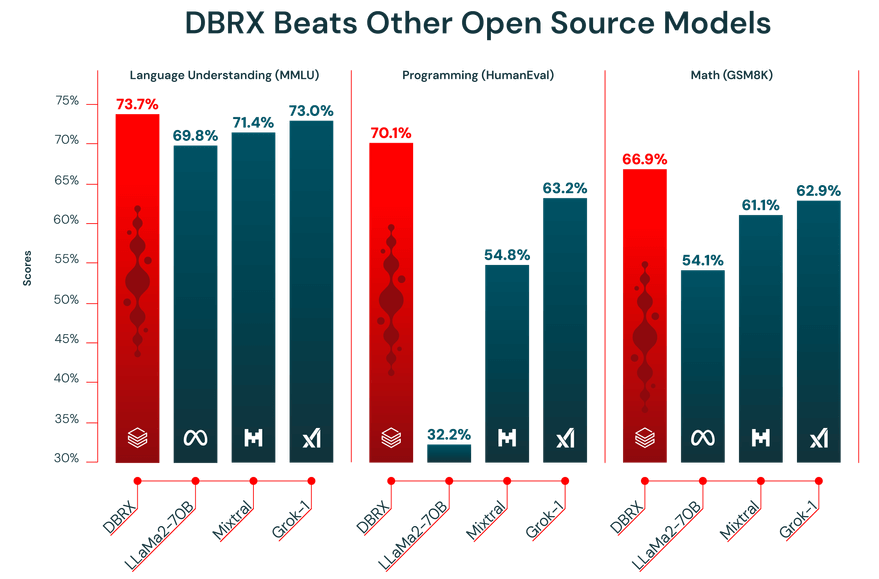
Además, DBRX cuenta con una ventana de contexto de 32 000 tokens. Esta es la cantidad de texto que el modelo puede considerar a la vez. Una ventana de contexto grande es muy útil para tareas complejas como resumir informes largos, examinar documentos legales extensos o crear sistemas avanzados de generación aumentada por recuperación (RAG), ya que permite al modelo mantener el contexto sin truncar ni olvidar información.
🎥 Vea este vídeo para descubrir cómo una coordinación de proyectos optimizada puede transformar su flujo de trabajo de entrenamiento de IA y eliminar la fricción que supone cambiar entre herramientas desconectadas. 👇🏽
Cómo acceder y realizar los ajustes en DBRX
DBRX ofrece dos vías de acceso principales, ambas con acceso completo a los pesos del modelo en condiciones comerciales permisivas. Puede utilizar Hugging Face para obtener la máxima flexibilidad o acceder directamente a través de Databricks para disfrutar de una experiencia más integrada.
Acceda a DBRX a través de Hugging Face.
Para los equipos que valoran la flexibilidad y ya se sienten cómodos con el ecosistema Hugging Face, acceder a DBRX a través del hub es la opción ideal. Le permite integrar el modelo en sus flujos de trabajo existentes basados en transformadores.
A continuación le indicamos cómo empezar:
- Crea o inicia sesión en tu cuenta de Hugging Face.
- Navegue hasta la tarjeta del modelo DBRX en el hub y acepte los términos de la licencia.
- Instale la biblioteca de transformadores junto con las dependencias necesarias, como accelerate.
- Utilice la clase AutoModelForCausalLM en su script de Python para cargar el modelo DBRX.
- Configure su canalización de inferencia, teniendo en cuenta que DBRX requiere una memoria GPU (VRAM) significativa para un funcionamiento eficaz.
📖 Más información: Cómo configurar la temperatura LLM
Acceda a DBRX a través de Databricks.
Si su equipo ya utiliza Databricks para la ingeniería de datos o el aprendizaje automático, acceder a DBRX a través de la plataforma es la forma más sencilla. Elimina las fricciones de configuración y le proporciona todas las herramientas que necesita para MLOps justo donde ya está trabajando.
Siga estos pasos en su entorno de trabajo de Databricks para empezar:
- Navega a la sección Model Garden o Mosaic IA.
- Seleccione DBRX Base o DBRX Instruct, según sus necesidades.
- Configure un punto final de servicio para el acceso a la API o ajuste un entorno de cuaderno para uso interactivo.
- Comience a probar la inferencia con muestras de indicaciones para asegurarse de que todo funciona correctamente antes de ampliar el entrenamiento o la implementación de su modelo de IA.
Este enfoque le brinda acceso sin interrupciones a herramientas como MLflow para el seguimiento de experimentos y Unity Catalog para la gobernanza de modelos.
📮 Información de ClickUp: El profesional medio dedica más de 30 minutos al día a buscar información relacionada con el trabajo, lo que supone más de 120 horas al año perdidas en buscar entre correos electrónicos, hilos de Slack y archivos dispersos.
Un asistente de IA inteligente integrado en su entorno de trabajo puede cambiar eso. Le presentamos ClickUp Brain.
Proporciona información y respuestas instantáneas al mostrar los documentos, conversaciones y detalles de tareas adecuados en cuestión de segundos, para que puedas dejar de buscar y empezar a trabajar.
Cómo ajustar DBRX y entrenar modelos de IA personalizados
Un modelo estándar, por muy potente que sea, nunca comprenderá los matices únicos de su empresa. Dado que DBRX es de código abierto, puede ajustarlo para crear un modelo personalizado que hable el idioma de su empresa o realice una tarea específica que desee que lleve a cabo.
Aquí tienes tres formas habituales de hacerlo:
1. Ajuste DBRX con los conjuntos de datos de Hugging Face.
Para los equipos que acaban de empezar o que trabajan en tareas comunes, los conjuntos de datos públicos de Hugging Face Hub son un recurso excelente. Están en formato predefinido y son fáciles de cargar, lo que significa que no tendrá que dedicar horas a preparar sus datos.
El proceso es bastante sencillo:
- Busque en el hub un conjunto de datos que se ajuste a su tarea (por ejemplo, seguimiento de instrucciones, resumir).
- Cárguelo utilizando la biblioteca de conjuntos de datos.
- Asegúrese de que los datos tengan un formato de pares de instrucciones y respuestas.
- Configure su script de entrenamiento con hiperparámetros como la tasa de aprendizaje y el tamaño del lote.
- Inicie el trabajo de entrenamiento, asegurándose de guardar los puntos de control durante periodos regulares.
- Evalúe el modelo ajustado en un conjunto de validación retenido para medir la mejora.
2. Ajuste DBRX con conjuntos de datos locales
Por lo general, obtendrá los mejores resultados si realiza ajustes con sus propios datos privados. Esto le permite enseñar al modelo la terminología, el estilo y los conocimientos específicos de su empresa. Solo tenga en cuenta que solo vale la pena si sus datos están limpios y bien preparados, y tienen un volumen suficiente.
Siga estos pasos para preparar sus datos internos:
- Recopilación de datos: recopile ejemplos de alta calidad de sus wikis, documentos y bases de datos internos.
- Conversión de formato: Estructure sus datos en un formato coherente de instrucción-respuesta, a menudo como líneas JSON.
- Filtrado de calidad: elimine cualquier ejemplo de baja calidad, duplicado o irrelevante.
- División de validación: reserve una pequeña parte de sus datos (normalmente entre el 10 y el 15 %) para evaluar el rendimiento del modelo.
- Revisión de privacidad: elimine u oculte cualquier información de identificación personal (PII) o datos confidenciales.
3. Ajuste DBRX con StreamingDataset
Si su conjunto de datos resulta ser demasiado grande para caber en la memoria de su máquina, no se preocupe, puede utilizar la biblioteca Streaming Dataset de Databricks. Le permite transmitir datos directamente desde el almacenamiento en la nube mientras se entrena el modelo, en lugar de cargarlos todos en la memoria a la vez.
Así es como puede hacerlo:
- Preparación de datos: limpie y estructure sus datos de entrenamiento, y luego almacénelos en un formato transmisible como JSONL o CSV en el almacenamiento en la nube.
- Conversión de formato de streaming: convierta su conjunto de datos a un formato compatible con streaming, como Mosaic Data Shard (MDS), para que se pueda leer de forma eficiente durante el entrenamiento.
- Configuración del cargador de entrenamiento: Configure su cargador de entrenamiento para que apunte al conjunto de datos remoto y defina una caché local para el almacenamiento temporal de datos.
- Inicialización del modelo: Inicie el proceso de ajuste fino de DBRX utilizando un marco de entrenamiento que tenga compatibilidad con StreamingDataset, como LLM Foundry.
- Entrenamiento basado en streaming: ejecute la tarea de entrenamiento mientras los datos se transmiten por lotes durante el entrenamiento, en lugar de cargarse por completo en la memoria.
- Puntos de control y recuperación: reanude el entrenamiento sin problemas si se interrumpe una ejecución, sin duplicar ni omitir datos.
- Evaluación e implementación: valida el rendimiento del modelo ajustado e impleméntalo utilizando tu configuración preferida de servicio o inferencia.
💡Consejo profesional: en lugar de crear un plan de entrenamiento DBRX desde cero, comience con la plantilla de hoja de ruta de proyectos de IA y aprendizaje automático de ClickUp y adáptela a las necesidades de su equipo. Proporciona una estructura clara para planificar conjuntos de datos, fases de entrenamiento, evaluación e implementación, para que pueda centrarse en organizar su trabajo en lugar de estructurar un flujo de trabajo.
Casos de uso de DBRX para el entrenamiento de modelos de IA
Una cosa es tener un modelo potente, pero otra muy distinta es saber exactamente dónde destaca.
Cuando no se tiene una idea clara de los puntos fuertes de un modelo, es fácil dedicar tiempo y recursos a intentar que funcione donde simplemente no encaja. Esto conduce a resultados mediocres y a la frustración.
La arquitectura única y los datos de entrenamiento de DBRX lo hacen excepcionalmente adecuado para varios casos de uso empresariales clave. Conocer estas fortalezas le ayuda a alinear el modelo con sus objetivos comerciales y maximizar el retorno de la inversión.
Generación de texto y creación de contenido
DBRX Instruct está perfectamente ajustado para seguir instrucciones y generar texto de alta calidad. Esto lo convierte en una potente herramienta para automatizar una amplia gama de tareas relacionadas con el contenido. Su gran ventana de contexto es una ventaja significativa, ya que le permite manejar documentos largos sin perder el hilo.
Puede utilizarlo para:
- Documentación técnica: genere y perfeccione manuales de productos, referencias de API y guías de usuario.
- Contenido de marketing: borradores de entradas de blog, boletines informativos por correo electrónico y actualizaciones en redes sociales.
- Generación de informes: resuma los resultados de datos complejos y cree resúmenes ejecutivos concisos.
- Traducción y localización: adapte el contenido existente a nuevos mercados y públicos.
Tareas de generación de código y depuración
Una parte importante de los datos de entrenamiento de DBRX incluía código, lo que lo convierte en un soporte LLM capaz para los desarrolladores. Puede ayudar a acelerar los ciclos de desarrollo mediante la automatización de tareas de codificación repetitivas y la asistencia en la resolución de problemas complejos.
Aquí tienes algunas formas en las que tu equipo de ingeniería puede aprovecharlo:
- Autocompletado de código: Genere automáticamente cuerpos de funciones a partir de comentarios o cadenas de documentación.
- Detección de errores: Analice fragmentos de código para identificar posibles errores o fallos lógicos.
- Explicación del código: Traduce algoritmos complejos o código heredado/a a un lenguaje sencillo.
- Generación de pruebas: cree pruebas unitarias basadas en la firma de una función y el comportamiento esperado.
RAG y aplicaciones de contexto largo
La generación aumentada por recuperación (RAG) es una potente técnica que basa las respuestas de un modelo en los datos privados de su empresa. Sin embargo, los sistemas RAG suelen tener dificultades con los modelos que tienen ventanas de contexto pequeñas, lo que obliga a realizar un fragmentado agresivo de los datos que puede hacer que se pierda contexto importante. La ventana de contexto de 32K de DBRX lo convierte en una base excelente para aplicaciones RAG robustas.
Esto le permite crear potentes herramientas internas, tales como:
- Búsqueda empresarial: cree un chatbot que responda a las preguntas de los empleados utilizando su base de conocimientos interna.
- Soporte al cliente: cree un agente que genere respuestas de soporte basadas en la documentación de su producto.
- Asistencia en la investigación: Desarrolla una herramienta que pueda sintetizar la información de cientos de páginas de artículos de investigación.
- Comprobación del cumplimiento normativo: verifique automáticamente los textos de marketing con respecto a las directrices internas de la marca o los documentos normativos.
Cómo integrar el entrenamiento de DBRX en el flujo de trabajo de su equipo
Un proyecto exitoso de entrenamiento de modelos de IA es mucho más que código y computación. Es un esfuerzo colaborativo en el que participan ingenieros de ML, científicos de datos, gerentes de producto y partes interesadas.
Cuando esta colaboración se dispersa entre cuadernos Jupyter, canales de Slack y herramientas de gestión de proyectos independientes, se crea una «proliferación de contextos», una situación en la que la información crítica del proyecto se dispersa entre demasiadas herramientas.
ClickUp resuelve ese problema. En lugar de tener que manejar múltiples herramientas, obtienes un entorno de trabajo de IA convergente en el que conviven la gestión de proyectos, la documentación y la comunicación, de modo que tus experimentos permanecen conectados desde la planificación hasta la ejecución y la evaluación.
No pierda nunca el seguimiento de los experimentos y el progreso.
Cuando se realizan múltiples experimentos, lo más difícil no es entrenar el modelo, sino el seguimiento de los cambios que se producen durante el proceso. ¿Qué versión del conjunto de datos se utilizó, qué tasa de aprendizaje funcionó mejor o qué ejecución se envió?
ClickUp le facilita enormemente este proceso. Puede realizar el seguimiento de cada ejecución de entrenamiento por separado en las tareas de ClickUp y, dentro de las tareas, puede utilizar Campos personalizados para registrar:
- Versión del conjunto de datos
- Hiperparámetros
- Variante del modelo (DBRX Base frente a DBRX Instruct)
- Estado del entrenamiento (en cola, en ejecución, en evaluación, implementado)
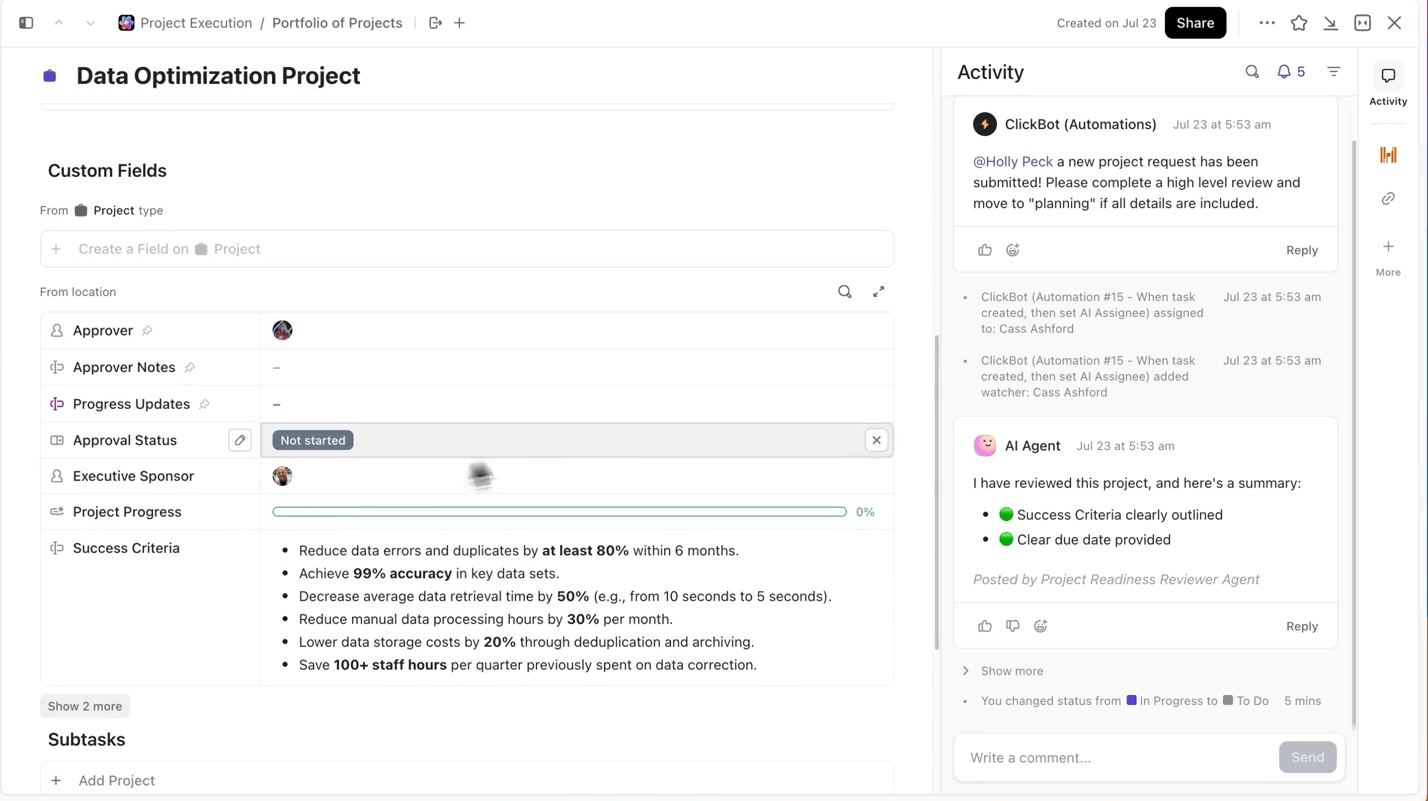
De esta manera, todos los experimentos documentados se pueden buscar, comparar fácilmente con otros y reproducir.
Mantenga la documentación del modelo vinculada al trabajo.
No es necesario saltar entre cuadernos Jupyter, archivos README o hilos de Slack para comprender el contexto de la tarea de un experimento.
Con ClickUp Docs, puede mantener su arquitectura de modelos, scripts de preparación de datos o métricas de evaluación organizados y accesibles documentándolos en un documento con función de búsqueda que enlaza directamente con las tareas experimentales de las que proceden.
💡Consejo profesional: mantén un resumen del proyecto actualizado en ClickUp Docs que detalle cada decisión, desde la arquitectura hasta la implementación, para que los nuevos miembros del equipo puedan ponerse al día con los detalles del proyecto sin tener que buscar en antiguos hilos.
Ofrezca visibilidad en tiempo real a las partes interesadas.
Los paneles de ClickUp muestran el progreso de los experimentos y la carga de trabajo del equipo en tiempo real. I
En lugar de compilar manualmente las actualizaciones o enviar correos electrónicos, los paneles se actualizan automáticamente en función de los datos de sus tareas. De este modo, las partes interesadas pueden consultar en cualquier momento el estado de las cosas y no tienen que interrumpirle con preguntas del tipo «¿cuál es el estado?».
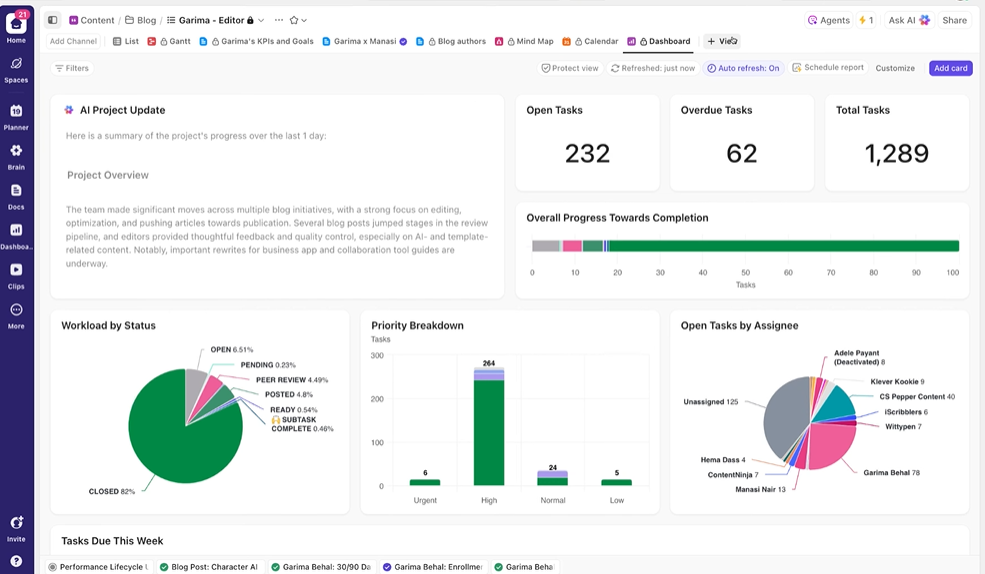
De esta manera, podrá centrarse en realizar experimentos en lugar de tener que realizar la elaboración de informes sobre ellos de forma manual.
Convierta la IA en su compañero inteligente para proyectos.
No es necesario revisar manualmente semanas de datos de entrenamiento para obtener un resumen de los experimentos realizados hasta el momento. Solo tiene que hacer una mención de @Brain en cualquier comentario de una tarea de ClickUp y ClickUp Brain le proporcionará la ayuda que necesita con todo el contexto de sus proyectos pasados y en curso.
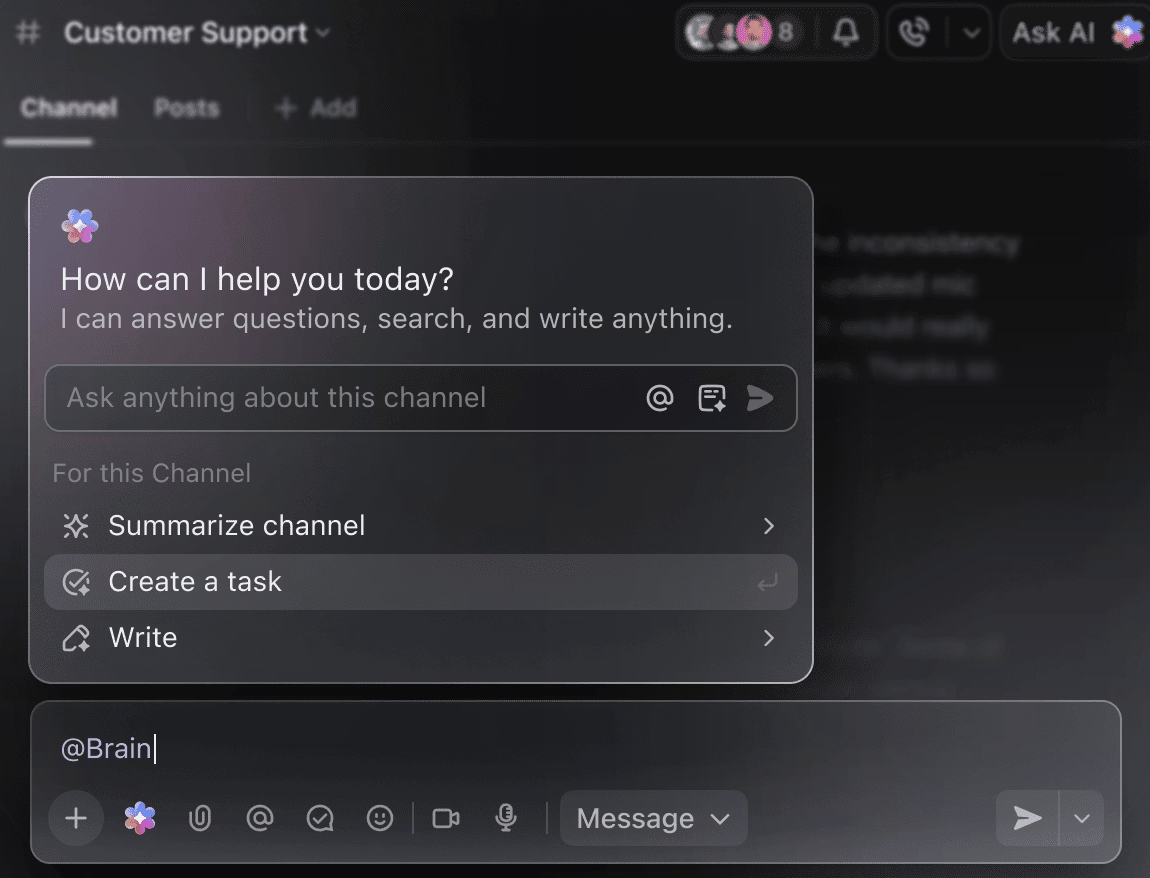
Puede pedirle a Brain que «resuma los experimentos de la semana pasada en 5 puntos clave» o que «redacte un documento con los últimos resultados de hiperparámetros», y obtendrá al instante un resultado pulido.
🧠 La ventaja de ClickUp: Los superagentes de ClickUp van mucho más allá: pueden automatizar flujos de trabajo completos basándose en los desencadenantes que usted defina, no solo responder a sus preguntas. Con los superagentes, puede crear automáticamente una nueva tarea de entrenamiento de DBRX cada vez que se carga un conjunto de datos, notificar a su equipo y enlazar los documentos relevantes cuando finaliza el entrenamiento o se alcanza un punto de control, y generar un resumen semanal del progreso y enviarlo a las partes interesadas sin que usted tenga que hacer nada.
Errores comunes que se deben evitar
Embarcarse en un proyecto de entrenamiento con DBRX es emocionante, pero algunos errores comunes pueden entorpecer su progreso. Evitar estos errores le ahorrará tiempo, dinero y mucha frustración.
- Subestimar los requisitos de hardware: DBRX es potente, pero también es grande. Intentar ejecutarlo en un hardware inadecuado provocará errores de memoria insuficiente y fallos en los trabajos de entrenamiento. Tenga en cuenta que DBRX (132B) requiere al menos 264 GB de VRAM para la inferencia de 16 bits, o aproximadamente entre 70 y 80 GB cuando se utiliza cuantificación de 4 bits.
- Omitir las comprobaciones de calidad de los datos: si los datos de entrada son erróneos, los resultados también lo serán. El ajuste fino de un conjunto de datos desordenado y de baja calidad solo enseñará al modelo a producir resultados desordenados y de baja calidad.
- Ignorar los límites de longitud del contexto: aunque la ventana de contexto de 32K de DBRX es generosa, no es infinita. Introducir en el modelo entradas que superen este límite dará como resultado un truncamiento silencioso y un rendimiento deficiente.
- Uso de Base cuando Instruct es adecuado: DBRX Base es un modelo sin procesar y preentrenado destinado a un entrenamiento adicional a gran escala. Para la mayoría de las tareas que requieren seguir instrucciones, debe comenzar con DBRX Instruct, que ya ha sido ajustado para ese propósito.
- Separar el trabajo de entrenamiento de la coordinación del proyecto: cuando el seguimiento de los experimentos se realiza en una herramienta y el plan del proyecto en otra, se crean silos de información. Utilice una plataforma integrada como ClickUp para sincronizar el trabajo técnico y la coordinación del proyecto.
- Descuidar la evaluación antes de la implementación: un modelo que funciona bien con sus datos de entrenamiento puede fallar estrepitosamente en el mundo real. Valide siempre su modelo ajustado en un conjunto de pruebas retenido antes de implementarlo en producción.
- Pasar por alto la complejidad del ajuste fino: dado que DBRX es un modelo de mezcla de expertos, los scripts de ajuste fino estándar pueden requerir bibliotecas especializadas como Megatron-LM o PyTorch FSDP para gestionar la fragmentación de parámetros en varias GPU.
DBRX frente a otras plataformas de entrenamiento de IA
La elección de una plataforma de entrenamiento de IA implica una disyuntiva fundamental: control frente a comodidad. Los modelos propietarios, que solo utilizan API, son fáciles de usar, pero te encierran en el ecosistema de un proveedor.
Los modelos de peso abierto como DBRX ofrecen un control total, pero requieren más conocimientos técnicos e infraestructura. Esta elección puede hacer que se sienta estancado, sin saber qué camino le ayudará realmente a alcanzar sus metas a largo plazo, un reto al que se enfrentan muchos equipos durante la adopción de la IA.
Esta tabla desglosa las diferencias clave para ayudarle a tomar una decisión informada.
| Ponderación | Abrir (Personalizado) | Propiedad exclusiva | Abrir (Personalizado) | Propiedad exclusiva |
| Ajuste fino | Control total | Basado en API | Control total | Basado en API |
| Autoalojamiento | Sí | No | Sí | No |
| Licencia | Modelo abierto DB | Términos de OpenAI | Comunidad Llama | Términos antropológicos |
| Contexto | 32K | 128 000 – 1 millón | 128K | 200 000 - 1 millón |
DBRX es la opción adecuada cuando necesitas un control total sobre el modelo, debes alojarlo tú mismo por motivos de seguridad o cumplimiento normativo, o deseas la flexibilidad de una licencia comercial permisiva. Si no dispones de una infraestructura de GPU dedicada, o si valoras más la rapidez de comercialización que la personalización profunda, las alternativas basadas en API pueden ser más adecuadas.
Empiece a entrenar de forma más inteligente con ClickUp.
DBRX le ofrece una base preparada para corporaciones con la que crear aplicaciones de IA personalizadas, con la transparencia y el control que no obtiene con los modelos propietarios. Su eficiente arquitectura MoE mantiene bajos los costes de inferencia y su diseño abierto facilita el ajuste. Pero una tecnología sólida es solo la mitad de la ecuación.
El verdadero éxito proviene de alinear su trabajo técnico con el flujo de trabajo colaborativo de su equipo. El entrenamiento de modelos de IA es un trabajo en equipo, y es fundamental sincronizar los experimentos, la documentación y la comunicación con las partes interesadas. Cuando se reúne todo en un único entorno de trabajo convergente y se reduce la dispersión del contexto, se pueden enviar mejores modelos más rápidamente.
Empieza gratis con ClickUp para coordinar tus proyectos de entrenamiento de IA en un único entorno de trabajo. ✨
Preguntas frecuentes
Puede supervisar el entrenamiento utilizando herramientas de ML estándar como TensorBoard, Weights & Biases o MLflow. Si está entrenando dentro del ecosistema Databricks, MLflow está integrado de forma nativa para un seguimiento perfecto de los experimentos.
Sí, DBRX se puede integrar en los procesos estándar de MLOps. Al contenerizar el modelo, puede implementarlo utilizando plataformas de orquestación como Kubeflow o flujos de trabajo CI/CD personalizados.
DBRX Base es el modelo preentrenado fundamental destinado a equipos que desean realizar un preentrenamiento continuo específico para un dominio o un ajuste profundo de la arquitectura. DBRX Instruct es una versión ajustada y optimizada para seguir instrucciones, lo que lo convierte en un mejor punto de partida para la mayoría de los desarrollos de aplicaciones.
La principal diferencia es el control. DBRX le ofrece acceso completo a los pesos del modelo para una personalización profunda y un autohospedaje, mientras que GPT-4 es un servicio solo API.
Las ponderaciones del modelo DBRX están disponibles de forma gratuita bajo la licencia Databricks Open Model License. Sin embargo, usted es responsable de los costes de la infraestructura informática necesaria para ejecutar o ajustar el modelo.